Embed Size (px)
Citation preview

1
Parallelism
Lecture notes from MKP and S. Yalamanchili
(2)
Overview
• Goal: Understand how to scale performance via parallelismv Execute multiple instructions in parallel – instruction
level parallelism (ILP)v Break up a program into multiple parallel instruction
streams – thread level parallelism (TLP)v Process multiple data items in parallel – data level
parallelism (DLP)
• Consequencesv Coordinating parallelism for correctnessv What about caching?

2
(3)
Reading
• Section 6.1 – 6.7
• Section 4.10, 5.10
(4)
Parallelism Sources
main: la $t0, L1li $t1, 4add $t2, $zero, $zero
Loop: lw $t3, 0($t0)add $t2, $t2, $t3addi $t0, $t0, 4addi $t1, $t1, -1bne $t1, $zero, loopbgt $t2, $0, thenmove $s0, $t2j exit
then: move $s1, $t2exit:
Execute in Parallel?
Execute Iterations in Parallel?

3
(5)
Characterizing Parallelism
• Characterization due to M. Flynn*
• Difference between parallel and concurrent
SISD SIMD
MISD MIMD
Single instruction multiple data stream computing, e.g., SSE
Data Streams
Inst
ruct
ion
Str
eam
s
Today serial computing cores (von Neumann model)
Today’s Multicore
*M. Flynn, (September 1972). "Some Computer Organizations and Their Effectiveness". IEEE Transactions on Computers, C–21 (9): 948–960t
Instruction Level Parallelism (ILP)
Lecture notes from MKP and S. Yalamanchili

4
(7)
Assessing Performance
• Ideal CPI is increased by dependencies
• Performance impact on CPI can be assessed by computing the impact on a per instruction basis
Increase in CPI = Base CPI + Probability_of_event * penalty_for_event
v For example, an event may be a branch misprediction or the occurrence of a data hazard
v The probability is computed for the occurrence of the event on an instruction
• Examples: pipelined processors
(8)
Instruction-Level Parallelism (ILP)(4.10)
• Pipelining: executing multiple instructions in parallel
• To increase ILPv Deeper pipeline
o Less work per stage Þ shorter clock cyclev Multiple issue
o Replicate pipeline stages Þ multiple pipelineso Start multiple instructions per clock cycleo CPI < 1, so use Instructions Per Cycle (IPC)o E.g., 4GHz 4-way multiple-issue
n 16 BIPS, peak CPI = 0.25, peak IPC = 4o But dependencies reduce this in practice

5
(9)
Multiple Issue
• Static multiple issuev Compiler groups instructions to be issued togetherv Packages them into “issue slots”v Compiler detects and avoids hazards
• Dynamic multiple issuev CPU examines instruction stream and chooses
instructions to issue each cyclev Compiler can help by reordering instructionsv CPU resolves hazards using advanced techniques at
runtime
(10)
MIPS with Static Dual Issue
• Two-issue packetsv One ALU/branch instructionv One load/store instructionv 64-bit aligned
o ALU/branch, then load/storeo Pad an unused instruction with nop
Address Instruction type Pipeline Stages
n ALU/branch IF ID EX MEM WB
n + 4 Load/store IF ID EX MEM WB
n + 8 ALU/branch IF ID EX MEM WB
n + 12 Load/store IF ID EX MEM WB
n + 16 ALU/branch IF ID EX MEM WB
n + 20 Load/store IF ID EX MEM WB

6
(11)
MIPS with Static Dual Issue
Addresscomputation
ALU computation
ALU operation Load/store
Aligned Instruction Pair
(12)
Instruction Level Parallelism (ILP)
IF ID MEM WB
• Single (program) thread of execution• Issue multiple instructions from the same
instruction stream• Average CPI<1• Often called out of order (OOO) cores
Multiple instructions in EX at the same time

7
(13)
Dynamically Scheduled Core
Results also sent to any waiting reservation stations
Reorders buffer for register writes Can supply
operands for issued instructions
Preserves dependencies
Hold pending operands
(14)
Limits of ILP
main: la $t0, L1li $t1, 4add $t2, $zero, $zero
Loop: lw $t3, 0($t0)
add $t2, $t2, $t3addi $t0, $t0, 4addi $t1, $t1, -1bne $t1, $zero, loopbgt $t2, $0, thenmove $s0, $t2j exit
then: move $s1, $t2exit:
Dependencies!

8
(15)
AMD Bulldozer
forum.beyond3d.comb
(16)
AMD Bobcat
http://hothardware.com
Later in this course
ECE 6100
ECE 6100
Later in this course
Instruction Level Parallelism (ILP)

9
(17)
Intel Atom
http://www.anandtech.com
Thread Level Parallelism (TLP)
Lecture notes from MKP and S. Yalamanchili

10
(19)
Overview
• Goal: Higher performance through parallelism
• Job-level (process-level) parallelismv High throughput for independent jobs
• Application-level parallelismv Single program (mulitiple threads) run on multiple
processors à speedup
• Each core can operate concurrently and in parallel
• Multiple threads may operate in a time sliced fashion on a single core
(20)
Thread Level Parallelism (TLP) (6.3, 6.4)
• Multiple threads of execution
• Exploit ILP in each thread
• Exploit concurrent execution across threads

11
(21)
Instruction and Data Streams
• Taxonomy due to M. Flynn
Data StreamsSingle Multiple
Instruction Streams
Single SISD:Intel Pentium 4
SIMD: SSE instructions of x86
Multiple MISD:No examples today
MIMD:Intel Xeon e5345
Example: Multithreading (MT) in a single address space
(22)
Recall The Executable Format
header
text
static data
relocsymboltabledebug
Object file ready to be linked and loaded
Linker Loader
Static Libraries
An executable instance or
Process
What does a loader do?

12
(23)
Process
• A process is a running program with statev Stack, memory, open filesv PC, registers
• The operating system keeps tracks of the state of all processorsv E.g., for scheduling processes
• There many processes for the same applicationv E.g., web browser
• Operating systems class for details
Code
Static data
Heap
Stack
DLL’s
(24)
Process Level Parallelism
Process Process Process
• Parallel processes and throughput computing• Each process itself does not run any faster

13
(25)
From Processes to Threads
• Switching processes on a core is expensivev A lot of state information to be managed
• If I want concurrency, launching a process is expensive
• How about splitting up a single process into parallel computations?
à Lightweight processes or threads!
(26)
Thread Parallel ExecutionProcess
thread

14
(27)
A Thread
• A separate, concurrently executable instruction stream within a process
• Minimum amount state to execute on a corev Program counter, registers, stackv Remaining state shared with the parent process
o Memory and files
• Support for creating threads
• Support for merging/terminating threads
• Support for synchronization between threadsv In accesses to shared data
Our datapath so far!
(28)
A Simple Example
Data Parallel Computation

15
(29)
Thread Execution: Basics
funcA()
Static data
Heap
Stack
funcB()
Stack
PC, registers,stack pointer
PC, registers,stack pointer
Thread #1
Thread #2
create_thread(funcB)
create_thread(funcA)
funcA() funcB()
WaitAllThreads()
end_thread() end_thread()
(30)
Threads Execution on a Single Core• Hardware threads
v Each thread has its own hardware state
• Switching between threads on each cycle to share the core pipeline – why?
IF ID MEM WBEXlw $t0, label($0)lw $t1, label1($0)and $t2, $t0, $t1andi $t3, $t1, 0xffff srl $t2, $t2, 12……
lw $t3, 0($t0)add $t2, $t2, $t3addi $t0, $t0, 4addi $t1, $t1, -1bne $t1, $zero, loop…….
Thread #1
Thread #2
lw
lw
lw lw
lw
lw
lw lwlwadd
lw lwlwaddand
No pipeline stall on load-to-use hazard!
Interleaved execution Improve
utilization !

16
(31)
An Example Datapath
From Poonacha Kongetira, Microarchitecture of the UltraSPARC T1 CPU
(32)
Conventional Multithreading• Zero-overhead context switch
• Duplicated contexts for threads
0:r0
0:r71:r0
1:r72:r0
2:r73:r0
3:r7
CtxtPtr Memory (shared by threads)
Register file
Courtesy H. H. Lee

17
(33)
Software Threads
funcA()
Static data
Heap
Stack
funcB()
Stack
PC, registers,stack pointer
PC, registers,stack pointer
Thread #1
Thread #2
create_thread(funcB)
create_thread(funcA)
funcA() funcB()
WaitAllThreads()
end_thread() end_thread()
Need to save and restore thread state
(34)
Execution Model: Multithreading
• Fine-grain multithreadingv Switch threads after each cyclev Interleave instruction execution
• Coarse-grain multithreadingv Only switch on long stall (e.g., L2-cache miss)v Simplifies hardware, but does not hide short stalls
(e.g., data hazards)v If one thread stalls (e.g., I/O), others are executed

18
(35)
Simultaneous Multithreading
• In multiple-issue dynamically scheduled processorsv Instruction-level parallelism across threadsv Schedule instructions from multiple threadsv Instructions from independent threads execute when
function units are available
• Example: Intel Pentium-4 HTv Two threads: duplicated registers, shared function
units and cachesv Known as Hyperthreading in Intel terminology
(36)36
Hyper-threading
• Implementation of Hyper-threading adds less than 5% to the chip area
• Principle: share major logic components (functional units) and improve utilization
• Architecture State: All core pipeline resources needed for executing a thread
Processor Execution Resources
Arch State
Processor Execution Resources
Processor Execution Resources
Processor Execution Resources
Arch State Arch State Arch State Arch State Arch State
2 CPU Without Hyper-threading 2 CPU With Hyper-threading

19
(37)
Multithreading with ILP: Examples
(38)
Thread Synchronization (6.5)Process
thread
Share data?

20
(39)
Thread Interactions
• What about shared data?v Need synchronization support
• Several different types of synchronization: we will look at one in detailv We are specifically interested in the exposure in the
ISA
(40)
Example: Communicating Threads
The Producer callswhile (1) {
while (count == BUFFER_SIZE); // do nothing
// add an item to the buffer++count;buffer[in] = item;in = (in + 1) % BUFFER_SIZE;
}
Producer Consumer
Thread 1

21
(41)
Example: Communicating Threads
The Consumer callswhile (1) {
while (count == 0); // do nothing
// remove an item from the buffer--count;item = buffer[out];out = (out + 1) % BUFFER_SIZE;
}
Producer Consumer
Thread 2
(42)
Uniprocessor Implementation• count++ could be implemented as
register1 = count;register1 = register1 + 1;count = register1;
• count-- could be implemented asregister2 = count;register2 = register2 – 1;count = register2;
• Consider this execution interleaving:S0: producer execute register1 = count {register1 = 5}S1: producer execute register1 = register1 + 1 {register1 = 6} S2: consumer execute register2 = count {register2 = 5} S3: consumer execute register2 = register2 - 1 {register2 = 4} S4: producer execute count = register1 {count = 6 } S5: consumer execute count = register2 {count = 4}

22
(43)
Synchronization• We need to prevent certain instruction
interleaving v Or at least be able to detect violations!
• Some sequence of operations (instructions) must happen atomicallyv E.g., register1 = count;
register1 = register1 + 1;count = register1;
v atomic operations/instructions
• Serializing access to shared resources is a basic requirement of concurrent computationv What are critical sections?
(44)
Synchronization
• Two processors sharing an area of memoryv P1 writes, then P2 readsv Data race if P1 and P2 don’t synchronize
o Result depends of order of accesses
• Hardware support requiredv Atomic read/write memory operationv No other access to the location allowed between the
read and write
• Could be a single instructionv E.g., atomic swap of register ↔ memoryv Or an atomic pair of instructions

23
(45)
Implementing an Atomic Operation
// lock object is shared by all threads
while (lock.getAndSet(true))
Thread.yield();
Update count;
lock.set(false);
Atomic
Atomic
(46)
Synchronization in MIPS
• Load linked: ll rt, offset(rs)
• Store conditional: sc rt, offset(rs)v Succeeds if location not changed since the ll
o Returns 1 in rtv Fails if location is changed
o Returns 0 in rt
• Example: atomic swap (to test/set lock variable)try: add $t0,$zero,$s4 ;copy exchange value
ll $t1,0($s1) ;load linked
sc $t0,0($s1) ;store conditional
beq $t0,$zero,try ;branch store fails
add $s4,$zero,$t1 ;put load value in $s4

24
(47)
Other Synchronization Primitives
• test&set(lock)
v Atomically read and set a lock variable
• swap r1, r2, [r0]
v With 1/0 values this functions as a lock variable
….and a few others
(48)
Commodity Multicore Processor
From www.zdnet.com
Coherent Shared Memory Programming Model

25
(49)
Core Microarchitecture
(50)
Parallel Programming
• Parallel software is the problem
• Need to get significant performance improvementv Otherwise, just use a faster uniprocessor, since it’s
easier!
• Difficultiesv Partitioningv Coordinationv Communications overhead

26
(51)
Amdahl’s Law (6.2)
• Sequential part can limit speedup
• Example: 100 processors, 90× speedup?v Tnew = Tparallelizable/100 + Tsequential
v
v Solving: Fparallelizable = 0.999
• Need sequential part to be 0.1% of original time
90/100F)F(1
1Speedupableparallelizableparalleliz
=+-
=
(52)
Scaling Example
• Workload: sum of 10 scalars, and 10 × 10 matrix sumv Speed up from 10 to 100 processors
• Single processor: Time = (10 + 100) × tadd
• 10 processorsv Time = 10 × tadd + 100/10 × tadd = 20 × taddv Speedup = 110/20 = 5.5 (55% of potential)
• 100 processorsv Time = 10 × tadd + 100/100 × tadd = 11 × taddv Speedup = 110/11 = 10 (10% of potential)
• Idealized modelv Assumes load can be balanced across processors

27
(53)
Scaling Example (cont)
• What if matrix size is 100 × 100?
• Single processor: Time = (10 + 10000) × tadd
• 10 processorsv Time = 10 × tadd + 10000/10 × tadd = 1010 × tadd
v Speedup = 10010/1010 = 9.9 (99% of potential)
• 100 processorsv Time = 10 × tadd + 10000/100 × tadd = 110 × tadd
v Speedup = 10010/110 = 91 (91% of potential)
• Idealized modelv Assuming load balanced
(54)
Strong vs Weak Scaling
• Strong scaling: problem size fixedv As in example
• Weak scaling: problem size proportional to number of processorsv 10 processors, 10 × 10 matrix
o Time = 20 × tadd
v 100 processors, 32 × 32 matrixo Time = 10 × tadd + 1000/100 × tadd = 20 × tadd
v Constant performance in this examplev For a fixed size system grow the number of
processors to improve performance

28
(55)
Cache Coherence (5.10)
• A shared variable may exist in multiple caches
• Multiple copies to improve latency
• This is a really a synchronization problem
(56)
Cache Coherence Problem
• Suppose two CPU cores share a physical address spacev Write-through caches
Time step
Event CPU A’s cache
CPU B’s cache
Memory
0 0
1 CPU A reads X 0 0
2 CPU B reads X 0 0 0
3 CPU A writes 1 to X 1 0 1
29
(57)
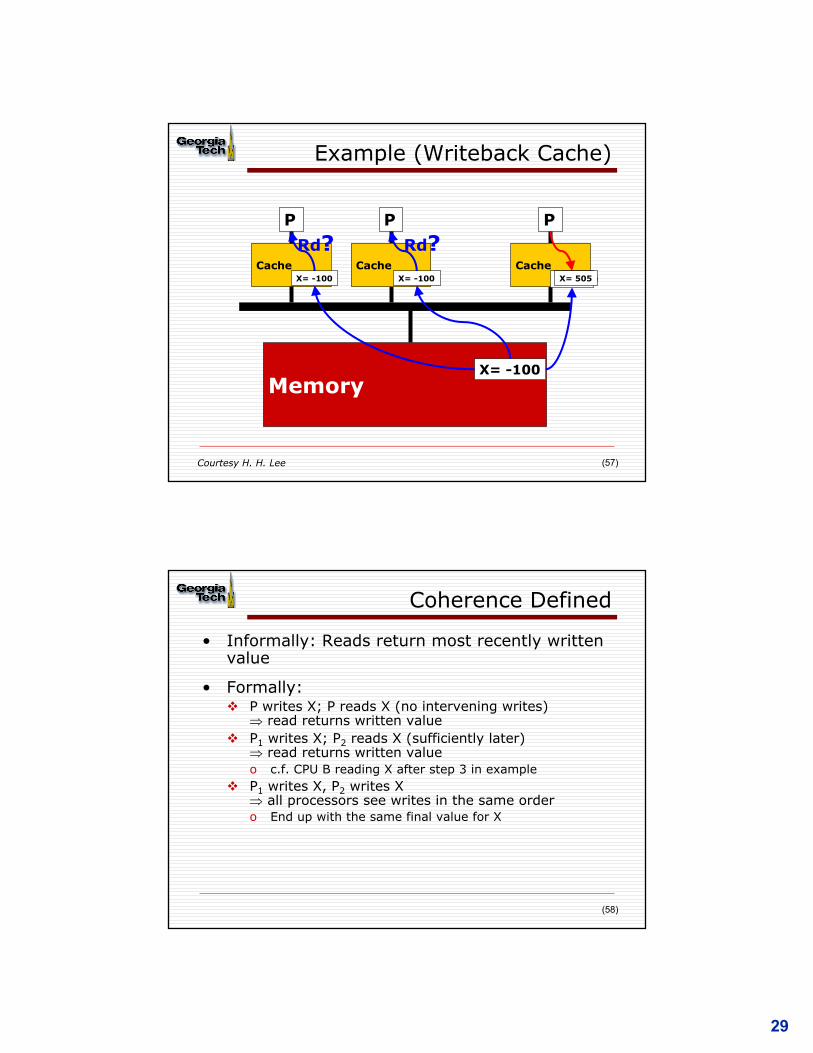
Example (Writeback Cache)
P
Cache
Memory
P
X= -100
X= -100Cache
P
CacheX= -100X= 505
Rd?X= -100
Rd?
Courtesy H. H. Lee
(58)
Coherence Defined
• Informally: Reads return most recently written value
• Formally:v P writes X; P reads X (no intervening writes)
Þ read returns written valuev P1 writes X; P2 reads X (sufficiently later)
Þ read returns written valueo c.f. CPU B reading X after step 3 in example
v P1 writes X, P2 writes XÞ all processors see writes in the same ordero End up with the same final value for X

30
(59)
Cache Coherence Protocols
• Operations performed by caches in multiprocessors to ensure coherencev Migration of data to local caches
o Reduces bandwidth for shared memoryv Replication of read-shared data
o Reduces contention for access
• Snooping protocolsv Each cache monitors bus reads/writes
• Directory-based protocolsv Caches and memory record sharing status of blocks
in a directory
(60)
Invalidating Snooping Protocols
• Cache gets exclusive access to a block when it is to be writtenv Broadcasts an invalidate message on the busv Subsequent read in another cache misses
o Owning cache supplies updated value
CPU activity Bus activity CPU A’s cache
CPU B’s cache
Memory
0CPU A reads X Cache miss for X 0 0CPU B reads X Cache miss for X 0 0 0CPU A writes 1 to X Invalidate for X 1 0CPU B read X Cache miss for X 1 1 1

31
(61)
Programming Model: Message Passing (6.7)
• Each processor has private physical address space
• Hardware sends/receives messages between processors
(62)
Parallelism
• Write message passing programs
• Explicit send and receive of datav Rather than accessing data in shared memory
send()
receive() send()
receive()
Process 2 Process 2

32
(63)
High Performance Computing
zdnet.com
• The dominant programming model is message passing
• Scales well but requires programmer effort• Science problems have fit this model well to
date
theregister.co.uk
(64)
A Simple MPI Program#include <stdio.h> #include <stdlib.h> #include <mpi.h> #include <math.h> int main(argc,argv) int argc; char *argv[]; { int myid, numprocs; int tag,source,destination,count; int buffer; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid); tag=1234; source=0; destination=1; count=1; if(myid == source){ buffer=5678; MPI_Send(&buffer,count,MPI_INT,destination,tag,MPI_COMM_WORLD); printf("processor %d sent %d\n",myid,buffer); } if(myid == destination){ MPI_Recv(&buffer,count,MPI_INT,source,tag,MPI_COMM_WORLD,&status); printf("processor %d got %d\n",myid,buffer); } MPI_Finalize(); }
The Message Passing Interface (MPI)Library
From http://geco.mines.edu/workshop/class2/examples/mpi/c_ex01.c

33
(65)
A Simple MPI Program#include "mpi.h" #include <stdio.h> #include <math.h> int main( int argc, char *argv[] ){ int n, myid, numprocs, i; double PI25DT = 3.141592653589793238462643; double mypi, pi, h, sum, x; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid); while (1) { if (myid == 0) { printf("Enter the number of intervals: (0 quits) "); scanf("%d",&n);
} MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);if (n == 0) break; else { h = 1.0 / (double) n; sum = 0.0; for (i = myid + 1; i <= n; i += numprocs) { x = h * ((double)i - 0.5); sum += (4.0 / (1.0 + x*x)); } mypi = h * sum; MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); if (myid == 0) printf("pi is approximately %.16f, Error is %.16f\n", pi, fabs(pi - PI25DT)); } } MPI_Finalize(); return 0; }
http://www.mcs.anl.gov/research/projects/mpi/usingmpi/examples/simplempi/main.htm
(66)
Loosely Coupled Clusters
• Network of independent computersv Each has private memory and OSv Connected using I/O system
o E.g., Ethernet/switch, Internet
• Suitable for applications with independent tasksv Web servers, databases, simulations, …
• High availability, scalable, affordable
• Problemsv Administration cost (prefer virtual machines)v Low interconnect bandwidth
o c.f. processor/memory bandwidth on an SMP

34
Data Level Parallelism (DLP)
Lecture notes from MKP and S. Yalamanchili
(68)
Data Parallelism
Process each square in parallel – data parallel
computation
Records
Each thread searches each group of records
in parallel
Image Processing Search

35
(69)
Characterizing Parallelism
• Characterization due to M. Flynn*
SISD SIMD
MISD MIMD
Single instruction multiple data stream computing, e.g., SSE
Data Streams
Inst
ruct
ion
Str
eam
s
Today serial computing cores (von Neumann model)
Today’s Multicore
*M. Flynn, (September 1972). "Some Computer Organizations and Their Effectiveness". IEEE Transactions on Computers, C–21 (9): 948–960t
(70)
Parallelism Categories
From http://en.wikipedia.org/wiki/Flynn%27s_taxonomy

36
(71)
Multimedia (3.6, 3.7, 3.8, 6.3)
• Lower dynamic range and precision requirementsv Do not need 32-bits!
• Inherent parallelism in the operations
(72)
Vector Computation
• Operate on multiple data elements (vectors) at a time
• Flexible definition/use of registers• Registers hold integers, floats (SP), doubles DP)
1x128 bit integer
4 x 32-bit single precision
2x64-bit double precision
8x16 short integers
128-bit Register

37
(73)
Processing Vectors
Memory
vector registers
• When is this more efficient?
• When is this not efficient?• Think of 3D graphics, linear algebra and media
processing
(74)
Programming Model: SIMD
• Operate elementwise on vectors of datav E.g., MMX and SSE instructions in x86
o Multiple data elements in 128-bit wide registers
• All processors execute the same instruction at the same timev Each with different data address, etc.
• Simplifies synchronization
• Reduced instruction control hardware
• Works best for highly data-parallel applications
• Data Level Parallelism

38
(75)
Case Study: Intel Streaming SIMDExtensions
• 8, 128-bit XMM registersv X86-64 adds 8 more registers XMM8-XMM15
• 8, 16, 32, 64 bit integers (SSE2)
• 32-bit (SP) and 64-bit (DP) floating point
• Signed/unsigned integer operations
• IEEE 754 floating point support
• Reading Assignment: v http://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
v http://neilkemp.us/src/sse_tutorial/sse_tutorial.html#I
(76)
Instruction Categories
• Floating point instructionsv Arithmetic, movementv Comparison, shufflingv Type conversion, bit level
• Integer
• Otherv e.g., cache management
• ISA extensions!
• Advanced Vector Extensions (AVX)v Successor to SSE
register
registermemory

39
(77)
Arithmetic View• Graphics and media processing operates on
vectors of 8-bit and 16-bit datav Use 64-bit adder, with partitioned carry chain
o Operate on 8×8-bit, 4×16-bit, or 2×32-bit vectorsv SIMD (single-instruction, multiple-data)
• Saturating operationsv On overflow, result is largest representable value
o c.f. 2s-complement modulo arithmeticv E.g., clipping in audio, saturation in video
4x16-bit 2x32-bit
(78)
SSE Example// A 16byte = 128bit vector structstruct Vector4{
float x, y, z, w;};
// Add two constant vectors and return the resulting vectorVector4 SSE_Add ( const Vector4 &Op_A, const Vector4 &Op_B ){
Vector4 Ret_Vector;
__asm{
MOV EAX Op_A // Load pointers into CPU regsMOV EBX, Op_B
MOVUPS XMM0, [EAX] // Move unaligned vectors to SSE regsMOVUPS XMM1, [EBX]
ADDPS XMM0, XMM1 // Add vector elementsMOVUPS [Ret_Vector], XMM0 // Save the return vector
}return Ret_Vector;
}From http://neilkemp.us/src/sse_tutorial/sse_tutorial.html#I
More complex example (matrix
multiply) in Section 3.8 – using AVX

40
(79)
Intel Xeon Phi
ww
w.a
nand
tech
.com
www.anandtech.com
www.techpowerup.com
(80)
Data Parallel vs. Traditional Vector
Vector Register
A
Vector Register
B
Vector Register
Cpipelined functional unit
registers
Vector Architecture
Data Parallel Architecture
Process each square in parallel – data parallel
computation

41
(81)
ISA View
• Separate core data path
• Can be viewed as a co-processor with a distinct set of instructions
ALU
Hi
Multiply Divide
Lo
$0$1
$31
Vector ALU
XMM0XMM1
XMM15
CPU/Core SIMD Registers
(82)
Study Guide• What is the difference between hardware MT
and software MT
• Distinguish between TLP and ILP
• Given two threads of computation, the MIPS pipeline, fine grained MT, show the state of the pipeline after 7 cycles
• How many threads do you need with fine grain FT before your branch penalties are no longer a problem?
• With coarse grain MT on a datapath with full fowarding, can you still have load-to-use hazards?

42
(83)
Study Guide (cont.)
• Name two differences between the coherent shared memory and message passing architectures
• What limits how much performance you can get from ILP?
• Which do you think would be more energy efficient, ILP or TLP? Why? (FYI: This is a complex issue)
(84)
Glossary
• Atomic operations • Coarse grain MT• Fine grained MT• Grid computing• Hyperthreading• Instruction Level
Parallelism (ILP)• Multithreading
• Message Passing Interface (MPI)
• Simultaneous MT• Strong scaling • Swap instruction• Test & set operation• Thread Level
Parallelism (TLP)• Weak scaling





























