Embed Size (px)
Citation preview

Partial Observability (State Uncertainty)
Assume non-determinism
Atomic model (for belief states and sensing actions) Factored model (Progression/Regression)Allow distributional information
POMDPs

Partial Observability The agent doesn’t quite know its
current state Orthogonal to the action uncertainty
Search is in the space of “sets” of states If you have no distributional information,
then there are 2s states If you have distributional information, then
there are _____ states [POMDPs]
How does the state uncertainty get resolved? By actions By (partial) observations
Observations States give out “percepts” that can
be observed Observations partition the belief
state
The agent now has a slew of new State Estimation problems Using sensing and action
outcomes to figure out what state it currently is in “state
estimation”/ “filtering” what state it will get to if doesn’t do
anything further “prediction” what state did it start from based on
its knowledge of the current state “smoothing”
..And planning problems Plan without any sensing
“Conformant” planning Plan with a commitment to use
sensing during execution “Contingency Planning” Interleaved sensing and
execution
We did a whole lot of discussion around this single slide; see the lecture video..

Always executable actions
How does theCardinality of beliefState change?
Why not stop as soon as goal state is in the belief state?

“Conformant” Belief-State Search

Not every state may give a percept; will have to go to a neighbor that does..
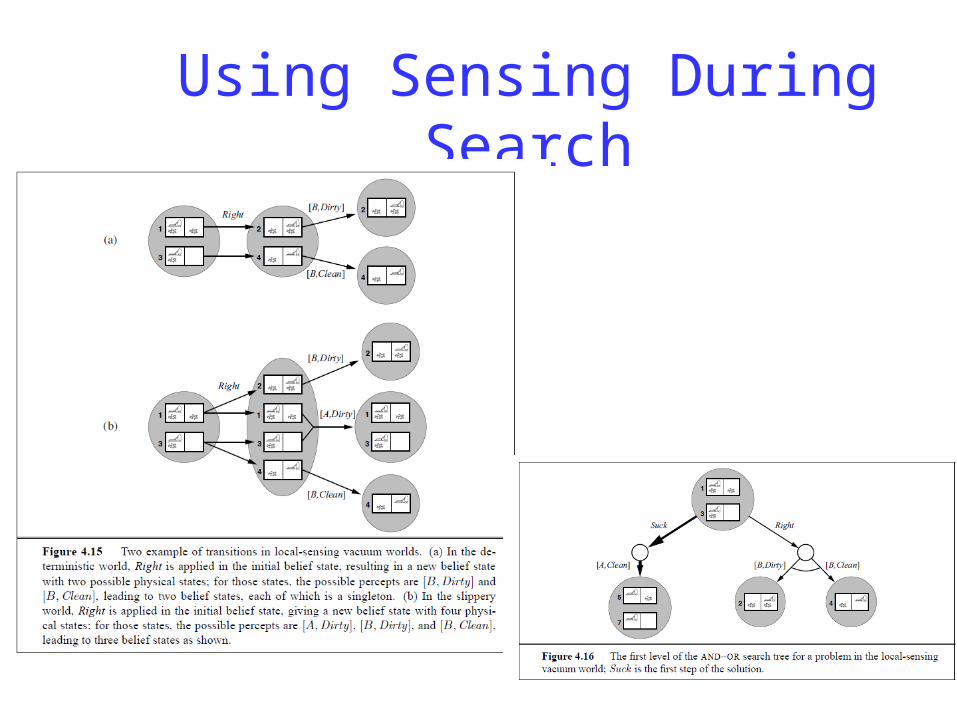
Using Sensing During Search
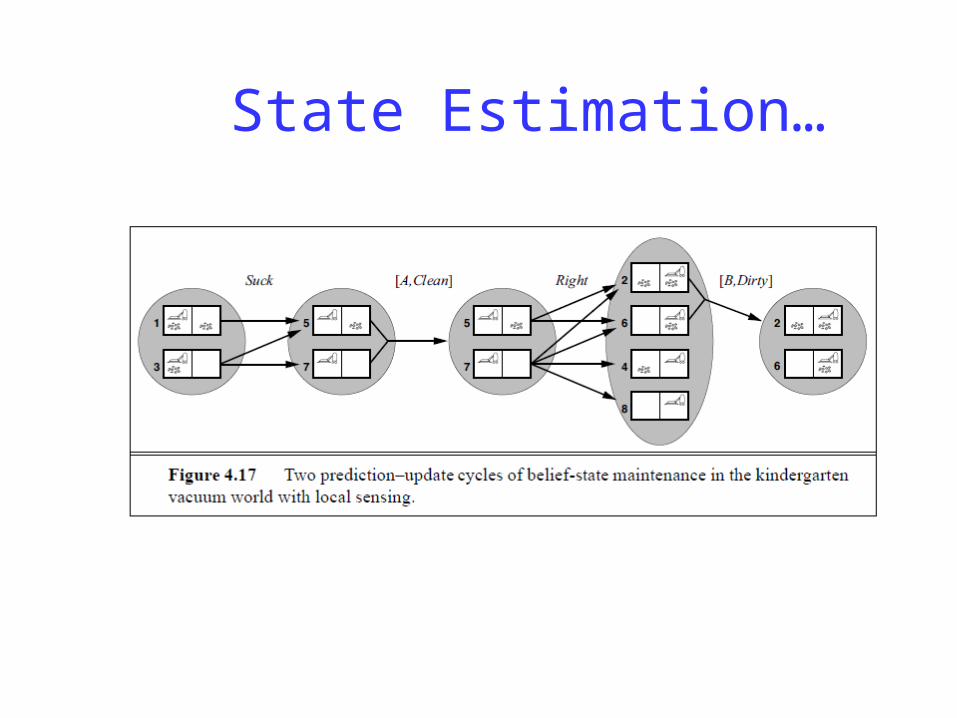
State Estimation…

Generality of Belief State Rep
Size of belief states duringSearch is never greater than |BI|
Size of belief states duringsearch can be greater or less than |BI|

State Uncertainty and Actions
The size of a belief state B is the number of states in it. For a world with k fluents, the size of a belief state can be between 1 (no
uncertainty) and 2k (complete uncertainty). Actions applied to a belief state can both increase and reduce the
size of a belief state A non-deterministic action applied to a singleton belief state will lead to a
larger (more uncertain) belief state A deterministic action applied to a belief state can reduce its uncertainty
E.g. B={(pen-standing-on-table) (pen-on-ground)}; Action A is sweep the table. Effect is B’={(pen-on-ground)}
Often, a good heuristic in solving problems with large belief-state uncertainty is to do actions that reduce uncertainty
E.g. when you are blind-folded and left in the middle of a room, you try to reach the wall and then follow it to the door. Reaching the wall is a way of reducing your positional uncertainty

How this all generalizes with uncertainty?
Actions can have stochastic outcomes (with known probabilities) Think of belief states as distributions over states. Actions
modify the distributions Can talk about “degree of satisfaction” of the goals
Observations further modify the distributions During search, you have to consider separate distributions During execution, you have to “update” the predicted
distribution. No longer an easy task.. Kalman Filters; Particle Filters.

A Robot localizing itself using particle filters

FACTORED REPRESENTATIONS FOR BELIEF-SPACE PLANNING
10/20

Representing Belief States

Belief State Rep (cont) Belief space planners have to search in the space of full
propositional formulas!! In contrast, classical state-space planners search in the
space of interpretations (since states for classical planning were interpretations).
Several headaches: Progression/Regression will have to be done over all states
consistent with the formula (could be exponential number). Checking for repeated search states will now involve checking the
equivalence of logical formulas (aaugh..!) To handle this problem, we have to convert the belief states into some
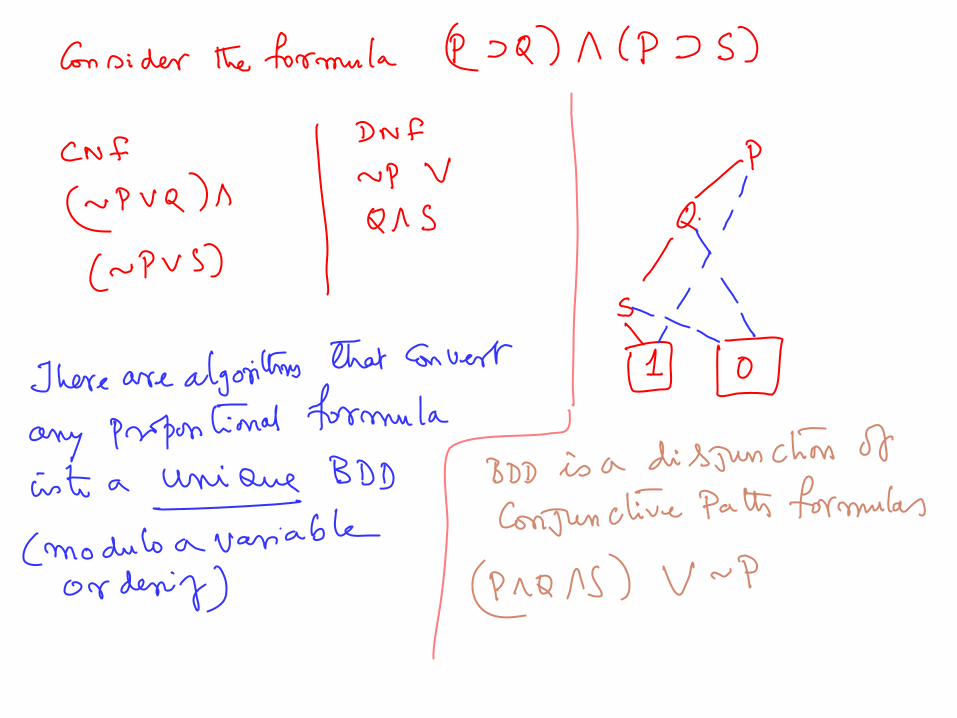
canonical representation. We already know the CNF and DNF representations. There is another one, called Ordered Binary Decision Diagrams that is both canonical and compact
OBDD can be thought of as a compact representation of the DNF version of the logical formula

Effective representations of logical formulas
Checking for repeated search states will now involve checking the equivalence of logical formulas (aaugh..!) To handle this problem, we have to convert the belief states into some
canonical representation. We already know the CNF and DNF representations. These are
normal forms but are not canonical Same formula may have multiple equivalent CNF/DNF representations
There is another one, called Reduced Ordered Binary Decision Diagrams that is both canonical and compact
ROBDD can be thought of as a compact representation of the DNF version of the logical formula
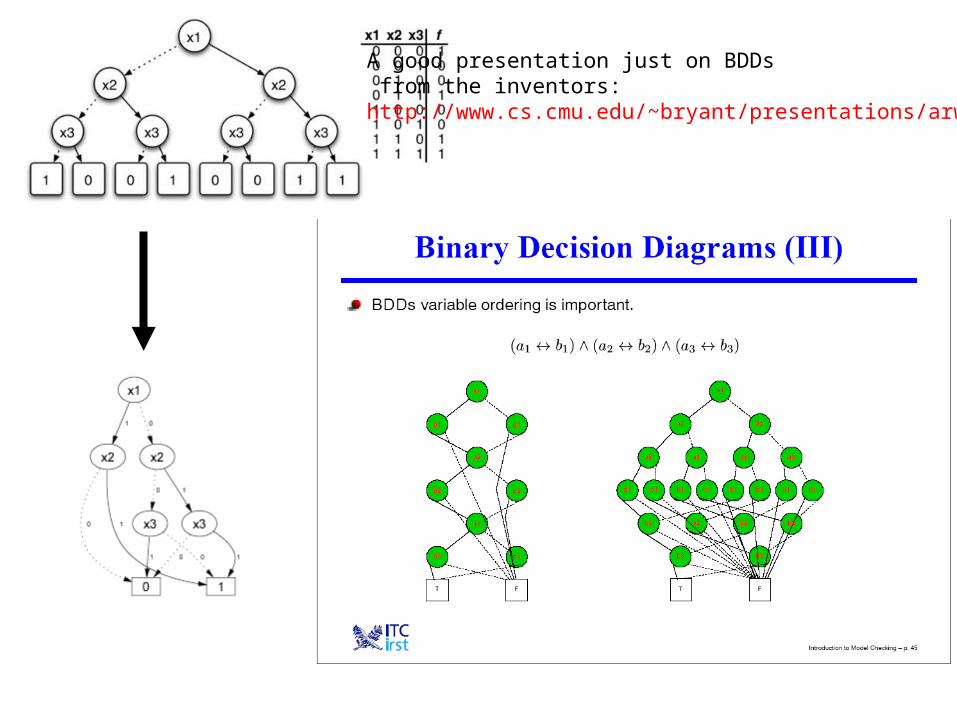
A good presentation just on BDDs from the inventors:http://www.cs.cmu.edu/~bryant/presentations/arw00.ppt

Symbolic Manipulation with OBDDs
Strategy Represent data as set of OBDDs
Identical variable orderings Express solution method as sequence of symbolic operations
Sequence of constructor & query operations Similar style to on-line algorithm
Implement each operation by OBDD manipulation Do all the work in the constructor operations
Key Algorithmic Properties Arguments are OBDDs with identical variable orderings Result is OBDD with same ordering Each step polynomial complexity
[From Bryant’s slides]
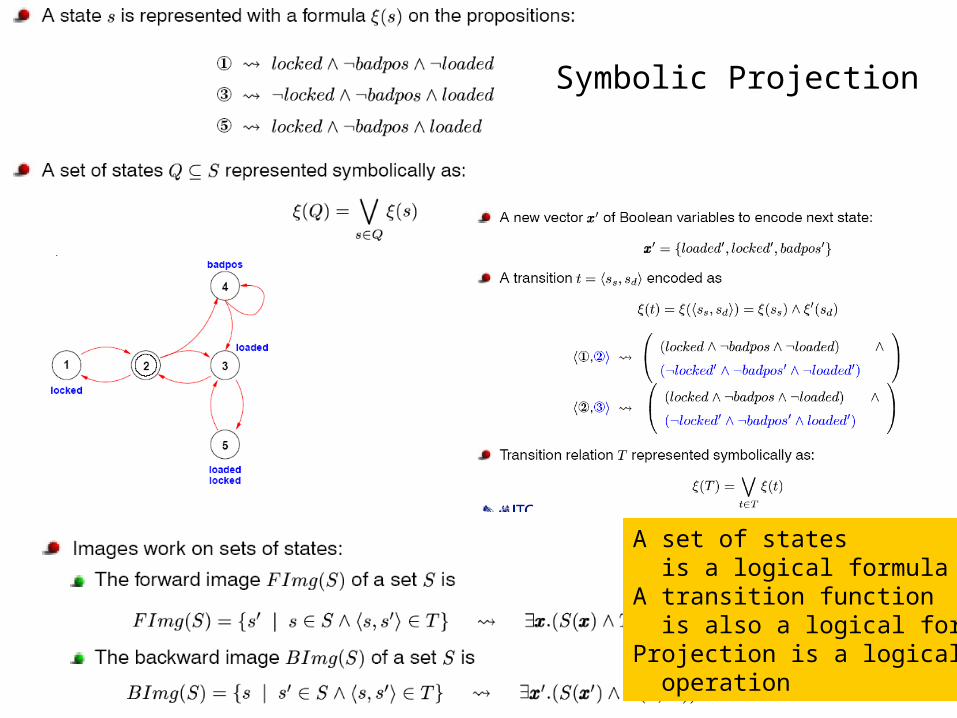
A set of states is a logical formulaA transition function is also a logical formulaProjection is a logical operation
Symbolic Projection
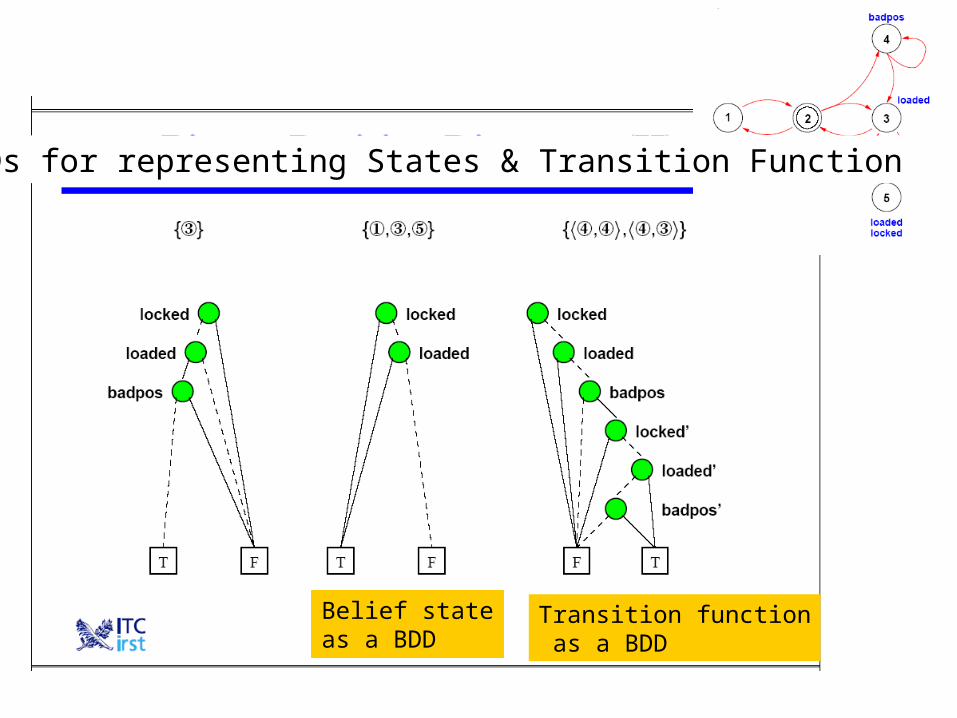
Transition function as a BDD
Belief stateas a BDD
BDDs for representing States & Transition Function
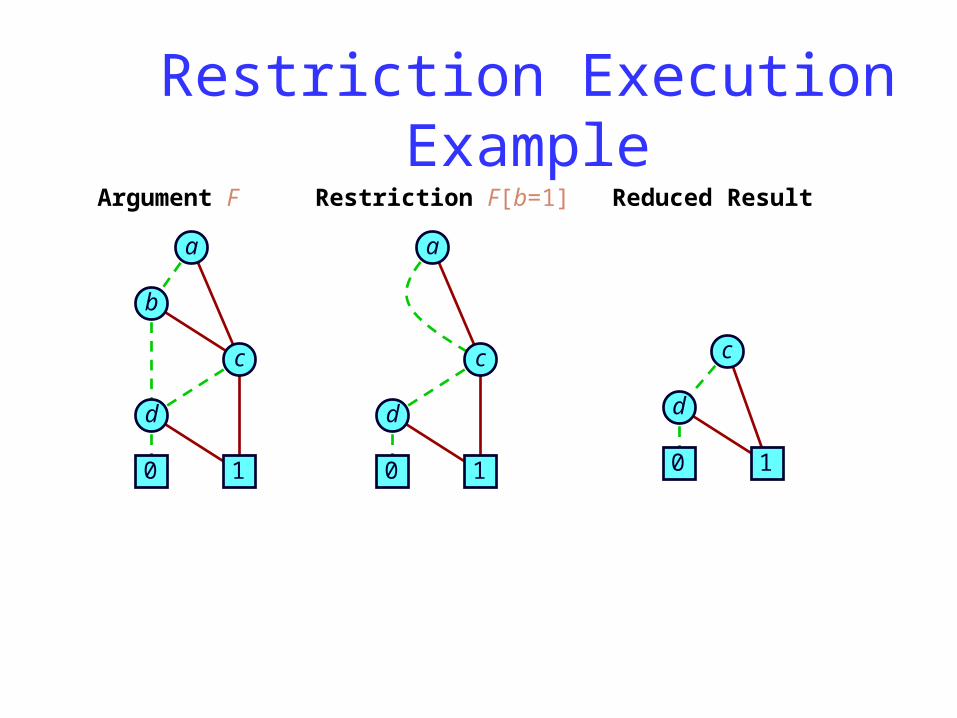
Argument F
Restriction Execution Example
0
a
b
c
d
1 0
a
c
d
1
Restriction F[b=1]
0
c
d
1
Reduced Result


BELIEF-SPACE PLANNING

Belief State Search: An Example Problem
Initial state: M is true and exactly one of P,Q,R are true
Goal: Need G
Actions:A1: M P => KA2: M Q => KA3: M R => LA4: K => GA5: L => G
Init State Formula: [(p & ~q & ~r)V(~p&q&~r)V(~p&~q&r)]&MDNF: [M&p&~q&~r]V[M&~p&~q&~r]V[M&~p&~q&r]CNF: (P V Q V R) & (~P V ~Q) &(~P V ~R) &(~Q V ~R) & M
DNF good for progression(clauses are
partial states)
CNF goodFor regression
Plan: ??

Progression & Regression
Progression with DNF The “constituents” (DNF clauses) look like partial states already. Think of
applying action to each of these constituents and unioning the result Action application converts each constituent to a set of new constituents Termination when each constituent entails the goal formula
Regression with CNF Very little difference from classical planning (since we already had partial
states in classical planning). THE Main difference is that we cannot split the disjunction into search
space Termination when each (CNF) clause is entailed by the initial state
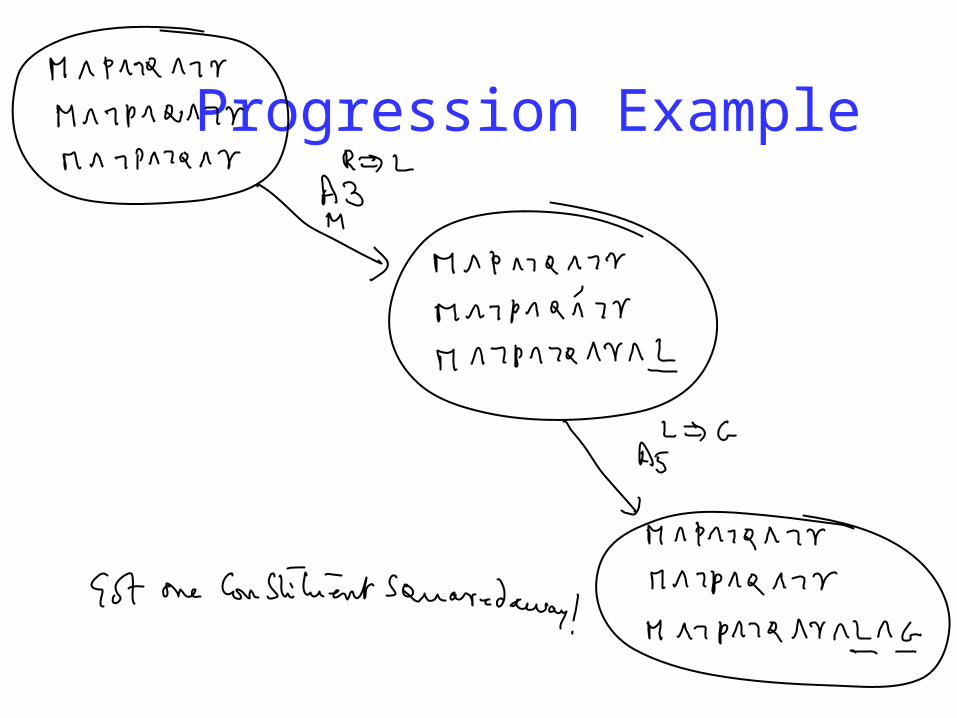
Progression Example
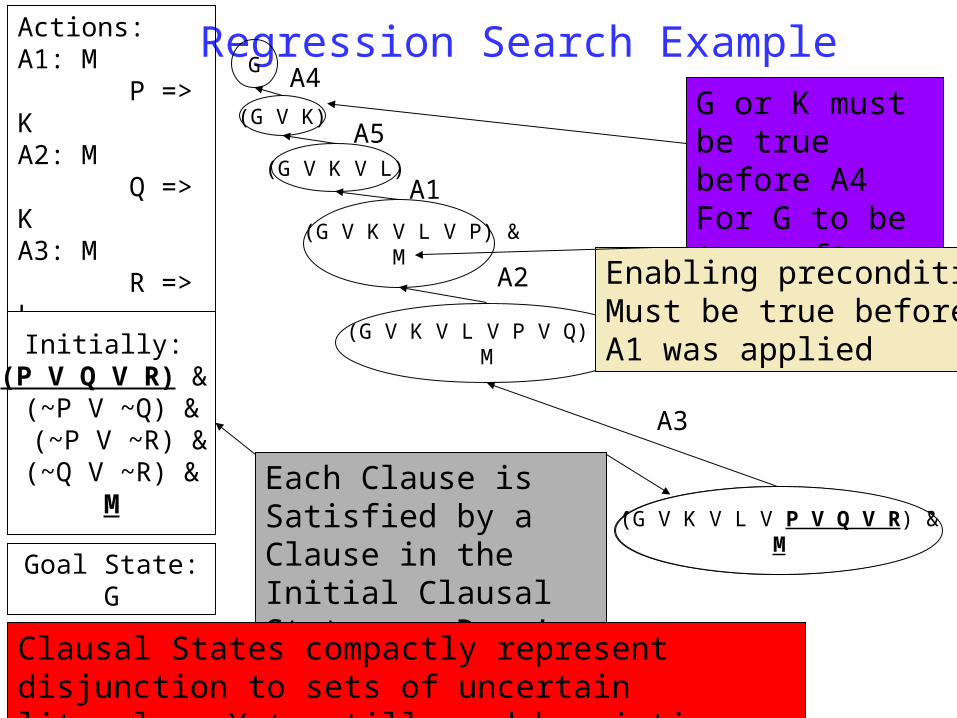
Regression Search ExampleActions:A1: M P => KA2: M Q => KA3: M R => LA4: K => GA5: L => G
Initially: (P V Q V R) &
(~P V ~Q) & (~P V ~R) & (~Q V ~R) &
M
Goal State:G
G
(G V K)
(G V K V L)
A4
A1
(G V K V L V P) & M
A2
A5
A3
G or K must be true before A4For G to be true after A4
(G V K V L V P V Q) & M
(G V K V L V P V Q V R) &M
Each Clause is Satisfied by a Clause in the Initial Clausal State -- Done! (5 actions)
Initially: (P V Q V R) &
(~P V ~Q) & (~P V ~R) & (~Q V ~R) &
M
Clausal States compactly represent disjunction to sets of uncertain literals – Yet, still need heuristics for the search
(G V K V L V P V Q V R) &M
Enabling preconditionMust be true beforeA1 was applied

Sensing: General observations Sensing can be thought in terms of
Speicific state variables whose values can be found OR sensing actions that evaluate truth of some boolean formula
over the state variables. Sense(p) ; Sense(pV(q&r))
A general action may have both causative effects and sensing effects Sensing effect changes the agent’s knowledge, and not the world Causative effect changes the world (and may give certain
knowledge to the agent) A pure sensing action only has sensing effects; a pure causative
action only has causative effects.

Sensing at Plan Time vs. Run Time
When applied to a belief state, AT RUN TIME the sensing effects of an action wind up reducing the cardinality of that belief state basically by removing all states that are not consistent with the sensed
effects AT PLAN TIME, Sensing actions PARTITION belief states
If you apply Sense-f? to a belief state B, you get a partition of B1: B&f and B2: B&~f
You will have to make a plan that takes both partitions to the goal state Introduces branches in the plan
If you regress two belief state B&f and B&~f over a sensing action Sense-f?, you get the belief state B

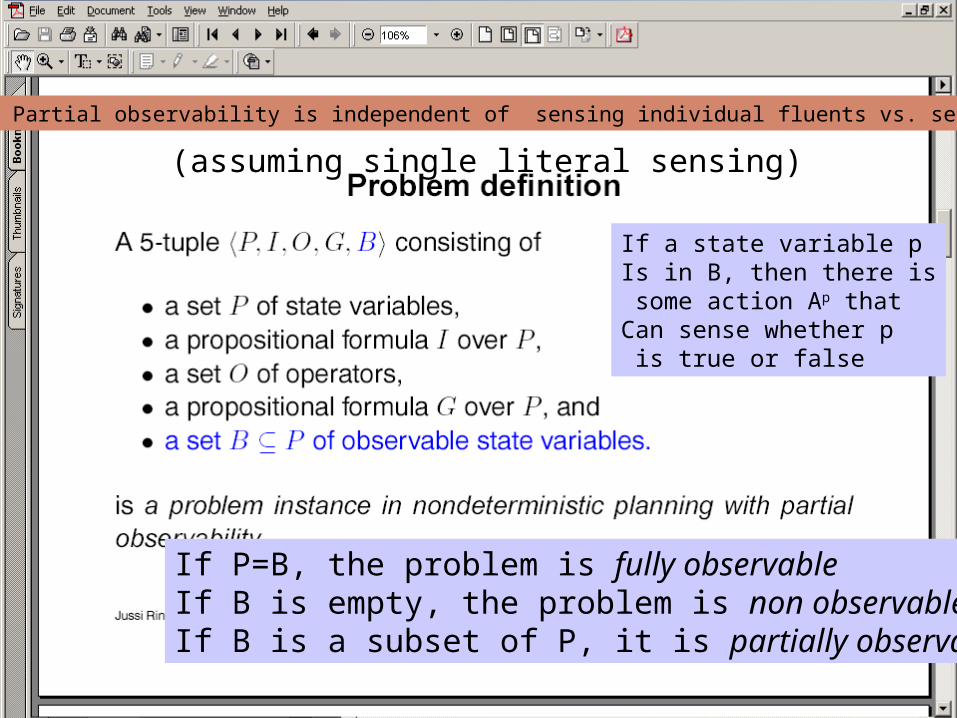
If a state variable pIs in B, then there is some action Ap thatCan sense whether p is true or false
If P=B, the problem is fully observableIf B is empty, the problem is non observableIf B is a subset of P, it is partially observable
Note: Full vs. Partial observability is independent of sensing individual fluents vs. sensing formulas.
(assuming single literal sensing)
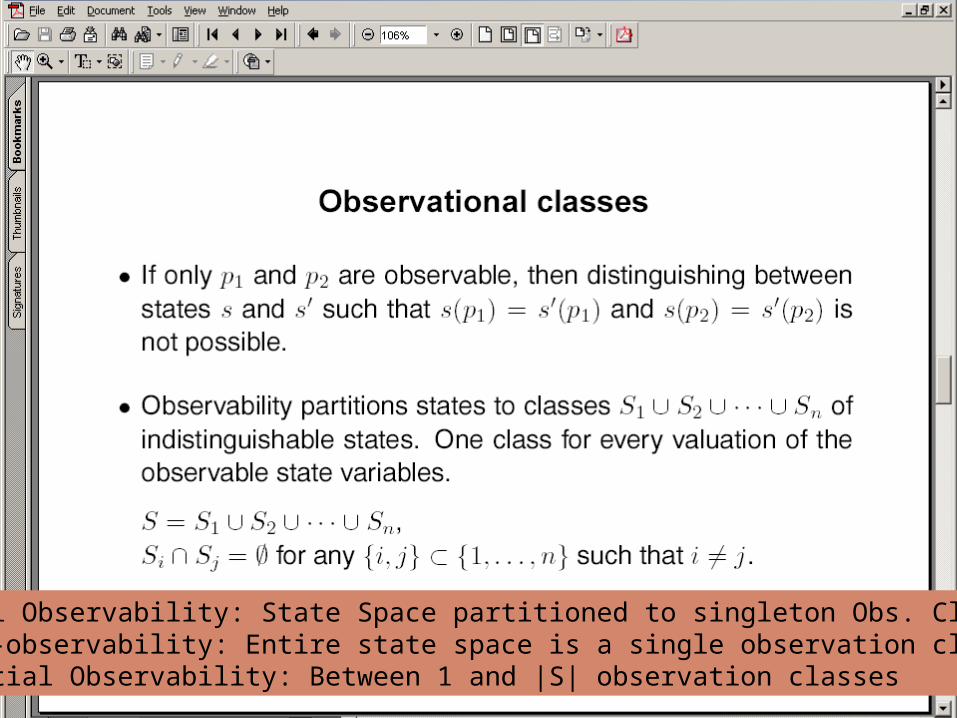
Full Observability: State Space partitioned to singleton Obs. ClassesNon-observability: Entire state space is a single observation class Partial Observability: Between 1 and |S| observation classes


A Simple Progression Algorithm in the presence of pure sensing actions
Call the procedure Plan(BI,G,nil) where Procedure Plan(B,G,P)
If G is satisfied in all states of B, then return P Non-deterministically choose:
I. Non-deterministically choose a causative action a that is applicable in B. Return Plan(a(B),G,P+a)
II. Non-deterministically choose a sensing action s that senses a formula f (could be a single state variable)
Let p’ = Plan(B&f,G,nil); p’’=Plan(B&~f,G,nil) /*Bf is the set of states of B in which f is true */
Return P+(s?:p’;p’’)
If we always pick I and never do II then we will produce conformantPlans (if we succeed).

Very simple ExampleA1 p=>r,~pA2 ~p=>r,p
A3 r=>g
O5 observe(p)
Problem: Init: don’t know p Goal: g
Plan: O5:p?[A1A3][A2A3]
Notice that in this case we also have a conformant plan: A1;A2;A3 --Whether or not the conformant plan is cheaper depends on how costly is sensing action O5 compared to A1 and A2

A more interesting example: MedicationThe patient is not Dead and may be Ill. The test paper is not Blue.We want to make the patient be not Dead and not IllWe have three actions: Medicate which makes the patient not ill if he is illStain—which makes the test paper blue if the patient is illSense-paper—which can tell us if the paper is blue or not.
No conformant plan possible here. Also, notice that I cannot be sensed directly but only through B
This domain is partially observable because the states (~D,I,~B) and (~D,~I,~B) cannot be distinguished

Need for explicit conditioning during regression (not needed for Fully Observable case)
If you have a goal state B, you can always write it as B&f and B&~f for any arbitrary f! (The goal Happy is achieved by achieving the twin goals Happy&rich as well as Happy&~rich) Of course, we need to pick the f
such that f/~f can be sensed (i.e. f and ~f defines an observational class feature)
This step seems to go against the grain of “goal-directedenss”—we may not know what to sense based on what our goal is after all!
Consider the Medicate problem. Coming from the goal of ~D&~I, we will never see the connection to sensing blue!
Notice the analogy to conditioning in evaluating a probabilistic query

Sensing: More things under the mat(which we won’t lift for now )
Sensing extends the notion of goals (and action preconditions). Findout goals: Check if Rao is awake vs. Wake up Rao
Presents some tricky issues in terms of goal satisfaction…! You cannot use “causative” effects to support “findout” goals
But what if the causative effects are supporting another needed goal and wind up affecting the goal as a side-effect? (e.g. Have-gong-go-off & find-out-if-rao-is-awake)
Quantification is no longer syntactic sugaring in effects and preconditions in the presence of sensing actions Rm* can satisfy the effect forall files remove(file); without KNOWING what are the
files in the directory! This is alternative to finding each files name and doing rm <file-name>
Sensing actions can have preconditions (as well as other causative effects); they can have cost
The problem of OVER-SENSING (Sort of like a beginning driver who looks all directions every 3 millimeters of driving; also Sphexishness) [XII/Puccini project] Handling over-sensing using local-closedworld assumptions
Listing a file doesn’t destroy your knowledge about the size of a file; but compressing it does. If you don’t recognize it, you will always be checking the size of
the file after each and every action
Review

Heuristics for Belief-Space Planning

Heuristics for Conformant Planning
First idea: Notice that “Classical planning” (which assumes full observability) is a “relaxation” of conformant planning So, the length of the classical planning solution is a
lowerbound (admissible heuristic) for conformant planning Further, the heuristics for classical planning are also
heuristics for conformant planning (albeit not very informed probably)
Next idea: Let us get a feel for how estimating distances between belief states differs from estimating those between states

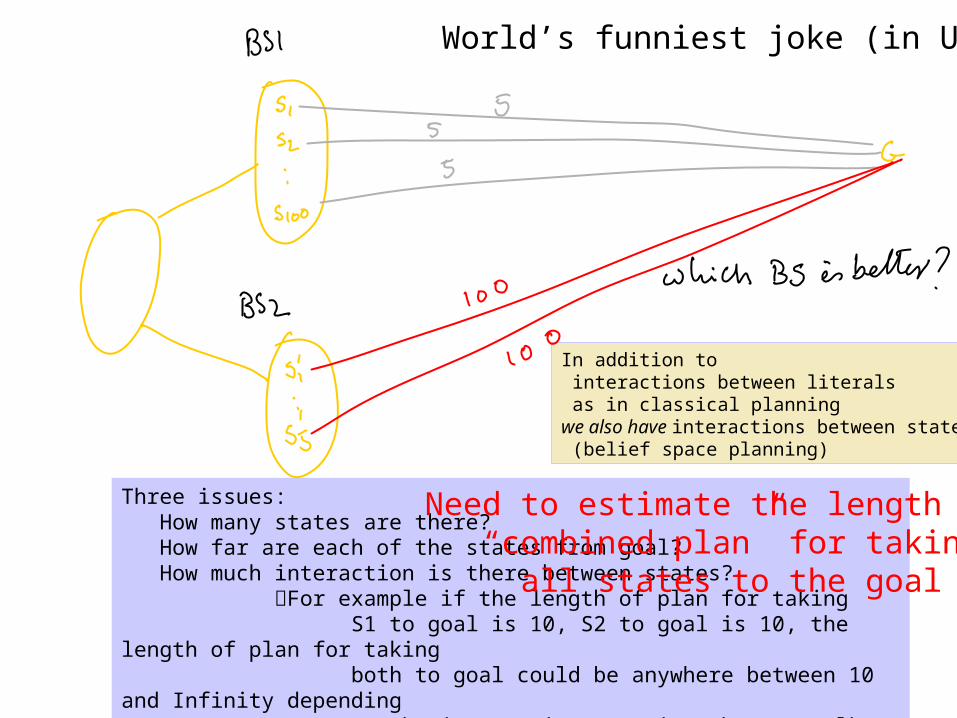
Three issues: How many states are there? How far are each of the states from goal? How much interaction is there between states? For example if the length of plan for taking S1 to goal is 10, S2 to goal is 10, the length of plan for taking both to goal could be anywhere between 10 and Infinity depending on the interactions [Notice that we talk about “state” interactions here just as we talked about “goal interactions” in classical planning]
Need to estimate the length of “combined plan” for taking all states to the goal
World’s funniest joke (in USA)
In addition to interactions between literals as in classical planningwe also have interactions between states (belief space planning)

Belief-state cardinality alone won’t be enough…
Early work on conformant planning concentrated exclusively on heuristics that look at the cardinality of the belief state The larger the cardinality of the belief state, the higher its uncertainty, and the
worse it is (for progression) Notice that in regression, we have the opposite heuristic—the larger the cardinality, the
higher the flexibility (we are satisfied with any one of a larger set of states) and so the better it is
From our example in the previous slide, cardinality is only one of the three components that go into actual distance estimation. For example, there may be an action that reduces the cardinality (e.g. bomb the
place ) but the new belief state with low uncertainty will be infinite distance away from the goal.
We will look at planning graph-based heuristics for considering all three components (actually, unless we look at cross-world mutexes, we won’t be considering the
interaction part…)
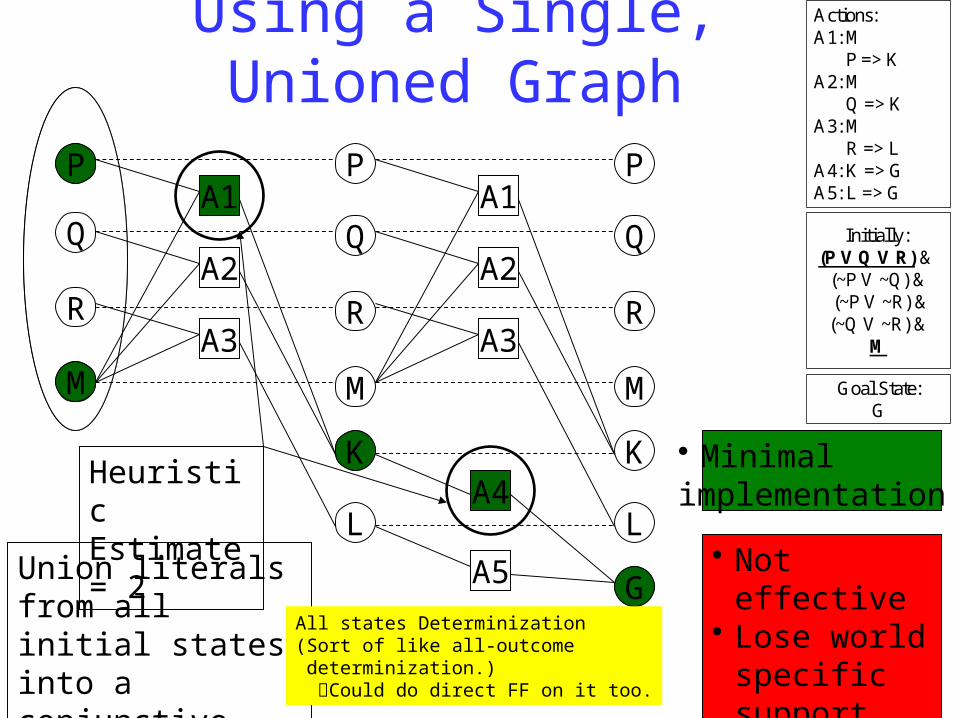
Using a Single, Unioned GraphPM
QM
RM
P
Q
R
M
A1
A2
A3
Q
R
M
K
LA4
GA5
PA1
A2
A3
Q
R
M
K
L
P
G
A4K
A1P
M
Heuristic Estimate = 2
• Not effective• Lose world
specific support information
Union literals from all initial states into a conjunctive initial graph level
• Minimal implementation
Actions:A1: M
P => KA2: M
Q => KA3: M
R => LA4: K => GA5: L => G
Goal State:G
Initially: (P V Q V R) &
(~P V ~Q) &(~P V ~R) &(~Q V ~R) &
M
All states Determinization (Sort of like all-outcome determinization.) Could do direct FF on it too.
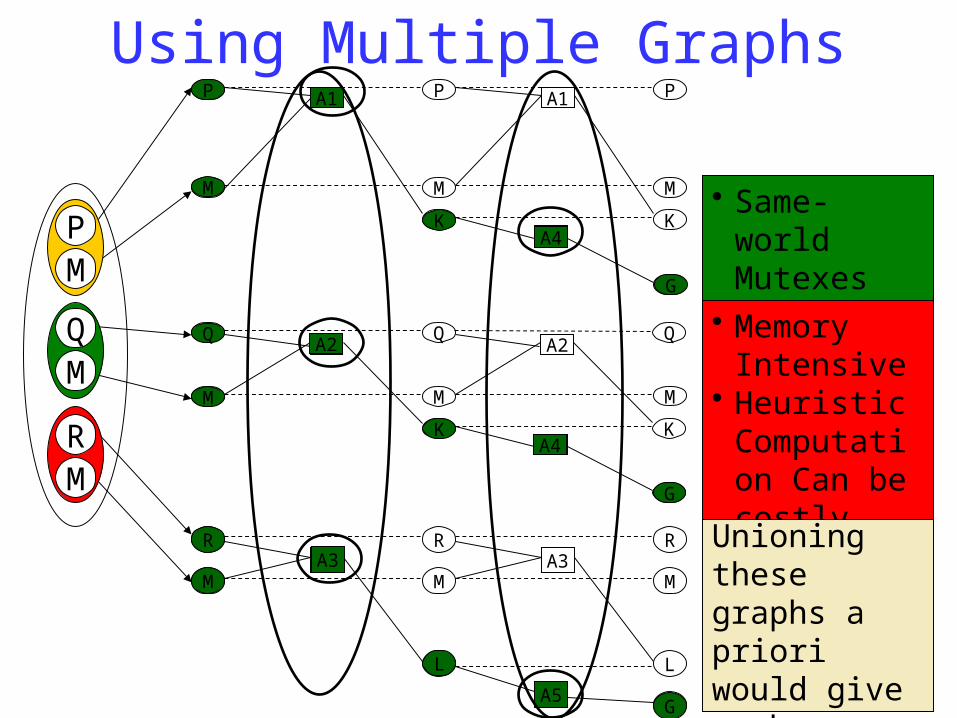
Using Multiple GraphsP
M
A1 P
M
K
A1 P
M
KA4
G
R
MA3
R
M
L
A3R
M
L
GA5
PM
QM
RM
Q
M
A2Q
M
K
A2Q
KA4
G
M
G
A4K
A1
M
P
G
A4K
A2Q
M
GA5
L
A3R
M
• Same-world Mutexes
• Memory Intensive
• Heuristic Computation Can be costly
Unioning these graphs a priori would give much savings …
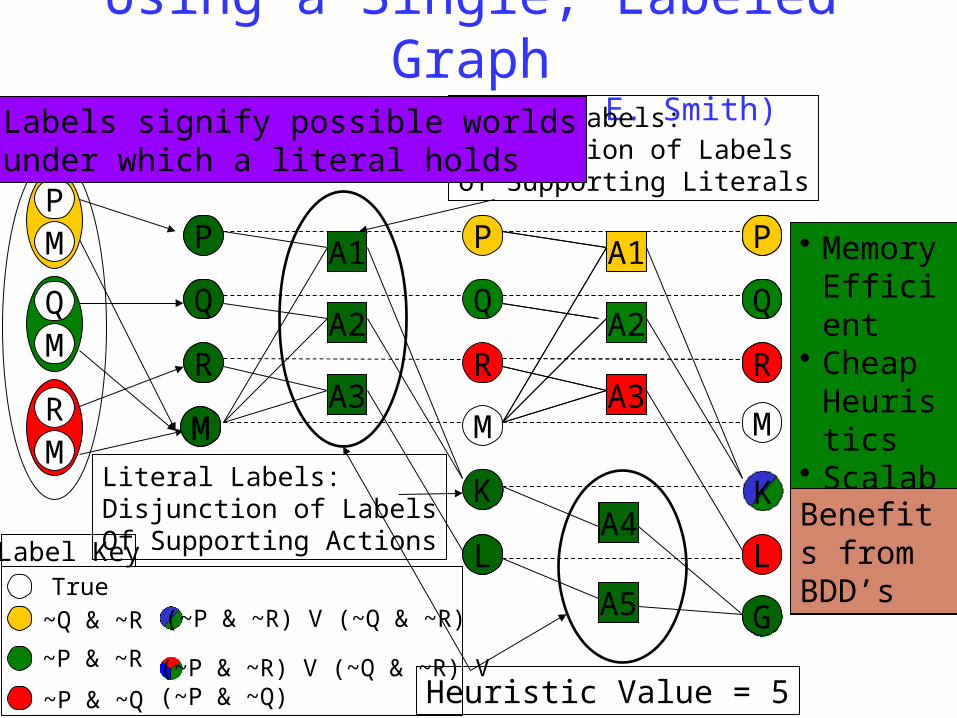
Using a Single, Labeled Graph(joint work with David E. Smith)
P
Q
R
A1
A2
A3
P
Q
R
M
L
A1
A2
A3
P
Q
R
L
A5
Action Labels:Conjunction of Labels of Supporting Literals
Literal Labels:Disjunction of LabelsOf Supporting Actions
PM
QM
RM
KA4
G
K
A1
A2
A3
P
Q
R
M
GA5
A4L
K
A1
A2
A3
P
Q
R
M
Heuristic Value = 5
• Memory Efficient
• Cheap Heuristics
• Scalable• Extensibl
eBenefits from BDD’s
~Q & ~R
~P & ~R
~P & ~Q
(~P & ~R) V (~Q & ~R)
(~P & ~R) V (~Q & ~R) V(~P & ~Q)
M
True
Label Key
Labels signify possible worldsunder which a literal holds

What about mutexes? In the previous slide, we considered only relaxed plans (thus ignoring any
mutexes) We could have considered mutexes in the individual world graphs to get better
estimates of the plans in the individual worlds (call these same world mutexes) We could also have considered the impact of having an action in one world on the
other world. Consider a patient who may or may not be suffering from disease D. There is a medicine M,
which if given in the world where he has D, will cure the patient. But if it is given in the world where the patient doesn’t have disease D, it will kill him. Since giving the medicine M will have impact in both worlds, we now have a mutex between “being alive” in world 1 and “being cured” in world 2!
Notice that cross-world mutexes will take into account the state-interactions that we mentioned as one of the three components making up the distance estimate.
We could compute a subset of same world and cross world mutexes to improve the accuracy of the heuristics… …but it is not clear whether or not the accuracy comes at too much additional cost to
have reasonable impact on efficiency.. [see Bryce et. Al. JAIR]

Heuristics for sensing
We need to compare the cumulative distance of B1 and B2 to goal with that of B3 to goal Notice that Planning cost is related to plan
size while plan exec cost is related to the length of the deepest branch (or expected length of a branch)
If we use the conformant belief state distance (as discussed last class), then we will be over-estimating the distance (since sensing may allow us to do shorter branch)
Bryce [ICAPS 05—submitted] starts wth the conformant relaxed plan and introduces sensory actions into the plan to estimate the cost more accurately
As
A
7
12,000
11,000
300
B1
B2
B3





























