Embed Size (px)
Citation preview

Computational Linguistics Colloquium
Modelling Inflection and Derivation of aMorphologically Rich Language
Jan Snajder
University of Zagreb, Faculty of Electrical Engineering and Computing, TakeLab
Institute for Computational Linguistics, University of HeidelbergDecember 6, 2012
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 1 / 65

Why morphology modelling?
Morphological processing is a prerequisite for many NLP tasks
Typical morphological processing tasks: (1) grouping, (2)segmentation, (3) full morphological analysis
This work focuses on morphological processing for IR/TM:due to morphological variation, the “meaning of a word getsdispersed” among several of its morphological variants
This problem can be addressed by morphological normalization:the grouping of morphologically related words and their replacementwith a single representative form
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 2 / 65

Why Croatian morphology?
Croatian is a heavily under-resourced language
Back in 2007: no morphological analyzer/lexicon
Initial goal: development of a procedure for inflectional andinflectional/derivational morphological normalization for Croatianlanguage suitable for IR/TM applications
Working hypotheses:
1 Positive effect of morphological normalization on IR/TMapplications is depends on the quality of the normalization
2 Due to morphological complexity of Croatian, satisfactory qualitycan only be reached using a linguistically-based approach
Focus gradually shifted towards building a full blown model ofCroatian morphology, suitable for morphological analysis in general
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 3 / 65

Outline
1 Background: morphology
2 Modelling inflection and derivation
3 Lexicon acquisition and paradigm guessing
4 Enter semantics: derivational relations
5 Evaluating morphological normalization
6 Wrap-up and future perspectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 4 / 65

By the end of this talk, you’ll. . .
1 have an impression of how difficult and tedious morphology modellingcan be, and why it’s a good thing that someone else has already doneit for your language
2 be familiar with one particular approach to modelling inflection andderivation
3 have an idea how to acquire a morphological lexicon using amorphology model
4 have a sense of why lexical semantics is important for derivation andvice versa
5 have an idea how one can evaluate morphological normalization
6 know a couple of Croatian words!
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 5 / 65

Outline
1 Background: morphology
2 Modelling inflection and derivation
3 Lexicon acquisition and paradigm guessing
4 Enter semantics: derivational relations
5 Evaluating morphological normalization
6 Wrap-up and future perspectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 6 / 65

Morphology
1 Inflectional morphology deals with how word-forms are formed fromthe stem. Word-forms express grammatical features of the word.
I fish→ fishes, kuca→ kucom, bogat→ najbogatijih
2 Derivational morphology deals with derivation of new words fromthe existing words using derivational affixes.The derived words are possibly of a different POS, but (almostalways) of a different meaning than the basis word.
I fish→ fishery, kuca→ kucanski, bogat→ bogatstvo
Typically accomplished by adding affixes (functional morphemes) to theword’s stem (the part of the word common to all inflectional variants).
3 Compounding deals with word formation that combines two or moreexisting words
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 7 / 65

Morphological typology(Pirkola, 2001)
Morhological complexity is determined by the degree of affixation andthe difficulty of affix segmentation
Traditional morphological typology: isolating, agglutinative,fusional, and polysynthetic languages
Most languages are mixed types. It is possible to describe themorphological complexity of each language using two variables:
I index of synthesis (IS): the amount of affixation (the averagenumber of morphemes per word in a language)
I index of fusion (IF): the ease with which affixes can besegmented in words (the average number of fused words in alanguage)
I defined separately for inflection, derivation, and compounding
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 8 / 65

Croatian morphology
Croatian is a morfologically complex (rich) language:
1 Many grammatical categories
I nouns: case, number; adjectives: case, gender, number,definiteness, degree; verbs: time, person, gender, number. . .
2 Fusion of grammatical categories/suffix ambiguity
I vojnik-e – ruk-e
3 Morphological syncretisms/homography
I pile→ pile/piliti/piti,
4 Alternations:
I vojnik→ vojnice, podatak→ podatci/podaci
5 Many derivational patterns
I iskljuciti – iskljucivati – iskljuciv – iskljucen – iskljucivanje –iskljucivost – iskljucni – . . .
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 9 / 65

Croatian morphology – example
riba ribe ribi ribu ribo ribom ribama ribanje ribanja ribanju ribanjem ribanjima ribar ribara ribaru ribare ribarom ribari ribarima
ribarenje ribarenja ribarenju ribarenjem ribarenjima ribarica ribarice ribarici ribaricu ribarico ribaricom ribaricama ribariti ribarit
ribarim ribaris ribari ribarimo ribarite ribare ribareci ribarivsi ribario ribarila ribarilo ribarili ribarile ribarnica ribarnice ribarnici
ribarnicu ribarnico ribarnicom ribarnicama ribarski ribarskog ribarskoga ribarskom ribarskome ribarskomu ribarskim ribarskih
ribarskima ribarske ribarsko ribarska ribarskoj ribarsku ribarstven ribarstvena ribarstvenu ribarstvenim ribarstveni ribarstvenih
ribarstvenima ribarstvene ribarstveno ribarstvenoj ribarstvenom ribarstveni ribarstvenog ribarstvenoga ribarstvenom ribarstvenome
ribarstvenomu ribarstvenim ribarstvenih ribarstvenima ribarstvene ribarstveno ribarstvena ribarstvenoj ribarstvenu ribarstvo
ribarstva ribarstvu ribarstvom ribarstvima ribarstava ribic ribica ribicu ribicem ribici ribicima ribice ribici ribicija ribiciju ribicijem
ribiciji ribicijima ribicije ribicki ribickog ribickoga ribickom ribickome ribickomu ribickim ribickih ribickima ribicke ribicko ribicka
ribickoj ribicku riblji ribljeg ribljega ribljem ribljom ribljemu ribljim ribljih ribljima riblje riblja ribljoj riblju ribnjak ribnjaka
ribnjaku ribnjace ribnjakom ribnjaci ribnjacima ribnjake ribnjacarski ribnjacarskog ribnjacarskoga ribnjacarskom ribnjacarskome
ribnjacarskomu ribnjacarskim ribnjacarskih ribnjacarskima ribnjacarske ribnjacarsko ribnjacarska ribnjacarskoj ribnjacarsku
ribnjacarstvo ribnjacarstva ribnjacarstvu ribnjacarstvom ribnjacarstava ribnjacarstvima ribnjacki ribnjackog ribnjackoga
ribnjackom ribnjackome ribnjackomu ribnjackim ribnjackih ribnjackima ribnjacke ribnjacko ribnjacka ribnjackoj ribnjacku
ribnjicarstvo ribnjicarstva ribnjicarstvu ribnjicarstvom ribnjicarstvima ribnjicarstava
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 10 / 65

Word-and-paradigm approach
The three basic models of morphology description (Hockett, 1954):
1 Item-and-arrangement (IA) – assumes agglutinative structure
2 Item-and-process (IP), e.g., two-level morphology, (Koskenniemi, 1983)
– assumes agglutinative structure, at least on the lexical level
3 Word-and-paradigm (WP)
Croatian morphology is fusional, hence:
IA is inadequate because one morpheme often expresses manygrammatical features
IP is inadequate because of frequent morphological syncretisms andmorphologically conditioned alternations
In WP, word formation rules are defined w.r.t. the grammatical categories(which may be fused) and the paradigm (a class of rules with similarinflection rules)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 11 / 65

Morphological normalization
Morphological normalization conflates morphological variants of asingle word or many words to a single and unique form, themorphological norm
I {walk,walking,walks,walked} → walkI {fish,fishes,fisher,fishers,fishery, . . . } → fish
Two main approaches:
1 Stemming – reducing of inflectional/derivational variants to a(pseudo)stem
F princesses → princ
2 Lemmatization – reducing of inflectional variants to alinguistically valid, canonical form
F princesses → princess
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 12 / 65

Morphological normalization – typical approaches
Lexicon-based lemmatization
Rule-based stemming
I (Lovins, 1968), (Paice, 1990), (Porter, 1980), Snowball project
Hybrid stemming (rules+corpus)
I (Krovetz, 1993), (Xu & Croft, 1998)
Machine learning-based lemmatization
I (Dzeroski & Erjavec, 2000), (Mladenic, 2002), (Plisson et al., 2008)
Unsupervised stemming (morphology induction)
I (Hafer & Weiss, 1974), (Adamson & Boreham, 1974; Majumder et al.,
2007), (Goldsmith, 2000), (Melucci & Orio, 2003), (Schone &
Jurafsky, 2001), (Goldsmith, 2000; Gelbukh et al., 2004; Majumder
et al., 2007)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 13 / 65

Outline
1 Background: morphology
2 Modelling inflection and derivation
3 Lexicon acquisition and paradigm guessing
4 Enter semantics: derivational relations
5 Evaluating morphological normalization
6 Wrap-up and future perspectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 14 / 65

Higher Order Functional Morphology (HOFM)(Snajder & Dalbelo Basic, 2008)
Inspired by the functional programming paradigm (Hudak, 1989)
I functions as abstractions of inflectional and derivational wordformation rules
I basic rules are modelled as higher-order functions (functionsthat map from/to functions)
I function composition serves to combine rules
Main idea: morphological descriptions that closely resemble thosefound in traditional grammar books
Generative-reductive model
Language-independent model
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 15 / 65

Transformations and HOFs
Transformation function t : S → S defines the stem transformation
The number of different transformation types is limited in practice:suffixation, prefixation, alternations, or combinations thereof
More complex transformations can be defined indirectly using HOFs
sfx : S → (S → S) suffixationpfx : S → (S → S) prefixation
asfx : ℘(S × S)→ (S → S) suffix alternation
sfx (a)
sfx (a)(vojnik) = vojnika
plt = asfx({(k, c), (g, z), (h, s)}
)(sfx (e) ◦ plt)(vojnik) = vojnice
(sfx (emu) ◦ plt ◦ pfx (naj))(jak) = najjacemu
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 16 / 65

Inflectional paradigm
Defines the distinct word-forms (along with the morphological tags)as transformations of the stem, as well as paradigm applicabilityconditions
Inflectional paradigm
p =(c,{(t0, x0), . . . , (ti, xi), . . . , (tn, xn)
})c : S → {>,⊥} – condition on the stemti : S → S – transformation functionsxi – morphological tags
By convention, t0 transforms the stem s into lemma l, i.e., l = t0(s).
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 17 / 65

Inflectional paradigm – example 1
Case Singular Plural
N. vojnik-∅ vojnic-iG. vojnik-a vojnik-aD. vojnik-u vojnic-imaA. vojnik-a vojnik-eV. vojnic-e vojnic-iL. vojnik-u vojnic-imaI. vojnik-om vojnic-ima
pvojnik =(λs.(ends({k, g, h}) ∧ ¬cgr),{
nul , sfx (a), sfx (u), sfx (om), sfx (e) ◦ plt , sfx (i) ◦ sbl , sfx (ima), sfx (e)})
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 18 / 65

Inflectional pattern – example 2
pbrz =(c, Ppi ∪ Ppd ∪ {ti ◦ tc : ti ∈ Pc} ∪ {ti ◦ tc ◦ ts : ti ∈ Ps}
)Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 19 / 65

Derivational pattern(Snajder & Dalbelo Basic, 2010)
Defines the transformation of the basis word into the derived wordand the word classes of the basis and the derived word
Derivational pattern
d = (t,P1,P2)
t the basis word’s stem into the derived word’s lemmaP1 and P2 are the basis and the derived word’s class, respectively
E.g., pattern brz→ brzina:
d1 =(sfx (ina), {pA1, pA2}, {pN2, pN3, pN4}
)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 20 / 65

Derivational pattern
Remarks:
(1) different patterns may be used to derive a word of the samesemantic class
(2) an identical transformation may be used to derive words ofdifferent semantic classes (e.g., suffix ambiguity).If also the word classes of the basis and the derived words areidentical, then the pattern itself is ambiguous.
(1) is not a concern for morphological normalization, while (2) occursrarely and may be ignored
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 21 / 65

Derivation
Derives LPPs given an LPPs and a derivational pattern
lDerive(l1, p1, (t,P1,P2)
)={{
(l2,P∗2 ) : l2 ∈ (t ◦ t−10 )(l1)}
if p1 ∈ P1 ∧ P∗2 6= ∅
∅ otherwise
P∗2 = {p2 ∈ P2 : p2 � l2}
d =(sfx (ak) ◦ try(plt),mNouns,mNouns
)lDerive(smijeh, pN04, d) =
{(smijesak, {pN28, pN47})
}lDerive(struk, pN04, d) =
{(strucak, {pN28, pN47})
}lDerive(jabuka, pN28, d) = ∅
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 22 / 65

HOFM extensions
1 Ambiguous transformations
I transformations modelled as non-functional relationst : S → ℘(S)
I motivated by the fact that many transformations are not injectiveI E.g.,. palatalization: k/c, g/z, h/s, c/c, z/z
(sfx (a) ◦ plt)−1(vojnice) = {vojnik, vojnic}
2 Morphological optionality
I modelling doublets and conditioning of alternations(sfx (i) ◦ opt(sbl)
)(tvrtk) = {tvrtci, tvrtki}(
sfx (ovi) ◦ try(rifx (ije, je)
)(cvijet) = {cvjetovi}
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 23 / 65

Model of Croatian morphology
Transformations
I suffixation, prefixation, phonologically and morhologicallyconditioned alternations
Inflectional morphology
I 93 paradigms: 48 for nouns, 32 for verbs and 13 for adjectivesI morphosyntactic tags according to MULTEXT-East (Erjavec
et al., 2003)
Derivational morphology
I 244 patterns for suffixal derivation between and among nouns,verbs, and adjectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 24 / 65

Model of Croatian morphology – transformations
Function Description Example of application
rsfx Stem suffix replacement rsfx (ij, ik)(akademija) = {akademik}sfx Suffixation sfx (a) = (vojnik) = {vojnika}pfx Prefixation (pfx (naj) ◦ sfx (a) ◦ jot)(brz) = {najbrzi}
pca1 PC stem alternation 1 (sfx (a) ◦ pca1 )(vrabc) = {vrapca}pca2 PC stem alternation 2 (pca2 ◦ sfx (ba))(svat) = {svadba}
sbl Sibilarization (sfx (i) ◦ sbl)(vojnik) = {vojnici}plt Palatalization (sfx (e) ◦ plt)(vojnik) = {vojnice}jot Jotation (jot(u) ◦ jot)(krv) = {krvlju}acg Consonant group alternation (sfx (u) ◦ acg)(mast) = {mascu}exa Stem extension with a (sfx (a) ◦ exa)(vrabc) = {vrabaca}exe Stem extension with e exa(Cakovc) = {Cakovec}jat1 Yat reflex alternation ije/je (sfx (ovi) ◦ jat1 )(snijeg) = {snjegovi}jat2 Yat reflex alternation ije/e (sfx (ovi) ◦ jat2 )(brijeg) = {bregovi}jat3 Yat reflex alternation ije/i (sfx (vati) ◦ jat3
−1)(izli) = {izlijevati}
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 25 / 65

Model of Croatian morphology – derivational patternsGroup Semantic category of the derived word # Example
N-1 Masculine agent nouns 21 banka→ bankarN-2 Masculine noun expressing a characteristic 5 sretan→ sretnikN-3 Masculine nouns for a follower 3 Franjo→ franjevacN-4 Female person nouns 11 prijatelj → prijateljicaN-5 Nouns for male and female person 5 izdati→ izdajicaN-6 Demonyms and ethnonyms 11 Varazdin→VarazdinacN-7 Nouns for animals and plants 6 otrovan→ otrovnicaN-8 Nouns for inanimate objects 11 mijenjati→mjenjacN-9 Nouns for places 9 cigla→ ciglanaN-10 Abstract nouns 18 prijatelj → prijateljstvoN-11 Deverbal (action) nouns 24 cuvati→ cuvanjeN-12 Diminutives and augmentatives 19 orah→ orascicN-13 Collective nouns 7 radnik→ radnistvoN-14 Other types of nouns 6 brod→ brodarina
A-1 Qualifying adjectives 35 mrak→mracanA-2 Possessive adjectives 19 djed→ djedovA-3 Passive verb adjectives 9 spasiti→ spasen
V-1 Imperfective verbs 12 baciti→ bacatiV-2 Diminutive and pejorative verbs 6 govoriti→ govorkatiV-3 Verbs derived from nouns 5 vecera→ veceratiV-4 Verbs derived from adjectives 2 sitan→ sitniti
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 26 / 65

Derivational transformations
1 Phonologically conditioned alternations are implicit in the model(attempted before every suffixation)
I d = (sfx (ski),nouns, pAdjectives)klub→ klupski , but automat→ automatski
2 Morphologically conditioned alternations are modelled explicitly
I d = (sfx (avati) ◦ try(jot), tiVerbs, tiVerbs)onecistiti→ oneciscavati , but odobriti→ odobravati
3 Transformation ambiguity 1: multiple derivations are possible
I d = (sfx (ovit) ◦ try(jat1|jat2),mNouns, qAdjectives)brijeg→ bregovit/brjegovit
4 Transformation ambiguity 2: inconsistencies
I d = (sfx (ar) ◦ opt(jot), fNouns,mNouns)tvornica→ tvornicar , but biblioteka→ bibliotekar
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 27 / 65

Outline
1 Background: morphology
2 Modelling inflection and derivation
3 Lexicon acquisition and paradigm guessing
4 Enter semantics: derivational relations
5 Evaluating morphological normalization
6 Wrap-up and future perspectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 28 / 65

Lexicon acquisition(Snajder et al., 2008)
Due to grammar ambiguity (overgeneration), a single word-formmay allow for the application of many inflectional patterns
⇒ Each word-form is lemmatized to 17 candidate LPPs on average(despite condition functions)
Morphological normalization that would make a direct use of thegrammar (reductive direction) would lack precision
The way to address this is to first use the grammar to acquire alexicon from corpus, and then to use the lexicon for normalization
An inflectional lexicon is a set of entries, each entry being a set ofLPPs
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 29 / 65

Acquisition algorithm in a nutshell
1 Apply the grammar in reductive direction on a chosen word-formfrom corpus in order to obtain a set of LPP candidates.One (or more, in case of homography) of the obtained LPPs will becorrect, while the others are spurious
2 Apply the grammar in generative direction on each LPP candidatein order to generate all its word-forms
3 Score the plausibilty of each LPP candidate based on the frequencyinformation from the corpus
I It is assumed that a correct LPP will have more of its word-formsattested in the corpus; spurious LPPs tend to generate invalid(non-existent) word-forms
I The best scored LPP consitutes a new lexicon entryI If there’s a tie, the best scored LPPs constitue an unresolved
lexicon entry
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 30 / 65

Acquisition algorithm – example
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 31 / 65

Acquisition algorithm
acquireLexicon(W0) = acquire(W0)
function acquire(W ) returns a set of lexicon entries {Ei}if W 6= ∅ thenw = (any ◦ wfpref )(W )
LPP ={(l, p) ∈ lmP(w) : accept(W, l, p)
}if LPP 6= ∅ then
bLPP = argmax(l,p)∈LPPscore(W0, l, p)
E = {lpp ∈ LPP : tie(W0, blf , lf )}WFS =
⋃(l,p)∈E lWfs(l, p)
return {E} ∪ acquire(W \WFS )else
return acquire(W \ {w})else
return ∅
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 32 / 65

LPP scoring measures
Basic (frequency-based) measures:
score0(W, l, p) = |lWfs(p, l) ∩W |score1(W, l, p) =
∑w∈lWfs(p,l)#(w,W0)
score2(W, l, p) = |lWfs(p, l) ∩W | / |lWfs(p, l)|
Heuristic measure:
scoreH(W, l, p) = 10 · score1(W, l, p) + β1 + β2
β1 =
4 if p ∈ PN0 if p ∈ PAqd
2 otherwiseβ2 =
{1 if l ∈W0
0 otherwise
Probabilistic measures:defined based on the expected distribution of word-forms P (t|p)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 33 / 65

LPP scoring measures – evaluation
Measure P R F1
All 4,33 100 8,29Arbitrary 0,40 0,40 0,40
score0 36,66 98,40 53,42score1 36,98 98,80 53,81score2 70,29 77,60 73,76
scoreH 70,78 94,00 80,76
scoreP1 74,28 82,00 77,95scoreP2 71,27 76,40 73,75scoreP3 65,25 67,60 66,40
score02 79,43 89,60 84,21score12 79.79 90.00 84.59score1P2 80,00 91,20 85,23score1P3 87,65 88,00 87,82
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 34 / 65

A machine learning approach: paradigm guessing(Snajder, 2012)
Guess the inflectional paradigm (and lemma) of a given word-form
1 Use the grammar (reductive+generative direction) to generatecandidate LPPs
2 Use supervised machine learning to train a model to decidewhich LPPs is correct based on a number of features
We focus on machine learning aspects: what are the relevant featuresand how well can we do?
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 35 / 65

Paradigm guessing – problem definition
Given word-form w, determine its correct stem s and its correctinflectional paradigm p
Given p, the lemma l can be derived from the stem s and vice versa,thus the problem can be re-casted as:
Problem definition
Given word-form w, determine its correct lemma-paradigm pair (LPP)(l, p). LPP is correct iff l is valid and p generates the valid word-forms ofthe stem obtained from l.
⇒ Binary classification problem (which candidate LPP is correct?)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 36 / 65

Features
String-based features – orthographic properties of lemma/stem
I incorrect LPPs tend to generate ill-formed stems/lemmas
Corpus-based features – frequencies or probability distributions ofword-forms/morphological tags in the corpus
I a correct LPP should have more of its word-forms attested in thecorpus
I every inflectional paradigm has its own distribution ofmorphological tags P (x|p). A correct LPP will generateword-forms that obey such a distribution
Other features – paradigmId and POS
22 features in total (146 binary-encoded features)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 37 / 65

String-based features
1 EndsIn
2 EndsInCgr
3 EndsInCons
4 EndsInNonPals
5 EndsInPals
6 EndsInVelars
7 LemmaSuffixProb – the probability P (sl|p)8 StemSuffixProb – the probability P (ss|p)9 StemLength
10 NumSyllables
11 OneSyllable
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 38 / 65

Corpus-based features
1 LemmaAttested
2 Score0 – number of attested word-form types
3 Score1 – sum of corpus frequencies of word-forms
4 Score2 – proportion of attested word-form types
5 Score3 – product of P (x|p) and P (x|l, p)6 Score4 – expected number of attested word-form types
7 Score5 – Kullback-Leibler divergence between p1 = P (x|p) andp2 = P (x|l, p)
8 Score6 – Jensen-Shannon divergence between p1 and p2
9 Score7 – cosine similarity between p1 and p2
Estimated on Vjesnik newspaper corpus (23 MW)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 39 / 65

Experimental setting
SVM with an RBF kernel (#features � #examples)
Training/testing data: hand-validated automatically acquiredinflectional lexicon
Positive examples: LPPs sampled from the lexicon – 5,000 fortraining and 5,000 for testing
Negative examples: generated using the grammar – 5,000 fortraining and 5,000 for testing
Total: 10,000 examples for training and 10,000 examples for testing
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 40 / 65

Evaluation – feature analysis
Some features are redundant while others may be irrelevant
Top-5 features with univariate filter selection:
I IG: StemSuffixProb, LemmaSuffixProb, Score6, Score5, Score7I GR: StemSuffixProb, LemmaSuffixProb, LemmaAttested, Score0,
Score5I RELIEF: ParadigmId, EndsIn, LemmaSuffixProb, Score5, Score2
Some features consistently low-ranked (e.g. POS, Score1)
Multivariate feature subset selection:
I CFS: StemSuffixProb, LemmaAttested, Score0I CSS: . . . (13 features)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 41 / 65

Evaluation – classification accuracy
Word-forms attested
Features (count) ≥ 1 ≤ 100 ≤ 10
All (22) 91.97 91.94 90.65String-based (13) 87.01 87.69 87.98Corpus-based (11) 87.78 86.59 82.04IG (5) 81.14 79.05 76.46GR (5) 59.76 80.90 77.29RELIEF (5) 90.62 90.60 89.27CFS (3) 81.69 79.51 78.67CSS (13) 27.41 91.56 90.37
Baseline 50.00 56.51 69.92
Subset of 5 features gives almost as good results as the full feature set
Decrease of accuracy on rare words is minimal
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 42 / 65

Outline
1 Background: morphology
2 Modelling inflection and derivation
3 Lexicon acquisition and paradigm guessing
4 Enter semantics: derivational relations
5 Evaluating morphological normalization
6 Wrap-up and future perspectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 43 / 65

Derivational relation
A derivational pattern implicitly defines a derivational relationbetween LPPs as a binary relation on S × P:
Derivational relation →d
(l1, p1)→d (l2, p2) ⇐⇒ (l2,P∗2 ) ∈ lDerive(d, l1, p1) ∧ p2 ∈ P∗2
E.g. (smijeh, pN04)→d (smijesak, pN47) holds, but(smijeh, pN04)→d (strucak, pN47) doesn’t
→d does not imply actual derivational relatedness. It merely implies:
I surface-forms matchI lexical categories match
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 44 / 65
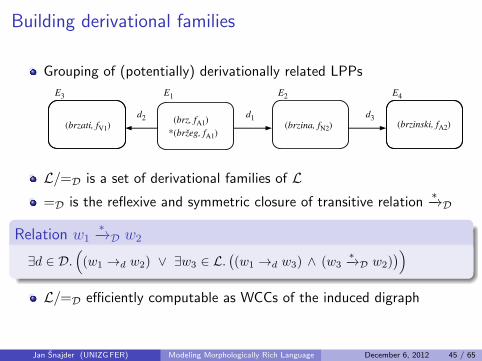
Building derivational families
Grouping of (potentially) derivationally related LPPs
L/=D is a set of derivational families of L=D is the reflexive and symmetric closure of transitive relation
∗−→D
Relation w1∗−→D w2
∃d ∈ D.((w1 →d w2) ∨ ∃w3 ∈ L.
((w1 →d w3) ∧ (w3
∗−→D w2)))
L/=D efficiently computable as WCCs of the induced digraph
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 45 / 65
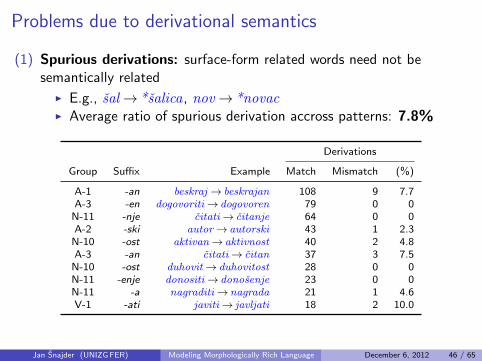
Problems due to derivational semantics
(1) Spurious derivations: surface-form related words need not besemantically related
I E.g., sal→ *salica, nov→ *novacI Average ratio of spurious derivation accross patterns: 7.8%
Derivations
Group Suffix Example Match Mismatch (%)
A-1 -an beskraj → beskrajan 108 9 7.7A-3 -en dogovoriti→ dogovoren 79 0 0
N-11 -nje citati→ citanje 64 0 0A-2 -ski autor→ autorski 43 1 2.3
N-10 -ost aktivan→ aktivnost 40 2 4.8A-3 -an citati→ citan 37 3 7.5
N-10 -ost duhovit→ duhovitost 28 0 0N-11 -enje donositi→ donosenje 23 0 0N-11 -a nagraditi→nagrada 21 1 4.6V-1 -ati javiti→ javljati 18 2 10.0
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 46 / 65

Problems due to derivational semantics
(2) Vagueness and ambiguity of semantic relations
1 Semantic shift (strength of relation)baciti→ bacati vs. baciti→ bacac
2 Polysemyizdavac – izdati – izdajica
3 Non-denotational aspects of meaning (register, connotation)cinovnik – cinovnicic
4 “Distance” of derivational relationsluga – sluziti – sluzben
5 Opaqueness (idioms, methaphors)morski pas
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 47 / 65

Strength of derivational relations
To prevent loss of information, derivational normalization may berestricted to specific subsets of the derivational patterns.
Derivational relations may be grouped according to the perceivedstrength of semantic relation:
Level 1 – strong relatedness: A-2, V-1(possesive adjectives and aspectual verb pairs)
Level 2 – moderate relatedness: A-1, A-3, V-3, V-4, N-4, N-11(descriptive and deverbal adjectives, verbs from adjectives and nouns,male/female noun pairs, deverbal nouns)
Level 3 – weak relatedness: all other groups
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 48 / 65

Derivational lexica
Equivalence classes over the inflectional lexicon:
Class size
Lexicon Entries Reduction (%) Average Maximum
L5 47,415 – – –L5-D1 44,477 6.20 1.07 5L5-D2 38,158 19.52 1.24 19L5-D3 34,310 27.64 1.38 53
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 49 / 65

Outline
1 Background: morphology
2 Modelling inflection and derivation
3 Lexicon acquisition and paradigm guessing
4 Enter semantics: derivational relations
5 Evaluating morphological normalization
6 Wrap-up and future perspectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 50 / 65

Evaluating morphological normalization
As usual, we can take two approaches:
1 Extrinsic evaluation – measures the effect on an IR/IE task2 Intrinsic evaluation – measures directly the quality of
morphological normalization
Extrinsic evaluation is important, but it does not give us an insightinto how the normalization procedure works
More importantly, extrinsic evaluation does not differentiate betweenthe cases in which normalization fails and the cases in which it isuseless
We focus on intrinsic evaluation
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 51 / 65

Intrinsic evaluation
Error counting method according to (Paice, 1996)
1 Understemming – not conflating morphologically relatedword-forms to the same stem (norm)fishery→ fisher, fisher→ fishslikom→ slik, slici→ slic
2 Overstemming – conflating morphologically unrelatedword-forms to the same stem (norm)divison→ div, divine→ divstanom→ stan, stanica→ stan
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 52 / 65

Intrinsic evaluation
Errors are counted on a manually compiled sample of word groups
Understemming index:
UI =#(pairs in each group normalized to different norms)
#(pairs in the group)
Overstemming index:
OI =#(pairs from different groups normalized to the same norm)
#(pairs in the group)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 53 / 65

Stemming indices – example
UI =1 · 3 + 1 · 1 + 1 · 3 + 0(
52
)+(22
) =7
10= 63.6%
OI =5 · 1 + 5 · 1(
72
) =11
21= 47.6%
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 54 / 65

Word sample
Determining group boundaries is notoriously difficult
Paice groups at two levels: “tight” and “loose” groups
The division is based on (an estimate of) the strength of semanticrelation
Problem: lexical semantics enters into the play(degree of similarity? polysemy? what is tight and what is loose?)
(1) {appriopriate, appropriately} {appropriations}
(2) {author, author’s, authors, autorship}
(3) {authoritarian} {authoritative} {authority, authorities}{authorized} {authorization}
(4) {cost, costing, costed, costs} {costly}
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 55 / 65

Modified Paice’s method(Snajder, 2010)
Grouping accoring to morphological, rather than lexico-semanticrelations:
1 Inflectional groups2 Derivational groups
Under- and overstemming errors are considered independently of thesemantic errors ⇒ morphology and semantics are kept apart
Simplifies grouping:
I The boundary between morphology and semantics is well defined(except perhaps for a few derivations)
I The boundary between inflection and derivation is well defined
Semantics is kept out of the picture and can be addressed separately(“semantically agnostic” evaluation)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 56 / 65

Word sample
10,000 word-forms from the Vjesnik corpus (Culture section)
5510 inflectional groups (on average 1.82 word-forms)
3773 derivational groups (on average 1.46 inflectional groups)
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 57 / 65

Word sample – example
(1) {arheolog} {arheologija, arheologiju}{arheoloska, arheoloske, arheoloski, arheoloskih}
(2) {arhitekt, arhitekta} {arhitekturi, arhitekturama}{arhitektonske, arhitektonskih, arhitektonskim}
(3) {arhiva, arhivima, arhivu} {arhivske, arhivskim, arhivskoj}{arhivar}
(4) {arija, arije, ariju}
(5) {izdajicom} {izdatke} {izdat, izdati} {izdaje, izdavati}{izdaje, izdajom} {izdanja, izdanje, izdanjem, izdanjima}{izdavaca, izdavace, izdavaci} {izdavacka}
(6) {grad, grada,grade, gradom, gradova} {gradska, gradske}
(7) {grade, gradimo, graditi} {gradnja, gradnje}
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 58 / 65

Measuring stemming quality
Trade-off between under- and overstemming
Inflectional/derivational stemming quality:
iSQ =2(1− iUI )(1− iOI )
2− iUI − iOIdSQ =
2(1− dUI )(1− dOI )
2− dUI − dOI
(iUI , iOI – on inflectional groups; dUI , dOI – on derivational groups)
Steming evaluated separatelly on inflectional/derivational level
In general, normalization may occur at both levels. Separate indicesdon’t tell us much about the stemming quality in such cases
But how much derivational normalization is “right”?
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 59 / 65

Measuring stemming quality
Inflectional word-forms must be conflated to a single norm, whereasderivationally unrelated word-forms must not
Combined inflectional-derivational stemming quality:
idSQ =2(1− iUI )(1− dOI )
2− iUI − dOI
Full inflectional conflation is the lower, while full derivationalconflation the upper bound for stemming; between these there is a“semantic gray area” (due to derivation)
Perfect stemmers will have idSQ = 1, but may still differ in howmuch derivation they address
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 60 / 65

Comparison of stemming quality
Method % iUI % iOI % iSQ % dOI % idSQ % dSS
Lexicon-based normalization:L5 5.79 5.56 94.32 3.15 95.51 1.47L5-D1 5.61 18.25 87.62 3.04 95.66 10.71L5-D2 5.02 47.07 67.98 9.52 92.68 41.09L5-D3 4.85 57.66 58.60 14.97 89.81 58.51
String prefix (baseline)P-6 44.98 50.82 51.94 6.22 69.35 30.43P-5 28.82 62.58 49.05 17.09 76.60 52.78P-4 16.40 77.86 35.01 46.01 65.61 73.37
Suffix stripping:S-1 47.76 15.39 64.60 5.76 67.22 3.63S-2 23.80 17.69 79.14 6.84 83.84 6.13
String-based distance clustering:D-1 34.25 19.30 72.46 3.45 78.23 7.88D-2 19.42 46.55 64.27 8.22 85.82 35.26D-3 13.91 61.79 52.93 18.34 83.82 59.70
Lemmatization:HML 5.62 1.96 96.17 0.36 96.94 0.94
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 61 / 65

Comparison of stemming quality
0
10
20
30
40
50
0 10 20 30 40 50
%dO
I (de
rivac
ijsko
pre
korje
nova
nje)
%iUI (flektivno potkorjenovanje)
P-4
P-5
P-6
L5 L5-D1
L5-D2
L5-D3
S-1
S-2
D-1
D-2
D-3
HML
P-4
P-5
P-6
DP-n
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 62 / 65

Outline
1 Background: morphology
2 Modelling inflection and derivation
3 Lexicon acquisition and paradigm guessing
4 Enter semantics: derivational relations
5 Evaluating morphological normalization
6 Wrap-up and future perspectives
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 63 / 65

Wrap-up
A generative-reductive model of inflection and derivation based onfunctional programming concepts
Inflectional model is used for lexicon acquisition from raw corpus
The correct inflectional paradigm can be guessed fairly accuratelyusing a supervised model with a couple of features
Derivational model may be used for derivational normalization, butthen the nature of derivational semantics must be taken into account,e.g., by restricting to specific derivational patterns
Morphological normalization can be evaluated intrinsically, taking intoaccount both inflection and derivation, but keeping semanics out ofthe picture
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 64 / 65

Future perspectives: DISMODS
DISMODS = Distributional Models of Derivational Semantics
Analyse the representation of derivationally related word pairs independency-based semantic space models
Construct representations of derivational processes in semanticspaces in order to support the automatic computation of semanticrepresentations of morphologically derived terms
Investigate how such models can be used to improve informationretrieval
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 65 / 65

Adamson, G., & Boreham, J. 1974.The Use of an Association Measure Based on Character Structure to Identify SemanticallyRelated Pairs of Words and Document Titles.Information Processing and Management, 10(7/8), 253–260.
Dzeroski, Saso, & Erjavec, Tomaz. 2000.Learning to Lemmatise Slovene Words.Pages 69–88 of: Learning language in logic, Lecture notes in computer science.
Erjavec, T., Krstev, C., Petkevic, V., Simov, K., Tadic, M., & Vitas, D. 2003.The MULTEXT-East Morphosyntactic Specifications for Slavic Languages.Pages 25–32 of: Proceedings of the EACL2003 Workshop on Morphological Processing ofSlavic Languages.
Gelbukh, Alexander, Alexandrov, Mikhail, & Han, Sang-Yong. 2004.Detecting Inflection Patterns in Natural Language by Minimization of MorphologicalModel.Progress in Pattern Recognition, Image Analysis and Applications, LNCS, 3287, 432–438.
Goldsmith, John. 2000.Automatic Language-Specific Stemming in Information Retrieval.Revised Papers from the Workshop of Cross-Language Evaluation Forum onCross-Language Information Retrieval and Evaluation, LNCS, 2069, 273–284.
Hafer, M., & Weiss, S. 1974.Word Segmentation by Letter Successor Varieties.Information Processing and Management, 10(11/12), 371–386.
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 65 / 65

Hockett, C. F. 1954.Two models of Grammatical Description.Word, 10, 210–234.
Hudak, Paul. 1989.Conception, evolution, and application of functional programming languages.ACM Computing Surveys, 21(3), 359–411.
Koskenniemi, K. 1983.Two-Level Morphology: A General Computational Model for Word-Form Recognition andProduction.Helsinki: Publications of the Department of General Linguistics, University of Helsinki.
Krovetz, R. 1993.Viewing Morphology as an Inference Process.Pages 191–203 of: Proceedings of the Sixteenth Annual International ACM SIGIRConference on Research and Development in Information Retrieval.
Lovins, Julie Beth. 1968.Development of a Stemming Algorithm.Translation and Computational Linguistics, 11(1), 22–31.
Majumder, Prasenjit, Mitra, Mandar, Parui, Swapan K., Kole, Gobinda, Mitra, Pabitra, &Datta, Kalyankumar. 2007.YASS: Yet another suffix stripper.ACM Transactions on Information Systems, 25(4), 18:1–18:20.
Melucci, Massimo, & Orio, Nicola. 2003.Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 65 / 65

A Novel Method for Stemmer Generation Based on Hidden Markov Models.Pages 131–138 of: Proceedings of CIKM’2003.
Mladenic, Dunja. 2002.Learning Word Normalization Using Word Suffix and Context from Unlabeled Data.Pages 427–434 of: Proceedings of the Nineteenth International Conference on MachineLearning, ICML 2002.
Paice, C. D. 1990.Another Stemmer.ACM SIGIR Forum, 24, 56–61.
Paice, C. D. 1996.Method for Evaluation of Stemming Algorithms Based on Error Counting.Journal of the American Society for Information Science, 47(8), 632–649.
Pirkola, Ari. 2001.Morphological Typology of Languages for IR.Journal of Documentation, 57(3), 330–348.
Plisson, Joel, Lavrac, Nada, Mladenic, Dunja, & Erjavec, Tomaz. 2008.Ripple Down Rule learning for automated word lemmatisation.AI Communications, 21(1), 15–26.
Porter, M. F. 1980.An Algorithm for Suffix Stripping.Program, 14(3), 130–137.
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 65 / 65

Schone, P., & Jurafsky, D. 2001.Knowledge-free Induction of Inflectional Morphologies.Pages 1–9 of: Proceedings of the North American Chapter Of The Association ForComputational Linguistics, NAACL 2001.
Snajder, Jan. 2010.Morfoloska normalizacija tekstova na hrvatskome jeziku za dubinsku analizu ipretrazivanje informacija.Ph.D. thesis, University of Zagreb, Faculty of Electrical Engineering and Computing,Zagreb.
Snajder, Jan. 2012.Guessing the Correct Inflectional Paradigm of Uknown Croatian Words.Pages 185–190 of: Proceedings of the Eight Language Technologies Conference(IS-JT’2012).
Snajder, Jan, & Dalbelo Basic, Bojana. 2008.Higher-Order Functional Representation of Croatian Inflectional Morphology.Pages 121–130 of: Proceedings of the 6th International Conference on Formal Approachesto South Slavic and Balkan Languages, FASSBL6.Dubrovnik, Croatia: Croatian Language Technologies Society.
Snajder, Jan, & Dalbelo Basic, Bojana. 2010.A Computational Model of Croatian Derivational Morphology.Pages 109–117 of: Proceedings of the 6th International Conference on Formal Approachesto South Slavic and Balkan Languages, FASSBL7.Dubrovnik, Croatia: Croatian Language Technologies Society.
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 65 / 65

Snajder, Jan, Dalbelo Basic, Bojana, & Tadic, Marko. 2008.Automatic Acquisition of Inflectional Lexica for Morphological Normalisation.Information Processing and Management, 44(5), 1720–1731.
Xu, Jinxi, & Croft, W. Bruce. 1998.Corpus-Based Stemming using Cooccurrence of Word Variants.ACM Transactions on Information Systems, 16(1), 61–81.
Jan Snajder (UNIZG FER) Modeling Morphologically Rich Language December 6, 2012 65 / 65





























