Embed Size (px)
Citation preview

Optimization SpaceExploration of the FastFlowParallel Skeleton Framework
Alexander Collins Christian Fensch Hugh Leather
University of EdinburghSchool of Informatics

What We Did
I Parallel skeletons provide easy abstraction forparallel programs
I Contain many manually tuned parameters
I Automatically tuning provides betterperformance
I Preliminary results that make auto-tuningfaster
1

Motivating Example
2

Motivating Example
2

Motivating Example
2

Motivating Example
2

Motivating Example
2

Motivating Example
2
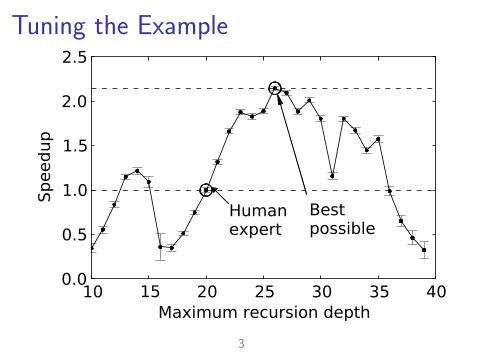
Tuning the Example
10 15 20 25 30 35 40Maximum recursion depth
0.0
0.5
1.0
1.5
2.0
2.5Sp
eedu
p
Humanexpert
Bestpossible
3

What Next?
I Humans failed
I Auto-tuning wonI Can we do even better?
I Multiple parametersI Multiple programsI Multiple platforms
4

Optimization Space Exploration
5

Parameters Investigated
I Number of workers
I Bounded or unbounded queues
I Size of queue’s buffer
I Cache alignment
I Maximum recursion depth
I Batch size
6

Speedup over a Human Expert
7

Speedup over a Human Expert
8

Speedup over a Human Expert
9

Visualising the Optimisation Space
10

Visualisation of Optimisation Space
11

Reducing the Size of the Search Space
I Two methods:I Remove useless parametersI Exploit linear dependencies
12

What is a Useless Parameter?
13

What is a Useful Parameter?
14

Removing Useless Parameters
buffertypecachealign
buffersizeseqthresh
batchsizenumworkers
Parameter
0%
10%
20%
30%
40%
50%Av
erag
e pe
rform
ance
loss
I Reduces size of search space by 6×
15

Exploiting Linear Dependencies
16

Exploiting Linear Dependencies
17

Exploiting Linear Dependencies
18

Conclusions
I Tuning parameters is very important
I Humans are bad at tuning
I Auto-tuning is much better
I Tuning is program and platform dependent
I Have shown preliminary results that makeauto-tuning faster
19

Optimization SpaceExploration of the FastFlowParallel Skeleton Framework
Alexander Collins Christian Fensch Hugh Leather
University of EdinburghSchool of Informatics

Speedup over a Human Expert
aquad cwc dtfibonacci
mandelbrotmatmul
nqueenspbzip2
quicksort swps3Average
1
2
3
4
5
6
78
Spee
dup
desktop phantom scuttle xxxii16 xxxii Average

Principal Components Analysis
N = 6 P = 5624
p =
(batchsize, buffersize, buffertype,cachealign, numworkers, seqthresh
)λ = (0.443, 0.419, 0.204, 0.138, 0.007, 0.003)
e =
0.023 0.814 −0.000 −0.003 −0.580 0.013
−0.015 0.581 0.002 0.002 0.814 −0.014−0.115 −0.001 0.005 −0.000 0.015 0.993
0.993 −0.010 −0.000 −0.001 0.028 0.115−0.001 −0.001 0.003 −1.000 0.003 −0.001−0.001 0.001 −1.000 −0.003 0.002 0.005
ν = (36%, 70%, 87%, 99%, 99%, 100%)

Is the subset representative?
0 500 1000 1500 2000
60%80%
100%
desk
top
0 500 1000 1500 2000
60%80%
100%
phanto
m
0 500 1000 1500 2000 2500 3000
60%80%
100%
Perc
enta
ge o
f best
pro
gra
m p
erf
orm
ance
scutt
le
0 500 1000 1500 2000 2500
60%80%
100%
xxxii1
6
0 1000 2000 3000 4000 5000 6000
Number of iterations
60%80%
100%
xxxii
Pla
tform

Programs
Program Description
aquad Adaptive Quadrature algorithm
cwc Implementation of CWC, a calculus for the representation andsimulation of biological systems
dt Implementation of the C4.5 decision tree algorithm
fibonacci Naıve recursive algorithm, without memoization, to computeFibonacci numbers
mandelbrot Mandelbrot fractal generator
matmul O(n3) nested-loops matrix multiplication
nqueens n-queens problem solver
pbzip2 Parallel bzip2 compression
quicksort Parallel quicksort
swps3 Smith-Waterman algorithm for gene sequence alignment

Platforms
Platform Processor Cores Freq. Memory L3 L2
xxxii 4× IntelXeonL7555
32 1.87GHz 64GB 4×24MB
32×256KB
xxxii16 2× IntelXeonL7555
16 1.87GHz 64GB 2×24MB
16×256KB
scuttle AMDPhenom IIX6 1055T
6 3.3GHz 8GB 1×6MB
1×512KB
phantom Intel XeonE5430
4 2.67GHz 8GB None 2×6MB
desktop Intel Core2 DuoE6400
2 2.13GHz 3GB None 1×2MB

Parameter Values
Parameter Values
numworkers 1, . . . , # cores × 1.5
buffertype Bounded or unbounded
buffersize 1, 2, 4, 8, . . . , 220
batchsize 1, 2, 4, 8, . . . , 220
cachealign 64, 128 or 256 bytes
seqthresh with aquad 0.02, 0.04, 0.06, . . . , 1
seqthresh with fibonacci 10, 11, 12, . . . , 44
seqthresh with nqueens 3, 4, 5, . . . , 15
seqthresh with quicksort 1, 2, 4, 8, . . . , 221

Outlier Removal
I Arithmetic mean is not a robust statistic
I An outlier will cause many more repeats
I Impractical
I Remove using interquartile range removal:[Q1 − k(Q3 − Q1),Q3 + k(Q3 − Q1)
]with k = 3

Quantifying Noise
I Repeats allow quantification ofnoise:
I Perform between 10 and 100repeats
I Stop if coefficient of variationdrops below 1% for a 99%confidence interval
I Use the arithmetic mean as anestimator of execution time
I And confidence intervals tocompare execution times

Skeletons Provided by FastFlow
I farm
I farm-with-feedback
I pipe










