Embed Size (px)
Citation preview

ISBN : 978-602-440-582-3 Perikanan
PT Penerbit IPB Press Jalan Taman Kencana No. 3, Bogor 16128 Telp. 0251 - 8355 158 E-mail: [email protected]
@IPBpress ipbpress Penerbit IPB Press
&
&

Teori & Aplikasi dalam
Bidang Perikanan


Teori & Aplikasi dalam Bidang
Perikanan
Penulis:
Dr Muhammad Yusuf, SPi, MSi
Dr Lukman Daris, SPi, MSi
Penerbit IPB Press Jalan Taman Kencana No. 3
Bogor - Indonesia
C01/11.2018

Judul Buku: Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
Penulis: Dr Muhammad Yusuf, SPi, MSi Dr
Lukman Daris, SPi, MSi
Editor: Dr Ismail Marsuki, SSi, MSi
Penyunting Bahasa: Fatrisia Ratnasari
Desain Sampul: Ahmad Syahrul Fakhri
Penata Isi: Alfyandi
Korektor: Dwi M Nastiti
Jumlah Halaman: 204 + 8 halaman romawi
Edisi/Cetakan: Cetakan Pertama, November 2018
PT Penerbit IPB Press Anggota IKAPI Jalan Taman Kencana No. 3, Bogor 16128 Telp. 0251 - 8355 158 E-mail: [email protected]
ISBN: 978-602-440-582-3
Dicetak oleh IPB Press Printing, Bogor - Indonesia Isi di Luar Tanggung Jawab Percetakan
© 2018, HAK CIPTA DILINDUNGI OLEH UNDANG-UNDANG Dilarang mengutip atau memperbanyak sebagian atau seluruh isi buku tanpa
izin tertulis dari penerbit

PRAKATA
Berbagai tools analysis dalam statistika, tidak hanya memberikan
kemudahan dalam analisis data penelitian tetapi juga seringkali
menimbulkan kebingungan dalam aplikasinya, disebabkan adanya
berbagai asumsi atau syarat yang harus dipenuhi, seperti syarat uji
statistik parametrik, di mana data harus berdistribusi normal, dan varian
(ragam) homogen. Uji statistik yang baik, tidak hanya mensyaratkan uji
data, tetapi juga uji instrumen, terutama pada penelitian yang
menggunakan kuesioner/angket sebagai instrumen pengumpulan data.
Pemilihan tools analysis yang tepat akan memberikan hasil yang benar.
Analisis Data menjadi bagian yang sangat penting dalam penelitian.
Pemahaman yang baik terhadap data (jenis, sumber, dan ukuran),
pengolahan data (tabulasi, input, uji instrumen, dan uji data) hingga uji
statistik menjadi mutlak, agar hasil penelitian sesuai dengan tujuan yang
ingin dicapai.
Buku ini diharapkan dapat memberikan pemahaman yang baik terkait
Analisis Data Penelitian khusunya pada bidang Perikanan, mulai definisi
dan konsepsi hingga aplikasinya dalam software statistik. Dalam buku ini,
dipaparkan tentang; jenis, sumber dan ukuran data, gambaran software
yang umum digunakan dalam analisis statistik, metode tabulasi dan input
data, uji instrumen, uji data, analisis statistik deskriptif, statistik
univariate, bivariate, dan multivariate, statistik parameterik dan non-
parameterik hingga pemodelan (SEM).
Bogor, Oktober 2018
Penulis,


DAFTAR ISI
PRAKATA ........................................................................................ 6
DAFTAR ISI................................................................................................ 8
BAB 1 DEFINISI & KONSEPSI ..................................................................... 1
BAB 2 JENIS, SUMBER, DAN UKURAN DATA ............................................. 7
BAB 3 TABULASI & INPUT DATA ............................................................. 34
BAB 4 UJI INSTRUMEN ........................................................................... 50
BAB 5 UJI DATA ...................................................................................... 67
BAB 6 STATISTIK DESKRIPTIF .................................................................. 88
BAB 7 STATISTIK UNIVARIATE ................................................................ 99
BAB 8 STATISTIK BIVARIATE ................................................................. 110
BAB 9 STATISTIK MULTIVARIATE .......................................................... 118
BAB 10 STATISTIK PARAMETRIK ........................................................... 142
BAB 11 STATISTIK NON-PARAMETRIK .................................................. 166
BAB 12 STRUCTURAL EQUATION MODEL (SEM) .................................. 189
REFERENSI ............................................................................................ 200
GLOSARIUM ......................................................................................... 207
INDEKS ................................................................................................. 212
RIWAYAT PENULIS ................................................................................ 217



BAB 1 DEFINISI &
KONSEPSI
Definisi dan konsepsi terkait data menjadi sangat penting. Data
merupakan input yang menentukan output “garbage in-garbage out”.
Data di zaman revolusi industri 4.0 saat ini juga menjadi hal yang sangat
menentukan. Pemanfaatan data pengguna Facebook oleh Cambridge
Analytica telah menentukan kemenangan Donald Trump dalam Pilpres
USA 2016. Donald Trump telah membuktikan keampuhan penggunaan
big data dalam politik.
Sebuah Pameo benar adanya ”Siapa yang menguasai informasi (data)
maka dia akan menguasai dunia”
... Basically, our goal is to organize the world’s information and to make it
universally accessible and useful ...
[Larry Page - CEO Google]
1.1. Konsepsi Data Pengolahan data adalah proses tranformasi data dengan suatu metode
analisis tertentu yang telah baku (valid) untuk memperoleh sebuah hasil
berupa informasi yang dapat menggambarkan data ataupun menjadi
dasar pengambilan keputusan. Judd et al. (1989) that data analysis is a
process of inspecting, cleansing, transforming, and modeling data with
the goal of discovering useful information, informing conclusions, and
supporting decision-making. Data Analysis is the process of systematically
applying statistical and/or logical techniques to describe and illustrate,
condense and recap, and evaluate data. Data analysis is a processfor
obtaining raw data and converting it into information useful for
decisionmaking by users. Data is collected and analyzed to answer
questions, test hypotheses or disprove theories.
Prinsipnya, pengolahan data merupakan sebuah proses yang terdiri atas;
input, process, output. Input merupakan masukan data yang telah valid
(processed data). Process merupakan tahapan mengubah data (input)

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
2
menjadi sebuah informasi. Sedangkan, output merupakan hasil analisis
berupa informasi yang memberikan gambaran data ataupun dasar dalam
pengambilan keputusan.
Data adalah catatan atas kumpulan fakta yang belum memiliki makna,
baik berupa simbol/lambang, angka, dan lain sebagainya. Data secara
garis besar dikelompokkan menjadi dua yakni 1) data mentah (raw
data/unprocessed data) dan 2) data uji (processed data). Data mentah
(unprocessed data) merupakan data yang belum dikoreksi atau data yang
belum valid. Data mentah (raw data) perlu dikoreksi/divalidasi untuk
menghilangkan pencilan data sehingga data valid digunakan sebagai
input analisis.
Penggunaan kata atau istilah “data” dalam bahasa Inggris pertama kali
pada tahun 1946, sedangkan ungkapan “pemrosesan data” pertama kali
digunakan pada tahun 1954. Meskipun perdebatan klasik tentang kata
“data” telah terjadi pada tahun 1920’s. Istilah umum untuk kata “data”
merupakan bentuk jamak dan umum digunakan, sedangkan bentuk
tunggalnya adalah “datum”.
Dalam Kamus English Oxpord Data didefinisikan “In Latin, data is the
plural of datum and, historically and in specialized scientific fields, it is
also treated as a plural in English, taking a plural verb, as in the data were
collected and classified. In modern non-scientific use, however, despite
the complaints of traditionalists, it is often not treated as a plural. Instead,
it is treated as a mass noun, similar to a word like information, which
cannot normally have a plural and which takes a singular verb. Sentences
such as data was (as well as data were) collected over a number of years
are now widely accepted in standard English”. Bab 1
Definisi & Konsepsi
input process output

The word data is the plural of Latin datum. A large class of practically
important statements are measurements or observations of variable.
Such statements may comprise numbers, words, or images” (Wikipedia,
2005). Datum is the representation of concepts or other entities, fixed in
or on a medium in a form suitable for communication, interpretation, or
processing by human beings or by automated systems (Wellisch 1996).
Menurut Webster New World Dictionary, data is things known or
assumed, yang berarti bahwa data itu sesuatu yang diketahui, yang
berarti telah terjadi dan merupakan fakta (bukti). Data dapat
memberikan gambaran tentang suatu keadaan atau kejadian. Data bisa
juga didefinisikan sebagai sekumpulan informasi atau nilai yang diperoleh
dari pengamatan (observasi) suatu objek.
Pengolahan data sangat bergantung pada tujuan analisis atau tujuan
penelitian yang dilakukan. Demikian halnya pada bidang perikanan,
analisis data yang dilakukan sangat terkait dengan tujuan pengumpulan
data yang dilakukan, seperti hubungan upaya penangkapan dengan hasil
tangkapan atau efektivitas penangkapan ikan, efektivitas perlakuan
dalam rancangan percobaan hingga pada aspek pemasaran produk
perikanan serta persepsi masyarakat/nelayan.
Data tidak hanya berfungsi sebagai sumber atau input dalam proses
pengolahan data, tetapi juga sebagai basis/dasar untuk membuat
keputusan, dasar suatu perencanaan, alat pengendali terhadap
pelaksanaan atau implementasi suatu aktivitas dan dasar evaluasi
terhadap suatu kegiatan/program.
1.2 Definisi Data Data didefinisikan sebagai deskripsi atau keterangan sebuah objek yang
belum memiliki makna secara utuh, dapat berupa angka (numeric),
karakter (text), gambar (image), suara (sound) ataupun lambang
(symbol). Beberapa definisi data menurut ahli, antara lain:
▪ Liew (2013) Data are recorded (captured and stored) symbols and
signal readings. Symbols include words (text and/or verbal),
numbers, diagrams, and images (still &/or video), which are the

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
4
building blocks of communication. Signals include sensor and/or
sensory readings of light, sound, smell, taste, and touch.
3
▪ Liew (2007) As symbols, ‘Data’ is the storage of intrinsic meaning, a
mere representation. The main purpose of data is to record activities
or situations, to attempt to capture the true picture or real event.
▪ Ackoff (1989) Data are defined as symbols that represent properties
of objects, events, and their environment.
▪ Bierly III, Kessler, & Christensen (2000) Data are representations
whose meanings are dependent upon the representation system (i.e.
symbols, language) used.
▪ Hoppe, Seising, Nurnberger, & Wenzel (2011) Data is given by simple
sequences of signs and symbols.
▪ Jankowski & Skowron (2007) Data is understood as a stream of
symbols data are primitive symbolic entities.
▪ Zins (2007) Data are sets of characters, symbols, numbers and audio/
visual bits that are represented and/or encountered in raw form.
▪ Davis (2002) Data merupakan bahan mentah bagi informasi yang
dirumuskan sebagai kelompok lambang-lambang tidak acak yang
menunjukkan tindakan-tindakan, hal-hal, dan sebagainya. Data
dibentuk dari lambang grafis seperti *, $ , &.
▪ Vardiansyah (2008) Data adalah catatan atas kumpulan fakta.
Arikunto (2002) Data sebagai semua fakta dan angka-angka yang
dapat dijadikan bahkan untuk menyusun sebuah informasi.
▪ Jogiyanto (2005) Data merupakan kenyataan yang menggambarkan
suatu kejadian-kejadian dan kesatuan nyata. Bab 1
Definisi & Konsepsi
Kotak 1:

Data akan sangat menentukan tingkat validitas model (output) yang
dihasilkan. Salah satu hal yang sangat menentukan tingkat validitasnya
adalah kesesuaian antara jenis data dan tools analysis (analysis
statistics) yang digunakan. Selanjutnya output dari tools analysis yang
digunakan akan menjawab tujuan analisis yang dilakukan. Data yang
baik adalah yang memenuhi syarat; objektif, representatif, up to date,
dan relevan atau sesuai dengan tujuan kajian.
Data merupakan sesuatu yang belum memiliki makna spesifik dan
sangat minim informasi. Sementara, informasi merupakan data yang
telah memiliki informasi tertentu.
1.3. Konsepsi Software Software/aplikasi hanya merupakan alat bantu analisis, pada prinsipnya
“Garbage In – Garbage Out” sehingga tujuan dan data dalam setiap
rencana analisis menjadi sangat penting. Secara makro, dasar keilmuan
software adalah Statistika, Ilmu Komputer, dan Ilmu Terapan yang terkait
dengan tujuan software, seperti Ilmu Perikanan dan Kelautan. Meskipun
demikian, terdapat beberapa software yang tidak spesifik untuk bidang
tertentu, seperti software statistik umumnya dapat digunakan untuk
kelompok keilmuan eksakta seperti; Ilmu Pertanian, Perikanan, Kelautan,
Peternakan, dan sebagainya maupun Kelompok Ilmu-ilmu Sosial, dan
Kelompok Ilmu Humaniora.
Berikut adalah beberapa definisi yang terkait dengan software dan
analisis:
▪ Hardware/perangkat keras adalah komponen fisik yang digunakan
sebagai bagian dari pengolahan data; PC, laptop, notebook, dan
lainlain. Terdiri dari: hardware input (keyboard, mouse); pemrosesan
(processor), dan output (monitor, speaker, printer).

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
6
5
▪ Software/perangkat lunak adalah suatu perangkat sistem yang
digunakan dalam pengolahan data, terdiri dari sistem operasi &
sistem aplikasi; Microsoft Excel, Excel Stat, SPSS, Minitab, SAS, SEM
(Lisrel, AMOS), EVIEWS, R-Software, STAT, Maple, AcrGis/ArcView/
ERMAPPER/ERDAS, Powersim/Vensim/Stella/Ithink/Madona,
SWOT/ AHP/ISM/PPA/ANP; Aplikasi Grab, Gojek (lebih populer
berbasis mobile, software-nya atau lazim disebut Android (Android
Inc. & Google), IOS (Apple), Windows Phone (Microsoft) etc.
▪ Tools adalah bagian dari software/aplikasi yang merupakan sub-sub
menu yang telah dirancang sesuai dengan kebutuhan dan kegunaan
software dengan formula/bahasa programming tertentu. Tools
merupakan formula matematika/statistik yang merupakan bagian
dari software/aplikasi, seperti Tools Analysis Descriptive, Analisis
Regresi, dan lain-lain).
Kotak 2:
Basis utama software adalah sistem komputer (bahasa programming),
terdiri atas; Sistem Operasi (OS; Windows XP, Linux, Vista Mac dsb.) dan
Sistem Aplikasi (Microsoft Office; Aplikasi Pengolah Kata/Word, Aplikasi
Angka atau Data/Excel, PPT, Publisher, Aplikasi Gambar Corel, Adobe
Photoshop, dan sebagainya). Di sisi lain software sangat terkait dengan
data. Aplikasi software dalam buku ini meliputi; aplikasi Microsoft
Excel, SPSS, dan MINITAB.
Software dalam perkembangan saat ini secara garis besar dapat
dikelompokkan berdasarkan basis pembuatannya (software building),
yakni software berbasis DESKTOP, software berbasis WEBSITE, dan
software berbasis ANDROID/IOS.

BAB 2 JENIS,
SUMBER, &
UKURAN DATA
Data tidak hanya terkait jenis, sumber, dan ukuran, tetapi juga terkait 3V;
volume (jumlah data/ukuran), velocity (aliran data/real time), dan variety
(ragam/format data)...
... Technology is just a tool. In terms of getting the kids working
together and motivating them, the teacher is the most important ...
[Bill Gates - CEO Microsoft]
2.1 Jenis Data Jenis data didefinisikan sebagai pengelompokan data berdasarkan
kriteria tertentu, seperti data berdasarkan sumbernya, berdasarkan
sifatnya, berdasarkan waktu pengumpulannya, berdasarkan susunannya,
berdasarkan notasinya, dan berdasarkan teknik pengukurannya, atau
berdasarkan ukurannya. Jenis data akan sangat menentukan teknik
analisis data (pengolahan data) yang akan digunakan.
Data berdasarkan sumbernya
1. Data Primer; data yang diperoleh atau dikumpulkan oleh peneliti
secara langsung atau pertama kali. Nazir (1988) menyebutkan bahwa
data primer merupakan data yang diperoleh secara langsung dari
lapangan/objek penelitian, baik berupa pengukuran, pengamatan
maupun wawancara. Data primer umumnya diperoleh langsung dari
objek penelitian, seperti data hasil pengukuran, observasi ataupun
wawancara dengan responden. Contoh: data kuesioner atau hasil
wawancara nelayan, wawancara pakar, dan lain-lain.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
8
2. Data Sekunder; data yang diperoleh atau dikumpulkan dari
sumbersumber yang telah ada atau telah dikumpulkan sebelumnya
oleh peneliti/lembaga lainnya. Nasution (2011) menyebutkan bahwa
data sekunder adalah data hasil pengumpulan orang lain dengan
maksud tersendiri dan mempunyai kategorisasi atau klasifikasi
menurut keperluan. Data sekunder biasanya diperoleh dari
perpustakaan atau laporan-laporan/dokumen, hasil peneliti
terdahulu. Contoh: data penangkapan ikan (statistik perikanan),
Daerah Dalam Angka (BPS), data iklim, data pasut, data arus, data
gelombang, dan lain-lain.
Data berdasarkan sifatnya
1. Data Kualitatif; data yang berbentuk kategorik atau data yang bukan
berbentuk bilangan/numerik. Menurut Muhadjir (1996) bahwa data
kualitatif adalah data yang disajikan dalam bentuk kata verbal bukan
dalam bentuk angka. Data kualitatif umumnya berbentuk
pernyataan verbal, simbol atau gambar. Contoh: persepsi
masyarakat terhadap pelarangan trawl, respons masyarakat
terhadap kebijakan perikanan secara umum, dan lain-lain.
2. Data Kuantitatif; data yang berbentuk numerik/bilangan. Menurut
Sugiyono (2010) bahwa data kuantitatif adalah jenis data yang dapat
diukur atau dihitung secara langsung, yang berupa informasi atau
penjelasan yang dinyatakan dengan bilangan atau berbentuk angka.
Data kuantitatif umumnya berupa bilangan. Contoh: jumlah hasil
tangkapan dalam kg atau ekor, jumlah unit tangkapan, dan lain-lain.
Data berdasarkan waktu pengambilannya
1. Data Time Series; data urut waktu atau data berkala. Data yang
terkumpul dari waktu ke waktu untuk memberikan gambaran
perkembangan suatu kegiatan/fenomena. Menurut Soejoeti (1987)
runtun waktu adalah himpunan observasi terutut dalam waktu atau
dalam dimensi lain. Contoh: data produksi perikanan tangkap dalam
kurun waktu 5 atau 10 tahun terakhir, data produksi budi daya, dan
lain-lain.

Bab 2 Jenis, Sumber &
Ukuran Data
9
2. Data Cross Section; data yang terkumpul pada suatu waktu tertentu
untuk memberikan gambaran perkembangan keadaan atau kegiatan
pada waktu itu. Menurut Gujarati (2003) bahwa data cross-section
merupakan suatu data yang terdiri dari satu atau lebih variabel yang
dikumpulkan pada waktu yang sama (at the same point in time).
Contoh: data sensus penduduk tahun 2010, data sensus ekonomi
tahun 2010, data inflasi tahun 2015, dan lain-lain.
Data berdasarkan susunannya
1. Data Tunggal (Single Data); Data tunggal atau disebut juga data acak
adalah data yang belum tersusun atau dikelompokkan ke dalam
kelaskelas interval (Hasan 2009). Contoh: Data hasil pengukuran ikan
tuna hasil tangkapan (dalam kg); 30-20-35-40-60-62-70-25 dst.
2. Data Berkelompok (Group Data); Data yang telah tersusun atau
dikelompokkan ke dalam kelas-kelas interval (Hasan 2009). Data
kelompok disusun dalam bentuk distribusi frekuensi atau tabel
frekuensi. Contoh: Data hasil pengukuran ikan tuna yang didasarkan
pada kelas kualitas ikan tuna yakni; great A, B, dan C di mana berat
ikan >60 kg (kelas A), 30–60 kg (kelas B), dan <30 kg (kelas C).
Data berdasarkan teknik pengukurannya
1. Data Diskrit; Data yang diperoleh dari hasil
perhitungan/menghitung. Contoh: jumlah ikan 10 ekor, jumlah
nelayan 100 orang, berat ikan 1000 kg, dan seterusnya.
2. Data Kontinu; Data yang diperoleh dari hasil pengukuran/mengukur.
Contoh: panjang ikan 10 cm, panjang kapal 15 m, dan seterusnya.
Data berdasarkan skalanya
1. Data Nominal; Data yang tidak memiliki jarak atau tidak ada makna
peringkat/urutan. Data yang diberikan pada objek atau kategori yang
tidak menggambarkan kedudukan objek atau kategori tersebut
terhadap objek atau kategori lainnya, tetapi hanya sekedar label atau
kode. Menurut Nazir (2003) bahwa data nominal adalah ukuran yang
paling sederhana, di mana angka yang diberikan kepada objek
mempunyai arti sebagai label saja dan tidak menunjukkan tingkatan

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
10
apapun. Lebih jauh disebutkan bahwa Daniel (1989) menyebut
bahwa skala nominal membedakan benda atau peristiwa yang satu
dengan yang lainnya berdasarkan nama (predikat). Ciri-ciri data
nominal adalah hanya memiliki atribut, atau nama, atau diskrit. Data
nominal merupakan data diskrit dan tidak memiliki urutan. Contoh:
Gender [1] laki-laki, [2] perempuan); Agama [1] Islam [2] Kristen, [3]
Budha, [4] Hindu; Pekerjaan [1] Pekerjaan Pokok [2] Sampingan, dan
seterusnya.
2. Data Ordinal; Data yang memiliki jarak atau urutan/peringkat antara
data yang satu dengan data lainnya. Menurut Nazir (2003) bahwa
data ordinal, selain memiliki nama (atribut), juga memiliki peringkat
atau urutan dan atau angka yang diberikan mengandung tingkatan.
Daniel (1989) menyebut bahwa skala ordinal membedakan benda
atau peristiwa yang satu dengan yang lainnya berdasarkan jumlah
relatif beberapa karakteristik tertentu yang dimiliki oleh
masingmasing benda atau peristiwa. Dalam data ordinal dikenal
skala Likert, skala Saaty, skala CIRAD. Skala Likert adalah suatu skala
psikometrik yang umum digunakan dalam angket/kuesioner (Likert
1932). Menurut Sugiyono (2010) bahwa Skala Likert digunakan untuk
mengukur sikap, pendapat, dan persepsi seseorang atau sekelompok
orang tentang fenomena sosial. Skala Saaty adalah skala data ordinal
yang khusus digunakan untuk memberikan penilaian dalam analisis
AHP (Yusuf 2017). Contoh: Tingkat pendidikan;[0] NS-Tidak Sekolah,
[1] SD, [2] SMP, [4]SMA, dan seterusnya.
Dalam data ordinal dikenal pula hukum favorable dan unfavorable.
Favorable rule menunjukkan nilai yang searah antara kategorik dan
numerik (misal; [0] nihil/tidak ada, [1] ada/sedikit, [2] banyak).
Unfavorable rule menunjukkan nilai yang tidak searah antara
kategorik dengan numerik (misal; [2] tidak ada/buruk, [1] sedang/
cukup, [0] banyak/bagus).
Tujuan pembuatan item favorable dan unfavorable untuk
menghindari bias berupa stereotip respons. Selain itu ada
kecenderungan responden memberi tanggapan secara mekanis
yaitu cenderung selalu setuju atau selalu tidak setuju. Item favorable
dan unfavorable diset dalam kuesioner dan diatur sedemikian dan

Bab 2 Jenis, Sumber &
Ukuran Data
11
bervariasi sehingga respons tidak mengembangkan bias stereotip
dan dapat minimalisasi tanggapan mekanis. Bias dapat dimaknai
sebagai preferensi pribadi, suka atau tidak suka, terutama ketika
kecenderungan mengganggu kemampuan untuk tidak memihak,
tidak berprasangka, atau objektif. Sementara, stereotip adalah
gagasan yang terbentuk sebelumnya yang mengatributkan
karakteristik tertentu ke semua anggota kelas atau kumpulan. Hal
tersebut dapat dipengaruhi oleh beberapa faktor, antara lain;
informasi, emosional, dan lingkungan.
3. Data Interval; Data yang memiliki jarak yang sama dari ciri atau sifat
objek yang diukur Nazir (2003). Data yang memiliki jarak atau
urutan/peringkat dalam bentuk interval/kelas-kelas tertentu. Daniel
(1989) menyebut bahwa skala interval membedakan benda atau
peristiwa yang satu dengan yang lainnya tidak hanya berdasarkan
nama (predikat) dan jumlah relatif, tetapi juga diurutkan. Selain itu,
data interval juga tidak memiliki nilai 0 (nol) mutlak, yakni nilai 0 yang
diperoleh memiliki nilai tertentu. Misal suhu udara (0 derajat celcius)
artinya kategorinya belum terlalu dingin jika dibandingkan dengan
minus derajat celcius. Contoh; Data hasil pengukuran ikan tuna yang
didasarkan pada kelas kualitas ikan tuna yakni; great A, B dan C di
mana berat ikan >60 kg (kelas A), 30–60 kg (kelas B), dan <30 kg
(kelas C). Usia Produktif Nelayan 25–60 th, usia tidak produktif >60
th, dan lain-lain.
4. Data Rasio; Ukuran yang memberikan keterangan tentang nilai
absolut dari objek yang diukur Nazir (2003). Daniel (1989) menyebut
bahwa skala rasio tidak hanya memiliki ke semua sifat-sifat yang
terdapat pada skala nominal, ordinal, dan interval, tetapi juga
memiliki nilai 0 (nol) mutlak. Data yang memiliki sifat-sifat data
nominal, data ordinal, dan data interval, dilengkapi dengan
kepemilikan nilai 0 (nol) absolut/mutlak. Data rasio dapat dibagi atau
dikali sehingga data rasio memiliki sifat dapat dibedakan, diurutkan,
berjarak, dan punya nol mutlak, contohnya umur nelayan, umur ikan,
berat ikan, dan lainlain. Ikan yang beratnya 10 kg berbeda secara
nyata dengan ikan yang beratnya 20 kg. Ukuran berat benda dapat
diurutkan mulai dari yang terberat hingga teringan. Perbedaan

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
12
antara ikan yang beratnya 10 kg dengan 20 kg memiliki rentang berat
yang sama dengan perbedaan antara ikan yang beratnya 20 kg
dengan 30 kg. Sementara, angka 0 kg menunjukkan tidak ada ikan
(berat) yang diukur. Ikan yang beratnya 20 kg, 2 kali lebih berat
dibandingkan dengan ikan yang beratnya 10 kg.
Sumber Data Sifat Data Waktu
Pengambilan Data Susunan Data Teknik
Pengukuran Data Skala Pengukuran Data
Data primer; bersumber dari tangan pertama (first hand data)
Data sekunder;
bersumber dari
dokumen/
laporan, dan
lain-lain (no
first hand data)
Data kualitatif; Data kategorik (baik, cukup, buruk)
Data kuantitatif; Data numerik (0,1,2,3,
dan
seterusnya)
Data cross section; data yang dikumpulkan pada suatu waktu tertentu (at a point of time) yang dapat menggambarkan keadaan/kegiatan pada waktu tersebut
Data time series;
data yang
dikumpulkan dari
waktu ke waktu
untuk memberikan
gambaran tentang
perkembangan
suatu
Data tunggal; data dinyatakan dalam bentuk daftar bilangan, dan umumnya data yang relatif sedikit (n<30)
Data kelompok; data yang berukuran besar (n >30) dan umumnya
data dalam
kelas-kelas
tertentu
Data kontinu; data hasil pengukuran (kontinu) 1 kg, 10 km, dan sebagainya
Data Diskrit; Data
hasil perhitungan
(diskrit) 10 orang;
100 ekor, dan
sebagainya
Data nominal; data yang tidak ada tingkatan/level, tidak ada yang tinggi atau rendah (skala label). Contoh: jenis kelamin, agama Ya = 1 dan Tidak = 0 Pria =1 dan Wanita=0 Hitam = 1, Abu-abu = 2, Putih = 2
Data ordinal; data yang memiliki tingkatan/level (skala peringkat). Contoh; SD, SMP, SMA
Data interval; memilki sifat data ordinal dan tidak memiliki 0 mutlak. Contoh: suhu (Celsius & Fahrenheit), IQ (tingkat kecerdasan)
Data rasio; data dapat dikelompokkan menurut tingkatannya, menurut jaraknya, dan menurut perbandingannya (skala mutlak), memiliki nilai 0 mutlak. Contoh: A berat ikan 20 kg
dan B 10 kg, berarti A lebih
berat dari B, dan keduanya
ada interval 10 kg. Selain
itu, berat ikan A = 2 kali
berat B
Kotak 3:
Jenis data dapat dikategorikan dalam 2 kategori utama, yakni; data metrik
dan non-metrik sehingga memudahkan dalam mengidentifikasi jenis
analisis statistik yang akan digunakan (Statistik Parametrik dan Statistik
Non-Paramterik). Steven (1968) berpendapat bahwa prosedurprosedur
statistik yang sesuai untuk penggunaan dengan data empirik ditentukan
oleh skala pengukuran yang dipakai ketika pengamatan.
Data Metrik [Data Numerik – Kuantitatif - Data Rasio-Interval]

Bab 2 Jenis, Sumber &
Ukuran Data
13
Data Non-Metrik [Data Kategorik - Kualitatif-Nominal-Ordinal]
2.2. Sumber Data Selain jenis data, hal lain terkait data adalah sumber data. Menurut
Arikunto (2005) sumber data adalah subjek dari mana suatu data dapat
diperoleh. Sedang menurut Riduan (2005) sumber data adalah tempat
data diperoleh dengan menggunakan metode tertentu baik berupa
manusia, artefak, ataupun dokumen-dokumen.
Secara umum data dapat bersumber dari 3 (tiga) sumber utama, yakni; 1)
bersumber dari lapangan (insitu), 2) bersumber dari pustaka (dokumen),
dan 3) bersumber dari responden (publik/pakar). Berdasarkan
sumbernya tersebut, peneliti dapat menentukan teknik pengambilan
datanya. Contoh data lapangan, dapat diambil/dikumpulkan dengan
teknik cuplik atau pengukuran insitu, observasi, dan lain-lain. Sementara,
jika bersumber dari pustaka maka dilakukan dengan teknik studi pustaka
(desk study) dan apabila bersumber dari publik/pakar maka dapat
dilakukan teknik wawancara atau interview.
- Data lapangan adalah data yang bersumber dari lapangan (field)
yang diperoleh baik melalui survei (wawancara), sampling (cuplik),
pengukuran langsung (insitu), maupun observasi (pengamatan
lapangan).
- Data pustaka adalah data yang bersumber dari dokumen, baik dalam
bentuk narasi (teks) maupun dalam bentuk gambar (chart/diagram/
map).
insitu

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
14
- Data responden adalah data yang bersumber dari responden baik
responden umum (publik) maupun responden khusus (pakar)
ataupun stakeholder kunci.
Kotak 4:
Jenis dan sumber data akan menentukan teknik/metode pengumpulan
atau pengambilan datanya, atau lazim disebut metode sampling.
Dalam sampling dikenal istilah sampling error dan non-sampling error.
Sampling error merupakan tingkat variasi nilai pengukuran antar
sampel atau antar responden, atau dikenal dengan presisi (semakin
tinggi maka semakin rentang terhadap kesalahan/error). Non-sampling
error merupakan kesalahan yang terjadi dalam proses pengukuran.
Dapat disebabkan oleh alat, teknik maupun human error. Non-
sampling error lazim disebut bias.
Presisi dan akurasi menjadi 2 hal penting dalam pengukuran. Presisi
dimaknai keadaan pasti dan akurasi dapat dimaknai sebagai keadaan
benar. Presisi adalah sejauh mana pengulangan pengukuran dalam
kondisi yang tidak berubah mendapatkan hasil yang sama (Taylor
1999). Ciri utama presisi adalah pengulangan. Sementara, akurasi
adalah tingkat kedekatan pengukuran kuantitas terhadap nilai yang
sebenarnya. Contoh: tancapan panah pada board score yang memiliki
akurasi tinggi adalah yang berada dalam lingkaran 10, sedangkan
presisi yang tinggi adalah lingkaran poin yang banyak dari sejumlah
ulangan panah.
2.3. Ukuran Data Ukuran data merupakan ukuran statistik yang dapat digunakan untuk
mengetahui pemusatan dan luas penyebaran data atau variasi data atau
homogenitas. Likert (1932) mendefinisikan pengukuran sebagai

Bab 2 Jenis, Sumber &
Ukuran Data
15
pemberian angka-angka terhadap benda-benda atau peristiwa peristiwa
menurut kaidah-kaidah tertentu, dan menunjukkan bahwa kaidah-kaidah
yang berbeda menghendaki skala-skala serta pengukuran-pengukuran
yang berbeda pula. Secara umum ukuran data dikelompokkan dalam 2
(dua) kelompok utama, yakni: 1) ukuran pemusatan data, dan 2) ukuran
penyebaran data.
Ukuran Pemusatan
Ukuran pemusatan data merupakan salah satu pengukuran data dalam
statistika. Ukuran pemusatan dapat diartikan sebagai nilai tunggal yang
mewakili suatu kumpulan data dan menunjukkan karakteristik dari data
tersebut. Menurut Howell (1982) bahwa ukuran pemusatan atau ukuran
lokasi adalah beberapa ukuran yang menyatakan di mana distribusi data
tersebut terpusat. Ukuran pemusatan data memberikan informasi
tentang titik-titik di mana data pengamatan terpusat atau terkumpul dan
dapat juga menjadi ciri khas dari kumpulan data pengamatan (Miller
1974). Ukuran pemusatan data meliputi; mean (nilai rataan), median
(nilai tengah), modus (nilai kemunculan), kuartil, desil, dan persentil.
Mean atau rata-rata atau rerata adalah suatu nilai hasil dari membagi
jumlah nilai data dengan banyaknya data. Rata-rata merupakan ukuran
pemusatan yang sering dan sangat familiar digunakan. Menurut Howel
(1982) terdapat beberapa jenis rata-rata: a) Rata rata hitung (mean), b)
Rata-rata tertimbang (weighted mean), c) Rata-rata ukur (geometric
mean), dan d) Rata-rata harmonis. Nilai mean menjadi kurang valid bila
jenis data nominal, ordinal atau interval, tetapi menjadi sangat akurat
untuk jenis data rasio. Rata-rata hitung disimbolkan dengan x. Formula
mean (rataan) sebagai berikut:
Mean data tunggal:
∑ni=1 xi
x =
n
Di mana; x : nilai
mean (rata-rata) xi :

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
16
nilai data ke-i n :
banyaknya data
Contoh:
Diketahui hasil pengukuran bobot ikan tuna (kg) diperoleh dari 10
nelayan, sebagai berikut:
Data ke- 1 2 3 4 5 6 7 8 9 10
Pengukuran (kg) 10 20 20 40 30 60 30 50 60 60
Penyelesaian:
Maka rata-rata berat ikan tuna akan diperoleh = 38 kg. Secara manual
sebagai berikut:
n xi =
380 i=1
n = 10
x = 10 + 20 + 20 + 40 + 30 + 60 + 30 + 50 + 60 + 60
10
x =
x =
38
Kesimpulan:
Rata-rata berat ikan tuna hasil tangkapan nelayan adalah 38 kg.
Penyelesaian dengan menggunakan software dapat dilakukan baik
dengan Microsoft Excel, SPSS, MINITAB, R Statistic, dan software
statistika lainnya.
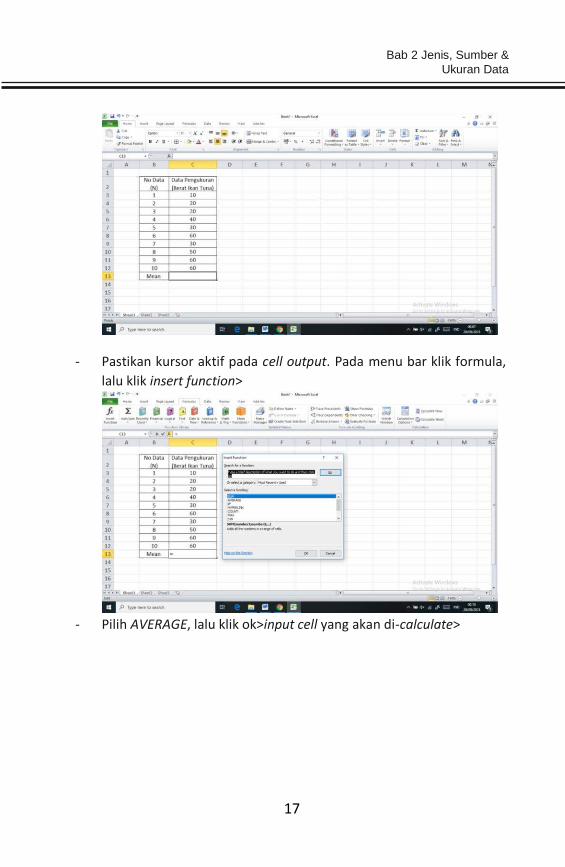
Berikut penyelesaian dengan Microsoft Excel.
- Input data ke dalam lembar kerja Microsoft Excel.
∑
Bab 2 Jenis, Sumber &
Ukuran Data
17
- Pastikan kursor aktif pada cell output. Pada menu bar klik formula,
lalu klik insert function>
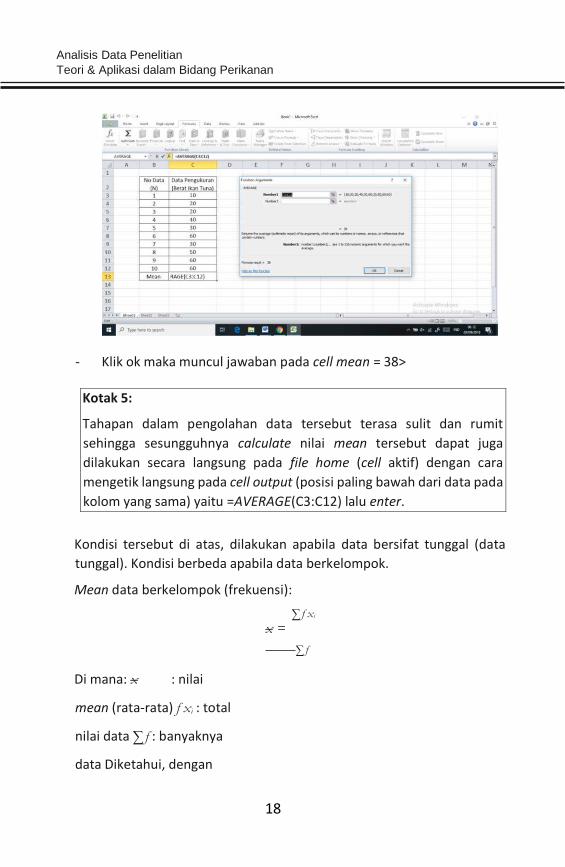
- Pilih AVERAGE, lalu klik ok>input cell yang akan di-calculate>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
18
- Klik ok maka muncul jawaban pada cell mean = 38>
Kotak 5:
Tahapan dalam pengolahan data tersebut terasa sulit dan rumit
sehingga sesungguhnya calculate nilai mean tersebut dapat juga
dilakukan secara langsung pada file home (cell aktif) dengan cara
mengetik langsung pada cell output (posisi paling bawah dari data pada
kolom yang sama) yaitu =AVERAGE(C3:C12) lalu enter.
Kondisi tersebut di atas, dilakukan apabila data bersifat tunggal (data
tunggal). Kondisi berbeda apabila data berkelompok.
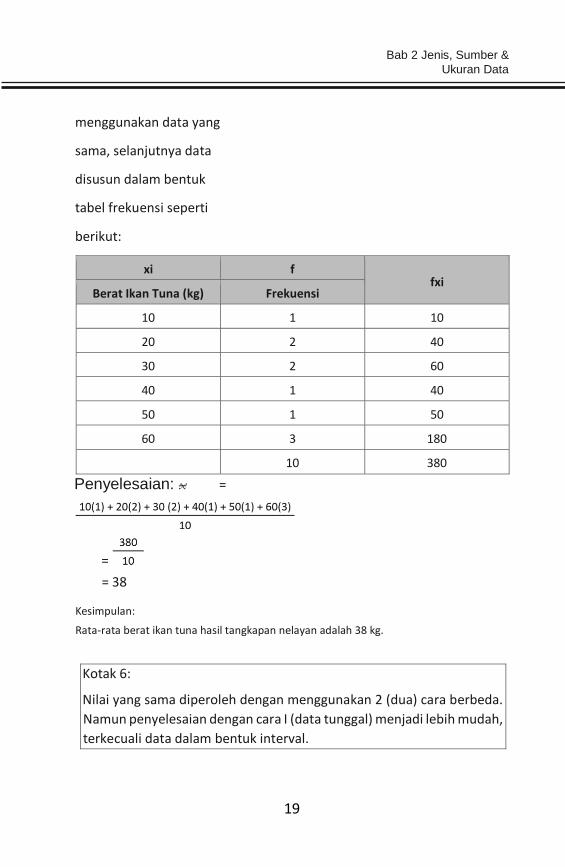
Mean data berkelompok (frekuensi):
∑ f xi
x =
∑ f
Di mana: x : nilai
mean (rata-rata) f xi : total
nilai data ∑ f : banyaknya
data Diketahui, dengan
Bab 2 Jenis, Sumber &
Ukuran Data
19
menggunakan data yang
sama, selanjutnya data
disusun dalam bentuk
tabel frekuensi seperti
berikut:
xi f fxi
Berat Ikan Tuna (kg) Frekuensi
10 1 10
20 2 40
30 2 60
40 1 40
50 1 50
60 3 180
10 380
Penyelesaian: x =
=
= 38
Kesimpulan:
Rata-rata berat ikan tuna hasil tangkapan nelayan adalah 38 kg.
Kotak 6:
Nilai yang sama diperoleh dengan menggunakan 2 (dua) cara berbeda.
Namun penyelesaian dengan cara I (data tunggal) menjadi lebih mudah,
terkecuali data dalam bentuk interval.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
20
Median atau nilai tengah adalah nilai yang diperoleh dari jumlah
sekelompok data yang posisi/letak data tersebut berada di tengah-
tengah setelah diurutkan. Pengurutan data dapat dilakukan dari terendah
ke tertinggi ataupun sebaliknya. Median menjadi lemah ketika digunakan
pada analisis kuantitatif, mengingat kemungkinan bilangan terendah dan
terendah akan sulit muncul sebagai nilai median. Namun demikian,
sangat kuat untuk digunakan pada data interval. Pengurutan data dapat
dilakukan dari data terkecil ke tertinggi atau sebaliknya. Median
disimbolkan dengan x’. Formula median (nilai tengah) sebagai berikut:
Median data ganjil :
x’= x n
Median data genap :
x’= x n 2 +2 x
Median data berkelompok :
n + f
x’= bb + ( 2 f k ) p
Di mana: x’ : nilai
tengah (median)
xn : nilai data ke-i yang posisinya di tengah setelah diurutkan
Contoh:
Diketahui hasil pengukuran berat ikan tuna diperoleh dari 10 data sebagai
berikut.
Data ke- 1 2 3 4 5 6 7 8 9 10
Pengukuran (kg) 10 20 20 40 30 60 30 50 60 60
Setelah diurutkan 10 20 20 30 30 40 50 60 60 60
Bab 2 Jenis, Sumber &
Ukuran Data
21
Diketahui bahwa banyaknya data adalah genap = 10 data maka formula
yang digunakan adalah menggunakan formula median untuk banyaknya
data genap.
Penyelesaian:
x5 + x
x’ = 6
Kesimpulan:
Median atau nilai tengah dari ikan tuna hasil tangkapan nelayan
tersebut adalah 35 kg.
Kotak 7:
Penyelesaian secara manual akan menjadi semakin sulit apabila data
dalam jumlah banyak sehingga bantuan software seperti Microsoft
Excel, SPSS, dan software statistika lainnya, akan sangat membantu
dalam estimasi nilai median tersebut. Berikut aplikasinya dalam
Microsoft Excel.
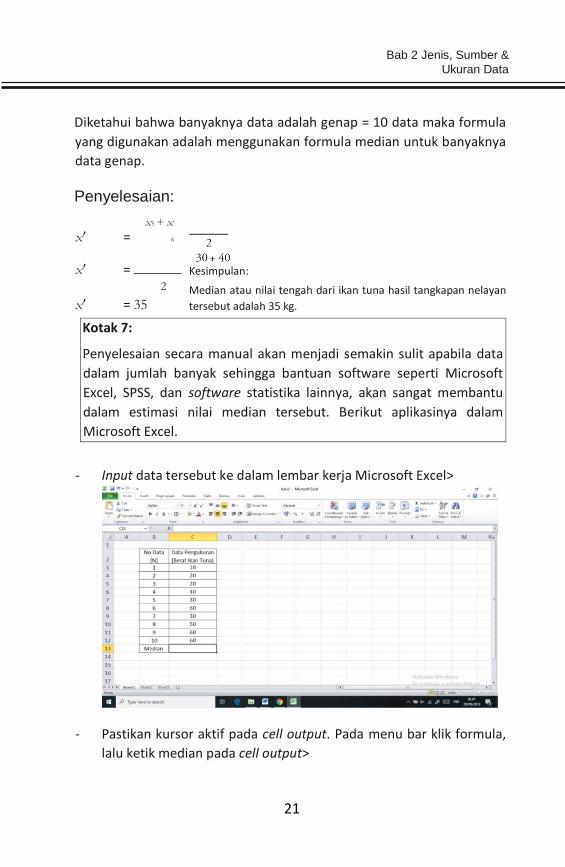
- Input data tersebut ke dalam lembar kerja Microsoft Excel>
- Pastikan kursor aktif pada cell output. Pada menu bar klik formula,
lalu ketik median pada cell output>
x’ = 2
x’ = 35
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
22
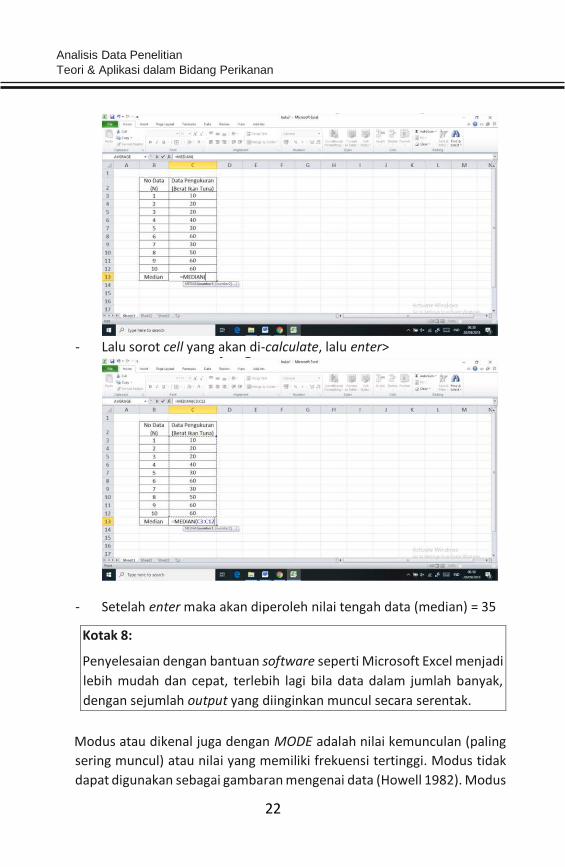
- Lalu sorot cell yang akan di-calculate, lalu enter>
- Setelah enter maka akan diperoleh nilai tengah data (median) = 35
Kotak 8:
Penyelesaian dengan bantuan software seperti Microsoft Excel menjadi
lebih mudah dan cepat, terlebih lagi bila data dalam jumlah banyak,
dengan sejumlah output yang diinginkan muncul secara serentak.
Modus atau dikenal juga dengan MODE adalah nilai kemunculan (paling
sering muncul) atau nilai yang memiliki frekuensi tertinggi. Modus tidak
dapat digunakan sebagai gambaran mengenai data (Howell 1982). Modus

Bab 2 Jenis, Sumber &
Ukuran Data
23
digunakan untuk gejala-gejala yang sering terjadi dan umumnya dipakai
sebagai nilai rata-rata bagi data kualitatif. Namun demikian, modus
sangat tidak valid (lemah) digunakan ketika jumlah bilangan data sama
dengan jumlah pembilangnya atau jumlah pilihan sama banyaknya
dengan jumlah yang memilih. Kondisi ini dapat terjadi pada penelitian
kualitatif dengan pendekatan expert (ahli), di mana jumlah ahli umumnya
sangat terbatas. Menurut Hora (2004) bahwa jumlah pakar yang
memadai dan memiliki presisi yang tinggi adalah 3 hingga 6 atau 7 orang.
Modus disimbolkan dengan x”. Formula modus (nilai sering muncul)
sebagai berikut:
Modus data tunggal :
x” = n”
Dimana; x” : nilai sering
muncul (modus)
n” : data yang nilainya sama dan paling banyak muncul
Contoh:
Diketahui data hasil pengukuran berat ikan tuna diperoleh dari 10 data,
sebagai berikut.
Data ke- 1 2 3 4 5 6 7 8 9 10
Pengukuran (kg) 10 20 20 40 30 60 30 50 60 60
Penyelesaian:
x” = n6; n9; n10 x”
= 60
Modus data berkelompok :
Mo = bb + ( d1 + d1 d2 ) p
Di mana: Mo
= Modus

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
24
bb = Batas bawah kelas modus d1 = frekuensi kelas
modus dikurangi frekuensi sebelumnya d2 = frekuensi
kelas modus dikurangi frekuensi sesudahnya p = panjang
interval kelas
Contoh:
Diketahui data hasil pengukuran ikan tuna (kg) hasil tangkapan nelayan
pancing (handline) sebagai berikut:
xi f
Berat Ikan Tuna (kg) Frekuensi
10–20 3
21–30 1
31–40 1
41–50 5
51–60 2
61–70 1
71–80 2
15
Mo = 45,5 + )1
Mo = 45,5 + ( 1
Mo = 45,5 + (0,57)1
Mo = 45,5 + (0,57)
Mo = 50
Kesimpulan: Modus data diperoleh adalah 50
Kotak 9:
Pendekatan perhitungan nilai modus dengan menggunakan distribusi
frekuensi kurang disarankan, mengingat validasi output yang

Bab 2 Jenis, Sumber &
Ukuran Data
25
dihasilkan. Namun sesungguhnya dengan melihat tabel frekuensi sudah
dapat diduga bawa nilai modus berada pada interval 41–50.
Kuartil adalah ukuran pemusatan data dengan membagi data menjadi 4
(empat) bagian. Howell (1982) bahwa kuartil adalah fraktil yang membagi
data menjadi empat bagian yang sama. Fraktil adalah nilai-nilai data yang
membagi seperangkat data yang telah diurutkan menjadi beberapa
bagian yang sama. Nilai-nilai kuartil diberi simbol Q1, Q2 (sama dengan
Median), dan Q3.
Sumber: http://idschool.net (2018)
Formula kuartil sangat bergantung pada banyaknya n (data) sebagai
berikut:
Untuk banyaknya data ganjil:
Q1 = x1/4(n+1)
Q2 = x1/2(n+1)
Q3 = x3/4(n+1)
Untuk banyaknya data genap : x(n+2)
Qi =
4 Di mana:
Qi : nilai Quartil ke-i n” :
banyaknya data
Contoh:
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
26
Diketahui hasil pengukuran berat ikan tuna (kg) hasil tangkapan nelayan
pancing (handline), sebagai berikut.
Data ke- 1 2 3 4 5 6 7 8 9 10 11
Pengukuran (kg) 10 20 20 40 30 60 30 50 60 60 70
Setelah diurutkan 10 20 20 30 30 40 50 60 60 60 70
Penyelesaian:
Karena banyaknya data adalah ganjil maka menggunakan rumus untuk
Quartil data ganjil.
Q1 = x1/4(11+1) = x3 = 20
Q1 = x1/4(11+1) = x6 = 40
Q1 = x1/4(11+1) = x9 = 60
Kesimpulan:
Diperoleh hasil bahwa nilai Q1 = 20, Q2=40 dan Q3=60.
Desil adalah ukuran pemusatan data dengan membagi data menjadi 10
(sepuluh) bagian. Howell (1982) bahwa desil adalah fraktil. Fraktil yang
membagi data menjadi sepuluh bagian yang sama, simbolnya adalah D1,
D2, .., D9.
Sumber: http://idschool.net (2018)
Formula desil sebagai berikut: i(n+1)
Di = 10
Di mana;

Bab 2 Jenis, Sumber &
Ukuran Data
27
Di : nilai Desil ke-i n” :
banyaknya data
Persentil adalah ukuran pemusatan data dengan membagi data menjadi
100 (seratus) bagian. Howell (1982) bahwa persentil adalah fraktil yang
membagi data menjadi seratus bagian yang sama, simbolnya adalah P1,
P2, …, P99.
Sumber: http://idschool.net (2018)
Formula persentil sebagai berikut: i(n+1)
Pi = 100
Di mana:
Pi : nilai Persentil
ke-i n” : banyaknya data
Ukuran Penyebaran
Ukuran penyebaran data merupakan salah satu ukuran data dalam
statistika, yakni ukuran yang menunjukkan seberapa jauh data menyebar
dari rata-rata. Menurut Howell (1982) bahwa ukuran penyebaran adalah
suatu ukuran baik parameter atau statistika untuk mengetahui seberapa
besar penyimpangan data. Melalui ukuran penyebaran dapat diketahui
seberapa jauh data-data menyebar dari titik pemusatannya. Umumnya
antara lain; range, simpangan rata-rata, ragam, dan simpangan baku.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
28
Range (rentang) merupakan selisih data terbesar (maksimum) dan data
terkecil (minimum). Menurut Walpole (1993), rentang (range)
dinotasikan sebagai R, menyatakan ukuran yang menunjukkan selisih nilai
antara maksimum dan minimum. Rentang cukup baik digunakan untuk
mengukur penyebaran data yang simetrik dan nilai datanya menyebar
merata. Ukuran ini menjadi tidak relevan jika nilai data maksimum dan
minimumnya merupakan nilai ekstrem. Rentang diestimasi dengan
formula menurut Walpole (1993), sebagai berikut:
R = Xmax – Xmin
Di mana;
R = Jangkauan
Xmaks = data terbesar
Xmin = data terkecil
Contoh:
Diketahui hasil pengukuran berat ikan tuna (kg) diperoleh dari 11 data,
seperti berikut.
Data ke- 1 2 3 4 5 6 7 8 9 10 11
Pengukuran (kg) 10 20 20 40 30 60 30 50 60 60 70
Penyelesaian:
Xmaks = 70
Xmin = 10
R = 70 -
10 R = 60
Kesimpulan:
Range atau jangkauan data tersebut adalah 60.
Kotak 10:
Kondisi yang berbeda, apabila data dalam bentuk kelompok (interval),
dimana terlebih dahulu harus diselesaikan Xmax dan Xmin.

Bab 2 Jenis, Sumber &
Ukuran Data
29
xi f
Berat Ikan Tuna (kg) Frekuensi
10–20 3
21–30 1
31–40 1
41–50 5
51–60 2
61–70 1
71–80 2
15
R = Xmax – Xmin
Xmax = 71 + 80/2 = 75,5
Xmin = 10 + 20/2 = 15
R = 75,5 - 15
R = 60,5
Kesimpulan:
Range atau jangkauan data tersebut adalah 60,5.
Simpangan rata-rata merupakan nilai rata-rata dari selisih setiap data
dengan nilai mean atau rataan hitungnya. Simpangan rata-rata umumnya
dilambangkan dengan SR dan di-calculate dengan formula sebagai
berikut:
Simpangan rata-rata data tunggal:
∑ni=1 |xi – x|
SR = n
Simpangan rata-rata data berkelompok:
∑ni=1 fi |xi – x|
SR = ∑ni=1 fi

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
30
Di mana:
SR = Simpangan rata-rata
xi = data ke-i x =
rataan hitung n = banyak
data fi = frekuensi data
ke-i
Contoh:
Diketahui hasil pengukuran berat ikan tuna (kg) hasil tangkapan nelayan
pancing (handline), sebagai berikut.
Data ke- 1 2 3 4 5 6
Pengukuran (kg) 10 20 20 40 30 60
Penyelesaian:
Estimasi nilai rataan (mean) dengan menggunakan formula mean.
S = (|10 - 30| + |20 - 30| + |20 - 30| + |40 - 30| + |30 - 30| + |60 -
30|)
S = 6 (80)
80
S = 6
S = 13,3
Kesimpulan:
Mean= 30 dengan Simpangan rata-rata berat ikan tuna adalah 13,33 kg.
Kotak 11:
Lakukan penjumlahan tanpa memerhatikan simbol positif/negatif.
Kondisi berbeda, bila data hasil pengukuran dalam bentuk interval atau
(kelas).
Bab 2 Jenis, Sumber &
Ukuran Data
31
Diketahui hasil pengukuran ikan hasil tangkapan nelayan yang dibagi
menjadi 7 kelas (grade) berdasarkan bobot ikan, seperti berikut:
Nilai f xi fxi xi-x f(xi-x)
10–14 3 12 36 14,33 42,99
15–19 1 17 17 9,33 9,33
20–24 1 22 22 4,33 4,33
25–29 5 27 135 0,67 3,33
30–34 2 32 64 5,67 11,33
35–39 1 37 37 10,67 10,67
40–44 2 42 84 15,67 31,33
Jumlah 15 27 395 0,67 113,32
Penyelesaian:
S =
S = 7,55
Kesimpulan:
Simpangan rata-rata berat ikan tuna adalah 7,55 kg.
Ragam (variance) adalah nilai yang menunjukkan besarnya penyebaran
data pada kelompok data. Menurut Walpole (1993) variansi (variance)
dinotasikan sebagai S2 atau σ2 adalah ukuran penyebaran data yang
mengukur rata-rata kuadrat jarak seluruh titik pengamatan dari nilai
tengah (mean). Ragam diestimasi dengan formula menurut Walpole
(1993), sebagai berikut:
Ragam data tunggal:
2 = ∑ni=1 |xi – x|2
S n
Ragam data berkelompok;
2 = ∑ni=1 fin |xi – fi x|2

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
32
S ∑ i=1
Di mana:
S2 = variasi
(ragam) xi = data
ke –i x = rataan hitung
n = banyak data fi
= frekuensi data ke-i
Simpangan baku (standar deviasi) merupakan akar dari jumlah kuadrat
deviasi dibagi banyaknya data. Menurut Walpole (1993) simpangan baku
(standard deviation) dinotasikan sebagi s atau σ, menunjukkan rata-rata
penyimpangan data dari harga rata-ratanya. Simpangan baku merupakan
akar pangkat dua dari variansi. Simpangan baku diestimasi dengan
formula menurut Walpole (1993), sebagai berikut:
Simpangan baku data tunggal (n<30):
S =
Simpangan baku data berkelompok (n<30):
∑ni=1 fi (xi – x )2
S = ∑ni=1 fi
Di mana:
S = Simpangan baku
xi = data ke –i x =
rataan hitung sampel n =
banyak data fi = frekuensi
data ke-i
∑ n i =1
( x
i – x ) 2
n

Bab 2 Jenis, Sumber &
Ukuran Data
33
Simpangan baku data berkelompok (n>30):
∑ni=1 (xi – µ )2 λ =
n – 1
Di mana:
λ = Simpangan baku xi
= data ke –i µ = rataan
hitung populasi n =
banyak data
Kotak 12:
Aplikasi analisis statistik dengan berbagai bantuan software menjadi
lebih mudah apabila dilakukan dengan sering dan banyak rumusnya
adalah “sering-berulang”.
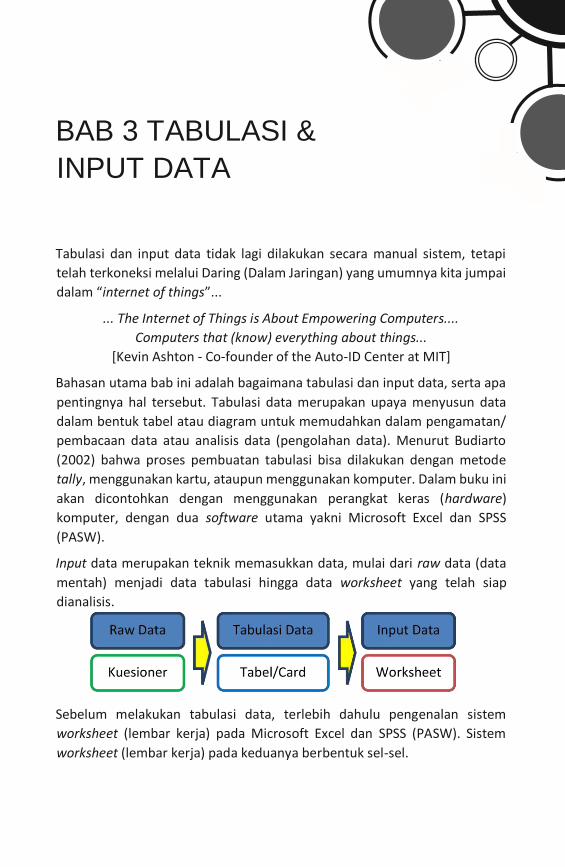
BAB 3 TABULASI &
INPUT DATA
Tabulasi dan input data tidak lagi dilakukan secara manual sistem, tetapi
telah terkoneksi melalui Daring (Dalam Jaringan) yang umumnya kita jumpai
dalam “internet of things”...
... The Internet of Things is About Empowering Computers....
Computers that (know) everything about things...
[Kevin Ashton - Co-founder of the Auto-ID Center at MIT]
Bahasan utama bab ini adalah bagaimana tabulasi dan input data, serta apa
pentingnya hal tersebut. Tabulasi data merupakan upaya menyusun data
dalam bentuk tabel atau diagram untuk memudahkan dalam pengamatan/
pembacaan data atau analisis data (pengolahan data). Menurut Budiarto
(2002) bahwa proses pembuatan tabulasi bisa dilakukan dengan metode
tally, menggunakan kartu, ataupun menggunakan komputer. Dalam buku ini
akan dicontohkan dengan menggunakan perangkat keras (hardware)
komputer, dengan dua software utama yakni Microsoft Excel dan SPSS
(PASW).
Input data merupakan teknik memasukkan data, mulai dari raw data (data
mentah) menjadi data tabulasi hingga data worksheet yang telah siap
dianalisis.
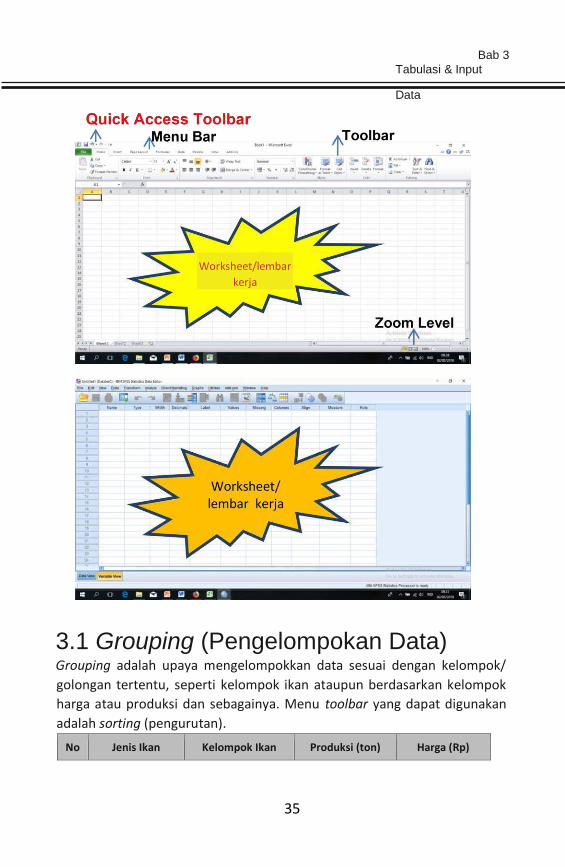
Sebelum melakukan tabulasi data, terlebih dahulu pengenalan sistem
worksheet (lembar kerja) pada Microsoft Excel dan SPSS (PASW). Sistem
worksheet (lembar kerja) pada keduanya berbentuk sel-sel.
Bab 3
Tabulasi & Input
Data
35
3.1 Grouping (Pengelompokan Data) Grouping adalah upaya mengelompokkan data sesuai dengan kelompok/
golongan tertentu, seperti kelompok ikan ataupun berdasarkan kelompok
harga atau produksi dan sebagainya. Menu toolbar yang dapat digunakan
adalah sorting (pengurutan).
No Jenis Ikan Kelompok Ikan Produksi (ton) Harga (Rp)
Worksheet/lembar kerja
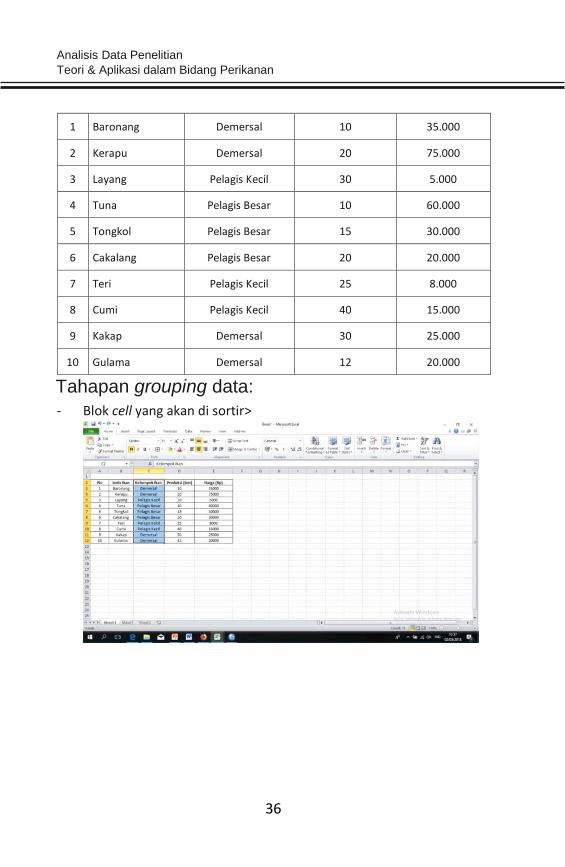
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
36
1 Baronang Demersal 10 35.000
2 Kerapu Demersal 20 75.000
3 Layang Pelagis Kecil 30 5.000
4 Tuna Pelagis Besar 10 60.000
5 Tongkol Pelagis Besar 15 30.000
6 Cakalang Pelagis Besar 20 20.000
7 Teri Pelagis Kecil 25 8.000
8 Cumi Pelagis Kecil 40 15.000
9 Kakap Demersal 30 25.000
10 Gulama Demersal 12 20.000
Tahapan grouping data:
- Blok cell yang akan di sortir>
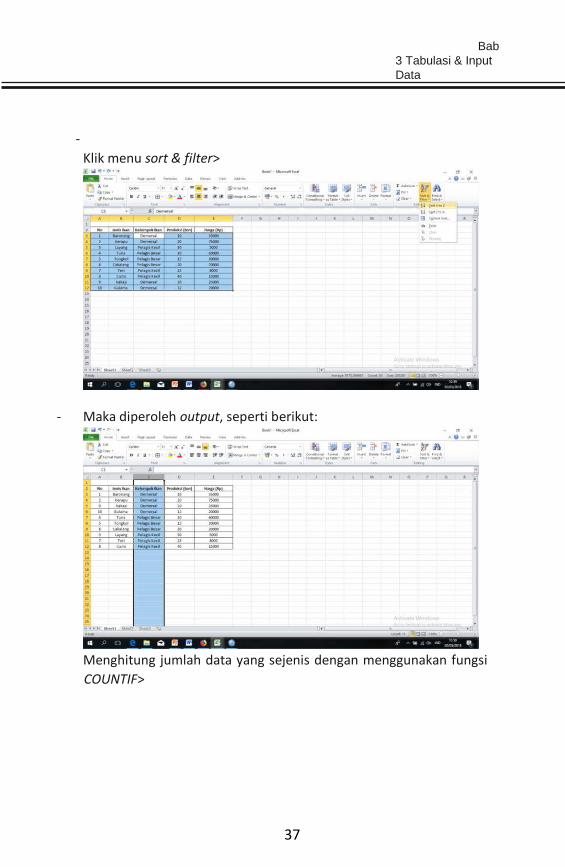
Bab
3 Tabulasi & Input
Data
-
37
Klik menu sort & filter>
- Maka diperoleh output, seperti berikut:
Menghitung jumlah data yang sejenis dengan menggunakan fungsi
COUNTIF>
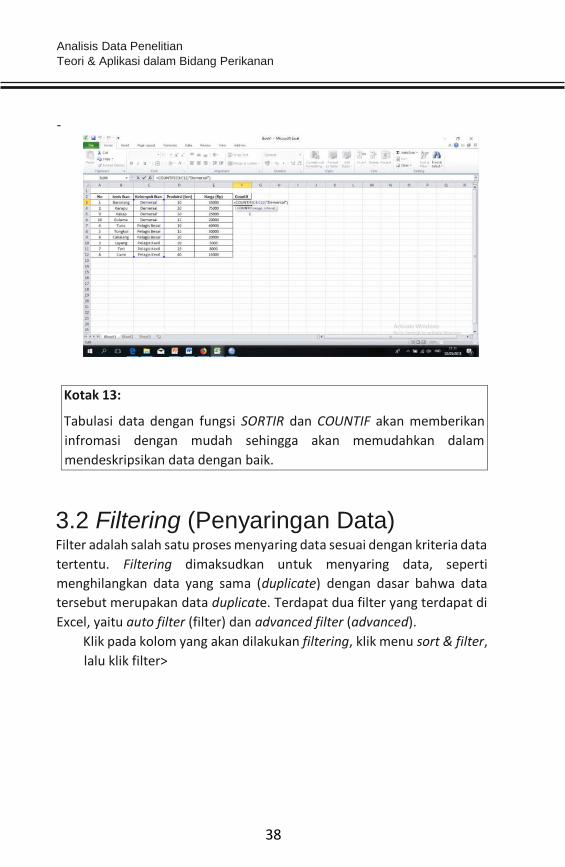
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
38
Kotak 13:
Tabulasi data dengan fungsi SORTIR dan COUNTIF akan memberikan
infromasi dengan mudah sehingga akan memudahkan dalam
mendeskripsikan data dengan baik.
3.2 Filtering (Penyaringan Data) Filter adalah salah satu proses menyaring data sesuai dengan kriteria data
tertentu. Filtering dimaksudkan untuk menyaring data, seperti
menghilangkan data yang sama (duplicate) dengan dasar bahwa data
tersebut merupakan data duplicate. Terdapat dua filter yang terdapat di
Excel, yaitu auto filter (filter) dan advanced filter (advanced).
Klik pada kolom yang akan dilakukan filtering, klik menu sort & filter,
lalu klik filter>
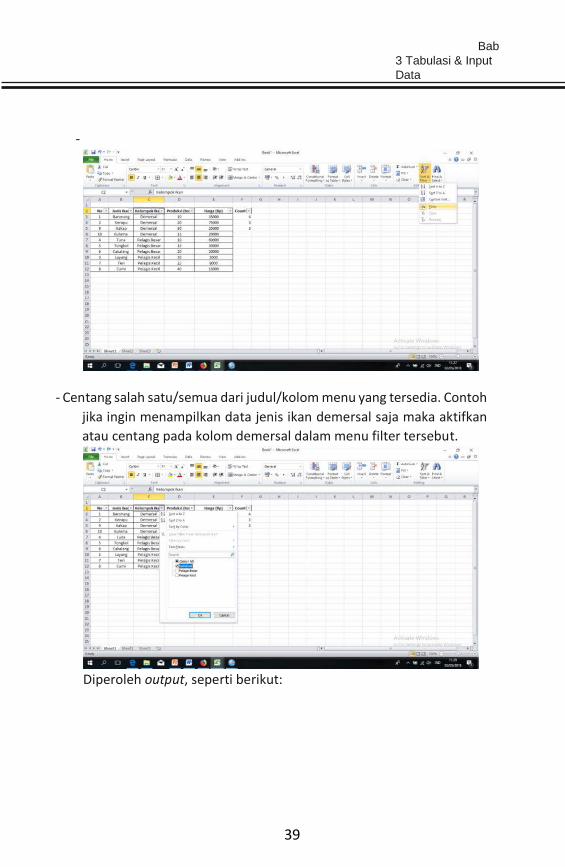
Bab
3 Tabulasi & Input
Data
-
39
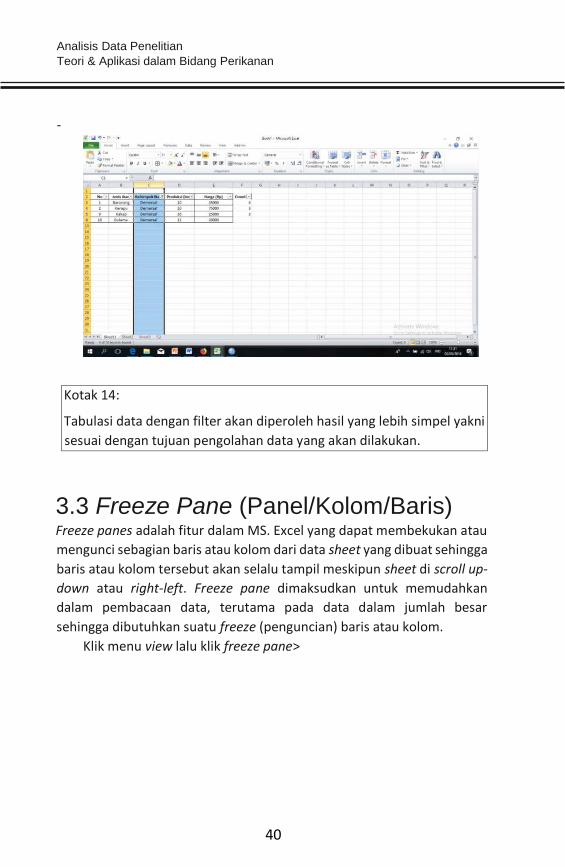
- Centang salah satu/semua dari judul/kolom menu yang tersedia. Contoh
jika ingin menampilkan data jenis ikan demersal saja maka aktifkan
atau centang pada kolom demersal dalam menu filter tersebut.
Diperoleh output, seperti berikut:
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
40
Kotak 14:
Tabulasi data dengan filter akan diperoleh hasil yang lebih simpel yakni
sesuai dengan tujuan pengolahan data yang akan dilakukan.
3.3 Freeze Pane (Panel/Kolom/Baris) Freeze panes adalah fitur dalam MS. Excel yang dapat membekukan atau
mengunci sebagian baris atau kolom dari data sheet yang dibuat sehingga
baris atau kolom tersebut akan selalu tampil meskipun sheet di scroll up-
down atau right-left. Freeze pane dimaksudkan untuk memudahkan
dalam pembacaan data, terutama pada data dalam jumlah besar
sehingga dibutuhkan suatu freeze (penguncian) baris atau kolom.
Klik menu view lalu klik freeze pane>

Bab
3 Tabulasi & Input
Data
-
41
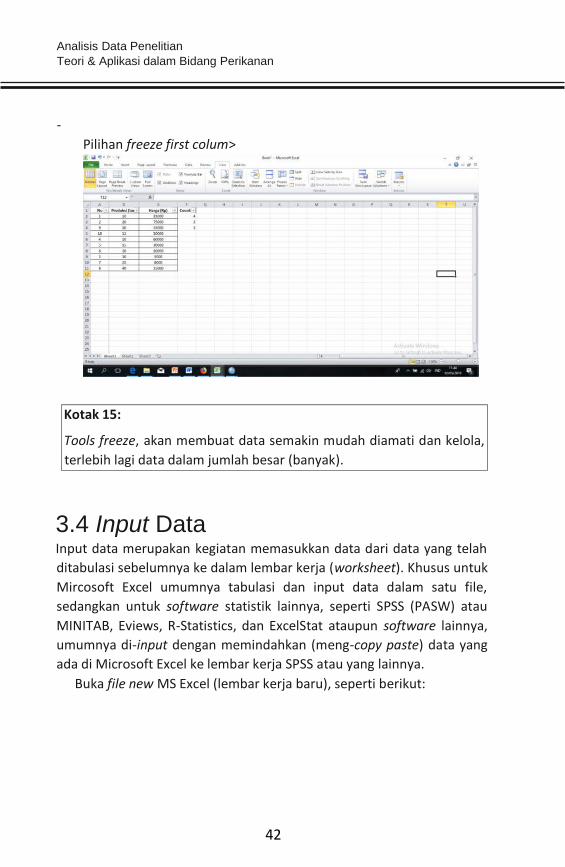
- Pilih salah satu pilihan yang ada (freeze pane untuk kolom dan baris
sekaligus; freeze top row untuk membekukan baris paling atas;
freeze first column untuk membekukan kolom pertama).
- Pilihan freeze top row>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
42
Pilihan freeze first colum>
Kotak 15:
Tools freeze, akan membuat data semakin mudah diamati dan kelola,
terlebih lagi data dalam jumlah besar (banyak).
3.4 Input Data Input data merupakan kegiatan memasukkan data dari data yang telah
ditabulasi sebelumnya ke dalam lembar kerja (worksheet). Khusus untuk
Mircosoft Excel umumnya tabulasi dan input data dalam satu file,
sedangkan untuk software statistik lainnya, seperti SPSS (PASW) atau
MINITAB, Eviews, R-Statistics, dan ExcelStat ataupun software lainnya,
umumnya di-input dengan memindahkan (meng-copy paste) data yang
ada di Microsoft Excel ke lembar kerja SPSS atau yang lainnya.
Buka file new MS Excel (lembar kerja baru), seperti berikut:

Bab
3 Tabulasi & Input
Data
-
43
Kotak 16:
Microsoft Excel adalah sebuah program aplikasi lembar kerja spreadsheet
yang dibuat dan didistribusikan oleh Microsoft Corporation yang dapat
dijalankan pada Microsoft Windows dan Mac OS. Microsoft Excel
menyediakan fitur untuk pengoperasian database seperti mengurutkan
data, melacak dan menampilkan data, melengkapi tabel dengan subtotal,
membuat rekapitulasi data, dan lain sebagainya. Spreadsheet Microsoft
Excel 2010 dapat memuat data yang sangat banyak, 1.048.576 baris dan
16.384 kolom for 1 worksheet.
Buka file new SPSS, lembar kerja baru, seperti berikut:
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
44
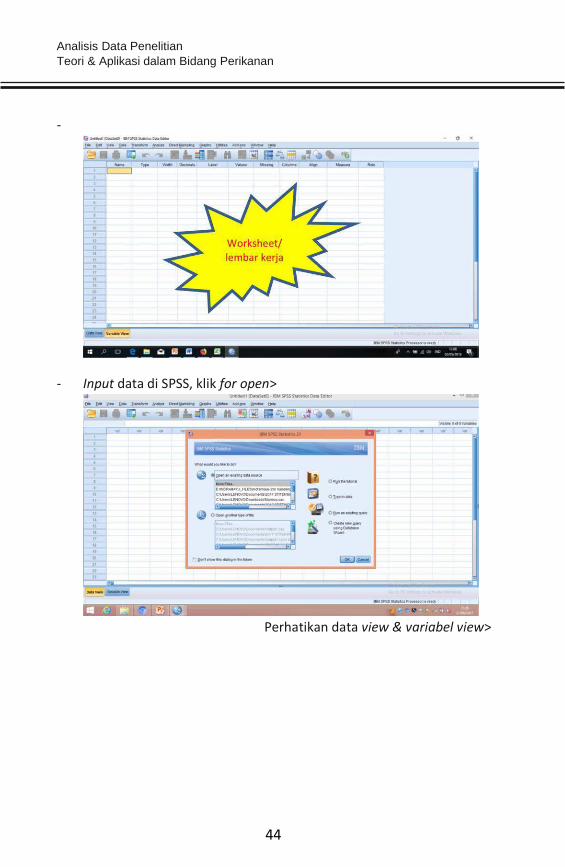
- Input data di SPSS, klik for open>
Perhatikan data view & variabel view>
Bab
3 Tabulasi & Input
Data
-
45
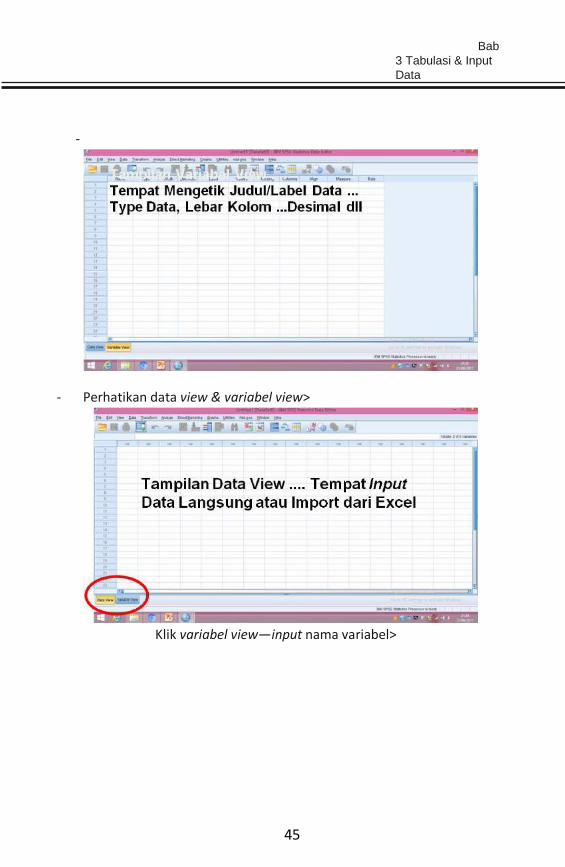
- Perhatikan data view & variabel view>
Klik variabel view—input nama variabel>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
46
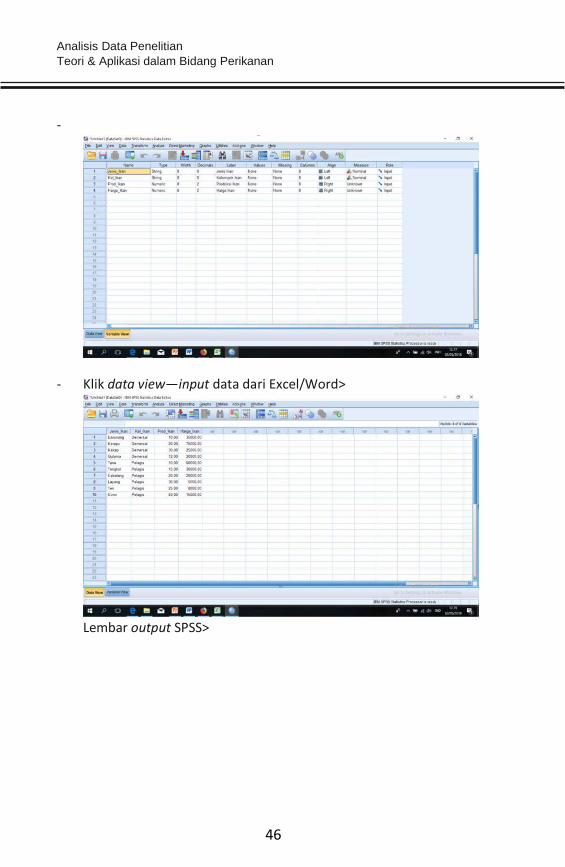
- Klik data view—input data dari Excel/Word>
Lembar output SPSS>
Bab
3 Tabulasi & Input
Data
-
47
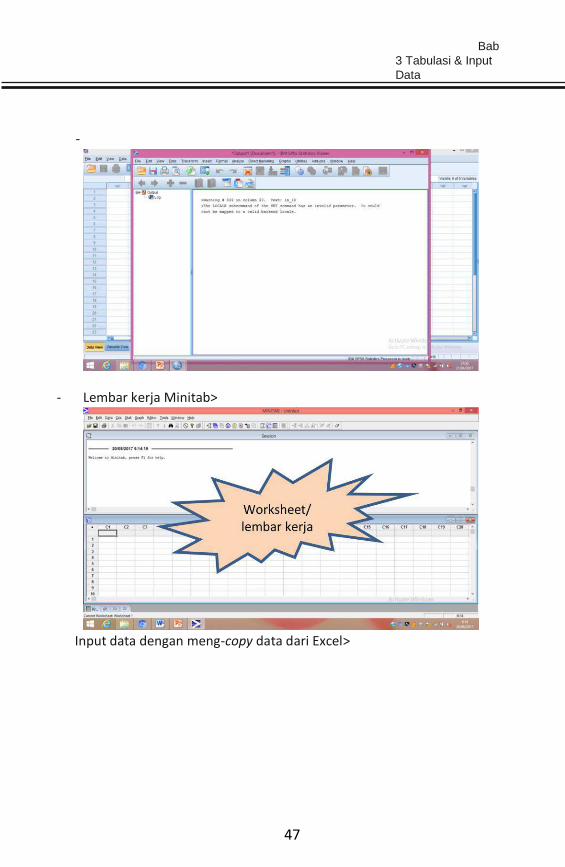
- Lembar kerja Minitab>
Input data dengan meng-copy data dari Excel>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
48
Kotak 17:
SPSS (Software Package Used for Statistical Analysis) merupakan program
komputer berbasis desktop yang digunakan untuk
menganalisis/mengolah data statitiska. SPSS merupakan software
pengolah data yang paling populer dalam dunia akademik, penelitian
maupun corporate, pemerintah, dan konsultan. Pada lembar kerja SPSS
(worksheet) terdapat 2 jendela yakni data view dan variabel view.


BAB 4 UJI
INSTRUMEN
Uji instrumen dimaksudkan untuk memperoleh keyakinan valid & handal
terhadap instrumen yang digunakan dalam mengumpulkan data. Uji
instrumen terdiri atas; uji validitas dan uji reliabilitas. Pengujian perlu
dilakukan sebagai wujud pembuktian...
... If you double the number of experiments you do per year you’re
going to double your inventiveness ...
[Jeff Bezos – CEO Amazon.Com]
Bahasan utama dalam bab ini adalah “apa itu uji instrumen, kapan
dilakukan uji instrumen serta apa saja jenis uji instrumen”. Uji instrumen
merupakan uji pendahuluan (pre test) yang dimaksudkan untuk
mengetahui sejauh mana instrumen atau alat yang digunakan dalam
penelitian valid (sahih) dan handal. Menurut Sugiyono (2006) bahwa
instrumen penelitian adalah suatu alat yang digunakan mengukur
kejadian (variabel penelitian) alam maupun sosial yang diamati.
Sementara, menurut Sudaryanto (2003) instrumen penelitian adalah alat
yang dapat digunakan untuk mengumpulkan data atau informasi
penelitian. Alat ukur tersebut dapat berupa skala atau tes. Menurut
Azwar (2006) sebuah tes yang baik harus memiliki beberapa kriteria
antara lain valid, reliable, standar, ekonomis, dan praktis. Uji instrumen
dilakukan sebelum ataupun setelah pengumpulan data (sampel)
penelitian. Jika sebelum pengumpulan data maka uji instrumen
dimaksudkan untuk memastikan apakah instrumen yang dirancang cukup
kuat dan valid untuk pengumpulan data, sedangkan jika setelah
pengumpulan data maka uji instrumen memastikan instrumen yang tidak
valid tidak digunakan dalam analisis data atau analisis statistik
selanjutnya.

Bab 4
Uji Instrumen
51
4.1 Uji Validitas Uji validitas merupakan upaya untuk memastikan tingkat kevalidan atau
kesahihan instrumen yang digunakan dalam penelitian (instrumen
pengumpulan data). Uji validitas dapat pula diartikan sebagai uji
ketepatan atau ketelitian suatu alat ukur yang digunakan dalam
penelitian. Dalam pengertian yang lebih mudah dipahami, uji validitas
adalah uji yang bertujuan menilai apakah seperangkat alat ukur telah
tepat mengukur apa yang seharusnya diukur. Berikut pendapat beberapa
ahli terkait definisi validitas.
▪ Sugiyono (2006) validitas merupakan derajat ketetapan antara data
yang terjadi pada objek penelitian dengan daya yang dapat
dilaporkan oleh peneliti.
▪ Azwar (1986) validitas berasal dari kata validity yang mempunyai arti
sejauh mana ketepatan dan kecermatan suatu alat ukur dalam
melakukan fungsi ukurnya.
▪ Arikunto (2006) validitas adalah suatu ukuran yang menunjukkan
tingkat kesahihan suatu tes.
▪ Nursalam (2003) validitas adalah suatu ukuran yang menunjukkan
tingkat kevalidan atau kesahihan suatu instrumen.
▪ Hamidi (2004), ada beberapa teknik yang dapat digunakan untuk
mengetahui validitas data, seperti trianggulasi dan member check.
▪ Allen dan Yen (1979) membagi validitas isi ke dalam dua kelompok
yaitu; validitas logis (logical validity) dan validitas konstruksi
(construct validity). Validitas logis dapat dicapai jika tampilan tes
tersebut telah meyakinkan untuk mengungkap atribut yang hendak
diukur. Validitas konstruksi dapat diartikan sebagai validitas yang
ditilik dari segi susunan, kerangka atau rekaannya.
Uji validitas juga dimaksudkan untuk mengetahui apakah instrumen yang
digunakan valid atau tidak. Uji ini digunakan untuk menunjukkan sejauh
mana alat ukur yang digunakan memiliki tingkat kecermatan yang tinggi
atau tidak. Ghozali (2009) menyatakan bahwa uji validitas digunakan
untuk mengukur sah atau valid tidaknya suatu instrumen/kuesioner.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
52
Untuk menguji validitas instrumen dapat digunakan cara analisis item,
yaitu mengorelasikan skor tiap-tiap item jawaban dengan skor total item
jawaban tersebut. Uji validitas dapat dilakukan dengan berbagai teknik,
seperti; Product Momen Pearson Correlation dan cara manual dengan
Microsoft Excel.
Korelasi Pearson (Product Moment) dilakukan dengan cara
mengorelasikan antara skor item dengan skor total item, akan diperoleh
nilai rhitung. Sedangkan, nilai rtabel diperoleh dari nilai table-r pada taraf
signifikansi 0,05 atau tingkat kepercayaan 95%, artinya suatu item
dianggap valid jika berkorelasi signifikan terhadap skor total pada tingkat
kepercayaan 95%.
Kotak 18:
Kriteria pengambilan keputusan uji validitas Product Moment Pearson
Correlation, yakni:
- Jika nilai rhitung> nilai rtabel, instrumen dinyatakan valid
- Jika nilai rhitung < nilai rtabel, instrumen dinyatakan tidak valid
Nilai rhitung diperoleh dari hasil analisis dengan pendekatan korelasi
Bivariate Pearson (Product Moment Pearson). Sementara, nilai rtabel
diperoleh dengan pembacaan table-r dengan rumus df=n-2 (n adalah
jumlah data).
Uji validitas dengan product moment pearson correlation menggunakan
prinsip korelasi (hubungan) antara masing-masing skor dengan skor total
yang diperoleh. Secara umum terdapat 2 (dua) validitas yakni; 1) Validitas
Konstruksi; merupakan validitas terhadap kelayakan instrumen
(kuesioner/ angket) yang digunakan atau dalam aplikasinya dapat
digunakan dengan mudah/tidak rigid. 2) Validitas Output; merupakan
validitas terhadap output atau hasil/jawaban dari instrumen yang
digunakan, apakah memenuhi atau tidak sebagai instrumen pengukur.
Uji validitas adalah suatu data dapat dipercaya kebenarannya sesuai
dengan kenyataan. Menurut Sugiyono (2009) bahwa valid berarti
instrumen tersebut dapat digunakan untuk mengukur apa yang

Bab 4
Uji Instrumen
53
seharusnya diukur. Valid menunjukkan derajat ketepatan antara data
yang sesungguhnya terjadi pada objek dengan data yang dapat
dikumpulkan oleh peneliti. Jika ada item yang tidak memenuhi syarat,
item tersebut tidak akan diteliti lebih lanjut. Syarat tersebut menurut
Sugiyono (2009) yang harus dipenuhi yaitu harus memiliki kriteria jika
nilai rhitung>rtabel atau nilai p<0,05.
Untuk menguji validitas yang digunakan dalam penelitian ini adalah
rumus koefisien korelasi Rank Spearman, yaitu:
6∑ di 2
r = 1 – n(n2 – 1)
Di mana; r : Koefisien Korelasi
Rank Spearman di : Selisih Setiap
Rank n : Banyaknya Pasangan Data
Contoh:
Diketahui hasil wawancara dengan kuesioner sebanyak 30 pertanyaan
terkait karakteristik individu dari 60 nelayan. Sebelum melakukan uji data
(uji lanjut) terlebih dahulu lakukan uji instrumen (uji validitas). Sebelum
data di-input ke worksheet SPSS, terlebih dahulu tabulasi data hasil
kuesioner tersebut ke dalam Microsoft Excel, seperti berikut:
Data hasil jawaban kuesioner 60 responden untuk 30 pertanyaan, terkait
karakteristik individu.
Responden Daftar Pertanyaan
1 3 5 6 7 8 9 10 .... .... 30
1 5 5 4 4 5 5 4 4 .... .... 5
2 4 4 4 4 5 5 5 4 .... .... 5
3 5 5 3 5 5 3 5 4 .... .... 4
4 4 5 3 4 3 3 5 4 .... .... 3
5 5 5 4 4 4 3 4 4 .... .... 5
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
54
6 5 5 4 4 4 4 5 4 .... .... 5
7 4 3 3 4 4 3 4 5 .... .... 5
8 5 5 5 5 5 4 5 4 .... .... 3
9 5 5 4 5 5 3 5 5 .... .... 5
10 4 5 4 5 4 3 5 4 .... .... 2
.... .... .... .... .... .... .... .... .... .... .... ....
.... .... .... .... .... .... .... .... .... .... .... ....
60 5 5 3 4 4 4 4 5 .... .... 4
- Tampilan data dalam Microsoft Excel, seperti berikut:
- Input data (menyusun data pada variabel view)>
Bab 4
Uji Instrumen
55
- Input data pada data view>
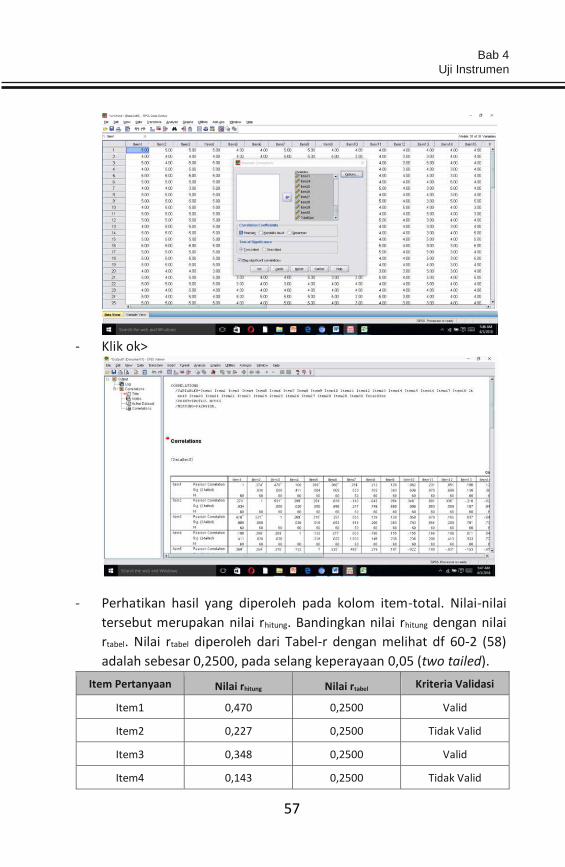
- Klik analyze—correlation--bivariate>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
56
- Pindahkan seluruh item ke kolom sebelah kanan>
- Klik (centang) Pearson>
Bab 4
Uji Instrumen
57
- Klik ok>
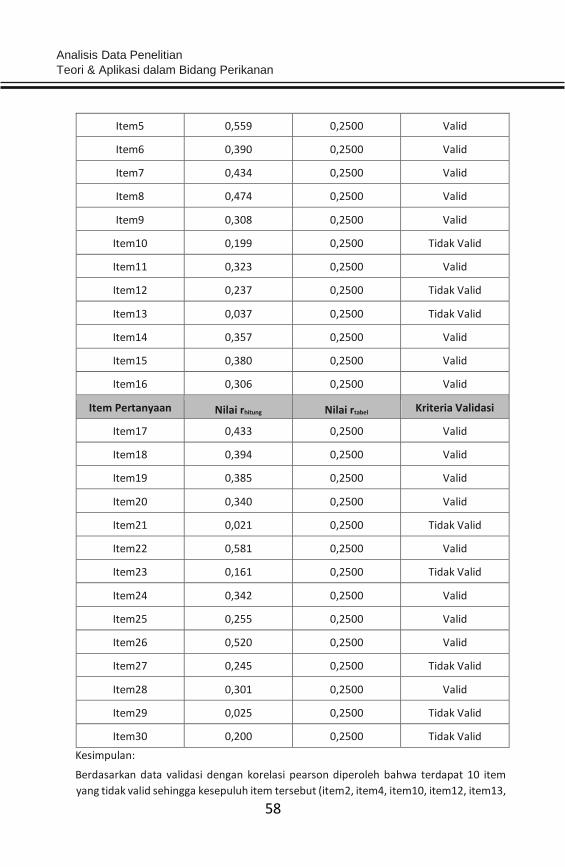
- Perhatikan hasil yang diperoleh pada kolom item-total. Nilai-nilai
tersebut merupakan nilai rhitung. Bandingkan nilai rhitung dengan nilai
rtabel. Nilai rtabel diperoleh dari Tabel-r dengan melihat df 60-2 (58)
adalah sebesar 0,2500, pada selang keperayaan 0,05 (two tailed).
Item Pertanyaan Nilai rhitung Nilai rtabel Kriteria Validasi
Item1 0,470 0,2500 Valid
Item2 0,227 0,2500 Tidak Valid
Item3 0,348 0,2500 Valid
Item4 0,143 0,2500 Tidak Valid
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
58
Item5 0,559 0,2500 Valid
Item6 0,390 0,2500 Valid
Item7 0,434 0,2500 Valid
Item8 0,474 0,2500 Valid
Item9 0,308 0,2500 Valid
Item10 0,199 0,2500 Tidak Valid
Item11 0,323 0,2500 Valid
Item12 0,237 0,2500 Tidak Valid
Item13 0,037 0,2500 Tidak Valid
Item14 0,357 0,2500 Valid
Item15 0,380 0,2500 Valid
Item16 0,306 0,2500 Valid
Item Pertanyaan Nilai rhitung Nilai rtabel Kriteria Validasi
Item17 0,433 0,2500 Valid
Item18 0,394 0,2500 Valid
Item19 0,385 0,2500 Valid
Item20 0,340 0,2500 Valid
Item21 0,021 0,2500 Tidak Valid
Item22 0,581 0,2500 Valid
Item23 0,161 0,2500 Tidak Valid
Item24 0,342 0,2500 Valid
Item25 0,255 0,2500 Valid
Item26 0,520 0,2500 Valid
Item27 0,245 0,2500 Tidak Valid
Item28 0,301 0,2500 Valid
Item29 0,025 0,2500 Tidak Valid
Item30 0,200 0,2500 Tidak Valid
Kesimpulan:
Berdasarkan data validasi dengan korelasi pearson diperoleh bahwa terdapat 10 item
yang tidak valid sehingga kesepuluh item tersebut (item2, item4, item10, item12, item13,

Bab 4
Uji Instrumen
59
item21, item23, item27, item29, dan item30) selanjutnya dihilangkan (tidak dianalisis
lebih lanjut) sehingga item yang dianalisis yaitu sebanyak 20 item untuk variabel X1
(karakteristik individu).
4.2 Uji Reliabilitas Uji Reliabilitas adalah uji instrumen yang dimaksudkan untuk mengetahui
sejauh mana ketahanan (kehandalan) suatu instrumen dalam
pengumpulan data. Uji ini akan menunjukkan sejauh mana pengukuran
dari suatu test tetap konsisten setelah dilakukan berulang ulang terhadap
subjek dan dalam kondisi yang sama. Penelitian dianggap dapat
diandalkan bila memberikan hasil yang konsisten untuk pengukuran yang
sama. Menurut Sugiyono (2006) menyatakan bahwa reliabilitas
menunjuk pada suatu pengertian bahwa instrumen yang digunakan
dalam penelitian untuk memperoleh informasi yang digunakan dapat
dipercaya sebagai alat pengumpulan data dan mampu mengungkap
informasi yang sebenarnya di lapangan. Reliabilitas menunjukkan sejauh
mana hasil pengukuran dengan alat/tools handal sehingga dapat
dipercaya atau diterima. Hasil pengukuran harus reliabel dalam artian
harus memiliki tingkat konsistensi dan kemantapan. Menurut Arikunto
(2006) reliabilitas menunjuk pada satu pengertian bahwa suatu
instrumen cukup dapat dipercaya untuk digunakan sebagai alat
pengumpul data karena instrumen tersebut sudah baik.
Reliabilitas menunjukkan bahwa alat tersebut konsisten apabila
digunakan untuk mengukur gejala yang sama pada lain waktu dan
tempat. Data yang diuji reliabilitasnya adalah data yang telah valid atau
telah dilakukan uji validitas dan valid. Metode yang biasa digunakan
untuk uji kehandalan adalah teknik ukur ulang dan teknik sekali ukur.
Teknik sekali ukur terdiri atas teknik genap-gasal, belah tengah, belah
acak, kuder richardson, teknik hoyd, dan alpha cronbach.
Penggunaan pengujian reliabilitas oleh peneliti adalah untuk menilai
konsistensi pada objek dan data, apakah instrumen yang digunakan
beberapa kali untuk mengukur objek yang sama akan menghasilkan data
yang sama. Berikut adalah salah satu uji reliabilitas yang biasa digunakan

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
60
yakni metode Internal Consistency dengan teknik belah dua dari
Spearman Brown (Split Half) dengan rumus sebagai berikut:
2rAB
r1 = 1 + rAB
Dimana:
r1 : Reliabilitas Internal Seluruh
Instrumen rAB : Korelasi Product Moment
Pearson
Indikator pengukuran reliabilitas menurut Sekaran (2000) yang membagi
tingkatan reliabilitas dengan kriteria sebagai berikut:
Nilai Reliabilitas Kriteria
0,8–1,0 Baik
0,6–0,799 Cukup Baik/Diterima
<0,6 Kurang Baik/Tidak Diterima
Menurut Rochaety et al. (2007) syarat minimum koefisien korelasi 0,6
karena dianggap memiliki titik aman dalam penentuan reliabilitas
instrumen dan juga secara umum banyak digunakan dalam penelitian.
Uji reliabilitas pada lembar observasi menggunakan inter-rater reliability.
Pengujian untuk lembar observasi menggunakan inter-rater reliability
yaitu dilakukan oleh 2 orang rater atau observer, kemudian dihitung
dengan menggunakan rumus Cohen Kappa. Formula Cohen Kappa adalah
sebagai berikut:
P0 – Pe
KK = 1 – Pe
Dengan:
1
Pe = N 2 ∑ N1 N2

Bab 4
Uji Instrumen
61
Di mana:
KK : Koefisien kesepakatan pengamatan
P0 : Proporsi frekuensi kesepakatan
Pe : Kemungkinan sepakat
N : Jumlah keseluruhan nilai yang menunjukkan munculnya gejala
yang teramati
N1 : Jumlah nilai kategori pertama untuk pengamat pertama
N2 : Jumlah nilai kategori pertama untuk pengamat kedua
Nilai Kappa menurut Murti (2006) nilai tingkat reliabilitas antar rater
menjadi tiga kategori antara lain:
Nilai Kappa Kriteria
<0,4 Buruk
0,4–0,60 Cukup
0,61–0,75 Memuaskan
> 0,75 Istimewa
Tahapan Uji Reliability:
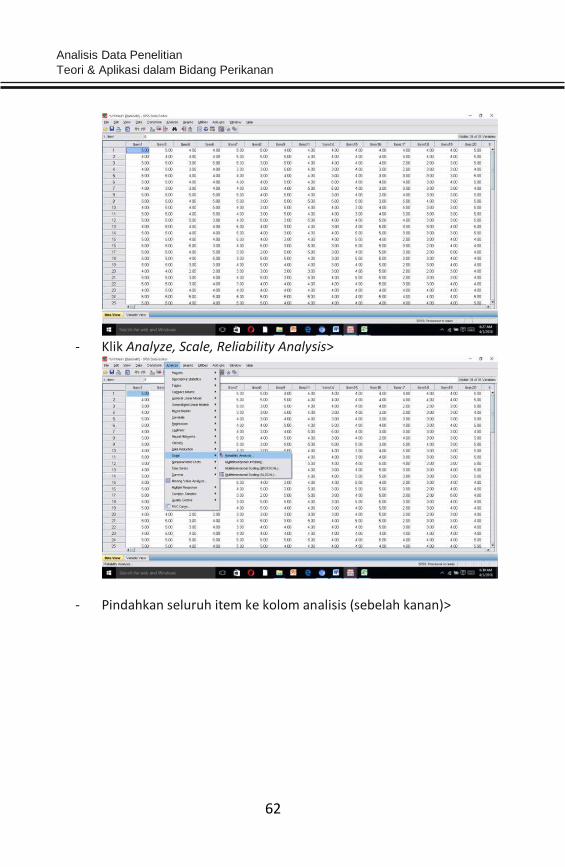
- Input data dalam worksheet SPSS>klik variabel view>
- Klik data view>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
62
- Klik Analyze, Scale, Reliability Analysis>
- Pindahkan seluruh item ke kolom analisis (sebelah kanan)>

Bab 4
Uji Instrumen
63
- Klik statistic dan centang item>
- Klik continue dan ok>
Reliabilit y Statistics
Cronbach’s Alpha N of Items
.684 21
Secara total diperoleh bahwa nilai Cronbach’s alpha adalah 0,684 atau
dikategorikan memuaskan (0,61–0,75). Sementara, secara parsial per
item sebagai berikut:
Item-Total Statistics

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
64
Scale Mean if Item
Deleted Scale Variance if Item
Deleted Corrected Item-Total
Correlation Cronbach’s Alpha if
Item Deleted
Item1 202.5500 131.404 .453 .674
Item3 202.4167 133.468 .299 .680
Item5 203.5333 124.592 .581 .658
Item6 203.3000 128.078 .372 .669
Item7 203.2833 127.664 .455 .666
Item8 203.4167 125.773 .436 .663
Item9 203.1500 130.943 .230 .677
Item11 203.1500 131.452 .298 .676
Item14 203.4667 129.338 .340 .672
Item15 203.2167 131.800 .317 .676
Item16 203.2167 130.817 .218 .677
Item17 204.0000 125.831 .429 .664
Item18 204.2667 130.063 .375 .672
Item-Total Statistics
Scale Mean if Item
Deleted Scale Variance if Item
Deleted Corrected Item-Total
Correlation Cronbach’s Alpha if
Item Deleted
Item19 203.7333 130.029 .390 .672
Item20 202.7667 132.046 .313 .677
Item22 203.2667 128.131 .512 .667
Item24 202.6000 132.956 .266 .679
Item25 203.3000 132.044 .223 .678
Item26 202.7500 129.106 .507 .669
Item28 202.7833 131.122 .246 .677
Total
Skor 82.5000 32.593 .933 .743
Kesimpulan:
Hasil seperti pada tabel di atas diperoleh bahwa nilai Cronbach’s Alpha adalah berada
pada range 0,61–0,75 atau dikategorikan memuaskan sehingga disimpulkan instrumen
yang digunakan reliable atau handal.
Kotak 19:

Bab 4
Uji Instrumen
65
Uji instrumen (validasi & reliability), menjadi sangat penting dilakukan,
mengingat validitas data yang diperoleh akan digunakan dalam analisis
dan menentukan hasil yang baik. Demikian pula uji kehandalan
(reliability) akan sangat berpengaruh terhadap kualitas data yang
dikumpulkan.


BAB 5 UJI DATA
Revolusi industri 4.0 with internet of things telah mengubah cara
berpikir dan bertindak. “Saat ini diskusi tidak lagi membicarakan apa
masalah yang dihadapi dan bagaimana menyelesaikannya, tetapi lebih
fokus pada informasi dan peluang (opportunities) apa yang ada di
dalamnya...
...the information is a great a way to reduce waste and increase
efficiency... [Kevin Ashton - Co-founder of the Auto-ID Center at
MIT]
Pertanyaan mendasar pada bab ini adalah “apa itu uji data, mengapa
harus uji data, kapan uji data dilakukan, dan apa saja jenis uji data”. Uji
data merupakan uji pendahuluan (pre test) yang dimaksudkan untuk
mengetahui keadaan data tersebut yang nantinya dapat menjadi dasar
penentuan analisis statistik yang akan dilakukan. Sebagaimana yang
dipahami bahwa analisis statistik sangat terkait dengan ukuran/skala
data dan asumsi-asumsi yang dipersyaratkan, seperti statistik parametrik
yang mensyaratkan data harus berdistribusi normal. Uji-t mensyaratkan
data kecil (<30) dengan 2 variabel maksimal, uji-z valid digunakan pada 2
variabel dengan data besar (>30), uji-F valid digunakan pada >2 variabel.
Uji data dilakukan sebelum analisis statistik inferensial dilakukan, dalam
artian bahwa peneliti harus memastikan sifat-sifat yang ada dalam data
tersebut. Secara umum uji data terdiri atas; uji normalitas, uji
autokorelasi, uji heteroskedastisitas, dan uji multikolineariti.
5.1. Uji Normalitas (Distribusi Normal) Uji Normalitas data dilakukan untuk memenuhi syarat atau asumsi dari
uji parametris yang akan dilakukan. Uji normalitas juga disebut dengan
istilah distribusi normal yang merupakan merupakan salah satu distribusi
probabilitas yang penting dalam analisis statistika. Distribusi normal

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
68
memiliki parameter berupa mean (rata-rata) dan simpangan baku. Uji
normalitas data dilakukan untuk menilai sebaran data pada kelompok
data atau variabel, apakah data terdistribusi normal atau tidak. Apabila
data yang diuji tersebut memenuhi (terdistribusi normal) maka dapat
dilakukan analisis lanjut statistika parameterik. Namun apabila tidak
maka dapat dilakukan transformasi data terlebih dahulu datau dilakukan
uji lanjut dengan statistika non-parameterik. Uji normalitas data
dilakukan dengan pendekatan Kolmogorov-Smirnov Test, dengan
menguji residual dari data.
Menurut Singgih (2014) dasar pengambilan keputusan bisa dilakukan
berdasarkan probabilitas (Asymtotic Significance), yakni: 1) Jika
probabilitas >0,05 maka distribusi dari model regresi adalah normal. 2)
Jika probabilitas <0,05 maka distribusi dari model regresi adalah tidak
normal. Berikut adalah contoh aplikasi uji normalitas dengan bantuan
software SPSS.
Contoh:
Diketahui hasil kuesioner terkait pendapatan nelayan yang dipengaruhi
oleh beberapa faktor antara lain Karakteristik (X1), Pendidikan (X2), dan
Lama Kerja sebagai nelayan (X3). Pendapatan nelayan menjadi variabel
independent (Y). Berikut tahapan uji normalitas data dengan software
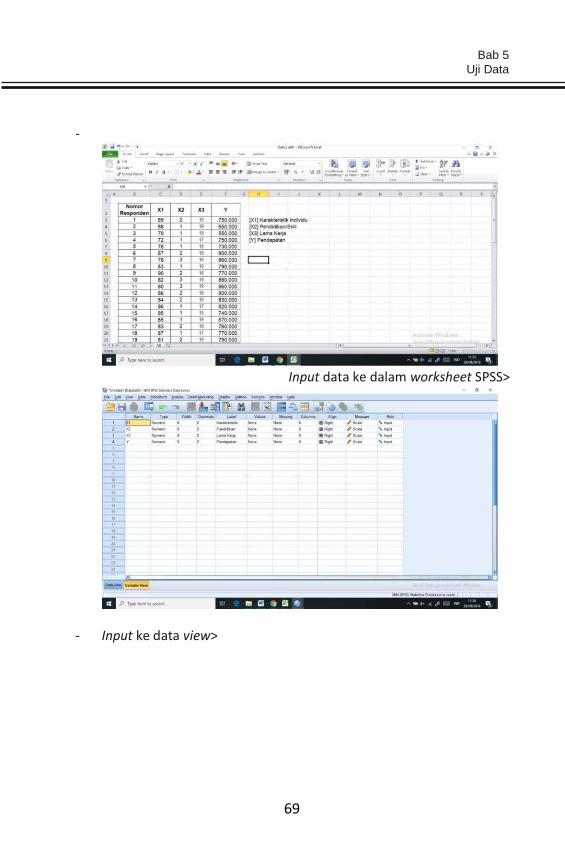
SPSS. Sebelum menginput data ke dalam lembar kerja (worksheet) SPSS,
terlebih dahulu tabulasi data keempat variabel tersebut pada Microsoft
Excel.
- Tabulasi data dalam MS. Excel>
Bab 5
Uji Data
-
69
Input data ke dalam worksheet SPSS>
- Input ke data view>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
70
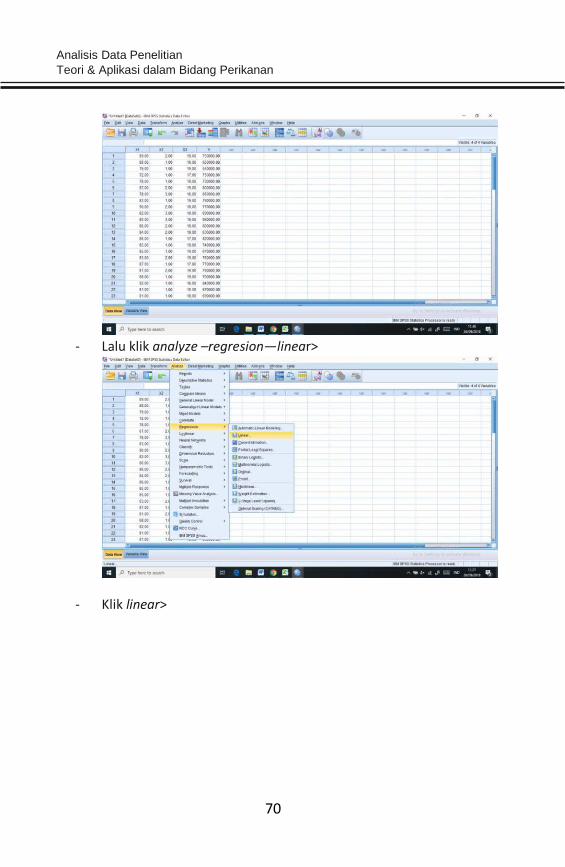
- Lalu klik analyze –regresion—linear>
- Klik linear>

Bab 5
Uji Data
-
71
Pindahkan variabel X1, X2, dan X3 ke kolom independen dan variabel
Y ke kolom dependen, selanjutnya klik save dan centang
unstandardized pada menu residual>
- Klik continue lalu klik ok maka muncul output analisis pada data view
berupa residual>
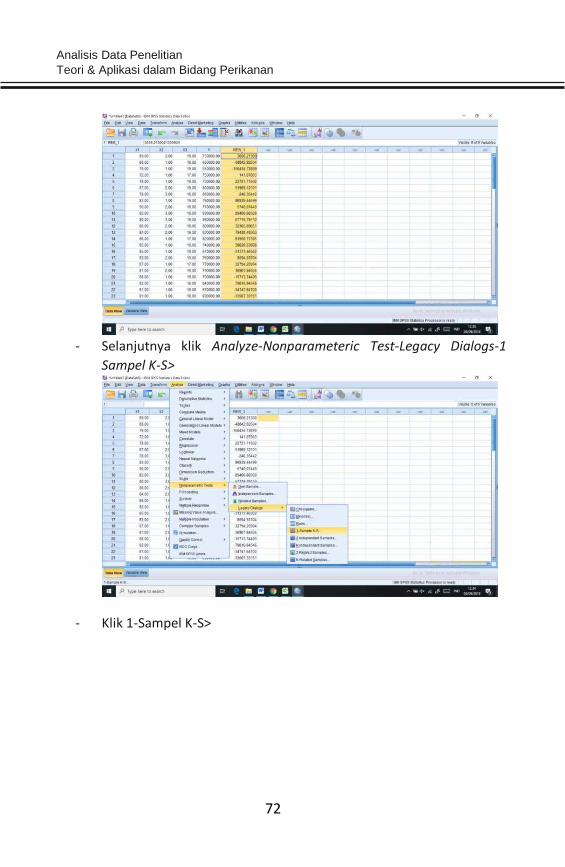
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
72
- Selanjutnya klik Analyze-Nonparameteric Test-Legacy Dialogs-1
Sampel K-S>
- Klik 1-Sampel K-S>
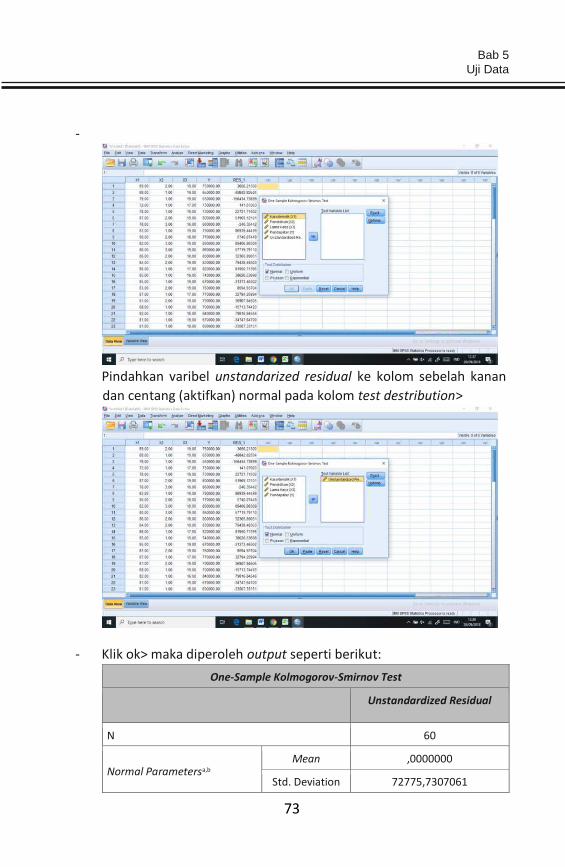
Bab 5
Uji Data
-
73
Pindahkan varibel unstandarized residual ke kolom sebelah kanan
dan centang (aktifkan) normal pada kolom test destribution>
- Klik ok> maka diperoleh output seperti berikut:
One-Sample Kolmogorov-Smirnov Test
Unstandardized Residual
N 60
Normal Parametersa,b Mean ,0000000
Std. Deviation 72775,7307061
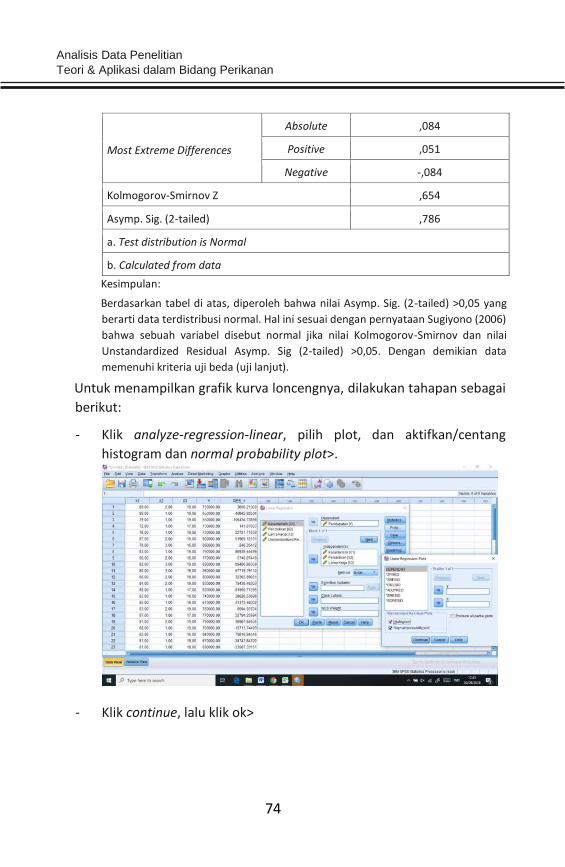
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
74
Most Extreme Differences
Absolute ,084
Positive ,051
Negative -,084
Kolmogorov-Smirnov Z ,654
Asymp. Sig. (2-tailed) ,786
a. Test distribution is Normal
b. Calculated from data
Kesimpulan:
Berdasarkan tabel di atas, diperoleh bahwa nilai Asymp. Sig. (2-tailed) >0,05 yang
berarti data terdistribusi normal. Hal ini sesuai dengan pernyataan Sugiyono (2006)
bahwa sebuah variabel disebut normal jika nilai Kolmogorov-Smirnov dan nilai
Unstandardized Residual Asymp. Sig (2-tailed) >0,05. Dengan demikian data
memenuhi kriteria uji beda (uji lanjut).
Untuk menampilkan grafik kurva loncengnya, dilakukan tahapan sebagai
berikut:
- Klik analyze-regression-linear, pilih plot, dan aktifkan/centang
histogram dan normal probability plot>.
- Klik continue, lalu klik ok>
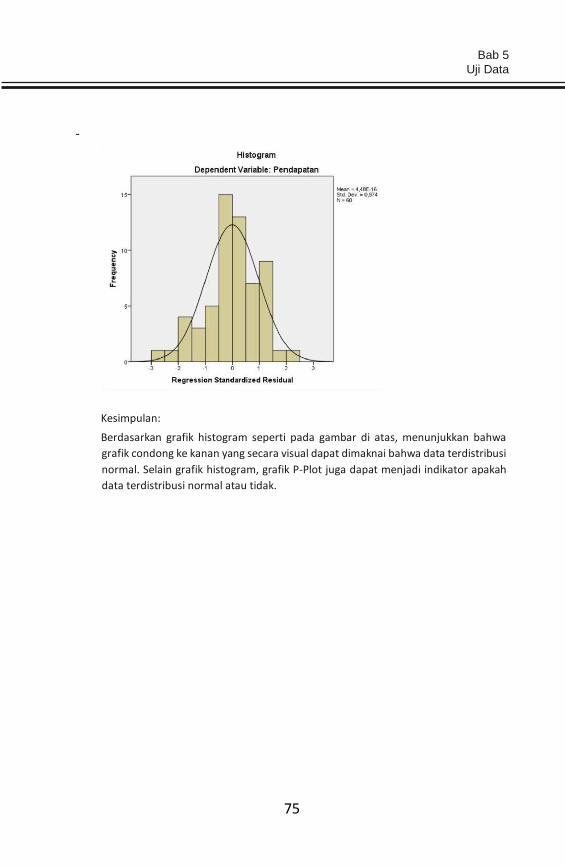
Bab 5
Uji Data
-
75
Kesimpulan:
Berdasarkan grafik histogram seperti pada gambar di atas, menunjukkan bahwa
grafik condong ke kanan yang secara visual dapat dimaknai bahwa data terdistribusi
normal. Selain grafik histogram, grafik P-Plot juga dapat menjadi indikator apakah
data terdistribusi normal atau tidak.

Bab 5
Uji Data
76
Berikut grafik P-Plot yang diperoleh dari hasil analisis regeresi linear.
Kesimpulan:
Secara grafik P-Plot tampak bahwa data tersebar mendekati garis diagonalnya, yang
secara visual dapat disimpulkan bahwa data terdistribusi normal sehingga valid
untuk dijadikan sebagai data penduga terhadap model regresi.
5.2 Uji Autokorelasi Uji Autokorelasi adalah sebuah uji statistik yang dilakukan untuk
mengetahui adakah korelasi variabel yang ada di dalam model prediksi
terhadap perubahan waktu. Dengan kata lain apakah terdapat hubungan
suatu variabel dari tahun t dengan tahun t-1 (tahun sebelumnya). Model
regresi yang baik adalah model yang tidak terdapat masalah autokorelasi
(Singgih 2006). Apabila terjadi autokorelasi maka model (persamaan)
tersebut menjadi tidak baik atau tidak layak dipakai sebagai prediksi
(peramalan). Oleh karena itu, apabila asumsi autokorelasi terjadi pada
sebuah model prediksi, nilai disturbance tidak lagi berpasangan secara
bebas, tetapi berpasangan secara autokorelasi. Uji autokorelasi di dalam
model regresi linear, harus dilakukan apabila data merupakan data time
series atau runtut waktu. Sebab yang dimaksud dengan autokorelasi
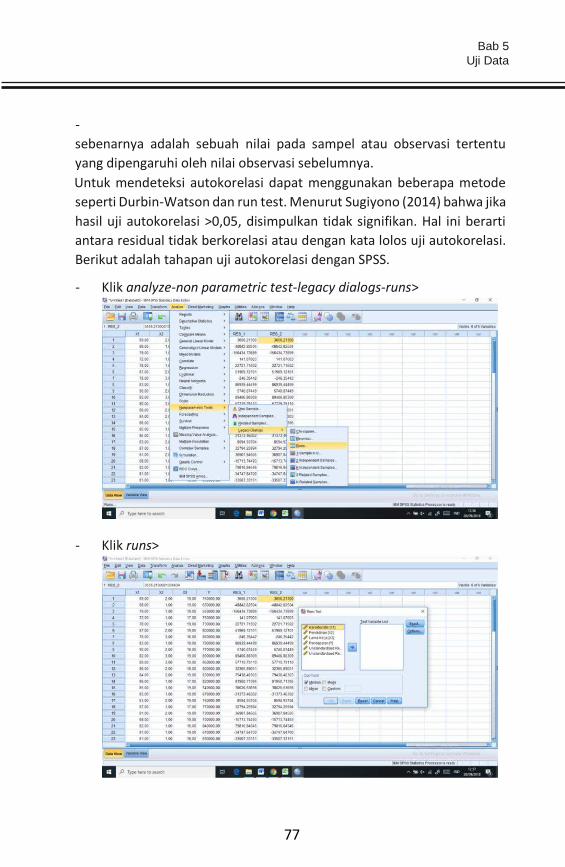
Bab 5
Uji Data
-
77
sebenarnya adalah sebuah nilai pada sampel atau observasi tertentu
yang dipengaruhi oleh nilai observasi sebelumnya.
Untuk mendeteksi autokorelasi dapat menggunakan beberapa metode
seperti Durbin-Watson dan run test. Menurut Sugiyono (2014) bahwa jika
hasil uji autokorelasi >0,05, disimpulkan tidak signifikan. Hal ini berarti
antara residual tidak berkorelasi atau dengan kata lolos uji autokorelasi.
Berikut adalah tahapan uji autokorelasi dengan SPSS.
- Klik analyze-non parametric test-legacy dialogs-runs>
- Klik runs>
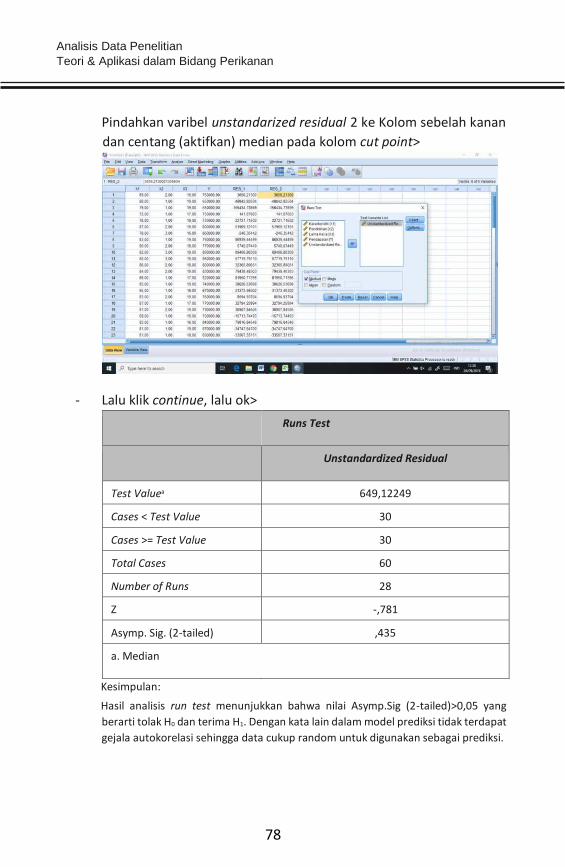
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
78
Pindahkan varibel unstandarized residual 2 ke Kolom sebelah kanan
dan centang (aktifkan) median pada kolom cut point>
- Lalu klik continue, lalu ok>
Runs Test
Unstandardized Residual
Test Valuea 649,12249
Cases < Test Value 30
Cases >= Test Value 30
Total Cases 60
Number of Runs 28
Z -,781
Asymp. Sig. (2-tailed) ,435
a. Median
Kesimpulan:
Hasil analisis run test menunjukkan bahwa nilai Asymp.Sig (2-tailed)>0,05 yang
berarti tolak H0 dan terima H1. Dengan kata lain dalam model prediksi tidak terdapat
gejala autokorelasi sehingga data cukup random untuk digunakan sebagai prediksi.

Bab 5
Uji Data
-
79
5.3 Uji Heteroskedastisitas Uji heteroskedastisitas adalah uji yang menilai apakah terdapat
ketidaksamaan varian dari residual untuk semua pengamatan pada
model regresi linear. Uji ini merupakan salah satu dari uji asumsi klasik
yang harus dilakukan pada regresi linear. Apabila asumsi
heteroskedastisitas tidak terpenuhi, model regresi dinyatakan tidak valid
sebagai alat penduga (prediksi).
Dalam persamaan regresi berganda perlu dilakukan uji mengenai sama
atau tidaknya varian residual dari observasi yang satu dengan observasi
lainnya. Apabila residual mempunyai varian yang sama, data mengalami
gejala homoskedastisitas, dan bila variannya tidak sama, data disebut
mengalami gejala heteroskedastisitas. Persamaan regresi yang baik
adalah persamaan yang tidak terjadi gejala heteroskedastisitas.Untuk
mendekteksi adanya heteroskedastisitas, digunakan uji Glejser (Sugiyono
2009). Sementara menurut Menurut Gujarati (2003) bahwa untuk
menguji ada tidaknya heteroskedastisitas digunakan uji rank Spearman
yakni mengorelasikan variabel independen terhadap nilai absolut dari
residual (error). Jika hasil uji menunjukkan nilai signifikan constant>0,05
maka dinyatakan lolos uji, di mana model regresi yang digunakan tidak
terjadi heteroskedastisitas atau valid untuk digunakan sebagai penduga
(prediksi).
Uji heteroskedastisitas perlu dilakukan agar diketahui apakah terdapat
penyimpangan dari syarat-syarat asumsi klasik pada regresi linear, di
mana dalam model regresi harus dipenuhi syarat tidak adanya
heteroskedastisitas. Hasil residual selanjutnya dibuat absolut agar nilai
redisual tersebut tidak ada yang minus. Berikut tahapan uji
heteroskedastisitas dengan bantuan software SPSS.
Lakukan transformasi data residual dengan formula ABS. Klik
transform-compute variable>

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
80
- Klik compute variable>
- Isikan Res3 pada kolom target variable dan ABS(RES_1) pada kolom
numeric expression, lalu klik ok>
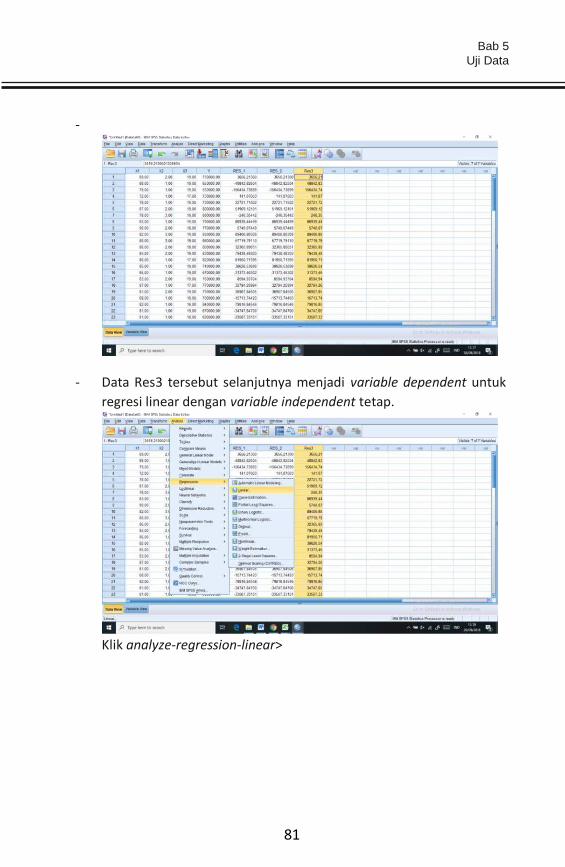
Bab 5
Uji Data
-
81
- Data Res3 tersebut selanjutnya menjadi variable dependent untuk
regresi linear dengan variable independent tetap.
Klik analyze-regression-linear>
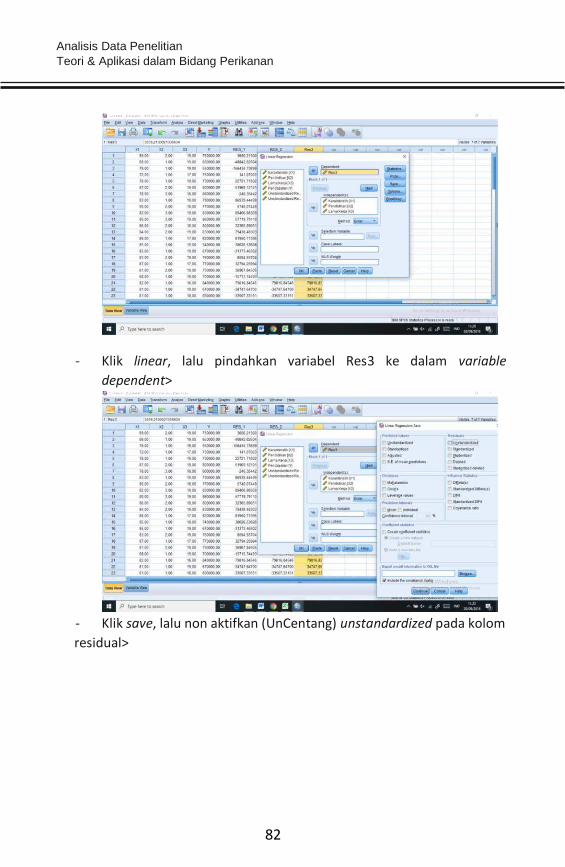
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
82
- Klik linear, lalu pindahkan variabel Res3 ke dalam variable
dependent>
- Klik save, lalu non aktifkan (UnCentang) unstandardized pada kolom
residual>

Bab 5
Uji Data
-
83
- Klik continue, lalu klik ok> Coefficientsa
Model Unstandardized Coefficients Standardized
Coefficients t Sig. B Std. Error Beta
(Constant) -30002,02 140444,182 -,214 ,832
Karakteristik -174,058 1050,687 -,022 -,166 ,869 1 Pendidikan -9303,524 9245,171 -,133 -1,006 ,319
Lama Kerja 6201,189 6015,619 ,136 1,031 ,307 a. Dependent Variable: Res3
Kesimpulan:
Hasil analisis Uji Glejser diperoleh bahwa nilai signifikansi (Sig.)>0,05 maka tolak H0
dan terima H1, atau dengan kata lain tidak terdapat gejala heteroskedastisitas.
Namun apabila terdapat gejala heteroskedastisitas, lakukan pendekatan Weighted
Least Square (WLS) untuk menghilangkan gejala heteroskedastisitas tersebut.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
84
5.4 Uji Multikolineariti Uji multikolineariti dimaksudkan untuk menguji model regresi apakah
terdapat korelasi antara variabel bebas (independent). Model regresi yang
baik adalah model yang di dalamnya tidak terdapat hubungan (korelasi)
antara variabel bebasnya. Apabila terjadi multikolineariti, dapat disimpulkan
bahwa variabel-variabel tersebut tidak ortogonal. Variabel ortogonal adalah
variabel bebas yang nilai korelasi antar sesama variabel bebas sama dengan
nol. Menurut Singgih (2003) apabila terbukti adanya multikolinieritas,
sebaiknya salah satu independen yang ada dikeluarkan dari model, lalu
pembuatan model regresi diulang kembali.
Untuk mendekteksi ada tidaknya multikolinearitas dengan melihat nilai
tolerance dan nilai inflasi Variance Inflation Factor (VIF) dn nilai tolerance.
Jika nilai VIF<10 dan nilai tolerance semua variabel bebas>0,10 maka dapat
disimpulkan bahwa tidak ada multikolonieritas antara variabel bebas dalam
model regresi atau dapat disebut lolos uji (Riduan 2005). Hal yang sama
menurut Gujarati (2003) pedoman suatu model regresi yang bebas
multikolinieritas adalah mempunyai angka tolerance mendekati 1 dan batas
VIF adalah 10, jika nilai VIF di bawah 10 maka tidak terjadi gejala
multikolinieritas. Lebih jauh menurut Singgih (2014) rumus yang digunakan
adalah sebagai berikut:
1 VIF
= T
Atau:
1 T =
VIF
Di mana:
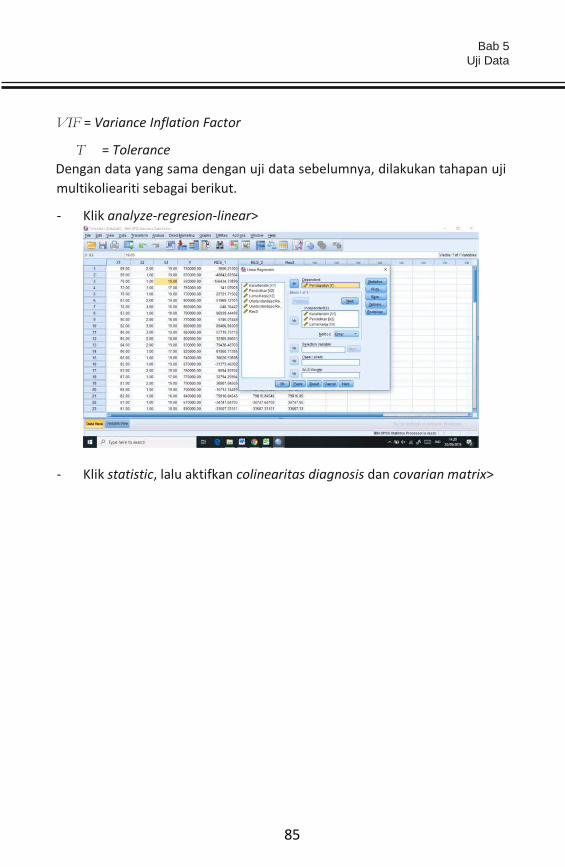
Bab 5
Uji Data
85
VIF = Variance Inflation Factor
T = Tolerance
Dengan data yang sama dengan uji data sebelumnya, dilakukan tahapan uji
multikolieariti sebagai berikut.
- Klik analyze-regresion-linear>
- Klik statistic, lalu aktifkan colinearitas diagnosis dan covarian matrix>
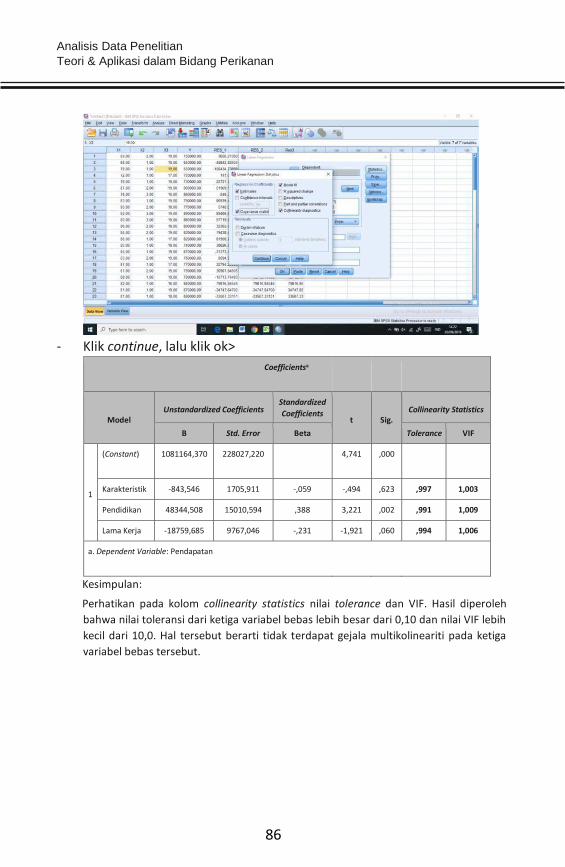
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
86
- Klik continue, lalu klik ok>
Coefficientsa
Model Unstandardized Coefficients
Standardized
Coefficients t Sig.
Collinearity Statistics
B Std. Error Beta Tolerance VIF
1
(Constant) 1081164,370 228027,220 4,741 ,000
Karakteristik -843,546 1705,911 -,059 -,494 ,623 ,997 1,003
Pendidikan 48344,508 15010,594 ,388 3,221 ,002 ,991 1,009
Lama Kerja -18759,685 9767,046 -,231 -1,921 ,060 ,994 1,006
a. Dependent Variable: Pendapatan
Kesimpulan:
Perhatikan pada kolom collinearity statistics nilai tolerance dan VIF. Hasil diperoleh
bahwa nilai toleransi dari ketiga variabel bebas lebih besar dari 0,10 dan nilai VIF lebih
kecil dari 10,0. Hal tersebut berarti tidak terdapat gejala multikolineariti pada ketiga
variabel bebas tersebut.


BAB 6 STATISTIK
DESKRIPTIF
Deskriptif merupakan gambaran data. Hoax adalah deskripsi palsu dari data
yang sesungguhnya (true). Hoax menjadi kata yang paling banyak dibully saat
ini, sedikit-sedikit hoax, itu hoax, ini hoax, semua hoax. Deskripsi data
dengan benar akan memberikan informasi yang penting ...
.. “Hoax is Hocus Pocus or Hoc est corpus which means Fake” ..
I think a simple rule of business is, if you do the things that are easier
first, then you can actually make a lot of progress ...
[Mark Zuckerberg CEO Facebook]
Secara umum statistik terbagi menjadi 2 (dua), yakni statistik deskriptif dan
statistik inferensia. Selanjutnya statistik inferensia terbagi menjadi
beberapa, yakni berdasarkan variabelnya terbagi menjadi 3 (tiga), yakni
statistik univariate, bivariate dan multivariate. Sementara berdasarkan
datanya, statistik inferensia terbagi menjadi 2 (dua) yakni, statistik
parameterik dan non-parametrik. Dalam bab ini, akan dijelaskan terkait
statistik deskriptif. Sedangkan statistik inferensia akan diurai per bab.
Statistika deskriptif sering juga disebut sebagai statistika deduktif yang
membahas tentang bagaimana merangkum sekumpulan data dalam bentuk
yang mudah dan cepat dibaca dan dipahami serta memberikan informasi
dalam bentuk tabel, grafik atau gambar lainnya. Dengan kata lain, statistik
deskriptif adalah metode analisis data yang berkaitan dengan pengolahan
dan penyajian suatu gugus data sehingga memberikan informasi yang
berguna. Statistika deskriptif hanya memberikan informasi mengenai data
yang dipunyai dan sama sekali tidak menarik kesimpulan apapun (inferensia)
tentang gugus induknya yang lebih besar (Siagian dan Sugiarto 2002). Berikut
pendapat beberapa ahli terkait definisi statistik deskriptif.

Bab 6
Statistik Deskriptif
89
▪ Nazir (2011) bahwa yang dimaksud dengan metode deskriptif adalah
untuk studi menentukan fakta dengan interpretasi yang tepat di mana
di dalamnya termasuk studi untuk melukiskan secara akurat sifat-sifat
dari beberapa fenomena kelompok dan individu serta studi untuk 65
menentukan frekuensi terjadinya suatu keadaan untuk meminimalisasi
bias dan memaksimumkan reabilitas. Metode deskripsi ini digunakan
untuk menjawab permasalah mengenai seluruh variabel penelitian
secara independen.
▪ Sudjana (1996) menjelaskan statistika deskriptif adalah fase statistika di
mana hanya berusaha melukiskan atau menganalisa kelompok yang
diberikan tanpa membuat atau menarik kesimpulan tentang populasi
atau kelompok yang lebih besar.
▪ Hasan (2002) menjelaskan bahwa statistik deskriptif adalah bagian dari
statistika yang mempelajari cara pengumpulan data dan penyajian data
sehingga mudah dipahami. Statistika deskriptif hanya berhubungan
dengan hal menguraikan atau memberikan keterangan-keterangan
mengenai suatu data atau keadaan. Dengan kata statistika deskriptif
berfungsi menerangkan keadaan, gejala, atau persoalan. Penarikan
kesimpulan pada statistika deskriptif (jika ada) hanya ditujukan pada
kumpulan data yang ada.
▪ Sugiyono (2014) menyebutkan analisis deskriptif adalah statistik yang
digunakan untuk menganalisa data dengan cara mendeskripsikan atau
menggambarkan data yang telah terkumpul sebagaimana adanya tanpa
bermaksud membuat kesimpulan yang berlaku untuk umum atau
generalisasi.
▪ Subagyo (2003) menyatakan bahwa yang dimaksud sebagai statistika
deskriptif adalah bagian statistika mengenai pengumpulan data,
penyajian, penentuan nilai-nilai statistika, pembuatan diagram atau
gambar mengenai sesuatu hal, di sini data yang disajikan dalam bentuk
yang lebih mudah dipahami atau dibaca.
Aplikasi statistik deskriptif banyak digunakan pada data-data yang banyak
(n>30) dan umumnya pada data-data yang diperoleh dari responden

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
90
maupun data time series untuk mengetahui nilai-nilai pemusatan dan
penyebaran. Berikut contoh analisis statistik deskriptif.
Contoh:
Diketahui data hasil survei nelayan terkait karakteristik individu
(pengalaman bekerja) dengan menggunakan kuesioner pada 60 responden,
diperoleh data sebagai berikut:
Nomor
responden
Lama Bekerja (tahun)
Nomor
responden
Lama Bekerja (tahun)
Nomor
responden
Lama Bekerja (tahun)
1 20 21 16 41 18
2 19 22 19 42 19
3 15 23 18 43 20
4 17 24 19 44 16
5 19 25 19 45 19
6 20 26 18 46 25
7 16 27 19 47 19
8 19 28 18 48 30
9 18 29 20 49 19
10 19 30 15 50 32
11 19 31 10 51 19
12 18 32 16 52 17
13 25 33 7 53 18
14 17 34 10 54 40
15 30 35 6 55 50
16 31 36 5 56 19
17 12 37 19 57 19
18 5 38 11 58 50
19 6 39 15 59 40
20 19 40 12 60 19
Bab 6
Statistik Deskriptif
91
Analisis statistik deskriptif dapat dilakukan pada semua software statistik,
dan umumnya statistik deskriptif menjadi salah satu tools pilihan yang
tersedia dalam software tersebut, seperti Microsoft Excel (data analysis),
SPSS, Minitab, Swanstat, dan lainnya. Dalam buku ini akan dicontohkan
aplikasi analisis statistik deskriptif MS.Excel dan SPSS. Berikut tahapannya:
- Tabulasi data dalam MS.Excel>
- Klik data pada menu bar, lalu klik data analysis>
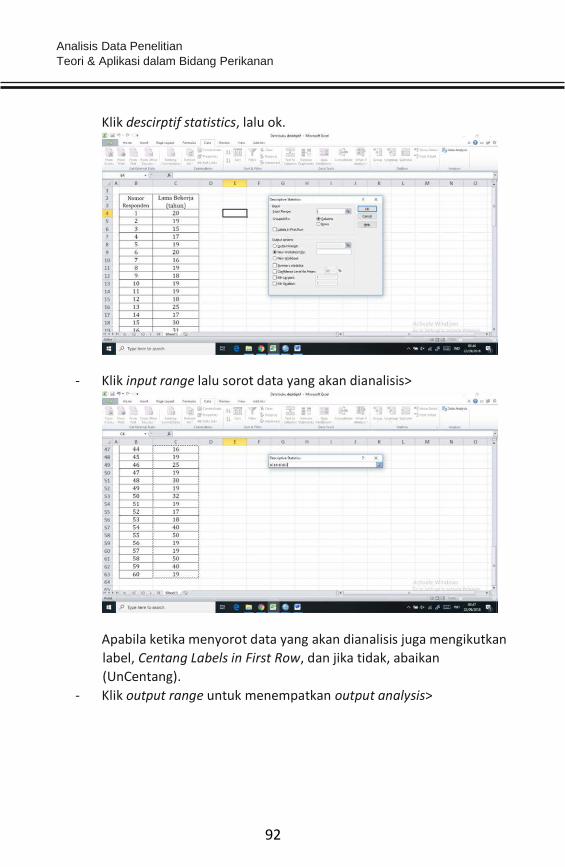
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
92
Klik descirptif statistics, lalu ok.
- Klik input range lalu sorot data yang akan dianalisis>
Apabila ketika menyorot data yang akan dianalisis juga mengikutkan
label, Centang Labels in First Row, dan jika tidak, abaikan
(UnCentang).
- Klik output range untuk menempatkan output analysis>
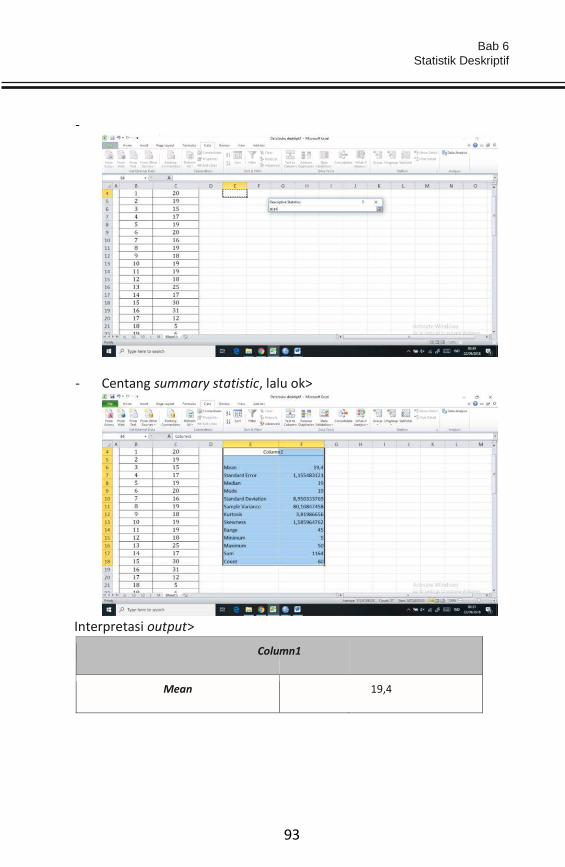
Bab 6
Statistik Deskriptif
-
93
- Centang summary statistic, lalu ok>
Interpretasi output>
Colu mn1
Mean 19,4
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
94
Standard Error 1,155483121
Median 19
Mode 19
Standard Deviation 8,950333769
Sample Variance 80,10847458
Kurtosis 3,81986656
Skewness 1,585964762
Range 45
Minimum 5
Maximum 50
Sum 1164
Count
60 Kesimpulan:
Output analysis data diperoleh bahwa total data adalah 60, dengan rata-rata (mean) lama
bekerja nelayan adalah 19,4 tahun. Nilai median dan modus adalah 19, dengan standar
deviasi = 8,95 dan varian sampel = 80,10. Nilai Kurtosis = 3,82 dan nilai Skewness = 1,58.
Makna nilai Skewness dan Kurtosis adalah ukuran untuk melihat distribusi data secara
grafik.
- Nilai Skewness menunjukkan kecondongan grafik distribusi data. Dengan nilai
Skewness=1,58 yakni berada pada nilai Z-Skewness antara -1,96 dan +1,96, berarti
data mendekati simetris.

Bab 6
Statistik Deskriptif
-
95
- Nilai Kurtosis menunjukkan keruncingan grafik distribusi data. Dengan nilai
Kurtosis=3,82 yakni dikategorikan grafik Leptokurtic, yaitu bagian tengah distribusi
data memiliki puncak yang lebih runcing (nilai keruncingan lebih dari >3).
- Kedua nilai tersebut menunjukkan bahwa data cenderung berdistribusi normal. Hal
tersebut juga tampak pada nilai mean, median, dan modus yang hampir sama
(berhimpit pada satu titik yakni 19) dengan kecondongan data ke arah kanan
(condong positif) di mana nilai mean lebih dari nilai modus (19,4>19).
Dengan data yang sama dilakukan analisis deskriptif dengan aplikasi
software SPSS, sebagai berikut:
- Input data ke dalam lembar kerja SPSS>
- Klik analyze-descriptive statistics-descriptive>

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
96
Klik descriptive>
- Pindahkan variabel Lama Bekerja ke sebelah kanan, lalu klik option
dan aktifkan (centang) semua deskripsi yang akan dianalisis>
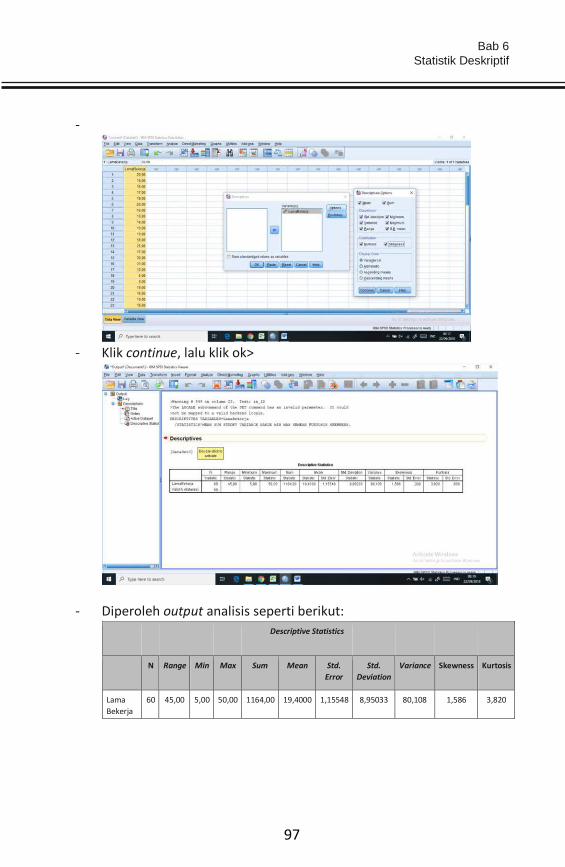
Bab 6
Statistik Deskriptif
-
97
- Klik continue, lalu klik ok>
- Diperoleh output analisis seperti berikut:
Descriptive Statistics
N Range Min Max Sum Mean Std.
Error Std.
Deviation Variance Skewness Kurtosis
Lama
Bekerja 60 45,00 5,00 50,00 1164,00 19,4000 1,15548 8,95033 80,108 1,586 3,820

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
98
Valid N
(listwise) 60
Kesimpulan:
Nilai yang diperoleh dari output analisis dengan aplikasi software SPSS adalah sama
dengan dengan output analysis dengan software MS.Excel.

BAB 7 STATISTIK
UNIVARIATE ... Instead of learning from other people’s success,
learn from their mistakes. Most of the people who fail share common
reasons
(to fail) whereas success can be attributed to various different kinds of
reasons ...
[Jack Ma – CEO Alibaba Group]
Statistik univariate adalah analisis statistika secara serentak dengan data
yang diamati hanya memiliki satu variabel dependen (variabel terikat) pada
setiap objek yang diamati. Menurut Notoadmodjo (2002) statistik univariate
adalah analisis yang dilakukan menganalisis tiap variabel dari hasil
penelitian. analisis univariate berfungsi untuk meringkas kumpulan data
hasil pengukuran sedemikian rupa sehingga kumpulan data tersebut
berubah menjadi informasi yang berguna. peringkasan tersebut dapat
berupa ukuran statistik, tabel, grafik. Univariate is a term commonly used in
statistics to describe a type of data which consists of observations on only a
single characteristic or attribute. A simple example of univariate data would
be the salaries of workers in industry (Kachigan 1986). Like all the other data,
univariate data can be visualized using graphs, images or other analysis tools
after the data is measured, collected, reported, and analyzed (Lacke 2010).
Statistik univariate kurang lebih sama dengan statistik deskriptif. Analisis
statistik univariate seperti halnya analisis tergolong analisis statistik
sederhana (simple analysis), yakni menganalisis terhadap 1 (satu) variabel
secara simultan (serentak). Analisis statistik univariate biasanya digunakan
untuk mengetahui distribusi frekuensi, pemusatan, penyebaran dan
normalitas data. Berikut adalah salah satu aplikasi analisis statistik univariate
pada bidang perikanan.
Contoh:
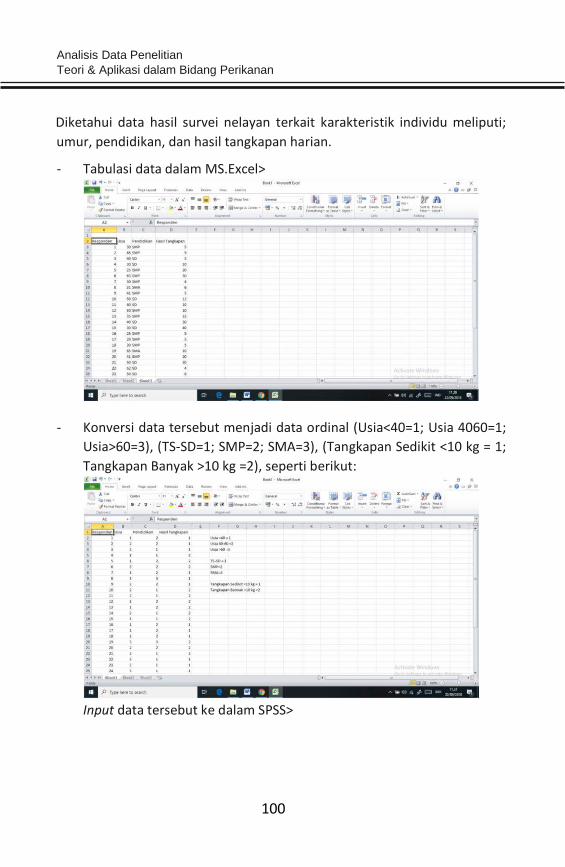
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
100
Diketahui data hasil survei nelayan terkait karakteristik individu meliputi;
umur, pendidikan, dan hasil tangkapan harian.
- Tabulasi data dalam MS.Excel>
- Konversi data tersebut menjadi data ordinal (Usia<40=1; Usia 4060=1;
Usia>60=3), (TS-SD=1; SMP=2; SMA=3), (Tangkapan Sedikit <10 kg = 1;
Tangkapan Banyak >10 kg =2), seperti berikut:
Input data tersebut ke dalam SPSS>
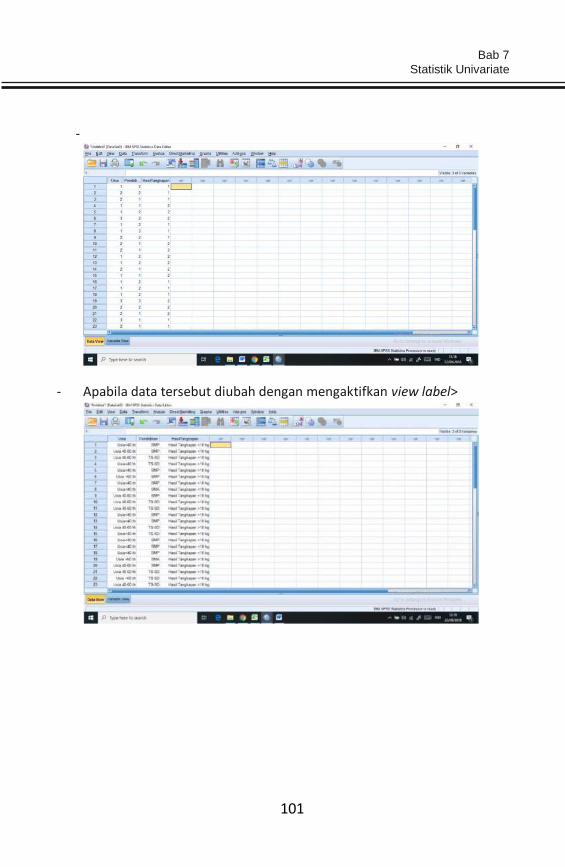
Bab 7
Statistik Univariate
-
101
- Apabila data tersebut diubah dengan mengaktifkan view label>
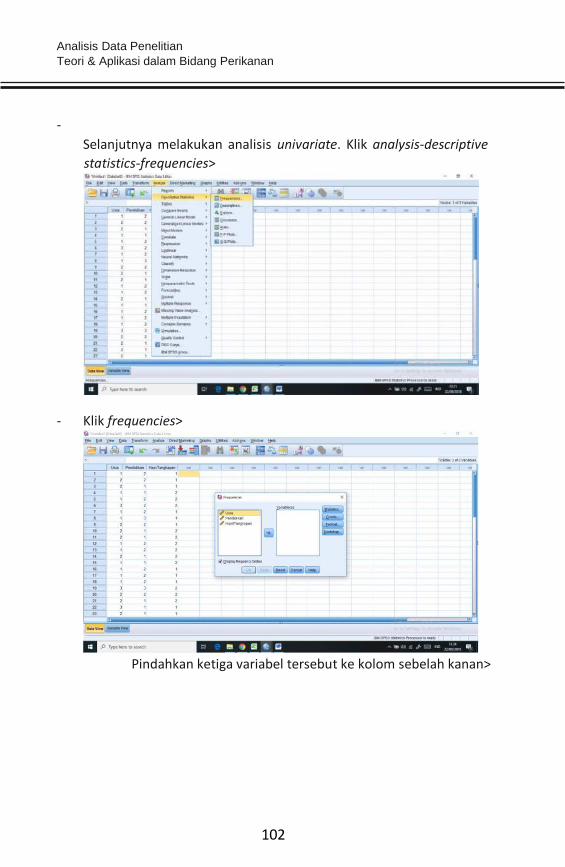
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
102
Selanjutnya melakukan analisis univariate. Klik analysis-descriptive
statistics-frequencies>
- Klik frequencies>
Pindahkan ketiga variabel tersebut ke kolom sebelah kanan>
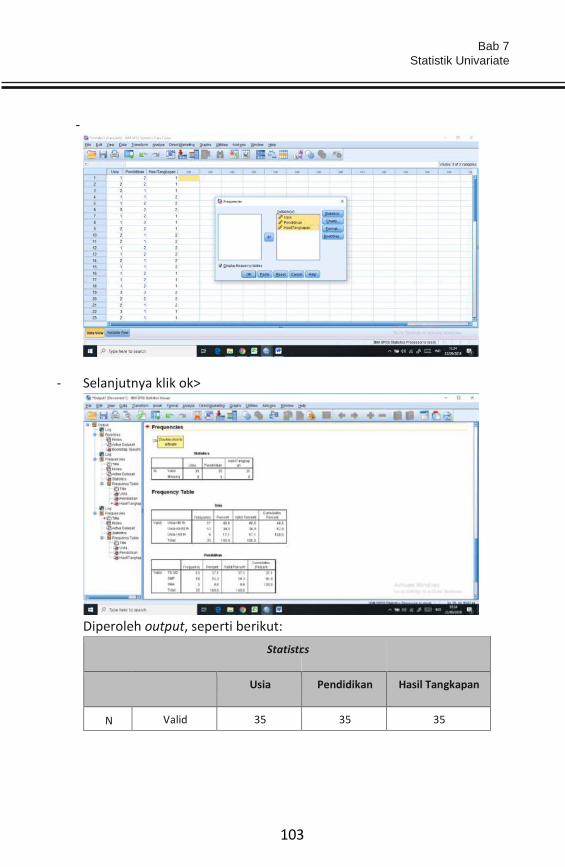
Bab 7
Statistik Univariate
-
103
- Selanjutnya klik ok>
Diperoleh output, seperti berikut:
Statisti cs
Usia Pendidikan Hasil Tangkapan
N Valid 35 35 35
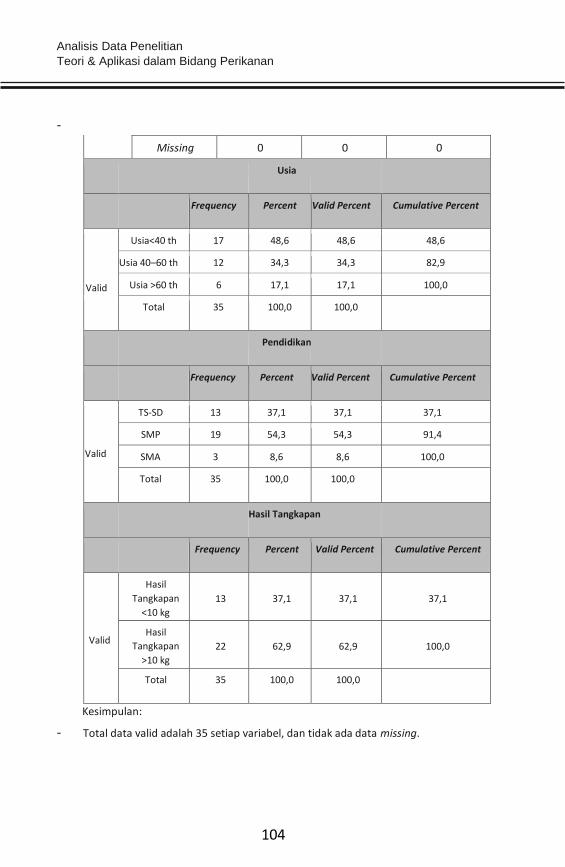
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
104
Missing 0 0 0
Usia
Frequency Percent Valid Percent Cumulative Percent
Valid
Usia<40 th 17 48,6 48,6 48,6
Usia 40–60 th 12 34,3 34,3 82,9
Usia >60 th 6 17,1 17,1 100,0
Total 35 100,0 100,0
Pendidikan
Frequency Percent Valid Percent Cumulative Percent
Valid
TS-SD 13 37,1 37,1 37,1
SMP 19 54,3 54,3 91,4
SMA 3 8,6 8,6 100,0
Total 35 100,0 100,0
Hasil Tangkapan
Frequency Percent Valid Percent Cumulative Percent
Valid
Hasil Tangkapan
<10 kg 13 37,1 37,1 37,1
Hasil Tangkapan
>10 kg 22 62,9 62,9 100,0
Total 35 100,0 100,0
Kesimpulan:
- Total data valid adalah 35 setiap variabel, dan tidak ada data missing.
Bab 7
Statistik Univariate
-
105
- Usia nelayan dominan adalah <40 th yakni 48,6%.
- Pendidikan dominan adalah tingkat pendidikan SMP yakni 54,3%.
- Hasil tangkapan dominan adalah bobot >10 kg, yakni 62,9% atau lebih dari setengah
jumlah nelayan.
Selanjutnya melakukan analisis Crosstabs guna melihat tabel silang
antara 2 variabel, dengan tahapan sebagai berikut:
Klik analyze—descriptive statistics—crosstabs>
- Klik crosstabs>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
106
Pindahkan variabel yang akan di analisis dengan Crosstab (tabel
silang), dan klik cell, lalu centang column dan total>
- Klik continue, lalu klik ok>
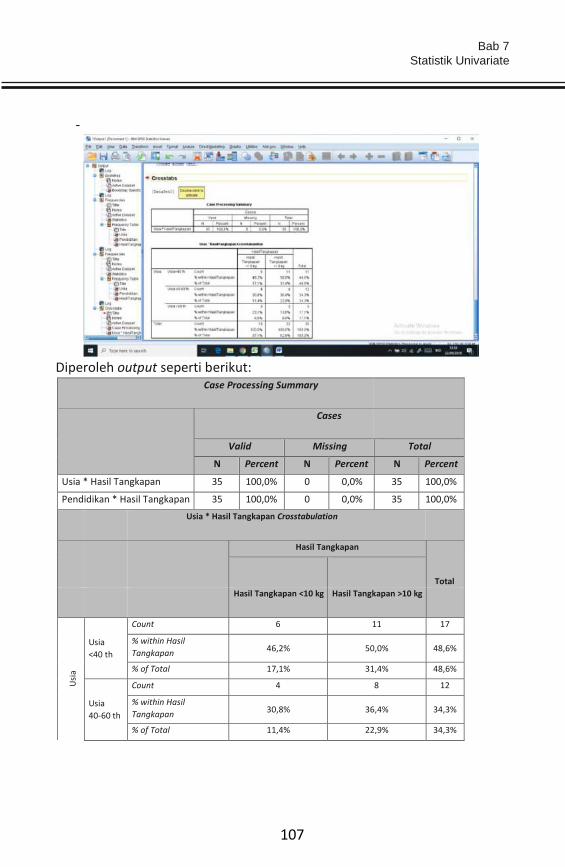
Bab 7
Statistik Univariate
-
107
Diperoleh output seperti berikut:
Case Processing Summary
Cases
Valid Missing Total N Percent N Percent N Percent
Usia * Hasil Tangkapan 35 100,0% 0 0,0% 35 100,0% Pendidikan * Hasil Tangkapan 35 100,0% 0 0,0% 35 100,0%
Usia * Hasil Tangkapan Crosstabulation
Hasil Tangkapan
Total
Hasil Tangkapan <10 kg Hasil Tangkapan >10 kg
Usia
<40 th
Count 6 11 17 % within Hasil Tangkapan 46,2% 50,0% 48,6%
% of Total 17,1% 31,4% 48,6%
Usia 40-60 th
Count 4 8 12 % within Hasil Tangkapan 30,8% 36,4% 34,3%
% of Total 11,4% 22,9% 34,3%

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
108
Usia
>60 th
Count 3 3 6 % within Hasil Tangkapan 23,1% 13,6% 17,1%
% of Total 8,6% 8,6% 17,1%
Total
Count 13 22 35 % within Hasil Tangkapan 100,0% 100,0% 100,0%
% of Total 37,1% 62,9% 100,0%
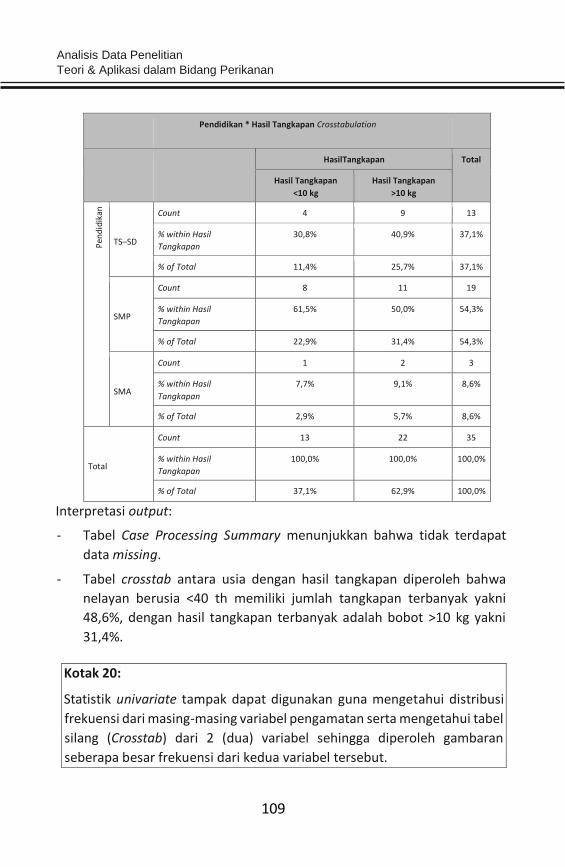
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
109
Pendidikan * Hasil Tangkapan Crosstabulation
HasilTangkapan Total
Hasil Tangkapan
<10 kg Hasil Tangkapan
>10 kg
TS–SD
Count 4 9 13
% within Hasil Tangkapan
30,8% 40,9% 37,1%
% of Total 11,4% 25,7% 37,1%
SMP
Count 8 11 19
% within Hasil Tangkapan
61,5% 50,0% 54,3%
% of Total 22,9% 31,4% 54,3%
SMA
Count 1 2 3
% within Hasil Tangkapan
7,7% 9,1% 8,6%
% of Total 2,9% 5,7% 8,6%
Total
Count 13 22 35
% within Hasil Tangkapan
100,0% 100,0% 100,0%
% of Total 37,1% 62,9% 100,0%
Interpretasi output:
- Tabel Case Processing Summary menunjukkan bahwa tidak terdapat
data missing.
- Tabel crosstab antara usia dengan hasil tangkapan diperoleh bahwa
nelayan berusia <40 th memiliki jumlah tangkapan terbanyak yakni
48,6%, dengan hasil tangkapan terbanyak adalah bobot >10 kg yakni
31,4%.
Kotak 20:
Statistik univariate tampak dapat digunakan guna mengetahui distribusi
frekuensi dari masing-masing variabel pengamatan serta mengetahui tabel
silang (Crosstab) dari 2 (dua) variabel sehingga diperoleh gambaran
seberapa besar frekuensi dari kedua variabel tersebut.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
110
BAB 8 STATISTIK
BIVARIATE
A brand for a company is like a reputation for a person. You earn
reputation by trying to do hard things well ...
[Jeff Bezos – CEO Amazon.Com]
Analisis bivariate adalah analisis statistik secara serentak dengan data yang
diamati terdiri dari 2 (dua) variabel dependen (variabel terikat) pada setiap
objek yang diamati. Bivariate analysis is one of the simplest forms of
quantitative (statistical) analysis. It involves the analysis of two variables
(often denoted as X, Y), for the purpose of determining the empirical
relationship between them (Babbie 2009). Analisis bivariate dikenal juga
dengan analisis korelasi. Analisis korelasi merupakan salah satu analisis
statistik yang dimaksudkan untuk mengetahui hubungan antar dua variabel.
Hubungan antara 2 variabel tersebut meliputi; signifikansi dan arah.
Menurut Croxton et al. (1968) korelasi merupakan teknik analisis statistik
yang digunakan untuk menguji atau mengetahui ada/tidaknya hubungan
serta arah hubungan dari dua variabel.
Secara umum analisis korelasi terdiri atas; a) Korelasi sederhana (Pearson
dan Spearman), b) Korelasi partial, dan c) Korelasi ganda.
- Korelasi Sederhana adalah suatu teknik statistik yang digunakan untuk
mengukur kekuatan hubungan antara 2 variabel dan juga mengetahui
bentuk hubungan keduanya dengan hasil yang bersifat kuantitatif.
Korelasi Pearson Product Moment merupakan korelasi yang digunakan
untuk data kontinu dan data diskrit. Korelasi pearson valid digunakan
untuk statistik parametrik dengan data berjumlah besar dan memiliki
ukuran parameter (mean dan standar deviasi). Korelasi Rank Spearman

merupakan korelasi yang digunakan untuk data diskrit dan kontinu,
namun untuk statistik non-parametrik.
Korelasi Parsial adalah suatu teknik statistik yang digunakan untuk
mengukur kekuatan hubungan antara 2 variabel antara variabel bebas
(independent) dan variabel tak bebas (dependent) dengan mengontrol
salah satu variabel bebas untuk melihat korelasi alaminya.
- Korelasi Ganda adalah suatu teknik statistik yang digunakan untuk
mengukur kekuatan hubungan antara tiga atau lebih variabel (dua atau
lebih variabel independen dan satu variabel dependent). Korelasi ganda
berkaitan dengan interkorelasi variabel-variabel independent
sebagaimana korelasi mereka dengan variabel dependent.
Kotak 21:
Korelasi = hubungan. Besar kecilnya hubungan antara dua variabel
dinyatakan dalam bilangan yang disebut koefisien korelasi. Nilai korelasi
memiliki rentang antara -1;0;+1. Nilai koefisien -1 &+1, menunjukkan
hubungan yang sempurna, sedangkan nilai koefisien 0 atau mendekati 0
dianggap tidak berhubungan. Kriteria korelasi (r) sebagai berikut:
[0] tidak ada korelasi; [0,01-0,5] korelasi lemah; [0,51-0,8] korelasi
sedang; [0,81-0,10] korelasi kuat; [>0,1] korelasi sempurna.
Tanda positif (+) dan negatif (-) menunjukkan arah hubungan. Tanda
positif menunjukkan arah hubungan searah, sedangkan tanda negatif
menunjukkan hubungan berlawanan.
Berikut adalah aplikasi analisis statistik bivariate (korelasi sederhana).
Diketahui data 12 petak tambak udang dengan data produksi dan data
pemberian pakan.
- Tabulasi data dalam MS. Excel>
Tambak Pemberian Pakan Produksi
1 50 4,0
2 60 5,0
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
112
3 40 1,5
4 10 0,5
5 20 1,3
6 30 3,0
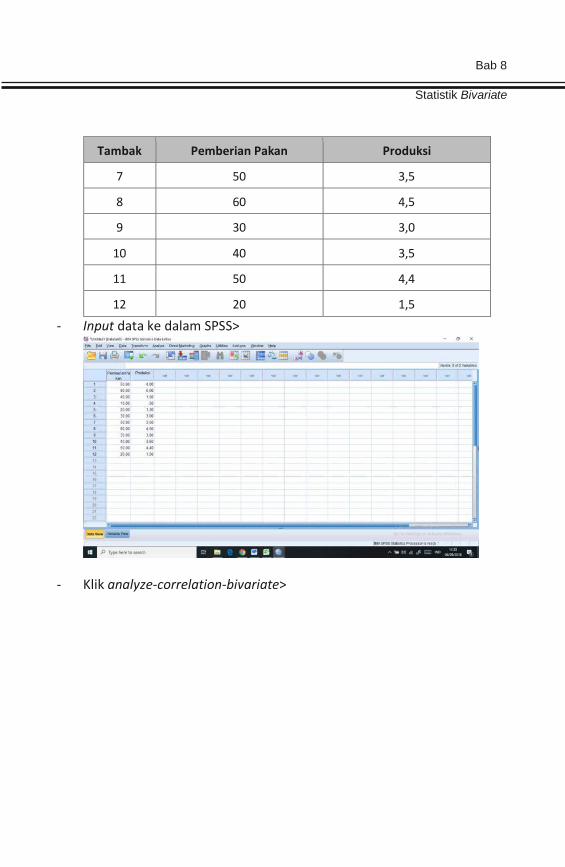
Bab 8
Statistik Bivariate
Tambak Pemberian Pakan Produksi
7 50 3,5
8 60 4,5
9 30 3,0
10 40 3,5
11 50 4,4
12 20 1,5
- Input data ke dalam SPSS>
- Klik analyze-correlation-bivariate>
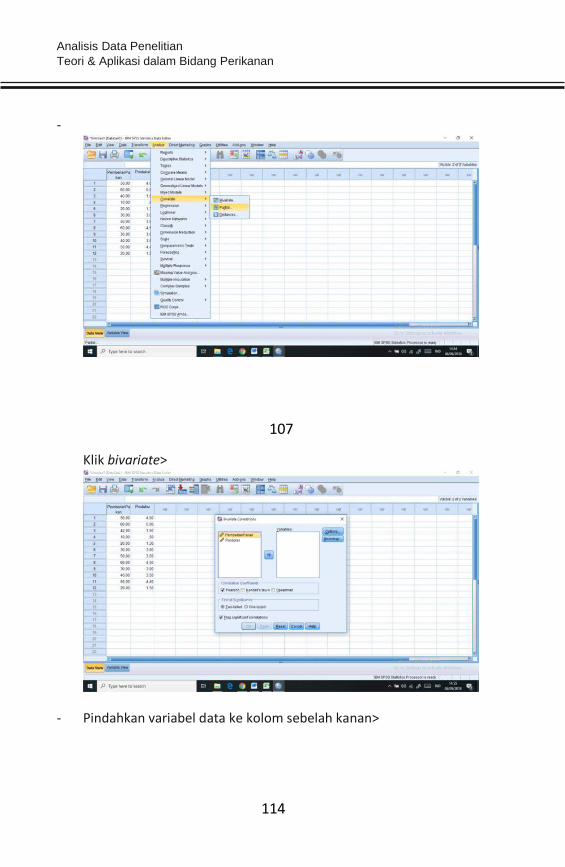
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
114
107
Klik bivariate>
- Pindahkan variabel data ke kolom sebelah kanan>
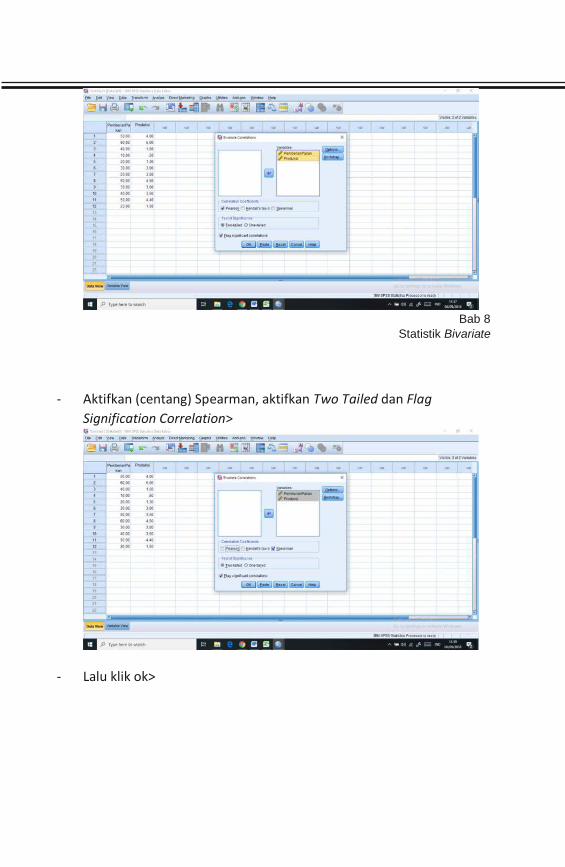
Bab 8
Statistik Bivariate
- Aktifkan (centang) Spearman, aktifkan Two Tailed dan Flag
Signification Correlation>
- Lalu klik ok>
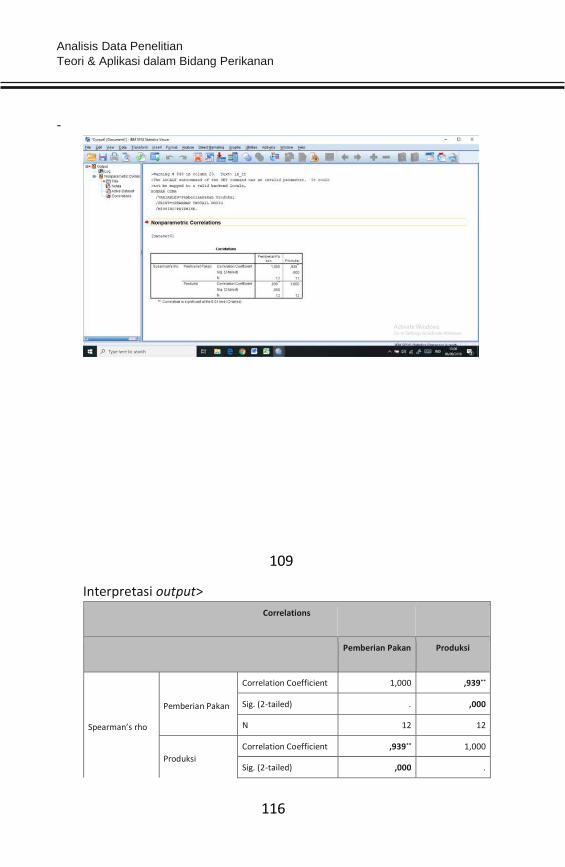
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
116
109
Interpretasi output>
Correlations
Pemberian Pakan Produksi
Spearman’s rho
Pemberian Pakan
Correlation Coefficient 1,000 ,939**
Sig. (2-tailed) . ,000
N 12 12
Produksi Correlation Coefficient ,939** 1,000
Sig. (2-tailed) ,000 .

N 12 12
**. Correlation is significant at the 0.01 level (2-tailed).
Kriteria penarikan keputusan koefisien korelasi yang mengacu pada
Sugiyono (2014), sebagai berikut:
Kesimpulan:
- Total data N=12
- Nilai Sig. (2-Tailed) adalah 0,000 dan nilai coeficient corelation =
0,939*. Dengan demikian disimpulkan bahwa terdapat hubungan
yang signifikan antara pemberian pakan dengan hasil produksi pada
tingkat kepercayaan 95%.
Dengan demikian, dapat disimpulkan bahwa pemberian pakan pada tambak
tersebut memberikan pengaruh yang signifikan terhadap peningkatan
produksinya.

BAB 9 STATISTIK
MULTIVARIATE It doesn’t matter if I failed. At least I passed
the concept on to others. Even if I don’t succeed, someone will
succeed ...
[Jack Ma – CEO Alibaba Group]
Analisis multivariate adalah analisis statistika secara serentak dengan
data yang diamati lebih dari dua variabel dependen (variabel terikat)
pada setiap objek yang diamati (Supranto 2004). Dengan kata lain analisis
multivariate adalah metode pengolahan variabel/data dalam jumlah
yang banyak, dengan tujuan adalah untuk mencari pengaruh variabel-
variabel tersebut terhadap suatu obyek secara simultan atau serentak.
Multivariate statistical analysis refers to multiple advanced techniques for
examining relationships among multiple variables at the same time
(Schervish 1987). Analisis multivariate dapat dilakukan untuk jenis data
metrik (rasio dan interval) maupun data non-metrik (nominal dan
interval).
9.1 Principal Component Analysis (PCA) Principal Component Analysis (PCA) atau Analisis Komponen Utama (AKU)
merupakan salah satu teknik statistika multivariate, yakni teknik yang
digunakan untuk menyederhanakan suatu data/mereduksi data, dengan
cara mentransformasi data secara linear sehingga terbentuk sistem
koordinat baru dengan varian maksimum. Analisis komponen utama
dapat digunakan untuk mereduksi dimensi suatu data tanpa mengurangi
karakteristik data tersebut secara signifikan. Analisis komponen utama
juga sering digunakan untuk menghindari masalah multikolinearitas
antar peubah bebas dalam model regresi berganda. Analisis komponen
utama merupakan analisis antara dari suatu proses penelitian yang besar
atau suatu awalan dari analisis berikutnya, bukan merupakan suatu
analisis yang langsung berakhir, misalnya komponen utama bisa

Bab 9
Statistik Multivariate
-
119
merupakan masukan untuk regresi berganda atau analisis faktor atau
analisis gerombol.
PCA adalah sebuah transformasi linier yang biasa digunakan pada
kompresi data. PCA juga merupakan teknik yang umum digunakan untuk
menarik fitur-fitur dari data pada sebuah skala berdimensi tinggi. PCA
memproyeksikan data ke dalam subspace. PCA adalah transformasi linear
untuk menentukan sistem koordinat yang baru dari data. Teknik PCA
dapat mengurangi dimensi dari data tanpa menghilangkan informasi
penting dari data tersebut. Analisis komponen utama merupakan suatu
teknik statistik untuk mengubah dari sebagian besar variabel asli yang
digunakan yang saling berkorelasi satu dengan yang lainnya menjadi satu
set variabel baru yang lebih kecil dan saling bebas (tidak berkorelasi).
Analisis komponen utama berguna untuk mereduksi data sehingga lebih
mudah untuk menginterpretasikan data-data tersebut (Johnson dan
Wichern 2002). Analisis komponen utama merupakan analisis antara dari
suatu proses penelitian yang besar atau suatu awalan dari analisis
berikutnya, bukan merupakan suatu analisis yang langsung berakhir.
Misalnya komponen utama bisa merupakan masukan untuk regresi
berganda atau analisis faktor. Menurut Hair et al. (2006), Analisis
Komponen Utama terkonsentrasi pada penjelasan struktur variansi dan
kovariansi melalui suatu kombinasi linear variabel-variabel asal dengan
tujuan utama melakukan reduksi data dan membuat interpretasi. Analisis
komponen utama lebih baik digunakan jika variabel-variabel asal saling
berkorelasi.
Principal Component Analysis (PCA) diperkenalkan pertama kali oleh Karl
Pearson tahun 1901 yang aplikasikan pada bidang biologi. Pada tahun
1947 teori ini diperkenalkan kembali oleh Karhunen, dan kemudian
dikembangkan oleh Loeve tahun l963 sehingga teori ini juga dinamakan
Karhunen-Loeve transform pada bidang ilmu telekomunikasi. Berikut
adalah tahapan analisis PCA dengan software MINITAB.
Buka software MINITAB>

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
120
- Input data dari file MS. Excel to Minitab>
- Klik stat-multivariate-principal components>
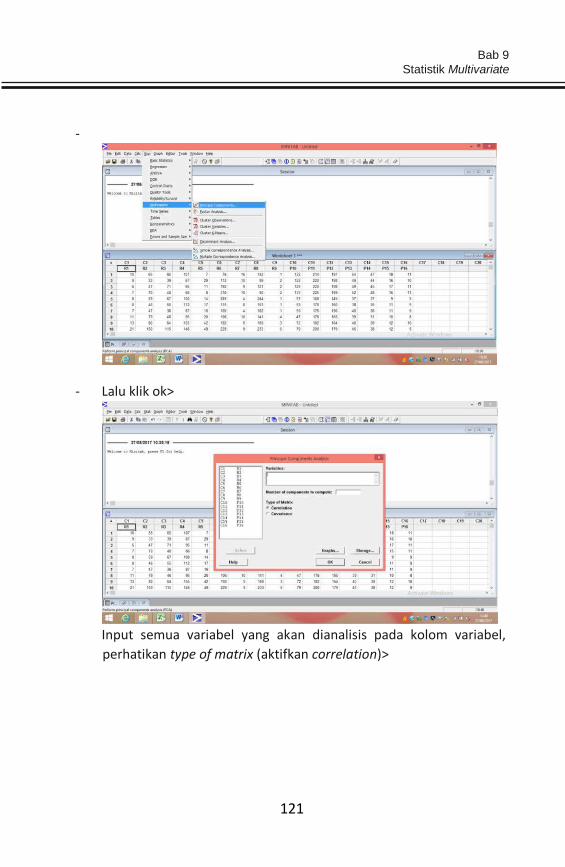
Bab 9
Statistik Multivariate
-
121
- Lalu klik ok>
Input semua variabel yang akan dianalisis pada kolom variabel,
perhatikan type of matrix (aktifkan correlation)>

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
122
- Lalu klik graphs untuk mengaktifkan scree plot & loading plots>
- Lalu klik ok>
Principal Component Analysis: R1; R2; R3; R4; R5; R6; R7; R8; R9; P10; P11; P12 Eigenanalysis of the
Correlation Matrix Eigenvalue0,73590,4635 0,3434
0,2287 Proportion0,0460,029 0,021
0,014 Cumulative0,9060,935 0,956
0,971
7,6019 3,7498 1,3977 1,0088
0,475 0,234 0,087 0,063
0,475 0,709 0,797 0,860
0,1718 0,0951 0,0677 0,0461
0,011 0,006 0,004 0,003
0,981 0,987 0,992 0,994
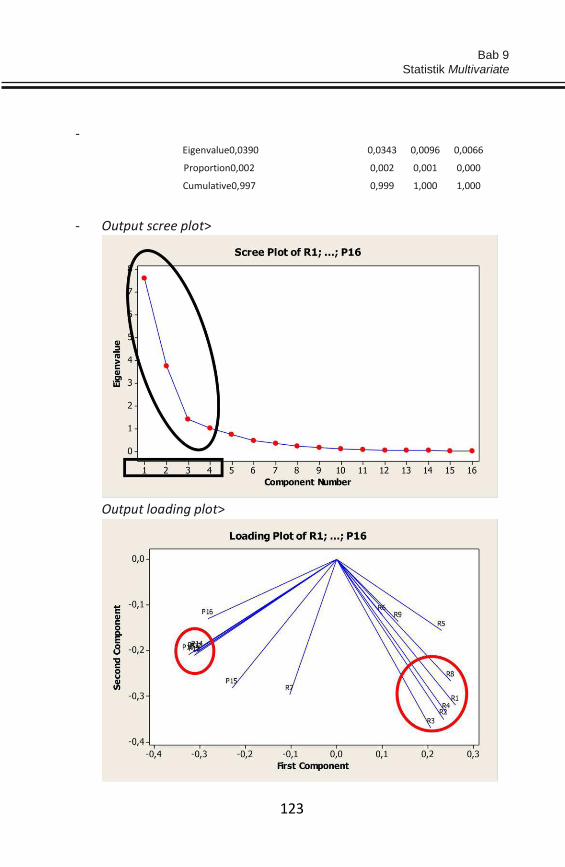
Bab 9
Statistik Multivariate
-
123
Eigenvalue0,0390 0,0343 0,0096 0,0066 Proportion0,002 0,002 0,001 0,000 Cumulative0,997 0,999 1,000 1,000
- Output scree plot>
Output loading plot>

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
124
Kesimpulan:
- Terdapat 4 faktor utama (komponen utama) yang terbentuk dengan nilai eigenvalue
>1,0 dengan proporsi keragaman mencapai 86,40%.
- Scree plot menunjukkan bahwa pada variabel 1 hingga 4 mengalami slope yang
tajam (curam) dan setelahnya landai. Hal tersebut menunjukkan bahwa kecuraman
(slope) menunjukkan keterwakilan variabel dalam faktor pembentuk (faktor utama).
- Proyeksi setiap variabel terhadap faktor/komponen 1; bahwa R1,R2,R3 dan R4
adalah yang memiliki kontribusi tertinggi.
Kotak 22:
Analisis Komponen Utama (PCA) merupakan salah satu tools analisis
statistik multivariate yang berguna untuk mereduksi data, serta dapat
digunakan untuk menghilangkan masalah multikolineariti dari data
(data terjadi korelasi antara peubah dalam variabel dependen).
9.2 Factor Analysis (FA) Faktor Analisis atau Analisis faktor merupakan salah satu statistik
multivariate yang bertujuan menganalisis variabel-variabel yang diduga
memiliki keterkaitan/korelasi satu sama lain sehingga keterkaitan
tersebut dapat dijelaskan dan dipetakan atau dikelompokkan dalam
faktor-faktor. Menurut Dennis (2006) bahwa analisis faktor merupakan
salah satu keluarga analisis multivariate yang bertujuan meringkas atau
mereduksi variabel amatan secara keseluruhan menjadi beberapa
variabel atau dimensi baru, akan tetapi variabel atau dimensi baru yang
terbentuk tetap mampu merepresentasikan variabel utama.
Asumsi mendasar dalam analisis factor adalah bahwa variabel-variabel
yang dianalisis memiliki keterkaitan atau saling berhubungan/berkorelasi
karena analisis faktor berusaha untuk mencari common dimension
(kesamaan dimensi) yang mendasari variabel-variabel tersebut. Tujuan
utama analisis faktor adalah untuk menjelaskan struktur hubungan
diantara banyak variabel dalam bentuk faktor atau vaiabel laten atau
variabel bentukan. Faktor yang terbentuk merupakan besaran acak
(random quantities) yang sebelumnya tidak dapat diamati atau diukur

Bab 9
Statistik Multivariate
-
125
atau ditentukan secara langsung. Berikut adalah tahapan analisis FA
dengan software MINITAB.
Kotak 23:
Dikenal dua pendekatan dalam FA, yaitu; Exploratory Factor Analysis
(EFA)dan Confirmatory Factor Analysis (CFA). EFA bila banyaknya faktor
yang terbentuk tidak ditentukan terlebih dahulu, dan CFA digunakan
apabila faktor yang terbentuk telah ditetapkan terlebih dahulu.
- Buka software MINITAB>
Input data ke dalam new worksheet MINITAB>
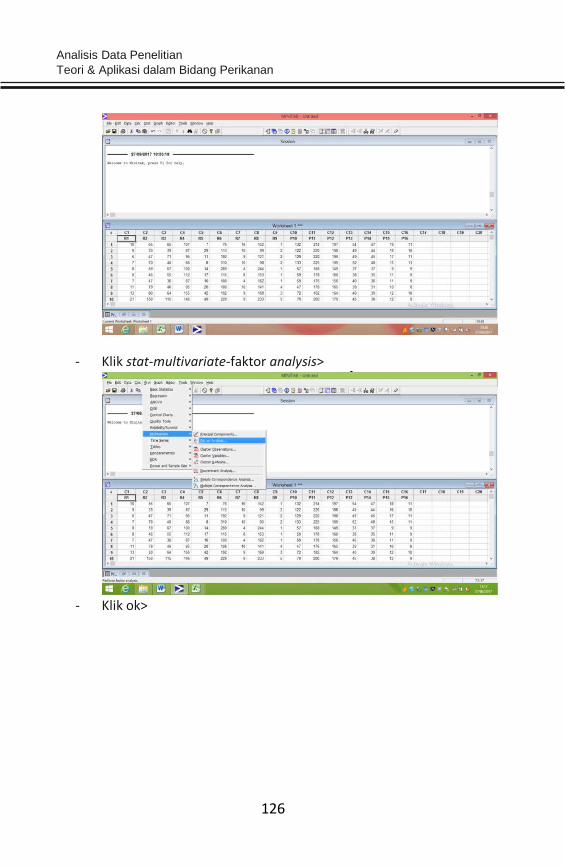
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
126
- Klik stat-multivariate-faktor analysis>
- Klik ok>
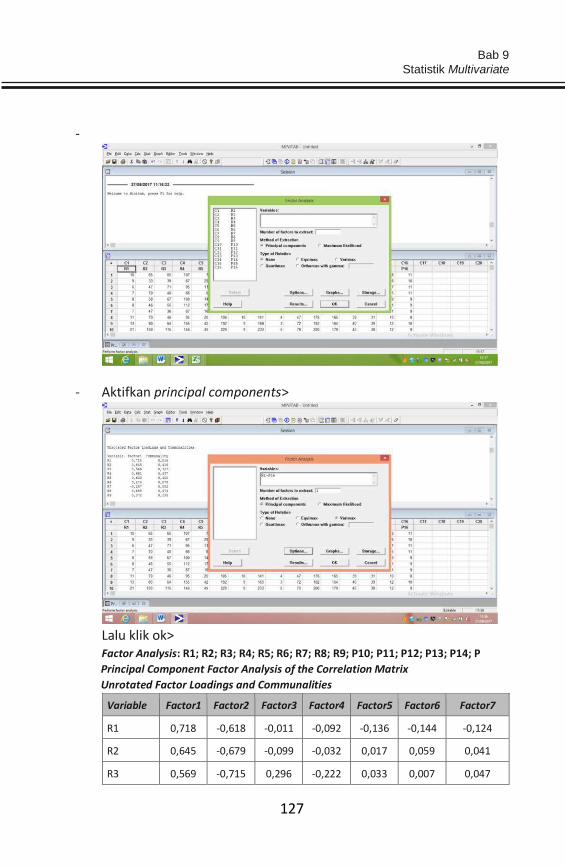
Bab 9
Statistik Multivariate
-
127
- Aktifkan principal components>
Lalu klik ok> Factor Analysis: R1; R2; R3; R4; R5; R6; R7; R8; R9; P10; P11; P12; P13; P14; P Principal Component Factor Analysis of the Correlation Matrix Unrotated Factor Loadings and Communalities
Variable Factor1 Factor2 Factor3 Factor4 Factor5 Factor6 Factor7
R1 0,718 -0,618 -0,011 -0,092 -0,136 -0,144 -0,124
R2 0,645 -0,679 -0,099 -0,032 0,017 0,059 0,041
R3 0,569 -0,715 0,296 -0,222 0,033 0,007 0,047
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
128
R4 0,661 -0,653 0,219 -0,169 0,096 -0,087 -0,006
R5 0,633 -0,303 -0,418 0,276 -0,183 -0,433 -0,089
R6 0,274 -0,235 0,407 0,776 0,219 -0,034 0,227
R7 -0,287 -0,575 0,175 0,269 -0,618 0,279 -0,104
R8 0,688 -0,516 0,109 -0,184 0,235 0,187 0,039
R9 0,372 -0,264 -0,814 0,148 0,220 0,184 0,007
P10 -0,897 0,039 -0,059 0,049 -0,093 0,039 -0,404
P11 -0,863 -0,394 -0,142 -0,017 -0,034 -0,115 0,196
P12 -0,852 -0,397 -0,089 -0,132 -0,076 -0,074 0,236
P13 -0,862 -0,408 -0,113 -0,102 -0,047 -0,096 0,064
P14 -0,842 -0,390 0,136 -0,106 0,190 -0,033 -0,118
P15 -0,634 -0,546 -0,322 0,182 0,116 0,224 -0,082
P16 -0,781 -0,254 0,206 0,199 0,281 -0,091 -0,363
Variance 7,6019 3,7498 1,3977 1,0088 0,7359 0,4635 0,3434
% Var 0,475 0,234 0,087 0,063 0,046 0,029 0,021
Kesimpulan:
- Data/variabel terbentuk ke dalam 4 faktor (nilai varian>1,0). Nilai negatif (-)
menunjukkan arah koefisien nilai untuk setiap faktor.
9.3 Multi Dimensional Scalling (MDS) Multidimensional Scaling (MDS) adalah tools analysis statistik yang
digunakan untuk memperoleh gambaran visual dari pola kedekatan
berupa kesamaan/kemiripan atau jarak di antara sekumpulan objek-
objek yang menjadi fokus kajian. MDS dapat menunjukkan dimensi
penilaian dari responden secara langsung ke dalam pola visualisasi
kedekatan mengenai kesamaan objek kajian. MDS merupakan suatu tools
analysis statistik yang paling umum digunakan dalam pemetaan
perceptual (perceptual mapping).
In Multidimensional Scaling, the objective is to transform the consumer
judgments of similarity or preferency (e.g. preference of story or brand)
into distance represented in multidimensional space. If object A dan B in

Bab 9
Statistik Multivariate
-
129
∑ = ( h =1) n
such a way that distance between them in multidimensional space is
similar that distance any other two pairsof object. The resultating
perceptual map show the relative positioning of all object, but additional
analysis is needed to asses which atrributes predict the position of each
object (Bronstein et al. 2006). Menurut Borg dan Groenen (2005) bahwa
MDS adalah sarana memvisualisasikan tingkat kemiripan masing-masing
kasus data set. Hal tersebut mengacu pada satu set teknik ordinasi terkait
yang digunakan dalam visualisasi informasi, khususnya untuk
menampilkan informasi yang terkandung dalam matriks jarak. Ini adalah
bentuk pengurangan dimensi non-linear. Lebih jauh bahwa algoritma
MDS bertujuan menempatkan setiap objek dalam ruang N-dimensi
sehingga jarak antar objek dapat dipertahankan sebaik mungkin.
MDS sangat populer dalam penelitian bidang pemasaran untuk
perbandingan brand, produk, hingga dan pada bidang psikologi. Bahkan
dalam bidang politik. MDS dapat digunakan untuk membandingkan calon
pemimpin antara kandidat yang satu dengan kandidat lainnya, dengan
berbagai parameter yang terukur. Pada bidang-bidang lain, seperti
kesehatan, pendidikan, pertanian dan perikanan juga banyak digunakan,
guna memperoleh gambaran kemiripan (similarity). Tools MDS
merupakan salah satu tools dalam analisis statistika multivariate yang
menunjukkan hubungan antar sejumlah objek dalam ruangan
multidimensional didasarkan pada penilaian responden mengenai
kemiripan/kedekatan (similarity) objek-objek tersebut.
Kedekatan antar objek diperoleh menggunakan jarak Euclid antara objek
ke-i dengan objek ke-j, dengan formula sebagai berikut:
dij (xih – xjh)2
Di mana:
dij = jarak antar objek ke-i dan objek ke-j Xih
= hasil pengukuran objek ke-i pada variabel h

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
130
Xjh = hasil pengukuran objek ke-j pada variabel h

Bab 9
Statistik Multivariate
131
Analisis MDS akan diperoleh output berupa; a) Perceptual Map (ordinasi),
b) R-Square (R2), dan c) STRESS (Standarized Residual Sum of Square).
- Perceptual map atau dikenal juga dengan istilah peta konfigurasi
atau ordinasi merupakan gambaran hubungan antara objek,
dinyatakan sebagai hubungan geometris antara titik-titik di dalam
ruang yang multidimensi, menunjukkan posisi (letak) suatu objek
dalam suatu peta (ordinasi). Menurut Hair et al. (2009) perceptual
map adalah representasi visual dari persepsi seorang responden
terhadap beberapa objek pada dua atau lebih dimensi. Selanjutnya
disebutkan bahwa setiap objek akan memiliki posisi spasial pada
peta persepsi tersebut yang merefleksikan kesamaan atau preferensi
(preference) ke objek lain dengan melihat dimensi-dimensi pada peta
persepsi.
- R-Square (R2) atau Koefisien Determinasi merupakan ukuran
kecocokan/ketepatan (goodness of fit measure) antara data dengan
garis estimasi regresi. R-Square (RSQ) menunjukkan besaran nilai
(persentase) data dapat menjelaskan model. Dengan kata lain
seberapa besar variabel independen dapat menjelaskan secara
keseluruhan variabel dependen. R-square (Squared Correlation)
merupakan kuadrat dari koefisien korelasi yang menunjukkan
proporsi varian dari optimalisasi penskalaan data yang
disumbangkan dari prosedur penskalaan multidimensional dan
merupakan ukuran kecocokan/ketepatan. Menurut Ghozali (2009)
bahwa koefisien determinasi atau R2 pada intinya mengukur
seberapa jauh kemampuan sebuah model dapat menerangkan
variasi variabel dependen (terikat). Nilai R2 berkisar antara 0 (nol)
dan 1 (satu) yang apabila dinyatakan dalam persentase antara 0%
hingga 100%. Nilai R2 yang kecil berarti memiliki variasi dependen
yang sangat terbatas dan nilai yang mendekati 1 berarti variabel-
variabel independen telah dapat memberi semua informasi yang
dibutuhkan untuk memprediksi variabel dependen. Dengan kata
lain, bahwa nilai yang mendekati 1 menunjukkan bahwa model dapat
dijelaskan dengan baik dari data yang ada atau nilai R-square
semakin mendekati 1 berarti data yang ada semakin terpetakan
dengan sempurna. Dalam Multidimensional Scaling (MDS), RSQ

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
132
mengindikasikan proporsi ragam input data yang dapat dijelaskan
oleh model MDS. Semakin tinggi RSQ, semakin baik model MDS.
Menurut Malhotra (2005), model RSQ dapat diterima bila RSQ > 0,6.
STRESS (Standarized Residual Sum of Square) merupakan ukuran
ketidakcocokan atau ketidaksesuaian (a lack of fit measure) antara
data dengan garis estimasi regresi. STRESS digunakan untuk melihat
apakah output mendekati keadaan yang sebenarnya atau tidak.
Semakin tinggi nilai STRESS semakin tidak cocok, sebaliknya semakin
mendekati nol (0), maka output yang dihasilkan semakin mirip
dengan keadaan yang sebenarnya. Nilai STRESS yang dapat ditolerir
adalah <20% (Kavanagh dan Pitcher 2004). Sedang menurut Kruskal
(1964) bahwa kriteria nilai STRESS untuk mendeteksi kelayakan
model, sebagai berikut:
Nilai Stress (%) Keterangan
0 – 2,50 Sempurna
2,51 – 5,0 Sangat Bagus
5,0 – 10,0 Baik
10,1 – 20,0 Cukup
>20 Kurang
Kotak 24:
Tools MDS adalah salah satu tools atau teknik analisis yang
dimaksudkan untuk melihat kedekatan (similarity) antar objek yang
dikaji. Prinsipnya semakin rapat/dekat antar objek-objek tersebut
maka semakin mirip/ sama antar objek tersebut. Jenis data dapat
berskala metrik (interval dan rasio) ataupun non-metrik (nominal dan
ordinal), sehingga MDS dapat digolongkan dalam statsitik parameterik
dan non-parametrik.
Validitas output MDS diukur dengan nilai stres dan nilai R2. Kedua nilai
tersebut berkebalikan. Semakin rendah nilai stres dan semakin tinggi
nilai R2 maka model semakin valid. Sebaliknya semakin tinggi nilai stres
dan semakin rendah nilai R2, model semakin tidak valid. Maksimum
nilai stres 20%, dan umumnya minimum nilai R2>80%.

Bab 9
Statistik Multivariate
-
133
Berikut adalah contoh aplikasi MDS dalam bidang perikanan. Diketahui
produk perikanan dalam bentuk kemasan, terdiri dari produk A, B, C, D
dan E. Kelima produk tersebut selanjutnya ingin diketahui kesamaannya
dari sisi; rasa, kandungan gizi, kemasan, harga, kelengkapan informasi,
dan kemudahan memperolehnya. Tahapannya sebagai berikut:
Menentukan jenis produk yang akan dibandingkan (dikaji), seperti;
Produk Bandeng Presto Merk A Merk B, dan lain-lain.
- Menentukan parameter penilaian, seperti; rasa, harga, dan lain-lain.
- Menentukan skala penilaian (good and bad), dengan menggunakan
skala ordinal (Likert), seperti; [1] rasa tidak enak, [2], rasa kurang
enak, [3] rasa cukup enak, [4] rasa enak, dan [5] rasa sangat enak.
PARAMETER GOOD SKALA BAD
RASA Sangat Enak 5 4 3 2 1 Tidak Enak
KANDUNGAN GIZI Sangat Lengkap 1 2 3 4 5 Tidak Lengkap
KEMASAN Sangat Menarik 1 2 3 4 5 Tidak Menarik
HARGA Sangat Mahal 1 2 3 4 5 Murah
KELENGKAPAN
INFORMASI Sangat Lengkap 5 4 3 2 1 Tidak Lengkap
KEMUDAHAN
MEMPEROLEH Sangat Mudah 1 2 3 4 5 Sulit
Note: Skala dapat bersifat favorable or unfavorable
- Menyusun daftar pertanyaan berupa kueisoner dan menentukan
responden.
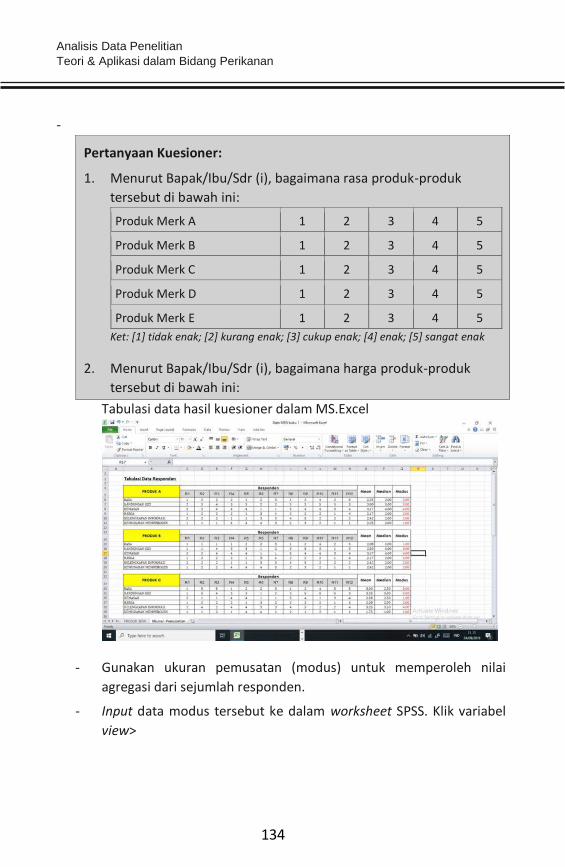
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
134
Pertanyaan Kuesioner:
1. Menurut Bapak/Ibu/Sdr (i), bagaimana rasa produk-produk
tersebut di bawah ini:
Produk Merk A 1 2 3 4 5
Produk Merk B 1 2 3 4 5
Produk Merk C 1 2 3 4 5
Produk Merk D 1 2 3 4 5
Produk Merk E 1 2 3 4 5
Ket: [1] tidak enak; [2] kurang enak; [3] cukup enak; [4] enak; [5] sangat enak
2. Menurut Bapak/Ibu/Sdr (i), bagaimana harga produk-produk
tersebut di bawah ini:
Tabulasi data hasil kuesioner dalam MS.Excel
- Gunakan ukuran pemusatan (modus) untuk memperoleh nilai
agregasi dari sejumlah responden.
- Input data modus tersebut ke dalam worksheet SPSS. Klik variabel
view>
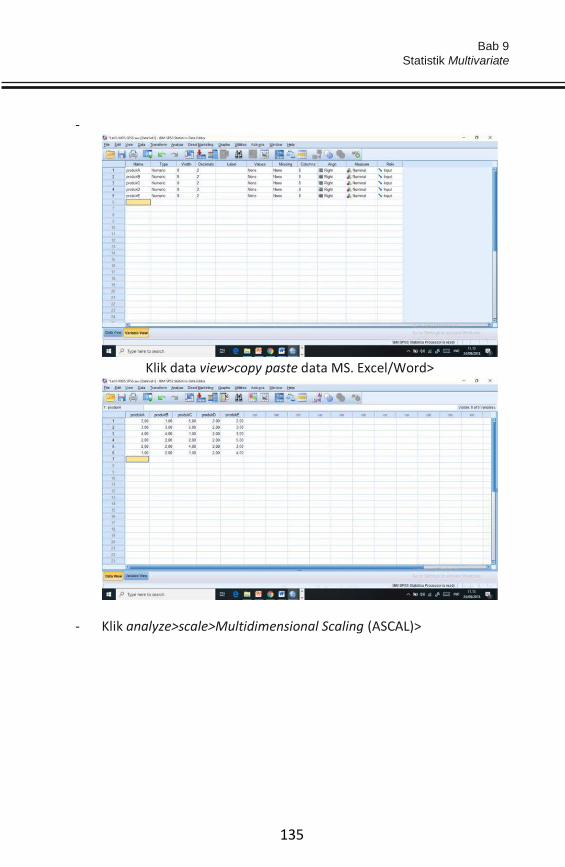
Bab 9
Statistik Multivariate
-
135
Klik data view>copy paste data MS. Excel/Word>
- Klik analyze>scale>Multidimensional Scaling (ASCAL)>
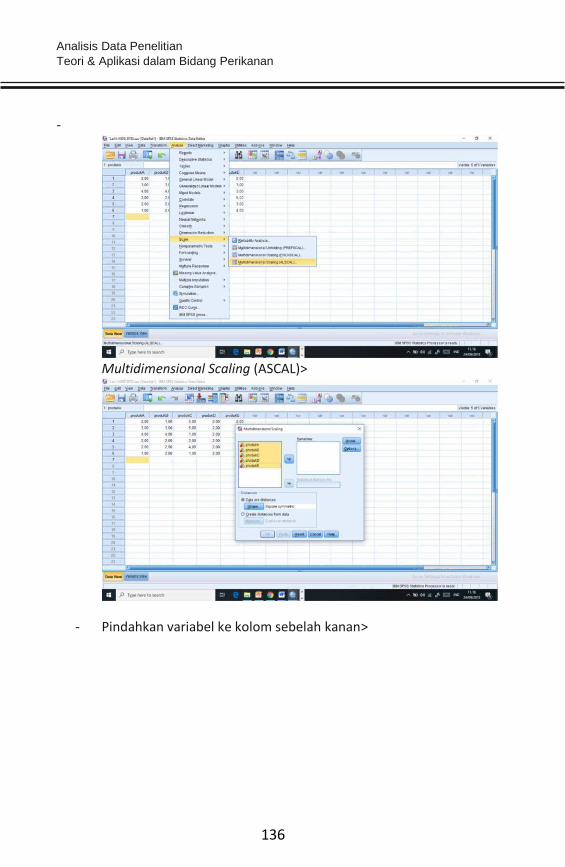
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
136
Multidimensional Scaling (ASCAL)>
- Pindahkan variabel ke kolom sebelah kanan>

Bab 9
Statistik Multivariate
-
137
Klik shape pada kotak data are distances>aktifkan rectangular>
- Klik continue>klik model>centang ordinal pada kotak level of
measurement>klik row pada kotak conditionality>
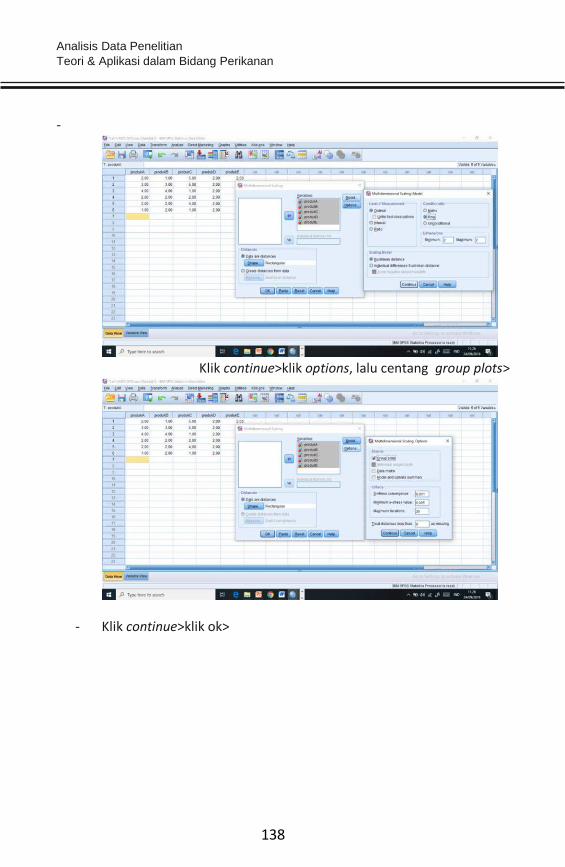
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
138
Klik continue>klik options, lalu centang group plots>
- Klik continue>klik ok>
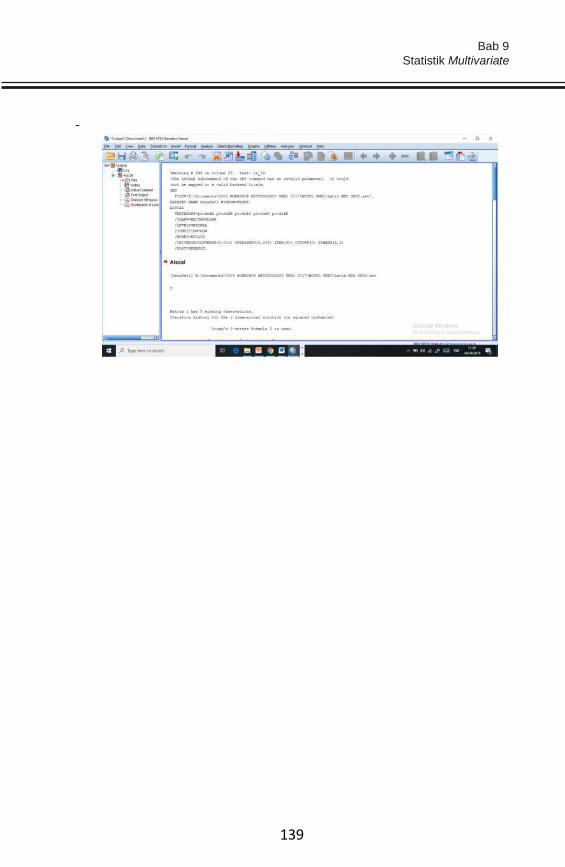
Bab 9
Statistik Multivariate
-
139
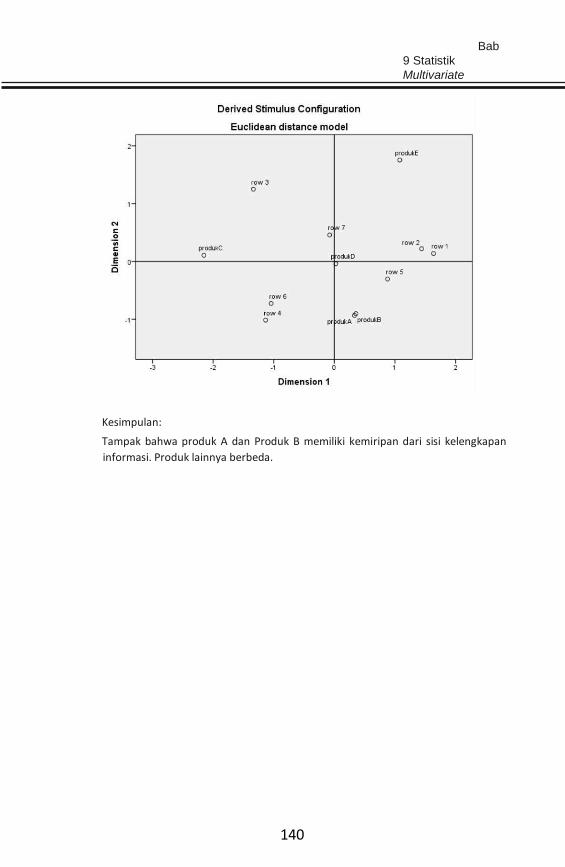
Bab
9 Statistik
Multivariate
140
Kesimpulan:
Tampak bahwa produk A dan Produk B memiliki kemiripan dari sisi kelengkapan
informasi. Produk lainnya berbeda.


BAB 10 STATISTIK
PARAMETRIK
If you double the number of experiments you do per year you’re
going to double your inventiveness ...
[Jeff Bezos – CEO Amazon.Com]
Statistik parametrik merupakan analisis statistik yang mensyaratkan
beberapa hal terkait data dan variannya. Menurut Siegel (1992) bahwa
test paramaterik adalah suatu tes yang modelnya menetapkan adanya
syarat-syarat tertentu tentang parameter populasi yang merupakan
sumber sampel penelitian. Dua syarat utama yang harus dipenuhi adalah
data berdistribusi normal dan memiliki varians homogen. Statistik
Parametrik adalah teknik yang didasarkan pada asumsi bahwa data yang
diambil mempunyai distribusi normal dan menggunakan data interval
dan rasio. Beberapa uji statistik yang termasuk dalam kategori statistik
parametrik, antara lain uji korelasi pearson, uji beda nyata (uji-t, uji-z dan
uji-f atau ANOVA).
Uji beda nyata merupakan salah satu kelompok analisis statistik
inferensia. Statistik inferensia adalah teknik analisis statistik (data) yang
dapat digunakan untuk menarik kesimpulan dari sampel (contoh) yang
diambil terhadap populasi (Likert 1932). Statistik inferensia merupakan
teknik analisis data yang digunakan untuk menentukan sejauh mana
kesamaan antara hasil yang diperoleh dari suatu sampel dengan hasil
yang akan didapat pada populasi secara keseluruhan. Statistik inferensia
membantu peneliti untuk mengetahui apakah hasil yang diperoleh dari
suatu sampel dapat digeneralisasi pada populasi (Creswell 2008). Lebih
jauh statistik inferensia adalah metode yang berhubungan dengan
analisis data pada sampel untuk digunakan untuk penggeneralisasian
pada populasi. Menurut Nisfiannoor (2009) bahwa penggunaan statistik

Bab 10
Statistik Parametrik
143
inferensia didasarkan pada peluang (probability) dan sampel yang dipilih
secara acak (random).
Uji beda merupakan salah satu uji hipotesa. Tahapan uji beda, meliputi;
a) Perumusan Hipotesis (H0 dan H1), b) Penentuan Uji Statistik (jenis uji-t,
uji-z or uji-f), c) Penentuan Tingkat Kepercayaan (%) atau Tingkat
Signifikansi (α), d) Analisis Data (aplikasi software or estimasi manual), e)
Kriteria Keputusan, dan f) Penarikan Kesimpulan.
10.1. Uji-t (t-Test) Uji t (t-test) merupakan uji koefisien regresi secara parsial yang bertujuan
untuk mengetahui signifikansi peran secara parsial antara variabel
independen terhadap variabel dependen dengan mengasumsikan bahwa
variabel independen lain dianggap konstan (Sugiyono 2014). Uji-t atau
disebut pula sampel t-test merupakan salah satu uji hipotesis atau uji
beda nyata, dan merupakan uji parsial. Uji hipotesis adalah uji yang
dimaksudkan untuk menguji hipotesis yang telah dibangun sebelumnya
apakah hipotesis tersebut benar atau salah (diterima atau ditolak).
Dengan uji hipotesis, peneliti dapat menguji berbagai teori yang
berhubungan dengan masalah-masalah yang sedang diteliti/dikaji.
Uji hipotesis t-test adalah uji hipotesis yang digunakan untuk mengetahui
apakah ada perbedaan rata-rata dari sampel yang diambil sehingga uji-t
juga dikenal dengan istilah uji rata-rata. Uji-t terbagi atas 3 (tiga) jenis
yakni; one sample t-test, paired sample t-test (dependent sampel t-test)
dan independent sample t-Test.
One sample t-Test (uji-t 1 sampel) atau uji rata-rata satu populasi;
adalah teknik analisis statistik (uji-t) yang digunakan untuk
membandingkan satu variabel bebas. Teknik ini digunakan untuk
menguji apakah nilai parameter berbeda secara signifikan atau tidak
dengan nilai rata-rata sampelnya. Pada uji-t 1 (satu) sampel, dilakukan
untuk satu sampel yang kemudian dianalisis apakah ada perbedaan rata-
rata dari sampel tersebut. One sample t test digolongkan kedalam
statistik pramaterik dan statistik univariate.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
144
Syarat utama uji-t 1 sampel adalah mengguji 1 parameter saja atau 1
perlakuan (univariate). Formula yang digunakan adalah sebagai berikut.
x – µ t
=
SD
Di mana;
t = nilai thitung x
= rata-rata sampel μ
= nilai parameter SD
= Standar Deviasi
N = Jumlah sampel
Paired sample t-Test (uji-t 2 sampel berpasangan) atau uji rata-rata data
berpasangan adalah teknik yang digunakan untuk membandingkan rata-
rata dua variabel dalam satu group atau disebut juga t-test dependent.
Analisis ini berguna untuk melakukan pengujian terhadap satu sampel
yang mendapatkan suatu perlakuan (treatment), kemudian akan
dibandingkan rata-rata dari sampel tersebut antara sebelum dan
sesudah perlakuan. Menurut t-test dependent atau Paired Sampel T-test
digunakan untuk membandingkan rata-rata dua set data (data sebelum
dan sesudah) yang saling berpasangan.
Syarat utama uji-t 2 sampel dependent adalah menguji 2 sampel yang
berpasangan (paired). Sampel berpasangan adalah sebuah kelompok
sampel dengan subjek yang sama namun mengalami dua perlakuan atau
pengukuran yang berbeda. Formula yang digunakan adalah sebagai
berikut.
t =
Di mana:
t = nilai thitung
N ( )
D SD N ( )

Bab 10
Statistik Parametrik
145
D = rata-rata selisih pengukuran sebelum dan
sesudah μ = nilai parameter
SD = Standar Deviasi selisih pengukuran
N = Jumlah sampel
Independent sample t-Test (uji-t 2 sampel bebas) atau uji rata-rata dua
populasi; adalah teknik yang digunakan untuk menentukan apakah dua
sampel yang tidak berhubungan memiliki rata-rata yang berbeda.
Independent sample t-test adalah jenis uji statistika yang bertujuan untuk
membandingkan rata-rata dua grup yang tidak saling berpasangan atau
tidak saling berkaitan. Tidak saling berpasangan dapat diartikan bahwa
penelitian dilakukan untuk 2 (dua) subjek sampel yang berbeda. Tujuan
teknik ini adalah membandingkan rata-rata dua grup yang tidak
berhubungan satu sama lain. Pertanyaannya, apakah kedua grup
tersebut mempunyai nilai rata-rata yang sama atau tidak secara
signifikan.
Syarat utama uji-t 2 sampel independen adalah menguji 2 sampel yang
tidak berpasangan (bebas). Formula yang digunakan adalah sebagai
berikut:
X1 –
X2 t = SX1 – X2 Di mana:
t = nilai thitung
X1 = rata-rata kelompok 1
X2 = rata-rata kelompok 2
Sx1-x2 = Standar Error Kedua Kelompok
Asumsi data yang harus dipenuhi dalam analisis ini adalah a) data
berskala interval/rasio, b) kelompok data saling bebas atau tidak
berpasangan, c) data setiap kelompok berdistribusi normal, d) data setiap
kelompok tidak terdapat outlier, dan e) varian antarkelompok sama atau
homogen. Dengan demikian sebelum melakukan Independent sample t-
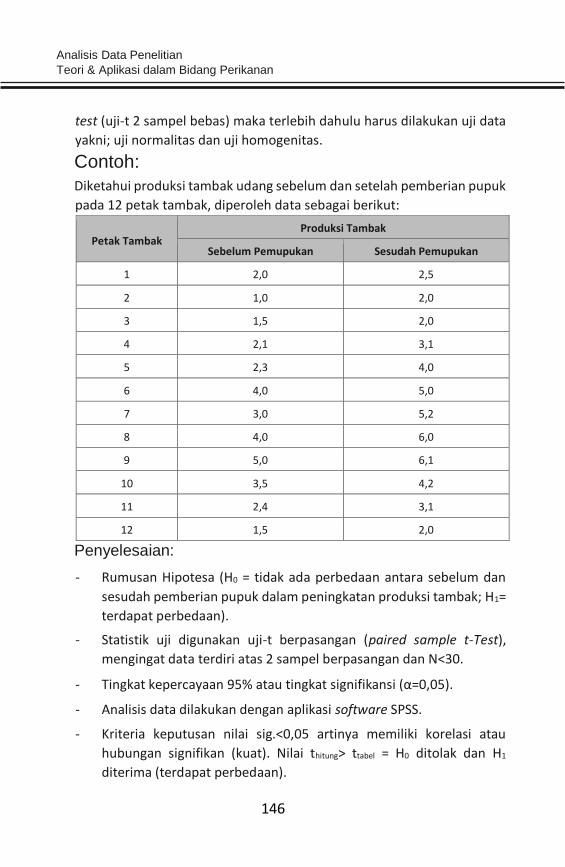
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
146
test (uji-t 2 sampel bebas) maka terlebih dahulu harus dilakukan uji data
yakni; uji normalitas dan uji homogenitas.
Contoh:
Diketahui produksi tambak udang sebelum dan setelah pemberian pupuk
pada 12 petak tambak, diperoleh data sebagai berikut:
Petak Tambak Produksi Tambak
Sebelum Pemupukan Sesudah Pemupukan
1 2,0 2,5
2 1,0 2,0
3 1,5 2,0
4 2,1 3,1
5 2,3 4,0
6 4,0 5,0
7 3,0 5,2
8 4,0 6,0
9 5,0 6,1
10 3,5 4,2
11 2,4 3,1
12 1,5 2,0
Penyelesaian:
- Rumusan Hipotesa (H0 = tidak ada perbedaan antara sebelum dan
sesudah pemberian pupuk dalam peningkatan produksi tambak; H1=
terdapat perbedaan).
- Statistik uji digunakan uji-t berpasangan (paired sample t-Test),
mengingat data terdiri atas 2 sampel berpasangan dan N<30.
- Tingkat kepercayaan 95% atau tingkat signifikansi (α=0,05).
- Analisis data dilakukan dengan aplikasi software SPSS.
- Kriteria keputusan nilai sig.<0,05 artinya memiliki korelasi atau
hubungan signifikan (kuat). Nilai thitung> ttabel = H0 ditolak dan H1
diterima (terdapat perbedaan).
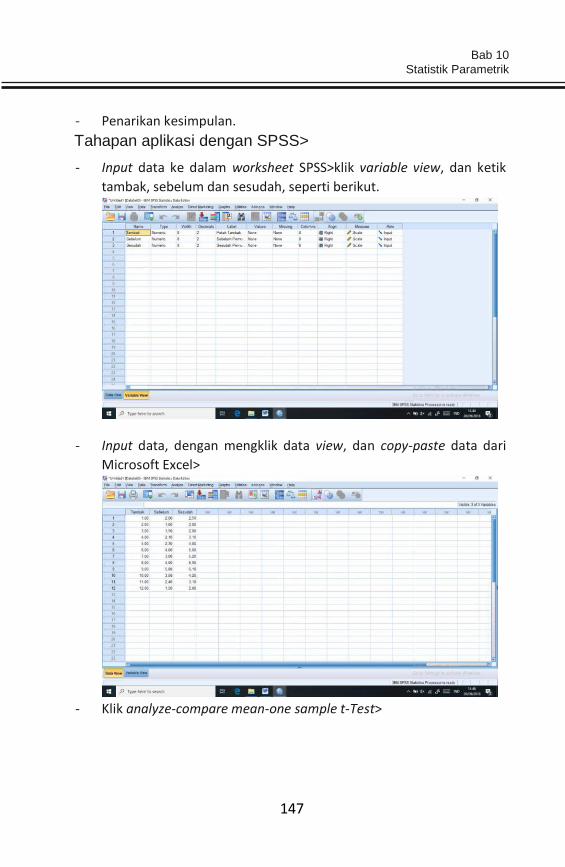
Bab 10
Statistik Parametrik
147
- Penarikan kesimpulan.
Tahapan aplikasi dengan SPSS>
- Input data ke dalam worksheet SPSS>klik variable view, dan ketik
tambak, sebelum dan sesudah, seperti berikut.
- Input data, dengan mengklik data view, dan copy-paste data dari
Microsoft Excel>
- Klik analyze-compare mean-one sample t-Test>
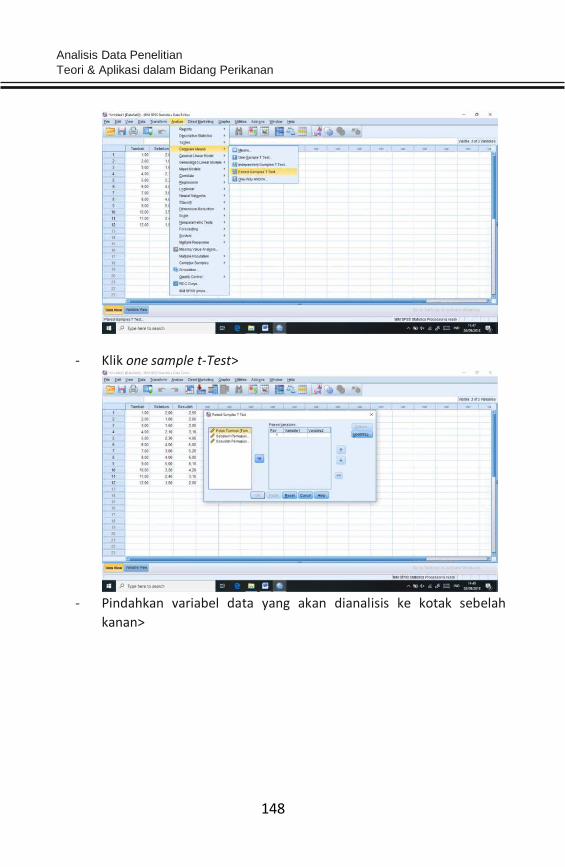
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
148
- Klik one sample t-Test>
- Pindahkan variabel data yang akan dianalisis ke kotak sebelah
kanan>
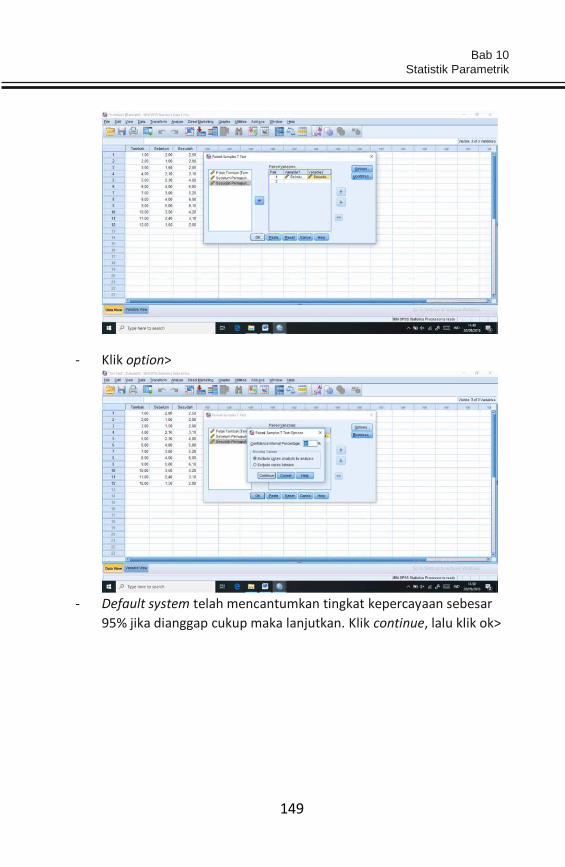
Bab 10
Statistik Parametrik
149
- Klik option>
- Default system telah mencantumkan tingkat kepercayaan sebesar
95% jika dianggap cukup maka lanjutkan. Klik continue, lalu klik ok>
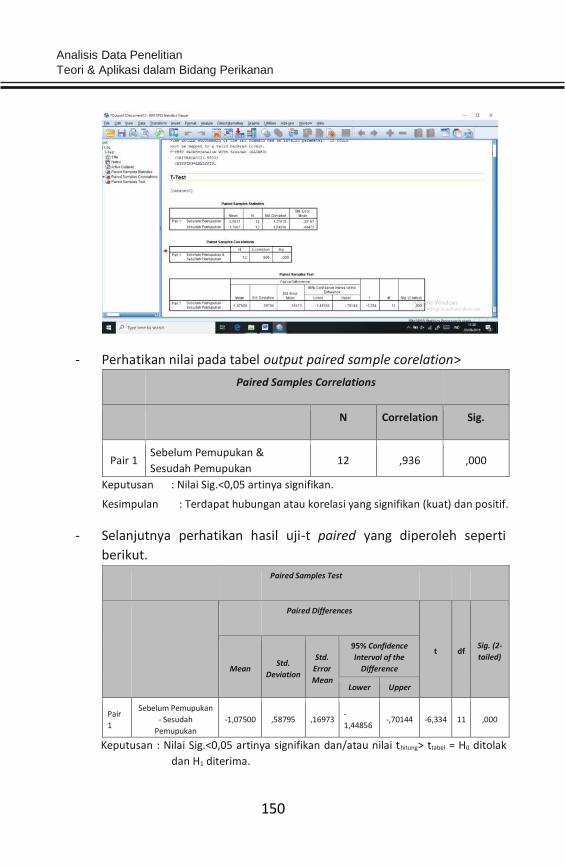
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
150
- Perhatikan nilai pada tabel output paired sample corelation>
Paired Samples Correlations
N Correlation Sig.
Pair 1 Sebelum Pemupukan &
Sesudah Pemupukan 12 ,936 ,000
Keputusan : Nilai Sig.<0,05 artinya signifikan.
Kesimpulan : Terdapat hubungan atau korelasi yang signifikan (kuat) dan positif.
- Selanjutnya perhatikan hasil uji-t paired yang diperoleh seperti
berikut.
Paired Samples Test
Paired Differences
t df Sig. (2-
tailed) Mean Std.
Deviation Std.
Error Mean
95% Confidence Interval of the
Difference
Lower Upper
Pair
1 Sebelum Pemupukan
- Sesudah
Pemupukan -1,07500 ,58795 ,16973 -
1,44856 -,70144 -6,334 11 ,000
Keputusan : Nilai Sig.<0,05 artinya signifikan dan/atau nilai thitung> ttabel = H0 ditolak
dan H1 diterima.

Bab 10
Statistik Parametrik
151
Kesimpulan : Terdapat perbedaan yang nyata antara sebelum dan sesudah
perlakuan pemberian pupuk pada tambak terhadap produksinya.
Dengan kata lain pemberian pupuk oleh petambak akan memberikan
peningkatan yang signifikan terhadap produksinya.
Kotak 25:
Penentuan df (degree of freedom) guna memperoleh nilai ttabel
didasarkan pada nilai α (0,05), df = N-k ; df=N-1. Di mana: N= jumlah
data, k=jumlah variabel dependen.
Contoh di atas N=12 dan k=1, maka df=12-1=11
10.2 Uji-z (z-Test) Uji-z prinsipnya sama dengan uji-t yakni merupakan uji hipotesis atau uji
dua pihak. Perbedaan mendasar antar uji-z dengan uji-t adalah pada
jumlah datanya. Uji-z valid digunakan pada jumlah data besar atau
N=>30. Syarat atau kriteria uji-z adalah a) Data berdistribusi normal, b)
Variance (σ2) diketahui, c) Ukuran sampel (n) besar ≥ 30.
Uji-z dikenal dengan uji rata-rata dan uji proporsi karena dapat menguji
sampel ataupun populasi. Uji-z terdiri atas uji rata-rata satu sampel, uji
rata-rata dua sampel, uji proposi satu populasi, dan uji proposi dua
populasi. Uji-z seperti halnya uji beda atau uji hipotesis lainnya (uji-t dan
uji-f), uji-z terdiri dari uji dua arah (uji dua sisi) dan hipotesis uji satu arah
(uji satu sisi). Uji dua arah digunakan untuk mengetahui apakah dua
populasi memiliki proporsi yang sama atau tidak (H0: P1=P2 H1: P1≠P2),
sedangkan uji satu arah digunakan untuk mengetahui apakah populasi
pertama memiliki proporsi yang lebih kecil atau lebih besar dibandingkan
dengan proporsi pada populasi kedua (H0: P1≥P2 H1:P1<P2).
Contoh:
Diketahui produksi tambak dari 45 petak tambak. Peneliti ingin
mengetahui apakah terdapat perbedaan dari rata-rata produksi dari 45
petak tambak tersebut. Berikut adalah data produksinya.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
152
Tambak (n)
Produksi
(kg) Tambak
(n) Produksi
(kg) Tambak
(n) Produksi
(kg)
1 2,0 16 2,5 31 2,3
2 2,0 17 2,0 32 4,0
3 1,5 18 2,0 33 3,0
4 2,0 19 3,1 34 4,0
5 2,0 20 4,0 35 5,0
6 4,0 21 5,0 36 3,5
7 3,0 22 5,2 37 2,4
8 4,0 23 6,0 38 1,5
9 5,0 24 6,1 39 1,6
10 3,5 25 4,2 40 1,7
11 2,4 26 3,1 41 2,0
12 1,5 27 2,0 42 1,0
13 1,6 28 2,5 43 1,5
14 1,8 29 2,9 44 2,1
15 2,0 30 3,0 45 2,3
Prinsipnya dalam aplikasi SPSS, tahapan uji-z satu sampel sama dengan uji-t untuk 1
sampel (one sampel t-test), yang membedakan mengapa digunakan uji-z karena jumlah
data besar (n>30).
Penyelesaian:
- Rumusan Hipotesa (H0 = rata-rata produksi udang di tambak adalah
sama; H1= rata-rata produksi udang di tambak adalah tidak sama).
- Statitik uji digunakan Uji-z1 sampel, mengingat data hanya berupa
data produksi dengan N>30.
- Tingkat kepercayaan 95% atau Tingkat signifikansi (α=0,05).
- Analisis data dilakukan dengan aplikasi software SPSS.
- Kriteria keputusan nilai Sig.<0,05 artinya signifikan (atau berbeda),
Nilai Zhitung>Ztabel = H0 ditolak dan H1 diterima (terdapat perbedaan).
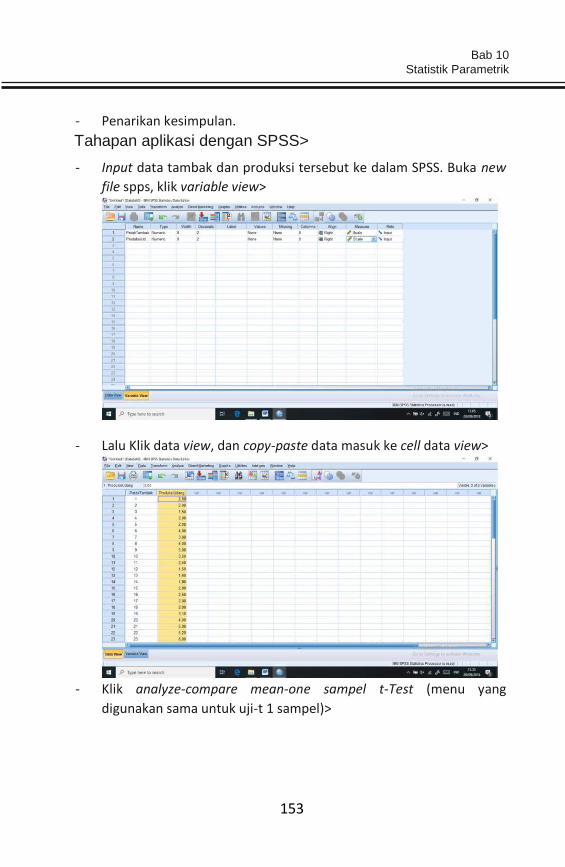
Bab 10
Statistik Parametrik
153
- Penarikan kesimpulan.
Tahapan aplikasi dengan SPSS>
- Input data tambak dan produksi tersebut ke dalam SPSS. Buka new
file spps, klik variable view>
- Lalu Klik data view, dan copy-paste data masuk ke cell data view>
- Klik analyze-compare mean-one sampel t-Test (menu yang
digunakan sama untuk uji-t 1 sampel)>
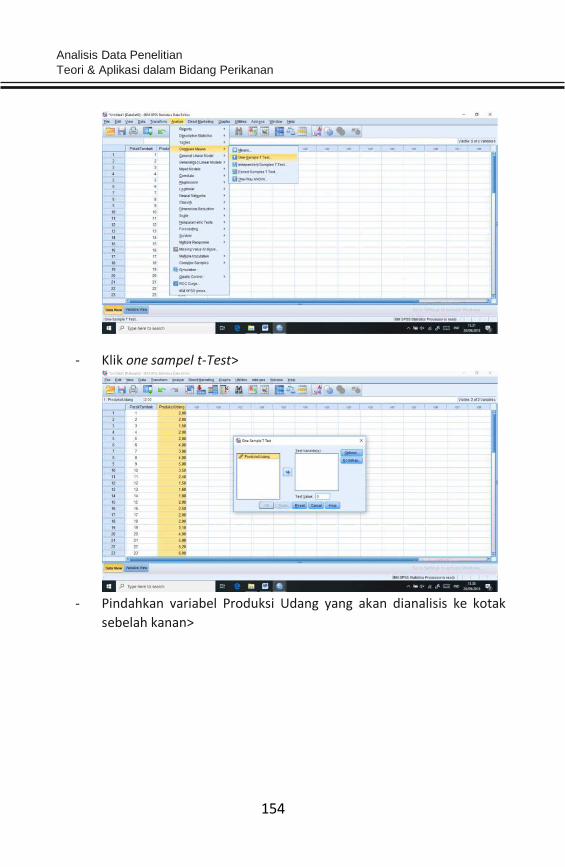
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
154
- Klik one sampel t-Test>
- Pindahkan variabel Produksi Udang yang akan dianalisis ke kotak
sebelah kanan>
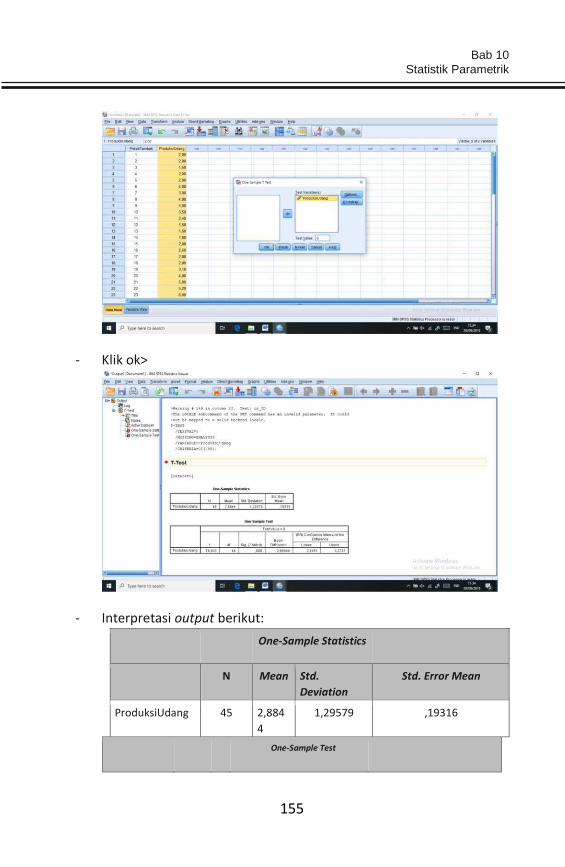
Bab 10
Statistik Parametrik
155
- Klik ok>
- Interpretasi output berikut:
One-Sample Statistics
N Mean Std.
Deviation Std. Error Mean
ProduksiUdang 45 2,884
4 1,29579 ,19316
One-Sample Test

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
156
Test Value = 0
t (z) df Sig. (2-tailed) Mean Difference 95% Confidence Interval of the
Difference
Lower Upper
ProduksiUdang 14,933 44 ,000 2,88444 2,4951 3,2737
Keputusan:
Nilai Sig.<0,05 artinya signifikan. Nilai Zhitung>Ztabel = H0 ditolak dan H1 diterima.
Kesimpulan:
Rata-rata produksi udang di tambak adalah tidak sama.
Kotak 26:
Nilai Ztabel diperoleh dari pembacaan tabel-z atau dikenal juga dengan
tabel distribusi normal. Tabel ini memiliki 2 parameter utama, yakni mean
dan simpangan baku. Cara penggunaannya; tentukan jenis hipotesanya 1
arah atau 2 arah. Hipotesa 1 arah/sisi (H0: P1=P2 H1: P1≠P2), atau
Hipotesa 2 arah/sisi (H0: P1≥P2H1:P1<P2).
Contoh di atas diperoleh simpangan baku = 1,29579.
Pada tabel-Z, carilah angka 1,2 pada kolom z (kolom paling kiri). Kemudian
cari angka 0,09 pada baris z (baris paling atas). Sel para pertemuan kolom
dan baris tersebut diperoleh 0,9015.
Dengan demikian, P (X<1,25) adalah 0,9015.
10.3. Uji-F (ANOVA) Uji F adalah pengujian terhadap koefisien regresi secara simultan yang
bertujuan mengetahui pengaruh semua variabel independen yang
terdapat di dalam model secara (simultan) terhadap variabel dependen
(Sugiyono 2014). Uji-F disebut pula Anova (Analysis of Variance) adalah
teknik analisis statistik yang menguji perbedaan rerata antar grup
(Spiegel et al. 2007). Grup yang dimaksud dapat berarti kelompok atau
jenis perlakuan. Teknik Anova banyak digunakan dalam kajian yang
terkait uji perlakuan seperti pada kajian perikanan (uji perlakuan tambak,
uji alat penangkapan ikan dan lain sebagainya). Prinsipnya sama dengan

Bab 10
Statistik Parametrik
157
uji-t dan uji-z, namun perbedaan mendasar adalah bahwa Anova dapat
menguji perbedaan lebih dari dua kelompok/perlakuan. Sedangkan uji-t
dan uji-z terbatas pada 2 (dua) kelompok atau perlakuan. Sampel berasal
dari kelompok yang independen. Syarat atau kriteria uji Anova adalah; a)
varian antarkelompok homogen, dan b) data berdistribusi normal.
Berikut adalah tahapan analisis Anova 1 arah (one way Anova).
Contoh:
Diketahui data produksi udang pada tambak dengan 3 (tiga) perlakuan
(treatment), yakni [A] pemberian pakan, [B] pemberian
pakan+pemupukan, [C] pemberian pakan+ pemupukan + pemasangan
aerasi.
Tambak Perlakuan (Treatment) Produksi
1 A pemberian pakan 5,0
2 B pemberian pakan+pemupukan 7,0
3 C pemberian pakan+ pemupukan + pemasangan
aerasi 10,5
4 A pemberian pakan 6,0
5 B pemberian pakan+pemupukan 7,5
6 C pemberian pakan+ pemupukan + pemasangan
aerasi 9,5
7 A pemberian pakan 7,0
8 B pemberian pakan+pemupukan 8,0
9 C pemberian pakan+ pemupukan + pemasangan
aerasi 10,0
10 A pemberian pakan 4,0
11 B pemberian pakan+pemupukan 6,0
12 C pemberian pakan+ pemupukan + pemasangan
aerasi 8,5
Penyelesaian:

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
158
- Rumusan Hipotesa (H0 = tidak terdapat perbedaan yang nyata dari
rata-rata produksi berdasarkan treatment/perlakuan; H1= terdapat
perbedaan).
- Statitik uji digunakan uji-F one-way Anova, mengingat data hanya
berupa data produksi dengan N>30.
- Tingkat kepercayaan 95% atau tingkat signifikansi (α=0,05).
- Analisis data dilakukan dengan aplikasi software SPSS.
- Kriteria keputusan nilai Sig.<0,05 artinya signifikan (atau berbeda),
Nilai Fhitung>Ftabel = H0 ditolak dan H1 diterima (terdapat perbedaan).
- Penarikan kesimpulan.
Tahapan aplikasi dengan SPSS>
- Input data ke dalam SPSS. Buka new file SPPS, klik variable view>
- Pada kolom “value” input kode dari perlakuan menjadi numerik (1=
A, 2=B, 3=C), seperti berikut:
Bab
10 Statistik
Parametrik
159
Input data ke dalam data view>
- Pada menubar, pilih analyze, compare means, one-way Anova>
- Klik one-way Anova>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
160
- Pindahkan kedua variabel kajian, di mana variabel produksi ke kolom
dependent list dan variabel treatment ke kolom faktor>
Klik tombol options, lalu aktifkan “descriptive” dan “homogenity of
variance test“>

Bab
10 Statistik
Parametrik
161
- Lalu klik continue, kemudian klik post hoc, Centang Bonferroni dan
Games-Howell serta biarkan significance level = 0,05>
- Klik continue, lalu klik ok maka muncul output>
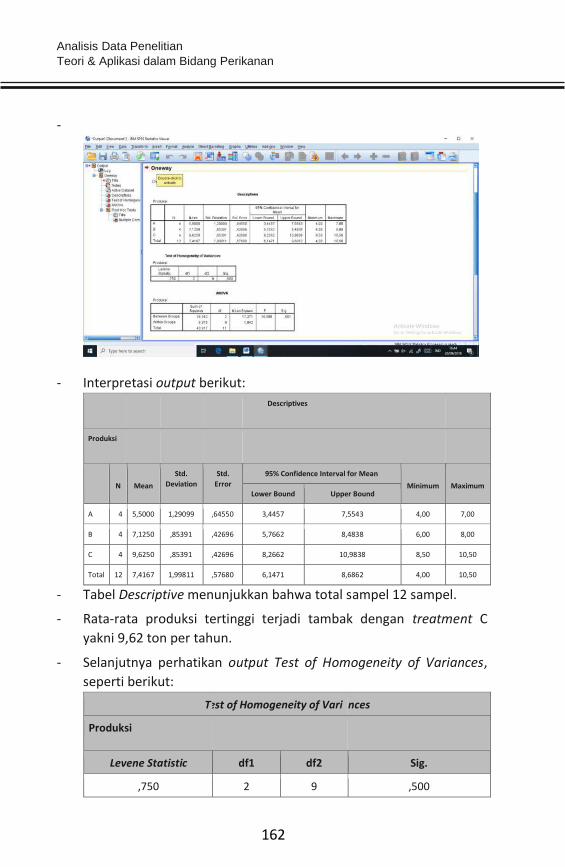
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
162
- Interpretasi output berikut:
Descriptives
Produksi
N Mean
Std. Deviation
Std.
Error 95% Confidence Interval for Mean
Minimum Maximum Lower Bound Upper Bound
A 4 5,5000 1,29099 ,64550 3,4457 7,5543 4,00 7,00
B 4 7,1250 ,85391 ,42696 5,7662 8,4838 6,00 8,00
C 4 9,6250 ,85391 ,42696 8,2662 10,9838 8,50 10,50
Total 12 7,4167 1,99811 ,57680 6,1471 8,6862 4,00 10,50
- Tabel Descriptive menunjukkan bahwa total sampel 12 sampel.
- Rata-rata produksi tertinggi terjadi tambak dengan treatment C
yakni 9,62 ton per tahun.
- Selanjutnya perhatikan output Test of Homogeneity of Variances,
seperti berikut:
T est of Homogeneity of Vari ances
Produksi
Levene Statistic df1 df2 Sig.
,750 2 9 ,500
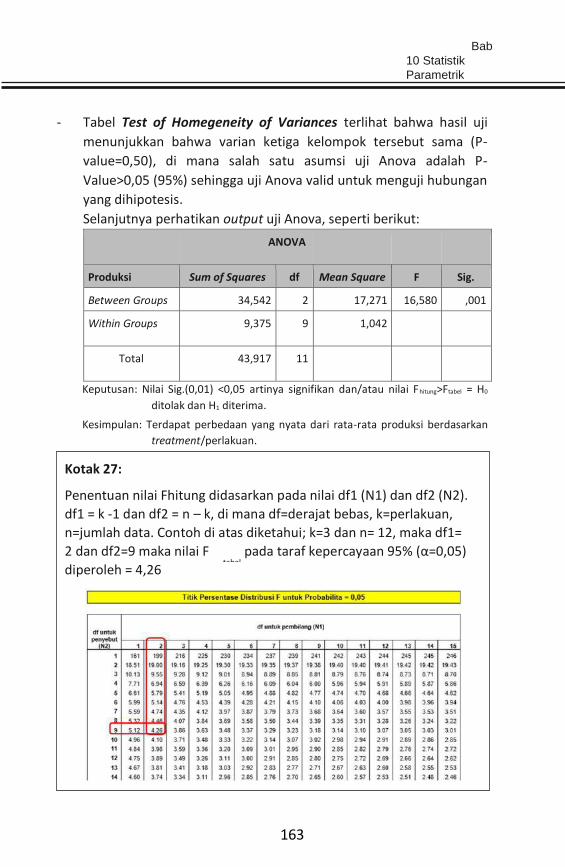
Bab
10 Statistik
Parametrik
163
- Tabel Test of Homegeneity of Variances terlihat bahwa hasil uji
menunjukkan bahwa varian ketiga kelompok tersebut sama (P-
value=0,50), di mana salah satu asumsi uji Anova adalah P-
Value>0,05 (95%) sehingga uji Anova valid untuk menguji hubungan
yang dihipotesis.
Selanjutnya perhatikan output uji Anova, seperti berikut:
ANOVA
Produksi Sum of Squares df Mean Square F Sig.
Between Groups 34,542 2 17,271 16,580 ,001
Within Groups 9,375 9 1,042
Total 43,917 11
Keputusan: Nilai Sig.(0,01) <0,05 artinya signifikan dan/atau nilai Fhitung>Ftabel = H0
ditolak dan H1 diterima.
Kesimpulan: Terdapat perbedaan yang nyata dari rata-rata produksi berdasarkan
treatment/perlakuan.
Kotak 27:
Penentuan nilai Fhitung didasarkan pada nilai df1 (N1) dan df2 (N2).
df1 = k -1 dan df2 = n – k, di mana df=derajat bebas, k=perlakuan,
n=jumlah data. Contoh di atas diketahui; k=3 dan n= 12, maka df1=
2 dan df2=9 maka nilai F tabel
pada taraf kepercayaan 95% (α=0,05)
diperoleh = 4,26
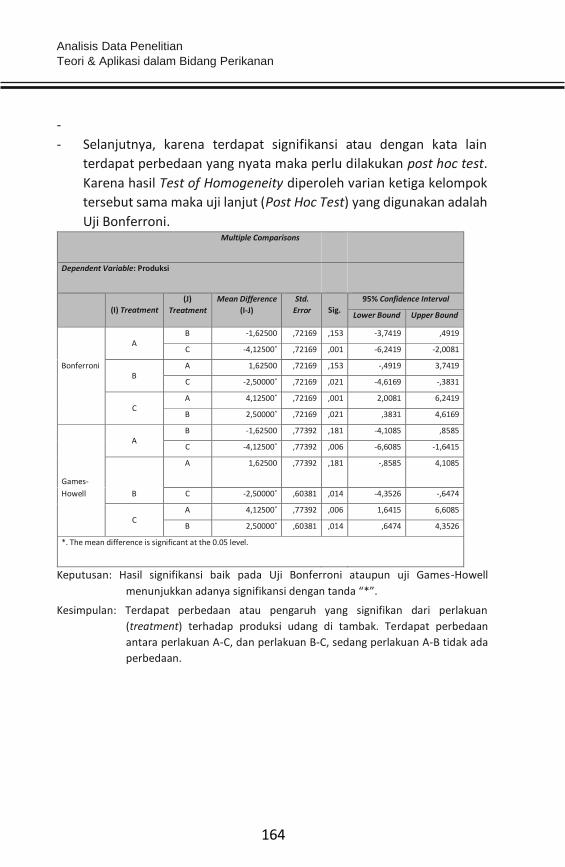
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
164
- Selanjutnya, karena terdapat signifikansi atau dengan kata lain
terdapat perbedaan yang nyata maka perlu dilakukan post hoc test.
Karena hasil Test of Homogeneity diperoleh varian ketiga kelompok
tersebut sama maka uji lanjut (Post Hoc Test) yang digunakan adalah
Uji Bonferroni. Multiple Comparisons
Dependent Variable: Produksi
(I) Treatment
(J) Treatment
Mean Difference (I-J)
Std.
Error Sig. 95% Confidence Interval
Lower Bound Upper Bound
A
B -1,62500 ,72169 ,153 -3,7419 ,4919 C -4,12500* ,72169 ,001 -6,2419 -2,0081
Bonferroni B
A 1,62500 ,72169 ,153 -,4919 3,7419 C -2,50000* ,72169 ,021 -4,6169 -,3831
C A 4,12500* ,72169 ,001 2,0081 6,2419 B 2,50000* ,72169 ,021 ,3831 4,6169
Games-
A B -1,62500 ,77392 ,181 -4,1085 ,8585 C -4,12500* ,77392 ,006 -6,6085 -1,6415
A 1,62500 ,77392 ,181 -,8585 4,1085
Howell B C -2,50000* ,60381 ,014 -4,3526 -,6474
C A 4,12500* ,77392 ,006 1,6415 6,6085 B 2,50000* ,60381 ,014 ,6474 4,3526
*. The mean difference is significant at the 0.05 level.
Keputusan: Hasil signifikansi baik pada Uji Bonferroni ataupun uji Games-Howell
menunjukkan adanya signifikansi dengan tanda “*”.
Kesimpulan: Terdapat perbedaan atau pengaruh yang signifikan dari perlakuan
(treatment) terhadap produksi udang di tambak. Terdapat perbedaan
antara perlakuan A-C, dan perlakuan B-C, sedang perlakuan A-B tidak ada
perbedaan.


BAB 11 STATISTIK
NON-PARAMETRIK
.. Discuss Memoranda, Not Slide Shows ...
[Jeff Bezos – CEO Amazon.Com]
“In Amazon, Bezos never wanted any of the discussion go unfruitful.
In order to achieve this, he removed the traditional slide-show
presentations where a person presents his views to a group of
people. Bezos found that this method lacks efficiency since no
person can have full concentration throughout the entire
presentation. And so, instead, Bezos made all meetings structured
around a 6-page narrative memo.
The presenter has to write his ideas out in complete sentences and
complete paragraphs. This method was found to achieve a deeper clarity
of thinking and much better efficiency”
Statistik non-parametrik merupakan analisis statistik yang tidak
mensyaratkan parameter-parameter populasi. Statistik non-parametrik
merupakan metode statistik yang dapat digunakan dengan mengabaikan
asumsi-asumsi yang melandasi penggunaan metode statistik parametrik,
terutama yang berkaitan dengan distribusi normal dan homogenitas.
Menurut Siegel (1992) bahwa tes non-paramaterik adalah suatu tes yang
modelnya tidak menetapkan syarat-syarat mengenai parameter populasi
yang merupakan induk sampel penelitian. Istilah lain yang sering
digunakan untuk statistik non-parametrik adalah statistik bebas distribusi
(distribution free statistics) dan uji bebas asumsi (assumption-freetest).
Menurut Spiegel (2007) bahwa statistik non-parametrik adalah jenis
statistik inferensia yang tidak mengharuskan data berdistribusi normal
dan jenis data yang digunakan adalah data nominal dan ordinal. Lebih
rinci menurut menurut Daniel (1989) bahwa terdapat dua tipe utama
prosedur statistik non-parametrik yakni a) prosedur-prosedur

Bab 11 Statistik Non-
Parameterik
167
nonparametrik murni dan b) prosedur-prosedur bebas distribusi
(distribution free procedures).
Beberapa uji statistik yang termasuk dalam kategori statistik
nonparametrik, antara lain; uji tanda (sign test), uji korelasi peringkat
(Spearman), uji peringkat 2 sampel (Wilcoxon), uji run, uji chi square,
Kruskal-Wallis, Mann-Whitney, Friedman, dan Kendall.
11.1 Mann-Whitney Mann-Whitney atau Mann Whitney U Test adalah salah satu uji statistik
non-parametrik. Mann Whitney U Test adalah bertujuan mengetahui
perbedaan median 2 (dua) kelompok bebas (independent). Uji
MannWhitney merupakan alternatif bagi uji-t karena tidak memenuhi
syarat statistik parametrik, di mana data berskala ordinal atau interval,
dan data tidak berdistribusi normal. Asumsi yang berlaku dalam uji Mann-
Whitney adalah a) Sampel berasal dari populasi adalah acak, b) Sampel
bersifat independen (bebas), c) Data berskala ordinal atau interval, dan
d) Data tidak berdistribusi normal.
Tahapan uji Mann-Whitney, meliputi a) Perumusan Hipotesis (H0 dan H1),
b) Penentuan Tingkat atau Signifikansi (Α) Tingkat Kepercayaan (%), c)
Analisis Data (aplikasi software), e) Kriteria Keputusan dan f) Penarikan
Kesimpulan.
Contoh:
Diketahui nelayan menggunakan alat tangkap pancing dengan alat bantu
umpan yang berbeda (umpan tiruan terbuat dari bulu sutra dan umpan
berupa potongan ikan). Berikut adalah data hasil tangkapan pancing
(produksi) dengan dua metode (treatment) yang berbeda tersebut.
No Treatment Produksi No Treatment Produksi
1 Umpan Tiruan 2,5 11 Umpan Ikan 4,5
2 Umpan Tiruan 1,5 12 Umpan Ikan 3,5
3 Umpan Tiruan 1,5 13 Umpan Ikan 5,6
4 Umpan Tiruan 2,4 14 Umpan Ikan 5,7

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
168
5 Umpan Tiruan 2,3 15 Umpan Ikan 4,0
6 Umpan Tiruan 2,6 16 Umpan Ikan 4,5
7 Umpan Tiruan 2,1 17 Umpan Ikan 4,5
8 Umpan Tiruan 2,3 18 Umpan Ikan 5,0
9 Umpan Tiruan 2,5 19 Umpan Ikan 5,2
10 Umpan Tiruan 4,5 20 Umpan Ikan 4,8
Penyelesaian:
- Rumusan Hipotesa (H0 = tidak ada perbedaan data satu dengan
lainnya; H1= terdapat perbedaan).
- Statitik uji digunakan Uji Mann Whitney, mengingat data tidak
memenuhi kriteria parametrik test uji-t.
- Tingkat kepercayaan 95% atau tingkat signifikansi (α=0,05).
- Analisis data dilakukan dengan aplikasi software SPSS.
- Kriteria keputusan nilai Sig.<0,05 artinya signifikan (nyata). Tolak H0
p(μ<α) untuk uji satu arah atau H0 p(μ<α/2) untuk uji dua arah.
- Penarikan kesimpulan.
Tahapan aplikasi dengan SPSS>
- Input data ke dalam Worksheet SPSS>
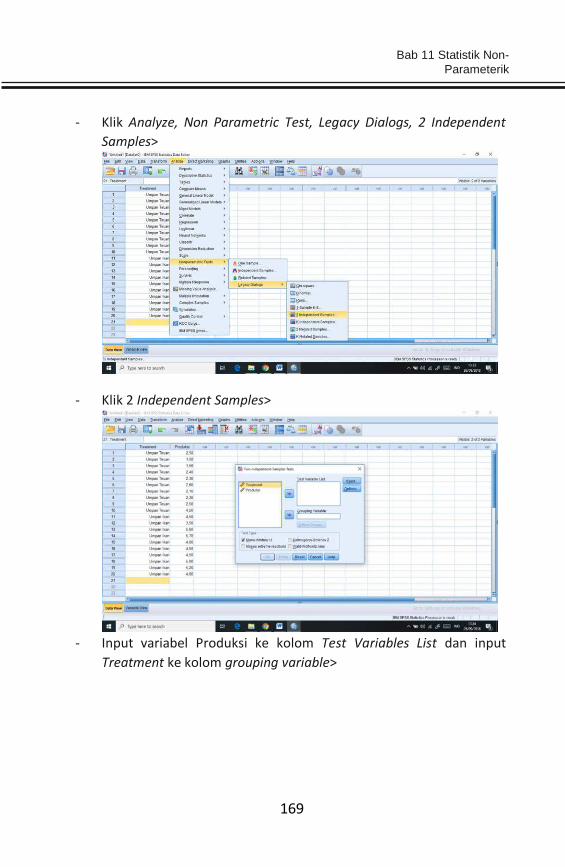
Bab 11 Statistik Non-
Parameterik
169
- Klik Analyze, Non Parametric Test, Legacy Dialogs, 2 Independent
Samples>
- Klik 2 Independent Samples>
- Input variabel Produksi ke kolom Test Variables List dan input
Treatment ke kolom grouping variable>
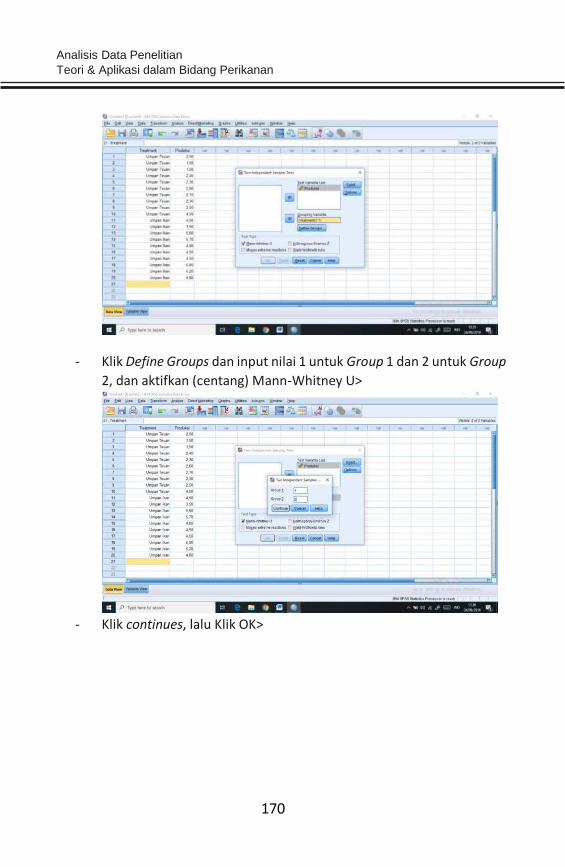
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
170
- Klik Define Groups dan input nilai 1 untuk Group 1 dan 2 untuk Group
2, dan aktifkan (centang) Mann-Whitney U>
- Klik continues, lalu Klik OK>
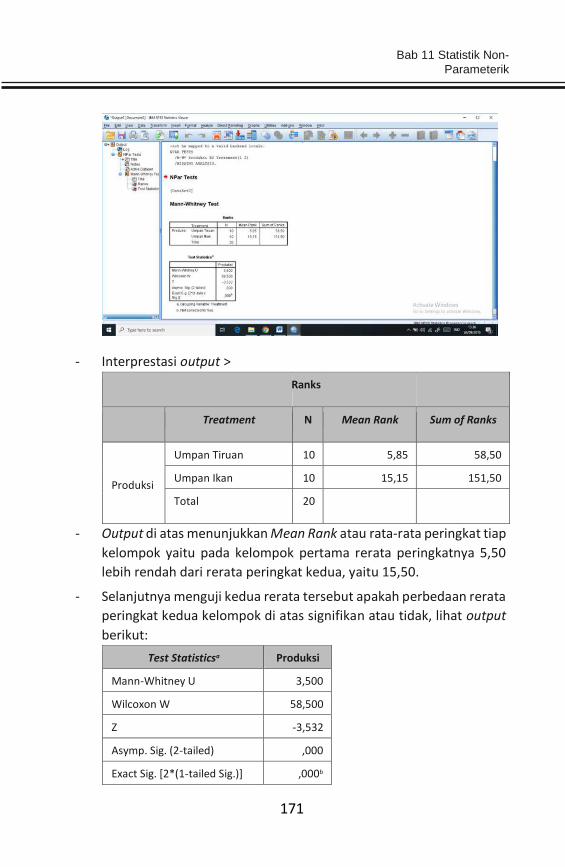
Bab 11 Statistik Non-
Parameterik
171
- Interprestasi output >
Ranks
Treatment N Mean Rank Sum of Ranks
Produksi
Umpan Tiruan 10 5,85 58,50
Umpan Ikan 10 15,15 151,50
Total 20
- Output di atas menunjukkan Mean Rank atau rata-rata peringkat tiap
kelompok yaitu pada kelompok pertama rerata peringkatnya 5,50
lebih rendah dari rerata peringkat kedua, yaitu 15,50.
- Selanjutnya menguji kedua rerata tersebut apakah perbedaan rerata
peringkat kedua kelompok di atas signifikan atau tidak, lihat output
berikut:
Test Statisticsa Produksi
Mann-Whitney U 3,500
Wilcoxon W 58,500
Z -3,532
Asymp. Sig. (2-tailed) ,000
Exact Sig. [2*(1-tailed Sig.)] ,000b

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
172
a. Grouping Variable:
Treatmen t
b. Not corrected for ties
Keputusan: Asymp. Sig. (2-tailed) 0,000<0,05 artinya signifikan Nilai Zhitung>Ztabel = H0
ditolak dan H1 diterima.
Kesimpulan: Terdapat perbedaan yang nyata (signifikan) dari kedua perlakuan yang
dilakukan.
11.2 Freidman Test Uji Friedman dilakukan untuk mengetahui perbedaan lebih dari dua
kelompok sampel yang saling berhubungan. Uji Friedman merupakan
alternative dari Anova 2-arah (two way analysis of variance). Uji ini
dilakukan jika asumsi-asumsi dalam statistik parametrik tidak terpenuhi,
atau juga karena sampel yang terlalu sedikit. Friedman Test
mensyaratkan tidak ada ulangan (replication) perlakuan yang diberikan
kepada unitunit percobaan. Artinya, hanya ada 1 (satu) pengamatan
untuk setiap perlakuan di dalam setiap blok. Asumsi dalam Friedman Test
adalah ketika asumsi-asumsi yang dibutuhkan oleh metode 2-way Anova
parametrik tidak terpenuhi, seperti data tidak terdistribusi normal, data
berskala ordinal.
Contoh:
Sebuah program pembangunan perikanan diujicobakan pada desa
nelayan. Peneliti ingin mengetahui bagaimana respons masyarakat
terhadap program tersebut pada 3 kondisi, yakni sebelum program
masuk, sewaktu program berjalan dan pasca program. Sampel diambil
pada masyarakat kunci (aparat desa, tokoh masyarakat, tokoh pemuda,
tokoh wanita, dan perwakilan kelompok masyarakat). Total responden
kunci adalah 10 orang. Data diukur dalam skala ordinal (1=respon rendah,
2=respon sedang, 3=respon tinggi). Apakah terdapat perbedaan antara
ketiga kelompok sampel tersebut? Data sampel sebagai berikut:
Responden Pre Program In Program Post Program
1 3 2 3

Bab 11 Statistik Non-
Parameterik
173
2 3 2 3
3 2 3 3
4 3 3 3
5 3 3 1
6 3 2 2
7 2 1 2
8 2 1 1
9 1 3 2
10 3 3 3
Penyelesaian:
- Rumusan Hipotesa (H0= tidak terdapat perbedaan nilai rata-rata
antara pre program, in program dan post program; H1= terdapat
perbedaan).
- Statitik uji digunakan Uji Friedman, mengingat data tidak memenuhi
kriteria parametrik test untuk uji Anova two-way (2 arah).
- Tingkat kepercayaan 95% atau tingkat signifikansi (α=0,05).
- Analisis data dilakukan dengan aplikasi software SPSS.
- Kriteria keputusan nilai Sig.<0,05 artinya signifikan (nyata). Tolak H0
p(μ<α) untuk uji satu arah, atau H0 p(μ<α/2) untuk uji dua arah.
- Penarikan kesimpulan.
Tahapan aplikasi dengan SPSS>
- Input data ke dalam worksheet SPSS>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
174
- Klik analyze > non parametrics > test-legacy dialogs > K related
samples>
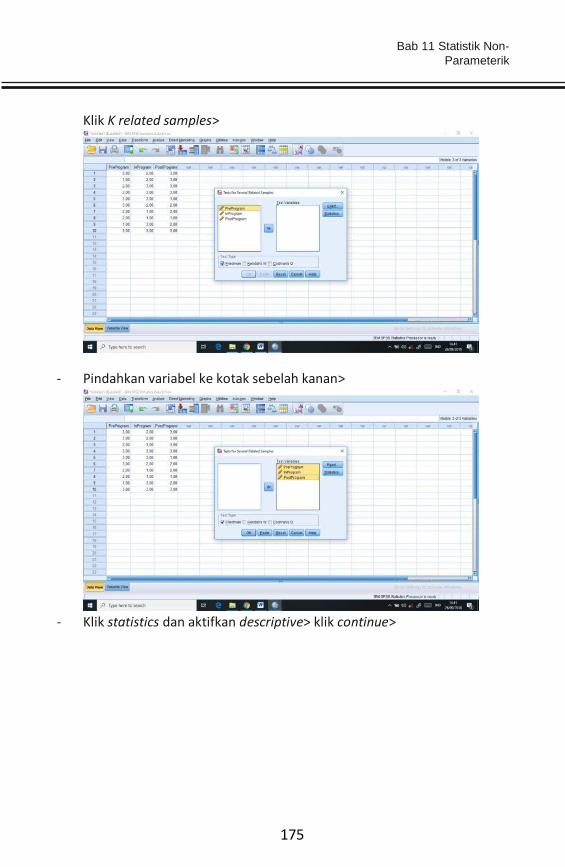
Bab 11 Statistik Non-
Parameterik
175
Klik K related samples>
- Pindahkan variabel ke kotak sebelah kanan>
- Klik statistics dan aktifkan descriptive> klik continue>
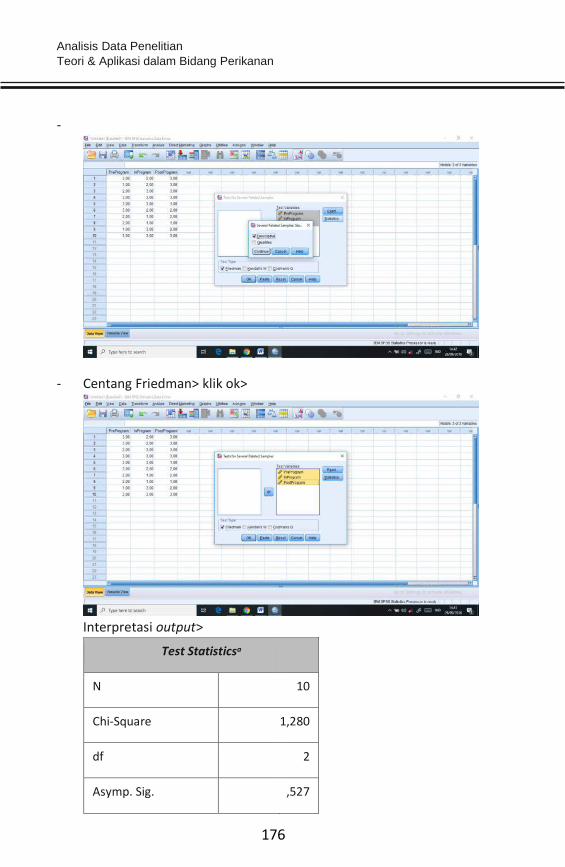
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
176
- Centang Friedman> klik ok>
Interpretasi output>
Test Statisticsa
N 10
Chi-Square 1,280
df 2
Asymp. Sig. ,527

Bab 11 Statistik Non-
Parameterik
177
a. Friedman Test
Keputusan: Asymp. Sig. 0,527> 0,05 artinya tidak signifikan dengan Nilai Chi-Square
1,280 = H0 diterima dan H1 ditolak.
Kesimpulan: Tidak terdapat perbedaan nilai rata-rata antara pre program, in
program, dan post program, artinya tidak terdapat perbedaan respons
terhadap program baik sebelum, ketikan maupun pasca program.
11.3 Kendall Test Uji Kendall merupakan uji koefisien korelasi yang termasuk dalam uji
statistik non-parametrik. Uji Kendall merupakan alternatif dari uji korelasi
dari data berpasangan yang tidak memenuhi kriteria statistik parametrik,
seperti data tidak berdisitribusi normal, data homoskedastisitas alias
tidak mengalami gejala heteroskedastisitas, data tidak mengalami
gejalan autokorelasi dan data tidak mengalami gejala multikolineariti. Uji
Kendall merupakan alternatif dari uji Pearson.
Uji Kendall dikenal juga dengan istilah uji Konkordansi atau Kendall Tau.
Menurut Field (2000) bahwa Kendall ‘Tau is nonparametric correlation
and it should be used rather than Spearman’s coeffecient when you have
a small data set with a large number of tied ranks, Kendall ‘Tau should be
used. Although Spearman’s statistic is the more popular of the two
coefficients, there is much to suggest that Kendall’s statistic is actually a
better estimate of the correlation in the population. Uji Kendall’s Tau
digunakan untuk melihat korelasi (hubungan) dari data dari data yang
bersumber dari subjek yang sama atau data berpasangan. Formula uji
Kendall’s Tau, sebagai berikut. S
λ =
1/2n(n – 1) Di mana:
λ = Nilai koefisien Kendall Tau.
S = Pembilang yang berasal dari jumlah konkordansi dan
diskonkordasi jenjang secara keseluruhan.
N = Jumlah sampel.
1 dan 2 = Konstanta.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
178
Contoh:
Peneliti ingin mengetahui hubungan antara data produksi perikanan
tangkap dengan data ekspornya yang dicatat dalam 1 tahun (12 bulan).
Dengan mengetahui apakah terdapat hubungan atau tidak maka dapat
direkomendasikan berbagai upaya (program).
Data Produksi (kg) Data Ekspor (kg)
2.000 100
2.400 200
3.000 300
4.000 250
2.000 300
1.800 300
2.000 260
3.000 280
3.200 300
4.000 320
5.000 350
3.500 350
Penyelesaian:
- Rumusan hipotesa (H0= tidak terdapat hubungan antara produksi
dan ekspor, H1= terdapat hubungan).
- Statitik uji digunakan uji Kendall Tau, mengingat data tidak
memenuhi kriteria parametrik test untuk uji korelasi 2 variabel (uji
Pearson) serta data bersumber dari subjek yang sama atau data
berpasangan.
Tingkat kepercayaan 95% atau tingkat signifikansi (α=0,05).
- Analisis data dilakukan dengan aplikasi software SPSS.
- Kriteria keputusan nilai Sig.<0,05 artinya signifikan (nyata).
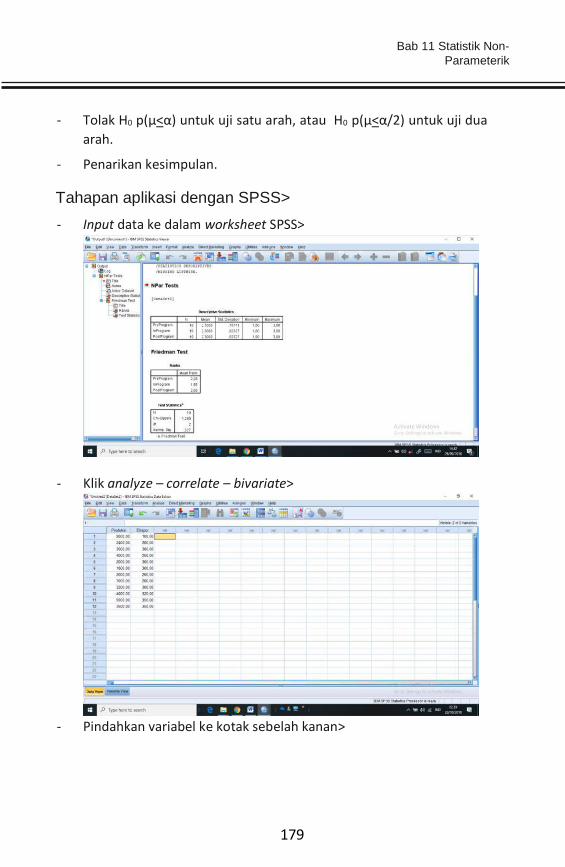
Bab 11 Statistik Non-
Parameterik
179
- Tolak H0 p(μ<α) untuk uji satu arah, atau H0 p(μ<α/2) untuk uji dua
arah.
- Penarikan kesimpulan.
Tahapan aplikasi dengan SPSS>
- Input data ke dalam worksheet SPSS>
- Klik analyze – correlate – bivariate>
- Pindahkan variabel ke kotak sebelah kanan>
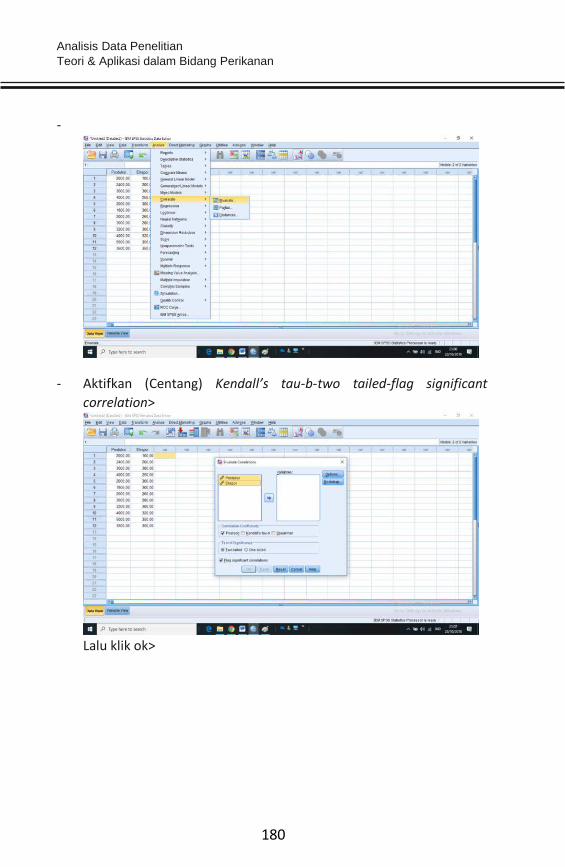
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
180
- Aktifkan (Centang) Kendall’s tau-b-two tailed-flag significant
correlation>
Lalu klik ok>

Bab 11 Statistik Non-
Parameterik
181
- Interpretasi output>
Correlations
Produksi Ekspor
Kendall’s
tau_b
Produksi
Correlation Coefficient 1,000 ,400
Sig. (2-tailed) . ,088
N 12 12
Ekspor
Correlation Coefficient ,400 1,000
Sig. (2-tailed) ,088 .
N 12 12
Keputusan: Nilai Sig. (2 tailed) diperoleh 0,088 > 0,05 yang berarti tidak signifikan
atau terima H0 dan tolak H1. Nilai korelasi juga relatif rendah yakni
0,400 sehingga tidak signifikan.
Kesimpulan: Tidak terdapat hubungan antara produksi dan ekspor.
11.4 Spearman Test Uji Spearman merupakan uji koefisien korelasi yang termasuk dalam uji
statistik non-parametrik. Uji Spearman merupakan alternatif dari uji
korelasi dari data tidak berpasangan atau dari subyek berbeda dan data
tidak memenuhi kriteria statistik parametrik, seperti data tidak
berdisitribusi normal, data homoskedastisitas alias tidak mengalami

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
182
gejala heteroskedastisitas, data tidak mengalami gejalan autokorelasi
dan data tidak mengalami gejala multikolineariti. Uji Spearman
merupakan alternatif dari uji Pearson.
Uji Spearman atau uji Spearman-rho merupakan uji asosiatif atau uji guna
mengetahui ada tidaknya hubungan (korelasi). Menurut Field (2000)
bahwa Spearman’s correlation coeffcient, r, is a nonparametric statistic
and so can be used when data have violated parametric assumptions such
as non-normally distribution data. Spearman’s test works by firt ranking
the data, and then applying pearson’s equation to those ranks”. Uji
Spearman-rho digunakan untuk melihat korelasi (hubungan) dari data
yang berasal dari subjek yang berbeda atau data tidak berpasangan.
Formula uji Spearman-rho, sebagai berikut:
6x ∑ni=1
D2 rs = nx(n2 – 1) Di mana:
rs = Korelasi Rank Spearman.
D = Perbedaan/selisih peringkat antara variabel bebas dan
terikat. n =
Jumlah sampel.
1 dan 6 = Konstanta.
Contoh:
Peneliti ingin mengetahui hubungan antara data produksi perikanan
tangkap elayan A dengan Nelayan B yang dicatat dalam 1 tahun (12
bulan). Dengan mengetahui apakah terdapat hubungan atau tidak maka
dapat direkomendasikan berbagai upaya (program).
Produksi Nelayan A (kg) Produksi Nelayan B (kg)
150 100
200 200
240 300
220 400
330 420

Bab 11 Statistik Non-
Parameterik
183
300 300
400 450
200 250
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
184
Produksi Nelayan A (kg) Produksi Nelayan B (kg)
260 260
280 270
300 320
350 300
Penyelesaian:
- Rumusan hipotesis (H0= tidak terdapat hubungan antara produksi
nelayan A dan B, H1= terdapat hubungan).
- Statitik uji digunakan uji Spearman-rho, mengingat data tidak
memenuhi kriteria parametrik test untuk uji korelasi 2 variabel (uji
Pearson) serta data bersumber dari subjek yang berbeda atau data tidak
berpasangan.
- Tingkat kepercayaan 95% atau tingkat signifikansi (α=0,05).
- Analisis data dilakukan dengan aplikasi software SPSS.
- Kriteria keputusan nilai Sig.<0,05 artinya signifikan (nyata).
- Tolak H0 p(μ<α) untuk uji satu arah, atau H0 p(μ<α/2) untuk uji dua arah.
- Penarikan kesimpulan.
Tahapan aplikasi dengan SPSS>
- Input data ke dalam worksheet SPSS>
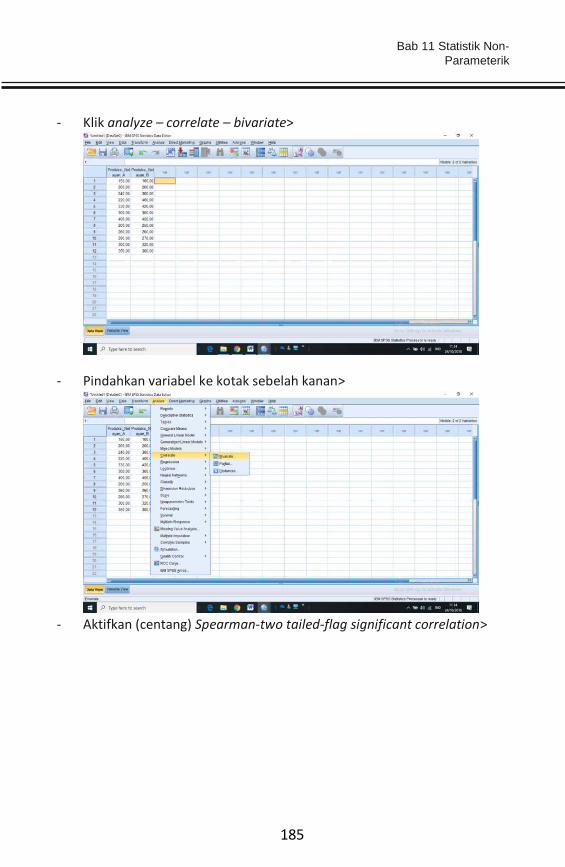
Bab 11 Statistik Non-
Parameterik
185
- Klik analyze – correlate – bivariate>
- Pindahkan variabel ke kotak sebelah kanan>
- Aktifkan (centang) Spearman-two tailed-flag significant correlation>
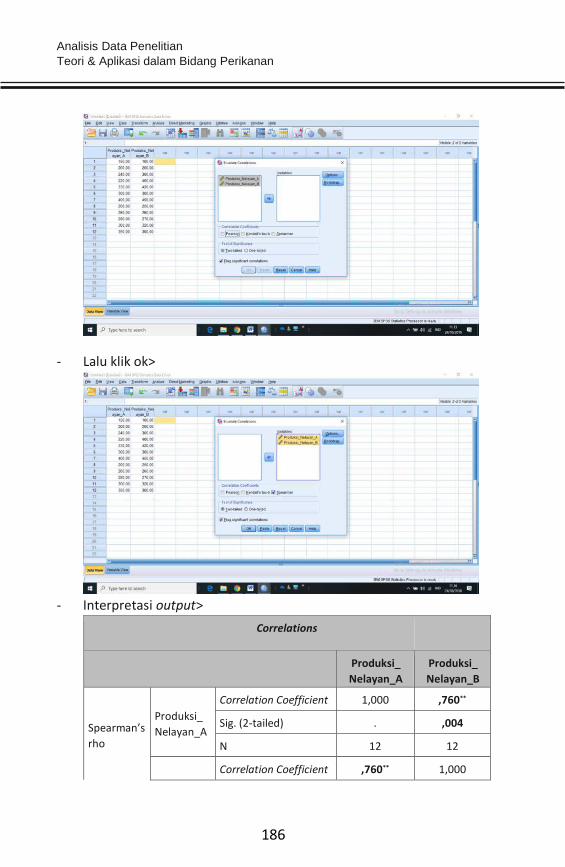
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
186
- Lalu klik ok>
- Interpretasi output>
Correlations
Produksi_
Nelayan_A Produksi_
Nelayan_B
Spearman’s
rho
Produksi_
Nelayan_A
Correlation Coefficient 1,000 ,760**
Sig. (2-tailed) . ,004
N 12 12
Correlation Coefficient ,760** 1,000

Bab 11 Statistik Non-
Parameterik
187
Produksi_
Nelayan_B Sig. (2-tailed) ,004 .
N 12 12
**. Correlation is significant at the 0.01 level (2-tailed).
Keputusan: Nilai Sig. (2 tailed) diperoleh 0,004< 0,05 yang berarti signifikan atau tolak
H0 dan terima H1. Nilai Korelasi juga menunjukkan 0,760** yang berarti
signifikan pada level 0,01 (1%) untuk uji 2 arah (two tailed).
Kesimpulan: Terdapat hubungan antara produksi Nelayan A dan produksi Nelayan B.
Kotak 28:
Statistik non parametrik adalah uji statistik alternatif, apabila data dan
varians data tidak memenuhi asumsi-asumsi pada statistik parametrik.
Asumsi data tersebutlah yang menjadi perbedaan mendasar antara
statistik parametrik & statistik non parametrik. Kelebihan uji statistik non
parametrik, yakni perhitungan sederhana dan cepat, data dapat berupa
data kualitatif (nominal atau ordinal), serta data tidak harus distribusi
normal. Sementara kelemahannya adalah tidak memanfaatkan semua
informasi dari sampel sehingga menjadi kurang efisien.


BAB 12
STRUCTURAL
EQUATION MODEL
(SEM) ... Base Your Strategy on Things That Won’t Change ...
[Jeff Bezos - CEO Amazon.Com]
“Majority of entrepreneurs would formulate their strategies by focusing
on things that would trend in next 10 years. Whereas Bezos always
formulated strategies on things that would remain stable over time,
there by putting his energy on something that customers would still
care in next 10 years. For e.g. Amazon always tried to become a
company that provided the cheapest goods because Bezos knew, for
the next 10 years or more, no customer would wish they could get costly
goods”
Structural Model Equation (SEM) merupakan teknik pemodelan statistik
cross-sectional yang umum, terutama linier, analisis faktor, analisis jalur, dan
regresi. SEM termasuk teknik confirmatory, dan bukan exploratory, yang
berarti peneliti lebih cenderung menggunakan SEM untuk menentukan
apakah suatu model tertentu valid daripada menggunakan SEM untuk
menemukan model yang ideal. Menurut Hox dan Bechger (1998) bahwa SEM
adalah suatu kombinasi analisis faktor dan analisis regresi atau analisis jalur.
Lebih jauh disebutkan bahwa dalam penyusunan variabel laten didasarkan
atas theoretical constructs yang juga dihitung berdasarkan metode regresi.
Selanjutnya model structural didasarkan atas covariances antara variabel
eksogen, variabel antara, dan variabel endogen. SEM dikenal juga dengan
Analysis of Covariance Structures atau model sebab akibat (causal
modeling).
Untuk meyakinkan agar model dapat diterima, digunakan kriteria Good of Fit
Index untuk Evaluasi Model, sebagai berikut.
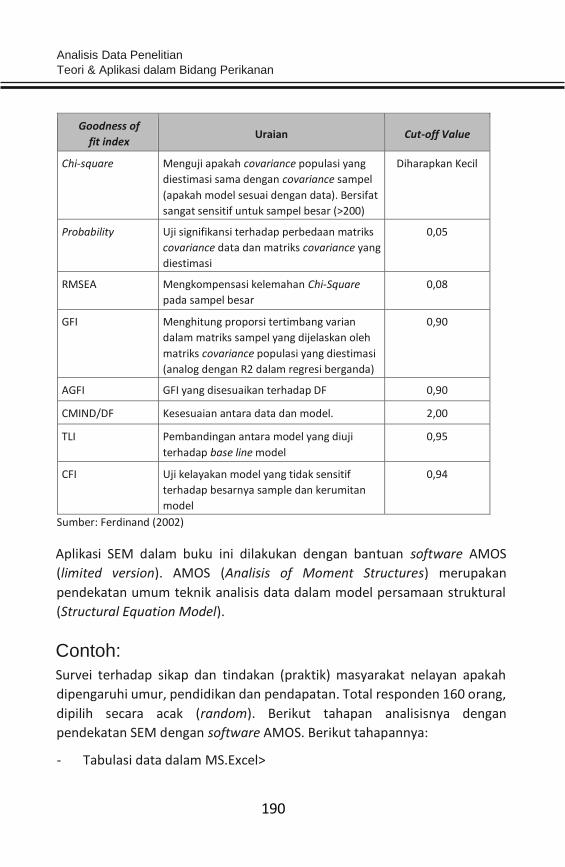
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
190
Goodness of
fit index Uraian Cut-off Value
Chi-square Menguji apakah covariance populasi yang
diestimasi sama dengan covariance sampel
(apakah model sesuai dengan data). Bersifat
sangat sensitif untuk sampel besar (>200)
Diharapkan Kecil
Probability Uji signifikansi terhadap perbedaan matriks
covariance data dan matriks covariance yang
diestimasi
0,05
RMSEA Mengkompensasi kelemahan Chi-Square
pada sampel besar 0,08
GFI Menghitung proporsi tertimbang varian
dalam matriks sampel yang dijelaskan oleh
matriks covariance populasi yang diestimasi
(analog dengan R2 dalam regresi berganda)
0,90
AGFI GFI yang disesuaikan terhadap DF 0,90
CMIND/DF Kesesuaian antara data dan model. 2,00
TLI Pembandingan antara model yang diuji
terhadap base line model 0,95
CFI Uji kelayakan model yang tidak sensitif terhadap besarnya sample dan kerumitan
model
0,94
Sumber: Ferdinand (2002)
Aplikasi SEM dalam buku ini dilakukan dengan bantuan software AMOS
(limited version). AMOS (Analisis of Moment Structures) merupakan
pendekatan umum teknik analisis data dalam model persamaan struktural
(Structural Equation Model).
Contoh:
Survei terhadap sikap dan tindakan (praktik) masyarakat nelayan apakah
dipengaruhi umur, pendidikan dan pendapatan. Total responden 160 orang,
dipilih secara acak (random). Berikut tahapan analisisnya dengan
pendekatan SEM dengan software AMOS. Berikut tahapannya:
- Tabulasi data dalam MS.Excel>
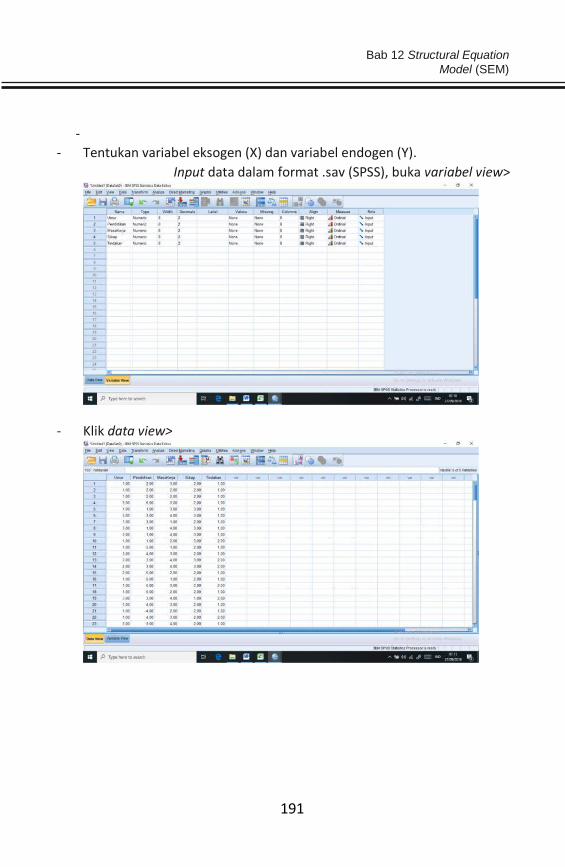
Bab 12 Structural Equation
Model (SEM)
-
191
- Tentukan variabel eksogen (X) dan variabel endogen (Y).
Input data dalam format .sav (SPSS), buka variabel view>
- Klik data view>
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
192
Buka software AMOS (tools ini telah terintegrasi dengan SPSS
terbaru), jadi dapat dibuka via SPSS>
- Maka akan terbuka lembar kerja AMOS>
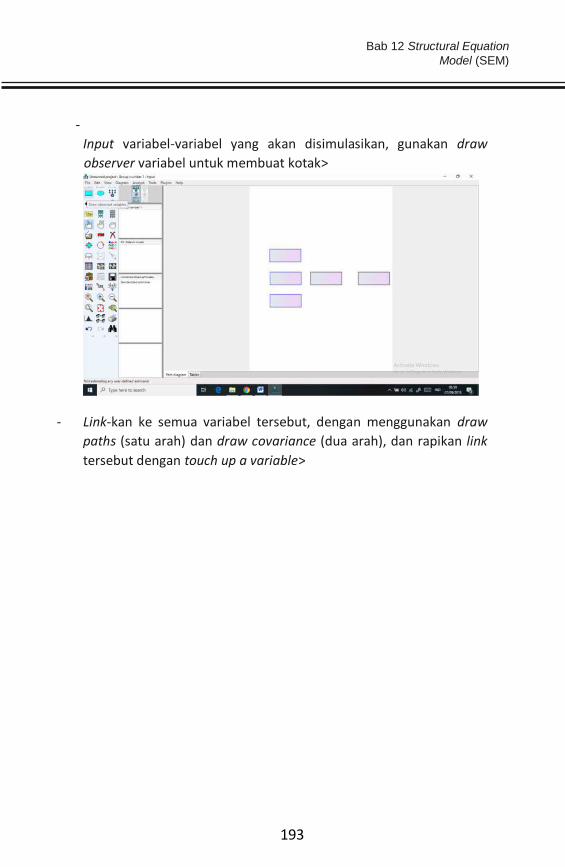
Bab 12 Structural Equation
Model (SEM)
-
193
Input variabel-variabel yang akan disimulasikan, gunakan draw
observer variabel untuk membuat kotak>
- Link-kan ke semua variabel tersebut, dengan menggunakan draw
paths (satu arah) dan draw covariance (dua arah), dan rapikan link
tersebut dengan touch up a variable>

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
194
Menambahkan error (epsilon) pada variabel terikat (dependent
variabel), seperti berikut;
- Input tulisan (simbol) error dengan klik plugins-name unobserved
variables>
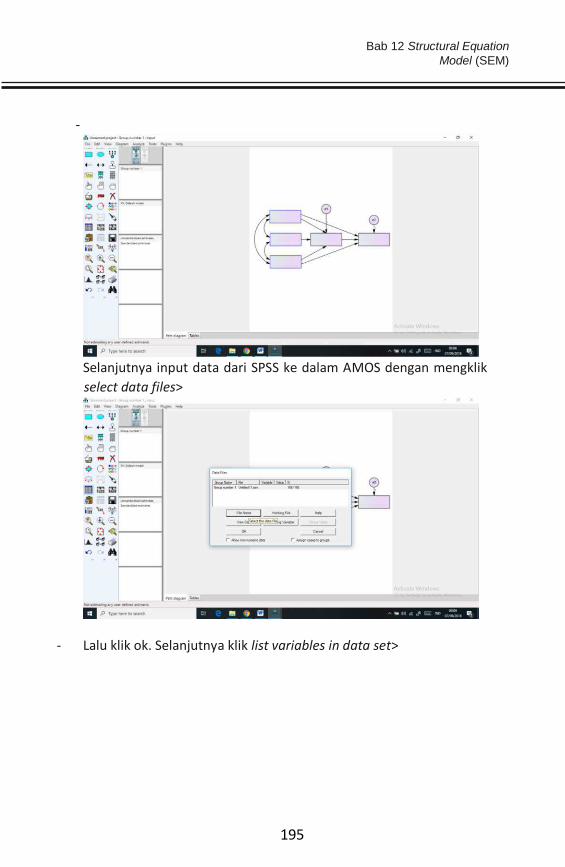
Bab 12 Structural Equation
Model (SEM)
-
195
Selanjutnya input data dari SPSS ke dalam AMOS dengan mengklik
select data files>
- Lalu klik ok. Selanjutnya klik list variables in data set>
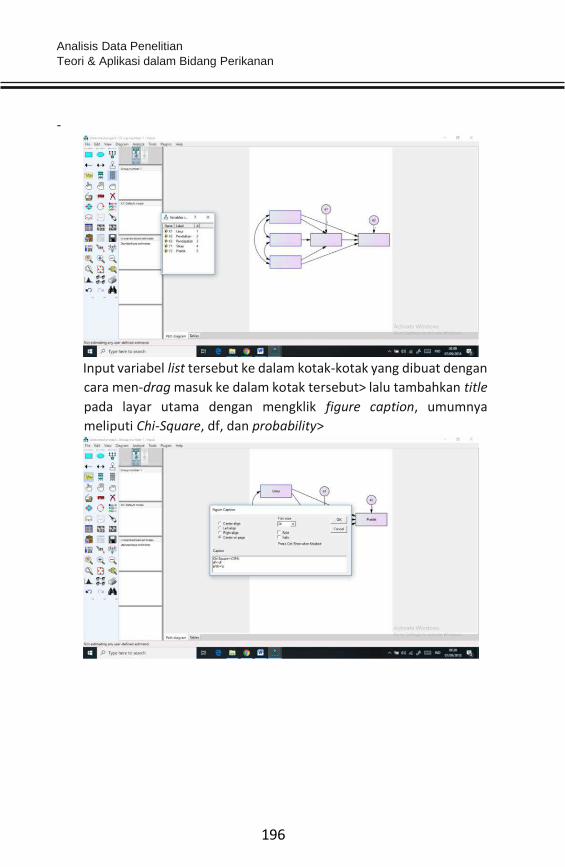
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
196
Input variabel list tersebut ke dalam kotak-kotak yang dibuat dengan
cara men-drag masuk ke dalam kotak tersebut> lalu tambahkan title
pada layar utama dengan mengklik figure caption, umumnya
meliputi Chi-Square, df, dan probability>
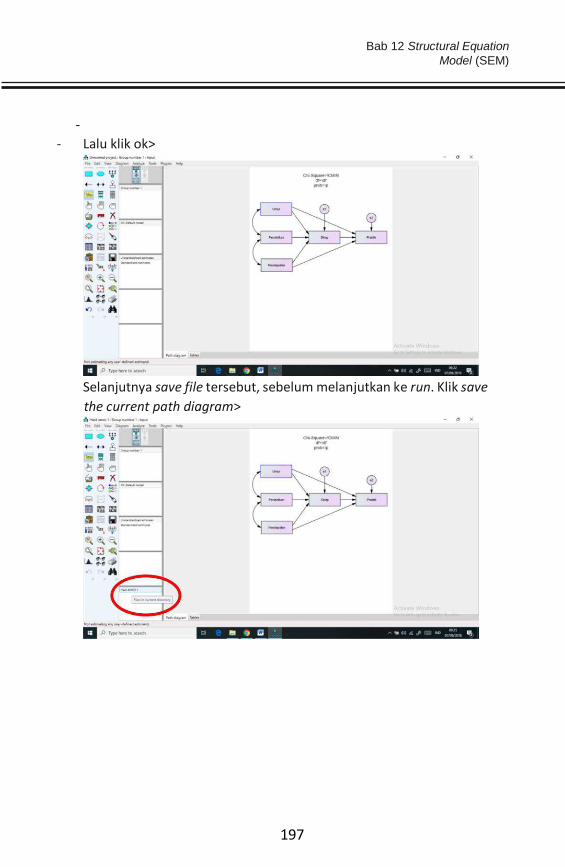
Bab 12 Structural Equation
Model (SEM)
-
197
- Lalu klik ok>
Selanjutnya save file tersebut, sebelum melanjutkan ke run. Klik save
the current path diagram>
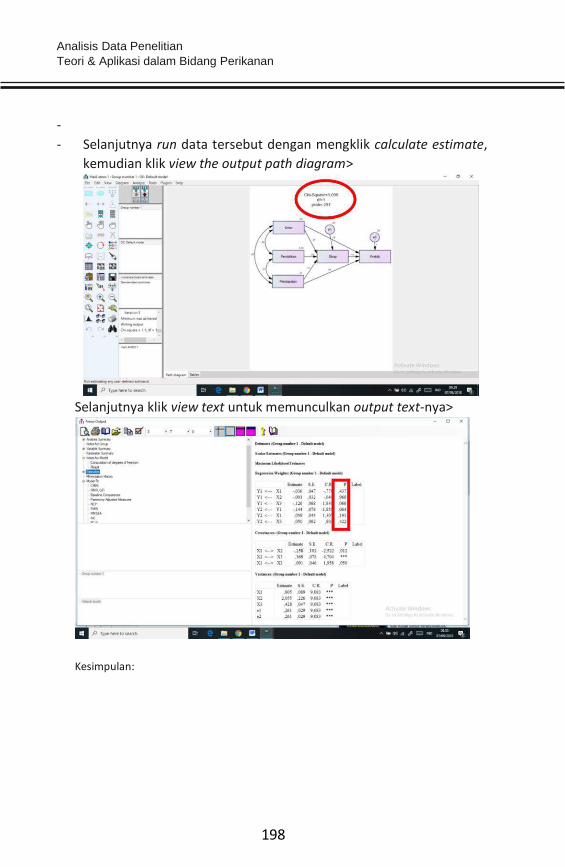
Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
-
198
- Selanjutnya run data tersebut dengan mengklik calculate estimate,
kemudian klik view the output path diagram>
Selanjutnya klik view text untuk memunculkan output text-nya>
Kesimpulan:

Bab 12 Structural Equation
Model (SEM)
-
199
Perhatikan output pada nilai P (P-value), hasil menunjukkan bahwa tidak terdapat
variabel independen yang berpengaruh secara langsung terhadap variabel dependen,
di mana P-value>0,05. Dalam artian bahwa umur, pendidikan, dan pendapatan secara
langsung tidak berpengaruh terhadap sikap dan praktik (tindakan). Tetapi secara tidak
langsung variabel umur, pendidikan, dan pendapatan berpengaruh nyata terhadap
praktik (tindakan). Dengan demikian, dalam pengelolaan perikanan, variabel-variabel
seperti; umur, pendidikan, dan pendapatan berpengaruh tidak langsung terhadap
praktik (tindakan).
Kotak 29:
Perbedaan mendasar analisis regresi, analisi jalur (path) dan SEM adalah
kemampuan SEM Analysis untuk mengungkap peran/pengaruh dari variabel
laten. Variabel laten merupakan variabel yang tidak terukur (unmeasure),
seperti bagaimana kecerdasan seseorang (intelegency) berpengaruh terhadap
kesejahteraannya.

REFERENSI
Ackoff RL 1989. From data to wisdom. Journal of
Applied Systems Analysis 16: 3–9.
Allen dan Yen. 1979. Fisika 2. Jakarta: Erlangga.
Arikunto S. 2006. Prosedur Penelitian: Suatu Pendekatan Praktek. Cetakan
ketiga Belas (Edisi RevisiVI). Jakarta PT Rineka Cipta.
Arikunto S. 2005. Manajemen Penelitian. Edisi Revisi. Jakarta: Rineka Cipta.
Arikunto S. 2002. Prosedur Penelitian: Suatu Pendekatan Praktek. Cetakan
kedua Belas (Edisi Revisi V). Jakarta PT Rineka Cipta.
Azwar S. 2006. Reliabilitas dan Validitas (Edisi III). Yogyakarta: Pustaka
Pelajar.
Azwar S. 1986. Reliabilitas dan Validitas: Interpretasi dan Komputasi.
Yogyakarta: Pustaka Pelajar.
Babbie ER. 2009. The Practice of Social Research, 12th edition, Wadsworth
Publishing. pp. 436–440.
Bierly III PE, Kessler EH, and Christensen EW. 2000. Organizational learning,
knowledge and wisdom. Journal of Organizational Change 13(6): 595–
618.
Borg I, Groenen P. 2005. Modern Multidimensional Scaling: Theory and
applications (2nd ed.). New York: Springer-Verlag. pp. 207–212.
Borg I, Groenen P. 2005. Modern Multidimensional Scaling: Theory and
applications (2nd ed.). New York: Springer-Verlag. pp. 207–212.
Bronstein AM, Bronstein MM, Kimmel R. 2006. Generalized
multidimensional scaling: a framework for isometry-invariant partial
surface matching. Proc. Natl. Acad. Sci. U.S.A. 103(5).
Budiarto E. 2002. Metodologi Penelitian Kedokteran: Sebuah Pengantar.
Jakarta: Buku Kedokteran EGC.

Croxton FE, Cowden DJ, K. Sidney. 1968. Applied General Statistics. Pitman.
p625.
Davis GB. 2002. Kerangka Dasar: Sistem Informasi Manajemen, Bagian I
Pengantar. Seri Manajemen No. 90-A. Cetakan Kedua Belas. Jakarta:
PT. Pustaka Binawan Pressindo.
Dennis C. 2006. The Essentials of Factor Analysis (edisi ke-3rd), Continuum
International, ISBN 978-0-8264-8000-2.
Daniel WW. 1989. Statistika Non Parametrik Terapan. George State
University. USA. Jakarta: PT Gramedia.
Ferdinand. A. 2002. Metode Penelitian Manajemen. Semarang: Badan
Penerbit Universitas Diponegoro.
Ghozali I. 2009. Aplikasi analisis Multivariate dengan Program SPSS.
Semarang: Badan Penerbit Universitas Diponegoro.
Gujarati D. 2003. Ekonometri Dasar (Terjemahan). Jakarta: Erlangga.
Hair JF, Rolph E. Anderson, Ronald L. Tatham, William C. Black. 2006.
Multivariate Data Analysis. Sixth Edition, Pearson Education Prentice
Hall, Inc.
Hamidi. 2004. Metode Penelitian Kualitatif: Aplikasi Praktis Pembuatan
Proposal dan Laporan Penelitian. Malang: UMM Press.
Hasan MI. 2002. Pokok-pokok Materi Statistika 1 (Statistik Deskriptif). Edisi
Kedua. Jakarta: PT. Bumi Aksara.
Hasan MI. 2009. analisis Data Penelitian Dengan Statistik. PT. Bumi Aksara.
Jakarta.
Hoppe A, Seising R, Nurnberger A, dan Wenzel C. 2011. Wisdom – The Blurry
Top Of Human Cognition In the DIKW-model?. [Tersedia pada:
http://www.atlantispress.com/php/download_paper.php?]
Hora SC. 2004. Probability judgments for continuous quantities: linear
combinations and calibration. Management Science 50: 597–604.
Hox JJ dan Bechger TM. 1998. An Introduction to Structural Equation
Modeling. Family Science Review 11: 354–373. Referensi

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
202
Jankowski A. dan A. Skowron. 2007. A wistech paradigm for intelligent
system. In Peters, J F. et al. (Eds.): Transactions on Rough Sets VI, LNCS
4374, 94–132, Springer-Verlag Berlin Heidelberg.
Jogiyanto. 2005. Analisis dan Desain Sistem Informasi. Yogyakarta: Penerbit
Andi.
Johnson N, Wichern D. 2002. Applied Multivariate Statistical Analysis. 5 th
Edition. New Jersey: Prentice Hall, Englewood Cliffs.
John W. Creswell. 2008. Educational Researchs: Planning, Conducting, And
Evaluating Quantitative and Qualitative Research, New Jersey, Pearson
Education Inc.
Judd C, G. McCleland. 1989. Data Analysis. Harcourt Brace Jovanovich. ISBN
0-15-516765-0.
Kavanagh P dan Pitcher TJ. 2004. Implementing Microsoft Excel Software For
Rapfish: A Technique For The Rapid Appraisal of Fisheries Status.
Fisheries Centre Research Reports. University of British Columbia.
Canada: 12 (2)
Kruskal JB. 1964. Multidimensional scaling by optimizing goodness of fit to a
nonmetric hypothesis. Psychometrika 29(1): 1–27.
Lacke PSM and J. Christopher. 2010. Introductory statistics (7th ed.).
Hoboken, NJ: John Wiley & Sons. ISBN 978-0-470-44466-5.
Liew A. 2013. DIKIW: Data, Information, Knowledge, Intelligence, Wisdom
and their Interrelationships. Business Management Dynamics Vol.2.
No.10: Pp.49–62.
Liew A. 2007. Data, information, knowledge, and their interrelationships.
Journal of Knowledge Management Practice 7(2).
Likert R. 1932. A Technique for the Measurement of Attitudes. Archives of
Psychology 140: 1–55.
Miller, C. Delbert. 1974. Handbook of Research Design and Social
Measurement. David McKay Company.
Muhadjir, N. 1996. Metodologi Penelitian Kualitatif. Yogyakarta:
Rakesarasin.

191
Murti B. 2006. Desain dan Ukuran Sampel untuk Penelitian Kuantitatif dan
Kualitatif di bidang Kesehatan. Yogyakarta: Gajah Mada University
Press. P.47
Nasution S. 2011. Metode Research. Jakarta: Bumi Aksara.
Nazir M. 2003. Metode Penelitian. Penerbit Ghalia Indonesia: Jakarta.
Nasution. 2011. Metode Research; Penelitian Ilmiah. Jakarta: PT Bumi
Aksara.
Nazir. 1988. Metode Penelitian. Jakarta: Ghalia Indonesia.
Nisfiannoor M. 2009. Pendekatan Statistika Modern untuk Ilmu Sosial.
Jakarta: Salemba Humatika.
Notoatmodjo S. 2002. Metodologi Penelitian Kesehatan. Cetakan II, Edisi
Revisi. Jakarta: Rineka Cipta.
Nursalam. 2003. Konsep dan Penerapan Metodologi Penelitian Ilmu
Keperawatan: Pedoman Skripsi, Tesis, dan Instrumen Penelitian
Keperawatan. 1th ed. Jakarta: Penerbit Salemba Medika.
Rochaety E, dkk. 2007. Metodologi Penelitian Bisnis: dengan Aplikasi SPSS,
Edisi Pertama. Penerbit Mitra Wacana Media: Jakarta.
Riduan. 2005. Dasar-dasar Statistika. Bandung: Penerbit Alfabeta.
Schervish, Mark J. 1987. A Review of Multivariate Analysis. Statistical Science
2(4): 396–413.
Sekaran U. 2006. Metodologi Penelitian untuk Bisnis. Edisi 4, Buku 1, Jakarta:
Salemba Empat.
Siegel S. 1992. Statistik Non Parameterik untuk Ilmu-Ilmu Sosial. Jakarta: PT
Gramedia.
Singgih S. 2003. Statistika Multivariat. Jakarta: PT Gramedia.
Singgih S. 2014. Statistik Multivariat Edisi Revisi. Jakarta: PT Elex Media
Komputindo.
Siagian D dan Sugiarto. 2002. Metode Statistika untuk Bisnis dan Ekonomi.
Jakarta: Gramedia Pustaka Utama.

Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
204
Soejoeti Zanzawi. 1987. Materi Pokok Analisis Runtun Waktu. Jakarta:
Karunika, Universitas Terbuka Referensi
Spiegel, Murray R. dan Larry J. Stephens. 2007. Statistik. Edisi Ketiga.
(Terjemahan). Jakarta: Erlangga.
Subagyo DP. 1998. Statistik Induktif. Yogyakarta: BPFE UGM.
Sudjana 1996. Metode Statistika. Bandung: PT Tarsito.
Sudaryanto. 2003. Teori dan Praktik analisis Wacana. Yogyakarta: Duta
Wacana University Press.
Sugiyono. 2014. Metode Penelitian Kuantitatif, Kualitatif, dan Kombinasi
(Mixed Methods). Bandung: Alfabeta
Sugiyono. 2010. Metode Penelitian Administratif. Bandung: Alfabeta.
Sugiyono. 2009. Metode Penelitian Kuantitatif, Kualitatif, R & D. (Edisi
Revisi). Bandung: Alfabeta.
Sugiyono. 2006. Metode Penelitian Kuantitatif, Kualitatif, R & D. Bandung:
Alfabeta.
Supranto J. 2004. Analisis Multivariat Arti dan Interpretasi. Jakarta: PT Rineka
Cipta.
Vardiansyah, Dani. 2008. Filsafat Ilmu Komunikasi: Suatu Pengantar. Jakarta:
Indeks.
Walpole RE. 1993. Pengantar Statistika. Jakarta: Gramedia Pustaka Utama.
Wellisch HH. 1996. Abstracting, indexing, classification, thesaurus.
construction: A glossary. Port Aransas, TX: American Society of
Indexers.
Yusuf M. 2017. Modul Training. Aplikasi Software Statistik Bidang Perikanan
& Kelautan. Fakultas Perikanan dan Kelautan Universitas Riau.
Pekanbaru.
Zins C. 2007. Conceptual Approaches for Defining Data, Information, and
Knowledge. Journal Of The American Society For Information Science
And Technology 58(4):479–493.

193


GLOSARIUM
Akurasi adalah keadaan benar (tepat).
Angket merupakan alat pengumpulan data sejenis
kuisinoer.
Asumsi adalah syarat dalam analisis yang harus dipenuhi.
Autokorelasi adalah pengujian terjadinya korelasi dalam model prediksi.
Bias adalah simpangan atau tingkat kesalahan.
Bivariate adalah uji statistik secara serentak yang terdiri dari 2 (dua) variabel
dependen (terikat) pada setiap objek yang diamati.
Cross Section adalah jenis data yang dikumpulkan berdasarkan waktu, yakni
pada suatu waktu tertentu.
Dependent adalah variabel terikat.
Desil adalah ukuran data yang dibagi menjadi 10 bagian.
Desk Study adalah studi pustaka atau studi literatur.
Diskrit adalah data hasil perhitungan.
Deskriptif adalah uji statistik yang hanya memberikan informasi mengenai
data yang dipunyai dan tidak menarik kesimpulan apa pun tentang
gugus induknya.
Hardware atau Perangkat Keras adalah komponen fisik yang digunakan
sebagai bagian dari analisis data; PC, Laptop, Notebook, etc.
Heteroskedastisitas adalah gambaran ketidaksamaan varian dari residual
untuk semua pengamatan pada model regresi linear.
Independent adalah variabel bebas.
Inferensia (l) adalah uji statistik yang dapat menarik kesimpulan dari gugus
data induknya.
Instrumen adalah alat yang digunakan dalam pengumpulan data. Analisis Data Penelitian

Teori & Aplikasi dalam Bidang Perikanan
Kontinyu adalah data hasil pengukuran.
Kuartil adalah ukuran data yang dibagi menjadi 4 bagian.
Model adalah representasi atau deskripsi yang menjelaskan suatu objek,
sistem, atau konsep.
Multikolineariti adalah gambaran korelasi antara variabel bebas
(independent).
Multivariate adalah uji statistik secara serentak yang diamati lebih dari 2
(dua) variabel dependen (terikat) pada setiap objek.
Normalitas adalah gambaran data berdistribusi normal atau memiliki rata-
rata nol dan simpangan baku sama dengan satu.
Non-Paramterik adalah uji statistik yang tidak mensyaratkan data populasi.
Parameterik adalah uji statistik yang mensyaratkan data memenuhi data
populasi berdistribusi normal dan memiliki varians homogen.
Persentil adalah ukuran data yang dibagi menjadi 100 bagian.
Presisi adalah keadaan pasti.
Ragam (variance) adalah nilai yang menunjukkan besarnya penyebaran data
pada kelompok data.
Range (rentang) adalah selisih data terbesar (maksimum) dan data terkecil
(minimum).
Reliabilitas adalah tingkat ketahanan Sampel
atau data.
Sampling adalah teknik pegambilan data.
Simpangan Baku (Standar Deviasi) adalah akar dari jumlah kuadrat deviasi
dibagi banyaknya data.
Simpangan rata-rata adalah nilai rata-rata dari selisih setiap data dengan
nilai mean atau rataan hitungnya.

Sistem adalah suatu kesatuan yang terdiri komponen atau elemen yang
dihubungkan bersama untuk memudahkan aliran informasi, materi
atau energi.
196 Glosarium
Software atau Perangkat Lunak adalah suatu perangkat sistem yang
digunakan dalam analisis data, terdiri dari sistem operasi & sistem
aplikasi; Microsoft Excel, SPSS, MINITAB, SEM (Lisrel, AMOS), etc.
Statistik adalah data, informasi atau kumpulan fakta-fakta.
Statistika (statistics) adalah ilmu tentang pengumpulan dan klasifikasi data.
Time Series adalah data runtut waktu.
Tools adalah formula matematika/statistik yang merupakan bagian dari
software/aplikasi, seperti; Tools Analysis Descriptive, Analysis
Regresi dan lain-lain.
Univariate adalah uji statistik secara serentak yang hanya memiliki satu
variabel dependen (terikat) pada setiap objek yang diamati.
Valid artinya sahih atau tingkat akurasi. Validitas
adalah tingkat kesahihan

197


INDEKS
A
Analisis, 2, 3, 5, 7, 9, 14, 26, 42,
43, 59, 60, 75, 76, 80,
85, 89, 94, 99, 100,
102, 107, 109, 110,
111, 112, 114, 118,
119, 122, 124, 129,
130, 131, 132, 134,
137, 138, 143, 154,
156, 158, 171, 180,
194, 196, 208, 213
Angket, 13, 61
Asumsi, 138, 158, 181, 187
Autokorelasi, 76, 86, 89
B
Berkelompok, 12
Bias, 14, 99
C
Cross Section, 11, 16
D
Data, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13,
15, 16, 18, 19, 20, 21, 22,
24, 25, 26, 27, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 47, 48, 49,
51, 58, 59, 60, 61, 62, 63, 67,
68, 69, 71, 75, 76, 77, 80, 83,
85,
86,
89,
90,
95,
98,
99,
100, 101, 102, 104, 106, 107,
108, 111, 112, 113, 114, 117,
121, 122, 123, 124, 126, 128,
129, 130, 131, 132, 139, 142,
144, 147, 148, 149, 154, 156,
158, 159, 160, 161, 164, 165,
166, 167, 171, 172, 173, 180,
181, 182, 183, 188, 189, 195,
196, 201, 203, 207
Dependent, 6, 80, 92, 123, 156,
157, 174, 200, 205
Desil, 21, 33, 34
Desk Study, 18
Deskriptif, 98, 99, 100, 102, 107,
112
Dimensi, 11, 130, 131, 138, 142
Diskrit, 12, 16
E
Error, 90, 200
F
Faktor, 14, 77, 130, 131, 137, 138,
142, 174, 194
Favorable, 14, 147
Frekuensi,12, 24, 25, 29, 31, 38, 40,

41, 70, 99, 112 Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
G
Group, 12, 111, 129, 185
H
Handal, 58, 68, 74
Hardware, 7, 213
Heteroskedastisitas, 76, 89, 90, 94
I
Independent, 77, 80, 92, 94, 123,
156, 158, 171, 181,
205
Input, 3, 22, 23, 27, 43, 51,
53, 55, 57, 63, 64, 71,
78, 104, 108, 113,
124, 132, 134, 139,
148, 160, 166, 172,
173, 183, 184, 189,
196, 199, 200, 202
Interval, 15, 16, 128, 164, 170,
176, 178
K
Karakteristik, 77, 94, 97
M
Mean, 21, 24, 37, 38, 40, 76,
106, 107, 123, 179
Median, 21, 26, 27, 29, 106,
107, 181
Metode, 2, 18, 43, 69, 86, 99,
130, 154, 180, 182,
188, 194
MINITAB, 8, 56, 102, 132
Model, 76, 85, 89, 90, 94, 95,
130, 144, 171, 194,
195, 196, 208
Modus, 21, 29, 30, 31, 106,
107, 148
Multikolineariti, 76, 94, 97
N
Nominal, 12, 16
Normal, 76, 82, 83, 84
Normalitas, 75, 76, 77, 112,
158
O
P
Kode, 13, 173
Konfigurasi, 145
Kontinyu, 12, 16
Kualitatif, 10, 16, 208, 210, 211
Kuantitatif, 11, 210, 211
Kuartil, 21, 32
Kuesioner, 10, 13, 14, 60, 61, 62,
77, 101, 147
Observasi, 10, 11, 18, 19, 70, 86,
89
Ordinal, 13, 14, 16, 152
Output, 2, 3, 7, 28, 46, 49, 61,
80, 83, 104, 110, 111,
116, 120, 121, 128,
143, 144, 163, 169,
176, 177, 186, 193,
203, 204
200

Pakar, 10, 18, 19, 30
Parameterik, 75, 76, 98, 180, 181
Persentil, 21, 34, 35
Peubah, 130
Process, 2, 3
Publik, 18, 19
R
Rasio, 15, 16
Raw, 2, 3, 6, 43
Reliabilitas, 68, 69, 207
Residual, 80, 83, 88, 93
Responden, 10, 14, 18, 19, 62,
100, 101, 142, 143,
147, 148, 188, 196
S
Sampel, 81, 157, 167, 168, 171,
181, 188, 210
Sampling, 19
SAVE, 80
Signifikan, 60, 86, 90, 129, 130,
156, 158, 159, 163,
164, 166, 170, 172,
177, 179, 182, 186,
187, 189, 193
Sistem, 7, 43, 130, 131
Skala, 13, 16, 147
Indeks
Software, 7, 111, 132, 138, 197, 209,
211, 213
SPSS, 8, 22, 43, 44, 51, 53, 56, 62, 71,
77, 78, 86, 90, 102, 107,
108, 111, 113,
124, 148, 159, 160,
166, 172, 182, 183,
189, 196, 197, 201,
208, 210
Stakeholder, 19
Statistik, 7, 8, 10, 20, 51, 59, 75,
85, 98, 99, 100, 102,
111, 112, 122, 123,
124, 131, 137, 142,
154, 156, 171, 180,
181, 187, 194
Statistika, 20, 22, 35, 76, 98, 99,
100, 111, 129, 130,
143, 157
Survei, 19, 101, 112
T
Test, 2, 58, 68, 75, 86, 89, 154, 155,
156, 157, 158, 166,
167, 168, 175, 178, 180,
181, 182, 189
Time Series, 11, 16
Tools, 68, 102, 112, 142, 143,
197

Tunggal, 12
201 Analisis Data Penelitian Teori & Aplikasi dalam Bidang Perikanan
U
Unfavorable, 14, 147
W
Worksheet, 44, 139, 148, 183, 189
V
Valid, 2, 3, 21, 29, 58, 60, 61, 67, 68, 75,
85, 89, 90, 117, 123, 164, 177, 194
Validitas, 58, 59, 60, 61, 62, 68
Variabel, 11, 58, 63, 75, 76, 77, 80, 83,
85, 89, 92, 94, 95, 99, 109, 111, 112,
115, 117, 118, 119, 122, 123,
126, 129, 131, 134, 137, 138, 142,
143, 144, 150, 155, 156, 161, 168,
171, 174, 184, 191, 194, 196, 199,
200, 202, 204
View, 63, 71, 80, 173

202

Riwayat Penulis
Dr Muhammad Yusuf, SPi, MSi dilahirkan di
Pinrang, 2 Maret 1977. Menamatkan pendidikan dasar hingga menengah
atas di Kabupaten Pinrang. Meraih gelar Sarjana pada tahun 2002 pada
jurusan Manajemen
Sumberdaya Perairan Fakultas Ilmu Kelautan dan Perikanan Universitas
Hasanuddin Makassar. Menyelesaikan pendidikan Magister dan Doktoral
di Institut Pertanian Bogor pada bidang Keahlian Pengelolaan dan
Pemodelan Lingkungan Hidup dan Sumberdaya Alam. Saat ini, Penulis
Mengajar di Universitas Cokroaminoto Makassar. Penulis juga
merupakan salah seorang trainer Aplikasi Software Penelitian dan
Penunjang Keputusan, khususnya pada bidang Pengelolaan Sumberdaya
Alam dan Lingkungan.
Dr Lukman Daris, SPi, MSi dilahirkan di Bone, 5 Desember 1970. Meraih
gelar Sarjana Perikanan pada tahun 2000, dan gelar Magister dan
Doktoral dari Universitas Hasanuddin pada bidang Sosial Ekonomi
Perikanan. Saat ini, Penulis merupakan Dosen Dipekerjakan (DPK) di
bawah LLDIKTI Wilayah IX Sulawesi pada Universitas Cokroaminoto
Makassar. Buku lain yang telah diterbitkan oleh penulis berjudul
“Dinamik Sosial Masyarakat Pesisir”.