Embed Size (px)
Citation preview

1
Perforce Backup Strategy & Disaster Recovery at National Instruments
Steven Lysohir

2
Why This Topic?
• Case study on large Perforce installation• Something for smaller sites to ponder as they grow• Stress the importance of planning for a disaster• Entertainment

3
Topics
• Personal & Company Intro• NI’s Development Environment• Perforce Architecture• Backup Strategy• Real Life Disasters & Lessons Learned• Best Practices• Questions?

4
Personal & Company Info• Steven Lysohir
– Systems Analyst focused mainly on global Perforce support at National Instruments
– 3 years in this role
• National Instruments– Produces hardware and software for the Test & Measurement industry
(PXI chassis & PCI cards, LabVIEW)– Global company headquartered in Austin, TX– Sales & Support offices worldwide– Distributed development (R&D branches)

5
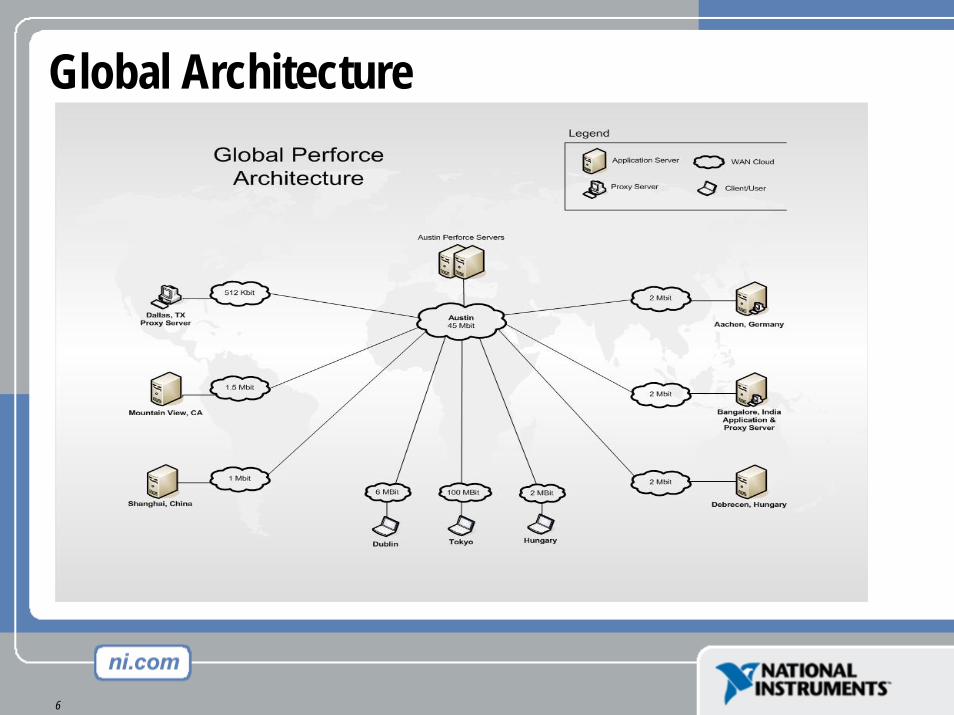
Development Environment
• Distributed development• Perforce used in 10 countries• Seven servers globally• Server operating systems vary from Linux AS to Windows 2000/2003
• Perforce Server versions range from 2001.1 to 2004.2• Used across organization (multiple business units)
6
Global Architecture

7
Dev Environment – Main Server
• Main Perforce server in Austin, TX• Perforce Metrics for main server
– Number of Users………………………1050– Number of Versioned Files…………...4,800,000– Size of Depots………………………….600 GB– Size of Database………………………21 GB– Number of Changelists………………..1,000,000– Number of Clients……………………...3500– Number of Commands Daily………….100,000

8
Hardware Architecture – Servers• Two identical servers
– Dell PowerEdge 2600• Dual 3.2 GHz Xeon processors• 4 GB RAM• Dual Gigabit network adapters
• First server is primary Perforce production server• Second server has multiple roles
– Failover server– Runs custom scripts– Storage for checkpoint and journal files
• 8 X 36 GB U320 15K drives• 2 disk RAID 1 array• 6 disk RAID 10 array

9
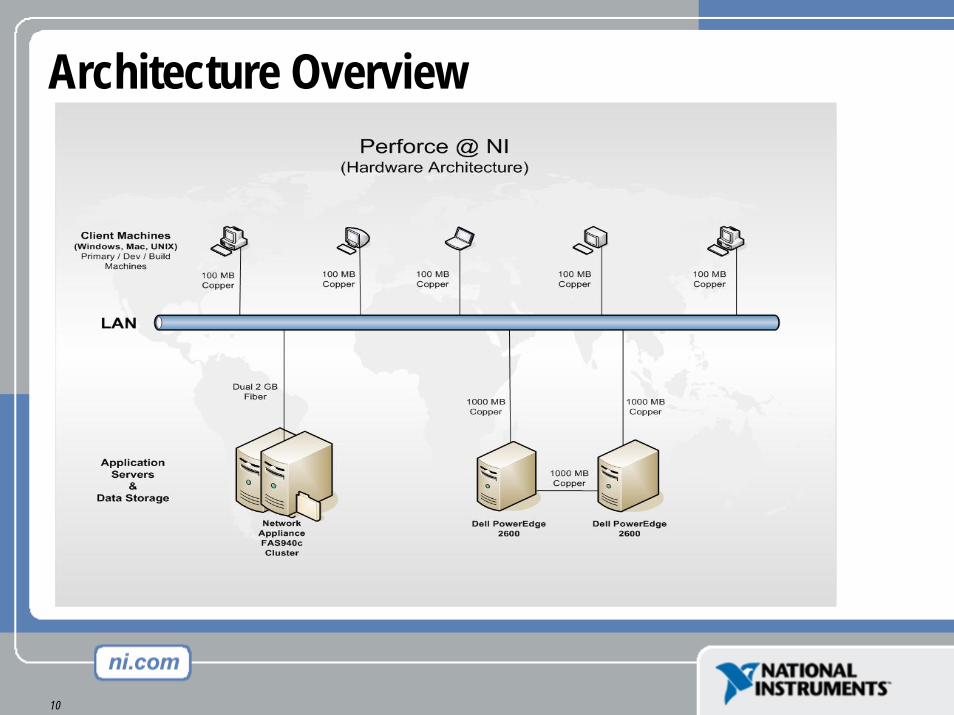
Hardware Architecture – Storage
• Network Attached Storage (NAS) device• NetApp FAS 940c cluster• Capable of performing point-in-time copies of data (snapshots)
• Connected to Perforce server through shared Gigabit over LAN
10
Architecture Overview

11
Application Architecture
• Journal & Log files stored on RAID 1 array• Database stored on RAID 10 array• Versioned files on NAS appliance• “Offline Database” stored in “offline” directory on RAID 10 array

12
Architecture Benefits• Identical Servers
– Failover with limited user impact– One step closer to clustering
• NAS Solution– Reliability– Recovery– Scalability– Performance
• Offline Database– Ability to perform nightly checkpoints without locking production database

13
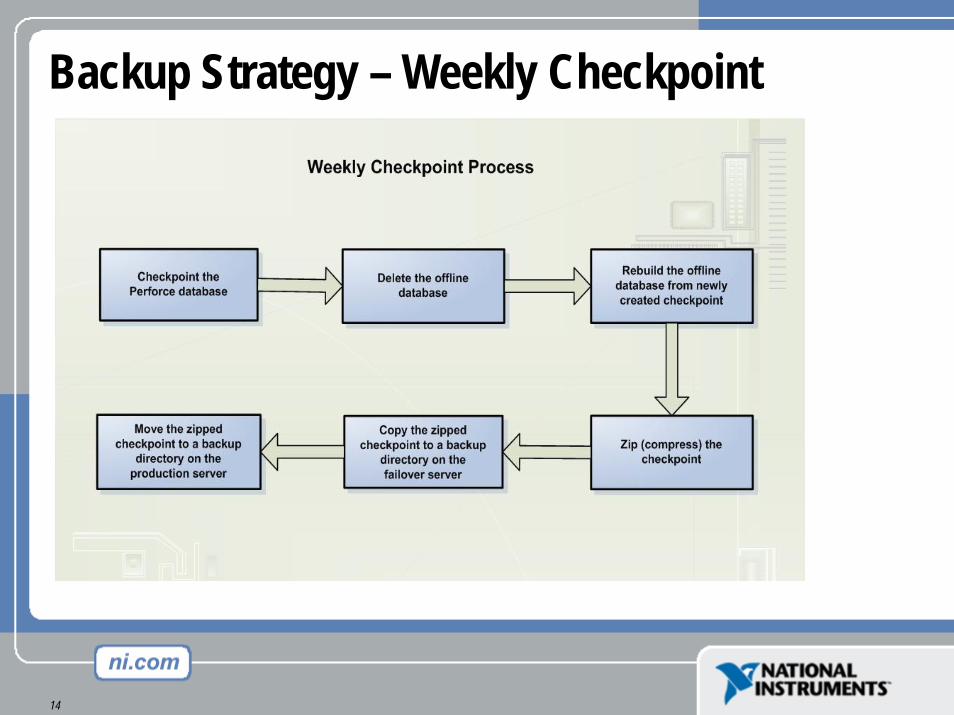
Backup Strategy
• Weekly checkpoint of production database• Daily checkpoint of “offline” database• Multiple daily snapshots & journal copies• Nightly tape backups
14
Backup Strategy – Weekly Checkpoint
15
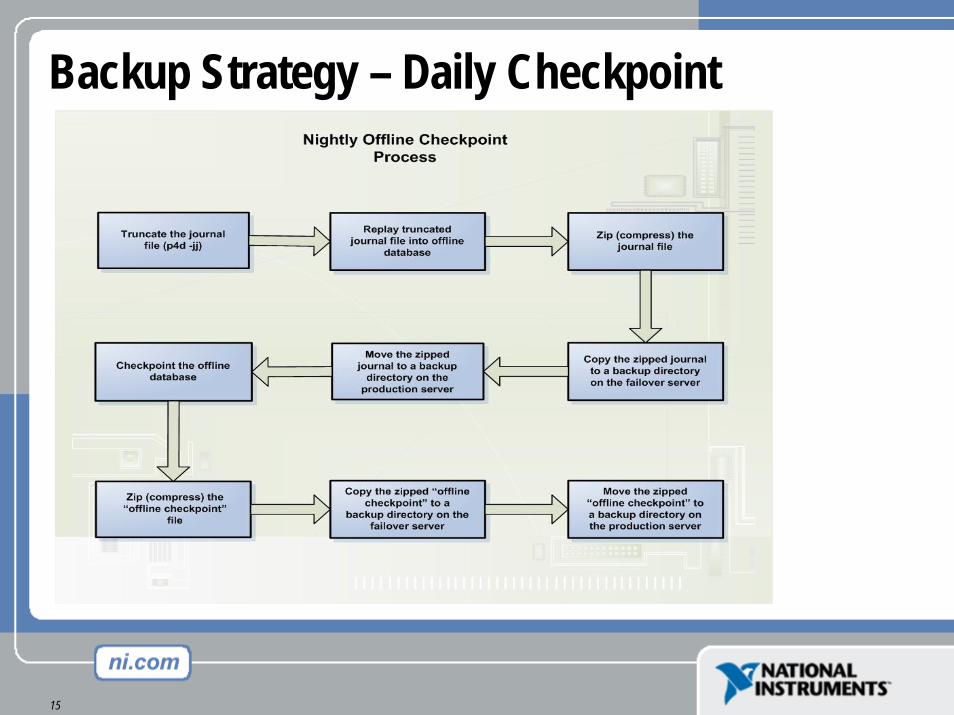
Backup Strategy – Daily Checkpoint

16
Backup Strategy – Snapshots
• Every 4 hours for versioned files• Copy P4 journal every 4 hours• Timing of these two events coincide to maintain data integrity

17
Backup Strategy Benefits
• Checkpoints & Journal Copy– Always a copy of the DB available on disk, current to within 4 hours– Switching to failover is more efficient since all data already resides on
failover server
• Snapshots– Ability to restore data directly from disk– No file locking during backups– Able to create backups “on the fly” during business hours

18
Backup Strategy – Tape Backups
• Application & Failover server receive full, nightly backups– P4 database & P4 Journal excluded– Backed up to tape through “offline” database & journal copy
• Versioned Files on NAS device– Receive full, nightly backups from a snapshot– Eliminates file locking

19
Backup Strategy – Test Restores
• Test restore of all versioned files and checkpoints performed every 6 months

20
Disaster 1 – Untested Recovery Plan• Background
– Moving depots from one share to another– Deleting depots from old share after move complete
• Issue– Wrong depot deleted from original share– Delete occurred around 11:30 PM and error not realized until next
business day– Approximately 5 GB of versioned files deleted from file system (and
right before a release!)

21
Disaster 1 – Where Do We Stand?
• Current State– Developers could continue to work on unaffected files– Deleted files reported “librarian” errors in Perforce
• Initial Response Plan– Notify users– Recover as many files from the snapshot as possible– Restore remaining files from tape– Run “p4 verify” to check for data integrity

22
Disaster 1 – Roadblocks• Only 30% of the data could be recovered from snapshot
– Recovered files were randomly located– No easy process to identify files to missing
• The full depot had to be recovered from tape– Restore of this magnitude was never tested– Restore continued to fail
• No clear communication to users on status

23
Disaster 1 – Final Resolution
• Storage & Backup vendors contacted for support– Custom work-around finally enabled the restore to complete
successfully– Restored full depot to “restore” directory on NAS device
• Script written to identify files that needed to be copied to production share
• Files copied through another script• “p4 verify” run to test for data integrity• Users notified of successful recovery

24
Disaster 1 – Lessons Learned• Good News
– All but 3 files were able to be recovered– This happened on a Friday
• Bad News– Took 3 days to perform untested recovery from tape
• Opportunities for Improvement– Test the restore process & document the procedure– Create more frequent snapshots– Develop clear channels of communication– Document a disaster recovery plan

25
Disaster 2 – Benefit of Frequent Snapshots
• Background– Implemented new backup hardware– Performed test restore of all Perforce versioned files
• Issue– Bug in backup software lead to restore over production data– Error realized within 15 minutes of test restore– Roughly 20% of production versioned files replaced with zero-length
files

26
Disaster 2 – Where Do We Stand?
• Current State– Developers could continue to work on unaffected files– Corrupted files reported “RCS” errors in Perforce
• Initial Response Plan– Notify users– Identify corrupted files– Restore corrupted files from snapshot– Run “p4 verify” to check for data integrity

27
Disaster 2 – Solution
• Perl script written to identify files• Used Perl script from last disaster to recover files from snapshot to production share
• “p4 verify” run to test for data integrity• Lost/Unrecoverable revisions obliterated from Perforce• Owners of these revisions notified

28
Disaster 2 – Snapshots Benefits
• Ease of recovery– Simple system copy commands– Ability to quickly automate recovery
• Speed of recovery– Issue was resolved in 8 hours (from discovery to resolution)– Actual recovery took 2 hours vs 3 days recovering from tape
• Ability to restore 99% of corrupted files– Snapshot of files taken at 12:00 PM– Corruption occurred at 12:30 PM

29
Disaster 2 – Lessons Learned• Roadblocks
– No clear channel of user communication– Users not notified of status– Perforce admin bombarded with support calls
• Opportunities for improvement– The Admin working on a technical solution should not have the burden
of user communication– Funnel all communication through IT Operations group– Document a disaster recovery plan (still lacking any documentation)

30
Disaster 3 – Application Server Crash
• Background– Users start to experience extremely slow performance from Perforce
application– Some users cannot connect to Perforce server– All file access on the Perforce server came to a virtual halt– Windows failed to start on 2nd reboot of server
• Issue– Raid controller on Perforce server crashed

31
Disaster 3 – Where Do We Stand?• Current State
– Server and application unavailable– Production database unavailable– Versioned files unaffected– Journal file recovered (copied before 2nd reboot)
• Next Steps– Notify users– Rebuild database from checkpoint on failover server– Replay journal into database– Switch production application to failover server

32
Disaster 3 – Solution• Communication to users channeled through IT Operations
group• Copied journal file from production server to failover server
(was possible before second reboot)• Rebuilt database from most current checkpoint on failover
server• Replayed journal file into rebuilt database• Swap names and IP addresses for production and failover
server• Started Perforce service and crossed fingers

33
Disaster 3 – Benefits of Architecture
• Failover Server– Failover with limited effort (journal copy & name/IP change)– Failover with no impact to users (other than downtime)
• NAS Device (external storage)– Eliminated the need to restore versioned files– Preserved data integrity of versioned files

34
Disaster 3 – Lessons Learned
• Journal file should be backed up (copied) more frequently
• Copy journal file on same schedule as snapshots• Need to finally document a disaster recovery plan

35
Best Practices – Backup Strategy• Frequent checkpoints• Frequent copies of journal file• Point-in-time copies (even disk based backups) can speed up
recovery times• Test your ability to restore data• Have some type of failover server in place that stores the most
recent Perforce data• Your backup/restore process is the first and most crucial step
in disaster recovery

36
Best Practices – Disaster Recovery
• Setup clear channels of communication• Have a plan and have it documented• Have related Perforce documentation, specific to your site
• Make your documentation idiot proof• Test recovery scenarios• Be able to verify your recovery was successful

37
Final Note
Make your Perforce environment as redundant as possible. If that can be accomplished, you may never have to revert to your disaster recovery plan.

38
Questions?

















![[Perforce] Admin Workshop](https://img.pdfslide.net/doc/110x75/555d6fb1d8b42a687b8b4f82/perforce-admin-workshop.jpg)







![[Perforce] Git Fusion](https://img.pdfslide.net/doc/110x75/5447723cb1af9f0b098b468d/perforce-git-fusion.jpg)
![[Paris merge world tour] Perforce Introducing Perforce Insights](https://img.pdfslide.net/doc/110x75/54843e1fb47959f10c8b4b7b/paris-merge-world-tour-perforce-introducing-perforce-insights.jpg)

![[Perforce] Component Based Development in Perforce](https://img.pdfslide.net/doc/110x75/548401935906b5ad158b46ee/perforce-component-based-development-in-perforce.jpg)
![[Perforce] Swarm Workshop](https://img.pdfslide.net/doc/110x75/554ba5bdb4c905b3618b4ebc/perforce-swarm-workshop.jpg)