Embed Size (px)
Citation preview

Performance Driven Crosstalk Elimination at
Compiler Level
TingTing HwangDepartment of Computer Science
Tsing Hua University, Taiwan
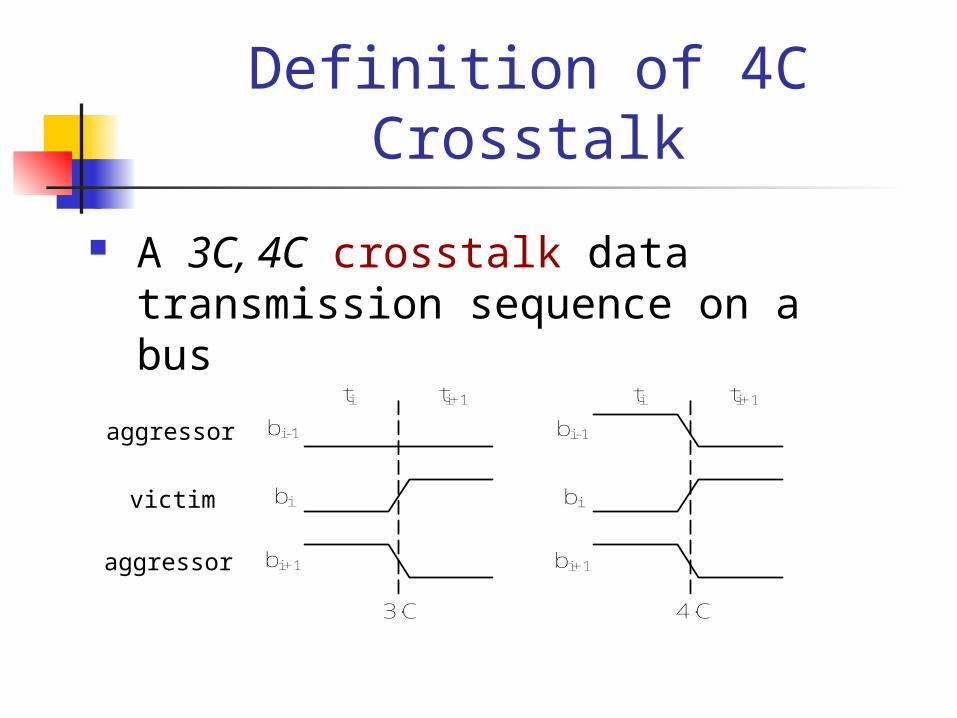
bi-1
bi
bi+1
ti ti+1 ti ti+1
bi-1
bi
bi+1
3·C 4·C
A 3C, 4C crosstalk data transmission sequence on a bus
Definition of 4C Crosstalk
victim
aggressor
aggressor
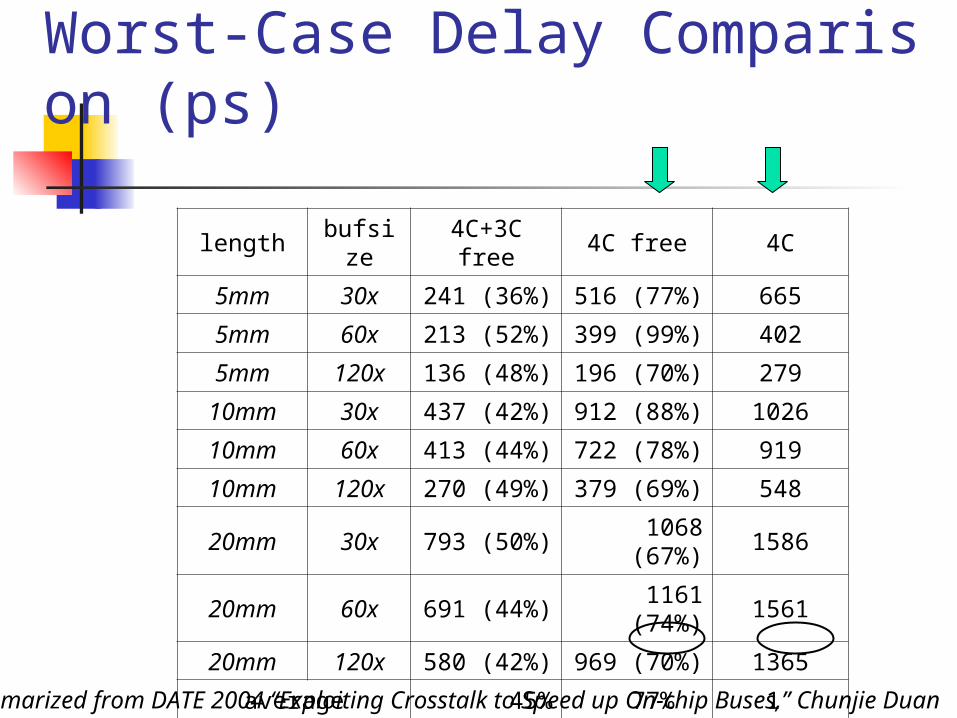
Worst-Case Delay Comparison (ps)
length bufsize 4C+3C free
4C free 4C
5mm 30x 241 (36%) 516 (77%) 665
5mm 60x 213 (52%) 399 (99%) 402
5mm 120x 136 (48%) 196 (70%) 279
10mm 30x 437 (42%) 912 (88%) 1026
10mm 60x 413 (44%) 722 (78%) 919
10mm 120x 270 (49%) 379 (69%) 548
20mm 30x 793 (50%)1068
(67%)1586
20mm 60x 691 (44%)1161
(74%)1561
20mm 120x 580 (42%) 969 (70%) 1365
average 45% 77% 1 Summarized from DATE 2004 “Exploiting Crosstalk to Speed up On-chip Buses,” Chunjie Duan

Previous Work
Bus encoding (expand Boolean space) Hardware overhead:
Encoders/Decoders/additional wires
Sender Encoder Decoder Receiverb n b
channel
Copied from ICCAD 2001 “Bus Encoding to Prevent Crosstalk Delay,” Bret Victor

Motivation Previous work using codec design
Logic level – no information of data Large area overhead (e.g., 128 bus
width: 128 + 85) Data sequences on an instruction
bus Known during compile time To eliminate crosstalk data sequence:
Instruction re-scheduling Register renaming

Problem Definition and Target Architecture
CPUInstruction
memory
Address
Instruction
Given a program, Generate a 4C (3C-and-4C)
crosstalk-free program (on an instruction bus)
Performed in compiler optimization

I4: SUB R4, R4, R8 100 0100 0100 1000I5: MUL R7, R9, R2 000 0111 1001 0010
Decomposing the input program to basic blocks
Crosstalk Elimination in Compiler Optimization
I1: ADD R0, R1, 4 101 0000 0001 0100
I2: OR R2, R5, R0 010 0010 0101 0000
I3: XOR R5, R9, R4 110 0101 1001 0100
Binary executable program
Crosstalk- free binary executable program
Step1
Instruction rescheduling
Register renaming
Step2
Step3
NOP insertion
Step4
Basic blocks
Interchange I4 and I5
I6: MUL R8, R4, R6 000 1000 0100 0110I5: MUL R7, R9, R2 000 0111 1001 0010
Rename R2 to R3
I2: OR R3, R5, R0 010 0011 0101 0000NOP 000 0000 0000 0000
NOP InsertionCrosstalk Free

Step 2: Instruction Re-scheduling
Instructions reordered under constraints of data dependency Construct a weighted Instruction
Adjacency Graph
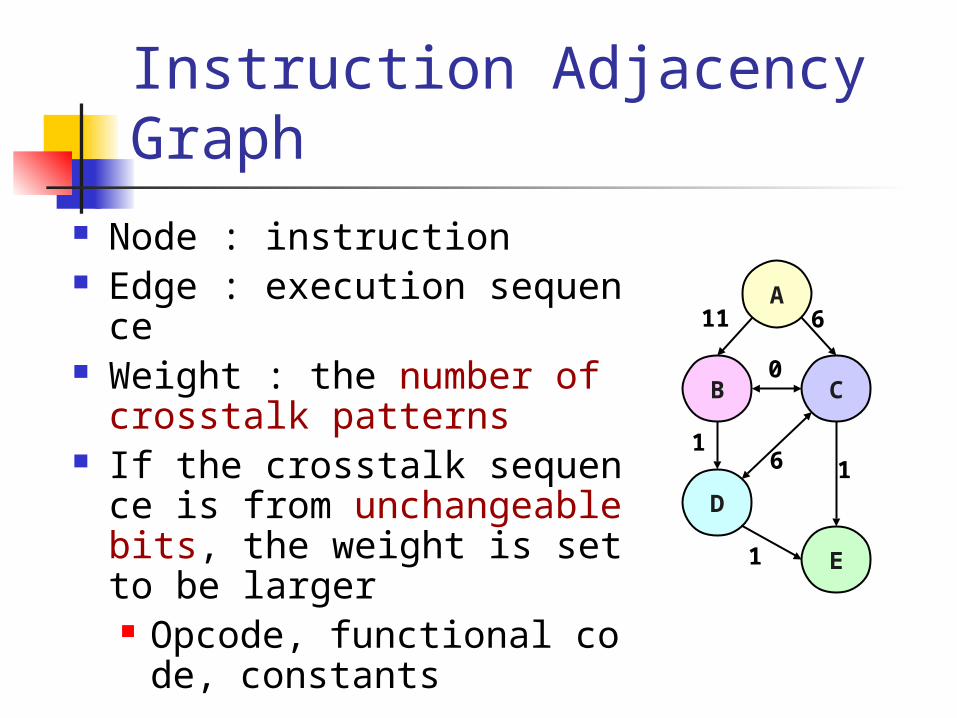
Instruction Adjacency Graph
Node : instruction Edge : execution sequence Weight : the number of crosst
alk patterns If the crosstalk sequence is fro
m unchangeable bits, the weight is set to be larger Opcode, functional code, co
nstants
A
B C
D
E
11
1
0
6
6
1
1

Instruction Re-scheduling
A weighted Instruction Adjacency Graph
Model instruction re-scheduling as a Traveling Salesman Problem (TSP) on IAG To find a minimum weighted path that
contains each node once and only once
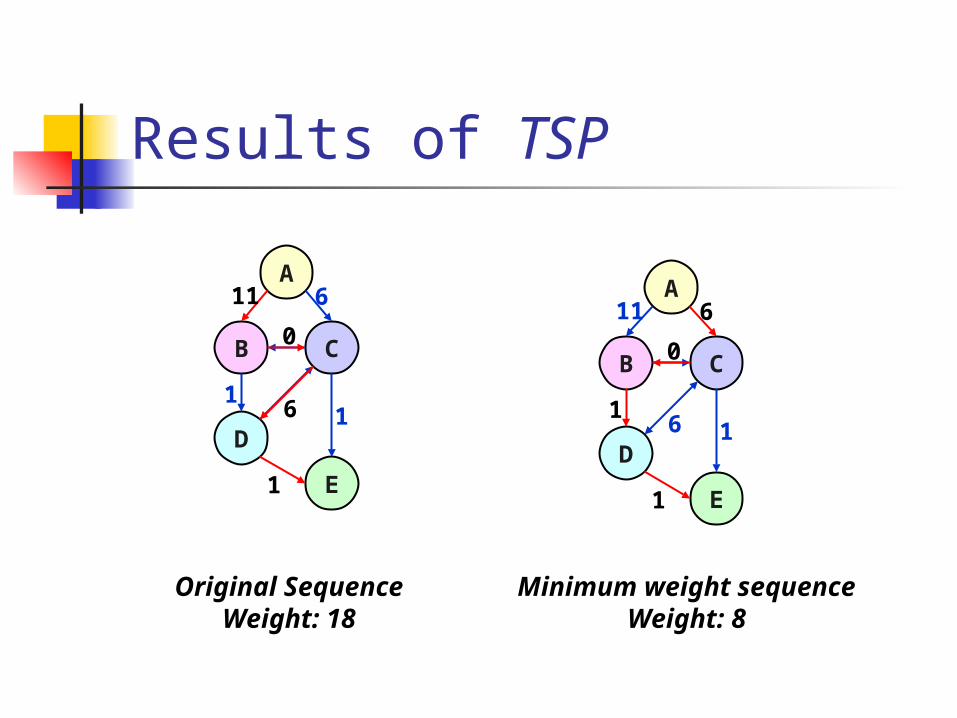
Results of TSP
A
B C
D
E
11
1
0
6
6
1
1
Original SequenceWeight: 18
A
B C
D
E
11
1
0
6
6
1
1
Minimum weight sequenceWeight: 8

Step 3: Register Renaming Registers can be renamed as long as live
in/out and system preservative registers are not renamed.
Weighted Register Adjacency Graph : RAG Node : register Edge between nodes RA and RB : registers
RA and RB are adjacent with each other Weight : frequency
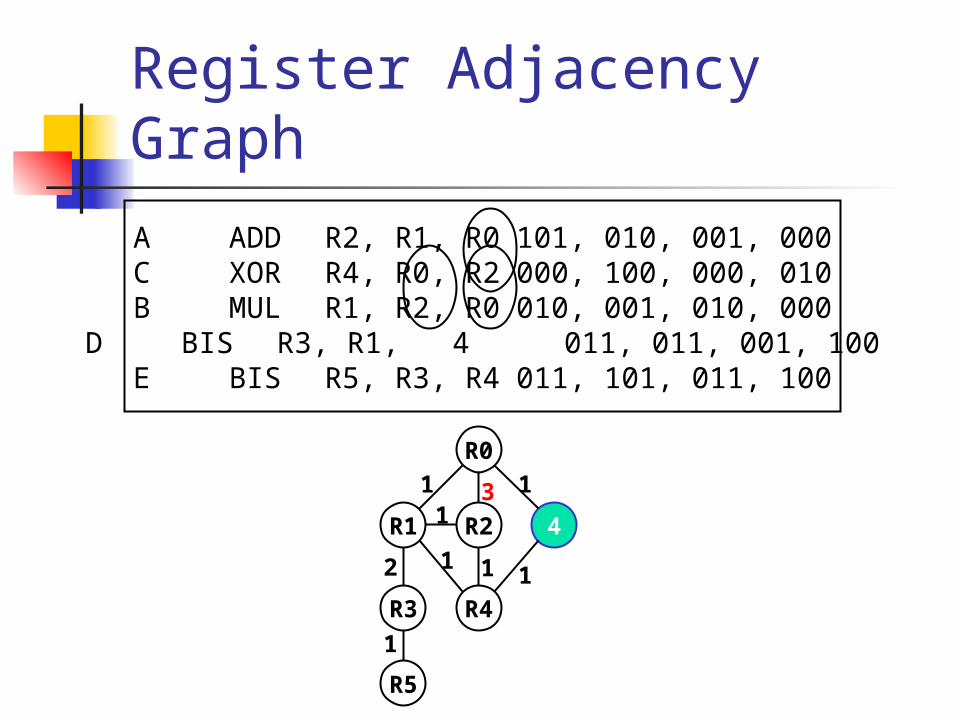
Register Adjacency Graph
R1
R0
R2 4
R3 R4
R5
1 3 1
2
1
1
111
A ADD R2, R1, R0 101, 010, 001, 000C XOR R4, R0, R2 000, 100, 000, 010B MUL R1, R2, R0 010, 001, 010, 000D BIS R3, R1, 4 011, 011, 001, 100E BIS R5, R3, R4 011, 101, 011, 100

4C Crosstalk-free Cliques
In order to rename all registers at a time, a database containing all kinds of 4C crosstalk-free cliques with 5-bit code is pre-constructed.

Register Renaming Algorithm
REGISTER-RENAMING ( )1. Construct RAG2. Do clique partitioning on RAG3. while ( RAG is not NULL ) {4. Select a clique with maximum
weight5. Reassign all registers in the clique6. Remove the clique from RAG7. }
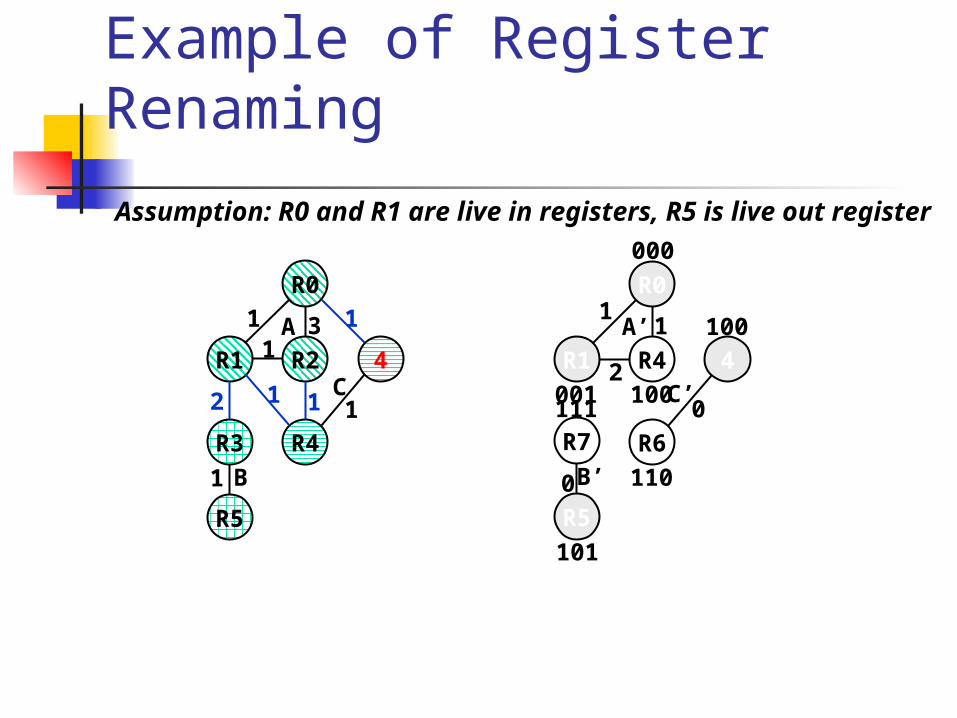
Example of Register Renaming
R1
R0
R2 4
R4R3
R5
1
2
1 31
1
111
A
B
CR1
R0
R4
000
001 1002
11
R5
R7
101
111
0
4
R6
100
110
0
A’
B’
C’
Assumption: R0 and R1 are live in registers, R5 is live out register

Step 4: NOP Insertion
An NOP Is inserted between two instructions
that induce 4C crosstalk Is crosstalk-free with all other
instructions Does not change program functionality Takes a clock period to execute and
one memory space to store -> overhead

Benchmarking Results
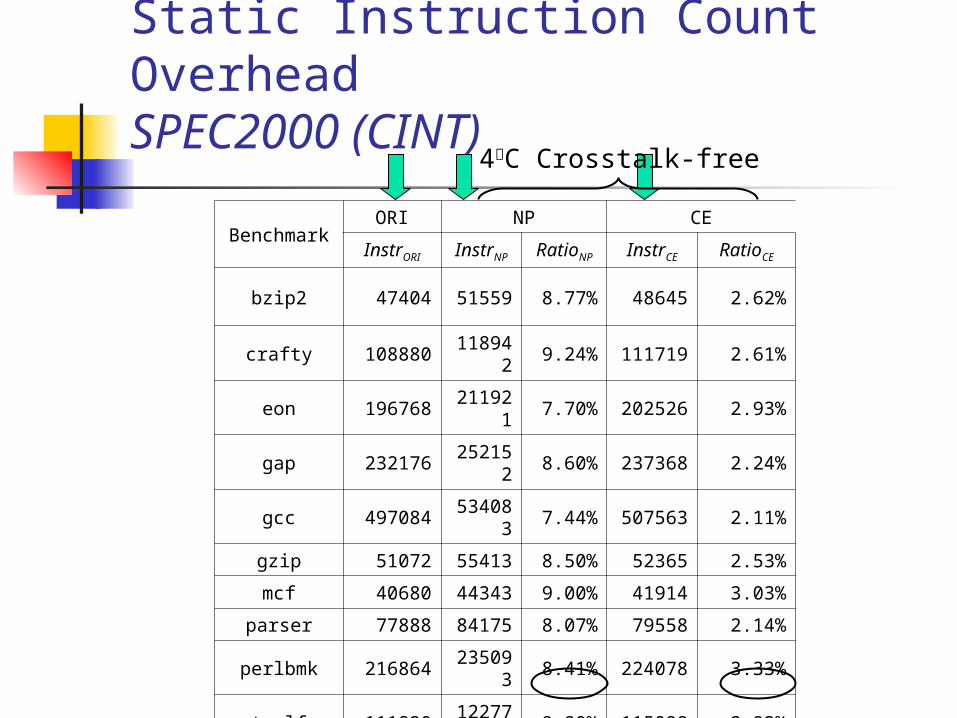
Static Instruction Count OverheadSPEC2000 (CINT)
BenchmarkORI NP CE
InstrORI InstrNP RatioNP InstrCE RatioCE
bzip2 47404 51559 8.77% 48645 2.62%
crafty 10888011894
29.24% 111719 2.61%
eon 19676821192
17.70% 202526 2.93%
gap 23217625215
28.60% 237368 2.24%
gcc 49708453408
37.44% 507563 2.11%
gzip 51072 55413 8.50% 52365 2.53%
mcf 40680 44343 9.00% 41914 3.03%
parser 77888 84175 8.07% 79558 2.14%
perlbmk 21686423509
38.41% 224078 3.33%
twolf 11182012277
89.80% 115098 2.93%
vortex 20435622042
17.86% 209400 2.47%
vpr 9244410100
59.26% 95141 2.92%
average 8.55% 2.65%
4﹒C Crosstalk-free
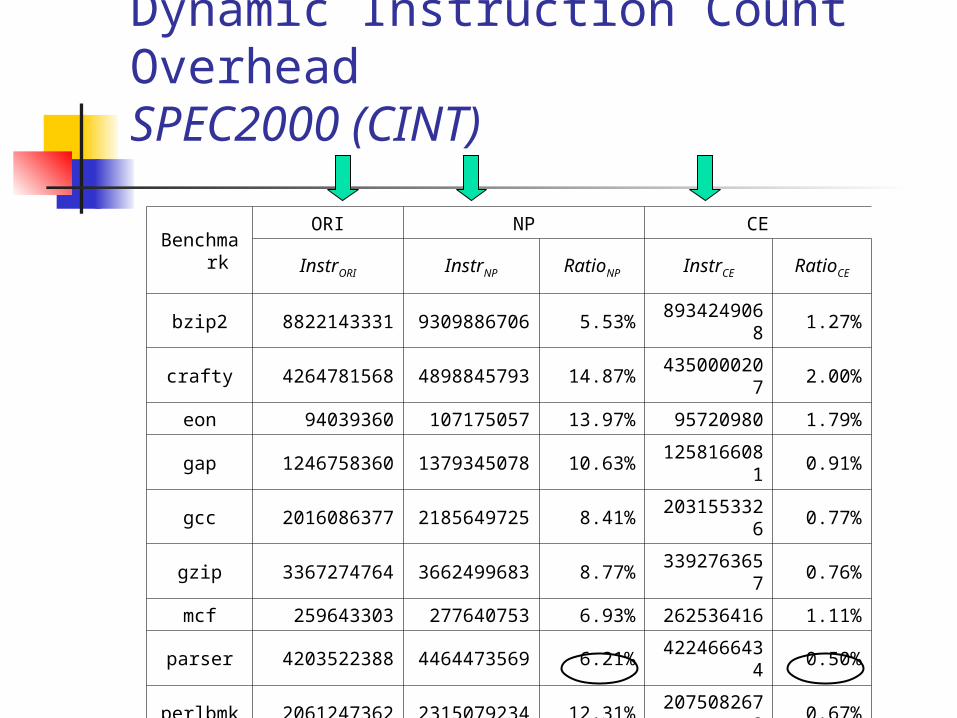
Dynamic Instruction Count OverheadSPEC2000 (CINT)
Benchmark
ORI NP CE
InstrORI InstrNP RatioNP InstrCE RatioCE
bzip2 8822143331930988670
65.53%
8934249068
1.27%
crafty 4264781568489884579
314.87%
4350000207
2.00%
eon 94039360 107175057 13.97% 95720980 1.79%
gap 1246758360137934507
810.63%
1258166081
0.91%
gcc 2016086377218564972
58.41%
2031553326
0.77%
gzip 3367274764366249968
38.77%
3392763657
0.76%
mcf 259643303 277640753 6.93% 262536416 1.11%
parser 4203522388446447356
96.21%
4224666434
0.50%
perlbmk 2061247362231507923
412.31%
2075082673
0.67%
twolf 258759073 289936212 12.05% 261004898 0.87%
vortex 9808168516107721143
879.83%
9905847855
1.00%
vpr 692814071 781107898 12.74% 703310218 1.52%
average 10.19% 1.10%

Computation of Improved Performance Ratio
0.10 um, bus length: 10mm Cycle length
With 4C : 1 Without 4C : 0.8
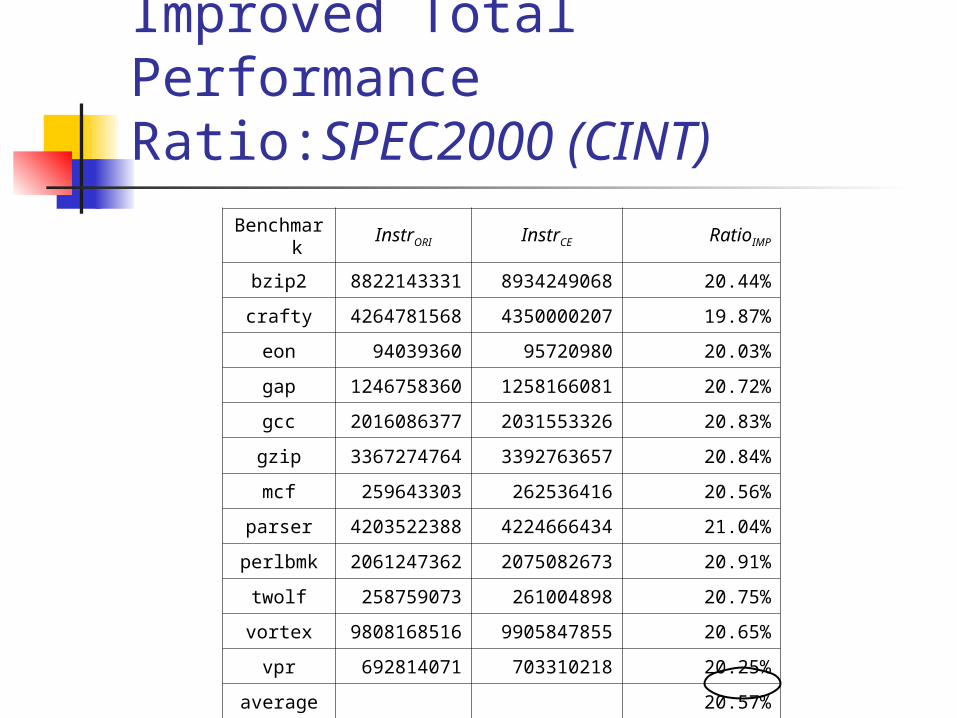
Improved Total Performance Ratio:SPEC2000 (CINT)
Benchmark
InstrORI InstrCE RatioIMP
bzip2882214333
18934249068 20.44%
crafty426478156
84350000207 19.87%
eon 94039360 95720980 20.03%
gap124675836
01258166081 20.72%
gcc 2016086377
2031553326 20.83%
gzip 3367274764
3392763657 20.84%
mcf 259643303 262536416 20.56%
parser420352238
84224666434 21.04%
perlbmk 2061247362
2075082673 20.91%
twolf 258759073 261004898 20.75%
vortex980816851
69905847855 20.65%
vpr 692814071 703310218 20.25%
average 20.57%

Thank you
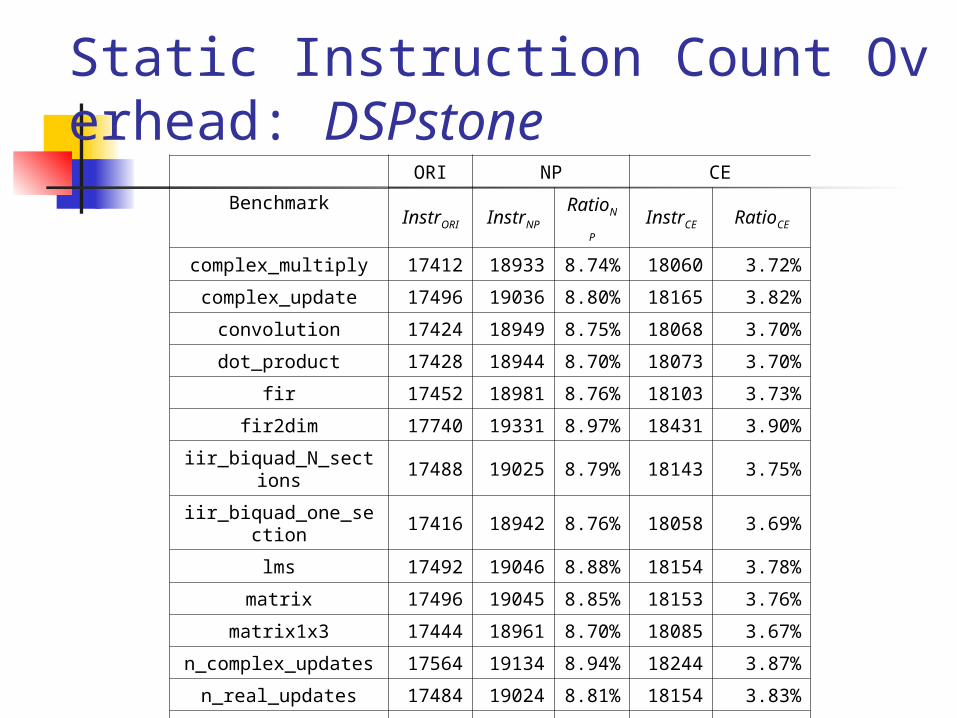
Static Instruction Count Overhead: DSPstone
Benchmark
ORI NP CE
InstrORI InstrNPRatioN
PInstrCE RatioCE
complex_multiply 17412 189338.74
%18060 3.72%
complex_update 17496 190368.80
%18165 3.82%
convolution 17424 189498.75
%18068 3.70%
dot_product 17428 189448.70
%18073 3.70%
fir 17452 189818.76
%18103 3.73%
fir2dim 17740 193318.97
%18431 3.90%
iir_biquad_N_sections 17488 190258.79
%18143 3.75%
iir_biquad_one_section 17416 18942
8.76%
18058 3.69%
lms 17492 190468.88
%18154 3.78%
matrix 17496 190458.85
%18153 3.76%
matrix1x3 17444 189618.70
%18085 3.67%
n_complex_updates 17564 191348.94
%18244 3.87%
n_real_updates 17484 190248.81
%18154 3.83%
real_update 17408 189338.76
%18050 3.69%
average 8.80%
3.76%
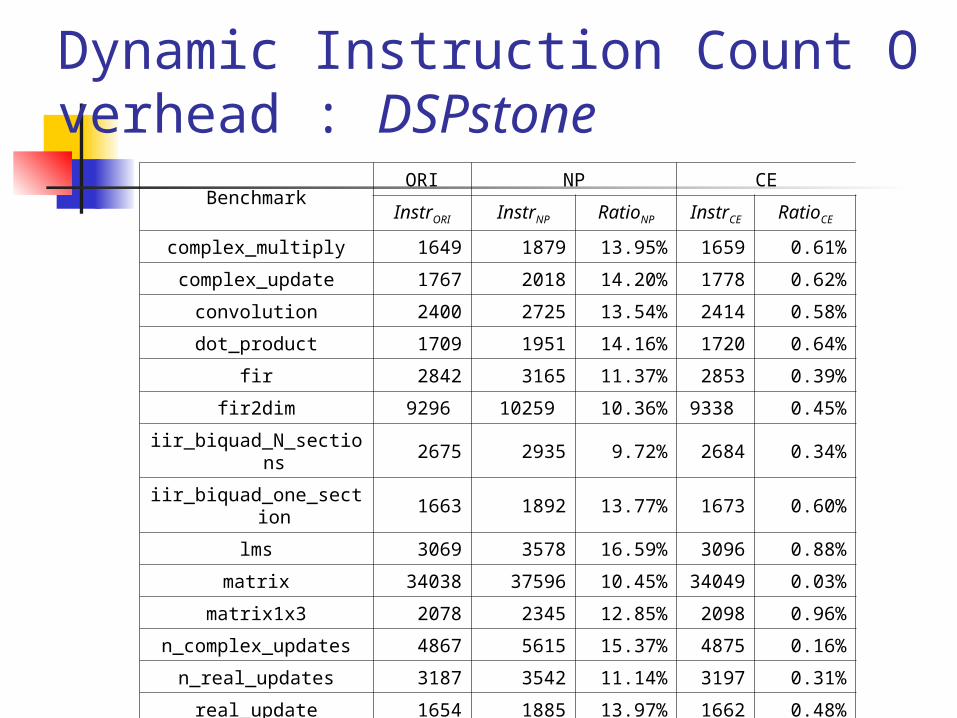
Dynamic Instruction Count Overhead : DSPstone
BenchmarkORI NP CE
InstrORI InstrNP RatioNP InstrCE RatioCE
complex_multiply 1649 1879 13.95% 1659 0.61%
complex_update 1767 2018 14.20% 1778 0.62%
convolution 2400 2725 13.54% 2414 0.58%
dot_product 1709 1951 14.16% 1720 0.64%
fir 2842 3165 11.37% 2853 0.39%
fir2dim 9296 10259 10.36% 9338 0.45%
iir_biquad_N_sections 2675 2935 9.72% 2684 0.34%
iir_biquad_one_section 1663 1892 13.77% 1673 0.60%
lms 3069 3578 16.59% 3096 0.88%
matrix 34038 37596 10.45% 34049 0.03%
matrix1x3 2078 2345 12.85% 2098 0.96%
n_complex_updates 4867 5615 15.37% 4875 0.16%
n_real_updates 3187 3542 11.14% 3197 0.31%
real_update 1654 1885 13.97% 1662 0.48%
average 12.96% 0.50%
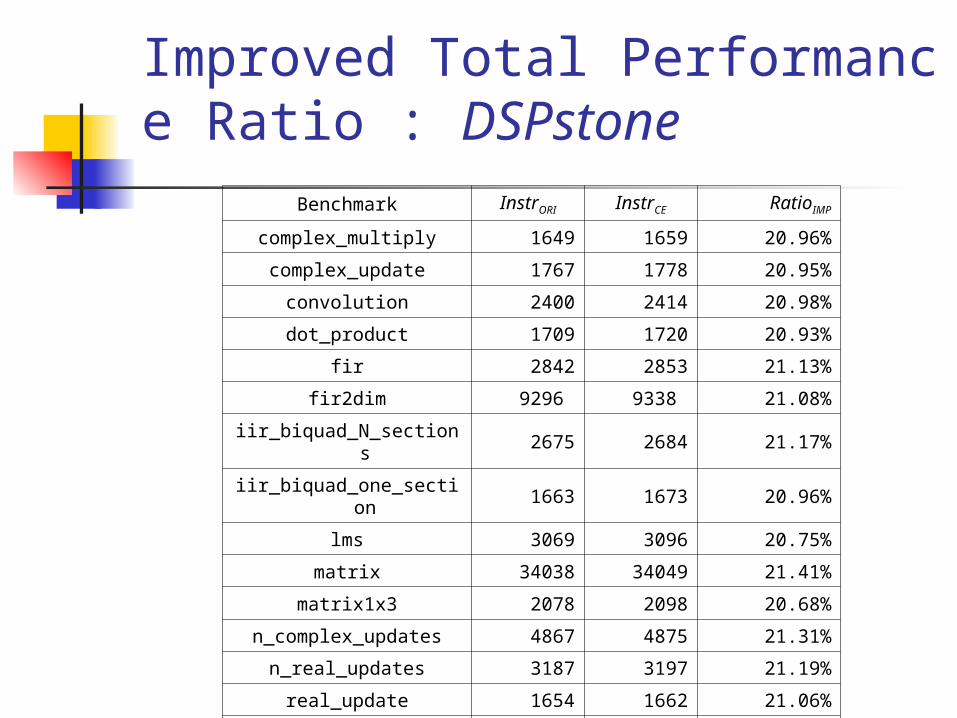
Improved Total Performance Ratio : DSPstone
Benchmark InstrORI InstrCE RatioIMP
complex_multiply 1649 1659 20.96%
complex_update 1767 1778 20.95%
convolution 2400 2414 20.98%
dot_product 1709 1720 20.93%
fir 2842 2853 21.13%
fir2dim 9296 9338 21.08%
iir_biquad_N_sections 2675 2684 21.17%
iir_biquad_one_section 1663 1673 20.96%
lms 3069 3096 20.75%
matrix 34038 34049 21.41%
matrix1x3 2078 2098 20.68%
n_complex_updates 4867 4875 21.31%
n_real_updates 3187 3197 21.19%
real_update 1654 1662 21.06%
average 19.78%





























