Embed Size (px)
Citation preview

PERLPractical Extraction Recording
Language

PART I

Follow the link below to go to the Perl Reference guide. This is has also been provided for you in the back of your workbook. As we go along, we will ask you questions. Guess where you can find the answers…
http://www.unc.edu/~husted/Work/PerlReference.htm
Learning the Language!

Download the Software
• This software is provided FREE for all of your Practical-Extraction-Recording needs.
• Retrieve Perl from ActiveState http://www.activestate.com/products/activeperl
This is the spot for the PC specific software!
• Save this on the desktop, and double-click to begin the installer. Now follow the directions and let us know if you have any question.

#!/usr/bin/perl#Lindsay Husted#password.pl#July 10, 2003#this program generates a random password##Generate a random numberprint "Enter a seed number: ";$seed = <STDIN>;chomp $seed;srand($seed ^ time);
Let’s walk through a script that will generate a password!
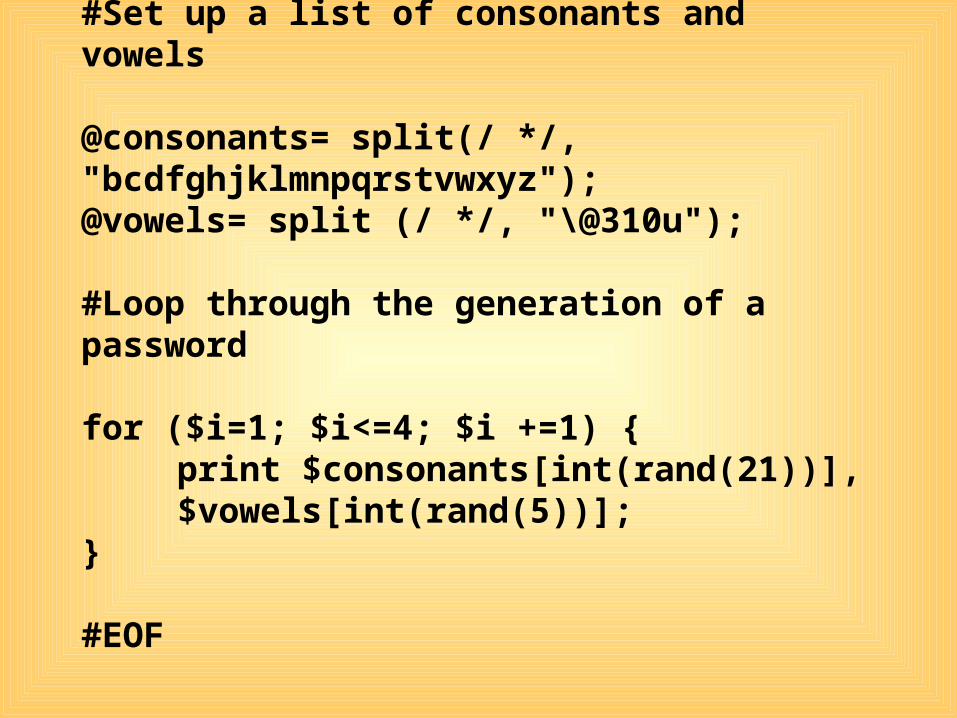
#Set up a list of consonants and vowels
@consonants= split(/ */, "bcdfghjklmnpqrstvwxyz");@vowels= split (/ */, "\@310u");
#Loop through the generation of a password
for ($i=1; $i<=4; $i +=1) { print $consonants[int(rand(21))],
$vowels[int(rand(5))];}
#EOF

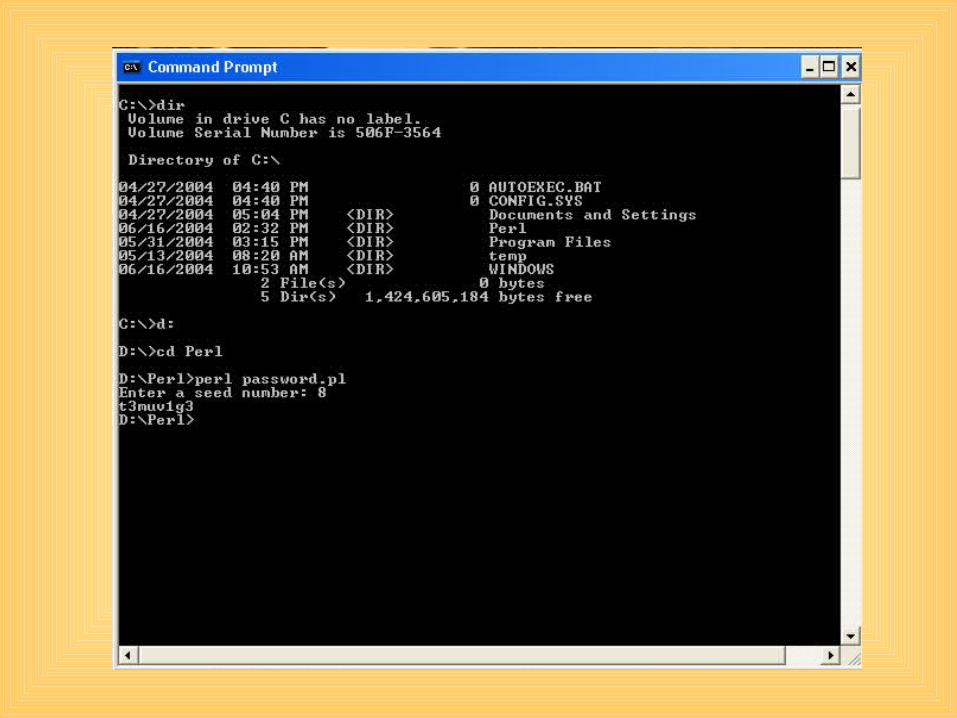
Running Your Script
• Be sure to save you script in your Perl folder. • What working directory are you in?
– Once you open your terminal or command prompt, type the UNIX command “dir”.
– Change your directory to your Perl folder.• To run your script type “perl password.pl”
– This calls on the Perl (ActiveState) program to open the specified file.

PART II

Filtering Script Template#!/usr/bin/perl –w#name#date#description of program
#Define and open source file, stop the program if there is an error
#Define and open output file, stop the program if there is an error
#Loop through the entire file, line by line#Read in a line#Process the line#Output the newly edited line to a new file
#End of script

#!/usr/bin/perl -w
The first line must be entered exactly as it is (including the pound sign) at the top of each Perl program. This line should always be the very first line in the file (not even comments should precede it). Unfortunately, an explanation of what this line does is beyond our present scope. For now, just recognize that it designates this file as a Perl script, and that it is essential.

#name#date
#description of programThe first few lines are comments. They should include the author of the script's name, the date the script was written (and possibly the dates it is modified as well), and a very brief description of what the program does (at most a short paragraph). No code or commands are necessary for this section of the file, only comments.

#Define and open source file, stop the program if there is an
error The next step will involve the first Perl commands. First, we must define a variable that identifies the location of the data file. Let's suppose that our file was named SampleData.txt and was located in the main directory of the C drive. The first command would look a lot like this:
$SourceFile = '<C:\SampleData.txt';The dollar sign tells the computer that this variable is a string (a set of characters), and the semicolon at the end of the line signals the end of this command. If your finished program doesn't run on the first try, often it is a result of forgetting to include a semicolon. The sign < is important because it identifies this as a read only file. (Cont’d ->)

#opening source file cont’d
Now that you have identified the source file, you have to have Perl try an open it. Use the open command to do this:
open(INFILE, $SourceFile) or die "The file $SourceFile could not be found.\n";
This command tries to open the file specified by $SourceFile. Now don't be alarmed, the die command merely reports the message that follows it if there is an error and stops the program. So if $SourceFile does not point to a valid file, the program stops. Note: The \n character simply represents a new line.

#Define and open output file, stop the program if there is an
error Opening an output file is very similar. First you specify a destination file for the program's output. Let's define our output file
$OutputFile= '>C:\FilteredData.txt';Now we have the location of our output file specified in a string variable called $OutputFile. Note the $ designates a string variable and the semicolon marks the end of the command. Also, in contrast to the read only marker < used when opening the source file, this command uses the write marker > to tell the computer this file will be for output. Don't worry if the file has not been created before the program runs; Perl will create the file for you. (Cont’d ->)

#opening otuput file cont’d
Like the input file, the output file has to be opened. Try:open(OUTFILE, $OutputFile) or die "The output file could not
be opened.\n";This command works exactly the same as it did when opening the input file.

#Loop through the entire file, line by line
With the input and ouput files open, we are ready to begin filtering the data. A convenient way to do this is to have Perl cycle through the data line by line. Try using a while loop like:
while (<INFILE>) {#add commands here
}This code executes all commands within the curly brackets until the entire source file has been read. Note that while is a special sort of command that does not require a semicolon after it. The rest of our commands will go inside the curly brackets so that they are executed while looping through the file.

#read in a line
To read in the next line of the file, add the command:$Line = $_;
This line creates a variable named $Line and assigns it the contents of the variable $_. $_ is a special Perl variable, and a full explanation of its contents is beyond our scope. For now, it suffices to know that the command above assigns to the variable $Line the current line of text from the source file. Do not forget the semicolon at the end of the line.

#process the line
Now that we have a line of text from the source file, we can edit its contents before sending it to the output file. However, if the current line is empty, we don't want to do anything to it, so we add the command:
if($Line eq "\n") { next }This command looks at the text stored in $Line. If $Line is blank (if it only contains a next line character) then Perl executes the next command. 'next' skips the rest of the commands within the while loop and returns to the top of the loop. Note that this command only has an effect if $Line equals something other than \n. Also observe that no semicolon is necessary after this line of code.

#more processing
If the line in question is not blank, the real fun begins. Let's change any commas we find into tabs. Don't be intimated by the appearance of the next command, it's actually not that complicated. Try:
$Line =~ s/,/\t/g;

#still processing
$Line =~ s/,/\t/g;The s identifies a search and subsitute action. The character between the first two slashes (/,/) is what the command searches for, in this case a comma. The character between the second and third slashes (/\t/) is what will be substituted whenever a match is found. In this case, \t is the code for a tab character. So each a tab character is substituted for each comma. Finally, the g stands for global. This ensures that all commas found are replaced. If you leave out the g then only the first comma on the line will be changed. To summarize, this command looks at the current line and replaces each and every comma with a tab character (denoted here by \t).

#output the newly edited line to a new file
At this point we are almost done. All we have to do is output the filtered line to our new data file. This can be easily done with the command:
print OUTIFLE $Line;As you might guess, this command prints the contents of $Line to the OUTFILE. Now the program is ready to handle a new line of output, so if no more commands are added the program returns to the top of loop.

#End of ScriptThe loop will continue until every line of the INFILE has been read. After the loop has finished running, the program is done. At the end of the program your source file will remain unchanged, but you should also have a newly filtered data file. Congratulations! You used Perl to filter data! You are now ready to try the optional filtering components available throughout the workbook.

Your final output~#David Hillman#8/01/03#This program changes a comma-delimited data file to a tab-delimited one #Define source file and open it, stop the program if there is an error$SourceFile = '<C:\SampleData.txt';open(INFILE, $SourceFile) or die "The database $SourceFile could not be found.\n"; #Define output file and open it, stop the program if there is an error$OutputFile = '>C:\FilteredData.txt';open(OUTFILE, $OutputFile) or die "The output file could not be opened.\n";

Final cont’d#loop through the entire source filewhile(<INFILE>) { #read in the next line of text from the source file$Line = $_; #if the line is blank, do nothingif($Line eq "\n") { next } #replace all commas with tabs$Line =~ s/,/\t/g; #add the newly edited line to the output fileprint OUTFILE $Line;}

PART III
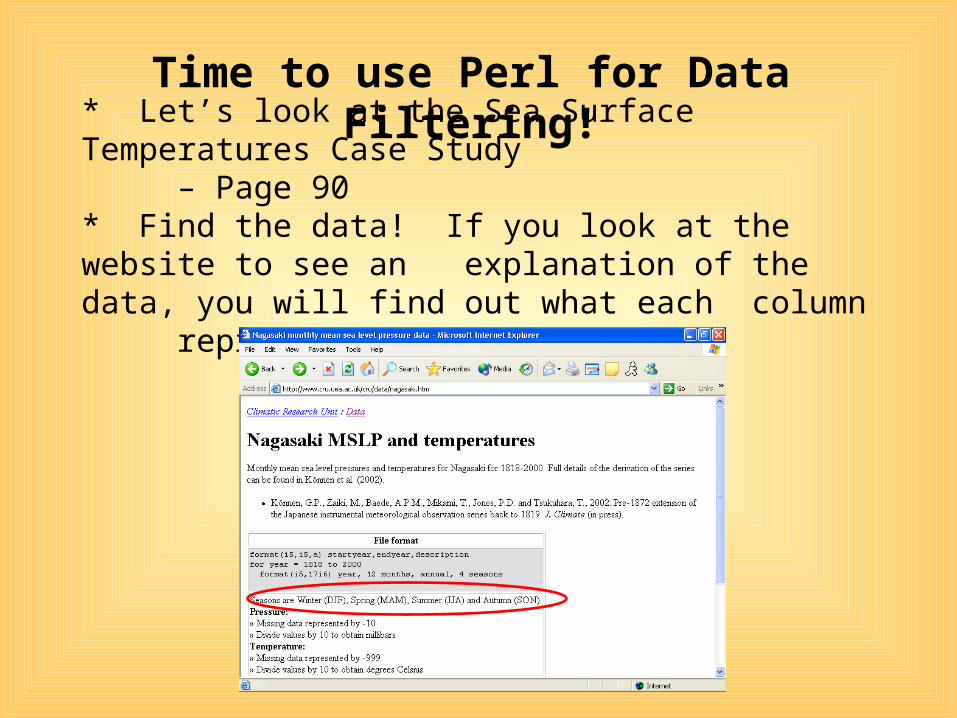
* Let’s look at the Sea Surface Temperatures Case Study– Page 90
* Find the data! If you look at the website to see an explanation of the data, you will find out what each column
represents.
Time to use Perl for Data Filtering!
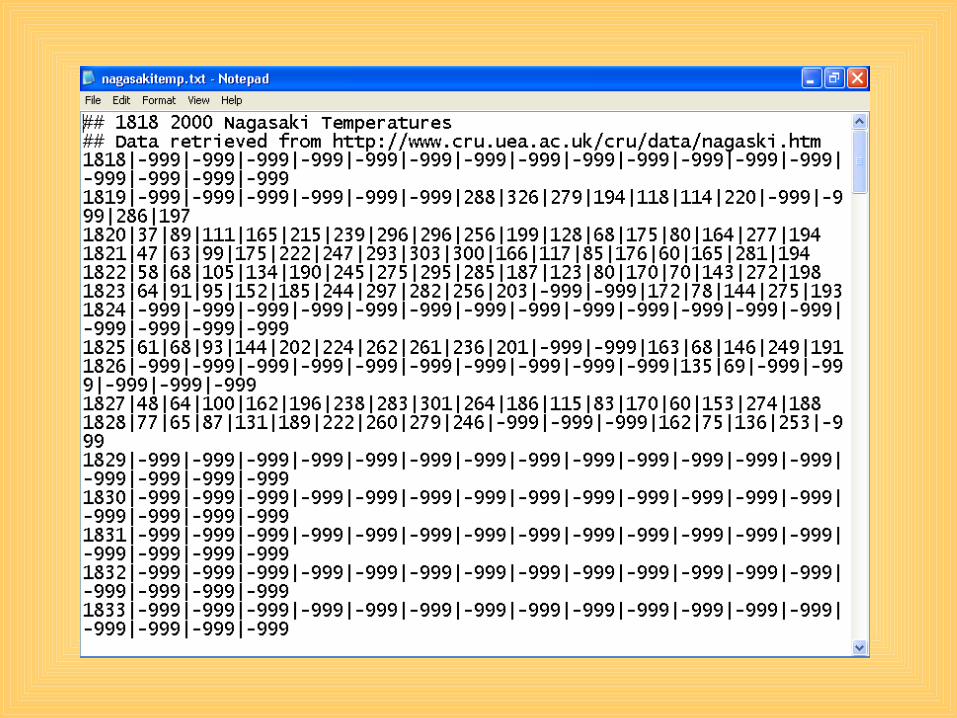

In your workbook…
• Now follow along with the instructions on Data Filtering – Page 92
• Use the Perl Reference guide provided
• Work slowly and pay careful attention to each line of script
• Ask us questions if you need help!





























