Embed Size (px)
Citation preview

Personalised Search on the
World Wide WebOriginally by Micarelli, Gasparetti, Sciarrone
& Gauch
http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2009/Book%20-%20The%20Adaptive%20Web/PersonalizedSearch.pdf

Group: Tiki
•Jan Vosecky: ⅓ Contribution
•Jonathan Abbey: ⅓ Contribution
•James Griffin: ⅓ Contribution

Contents• Introduction
• Searching The World Wide Web
• Personalised Search
• Contextual Search
• Rich User Models
• Collaborative Search Engines
• Adaptive Result Clustering
• Conclusions

Searching The WWW
•A large, highly dynamic environment
•Three main modes of interaction:
•Searching by Surfing
•Searching by Query
•Recommendation

Searching by Query
•Most popular way that users begin seeking information
•String queries, on average 2-3 terms, sent to a search engine
•Classic Information Retrieval (IR) model
•Information Filtering is more appropriate to the WWW, but suffers from computational complexity

Personalised Search
•Aims to provide individualised collections of pages
•Motivated by two problems:
•Information Overload Problem: over-abundance of resources
•Vocabulary Problem: issues with polysemy (multiple meanings for one word) and synonymy (multiple words for one meaning)

User Model•Needs to build a user model, either...
•...explicitly - the system learns by asking the user
•...implicitly - the system learns by observing the user
•...or a combination of both
•Applied...•...as a part of the retrieval process•...through re-ranking the IR results•...through modifying the user’s query

Personalisation Approaches
MethodMethod TechniqTechniqueue Typical Input DataTypical Input Data
Current Context
implicitdocuments, emails,
history
Search History implicitpast queries, selected
resultsRich User Models
bothpast queries, user
feedback
Collaborative bothuser ratings, past
queriesResult
Clusteringexplicit selected clusters
Hypertextual Data
bothqueries, selected
pages

Contextual Search
•Based on the user’s current context
•Implicit feedback unobtrusively draws usage data by tracking and monitoring the user
•Similar to ‘Search History’, but instead draws from what the user is currently working on or in

Contextual Search
•Just-in-Time IR (JITIR) (Rhodes), suggests information such as related documents based on what the user is currently reading or typing
•Watson monitors the user’s actions and predicts the user’s needs, using search engines such as Yahoo! and news sources such as Reuters

Rich User Models
• Build and update a User Model/Profile
•Semantic network representation
• Using explicit user feedback

ifWeb• User profile is represented as a weighted
semantic network•Nodes correspond to terms (concepts) from
documents the user identified as positive or negative• relevance feedback
•Arcs link pairs of terms that co-occurred in a document
• High-level operation:•Collection of documents presented to the user,
based on their profile•Update the user profile based on the user’s
selection from the results•“Rent”: weight of concepts not used decreases
with time

Wifs• Filtering of search results
returned by a search engine
• User model consists of• Slots, which contain topics
• Each slot is associated with other co-keywords
• Database of topics is built manually by experts
• Document is represented as• Planets = topics, found in the
database
• Satellites = co-keywords associated with topics
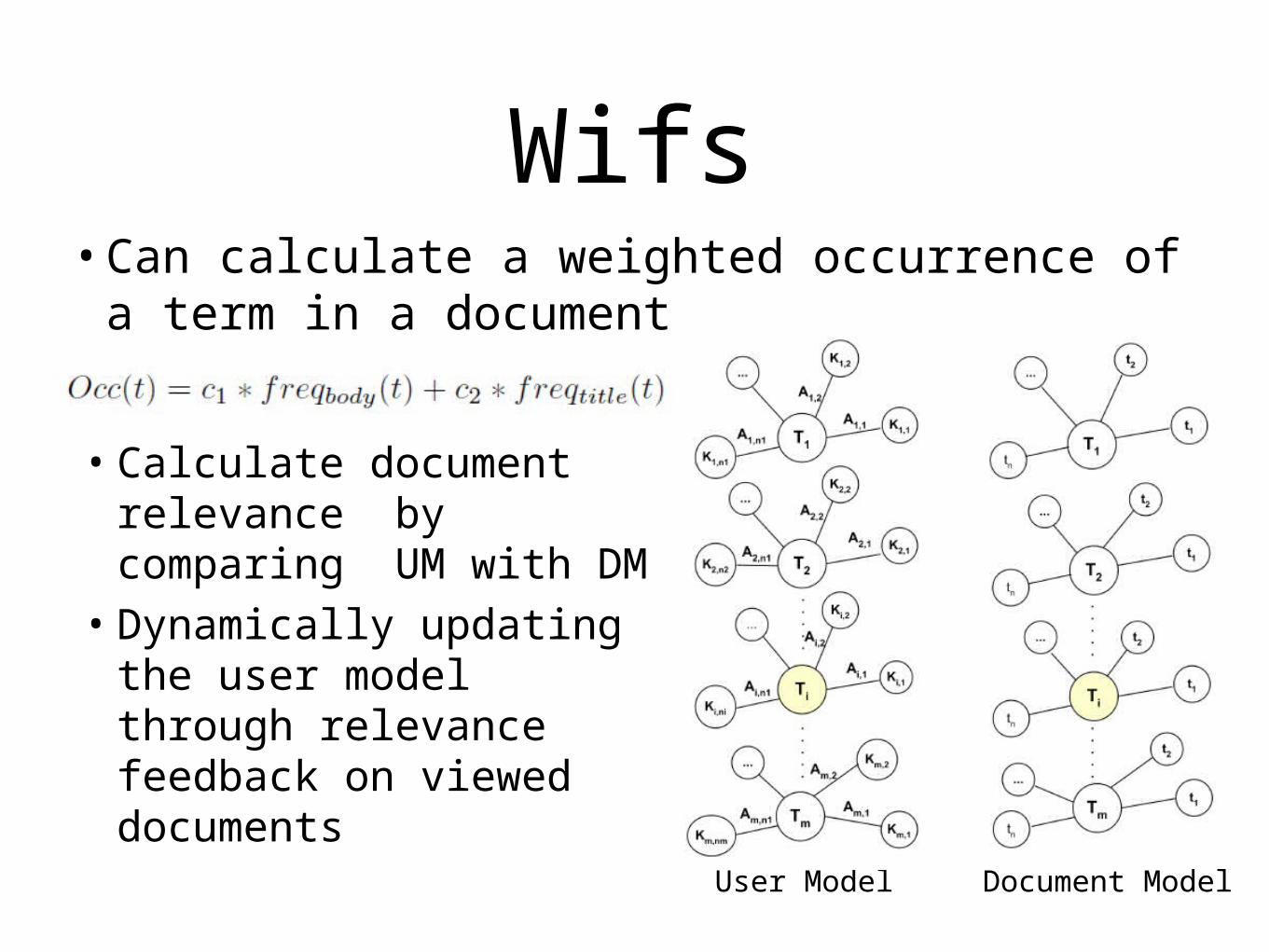
Wifs• Can calculate a weighted occurrence of a
term in a document
User Model Document Model
• Calculate document relevance by comparing UM with DM
• Dynamically updating the user model through relevance feedback on viewed documents

InfoWeb• Retrieval of digital library documents
• User modelling through a stereotype knowledge base•Most typical document for a category of users•Represented as a document vector•Defined by a domain expert
• Document clustering, with stereotypes being initial cluster centres
• User profile updated by explicit relevance feedback
• Query expansion based on the user profile

Collaborative Search Engines
• Improves search results by learning from the experience of a group of users
• Calculate similarity measures among user needs
•Queries ↔ selected documents from results•Relatedness among two queries might not depend on actual query terms, but on the documents returned •E.g. ‘handheld devices’ and ‘mobile computers’

Collaborative Search Engines
• Eurekster.com – search engine with collaborative (social) filtering•Stores all results selected by users for each query
•Social ranking: preferences are shared among a community of users with same interests
•Individual ranking: individual user preferences also taken into account when ranking results

Collaborative Search Engines
• I-Spy – collaborative search engine•Analyses interests of communities of users•Community = users of a specialised web site
•Statistical model of query-page relevance•Probability a page p is selected by a user as a result of query q•No need for document content analysis

Adaptive Result Clustering
•Queries often return thousands of results
•Impossible to sift through
•Groups results into clusters
•By topic
•Exhaustive partition / Hierarchical tree
•Clusters ranked against query
•User navigates clusters

Requirements•Usually after results retrieved
•Must be fast
•Usually take document snippets
•Set number & organisation of clusters
•Maximise ease of navigation
•Cluster descriptions
•Concise & accurate

Web Clustering•CLUSTY
•Organise into folder structure by topic
•KARTOO
•Folder structure
•Graphic interactive map
•Mouse-over descriptions
•Resource icons sized by relevance

Web Clustering•SnakeT
•Users can select most relevant cluster subset
•Query refined using contained keywords
•Scatter/Gather
•Users select cluster(s) for further analysis
•Re-organises selection to small number of clusters
•Resources shown when clusters small

Conclusions•Possible solution to overloading problem
•Increased recent interest
•Personalisation simplifies searching
•Also recommendation, data gathering
•Novel and lively field
•New approaches likely in next few years

Current Work•Building ontology-based UMs implicitly
•Mapping metadata and ontology concepts to UM stored concepts
•Logical mapping rules & description logics
•Plan recognition
•Recognition and predication of goals
•Language semantic analysis
•Relation to user queries

Any Questions?





























