Embed Size (px)
Citation preview

Physical Causality of Action Verbs in Grounded Language Understanding
Qiaozi Gao† Malcolm Doering‡∗ Shaohua Yang† Joyce Y. Chai††Computer Science and Engineering, Michigan State University, East Lansing, MI, USA
‡Department of Systems Innovation, Osaka University, Toyonaka, Osaka, Japan{gaoqiaoz, yangshao, jchai}@msu.edu
Abstract
Linguistics studies have shown that actionverbs often denote some Change of State(CoS) as the result of an action. However,the causality of action verbs and its poten-tial connection with the physical world hasnot been systematically explored. To ad-dress this limitation, this paper presents astudy on physical causality of action verbsand their implied changes in the physi-cal world. We first conducted a crowd-sourcing experiment and identified eigh-teen categories of physical causality foraction verbs. For a subset of these cat-egories, we then defined a set of detec-tors that detect the corresponding changefrom visual perception of the physical en-vironment. We further incorporated phys-ical causality modeling and state detec-tion in grounded language understanding.Our empirical studies have demonstratedthe effectiveness of causality modeling ingrounding language to perception.
1 Introduction
Linguistics studies have shown that action verbsoften denote some change of state (CoS) as theresult of an action, where the change of state of-ten involves an attribute of the direct object of theverb (Hovav and Levin, 2010). For example, theresult of “slice a pizza” is that the state of the ob-ject (pizza) changes from one big piece to severalsmaller pieces. This change of state can be per-ceived from the physical world. In Artificial Intel-ligence (Russell and Norvig, 2010), decades of re-search on planning, for example, back to the earlydays of the STRIPS planner (Fikes and Nilsson,
∗This work was conducted at Michigan State Universitywhere the author received his MS degree.
1971), have defined action schemas to capture thechange of state caused by a given action. Basedon action schemas, planning algorithms can be ap-plied to find a sequence of actions to achieve a goalstate (Ghallab et al., 2004). The state of the phys-ical world is a very important notion and chang-ing the state becomes a driving force for agents’actions. Thus, motivated by linguistic literatureon action verbs and AI literature on action repre-sentations, in our view, modeling change of phys-ical state for action verbs, in other words, physicalcausality, can better connect language to the phys-ical world.
Although this kind of physical causality hasbeen described in linguistic studies (Hovav andLevin, 2010), a detailed account of potentialcausality that could be denoted by an action verb islacking. For example, in VerbNet (Schuler, 2005)the semantic representation for various verbs mayindicate that a change of state is involved, but itdoes not provide the specifics associated with theverb’s meaning (e.g., to what attribute of its pa-tient the changes might occur).
To address this limitation, we have conductedan empirical investigation on verb semantics froma new angle of how they may change the state ofthe physical world. As the first step in this inves-tigation, we selected a set of action verbs from acooking domain and conducted a crowd-sourcingstudy to examine the potential types of causalityassociated with these verbs. Motivated by lin-guistics studies on typology for gradable adjec-tives, which also have a notion of change alonga scale (Dixon and Aikhenvald, 2006), we devel-oped a set of eighteen main categories to charac-terize physical causality. We then defined a set ofchange-of-state detectors focusing on visual per-ception. We further applied two approaches, aknowledge-driven approach and a learning-basedapproach, to incorporate causality modeling in

grounded language understanding. Our empiricalresults have demonstrated that both of these ap-proaches achieve significantly better performancein grounding language to perception compared toprevious approaches (Yang et al., 2016).
2 Related Work
The notion of causality or causation has been ex-plored in psychology, linguistics, and computa-tional linguistics from a wide range of perspec-tives. For example, different types of causal re-lations such as causing, enabling, and prevent-ing (Goldvarg and Johnson-Laird, 2001; Wolffand Song, 2003) have been studied extensively aswell as their linguistic expressions (Wolff, 2003;Song and Wolff, 2003; Neeleman et al., 2012)and automated extraction of causal relations fromtext (Blanco et al., 2008; Mulkar-Mehta et al.,2011; Radinsky et al., 2012; Riaz and Girju,2014). Different from these previous works, thispaper focuses on the physical causality of actionverbs, in other words, change of state in the phys-ical world caused by action verbs as described in(Hovav and Levin, 2010). This is motivated byrecent advances in computer vision, robotics, andgrounding language to perception and action.
A recent trend in computer vision has startedlooking into intermediate representations beyondlower-level visual features for action recogni-tion, for example, by incorporating object affor-dances (Koppula et al., 2013) and causality be-tween actions and objects (Fathi and Rehg, 2013).Fathi and Rehg (2013) have borken down detec-tion of actions to detection of state changes fromvideo frames. Yang and colleagues (2013; 2014)have developed an object segmentation and track-ing method to detect state changes (or, in theirterms, consequences of actions) for action recog-nition. More recently, Fire and Zhu (2015) havedeveloped a framework to learn perceptual causalstructures between actions and object statuses invideos.
In the robotics community, as robots’ low-levelcontrol systems are often pre-programmed to han-dle (and thus execute) only primitive actions, ahigh-level language command will need to betranslated to a sequence of primitive actions inorder for the corresponding action to take place.To make such translation possible, previous works(She et al., 2014a; She et al., 2014b; Misra et al.,2015; She and Chai, 2016) explicitly model verbs
with predicates describing the resulting states ofactions. Their empirical evaluations have demon-strated how incorporating resulting states into verbrepresentations can link language with underlyingplanning modules for robotic systems. These re-sults have motivated a systematic investigation onmodeling physical causality for action verbs.
Although recent years have seen an increas-ing amount of work on grounding language toperception (Yu and Siskind, 2013; Walter et al.,2013; Liu et al., 2014; Naim et al., 2015; Liuand Chai, 2015), no previous work has investi-gated the link between physical causality denotedby action verbs and the change of state visuallyperceived. Our work here intends to address thislimitation and examine whether the causality de-noted by action verbs can provide top-down in-formation to guide visual processing and improvegrounded language understanding.
3 Modeling Physical Causality for ActionVerbs
3.1 Linguistics Background on Action Verbs
Verb semantics have been studied extensively inlinguistics (Pustejovsky, 1991; Levin, 1993; Bakeret al., 1998; Kingsbury and Palmer, 2002). Partic-ularly, for action verbs (such as run, throw, cook),Hovav and Levin (Hovav and Levin, 2010) pro-pose that they can be divided into two types: man-ner verbs that “specify as part of their meaninga manner of carrying out an action” (e.g., nibble,rub, scribble, sweep, flutter, laugh, run, swim), andresult verbs that “specify the coming about of aresult state” (e.g., clean, cover, empty, fill, chop,cut, melt, open, enter). Result verbs can be furtherclassified into three categories: Change of Stateverbs, which denote a change of state for a prop-erty of the verb’s object (e.g. “to warm”); Inher-ently Directed Motion verbs, which denote move-ment along a path in relation to a landmark object(e.g. “to arrive”); and Incremental Theme verbs,which denote the incremental change of volumeor area of the object (e.g. “to eat”) (Levin and Ho-vav, 2010). In this work, we mainly focus on re-sult verbs. Unlike Hovav and Levin’s definition ofChange of State verbs, we use the term change ofstate in a more general way such that the location,volume, and area of an object are part of its state.
Previous linguistic studies have also shownthat result verbs often specify movement alonga scale (Hovav and Levin, 2010), i.e., they are

verbs of scalar change. A scale is “a set of pointson a particular dimension (e.g. height, tempera-ture, cost)”. In the case of verbs, the dimensionis an attribute of the object of the verb. For ex-ample, “John cooled the coffee” means that thetemperature attribute of the object coffee has de-creased. Kennedy and McNally give a very de-tailed description of scale structure and its vari-ations (Kennedy and McNally, 2005). Interest-ingly, gradable adjectives also have their seman-tics defined in terms of a scale structure. Dixonand Aikhenvald have defined a typology for adjec-tives which include categories such as Dimension,Color, Physical Property, Quantification, and Posi-tion (Dixon and Aikhenvald, 2006). The connec-tion between gradable adjectives and result verbsthrough scale structure motivates us to use theDixon typology as a basis to define our categoriza-tion of causality for verbs.
In summary, previous linguistic literature hasprovided abundant evidence and discussion onchange of state for action verbs. It has also pro-vided extensive knowledge on potential dimen-sions that can be used to categorize change of stateas described in this paper.
3.2 A Crowd-sourcing Study
Motivated by the above linguistic insight, we haveconducted a pilot study to examine the feasibilityof causality modeling using a small set of verbswhich appear in the TACoS corpus (Regneri etal., 2013). This corpus is a collection of natu-ral language descriptions of actions that occur ina set of cooking videos. This is an ideal datasetto start with since it contains mainly descriptionsof physical actions. Possibly because most actionsin the cooking domain are goal-directed, a major-ity of the verbs in TACoS denote results of actions(changes of state) which can be observed in theworld.
More specifically, we chose ten verbs (clean,rinse, wipe, cut, chop, mix, stir, add, open, shake))based on the criteria that they occur relatively fre-quently in the corpus and take a variety of differentobjects as their patient. We paired each verb withthree different objects in the role of patient. Nouns(e.g., cutting board, dish, counter, knife, hand, cu-cumber, beans, leek, eggs, water, break, bowl, etc.)were chosen based on the criteria that they repre-sent objects dissimilar to each other, since we hy-pothesize that the change of state indicated by the
verb will differ depending on the object’s features.Each verb-noun pair was presented to turkers
via Amazon Mechanical Turk (AMT) and theywere asked to describe (by text) the changes ofstate that occur to the object as a result of theverb. The descriptions were collected under twoconditions: (1) without showing the correspond-ing video clips (so turkers would have to usetheir imagination of the physical situation) and(2) showing the corresponding video clips. Foreach condition and each verb-noun pair, we col-lected 30 turkers’ responses, which resulted in atotal of 1800 natural language responses describ-ing change of state.
3.3 Categorization of Change of State
Based on Dixon and Aikhenvald’s typology for ad-jectives (Dixon and Aikhenvald, 2006) and turk-ers’ responses, we identified a categorization tocharacterize causality, as shown in Table 1. Thiscategorization is also driven by the expectationthat these attributes can be potentially recognizedfrom the physical world by artificial agents. Thefirst column specifies the type of state change andthe second column specifies specific attributes re-lated to the type. The third column specifies theparticular value associated with the attribute, e.g.,it could be a binary categorization on whether achange happens or not (i.e., changes), or a direc-tion along a scale (i.e., increase/decrease), or aspecific value (i.e., specific such as “five pieces”).In total, we have identified eighteen causality cat-egories corresponding to eighteen attributes asshown in Table 1.
An important motivation of modeling physicalcausality is to provide guidance for visual pro-cessing. Our hypothesis is that once a languagedescription is given together with its correspond-ing visual scene, potential causality of verbs orverb-noun pairs can trigger some visual detectorsassociated with the scene. This can potentiallyimprove grounded language understanding (e.g.,grounding nouns to objects in the scene). Next wegive a detailed account on these visual detectorsand their role in grounded language understand-ing.
4 Visual Detectors based on PhysicalCausality
The changes of state associated with the eighteenattributes can be detected from the physical world
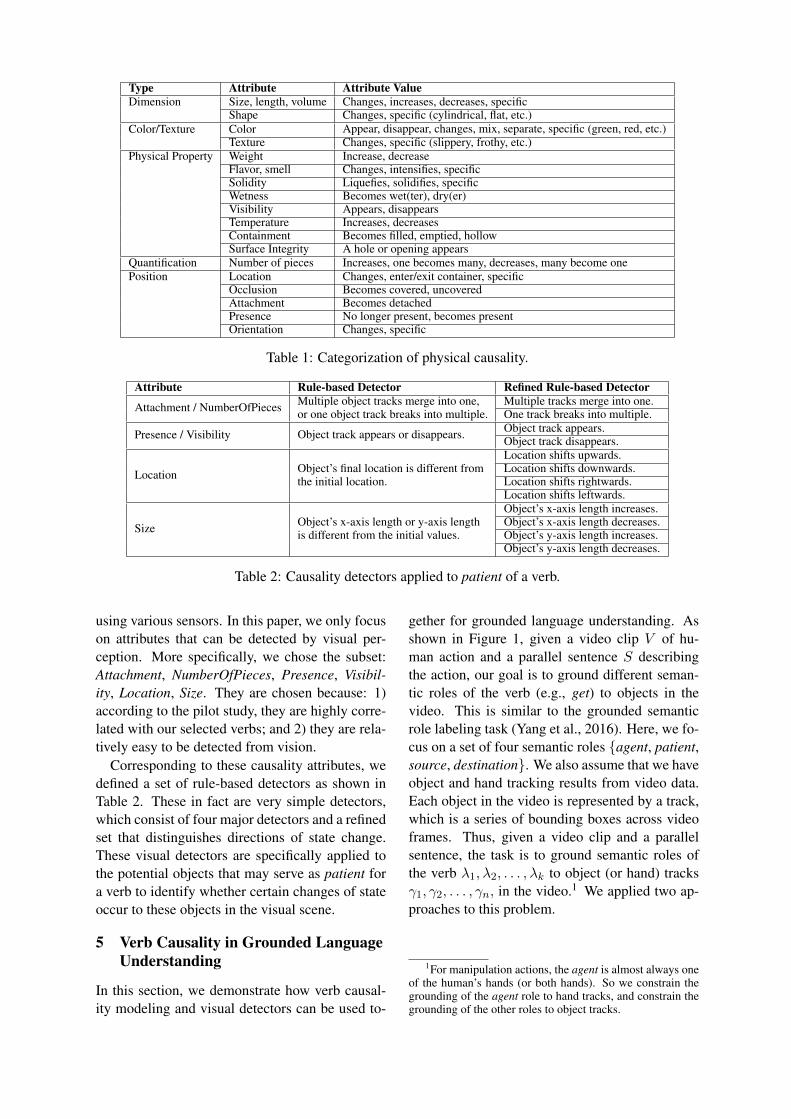
Type Attribute Attribute ValueDimension Size, length, volume Changes, increases, decreases, specific
Shape Changes, specific (cylindrical, flat, etc.)Color/Texture Color Appear, disappear, changes, mix, separate, specific (green, red, etc.)
Texture Changes, specific (slippery, frothy, etc.)Physical Property Weight Increase, decrease
Flavor, smell Changes, intensifies, specificSolidity Liquefies, solidifies, specificWetness Becomes wet(ter), dry(er)Visibility Appears, disappearsTemperature Increases, decreasesContainment Becomes filled, emptied, hollowSurface Integrity A hole or opening appears
Quantification Number of pieces Increases, one becomes many, decreases, many become onePosition Location Changes, enter/exit container, specific
Occlusion Becomes covered, uncoveredAttachment Becomes detachedPresence No longer present, becomes presentOrientation Changes, specific
Table 1: Categorization of physical causality.
Attribute Rule-based Detector Refined Rule-based Detector
Attachment / NumberOfPieces Multiple object tracks merge into one,or one object track breaks into multiple.
Multiple tracks merge into one.One track breaks into multiple.
Presence / Visibility Object track appears or disappears. Object track appears.Object track disappears.
Location Object’s final location is different fromthe initial location.
Location shifts upwards.Location shifts downwards.Location shifts rightwards.Location shifts leftwards.
Size Object’s x-axis length or y-axis lengthis different from the initial values.
Object’s x-axis length increases.Object’s x-axis length decreases.Object’s y-axis length increases.Object’s y-axis length decreases.
Table 2: Causality detectors applied to patient of a verb.
using various sensors. In this paper, we only focuson attributes that can be detected by visual per-ception. More specifically, we chose the subset:Attachment, NumberOfPieces, Presence, Visibil-ity, Location, Size. They are chosen because: 1)according to the pilot study, they are highly corre-lated with our selected verbs; and 2) they are rela-tively easy to be detected from vision.
Corresponding to these causality attributes, wedefined a set of rule-based detectors as shown inTable 2. These in fact are very simple detectors,which consist of four major detectors and a refinedset that distinguishes directions of state change.These visual detectors are specifically applied tothe potential objects that may serve as patient fora verb to identify whether certain changes of stateoccur to these objects in the visual scene.
5 Verb Causality in Grounded LanguageUnderstanding
In this section, we demonstrate how verb causal-ity modeling and visual detectors can be used to-
gether for grounded language understanding. Asshown in Figure 1, given a video clip V of hu-man action and a parallel sentence S describingthe action, our goal is to ground different seman-tic roles of the verb (e.g., get) to objects in thevideo. This is similar to the grounded semanticrole labeling task (Yang et al., 2016). Here, we fo-cus on a set of four semantic roles {agent, patient,source, destination}. We also assume that we haveobject and hand tracking results from video data.Each object in the video is represented by a track,which is a series of bounding boxes across videoframes. Thus, given a video clip and a parallelsentence, the task is to ground semantic roles ofthe verb λ1, λ2, . . . , λk to object (or hand) tracksγ1, γ2, . . . , γn, in the video.1 We applied two ap-proaches to this problem.
1For manipulation actions, the agent is almost always oneof the human’s hands (or both hands). So we constrain thegrounding of the agent role to hand tracks, and constrain thegrounding of the other roles to object tracks.

Languagedescrip.on:Themangetsaknifefromthedrawer.
Verb:“get”
Agent:groundtothehandinthegreenbox
Pa.ent:“knife”,groundtotheobjectintheredbox
Source:“drawer”,groundtotheobjectinthebluebox
Figure 1: Grounding semantic roles of the verbget in the sentence: the man gets a knife from thedrawer.
5.1 Knowledge-driven Approach
We intend to establish that the knowledge of phys-ical causality for action verbs can be acquired di-rectly from the crowd and such knowledge can becoupled with visual detectors for grounded lan-guage understanding.
Acquiring Knowledge. To acquire knowledgeof verb causality, we collected a larger dataset ofcausality annotations based on sentences from theTACoS Multilevel corpus (Rohrbach et al., 2014),through crowd-sourcing on Amazon MechanicalTurk. Annotators were shown a sentence contain-ing a verb-patient pair (e.g., “The person chopsthe cucumber into slices on the cutting board”).And they were asked to annotate the change ofstate that occurred to the patient as a result of theverb by choosing up to three options from the 18causality attributes. Each sentence was annotatedby three different annotators.
This dataset contains 4391 sentences, with 178verbs, 260 nouns, and 1624 verb-noun pairs. Af-ter summarizing the annotations from three differ-ent annotators, each sentence is represented by a18-dimension causality vector. In the vector, anelement is 1 if at least two annotators labeled thecorresponding causality attribute as true, 0 other-wise. For 83% of all the annotated sentences, atleast one causality attribute was agreed on by atleast two people.
From the causality annotation data, we can ex-tract a verb causality vector c(v) for each verbby averaging all causality vectors of the sentences
that contain this verb v.
Applying Knowledge. Since the collected causal-ity knowledge was only for the patient, we firstlook at the grounding of patient. Given a sen-tence containing a verb v and its patient, we wantto ground the patient to one of the object tracksin the video clip. Suppose we have the causal-ity knowledge, i.e., c(v), for the verb. For eachcandidate track in the video, we can generate acausality detection vector d(γi), using the pre-defined causality detectors. A straightforward wayis to ground the patient to the object track whosecausality detection results has the best coherencewith the causality knowledge of the verb. The co-herence is measured by the cosine similarity be-tween c(v) and d(γi).2
Since objects in other semantic roles often haverelations with the patient during the action, oncewe have grounded the patient, we can use it as ananchor point to ground the other three semanticroles. To do this, we define two new detectors forgrounding each role as shown in Table 3. Thesedetectors are designed using some common senseknowledge, e.g., source is likely to be the initiallocation of the patient; destination is likely to bethe final location of the patient; agent is likely tobe the hand that touches the patient. With thesenew detectors, we simply ground a role to the ob-ject (or hand) track that has the largest number ofpositive detections from the corresponding detec-tors.
It is worth noting that although currently weonly acquired knowledge for verbs that appear inthe cooking domain, the same approach can be ex-tended to verbs in other domains. The detectorsassociated with attributes are expected to remainthe same. The significance of this knowledge-driven method is that, once you have the causalityknowledge of a verb, it can be directly applied toany domain without additional training.
5.2 Learning-based Approach
Our second approach is based on learning fromtraining data. A key requirement for this approachis the availability of annotated data where the ar-guments of a verb are already correctly groundedto the objects in the visual scene. Then we canlearn the association between detected causality
2In the case that not every causality attribute has a corre-sponding detector, we need to first condense c(v) to the samedimensionality with d(γi).

Semantic Role Rule-based Detector
Source
Patient track appears within itsbounding box.Its track is overlapping with thepatient track at the initial frame.
Destination
Patient track disappears withinits bounding box.Its track is overlapping with thepatient track at the final frame.
Agent
Its track is overlapping with thepatient track when the patient trackappears or disappears.Its track is overlapping with thepatient track when the patient trackstarts moving or stops moving.
Table 3: Causality detectors for grounding source,destination, and agent.
attributes and verbs. We use Conditional RandomField (CRF) to model the semantic role ground-ing problem. In this approach, causality detectionresults are used as features in the model.
An example CRF factor graph is shown in Fig-ure 2. The structure of CRF graph is createdbased on the extracted semantic roles, which al-ready abstracts away syntactic variations such asactive/passive constructions. This CRF model issimilar to the ones in (Tellex et al., 2011) and(Yang et al., 2016), where φ1, . . . , φ4 are binaryrandom variables, indicating whether the ground-ing is correct. In the learning stage, we use thefollowing objective function:
p(Φ|λ1, . . . , λk, γ1, . . . , γk, v)
=1
Z
∏i
Ψi(φi, λi, γ1, . . . , γk, v) (1)
where Φ is the binary random vector [φ1, . . . , φk],and v is the verb. Z is the normalization constant.Ψi is the potential function that takes the followinglog-linear form:
Ψi(φi, λi,Γ, v) = exp
(∑l
wlfl(φi, λi,Γ, v)
)(2)
where fl is a feature function, wl is feature weightto be learned, and Γ = [γ1, . . . , γk] are the ground-ings. In our model, we use the following features:
1. Joint features between a track label of γi anda word occurrence in λi.
2. Joint features between each of the causalitydetection results and a verb v. Causality de-tection includes all the detectors in Table 2and Table 3. Note that the causality detectors
Figure 2: The CRF factor graph of the sentence:the man gets a knife from the drawer.
shown in Table 3 capture relations betweengroundings of different semantic roles.
During learning, gradient ascent with L2 regular-ization is used for parameter learning.
Compared to (Tellex et al., 2011) and (Yang etal., 2016), a key difference in our model is the in-corporation of causality detectors. These previousworks (Tellex et al., 2011; Yang et al., 2016) ap-ply geometric features, for example, to capture re-lations, distance, and relative directions betweengrounding objects. These geometric features canbe noisy. In our model, features based on causal-ity detectors are motivated and informed by theunderlying causality models for corresponding ac-tion verbs.
In the inference step, we want to find the mostprobable groundings. Given a video clip and itsparallel sentence, we fix the Φ to be true, andsearch for groundings γ1, . . . , γk that maximizethe probability as in Equation 1. To reduce thesearch space we apply beam search to ground inthe following order: patient, source, destination,agent.
5.3 Experiments and Results
We conducted our experiments using the datasetfrom (Yang et al., 2016). This dataset was devel-oped from a subset of the TACoS corpus (Reg-neri et al., 2013). It contains a set of video clipspaired with natural language descriptions relatedto two cooking tasks “cutting cucumber” and “cut-ting bread”. Each task has 5 videos showing howdifferent people perform the same task, and eachof these videos was split into pairs of video clipsand corresponding sentences. For each video clip,objects are annotated with bounding boxes, tracks,
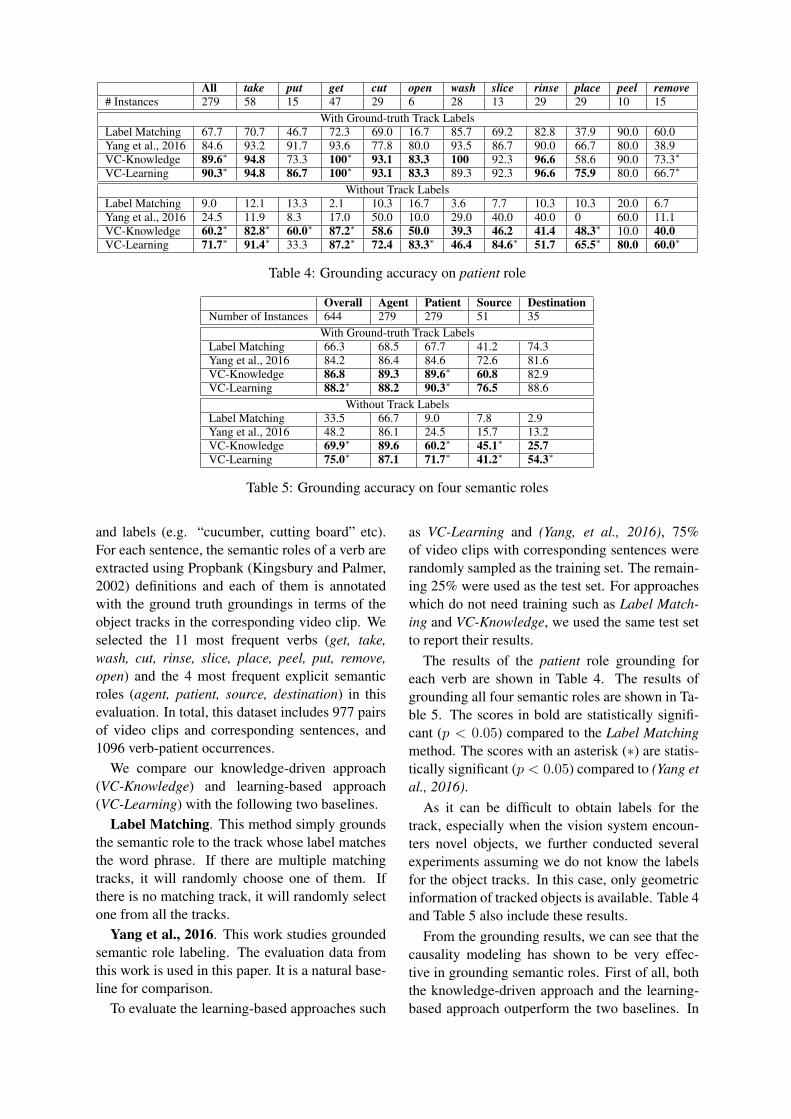
All take put get cut open wash slice rinse place peel remove# Instances 279 58 15 47 29 6 28 13 29 29 10 15
With Ground-truth Track LabelsLabel Matching 67.7 70.7 46.7 72.3 69.0 16.7 85.7 69.2 82.8 37.9 90.0 60.0Yang et al., 2016 84.6 93.2 91.7 93.6 77.8 80.0 93.5 86.7 90.0 66.7 80.0 38.9VC-Knowledge 89.6∗ 94.8 73.3 100∗ 93.1 83.3 100 92.3 96.6 58.6 90.0 73.3∗
VC-Learning 90.3∗ 94.8 86.7 100∗ 93.1 83.3 89.3 92.3 96.6 75.9 80.0 66.7∗
Without Track LabelsLabel Matching 9.0 12.1 13.3 2.1 10.3 16.7 3.6 7.7 10.3 10.3 20.0 6.7Yang et al., 2016 24.5 11.9 8.3 17.0 50.0 10.0 29.0 40.0 40.0 0 60.0 11.1VC-Knowledge 60.2∗ 82.8∗ 60.0∗ 87.2∗ 58.6 50.0 39.3 46.2 41.4 48.3∗ 10.0 40.0VC-Learning 71.7∗ 91.4∗ 33.3 87.2∗ 72.4 83.3∗ 46.4 84.6∗ 51.7 65.5∗ 80.0 60.0∗
Table 4: Grounding accuracy on patient role
Overall Agent Patient Source DestinationNumber of Instances 644 279 279 51 35
With Ground-truth Track LabelsLabel Matching 66.3 68.5 67.7 41.2 74.3Yang et al., 2016 84.2 86.4 84.6 72.6 81.6VC-Knowledge 86.8 89.3 89.6∗ 60.8 82.9VC-Learning 88.2∗ 88.2 90.3∗ 76.5 88.6
Without Track LabelsLabel Matching 33.5 66.7 9.0 7.8 2.9Yang et al., 2016 48.2 86.1 24.5 15.7 13.2VC-Knowledge 69.9∗ 89.6 60.2∗ 45.1∗ 25.7VC-Learning 75.0∗ 87.1 71.7∗ 41.2∗ 54.3∗
Table 5: Grounding accuracy on four semantic roles
and labels (e.g. “cucumber, cutting board” etc).For each sentence, the semantic roles of a verb areextracted using Propbank (Kingsbury and Palmer,2002) definitions and each of them is annotatedwith the ground truth groundings in terms of theobject tracks in the corresponding video clip. Weselected the 11 most frequent verbs (get, take,wash, cut, rinse, slice, place, peel, put, remove,open) and the 4 most frequent explicit semanticroles (agent, patient, source, destination) in thisevaluation. In total, this dataset includes 977 pairsof video clips and corresponding sentences, and1096 verb-patient occurrences.
We compare our knowledge-driven approach(VC-Knowledge) and learning-based approach(VC-Learning) with the following two baselines.
Label Matching. This method simply groundsthe semantic role to the track whose label matchesthe word phrase. If there are multiple matchingtracks, it will randomly choose one of them. Ifthere is no matching track, it will randomly selectone from all the tracks.
Yang et al., 2016. This work studies groundedsemantic role labeling. The evaluation data fromthis work is used in this paper. It is a natural base-line for comparison.
To evaluate the learning-based approaches such
as VC-Learning and (Yang, et al., 2016), 75%of video clips with corresponding sentences wererandomly sampled as the training set. The remain-ing 25% were used as the test set. For approacheswhich do not need training such as Label Match-ing and VC-Knowledge, we used the same test setto report their results.
The results of the patient role grounding foreach verb are shown in Table 4. The results ofgrounding all four semantic roles are shown in Ta-ble 5. The scores in bold are statistically signifi-cant (p < 0.05) compared to the Label Matchingmethod. The scores with an asterisk (∗) are statis-tically significant (p < 0.05) compared to (Yang etal., 2016).
As it can be difficult to obtain labels for thetrack, especially when the vision system encoun-ters novel objects, we further conducted severalexperiments assuming we do not know the labelsfor the object tracks. In this case, only geometricinformation of tracked objects is available. Table 4and Table 5 also include these results.
From the grounding results, we can see that thecausality modeling has shown to be very effec-tive in grounding semantic roles. First of all, boththe knowledge-driven approach and the learning-based approach outperform the two baselines. In

All take put get cut open wash slice rinse place peel removeVC-Knowledge 89.6 94.8 73.3 100 93.1 83.3 100 92.3 96.6 58.6 90.0 73.3P-VC-Knowledge 89.9 96.6 73.3 100 96.6 66.7 100 92.3 96.6 65.5 90.0 60.0
Table 6: Grounding accuracy on patient role using predicted causality knowledge.
particular, our knowledge-driven approach (VC-Knowledge) even outperforms the trained model(Yang et al., 2016). Our learning-based approach(VC-Learning) achieves the best overall perfor-mance. In the learning-based approach, causal-ity detection results can be seen as a set of in-termediate visual features. The reason that ourlearning-based approach significantly outperformsthe similar model in (Yang et al., 2016) is that thecausality categorization provides a good guidelinefor designing intermediate visual features. Thesecausality detectors focus on the changes of state ofobjects, which are more robust than the geometricfeatures used in (Yang et al., 2016).
In the setting of no object recognition labels,VC-Knowledge and VC-Learning also generatesignificantly better grounding accuracy than thetwo baselines. This once again demonstrates theadvantage of using causality detection results asintermediate visual features. All these results il-lustrate the potential of causality modeling forgrounded language understanding.
The results in Table 5 also indicate that ground-ing source or destination is more difficult thangrounding patient or agent. One reason could bethat source and destination do not exhibit obvi-ous change of state as a result of action, so theirgroundings usually depend on the correct ground-ing of other roles such as patient.
Since automated tracking for this TACoSdataset is notably difficult due to the complexityof the scene and the lack of depth information, ourcurrent results are based on annotated tracks. Butobject tracking algorithms have made significantprogress in recent years (Yang et al., 2013; Milanet al., 2014). We intend to apply our algorithmswith automated tracking on real scenes in the fu-ture.
6 Causality Prediction for New Verbs
While various methods can be used to acquirecausality knowledge for verbs, it may be the casethat during language grounding, we do not knowthe causality knowledge for every verb. Further-more, manual annotation/acquisition of causalityknowledge for all verbs can be time-consuming.
In this section, we demonstrate that the existingcausality knowledge for some seed verbs can beused to predict causality for new verbs of whichwe have no knowledge.
We formulate the problem as follows. Supposewe have causality knowledge for a set of seedverbs as training data. Given a new verb, whosecausality knowledge is not known, our goal is topredict the causality attributes associated with thisnew verb. Although the causality knowledge isunknown, it is easy to compute Distributional Se-mantic Models (DSM) for this verb. Then our goalis to find the causality vector c′ that maximizes
arg maxc′
p(c′|v), (3)
where v is the DSM vector for the verb v. Theusage of DSM vectors is based on our hypothe-sis that the textual context of a verb can reveal itspossible causality information. For example, thecontextual words “pieces” and “halves” may indi-cate the CoS attribute “NumberOfPieces” for theverb “cut”.
We simplify the problem by assuming thatthe causality vector c′ takes binary values, andalso assuming the independence between differentcausality attributes. Thus, we can formulate thistask as a group of binary classification problems:predicting whether a particular causality attributeis positive or negative given the DSM vector of averb. We apply logistic regression to train a sep-arate classifier for each attribute. Specifically, forthe features of a verb, we use the DistributionalMemory (typeDM) (Baroni and Lenci, 2010) vec-tor. The class label indicates whether the corre-sponding attribute is associated with the verb.
In our experiment we chose six attributes tostudy: Attachment, NumberOfPieces, Presence,Visibility, Location, and Size. For each one of theeleven verbs in the grounding task, we predict itscausality knowledge using classifiers trained on allother verbs (i.e., 177 verbs in training set). Toevaluate the predicted causality vectors, we ap-plied them in the knowledge-driven approach (P-VC-Knowledge). Grounding results were com-pared with the same method using the causal-ity knowledge collected via crowd-sourcing. Ta-

ble 6 shows the grounding accuracy on the pa-tient role for each verb. For most verbs, us-ing the predicted knowledge achieves very simi-lar performance compared to using the collectedknowledge. The overall grounding accuracy of us-ing the predicted knowledge on all four semanticroles is only 0.3% lower than using the collectedknowledge. This result demonstrates that physicalcausality of action verbs, as part of verb semantics,can be learned through Distributional Semantics.
7 Conclusion
This paper presents, to the best of our knowledge,the first attempt that explicitly models the physicalcausality of action verbs. We have applied causal-ity modeling to the task of grounding semanticroles to the environment using two approaches: aknowledge-based approach and a learning-basedapproach.
Our empirical evaluations have shown en-couraging results for both approaches. Whenannotated data is available (in which seman-tic roles of verbs are grounded to physical ob-jects), the learning-based approach, which learnsthe associations between verbs and causality de-tectors, achieves the best overall performance.On the other hand, the knowledge-based ap-proach also achieves competitive performance(even better than previous learned models), with-out any training. The most exciting aspect aboutthe knowledge-based approach is that causalityknowledge for verbs can be acquired from humans(e.g., through crowd-sourcing) and generalized tonovel verbs about which we have not yet acquiredcausality knowledge.
In the future, we plan to build a resource formodeling physical causality for action verbs. Asobject recognition and tracking are undergoingsignificant advancements in the computer visionfield, such a resource together with causality de-tectors can be immediately applied for any ap-plications that require grounded language under-standing.
Acknowledgments
This work was supported in part by the Na-tional Science Foundation (IIS-1208390 and IIS-1617682) and DARPA under the SIMPLEX pro-gram through UCLA (N66001-15-C-4035). Theauthors would like to thank anonymous reviewersfor valuable comments and suggestions.
ReferencesCollin F Baker, Charles J Fillmore, and John B Lowe.
1998. The berkeley framenet project. In Proceed-ings of the 17th international conference on Compu-tational linguistics-Volume 1, pages 86–90. Associ-ation for Computational Linguistics.
Marco Baroni and Alessandro Lenci. 2010. Dis-tributional memory: A general framework forcorpus-based semantics. Computational Linguis-tics, 36(4):673–721.
Eduardo Blanco, Nuria Castell, and Dan I Moldovan.2008. Causal relation extraction. In Proceedingsof the Sixth International Language Resources andEvaluation (LREC’08).
Robert MW Dixon and Alexandra Y Aikhenvald.2006. Adjective Classes: A Cross-linguistic Typol-ogy. Explorations in Language and Space C. OxfordUniversity Press.
Alahoum Fathi and James M Rehg. 2013. Modelingactions through state changes. In Computer Visionand Pattern Recognition (CVPR), 2013 IEEE Con-ference on, pages 2579–2586. IEEE.
Richard E. Fikes and Nils J. Nilsson. 1971. Strips: Anew approach to the application of theorem provingto problem solving. In Proceedings of the 2Nd Inter-national Joint Conference on Artificial Intelligence,IJCAI’71, pages 608–620, San Francisco, CA, USA.Morgan Kaufmann Publishers Inc.
Amy Fire and Song-Chun Zhu. 2015. Learning per-ceptual causality from video. ACM Transactions onIntelligent Systems and Technology (TIST), 7(2):23.
Malik Ghallab, Dana Nau, and Paolo Traverso. 2004.Automated planning: theory & practice. Elsevier.
Eugenia Goldvarg and Philip N Johnson-Laird. 2001.Naive causality: A mental model theory ofcausal meaning and reasoning. Cognitive science,25(4):565–610.
Malka Rappaport Hovav and Beth Levin. 2010. Re-flections on Manner / Result Complementarity. Lex-ical Semantics, Syntax, and Event Structure, pages21–38.
Christopher Kennedy and Louise McNally. 2005.Scale structure and the semantic typology of grad-able predicates. Language, 81(2)(0094263):345–381.
Paul Kingsbury and Martha Palmer. 2002. From tree-bank to propbank. In Proceedings of the 3rd In-ternational Conference on Language Resources andEvaluation (LREC2002).
Hema Swetha Koppula, Rudhir Gupta, and AshutoshSaxena. 2013. Learning human activities and objectaffordances from rgb-d videos. The InternationalJournal of Robotics Research, 32(8):951–970.

Beth Levin and Malka Rappaport Hovav. 2010. Lex-icalized scales and verbs of scalar change. In 46thAnnual Meeting of the Chicago Linguistics Society.
Beth Levin. 1993. English verb classes and alter-nations: A preliminary investigation. University ofChicago press.
Changsong Liu and Joyce Y. Chai. 2015. Learn-ing to mediate perceptual differences in situatedhuman-robot dialogue. In Proceedings of the29th AAAI Conference on Artificial Intelligence(AAAI15), pages 2288–2294, Austin, TX.
Changsong Liu, Lanbo She, Rui Fang, and Joyce Y.Chai. 2014. Probabilistic labeling for efficient ref-erential grounding based on collaborative discourse.In Proceedings of the 52nd Annual Meeting of theAssociation for Computational Linguistics (Volume2: Short Papers), pages 13–18, Baltimore, MD.
Anton Milan, Stefan Roth, and Kaspar Schindler.2014. Continuous energy minimization for multi-target tracking. Pattern Analysis and Machine Intel-ligence, IEEE Transactions on, 36(1):58–72.
Dipendra Kumar Misra, Kejia Tao, Percy Liang, andAshutosh Saxena. 2015. Environment-driven lex-icon induction for high-level instructions. In Pro-ceedings of the 53rd Annual Meeting of the Associ-ation for Computational Linguistics and the 7th In-ternational Joint Conference on Natural LanguageProcessing (Volume 1: Long Papers), pages 992–1002, Beijing, China, July. Association for Compu-tational Linguistics.
Rutu Mulkar-Mehta, Christopher Welty, Jerry RHoobs, and Eduard Hovy. 2011. Using granularityconcepts for discovering causal relations. In Pro-ceedings of the FLAIRS conference.
Iftekhar Naim, Young C. Song, Qiguang Liu, LiangHuang, Henry Kautz, Jiebo Luo, and Daniel Gildea.2015. Discriminative unsupervised alignment ofnatural language instructions with correspondingvideo segments. In Proceedings of NAACL HLT2015, pages 164–174, Denver, Colorado, May–June.Association for Computational Linguistics.
Ad Neeleman, Hans Van de Koot, et al. 2012. The lin-guistic expression of causation. The Theta System:Argument Structure at the Interface, page 20.
J Pustejovsky. 1991. The syntax of event structure.Cognition, 41(1-3):47–81.
Kira Radinsky, Sagie Davidovich, and ShaulMarkovitch. 2012. Learning causality fornews events prediction. In Proceedings of the 21stinternational conference on World Wide Web, pages909–918. ACM.
Michaela Regneri, Marcus Rohrbach, Dominikus Wet-zel, Stefan Thater, Bernt Schiele, and ManfredPinkal. 2013. Grounding action descriptions invideos. Transactions of the Association for Com-putational Linguistics (TACL), 1:25–36.
Mehwish Riaz and Roxana Girju. 2014. In-depth ex-ploitation of noun and verb semantics to identifycausation in verb-noun pairs. In 15th Annual Meet-ing of the Special Interest Group on Discourse andDialogue (SIGDial), page 161.
Anna Rohrbach, Marcus Rohrbach, Wei Qiu, An-nemarie Friedrich, Manfred Pinkal, and BerntSchiele. 2014. Coherent multi-sentence video de-scription with variable level of detail. In PatternRecognition, pages 184–195. Springer.
S. Russell and P. Norvig. 2010. Artificial Intelligence:A Modern Approach. Prentice Hall.
Karin Kipper Schuler. 2005. VerbNet: A Broad-Coverage, Comprehensive Verb Lexicon. Ph.D. the-sis, University of Pennsylvania.
Lanbo She and Joyce Y. Chai. 2016. Incremental ac-quisition of verb hypothesis space towards physicalworld interaction. In Proceedings of the 54th An-nual Meeting of the Association for ComputationalLinguistics (ACL), Berlin, Germany.
Lanbo She, Yu Cheng, Joyce Chai, Yunyi Jia, ShaohuaYang, and Ning Xi. 2014a. Teaching robots new ac-tions through natural language instructions. In RO-MAN, 2014 IEEE, Edinburgh, UK, August.
Lanbo She, Shaohua Yang, Yu Cheng, Yunyi Jia,Joyce Chai, and Ning Xi. 2014b. Back to theblocks world: Learning new actions through situ-ated human-robot dialogue. In Proceedings of theSIGDIAL 2014 Conference, Philadelphia, US, June.
Grace Song and Phillip Wolff. 2003. Linking percep-tual properties to the linguistic expression of causa-tion. Language, culture and mind, pages 237–250.
Stefanie Tellex, Thomas Kollar, Steven Dickerson,Matthew R Walter, Ashis Gopal Banerjee, Seth JTeller, and Nicholas Roy. 2011. Understandingnatural language commands for robotic navigationand mobile manipulation. In Association for the Ad-vancement of Artificial Intelligence (AAAI).
Matthew R Walter, Sachithra Hemachandra, BiancaHomberg, Stefanie Tellex, and Seth Teller. 2013.Learning semantic maps from natural language de-scriptions. In Robotics: Science and Systems.
Phillip Wolff and Grace Song. 2003. Models of cau-sation and the semantics of causal verbs. CognitivePsychology, 47(3):276–332.
Phillip Wolff. 2003. Direct causation in the linguisticcoding and individuation of causal events. Cogni-tion, 88(1):1–48.
Yezhou Yang, Cornelia Fermuller, and Yiannis Aloi-monos. 2013. Detection of manipulation actionconsequences (mac). In Proceedings of the IEEEConference on Computer Vision and Pattern Recog-nition, pages 2563–2570.

Yezhou Yang, Anupam Guha, C Fermuller, and Yian-nis Aloimonos. 2014. A cognitive system for un-derstanding human manipulation actions. Advancesin Cognitive Sysytems, 3:67–86.
Shaohua Yang, Qiaozi Gao, Changsong Liu, CaimingXiong, Song-Chun Zhu, and Joyce Y. Chai. 2016.Grounded semantic role labeling. In Proceedings ofthe 2016 Conference of the North American Chap-ter of the Association for Computational Linguistics,San Diego, CA.
Haonan Yu and Jeffrey Mark Siskind. 2013. Groundedlanguage learning from video described with sen-tences. In Proceedings of the 51st Annual Meet-ing of the Association for Computational Linguistics(Volume 1: Long Papers), pages 53–63.





























