Embed Size (px)
Citation preview

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 1/24
Comple x Systems 4 (1990) 51 -7 4
Stochastic Approx imation andMultilayer Perceptrons:
The G ain B ackp ropagation Algori thm
P.J . GawthropD. Sbarbaro
Departm ent of Mechanical En gineering, Th e University,Glasgow G12 8QQ , Uni ted Kingd om
Abstract . A standard general algorithm, the sto chastic a pproxima-t ion algorithm of Alb ert and Gardner [1] , is appli ed in a n ew cont extto compute the w eights of a multilayer per ceptron network. Thisleads to a new algorithm, th e gain b ackpropagation algorithm, whichis rel at ed t o, b ut significantly different from , the standa rd bac kprop-agat ion algorith m [ 2]. Som e simulation exa mples sho w th e potent ialan d limita t ions of t he pr oposed a pproach and p rovide com parisonswit h the co nventional ba ckpropagation al gorithm.
1. Introduct io n
As part of a l arger research p rogram aimed at cross fertilizat ion of the dis ci-plines of ne ura l n etwork s / pa rallel di stributed p rocessing a nd contro l /system stheory , t his pa per brings together a sta ndard cont rol /systems t heor y te c h-nique ( th e stoch astic ap p roximation algo rithm of Al bert and Gardn er [1]) an da neura l ne tworks/ para llel distri buted process ing techniq ue (the mu lti layerp ercep tron). Fr om t he con trol /systems theo ry p oin t of v iew, th i s introducesthe possi bility of adaptive nonl inear t rans for mat ions with a genera l st ru ctur e;from the n eur al n etwork s / par a llel di stribu te d process ing po in t of view, t hisendow s t he m ultilayer perceptron with a more power ful l earn ing a lgorit hm .
The pro b lem is ap p roached from an eng ineering, ra ther th an a psysi olog-ica l, pe rspective . In p articular, no claim of p hysiolog ica l r elev an ce is ma de ,nor do we constra in th e solu t ion by the conven tiona l loosely cou pled p aral-lel di st ributed p rocessing a rchi tecture . Th e a im is t o find a go od lea rnin galgorithm ; the app ropriate archi t ecture for im plement a tion is a mat ter forfur th er inves tigatio n .
Multilay er percep trons ar e feedforward n et s with on e or mor e layers ofnod es be tween the inp ut and output nodes . T h ese addition al layers containh idden units or nodes that are not di r ectly conne c te d to both th e input a nd
© 1990 Complex Systems P ublications, In c.

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 2/24
52 P.J . Gawthrop and D. Sbtubero
output nodes. These hidden un its contain nonlineari ties and t he resu lta ntnet work is po tent ially capa ble of g enerating m appings not at ta ina ble by apur ely lin ear network. The cap abilities of this ne twork to solve diff erentkind s of pr oblems have b een demonstr ated elsewhere [2- 4] .
However , for e ach particul ar problem , the network mu st be trained; t ha tis , the weights go verning t he str eng th s of th e co nnect ions b etween units mu stb e varied in or der to get th e t arget out put c orresponding to the inp ut presented . Th e mos t popul ar met hod for trainin g is backprop agation (B P ) [2],b ut t his t raining me thod requires a large number of i ter ations b efore t henetwo rk gene rates a sa t isfactory app roximation to t he ta rget mappi ng . Improv ed r ates of conv ergence a rise from t he simulate d ann ealing t echnique [ 5].
As a resu lt of th e resear ch ca rried ou t by a numb er o f workers du r ing t helas t two year s, seve ral alg ori thm s have been publish ed, eac h wit h differentch aracter istics an d prop erties .
Bourland [6] shows t hat f or t he a utoassociator , th e nonlinearities o f t heh idd en units are us eless an d the opt i mal pa r ameter values ca n be deriveddir ect ly by purely line ar te chnique of sin gular v alue decompositi on (SVD) [7].
G rossman [5] introduced an a lgorithm called choic e internal r epresenta-ti on for two-l ayer neural n etworks, composed of bin ary lin ear thr esholds. Th emet hod pe rforms an effic ient sear ch in the space of intern al re presentations;when a correct s et is found , th e weights ca n b e found by a lo cal p erce ptronlea rning r ule [8].
Broom head [9] u ses the me thod o f ra dial ba sis fun ction (RBF) a s t hetechn ique to a djust t he we ights o f n etworks wit h G aussian or m ul tiquad raticunit s. Th e system represents a ma p from an n- dimensional inp ut sp ace toan m-dim ensiona l ou t put space .
Mitchison [1 0] s tudied the bounds on th e learning cap acity of seve r alnetworks and then deve loped the least action a lgorit hm. This a lgorithmis not guar anteed to find every so lut ion , but is m uch more effici ent th anBP in th e task of learn ing r andom vecto rs ; it is a ve rsion of the so -called"co mm ittee machine" algo rithm [11] , wh ich is fo rmulate d in te rm s of d iscr etelin ear thr esholds.
Th e princ ipal cha racteristics of these a lgorithms are s um m arized inta ble 1.Th e aim of th is p aper is not to g ive a p hysiologically plausibl e algo rithm ,
but r ath er to give one th at is us eful in engineering app lications. In particular,t he p rob lem is viewed w ith in a standard framework for the optimization ofnon lin ear systems : the "stochast ic approximation" a lgor ithm of A lbert andGardn er [1,7] .
Th e me thod is related to the celebra ted BP algo rithm [2], and th is relat ionship will be explore d in the paper . However, the simul at ions pr esented
in t his paper ind i cat e t hat our m ethod converges to a sa t isfactory solutionmu ch faster th an th e BP algor ithm [2].
As Minsky and Pa p ert [12] have pointed out, the BP a lgorithm is a hillclimbin g a lgor it hm with all the problems implied by s uch m ethods. Ou rmeth od ca n also be viewed a s a hill-climbin g algor ithm, but it is more sophis -

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 3/24
The Ga in Backpropagation A lgorithm 53
I Activation function I Type of inputs I Main applications ISVD linear continuous or autoassociators
discreteChoice binary linear discrete logic functions
thresholdLeast action linear threshold discrete logic functionsRBF Gaussian or continuous or in t erpolation
multiquadratic discreteBP sigmoid discrete or gen eral
continuous
I Name
Table 1: Algorithm summary .
ti cated than t he s tandard BP method. In particu lar, un l ike th e BP m ethod,the cost function approximately minimized by our algorithm is based on pastas we ll as current data .
Perhaps even more impor tant ly, our method provides a bridge betweenneural network /PDP approaches and well -developed techn iques arising fromcontrol and systems theory . On e consequence of this is that the pow erfu l analyti cal techniques associated with control and system th eory can be brought
to b ear on neural network /PDP algorithms. Some ini tia l ideas ar e sk et chedout in section 5 .Th e paper is organized as follows. Section 2 pr o vides an outlin e of th e
s ta ndard stochastic approxim ation [1,7] in a general s etting. Section 3 appliesthe t echnique to the multilayer perceptron and consid er s a numb er of spe cialcases:
th e XOR problem [2],
the parity problem [2],
th e symmetry probl em [2], and
coor d inate transforma tion [13].
Sect ion 4 provides some simulati on evidence for th e sup erior p erforman ce ofou r alg orithm. Section 5 outlines possibl e analy tical appr oach es t o convergen ce. Section 6 concludes th e pap er.
2. The s tochas t ic approximat ion a lgor ithm
2 .1 Parametr ic linearization
The stocha st ic a p proximatio n t ech niqu e dea ls wi th t he gene ra l nonlinear system of t he f orm
(2.1)

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 4/24
54 P.J. Gawthrop and D. Sbarbaro
where () is th e parameter vector (n p x 1) cont aining the n p system p arameters,X, is t he input v ec tor (ni x 1) conta ining th e n i sy ste m inputs at (integer)time t. Y; is th e syst em outp ut vect or at t ime t. F ((), X t ) is a no nlinear, bu tdifferentiable, func t ion of t he tw o arguments () an d Xt.
In th e con text o f th e layered n eural n etworks dis cussed in t his paper, Y;
is t he ne twork output and X, t he input ( training patt ern) at t ime t and ()
conta ins th e n etwork weight s. Following Alb ert an d Gardn er [1], t he firststep in th e derivation of th e learning algorithm is to find a local line arizationof equation (2.1) about a nominal parameter vector ()o.
Exp an d ing F around ()o in a first-ord er Taylor seri es g ives
wh ere
F ' = ofo)
(2.2 )
(2.3)
and E is th e approx im a tion erro r re presenting the high er t erm s i n t he seriesexp ansion.
D efining
(2.4 )
a nd
(2 .5)
equation 2.2 then be comes
(2 .6)
T his equat ion f orms the desired linear a pproximation of th e fun ction F ((), Xt ),wit h E repr esent ing th e ap proximation e rror, and f orms t he basi s of a leastsqua res type algo rit hm t o esti ma te ().
2 .2 Least -squares a nd t h e pseudoinverse
Th is section app lies t he s tandard (nonrecursive) a nd rec ursive l east-squ ar ealgorithm to the estimation of () in the linearized equat ion (2.6) , but withone difference : a pseudoinverse is used to avo id d ifficulti es with a no n-uniqueoptimal estimate for t he paramet ers, which ma n ifests itse lf as a si ngular data-dependen t ma trix [7]. •
T he standard
lea st-square cost f unction with expo nent ial discounting ofdat a is
(2.7)

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 5/24
The Ga in B ackpropagation Al gorithm 55
(2.9)
wh ere the exponent ial f orgetting factor A gives different weights to differentob servations and T is the number of presentat ions of the diff erent traini ngse ts.
Us ing standard manipulation s, t he value of the param eter vector B minimi zing th e cost function is ob tained from the lin ear alg ebr ai c e quation
T
STBT = L AT- tX tYt (2 .8)t=1
wh ere th e m atr ix ST(n p x np ) is given byT
ST = L A T - tXtxTt=1
Wh en applied to th e layer ed neural networks disc ussed in th is pap er, STwill us u ally be singular (or at l east nearly singular), thus th e est i ma t e willbe non -unique. Th is non -un iqueness is of no consequ ence when comp utingthe network ou tput, b ut it is vita l to t ake it in to account in t he comp utati onof th e estimates .
Here the min imum norm solution for B is chosen a sT
BT = S f L AT-H IXtYt (2.10)t=1
wh ere S f is a pseudoinverse of ST.In pract ice, a r ecursive form of (2.10) is requ ired. Using st andard manip
ulations" " + -OH = Ot + S; Xt et (2.11)
wh ere th e error et is given b y- "T -
et = (Ye - 0t Xd (2.12)
but, using (2.4) and (2 .5),
- "T - "Ye - 0t X, ~ Ye - F(Ot,X t) (2 .13)
and finally (2.11) becomes" - + - "OtH = Ot + S; Xt(Ye - F(O , X t)) (2. 14)
S, can b e rec ursively updated as- - T
St = ASt_l + XtX t (2.15)
Indeed, st itse lf ca n be updated di rect ly [ 7], but the detai ls are not p urs uedfurther her e.
D ata is d iscarded at an expon entia l rate with t ime cons t ant T giv en b y1
T = - - (2. 16)I -A
wh ere T is in uni ts of samples. This feature is necessary to discount old information correspond ing to estim ates far from the con vergence point and thusin appropriate to the lin earized model about the de sired nominal param etervector 0° .

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 6/24
56 P.J . Gawthrop and D. Sbarbaro
3. The multi layer percept r on
At a g iven t ime t, the i th l ayer of a multil ayer perceptron ca n b e represent edby
v. = W ;X i
wh ere Xi is giv en by
( Xi )i =
an d Xi by
(3 .1)
(3 .2)
(3 .3)
Th e uni t last e lement of Xi corresponds t o an offs et t erm when multi plied by
th e a ppropriate weight vector. Equation (3.1) describ es th e lin ear p art of thelayer w here Xi (n i + 1 x l ) cont ain the ni inputs to t he l ayer together with 1 inth e last e lem ent, W i (ni + 1 x ni+d maps th e input to th e lin ear output of t helayer, and Wi (ni X niH) does not contain th e offset weights. Equation (3 .3)descr ibes t he nonlinear part of the layer where the fun ction J maps eachelement of Yi- l , the linear output of th e previous layer, to e ach e lement of Xi .A specia l case of the nonlinear transformation of equation (3 .3) occurs wheneac h element X of the vector Xi is obtained from th e corresponding el ementY of t he m a tr i x Yi- l by the sam e nonlinear fun ction:
X = f(y ) (3.4)
(3 .5)
Th ere a re many po ssible c hoices for f(y) in equati on (3 .4), but , like th ebackpropagation a lgorithm [2], our method requires f(y) to be diff erentiable.T ypica l functions are the weighted sigmoid function [2]
1f( y) = 1 + e - CXY
and t he w eight ed hyperbolic tang ent fun ctioneCX Y _ e - cxy
f (y) = tanh( ay) = - - -eCXY + e - CXY
(3 .6)
T he former i s appropriate to logic levels of 0 and 1; t he la t t er i s appropriateto logic levels of - 1 and 1. Th e derivative of the function in equation (3.5)I S
J' (y ) = ~ := ax(l - x)
and that of the fu nction in equat ion (3.6) is
dx 2J' (y) = dy = a( l + x )(l - x ) = a( l - x )
(3.7)
(3.8)

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 7/24
The Gain Backpropagation Algoritbm 57
The multilayer perceptron may thus be regarded a s a special case of thefunction displayed in equat ion (2.1) where, at t ime t, 1'; = XN, 0° is a columnvector containing the elements of all the Wi matrices and X; = X l . To applyth e algorithm in section 2 , however, it is necessary to find an expr essionfor x, = F'(OO,X ) as in equation (2.6) . Becaus e of th e simpl e recursivefeedforward structure of the multilayer perceptron, it is possible to obtain asimple recursive algorithm for the computation of the elements of Xt. Th ea lgorithm is, not surprisingly, related to the BP algorithm .
As a first step, define the incremen tal gain matrix G i relating the ithlayer to the ne t output evaluated for a given set of weights an d ne t inputs.
G . _ OXN
• - OXi
Using the chain rule [14], it follows that
G. - G. OXi+! °Yi• - .+1 oYi OXi
and using equations (3 .1) an d (3.3)
(3 .9)
(3.10)
(3 .11 )
(3 .12)
Equation (3 .11) will be called the gain backpropagation alg oritbm or GBP.By d efinition,
OXNGN = OXN = In;
wher e In; is the n i X n i uni t matri x .Appl ying th e chain rule once more ,
OXN OXN OXi+!oW i = OXi+l oW;
(3.13)
(3 .14)
Substituting from equations (3.1), (3.3), an d (3.9), equation (3.13) be comes
OXN _ G OXi+loW i - i+! oW i
3. 1 The algorithm
Initially :
1. Set the elements of the weight matrices Wi to small random values andload the corresponding elements into the column vector 00 ·
2. Set>. between .95 and .99 and th e matrix So to sol where I is a unitmatri x of appropria te dimension a nd So a small number.

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 8/24
58 P .J. Gawthrop and D . Sbarbaro
Figure 1: Architecture to solve the XOR problem.
At each time step:
1. Present an input X, = X l '
2. Propagate the input forward through the network using equations (3 .1)and (3.3) to give Xi and Yi for each layer.
3. Given Xi for each layer, propagate the incremental gain matrix G, back-ward using the gain backpropagation of equations (3 .11) and (3.12).
4. Compute the partial derivative OXN/OW i using equation (3.14) andload the corresponding elements into the column vector X.
5. U pd at e t he matrix St using (2.15) and find its pseudoinverse s; (orupdate s; directly [7]) .
6. Compute the outpu t error et from equation (2.12).
7. Update the parameter vector B using equation (2.14).
8. Reconstruct the weight matrices Wi from the parameter vector B•
3.2 The XOR problem
The architecture for solving the XO R problem with two hidden uni ts and nodirect connections from inputs to output is shown in figure 1.
In this case, the weight and input matrices for layer 1 are of the form
(3. 15)
The last row ofthe matrix in equation (3.15) corresponds to the offset t erms.The weight and input matrices for layer 2 are of the form
(3.16)

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 9/24
The Gain Ba ckpropagation Algori thm 59
Once again, t he last row of th e ma t rix i n equ ation (3.16) corr esponds t o t heoffset t erm.
App lying th e G BP a lgorithm (3 .11) gives
He nce , u sing (3.14) and (3.12),
O X3 - ,o W
2= x d (Y2) = x2 x 3( 1 - X3 )
and u sing (3.14) a nd ( 3.17)
OX3 = G2
OX2
O W l O W l
(3.17)
(3.18)
(3 .19)
T hus, in thi s ca se, t he t erms X and () linearize d eq uation (2.6) are givenby
X l l X2 1 (1 - X 21)X 3 (1 - X3 )W 2l1
X12 X21 (1 - X21 )X 3 (1 - X3 ) W2l1
X21 (1 - X21 )X3 (1 - X3)W2l1
X ll X22( 1 - x2 2 )x3 ( 1 - X3 )W 221
X12 X 22( 1 - x 22 )x3 ( 1 - X3 )W 2 21
x 22(1 - x2 2 )x 3 ( 1 - X3 )W22 1
X21X 3( 1 - X3 )
X2 1X3 (1 - X3 )
x3 (1 - X3 )
W l l l
W l2 1
W l3 1
W 112
()= W l22
Wl3 2
W 211
W 221
W23 1
(3.20)
3 .3 T h e pari ty p roblem
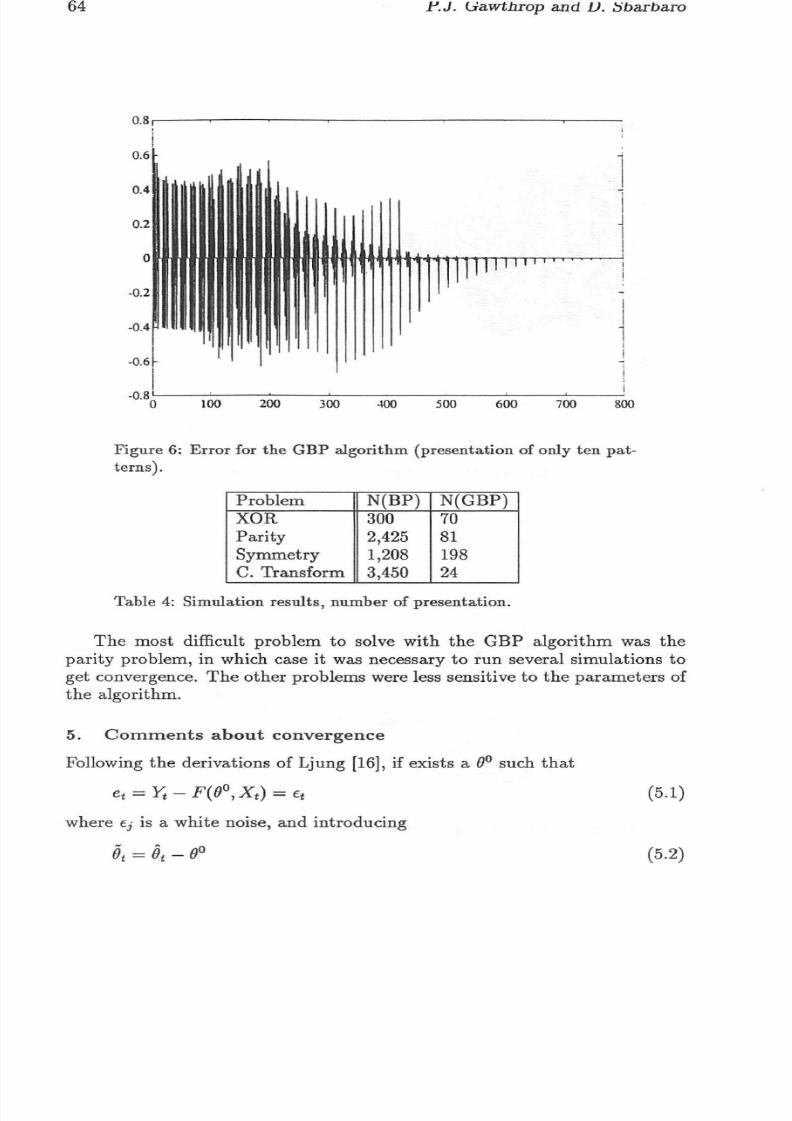
In t his p roblem [2] , the ou tpu ts of t he n etwork mu st be TRUE if the inputpatt ern conta ins a n odd nu mber of I s and FALSE other wise . T he st ruct ureis shown in figure 5; there are 1 6 pa ttern and 4 hi dd en units .
Th is is a ver y dema nding proble m, b ecause th e solution ta kes full adva nta ge of t he nonlinear charac teris t ics of th e hi dden un it s in orde r to pro ducean outpu t sens itiv e to a change in o nly one inpu t .
T he linea rization is simila r t o tha t of t he XO R net work except tha t W I
is 4 x 4, W 2 is 4 x 1, and inp ut ve ctor X l is 4 x 1.
3.4 T h e symm et ry problem
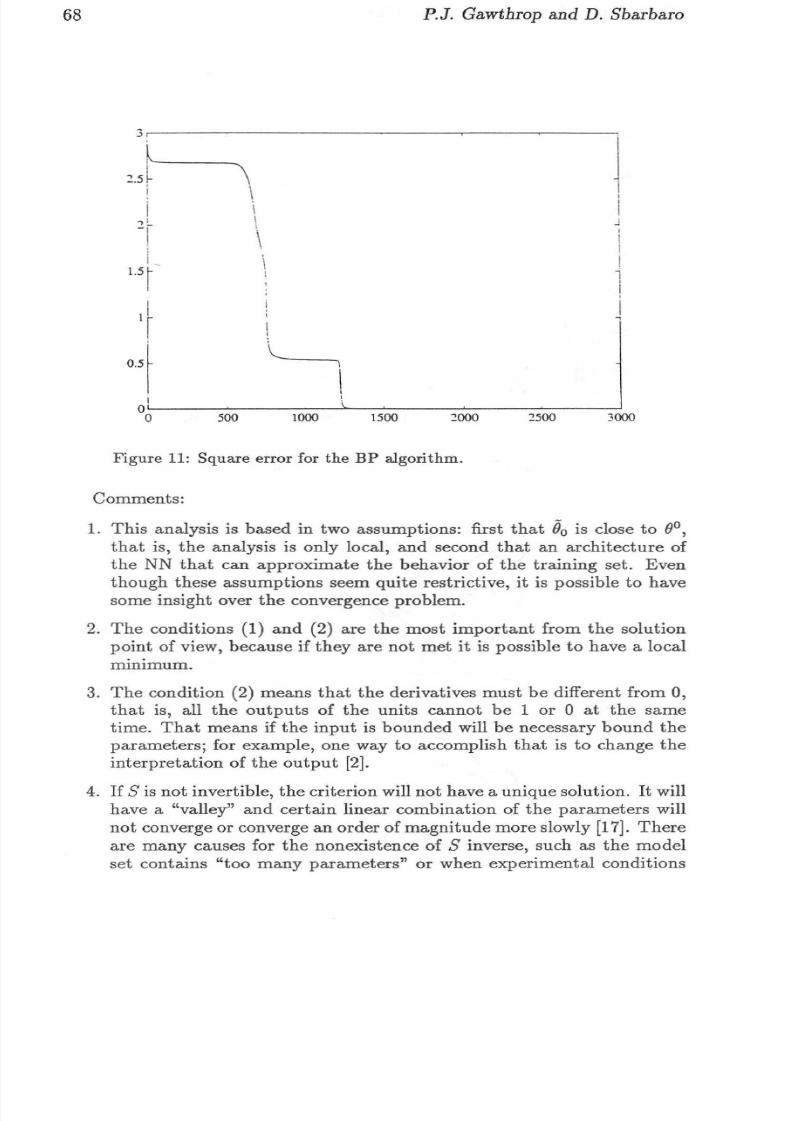
The out put of the network mus t be TR UE if th e input p attern is symmet r icabout it s center and FALSE otherwise. The a ppropriate structur e is shownin fig ure 10 .
The linearization is si milar to th at of th e XO R network ex cept that WI
is 6 x 2 , W 2 is 2 x 1 , a nd input vector X l is 6 x 1.

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 10/24
60
I Probl em
P.J. Gawthrop and D . Sbarbaro
I Gain (B P) Momentum (BP) A (BP) IXOR 0.5 0.9 0.95Pa rity 0.5 0. 9 0.98Symm etr y 0.1 0 .9 0.99C. t ransform 0.02 0.95 0.9 9
Tab le 2: Para meters u sed in t he simulat ions.
X l X2 Y0 0 0.91 0 0.10 1 0.11 1 0.9
Tab le 3: P att erns f or the XOR pro blem.
3.5 C oordin a t e t ransformat ion
The Cartes ian endpoint p osit ion of a r igid two -link man ipulator (figure 14)is g iven by
X = L I COS(OI) + L 2 COS(OI + O2 )
y = L I sin( OI ) + L2 sin ( OI + O )
(3.21)
(3.22)
where [x, y] is t he position in t he pla ne, L I = 0.3m, L 2 = 0.2m are th elengths of the links. The joints an gles ar e 01> O ,
Equation (3.21) an d (3.22) show that it is poss ible to produce this kindof tr ansformatio n usi ng the str ucture shown in fig ure 15.
Th e linearization i s similar to that of the XOR network except that WIis 2 x 10, W 2 is 10 x 1, a nd i np ut vector X l is 10 x 1.
4. Simulations
Th e simple multilayer percept rons disc ussed in section 3 were implem entedin M atlab [15] and a number of simulation exp eriments were performed toeva luate the proposed algorithm and compare its performance with th e conventi onal BP algorithm. The values of the parameters used in eac h problemare shown in table 2.
4 .1 The XOR problem
Th e t ra in ing patterns used are shown in tabl e 3. The con ventional BP and
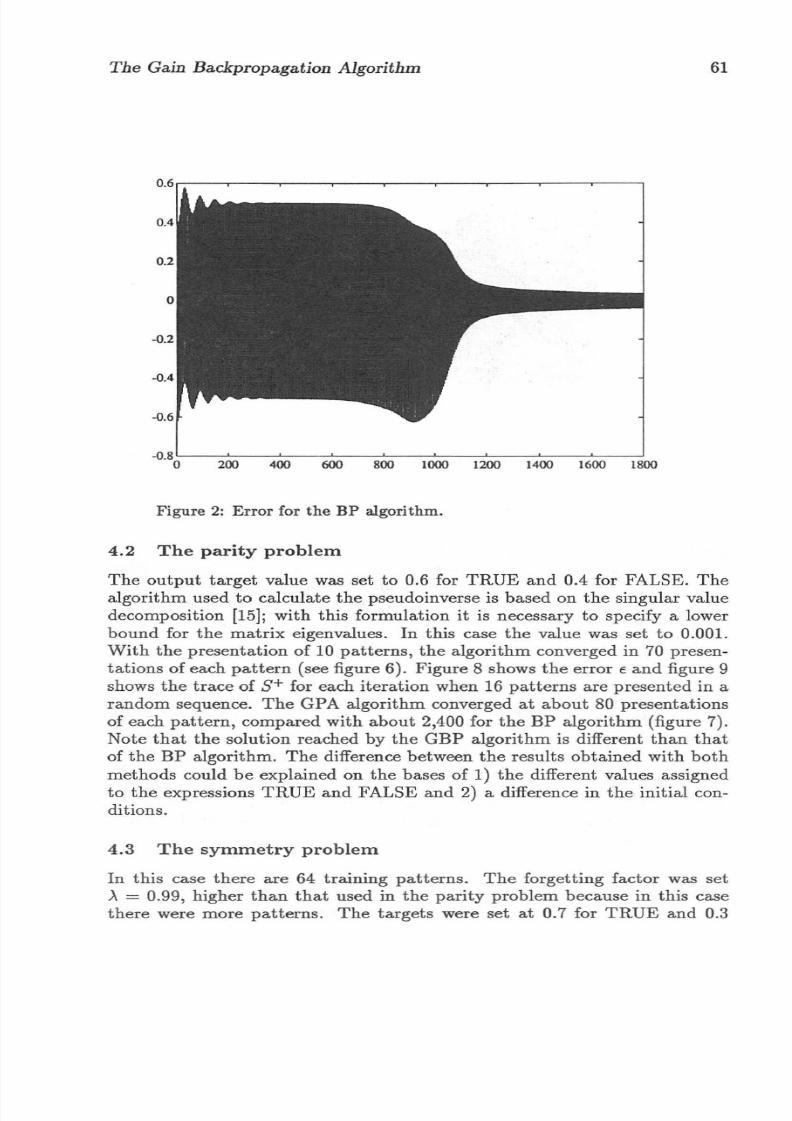
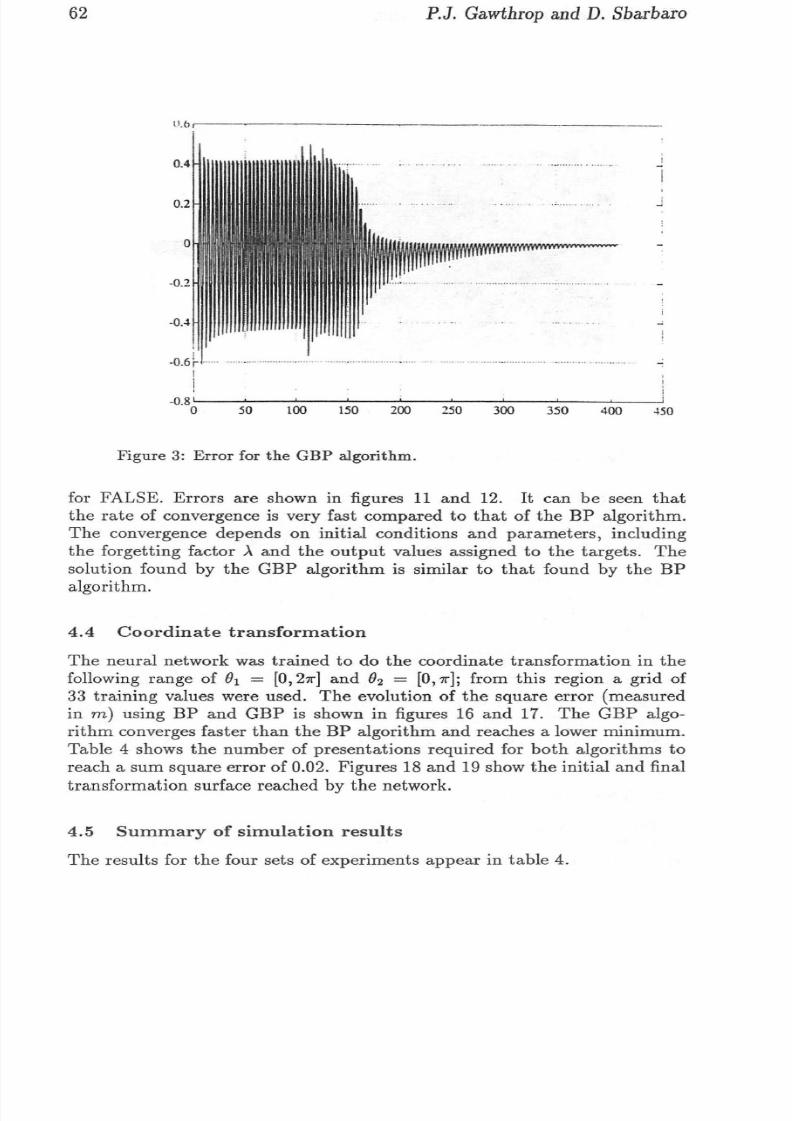
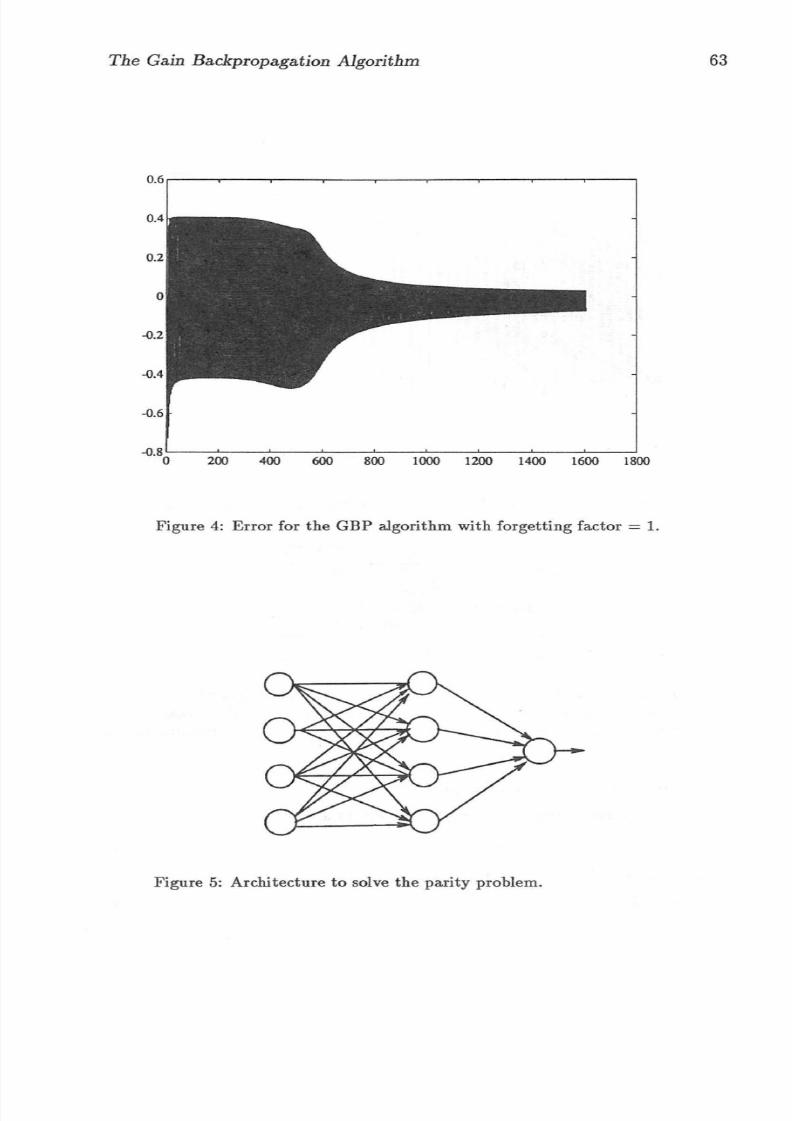
GBP algorithms were simulated . Figure 2 shows the perform ance of th e BPalgorithm, and figur e 3 shows th e pe rformance of the GBP algori thm .T he re duction in the number of it erations is four -fold for th e sa me err or .Th e effect o f discoun ting past da t a is shown in figure 4 ; with a for getting
factor eq ua l to 1, the algorithm d oes not converge .
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 11/24
Th e Gain Backprop agation Algorithm 61
200 400 600 800 1000 1200 1400 1600 1800
Figure 2 : Error for the BP algorithm.
4.2 The p a r i t y pr oblem
T he output tar get value was set to 0 .6 for TRUE and 0.4 fo r FALSE. T healgorithm used to calculate the pseudoinverse is based on the singu la r va luedecomposition [15]; with this fo rmulation it is necessary to specify a lower
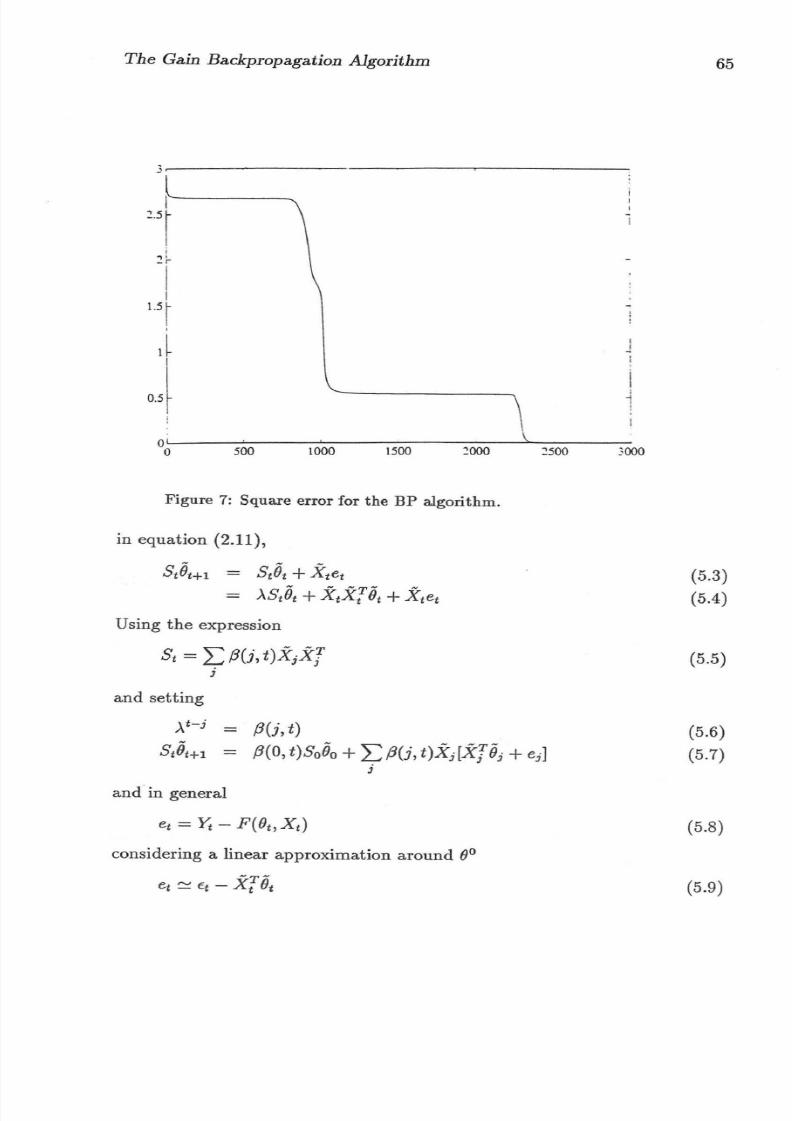
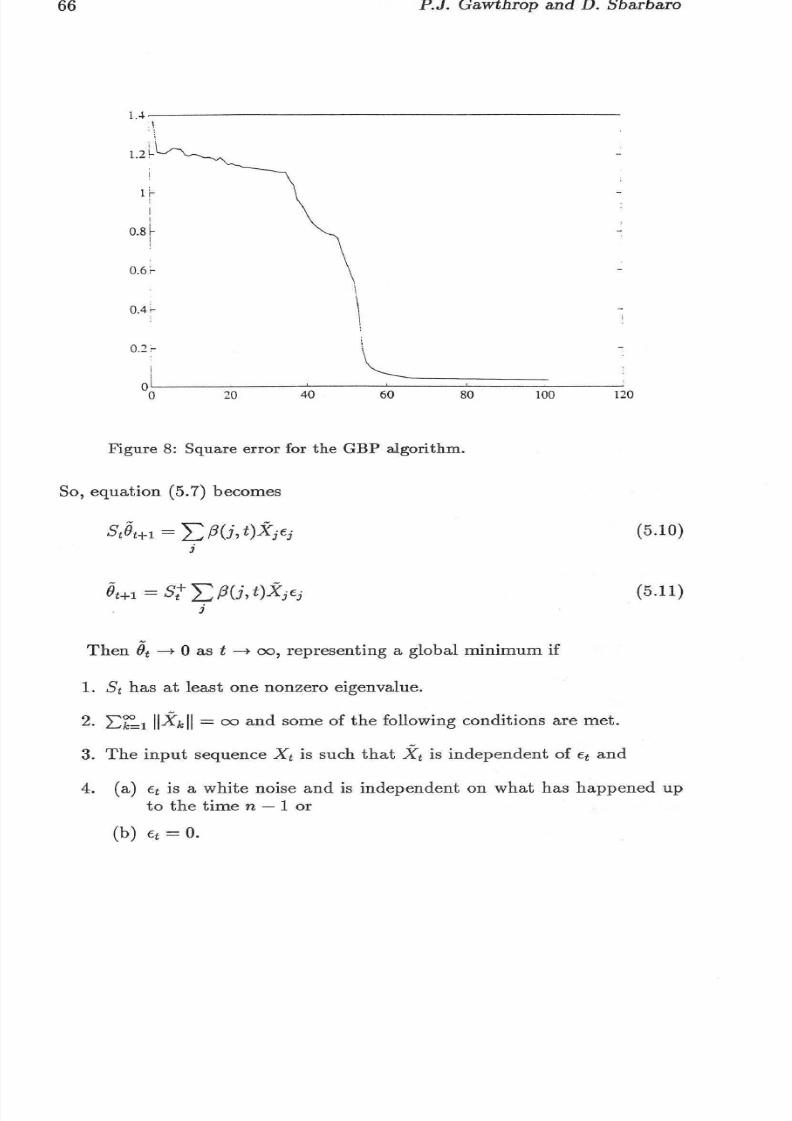
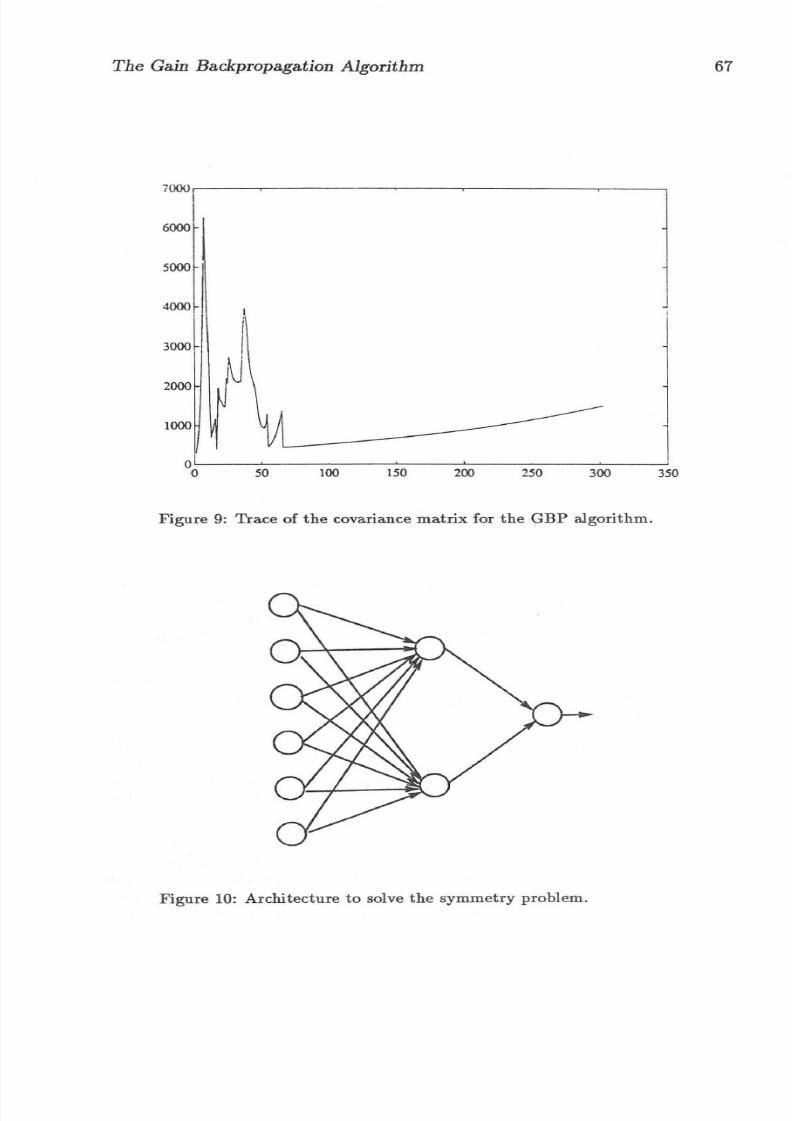
bound for the matrix eigenvalues. In this case the value was set to O.OOLWith the presentation of 10 patterns, the algorithm converged in 70 presen-tations of each pattern (see figure 6). Figure 8 shows the error e and figure 9shows the trace of S+ for each iteration when 16 patterns are presented in arandom sequence. The GPA algorithm converged at about 80 presentationsof each pattern, compared with about 2,400 for the BP algorithm (figure 7).Note that the solution reached by the GBP algorithm is different than thatof the BP algorithm. The difference between the results obtained wit h bothmethods could be explained on the bases of 1) the different values assigned
to the expression s TRUE an d FALSE an d 2) a difference in t he initial con-ditions.
4.3 The symmetry problem
In this case there are 64 training patterns. The forgetting factor was set). = 0.99, higher th an t ha t used in the parity problem because in this casethere were more patterns. Th e targets were set at 0.7 for TRUE an d 0.3
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 12/24
62 P.J. Gawthrop and D . Sbarbar o
I1. b " - - - - - - - - - _
-O .6f- . " ' m . "
ij
j
Figure 3: Error for the GBP algorithm.
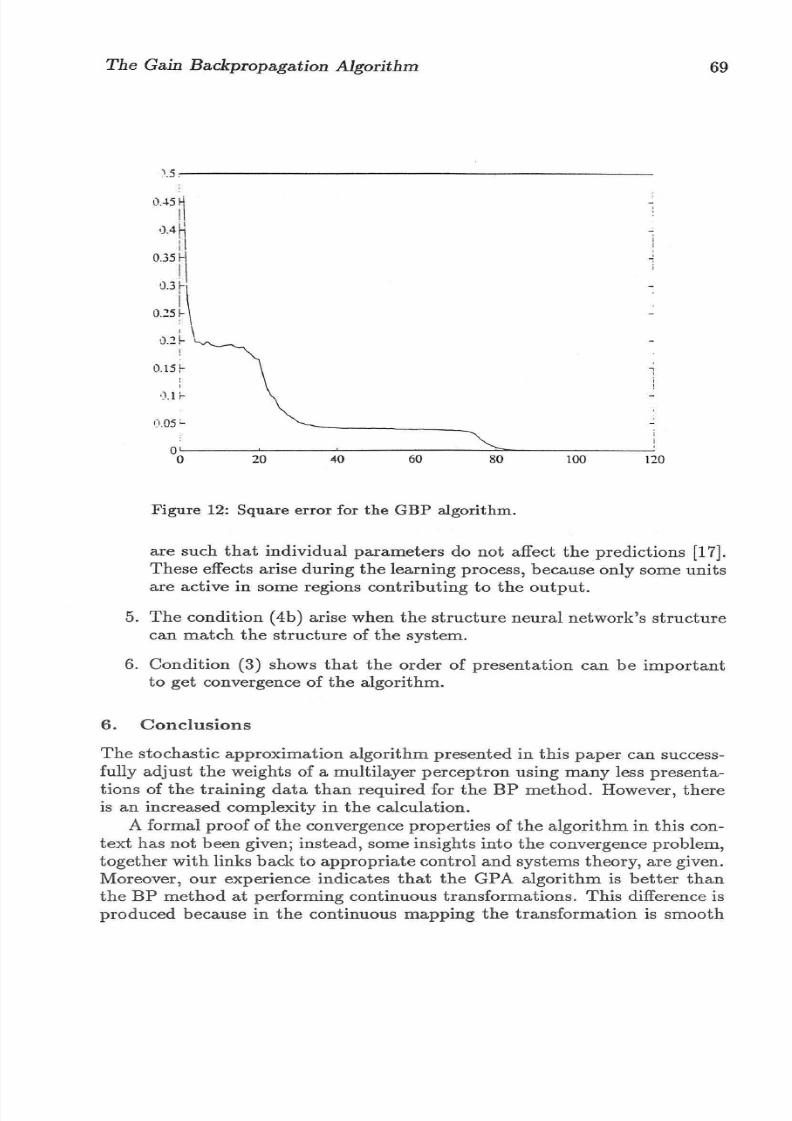
for FALSE . Errors are shown in figures 11 and 12 . I t can be seen thatth e rate of convergence is very fast compared to that of the BP algorithm.Th e convergence d epends on initial conditions and paramet ers, includingth e forgetting factor .A and the output value s assigned to th e targets. Thesolution found by the GBP algorithm is similar to th at found by th e BPa lgorithm.
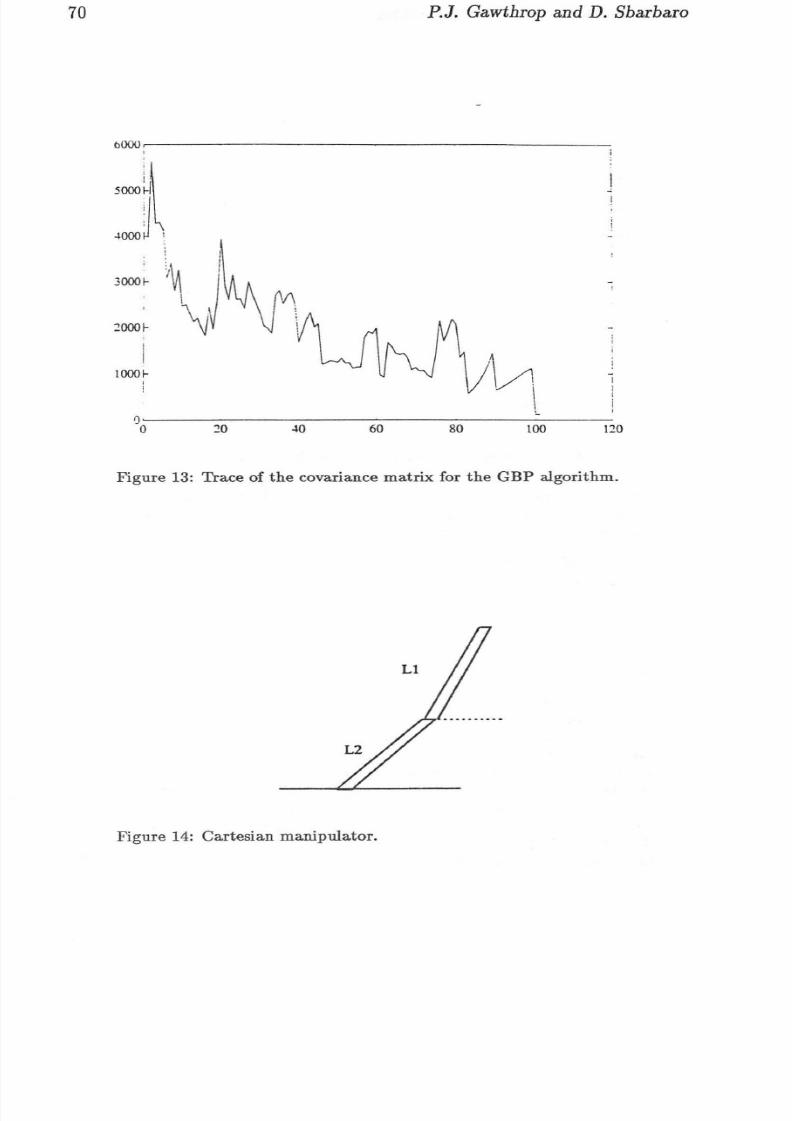
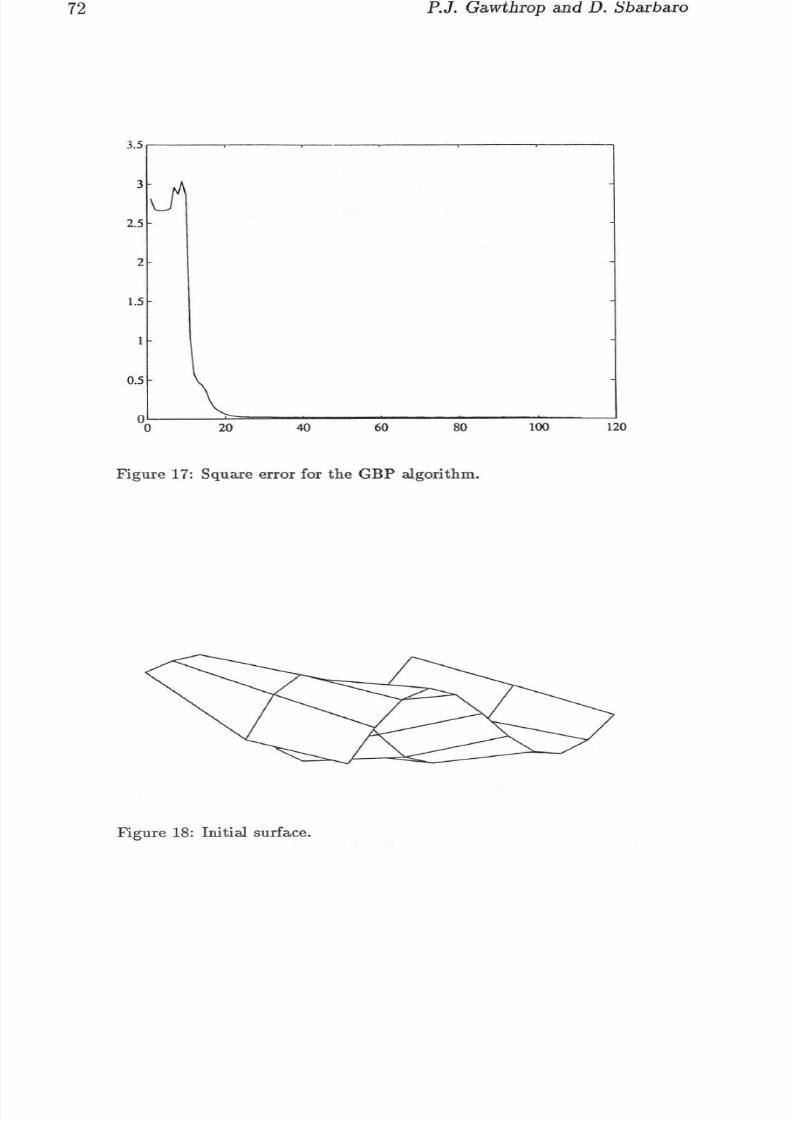
4.4 Coordinate transformationThe neur al network was trained to do the coordinate transformation in thefollowing range of ()1 = [0, 21l'] and ()2 = [O, 1l']j from this region a grid of33 training va lues were used. The evolution of the square error (measuredin m) using BP and GBP is shown in figures 16 and 17 . The GBP a lgorit hm c onverges faster than t he BP a lgorithm and reaches a lo wer minimum .Table 4 shows the numb er of presentati ons required for bo th algor ithms torea ch a sum square error of 0 .02. Figures 18 an d 19 show th e in it ial a nd finaltran sfo rmation surface r eached by the network.
4.5 Summary of s imu la ti on re su lt s
Th e results for th e four s ets of experiments ap pea r in t able 4 .
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 13/24
The Gain Backpropagation Algorithm 63
-0.6
800 1000 1200 1 400 1600 1800000000- O. 8 ' - -- ~ - - - ' - - - ~- - - ' -- - ' - -- ~ - - ~ - ~ ~- - '
o
Figur e 4 : Error for th e GBP algor i thm with f orgetting fac tor = 1.
Fi gu r e 5: Archi tec tur e to solve th e p arity pro blem.
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 14/24
64 .P.J . Gawthrop and lJ . ~ b a rb a r o
0.8 r l - - ~ - - - - ~ - - -- - - - - - - - - --
0.6
I
I1I
!
!
600 700 80000!
3000000
-0.6
I_0.8L..!- - - ' -- - ~ - - ~ - -- - - - - - ' - - - ~ - - - - '
o
Figure 6: Error for the GBP algorithm (presentation of only ten patt erns).
Problem N(BP) N(GBP)XOR 300 70Parity 2,425 81Symmetry 1,208 198C. Transform 3,450 24
Table 4: Simulation results, number of presentation.
Th e most difficult problem to solve with the GBP algor ithm wa s thepar ity prob lem, in wh ich case i t was necessary to run severa l simu latio ns toge t conv ergence. The othe r problems were less sens itive to the parameters ofthe algorithm .
5 . Comments abou t convergence
Following the derivations of Ljung [16], if exists a ()O such that
e t = Yt - F(()O,X t ) = f t (5.1)wher e f j is a white noise, and introducing
- . °)t = ( ) t - ( ) (5 .2)
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 15/24
Th e Gain Backpropagation Algorithm 65
3000\
2000 250050000000O L - - ~ - - - ~ -- - c - : - -- - - - = - : - : - : -- - - ' - - - : - : : : ~ - - - - - : - : .
o
Figure 7: Square error for the BP algorithm.
in equation (2 .11) ,
StOHl StOt + Xtet- - - T- -
= )..SA + XtX t 0t + Xtet(5.3)(5.4)
Using the expression
s, = I : {j(j, t)XjXTj
(5.5)
and setting
)..t- j =StOHl
(j(j, t)
{j(D,t)SoOo + I : {j(j, t)Xj[X! OJ + ei]i
(5.6)(5 .7)
and in gener al(5 .8)
considering a linear approximation around 00
- T -et ~ tt - X t Ot (5.9)
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 16/24
66 P.J. Gaw throp and D. Sberbe r o
1.4 -- -- - -- - - - - - - - - - - - - - - - -, \
lr-
I,0 8 ~
I
0.6;-
\
0.4 ~
\0.2;- ~
0 1
0 20 40 60 80 100 120
Figure 8: Square erro r for the GBP algorithm.
So, equation (5.7) becomes
StOHl = L (J(j, t)XjEjj
OtH = S : L (J(j, t)XjEjj
Then Ot - + 0 as t - + 0 0 , representing a global minimum if
1. S, h as at least one nonzero eigenva lue.
2. E ~ lIIXkI = 0 0 and some of the following conditions a re met.
3. The input sequence X; is such that Xt is ind ependent of f t and
(5.10)
(5.11)
4 . (a) Et is a white no ise and is independent on what has happened upto the time n - 1 or
(b) E t = O .
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 17/24
The Gain Backpropagation Algorithm 67
7000I
I6000
1
•000 I
3000 l
iI
2000~
1000
0 1
o 50 100 150 200 250 300 350
Figure 9: Trace of th e covariance matri x for the GBP al gori thm .
Figure 10: Architecture to solve the symmetr y probl em.
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 18/24
68 P .J . Gawthrop an d D. S bsrbeto
JIII
I.;,1Iii
i
j2000 2500 3000
L - ,\:\
500 1000 15 00
IO L I - - - ~ - - _ _ , __ : _ : _ - - "- ~ - - - ~ - -_ _ , _~ - -~o
3, - - - - -- - - - - --- - - - - - - - - - - - -.....,
Figure 11 : Squ are error fo r the BP algo rith m.
Comments:
1. This a nalysis i s b ased in t wo as sumptions : first t hat 00 is close to eo,
t ha t i s, the analysis is only local, and sec ond t hat an arch itecture oft he NN th at can approx imate the behav ior of the t raining set. Ev enthou gh these ass umptions seem quite restrictive, it i s possible t o havesome insight over the convergence problem.
2. Th e conditions ( 1) and (2) are the most impo rtant from the solut ionp oint o f view , bec au se if th ey are not met it is possibl e to hav e a loca lr rummum ,
3. Th e cond it ion (2) means th at the deriva tive s must be d iffer ent from 0,that is, all t he o ut put s of the units cannot be 1 or 0 at the samet ime. That me ans if the input is bounded will be necessary bound thep arameters; fo r ex ample, one way to acco mplish that is to cha nge theint erpr etation of the ou tput [2].
4. I f S is not i nvertible, the criterion will not ha ve a unique so lution . It willhave a "va lley" and certain linear combinat ion of t he p arameters willno t converge or converge an order of magnit ude m ore slowly [1 7]. Thereare many ca uses for the nonexistence of S inverse, such as the modelset co nt ains "too m any param eters" or when exper imen ta l conditions
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 19/24
Th e Gain B ackpropagation Algorithm 69
' .S.- - - - - - - - - - - - - - - - - - - - - - - -
L ' . - tS ~
'J.4HII
03Si\0.3 ~
o2sl\( )2 ~ \
O IS r,
'1.1 r
(I.OS t,
no000000O ' - -- - - ~ - - ~ - - -- - - - - - - " '- - - -- - - - - - '
o
Figure 12: Squa re err or fo r t he GBP algor ithm.
are su ch t hat i n dividual parameters do not a ffect t he p redictions [17] .Th ese effects ari se durin g t he learning proce ss, be cause only s ome unitsare a ctive in some regions cont ribut ing to t he outpu t .
5. T he condi t ion ( 4b ) arise when t he st ructure neural ne twork's st ru ctu recan m atch t he st ructure of the system.
6. Condit ion (3) shows that the order of pr esentat ion ca n be impo rta ntto get conver gence of the algorithm .
6. C o ncl u si ons
The stochastic approximation algorithm presented in this paper can successfully adju st t he weights of a mult ilayer pe rceptron using many less presenta
tions of t he training data t han required for the BP method . Howe ver, thereis an increased complexity in the calculation.
A formal proof of the convergence properties of the algorithm in this context has not been given; instead, some insight s into the convergence problem,to gether w ith links back to appropriate control and systems theory, are given .Moreover, our experience indicates that the GPA algorithm is better thanthe BP method at performing continuous transformations. This differenc e isproduced because in th e continuous mapping the transformation is smooth
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 20/24
70 P.J . Gawthrop and D. Sb arbaro
b O O O ~,- - - - - - - - - - - - - - - - - - - - - -
I
il O O O ~
' ~\4000L
. \1 I3 0 0 0~ V
IV!l
1"00000000- - - - - - - - - - - --- - - - - --- - -o
Figure 13: Trace of th e covariance matrix for the GBP algorithm .
Figure 14 : C artes ian manipulator .
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 21/24
The Gain Backp ropagation Algorithm 71
Figure 1 5: Archit ectur e to so lve th e coordinate t r ansformation p rob -lem.
2.5
2
1.5
1000 1500 2000 2500 3000 3500 4000 450000° OL _ ~ _ ~ _ ~ - - ~ - =: : : L : := = = = = == = d
0.5
Figure 16 : Squ ar e e rror for th e BP algorithm .
8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 22/24
72 P.J. Gawthrop and D . Sberbsro
3 . 5 r - - - ~ - - - ~ - - - -~ - - - ~ - - - ~ - - -- - .
2.5
2
1.5
0 .5
\20 40 60 80 100 1 20
Figure 17: Square error for th e G BP algorithm.
Figure 18: Initial surface .

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 23/24
The Gain Backpropagation Algorithm
Figure 19 : Final and reference surface.
73
and it is possible to h ave a great number of patterns (theoretically infinite)and only a small number are used to train the NN, so it is possible t o choosean adequate training set for a smooth representat ion, giving a better behaviorin terms of convergence.
A diffe rent situation arises in the discrete case, where it is possib le tohave some i nput pat te rns that do not differ very much from each o ther a ndyet produce a very different system output. In terms of our interpretations,thi s means a rapid ly varying hypersurface and therefore a very hard surfaceto match with few components.
Further work is in progress to establ ish more clearly under prec isely whatcondi tions it is possible to get convergence to the required global solution.
References
[1] A.E . Albert and L.A. Gardner, Stochastic Approximation and NonlinearRegression (MIT Press, Cambridge, MA, 1967).
[2] J.L. McClelland and D .E. Rumelhart, Explorations in Parallel DistributedProcessi ng (MIT Press, Cambridge, MA 1988).
[3] T.J. Sejnowski , "Neural network learning algorithms," in Neural Computers(Springer-Verlag, 1988) 291-300 .
[4] R . Hecht-Nilsen , "Neurocomputer applications," in Neural Computers(Springer-Verlag, 1988) 445-453.

8/3/2019 P.J. Gawthrop and D. Sbarbaro- Stochastic Approximation and Multilayer Perceptrons: The Gain Backpropagation Alg…
http://slidepdf.com/reader/full/pj-gawthrop-and-d-sbarbaro-stochastic-approximation-and-multilayer-perceptrons 24/24
74 P.J. Gawthrop and D. Sbarbaro
[5] R. Meir, T . Grossman, an d E . Do many, "Learning by choice of in ternalrepresentations," Complex Systems, 2 (1988) 555-575 .
[6] H . Bourland and Y . Kamp , "Auto-association by multilayer perceptrons andsingul ar value decomp osition," Biological C ybernetics, 5 9 (1988) 291 -29 4.
[7] A .E . Albert, Regression and the Moore-P enrose Pseudoinverse (AcademicPress , New York, 1972) .
[8] L.B. Widrow an d R. Wint er, " Neural ne ts for adaptive filte ring and adapt i vepattern recognition," IEEE Computer, 21 (1988) 25-39 .
[9] D .S. Broomhead an d D. Lowe, "Multivariable functional int erpol ation anda daptive networks ," Compl ex Systems, 2 (1988) 321-355 .
[10] G.J. Mit chison and R.M . Durbin , "Bounds on th e learning capacit y of somemultil ayer networks," Biological Cybernetic s, 60 (1989) 3 45-356 .
[11] N .J . Nilsson, Learning Machines (McGraw-Hill , New York , 1974).
[12] M.L . Minsky and S .A. Pap ert, P erceptrons (MIT Press, Cambridg e, MA,1988).
[13] G. Josin, "N eural -space gen eralization of a topolog ical transformation ," Biological Cybernet ics, 59 (1988) 283 -290.
[14] W .F . Trench and B . Kolman, Multivariab le Calcu lus wit h Line ar Algebraand Series (Academic Press, New York, 1974) .
[15] C . Moler , J. Little, and S . Bangert, MATLAB User's Guide (MathworksInc., 1987 ).
[16] L. Ljun g, Systems Iden tification - Theory for th e User (Pr enti ce Hall, Englewood Cliffs, NJ , 1987).
[17] L. Ljung and T. Soders trom, Parameter Identification (MIT Press, London,1983).





























