Embed Size (px)
Citation preview

Politecnico di Milano
Facolta di Ingegneria dei Sistemi
Corso di Laurea Magistrale in Ingegneria Matematica
Progetto per il corso di
Programmazione Avanzata per il Calcolo Scientifico
Problemi di controllo ottimo guidati da tecniche statistiche per il
trattamento di dati spaziali
Stefano PaganiMatricola 782956
Anno Accademico 2012-2013

Indice
Indice
1 Introduzione 2
2 Approccio statistico per dati spaziali 3
2.1 Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Caso test Meuse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
3 Variogramma 5
3.1 Principali nozioni teoriche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53.2 Implementazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.3 Caso test Meuse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4 Kriging 14
4.1 Principali nozioni teoriche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.2 Implementazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164.3 Caso test Meuse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5 Co-kriging 20
5.1 Principali nozioni teoriche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.2 Implementazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215.3 Caso test Meuse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
6 Problemi di controllo con osservazioni puntuali 24
6.1 Osservazioni della soluzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246.2 Osservazioni del gradiente della soluzione . . . . . . . . . . . . . . . . . . . . . . . 25
7 Applicazioni 27
7.1 Caso test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277.2 Approccio ibrido . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 327.3 Stratigrafia del sottosuolo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
8 Conclusioni 39
Riferimenti bibliografici 40
1

Introduzione
1 Introduzione
Un tipico problema di analisi spaziale consiste nel fornire una stima del valore di una variabilein aree in cui non si hanno a disposizione misurazioni della variabile stessa. Per poterla rica-vare l’idea empirica di base e quella di costruire delle metodologie di previsione che utilizzinole informazioni delle osservazioni a disposizione, pesandole in funzione della loro vicinanza (piuimportanti) o lontanza (meno importanti).
In questo elaborato vogliamo analizzare la situazione in cui si vuole ricostruire la soluzione diun dato problema differenziale avendo a disposizione dei dati distribuiti spazialmente, ovvero delleosservazioni della soluzione e del suo gradiente. L’approccio tipicamente utilizzato in questi casie di tipo statistico, mediante la costruzione di opportuni predittori in base ai valori a disposizionee alle distanze tra i punti osservati e da predire. Lo scopo e quello di studiare questi strumenti(noti come modelli di kriging e co-kriging) e di fornire un’opportuna implementazione medianteun codice C++11, in modo da poterli utilizzare per una diretta risoluzione di alcuni problemi digeostatistica e come supporto nella costruzione di problemi di controllo rivolti alle stesse appli-cazioni. Infatti, nelle situazioni in cui si conosce il modello sottostante al fenomeno osservato,oppure in cui si ha sufficiente evidenza del fenomeno fisico per ricavarne un modello, e possibilecostruire un opportuno problema di controllo, in cui, attraverso la ricostruzione di un termineforzante o di una condizione al contorno, si cerca di approssimare la soluzione globale.
Nelle prime sezioni approfondiremo la costruzione dei modelli statistici, mostrandone gli aspet-ti teorici e algoritmici, e le tecniche utilizzate per loro implementazione. La spiegazione saraaccompagnata passo dopo passo da una prima applicazione relativa alla diffusione di un datoinquinante in una regione olandese (Meuse), che permetta di mostrare la diretta applicazione deimodelli descritti. In una seconda fase costruiremo un metodo ibrido tra l’approccio statisticoe quello legato al controllo ottimo, che permetta di pesare in maniera diversa le osservazioni adisposizione, in modo da minimizzare la propagazione di eventuali errori. Infine introdurremol’applicazione che ha ispirato l’analisi e lo sviluppo di tale metodologia, ovvero un problema diricostruzione della stratigrafia del sottosuolo, basato su un modello a potenziale con controllodistribuito su tutto il dominio Ω.
2

Approccio statistico per dati spaziali
2 Approccio statistico per dati spaziali
2.1 Introduzione
In questa prima sezione introduciamo i concetti chiave per l’analisi e l’interpretazione di due ap-procci, noti come kriging e co-kriging, tipicamente sfruttati per la ricostruzione di distribuzionispaziali a partire da alcune osservazioni note (per approfondimenti si veda [Cre93]). La stessaapplicazione che ha motivato il progetto si colloca nell’ambito della geostatistica, che si occupadi valutare l’autocorrelazione spaziale dei dati. Attualmente citiamo come riferimenti principaliper l’applicazione a cui siamo interessati [CAGL04] e [GCC+08].
Nell’affrontare un generico problema di geostatistica e necessario:
• raccogliere e analizzare le osservazioni a disposizione;
• stimare le relazioni spaziali tra i punti associati alle osservazioni note (tramite variogramma);
• stimare la risorsa di interesse (tramite kriging/co-kriging).
In questo contesto, si ipotizza che i dati, se sono stati raccolti mediante la stessa tecnica, sianorealizzazioni di una distribuzione multivariata (tipicamente una normale) e che la loro correlazionesi manifesti rispetto alla loro posizione nello spazio. Se invece i dati raccolti sono affetti da errorisperimentali o rumore e possibile modificare il modello gaussiano aggiungendo una componenteopportuna che modelli tale comportamento.
Il kriging e una tecnica di tipo interpolatorio che sfrutta un’opportuna combinazione linearedelle osservazioni per stimare il valore della variabile di interesse in un punto non campionato.Da un punto di vista operativo, l’interpolazione viene effettuata tenendo conto delle distanzetra il punto da stimare e i dati noti e da quelle tra i dati noti stessi (quindi del loro gradodi addensamento o clustering). La caratteristica principale del metodo geostatistico consistenel definire un criterio di pesatura che tiene conto della geometria del campionamento e dellasottostruttura di continuita spaziale (individuata dal variogramma).
Ovvero, il modello statistico ci consente di costruire, sulla base di un modello di variabilitaspaziale, il predittore BLUP (Best Linear Unbiased Prediction) Z(s) : s ∈ Ω della variabileincognita, a partire da osservazioni note si
Ni=1. Nel caso del kriging/co-kriging il predittore
Z(s) e una combinazione lineare delle osservazioni a disposizione Z(
siNi=1
)
, con opportuni pesiλi
Ni=1, che saranno le incognite che il metodo dovra determinare:
Z(s) =
N∑
i=1
λiZ(si) + C.
2.2 Caso test Meuse
Come primo caso test per provare il funzionamento del codice, utilizziamo un dataset, di cui epresente una ricca letteratura (si veda ad esempio il relativo pacchetto di R), riguardante l’in-quinamento da metalli pesanti del suolo attorno al fiume Meuse nel sud dei Paesi Bassi. Poichequesto fiume nel tempo e stato soggetto a numerose inondazioni, si e riscontrata nelle regioni limi-trofe una presenza anomala di sostanze inquinanti di tipo chimico (tra cui Zn, Pb e Cd) e di tipoorganico (tra cui pesticidi e idrocarburi aromatici policiclici). E quindi ragionevole aspettarsi lapresenza di una dipendenza spaziale della concentrazione di tali sostanze e anche una dipendenza
3
Approccio statistico per dati spaziali
tra le varie sostanze presenti.
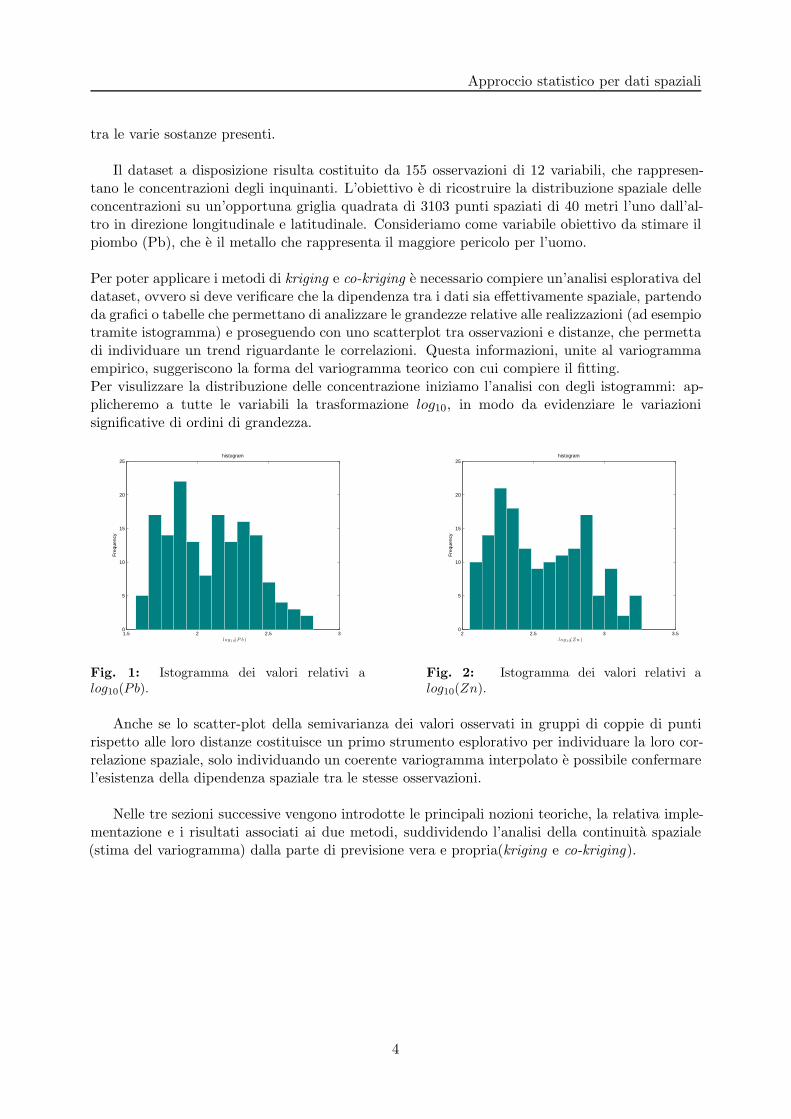
Il dataset a disposizione risulta costituito da 155 osservazioni di 12 variabili, che rappresen-tano le concentrazioni degli inquinanti. L’obiettivo e di ricostruire la distribuzione spaziale delleconcentrazioni su un’opportuna griglia quadrata di 3103 punti spaziati di 40 metri l’uno dall’al-tro in direzione longitudinale e latitudinale. Consideriamo come variabile obiettivo da stimare ilpiombo (Pb), che e il metallo che rappresenta il maggiore pericolo per l’uomo.
Per poter applicare i metodi di kriging e co-kriging e necessario compiere un’analisi esplorativa deldataset, ovvero si deve verificare che la dipendenza tra i dati sia effettivamente spaziale, partendoda grafici o tabelle che permettano di analizzare le grandezze relative alle realizzazioni (ad esempiotramite istogramma) e proseguendo con uno scatterplot tra osservazioni e distanze, che permettadi individuare un trend riguardante le correlazioni. Questa informazioni, unite al variogrammaempirico, suggeriscono la forma del variogramma teorico con cui compiere il fitting.Per visulizzare la distribuzione delle concentrazione iniziamo l’analisi con degli istogrammi: ap-plicheremo a tutte le variabili la trasformazione log10, in modo da evidenziare le variazionisignificative di ordini di grandezza.
1.5 2 2.5 30
5
10
15
20
25
Fre
quen
cy
l og 1 0(P b )
histogram
Fig. 1: Istogramma dei valori relativi alog10(Pb).
2 2.5 3 3.50
5
10
15
20
25
Fre
quen
cy
l og 1 0(Zn )
histogram
Fig. 2: Istogramma dei valori relativi alog10(Zn).
Anche se lo scatter-plot della semivarianza dei valori osservati in gruppi di coppie di puntirispetto alle loro distanze costituisce un primo strumento esplorativo per individuare la loro cor-relazione spaziale, solo individuando un coerente variogramma interpolato e possibile confermarel’esistenza della dipendenza spaziale tra le stesse osservazioni.
Nelle tre sezioni successive vengono introdotte le principali nozioni teoriche, la relativa imple-mentazione e i risultati associati ai due metodi, suddividendo l’analisi della continuita spaziale(stima del variogramma) dalla parte di previsione vera e propria(kriging e co-kriging).
4

Variogramma
3 Variogramma
In numerose applicazioni, come ad esempio in campo ambientale o in idrologia, dove l’informazio-ne e tipicamente costituita da poche osservazioni irregolarmente distribuite, la descrizione dellacontinuita spaziale rappresenta la prima fase per giungere infine alla stima e quindi alla ricostru-zione della variabile spaziale oggetto di studio sull’intero dominio. Tale descrizione, che servea sintetizzare ed a evidenziare le caratteristiche principali di un insieme di osservazioni, vieneeffettuata in geostatistica mediante il semivariogramma.
3.1 Principali nozioni teoriche
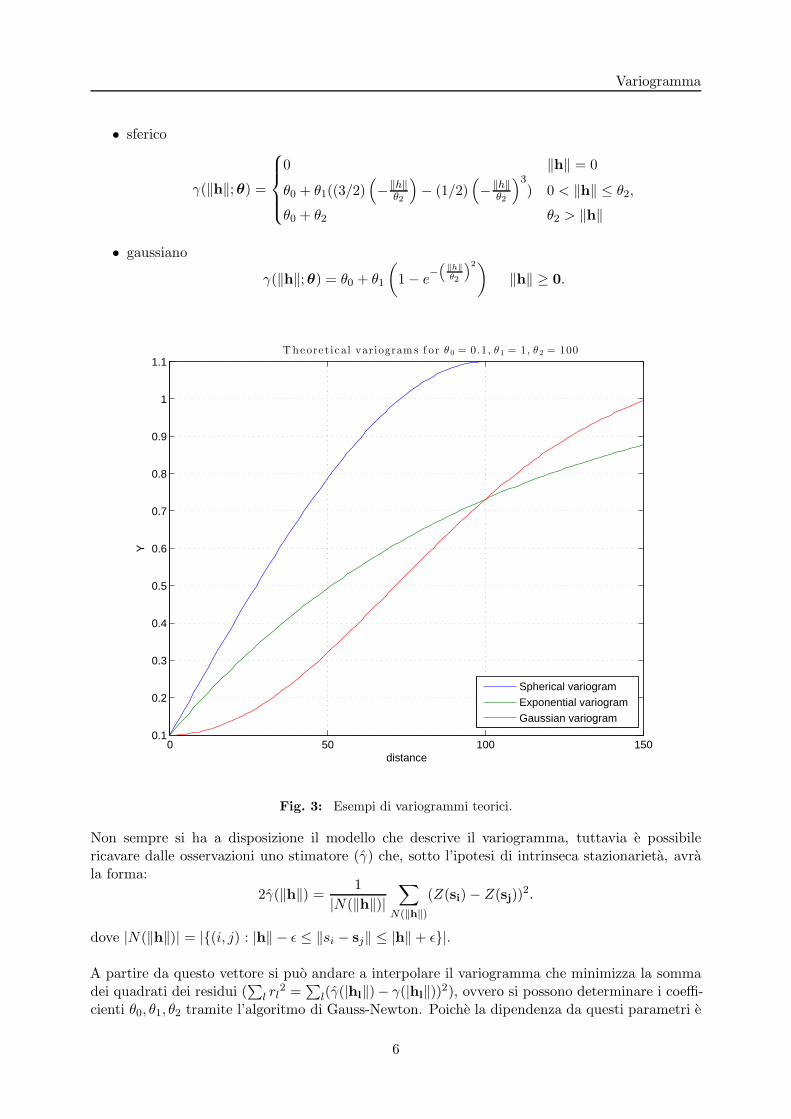
Il semivariogramma e una funzione γ : Rn → [0,+∞) che, ricevendo in ingresso la distanza tradue punti ‖h‖ = ‖si − sj‖, descrive la loro dipendenza spaziale rispetto a un certo processo sto-castico o a un determinato campo variabile (si definira variogramma la funzione 2γ(‖h‖)). Talefunzione tipicamente presenta una dipendenza da soli tre parametri, chiamati range, sill e nugget,che permettono di cogliere delle informazioni di base sulla distribuzione delle osservazioni. Seil semi-variogramma raggiunge un valore limite (chiamato sill), significa che esiste una distanza,detta range, oltre la quale la variabile di interesse non presenta piu dipendenza spaziale, ovveroil range individua le zone di influenza di un campione. Il nugget rappresenta una discontinuitadella variabile localizzata nell’origine che modellizza l’errore sperimentale di misurazione o l’ina-deguatezza della griglia spaziale su cui si effettua la misurazione. Per ulteriori approfondimentisi veda ad esempio [Cre93].
Il processo di stima del variogramma richiede la costruzione di uno stimatore empirico e ladeterminazione dei parametri di un modello parametrico opportunamente scelto, che siano ottimisecondo un criterio stabilito (ad esempio i minimi quadrati). Una volta stimato il variogrammaottenuto puo essere trattato come un parametro che verra valutato in funzione delle osservazioni,o in funzione dei punti in cui si vuole effettuare la previsione. Ci limitiamo a ricordare che il va-riogramma sara caratterizzato da certe proprieta, tra le quali l’essere condizionatamente definitanon negativa, simmetrica, nulla in 0 e con asintoto al crescere della distanza ‖h‖ (per modellizzarela diminuzione della correlazione tra i punti).
Diremo il modello statistico intrinsecamente stazionario se:
E(Z(s+ h)− Z(s)) = 0 var(Z(s+ h)− Z(s)) = 2γ(‖h‖),
mentre definiremo il modello debolmente (o del second’ordine) stazionario se:
E(Z(s)) = µ Cov(Z(si), Z(sj)) = C(si − sj),
dove C rappresenta il covariogramma, che, sotto l’ipotesi di ergodicita (C(‖h‖) → 0 per ‖h‖) → 0),si puo legare direttamente al variogramma, ovvero
γ(‖h‖) = C(0)− C(‖h‖).
Tale proprieta risulta interessante per quei variogrammi che definiscono un range limitato, inquanto permette di avere una funzione che si annulla per tutti quei valori al di fuori del range.Riportiamo alcuni esempi dei principali variogrammi:
• esponenziale
γ(‖h‖;θ) = θ0 + θ1
(
1− e−
‖h‖θ2
)
‖h‖ ≥ 0,
5
Variogramma
• sferico
γ(‖h‖;θ) =
0 ‖h‖ = 0
θ0 + θ1((3/2)(
−‖h‖θ2
)
− (1/2)(
−‖h‖θ2
)3) 0 < ‖h‖ ≤ θ2,
θ0 + θ2 θ2 > ‖h‖
• gaussiano
γ(‖h‖;θ) = θ0 + θ1
(
1− e−(
‖h‖θ2
)2)
‖h‖ ≥ 0.
0 50 100 1500.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
distance
Y
Theore tic al variogram s f or θ 0 = 0 .1 , θ 1 = 1 , θ 2 = 100
Spherical variogram
Exponential variogram
Gaussian variogram
Fig. 3: Esempi di variogrammi teorici.
Non sempre si ha a disposizione il modello che descrive il variogramma, tuttavia e possibilericavare dalle osservazioni uno stimatore (γ) che, sotto l’ipotesi di intrinseca stazionarieta, avrala forma:
2γ(‖h‖) =1
|N(‖h‖)|
∑
N(‖h‖)
(Z(si)− Z(sj))2.
dove |N(‖h‖)| = |(i, j) : |h‖ − ǫ ≤ ‖si − sj‖ ≤ |h‖+ ǫ|.
A partire da questo vettore si puo andare a interpolare il variogramma che minimizza la sommadei quadrati dei residui (
∑
l rl2 =
∑
l(γ(|hl‖)− γ(|hl‖))2), ovvero si possono determinare i coeffi-
cienti θ0, θ1, θ2 tramite l’algoritmo di Gauss-Newton. Poiche la dipendenza da questi parametri e
6

Variogramma
presente solo nel variogramma che vogliamo interpolare, possiamo scrivere il metodo iterativo co-struendo il Jacobiano (Jγ) del solo variogramma (al posto del residuo). In questo caso l’iterazionediviene:
θk+1 = θ
k + (JγTJγ)
−1JγT r. (1)
con θ = (θ0, θ1, θ2)T e r il vettore con componenti i residui valutati nei punti noti. Osserviamo che
il metodo risulta ben definito nella costruzione dello Jacobiano per i variogrammi esponenziale ogaussiano, dove e immediata la composizione delle derivate, per il caso sferico invece si sfruttanole differenze finite per l’approssimazione della derivata rispetto al terzo parametro.
Nel caso di un processo multivariato, in cui ogni componente abbia il proprio variogramma,si puo generalizzare definendo i cross-variogrammi come:
var(Zi(s+ h)− Zj(s)) = 2γij(‖h‖)
oppureCov(Zi(s+ h)− Zi(s), Zj(s+ h)− Zj(s)) = 2νij(‖h‖).
La stima del cross-variogramma empirico puo essere fatta in base a numerose tecniche; adesempio una scelta possibile e quella di utilizzare come stimatore la seguente espressione:
2γ1,2(‖h‖) =1
|N(‖h‖)|
∑
N(‖h‖)
(Z1(si)− Z1(sj))(Z2(si)− Z2(sj)),
con |N(‖h‖)| = |(i, j) : ‖h‖ − ǫ ≤ ‖si − sj‖ ≤ ‖h‖ + ǫ|. A partire dal vettore γ, nell’ipotesipiu semplice, si puo andare a interpolare il variogramma come nel caso monocomponente, mini-mizzando la somma dei quadrati dei residui, ovvero determinando i coefficienti θ0, θ1, θ2 tramitel’algoritmo di Gauss-Newton.
3.2 Implementazione
In questa sottosezione vogliamo sottolineare alcune caratteristiche del codice implementato, inparticolare ci soffermeremo sulle funzioni in grado di gestire il variogramma, di costruire il suostimatore empirico e di operare il fitting di quello teorico.
Poiche le componenti fondamentali per lo studio della continuita spaziale sono il dataset (pun-ti geometrici e osservazioni) e il variogramma teorico, si e scelto di predisporre due classi chepermettano di contenere queste informazioni e di rielaborarle.
Per avere a disposizione il variogramma teorico e le sue derivate, come funzioni della distanza(‖h‖) e dei parametri (θ0, θ1, θ2), utilizziamo una lambda function, ovvero un costrutto introdottocon il nuovo standard (C++11) che ci permetta di creare una funzione inline, ad esempio:
1 auto SphericalVariogram = []( Real h, Real theta0 ,Real theta1 , Real theta2)
2 return ( theta0 + theta1 )*(h>theta2) + ( theta0 + theta1 *(3* h/(2* theta2)
3 - (1./2)*( h/theta2 )*(h/theta2 )*(h/theta2) ) )*(h<= theta2) ;
4 ;
Questo costrutto ci permette di ottenere, oltre alla maggiore efficienza dovuta all’operazionedi inlining, anche la possibilita di passarlo ad altre funzioni senza dover definire un puntatorea funzione (nella standard library si trovano funzioni appositamente costruite per ricevere iningresso tali costrutti e eseguire in maniera piu efficace certe operazioni). Abbiamo raccoltoalcuni variogrammi all’interno del file correlationModels.hpp, ma si e scelto di lasciare libertaall’utente di includerne altri basati sul costrutto precedente. Per fare questo si fornisce unaclasse VariogramStorage che gestisca il variogramma, il co-variogramma e le sue derivate, di cuiriportiamo lo scheletro principale:
7

Variogramma
1 class VariogramStorage
2
3 public:
4 VariogramStorage ( ... ) ... ;
5 ...
6 private:
7 std:: function <Real (Real ,Real ,Real ,Real )> var;
8 std:: function <Real(Real ,Real ,Real ,Real )> cvar;
9 std:: vector <std :: function <Real (Real ,Real ,Real ,Real)> > derivatives ;
10 ;
All’utente e solo richiesto di chiamare il costruttore per inserire all’interno della classe il va-riogramma di cui vorrebbe fare uso e il covariogramma e le derivate associate; la classe contienepoi delle funzioni che permettono di estrarre le informazioni necessarie.
Il secondo contenitore necessario, implementato mediante la classe DataStorage, permette diraccogliere le informazioni riguardati il dataset (insieme dei punti geometrici e i valori associatidelle variabili aleatorie) e riguardanti il variogramma empirico e teorico associati. Inoltre dovendolavorare lungo tutto il processo (pre-processing e fase di previsione vera e propria) con le distanzetra i punti delle osservazioni a disposizione il costruttore svolge questi calcoli una sola volta e tienememorizzate le distanze in una matrice triangolare superiore (dove la posizione (i, j) contiene ilvalore riferito alla distanza tra l’i-simo punto e il j-simo punto).
Riportiamo l’albero delle dipendenze dei file generati, osserviamo che la classe DataStorage
fa quindi da sintesi tra tutte le strutture necessarie al pre-processing, ovvero quelle relative allostudio del variogramma, e da strumento di partenza per l’operazione di previsione.
Fig. 4: Albero delle dipendenze con padre DataStorage.hpp.
Fig. 5: Albero delle dipendenze con figlio DataStorage.hpp.
8

Variogramma
All’interno del file DataStorage.hpp l’implementazione prevede una classe base DataStora-
ge<CoordType,N>, che permette, coerentemente a quanto fatto per la classe Point in points.hpp,di lasciare liberta ai futuri utenti di utilizzare il codice anche in dimensione diversa da 2 conun’opportuna specializzazione della classe.
1 template <typename CoordType , unsigned int N>
2 class DataStorage
3
4 DataStorage (const std :: vector <Geom :: Point <CoordType ,N> > &Data )
5
6 std:: cerr << "Need a class specialization for this dimension ";
7 ;
8
9 ~DataStorage ();
10
11 inline CoordType getMinh () return minh ; ;
12 inline CoordType getMaxh () return maxh ; ;
13 Eigen:: SparseMatrix <CoordType > getDistance () return distance ; ;
14
15 private:
16 CoordType maxh ,minh ;
17 Eigen:: SparseMatrix <CoordType > distance ;
18 ;
Riportiamo di seguito lo scheletro della specializzazione per il caso bidimensionale, in modo daevidenziare la presenza del calcolo della matrice delle distanze all’interno del costruttore e dellefunzioni per il calcolo del variogramma empirico e per il calcolo dei coefficienti del variogrammateorico.
1 // specialization
2 template <typename CoordType >
3 class DataStorage <CoordType ,2>
4
5 public:
6 DataStorage (const std :: vector <Geom :: Point <CoordType ,2> > &Data )
7
8 // compute the matrix of distances
9 ;
10
11 std::pair <.., .. > computeEmpiricalVar ( ...)
12
13 // compute the vector of empirical variogram
14 ;
15
16 std:: tuple <.,.,.> computeTheta ( ... )
17
18 // compute parameters of theoretical variogram with Gauss -Newton method
19 ;
20
21 inline CoordType getMinh () return minh ; ;
22 inline CoordType getMaxh () return maxh ; ;
23 Eigen:: SparseMatrix <CoordType > getDistance () return distance ; ;
24
25 private:
26 CoordType maxh ,minh ;
27 Eigen:: SparseMatrix <CoordType > distance ;
28 ;
Utilizzando l’ereditarieta distinguiamo due ulteriori classi in base al metodo che si vorra appli-care in seguito: il kriging infatti lavora su una sola variabile, richiedendo quindi come informazioni
9

Variogramma
di input un solo variogramma teorico e la matrice delle distanze, viceversa il co-kriging lavoracon due variabili (una principale e una di appoggio), richiedendo quindi un variogramma per ognivariabile e uno che ne descriva la cross-dipendenza.
Fig. 6: Ereditarieta della specializzazione di DataStorage per punti di dimensione 2.
Per entrambe le classi proponiamo due costruttori diversi:
1. il primo riceve tutte le informazioni necessarie alla previsione, nel caso in cui si conosca apriori il modello sottostante (in questo caso richiamando il costuttore DataStorage l’unicaoperazione effettuata e la costruzione della matrice delle distanze);
1 DataKriging ( const std:: vector <Geom :: Point <CoordType ,2> > &D,
2 VariogramStorage &v,
3 const std::tuple <CoordType ,CoordType ,CoordType > &t ) :
4 DataStorage <CoordType ,2>(D)
5
6 var=v;
7 theta=t;
8 ;
2. il secondo invece, da utilizzare nel caso di assenza di informazioni a priori, procede auto-maticamente con la costruzione della matrice delle distanze, con il calcolo del variogrammaempirico e con la determinazione dei parametri del variogramma teorico mediante l’algo-ritmo di Gauss-Newton. Il codice e stato pensato in modo da minimizzare l’interventodell’utente, producendo automaticamente un’analisi completa del dataset.
1 DataKriging (const std:: vector <Geom ::Point <CoordType ,2> > & Da ,
2 const Eigen:: VectorXd &y, VariogramStorage &v,
3 const std:: tuple <CoordType ,CoordType ,CoordType > &theta0 ,
4 int numCamp , CoordType toll , int maxiter) :
5 DataStorage <CoordType ,2>(Da)
6
7 // save
8 // compute empirical variogram
9 // computeTheta
10 ;
Infine osserviamo che risulta necessario gestire due tipi di eccezioni: la divisione per 0, che puooccorrere nella costruzione del variogramma empirico se i punti a disposizione sono minori deipunti che si vogliono costruire, e l’overflow, dovuto al tentativo di fitting dei coefficienti delvariogramma teorico con una guess iniziale troppo lontana dalla soluzione finale o dall’uso diun variogramma teorico non coerente con i dati a disposizione. Non avendo a disposizione ilfloating-point environment (FENV) (non supportato da clang) andiamo a definire l’exception nelseguente modo:
10

Variogramma
1 // Bad division
2 class BadDivision : public std:: runtime_error
3 public:
4 BadDivision (std :: string const & s): runtime_error (s);
5 virtual ~BadDivision ()
6 ;
7
8 //! Zero division
9 class ZeroDivision : public BadDivision
10 public:
11 ZeroDivision (std :: string const & s="Divide by zero"):
12 BadDivision (s)
13 virtual ~ ZeroDivision ()
14 ;
e utilizziamo il costrutto try-catch per catturare l’eccezione lanciata dal blocco try , adesempio nel caso della stima del variogramma empirico:
1 try
2 Empirical [i]= Empirical [i]/(2*Nh[i]);
3 test_fpe_exception (true );
4
5 catch (BadDivision & x)
6 std ::cerr <<x.what ()<<std:: endl ;
7
oppure per l’implementazione dell’algoritmo di Gauss-Newton:
1 do
2 ++ iter ;
3 thetaOld =theta;
4 // compute Jacobian
5 for(auto i=0; i<numCamp -1; ++i)
6
7 Jf(i,0)= whichV. dTheta0Variogram ()( pos[i], theta(0), theta(1), theta (2) );
8 Jf(i ,1)= whichV. dTheta1Variogram ()( pos[i], theta(0), theta(1), theta (2) );
9 Jf(i ,2)= whichV. dTheta2Variogram ()( pos[i], theta(0), theta(1), theta (2) );
10 r(i)= empirical [i]-whichV.variogram ()( pos[i], theta(0), theta(1), theta (2));
11
12 JfT=Jf.transpose (); // transpose
13 // solve and check that the solution do not diverge
14 try
15
16 theta=( JfT * Jf ). llt (). solve(JfT*r);
17 test_fpe_exception (true );
18
19 catch (BadFPOper & x)
20
21 std ::cerr <<x.what ()<<std:: endl ;
22 std ::cerr <<"Try another variogram or change initial guess!"<<std:: endl ;
23 throw "Abort";
24
25 catch ( BadDivision & x)
26 std ::cerr <<x.what ()<<std:: endl ;
27
28 catch (...)
29 std ::cout <<"Another (unknown) exception occurred "<<std:: endl ;
30
31
32 theta=theta+thetaOld ;
33
11

Variogramma
34 while( (fabs ( theta(0)- thetaOld (0) ) > toll || ... &&iter <maxiter );
3.3 Caso test Meuse
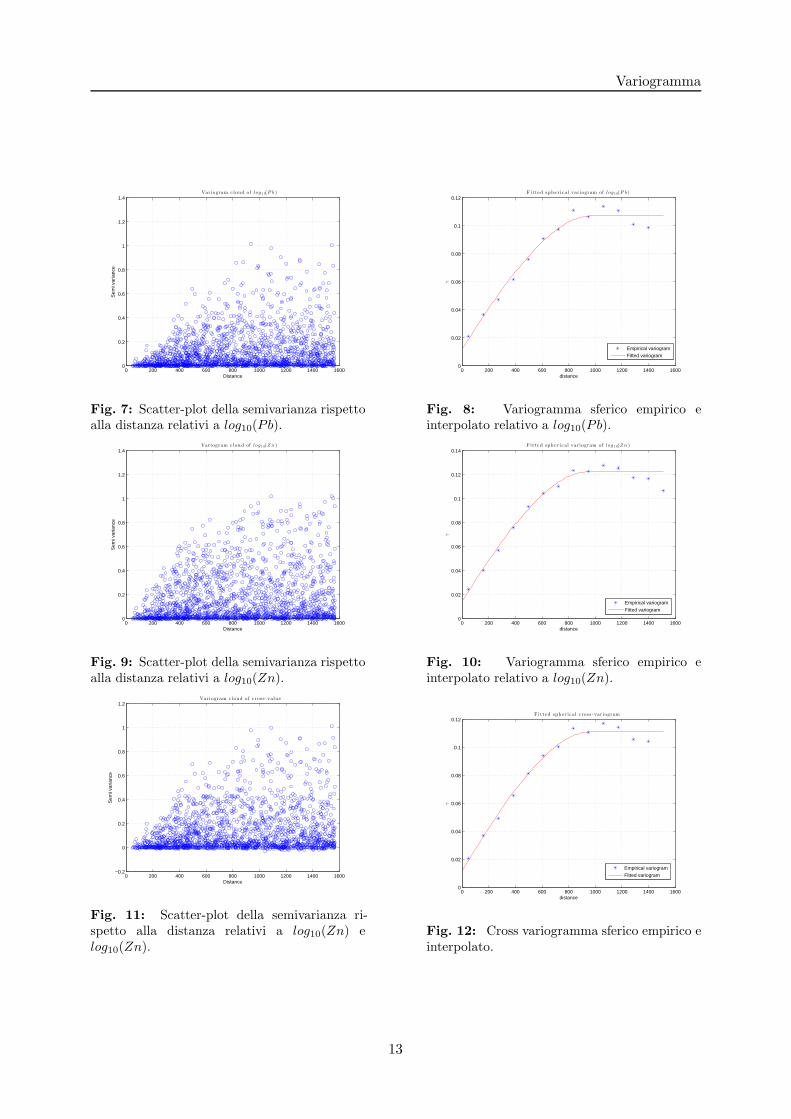
Riportiamo i risultati ottenuti utilizzando il codice con i dati provenienti dal caso test introdottonella sezione (2.2). In particolare nelle figure successive vengono presentati gli andamenti delloscatter-plot e del variogramma empirico e teorico con coefficienti determinati con il metodo diGauss-Newton per la variabile di interesse log10(Pb), per la co-variabile log10(Zn) e infine la lorocross-dipendenza spaziale. Osserviamo che sia dagli scatter-plot che dalla rappresentazione delvariogramma empirico abbiamo evidenza per concludere che esiste una dipendenza spaziale siaper le singole variabili che tra una variabile e l’altra. La presenza di un valore asintotico suggerisceil fitting tramite variogramma sferico (riportato anch’esso nelle figure). La rappresentazione deirisultati e stata effettuata con l’utilizzo di MATLAB.
12
Variogramma
0 200 400 600 800 1000 1200 1400 16000
0.2
0.4
0.6
0.8
1
1.2
1.4
Sem
i var
ianc
e
Distance
Variogram c loud of log 1 0(P b )
Fig. 7: Scatter-plot della semivarianza rispettoalla distanza relativi a log10(Pb).
0 200 400 600 800 1000 1200 1400 16000
0.02
0.04
0.06
0.08
0.1
0.12
distance
γ
F itte d sphe ric al variogram of log 1 0(P b )
Empirical variogram
Fitted variogram
Fig. 8: Variogramma sferico empirico einterpolato relativo a log10(Pb).
0 200 400 600 800 1000 1200 1400 16000
0.2
0.4
0.6
0.8
1
1.2
1.4
Sem
i var
ianc
e
Distance
Variogram c loud of log 1 0(Zn )
Fig. 9: Scatter-plot della semivarianza rispettoalla distanza relativi a log10(Zn).
0 200 400 600 800 1000 1200 1400 16000
0.02
0.04
0.06
0.08
0.1
0.12
0.14
distance
γF itte d sphe ric al variogram of log 1 0(Zn )
Empirical variogram
Fitted variogram
Fig. 10: Variogramma sferico empirico einterpolato relativo a log10(Zn).
0 200 400 600 800 1000 1200 1400 1600−0.2
0
0.2
0.4
0.6
0.8
1
1.2
Sem
i var
ianc
e
Distance
Variogram c loud of c ross- valu e
Fig. 11: Scatter-plot della semivarianza ri-spetto alla distanza relativi a log10(Zn) elog10(Zn).
0 200 400 600 800 1000 1200 1400 16000
0.02
0.04
0.06
0.08
0.1
0.12
distance
γ
F itte d sphe ric al c ross- variogram
Empirical variogram
Fitted variogram
Fig. 12: Cross variogramma sferico empirico einterpolato.
13

Kriging
4 Kriging
Il kriging consiste nella determinazione di un modello statistico a partire dai dati disponibili, tra-mite la definizione del variogramma, seguita dalla costruzione di un previsore ottimo dato dallacombinazione lineare dei dati.
4.1 Principali nozioni teoriche
In statistica l’affidabilita di un modello si misura utilizzando lo standard error, in particolare aven-do a disposizione dati dipendenti tra di loro si utilizza l’errore quadrati medio (MSE). Il kriging equel metodo che, per predire Z(s0), permette di trovare l’insieme di coefficienti della combinazio-ne lineare delle osservazioni Z(s1), Z(s2), .., Z(sn) piu affidabile, ovvero che minimizzi l’errorequadratico medio.Quindi in generale il metodo genera un predittore del tipo:
p∗(Z; s0) =
n∑
i=1
λiZ(si −m(si)) +m(s0).
dove i pesi λi sono ricavati minimizzando l’errore quadratico medio sotto il vincolo di non distor-sione. Infatti l’assunzione che le osservazioni siano distribuite come un campione gaussiano, cipermette di avere una distribuzione congiunta (Z(s0),Z
′) gaussiana, la media E(Z(s0)|Z) linearein Z e dipendente solamente da µ(si), e C(si, sj) = cov(Z(si), Z(sj)). Poiche il miglior predittorein grado di minimizzare MSE e E(Z(s0)|Z), in questo caso otteniamo il predittore lineare di cuisopra.
Si distinguono tre tipi di kriging in relazione alla stazionarieta o meno del processo considerato:simple (se stazionario a media nota), ordinary (se stazionario a media incognita) e universal kriging(se non stazionario, con media espressa mediante un coefficiente di drift). In tutti e tre i casi ladeterminazione dei coefficienti avviene tramite la minimizzazione dell’errore quadratico mediosotto il vincolo di non distorsione:
λλλ = argminλ∈Rn|E[Z∗(s0)]=[Z(s0)]
V ar[
n∑
i=1
λiZ(si)− Z(s0)].
Questo si traduce dal punto di vista matematico in un sistema lineare di equazioni la cui solu-zione e esattamente l’insieme di coefficienti λi forniscono la migliore previsione possibile (quellaaffetta dalla minor incertezza). I coefficienti della matrice e del vettore che formano il sistemalineare sono tutte valutazioni del variogramma: nel caso della matrice con elementi valutati nelledistanze tra i punti del dataset e nel caso dei vettori con elementi valutati nelle distanze tra ilpunto da prevedere (s0) e i punti noti.
Poiche nel simple kriging la mediam e nota, non compaiono ulteriori vincoli di non distorsione,quindi la struttura del sistema da risolvere e del tipo:
γ(0) γ(‖s1 − s2‖) · · · γ(‖s1 − sn‖)γ(‖s2 − s1‖) γ(0) · · · γ(‖s2 − sn‖)
.... . .
...γ(‖sn − s1‖) γ(‖sn − s2‖) · · · γ(0)
λ1λ2...λn
=
γ(‖s0 − s1‖)γ(‖s0 − s2‖)
...γ(‖s0 − sn‖)
(2)
14

Kriging
Oltre al predittore e possibile determinare una stima, detta varianza di kriging, della variabilitaadella stima puntuale fornita dal metodo. Questa varianza e esprimibile per il simple kriging come:
σ2SK =
n∑
1
λiγi(s0 − si).
Nel sottocaso dell’ordinary kriging, avendo la media µ incognita, si costruisce il modello conla seguente assunzione
Z(s) = µ+ δ(s);
ne consegue che il predittore sara
p∗(Z; s0) =
n∑
i=1
λiZ(si) t.c.
n∑
i=1
λi = 1
dove la seconda equazione rappresenta il vincolo di non distorsione. Si tratta in questo caso dirisolvere il seguente sistema lineare:
γ(0) γ(‖s1 − s2‖) · · · γ(‖s1 − sn‖) 1γ(‖s2 − s1‖) γ(0) · · · γ(‖s2 − sn‖) 1
.... . .
...γ(‖sn − s1‖) γ(‖sn − s2‖) · · · γ(0) 1
1 1 · · · 1 0
λ1λ2...λnν
=
γ(‖s0 − s1‖)γ(‖s0 − s2‖)
...γ(‖s0 − sn‖)
1
(3)
dove l’ultima riga e l’ultima colonna della matrice sono dovute al rilassamento mediante molti-plicatore di Lagrange (ν) del vincolo di non distorsione. In questo caso la varianza di ordinarykriging e esprimibile come:
σ2OK =
n∑
1
λiγi(s0 − si) + ν.
Infine lo universal kriging costruisce un modello con la presenza del drift:
Z(s) = µ(s) + δ(s) µ(s) =m∑
k=1
akfk(s)
ne consegue che il predittore sara
p∗(Z; s0) =n∑
i=1
λiZ(si) t.c.n∑
i=1
λifk(si) = fk(s0) k = 1 : m+ 1
dove la seconda equazione rappresenta gli m + 1 vincoli di non distorsione. Si tratta in questocaso di risolvere il seguente sistema lineare:
γ(0) · · · γ(‖s1 − sn‖) 1 f1(s1) · · · fm(s1)...
. . .... 1
......
γ(‖sn − s1‖) · · · γ(0) 1 f1(sn) · · · fm(sn)1 1 1 0 0 0
f1(s1) · · · f1(sn) 0 · · ·...
...... 0 0
fm(s1) · · · fm(sn) 0 0 0
λ1λ2...λnν0ν1...νm
=
γ(‖s0 − s1‖)γ(‖s0 − s2‖)
...γ(‖s0 − sn‖)
1f1(s0)
...fm(s0)
(4)
15

Kriging
con m + 1 moltiplicatori di Lagrange(νk) dei vincoli di non distorsione sopra citati. In questasituazione la varianza dello universal kriging e esprimibile come:
σ2UK =n∑
1
λiγi(s0 − si) +m∑
k=1
νkfk(s0).
4.2 Implementazione
Per ragioni computazionali di gestione opportuna della memoria, avendo a che fare con matricidi grandi dimensioni, si preferisce riformulare i sistemi lineari in funzione del co-variogrammaC, che ricordiamo puo essere legato, sotto l’ipotesi di ergodicita (C(‖h‖) → 0 per ‖h‖) → 0),direttamente al variogramma:
γ(‖h‖) = C(0)− C(‖h‖).
In questo modo riusciamo a ottenere una matrice sparsa nel caso di variogramma sferico, dovericordiamo che per distanze maggiori del range, definito da θ2, il variogramma γ(‖h‖) = θ0 + θ1e quindi il co-variogramma C(‖h‖) = 0. Tale formulazione fornisce potenzialmente due vantaggi:
• la possibilita di utilizzare matrici sparse;
• migliori proprieta associate alla matrice che permettono di ricavare piu facilmente la pseudo-inversa.
Facendo uso della libreria Eigen e necessario un compromesso tra i due in quanto non e ancorapresente l’implementazione della singular value decomposition per matrici sparse. Poiche la pre-visione con il kriging ha come punto fondamentale la costruzione della pseudoinversa si e sceltodi sacrificare la possibilita di minimizzare la memoria utilizzata (obiettivo che nelle altre parti delcodice si e cercato di perseguire).
In base a quanto anticipato nella precedente sezione i sistemi lineari associati ai tre tipi dikriging (2), (3) e (4) sono diversi tra di loro, questo implica la necessita di definire per ognunouna classe diversa con costruttore e funzioni per la predizione diverse tra di loro. Tale scelta emotivata inoltre dalla possibilita di rendere maggiormente efficiente la previsione ripetuta per piupunti: fornendo dei costruttori che implementino la pseudoinversa della matrice il lavoro di pre-visione prevede quindi operazioni di tipo prodotto matrice vettore (al piu di complessita O(N2)).Inoltre per ogni previsione e necessario creare solamente il vettore associato ad ogni valutazione,in quanto la matrice rimane associata alla classe.
La struttura di base del codice prevede quindi la presenza di due costruttori, che si preoccupinoentrambi di costruire (localmente e temporaneamente) la matrice dei covariogrammi e di calcolaree memorizzare la sua pseudoinversa (non abbiamo risultati a priori di invertibilita della matrice),ma con variabili di input diverse tra di loro:
1. un primo costruttore coerentemente con la struttura fino ad ora implementata riceve iningresso la classe DataKriging, in cui ha tutte le informazioni necessarie per la previsione(e pensato per l’utente che avendo a disposizione il solo dataset iniziale necessita dell’interoprocesso di stima e previsione);
1 SimpleKriging ( DataKriging <CoordType > & dataK , const CoordType Ym)
2
3 ...
4
16

Kriging
2. un secondo costruttore, pensato per l’utente che vuole solo utilizzare questa parte di codice,richiede di fornire le sole informazioni di base per la computazione.
1 SimpleKriging (Eigen:: SparseMatrix <CoordType > distance ,
2 const CoordType Ym ,
3 const std:: function <Real(Real ,Real ,Real ,Real )> &wV ,
4 const std:: tuple <Real ,Real ,Real > &T)
5
6
7
Osserviamo che una volta chiamato uno di questi costruttori le uniche informazioni da mantenerein memoria sono:
• la pseudo inversa (Eigen::MatrixXd);
• il variogramma / covariogramma (std::function<Real(Real,Real,Real,Real)>);
• i valori dei parametri associati al variogramma (std::tuple<Real,Real,Real>).
La classe si completa poi di due predittori diversi, uno per la previsione della variabile per unsingolo punto, il secondo invece per una griglia di punti. Riportiamo di seguito la struttura dellaclasse relativa al simple kriging :
1 template <typename CoordType >
2 class SimpleKriging
3
4 public:
5
6 SimpleKriging ( . , . , . )
7
8 // build the matrix of co -variograms
9 // compute SVD
10
11
12 ~SimpleKriging ();
13
14 std:: pair <CoordType ,CoordType > predictor ( . , . , . )
15
16 // compute the vector of the system
17 // get the coefficients
18 // compute the linear combination and the simple kriging variance
19
20
21 std:: vector <std ::pair <CoordType ,CoordType > > GridPredictor ( )
22
23 private:
24 Eigen:: MatrixXd PseudoGamma ;
25
26 CoordType Ymean;
27
28 std:: tuple <Real ,Real ,Real > theta;
29
30 std:: function <Real(Real ,Real ,Real ,Real )> whichVariogram ;
31 ;
Avendo a disposizione le informazioni contenute nella classe il predittore non fa altro che calcolarei pesi λi con un operazione di tipo moltiplicazione matrice vettore, costruisce la combinazionelineare con le osservazioni a disposizione e valuta anche la varianza di kriging. Lo schema relativodel codice:
17

Kriging
1 std::pair < .. , ...> predictor ( coord , Points , Z )
2
3 // get dimension
4 auto m=coord.size ();
5 // initializating vector (right side of the system)
6 Eigen:: VectorXd gam(m);
7 for (auto i=0; i<m; ++i)
8
9 gam(i)= whichVariogram ( DistanceEucl (P,coord[i]) , std::get <0>( theta),
10 std ::get <1>( theta), std::get <2>( theta) );
11
12
13 // computation of the prediction :
14
15 // get the coefficients
16 Eigen:: VectorXd lambda=PseudoGamma *gam;
17
18 // compute the linear combination and the simple kriging variance
19 Real Ysol =0., sigma2=std::get <0>( theta)+ std ::get <1>( theta);
20 for(auto i=0; i<m ; ++i)
21
22 Ysol += lambda(i)*(YY(i)-Ymean);
23 sigma2 -= lambda(i)* gam(i);
24
25 Ysol += Ymean;
26
27 // return the prediction and the simple kriging variance
28 return std :: make_pair (Ysol ,sigma2);
29
30 ;
4.3 Caso test Meuse
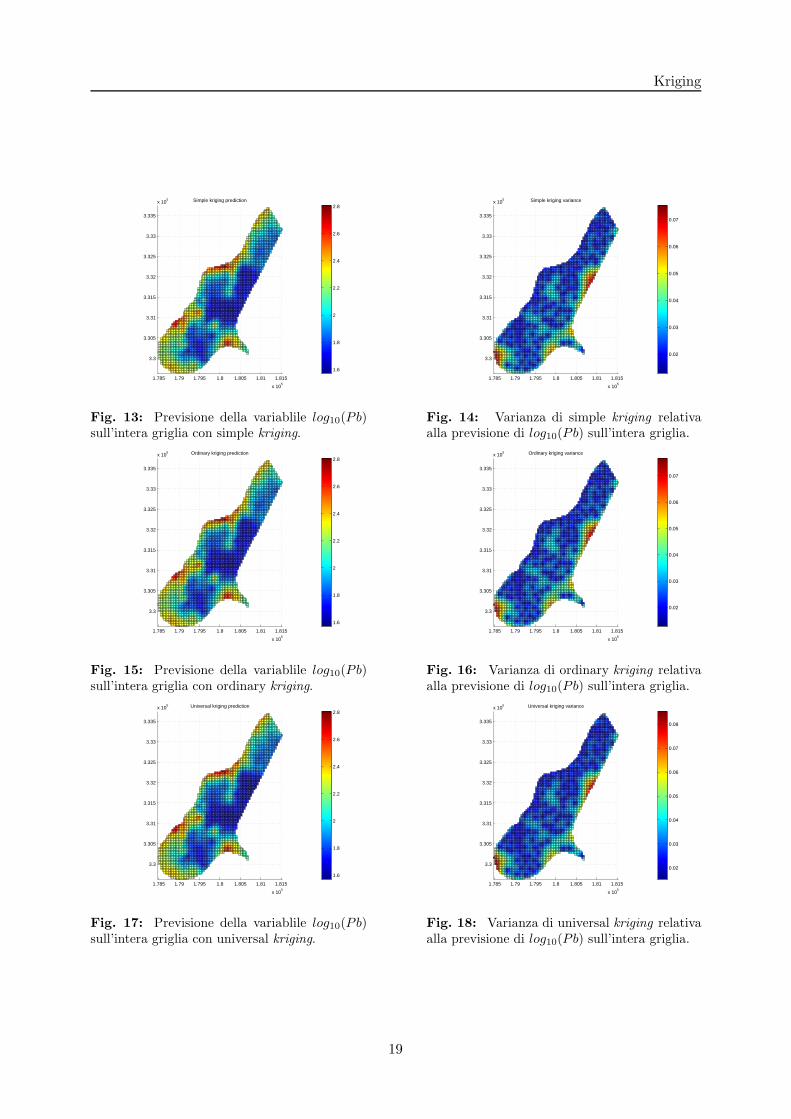
Riportiamo in relazione al caso test introdotto nella sezione (2.2) i risultati ottenuti nella previsio-ne della variabile log10(Pb) e della sua varianza, applicando i modelli di kriging (simple, ordinarye universal). Osserviamo che per questo caso test i risultati sono sostanzialmente equivalenti,notiamo soltanto che la varianza presenta delle regioni in cui e minore rispetto agli altri metodiper lo universal kriging, che infatti e quel metodo che racchiude il maggior numero di informazioni,avendo l’aggiuntiva parte di drift. Tra i tre metodi e pero quello che richiede il maggiore costocomputazionale, avendo il sistema associato di maggiori dimensioni.
18
Kriging
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Simple kriging prediction
1.6
1.8
2
2.2
2.4
2.6
2.8
Fig. 13: Previsione della variablile log10(Pb)sull’intera griglia con simple kriging.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Simple kriging variance
0.02
0.03
0.04
0.05
0.06
0.07
Fig. 14: Varianza di simple kriging relativaalla previsione di log10(Pb) sull’intera griglia.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Ordinary kriging prediction
1.6
1.8
2
2.2
2.4
2.6
2.8
Fig. 15: Previsione della variablile log10(Pb)sull’intera griglia con ordinary kriging.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Ordinary kriging variance
0.02
0.03
0.04
0.05
0.06
0.07
Fig. 16: Varianza di ordinary kriging relativaalla previsione di log10(Pb) sull’intera griglia.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Universal kriging prediction
1.6
1.8
2
2.2
2.4
2.6
2.8
Fig. 17: Previsione della variablile log10(Pb)sull’intera griglia con universal kriging.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Universal kriging variance
0.02
0.03
0.04
0.05
0.06
0.07
0.08
Fig. 18: Varianza di universal kriging relativaalla previsione di log10(Pb) sull’intera griglia.
19

Co-kriging
5 Co-kriging
Il co-kriging consente di considerare una o piu variabili (dette co-variabili), oltre a quella che sivuole stimare, in modo da aggiungere informazioni al modello usato per effettuare la previsione.Queste ultime possono essere misurate negli stessi punti, ma anche in punti diversi, fatto cheaccresce la complessita del problema.
5.1 Principali nozioni teoriche
La scelta della co-variabile e motivata dalla presenza di una correlazione con la variabile obiettivo,e dalla correlazione spaziale della stessa. Come anticipato nella sezione (2) i test esplorativi chepossiamo effettuare sono l’analisi degli scatter-plot e la costruzione dei cross-variogrammi empirici.
Avendo a disposizione i variogrammi per le singole componenti e il cross variogramma, nell’i-potesi di simmetria, si costruisce il sistema associato, come nel caso del kriging, andando pero asostituire ogni elemento con una sottomatrice:
γ(‖si − sj‖) =
[
γ1(‖si − sj‖) γcross(‖si − sj‖)γcross(‖si − sj‖) γ2(‖si − sj‖)
]
(5)
Ne segue che per l’ordinary co-kriging la struttura del sistema da risolvere e del tipo:
γ(0) γ(‖s1 − s2‖) · · · γ(‖s1 − sn‖) 1
γ(‖s2 − s1‖) γ(0) · · · γ(‖s2 − sn‖) 1
.... . .
...γ(‖sn − s1‖) γ(‖sn − s2‖) · · · γ(0) 1
1 1 · · · 1 0
λ1λ2...λnν
=
γ(‖s0 − s1‖)γ(‖s0 − s2‖)
...γ(‖s0 − sn‖)
1
e che la varianza di ordinary co-kriging e esprimibile come:
σ2OCK =
n∑
1
λiγi(s0 − si).
Invece per lo universal co-kriging la struttura del sistema da risolvere e del tipo:
γ(0) · · · γ(‖s1 − sn‖) 1 f1(s1) · · · fm(s1)...
. . .... 1
......
γ(‖sn − s1‖) · · · γ(0) 1 f1(sn) · · · fm(sn)1 1 1 0 0 0
f1(s1) · · · f1(sn) 0 · · ·...
...... 0 0
fm(s1) · · · fm(sn) 0 0 0
λ1λ2...λnν0ν1...νm
=
γ(‖s0 − s1‖)γ(‖s0 − s2‖)
...γ(‖s0 − sn‖)
1
f1(s0)...
fm(s0)
La varianza di universal co-kriging e esprimibile come:
σ2UCK =
n∑
1
λiγi(‖s0 − si‖) +
m∑
k=1
νkfk(s0)
Per ulteriori approfondimenti si veda ad esempio [Mye82].
20

Co-kriging
5.2 Implementazione
L’implementazione relativa segue la struttura introdotta per il kriging, ovvero viene implementatauna classe con due costruttori e due funzioni per la previsione di un singolo punto o di unagriglia di punti. Dovendo lavorare con due variabili il sistema lineare associato ha dimensionedoppia rispetto all’equivalente dato dal kriging, quindi la complessita computazionale associataalla risoluzione del sistema lineare cresce notevolmente. In particolare possiamo individuarecome due colli di bottiglia dell’esecuzione la costruzione della pseudoinversa e la predizione sullagriglia di punti. L’idea, dove e possibile, e quella di sfruttare la possibilita di parallelizzareil codice per ridurre al minimo i tempi di esecuzione. Per quanto riguarda il primo collo dibottiglia, dovendo utilizzare funzioni della libreria Eigen non e possibile intervenire, a menodi andare a scrivere una nuova funzione per il calcolo della della singular value decomposition(potrebbe essere un possibile sviluppo futuro del codice un implementazione per matrici sparsecon parallelizzazione). Invece riguardo il secondo collo di bottiglia il nuovo standard permette diutilizzare una programmazionemultithreading (ancora in via di sviluppo) che permette di sfruttareintensivamente le caratteristiche dei processori di ultima generazione. Utilizzando l’ambiente<thread> e possibile al momento chiamare funzioni statiche da assegnare ad ogni thread perl’esecuzione parallela: nel caso della previsione su una griglia di punti si vuole quindi suddividerel’intero vettore in un numero di sottovettori pari al numero di threads disponibili (8 per unprocessore Intel Core i7 quad-core di terza generazione) su cui eseguire in parallelo la previsione.La sintassi del codice e la seguente:
1 std:: vector <std ::pair <CoordType ,CoordType > > GridPredictorParallel( .,.,. )
2
3 const size_t nr_threads = std:: thread:: hardware_concurrency();
4 size_t nr_elements =Grid .size () ;
5 std:: vector <std ::thread > threads;
6
7 std:: vector <std ::pair <CoordType ,CoordType > > result;
8 result.resize( nr_elements );
9
10 std:: vector <size_t > limits;
11 limits. emplace_back (0);
12 for ( auto i=1; i<= nr_threads ; ++i )
13
14 limits. emplace_back ( (nr_elements *i)/ nr_threads );
15
16
17 for (size_t i=0; i< nr_threads ; ++i)
18
19 threads.push_back (std:: thread( GridPredictorStatic , std:: ref(coord), ..);
20
21
22 for (auto &t:threads )
23
24 t.join ();
25
26
27 return result;
28
29 ;
I risultati in termini di speed-up sono evidenti, infatti utilizzando l’ambiente <chrono> possiamoisolare il tempo di esecuzione per la predizione su una griglia di 3103 punti con direttiva al
21

Co-kriging
compilatore -0:sequenziale parallelo
ordinary co-kriging 0.399736s 0.138351suniversal co-kriging 0.927662s 0.322622s
5.3 Caso test Meuse
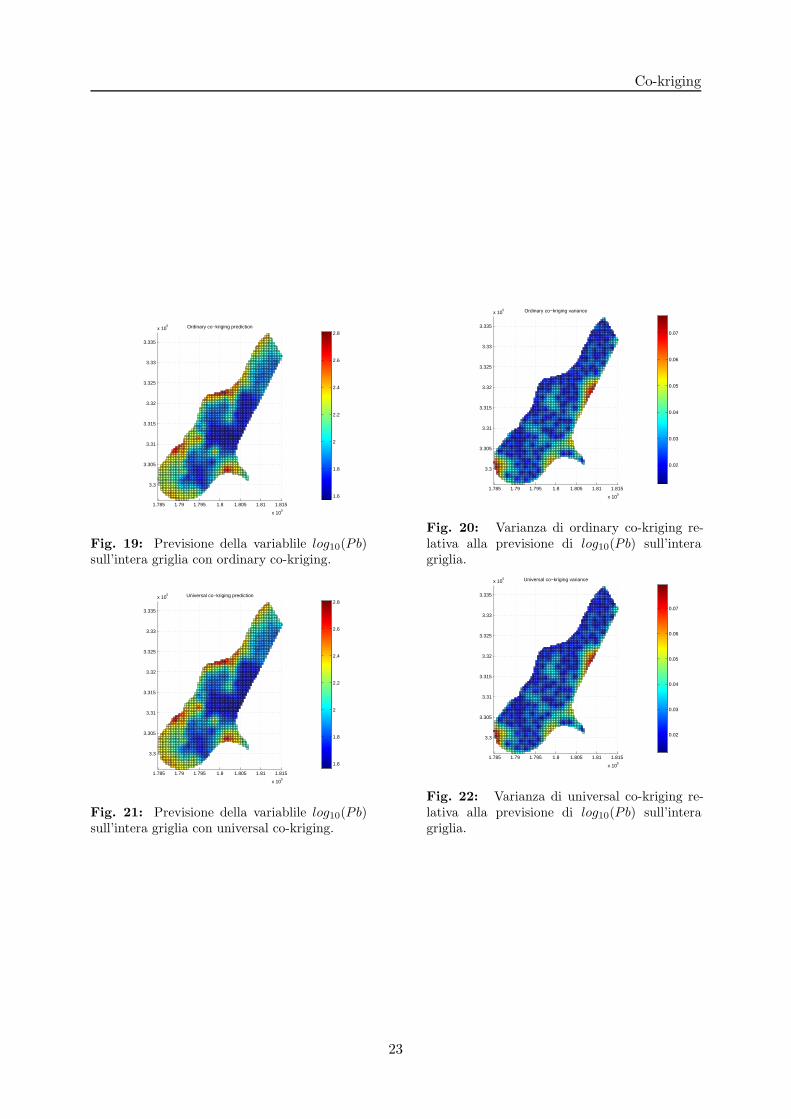
Riportiamo in relazione al caso test introdotto nella sezione (2.2) i risultati ottenuti nella previ-sione della variabile log10(Pb) e della sua varianza, applicando i modelli di co-kriging (ordinarye universal) con variabile di appoggio log10(Zn). Osserviamo che per questo caso test i risultatisono sostanzialmente equivalenti, a meno della varianza che risulta minore rispetto ai risultatiottenuti con kriging, grazie alle informazioni aggiuntive fornite dalla co-variabile.
22
Co-kriging
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Ordinary co−kriging prediction
1.6
1.8
2
2.2
2.4
2.6
2.8
Fig. 19: Previsione della variablile log10(Pb)sull’intera griglia con ordinary co-kriging.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Ordinary co−kriging variance
0.02
0.03
0.04
0.05
0.06
0.07
Fig. 20: Varianza di ordinary co-kriging re-lativa alla previsione di log10(Pb) sull’interagriglia.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Universal co−kriging prediction
1.6
1.8
2
2.2
2.4
2.6
2.8
Fig. 21: Previsione della variablile log10(Pb)sull’intera griglia con universal co-kriging.
1.785 1.79 1.795 1.8 1.805 1.81 1.815
x 105
3.3
3.305
3.31
3.315
3.32
3.325
3.33
3.335
x 105
Universal co−kriging variance
0.02
0.03
0.04
0.05
0.06
0.07
Fig. 22: Varianza di universal co-kriging re-lativa alla previsione di log10(Pb) sull’interagriglia.
23

Problemi di controllo con osservazioni puntuali
6 Problemi di controllo con osservazioni puntuali
Dopo aver sviluppato nelle precedenti sezioni la metodologia di base per la risoluzione di ungenerico problema di kriging e co-kriging, concentriamo ora l’attenzione sulla formulazione diun opportuno problema di controllo, motivato dall’applicazione che ha ispirato il progetto. Loscopo e permettere la ricostruizione, a partire da osservazioni puntuali, di una certa distribuzionespaziale che sara rappresentata dalla soluzione y(u) del relativo problema di controllo ottimo.
6.1 Osservazioni della soluzione
Consideriamo un generico problema primale con controllo distribuito
a(y(u), v) =< f + u, v >∗ ∀v ∈ V, (6)
in modo da fornire una formulazione generale, e definiamo il funzionale costo in modo da garantireche la soluzione y(u) che intendiamo ricostruire si avvicini a sufficienza (in senso puntuale inquesto caso) alle Nd osservazioni ydi
Nd
i=1 note nei punti di = (di,x, di,y) ∈ ΩNd
i=1. In questo casoil funzionale da minimizzare e
J(u) =1
2
Nd∑
i=1
αi(y(di)− ydi)2 +
δ
2‖u‖2U , (7)
con αi e δ costanti positive, che permettono, se necessario, di pesare in maniera opportuna idue termini: il primo rappresenta la differenza nel senso dei minimi quadrati tra la soluzionedel problema primale e le osservazioni ydi
Nd
i=1, il secondo (detto di penalizzazione) ha un ruolostabilizzante/regolarizzante, ovvero bilancia la non iniettivita dell’operatore C di osservazione,che in questo caso associa alla soluzione y(u) il valore nei punti di.
Poiche l’osservazione puntuale non ci permette di utilizzare gli usuali spazi di Banach (H1(Ω), L2(Ω)),scegliamo di approssimare il dato puntuale estendendo l’immagine dell’operatore C a un intornodei punti di, attraverso la convoluzione con funzioni gaussiane, centrate nei punti di = (di,x, di,y),del tipo
fi(x, y) =1
2πσxσye− 1
2((
x−di,x
σx)2
+(y−di,y
σy)2
). (8)
Dovendo approssimare un dato puntuale, vorremmo garantire che l’errore introdotto da talerilassamento sia trascurabile. Un primo indicatore della quantita di massa considerata e dato dalsupporto delle funzioni fi, che possiamo ragionevolmente approssimare con un intorno di raggio3
σxσy
σ2x+σ2
y.
In questo caso, invece che minimizzare il funzionale costo (7), possiamo considerare il seguenteproblema di controllo: trovare u ∈ Uad ⊂ U = L2(Ω) tale che
J(u) = minu∈Uad
1
2
Nd∑
i=1
αi
∫
Ω(y(u)− ydi)
2fi +δ
2‖u‖2U (9)
dove y(u) e la soluzione di (6). In questo caso l’operatore di osservazione C ∈ L(H1(Ω), L2f (Ω))
non e iniettivo (il supporto e un sottoinsieme proprio di Ω), quindi risulta necessario considerareun termine di penalizzazione, con δ > 0; con L2
f (Ω) intendiamo lo spazio L2(Ω) pesato con lefi relative ai punti di, ovvero l’operatore osservazione C deve essere inteso come una somma di
24

Problemi di controllo con osservazioni puntuali
operatori Ci ∈ L(H1(Ω), L2fi(Ω)).
Possiamo inoltre definire il funzionale Lagrangiano:
L(y, p, u) =1
2
Nd∑
i=1
αi
∫
Ω(y − ydi)
2fidx+δ
2‖u‖2U − a(y, p) + (f + u, p)L2(Ω) (10)
da cui annullando le derivate di L otteniamo le condizioni di ottimalita per (6)-(9). In particolareannullando Ly(y, p, u)ψ ∀ψ ∈ V otteniamo il seguente problema aggiunto:
a∗(p, ψ) =
Nd∑
i=1
αi
∫
Ω(y − ydi)fiψ ∀ψ ∈ V, (11)
mentre il principio di minimo si ottiene imponendo Lu(y, p, u)(h− u) ≥ 0 ∀h ∈ Uad :
(p+ δu, h− u)L2(Ω) ≥ 0 ∀h ∈ Uad. (12)
6.2 Osservazioni del gradiente della soluzione
Consideriamo due casi, ovvero due gruppi di dati a disposizione diversi, il primo costituito daNs coppie di punti (si, s
′i)
Ns
i=1 caratterizzate dallo stesso valore dell’osservazione, che rimane
per ognuna incognita, e il secondo costituito da Ng punti gjNg
j=1 di cui conosciamo nj, ovverola direzione normale al gradiente della distribuzione spaziale cercata. Arricchiamo il funzionalecosto dei seguenti elementi, che ci permettono di modellare questi ulteriori dati che abbiamo adisposizione:
J(y(u)) =1
2
Ns∑
i=1
βi(y(si)− y(s′i))2 +
Ng∑
j=1
γj2‖∇y(gj) · nj‖
2 +δ
2‖u‖2U . (13)
In particolare e possibile riscrivere i primi due termini del funzionale costo in un unico modo, chepermette di modellare simultaneamente entrambe le condizioni.
Consideriamo per primo il dato costituito dalle coppie di punti con osservazione coincidente,ma incognita: sfruttando il teorema fondamentale del calcolo si ha:
y(si)− y(s′i) =
∫ s′i
si
∂νy, (14)
dove ν e il versore lungo la direzione congiungente i due punti e l’integrale e calcolato lungoil segmento [si, s
′i]. Ricordando la maggiore regolarita che possiamo garantire sulla soluzione,
utilizziamo il seguente risultato di immersione:
Teorema 1. Sia Ω limitato e lipschtziano e m > n2 (m intero), allora Hm(Ω) → C(Ω).
Di conseguenza, possiamo provare che, nel caso bidimensionale H2(Ω) → C(Ω), ovvero si hache l’operatore di osservazione e tale che C ∈ L(H2(Ω), C(Ω)), ma non e iniettivo (risulta quindinecessario il termine di penalizzazione δ > 0). Quindi per il primo caso possiamo riscrivere ilfunzionale costo come segue:
J(u) =1
2
Ns∑
i=1
βi
(
∫ s′i
si
∂νy
)2
+δ
2‖u‖2U , (15)
25

Problemi di controllo con osservazioni puntuali
per il quale il differenziale secondo Frechet risulta dato da
J ′(u)h =
Ns∑
i=1
βi
(
∫ s′i
si
∂νy
)(
∫ s′i
si
∂νy(h)
)
+ δ(u, h)U ∀h ∈ Uad. (16)
Ricaviamo il problema aggiunto, per il quale ricordiamo che y(u) e un termine noto: trovarep = p(u) ∈ V tale che:
a∗(p, ψ) =
Ns∑
i=1
βi
(
∫ s′i
si
∂νy(u)
)(
∫ s′i
si
∂νψ
)
∀ψ ∈ V, (17)
dove il secondo membro di (17) risulta essere un elemento di V ∗, grazie alla disuguaglianza ditraccia.
Possiamo inoltre sfruttare questo appena ricavato per approssimare il secondo termine di (13),
che tiene conto dei valori della normale nj in un gruppo di Ng punti gjNg
j=1. Nota la direzionedella normale, possiamo approssimare il gradiente del dato spaziale al primo ordine mediante laricostruire della tangente, imponendo lo stesso valore per tre punti consecutivi lungo la direzioneortogonale alla normale, ovvero imponendo per ogni coppia la condizione appena ricavata.
La formulazione del problema nel secondo caso risulta dunque trovare u ∈ Uad tale che
J(u) = minu∈Uad
1
2
Ng∑
j=1
γj
(
∫ gj+ǫ
gj
∂νy
)2
+1
2
Ng∑
j=1
γj
(
∫ gj
gj−ǫ
∂νy
)2
+δ
2‖u‖2U , (18)
dove abbiamo sdoppiato il segmento tangente [gj−ǫ, gj+ǫ], in due sotto segmenti [gj−ǫ, gj ] e[gj , gj+ǫ] su cui andiamo a integrare.
Per ricavare le condizioni di ottimalita definiamo il funzionale Lagrangiano:
L(y, p, u) =1
2
Ng∑
j=1
γj(
∫ gj
gj−ǫ
∂νy)2 +
1
2
Ng∑
j=1
γj(
∫ gj+ǫ
gj
∂νy)2 +
δ
2‖u‖2U − a(y, p)+ (f +u, p)L2(Ω); (19)
annullando Ly(y, p, u)ψ ∀ψ ∈ V otteniamo il seguente problema aggiunto:
a∗(p, ψ) =
Ng∑
j=1
γj(
∫ gi
gi−ǫ
∂ν y)(
∫ gi
gi−ǫ
∂νψ) +
Ng∑
i=1
γj(
∫ gj+ǫ
gj
∂ν y)(
∫ gj+ǫ
gj
∂νψ) ∀ψinV, (20)
mentre il principio di minimo si ottiene imponendo Lu(y, p, u)(h− u) ≥ 0 ∀h ∈ Uad:
(p+ δu, h− u)L2(Ω) ≥ 0 ∀h ∈ Uad. (21)
26

Applicazioni
7 Applicazioni
7.1 Caso test
Consideriamo nel dominio Ω = (−π, π)×(0, π) la funzione f(x, y) = sin(x) sin(y) come la soluzioneche vorremmo ricostruire mediante il problema di controllo o mediante il metodo statistico delkriging o del co-kriging. Costruiamo un campione di punti casuali presi all’interno di questodominio, che consideriamo essere le osservazioni a disposizione del valore di f(xi, yi) e dellederivate ∂f
∂xe ∂f
∂y.
Vogliamo analizzare, calcolando l’errore rispetto alla soluzione esatta f in norma L2(Ω) eH1(Ω), rispettivamente le metodologie di kriging, co-kriging, problema di controllo con dati sullasoluzione e problema di controllo con i dati sia sulla soluzione, che sulle derivate. L’ipotesi,necessaria per costruire il modello di controllo, e quella di conoscere il modello sottostante, ovveroil problema di stato (equazione di diffusione). Viceversa i coefficienti del variogramma del kriginge del co-kriging potrebbero essere calcolati empiricamente dai dati, ottenendo delle stime affetteda ulteriori errori nei casi con pochi dati a disposizione. Con lo scopo di fornire ai due modellile stesse condizioni, ipotizziamo di conoscere tali coefficienti a priori (sono stati calcolati nellasituazione con il maggior numero di dati a disposizione).
Coeff f-variable co-variable cross-variable
θ0 0.0 0.0 0.0
θ1 0.2 0.34 0.3
θ2 2.66 2.9 2.8
Ricordiamo che i modelli statistici ci permettono di associare a ogni predizione una varianza,definita varianza di kriging (o co-kriging rispettivamente), e quindi e possibile costruire un inter-vallo di confidenza all’interno del quale si puo trovare la soluzione cercata. Per la nostra primaanalisi ci soffermeremo solamente sui valori predetti, in un secondo momento per considerare ipossibili errori di misura andremo a considerare anche la varianza. Poiche il metodo ci fornisceun predittore di tipo puntuale, le norme sono state calcolate andando a ricostruire le linee dilivello interpolando i valori predetti su una griglia sufficientemente fitta, in modo da garantire chel’errore introdotto dall’interpolante e l’errore dovuto all’integrazione numerica nel calcolo dellenorme siano trascurabili rispetto all’andamento dell’errore del metodo che vogliamo considerare.
Riguardo al problema di controllo, consideriamo il problema trovare y(u):
−∆y(u) = u in Ω
y = 0 su ∂Ω(22)
e il seguente funzionale costo
J(u) =1
2
Nd∑
i=1
αi
∫
Ω(y(u)− ydi)
2fi +1
2
Ns∑
i=1
γi(
∫ s′i
si
∂νy(u))2 +
δ
2‖u‖2U . (23)
27
Applicazioni
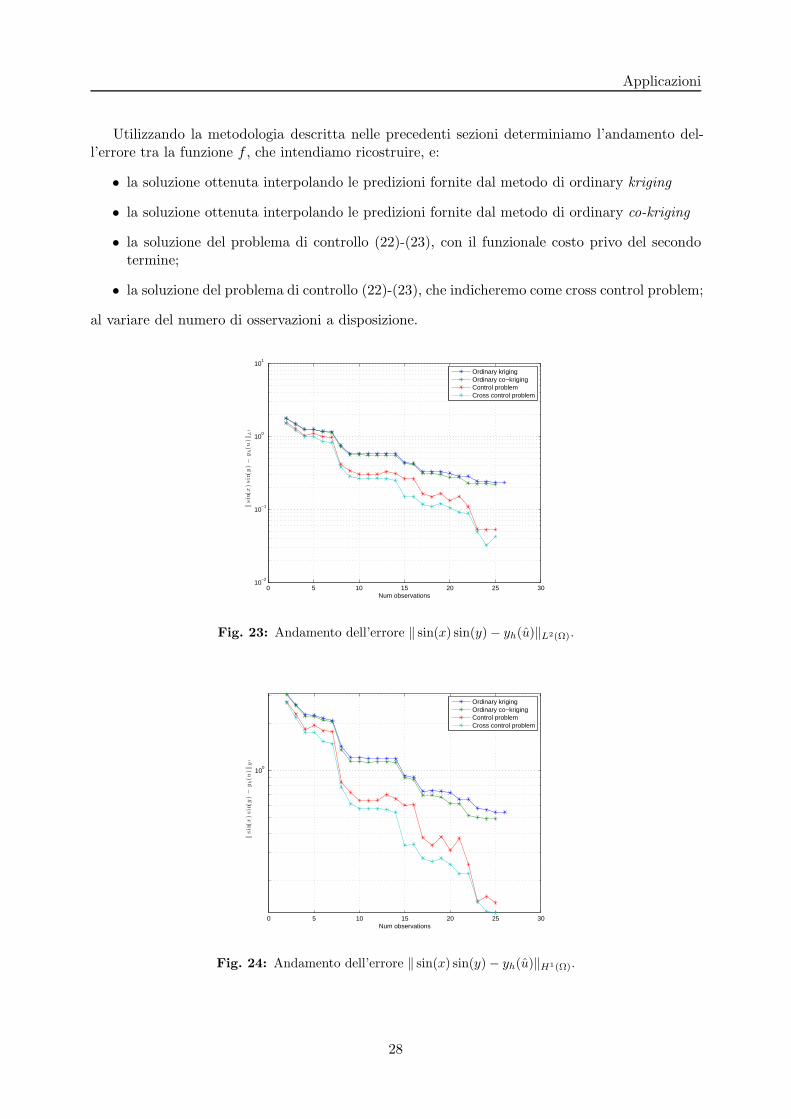
Utilizzando la metodologia descritta nelle precedenti sezioni determiniamo l’andamento del-l’errore tra la funzione f , che intendiamo ricostruire, e:
• la soluzione ottenuta interpolando le predizioni fornite dal metodo di ordinary kriging
• la soluzione ottenuta interpolando le predizioni fornite dal metodo di ordinary co-kriging
• la soluzione del problema di controllo (22)-(23), con il funzionale costo privo del secondotermine;
• la soluzione del problema di controllo (22)-(23), che indicheremo come cross control problem;
al variare del numero di osservazioni a disposizione.
0 5 10 15 20 25 3010
−2
10−1
100
101
Num observations
‖sin(x)sin(y)−
yh(u
)‖L
2
Ordinary krigingOrdinary co−krigingControl problemCross control problem
Fig. 23: Andamento dell’errore ‖ sin(x) sin(y)− yh(u)‖L2(Ω).
0 5 10 15 20 25 30
100
Num observations
‖sin(x)sin(y)−
yh(u
)‖H
1
Ordinary krigingOrdinary co−krigingControl problemCross control problem
Fig. 24: Andamento dell’errore ‖ sin(x) sin(y)− yh(u)‖H1(Ω).
28

Applicazioni
Osserviamo dall’andamento dell’errore che, nel caso in cui occorre ricostruire una funzioneregolare, la migliore approssimazione viene fornita dal problema di controllo con entrambi i tipidi osservazioni. Questo non e sorprendente, in quanto la soluzione del problema differenzialeviene naturalmente regolarizzata dalla presenza del termine di diffusione; viceversa l’approcciostatistico, per come e stato considerato, si basa sulla funzione variogramma, che risulta continuama non derivabile con continuita. In particolare, in questo secondo caso ci aspettiamo una buonaapprossimazione della soluzione in un intorno sufficientemente piccolo delle osservazioni, e unagraduale perdita di informazione man mano che la distanza dai punti in cui sono state raccoltele osservazioni aumenta.
Un’importante peculiarita del problema di controllo ottimo e quella di lasciare totale libertanella scelta dell’approssimazione numerica dei due problemi all’interno del metodo iterativo. Adesempio nel caso sia ipotizzabile un’alta regolarita sulla soluzione, si potrebbe utilizzare il metododegli elementi spettrali, oppure dove ci si aspetta la presenza di scarsa regolarita un metodo ditipo Discontinuous-Galerkin.
Inoltre nel caso in cui non si conosca il modello da cui arrivano le discretizzazione, il problemadi controllo ottimo ci permette di variare arbitrariamente nella sua definizione il problema distato, la cui soluzione ipotizziamo che sia la distribuzione spaziale cercata. Questa liberta non eriscontrabile nei metodi statistici, dove al piu e possibile variare la scelta dei variogrammi e deicoefficienti, garantendo pero una buona approssimazione della distribuzione solo a livello locale enon globale.
Di contro, il costo computazionale per l’applicazione del modello di co-kriging (che richiede unasemplice risoluzione di un sistema lineare) e di molto minore rispetto alla complessita del metodoiterativo. Nella sezione successiva cercheremo di mostrare come il maggior costo computazionalerichiesto dalla soluzione del problema di controllo, garantisca tuttavia una migliore robustezzadella stima rispetto a eventuali errori sperimentali.
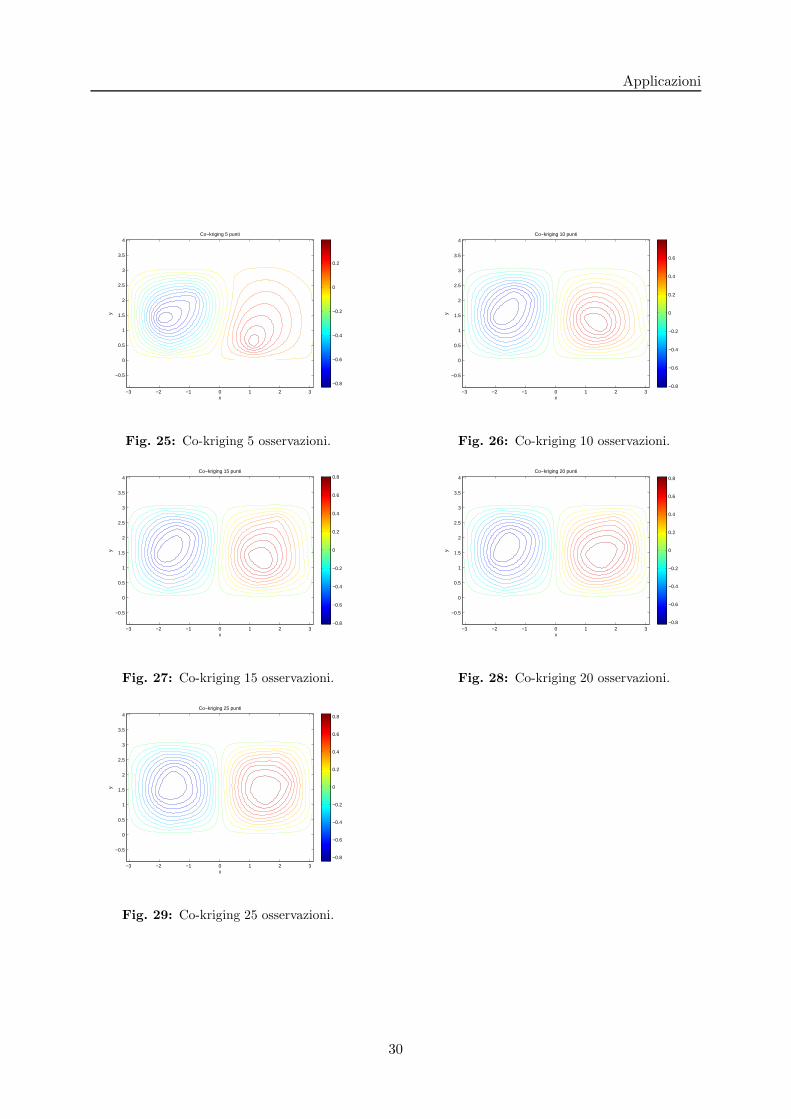
Riportiamo nelle prossime figure gli andamenti della soluzione ottenuta mediante il metododel co-kriging all’aumentare delle osservazioni a disposizione, e mediante il problema di controlloottimo, considerando sia le osservazioni della soluzione che del suo gradiente.
29
Applicazioni
x
y
Co−kriging 5 punti
−3 −2 −1 0 1 2 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
−0.8
−0.6
−0.4
−0.2
0
0.2
Fig. 25: Co-kriging 5 osservazioni.
x
y
Co−kriging 10 punti
−3 −2 −1 0 1 2 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
Fig. 26: Co-kriging 10 osservazioni.
x
y
Co−kriging 15 punti
−3 −2 −1 0 1 2 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
Fig. 27: Co-kriging 15 osservazioni.
x
y
Co−kriging 20 punti
−3 −2 −1 0 1 2 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
Fig. 28: Co-kriging 20 osservazioni.
x
y
Co−kriging 25 punti
−3 −2 −1 0 1 2 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
Fig. 29: Co-kriging 25 osservazioni.
30

Applicazioni
IsoValue-0.903739-0.830116-0.756492-0.682869-0.609246-0.535623-0.461999-0.388376-0.314753-0.241129-0.167506-0.0938828-0.02025950.05336380.1269870.200610.2742340.3478570.421480.495104
Fig. 30: Problema di controllo 5 osservazioni.
IsoValue-0.916958-0.82156-0.726162-0.630764-0.535366-0.439968-0.34457-0.249173-0.153775-0.05837690.0370210.1324190.2278170.3232150.4186120.514010.6094080.7048060.8002040.895602
Fig. 31: Problema di controllo 10 osservazioni.IsoValue-0.923636-0.827073-0.73051-0.633948-0.537385-0.440822-0.344259-0.247696-0.151133-0.05457070.04199210.1385550.2351180.3316810.4282430.5248060.6213690.7179320.8144950.911057
Fig. 32: Problema di controllo 15 osservazioni.
IsoValue-0.928155-0.830755-0.733355-0.635955-0.538554-0.441154-0.343754-0.246354-0.148954-0.05155340.04584690.1432470.2406470.3380470.4354480.5328480.6302480.7276480.8250490.922449
Fig. 33: Problema di controllo 20 osservazioni.IsoValue-0.944985-0.846063-0.747142-0.648221-0.5493-0.450379-0.351458-0.252537-0.153616-0.05469470.04422640.1431470.2420690.340990.4399110.5388320.6377530.7366740.8355950.934516
Fig. 34: Problema di controllo 25 osservazioni.
31

Applicazioni
7.2 Approccio ibrido
Utilizziamo ora l’approccio statistico per calcolare i coefficienti αi e γi del funzionale costo (23),con l’intento di generare una procedura in grado di assorbire, in maniera efficace, eventuali erroridi misurazione.
Utilizziamo il metodo del co-kriging per operare una cross-validazione: per ogni osservazioneyi costruiamo la sua predizione y ottenuta da un problema in cui e stata eliminata dai dati iniziali.Osserviamo che a questo punto abbiamo a disposizione due informazioni:
• la predizione yi, confrontabile tramite cross-validazione con i dati a disposizione;
• la varianza di co-krigingσkgi .
Una possibile scelta dei coefficienti potrebbe allora essere quella di prevedere:
• diretta proporzionalita rispetto a |yi − yi|2,
• inversa proporzionalita rispetto alla varianza di co-kriging σkgi ,
con l’idea di attribuire un maggior peso a quei dati che non si riescono a ricostruire con la cross-validazione, e viceversa un minor peso se e possibile ottenere lo stesso risultato predicendo apartire dai dati presenti.
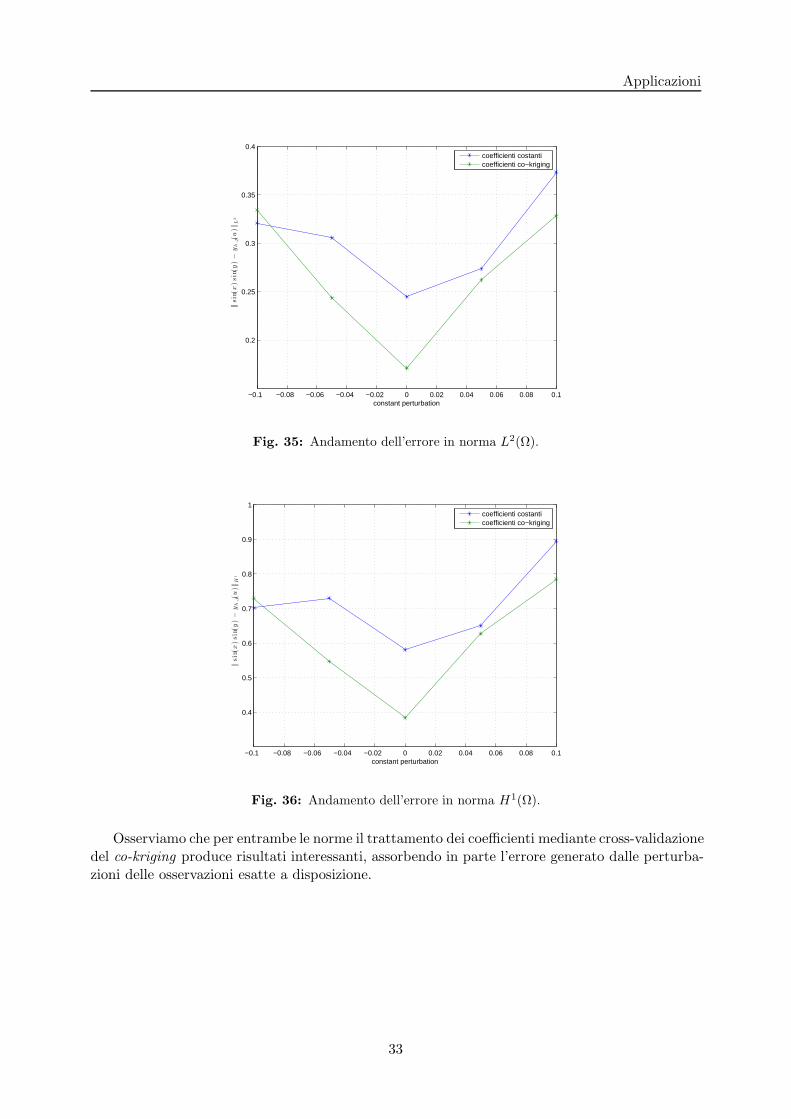
Con lo scopo di testare la risposta rispetto a possibili errori sperimentali, individuiamo ungruppo di osservazioni che andremo a perturbare con un valore costante p ∈ [−0.1, 0.1] perconfrontare il modello a coefficienti costanti rispetto all’approccio appena proposto. Riportiamonelle due figure successive il grafico dell’errore in norma L2(Ω) e H1(Ω) rispetto alla soluzioneesatta f(x, y) = sin(x)sin(y).
32
Applicazioni
−0.1 −0.08 −0.06 −0.04 −0.02 0 0.02 0.04 0.06 0.08 0.1
0.2
0.25
0.3
0.35
0.4
constant perturbation
‖sin(x)sin(y)−
yh,p(u
)‖L
2
coefficienti costanticoefficienti co−kriging
Fig. 35: Andamento dell’errore in norma L2(Ω).
−0.1 −0.08 −0.06 −0.04 −0.02 0 0.02 0.04 0.06 0.08 0.1
0.4
0.5
0.6
0.7
0.8
0.9
1
constant perturbation
‖sin(x)sin(y)−
yh,p(u
)‖H
1
coefficienti costanticoefficienti co−kriging
Fig. 36: Andamento dell’errore in norma H1(Ω).
Osserviamo che per entrambe le norme il trattamento dei coefficienti mediante cross-validazionedel co-kriging produce risultati interessanti, assorbendo in parte l’errore generato dalle perturba-zioni delle osservazioni esatte a disposizione.
33
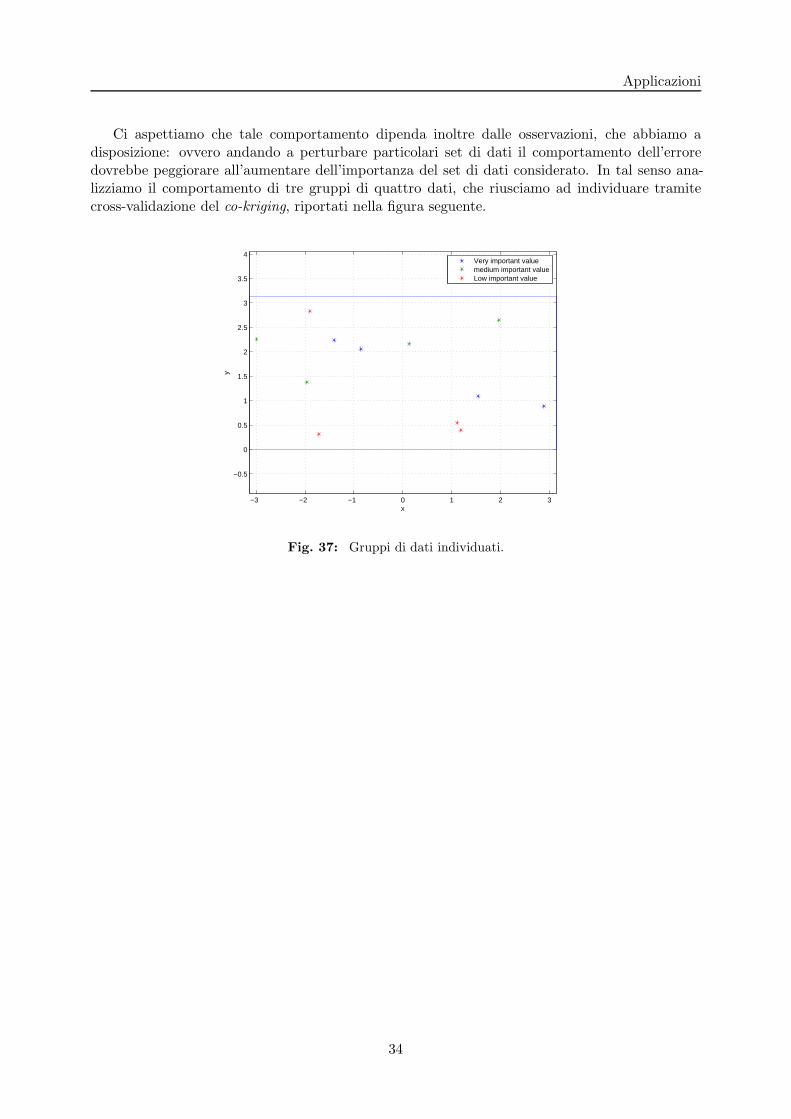
Applicazioni
Ci aspettiamo che tale comportamento dipenda inoltre dalle osservazioni, che abbiamo adisposizione: ovvero andando a perturbare particolari set di dati il comportamento dell’erroredovrebbe peggiorare all’aumentare dell’importanza del set di dati considerato. In tal senso ana-lizziamo il comportamento di tre gruppi di quattro dati, che riusciamo ad individuare tramitecross-validazione del co-kriging, riportati nella figura seguente.
−3 −2 −1 0 1 2 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
x
y
Very important valuemedium important valueLow important value
Fig. 37: Gruppi di dati individuati.
34
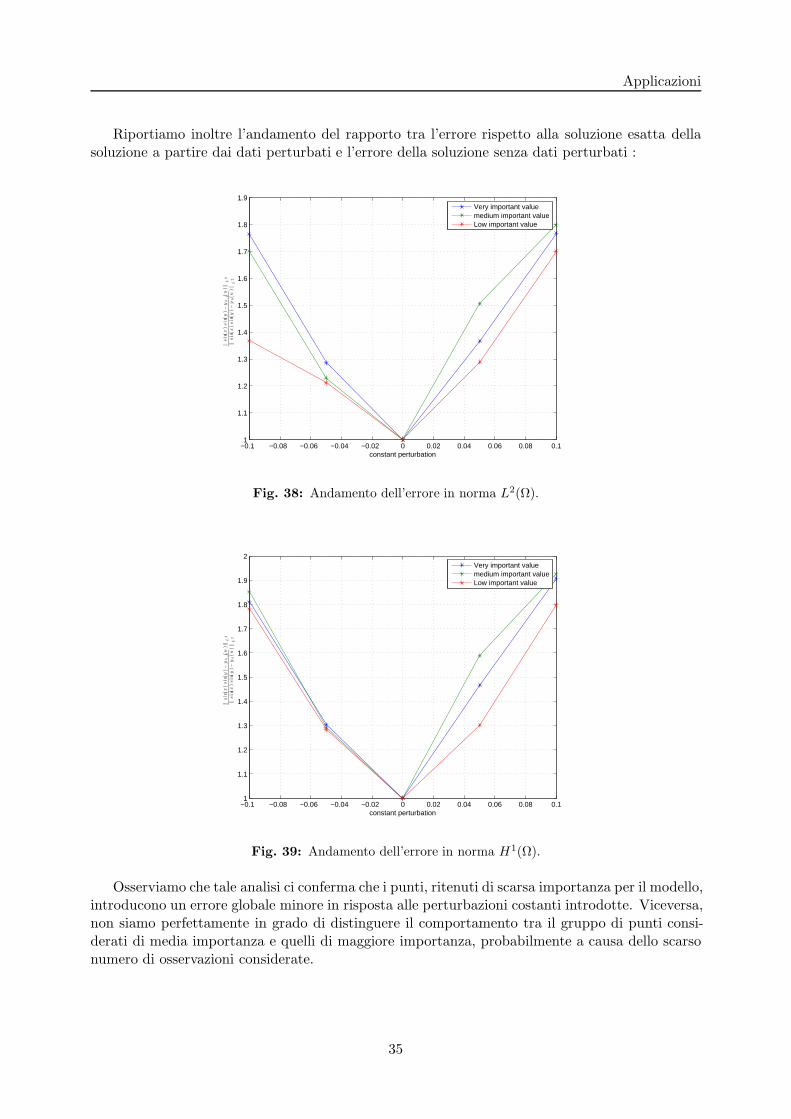
Applicazioni
Riportiamo inoltre l’andamento del rapporto tra l’errore rispetto alla soluzione esatta dellasoluzione a partire dai dati perturbati e l’errore della soluzione senza dati perturbati :
−0.1 −0.08 −0.06 −0.04 −0.02 0 0.02 0.04 0.06 0.08 0.11
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
constant perturbation
‖sin(x)sin(y)−yh,p(u)‖
L2
‖sin(x)sin(y)−yh(u)‖
L2
Very important valuemedium important valueLow important value
Fig. 38: Andamento dell’errore in norma L2(Ω).
−0.1 −0.08 −0.06 −0.04 −0.02 0 0.02 0.04 0.06 0.08 0.11
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
constant perturbation
‖sin(x)sin(y)−yh,p(u)‖
L2
‖sin(x)sin(y)−yh(u)‖
L2
Very important valuemedium important valueLow important value
Fig. 39: Andamento dell’errore in norma H1(Ω).
Osserviamo che tale analisi ci conferma che i punti, ritenuti di scarsa importanza per il modello,introducono un errore globale minore in risposta alle perturbazioni costanti introdotte. Viceversa,non siamo perfettamente in grado di distinguere il comportamento tra il gruppo di punti consi-derati di media importanza e quelli di maggiore importanza, probabilmente a causa dello scarsonumero di osservazioni considerate.
35

Applicazioni
7.3 Stratigrafia del sottosuolo
La stratigrafia del sottosuolo si basa su i seguenti concetti di base empirici:
• legge di sovrapposizione di Steno : esiste un ordinamento temporale degli strati, ovverosi ipotizza che ogni strato e piu antico degli strati superiori ad esso;
• legge di orizzontalita degli strati : sotto l’azione della gravita, i sedimenti si sonoinizialmente disposti in maniera uniforme rispetto all’orizzontale (ovvero si ipotizza l’assenzadi movimenti tettonici).
• continuita orizzontale : ciascuno strato di roccia sedimentaria ha una propria estensionelaterale. Di conseguenza la presenza di separazioni fisiche (per esempio da una valle o altrofenomeno erosionale) non esclude la possibilita che originariamente siano stati continui.
• legge di non conformita di Hutton : processi come vulcanesimo o orogenesi creanostrati di roccia non conformi alla disposizione temporale.
Partendo da queste osservazioni vogliamo determinare la distribuzione degli strati attraversoun problema di controllo, che si poggera sulla legge si sovrapposizione e sulla legge di orizzontalitadegli strati (escludendo, per semplicita fenomeni erosionali o di vulcanesimo). Si potra in unsecondo momento intervenire sui risultati, introducendo metodologie in grado di rilassare le ipotesisemplificative.
Consideriamo, a titolo di esempio, un caso semplice in cui su un dominio Ω = (0, 6)× (0, 2) incui e stata definita una mappa che fa corrispondere ogni livello stratigrafico a un valore nell’inter-vallo [0, 1], in modo da riportare il problema al livello degli esempi fin qui rappresentati. Lo scopoe quello di mostrare oltre all’applicazione le criticita associate a questo specifico problema.Consideriamo il problema di stato: trovare y = y(u) tale che
−∆y = u in Ω
y = 0 su Γup
y = 1 su Γdown
∂y∂n
= 0 su Γn
(24)
con ∂Ω = Γup ∪ Γdown ∪ Γn, dove Γup = (0, 6) × 2, Γdown = (0, 6) × 0 e Γn = 0 × (0, 2) ∪6 × (0, 2). La corrispondente forma debole risulta essere: trovare y = y(u) ∈ H1
0,Γup∪Γdown(Ω)
tale chea(y, v) = (Ry + u, v)L2(Ω) ∀v ∈ H1
Γup∪Γdown(25)
con
a(y, v) =
∫
Ω∇y · ∇v (26)
e Ry un opportuno rilevamento che consenta di imporre condizioni omogenee sui lati di Dirichlet.Il funzionale costo J e dato da:
J(u) =1
2
Nd∑
i=1
αi
∫
Ω(y(u)− ydi)
2fi +1
2
Ng∑
j=1
γj
(
∫ gj+ǫ
gj
∂νy
)2
+1
2
Ng∑
j=1
γj
(
∫ gj
gj−ǫ
∂νy
)2
+δ
2‖u‖2L2(Ω)
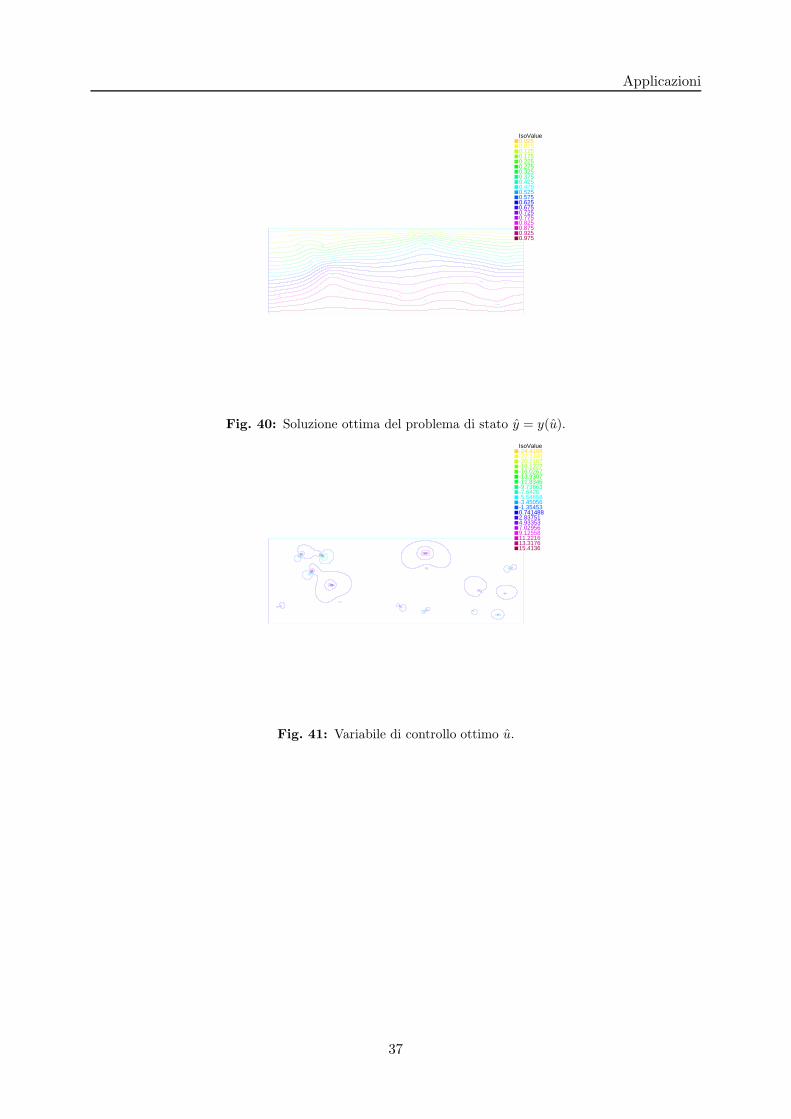
(27)Riportiamo nella prima figura la risoluzione numerica del problema (25)-(27) e la relatava
variabile di controllo ottimo u.
36
Applicazioni
IsoValue0.0250.0750.1250.1750.2250.2750.3250.3750.4250.4750.5250.5750.6250.6750.7250.7750.8250.8750.9250.975
Fig. 40: Soluzione ottima del problema di stato y = y(u).
IsoValue-24.4108-22.3148-20.2187-18.1227-16.0267-13.9307-11.8346-9.73863-7.6426-5.54658-3.45056-1.354530.7414882.837514.933537.029569.1255811.221613.317615.4136
Fig. 41: Variabile di controllo ottimo u.
37
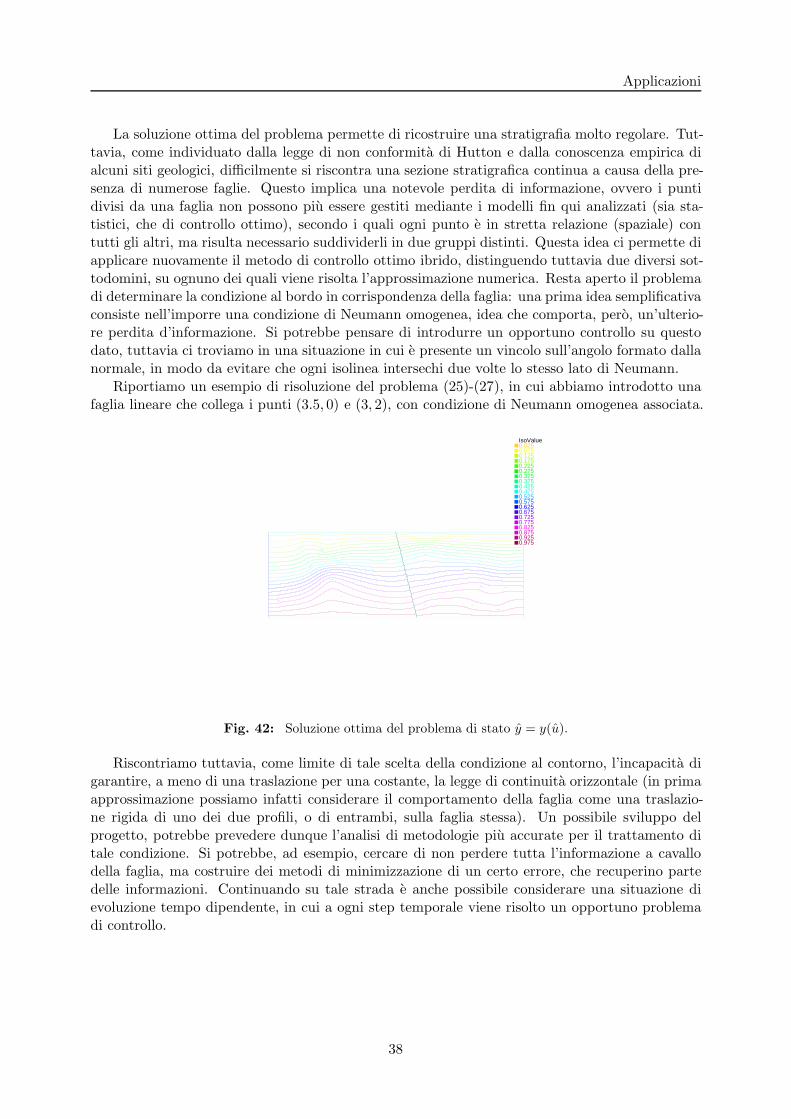
Applicazioni
La soluzione ottima del problema permette di ricostruire una stratigrafia molto regolare. Tut-tavia, come individuato dalla legge di non conformita di Hutton e dalla conoscenza empirica dialcuni siti geologici, difficilmente si riscontra una sezione stratigrafica continua a causa della pre-senza di numerose faglie. Questo implica una notevole perdita di informazione, ovvero i puntidivisi da una faglia non possono piu essere gestiti mediante i modelli fin qui analizzati (sia sta-tistici, che di controllo ottimo), secondo i quali ogni punto e in stretta relazione (spaziale) contutti gli altri, ma risulta necessario suddividerli in due gruppi distinti. Questa idea ci permette diapplicare nuovamente il metodo di controllo ottimo ibrido, distinguendo tuttavia due diversi sot-todomini, su ognuno dei quali viene risolta l’approssimazione numerica. Resta aperto il problemadi determinare la condizione al bordo in corrispondenza della faglia: una prima idea semplificativaconsiste nell’imporre una condizione di Neumann omogenea, idea che comporta, pero, un’ulterio-re perdita d’informazione. Si potrebbe pensare di introdurre un opportuno controllo su questodato, tuttavia ci troviamo in una situazione in cui e presente un vincolo sull’angolo formato dallanormale, in modo da evitare che ogni isolinea intersechi due volte lo stesso lato di Neumann.
Riportiamo un esempio di risoluzione del problema (25)-(27), in cui abbiamo introdotto unafaglia lineare che collega i punti (3.5, 0) e (3, 2), con condizione di Neumann omogenea associata.
IsoValue0.0250.0750.1250.1750.2250.2750.3250.3750.4250.4750.5250.5750.6250.6750.7250.7750.8250.8750.9250.975
Fig. 42: Soluzione ottima del problema di stato y = y(u).
Riscontriamo tuttavia, come limite di tale scelta della condizione al contorno, l’incapacita digarantire, a meno di una traslazione per una costante, la legge di continuita orizzontale (in primaapprossimazione possiamo infatti considerare il comportamento della faglia come una traslazio-ne rigida di uno dei due profili, o di entrambi, sulla faglia stessa). Un possibile sviluppo delprogetto, potrebbe prevedere dunque l’analisi di metodologie piu accurate per il trattamento ditale condizione. Si potrebbe, ad esempio, cercare di non perdere tutta l’informazione a cavallodella faglia, ma costruire dei metodi di minimizzazione di un certo errore, che recuperino partedelle informazioni. Continuando su tale strada e anche possibile considerare una situazione dievoluzione tempo dipendente, in cui a ogni step temporale viene risolto un opportuno problemadi controllo.
38

Conclusioni
8 Conclusioni
In questo progetto sono state analizzate e implementate delle metodologie statistiche per la ri-costruzione di dati distribuiti spazialmente e sono state utilizzate per lo sviluppo di problemi dicontrollo con osservazioni puntuali della soluzione stessa o del gradiente (ovvero nota la direzionedella tangente o della normale alla soluzione incognita).
Partendo dall’analisi algoritmica delle metodologie di kriging e co-kriging si sono mostrati idettagli implementativi e una prima possibile applicazione a un caso test noto in letteratura. Suc-cessivamente si e analizzato dal punto di vista teorico la costruzione di un problema di controllo,in cui il funzionale costo minimizzi la distanza della soluzione y(u) dalle osservazioni note, oppurela distanza della direzione del suo gradiente rispetto alla normale nota. Il caso test, che abbiamoanalizzato nella sezione (7.1), consiste nel ricostruire una funzione nota (f = sin(x) sin(y)) a par-tire da osservazioni campionate casualmente. Abbiamo confrontato, all’aumentare del numero diosservazioni a disposizione, i risultati ottenuti dai diversi metodi applicabili (statistici di kriginge co-kriging e metodi di controllo ottimo). Abbiamo poi osservato che, calcolando i coefficientidel funzionale costo associati a ogni osservazione mediante cross-validazione con una tecnica ditipo co-kriging, riusciamo a ottenere un metodo piu accurato e piu robusto alle perturbazioni deidati a disposizione, e quindi a eventuali errori sperimentali, ma caratterizzato da maggiori onericomputazionali.
Infine, abbiamo mostrato come i casi test considerati possano costituire un punto di parten-za per la ricostruzione della stratigrafia del sottosuolo, problema che ha ispirato l’intero lavoro.In quest’ultima parte si e voluto mettere in evidenza quali siano le nuove problematiche che sidebbono affrontare in questa applicazione specifica, e quali potrebbero essere le evoluzioni in talsenso del lavoro fin qui svolto.
Riguardo l’aspetto implementativo lasciamo la possibilita a futuri utenti di utilizzare il codice,con opportune modifiche, anche per casi non bidimensionali (operando specializzazione delle re-lative classi); inoltre per migliorare l’efficienza del codice stesso e necessaria un’implementazionedella SV D che sia parallelizzabile, in modo da ridurre i tempi di esecuzione.
39

Riferimenti bibliografici
Riferimenti bibliografici
[CAGL04] Jean-Paul Chiles, Christophe Aug, Antonio Guillen, and T Lees. Modelling of Geo-metry of Geological Units and its Uncertainty in 3D From Structural Data:˜ThePotential-Field Method. Perth, 2004.
[Cre93] Noel A. C. Cressie. Statistics for Spatial Data. Wiley, revised edition edition, January1993.
[GCC+08] A Guillen, Ph Calcagno, G Courrioux, A Joly, and P Ledru. Geological modelling fromfield data and geological knowledge: Part II. Modelling validation using gravity andmagnetic data inversion: Recent Advances in Computational Geodynamics: Theory,Numerics and Applications. Physics of the Earth and Planetary Interiors, 171(1-4):158–169, 2008.
[Mye82] D Myers. Matrix Formulation of Co-Kriging. Mathematical Geology, 14(3), 1982.
40





























