Embed Size (px)
Citation preview

Porting the physical parametrizations on GPUs using directives
X. Lapillonne, O. Fuhrer,
Cristiano Padrin, Piero Lanucara, Alessandro Cheloni
Eidgenössisches Departement des Innern EDIBundesamt für Meteorologie und Klimatologie MeteoSchweiz

2 08/09/2011, COSMO GM X. Lapillonne
Outline
• Computing with GPUs
• COSMO parametrizations on GPUs using directives
• Running COSMO on an hybrid system
• Summary
3 08/09/2011, COSMO GM X. Lapillonne
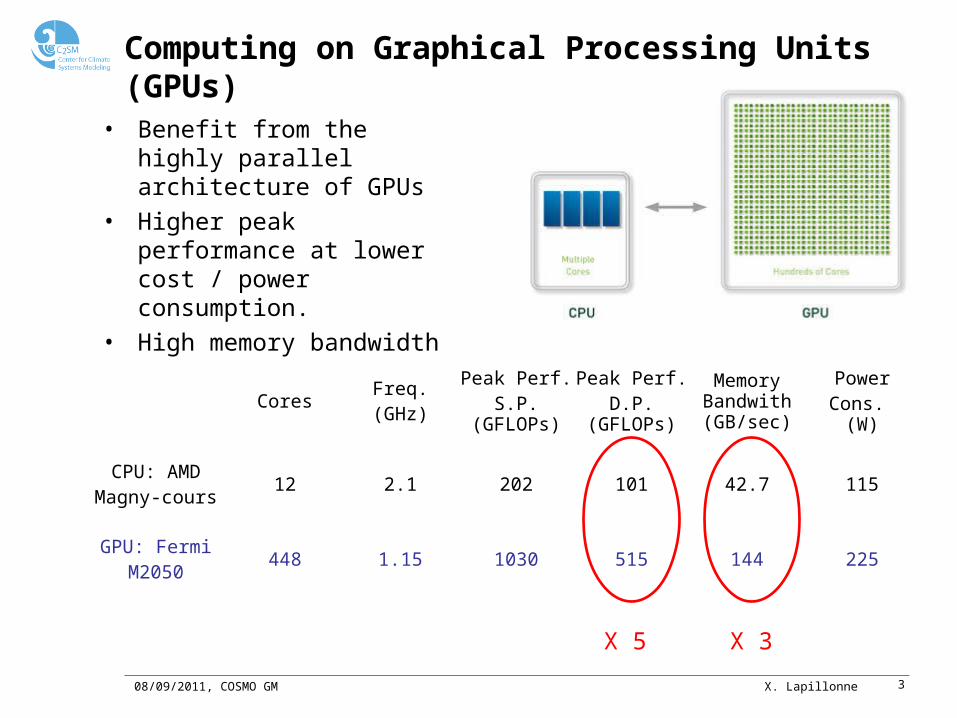
Computing on Graphical Processing Units (GPUs)
• Benefit from the highly parallel architecture of GPUs
• Higher peak performance at lower cost / power consumption.
• High memory bandwidth
CoresFreq.(GHz)
Peak Perf.S.P.
(GFLOPs)
Peak Perf.D.P.
(GFLOPs)
Memory Bandwith (GB/sec)
PowerCons.
(W)
CPU: AMDMagny-cours
12 2.1 202 101 42.7 115
GPU: FermiM2050
448 1.15 1030 515 144 225
X 5 X 3
4 08/09/2011, COSMO GM X. Lapillonne
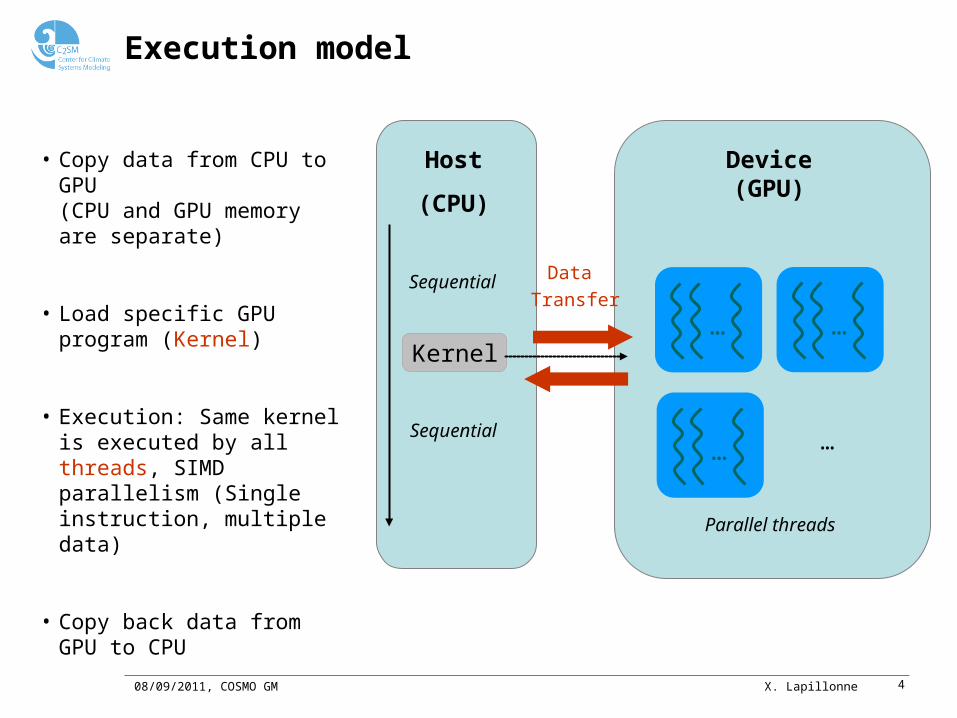
Execution model
Host
(CPU)
Kernel
Sequential
Sequential
Device(GPU)
Data
Transfer
• Copy data from CPU to GPU(CPU and GPU memory are separate)
• Load specific GPU program (Kernel)
• Execution: Same kernel is executed by all threads, SIMD parallelism (Single instruction, multiple data)
• Copy back data from GPU to CPU
… …
… …
Parallel threads

5 08/09/2011, COSMO GM X. Lapillonne
Outline
• Computing with GPUs
• COSMO parametrizations on GPUs using directives
• Running COSMO on an hybrid system
• Summary

6 08/09/2011, COSMO GM X. Lapillonne
The directive approach, an example
!$acc data region local(a,b)!$acc update device(b) !initialization !$acc region do k=1,nlev do i=1,N a(i,k)=0.0D0 end do end do !$acc end region
! first layer !$acc region do i=1,N a(i,1)=0.1D0 end do !$acc end region
! vertical computation !$acc region do k=2,nlev do i=1,N a(i,k)=0.95D0*a(i,k-1)+exp(-2*a(i,k)**2)*b(i,k) end do end do !$acc end region !$acc update host(a)!$acc end data region
!$acc data region local(a,b)!$acc update device(b) !initialization !$acc region do kernel do i=1,N do k=1,nlev a(i,k)=0.0D0 end do end do !$acc end region
! first layer !$acc region do i=1,N a(i,1)=0.1D0 end do !$acc end region
! vertical computation !$acc region do kernel do i=1,N do k=2,nlev a(i,k)=0.95D0*a(i,k-1)+exp(-2*a(i,k)**2)*b(i,k) end do end do !$acc end region !$acc update host(a)!$acc end data region
N=1000, nlev=60: t= 555 μs t= 225 μs
note : PGI directives
Loop reordering
3 different kernels
Array “a” remains on the GPU between the different kernel calls

7 08/09/2011, COSMO GM X. Lapillonne
Cosmo physical parametrizations with directives
Note: Directives are tested in standalone version of various parametrizations
• OMP-acc : discussed within the OMP committee, currently only supported by a test version of the Cray compiler.+ : possible future standardcurrently ported: microphysics (hydci_pp), radiation (fesft)
• PGI directives: developed by PGI compiler, quite advance.+ : most mature, OMP-acc are a subset of PGI directives- : vendor specificcurrently ported: microphysics (hydci_pp), radiation (fesft), turbulence (turbdiff)
• F2C-ACC: developed by NOAA+ : freely available, generates CUDA code (possibility to further optimize and debug at this stage)- : on going projectcurrently ported: microphysics (hydci_pp)

8 08/09/2011, COSMO GM X. Lapillonne
Cosmo physical parametrizations with directives
• Specific GPU optimizations have been introduced: • loop reordering (if necessary)• replacement of arrays with scalars
• For a typical COSMO-2 simulation on a CPU cluster, the subroutines hydci_pp, fesft and turbdiff represent respectively 6.7%, 8% and 7.3% of the total execution time.
9 08/09/2011, COSMO GM X. Lapillonne
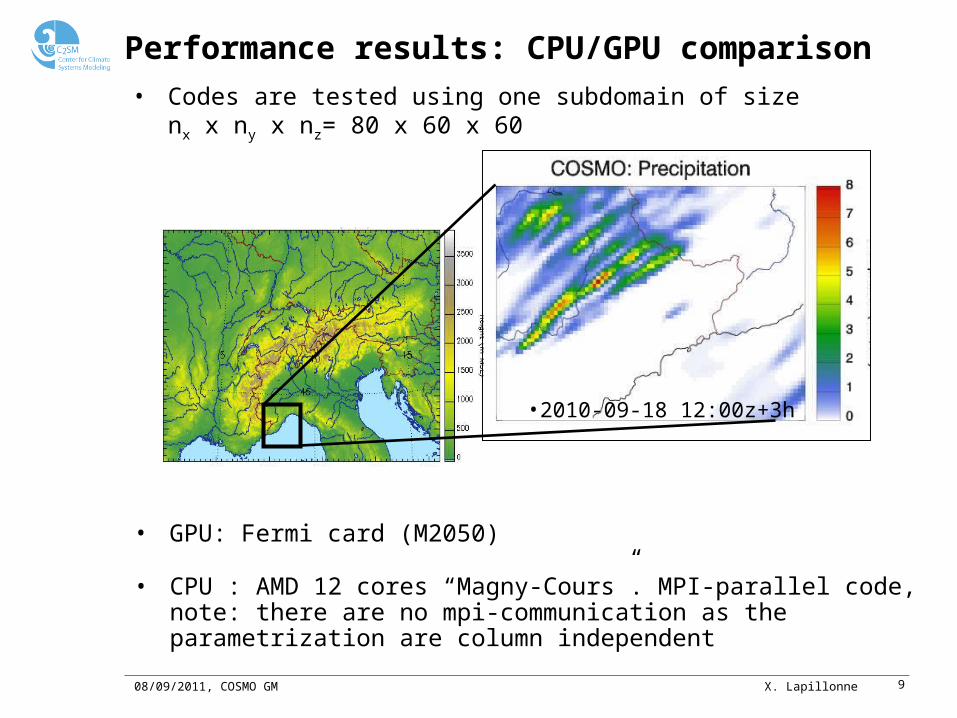
Performance results: CPU/GPU comparison
• CPU : AMD 12 cores “Magny-Cours”. MPI-parallel code, note: there are no mpi-communication as the parametrization are column independent
• GPU: Fermi card (M2050)
•2010-09-18 12:00z+3h
• Codes are tested using one subdomain of size nx x ny x nz= 80 x 60 x 60
10 08/09/2011, COSMO GM X. Lapillonne
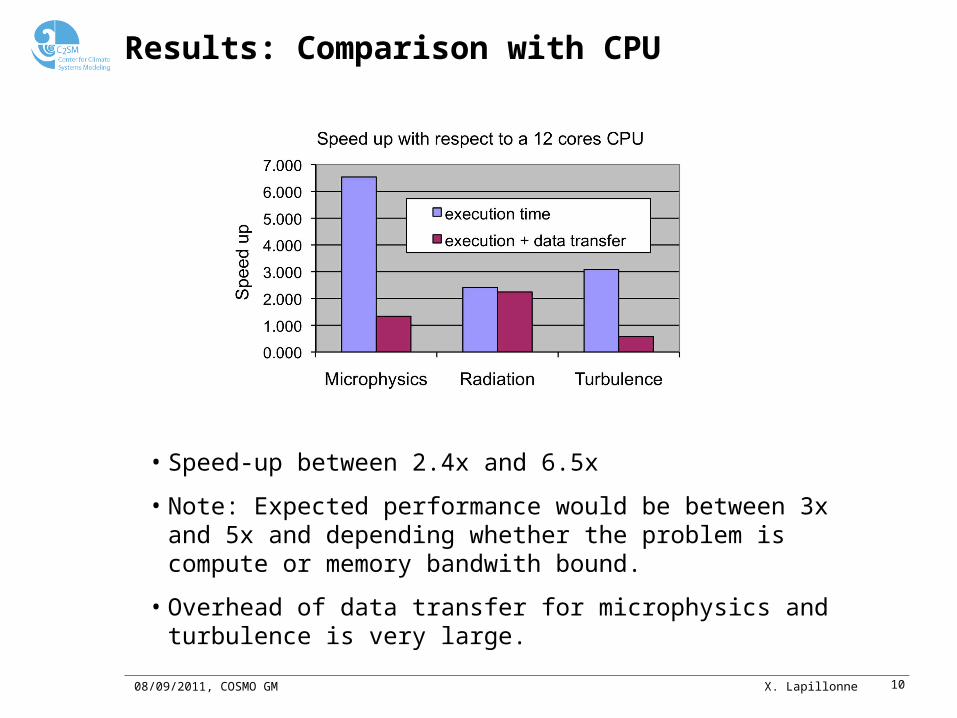
Results: Comparison with CPU
• Speed-up between 2.4x and 6.5x
• Note: Expected performance would be between 3x and 5x and depending whether the problem is compute or memory bandwith bound.
• Overhead of data transfer for microphysics and turbulence is very large.
11 08/09/2011, COSMO GM X. Lapillonne
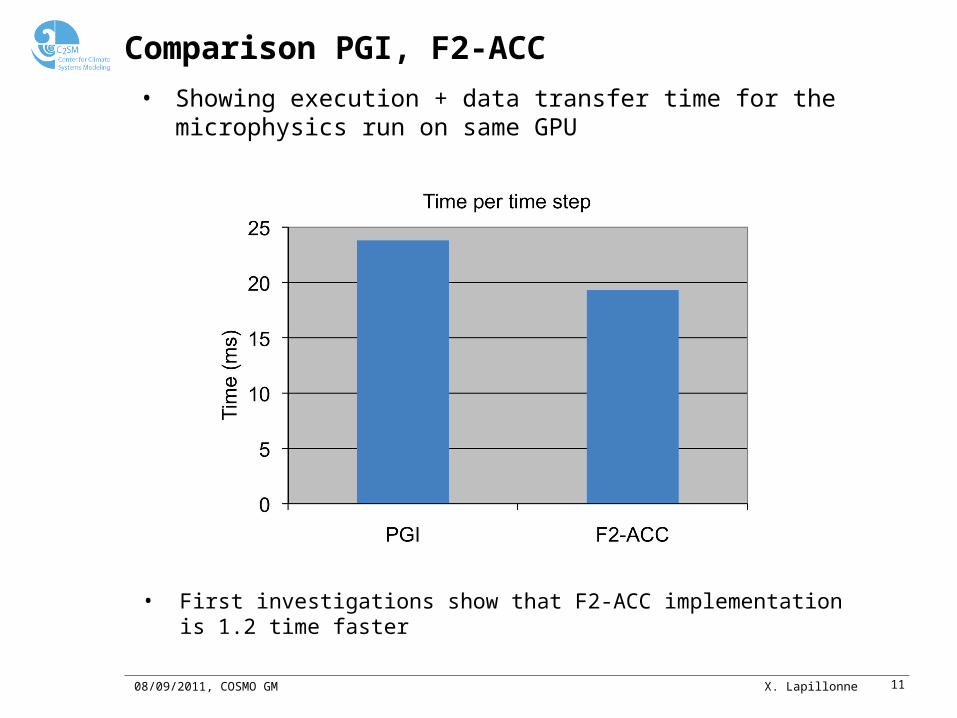
Comparison PGI, F2-ACC
• First investigations show that F2-ACC implementation is 1.2 time faster
• Showing execution + data transfer time for the microphysics run on same GPU

12 08/09/2011, COSMO GM X. Lapillonne
Outline
• Computing with GPUs
• COSMO parametrizations on GPUs using directives
• Running COSMO on an hybrid system
• Summary
13 08/09/2011, COSMO GM X. Lapillonne
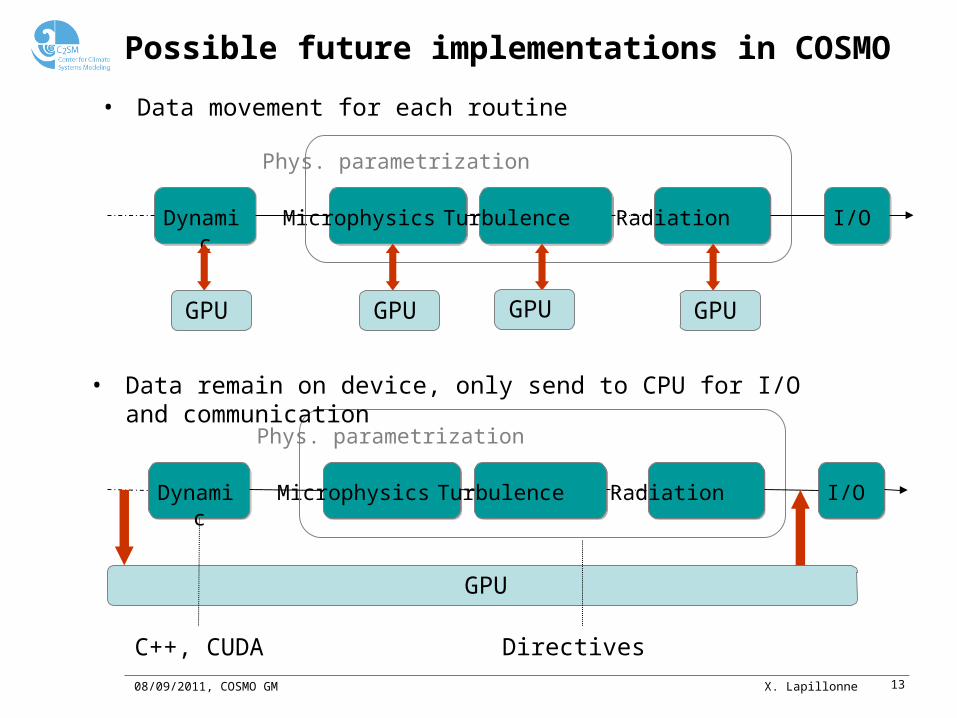
Possible future implementations in COSMO
Dynamic Microphysics Turbulence Radiation
Phys. parametrization
I/O
GPU
Dynamic Microphysics Turbulence Radiation
Phys. parametrization
I/O
GPU GPU GPU GPU
• Data movement for each routine
• Data remain on device, only send to CPU for I/O and communication
C++, CUDA Directives
14 08/09/2011, COSMO GM X. Lapillonne
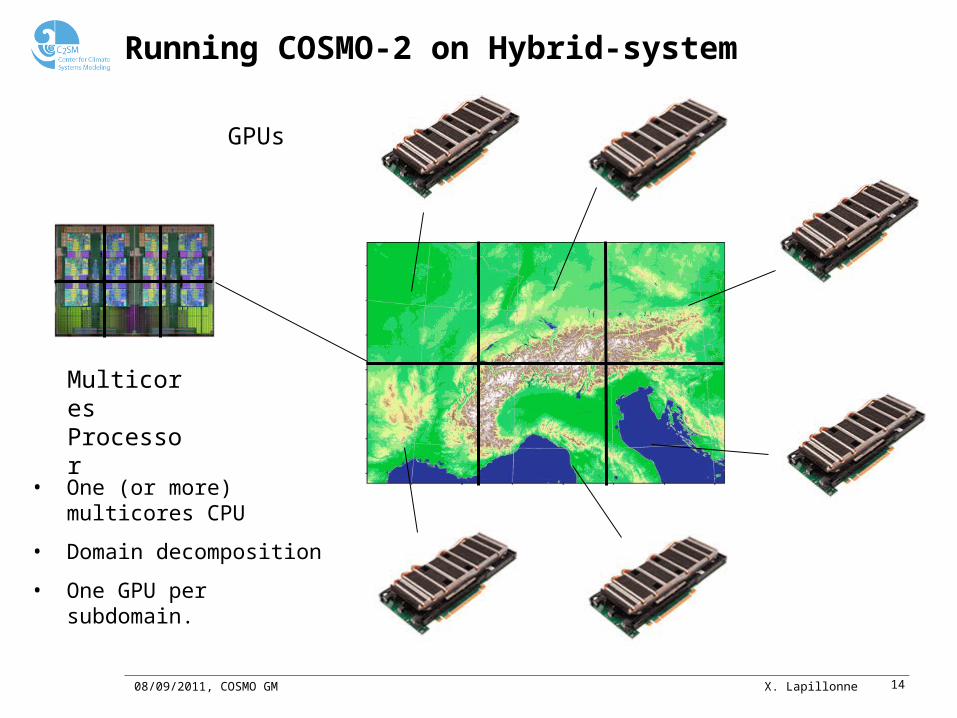
Running COSMO-2 on Hybrid-system
Multicores Processor
GPUs
• One (or more) multicores CPU
• Domain decomposition
• One GPU per subdomain.

15 08/09/2011, COSMO GM X. Lapillonne
Outline
• Computing with GPUs
• COSMO parametrizations on GPUs using directives
• Running COSMO on an hybrid system
• Summary

16 08/09/2011, COSMO GM X. Lapillonne
Summary
• In the frame of POMPA investigations are carried out to port the COSMO code to GPU architecture
• Different directive approaches are considered to port the physical parametrizations on such architecture: PGI, OMP-acc and F2-ACC.
• Comparing with a high-end 12 cores CPU, a speed up between 2.4x and 6.5x was observed using one Fermi GPU card with PGI
• These results are within the expected values considering hardware properties
• The large overhead of data transfer shows that the full GPU approach (i.e. data remains on the GPU, all computation on the device) is the prefered approach for COSMO
• First investigations on the microphysics show a speed up of 1.2x with respect to PGI implementation on the GPU

17 08/09/2011, COSMO GM X. Lapillonne
Additional slides
18 08/09/2011, COSMO GM X. Lapillonne
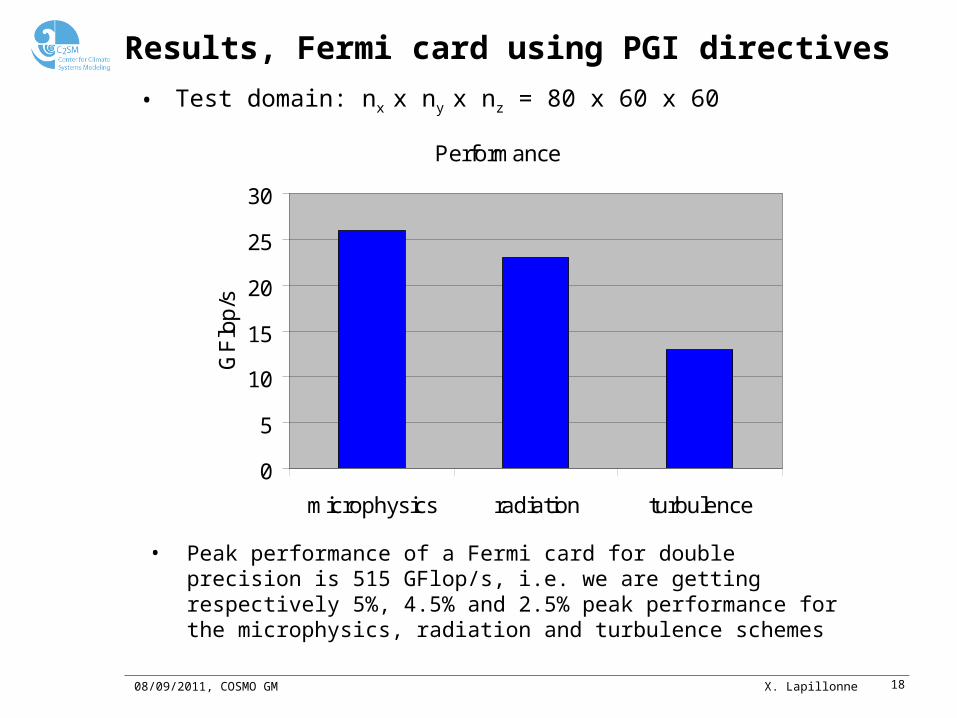
Results, Fermi card using PGI directives
Performance
0
5
10
15
20
25
30
microphysics radiation turbulence
GF
lop/
s
• Peak performance of a Fermi card for double precision is 515 GFlop/s, i.e. we are getting respectively 5%, 4.5% and 2.5% peak performance for the microphysics, radiation and turbulence schemes
• Test domain: nx x ny x nz = 80 x 60 x 60
19 08/09/2011, COSMO GM X. Lapillonne
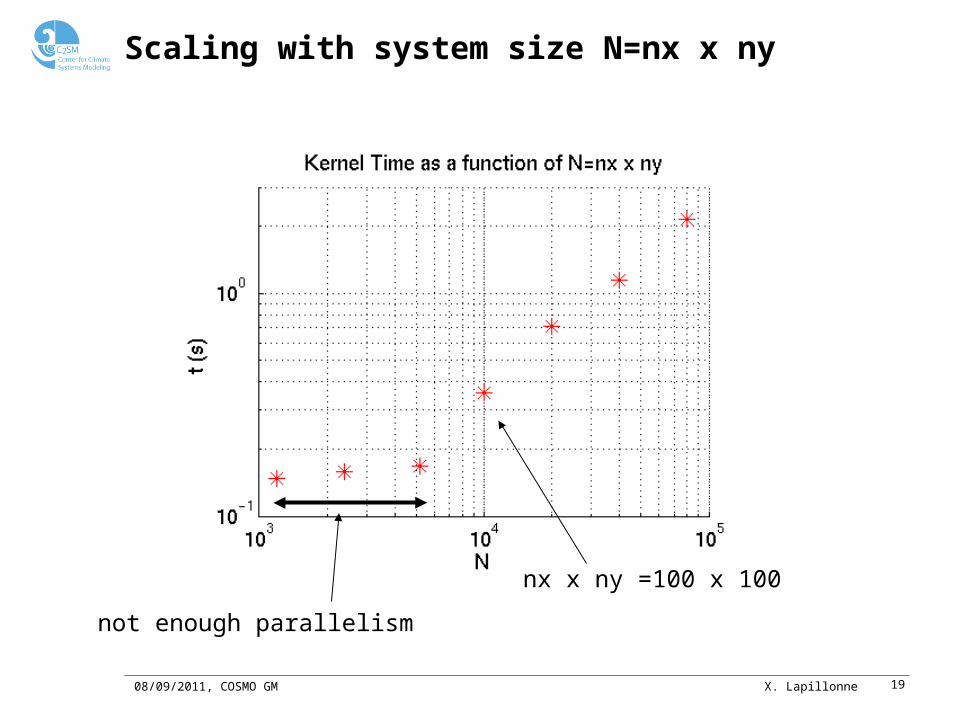
Scaling with system size N=nx x ny
nx x ny =100 x 100
not enough parallelism

20 08/09/2011, COSMO GM X. Lapillonne
!$omp acc_data acc_shared(a,b,c)!$omp acc_update acc(a,b)!$omp acc_region do k = 1,n1 do i = 1,n3 c(i,k) = 0.0 do j = 1,n2
c(i,k) = c(i,k) + a(i,j) * b(j,k) enddo enddo enddo !$omp end acc_region!$omp acc_update host(c) !$omp end acc_data
The directive approach
Example with OMP-acc:
Generates kernel at loop level

21 08/09/2011, COSMO GM X. Lapillonne
Computing on Graphical Processing Units (GPUs)
• To be efficient the code needs to take advantage of fine grain parallelism so as to execute 1000s of threads in parallel.
• GPU code:
• Programming level: OpenCL, CUDA, CUDA Fortran (PGI) … Best performance, but require complete rewrite
• Directive based approach: OpenMP-acc, PGI, HMPP, F2-ACC Smaller modifications to original code The resulting code is still understandable by Fortran
programmers and can be easily modified Possible performance sacrifice with respect to CUDA code No standard for the moment (but work within the OMP
commitee)
• Data transfer time between host and GPU may strongly reduce the overall performance














