Embed Size (px)
Citation preview

Presented by Cathrin Weiss, Panagiotis Karras, Abraham Bernstein
Department of Informatics, University of Zurich
27-02-2015
Summarized by: Arpit Gagneja
Hexastore: Sextuple Indexing for Semantic Web
Data Management

OverviewHexastore – Sextuple Indexing
A Triple (S, P, O) can be represented in six ways (3! = 6)SPO, SOP, PSO, POS, OSP, OPS (Takes the idea of vertical
partitioning to its full logical conclusion)
Every possible indexing scheme can be materializedAllows quick and scalable query processingUp to five times bigger index space is needed
In this presentation,Review conventional RDF storage structuresIntroduction to HexastoreDiscussion

Physical Designs for RDF Storage (1/4)Sample triplets
SELECT ?titleWHERE {
?book <title> ?title.?book <author> <Fox, Joe>.?book <copyright> <2001>
}
Join! Join! (Will see merge pairwise join in Hexastore!, How merge pairwise join is effective? Will see)
Entire Table Scan!
Redundancy!

Clustered Property TableContains clusters of properties that tend to
be defined together
Physical Designs for RDF Storage (2/4)

Physical Designs for RDF Storage (3/4)Property-Class Table
Exploits the type property of subjects to cluster similar sets of subjects together in the same table
Unlike clustered property table, a property may exist in multiple property-class tablesValues of the type propertyValues of the type property

Physical Designs for RDF Storage (4/4)Vertically Partitioned Table
The giant table is rewritten into n two column tables where n is the number of unique properties in the data
We don’t have toMaintain null valuesHave a certain clustering algorithm
subjectsubject
propertyproperty
objectobject

MotivationThe problem of having non-property-bound
queries
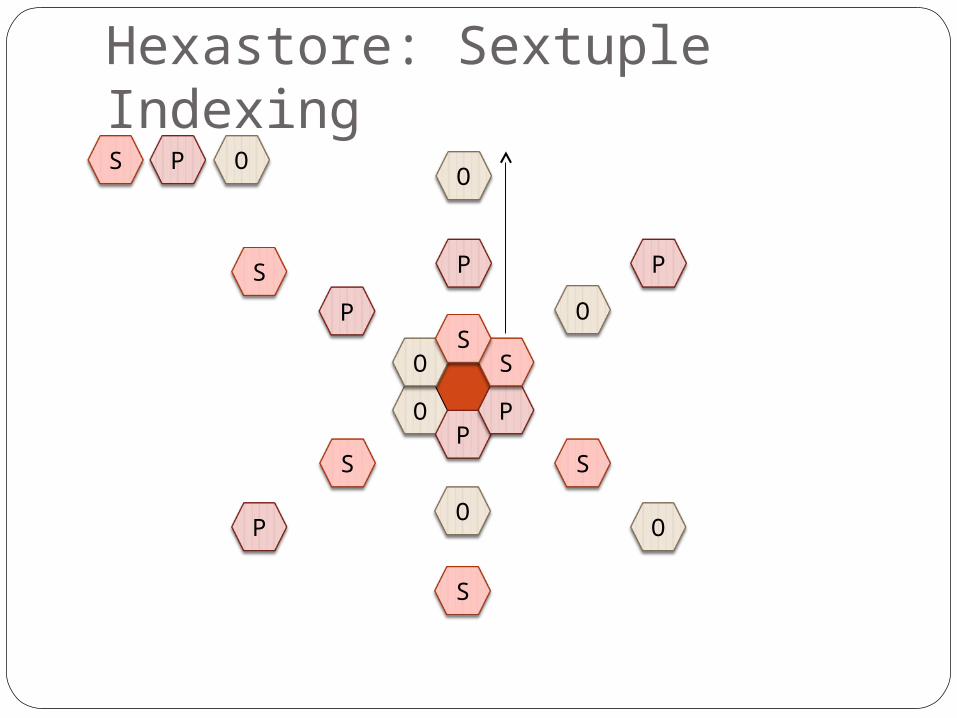
Hexastore: Sextuple Indexing
OP
P
O SS
O
P
P
S
S
PO
S
S
O
P
OOPS
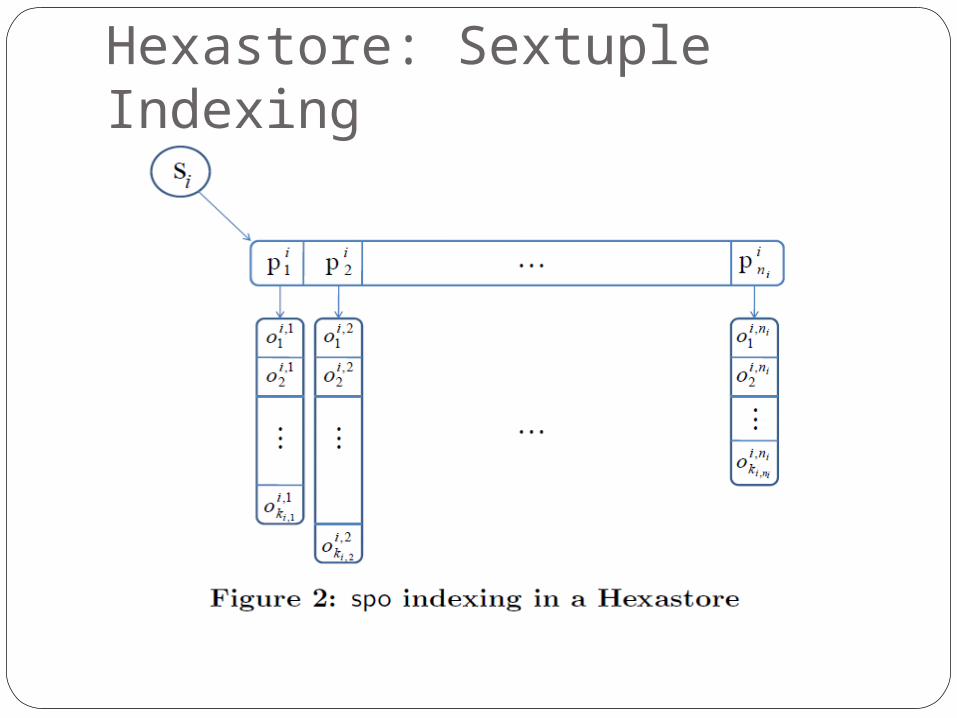
Hexastore: Sextuple Indexing

Five-fold Increase in Index SpaceSharing The Same Terminal Lists
SPO-PSO, SOP-OSP, POS-OPS
The key of each of the three resources in a triple appears in two headers and two vectors, but only in one list

Mapping Dictionary Replacing all literals by unique IDs using a mapping dictionary
Removes redundancy and helps in saving a lot of space We can concentrate on a logical index structure rather than the
physical storage design
S P O
object214 hasColor blue
object214 belongsTo
object352
… … …S P O
0 1 2
0 3 4
… … …
ID Value
0 object214
1 hasColor
… …

Clustered B+-Tree (RDF-3X, VLDB 2008)
Store everything in a clustered B+-TreeTriples are sorted in lexicographical order
Allowing the conversion of SPARQL patterns into range scan
We don’t have to do entire table scan002 …
000 001 002 003
S P O
0 1 2
0 3 4
… … …
Actually, we don’t need this table!Actually, we don’t need this table!
ID Value
0 object214
1 hasColor
… …
<Mapping Dictionary>

ArgumentationConcise and Efficient Handling of Multi-valued
ResourcesIndex can contain multiple itemscf. Multi-valued Property Table
Avoidance of NULLsOnly those RDF elements that are relevant to a
particular other element need to be stored in a particular index
No ad-hoc Choices NeededMost other RDF data storage schemes require several
ad-hoc decisions about their data representation architectureex. Clustered Property Table (which properties to be stored
together)

ArgumentationReduced I/O cost
Other RDF storage schemes may need to access multiple tables which are irrelevant to a queryQueries that are not bounded by property
All First-step Pairwise Joins are Fast Merge-JoinsThe key of resources in all vectors and lists used
in a Hexastore are sortedReduction of Unions and Joins
ex. a list of subjects related to two particular objects through any propertyHexastore can use osp index

Treating the Path Expression ProblemSelect B.subj
FROM triples AS A, triples AS BWHERE A.prop = wasBornAND A.obj = ‘1860’AND A.subj = B.objAND B.prop = ‘Author’
A path expression requires (n-1) subject-object self-joins where n is the length of the pathVertical Partitioning
Materialized Path Expressions (A.author:wasBorn = ‘1860’)
n-1C2 = O(n2) possible additional properties
Hexastore(n-1) merge-join using pso and pos indices

Experimental Evaluation Setup
2.8GHz dual core, 16GB RAM
Competitors Column-oriented Vertical Partitioning Approaches
COVP1 – PSO Index COVP2 – PSO Index + POS Index (second copy)
Hexastore SPO, SOP, PSO, POS, OSP, OPS
Datasets Barton, MIT library data, 61 mil. triples, 258 properties LUBM, A synthetic benchmark data set(10 univ.), 6.8 mil. triples, 18
predicates

Performance (Barton Data)

Performance (LUBM, 10)
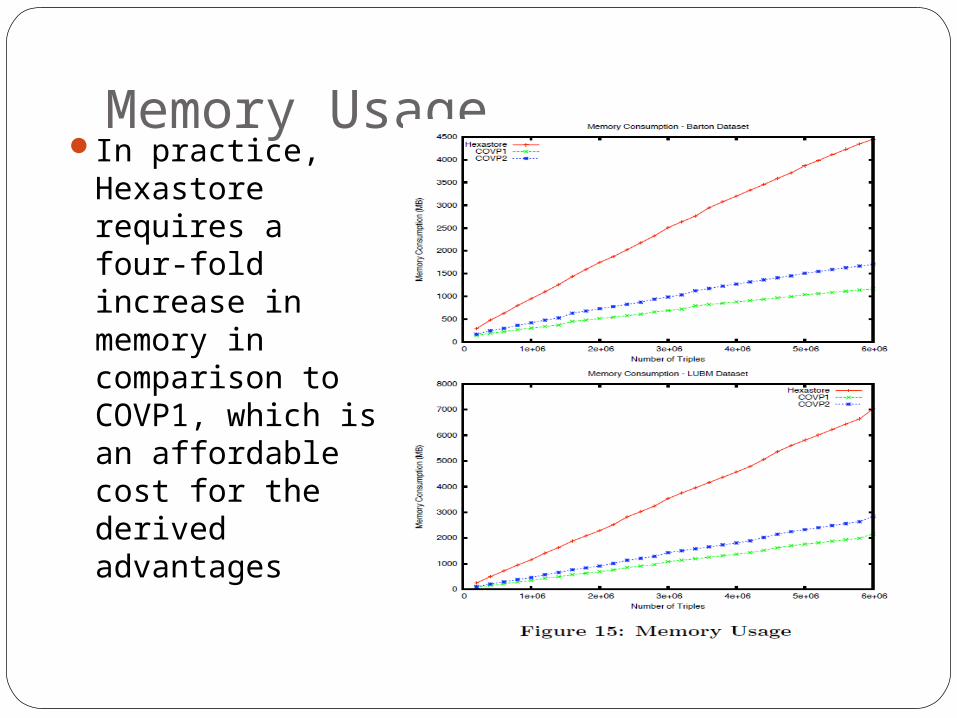
Memory UsageIn practice,
Hexastore requires a four-fold increase in memory in comparison to COVP1, which is an affordable cost for the derived advantages

ConclusionHexastore: Sextuple-Indexing Scheme
Worst-case five-fold storage increase in comparison to a conventional triples table
Quick and scalable general-purpose query processingAll pairwise joins in a Hexastore can be rendered as
merge joins
Optimizations:Some indexing patterns never used like
<o,s,p>Database Cracking suggested in paper

Thank You

![An Energy and Bandwidth Efficient Ray Tracing Architecturedkopta/papers/hwrt_hpg13.pdfAila and Karras [Aila and Karras 2010] focus on reducing off-chip bandwidth by partitioning the](https://img.pdfslide.net/doc/110x75/61468ae77599b83a5f004a06/an-energy-and-bandwidth-efficient-ray-tracing-dkoptapapershwrthpg13pdf-aila.jpg)


























