Embed Size (px)
Citation preview

Privacy Preserving Market Basket Data Analysis
Ling Guo, Songtao Guo, Xintao Wu
University of North Carolina at Charlotte

2
Market Basket Data
TID milk sugar bread … cereals
1 1 0 1 … 1
2 0 1 1 … 1
3 1 0 0 … 1
4 1 1 1 … 0
. . . . … .
N 0 1 1 … 0
1: presence 0: absence
…
Association rule (R.Agrawal SIGMOD 1993)
with support and confidence
YX )(XYPs
)(
)(
XP
XYPc

3
Other measures
2 x 2 contingency table
Objective measures for A=>B

4
Related Work
• Privacy preserving association rule mining Data swapping Frequent itemset or rule hiding Inverse frequent itemset mining Item randomization

5
Item Randomization
TID milk sugar bread … cereals
1 1 0 1 1
2 0 1 1 1
3 1 0 0 1
4 1 1 1 0
. . . . … .
N 0 1 1 0
TID milk sugar bread … cereals
1 0 1 1 1
2 1 1 1 0
3 1 1 1 1
4 0 0 1 1
. . . . … .
N 1 1 0 1
Original Data Randomized Data
To what extent randomization affects mining results? (Focus) To what extent it protects privacy?

6
Randomized Response ([ Stanley Warner; JASA 1965])
: Cheated in the exam : Didn’t cheat in the exam
Cheated in exam
Didn’t cheat
AAA
A
Randomization device
Do you belong to A? (p)
Do you belong to ?(1-p)A…
)1)(1( pp AA 12
ˆ
12
1ˆ
pp
pAW
1
“Yes” answer
“No” answer
As: Unbiased estimate of is: A
Procedure:
Purpose: Get the proportion( ) of population members that cheated in the exam.
A
…
Purpose

7
Application of RR in MBD
• RR can be expressed by matrix as: ( 0: No 1:Yes)
=
Extension to multiple variables
e.g., for 2 variables
Unbiased estimate of is:
),,,( 11100100
P
ˆˆ 1P
0
1p1
0
1
p p1
p
)...( 21 mPPP stands for Kronecker product
)()ˆ( 1 ndisp 111 )()ˆ( PPndisp
diagonal matrix with elements
),,,( 11100100
10
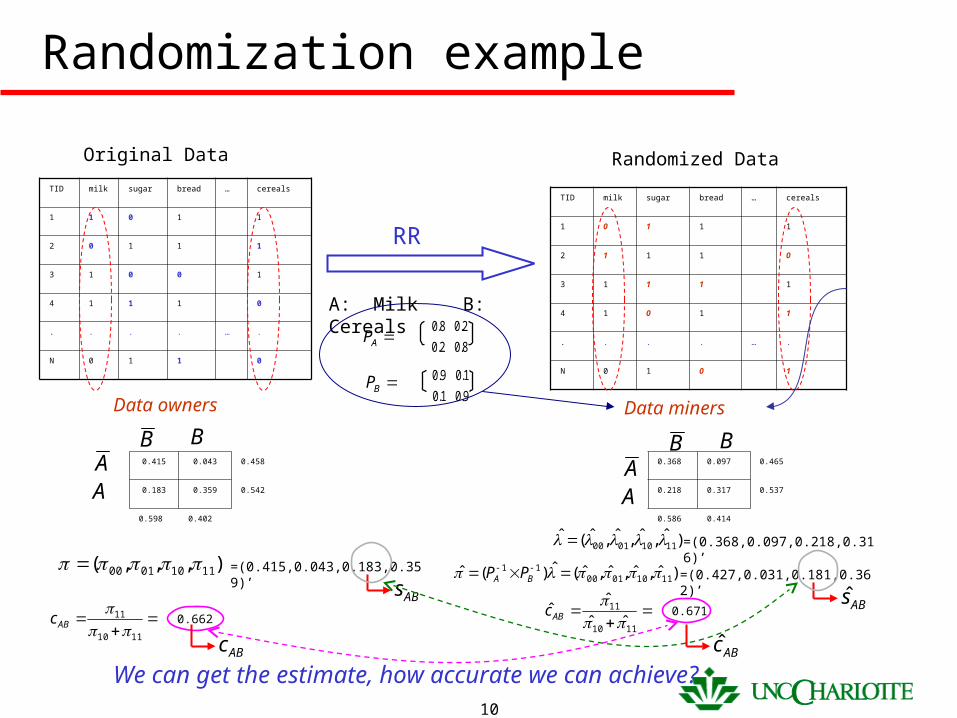
Randomization example
TID milk sugar bread … cereals
1 1 0 1 1
2 0 1 1 1
3 1 0 0 1
4 1 1 1 0
. . . . … .
N 0 1 1 0
Original Data Randomized Data
TID milk sugar bread … cereals
1 0 1 1 1
2 1 1 1 0
3 1 1 1 1
4 1 0 1 1
. . . . … .
N 0 1 0 1
RR
A: Milk B: Cereals
8.02.0
2.08.0AP
9.01.0
1.09.0BP
0.415 0.043 0.458
0.183 0.359 0.542
0.598 0.402
A
AA
B B0.368 0.097 0.465
0.218 0.317 0.537
0.586 0.414
B B
A
),,,( 11100100 )ˆ,ˆ,ˆ,ˆ(ˆ
11100100
)ˆ,ˆ,ˆ,ˆ(ˆ)(ˆ 1110010011
BA PP=(0.415,0.043,0.183,0.359)’=(0.427,0.031,0.181,0.362)’
ABsABs
1110
11
ABc 0.662
1110
11
ˆˆ
ˆˆ
ABc 0.671
We can get the estimate, how accurate we can achieve?ABc ABc
=(0.368,0.097,0.218,0.316)’
Data minersData owners

11
Motivation
31.5
35.936.3
22.1
12.3
23.8
%23min s
min26 ˆˆ sss
min6 ss
min2 ss Frequent set
Not frequent set
Estimated values
Original values
Rule 6 is falsely recognized from estimated value!
Lower& Upper bound
min2 ss l
min6 ss l
Frequent set with high confidence
Frequent set without confidence
Both are frequent set

12
Accuracy on Support S
• Estimate of support
• Variance of support
• Interquantile range (normal dist.)
ˆ)...(ˆˆ 111
1 kPPP
111 )ˆˆˆ()1()ˆv(oc PPn
5
11
10
01
00
10
566.6777.2478.1311.2
777.2667.5244.0134.3
478.1244.0902.2668.1
311.2134.3668.1113.7
ˆ
ˆ
ˆ
ˆ
)ˆv(oc
)ˆar(v 11)ˆ,ˆv(oc 1110
00 01 10 11
)ˆ(ˆˆ,)ˆ(ˆˆ1111 2/2/ kkkk iiaiiiiaii arzarz
0.362
0.346 0.378
)362.0,181.0,031.0,427.0(ˆ)()ˆˆˆˆ(ˆ 12
1111,10,01,00 PP
11

13
Accuracy on Confidence C
• Estimate of confidence A =>B
• Variance of confidence
• Interquantile range (ratio dist. is F(w))
Loose range derived on Chebyshev’s theorem
1110
11
ˆˆ
ˆ
ˆ
ˆˆ
A
AB
s
sc
)ˆ,ˆ(ˆˆ
ˆˆ2)ˆ(ˆ
ˆ
ˆ)ˆ(ˆ
ˆ
ˆ)ˆ(ˆ 10114
1
1110104
1
211
1141
210
ocararcar
)ˆar(v1
ˆ,)ˆar(v1
ˆ cccc
2/1 kwhere
Let be a random variable with expected value and finite
variance .Then for any real
X 2 0k
2/1)Pr( kkX
14
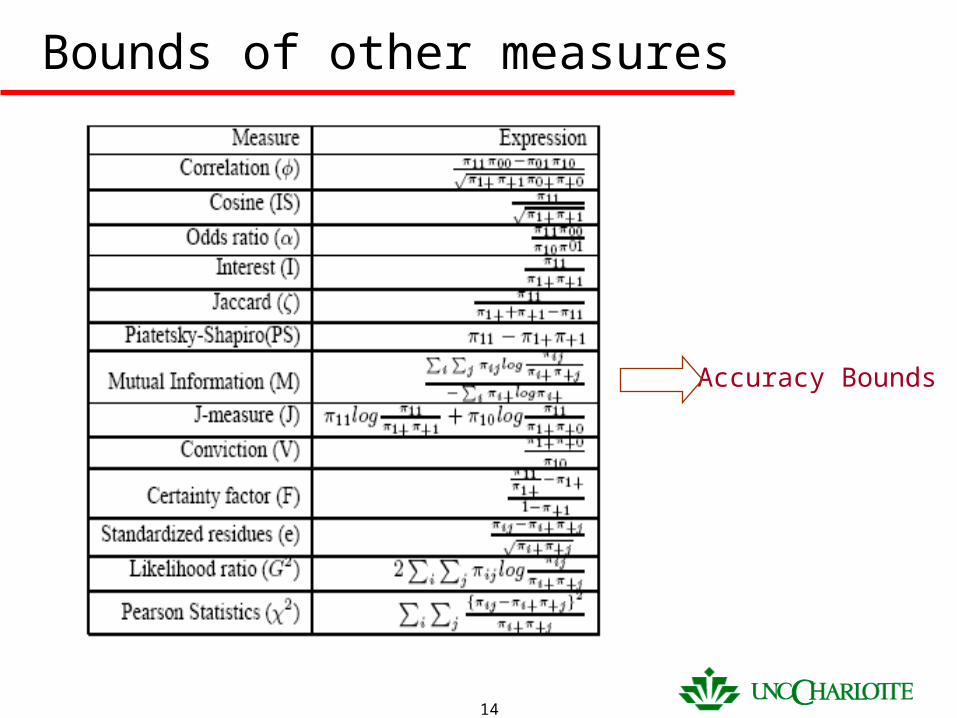
Bounds of other measures
Accuracy Bounds

15
General Framework
Step1: Estimation Express the measure as one derived function from the observed variables ( or their
marginal totals , ).
Compute the estimated measure value.
Step2: Variance of the estimated measure Get the variance of the estimated measure (a function with multi known variables) through
Taylor approximation
Step 3: Derive the interquantile range through Chebyshev's theorem
)(),()(')(')()}('{)}({1
2
1
rjij
k
jiii
k
ii nxxcoggxargxgar
i jij

16
Example for with two variables
Step 1: Get the estimate of the measure
Step 2: Get the variance of the estimated measure
Step 3: Derive the interquantile range through Chebyshev's theorem .
2
}ˆˆ
)ˆˆˆ(ˆˆ
)ˆˆˆ(ˆˆ
)ˆˆˆ(ˆˆ
)ˆˆˆ({ˆ
11
21111
01
20110
10
21001
00
200002
n
),()ˆ
()ˆ
()()ˆ
(}ˆ{24
1
22
24
1
2ji
jji ii
ii
xxcoxx
xarx
ar
001 x 012 x 103 x 114 xWhere: , , ,

17
Accuracy Bounds
• With unknown distribution, Chebyshev theorm only gives loose bounds.
Bounds of the support vs. varying p

18
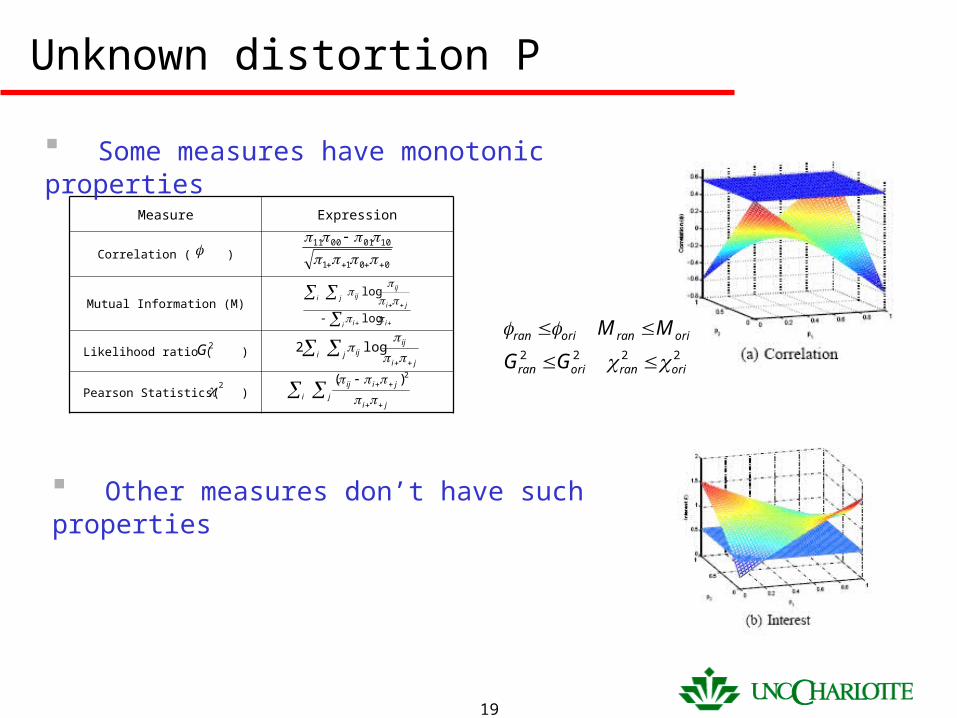
Distortion
• All the above discussions assume distortion matrices P are known to data miners P could be exploited by attackers to improve the posteriori
probability of their prediction on sensitive items
• How about not releasing P? Disclosure risk is decreased Data mining result?
19
Unknown distortion P
2222oriranoriran
oriranoriran
GG
MM
Measure Expression
Correlation ( )
Mutual Information (M)
Likelihood ratio ( )
Pearson Statistics( )
0011
10010011
i ii
ji
ijijji
log
log
2Gji
ij
j iji
log2
2
j
ji
jiij
i 2)(
Some measures have monotonic properties
Other measures don’t have such properties

20
Applications: hypothesis test
From the randomized data, if we discover an itemset which satisfies , we can guarantee dependence exists among the original itemset since .
Still be able to derive the strong dependent itemsets from the randomized data
22ranori
22 ran
2
No false positive

21
Conclusion
• Propose a general approach to deriving accuracy bounds of various measures adopted in MBD analysis
• Prove some measures have monotonic property and some data mining tasks can be conducted directly on randomized data (without knowing the distortion). No false positive pattern exists in the mining result.

22
Future Work
• Which measures are more sensible to randomization?
• The tradeoff between the privacy of individual data and the accuracy of data mining results
• Accuracy vs. disclosure analysis for general categorical data

23
Acknowledgement
• NSF IIS-0546027
• Ph.D. students
Ling Guo Songtao Guo

24
QA&





























