Embed Size (px)
Citation preview

Probability and Probability and Information RetrievalInformation Retrieval
Introduction toIntroduction toArtificial IntelligenceArtificial Intelligence
COS302COS302
Michael L. LittmanMichael L. Littman
Fall 2001Fall 2001

AdministrationAdministration
Foundations of Statistical Natural Foundations of Statistical Natural Language ProcessingLanguage Processing
By Christopher D. Manning and By Christopher D. Manning and Hinrich SchutzeHinrich Schutze
Grade distributions online.Grade distributions online.

The IR ProblemThe IR Problem
queryquery• doc1doc1• doc2doc2• doc3doc3
......
Sort docs in order of relevance to Sort docs in order of relevance to query.query.

Example QueryExample Query
Query: Query: The 1929 World SeriesThe 1929 World Series
384,945,633 results in Alta Vista384,945,633 results in Alta Vista• GNU's Not Unix! - the GNU Project and GNU's Not Unix! - the GNU Project and
the Free Software Foundation (FSF)the Free Software Foundation (FSF)• Yahoo! SingaporeYahoo! Singapore• The USGenWeb Project - Home PageThe USGenWeb Project - Home Page• ……

Better List (Google)Better List (Google)
• TSN Archives: The 1929 World TSN Archives: The 1929 World SeriesSeries
• Baseball Almanac - World Series Baseball Almanac - World Series MenuMenu
• 1929 World Series - PHA vs. CHC - 1929 World Series - PHA vs. CHC - Baseball-Reference.comBaseball-Reference.com
• World Series Winners (1903-1929) World Series Winners (1903-1929) (Baseball World)(Baseball World)

GoalGoal
Should return as many relevant docs Should return as many relevant docs as possibleas possible
recallrecall
Should return as few irrelevant docs Should return as few irrelevant docs as possibleas possibleprecisionprecision
Typically a tradeoff…Typically a tradeoff…

Main InsightsMain Insights
How identify “good” docs?How identify “good” docs?• More words in common is good.More words in common is good.• Rare words more important than Rare words more important than
common words.common words.• Long documents carry less weight, Long documents carry less weight,
all other things being equal.all other things being equal.

Bag of Words ModelBag of Words Model
Just pay attention to which words Just pay attention to which words appear in document and query.appear in document and query.
Ignore order.Ignore order.

Boolean IRBoolean IR
"and" all uncommon words"and" all uncommon words
Most web search engines.Most web search engines.• Altavista: 79,628 hitsAltavista: 79,628 hits• fastfast• not so accurate by itselfnot so accurate by itself

Example: BiographyExample: Biography
Science and Science and thethe Modern Modern WorldWorld (1925), a (1925), a seriesseries of lectures given in the United of lectures given in the United States, served as an introduction to his States, served as an introduction to his later metaphysics.later metaphysics.
Whitehead's most important book, Whitehead's most important book, Process Process and Realityand Reality ( (19291929), took this theory to a ), took this theory to a level of even greater generality.level of even greater generality.
http://www-groups.dcs.st-and.ac.uk/~history/Mathematiciahttp://www-groups.dcs.st-and.ac.uk/~history/Mathematicians/Whitehead.htmlns/Whitehead.html

Vector-space ModelVector-space Model
For each word in common between For each word in common between document and query, compute a weight. document and query, compute a weight. Sum the weights.Sum the weights.
tf = (term frequency) number of times tf = (term frequency) number of times term appears in the documentterm appears in the document
idf = (inverse document frequency) divide idf = (inverse document frequency) divide by number of times term appears in any by number of times term appears in any documentdocument
Also various forms of document-length Also various forms of document-length normalization.normalization.
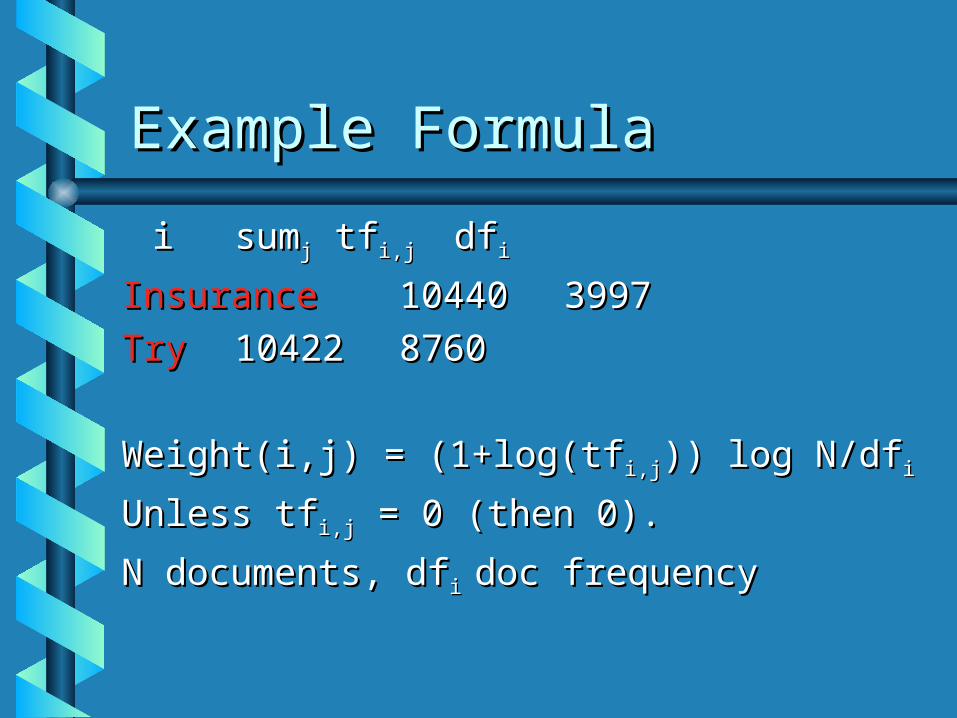
Example FormulaExample Formula
ii sumsumjj tf tfi,j i,j dfdfii
InsuranceInsurance 1044010440 39973997
TryTry 1042210422 87608760
Weight(i,j) = (1+log(tfWeight(i,j) = (1+log(tfi,ji,j)) log N/df)) log N/dfii
Unless tfUnless tfi,ji,j = 0 (then 0). = 0 (then 0).
N documents, dfN documents, dfi i doc frequencydoc frequency

Cosine NormalizationCosine Normalization
Cos(q,d) = sumCos(q,d) = sumii q qii d dii / /
sqrt(sumsqrt(sumii q qii22) sqrt(sum) sqrt(sumii d dii
22))
Downweights long documents.Downweights long documents.
(Perhaps too much.)(Perhaps too much.)

Probabilistic ApproachProbabilistic Approach
Lots of work studying different Lots of work studying different weighting schemes.weighting schemes.
Often very Often very ad hocad hoc, empirically , empirically motivated.motivated.
Is there an analog of A* for IR? Is there an analog of A* for IR? Elegant, simple, effective?Elegant, simple, effective?

Language ModelsLanguage Models
Probability theory is gaining Probability theory is gaining popularity. Originally speech popularity. Originally speech recognition:recognition:
If we can assign probabilities to If we can assign probabilities to sentence and phonemes, we can sentence and phonemes, we can choose the sentence that choose the sentence that minimizes the chance that we’re minimizes the chance that we’re wrong…wrong…

Probability BasicsProbability Basics
Pr(A): Probability A is truePr(A): Probability A is true
Pr(AB): Prob. both A & B are truePr(AB): Prob. both A & B are true
Pr(~A): Prob. of not A: 1-Pr(A)Pr(~A): Prob. of not A: 1-Pr(A)
Pr(A|B): Prob. of A given BPr(A|B): Prob. of A given B
Pr(AB)/Pr(B)Pr(AB)/Pr(B)
Pr(A+B): Probability A or B is truePr(A+B): Probability A or B is true
Pr(A) + Pr(B) – Pr(AB)Pr(A) + Pr(B) – Pr(AB)

Venn DiagramVenn Diagram
A
B
AB

Bayes RuleBayes Rule
Pr(A|B) = Pr(B|A) Pr(A) / Pr(B)Pr(A|B) = Pr(B|A) Pr(A) / Pr(B)
because because
Pr(AB) = Pr (B) Pr(A|B) = Pr(B|A) Pr(A)Pr(AB) = Pr (B) Pr(A|B) = Pr(B|A) Pr(A)
The most basic form of “learning”: The most basic form of “learning”: • picking a likely model given the datapicking a likely model given the data• adjusting beliefs in light of new evidence adjusting beliefs in light of new evidence

Probability Cheat SheetProbability Cheat Sheet
Chain rule:Chain rule:
Pr(A,X|Y) = Pr(A|Y) Pr(X|A,Y)Pr(A,X|Y) = Pr(A|Y) Pr(X|A,Y)
Summation rule:Summation rule:
Pr(X|Y) = Pr(A X | Y) + Pr(~A X | Y)Pr(X|Y) = Pr(A X | Y) + Pr(~A X | Y)
Bayes rule:Bayes rule:
Pr(A|BX) = Pr(B|AX) Pr(A|X)/Pr(B|X)Pr(A|BX) = Pr(B|AX) Pr(A|X)/Pr(B|X)

Speech ExampleSpeech Example
Pr(sentence|phonemes)Pr(sentence|phonemes)
=Pr(phonemes|sentence) =Pr(phonemes|sentence) Pr(sentence) / Pr(phonemes)Pr(sentence) / Pr(phonemes)
Pronunciation model
Constant
Language model

Classification ExampleClassification Example
Given a song title, guess if it’s a Given a song title, guess if it’s a country song or a rap song.country song or a rap song.
• U Got it BadU Got it Bad• Cowboy Take Me AwayCowboy Take Me Away• Feelin’ on Yo BootyFeelin’ on Yo Booty• When God-Fearin' Women Get The BluesWhen God-Fearin' Women Get The Blues• God Bless the USAGod Bless the USA• Ballin’ out of ControlBallin’ out of Control

Probabilistic ClassificationProbabilistic Classification
Language model gives:Language model gives:• Pr(T|R), Pr(T|C), Pr(C), Pr(R)Pr(T|R), Pr(T|C), Pr(C), Pr(R)
Compare Compare • Pr(R|T) vs. Pr(C|T)Pr(R|T) vs. Pr(C|T)• Pr(T|R) Pr(R) / Pr(T) vs. Pr(T|C) Pr(T|R) Pr(R) / Pr(T) vs. Pr(T|C)
Pr(C) / Pr(T)Pr(C) / Pr(T)• Pr(T|R) Pr(R) vs. Pr(T|C) Pr(C)Pr(T|R) Pr(R) vs. Pr(T|C) Pr(C)

Naïve BayesNaïve Bayes
Pr(T|C)Pr(T|C)
Generate words independentlyGenerate words independently
Pr(wPr(w11 w w22 w w33 … w … wnn|C)|C)
= Pr(w= Pr(w11|C) Pr(w|C) Pr(w22|C) … Pr(w|C) … Pr(wnn|C)|C)
So, Pr(party|R) = 0.02, Pr(party|C) So, Pr(party|R) = 0.02, Pr(party|C) = 0.001= 0.001

Estimating Naïve BayesEstimating Naïve Bayes
Where would these numbers come Where would these numbers come from?from?
Take a list of country song titles.Take a list of country song titles.
First attempt:First attempt:
Pr(w|C) = count(w; C)Pr(w|C) = count(w; C)
/ sum/ sumww count(w; C) count(w; C)

SmoothingSmoothing
Problem: Unseen words. Pr(party|C) Problem: Unseen words. Pr(party|C) = 0= 0
Pr(Even Party Cowboys Get the Pr(Even Party Cowboys Get the Blues) = 0Blues) = 0
Laplace Smoothing:Laplace Smoothing:
Pr(w|C) = (1+count(w; C))Pr(w|C) = (1+count(w; C))
/ sum/ sumww (1+count(w; C)) (1+count(w; C))

Other ApplicationsOther Applications
FilteringFiltering• AdvisoriesAdvisories
Text classificationText classification• Spam vs. importantSpam vs. important• Web hierarchyWeb hierarchy• Shakespeare vs. JeffersonShakespeare vs. Jefferson• French vs. EnglishFrench vs. English

IR ExampleIR Example
Pr(d|q) = Pr(q|d) Pr(d) / Pr(q)Pr(d|q) = Pr(q|d) Pr(d) / Pr(q)
Language model
Prior belief d is relevant(assume equal)
Constant
Can view each document like a Can view each document like a category for classification.category for classification.

Smoothing MattersSmoothing Matters
p(w|d) =p(w|d) =
ppss(w|d) if count(w;d)>0 (seen)(w|d) if count(w;d)>0 (seen)p(w|collection) if count(w;d)=0p(w|collection) if count(w;d)=0
ppss(w|d): estimated from document (w|d): estimated from document and smoothedand smoothed
p(w|collection): estimated from p(w|collection): estimated from corpus and smoothedcorpus and smoothed
Equivalent effect to TF-IDF.Equivalent effect to TF-IDF.

What to LearnWhat to Learn
IR problem and TF-IDF.IR problem and TF-IDF.
Unigram language models.Unigram language models.
Naïve Bayes and simple Bayesian Naïve Bayes and simple Bayesian classification.classification.
Need for smoothing.Need for smoothing.

Homework 6 (due 11/14)Homework 6 (due 11/14)
1.1. Use the web to find sentences to Use the web to find sentences to support the analogy support the analogy traffic:street::water:riverbed. Give the traffic:street::water:riverbed. Give the sentences and their sources.sentences and their sources.
2.2. Two common Boolean operators in IR Two common Boolean operators in IR are “and” and “or”. (a) Which would are “and” and “or”. (a) Which would you choose to improve recall? (b) you choose to improve recall? (b) Which would you use to improve Which would you use to improve precision?precision?

Homework 6 (cont’d)Homework 6 (cont’d)
3. Argue that the language modeling 3. Argue that the language modeling approach to IR gives an effect like approach to IR gives an effect like TF-IDF. (a) First, argue that Pr(q|d) TF-IDF. (a) First, argue that Pr(q|d) > Pr(q’|d) if q’ is just like q but > Pr(q’|d) if q’ is just like q but





























