Embed Size (px)
Citation preview

Proceedings of theLinux Symposium
Volume One
July 21st–24th, 2004Ottawa, Ontario
Canada


Contents
TCP Connection Passing 9
Werner Almesberger
Cooperative Linux 23
Dan Aloni
Build your own Wireless Access Point 33
Erik Andersen
Run-time testing of LSB Applications 41
Stuart Anderson
Linux Block IO—present and future 51
Jens Axboe
Linux AIO Performance and Robustness for Enterprise Workloads 63
Suparna Bhattacharya
Methods to Improve Bootup Time in Linux 79
Tim R. Bird
Linux on NUMA Systems 89
Martin J. Bligh
Improving Kernel Performance by Unmapping the Page Cache 103
James Bottomley
Linux Virtualization on IBM Power5 Systems 113
Dave Boutcher

The State of ACPI in the Linux Kernel 121
Len Brown
Scaling Linux to the Extreme 133
Ray Bryant
Get More Device Drivers out of the Kernel! 149
Peter Chubb
Big Servers—2.6 compared to 2.4 163
Wim A. Coekaerts
Multi-processor and Frequency Scaling 167
Paul Devriendt
Dynamic Kernel Module Support: From Theory to Practice 187
Matt Domsch
e100 weight reduction program 203
Scott Feldman
NFSv4 and rpcsec_gss for linux 207
J. Bruce Fields
Comparing and Evaluating epoll, select, and poll Event Mechanisms 215
Louay Gammo
The (Re)Architecture of the X Window System 227
James Gettys
IA64-Linux perf tools for IO dorks 239
Grant Grundler

Carrier Grade Server Features in the Linux Kernel 255
Ibrahim Haddad
Demands, Solutions, and Improvements for Linux Filesystem Security 269
Michael Austin Halcrow
Hotplug Memory and the Linux VM 287
Dave Hansen


Conference Organizers
Andrew J. Hutton,Steamballoon, Inc.Stephanie Donovan,Linux SymposiumC. Craig Ross,Linux Symposium
Review Committee
Jes Sorensen,Wild Open Source, Inc.Matt Domsch,DellGerrit Huizenga,IBMMatthew Wilcox,Hewlett-PackardDirk Hohndel,IntelVal Henson,Sun MicrosystemsJamal Hadi Salimi,ZnyxAndrew Hutton,Steamballoon, Inc.
Proceedings Formatting Team
John W. Lockhart,Red Hat, Inc.
Authors retain copyright to all submitted papers, but have granted unlimited redistribution rightsto all as a condition of submission.

8 • Linux Symposium 2004 • Volume One

TCP Connection Passing
Werner [email protected]
Abstract
tcpcp is an experimental mechanism that al-lows cooperating applications to pass owner-ship of TCP connection endpoints from oneLinux host to another one. tcpcp can be usedbetween hosts using different architectures anddoes not need the other endpoint of the con-nection to cooperate (or even to know what’sgoing on).
1 Introduction
When designing systems for load-balancing,process migration, or fail-over, there is even-tually the point where one would like to beable to “move” a socket from one machine toanother one, without losing the connection onthat socket, similar to file descriptor passing ona single host. Such a move operation usuallyinvolves at least three elements:
1. Moving any application space state re-lated to the connection to the new owner.E.g. in the case of a Web server serv-ing large static files, the application statecould simply be the file name and the cur-rent position in the file.
2. Making sure that packets belonging to theconnection are sent to the new owner ofthe socket. Normally this also means thatthe previous owner should no longer re-ceive them.
3. Last but not least, creating compatiblenetwork state in the kernel of the new con-nection owner, such that it can resume thecommunication where the previous ownerleft off.
Origin (server)
Destination (server)
Application state
Kernel state
Packet routing
User spaceKernel
(client)Peer
App
App
Figure 1: Passing one end of a TCP connectionfrom one host to another.
Figure 1 illustrates this for the case of a client-server application, where one server passesownership of a connection to another server.We shall call the host from which ownership ofthe connection endpoint is taken theorigin, thehost to which it is transferred thedestination,and the host on the other end of the connection(which does not change) thepeer.
Details of moving the application state are be-yond the scope of this paper, and we will onlysketch relatively simple examples. Similarly,we will mention a few ways for how the redi-rection in the network can be accomplished,but without going into too much detail.

10 • Linux Symposium 2004 • Volume One
The complexity of the kernel state of a networkconnection, and the difficulty of moving thisstate from one host to another, varies greatlywith the transport protocol being used. Amongthe two major transport protocols of the Inter-net, UDP [1] and TCP [2], the latter clearlypresents more of a challenge in this regard.Nevertheless, some issues also apply to UDP.
tcpcp (TCP Connection Passing) is a proof ofconcept implementation of a mechanism thatallows applications to transport the kernel stateof a TCP endpoint from one host to another,while the connection is established, and with-out requiring the peer to cooperate in any way.tcpcp is not a complete process migration orload-balancing solution, but rather a buildingblock that can be integrated into such systems.tcpcp consists of a kernel patch (at the timeof writing for version 2.6.4 of the Linux ker-nel) that implements the operations for dump-ing and restoring the TCP connection end-point, a library with wrapper functions (seeSection 3), and a few applications for debug-ging and demonstration.
The project’s home page is athttp://tcpcp.sourceforge.net/
The remainder of this paper is organized as fol-lows: this section continues with a descriptionof the context in which connection passing ex-ists. Section 2 explains the connection pass-ing operation in detail. Section 3 introducesthe APIs tcpcp provides. The information thatdefines a TCP connection and its state is de-scribed in Section 4. Sections 5 and 6 discusscongestion control and the limitations TCP im-poses on checkpointing. Security implicationsof the availability and use of tcpcp are exam-ined in Section 7. We conclude with an outlookon future direction the work on tcpcp will takein Section 8, and the conclusions in Section 9.
The excellent “TCP/IP Illustrated” [3] is rec-ommended for readers who wish to refresh
their memory of TCP/IP concepts and termi-nology.
1.1 There is more than one way to do it
tcpcp is only one of several possible meth-ods for passing TCP connections among hosts.Here are some alternatives:
In some cases, the solution is to avoid pass-ing the “live” TCP connection, but to termi-nate the connection between the origin and thepeer, and rely on higher protocol layers to re-establish a new connection between the des-tination and the peer. Drawbacks of this ap-proach include that those higher layers need toknow that they have to re-establish the connec-tion, and that they need to do this within anacceptable amount of time. Furthermore, theymay only be able to do this at a few specificpoints during a communication.
The use of HTTP redirection [4] is a simpleexample of connection passing above the trans-port layer.
Another approach is to introduce an intermedi-ate layer between the application and the ker-nel, for the purpose of handling such redirec-tion. This approach is fairly common in pro-cess migration solutions, such as Mosix [5],MIGSOCK [6], etc. It requires that the peerbe equipped with the same intermediate layer.
1.2 Transparency
The key feature of tcpcp is that the peer can beleft completely unaware that the connection ispassed from one host to another. In detail, thismeans:
• The peer’s networking stack can be used“as is,” without modification and withoutrequiring non-standard functionality
• The connection is not interrupted

Linux Symposium 2004 • Volume One • 11
• The peer does not have to stop sending
• No contradictory information is sent to thepeer
• These properties apply to all protocol lay-ers visible to the peer
Furthermore, tcpcp allows the connection to bepassed at any time, without needing to syn-chronize the data stream with the peer.
The kernels of the hosts between which theconnection is passed both need to supporttcpcp, and the application(s) on these hosts willtypically have to be modified to perform theconnection passing.
1.3 Various uses
Application scenarios in which the functional-ity provided by tcpcp could be useful includeload balancing, process migration, and fail-over.
In the case of load balancing, an applicationcan send connections (and whatever processingis associated with them) to another host if thelocal one gets overloaded. Or, one could have ahost acting as a dispatcher that may perform aninitial dialog and then assigns the connectionto a machine in a farm.
For process migration, tcpcp would be in-voked when moving a file descriptor linked to asocket. If process migration is implemented inthe kernel, an interface would have to be addedto tcpcp to allow calling it in this way.
Fail-over is tricker, because there is normallyno prior indication when the origin will be-come unavailable. We discuss the issues aris-ing from this in more detail in Section 6.
2 Passing the connection
Figure 2 illustrates the connection passing pro-cedure in detail.
1. The application at the origin initiates theprocedure by requesting retrieval of whatwe call theInternal Connection Informa-tion (ICI) of a socket. The ICI containsall the information the kernel needs to re-create a TCP connection endpoint
2. As a side-effect of retrieving the ICI,tcpcp isolatesthe connection: all incom-ing packets are silently discarded, and nopackets are sent. This is accomplishedby setting up a per-socket filter, and bychanging the output function. Isolatingthe socket ensures that the state of the con-nection being passed remains stable at ei-ther end.
3. The kernel copies all relevant variables,plus the contents of the out-of-order andsend/retransmit buffers to the ICI. Theout-of-order buffer contains TCP seg-ments that have not been acknowledgedyet, because an earlier segment is stillmissing.
4. After retrieving the ICI, the applicationempties the receive buffer. It can eitherprocess this data directly, or send it alongwith the other information, for the desti-nation to process.
5. The origin sends the ICI and any relevantapplication state to the destination. Theapplication at the origin keeps the socketopen, to ensure that it stays isolated.
6. The destination opens a new socket. Itmay then bind it to a new port (there areother choices, described below).

12 • Linux Symposium 2004 • Volume One
Vars Send/Retr OutOfOrder
Receive OutOfOrder
Receive OutOfOrder
Send/Retransmit
Send/Retransmit ACK
(Re)transmit, or send ACK (10)
Isolate connection (2)
Copy kernel state to ICI (3)
Switch network traffic (8)
Get ICI (1)
Empty receive buffer (4)
Bind port (6)
Set ICI (7)
Data flow in networking stack Data transfer Command
Activate connection (9)
Send application state and ICI to new host (5)
Application
Application
TCP
TCP
Router, switch, ...
Network path to peer
Internal Connection Information
Dest
inat
ion
Orig
in
Figure 2: Passing a TCP connection endpoint in ten easy steps.
7. The application at the destination now setsthe ICI on the socket. The kernel createsand populates the necessary data struc-tures, but does not send any data yet. Thecurrent implementation makes no use ofthe out-of-order data.
8. Network traffic belonging to the connec-tion is redirected from the origin to thedestination host. Scenarios for this are de-scribed in more detail below. The applica-tion at the origin can now close the socket.
9. The application at the destination makes acall toactivatethe connection.
10. If there is data to transmit, the kernelwill do so. If there is no data, an other-wise empty ACK segment (like a windowprobe) is sent to wake up the peer.
Note that, at the end of this procedure, thesocket at the destination is a perfectly normalTCP endpoint. In particular, this endpoint canbe passed to another host (or back to the origi-nal one) with tcpcp.
2.1 Local port selection
The local port at the destination can be selectedin three ways:
• The destination can simply try to use thesame port as the origin. This is necessaryif no address translation is performed onthe connection.
• The application can bind the socket beforesetting the ICI. In this case, the port in theICI is ignored.

Linux Symposium 2004 • Volume One • 13
• The application can also clear the portinformation in the ICI, which will causethe socket to be bound to any availableport. Compared to binding the socket be-fore setting the ICI, this approach has theadvantage of using the local port numberspace much more efficiently.
The choice of the port selection method de-pends on how the environment in which tcpcpoperates is structured. Normally, either the firstor the last method would be used.
2.2 Switching network traffic
There are countless ways for redirecting IPpackets from one host to another, without helpfrom the transport layer protocol. They in-clude redirecting part of the link layer, inge-nious modifications of how link and networklayer interact [7], all kinds of tunnels, networkaddress translation (NAT), etc.
Since many of the techniques are similar tonetwork-based load balancing, the Linux Vir-tual Server Project [8] is a good starting pointfor exploring these issues.
While a comprehensive study of this topic ifbeyond the scope of this paper, we will brieflysketch an approach using a static route, be-cause this is conceptually straightforward andrelatively easy to implement.
Server A
Server B
GW Client
ipA, ipX
ipB, ipX
ipX
ipX gw ipA ipX gw ipB
Figure 3: Redirecting network traffic using astatic route.
The scenario shown in Figure 3 consists of twoserversA andB, with interfaces with the IP ad-dressesipA andipB, respectively. Each serveralso has a virtual interface with the addressipX . ipA , ipB, andipX are on the same subnet,and also the gateway machine has an interfaceon this subnet.
At the gateway, we create a static route as fol-lows:
route add ipX gw ipA
When the client connects to the addressipX , itreaches hostA. We can now pass the connec-tion to hostB, as outlined in Section 2. In Step8, we change the static route on the gateway asfollows:
route del ipXroute add ipX gw ipB
One major limitation of this approach is ofcourse that this routing change affects all con-nections toipX , which is usually undesirable.Nevertheless, this simple setup can be used todemonstrate the operation of tcpcp.
3 APIs
The API for tcpcp consists of a low-level partthat is based on getting and setting socket op-tions, and a high-level library that providesconvenient wrappers for the low-level API.
We mention only the most important aspects ofboth APIs here. They are described in more de-tail in the documentation that is included withtcpcp.
3.1 Low-level API
The ICI is retrieved by getting theTCP_ICIsocket option. As a side-effect, the connectionis isolated, as described in Section 2. The ap-plication can determine the maximum ICI size

14 • Linux Symposium 2004 • Volume One
for the connection in question by getting theTCP_MAXICISIZE socket option.
Example:
void *buf;int ici_size;size_t size = sizeof(int);
getsockopt(s,SOL_TCP,TCP_MAXICISIZE,&ici_size,&size);
buf = malloc(ici_size);size = ici_size;getsockopt(s,SOL_TCP,TCP_ICI,
buf,&size);
The connection endpoint at the destination iscreated by setting theTCP_ICI socket option,and the connection is activated by “setting”the TCP_CP_FNsocket option to the valueTCPCP_ACTIVATE.1
Example:
int sub_function = TCPCP_ACTIVATE;
setsockopt(s,SOL_TCP,TCP_ICI,buf,size);
/* ... */setsockopt(s,SOL_TCP,TCP_CP_FN,
&sub_function,sizeof(sub_function));
3.2 High-level API
These are the most important functions pro-vided by the high-level API:
void *tcpcp_get(int s);int tcpcp_size(const void *ici);int tcpcp_create(const void *ici);int tcpcp_activate(int s);
1The use of a multiplexed socket option is admittedlyugly, although convenient during development.
tcpcp_get allocates a buffer for the ICI, andretrieves that ICI (isolating the connection as aside-effect). The amount of data in the ICI canbe queried by callingtcpcp_size on it.
tcpcp_create sets an ICI on a socket, andtcpcp_activate activates the connection.
4 Describing a TCP endpoint
In this section, we describe the parameters thatdefine a TCP connection and its state. tcpcpcollects all the information it needs to re-createa TCP connection endpoint in a data structurewe callInternal Connection Information(ICI).
The ICI is portable among systems supportingtcpcp, irrespective of their CPU architecture.
Besides this data, the kernel maintains a largenumber of additional variables that can eitherbe reset to default values at the destination(such as congestion control state), or that areonly rarely used and not essential for correctoperation of TCP (such as statistics).
4.1 Connection identifier
Each TCP connection in the global Internet orany private internet [9] is uniquely identified bythe IP addresses of the source and destinationhost, and the port numbers used at both ends.
tcpcp currently only supports IPv4, but canbe extended to support IPv6, should the needarise.
4.2 Fixed data
A few parameters of a TCP connection are ne-gotiated during the initial handshake, and re-main unchanged during the life time of theconnection. These parameters include whetherwindow scaling, timestamps, or selective ac-knowledgments are used, the number of bits by

Linux Symposium 2004 • Volume One • 15
Connection identifierip.v4.ip_src IPv4 address of the host on which the ICI was recorded (source)ip.v4.ip_dst IPv4 address of the peer (destination)tcp_sport Port at the source hosttcp_dport Port at the destination hostFixed at connection setuptcp_flags TCP flags (window scale, SACK, ECN, etc.)snd_wscale Send window scalercv_wscale Receive window scalesnd_mss Maximum Segment Size at the source hostrcv_mss MSS at the destination hostConnection statestate TCP connection state (e.g. ESTABLISHED)Sequence numberssnd_nxt Sequence number of next new byte to sendrcv_nxt Sequence number of next new byte expected to receiveWindows (flow-control)snd_wnd Window received from peerrcv_wnd Window advertised to peerTimestampsts_gen Current value of the timestamp generatorts_recent Most recently received timestamp
Table 1: TCP variables recorded in tcpcp’s Internal Connection Information (ICI) structure.
which the window is shifted, and the maximumsegment sizes (MSS).
These parameters are used mainly for sanitychecks, and to determine whether the destina-tion host is able to handle the connection. Thereceived MSS continues of course to limit thesegment size.
4.3 Sequence numbers
The sequence numbers are used to synchronizeall aspects of a TCP connection.
Only the sequence numbers we expect to seein the network, in either direction, are neededwhen re-creating the endpoint. The kernel usesseveral variables that are derived from these se-quence numbers. The values of these variables
either coincide withsnd_nxt andrcv_nxtin the state we set up, or they can be calculatedby examining the send buffer.
4.4 Windows (flow-control)
The (flow-control) window determines howmuch more data can be sent or received with-out overrunning the receiver’s buffer.
The window the origin received from the peeris also the window we can use after re-creatingthe endpoint.
The window the origin advertised to the peerdefines the minimum receive buffer size at thedestination.

16 • Linux Symposium 2004 • Volume One
4.5 Timestamps
TCP can use timestamps to detect old segmentswith wrapped sequence numbers [10]. Thismechanism is calledProtect Against WrappedSequence numbers(PAWS).
Linux uses a global counter (tcp_time_stamp ) to generate local timestamps. If amoved connection were to use the counter atthe new host, local round-trip-time calculationmay be confused when receiving timestampreplies from the previous connection, and thepeer’s PAWS algorithm will discard segmentsif timestamps appear to have jumped back intime.
Just turning off timestamps when moving theconnection is not an acceptable solution, eventhough [10] seems to allow TCP to just stopsending timestamps, because doing so wouldbring back the problem PAWS tries to solvein the first place, and it would also reduce theaccuracy of round-trip-time estimates, possiblydegrading the throughput of the connection.
A more satisfying solution is to synchroniza-tion the local timestamp generator. This isaccomplished by introducing a per-connectiontimestamp offset that is added to the valueof tcp_time_stamp . This calculation ishidden in the macrotp_time_stamp(tp) ,which just becomestcp_time_stamp if thekernel is configured without tcpcp.
The addition of the timestamp offset is the onlymajor change tcpcp requires in the existingTCP/IP stack.
4.6 Receive buffers
There are two buffers at the receiving side:the buffer containing segments received out-of-order (see Section 2), and the buffer with datathat is ready for retrieval by the application.
tcpcp currently ignores both buffers: the out-of-order buffer is copied into the ICI, but notused when setting up the new socket. Any datain the receive buffer is left for the applicationto read and process.
4.7 Send buffer
The send and retransmit buffer contains datathat is no longer accessible through the socketAPI, and that cannot be discarded. It is there-fore placed in the ICI, and used to populate thesend buffer at the destination.
4.8 Selective acknowledgments
In Section 5 of [11], the use of inbound SACKinformation is left optional. tcpcp takes advan-tage of this, and neither preserves SACK infor-mation collected from inbound segments, northe history of SACK information sent to thepeer.
Outbound SACKs convey information aboutthe receiver’s out-of-order queue. Fortunately,[11] declares this information as purely advi-sory. In particular, if reception of data has beenacknowledged with a SACK, this does not im-ply that the receiver has to remember havingdone so. First, it can request retransmission ofthis data, and second, when constructing newSACKs, the receiver is encouraged to includeinformation from previous SACKs, but is un-der no obligation to do so.
Therefore, while [11] discourages losingSACK information, doing so does not violateits requirements.
Losing SACK information may temporarilydegrade the throughput of the TCP connec-tion. This is currently of little concern, be-cause tcpcp forces the connection into slowstart, which has even more drastic performanceimplications.

Linux Symposium 2004 • Volume One • 17
SACK recovery may need to be reconsid-ered once tcpcp implements more sophisticatedcongestion control.
4.9 Other data
The TCP connection state is currently alwaysESTABLISHED. It may be useful to also al-low passing connections in earlier states, e.g.SYN_RCVD. This is for further study.
Congestion control data and statistics are cur-rently omitted. The new connection starts withslow-start, to allow TCP to discover the char-acteristics of the new path to the peer.
5 Congestion control
Most of the complexity of TCP is in its conges-tion control. tcpcp currently avoids touchingcongestion control almost entirely, by settingthe destination to slow start.
This is a highly conservative approach that isappropriate if knowing the characteristics ofthe path between the origin and the peer doesnot give us any information on the characteris-tics of the path between the destination and thepeer, as shown in the lower part of Figure 4.
However, if the characteristics of the two pathscan be expected to be very similar, e.g. if thehosts passing the connection are on the sameLAN, better performance could be achieved byallowing tcpcp to resume the connection at ornearly at full speed.
Re-establishing congestion control state is forfurther study. To avoid abuse, such an opera-tion can be made available only to sufficientlytrusted applications.
Origin
Destination
? Peer
High−speed LAN
WAN
Characteristics may differGo to slow−start
Characteristics are identicalReuse congestion control state
Figure 4: Depending on the structure of thenetwork, the congestion control state of theoriginal connection may or may not be reused.
6 Checkpointing
tcpcp is primarily designed for scenarios,where the old and the new connection ownerare both functional during the process of con-nection passing.
A similar usage scenario would if the nodeowning the connection occasionally retrieves(“checkpoints”) the momentary state of theconnection, and after failure of the connectionowner, another node would then use the check-point data to resurrect the connection.
While apparently similar to connection pass-ing, checkpointing presents several problemswhich we discuss in this section. Note that thisis speculative and that the current implementa-tion of tcpcp does not support any of the exten-

18 • Linux Symposium 2004 • Volume One
sions discussed here.
We consider the send and receive flow of theTCP connection separately, and we assume thatsequence numbers can be directly translated toapplication state (e.g. when transferring a file,application state consists only of the actual fileposition, which can be trivially mapped to andfrom TCP sequence numbers). Furthermore,we assume the connection to be in ESTAB-LISHED state at both ends.
6.1 Outbound data
One or more of the following events may occurbetween the last checkpoint and the momentthe connection is resurrected:
• the sender may have enqueued more data
• the receiver may have acknowledgedmore data
• the receiver may have retrieved more data,thereby growing its window
Assuming that no additional data has been re-ceived from the peer, the new sender can sim-ply re-transmit the last segment. (Alternatively,tcp_xmit_probe_skb might be useful forthe same purpose.) In this case, the followingprotocol violations can occur:
• The sequence number may have wrapped.This can be avoided by making surethat a checkpoint is never older than theMaximum Segment Lifetime (MSL)2, andthat less than231 bytes are sent betweencheckpoints.
• If using PAWS, the timestamp may be be-low the last timestamp sent by the oldsender. The best solution for avoiding this
2[2] specifies a MSL of two minutes.
is probably to tightly synchronize clockon the old and the new connection owner,and to make a conservative estimate of thenumber of ticks of the local timestampclock that have passed since taking thecheckpoint. This assumes that the times-tamp clock ticks roughly in real time.
Since new data in the segment sent after res-urrecting the connection cannot exceed the re-ceiver’s window, the only possible outcomesare that the segment contains either new data,or only old data. In either case, the receiverwill acknowledge the segment.
Upon reception of an acknowledgment, eitherin response to the retransmitted segment, orfrom a packet in flight at the time when the con-nection was resurrected, the sender knows howfar the connection state has advanced since thecheckpoint was taken.
If the sequence number from the acknowl-edgment is belowsnd_nxt , no special ac-tion is necessary. If the sequence number isabovesnd_nxt , the sender would exception-ally treat this as a valid acknowledgment.3
As a possible performance improvement, thesender may notify the application once a newsequence number has been received, and theapplication could then skip over unnecessarydata.
6.2 Inbound data
The main problem with checkpointing of in-coming data is that TCP will acknowledge datathat has not yet been retrieved by the applica-tion. Therefore, checkpointing would have todelay outbound acknowledgments until the ap-plication has actually retrieved them, and has
3Note that this exceptional condition does not neces-sarily have to occur with the first acknowledgment re-ceived.

Linux Symposium 2004 • Volume One • 19
checkpointed the resulting state change.
To intercept all types of ACKs, tcp_transmit_skb would have to be changedto sendtp->copied_seq instead oftp->rcv_nxt . Furthermore, a new API functionwould be needed to trigger an explicit acknowl-edgment after the data has been stored or pro-cessed.
Putting acknowledges under application con-trol would change their timing. This may upsetthe round-trip time estimation of the peer, andit may also cause it to falsely assume changesin the congestion level along the path.
7 Security
tcpcp bypasses various sets of access and con-sistency checks normally performed when set-ting up TCP connections. This section ana-lyzes the overall security impact of tcpcp.
7.1 Two lines of defense
When setting TCP_ICI, the kernel has nomeans of verifying that the connection infor-mation actually originates from a compatiblesystem. Users may therefore manipulate con-nection state, copy connection state from arbi-trary other systems, or even synthesize connec-tion state according to their wishes. tcpcp pro-vides two mechanisms to protect against inten-tional or accidental mis-uses:
1. tcpcp only takes as little information aspossible from the user, and re-generatesas much of the state related to the TCPconnection (such as neighbour and desti-nation data) as possible from local infor-mation. Furthermore, it performs a num-ber of sanity checks on the ICI, to ensureits integrity, and compatibility with con-
straints of the local system (such as buffersize limits and kernel capabilities).
2. Many manipulations possible throughtcpcp can be shown to be availablethrough other means if the application hasthe CAP_NET_RAWcapability. There-fore, establishing a new TCP connectionwith tcpcp also requires this capability.This can be relaxed on a host-wide basis.
7.2 Retrieval of sensitive kernel data
Getting TCP_ICI may retrieve informationfrom the kernel that one would like to hidefrom unprivileged applications, e.g. detailsabout the state of the TCP ISN generator. Sincethe equally unprivilegedTCP_INFO alreadygives access to most TCP connection meta-data, tcpcp does not create any new vulnera-bilities.
7.3 Local denial of service
SettingTCP_ICI could be used to introduceinconsistent data in the TCP stack, or the ker-nel in general. Preventing this relies on the cor-rectness and completeness of the sanity checksmentioned before.
tcpcp can be used to accumulate stale data inthe kernel. However, this is not very differentfrom e.g. creating a large number of unusedsockets, or letting buffers fill up in TCP con-nections, and therefore poses no new securitythreat.
tcpcp can be used to shutdown connections be-longing to third party applications, providedthat the usual access restrictions grant access tocopies of their socket descriptors. This is sim-ilar to executingshutdown on such sockets,and is therefore believed to pose no new threat.

20 • Linux Symposium 2004 • Volume One
7.4 Restricted state transitions
tcpcp could be used to advance TCP connec-tion state past boundaries imposed by internalor external control mechanisms. In particular,conspiring applications may create TCP con-nections without ever exchanging SYN pack-ets, bypassing SYN-filtering firewalls. SinceSYN-filtering firewalls can already be avoidedby privileged applications, sites depending onSYN-filtering firewalls should therefore usethe default setting of tcpcp, which makes itsuse also a privileged operation.
7.5 Attacks on remote hosts
The ability to setTCP_ICI makes it easyto commit all kinds of of protocol violations.While tcpcp may simplify implementing suchattacks, this type of abuses has always beenpossible for privileged users, and therefore,tcpcp poses no new security threat to systemsproperly resistant against network attacks.
However, if a site allows systems where onlytrusted users may be able to communicate withotherwise shielded systems with known remoteTCP vulnerabilities, tcpcp could be used for at-tacks. Such sites should use the default set-ting, which makes settingTCP_ICI a privi-leged operation.
7.6 Security summary
To summarize, the author believes that the de-sign of tcpcp does not open any new exploits iftcpcp is used in its default configuration.
Obviously, some subtleties have probably beenoverlooked, and there may be bugs inadver-tently leading to vulnerabilities. Therefore,tcpcp should receive public scrutiny before be-ing considered fit for regular use.
8 Future work
To allow faster connection passing amonghosts that share the same, or a very similar pathto the peer, tcpcp should try to avoid going toslow start. To do so, it will have to pass morecongestion control information, and integrate itproperly at the destination.
Although not strictly part of tcpcp, the redirec-tion apparatus for the network should be fur-ther extended, in particular to allow individualconnections to be redirected at that point too,and to include some middleware that coordi-nates the redirecting with the changes at thehosts passing the connection.
It would be very interesting if connection pass-ing could also be used for checkpointing. Theanalysis in Section 6 suggests that at least lim-ited checkpointing capabilities should be feasi-ble without interfering with regular TCP oper-ation.
The inner workings of TCP are complex andeasily disturbed. It is therefore important tosubject tcpcp to thorough testing, in particu-lar in transient states, such as during recoveryfrom lost segments. The umlsim simulator [12]allows to generate such conditions in a deter-ministic way, and will be used for these tests.
9 Conclusion
tcpcp is a proof of concept implementation thatsuccessfully demonstrates that an endpoint ofa TCP connection can be passed from one hostto another without involving the host at the op-posite end of the TCP connection. tcpcp alsoshows that this can be accomplished with a rel-atively small amount of kernel changes.
tcpcp in its present form is suitable for exper-imental use as a building block for load bal-ancing and process migration solutions. Future

Linux Symposium 2004 • Volume One • 21
work will focus on improving the performanceof tcpcp, on validating its correctness, and onexploring checkpointing capabilities.
References
[1] RFC768; Postel, Jon.User DatagramProtocol, IETF, August 1980.
[2] RFC793; Postel, Jon.TransmissionControl Protocol, IETF, September 1981.
[3] Stevens, W. Richard.TCP/IP Illustrated,Volume 1 – The Protocols,Addison-Wesley, 1994.
[4] RFC2616; Fielding, Roy T.; Gettys,James; Mogul, Jeffrey C.; FrystykNielsen, Henrik; Masinter, Larry; Leach,Paul J.; Berners-Lee, Tim.HypertextTransfer Protocol – HTTP/1.1, IETF,June 1999.
[5] Bar, Moshe.OpenMosix, Proceedings ofthe 10th International Linux SystemTechnology Conference(Linux-Kongress 2003), pp. 94–102,October 2003.
[6] Kuntz, Bryan; Rajan, Karthik.MIGSOCK – Migratable TCP Socket inLinux, CMU, M.Sc. Thesis, February2002.http://www-2.cs.cmu.edu/
~softagents/migsock/MIGSOCK.
[7] Leite, Fábio Olivé.Load-Balancing HAClusters with No Single Point of Failure,Proceedings of the 9th InternationalLinux System Technology Conference(Linux-Kongress 2002), pp. 122–131,September 2002.http://www.linux-kongress.org/2002/papers/lk2002-leite.html
[8] Linux Virtual Server Project, http://www.linuxvirtualserver.org/
[9] RFC1918; Rekhter, Yakov; Moskowitz,Robert G.; Karrenberg, Daniel; de Groot,Geert Jan; Lear, Eliot.AddressAllocation for Private Internets, IETF,February 1996.
[10] RFC1323; Jacobson, Van; Braden, Bob;Borman, Dave.TCP Extensions for HighPerformance, IETF, May 1992.
[11] RFC2018; Mathis, Matt; Mahdavi,Jamshid; Floyd, Sally; Romanow, Allyn.TCP Selective AcknowledgementOptions, IETF, October 1996.
[12] Almesberger, Werner.UML Simulator,Proceedings of the Ottawa LinuxSymposium 2003, July 2003.http://archive.linuxsymposium.
org/ols2003/Proceedings/
All-Reprints/
Reprint-Almesberger-OLS2003.

22 • Linux Symposium 2004 • Volume One

Cooperative Linux
Abstract
In this paper I’ll describe Cooperative Linux, aport of the Linux kernel that allows it to run asan unprivileged lightweight virtual machine inkernel mode, on top of another OS kernel. It al-lows Linux to run under any operating systemthat supports loading drivers, such as Windowsor Linux, after minimal porting efforts. The pa-per includes the present and future implemen-tation details, its applications, and its compar-ison with other Linux virtualization methods.Among the technical details I’ll present theCPU-complete context switch code, hardwareinterrupt forwarding, the interface between thehost OS and Linux, and the management of theVM’s pseudo physical RAM.
1 Introduction
Cooperative Linux utilizes the rather under-used concept of a Cooperative Virtual Machine(CVM), in contrast to traditional VMs thatare unprivileged and being under the completecontrol of the host machine.
The termCooperative is used to describe twoentities working in parallel, e.g. coroutines [2].In that sense the most plain description of Co-operative Linux is turning two operating sys-tem kernels into two big coroutines. In thatmode, each kernel has its own complete CPUcontext and address space, and each kernel de-cides when to give control back to its partner.
However, only one of the two kernels has con-
trol on the physical hardware, where the otheris provided only with virtual hardware abstrac-tion. From this point on in the paper I’ll referto these two kernels as the host operating sys-tem, and the guest Linux VM respectively. Thehost can be every OS kernel that exports basicprimitives that provide the Cooperative Linuxportable driver to run in CPL0 mode (ring 0)and allocate memory.
The special CPL0 approach in CooperativeLinux makes it significantly different thantraditional virtualization solutions such asVMware, plex86, Virtual PC, and other meth-ods such as Xen. All of these approaches workby running the guest OS in a less privilegedmode than of the host kernel. This approachallowed for the extensive simplification of Co-operative Linux’s design and its short early-beta development cycle which lasted only onemonth, starting from scratch by modifying thevanilla Linux 2.4.23-pre9 release until reach-ing to the point where KDE could run.
The only downsides to the CPL0 approach isstability and security. If it’s unstable, it has thepotential to crash the system. However, mea-sures can be taken, such as cleanly shutting itdown on the first internal Oops or panic. An-other disadvantage is security. Acquiring rootuser access on a Cooperative Linux machinecan potentially lead to root on the host ma-chine if the attacker loads specially crafted ker-nel module or uses some very elaborated ex-ploit in case which the Cooperative Linux ker-nel was compiled without module support.

24 • Linux Symposium 2004 • Volume One
Most of the changes in the Cooperative Linuxpatch are on the i386 tree—the only supportedarchitecture for Cooperative at the time of thiswriting. The other changes are mostly addi-tions of virtual drivers: cobd (block device),conet (network), and cocon (console). Most ofthe changes in the i386 tree involve the initial-ization and setup code. It is a goal of the Coop-erative Linux kernel design to remain as closeas possible to the standalone i386 kernel, so allchanges are localized and minimized as muchas possible.
2 Uses
Cooperative Linux in its current early statecan already provide some of the uses thatUser Mode Linux[1] provides, such as vir-tual hosting, kernel development environment,research, and testing of new distributions orbuggy software. It also enabled new uses:
• Relatively effortless migration pathfrom Windows. In the process of switch-ing to another OS, there is the choice be-tween installing another computer, dual-booting, or using a virtualization soft-ware. The first option costs money, thesecond is tiresome in terms of operation,but the third can be the most quick andeasy method—especially if it’s free. Thisis where Cooperative Linux comes in. Itis already used in workplaces to convertWindows users to Linux.
• Adding Windows machines to Linuxclusters. The Cooperative Linux patchis minimal and can be easily combinedwith others such as the MOSIX or Open-MOSIX patches that add clustering ca-pabilities to the kernel. This work inprogress allows to add Windows machinesto super-computer clusters, where oneillustration could tell about a secretary
workstation computer that runs Cooper-ative Linux as a screen saver—when thesecretary goes home at the end of the dayand leaves the computer unattended, theoffice’s cluster gets more CPU cycles forfree.
• Running an otherwise-dual-bootedLinux system from the other OS. TheWindows port of Cooperative Linuxallows it to mount real disk partitionsas block devices. Numerous people areusing this in order to access, rescue, orjust run their Linux system from theirext3 or reiserfs file systems.
• Using Linux as a Windows firewall onthe same machine. As a likely competi-tor to other out-of-the-box Windows fire-walls, iptables along with a stripped-downCooperative Linux system can potentiallyserve as a network firewall.
• Linux kernel development / debugging/ research and study on another operat-ing systems.
Digging inside a running CooperativeLinux kernel, you can hardly tell thedifference between it and a standaloneLinux. All virtual addresses are thesame—Oops reports look familiar and thearchitecture dependent code works in thesame manner, excepts some transparentconversions, which are described in thenext section in this paper.
• Development environment for portingto and from Linux.
3 Design Overview
In this section I’ll describe the basic meth-ods behind Cooperative Linux, which include

Linux Symposium 2004 • Volume One • 25
complete context switches, handling of hard-ware interrupts by forwarding, physical ad-dress translation and the pseudo physical mem-ory RAM.
3.1 Minimum Changes
To illustrate the minimal effect of the Cooper-ative Linux patch on the source tree, here is adiffstat listing of the patch on Linux 2.4.26 asof May 10, 2004:
CREDITS | 6Documentation/devices.txt | 7Makefile | 8arch/i386/config.in | 30arch/i386/kernel/Makefile | 2arch/i386/kernel/cooperative.c | 181 +++++arch/i386/kernel/head.S | 4arch/i386/kernel/i387.c | 8arch/i386/kernel/i8259.c | 153 ++++arch/i386/kernel/ioport.c | 10arch/i386/kernel/process.c | 28arch/i386/kernel/setup.c | 61 +arch/i386/kernel/time.c | 104 +++arch/i386/kernel/traps.c | 9arch/i386/mm/fault.c | 4arch/i386/mm/init.c | 37 +arch/i386/vmlinux.lds | 82 +-drivers/block/Config.in | 4drivers/block/Makefile | 1drivers/block/cobd.c | 334 ++++++++++drivers/block/ll_rw_blk.c | 2drivers/char/Makefile | 4drivers/char/colx_keyb.c | 1221 +++++++++++++*drivers/char/mem.c | 8drivers/char/vt.c | 8drivers/net/Config.in | 4drivers/net/Makefile | 1drivers/net/conet.c | 205 ++++++drivers/video/Makefile | 4drivers/video/cocon.c | 484 +++++++++++++++include/asm-i386/cooperative.h | 175 +++++include/asm-i386/dma.h | 4include/asm-i386/io.h | 27include/asm-i386/irq.h | 6include/asm-i386/mc146818rtc.h | 7include/asm-i386/page.h | 30include/asm-i386/pgalloc.h | 7include/asm-i386/pgtable-2level.h | 8include/asm-i386/pgtable.h | 7include/asm-i386/processor.h | 12include/asm-i386/system.h | 8include/linux/console.h | 1include/linux/cooperative.h | 317 +++++++++include/linux/major.h | 1init/do_mounts.c | 3init/main.c | 9kernel/Makefile | 2kernel/cooperative.c | 254 +++++++kernel/panic.c | 4kernel/printk.c | 650 files changed, 3828 insertions(+), 74 deletions(-)
3.2 Device Driver
The device driver port of Cooperative Linuxis used for accessing kernel mode and usingthe kernel primitives that are exported by the
host OS kernel. Most of the driver is OS-independent code that interfaces with the OSdependent primitives that include page alloca-tions, debug printing, and interfacing with userspace.
When a Cooperative Linux VM is created, thedriver loads a kernel image from a vmlinuxfile that was compiled from the patched kernelwith CONFIG_COOPERATIVE. The vmlinuxfile doesn’t need any cross platform tools in or-der to be generated, and the same vmlinux filecan be used to run a Cooperative Linux VM onseveral OSes of the same architecture.
The VM is associated with a per-processresource—a file descriptor in Linux, or a de-vice handle in Windows. The purpose of thisassociation makes sense: if the process run-ning the VM ends abnormally in any way, allresources are cleaned up automatically from acallback when the system frees the per-processresource.
3.3 Pseudo Physical RAM
In Cooperative Linux, we had to work aroundthe Linux MM design assumption that the en-tire physical RAM is bestowed upon the ker-nel on startup, and instead, only give Cooper-ative Linux a fixed set of physical pages, andthen only do the translations needed for it towork transparently in that set. All the memorywhich Cooperative Linux considers as physi-cal is in that allocated set, which we call thePseudo Physical RAM.
The memory is allocated in the host OSusing the appropriate kernel function—alloc_pages() in Linux andMmAllocatePagesForMdl() inWindows—so it is not mapped in any ad-dress space on the host for not wasting PTEs.The allocated pages are always resident andnot freed until the VM is downed. Page tables

26 • Linux Symposium 2004 • Volume One
--- linux/include/asm-i386/pgtable-2level.h 2004-04-20 08:04:01.000000000 +0300+++ linux/include/asm-i386/pgtable-2level.h 2004-05-09 16:54:09.000000000 +0300@@ -58,8 +58,14 @@
}#define ptep_get_and_clear(xp) __pte(xchg(&(xp)->pte_low, 0))#define pte_same(a, b) ((a).pte_low == (b).pte_low)
-#define pte_page(x) (mem_map+((unsigned long)(((x).pte_low >> PAGE_SHIFT))))#define pte_none(x) (!(x).pte_low)
++#ifndef CONFIG_COOPERATIVE+#define pte_page(x) (mem_map+((unsigned long)(((x).pte_low >> PAGE_SHIFT))))
#define __mk_pte(page_nr,pgprot) __pte(((page_nr) << PAGE_SHIFT) | pgprot_val(pgprot))+#else+#define pte_page(x) CO_VA_PAGE((x).pte_low)+#define __mk_pte(page_nr,pgprot) __pte((CO_PA(page_nr) & PAGE_MASK) | pgprot_val(pgprot))+#endif
#endif /* _I386_PGTABLE_2LEVEL_H */
Table 1: Example of MM architecture dependent changes
are created for mapping the allocated pagesin the VM’s kernel virtual address space. TheVM’s address space resembles the addressspace of a regular kernel—the normal RAMzone is mapped contiguously at 0xc0000000.
The VM address space also has its ownspecial fixmaps—the page tables themselvesare mapped at 0xfef00000 in order to pro-vide an O(1) ability for translating PPRAM(Psuedo-Physical RAM) addresses to physicaladdresses when creating PTEs for user spaceand vmalloc() space. On the other wayaround, a special physical-to-PPRAM map isallocated and mapped at 0xff000000, to speedup handling of events such as pages faultswhich require translation of physical addressesto PPRAM address. This bi-directional mem-ory address mapping allows for a negligibleoverhead in page faults and user space map-ping operations.
Very few changes in the i386 MMU macroswere needed to facilitate the PPRAM. An ex-ample is shown in Table 1. Around an #ifdefof CONFIG_COOPERATIVEthe__mk_pte()low level MM macro translates a PPRAMstruct page to a PTE that maps the real phys-ical page. Respectively,pte_page() takesa PTE that was generated by__mk_pte()
and returns the corresponding struct page forit. Other macros such aspmd_page() andload_cr3() were also changed.
3.4 Context Switching
The Cooperative Linux VM uses only one hostOS process in order to provide a context for it-self and its processes. That one process, namedcolinux-daemon, can be called a Super Processsince it frequently calls the kernel driver to per-form a context switch from the host kernel tothe guest Linux kernel and back. With the fre-quent (HZ times a second) host kernel entries,it is able able to completely control the CPUand MMU without affecting anything else inthe host OS kernel.
On the Intel 386 architecture, a complete con-text switch requires that the top page direc-tory table pointer register—CR3—is changed.However, it is not possible to easily changeboth the instruction pointer (EIP) and CR3 inone instruction, so it implies that the code thatchanges CR3 must be mapped in both contextsfor the change to be possible. It’s problematicto map that code at the same virtual addressin both contexts due to design limitations—thetwo contexts can divide the kernel and user ad-

Linux Symposium 2004 • Volume One • 27
dress space differently, such that one virtual ad-dress can contain a kernel mapped page in oneOS and a user mapped page in another.
In Cooperative Linux the problem was solvedby using an intermediate address space duringthe switch (referred to as the ‘passage page,’see Figure 1). The intermediate address spaceis defined by a specially created page tables inboth the guest and host contexts and maps thesame code that is used for the switch (passagecode) at both of the virtual addresses that areinvolved. When a switch occurs, first CR3 ischanged to point to the intermediate addressspace. Then, EIP is relocated to the other map-ping of the passage code using a jump. Finally,CR3 is changed to point to the top page tabledirectory of the other OS.
The single MMU page that contains the pas-sage page code, also contains the saved state ofone OS while the other is executing. Upon thebeginning of a switch, interrupts are turned off,and a current state is saved to the passage pageby the passage page code. The state includesall the general purpose registers, the segmentregisters, the interrupt descriptor table register(IDTR), the global descriptor table (GDTR),the local descriptor register (LTR), the task reg-ister (TR), and the state of the FPU / MMX/ SSE registers. In the middle of the passagepage code, it restores the state of the other OSand interrupts are turned back on. This processis akin to a “normal” process to process contextswitch.
Since control is returned to the host OS on ev-ery hardware interrupt (described in the follow-ing section), it is the responsibility of the hostOS scheduler to give time slices to the Cooper-ative Linux VM just as if it was a regular pro-cess.
0xFFFFFFFF
Host OSIntermediateGuest Linux
0x80000000
Figure 1: Address space transition during anOS cooperative kernel switch, using an inter-mapped page
3.5 Interrupt Handling and Forwarding
Since a complete MMU context switch also in-volves the IDTR, Cooperative Linux must setan interrupt vector table in order to handle thehardware interrupts that occur in the systemduring its running state. However, CooperativeLinux only forwards the invocations of inter-rupts to the host OS, because the latter needsto know about these interrupts in order to keepfunctioning and support the colinux-daemonprocess itself, regardless to the fact that exter-nal hardware interrupts are meaningless to theCooperative Linux virtual machine.
The interrupt vectors for the internal processorexceptions (0x0–0x1f) and the system call vec-tor (0x80) are kept like they are so that Coop-erative Linux handles its own page faults andother exceptions, but the other interrupt vectorspoint to special proxy ISRs (interrupt serviceroutines). When such an ISR is invoked duringthe Cooperative Linux context by an externalhardware interrupt, a context switch is made tothe host OS using the passage code. On the

28 • Linux Symposium 2004 • Volume One
other side, the address of the relevant ISR ofthe host OS is determined by looking at its IDT.An interrupt call stack is forged and a jump oc-curs to that address. Between the invocation ofthe ISR in the Linux side and the handling ofthe interrupt in the host side, the interrupt flagis disabled.
The operation adds a tiny latency to interrupthandling in the host OS, but it is quite ne-glectable. Considering that this interrupt for-warding technique also involves the hardwaretimer interrupt, the host OS cannot detect thatits CR3 was hijacked for a moment and there-fore no exceptions in the host side would occuras a result of the context switch.
To provide interrupts for the virtual devicedrivers of the guest Linux, the changes in thearch code include a virtual interrupt controllerwhich receives messages from the host OSon the occasion of a switch and invokesdo_IRQ() with a forged struct pt_args .The interrupt numbers are virtual and allocatedon a per-device basis.
4 Benchmarks And Performance
4.1 Dbench results
This section shows a comparison between UserMode Linux and Cooperative Linux. The ma-chine which the following results were gener-ated on is a 2.8GHz Pentium 4 with HT en-abled, 512GB RAM, and a 120GB SATA Max-tor hard-drive that hosts ext3 partitions. Thecomparison was performed using the dbench1.3-2 package of Debian on all setups.
The host machine runs the Linux 2.6.6 kernelpatched with SKAS support. The UML kernelis Linux 2.6.4 that runs with 32MB of RAM,and is configured to use SKAS mode. The Co-operative Linux kernel is a Linux 2.4.26 kerneland it is configured to run with 32MB of RAM,
same as the UML system. The root file-systemof both UML and Cooperative Linux machinesis the same host Linux file that contains an ext3image of a 0.5GB minimized Debian system.
The commands ‘dbench 1’, ‘dbench 3’, and‘dbench 10’ were run in 3 consecutive runs foreach command, on the host Linux, on UML,and on Cooperative Linux setups. The resultsare shown in Table 2, Table 3, and Table 4.
System Throughput Netbench43.813 54.766
Host 50.117 62.64744.128 55.16010.418 13.022
UML 9.408 11.7609.309 11.636
10.418 13.023coLinux 12.574 15.718
12.075 15.094
Table 2: output of dbench 10 (units are inMB/sec)
System Throughput Netbench43.287 54.109
Host 41.383 51.72959.965 74.95611.857 14.821
UML 15.143 18.92914.602 18.25224.095 30.119
coLinux 32.527 40.65936.423 45.528
Table 3: output of dbench 3 (units are inMB/sec)
4.2 Understanding the results
From the results in these runs, ‘dbench 10’,‘dbench 3’, and ‘dbench 1’ show 20%, 123%,and 303% increase respectively, compared toUML. These numbers relate to the number
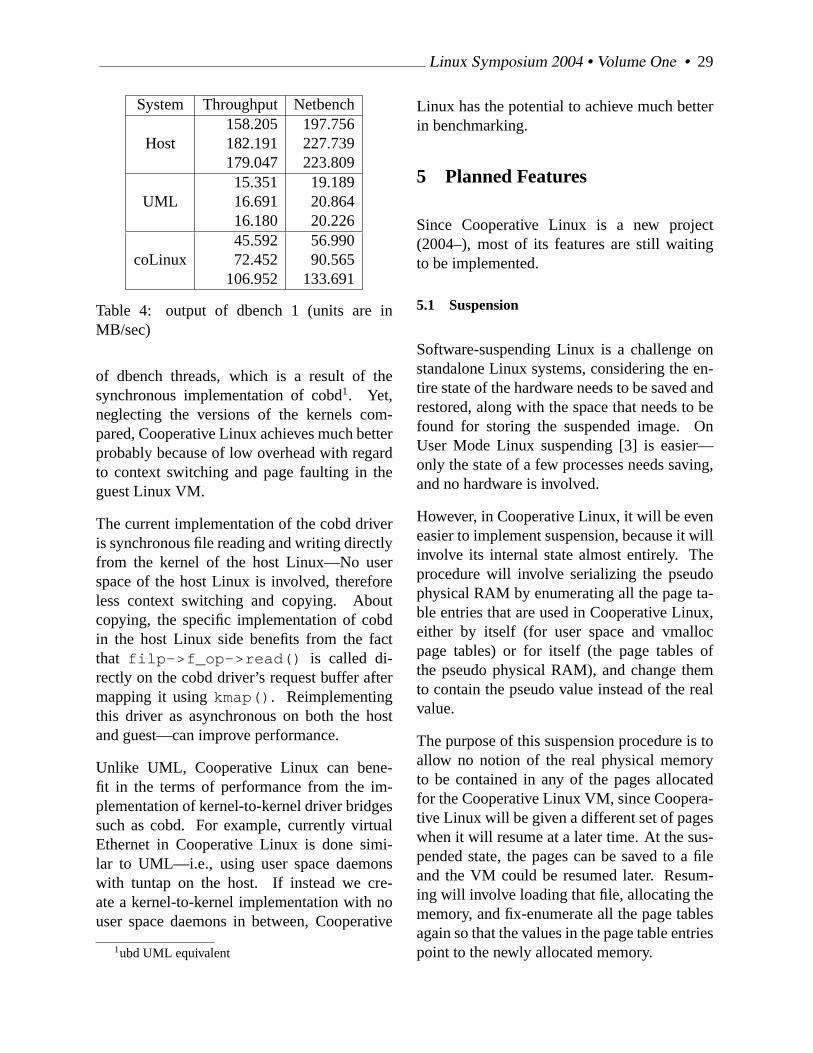
Linux Symposium 2004 • Volume One • 29
System Throughput Netbench158.205 197.756
Host 182.191 227.739179.047 223.80915.351 19.189
UML 16.691 20.86416.180 20.22645.592 56.990
coLinux 72.452 90.565106.952 133.691
Table 4: output of dbench 1 (units are inMB/sec)
of dbench threads, which is a result of thesynchronous implementation of cobd1. Yet,neglecting the versions of the kernels com-pared, Cooperative Linux achieves much betterprobably because of low overhead with regardto context switching and page faulting in theguest Linux VM.
The current implementation of the cobd driveris synchronous file reading and writing directlyfrom the kernel of the host Linux—No userspace of the host Linux is involved, thereforeless context switching and copying. Aboutcopying, the specific implementation of cobdin the host Linux side benefits from the factthat filp->f_op->read() is called di-rectly on the cobd driver’s request buffer aftermapping it usingkmap() . Reimplementingthis driver as asynchronous on both the hostand guest—can improve performance.
Unlike UML, Cooperative Linux can bene-fit in the terms of performance from the im-plementation of kernel-to-kernel driver bridgessuch as cobd. For example, currently virtualEthernet in Cooperative Linux is done simi-lar to UML—i.e., using user space daemonswith tuntap on the host. If instead we cre-ate a kernel-to-kernel implementation with nouser space daemons in between, Cooperative
1ubd UML equivalent
Linux has the potential to achieve much betterin benchmarking.
5 Planned Features
Since Cooperative Linux is a new project(2004–), most of its features are still waitingto be implemented.
5.1 Suspension
Software-suspending Linux is a challenge onstandalone Linux systems, considering the en-tire state of the hardware needs to be saved andrestored, along with the space that needs to befound for storing the suspended image. OnUser Mode Linux suspending [3] is easier—only the state of a few processes needs saving,and no hardware is involved.
However, in Cooperative Linux, it will be eveneasier to implement suspension, because it willinvolve its internal state almost entirely. Theprocedure will involve serializing the pseudophysical RAM by enumerating all the page ta-ble entries that are used in Cooperative Linux,either by itself (for user space and vmallocpage tables) or for itself (the page tables ofthe pseudo physical RAM), and change themto contain the pseudo value instead of the realvalue.
The purpose of this suspension procedure is toallow no notion of the real physical memoryto be contained in any of the pages allocatedfor the Cooperative Linux VM, since Coopera-tive Linux will be given a different set of pageswhen it will resume at a later time. At the sus-pended state, the pages can be saved to a fileand the VM could be resumed later. Resum-ing will involve loading that file, allocating thememory, and fix-enumerate all the page tablesagain so that the values in the page table entriespoint to the newly allocated memory.

30 • Linux Symposium 2004 • Volume One
Another implementation strategy will be to justdump everything on suspension as it is, buton resume—enumerate all the page table en-tries and adjust between the values of the oldRPPFNs2 and new RPPFNs.
Note that a suspended image could be createdunder one host OS and be resumed in anotherhost OS of the same architecture. One couldcarry a suspended Linux on a USB memory de-vice and resume/suspend it on almost any com-puter.
5.2 User Mode Linux[1] inside CooperativeLinux
The possibility of running UML inside Coop-erative Linux is not far from being immediatelypossible. It will allow to bring UML with all itsglory to operating systems that cannot supportit otherwise because of their user space APIs.Combining UML and Cooperative Linux can-cels the security downside that running Coop-erative Linux could incur.
5.3 Live Cooperative Distributions
Live-CD distributions like KNOPPIX can beused to boot on top of another operating systemand not only as standalone, reaching a largersector of computer users considering the hostoperating system to be Windows NT/2000/XP.
5.4 Integration with ReactOS
ReactOS, the free Windows NT clone, will beincorporating Cooperative Linux as a POSIXsubsystem.
5.5 Miscellaneous
• Virtual frame buffer support.
2real physical page frame numbers
• Incorporating features from User ModeLinux, e.g. humfs3.
• Support for more host operating systemssuch as FreeBSD.
6 Conclusions
We have discussed how Cooperative Linuxworks and its benefits—apart from being aBSKH4, Cooperative Linux has the potentialto become an alternative to User Mode Linuxthat enhances on portability and performance,rather than on security.
Moreover, the implications that CooperativeLinux has on what is the media defines as‘Linux on the Desktop’—are massive, as theworld’s most dominant albeit proprietary desk-top OS supports running Linux distributionsfor free, as another software, with the aimed-for possibility that the Linux newbie wouldswitch to the standalone Linux. As user-friendliness of the Windows port will improve,the exposure that Linux gets by the averagecomputer user can increase tremendously.
7 Thanks
Muli Ben Yehuda, IBM
Jun Okajima, Digital Infra
Kuniyasu Suzaki, AIST
References
[1] Jeff Dike. User Mode Linux.http://user-mode-linux.sf.net .
3A recent addition to UML that provides an host FSimplementation that uses files in order to store its VFSmetadata
4Big Scary Kernel Hack

Linux Symposium 2004 • Volume One • 31
[2] Donald E. Knuth.The Art of ComputerProgramming, volume 1.Addison-Wesley, Reading, Massachusetts,1997. Describes coroutines in their puresense.
[3] Richard Potter. Scrapbook for User ModeLinux. http://sbuml.sourceforge.net/ .

32 • Linux Symposium 2004 • Volume One

Build your own Wireless Access Point
Erik AndersenCodepoet Consulting
Abstract
This presentation will cover the software, tools,libraries, and configuration files needed toconstruct an embedded Linux wireless accesspoint. Some of the software available for con-structing embedded Linux systems will be dis-cussed, and selection criteria for which tools touse for differing embedded applications will bepresented. During the presentation, an embed-ded Linux wireless access point will be con-structed using the Linux kernel, the uClibc Clibrary, BusyBox, the syslinux bootloader, ipt-ables, etc. Emphasis will be placed on themore generic aspects of building an embed-ded Linux system using BusyBox and uClibc.At the conclusion of the presentation, the pre-senter will (with luck) boot up the newly con-structed wireless access point and demonstratethat it is working perfectly. Source code, buildsystem, cross compilers, and detailed instruc-tions will be made available.
1 Introduction
When I began working on embedded Linux,the question of whether or not Linux was smallenough to fit inside a particular device was adifficult problem. Linux distributions1 have
1The term “distribution” is used by the Linux com-munity to refer to a collection of software, includingthe Linux kernel, application programs, and needed li-brary code, which makes up a complete running system.Sometimes, the term “Linux” or “GNU/Linux” is alsoused to refer to this collection of software.
historically been designed for server and desk-top systems. As such, they deliver a full-featured, comprehensive set of tools for justabout every purpose imaginable. Most Linuxdistributions, such as Red Hat, Debian, orSuSE, provide hundreds of separate softwarepackages adding up to several gigabytes ofsoftware. The goal of server or desktop Linuxdistributions has been to provide as much valueas possible to the user; therefore, the largesize is quite understandable. However, thishas caused the Linux operating system to bemuch larger then is desirable for building anembedded Linux system such as a wireless ac-cess point. Since embedded devices repre-sent a fundamentally different target for Linux,it became apparent to me that embedded de-vices would need different software than whatis commonly used on desktop systems. I knewthat Linux has a number of strengths whichmake it extremely attractive for the next gen-eration of embedded devices, yet I could seethat developers would need new tools to takeadvantage of Linux within small, embeddedspaces.
I began working on embedded Linux in themiddle of 1999. At the time, building an ‘em-bedded Linux’ system basically involved copy-ing binaries from an existing Linux distributionto a target device. If the needed software didnot fit into the required amount of flash mem-ory, there was really nothing to be done aboutit except to add more flash or give up on theproject. Very little effort had been made todevelop smaller application programs and li-

34 • Linux Symposium 2004 • Volume One
braries designed for use in embedded Linux.
As I began to analyze how I could save space,I decided that there were three main areas thatcould be attacked to shrink the footprint of anembedded Linux system: the kernel, the set ofcommon application programs included in thesystem, and the shared libraries. Many peopledoing Linux kernel development were at leasttalking about shrinking the footprint of the ker-nel. For the past five years, I have focused onthe latter two areas: shrinking the footprint ofthe application programs and libraries requiredto produce a working embedded Linux system.This paper will describe some of the softwaretools I’ve worked on and maintained, which arenow available for building very small embed-ded Linux systems.
2 The C Library
Let’s take a look at an embedded Linux system,the Linux Router Project, which was availablein 1999. http://www.linuxrouter.org/
The Linux Router Project, begun by DaveCinege, was and continues to be a very com-monly used embedded Linux system. Its self-described tagline reads “A networking-centricmicro-distribution of Linux” which is “smallenough to fit on a single 1.44MB floppy disk,and makes building and maintaining routers,access servers, thin servers, thin clients,network appliances, and typically embeddedsystems next to trivial.” First, let’s downloada copy of one of the Linux Router Project’s“idiot images.” I grabbed my copy fromthe mirror site atftp://sunsite.unc.edu/
pub/Linux/distributions/linux-router/
dists/current/idiot-image_1440KB_FAT_
2.9.8_Linux_2.2.gz .
Opening up the idiot-image there are severalvery interesting things to be seen.
# gunzip \
idiot-image_1440KB_FAT_2.9.8_Linux_2.2.gz# mount \
idiot-image_1440KB_FAT_2.9.8_Linux_2.2 \/mnt -o loop
# du -ch /mnt/*34K /mnt/etc.lrp6.0K /mnt/ldlinux.sys512K /mnt/linux512 /mnt/local.lrp1.0K /mnt/log.lrp17K /mnt/modules.lrp809K /mnt/root.lrp512 /mnt/syslinux.cfg1.0K /mnt/syslinux.dpy1.4M total
# mkdir test# cd test# tar -xzf /mnt/root.lrp
# du -hs2.2M .2.2M total
# du -ch bin root sbin usr var460K bin8.0K root264K sbin12K usr/bin304K usr/sbin36K usr/lib/ipmasqadm40K usr/lib360K usr56K var/lib/lrpkg60K var/lib4.0K var/spool/cron/crontabs8.0K var/spool/cron12K var/spool76K var1.2M total
# du -ch lib24K lib/POSIXness1.1M lib1.1M total
# du -h lib/libc-2.0.7.so644K lib/libc-2.0.7.so
Taking a look at the software contained inthis embedded Linux system, we quickly no-tice that in a software image totaling 2.2Megabytes, the libraries take up over half thespace. If we look even closer at the set oflibraries, we quickly find that the largest sin-gle component in the entire system is the GNUC library, in this case occupying nearly 650k.What is more, this is a very old version ofthe C library; newer versions of GNU glibc,

Linux Symposium 2004 • Volume One • 35
such as version 2.3.2, are over 1.2 Megabytesall by themselves! There are tools availablefrom Linux vendors and in the Open Sourcecommunity which can reduce the footprint ofthe GNU C library considerably by strippingunwanted symbols; however, using such toolsprecludes adding additional software at a laterdate. Even when these tools are appropriate,there are limits to the amount of size which canbe reclaimed from the GNU C library in thisway.
The prospect of shrinking a single library thattakes up so much space certainly looked likelow hanging fruit. In practice, however, re-placing the GNU C library for embedded Linuxsystems was not easy task.
3 The origins of uClibc
As I despaired over the large size of the GNUC library, I decided that the best thing to dowould be to find another C library for Linuxthat would be better suited for embedded sys-tems. I spent quite a bit of time looking around,and after carefully evaluating the various OpenSource C libraries that I knew of2, I sadlyfound that none of them were suitable replace-ments for glibc. Of all the Open Source C li-braries, the library closest to what I imaginedan embedded C library should be was calleduC-libc and was being used for uClinux sys-tems. However, it also had many problems atthe time—not the least of which was that uC-libc had no central maintainer. The only mech-anism being used to support multiple architec-
2The Open Source C libraries I evaluated atthe time included Al’s Free C RunTime library(no longer on the Internet); dietlibc available fromhttp://www.fefe.de/dietlibc/ ; the minix Clibrary available from http://www.cs.vu.nl/cgi-bin/raw/pub/minix/ ; the newlib libraryavailable from http://sources.redhat.com/newlib/ ; and the eCos C library available fromftp://ecos.sourceware.org/pub/ecos/ .
tures was a complete source tree fork, and therehad already been a few such forks with plentyof divergant code. In short, uC-libc was a messof twisty versions, all different. After spendingsome time with the code, I decided to fix it, andin the process changed the name touClibc(no hyphen).
With the help of D. Jeff Dionne, one of the cre-ators of uClinux3, I ported uClibc to run onIntel compatible x86 CPUs. I then grafted inthe header files from glibc 2.1.3 to simplifysoftware ports, and I cleaned up the resultingbreakage. The header files were later updatedagain to generally match glibc 2.3.2. This ef-fort has made porting software from glibc touClibc extremely easy. There were, however,many functions in uClibc that were either bro-ken or missing and which had to be re-writtenor created from scratch. When appropriate, Isometimes grafted in bits of code from the cur-rent GNU C library and libc5. Once the coreof the library was reasonably solid, I beganadding a platform abstraction layer to allowuClibc to compile and run on different types ofCPUs. Once I had both the ARM and x86 plat-forms basically running, I made a few smallannouncements to the Linux community. Atthat point, several people began to make reg-ular contributions. Most notably was ManuelNovoa III, who began contributing at that time.He has continued working on uClibc and isresponsible for significant portions of uClibcsuch as the stdio and internationalization code.
After a great deal of effort, we were able tobuild the first shared library version of uClibcin January 2001. And earlier this year we wereable to compile a Debian Woody system usinguClibc4, demonstrating the library is now able
3uClinux is a port of Linux designed to run on micro-controllers which lack Memory Management Units(MMUs) such as the Motorolla DragonBall or theARM7TDMI. The uClinux web site is found athttp://www.uclinux.org/ .
4http://www.uclibc.org/dists/

36 • Linux Symposium 2004 • Volume One
to support a complete Linux distribution. Peo-ple now use uClibc to build versions of Gentoo,Slackware, Linux from Scratch, rescue disks,and even live Linux CDs5. A number of com-mercial products have also been released usinguClibc, such as wireless routers, network at-tached storage devices, DVD players, etc.
4 Compiling uClibc
Before we can compile uClibc, we must firstgrab a copy of the source code and unpack itso it is ready to use. For this paper, we will justgrab a copy of the daily uClibc snapshot.
# SITE=http://www.uclibc.org/downloads# wget -q $SITE/uClibc-snapshot.tar.bz2
# tar -xjf uClibc-snapshot.tar.bz2# cd uClibc
uClibc requires a configuration file,.config ,that can be edited to change the way the li-brary is compiled, such as to enable or dis-able features (i.e. whether debugging supportis enabled or not), to select a cross-compiler,etc. The preferred method when starting fromscratch is to runmake defconfig followedby make menuconfig . Since we are goingto be targeting a standard Intel compatible x86system, no changes to the default configurationfile are necessary.
5 The Origins of BusyBox
As I mentioned earlier, the two componentsof an embedded Linux that I chose to worktowards reducing in size were the shared li-braries and the set common application pro-grams. A typical Linux system contains a vari-ety of command-line utilities from numerous
5Puppy Linux available from http://www.goosee.com/puppy/ is a live linux CD system builtwith uClibc that includes such favorites as XFree86 andMozilla.
different organizations and independent pro-grammers. Among the most prominent of theseutilities were GNU shellutils, fileutils, textutils(now combined to form GNU coreutils), andsimilar programs that can be run within a shell(commands such assed , grep , ls , etc.).The GNU utilities are generally very high-quality programs, and are almost without ex-ception very, very feature-rich. The large fea-ture set comes at the cost of being quite large—prohibitively large for an embedded Linux sys-tem. After some investigation, I determinedthat it would be more efficient to replace themrather than try to strip them down, so I beganlooking at alternatives.
Just as with alternative C libraries, there wereseveral choices for small shell utilities: BSDhas a number of utilities which could be used.The Minix operating system, which had re-cently released under a free software license,also had many useful utilities. Sash, the standalone shell, was also a possibility. After quitea lot of research, the one that seemed to bethe best fit was BusyBox. It also appealed tome because I was already familiar with Busy-Box from its use on the Debian boot flop-pies, and because I was acquainted with BrucePerens, who was the maintainer. Starting ap-proximately in October 1999, I began enhanc-ing BusyBox and fixing the most obvious prob-lems. Since Bruce was otherwise occupied andwas no longer actively maintaining BusyBox,Bruce eventually consented to let me take overmaintainership.
Since that time, BusyBox has gained a largefollowing and attracted development talentfrom literally the whole world. It has beenused in commercial products such as the IBMLinux wristwatch, the Sharp Zaurus PDA, andLinksys wireless routers such as the WRT54G,with many more products being released all thetime. So many new features and applets havebeen added to BusyBox, that the biggest chal-

Linux Symposium 2004 • Volume One • 37
lenge I now face is simply keeping up with allof the patches that get submitted!
6 So, How Does It Work?
BusyBox is a multi-call binary that combinesmany common Unix utilities into a single exe-cutable. When it is run, BusyBox checks if itwas invoked via a symbolic link (asymlink ),and if the name of the symlink matches thename of an applet that was compiled into Busy-Box, it runs that applet. If BusyBox is invokedas busybox , then it will read the commandline and try to execute the applet name passedas the first argument. For example:
# ./busybox dateWed Jun 2 15:01:03 MDT 2004
# ./busybox echo "hello there"hello there
# ln -s ./busybox uname# ./unameLinux
BusyBox is designed such that the developercompiling it for an embedded system can selectexactly which applets to include in the final bi-nary. Thus, it is possible to strip out support forunneeded and unwanted functionality, result-ing in a smaller binary with a carefully selectedset of commands. The customization granu-larity for BusyBox even goes one step further:each applet may contain multiple features thatcan be turned on or off. Thus, for example, ifyou do not wish to include large file support,or you do not need to mount NFS filesystems,you can simply turn these features off, furtherreducing the size of the final BusyBox binary.
7 Compiling Busybox
Let’s walk through a normal compile of Busy-Box. First, we must grab a copy of the Busy-Box source code and unpack it so it is ready touse. For this paper, we will just grab a copy ofthe daily BusyBox snapshot.
# SITE=http://www.busybox.net/downloads# wget -q $SITE/busybox-snapshot.tar.bz2# tar -xjf busybox-snapshot.tar.bz2# cd busybox
Now that we are in the BusyBox source di-rectory we can configure BusyBox so that itmeets the needs of our embedded Linux sys-tem. This is done by editing the file.configto change the set of applets that are compiledinto BusyBox, to enable or disable features(i.e. whether debugging support is enabled ornot), and to select a cross-compiler. The pre-ferred method when starting from scratch isto runmake defconfig followed bymakemenuconfig . Once BusyBox has been con-figured to taste, you just need to runmake tocompile it.
8 Installing Busybox to a Target
If you then want to install BusyBox onto atarget device, this is most easily done by typ-ing: make install . The installation scriptautomatically creates all the required directo-ries (such as/bin , /sbin , and the like) andcreates appropriate symlinks in those directo-ries for each applet that was compiled into theBusyBox binary.
If we wanted to install BusyBox to the direc-tory /mnt, we would simply run:
# make PREFIX=/mnt install
[--installation text omitted--]

38 • Linux Symposium 2004 • Volume One
9 Let’s build something thatworks!
Now that I have certainly bored you to death,we finally get to the fun part, building our ownembedded Linux system. For hardware, I willbe using a Soekris 4521 system6 with an 133Mhz AMD Elan CPU, 64 MB main memory,and a generic Intersil Prism based 802.11b cardthat can be driven using thehostap 7 driver.The root filesystem will be installed on a com-pact flash card.
To begin with, we need to create toolchain withwhich to compile the software for our wire-less access point. This requires we first com-pile GNU binutils8, then compile the GNUcompiler collection—gcc9, and then compileuClibc using the newly created gcc compiler.With all those steps completed, we must fi-nally recompile gcc using using the newlybuilt uClibc library so thatlibgcc_s andlibstdc++ can be linked with uClibc.
Fortunately, the process of creating a uClibctoolchain can be automated. First we will goto the uClibc website and obtain a copy of theuClibcbuildroot by going here:
http://www.uclibc.org/cgi-bin/
cvsweb/buildroot/
and clicking on the “Download tarball” link10.This is a simple GNU make based build systemwhich first builds a uClibc toolchain, and thenbuilds a root filesystem using the newly builtuClibc toolchain.
For the root filesystem of our wireless access
6http://www.soekris.com/net4521.htm7http://hostap.epitest.fi/8http://sources.redhat.com/
binutils/9http://gcc.gnu.org/
10http://www.uclibc.org/cgi-bin/cvsweb/buildroot.tar.gz?view=tar
point, we will need a Linux kernel, uClibc,BusyBox, pcmcia-cs, iptables, hostap, wtools,bridgeutils, and the dropbear ssh server. Tocompile these programs, we will first edit thebuildroot Makefile to enable each of theseitems. Figure 1 shows the changes I made tothe buildroot Makefile:
Runningmake at this point will download theneeded software packages, build a toolchain,and create a minimal root filesystem with thespecified software installed.
On my system, with all the software packagespreviously downloaded and cached locally, acomplete build took 17 minutes, 19 seconds.Depending on the speed of your network con-nection and the speed of your build system,now might be an excellent time to take a lunchbreak, take a walk, or watch a movie.
10 Checking out the new RootFilesystem
We now have our root filesystem finished andready to go. But we still need to do a littlemore work before we can boot up our newlybuilt embedded Linux system. First, we needto compress our root filesystem so it can beloaded as an initrd.
# gzip -9 root_fs_i386# ls -sh root_fs_i386.gz1.1M root_fs_i386.gz
Now that our root filesystem has been com-pressed, it is ready to install on the boot media.To make things simple, I will install the Com-pact Flash boot media into a USB card readerdevice, and copy files using the card reader.
# ms-sys -s /dev/sdaPublic domain master boot recordsuccessfully written to /dev/sda

Linux Symposium 2004 • Volume One • 39
--- Makefile+++ Makefile@@ -140,6 +140,6 @@
# Unless you want to build a kernel, I recommend just using# that...
-TARGETS+=kernel-headers-#TARGETS+=linux+#TARGETS+=kernel-headers+TARGETS+=linux
#TARGETS+=system-linux
@@ -150,5 +150,5 @@#TARGETS+=zlib openssl openssh# Dropbear sshd is much smaller than openssl + openssh
-#TARGETS+=dropbear_sshd+TARGETS+=dropbear_sshd
# Everything needed to build a full uClibc development system!@@ -175,5 +175,5 @@
# Some stuff for access points and firewalls-#TARGETS+=iptables hostap wtools dhcp_relay bridge+TARGETS+=iptables hostap wtools dhcp_relay bridge
#TARGETS+=iproute2 netsnmp
Figure 1: Changes to the buildroot Makefile
# mkdosfs /dev/sda1mkdosfs 2.10 (22 Sep 2003)
# syslinux /dev/sda1
# cp root_fs_i386.gz /mnt/root_fs.gz
# cp build_i386/buildroot-kernel /mnt/linux
So we now have a copy of our root filesystemand Linux kernel on the compact flash disk. Fi-nally, we need to configure the bootloader. Incase you missed it a few steps ago, we are us-ing the syslinux bootloader for this example.I happen to have a ready to use syslinux con-figuration file, so I will now install that to thecompact flash disk as well:
# cat syslinux.cfgTIMEOUT 0PROMPT 0DEFAULT linuxLABEL linux
KERNEL linux
APPEND initrd=root_fs.gz \console=ttyS0,57600 \root=/dev/ram0 boot=/dev/hda1,msdos rw
# cp syslinux.cfg /mnt
And now, finally, we are done. Our embeddedLinux system is complete and ready to boot.And you know what? It is very, very small.Take a look at Table 1.
With a carefully optimized Linux kernel(which this kernel unfortunately isn’t) wecould expect to have even more free space.And remember, every bit of space we save ismoney that embedded Linux developers don’thave to spend on expensive flash memory. Sonow comes the final test; it is now time to bootfrom our compact flash disk. Here is what youshould see.
[----kernel boot messages snipped--]

40 • Linux Symposium 2004 • Volume One
# ll /mnttotal 1.9Mdrwxr-r- 2 root root 16K Jun 2 16:39 ./drwxr-xr-x 22 root root 4.0K Feb 6 07:40 ../-r-xr-r- 1 root root 7.7K Jun 2 16:36 ldlinux.sys*-rwxr-r- 1 root root 795K Jun 2 16:36 linux*-rwxr-r- 1 root root 1.1M Jun 2 16:36 root_fs.gz*-rwxr-r- 1 root root 170 Jun 2 16:39 syslinux.cfg*
Table 1: Output ofls -lh /mnt .
Freeing unused kernel memory: 64k freed
Welcome to the Erik’s wireless access point.
uclibc login: root
BusyBox v1.00-pre10 (2004.06.02-21:54+0000)Built-in shell (ash)Enter ’help’ for a list of built-in commands.
# du -h / | tail -n 12.6M
#
And there you have it—your very own wire-less access point. Some additional configura-tion will be necessary to start up the wirelessinterface, which will be demonstrated duringmy presentation.
11 Conclusion
The two largest components of a standardLinux system are the utilities and the libraries.By replacing these with smaller equivalents amuch more compact system can be built. Us-ing BusyBox and uClibc allows you to cus-tomize your embedded distribution by strip-ping out unneeded applets and features, thusfurther reducing the final image size. Thisspace savings translates directly into decreasedcost per unit as less flash memory will be re-quired. Combine this with the cost savings ofusing Linux, rather than a more expensive pro-prietary OS, and the reasons for using Linuxbecome very compelling. The example Wire-less Access point we created is a simple but
useful example. There are thousands of otherpotential applications that are only waiting foryou to create them.

Run-time testing of LSB Applications
Stuart AndersonFree Standards Group
Matt ElderUniversity of South Caroilina
Abstract
The dynamic application test tool is capableof checking API usage at run-time. The LSBdefines only a subset of all possible parame-ter values to be valid. This tool is capable ofchecking these value while the application isrunning.
This paper will explain how this tool works,and highlight some of the more interesting im-plementation details such as how we managedto generate most of the code automatically,based on the interface descriptions containedin the LSB database.
Results to date will be presented, along withfuture plans and possible uses for this tool.
1 Introduction
The Linux Standard Base (LSB) Project be-gan in 1998, when the Linux community cametogether and decided to take action to pre-vent GNU/Linux based operating systems fromfragmenting in the same way UNIX operatingsystems did in the 1980s and 1990s. The LSBdefines the Application Binary Interface (ABI)for the core part of a GNU/Linux system. Asan ABI, the LSB defines the interface betweenthe operating system and the applications. Acomplete set of tests for an ABI must be capa-ble of measuring the interface from both sides.
Almost from the beginning, testing has been
a cornerstone of the project. The LSB wasoriginally organized around 3 components: thewritten specification, a sample implementa-tion, and the test suites. The written specifica-tion is the ultimate definition of the LSB. Boththe sample implementation, and the test suitesyield to the authority of the written specifica-tion.
The sample implementation (SI) is a minimalsubset of a GNU/Linux system that provides aruntime that implements the LSB, and as littleelse as possible. The SI is neither intended tobe a minimal distribution, nor the basis for adistribution. Instead, it is used as both a proofof concept and a testing tool. Applicationswhich are seeking certification are required toprove they execute correctly using the SI andtwo other distributions. The SI is also used tovalidate the runtime test suites.
The third component is testing. One of thethings that strengthens the LSB is its ability tomeasure, and thus prove, conformance to thestandard. Testing is achieved with an array ofdifferent test suites, each of which measures adifferent aspect of the specification.
LSB Runtime
• cmdchk
This test suite is a simple existence testthat ensures the required LSB commandsand utilities are found on an LSB con-forming system.

42 • Linux Symposium 2004 • Volume One
• libchk
This test suite checks the libraries re-quired by the LSB to ensure they con-tain the interfaces and symbol versions asspecified by the LSB.
• runtimetests
This test suite measures the behavior ofthe interfaces provided by the GNU/Linuxsystem. This is the largest of the testsuites, and is actually broken down intoseveral components, which are referred tocollectively as the runtime tests. Thesetests are derived from the test suites usedby the Open Group for UNIX branding.
LSB Packaging
• pkgchk
This test examines an RPM format pack-age to ensure it conforms to the LSB.
• pkginstchk
This test suite is used to ensure that thepackage management tool provided by aGNU/Linux system will correctly installLSB conforming packages. This suite isstill in early stages of development.
LSB Application
• appchk
This test performs a static analysis of anapplication to ensure that it only useslibraries and interfaces specified by theLSB.
• dynchk
This test is used to measure an applica-tions use of the LSB interfaces during itsexecution, and is the subject of this paper.
2 The database
The LSB Specification contains over 6600 in-terfaces, each of which is associated with a li-brary and a header file, and may have parame-ters. Because of the size and complexity of thedata describing these interfaces, a database isused to maintain this information.
It is impractical to try and keep the specifica-tion, test suites and development libraries andheaders synchronized for this much data. In-stead, portions of the specification and tests,and all of the development headers and li-braries are generated from the database. Thisensures that as changes are made to thedatabase, the changes are propagated to theother parts of the project as well.
Some of the relevant data components in thisDB are Libraries, Headers, Interfaces, andTypes. There are also secondary componentsand relations between all of the components. Ashort description of some of these is needed be-fore moving on to how the dynchk test is con-structed.
2.1 Library
The LSB specifies 17 shared libraries, whichcontains the 6600 interfaces. The interfacesin each library are grouped into logical unitscalled a LibGroup. The LibGroups help to or-ganize the interfaces, which is very useful inthe written specification, but isn’t used muchelsewhere.
2.2 Interface
An Interface represents a globally visible sym-bol, such as a function, or piece of data. Inter-faces have a Type, which is either the type ofthe global data or the return type of the func-tion. If the Interface is a function, then it willhave zero or more Parameters, which form a

Linux Symposium 2004 • Volume One • 43
LibGroup LibGroup
Library
InterfaceInterfaceInterface
LibGroup
Figure 1: Relationship between Library, Lib-Group and Interface
Interface
Type Parameter Parameter Parameter
Type Type Type
Figure 2: Relationship between Interface, Typeand Parameter
set of Types ordered by their position in the pa-rameter list.
2.3 Type
As mentioned above, the database containsenough information to be able to generateheader files which are a part of the LSB de-velopment tools. This means that the databasemust be able to represent Clanguage types. TheType and TypeMember tables provide these.These tables are used recursively. If a Type isdefined in terms of another type, then it willhave a base type that points to that other type.
For structs and unions, the TypeMemeber table
Tid Ttype Tname Tbasetype1 Intrinsic int 02 Pointer int * 1
Table 1: Example of recursion in Type table forint *
struct foo {int a;int *b;
}
Figure 3: Sample struct
is used to hold the ordered list of members. En-tries in the TypeMember table point back to theType table to describe the type of each member.For enums, the TypeMember table is also usedto hold the ordered list of values.
Tid Ttype Tname Tbasetype1 Intrinsic int 02 Pointer int * 13 Struct foo 0
Table 2: Contents of Type table
The structure shown in Figure 3 is representedby the entries in the Type table in Table 2 andthe TypeMember table in Table 3.
2.4 Header
Headers, like Libraries, have their contents ar-ranged into logical groupings known a Header-Groups. Unlike Libraries, these HeaderGroupsare ordered so that the proper sequence ofdefinitions within a header file can be main-tained. HeaderGroups contain Constant defi-nitions (i.e. #define statements) and Type def-initions. If you examine a few well designedheader files, you will notice a pattern of a com-ment followed by related constant definitionsand type definitions. The entire header file canbe viewed as a repeating sequence of this pat-

44 • Linux Symposium 2004 • Volume One
Tmid TMname TMtypeid TMposition TMmemberof10 a 1 0 311 b 2 1 3
Table 3: Contents of TypeMember
FunctionDeclarations
HeaderGroup 1Constants
Types
HeaderGroup 2Constants
Types
HeaderGroup 3Constants
Types
Figure 4: Organization of Headers
tern. This pattern is the basis for the Header-Group concept.
2.5 TypeType
One last construct in our database should bementioned. While we are able to repre-sent a syntactic description of interfaces andtypes in the database, this is not enough toautomatically generate meaningful test cases.We need to add some semantic informationthat better describes how the types in struc-tures and parameters are used. As an exam-ple,struct sockaddr contains a member,sa_family , of type unsigned short. The
compiler will of course ensure that only val-ues between 0 and216 − 1 will be used, butonly a few of those values have any meaningin this context. By adding the semantic infor-mation that this member holds a socket fam-ily value, the test generator can cause the valuefound insa_family to be tested against thelegal socket families values (AF_INET , AF_INET6 , etc), instead of just ensuring the valuefalls between 0 and216−1, which is really justa noop test.
Example TypeType entries
• RWaddress
An address from the process space thatmust be both readable and writable.
• Rdaddress
An address from the process space thatmust be at least readable.
• filedescriptor
A small integer value greater than or equalto 0, and less than the maximum file de-scriptor for the process.
• pathname
The name of a file or directory that shouldbe compared against the Filesystem Hier-archy Standard.
2.6 Using this data
As mentioned above, the data in the database isused to generate different portions of the LSBproject. This strategy was adopted to ensure

Linux Symposium 2004 • Volume One • 45
these different parts would always be in sync,without having to depend on human interven-tion.
The written specification contains tables of in-terfaces, and data definitions (constants andtypes). These are all generated from thedatabase.
The LSB development environment1 consistsof stub libraries and header files that containonly the interfaces defined by the LSB. Thisdevelopment environment helps catch the useof non-LSB interfaces during the developmentor porting of an application instead of beingsurprised by later test results. Both the stublibraries and headers are produced by scriptspulling data from the database.
Some of the test suites described previouslyhave components which are generated from thedatabase.Cmdchk and libchk have lists ofcommands and interfaces respectively whichare extracted from the database. The static ap-plication test tool,appchk , also has a list ofinterfaces that comes from the database. Thedynamic application test tool,dynchk , has themajority of its code generated from informa-tion in the database.
3 The Dynamic Checker
The static application checker simply examinesan executable file to determine if it is usinginterfaces beyond those allowed by the LSB.This is very useful to determine if an appli-cation has been built correctly. However, isunable to determine if the interfaces are usedcorrectly when the application is executed. Adifferent kind of test is required to be able toperform this level of checking. This new testmust interact with the application while it is
1See the May Issue ofLinux Journalfor more infor-mation on the LSB Development Environment.
running, without interfering with the executionof the application.
This new test has two major components: amechanism for hooking itself into an applica-tion, and a collection of functions to performthe tests for all of the interfaces. These compo-nents can mostly be developed independentlyof each other.
3.1 The Mechanism
The mechanism for interacting with the appli-cation must be transparent and noninterferingto the application. We considered the approachused by 3 different tools: abc, ltrace, and fake-root.
• abc —This tool was the inspiration forour new dynamic checker.abc was de-veloped as part of the SVR4 ABI testtools. abc works by modifying the tar-get application. The application’s exe-cutable is modified to load a different ver-sion of the shared libraries and to call adifferent version of each interface. Thisis accomplished by changing the stringsin the symbol table andDT_NEEDEDrecords. For example,libc.so.1 ischanged toLiBc.So.1 , andfread()is changed toFrEaD() . The test setis then located in/usr/lib/LiBc.So.1 , which in turns loads the original/usr/lib/libc.so.1 . This mecha-nism works, but the requirement to mod-ify the executable file is undesirable.
• ltrace —This tool is similar tostrace , except that it traces callsinto shared libraries instead of calls intothe kernel. ltrace uses the ptraceinterface to control the application’sprocess. With this approach, the test setsare located in a separate program and areinvoked by stopping the application upon

46 • Linux Symposium 2004 • Volume One
entry to the interface being tested. Thisapproach has two drawbacks: first, thecode required to decode the process stackand extract the parameters is unique toeach architecture, and second, the teststhemselves are more complicated to writesince the parameters have to be fetchedfrom the application’s process.
• fakeroot —This tool is used to cre-ate an environment where an unprivilegedprocess appears to have root privileges.fakeroot usesLD_PRELOADto loadan additional shared library before any ofthe shared libraries specified by theDT_NEEDEDrecords in the executable. Thisextra library contains a replacement func-tion for each file manipulation function.The functions in this library will be se-lected by the dynamic linker instead of thenormal functions found in the regular li-braries. The test sets themselves will per-form tests of the parameters, and then callthe original version of the functions.
We chose to use theLD_PRELOADmecha-nism because we felt it was the simplest to use.Based on this mechanism, a sample test caselooks like Figure 5.
One problem that must be avoided when us-ing this mechanism is recursion. If the abovefunction just calledread() at the end, itwould end up calling itself again. Instead, theRTLD_NEXTflag passed todlsym() tells thedynamic linker to look up the symbol on oneof the libraries loaded after the current library.This will get the original version of the func-tion.
3.2 Test set organization
The test set functions are organized into 3 lay-ers. The top layer contains the functions thatare test stubs for the LSB interfaces. These
functions are implemented by calling the func-tions in layers 2 and 3. An example of a func-tion in the first layer was given in Figure 5.
The second layer contains the functions thattest data structures and types which are passedin as parameters. These functions are also im-plemented by calling the functions in layer 3and other functions in layer 2. A function inthe second layer looks like Figure 6.
The third layer contains functions that test thetypes which have been annotated with addi-tional semantic information. These functionsoften have to perform nontrivial operations totest the assertion required for these supplemen-tal types. Figure 7 is an example of a layer 3function.
Presently, there are 3056 functions in layer 1(tests forlibstdc++ are not yet being gen-erated), 106 functions in layer 2, and just a fewin layer 3. We estimate that the total number offunctions in layer 3 upon completion of the testtool will be on the order of several dozen. Thefunctions in the first two layers are automati-cally generated based on the information in thedatabase. Functions in layer 3 are hand coded.
3.3 Automatic generation of the tests
In Table 4, is a summary of the size of the testtool so far. As work progresses, these num-bers will only get larger. Most of the code inthe test is very repetitive, and prone to errorswhen edited manually. The ability to automatethe process of creating this code is highly de-sirable.
Let’s take another look at the sample functionfrom layer 1. This time, however, lets replacesome of the code with a description of the in-formation it represents. See Figure 8 for thisparameterized version.
All of the occurrences of the stringread are

Linux Symposium 2004 • Volume One • 47
ssize_t read (int arg0, void *arg1, size_t arg2) {if (!funcptr)
funcptr = dlsym(RTLD_NEXT, "read");validate_filedescriptor(arg0, "read");validate_RWaddress(arg1, "read");validate_size_t(arg2, "read");return funcptr(arg0, arg1, arg2);
}
Figure 5: Test case for read() function
void validate_struct_sockaddr_in(struct sockaddr_in *input,char *name) {
validate_socketfamily(input->sin_family,name);validate_socketport(input->sin_port,name);validate_IPv4Address((input->sin_addr), name);
}
Figure 6: Test case for validatingstruct sockaddr_in
Module Files Lines of Codelibc 752 19305libdl 5 125libgcc_s 13 262libGL 450 11046libICE 49 1135libm 281 6568libncurses 266 6609libpam 13 335libpthread 82 2060libSM 37 865libX11 668 16112libXext 113 2673libXt 288 7213libz 39 973structs 106 1581
Table 4: Summary of generated code
actually just the function name, and could havebeen replaced also.
The same thing can be done for the samplefunction from layer 2 as is seen in Figure 9.
These two examples, now represent templatesthat can be used to create the functions for lay-ers 1 and 2. From the previous description ofthe database, you can see that there is enoughinformation available to be able to instantiatethese templates for each interfaces, and struc-ture used by the LSB.
The automation is implemented by 2 perlscripts:gen_lib.pl andgen_tests.pl .These scripts generate the code for layers 1 and2 respectively.
Overall, these scripts work well, but we haverun into a few interesting situations along theway.
3.4 Handling the exceptions
So far, we have come up with an overall archi-tecture for the test tool, selected a mechanismthat allows us to hook the tests into the runningapplication, discovered the pattern in the testfunctions so that we could create a template for

48 • Linux Symposium 2004 • Volume One
void validate_filedescriptor(const int fd, const char *name) {if (fd >= lsb_sysconf(_SC_OPEN_MAX))
ERROR("fd too big");else if (fd < 0)
ERROR("fd negative");}
Figure 7: Test case for validating a filedescriptor
return-type read (list of parameters) {if (!funcptr)
funcptr = dlsym(RTLD_NEXT, "read");validate_parameter1 type(arg0, "read");validate_parameter2 type(arg1, "read");validate_parameter3 type(arg2, "read");return funcptr(arg0, arg1, arg2);
}
Figure 8: Parameterized test case for a function
automatically generating the code, and imple-mented the scripts to generate all of the testscases. The only problem is that now we runinto the real world, where things don’t alwaysfollow the rules.
Here are a few of the interesting situations wehave encountered
• Variadic Functions
Of the 725 functions in libc, 25 of themtake a variable number of parameters.This causes problems in the generation ofthe code for the test case, but most impor-tantly it affects our ability to know howto process the arguments. These func-tion have to be written by hand to han-dle the special needs of these functions.For the functions in theexec , printfandscanf families, the test cases can beimplemented by calling the varargs formof the function (execl() can be imple-mented usingexecv() ).
• open()
In addition to the problems of being avariadic function, the third parameter toopen() and open64() is only validif the O_CREATflag is set in the sec-ond parameter to these functions. Thissimple exception requires a small amountof manual intervention, so these functionhave to be maintained by hand.
• memory allocation
One of the recursion problems we ran intois that memory will be allocated withinthe dlsym() function call, so the im-plementation of one test case ends up in-voking the test case for one of the mem-ory allocation routines, which by defaultwould calldlsym() , creating the recur-sion. This cycle had to be broken by hav-ing the test cases for these routines calllibc private interfaces to memory alloca-tion.
• changing memory map

Linux Symposium 2004 • Volume One • 49
void validate_struct_structure name(struct structure name*input, char *name) {
validate_type of member 1(input->name of member 1, name);validate_type of member 2(input->name of member 2, name);validate_type of member 3((input->name of member 3), name);
}
Figure 9: Parameterized test case for a struct
Pointers are validated by making sure theycontain an address that is valid for the pro-cess./proc/self/maps is read to ob-tain the memory map of the current pro-cess. These results are cached, for perfor-mance reasons, but usually, the memorymap of the process will change over time.Both the stack and the heap will grow,resulting in valid pointers being checkedagainst a cached copy of the memory map.In the event a pointer is found to be in-valid, the memory map is re-read, and thepointer checked again. Themmap() andmunmap() test cases are also maintainedby hand so that they can also cause thememory map to be re-read.
• hidden ioctl()s
By design, the LSB specifies interfacesat the highest possible level. One exam-ple of this, is the use of the termio func-tions, instead of specifying the underly-ing ioctl() interface. It turns out thatthis tool catches the underlyingioctl()calls anyway, and flags it as an error. Thesolution is for the termio functions the seta flag indicating that theioctl() testcase should skip its tests.
• Optionally NULL parameters
Many interfaces have parameters whichmay be NULL. This triggerred lots ofwarnings for many programs. The solu-tion was to add a flag that indicated thatthe Parameter may be NULL, and to not
try to validate the pointer, or the data be-ing pointed to.
No doubt, there will be more interesting situ-ations to have to deal with before this tool iscompleted.
4 Results
As of the deadline for this paper, results arepreliminary, but encouraging. The tool is ini-tially being tested against simple commandssuch as ls and vi, and some X Windows clientssuch as xclock and xterm. The tool is correctlyinserting itself into the application under test,and we are getting some interesting results thatwill be examined more closely.
One example is vi passes a NULL to__strtol_internal several times duringstartup.
The tool was designed to work across all archi-tectures. At present, it has been built and testedon only the IA32 and IA64 architectures. Nosignificant problems are anticipate on other ar-chitectures.
Additional results and experience will be pre-sented at the conference.

50 • Linux Symposium 2004 • Volume One
5 Future Work
There is still much work to be done. Some ofthe outstanding tasks are highlighted here.
• AdditionalTypeTypes
Semantic information needs to be addedfor additional parameters and structures.The additional layer 3 tests that corre-spond to this information must also be im-plemented.
• Architecture-specific interfaces
As we found in the LSB, there are someinterfaces, and types that are unique to oneor more architectures. These need to behandled properly so they are not part ofthe tests when built on an architecture forwhich they don’t apply.
• Unions
Although Unions are represented in thedatabase in the same way as structures,the database does not contain enough in-formation to describe how to interpret ortest the contents of a union. Test cases thatinvolve unions may have to be written byhand.
• Additional libraries
The information in the database for thegraphics libraries and forlibstdc++ isincomplete, therefore, it is not possible togenerate all of the test cases for those li-braries. Once the data is complete, the testcases will also be complete.

Linux Block IO—present and future
Jens AxboeSuSE
Abstract
One of the primary focus points of 2.5 was fix-ing up the bit rotting block layer, and as a result2.6 now sports a brand new implementation ofbasically anything that has to do with passingIO around in the kernel, from producer to diskdriver. The talk will feature an in-depth lookat the IO core system in 2.6 comparing to 2.4,looking at performance, flexibility, and addedfunctionality. The rewrite of the IO schedulerAPI and the new IO schedulers will get a fairtreatment as well.
No 2.6 talk would be complete without 2.7speculations, so I shall try to predict whatchanges the future holds for the world of Linuxblock I/O.
1 2.4 Problems
One of the most widely criticized pieces ofcode in the 2.4 kernels is, without a doubt, theblock layer. It’s bit rotted heavily and lacksvarious features or facilities that modern hard-ware craves. This has led to many evils, rang-ing from code duplication in drivers to mas-sive patching of block layer internals in ven-dor kernels. As a result, vendor trees can eas-ily be considered forks of the 2.4 kernel withrespect to the block layer code, with all ofthe problems that this fact brings with it: 2.4block layer code base may as well be consid-ered dead, no one develops against it. Hard-ware vendor drivers include many nasty hacks
and #ifdef’s to work in all of the various2.4 kernels that are out there, which doesn’t ex-actly enhance code coverage or peer review.
The block layer fork didn’t just happen for thefun of it of course, it was a direct result ofthe various problem observed. Some of theseare added features, others are deeper rewritesattempting to solve scalability problems withthe block layer core or IO scheduler. In thenext sections I will attempt to highlight specificproblems in these areas.
1.1 IO Scheduler
The main 2.4 IO scheduler is calledelevator_linus , named after the benev-olent kernel dictator to credit him for someof the ideas used. elevator_linus is aone-way scan elevator that always scans inthe direction of increasing LBA. It manageslatency problems by assigning sequencenumbers to new requests, denoting how manynew requests (either merges or inserts) maypass this one. The latency value is dependenton data direction, smaller for reads than forwrites. Internally, elevator_linus usesa double linked list structure (the kernelsstruct list_head ) to manage the requeststructures. When queuing a new IO unit withthe IO scheduler, the list is walked to find asuitable insertion (or merge) point yielding anO(N) runtime. That in itself is suboptimal inpresence of large amounts of IO and to makematters even worse, we repeat this scan if therequest free list was empty when we entered

52 • Linux Symposium 2004 • Volume One
the IO scheduler. The latter is not an errorcondition, it will happen all the time for evenmoderate amounts of write back against aqueue.
1.2 struct buffer_head
The main IO unit in the 2.4 kernel is thestruct buffer_head . It’s a fairly unwieldystructure, used at various kernel layers for dif-ferent things: caching entity, file system block,and IO unit. As a result, it’s suboptimal for ei-ther of them.
From the block layer point of view, the twobiggest problems is the size of the structureand the limitation in how big a data region itcan describe. Being limited by the file systemone blocksemantics, it can at most describe aPAGE_CACHE_SIZEamount of data. In Linuxon x86 hardware that means 4KiB of data. Of-ten it can be even worse: raw io typically usesthe soft sector size of a queue (default 1KiB)for submitting io, which means that queuingeg 32KiB of IO will enter the io scheduler 32times. To work around this limitation and getat least to a page at the time, a 2.4 hack wasintroduced. This is calledvary_io . A driveradvertising this capability acknowledges that itcan managebuffer_head’s of varying sizesat the same time. File system read-ahead, an-other frequent user of submitting larger sizedio, has no option but to submit the read-aheadwindow in units of the page size.
1.3 Scalability
With the limit on buffer_head IO size andelevator_linus runtime, it doesn’t take alot of thinking to discover obvious scalabilityproblems in the Linux 2.4 IO path. To add in-sult to injury, the entire IO path is guarded by asingle, global lock:io_request_lock . Thislock is held during the entire IO queuing op-eration, and typically also from the other end
when a driver subtracts requests for IO sub-mission. A single global lock is a big enoughproblem on its own (bigger SMP systems willsuffer immensely because of cache line bounc-ing), but add to that long runtimes and you havea really huge IO scalability problem.
Linux vendors have long shipped lock scalabil-ity patches for quite some time to get aroundthis problem. The adopted solution is typicallyto make the queue lock a pointer to a driver lo-cal lock, so the driver has full control of thegranularity and scope of the lock. This solu-tion was adopted from the 2.5 kernel, as we’llsee later. But this is another case where driverwriters often need to differentiate between ven-dor and vanilla kernels.
1.4 API problems
Looking at the block layer as a whole (includ-ing both ends of the spectrum, the producersand consumers of the IO units going throughthe block layer), it is a typical example of codethat has been hacked into existence withoutmuch thought to design. When things brokeor new features were needed, they had beengrafted into the existing mess. No well de-fined interface exists between file system andblock layer, except a few scattered functions.Controlling IO unit flow from IO schedulerto driver was impossible: 2.4 exposes the IOscheduler data structures (the->queue_head
linked list used for queuing) directly to thedriver. This fact alone makes it virtually im-possible to implement more clever IO schedul-ing in 2.4. Even the recently (in the 2.4.20’s)added lower latency work was horrible to workwith because of this lack of boundaries. Veri-fying correctness of the code is extremely dif-ficult; peer review of the code likewise, since areviewer must be intimate with the block layerstructures to follow the code.
Another example on lack of clear direction is

Linux Symposium 2004 • Volume One • 53
the partition remapping. In 2.4, it’s the driver’sresponsibility to resolve partition mappings.A given request contains a device and sectoroffset (i.e. /dev/hda4 , sector 128) and thedriver must map this to an absolute device off-set before sending it to the hardware. Not onlydoes this cause duplicate code in the drivers,it also means the IO scheduler has no knowl-edge of the real device mapping of a particularrequest. This adversely impacts IO schedulingwhenever partitions aren’t laid out in strict as-cending disk order, since it causes the io sched-uler to make the wrong decisions when order-ing io.
2 2.6 Block layer
The above observations were the initial kick offfor the 2.5 block layer patches. To solve someof these issues the block layer needed to beturned inside out, breaking basically anything-io along the way.
2.1 bio
Given that struct buffer_head was oneof the problems, it made sense to start fromscratch with an IO unit that would be agree-able to the upper layers as well as the drivers.The main criteria for such an IO unit would besomething along the lines of:
1. Must be able to contain an arbitraryamount of data, as much as the hardwareallows. Or as much that makessenseatleast, with the option of easily pushingthis boundary later.
2. Must work equally well for pages thathave a virtual mapping as well as ones thatdo not.
3. When entering the IO scheduler anddriver, IO unit must point to an absolutelocation on disk.
4. Must be able to stack easily for IO stackssuch as raid and device mappers. This in-cludes full redirect stacking like in 2.4, aswell as partial redirections.
Once the primary goals for the IO struc-ture were laid out, thestruct bio wasborn. It was decided to base the layouton a scatter-gather type setup, with thebio
containing a map of pages. If the mapcount was made flexible, items 1 and 2 onthe above list were already solved. Theactual implementation involved splitting thedata container from thebio itself into astruct bio_vec structure. This was mainlydone to ease allocation of the structures sothat sizeof(struct bio) was always con-stant. Thebio_vec structure is simply a tu-ple of {page, length, offset} , and thebio can be allocated with room for anythingfrom 1 to BIO_MAX_PAGES. Currently Linuxdefines that as 256 pages, meaning we can sup-port up to 1MiB of data in a singlebio fora system with 4KiB page size. At the timeof implementation, 1MiB was a good deal be-yond the point where increasing the IO size fur-ther didn’t yield better performance or lowerCPU usage. It also has the added bonus ofmaking thebio_vec fit inside a single page,so we avoid higher order memory allocations(sizeof(struct bio_vec) == 12 on 32-bit, 16 on 64-bit) in the IO path. This is animportant point, as it eases the pressure on thememory allocator. For swapping or other lowmemory situations, we ideally want to stressthe allocator as little as possible.
Different hardware can support different sizesof io. Traditional parallel ATA can do a max-imum of 128KiB per request, qlogicfc SCSIdoesn’t like more than 32KiB, and lots of highend controllers don’t impose a significant limiton max IO size but may restrict the maximumnumber of segments that one IO may be com-posed of. Additionally, software raid or de-

54 • Linux Symposium 2004 • Volume One
vice mapper stacks may like special alignmentof IO or the guarantee that IO won’t crossstripe boundaries. All of this knowledge is ei-ther impractical or impossible to statically ad-vertise to submitters of io, so an easy inter-face for populating abio with pages was es-sential if supporting large IO was to becomepractical. The current solution isint bio_
add_page() which attempts to add a singlepage (full or partial) to abio . It returns theamount of bytes successfully added. Typicalusers of this function continue adding pagesto abio until it fails—then it is submitted forIO throughsubmit_bio() , a newbio is al-located and populated until all data has goneout. int bio_add_page() uses staticallydefined parameters inside the request queue todetermine how many pages can be added, andattempts to query a registeredmerge_bvec_
fn for dynamic limits that the block layer can-not know about.
Drivers hooking into the block layer before theIO scheduler1 deal withstruct bio directly,as opposed to thestruct request that areoutput after the IO scheduler. Even though thepage addition API guarantees that they neverneed to be able to deal with abio that is toobig, they still have to manage local splits atsub-page granularity. The API was defined thatway to make it easier for IO submitters to man-age, so they don’t have to deal with sub-pagesplits. 2.6 block layer defines two ways todeal with this situation—the first is the generalclone interface.bio_clone() returns a cloneof abio . A clone is defined as a private copy ofthebio itself, but with a sharedbio_vec pagemap list. Drivers can modify the clonedbio
and submit it to a different device without du-plicating the data. The second interface is tai-lored specifically to single page splits and waswritten by kernel raid maintainer Neil Brown.The main function isbio_split() which re-
1Also known as atmake_request time.
turns astruct bio_pair describing the twoparts of the originalbio . The twobio ’s canthen be submitted separately by the driver.
2.2 Partition remapping
Partition remapping is handled inside the IOstack before going to the driver, so that bothdrivers and IO schedulers have immediate fullknowledge of precisely where data should endup. The device unfolding is done automati-cally by the same piece of code that resolvesfull bio redirects. The worker function isblk_partition_remap() .
2.3 Barriers
Another feature that found its way to some ven-dor kernels is IO barriers. A barrier is definedas a piece of IO that is guaranteed to:
• Be on platter (or safe storage at least)when completion is signaled.
• Not proceed any previously submitted io.
• Not be proceeded by later submitted io.
The feature is handy for journalled file sys-tems, fsync, and any sort of cache bypassingIO2 where you want to provide guarantees ondata order and correctness. The 2.6 code isn’teven complete yet or in the Linus kernels, but ithas made its way to Andrew Morton’s -mm treewhich is generally considered a staging area forfeatures. This section describes the code so far.
The first type of barrier supported is a softbarrier. It isn’t of much use for data in-tegrity applications, since it merely impliesordering inside the IO scheduler. It is sig-naled with theREQ_SOFTBARRIERflag insidestruct request . A stronger barrier is the
2Such types of IO includeO_DIRECTor raw.

Linux Symposium 2004 • Volume One • 55
hard barrier. From the block layer and IOscheduler point of view, it is identical to thesoft variant. Drivers need to know about itthough, so they can take appropriate measuresto correctly honor the barrier. So far the idedriver is the only one supporting a full, hardbarrier. The issue was deemed most impor-tant for journalled desktop systems, where thelack of barriers and risk of crashes / power losscoupled with ide drives generally always de-faulting to write back caching caused signifi-cant problems. Since the ATA command setisn’t very intelligent in this regard, the ide solu-tion adopted was to issue pre- and post flusheswhen encountering a barrier.
The hard and soft barrier share the feature thatthey are both tied to a piece of data (abio ,really) and cannot exist outside of data con-text. Certain applications of barriers would re-ally like to issue a disk flush, where finding outwhich piece of data to attach it to is hard orimpossible. To solve this problem, the 2.6 bar-rier code added theblkdev_issue_flush()
function. The block layer part of the code is ba-sically tied to a queue hook, so the driver issuesthe flush on its own. A helper function is pro-vided for SCSI type devices, using the genericSCSI command transport that the block layerprovides in 2.6 (more on this later). Unlikethe queued data barriers, a barrier issued withblkdev_issue_flush() works on all inter-esting drivers in 2.6 (IDE, SCSI, SATA). Theonly missing bits are drivers that don’t belongto one of these classes—things likeCISS andDAC960.
2.4 IO Schedulers
As mentioned in section 1.1, there are a num-ber of known problems with the default 2.4 IOscheduler and IO scheduler interface (or lackthereof). The idea to base latency on a unit ofdata (sectors) rather than a time based unit ishard to tune, or requires auto-tuning at runtime
and this never really worked out. Fixing theruntime problems withelevator_linus isnext to impossible due to the data structure ex-posing problem. So before being able to tackleany problems in that area, a neat API to the IOscheduler had to be defined.
2.4.1 Defined API
In the spirit of avoiding over-design3, the APIwas based on initial adaption ofelevator_
linus , but has since grown quite a bit as newerIO schedulers required more entry points to ex-ploit their features.
The core function of an IO scheduler is, natu-rally, insertion of new io units and extraction ofditto from drivers. So the first 2 API functionsare defined,next_req_fn andadd_req_fn .If you recall from section 1.1, a new IOunit is first attempted merged into an exist-ing request in the IO scheduler queue. Andif this fails and the newly allocated requesthas raced with someone else adding an adja-cent IO unit to the queue in the mean time,we also attempt to mergestruct request s.So 2 more functions were added to cater tothese needs,merge_fn andmerge_req_fn .Cleaning up after a successful merge is donethroughmerge_cleanup_fn . Finally, a de-fined IO scheduler can provide init and exitfunctions, should it need to perform any dutiesduring queue init or shutdown.
The above described the IO scheduler APIas of 2.5.1, later on more functions wereadded to further abstract the IO scheduleraway from the block layer core. More detailsmay be found in thestruct elevator_s in<linux/elevator.h> kernel include file.
3Some might, rightfully, claim that this is worse thanno design

56 • Linux Symposium 2004 • Volume One
2.4.2 deadline
In kernel 2.5.39,elevator_linus was fi-nally replaced by something more appropriate,the deadlineIO scheduler. The principles be-hind it are pretty straight forward — new re-quests are assigned an expiry time in millisec-onds, based on data direction. Internally, re-quests are managed on two different data struc-tures. The sort list, used for inserts and frontmerge lookups, is based on a red-black tree.This providesO(log n) runtime for both inser-tion and lookups, clearly superior to the dou-bly linked list. Two FIFO lists exist for track-ing request expiry times, using a double linkedlist. Since strict FIFO behavior is maintainedon these two lists, they run inO(1) time. Forback merges it is important to maintain goodperformance as well, as they dominate the to-tal merge count due to the layout of files ondisk. So deadline added a merge hash forback merges, ideally providingO(1) runtimefor merges. Additionally,deadlineadds a one-hit merge cache that is checked even before go-ing to the hash. This gets surprisingly good hitrates, serving as much as 90% of the mergeseven for heavily threaded io.
Implementation details aside,deadlinecontin-ues to build on the fact that the fastest way toaccess a single drive, is by scanning in the di-rection of ascending sector. With its superiorruntime performance,deadline is able to sup-port very large queue depths without sufferinga performance loss or spending large amountsof time in the kernel. It also doesn’t suffer fromlatency problems due to increased queue sizes.When a request expires in the FIFO,dead-line jumps to that disk location and starts serv-ing IO from there. To prevent accidental seekstorms (which would further cause us to missdeadlines),deadline attempts to serve a num-ber of requests from that location before jump-ing to the next expired request. This means thatthe assigned request deadlines are soft, not a
specific hard target that must be met.
2.4.3 Anticipatory IO scheduler
While deadline works very well for mostworkloads, it fails to observe the natural depen-dencies that often exist between synchronousreads. Say you want to list the contents ofa directory—that operation isn’t merely a sin-gle sync read, it consists of a number of readswhere only the completion of the final requestwill give you the directory listing. Withdead-line, you could get decent performance fromsuch a workload in presence of other IO activi-ties by assigning very tight read deadlines. Butthat isn’t very optimal, since the disk will beserving other requests in between the depen-dent reads causing a potentially disk wide seekevery time. On top of that, the tight deadlineswill decrease performance on other io streamsin the system.
Nick Piggin implemented an anticipatory IOscheduler [Iyer] during 2.5 to explore some in-teresting research in this area. The main ideabehind the anticipatory IO scheduler is a con-cept calleddeceptive idleness. When a processissues a request and it completes, it might beready to issue a new request (possibly closeby) immediately. Take the directory listing ex-ample from above—it might require 3–4 IOoperations to complete. When each of themcompletes, the process4 is ready to issue thenext one almost instantly. But the traditionalio scheduler doesn’t pay any attention to thisfact, the new request must go through the IOscheduler and wait its turn. Withdeadline, youwould have to typically wait 500 millisecondsfor each read, if the queue is held busy by otherprocesses. The result is poor interactive per-formance for each process, even though overallthroughput might be acceptable or even good.
4Or the kernel, on behalf of the process.

Linux Symposium 2004 • Volume One • 57
Instead of moving on to the next request froman unrelated process immediately, the anticipa-tory IO scheduler (hence forth known asAS)opens a small window of opportunity for thatprocess to submit a new IO request. If that hap-pens,ASgives it a new chance and so on. Inter-nally it keeps a decaying histogram of IOthinktimesto help the anticipation be as accurate aspossible.
Internally,AS is quite likedeadline. It uses thesame data structures and algorithms for sort-ing, lookups, and FIFO. If the think time is setto 0, it is very close todeadline in behavior.The only differences are various optimizationsthat have been applied to either scheduler al-lowing them to diverge a little. IfAS is able toreliably predict when waiting for a new requestis worthwhile, it gets phenomenal performancewith excellent interactiveness. Often the sys-tem throughput is sacrificed a little bit, so de-pending on the workloadAS might not be thebest choice always. The IO storage hardwareused, also plays a role in this—a non-queuingATA hard drive is a much better fit than a SCSIdrive with a large queuing depth. The SCSIfirmware reorders requests internally, thus of-ten destroying any accounting thatAS is tryingto do.
2.4.4 CFQ
The third new IO scheduler in 2.6 is calledCFQ. It’s loosely based on the ideas onstochastic fair queuing (SFQ [McKenney]).SFQ is fair as long as its hashing doesn’t col-lide, and to avoid that, it uses a continuallychanging hashing function. Collisions can’t becompletely avoided though, frequency will de-pend entirely on workload and timing.CFQis an acronym for completely fair queuing, at-tempting to get around the collision problemthat SFQ suffers from. To do so,CFQ doesaway with the fixed number of buckets that
processes can be placed in. And using reg-ular hashing technique to find the appropriatebucket in case of collisions, fatal collisions areavoided.
CFQ deviates radically from the concepts thatdeadline and AS is based on. It doesn’t as-sign deadlines to incoming requests to main-tain fairness, instead it attempts to dividebandwidth equally among classes of processesbased on some correlation between them. Thedefault is to hash on thread group id, tgid.This means that bandwidth is attempted dis-tributed equally among the processes in thesystem. Each class has its own request sortand hash list, using red-black trees again forsorting and regular hashing for back merges.When dealing with writes, there is a little catch.A process will almost never be performing itsown writes—data is marked dirty in context ofthe process, but write back usually takes placefrom the pdflushkernel threads. SoCFQ isactually dividing read bandwidth among pro-cesses, while treating each pdflush thread as aseparate process. Usually this has very minorimpact on write back performance. Latency ismuch less of an issue with writes, and goodthroughput is very easy to achieve due to theirinherent asynchronous nature.
2.5 Request allocation
Each block driver in the system has at leastone request_queue_t request queue struc-ture associated with it. The recommendedsetup is to assign a queue to each logicalspindle. In turn, each request queue hasa struct request_list embedded whichholds freestruct request structures usedfor queuing io. 2.4 improved on this situationfrom 2.2, where a single global free list wasavailable to add one per queue instead. Thisfree list was split into two sections of equalsize, for reads and writes, to prevent either

58 • Linux Symposium 2004 • Volume One
direction from starving the other5. 2.4 stati-cally allocated a big chunk of requests for eachqueue, all residing in the precious low memoryof a machine. The combination ofO(N) run-time and statically allocated request structuresfirmly prevented any real world experimenta-tion with large queue depths on 2.4 kernels.
2.6 improves on this situation by dynamicallyallocating request structures on the fly instead.Each queue still maintains its request free listlike in 2.4. However it’s also backed by a mem-ory pool6 to provide deadlock free allocationseven during swapping. The more advancedio schedulers in 2.6 usually back each requestby its own private request structure, furtherincreasing the memory pressure of each re-quest. Dynamic request allocation lifts some ofthis pressure as well by pushing that allocationinside two hooks in the IO scheduler API—set_req_fn and put_req_fn . The latterhandles the later freeing of that data structure.
2.6 Plugging
For the longest time, the Linux block layer hasused a technique dubbedplugging to increaseIO throughput. In its simplicity, pluggingworks sort of like the plug in your tub drain—when IO is queued on an initially empty queue,the queue is plugged. Only when someone asksfor the completion of some of the queued IO isthe plug yanked out, and io is allowed to drainfrom the queue. So instead of submitting thefirst immediately to the driver, the block layerallows a small buildup of requests. There’snothing wrong with the principle of plugging,and it has been shown to work well for a num-ber of workloads. However, the block layermaintains a global list of plugged queues in-side thetq_disk task queue. There are threemain problems with this approach:
5In reality, to prevent writes for consuming all re-quests.
6mempool_t interface from Ingo Molnar.
1. It’s impossible to go backwards from thefile system and find the specific queue tounplug.
2. Unplugging one queue throughtq_disk
unplugs all plugged queues.
3. The act of plugging and unpluggingtouches a global lock.
All of these adversely impact performance.These problems weren’t really solved until latein 2.6, when Intel reported a huge scalabilityproblem related to unplugging [Chen] on a 32processor system. 93% of system time wasspent due to contention onblk_plug_lock ,which is the 2.6 direct equivalent of the 2.4tq_disk embedded lock. The proposed so-lution was to move the plug lists to a per-CMU structure. While this would solve thecontention problems, it still leaves the other 2items on the above list unsolved.
So work was started to find a solution thatwould fix all problems at once, and just gen-erally Feel Right. 2.6 contains a link be-tween the block layer and write out pathswhich is embedded inside the queue, astruct backing_dev_info . This structureholds information on read-ahead and queuecongestion state. It’s also possible to go froma struct page to the backing device, whichmay or may not be a block device. So itwould seem an obvious idea to move to a back-ing device unplugging scheme instead, gettingrid of the globalblk_run_queues() unplug-ging. That solution would fix all three issues atonce—there would be no global way to unplugall devices, only target specific unplugs, andthe backing device gives us a mapping frompage to queue. The code was rewritten to dojust that, and provide unplug functionality go-ing from a specificstruct block_device ,page, or backing device. Code and interfacewas much superior to the existing code base,

Linux Symposium 2004 • Volume One • 59
and results were truly amazing. Jeremy Hig-don tested on an 8-way IA64 box [Higdon] andgot 75–80 thousand IOPS on the stock kernelat 100% CPU utilization, 110 thousand IOPSwith the per-CPU Intel patch also at full CPUutilization, and finally 200 thousand IOPS atmerely 65% CPU utilization with the backingdevice unplugging. So not only did the newcode provide a huge speed increase on thismachine, it also went from being CPU to IObound.
2.6 also contains some additional logic tounplug a given queue once it reaches thepoint where waiting longer doesn’t make muchsense. So where 2.4 will always wait for an ex-plicit unplug, 2.6 can trigger an unplug whenone of two conditions are met:
1. The number of queued requests reach acertain limit,q->unplug_thresh . Thisis device tweak able and defaults to 4.
2. When the queue has been idle forq->
unplug_delay . Also device tweak able,and defaults to 3 milliseconds.
The idea is that once a certain number ofrequests have accumulated in the queue, itdoesn’t make much sense to continue waitingfor more—there is already an adequate numberavailable to keep the disk happy. The time limitis really a last resort, and should rarely trig-ger in real life. Observations on various workloads have verified this. More than a handful ortwo timer unplugs per minute usually indicatesa kernel bug.
2.7 SCSI command transport
An annoying aspect of CD writing applicationsin 2.4 has been the need to use ide-scsi, neces-sitating the inclusion of the entire SCSI stackfor only that application. With the clear major-ity of the market being ATAPI hardware, this
becomes even more silly. ide-scsi isn’t withoutits own class of problems either—it lacks theability to use DMA on certain writing types.CDDA audio ripping is another application thatthrives with ide-scsi, since the native uniformcdrom layer interface is less than optimal (putmildly). It doesn’t have DMA capabilities atall.
2.7.1 Enhancing struct request
The problem with 2.4 was the lack of abil-ity to generically send SCSI “like” commandsto devices that understand them. Historically,only file system read/write requests could besubmitted to a driver. Some drivers made upfaked requests for other purposes themselvesand put then on the queue for their own con-sumption, but no defined way of doing this ex-isted. 2.6 adds a new request type, marked bytheREQ_BLOCK_PCbit. Such a request can beeither backed by abio like a file system re-quest, or simply has a data and length field set.For both types, a SCSI command data block isfilled inside the request. With this infrastruc-ture in place and appropriate update to driversto understand these requests, it’s a cinch to sup-port a much better direct-to-device interface forburning.
Most applications use the SCSI sg API for talk-ing to devices. Some of them talk directly tothe /dev/sg* special files, while (most) oth-ers use theSG_IO ioctl interface. The for-mer requires a yet unfinished driver to trans-form them into block layer requests, but the lat-ter can be readily intercepted in the kernel androuted directly to the device instead of throughthe SCSI layer. Helper functions were addedto make burning and ripping even faster, pro-viding DMA for all applications and withoutcopying data between kernel and user space atall. So the zero-copy DMA burning was pos-sible, and this even without changing most ap-

60 • Linux Symposium 2004 • Volume One
plications.
3 Linux-2.7
The 2.5 development cycle saw the most mas-sively changed block layer in the history ofLinux. Before 2.5 was opened, Linus hadclearly expressed that one of the most impor-tant things that needed doing, was the blocklayer update. And indeed, the very first thingmerged was the complete bio patch into 2.5.1-pre2. At that time, no more than a handfuldrivers compiled (let alone worked). The 2.7changes will be nowhere as severe or drastic.A few of the possible directions will follow inthe next few sections.
3.1 IO Priorities
Prioritized IO is a very interesting area thatis sure to generate lots of discussion and de-velopment. It’s one of the missing pieces ofthe complete resource management puzzle thatseveral groups of people would very much liketo solve. People running systems with manyusers, or machines hosting virtual hosts (orcompleted virtualized environments) are dy-ing to be able to provide some QOS guaran-tees. Some work was already done in thisarea, so far nothing complete has materialized.The CKRM [CKRM] project spear headed byIBM is an attempt to define global resourcemanagement, including io. They applied a lit-tle work to theCFQ IO scheduler to provideequal bandwidth between resource manage-ment classes, but at no specific priorities. Cur-rently I have aCFQ patch that is 99% completethat provides full priority support, using the IOcontexts introduced byAS to manage fair shar-ing over the full time span that a process ex-ists7. This works well enough, but only works
7CFQ currently tears down class structures as soonas it is empty, it doesn’t persist over process life time.
for that specific IO scheduler. A nicer solutionwould be to create a scheme that works inde-pendently of the io scheduler used. That wouldrequire a rethinking of the IO scheduler API.
3.2 IO Scheduler switching
Currently Linux provides no less than 4 IOschedulers—the 3 mentioned, plus a forthdubbednoop. The latter is a simple IO sched-uler that does no request reordering, no latencymanagement, and always merges whenever itcan. Its area of application is mainly highlyintelligent hardware with huge queue depths,where regular request reordering doesn’t makesense. Selecting a specific IO scheduler caneither be done by modifying the source of adriver and putting the appropriate calls in thereat queue init time, or globally for any queue bypassing theelevator=xxx boot parameter.This makes it impossible, or at least very im-practical, to benchmark different IO schedulerswithout many reboots or recompiles. Someway to switch IO schedulers per queue and onthe fly is desperately needed. Freezing a queueand letting IO drain from it until it’s empty(pinning new IO along the way), and then shut-ting down the old io scheduler and moving tothe new scheduler would not be so hard to do.The queues expose various sysfs variables al-ready, so the logical approach would simply beto:
# echo deadline > \/sys/block/hda/queue/io_scheduler
A simple but effective interface. At least twopatches doing something like this were alreadyproposed, but nothing was merged at that time.
4 Final comments
The block layer code in 2.6 has come a longway from the rotted 2.4 code. New features

Linux Symposium 2004 • Volume One • 61
bring it more up-to-date with modern hard-ware, and completely rewritten from scratchcore provides much better scalability, perfor-mance, and memory usage benefiting any ma-chine from small to really huge. Going backa few years, I heard constant complaints aboutthe block layer and how much it sucked andhow outdated it was. These days I rarelyhear anything about the current state of affairs,which usually means that it’s doing pretty wellindeed. 2.7 work will mainly focus on fea-ture additions and driver layer abstractions (ourconcept of IDE layer, SCSI layer etc will beseverely shook up). Nothing that will wreakhavoc and turn everything inside out like 2.5did. Most of the 2.7 work mentioned aboveis pretty light, and could easily be back portedto 2.6 once it has been completed and tested.Which is also a good sign that nothing reallyradical or risky is missing. So things are set-tling down, a sign of stability.
References
[Iyer] Sitaram Iyer and Peter Druschel,Anticipatory scheduling: A diskscheduling framework to overcomedeceptive idleness in synchronous I/O,18th ACM Symposium on OperatingSystems Principles,http://www.cs.rice.edu/~ssiyer/r/antsched/antsched.ps.gz ,2001
[McKenney] Paul E. McKenney,StochasticFairness Queuing, INFOCOMhttp://rdrop.com/users/paulmck/paper/sfq.2002.06.04.pdf ,1990
[Chen] Kenneth W. Chen,per-cpublk_plug_list, Linux kernel mailing listhttp://www.ussg.iu.edu/hypermail/linux/kernel/0403.0/0179.html , 2004
[Higdon] Jeremy Higdon,Re: [PATCH]per-backing dev unplugging #2, Linuxkernel mailing listhttp://marc.theaimsgroup.com/?l=linux-kernel&m=107941470424309&w=2 , 2004
[CKRM] IBM, Class-based Kernel ResourceManagement (CKRM),http://ckrm.sf.net , 2004
[Bhattacharya] Suparna Bhattacharya,Noteson the Generic Block Layer Rewrite inLinux 2.5, General discussion,Documentation/block/biodoc.txt , 2002

62 • Linux Symposium 2004 • Volume One

Linux AIO Performance and Robustness forEnterprise Workloads
Suparna Bhattacharya,IBM ([email protected])
John Tran,IBM ([email protected])
Mike Sullivan,IBM ([email protected])
Chris Mason,SUSE([email protected])
1 Abstract
In this paper we address some of the issuesidentified during the development and stabi-lization of Asynchronous I/O (AIO) on Linux2.6.
We start by describing improvements made tooptimize the throughput of streaming bufferedfilesystem AIO for microbenchmark runs.Next, we discuss certain tricky issues in en-suring data integrity between AIO Direct I/O(DIO) and buffered I/O, and take a deeper lookat synchronized I/O guarantees, concurrentI/O, write-ordering issues and the improve-ments resulting from radix-tree based write-back changes in the Linux VFS.
We then investigate the results of using Linux2.6 filesystem AIO on the performance met-rics for certain enterprise database workloadswhich are expected to benefit from AIO, andmention a few tips on optimizing AIO for suchworkloads. Finally, we briefly discuss the is-sues around workloads that need to combineasynchronous disk I/O and network I/O.
2 Introduction
AIO enables a single application thread tooverlap processing with I/O operations for bet-ter utilization of CPU and devices. AIO can
improve the performance of certain kinds ofI/O intensive applications like databases, web-servers and streaming-content servers. Theuse of AIO also tends to help such applica-tions adapt and scale more smoothly to varyingloads.
2.1 Overview of kernel AIO in Linux 2.6
The Linux 2.6 kernel implements in-kernelsupport for AIO. A low-level native AIO sys-tem call interface is provided that can be in-voked directly by applications or used by li-brary implementations to build POSIX/SUSsemantics. All discussion hereafter in this pa-per pertains to the native kernel AIO interfaces.
Applications can submit one or moreI/O requests asynchronously using theio_submit() system call, and ob-tain completion notification using theio_getevents() system call. EachI/O request specifies the operation (typicallyread/write), the file descriptor and the pa-rameters for the operation (e.g., file offset,buffer). I/O requests are associated with thecompletion queue (ioctx) they were submittedagainst. The results of I/O are reported ascompletion events on this queue, and reapedusingio_getevents() .
The design of AIO for the Linux 2.6 kernel hasbeen discussed in [1], including the motivation

64 • Linux Symposium 2004 • Volume One
behind certain architectural choices, for exam-ple:
• Sharing a common code path for AIO andregular I/O
• A retry-based model for AIO continua-tions across blocking points in the case ofbuffered filesystem AIO (currently imple-mented as a set of patches to the Linux 2.6kernel) where worker threads take on thecaller’s address space for executing retriesinvolving access to user-space buffers.
2.2 Background on retry-based AIO
The retry-based model allows an AIO requestto be executed as a series of non-blocking it-erations. Each iteration retries the remain-ing part of the request from where the last it-eration left off, re-issuing the correspondingAIO filesystem operation with modified argu-ments representing the remaining I/O. The re-tries are “kicked” via a special AIO waitqueuecallback routine,aio_wake_function() ,which replaces the default waitqueue entryused for blocking waits.
The high-level retry infrastructure is respon-sible for running the iterations in the addressspace context of the caller, and ensures thatonly one retry instance is active at a given time.This relieves the fops themselves from havingto deal with potential races of that sort.
2.3 Overview of the rest of the paper
In subsequent sections of this paper, we de-scribe our experiences in addressing several is-sues identified during the optimization and sta-bilization efforts related to the kernel AIO im-plementation for Linux 2.6, mainly in the areaof disk- or filesystem-based AIO.
We observe, for example, how I/O patternsgenerated by the common VFS code paths
used by regular and retry-based AIO couldbe non-optimal for streaming AIO requests,and we describe the modifications that ad-dress this finding. A different set of prob-lems that has seen some development ac-tivity are the races, exposures and poten-tial data-integrity concerns between direct andbuffered I/O, which become especially trickyin the presence of AIO. Some of these issuesmotivated Andrew Morton’s modified page-writeback design for the VFS using taggedradix-tree lookups, and we discuss the implica-tions for the AIOO_SYNCwrite implementa-tion. In general, disk-based filesystem AIO re-quirements for database workloads have been aguiding consideration in resolving some of thetrade-offs encountered, and we present someinitial performance results for such workloads.Lastly, we touch upon potential approaches toallow processing of disk-based AIO and com-munications I/O within a single event loop.
3 Streaming AIO reads
3.1 Basic retry pattern for single AIO read
The retry-based design for buffered filesystemAIO read works by converting each blockingwait for read completion on a page into aretryexit. The design queues an asynchronous no-tification callback and returns the number ofbytes for which the read has completed so farwithout blocking. Then, when the page be-comes up-to-date, the callback kicks off a retrycontinuation in task context. This retry contin-uation invokes the same filesystem read opera-tion again using the caller’s address space, butthis time with arguments modified to reflect theremaining part of the read request.
For example, given a 16KB read request start-ing at offset 0, where the first 4KB is alreadyin cache, one might see the following sequenceof retries (in the absence of readahead):

Linux Symposium 2004 • Volume One • 65
first time:fop->aio_read(fd, 0, 16384) = 4096
and when read completes for the second page:fop->aio_read(fd, 4096, 12288) = 4096
and when read completes for the third page:fop->aio_read(fd, 8192, 8192) = 4096
and when read completes for the fourth page:fop->aio_read(fd, 12288, 4096) = 4096
3.2 Impact of readahead on single AIO read
Usually, however, the readahead logic attemptsto batch read requests in advance. Hence, moreI/O would be seen to have completed at eachretry. The logic attempts to predict the optimalreadahead window based on state it maintainsabout the sequentiality of past read requests onthe same file descriptor. Thus, given a maxi-mum readahead window size of 128KB, the se-quence of retries would appear to be more likethe following example, which results in signif-icantly improved throughput:
first time:fop->aio_read(fd, 0, 16384) = 4096,
after issuing readaheadfor 128KB/2 = 64KB
and when read completes for the above I/O:fop->aio_read(fd, 4096, 12288) = 12288
Notice that care is taken to ensure that reada-heads are not repeated during retries.
3.3 Impact of readahead on streaming AIOreads
In the case of streaming AIO reads, a sequenceof AIO read requests is issued on the samefile descriptor, where subsequent reads are sub-mitted without waiting for previous requests tocomplete (contrast this with a sequence of syn-chronous reads).
Interestingly, we encountered a significantthroughput degradation as a result of the in-terplay of readahead and streaming AIO reads.To see why, consider the retry sequence forstreaming random AIO read requests of 16KB,
whereo1, o2, o3, ... refer to the ran-dom offsets where these reads are issued:
first time:fop->aio_read(fd, o1, 16384) = -EIOCBRETRY,
after issuing readahead for 64KBas the readahead logic sees the first pageof the read
fop->aio_read(fd, o2, 16384) = -EIOCBRETRY,after issuing readahead for 8KB (noticethe shrinkage of the readahead windowbecause of non-sequentiality seen by thereadahead logic)
fop->aio_read(fd, o3, 16384) = -EIOCBRETRY,after maximally shrinking the readaheadwindow, turning off readahead and issuing4KB read in the slow path
fop->aio_read(fd, o4, 16384) = -EIOCBRETRY,after issuing 4KB read in the slow path
.
.and when read completes for o1
fop->aio_read(fd, o1, 16384) = 16384and when read completes for o2
fop->aio_read(fd, o2, 16384) = 8192and when read completes for o3
fop->aio_read(fd, o3, 16384) = 4096and when read completes for o4
fop->aio_read(fd, o3, 16384) = 4096..
In steady state, this amounts to a maximally-shrunk readahead window with 4KB reads atrandom offsets being issued serially one at atime on a slow path, causing seek storms anddriving throughputs down severely.
3.4 Upfront readahead for improved stream-ing AIO read throughputs
To address this issue, we made the readaheadlogic aware of the sequentiality of all pages in asingle read request upfront—before submittingthe next read request. This resulted in a moredesirable outcome as follows:
fop->aio_read(fd, o1, 16384) = -EIOCBRETRY,after issuing readahead for 64KBas the readahead logic sees all the 4pages for the read
fop->aio_read(fd, o2, 16384) = -EIOCBRETRY,after issuing readahead for 20KB, as thereadahead logic sees all 4 pages of theread (the readahead window shrinks to4+1=5 pages)

66 • Linux Symposium 2004 • Volume One
fop->aio_read(fd, o3, 16384) = -EIOCBRETRY,after issuing readahead for 20KB, as thereadahead logic sees all 4 pages of theread (the readahead window is maintainedat 4+1=5 pages)
.
.and when read completes for o1
fop->aio_read(fd, o1, 16384) = 16384and when read completes for o2
fop->aio_read(fd, o2, 16384) = 16384and when read completes for o3
fop->aio_read(fd, o3, 16384) = 16384..
3.5 Upfront readahead and sendfile regres-sions
At first sight it appears that upfront readaheadis a reasonable change for all situations, sinceit immediately passes to the readahead logicthe entire size of the request. However, it hasthe unintended, potential side-effect of losingpipelining benefits for really large reads, or op-erations like sendfile which involve post pro-cessing I/O on the contents just read. One wayto address this is to clip the maximum sizeof upfront readahead to the maximum reada-head setting for the device. To see why eventhat may not suffice for certain situations, letus take a look at the following sequence fora webserver that uses non-blocking sendfile toserve a large (2GB) file.
sendfile(fd, 0, 2GB, fd2) = 8192,tells readahead about up to 128KBof the read
sendfile(fd, 8192, 2GB - 8192, fd2) = 8192,tells readahead about 8KB - 132KBof the read
sendfile(fd, 16384, 2GB - 16384, fd2) = 8192,tells readahead about 16KB-140KBof the read
...
This confuses the readahead logic about theI/O pattern which appears to be 0–128K, 8K–132K, 16K–140K instead of clear sequentialityfrom 0–2GB that is really appropriate.
To avoid such unanticipated issues, upfrontreadahead required a special case for AIO
alone, limited to the maximum readahead set-ting for the device.
3.6 Streaming AIO read microbenchmarkcomparisons
We explored streaming AIO throughput im-provements with the retry-based AIO imple-mentation and optimizations discussed above,using a custom microbenchmark called aio-stress [2]. aio-stress issues a stream of AIOrequests to one or more files, where one canvary several parameters including I/O unit size,total I/O size, depth of iocbs submitted at atime, number of concurrent threads, and typeand pattern of I/O operations, and reports theoverall throughput attained.
The hardware included a 4-way 700MHzPentium® III machine with 512MB of RAMand a 1MB L2 cache. The disk subsystemused for the I/O tests consisted of an AdaptecAIC7896/97 Ultra2 SCSI controller connectedto a disk enclosure with six 9GB disks, oneof which was configured as an ext3 filesystemwith a block size of 4KB for testing.
The runs compared aio-stress throughputs forstreaming random buffered I/O reads (i.e.,without O_DIRECT), with and without thepreviously described changes. All the runswere for the case where the file was not al-ready cached in memory. The above graphsummarizes how the results varied across in-dividual request sizes of 4KB to 64KB, whereI/O was targeted to a single file of size 1GB,the depth of iocbs outstanding at a time being64KB. A third run was performed to find outhow the results compared with equivalent runsusing AIO-DIO.
With the changes applied, the results showedan approximate 2x improvement across allblock sizes, bringing throughputs to levels thatmatch the corresponding results using AIO-DIO.

Linux Symposium 2004 • Volume One • 67
0
5
10
15
20
25
0 10 20 30 40 50 60 70
aio-
stre
ss th
roug
hput
(MB
/s)
request size (KB)
Streaming AIO read results with aio-stress
FSAIO (non-cached) 2.6.2 VanillaFSAIO (non-cached) 2.6.2 PatchedAIO-DIO 2.6.2 Vanilla
Figure 1: Comparisons of streaming randomAIO read throughputs
4 AIO DIO vs cached I/O integrityissues
4.1 DIO vs buffered races
Stephen Tweedie discovered several races be-tween DIO and buffered I/O to the same file[3]. These races could lead to potential stale-data exposures and even data-integrity issues.Most instances were related to situations whenin-core meta-data updates were visible beforeactual instantiation or resetting of correspond-ing data blocks on disk. Problems could alsoarise when meta-data updates were not visibleto other code paths that could simultaneouslyupdate meta-data as well. The races mainly af-fected sparse files due to the lack of atomicitybetween the file flush in the DIO paths and ac-tual data block accesses.
The solution that Stephen Tweedie cameup with, and which Badari Pulavarty re-ported to Linux 2.6, involved protecting blocklookups and meta-data updates with the inodesemaphore (i_sem ) in DIO paths for both readand write, atomically with the file flush. Over-writing of sparse blocks in the DIO write pathwas modified to fall back to buffered writes.Finally, an additional semaphore (i_alloc_sem) was introduced to lock out deallocation
of blocks by a truncate while DIO was inprogress. The semaphore was implementedheld in shared mode by DIO and in exclusivemode by truncate.
Note that handling the new locking rules (i.e.,lock ordering of i_sem first and theni_alloc_sem ) while allowing for filesystem-specific implementations of the DIO and file-write interfaces had to be handled with somecare.
4.2 AIO-DIO specific races
The inclusion of AIO in Linux 2.6 added sometricky scenarios to the above-described prob-lems because of the potential races inherent inreturning without waiting for I/O completion.The interplay of AIO-DIO writes and truncatewas a particular worry as it could lead to cor-ruption of file data; for example, blocks couldget deallocated and reallocated to a new filewhile an AIO-DIO write to the file was still inprogress. To avoid this, AIO-DIO had to returnwith i_alloc_sem held, and only release itas part of I/O completion post-processing. No-tice that this also had implications for AIO can-cellation.
File size updates for AIO-DIO file extendscould expose unwritten blocks if they hap-pened before I/O completed asynchronously.The case involving fallback to buffered I/Owas particularly non-trivial if a single requestspanned allocated and sparse regions of afile. Specifically, part of the I/O could havebeen initiated via DIO then continued asyn-chronously, while the fallback to buffered I/Ooccurred and signaled I/O completion to theapplication. The application may thus havereused its I/O buffer, overwriting it with otherdata and potentially causing file data corrup-tion if writeout to disk had still been pending.
It might appear that some of these problems

68 • Linux Symposium 2004 • Volume One
could be avoided if I/O schedulers guaranteedthe ordering of I/O requests issued to the samedisk block. However, this isn’t a simple propo-sition in the current architecture, especially ingeneralizing the design to all possible cases,including network block devices. The use ofI/O barriers would be necessary and the costsmay not be justified for these special-case situ-ations.
Instead, a pragmatic approach was taken in or-der to address this based on the assumptionsthat true asynchronous behaviour was reallymeaningful in practice, mainly when perform-ing I/O to already-allocated file blocks. Forexample, databases typically preallocate filesat the time of creation, so that AIO writesduring normal operation and in performance-critical paths do not extend the file or encountersparse regions. Thus, for the sake of correct-ness, synchronous behaviour may be tolerablefor AIO writes involving sparse regions or fileextends. This compromise simplified the han-dling of the scenarios described earlier. AIO-DIO file extends now wait for I/O to completeand update the file size. AIO-DIO writes span-ning allocated and sparse regions now wait forpreviously- issued DIO for that request to com-plete before falling back to buffered I/O.
5 Concurrent I/O with synchro-nized write guarantees
An application opts for synchronized writes(by using theO_SYNCoption on file open)when the I/O must be committed to disk be-fore the write request completes. In the caseof DIO, writes directly go to disk anyway. Forbuffered I/O, data is first copied into the pagecache and later written out to disk; if synchro-nized I/O is specified then the request returnsonly after the writeout is complete.
An application might also choose to synchro-
nize previously-issued writes to disk by invok-ing fsync(), which writes back data from thepage cache to disk and waits for writeout tocomplete before returning.
5.1 Concurrent DIO writes
DIO writes formerly held the inode semaphorein exclusive mode until write completion. Thishelped ensure atomicity of DIO writes andprotected against potential file data corruptionraces with truncate. However, it also meant thatmultiple threads or processes submitting par-allel DIOs to different parts of the same fileeffectively became serialized synchronously.If the same behaviour were extended to AIO(i.e., having thei_sem held through I/O com-pletion for AIO-DIO writes), it would signif-icantly degrade throughput of streaming AIOwrites as subsequent write submissions wouldblock until completion of the previous request.
With the fixes described in the previous sec-tion, such synchronous serialization is avoid-able without loss of correctness, as the inodesemaphore needs to be held only when lookingup the blocks to write, and not while actual I/Ois in progress on the data blocks. This could al-low concurrent DIO writes on different parts ofa file to proceed simultaneously, and efficientthroughputs for streaming AIO-DIO writes.
5.2 Concurrent O_SYNCbuffered writes
In the original writeback design in the LinuxVFS, per-address space lists were maintainedfor dirty pages and pages under writeback fora given file. Synchronized write was imple-mented by traversing these lists to issue write-outs for the dirty pages and waiting for write-back to complete on the pages on the writebacklist. The inode semaphore had to be held allthrough to avoid possibilities of livelocking onthese lists as further writes streamed into thesame file. While this helped maintain atomicity

Linux Symposium 2004 • Volume One • 69
of writes, it meant that parallelO_SYNCwritesto different parts of the file were effectivelyserialized synchronously. Further, dependenceon i_sem -protected state in the address spacelists across I/O waits made it difficult to retry-enable this code path for AIO support.
In order to allow concurrentO_SYNCwrites tobe active on a file, the range of pages to bewritten back and waited on could instead beobtained directly through a radix-tree lookupfor the range of offsets in the file that was be-ing written out by the request [4]. This wouldavoid traversal of the page lists and hence theneed to holdi_sem across the I/O waits. Suchan approach would also make it possible tocompleteO_SYNCwrites as a sequence of non-blocking retry iterations across the range ofbytes in a given request.
5.3 Data-integrity guarantees
Background writeout threads cannot block onthe inode semaphore like O_SYNC/fsync writ-ers. Hence, with the per-address space listswriteback model, some juggling involvingmovement across multiple lists was requiredto avoid livelocks. The implementation hadto make sure that pages which by chance gotpicked up for processing by background write-outs didn’t slip from consideration when wait-ing for writeback to complete for a synchro-nized write request. The latter would be partic-ularly relevant for ensuring synchronized-writeguarantees that impacted data integrity for ap-plications. However, as Daniel McNeil’s anal-ysis would indicate [5], getting this right re-quired the writeback code to write and waitupon I/O and dirty pages which were initiatedby other processes, and that turned out to befairly tricky.
One solution that was explored was per-address space serialization of writeback to en-sure exclusivity to synchronous writers and
shared mode for background writers. It in-volved navigating issues with busy-waits inbackground writers and the code was begin-ning to get complicated and potentially fragile.
This was one of the problems that finallyprompted Andrew Morton to change the entireVFS writeback code to use radix-tree walks in-stead of the per-address space pagelists. Themain advantage was that avoiding the needfor movement across lists during state changes(e.g., when re-dirtying a page if its buffers werelocked for I/O by another process) reduced thechances of pages getting missed from consid-eration without the added serialization of entirewritebacks.
6 Tagged radix-tree based write-back
For the radix-tree walk writeback design to per-form as well as the address space lists-basedapproach, an efficient way to get to the pagesof interest in the radix trees is required. Thisis especially so when there are many pages inthe pagecache but only a few are dirty or underwriteback. Andrew Morton solved this prob-lem by implementing tagged radix-tree lookupsupport to enable lookup of dirty or writebackpages in O(log64(n)) time [6].
This was achieved by adding tag bits for eachslot to each radix-tree node. If a node istagged, then the corresponding slots on all thenodes above it in the tree are tagged. Thus,to search for a particular tag, one would keepgoing down sub-trees under slots which havethe tag bit set until the tagged leaf nodes areaccessed. A tagged gang lookup function isused for in-order searches for dirty or write-back pages within a specified range. Theselookups are used to replace the per-address-space page lists altogether.

70 • Linux Symposium 2004 • Volume One
To synchronize writes to disk, a tagged radix-tree gang lookup of dirty pages in the byte-range corresponding to the write request is per-formed and the resulting pages are written out.Next, pages under writeback in the byte-rangeare obtained through a tagged radix-tree ganglookup of writeback pages, and we wait forwriteback to complete on these pages (withouthaving to hold the inode semaphore across thewaits). Observe how this logic lends itself to bebroken up into a series of non-blocking retry it-erations proceeding in-order through the range.
The same logic can also be used for a wholefile sync, by specifying a byte-range that spansthe entire file.
Background writers also use tagged radix-treegang lookups of dirty pages. Instead of alwaysscanning a file from its first dirty page, the in-dex where the last batch of writeout terminatedis tracked so the next batch of writeouts can bestarted after that point.
7 Streaming AIO writes
The tagged radix-tree walk writeback approachgreatly simplifies the design of AIO support forsynchronized writes, as mentioned in the previ-ous section,
7.1 Basic retry pattern for synchronized AIOwrites
The retry-based design for buffered AIOO_SYNCwrites works by converting each block-ing wait for writeback completion of a pageinto a retry exit. The conversion point queuesan asynchronous notification callback and re-turns to the caller of the filesystem’s AIOwrite operation the number of bytes for whichwriteback has completed so far without block-ing. Then, when writeback completes for thatpage, the callback kicks off a retry continuationin task context which invokes the same AIO
write operation again using the caller’s addressspace, but this time with arguments modified toreflect the remaining part of the write request.
As writeouts for the range would have alreadybeen issued the first time before the loop towait for writeback completion, the implemen-tation takes care not to re-dirty pages or re-issue writeouts during subsequent retries ofAIO write. Instead, when the code detects thatit is being called in a retry context, it simplyfalls through directly to the step involving wait-on-writeback for the remaining range as speci-fied by the modified arguments.
7.2 Filtered waitqueues to avoid retry stormswith hashed wait queues
Code that is in a retry-exit path (i.e., the returnpath following a blocking point where a retry isqueued) should in general take care not to callroutines that could wakeup the newly-queuedretry.
One thing that we had to watch for was callsto unlock_page() in the retry-exit path.This could cause a redundant wakeup if anasync wait-on-page writeback was just queuedfor that page. The redundant wakeup wouldarise if the kernel used the same waitqueueon unlock as well as writeback completion fora page, with the expectation that the waiterwould check for the condition it was waitingfor and go back to sleep if it hadn’t occurred. Inthe AIO case, however, a wakeup of the newly-queued callback in the same code path couldpotentially trigger a retry storm, as retries kepttriggering themselves over and over again forthe wrong condition.
The interplay of unlock_page() andwait_on_page_writeback() withhashed waitqueues can get quite tricky forretries. For example, consider what happenswhen the following sequence in retryable codeis executed at the same time for 2 pages,px

Linux Symposium 2004 • Volume One • 71
and py, which happen to hash to the samewaitqueue (Table 1).
lock_page(p)check condition and processunlock_page(p)if (wait_on_page_writeback_wq(p)
== -EIOCBQUEUED)return bytes_done
The above code could keep cycling betweenspurious retries onpx andpy until I/O is done,wasting precious CPU time!
If we can ensure specificity of the wakeup withhashed waitqueues then this problem can beavoided. William Lee Irwin’s implementationof filtered wakeup support in the recent Linux2.6 kernels [7] achieves just that. The wakeuproutine specifies a key to match before invok-ing the wakeup function for an entry in thewaitqueue, thereby limiting wakeups to thoseentries which have a matching key. For pagewaitqueues, the key is computed as a functionof the page and the condition (unlock or write-back completion) for the wakeup.
7.3 Streaming AIO write microbenchmarkcomparisons
The following graph compares aio-stressthroughputs for streaming random bufferedI/O O_SYNCwrites, with and without thepreviously-described changes. The compari-son was performed on the same setup used forthe streaming AIO read results discussed ear-lier. The graph summarizes how the results var-ied across individual request sizes of 4KB to64KB, where I/O was targeted to a single fileof size 1GB and the depth of iocbs outstand-ing at a time was 64KB. A third run was per-formed to determine how the results comparedwith equivalent runs using AIO-DIO.
With the changes applied, the results showedan approximate 2x improvement across all
0
2
4
6
8
10
12
14
16
18
0 10 20 30 40 50 60 70
aio-
stre
ss th
roug
hput
(MB
/s)
request size (KB)
Streaming AIO O_SYNC write results with aio-stress
FSAIO 2.6.2 VanillaFSAIO 2.6.2 PatchedAIO-DIO 2.6.2 Vanilla
Figure 2: Comparisons of streaming randomAIO write throughputs.
block sizes, bringing throughputs to levels thatmatch the corresponding results using AIO-DIO.
8 AIO performance analysis fordatabase workloads
Large database systems leveraging AIO canshow marked performance improvements com-pared to those systems that use synchronousI/O alone. We use IBM® DB2® UniversalDatabase™ V8 running an online transactionprocessing (OLTP) workload to illustrate theperformance improvement of AIO on raw de-vices and on filesystems.
8.1 DB2 page cleaners
A DB2 page cleaner is a process responsiblefor flushing dirty buffer pool pages to disk.It simulates AIO by executing asynchronouslywith respect to the agent processes. The num-ber of page cleaners and their behavior can betuned according to the demands of the system.The agents, freed from cleaning pages them-selves, can dedicate their resources (e.g., pro-cessor cycles) towards processing transactions,thereby improving throughput.

72 • Linux Symposium 2004 • Volume One
CPU1 CPU2lock_page(px)...unlock_page(px)
lock_page(py)wait_on_page_writeback_wq(px) ...
unlock_page(py) -> wakes up p1triggering
<----------------------------------- a retrylock_page(px) wait_on_page_writeback_wq(py)...unlock_page(py) ---- wakes up py --- causes retry ---->
Table 1: Retry storm livelock with redundant wakeups on hashed wait queues
8.2 AIO performance analysis for raw devices
Two experiments were conducted to measurethe performance benefits of AIO on raw de-vices for an update-intensive OLTP databaseworkload. The workload used was derivedfrom a TPC[8] benchmark, but is in no waycomparable to any TPC results. For the first ex-periment, the database was configured with onepage cleaner using the native Linux AIO inter-face. For the second experiment, the databasewas configured with 55 page cleaners all usingthe synchronous I/O interface. These experi-ments showed that a database, properly con-figured in terms of the number of page clean-ers with AIO, can out-perform a properly con-figured database using synchronous I/O pagecleaning.
For both experiments, the system configurationconsisted of DB2 V8 running on a 2-way AMDOpteron system with Linux 2.6.1 installed. Thedisk subsystem consisted of two FAStT 700storage servers, each with eight disk enclo-sures. The disks were configured as RAID-0arrays with a stripe size of 256KB.
Table 2 shows the relative database perfor-mance with and without AIO. Higher numbersare better. The results show that the databaseperformed 9% better when configured with one
page cleaner using AIO, than when it wasconfigured with 55 page cleaners using syn-chronous I/O.
Configuration RelativeThroughput
1 page cleaner with AIO 13355 page cleaners without AIO 122
Table 2: Database performance with and with-out AIO.
Analyzing the I/O write patterns (see Table 3),we see that one page cleaner using AIO wassufficient to keep the buffer pools clean un-der a very heavy load, but that 55 page clean-ers using synchronous I/O were not, as in-dicated by the 30% agent writes. This datasuggests that more page cleaners should havebeen configured to improve the performance ofthe case with synchronous I/O. However, ad-ditional page cleaners consumed more mem-ory, requiring a reduction in bufferpool sizeand thereby decreasing throughput. For thetest configuration, 55 cleaners was the optimalnumber before memory constraints arose.
8.3 AIO performance analysis for filesystems
This section examines the performance im-provements of AIO when used in conjunctionwith filesystems. This experiment was per-

Linux Symposium 2004 • Volume One • 73
Configuration Page cleaner Agentwrites (%) writes (%)
1 page cleaner withAIO
100 0
55 page cleaners with-out AIO
70 30
Table 3: DB2 write patterns for raw deviceconfigurations.
formed using the same OLTP benchmark as inthe previous section.
The test system consisted of two 1GHz AMDOpteron processors, 4GB of RAM and twoQLogic 2310 FC controllers. Attached to theserver was a single FAStT900 storage serverand two disk enclosures with a total of 28 15KRPM 18GB drives. The Linux kernel usedfor the examination was 2.6.0+mm1, which in-cludes the AIO filesystem support patches [9]discussed in this paper.
The database tables were spread across multi-ple ext2 filesystem partitions. Database logswere stored on a single raw partition.
Three separate tests were performed, utilizingdifferent I/O methods for the database pagecleaners.
Test 1. Synchronous (Buffered) I/O.
Test 2. Asynchronous (Buffered) I/O.
Test 3. Direct I/O.
The results are shown in Table 4 as rela-tive commercial processing scores using syn-chronous I/O as the baseline (i.e., higher is bet-ter).
Looking at the efficiency of the page clean-ers (see Table 5), we see that the use of AIOis more successful in keeping the buffer poolsclean. In the synchronous I/O and DIO cases,the agents needed to spend more time cleaning
Configuration Commercial ProcessingScores
Synchronous I/O 100AIO (Buffered) 113.7DIO 111.9
Table 4: Database performance on filesystemswith and without AIO.
buffer pool pages, resulting in less time pro-cessing transactions.
Configuration Page cleaner Agentwrites (%) writes (%)
Synchronous I/O 37 63AIO (buffered) 100 0DIO 49 51
Table 5: DB2 write patterns for filesystem con-figurations.
8.4 Optimizing AIO for database workloads
Databases typically use AIO for streamingbatches of random, synchronized write re-quests to disk (where the writes are directedto preallocated disk blocks). This has beenfound to improve the performance of OLTPworkloads, as it helps bring down the num-ber of dedicated threads or processes neededfor flushing updated pages, and results in re-duced memory footprint and better CPU uti-lization and scaling.
The size of individual write requests is deter-mined by the page size used by the database.For example, a DB2 UDB installation mightuse a database page size of 8KB.
As observed in previous sections, the use ofAIO helps reduce the number of database pagecleaner processes required to keep the buffer-pool clean. To keep the disk queues maximallyutilized and limit contention, it may be prefer-able to have requests to a given disk streamedout from a single page cleaner. Typically aset of of disks could be serviced by each page

74 • Linux Symposium 2004 • Volume One
cleaner if and when multiple page cleanersneed to be used.
Databases might also use AIO for reads, for ex-ample, for prefetching data to service queries.This usually helps improve the performance ofdecision support workloads. The I/O patterngenerated in these cases is that of streamingbatches of large AIO reads, with sizes typicallydetermined by the file allocation extent sizeused by the database (e.g., a DB2 installationmight use a database extent size of 256KB).For installations using buffered AIO reads, tun-ing the readahead setting for the correspondingdevices to be more than the extent size wouldhelp improve performance of streaming AIOreads (recall the discussion in Section 3.5).
9 Addressing AIO workloads in-volving both disk and communi-cations I/O
Certain applications need to handle both disk-based AIO and communications I/O. For com-munications I/O, the epoll interface—whichprovides support for efficient scalable eventpolling in Linux 2.6—could be used as ap-propriate, possibly in conjunction withO_NONBLOCKsocket I/O. Disk-based AIO onthe other hand, uses the native AIO APIio_getevents for completion notification. Thismakes it difficult to combine both types of I/Oprocessing within a single event loop, evenwhen such a model is a natural way to programthe application, as in implementations of theapplication on other operating systems.
How do we address this issue? One option is toextend epoll to enable it to poll for notificationof AIO completion events, so that AIO comple-tion status can then be reaped in a non-blockingmanner. This involves mixing both epoll andAIO API programming models, which is notideal.
9.1 AIO poll interface
Another alternative is to add support forpolling an event on a given file descriptorthrough the AIO interfaces. This function, re-ferred to as AIO poll, can be issued throughio_submit() just like other AIO opera-tions, and specifies the file descriptor andthe eventset to wait for. When the eventoccurs, notification is reported throughio_getevents() .
The retry-based design of AIO poll works byconverting the blocking wait for the event intoa retry exit.
The generic synchronous polling code fitsnicely into the AIO retry design, so most of theoriginal polling code can be used unchanged.The private data area of the iocb can be usedto hold polling-specific data structures, and afew special cases can be added to the genericpolling entry points. This allows the AIO pollcase to proceed without additional memory al-locations.
9.2 AIO operations for communications I/O
A third option is to add support for AIO op-erations for communications I/O. For exam-ple, AIO support for pipes has been imple-mented by converting the blocking wait forI/O on pipes to aretry exit. The generic pipecode was also structured such that conversionto AIO retries was quite simple, the only signif-icant change was using the currentio_waitcontext instead of a locally defined waitqueue,and returning early if no data was available.
However, AIO pipe testing did show signifi-cantly more context switches then the 2.4 AIOpipe implementation, and this was coupledwith much lower performance. The AIO corefunctions were relying on workqueues to domost of the retries, and this resulted in constant

Linux Symposium 2004 • Volume One • 75
switching between the workqueue threads anduser processes.
The solution was to change the AIO coreto do retries inio_submit() and in io_getevents() . This allowed the process todo some of its own work while it is scheduledin. Also, retries were switched to a delayedworkqueue, so that bursts of retries would trig-ger fewer context switches.
While delayed wakeups helped with pipeworkloads, it also caused I/O stalls in filesys-tem AIO workloads. This was because a de-layed wakeup was being used even when a userprocess was waiting inio_getevents() .When user processes are actively waiting forevents, it proved best to trigger the workerthread immediately.
General AIO support for network operationshas been considered but not implemented so farbecause of lack of supporting study that pre-dicts a significant benefit over what epoll andnon-blocking I/O can provide, except for thescope for enabling potential zero-copy imple-mentations. This is a potential area for futureresearch.
10 Conclusions
Our experience over the last year with AIO de-velopment, stabilization and performance im-provements brought us to design and imple-mentation issues that went far beyond the ini-tial concern of converting key I/O blockingpoints to be asynchronous.
AIO uncovered scenarios and I/O patterns thatwere unlikely or less significant with syn-chronous I/O alone. For example, the issues wediscussed around streaming AIO performancewith readahead and concurrent synchronizedwrites, as well as DIO vs buffered I/O com-plexities in the presence of AIO. In retrospect,
this was the hardest part of supporting AIO—modifiying code that was originally designedonly for synchronous I/O.
Interestingly, this also meant that AIO ap-peared to magnify some problems early. Forexample, issues with hashed waitqueues thatled to the filtered wakeup patches, and reada-head window collapses with large randomreads which precipitated improvements to thereadahead code from Ramachandra Pai. Ul-timately, many of the core improvements thathelped AIO have had positive benefits in al-lowing improved concurrency for some of thesynchronous I/O paths.
In terms of benchmarking and optimizingLinux AIO performance, there is room formore exhaustive work. Requirements for AIOfsync support are currently under considera-tion. There is also a need for more widely usedAIO applications, especially those that take ad-vantaged of AIO support for buffered I/O orbring out additional requirements like networkI/O beyond epoll or AIO poll. Finally, investi-gations into API changes to help enable moreefficient POSIX AIO implementations basedon kernel AIO support may be a worthwhileendeavor.
11 Acknowledgements
We would like to thank the many peopleon the [email protected] [email protected] lists who provided us with valu-able comments and suggestions during ourdevelopment efforts.
We would especially like to acknowledge theimportant contributions of Andrew Morton,Daniel McNeil, Badari Pulavarty, StephenTweedie, and William Lee Irwin towards sev-eral pieces of work discussed in this paper.

76 • Linux Symposium 2004 • Volume One
This paper and the work it describes wouldn’thave been possible without the efforts of JanetMorgan in many different ways, starting fromreview, test and debugging feedback to joiningthe midnight oil camp to help with modifica-tions and improvements to the text during thefinal stages of the paper.
We also thank Brian Twitchell, Steve Pratt,Gerrit Huizenga, Wayne Young, and JohnLumby from IBM for their help and discus-sions along the way.
This work was a part of the Linux Scalabil-ity Effort (LSE) on SourceForge, and furtherinformation about Linux 2.6 AIO is availableat the LSE AIO web page [10]. All the ex-ternal AIO patches including AIO support forbuffered filesystem I/O, AIO poll and AIO sup-port for pipes are available at [9].
12 Legal Statement
This work represents the view of the authors anddoes not necessarily represent the view of IBM.
IBM, DB2 and DB2 Universal Database are reg-istered trademarks of International Business Ma-chines Corporation in the United States and/or othercountries.
Linux is a registered trademark of Linus Torvalds.
Pentium is a trademark of Intel Corporation in theUnited States, other countries, or both.
Other company, product, and service names may betrademarks or service marks of others.
13 Disclaimer
The benchmarks discussed in this paper were con-ducted for research purposes only, under laboratoryconditions. Results will not be realized in all com-puting environments.
References
[1] Suparna Bhattacharya, BadariPulavarthy, Steven Pratt, and JanetMorgan. Asynchronous i/o support forlinux 2.5. InProceedings of the LinuxSymposium. Linux Symposium, Ottawa,July 2003.http://archive.
linuxsymposium.org/ols2003/
Proceedings/All-Reprints/
Reprint-Pulavarty-OLS2003.pdf .
[2] Chris Mason. aio-stressmicrobenchmark.ftp://ftp.suse.com/pub/people/
mason/utils/aio-stress.c .
[3] Stephen C. Tweedie. Posting on dio racesin 2.4.http://marc.theaimsgroup.
com/?l=linux-fsdevel&m=
105597840711609&w=2 .
[4] Andrew Morton. O_sync speedup patch.http:
//www.kernel.org/pub/linux/
kernel/people/akpm/patches/2.
6/2.6.0/2.6.0-mm1/broken-out/
O_SYNC-speedup-2.patch .
[5] Daniel McNeil. Posting on synchronizedwriteback races.http://marc.theaimsgroup.com/
?l=linux-aio&m=
107671729611002&w=2 .
[6] Andrew Morton. Posting on in-ordertagged radix tree walk based vfswriteback.http://marc.theaimsgroup.com/
?l=bk-commits-head&m=
108184544016117&w=2 .
[7] William Lee Irwin. Filtered wakeuppatch.http://marc.theaimsgroup.
com/?l=bk-commits-head&m=
108459430513660&w=2 .

Linux Symposium 2004 • Volume One • 77
[8] Transaction processing performancecouncil.http://www.tpc.org .
[9] Suparna Bhattacharya (withcontributions from Andrew Morton &Chris Mason). Additional 2.6 LinuxKernel Asynchronous I/O patches.http:
//www.kernel.org/pub/linux/
kernel/people/suparna/aio .
[10] LSE team. Kernel Asynchronous I/O(AIO) Support for Linux.http://lse.sf.net/io/aio.html .

78 • Linux Symposium 2004 • Volume One

Methods to Improve Bootup Time in Linux
Tim R. BirdSony Electronics
Abstract
This paper presents several techniques for re-ducing the bootup time of the Linux kernel, in-cluding Execute-In-Place (XIP), avoidance ofcalibrate_delay() , and reduced prob-ing by certain drivers and subsystems. Usinga variety of techniques, the Linux kernel canbe booted on embedded hardware in under 500milliseconds. Current efforts and future direc-tions of work to improve bootup time are de-scribed.
1 Introduction
Users of consumer electronics products expecttheir devices to be available for use very soonafter being turned on. Configurations of Linuxfor desktop and server markets exhibit boottimes in the range of 20 seconds to a few min-utes, which is unacceptable for many consumerproducts.
No single item is responsible for overall poorboot time performance. Therefore a numberof techniques must be employed to reduce theboot up time of a Linux system. This paperpresents several techniques which have beenfound to be useful for embedded configurationsof Linux.
2 Overview of Boot Process
The entire boot process of Linux can beroughly divided into 3 main areas: firmware,kernel, and user space. The following is a listof events during a typical boot sequence:
1. power on
2. firmware (bootloader) starts
3. kernel decompression starts
4. kernel start
5. user space start
6. RC script start
7. application start
8. first available use
This paper focuses on techniques for reducingthe bootup time up until the start of user space.That is, techniques are described which reducethe firmware time, and the kernel start time.This includes activities through the completionof event 4 in the list above.
The actual kernel execution begins withthe routinestart_kernel() , in the fileinit/main.c .
An overview of major steps in the initializationsequence of the kernel is as follows:

80 • Linux Symposium 2004 • Volume One
• start_kernel()
– init architecture
– init interrupts
– init memory
– start idle thread
– call rest_init()
* start ‘init’ kernel thread
The init kernel thread performs a fewother tasks, then callsdo_basic_setup() ,which calls do_initcalls() , to runthrough the array of initialization routines fordrivers statically linked in the kernel. Finally,this thread switches to user space byexecve -ing to the first user space program, usually/sbin/init .
• init (kernel thread)
– call do_basic_setup()
* call do_initcalls()
· init buses and drivers
– prepare and mount root filesystem
– call run_init_process()
* call execve() to start userspace process
3 Typical Desktop Boot Time
The boot times for a typical desktop systemwere measured and the results are presentedbelow, to give an indication of the major areasin the kernel where time is spent. While thenumbers in these tests differ somewhat fromthose for a typical embedded system, it is use-ful to see these to get an idea of where some ofthe trouble spots are for kernel booting.
3.1 System
An HP XW4100 Linux workstation systemwas used for these tests, with the followingcharacteristics:
• Pentium 4 HT processor, running at 3GHz
• 512 MB RAM
• Western Digital 40G hard drive on hda
• Generic CDROM drive on hdc
3.2 Measurement method
The kernel used was 2.6.6, with the KFI patchapplied. KFI stands for “Kernel Function In-strumentation”. This is an in-kernel systemto measure the duration of each function ex-ecuted during a particular profiling run. Ituses the-finstrument-functions op-tion of gcc to instrument kernel functionswith callouts on each function entry and exit.This code was authored by developers at Mon-taVista Software, and a patch for 2.6.6 is avail-able, although the code is not ready (as of thetime of this writing) for general publication.Information about KFI and the patch are avail-able at:
http://tree.celinuxforum.org/pubwiki
/moin.cgi
/KernelFunctionInstrumentation
3.3 Key delays
The average time for kernel startup of the testsystem was about 7 seconds. This was theamount of time for just the kernel and NOT thefirmware or user space. It corresponds to theperiod of time between events 4 and 5 in theboot sequence listed in Section 2.

Linux Symposium 2004 • Volume One • 81
Some key delays were found in the kernelstartup on the test system. Table 1 showssome of the key routines where time was spentduring bootup. These are the low-level rou-tines where significant time was spent insidethe functions themselves, rather than in sub-routines called by the functions.
Kernel Function No. of Avg. call Totalcalls time time
delay_tsc 5153 1 5537default_idle 312 1 325get_cmos_time 1 500 500psmouse_sendbyte 44 2.4 109pci_bios_find_device 25 1.7 44atkbd_sendbyte 7 3.7 26calibrate_delay 1 24 24
Note: Times are in milliseconds.
Table 1: Functions consuming lots of time dur-ing a typical desktop Linux kernel startup.
Note that over 80% of the total time of thebootup (almost 6 seconds out of 7) was spentbusywaiting indelay_tsc() or spinning inthe routinedefault_idle() . It appearsthat great reductions in total bootup time couldbe achieved if these delays could be reduced,or if it were possible to run some initializationtasks concurrently.
Another interesting point is that the routineget_cmos_time() was extremely variablein the length of time it took. Measurementsof its duration ranged from under 100 millisec-onds to almost one second. This routine, andmethods to avoid this delay and variability, arediscussed in section 9.
3.4 High-level delay areas
Since delay_tsc() is used (via variousdelay mechanisms) for busywaiting by anumber of different subsystems, it is helpful toidentify the higher-level routines which end upinvoking this function.
Table 2 shows some high-level routines calledduring kernel initialization, and the amount oftime they took to complete on the test ma-chine. Duration times marked with a tilde de-note functions which were highly variable induration.
Kernel Function Duration time
ide_init 3327time_init ~500isapnp_init 383i8042_init 139prepare_namespace ~50calibrate_delay 24
Note: Times are in milliseconds.
Table 2: High-level delays during a typicalstartup.
For a few of these, it is interesting to examinethe call sequences underneath the high-levelroutines. This shows the connection betweenthe high-level routines that are taking a longtime to complete and the functions where thetime is actually being spent.
Figures 1 and 2 show some call sequences forhigh-level calls which take a long time to com-plete.
In each call tree, the number in parentheses isthe number of times that the routine was calledby the parent in this chain. Indentation showsthe call nesting level.
For example, in Figure 1,do_probe() iscalled a total of 31 times byprobe_hwif() ,and it callside_delay_50ms() 78 times,andtry_to_identify() 8 times.
The timing data for the test system showedthat IDE initialization was a significant con-tributor to overall bootup time. The call se-quence underneathide_init() shows thata large number of calls are made to the routineide_delay_50ms() , which in turn calls

82 • Linux Symposium 2004 • Volume One
ide_init->probe_for_hwifs(1)->
ide_scan_pcibus(1)->ide_scan_pci_dev(2)->
piix_init_one(2)->init_setup_piix(2)->
ide_setup_pci_device(2)->probe_hwif_init(2)->
probe_hwif(4)->do_probe(31)->
ide_delay_50ms(78)->__const_udelay(3900)->
__delay(3900)->delay_tsc(3900)
try_to_identify(8)->actual_try_to_identify(8)->
ide_delay_50ms(24)->__const_udelay(1200)->
__delay(1200)->delay_tsc(1200)
Figure 1: IDE init call tree
isapnp_init->isapnp_isolate(1)->
isapnp_isolate_rdp_select(1)->__const_udelay(25)->
__delay(25)->delay_tsc(25)
isapnp_key(18)->__const_udelay(18)->
__delay(18)->delay_tsc(18)
Figure 2: ISAPnP init call tree
__const_udelay() very many times. Thebusywaits inide_delay_50ms() alone ac-counted for over 5 seconds, or about 70% ofthe total boot up time.
Another significant area of delay was the ini-tialization of the ISAPnP system. This tookabout 380 milliseconds on the test machine.
Both the mouse and the keyboard drivers usedcrude busywaits to wait for acknowledgementsfrom their respective hardware.
Finally, the routinecalibrate_delay()took about 25 milliseconds to run, to computethe value ofloops_per_jiffy and print(the related)BogoMips for the machine.
The remaining sections of this paper discussvarious specific methods for reducing bootuptime for embedded and desktop systems. Someof these methods are directly related to some ofthe delay areas identified in this test configura-tion.
4 Kernel Execute-In-Place
A typical sequence of events during bootup isfor the bootloader to load a compressed kernelimage from either disk or Flash, placing it intoRAM. The kernel is decompressed, either dur-ing or just after the copy operation. Then thekernel is executed by jumping to the functionstart_kernel() .
Kernel Execute-In-Place (XIP) is a mechanismwhere the kernel instructions are executed di-rectly from ROM or Flash.
In a kernel XIP configuration, the step of copy-ing the kernel code segment into RAM is omit-ted, as well as any decompression step. In-stead, the kernel image is stored uncompressedin ROM or Flash. The kernel data segmentsstill need to be initialized in RAM, but by elim-inating the text segment copy and decompres-sion, the overall effect is a reduction in the timerequired for the firmware phase of the bootup.
Table 3 shows the differences in time durationfor various parts of the boot stage for a sys-tem booted with and without use of kernel XIP.The times in the table are shown in millisec-onds. The table shows that using XIP in thisconfiguration significantly reduced the time tocopy the kernel to RAM (because only the datasegments were copied), and completely elim-inated the time to decompress the kernel (453milliseconds). However, the kernel initializa-tion time increased slightly in the XIP configu-ration, for a net savings of 463 milliseconds.
In order to support an Execute-In-Place con-

Linux Symposium 2004 • Volume One • 83
Boot Stage Non-XIP time XIP time
Copy kernel to RAM 85 12Decompress kernel 453 0Kernel initialization 819 882Total kernel boot time 1357 894
Note: Times are in milliseconds. Results are forPowerPC 405 LP at 266 MHz
Table 3: Comparison of Non-XIP vs. XIPbootup times
figuration, the kernel must be compiled andlinked so that the code is ready to be exe-cuted from a fixed memory location. Thereare examples of XIP configurations for ARM,MIPS and SH platforms in the CELinuxsource tree, available at:http://tree.celinuxforum.org/
4.1 XIP Design Tradeoffs
There are tradeoffs involved in the use of XIP.First, it is common for access times to flashmemory to be greater than access times toRAM. Thus, a kernel executing from Flashusually runs a bit slower than a kernel execut-ing from RAM. Table 4 shows some of the re-sults from running thelmbench benchmarkon system, with the kernel executing in a stan-dard non-XIP configuration versus an XIP con-figuration.
Operation Non-XIP XIP
stat() syscall 22.4 25.6fork a process 4718 7106context switching for 16processes and 64k data size
932 1109
pipe communication 248 548
Note: Times are in microseconds. Results are forlmbench benchmark run on OMAP 1510 (ARM9 at168 MHz) processor
Table 4: Comparison of Non-XIP and XIP per-formance
Some of the operations in the benchmark tooksignificantly longer with the kernel run in theXIP configuration. Most individual operationstook about 20% to 30% longer. This perfor-mance penalty is suffered permanently whilethe kernel is running, and thus is a seriousdrawback to the use of XIP for reducing bootuptime.
A second tradeoff with kernel XIP is betweenthe sizes of various types of memory in thesystem. In the XIP configuration the kernelmust be stored uncompressed, so the amountof Flash required for the kernel increases, andis usually about doubled, versus a compressedkernel image used with a non-XIP configura-tion. However, the amount of RAM requiredfor the kernel is decreased, since the kernelcode segment is never copied to RAM. There-fore, kernel XIP is also of interest for reducingthe runtime RAM footprint for Linux in em-bedded systems.
There is additional research under way to in-vestigate ways of reducing the performanceimpact of using XIP. One promising techniqueappears to be the use of “partial-XIP,” where ahighly active subset of the kernel is loaded intoRAM, but the majority of the kernel is executedin place from Flash.
5 Delay Calibration Avoidance
One time-consuming operation inside the ker-nel is the process of calibrating the value usedfor delay loops. One of the first routines inthe kernel,calibrate_delay() , executesa series of delays in order to determine the cor-rect value for a variable calledloops_per_jiffy , which is then subsequently used to ex-ecute short delays in the kernel.
The cost of performing this calibration is, in-terestingly, independent of processor speed.Rather, it is dependent on the number of iter-

84 • Linux Symposium 2004 • Volume One
ations required to perform the calibration, andthe length of each iteration. Each iteration re-quires 1 jiffy, which is the length of time de-fined by the HZ variable.
In 2.4 versions of the Linux kernel, most plat-forms defined HZ as 100, which makes thelength of a jiffy 10 milliseconds. A typicalnumber of iterations for the calibration opera-tion is 20 to 25, making the total time requiredfor this operation about 250 milliseconds.
In 2.6 versions of the Linux kernel, a few plat-forms (notably i386) have changed HZ to 1000,making the length of a jiffy 1 millisecond. Onthose platforms, the typical cost of this calibra-tion operation has decreased to about 25 mil-liseconds. Thus, the benefit of eliminating thisoperation on most standard desktop systemshas been reduced. However, for many embed-ded systems, HZ is still defined as 100, whichmakes bypassing the calibration useful.
It is easy to eliminate the calibration operation.You can directly edit the code ininit/main.
c:calibrate_delay() to hardcode a valuefor loops_per_jiffy , and avoid the cali-bration entirely. Alternatively, there is a patchavailable athttp://tree.celinuxforum.
org/pubwiki/moin.cgi/PresetLPJ
This patch allows you to use a kernel config-uration option to specify a value forloops_per_jiffy at kernel compile time. Alterna-tively, the patch also allows you to use a ker-nel command line argument to specify a presetvalue forloops_per_jiffy at kernel boottime.
6 Avoiding Probing During Bootup
Another technique for reducing bootup time isto avoid probing during bootup. As a generaltechnique, this can consist of identifying hard-ware which is known not to be present on one’s
machine, and making sure the kernel is com-piled without the drivers for that hardware.
In the specific case of IDE, the kernel sup-ports options at the command line to allow theuser to avoid performing probing for specificinterfaces and devices. To do this, you canuse the IDE and harddrivenoprobe optionsat the kernel command line. Please see thefile Documentation/ide.txt in the ker-nel source tree for details on the syntax of usingthese options.
On the test machine, IDEnoprobe optionswere used to reduce the amount of probing dur-ing startup. The test machine had only a harddrive on hda (ide0 interface, first device) anda CD-ROM drive on hdc (ide1 interface, firstdevice).
In one test,noprobe options were specifiedto suppress probing of non-used interfaces anddevices. Specifically, the following argumentswere added to the kernel command line:
hdb=none hdd=none ide2=noprobe
The kernel was booted and the result wasthat the functionide_delay_50ms() wascalled only 68 times, anddelay_tsc() wascalled only 3453 times. During a regularkernel boot without these options specified,the functionide_delay_50ms() is called102 times, anddelay_tsc() is called 5153times. Each call todelay_tsc() takesabout 1 millisecond, so the total time savingsfrom using these options was 1700 millisec-onds.
These IDEnoprobe options have been avail-able at least since the 2.4 kernel series, and arean easy way to reduce bootup time, withouteven having to recompile the kernel.

Linux Symposium 2004 • Volume One • 85
7 Reducing Probing Delays
As was noted on the test machine, IDE ini-tialization takes a significant percentage ofthe total bootup time. Almost all of thistime is spent busywaiting in the routineide_delay_50ms() .
It is trivial to modify the value of the time-out used in this routine. As an experiment,this code (located in the filedrivers/ide/ide.c ) was modified to only delay 5 millisec-onds instead of 50 milliseconds.
The results of this change were interesting.When a kernel with this change was run onthe test machine, the total time for theide_init() routine dropped from 3327 millisec-onds to 339 milliseconds. The total time spentin all invocations of ide_delay_50ms()was reduced from 5471 milliseconds to 552milliseconds. The overall bootup time was re-duced accordingly, by about 5 seconds.
The ide devices were successfully detected,and the devices operated without problem onthe test machine. However, this configurationwas not tested exhaustively.
Reducing the duration of the delay in theide_delay_50ms() routine provides a substan-tial reduction in the overall bootup time for thekernel on a typical desktop system. It also haspotential use in embedded systems where PCI-based IDE drives are used.
However, there are several issues with thismodification that need to be resolved. Thischange may not support legacy hardwarewhich requires long delays for proper probingand initializing. The kernel code needs to beanalyzed to determine if any callers of this rou-tine really need the 50 milliseconds of delaythat they are requesting. Also, it should be de-termined whether this call is used only in ini-tialization context or if it is used during regular
runtime use of IDE devices also.
Also, it may be that 5 milliseconds does notrepresent the lowest possible value for this de-lay. It is possible that this value will need tobe tuned to match the hardware for a particularmachine. This type of tuning may be accept-able in the embedded space, where the hard-ware configuration of a product may be fixed.But it may be too risky to use in desktop con-figurations of Linux, where the hardware is notknown ahead of time.
More experimentation, testing and validationare required before this technique should beused.
IMPORTANT NOTE: You should probably notexperiment with this modification on produc-tion hardware unless you have evaluated therisks.
8 Using the “quiet” Option
One non-obvious method to reduce overheadduring booting is to use thequiet option onthe kernel command line. This option changesthe loglevel to 4, which suppresses the outputof regular (non-emergency) printk messages.Even though the messages are not printed tothe system console, they are still placed in thekernel printk buffer, and can be retrieved afterbootup using thedmesg command.
When embedded systems boot with a serialconsole, the speed of printing the charactersto the console is constrained by the speed ofthe serial output. Also, depending on thedriver, some VGA console operations (such asscrolling the screen) may be performed in soft-ware. For slow processors, this may take a sig-nificant amount of time. In either case, the costof performing output of printk messages duringbootup may be high. But it is easily eliminatedusing thequiet command line option.

86 • Linux Symposium 2004 • Volume One
Table 5 shows the difference in bootup time ofusing thequiet option and not, for two dif-ferent systems (one with a serial console andone with a VGA console).
9 RTC Read Synchronization
One routine that potentially takes a long timeduring kernel startup isget_cmos_time() .This routine is used to read the value of the ex-ternal real-time clock (RTC) when the kernelboots. Currently, this routine delays until theedge of the next second rollover, in order to en-sure that the time value in the kernel is accuratewith respect to the RTC.
However, this operation can take up to one fullsecond to complete, and thus introduces up to1 second of variability in the total bootup time.For systems where the target bootup time is un-der 1 second, this variability is unacceptable.
The synchronization in this routine is easyto remove. It can be eliminated by re-moving the first two loops in the functionget_cmos_time() , which is located ininclude/asm-i386/mach-default/
mach_time.h for the i386 architecture. Sim-ilar routines are present in the kernel sourcetree for other architectures.
When the synchronization is removed, the rou-tine completes very quickly.
One tradeoff in making this modification is thatthe time stored by the Linux kernel is no longercompletely synchronized (to the boundary of asecond) with the time in the machine’s realtimeclock hardware. Some systems save the systemtime back out to the hardware clock on systemshutdown. After numerous bootups and shut-downs, this lack of synchronization will causethe realtime clock value to drift from the cor-rect time value.
Since the amount of un-synchronization is upto a second per boot cycle, this drift can besignificant. However, for some embedded ap-plications, this drift is unimportant. Also, insome situations the system time may be syn-chronized with an external source anyway, sothe drift, if any, is corrected under normal cir-cumstances soon after booting.
10 User space Work
There are a number of techniques currentlyavailable or under development for user spacebootup time reductions. These techniques are(mostly) outside the scope of kernel develop-ment, but may provide additional benefits forreducing overall bootup time for Linux sys-tems.
Some of these techniques are mentioned brieflyin this section.
10.1 Application XIP
One technique for improving applicationstartup speed is application XIP, which is sim-ilar to the kernel XIP discussed in this paper.To support application XIP the kernel must becompiled with a file system where files can bestored linearly (where the blocks for a file arestored contiguously) and uncompressed. Onefile system which supports this is CRAMFS,with the LINEAR option turned on. This is aread-only file system.
With application XIP, when a program is ex-ecuted, the kernel program loader maps thetext segments for applications directly from theflash memory of the file system. This saves thetime required to load these segments into sys-tem RAM.

Linux Symposium 2004 • Volume One • 87
Platform Speed console w/o quiet with quiet differencetype option option
SH-4 SH7751R 240 MHz VGA 637 461 176OMAP 1510 (ARM 9) 168 MHz serial 551 280 271
Note: Times are in milliseconds
Table 5: Bootup time with and without thequiet option
10.2 RC Script improvements
Also, there are a number of projects whichstrive to decrease total bootup time of a systemby parallelizing the execution of the systemrun-command scripts (“RC scripts”). There isa list of resources for some of these projects atthe following web site:
http://tree.celinuxforum.org/pubwiki/moin.cgi/
BootupTimeWorkingGroup
Also, there has been some research conductedin reducing the overhead of running RC scripts.This consists of modifying the multi-functionprogrambusybox to reduce the number andcost of forks during RC script processing, andto optimize the usage of functions builtin to thebusybox program. Initial testing has shown areduction from about 8 seconds to 5 secondsfor a particular set of Debian RC scripts on anOMAP 1510 (ARM 9) processor, running at168 MHz.
11 Results
By use of the some of the techniques men-tioned in this paper, as well as additional tech-niques, Sony was able to boot a 2.4.20-basedLinux system, from power on to user space dis-play of a greeting image and sound playback,in 1.2 seconds. The time from power on to theend of kernel initialization (first user space in-struction) in this configuration was about 110
milliseconds. The processor was a TI OMAP1510 processor, with an ARM9-based core,running at 168 MHz.
Some of the techniques used for reducing thebootup time of embedded systems can also beused for desktop or server systems. Often, itis possible, with rather simple and small mod-ifications, to decrease the bootup time of theLinux kernel to only a few seconds. In thedesktop configuration of Linux presented here,techniques from this paper were used to re-duced the total bootup time from around 7 sec-onds to around 1 second. This was with noloss of functionality that the author could de-tect (with limited testing).
12 Further Research
As stated in the beginning of the paper, numer-ous techniques can be employed to reduce theoverall bootup time of Linux systems. Furtherwork continues or is needed in a number of ar-eas.
12.1 Concurrent Driver Init
One area of additional research that seemspromising is to structure driver initializationsin the kernel so that they can proceed in par-allel. For some items, like IDE initialization,there are large delays as buses and devices areprobed and initialized. The time spent in suchbusywaits could potentially be used to performother startup tasks, concurrently with the ini-

88 • Linux Symposium 2004 • Volume One
tializations waiting for hardware events to oc-cur or time out.
The big problem to be addressed with con-current initialization is to identify what ker-nel startup activities can be allowed to occurin parallel. The kernel init sequence is alreadya carefully ordered sequence of events to makesure that critical startup dependencies are ob-served. Any system of concurrent driver ini-tialization will have to provide a mechanismto guarantee sequencing of initialization taskswhich have order dependencies.
12.2 Partial XIP
Another possible area of further investiga-tion, which has already been mentioned, is“partial XIP,” whereby the kernel is executedmostlyin-place. Prototype code already existswhich demonstrates the mechanisms necessaryto move a subset of an XIP-configured kernelinto RAM, for faster code execution. The keyto making partial kernel XIP useful will be toensure correct identification (either statically ordynamically) of the sections of kernel code thatneed to be moved to RAM. Also, experimenta-tion and testing need to be performed to deter-mine the appropriate tradeoff between the sizeof the RAM-based portion of the kernel, andthe effect on bootup time and system runtimeperformance.
12.3 Pre-linking and Lazy Linking
Finally, research is needed into reducing thetime required to fixup links between programsand their shared libraries.
Two systems that have been proposed and ex-perimented with are pre-linking and lazy link-ing. Pre-linking involves fixing the location invirtual memory of the shared libraries for a sys-tem, and performing fixups on the programs ofthe system ahead of time. Lazy linking consists
of only performing fixups on demand as libraryroutines are called by a running program.
Additional research is needed with both ofthese techniques to determine if they can pro-vide benefit for current Linux systems.
13 Credits
This paper is the result of work performed bythe Bootup Time Working Group of the CELinux forum (of which the author is Chair).I would like to thank developers at some ofCELF’s member companies, including Hitachi,Intel, Mitsubishi, MontaVista, Panasonic, andSony, who contributed information or codeused in writing this paper.

Linux on NUMA Systems
Martin J. [email protected]
Matt [email protected]
Darren [email protected]
Gerrit [email protected]
Abstract
NUMA is becoming more widespread in themarketplace, used on many systems, small orlarge, particularly with the advent of AMDOpteron systems. This paper will cover a sum-mary of the current state of NUMA, and futuredevelopments, encompassing the VM subsys-tem, scheduler, topology (CPU, memory, I/Olayouts including complex non-uniform lay-outs), userspace interface APIs, and networkand disk I/O locality. It will take a broad-basedapproach, focusing on the challenges of creat-ing subsystems that work for all machines (in-cluding AMD64, PPC64, IA-32, IA-64, etc.),rather than just one architecture.
1 What is a NUMA machine?
NUMA stands for non-uniform memory archi-tecture. Typically this means that not all mem-ory is the same “distance” from each CPU inthe system, but also applies to other featuressuch as I/O buses. The word “distance” in thiscontext is generally used to refer to both la-tency and bandwidth. Typically, NUMA ma-chines can access any resource in the system,just at different speeds.
NUMA systems are sometimes measured witha simple “NUMA factor” ratio of N:1—meaning that the latency for a cache miss mem-ory read from remote memory isN times the la-tency for that from local memory (for NUMAmachines,N > 1). Whilst such a simple de-scriptor is attractive, it can also be highly mis-leading, as it describes latency only, not band-width, on an uncontended bus (which is notparticularly relevant or interesting), and takesno account of inter-node caches.
The termnodeis normally used to describe agrouping of resources—e.g., CPUs, memory,and I/O. On some systems, a node may con-tain only some types of resources (e.g., onlymemory, or only CPUs, or only I/O); on oth-ers it may contain all of them. The intercon-nect between nodes may take many differentforms, but can be expected to be higher latencythan the connection within a node, and typi-cally lower bandwidth.
Programming for NUMA machines generallyimplies focusing onlocality—the use of re-sources close to the device in question, andtrying to reduce traffic between nodes; thistype of programming generally results in bet-ter application throughput. On some machineswith high-speed cross-node interconnects, bet-

90 • Linux Symposium 2004 • Volume One
ter performance may be derived under certainworkloads by “striping” accesses across mul-tiple nodes, rather than just using local re-sources, in order to increase bandwidth. Whilstit is easy to demonstrate a benchmark thatshows improvement via this method, it is dif-ficult to be sure that the concept is generallybenefical (i.e., with the machine under fullload).
2 Why use a NUMA architecture tobuild a machine?
The intuitive approach to building a large ma-chine, with many processors and banks ofmemory, would be simply to scale up the typ-ical 2–4 processor machine with all resourcesattached to a shared system bus. However, re-strictions of electronics and physics dictate thataccesses slow as the length of the bus grows,and the bus is shared amongst more devices.
Rather than accept this global slowdown for alarger machine, designers have chosen to in-stead give fast access to a limited set of localresources, and reserve the slower access timesfor remote resources.
Historically, NUMA architectures have onlybeen used for larger machines (more than 4CPUs), but the advantages of NUMA havebeen brought into the commodity marketplacewith the advent of AMD’s x86-64, which hasone CPU per node, and local memory for eachprocessor. Linux supports NUMA machinesof every size from 2 CPUs upwards (e.g., SGIhave machines with 512 processors).
It might help to envision the machine as agroup of standard SMP machines, connectedby a very fast interconnect somewhat like a net-work connection, except that the transfers overthat bus are transparent to the operating sys-tem. Indeed, some earlier systems were built
exactly like that; the older Sequent NUMA-Q hardware uses a standard 450NX 4 proces-sor chipset, with an SCI interconnect pluggedinto the system bus of each node to unify them,and pass traffic between them. The complexpart of the implementation is to ensure cache-coherency across the interconnect, and suchmachines are often referred to asCC-NUMA(cache coherent NUMA). As accesses over theinterconnect are transparent, it is possible toprogram such machines as if they were stan-dard SMP machines (though the performancewill be poor). Indeed, this is exactly how theNUMA-Q machines were first bootstrapped.
Often, we are asked why people do not useclusters of smaller machines, instead of a largeNUMA machine, as clusters are cheaper, sim-pler, and have a better price:performance ra-tio. Unfortunately, it makes the programmingof applications much harder; all of the inter-communication and load balancing now has tobe more explicit. Some large applications (e.g.,database servers) do not split up across mul-tiple cluster nodes easily—in those situations,people often use NUMA machines. In addi-tion, the interconnect for NUMA boxes is nor-mally very low latency, and very high band-width, yielding excellent performance. Themanagement of a single NUMA machine isalso simpler than that of a whole cluster withmultiple copies of the OS.
We could either have the operating systemmake decisions about how to deal with the ar-chitecture of the machine on behalf of the userprocesses, or give the userspace application anAPI to specify how such decisions are to bemade. It might seem, at first, that the userspaceapplication is in a better position to make suchdecisions, but this has two major disadvan-tages:
1. Every application must be changed to sup-port NUMA machines, and may need to

Linux Symposium 2004 • Volume One • 91
be revised when a new hardware platformis released.
2. Applications are not in a good positionto make global holistic decisions aboutmachine resources, coordinate themselveswith other applications, and balance deci-sions between them.
Thus decisions on process, memory and I/Oplacement are normally best left to the oper-ating system, perhaps with some hints fromuserspace about which applications group to-gether, or will use particular resources heavily.Details of hardware layout are put in one place,in the operating system, and tuning and modi-fication of the necessary algorithms are doneonce in that central location, instead of in ev-ery application. In some circumstances, theapplication or system administrator will wantto override these decisions with explicit APIs,but this should be the exception, rather than thenorm.
3 Linux NUMA Memory Support
In order to manage memory, Linux requiresa page descriptor structure (struct page )for each physical page of memory present inthe system. This consumes approximately 1%of the memory managed (assuming 4K pagesize), and the structures are grouped into an ar-ray calledmem_map. For NUMA machines,there is a separate array for each node, calledlmem_map. The mem_mapand lmem_maparrays are simple contiguous data structures ac-cessed in a linear fashion by their offset fromthe beginning of the node. This means that thememory controlled by them is assumed to bephysically contiguous.
NUMA memory support is enabled byCONFIG_DISCONTIGMEMand CONFIG_NUMA. A node descriptor called astruct
pgdata_t is created for each node. Cur-rently we do not support discontiguous mem-ory within a node (though large gaps in thephysical address space are acceptable betweennodes). Thus we must still create page descrip-tor structures for “holes” in memory within anode (and then mark them invalid), which willwaste memory (potentially a problem for largeholes).
Dave McCracken has picked up DanielPhillips’ earlier work on a better data struc-ture for holding the page descriptors, calledCONFIG_NONLINEAR. This will allow themapping of discontigous memory ranges in-side each node, and greatly simplify the ex-isting code for discontiguous memory on non-NUMA machines.
CONFIG_NONLINEARsolves the problem bycreating an artificial layer of linear addresses.It does this by dividing the physical addressspace into fixed size sections (akin to verylarge pages), then allocating an array to allowtranslations from linear physical address to truephysical address. This added level of indirec-tion allows memory with widely differing truephysical addresses to appear adjacent to thepage allocator and to be in the same zone, witha single struct page array to describe them. Italso provides support for memory hotplug byallowing new physical memory to be added toan existing zone and struct page array.
Linux normally allocates memory for a processon the local node, i.e., the node that the pro-cess is currently running on.alloc_pageswill call alloc_pages_node for the cur-rent processor’s node, which will pass the rele-vant zonelist (pgdat->node_zonelists )to the core allocator (__alloc_pages ). Thezonelists are built bybuild_zonelists ,and are set up to allocate memory in a round-robin fashion, starting from the local node (thiscreates a roughly even distribution of memory

92 • Linux Symposium 2004 • Volume One
pressure).
In the interest of reducing cross-node traffic,and reducing memory access latency for fre-quently accessed data and text, it is desirableto replicate any such memory that is read-onlyto each node, and use the local copy on any ac-cesses, rather than a remote copy. The obviouscandidates for such replication are the kerneltext itself, and the text of shared libraries suchas libc. Of course, this faster access comesat the price of increased memory usage, butthis is rarely a problem on large NUMA ma-chines. Whilst it might be technically possibleto replicate read/write mappings, this is com-plex, of dubious utility, and is unlikely to beimplemented.
Kernel text is assumed by the kernel itself toappear at a fixed virtual address, and to changethis would be problematic. Hence the easiestway to replicate it is to change the virtual tophysical mappings for each node to point at adifferent address. On IA-64, this is easy, sincethe CPU provides hardware assistance in theform of a pinned TLB entry.
On other architectures this proves more diffi-cult, and would depend on the structure of thepagetables. On IA-32 with PAE enabled, aslong as the user-kernel split is aligned on aPMD boundary, we can have a separate ker-nel PMD for each node, and point the vmallocarea (which uses small page mappings) back toa globally shared set of PTE pages. The PMDentries for theZONE_NORMALareas normallynever change, so this is not an issue, thoughthere is an issue withioremap_nocachethat can change them (GART trips over this)and speculative execution means that we willhave to deal with that (this can be a slow-paththat updates all copies of the PMDs though).
Dave Hansen has created a patch to replicateread only pagecache data, by adding a per-nodedata structure to each node of the pagecache
radix tree. As soon as any mapping is openedfor write, the replication is collapsed, makingit safe. The patch gives a 5%–40% increase inperformance, depending on the workload.
In the 2.6 Linux kernel, we have a per-nodeLRU for page management and a per-nodeLRU lock, in place of the global structuresand locks of 2.4. Not only does this reducecontention through finer grained locking, italso means we do not have to search othernodes’ page lists to free up pages on one nodewhich is under memory pressure. Moreover,we get much better locality, as only the lo-cal kswapd process is accessing that node’spages. Before splitting the LRU into per-nodelists, we were spending 50% of the system timeduring a kernel compile just spinning wait-ing for pagemap_lru_lock (which was thebiggest global VM lock at the time). Con-tention for thepagemap_lru_lock is nowso small it is not measurable.
4 Sched Domains—a Topology-aware Scheduler
The previous Linux scheduler, the O(1) sched-uler, provided some needed improvements tothe 2.4 scheduler, but shows its age as morecomplex system topologies become more andmore common. With technologies such asNUMA, Symmetric Multi-Threading (SMT),and variations and combinations of these, theneed for a more flexible mechanism to modelsystem topology is evident.
4.1 Overview
In answer to this concern, the mainline 2.6tree (linux-2.6.7-rc1 at the time of this writing)contains an updated scheduler with support forgeneric CPU topologies with a data structure,struct sched_domain , that models thearchitecture and defines scheduling policies.

Linux Symposium 2004 • Volume One • 93
Simply speaking, sched domains group CPUstogether in a hierarchy that mimics that of thephysical hardware. Since CPUs at the bot-tom of the hierarchy are most closely related(in terms of memory access), the new sched-uler performs load balancing most often at thelower domains, with decreasing frequency ateach higher level.
Consider the case of a machine with two SMTCPUs. Each CPU contains a pair of virtualCPU siblings which share a cache and the coreprocessor. The machine itself has two physi-cal CPUs which share main memory. In sucha situation, treating each of the four effectiveCPUs the same would not result in the bestpossible performance. With only two tasks,for example, the scheduler should place oneon CPU0 and one on CPU2, and not on thetwo virtual CPUs of the same physical CPU.When running several tasks it seems natural totry to place newly ready tasks on the CPU theylast ran on (hoping to take advantage of cachewarmth). However, virtual CPU siblings sharea cache; a task that was running on CPU0,then blocked, and became ready when CPU0was running another task and CPU1 was idle,would ideally be placed on CPU1. Sched do-mains provide the structures needed to realizethese sorts of policies. With sched domains,each physical CPU represents a domain con-taining the pair of virtual siblings, each repre-sented in asched_group structure. Thesetwo domains both point to a parent domainwhich contains all four effective processors intwo sched_group structures, each contain-ing a pair of virtual siblings. Figure 1 illus-trates this hierarchy.
Next consider a two-node NUMA machinewith two processors per node. In this examplethere are no virtual sibling CPUs, and there-fore no shared caches. When a task becomesready and the processor it last ran on is busy,the scheduler needs to consider waiting un-
Figure 1: SMT Domains
til that CPU is available to take advantage ofcache warmth. If the only available CPU ison another node, the scheduler must carefullyweigh the costs of migrating that task to an-other node, where access to its memory willbe slower. The lowest level sched domains ina machine like this will contain the two pro-cessors of each node. These two CPU leveldomains each point to a parent domain whichcontains the two nodes. Figure 2 illustrates thishierarchy.
Figure 2: NUMA Domains
The next logical step is to consider an SMTNUMA machine. By combining the previoustwo examples, the resulting sched domain hier-archy has three levels, sibling domains, physi-cal CPU domains, and the node domain. Fig-ure 3 illustrates this hierarchy.
The unique AMD Opteron architecture war-rants mentioning here as it creates a NUMAsystem on a single physical board. In this case,however, each NUMA node contains only one

94 • Linux Symposium 2004 • Volume One
Figure 3: SMT NUMA Domains
physical CPU. Without careful considerationof this property, a typical NUMA sched do-mains hierarchy would perform badly, tryingto load balance single CPU nodes often (an ob-vious waste of cycles) and between node do-mains only rarely (also bad since these actuallyrepresent the physical CPUs).
4.2 Sched Domains Implementation
4.2.1 Structure
The sched_domain structure stores pol-icy parameters and flags and, along withthe sched_group structure, is the primarybuilding block in the domain hierarchy. Fig-ure 4 describes these structures. Thesched_domain structure is constructed into an up-wardly traversable tree via the parent pointer,the top level domain setting parent to NULL.The groups list is a circular list of ofsched_group structures which essentially define theCPUs in each child domain and the relativepower of that group of CPUs (two physicalCPUs are more powerful than one SMT CPU).The span member is simply a bit vector with a1 for every CPU encompassed by that domainand is always the union of the bit vector stored
in each element of the groups list. The remain-ing fields define the scheduling policy to be fol-lowed while dealing with that domain, see Sec-tion 4.2.2.
While the hierarchy may seem simple, the de-tails of its construction and resulting tree struc-tures are not. For performance reasons, thedomain hierarchy is built on a per-CPU basis,meaning each CPU has a unique instance ofeach domain in the path from the base domainto the highest level domain. These duplicatestructures do share thesched_group struc-tures however. The resulting tree is difficult todiagram, but resembles Figure 5 for the ma-chine with two SMT CPUs discussed earlier.
In accordance with common practice, eacharchitecture may specify the construction ofthe sched domains hierarchy and the pa-rameters and flags defining the various poli-cies. At the time of this writing, only i386and ppc64 defined custom construction rou-tines. Both architectures provide for SMTprocessors and NUMA configurations. With-out an architecture-specific routine, the kerneluses the default implementations insched.c ,which do take NUMA into account.

Linux Symposium 2004 • Volume One • 95
struct sched_domain {/* These fields must be setup */struct sched_domain *parent; /* top domain must be null terminated */struct sched_group *groups; /* the balancing groups of the domain */cpumask_t span; /* span of all CPUs in this domain */unsigned long min_interval; /* Minimum balance interval ms */unsigned long max_interval; /* Maximum balance interval ms */unsigned int busy_factor; /* less balancing by factor if busy */unsigned int imbalance_pct; /* No balance until over watermark */unsigned long long cache_hot_time; /* Task considered cache hot (ns) */unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */unsigned int per_cpu_gain; /* CPU % gained by adding domain cpus */int flags; /* See SD_* */
/* Runtime fields. */unsigned long last_balance; /* init to jiffies. units in jiffies */unsigned int balance_interval; /* initialise to 1. units in ms. */unsigned int nr_balance_failed; /* initialise to 0 */
};
struct sched_group {struct sched_group *next; /* Must be a circular list */cpumask_t cpumask;unsigned long cpu_power;
};
Figure 4: Sched Domains Structures
4.2.2 Policy
The new scheduler attempts to keep the sys-tem load as balanced as possible by running re-balance code when tasks change state or makespecific system calls, we will call thiseventbalancing, and at specified intervals measuredin jiffies, calledactive balancing. Tasks mustdo something for event balancing to take place,while active balancing occurs independent ofany task.
Event balance policy is defined in eachsched_domain structure by setting a com-bination of the #defines of figure 6 in the flagsmember.
To define the policy outlined for the dual SMTprocessor machine in Section 4.1, the low-est level domains would setSD_BALANCE_NEWIDLEand SD_WAKE_IDLE(as there isno cache penalty for running on a differ-ent sibling within the same physical CPU),SD_SHARE_CPUPOWERto indicate to thescheduler that this is an SMT processor (the
scheduler will give full physical CPU ac-cess to a high priority task by idling thevirtual sibling CPU), and a few commonflags SD_BALANCE_EXEC, SD_BALANCE_CLONE, and SD_WAKE_AFFINE. The nextlevel domain represents the physical CPUsand will not setSD_WAKE_IDLEsince cachewarmth is a concern when balancing acrossphysical CPUs, norSD_SHARE_CPUPOWER.This domain adds theSD_WAKE_BALANCEflag to compensate for the removal ofSD_WAKE_IDLE. As discussed earlier, an SMTNUMA system will have these two domainsand another node-level domain. This do-main removes theSD_BALANCE_NEWIDLEand SD_WAKE_AFFINEflags, resulting infar fewer balancing across nodes than withinnodes. When one of these events occurs, thescheduler search up the domain hierarchy andperforms the load balancing at the highest leveldomain with the corresponding flag set.
Active balancing is fairly straightforward andaids in preventing CPU-hungry tasks from hog-ging a processor, since these tasks may only

96 • Linux Symposium 2004 • Volume One
#define SD_BALANCE_NEWIDLE 1 /* Balance when about to become idle */#define SD_BALANCE_EXEC 2 /* Balance on exec */#define SD_BALANCE_CLONE 4 /* Balance on clone */#define SD_WAKE_IDLE 8 /* Wake to idle CPU on task wakeup */#define SD_WAKE_AFFINE 16 /* Wake task to waking CPU */#define SD_WAKE_BALANCE 32 /* Perform balancing at task wakeup */#define SD_SHARE_CPUPOWER 64 /* Domain members share cpu power */
Figure 6: Sched Domains Policies
Figure 5: Per CPU Domains
rarely trigger event balancing. At each re-balance tick, the scheduler starts at the low-est level domain and works its way up, check-ing the balance_interval and last_balance fields to determine if that domainshould be balanced. If the domain is alreadybusy, thebalance_interval is adjustedusing thebusy_factor field. Other fieldsdefine how out of balance a node must be be-fore rebalancing can occur, as well as somesane limits on cache hot time and min and maxbalancing intervals. As with the flags for eventbalancing, the active balancing parameters aredefined to perform less balancing at higher do-mains in the hierarchy.
4.3 Conclusions and Future Work
Figure 7: Kernbench Results
To compare the O(1) scheduler of mainlinewith the sched domains implementation in themm tree, we ran kernbench (with the-j optionto make set to 8, 16, and 32) on a 16 CPU SMTmachine (32 virtual CPUs) on linux-2.6.6 andlinux-2.6.6-mm3 (the latest tree with sched do-mains at the time of the benchmark) with andwithout CONFIG_SCHED_SMTenabled. Theresults are displayed in Figure 7. The O(1)scheduler evenly distributed compile tasks ac-cross virtual CPUs, forcing tasks to share cacheand computational units between virtual sib-ling CPUs. The sched domains implementa-tion with CONFIG_SCHED_SMTenabled bal-anced the load accross physical CPUs, makingfar better use of CPU resources when runningfewer tasks than CPUs (as in the j8 case) sinceeach compile task would have exclusive accessto the physical CPU. Surprisingly, sched do-mains (which would seem to have more over-head than the mainline scheduler) even showedimprovement for the j32 case, where it doesn’t

Linux Symposium 2004 • Volume One • 97
benefit from balancing across physical CPUsbefore virtual CPUs as there are more tasksthan virtual CPUs. Considering the sched do-mains implementation has not been heavilytested or tweaked for performance, some finetuning is sure to further improve performance.
The sched domains structures replace the ex-panding set of#ifdefs of the O(1) sched-uler, which should improve readability andmaintainability. Unfortunately, the per CPUnature of the domain construction results in anon-intuitive structure that is difficult to workwith. For example, it is natural to discuss thepolicy defined at “the” top level domain; un-fortunately there areNR_CPUStop level do-mains and, since they are self-adjusting, eachone could conceivably have a different set offlags and parameters. Depending on whichCPU the scheduler was running on, it could be-have radically differently. As an extension ofthis research, an effort to analyze the impact ofa unified sched domains hierarchy is needed,one which only creates one instance of eachdomain.
Sched domains provides a needed structuralchange to the way the Linux scheduler viewsmodern architectures, and provides the pa-rameters needed to create complex schedulingpolicies that cater to the strengths and weak-nesses of these systems. Currently only i386and ppc64 machines benefit from arch specificconstruction routines; others must now stepforward and fill in the construction and param-eter setting routines for their architecture ofchoice. There is still plenty of fine tuning andperformance tweaking to be done.
5 NUMA API
5.1 Introduction
One of the biggest impediments to the ac-ceptance of a NUMA API for Linux was alack of understanding of what its potential usesand users would be. There are two schoolsof thought when it comes to writing NUMAcode. One says that the OS should take careof all the NUMA details, hide the NUMA-ness of the underlying hardware in the ker-nel and allow userspace applications to pre-tend that it’s a regular SMP machine. Linuxdoes this by having a process scheduler anda VMM that make intelligent decisions basedon the hardware topology presented by arch-specific code. The other way to handle NUMAprogramming is to provide as much detail aspossible about the system to userspace andallow applications to exploit the hardware tothe fullest by giving scheduling hints, mem-ory placement directives, etc., and the NUMAAPI for Linux handles this. Many applications,particularly larger applications with many con-current threads of execution, cannot fully uti-lize a NUMA machine with the default sched-uler and VM behavior. Take, for example, adatabase application that uses a large region ofshared memory and many threads. This appli-cation may have a startup thread that initializesthe environment, sets up the shared memoryregion, and forks off the worker threads. Thedefault behavior of Linux’s VM for NUMA isto bring pages into memory on the node thatfaulted them in. This behavior for our hy-pothetical app would mean that many pageswould get faulted in by the startup thread onthe node it is executing on, not necessarily onthe node containing the processes that will ac-tually use these pages. Also, the forked workerthreads would get spread around by the sched-uler to be balanced across all the nodes andtheir CPUs, but with no guarantees as to which

98 • Linux Symposium 2004 • Volume One
threads would be associated with which nodes.The NUMA API and scheduler affinity syscallsallow this application to specify that its threadsbe pinned to particular CPUs and that its mem-ory be placed on particular nodes. The appli-cation knows which threads will be workingwith which regions of memory, and is betterequipped than the kernel to make those deci-sions.
The Linux NUMA API allows applicationsto give regions of their own virtual memoryspace specific allocation behaviors, called poli-cies. Currently there are four supported poli-cies: PREFERRED, BIND, INTERLEAVE,and DEFAULT. The DEFAULT policy is thesimplest, and tells the VMM to do what itwould normally do (ie: pre-NUMA API) forpages in the policied region, and fault themin from the local node. This policy appliesto all regions, but is overridden if an appli-cation requests a different policy. The PRE-FERRED policy allows an application to spec-ify one node that all pages in the policied re-gion should come from. However, if the spec-ified node has no available pages, the PRE-FERRED policy allows allocation to fall backto any other node in the system. The BINDpolicy allows applications to pass in a node-mask, a bitmap of nodes, that the VM is re-quired to use when faulting in pages from a re-gion. The fourth policy type, INTERLEAVE,again requires applications to pass in a node-mask, but with the INTERLEAVE policy, thenodemask is used to ensure pages are faultedin in a round-robin fashion from the nodesin the nodemask. As with the PREFERREDpolicy, the INTERLEAVE policy allows pageallocation to fall back to other nodes if nec-essary. In addition to allowing a process topolicy a specific region of its VM space, theNUMA API also allows a process to policyits entire VM space with a process-wide pol-icy, which is set with a different syscall:set_mempolicy() . Note that process-wide poli-
cies are not persistent over swapping, howeverper-VMA policies are. Please also note thatnone of the policies will migrate existing (al-ready allocated) pages to match the binding.
The actual implementation of the in-kernelpolicies uses astruct mempolicy that ishung off the struct vm_area_struct .This choice involves some tradeoffs. The firstis that, previous to the NUMA API, the per-VMA structure was exactly 32 bytes on 32-bit architectures, meaning that multiplevm_area_struct s would fit conveniently in asingle cacheline. The structure is now a lit-tle larger, but this allowed us to achieve a per-VMA granularity to policied regions. This isimportant in that it is flexible enough to binda single page, a whole library, or a whole pro-cess’ memory. This choice did lead to a sec-ond obstacle, however, which was for sharedmemory regions. For shared memory regions,we really want the policy to be shared amongstall processes sharing the memory, but VMAsare not shared across separate tasks. The solu-tion that was implemented to work around thiswas to create a red-black tree of “shared pol-icy nodes” for shared memory regions. Dueto this, calls were added to thevm_ops struc-ture which allow the kernel to check if a sharedregion has any policies and to easily retrievethese shared policies.
5.2 Syscall Entry Points
1. sys_mbind(unsigned long start, unsignedlong len, unsigned long mode, unsignedlong *nmask, unsigned long maxnode,unsigned flags);
Bind the region of memory[start,start+len) according tomode andflags on the nodes enumerated innmask and having a maximum possiblenode number ofmaxnode .
2. sys_set_mempolicy(int mode, unsigned

Linux Symposium 2004 • Volume One • 99
long *nmask, unsigned long maxnode);
Bind the entire address space of the cur-rent process according tomode on thenodes enumerated innmask and hav-ing a maximum possible node number ofmaxnode .
3. sys_get_mempolicy(int *policy, unsignedlong *nmask, unsigned long maxnode,unsigned long addr, unsigned long flags);
Return the current binding’s mode inpolicy and node enumeration innmask based on themaxnode , addr ,andflags passed in.
In addition to the raw syscalls discussed above,there is a user-level library called “libnuma”that attempts to present a more cohesive inter-face to the NUMA API, topology, and sched-uler affinity functionality. This, however, isdocumented elsewhere.
5.3 At mbind() Time
After argument validation, the passed-in list ofnodes is checked to make sure they are all on-line. If the node list is ok, a new memory policystructure is allocated and populated with thebinding details. Next, the given address rangeis checked to make sure the vma’s for the re-gion are present and correct. If the region is ok,we proceed to actually install the new policyinto all the vma’s in that range. For most typesof virtual memory regions, this involves simplypointing thevma->vm_policy to the newlyallocated memory policy structure. For sharedmemory, hugetlbfs, and tmpfs, however, it’snot quite this simple. In the case of a memorypolicy for a shared segment, a red-black treeroot node is created, if it doesn’t already exist,to represent the shared memory segment andis populated with “shared policy nodes.” Thisallows a user to bind a single shared memorysegment with multiple different bindings.
5.4 At Page Fault Time
There are now several new and differ-ent flavors ofalloc_pages() style func-tions. Previous to the NUMA API, thereexistedalloc_page() , alloc_pages()and alloc_pages_node() . Without go-ing into too much detail,alloc_page()and alloc_pages() both calledalloc_pages_node() with the current node id asan argument.alloc_pages_node() allo-cated2order pages from a specific node, andwas the only caller to thereal page allocator,__alloc_pages() .
alloc_page() alloc_pages()
__alloc_pages()
alloc_pages_node()
Figure 8: oldalloc_pages
With the introduction of the NUMA API, non-NUMA kernels still retain the oldalloc_page*() routines, but the NUMA alloca-tors have changed.alloc_pages_node()and __alloc_pages() , the core routinesremain untouched, but all calls toalloc_page() /alloc_pages() now end up call-ing alloc_pages_current() , a newfunction.

100 • Linux Symposium 2004 • Volume One
There has also been the additionof two new page allocation func-tions: alloc_page_vma() andalloc_page_interleave() .alloc_pages_current() checks that thesystem is not currentlyin_interrupt() ,and if it isn’t, uses the current pro-cess’s process policy for allocation. Ifthe system is currently in interrupt con-text, alloc_pages_current() fallsback to the old default allocation scheme.alloc_page_interleave() allocatespages from regions that are bound with aninterleave policy, and is broken out separatelybecause there are some statistics kept forinterleaved regions. alloc_page_vma()is a new allocator that allocates only sin-gle pages based on a per-vma policy. Thealloc_page_vma() function is the onlyone of the new allocator functions that must becalled explicity, so you will notice that somecalls toalloc_pages() have been replacedby calls toalloc_page_vma() throughoutthe kernel, as necessary.
5.5 Problems/Future Work
There is no checking that the nodes re-quested are online at page fault time, so in-teractions with hotpluggable CPUs/memorywill be tricky. There is an asymmetry be-tween how you bind a memory region anda whole process’s memory: One call takesa flags argument, and one doesn’t. Alsothe maxnode argument is a bit strange,the get/set_affinity calls take a number ofbytes to be read/written instead of a max-imum CPU number. Thealloc_page_interleave() function could be dropped ifwe were willing to forgo the statistics that arekept for interleaved regions. Again, a lack ofsymmetry exists because other types of poli-cies aren’t tracked in any way.
6 Legal statement
This work represents the view of the authors, anddoes not necessarily represent the view of IBM.
IBM, NUMA-Q and Sequent are registerd trade-marks of International Business Machines Corpo-ration in the United States, other contries, or both.Other company, product, or service names may betrademarks of service names of others.
References
[LWN] LWN Editor, “Scheduling Domains,”http://lwn.net/Articles/80911/
[MM2] Linux 2.6.6-rc2/mm2 source,http://www.kernel.org
Linux Symposium 2004 • Volume One • 101
alloc_page()
alloc_pages()
__alloc_pages()
alloc_pages_node()
alloc_pages_current()
alloc_page_interleave()
alloc_page_vma()Both UP/SMP & NUMA
NUMA only
UP/SMP only
Figure 9: newalloc_pages

102 • Linux Symposium 2004 • Volume One

Improving Kernel Performance by Unmapping thePage Cache
James BottomleySteelEye Technology, Inc.
Abstract
The current DMA API is written on the found-ing assumption that the coherency is beingdone between the device and kernel virtual ad-dresses. We have a different API for coherencybetween the kernel and userspace. The upshotis that every Process I/O must be flushed twice:Once to make the user coherent with the kerneland once to make the kernel coherent with thedevice. Additionally, having to map all pagesfor I/O places considerable resource pressureon x86 (where any highmem page must be sep-arately mapped).
We present a different paradigm: Assume thatby and large, read/write data is only requiredby a single entity (the major consumers of largemultiply shared mappings are libraries, whichare read only) and optimise the I/O path for thiscase. This means that any other shared con-sumers of the data (including the kernel) mustseparately map it themselves. The DMA APIwould be changed to perform coherence to thepreferred address space (which could be thekernel). This is a slight paradigm shift, becausenow devices that need to peek at the data mayhave to map it first. Further, to free up morespace for this mapping, we would break the as-sumption that any page in ZONE_NORMALis automatically mapped into kernel space.
The benefits are that I/O goes straight fromthe device into the user space (for processors
that have virtually indexed caches) and the ker-nel has quite a large unmapped area for use inkmapping highmem pages (for x86).
1 Introduction
In the Linux kernel1 there are two addressingspaces: memory physical which is the locationin the actual memory subsystem and CPU vir-tual, which is an address the CPU’s MemoryManagement Unit (MMU) translates to a mem-ory physical address internally. The Linux ker-nel operates completely in CPU virtual space,keeping separate virtual spaces for the kerneland each of the current user processes. How-ever, the kernel also has to manage the map-pings between physical and virtual spaces, andto do that it keeps track of where the physicalpages of memory currently are.
In the Linux kernel, memory is split into zonesin memory physical space:
• ZONE_DMA: A historical region whereISA DMAable memory is allocated from.On x86 this is all memory under 16MB.
• ZONE_NORMAL: This is where normallyallocated kernel memory goes. Where
1This is not quite true, there are kernels for proces-sors without memory management units, but these arevery specialised and won’t be considered further

104 • Linux Symposium 2004 • Volume One
this zone ends depends on the architec-ture. However, all memory in this zoneis mapped in kernel space (visible to thekernel).
• ZONE_HIGHMEM: This is where the restof the memory goes. Its characteristic isthat it is not mapped in kernel space (thusthe kernel cannot access it without firstmapping it).
1.1 The x86 and Highmem
The main reason for the existence ofZONE_HIGHMEMis a peculiar quirk on the x86 pro-cessor which makes it rather expensive to havedifferent page table mappings between the ker-nel and user space. The root of the problemis that the x86 can only keep one set of physi-cal to virtual mappings on-hand at once. Sincethe kernel and the processes occupy differentvirtual mappings, the TLB context would haveto be switched not only when the processorchanges current user tasks, but also when thecurrent user task calls on the kernel to per-form an operation on its behalf. The time takento change mappings, called the TLB flushingpenalty, contributes to a degradation in processperformance and has been measured at around30%[1]. To avoid this penalty, the Kernel anduser spaces share a partitioned virtual addressspace so that the kernel is actually mapped intouser space (although protected from user ac-cess) and vice versa.
The upshot of this is that the x86 userspaceis divided 3GB/1GB with the virtual ad-dress range 0x00000000-0xbfffffffbeing available for the user process and0xc0000000-0xffffffff being reservedfor the kernel.
The problem, for the kernel, is that it now onlyhas 1GB of virtual address to play withinclud-ing all memory mapped I/O regions. The re-sult being thatZONE_NORMALactually ends
at around 850kb on most x86 boxes. Sincethe kernel must also manage the mappings forevery user process (and these mappings mustbe memory resident), the larger the physicalmemory of the kernel becomes, the less ofZONE_NORMALbecomes available to the ker-nel. On a 64GB x86 box, the usable mem-ory becomes minuscule and has lead to theproposal[2] to use a 4G/4G split and just ac-cept the TLB flushing penalty.
1.2 Non-x86 and Virtual Indexing
Most other architectures are rather better im-plemented and are able to cope easily with sep-arate virtual spaces for the user and the ker-nel without imposing a performance penaltytransitioning from one virtual address space toanother. However, there are other problemsthe kernel’s penchant for keeping all memorymapped causes, notably with Virtual Indexing.
Virtual Indexing[3] (VI) means that the CPUcache keeps its data indexed by virtual address(rather than by physical address like the x86does). The problem this causes is that if multi-ple virtual address spaces have the same physi-cal address mapped, but at different virtual ad-dresses then the cache may contain duplicateentries, called aliases. Managing these aliasesbecomes impossible if there are multiple onesthat become dirty.
Most VI architectures find a solution to themultiple cache line problem by having a “con-gruence modulus” meaning that if two virtualaddresses are equal modulo this congruence(usually a value around 4MB) then the cachewill detect the aliasing and keep only a singlecopy of the data that will be seen by all the vir-tual addresses.
The problems arise because, although archi-tectures go to great lengths to make sure alluser mappings are congruent, because the ker-

Linux Symposium 2004 • Volume One • 105
nel memory is always mapped, it is highly un-likely that any given kernel page would be con-gruent to a user page.
1.3 The solution: UnmappingZONE_NORMAL
It has already been pointed out[4] that x86could recover some of its preciousZONE_NORMALspace simply by moving page tableentries into unmapped highmem space. How-ever, the penalty of having to map and unmapthe page table entries to modify them turnedout to be unacceptable.
The solution, though, remains valid. Thereare many pages of data currently inZONE_NORMALthat the kernel doesn’t ordinarily use.If these could be unmapped and their vir-tual address space given up then the x86 ker-nel wouldn’t be facing quite such a memorycrunch.
For VI architectures, the problems stem fromhaving unallocated kernel memory alreadymapped. If we could keep the majority of ker-nel memory unmapped, and map it only whenwe really need to use it, then we would standa very good chance of being able to map thememory congruently even in kernel space.
The solution this paper will explore is that ofkeeping the majority of kernel memory un-mapped, mapping it only when it is used.
2 A closer look at Virtual Indexing
As well as the aliasing problem, VI architec-tures also have issues with I/O coherency onDMA. The essence of the problem stems fromthe fact that in order to make a device ac-cess to physical memory coherent, any cachelines that the processor is holding need to beflushed/invalidates as part of the DMA trans-action. In order to do DMA, a device simplypresents a physical address to the system with
a request to read or write. However, if the pro-cessor indexes the caches virtually, it will haveno idea whether it is caching this physical ad-dress or not. Therefore, in order to give theprocessor an idea of where in the cache the datamight be, the DMA engines on VI architecturesalso present a virtual index (called the “coher-ence index”) along with the physical address.
2.1 Coherence Indices and DMA
The Coherence Index is computed by the pro-cessor on a per page basis, and is used to iden-tify the line in the cache belonging to the phys-ical address the DMA is using.
One will notice that this means the coherenceindex must be computed oneveryDMA trans-action for aparticular address space (although,if all the addresses are congruent, one may sim-ply pick any one). Since, at the time the dmamapping is done, the only virtual address thekernel knows about is the kernel virtual ad-dress, it means that DMA is always done co-herently with the kernel.
In turn, since the kernel address is pretty muchnot congruent with any user address, before theDMA is signalled as being completed to theuser process, the kernel mapping and the usermappings must likewise be made coherent (us-ing theflush_dcache_page() function).However, since the majority of DMA transac-tions occur onuserdata in which the kernel hasno interest, the extra flush is simply an unnec-essary performance penalty.
This performance penalty would be eliminatedif either we knew that the designated kernel ad-dress was congruent to all the user addressesor we didn’t bother to map the DMA regioninto kernel space and simply computed the co-herence index from a given user process. Thelatter would be preferable from a performancepoint of view since it eliminates an unneces-

106 • Linux Symposium 2004 • Volume One
sary map and unmap.
2.2 Other Issues with Non-Congruence
On the parisc architecture, there is an architec-tural requirement that we don’t simultaneouslyenable multiple read and write translations ofa non-congruent address. We can either enablea single write translation or multiple read (butno write) translations. With the current mannerof kernel operation, this is almost impossibleto satisfy without going to enormous lengths inour page translation and fault routines to workaround the issues.
Previously, we were able to get away withignoring this restriction because the machinewould only detect it if we allowed multiplealiases to become dirty (something Linux neverdoes). However, in the next generation sys-tems, this condition will be detected when itoccurs. Thus, addressing it has become criti-cal to providing a bootable kernel on these newmachines.
Thus, as well as being a simple performanceenhancement, removing non-congruence be-comes vital to keeping the kernel booting onnext generation machines.
2.3 VIPT vs VIVT
This topic is covered comprehensively in [3].However, there is a problem in VIPT caches,namely that if we are reusing the virtual ad-dress in kernel space, we must flush the pro-cessor’s cache for that page on this re-use oth-erwise it may fall victim to stale cache refer-ences that were left over from a prior use.
Flushing a VIPT cache is easier said than done,since in order to flush, a valid translation mustexist for the virtual address in order for theflush to be effective. This causes particularproblems for pages that were mapped to a user
space process, since the address translationsare destroyedbeforethe page is finally freed.
3 Kernel Virtual Space
Although the kernel is nominally mapped inthe same way the user process is (and can the-oretically be fragmented in physical space), infact it is usually offset mapped. This meansthere is a simple mathematical relation be-tween the physical and virtual addresses:
virtual = physical + __PAGE_OFFSET
where __PAGE_OFFSETis an architecturedefined quantity. This type of mapping makesit very easy to calculate virtual addresses fromphysical ones and vice versa without having togo to all the bother (and CPU time) of havingto look them up in the kernel page tables.
3.1 Moving away from Offset Mapping
There’s another wrinkle on some architecturesin that if an interruption occurs, the CPUturns off virtual addressing to begin process-ing it. This means that the kernel needs tosave the various registers and turn virtual ad-dressing back on, all in physical space. Ifit’s no longer a simple matter of subtracting__PAGE_OFFSETto get the kernel stack forthe process, then extra time will be consumedin the critical path doing potentially cache coldpage table lookups.
3.2 Keeping track of Mapped pages
In general, when mapping a page we will ei-ther require that it goes in the first availableslot (for x86), or that it goes at the first avail-able slot congruent with a given address (for VIarchitectures). All we really require is a sim-ple mechanism for finding the first free page

Linux Symposium 2004 • Volume One • 107
virtual address given some specific constraints.However, since the constraints are architecturespecific, the specifics of this tracking are alsoimplemented in architectures (see section 5.2for details on parisc).
3.3 Determining Physical address from Virtualand Vice-Versa
In the Linux kernel, the simple macros__pa() and__va() are used to do physicalto virtual translation. Since we are now fillingthe mappings in randomly, this is no longer asimple offset calculation.
The kernel does have help for finding the vir-tual address of a given page. There is anoptional virtual entry which is turned onand populated with the page’s current virtualaddress when the architecture definesWANT_
PAGE_VIRTUAL. The__va() macro can beprogrammed simply to do this lookup.
To find the physical address, the best method isprobably to look the page up in the kernel pagetable mappings. This is obviously less efficientthan a simple subtraction.
4 Implementing the unmapping ofZONE_NORMAL
It is not surprising, given that the entire kernelis designed to operate withZONE_NORMALmapped it is surprising that unmapping it turnsout to be fairly easy. The primary reason forthis is the existence of highmem. Since pagesin ZONE_HIGHMEMare always unmapped andsince they are usually assigned to user pro-cesses, the kernel must proceed on the assump-tion that it potentially has to map into its ad-dress space any page from a user process thatit wishes to touch.
4.1 Booting
The kernel has an entire bootmem API whosesole job is to cope with memory allocationswhile the system is booting and before paginghas been initialised to the point where normalmemory allocations may proceed. On parisc,we simply get the available page ranges fromthe firmware, map them all and turn them overlock stock and barrel to bootmem.
Then, when we’re ready to begin paging, wesimply release all the unallocated bootmempages for the kernel to use from itsmem_map2
array of pages.
We can implement the unmapping idea simplyby covering all our page ranges with an offsetmap for bootmem, but then unmapping all theunreserved pages that bootmem releases to themem_maparray.
This leaves us with the kernel text and data sec-tions contiguously offset mapped, and all otherboot time
4.2 Pages Coming From User Space
The standard mechanisms for mapping poten-tial highmem pages from user space for thekernel to see arekmap, kunmap, kmap_atomic , and kmap_atomic_to_page .Simply hijacking them and divorcing their im-plementation fromCONFIG_HIGHMEMis suf-ficient to solve all user to kernel problemsthat arise because of the unmapping ofZONE_NORMAL.
4.3 In Kernel Problems: Memory Allocation
Since now every free page in the system willbe unmapped, they will have to be mapped
2This global array would be a set of per-zone arrayson NUMA

108 • Linux Symposium 2004 • Volume One
before thekernel can use them (pages allo-cated for use in user space have no need tobe mapped additionally in kernel space at al-location time). The engine for doing this is asingle point in__alloc_pages() which isthe central routine for allocating every page inthe system. In the single successful page re-turn, the page is mapped for the kernel to use itif __GFP_HIGHis not set—this simple test issufficient to ensure that kernel pages only aremapped here.
The unmapping is done in two separate rou-tines: __free_pages_ok() for freeing bulkpages (accumulations of contiguous pages) andfree_hot_cold_page() for freeing singlepages. Here, since we don’t know the gfp maskthe page was allocated with, we simply checkto see if the page is currently mapped, and un-map it if it is before freeing it. There is anotherside benefit to this: the routine that transfers allthe unreserved bootmem to themem_mapar-ray does this via__free_pages() . Thus,we additionally achieve the unmapping of allthe free pages in the system after booting withvirtually no additional effort.
4.4 Other Benefits: Variable size pages
Although it wasn’t the design of this structureto provide variable size pages, one of the ben-efits of this approach is now that the pages thatare mapped as they are allocated. Since pagesin the kernel are allocated with a specified or-der (the power of two of the number of con-tiguous pages), it becomes possible to coverthem with a TLB entry that is larger than theusual page size (as long as the architecture sup-ports this). Thus, we can take theorder ar-gument to__alloc_pages() and work outthe smallest number of TLB entries that weneed to allocate to cover it.
Implementation of variable size pages is actu-ally transparent to the system; as far as Linux
is concerned, the page table entries it deal withdescribe 4k pages. However, we add additionalflags to the pte to tell the software TLB routinethat actually we’d like to use a larger size TLBto access this region.
As a further optimisation, in the architecturespecific routines that free the boot mem, we canremap the kernel text and data sections with thesmallest number of TLB entries that will en-tirely cover each of them.
5 Achieving The VI architectureGoal: Fully Congruent Aliasing
The system possesses every attribute it nowneeds to implement this. We no-longer mapany user pages into kernel space unless the ker-nel actually needs to touch them. Thus, thepages will have congruent user addresses allo-cated to them in user spacebeforewe try tomap them in kernel space. Thus, all we haveto do is track up the free address list in incre-ments of the congruence modulus until we findan empty place to map the page congruently.
5.1 Wrinkles in the I/O Subsystem
The I/O subsystem is designed to operate with-out mapping pages into the kernelat all. Thisbecomes problematic for VI architectures be-cause we have to know the user virtual addressto compute the coherence index for the I/O.If the page is unmapped in kernel space, wecan no longer make it coherent with the kernelmapping and, unfortunately, the information inthe BIO is insufficient to tell us the user virtualaddress.
The proposal for solving this is to add an ar-chitecture defined set of elements tostructbio_vec and an architecture specific func-tion for populating this (possibly empty) set ofelements as the biovec is created. In parisc,

Linux Symposium 2004 • Volume One • 109
we need to add an extra unsigned long forthe coherence index, which we compute froma pointer to the mm and the user virtual ad-dress. The architecture defined components arepulled into struct scatterlist by yetanother callout when the request is mapped forDMA.
5.2 Tracking the Mappings in ZONE_DMA
Since the tracking requirements vary depend-ing on architectures: x86 will merely wish tofind the first free pte to place a page into; how-ever VI architectures will need to find the firstfree pte satisfying the congruence requirements(which vary by architecture), the actual mech-anism for finding a free pte for the mappingneeds to be architecture specific.
On parisc, all of this can be done inkmap_kernel() which merely uses rmap[5] to de-termine if the page is mapped in user spaceand find the congruent address if it is. Weuse a simple hash table based bitmap with onebucket representing the set of available congru-ent pages. Thus, finding a page congruent toany given virtual address is the simple compu-tation of finding the first set bit in the congru-ence bucket. To find an arbitrary page, we keepa global bucket counter, allocating a page fromthat bucket and then incrementing the counter3.
6 Implementation Details on PA-RISC
Since the whole thrust of this project was to im-prove the kernel on PA-RISC (and bring it backinto architectural compliance), it is appropriateto investigate some of the other problems thatturned up during the implementation.
3This can all be done locklessly with atomic incre-ments, since it doesn’t really matter if we get two allo-cations from the same bucket because of race conditions
6.1 Equivalent Mapping
The PA architecture has a software TLB mean-ing that in Virtual mode, if the CPU accessesan address that isn’t in the CPU’s TLB cache,it will take a TLB fault so the software routinecan locate the TLB entry (by walking the pagetables) and insert it into the CPU’s TLB. Ob-viously, this type of interruption must be han-dled purely by referencing physical addresses.In fact, the PA CPU is designed to have fast andslow paths for faults and interruptions. The fastpaths (since they cannot take another interrup-tion, i.e. not a TLB miss fault) must all operateon physical addresses. To assist with this, thePA CPU even turns off virtual addressing whenit takes an interruption.
When the CPU turns off virtual address trans-lation, it is said to be operating in absolutemode. All address accesses in this mode arephysical. However, all accesses in this modealso go through the CPU cache (which meansthat for this particular mode the cache is ac-tually Physically Indexed). Unfortunately, thiscan also set up unwanted aliasing between thephysical address and its virtual translation. Thefix for this is to obey the architectural definitionfor “equivalent mapping.” Equivalent mappingis defined as virtual and physical addresses be-ing equal; however, we benefit from the obvi-ous loophole in that the physical and virtual ad-dresses don’t have to be exactly equal, merelyequal modulo the congruent modulus.
All of this means that when a page is allocatedfor use by the kernel, we must determine if itwill ever be used in absolute mode, and make itequivalently mapped if it will be. At the time ofwriting, this was simply implemented by mak-ing all kernel allocated pages equivalent. How-ever, really all that needs to be equivalentlymapped is
1. the page tables (pgd, pmd and pte),

110 • Linux Symposium 2004 • Volume One
2. the task structure and
3. the kernel stacks.
6.2 Physical to Virtual address Translation
In the interruption slow path, where we saveall the registers and transition to virtual mode,there is a point where execution must beswitched (and hence pointers moved fromphysical to virtual). Currently, with offsetmapping, this is simply done by and additionof __PAGE_OFFSET. However, in the newscheme we cannot do this, nor can we callthe address translation functions when in ab-solute mode. Therefore, we had to reorgan-ise the interruption paths in the PA code sothat both the physical and virtual address wasavailable. Currently parisc uses a control reg-ister (%cr30 ) to store the virtual address ofthestruct thread_info . We altered allpaths to change%cr30 to contain the physi-cal address ofstruct thread_info andalso added a physical address pointer to thestruct task_struct to the thread info.This is sufficient to perform all the necessaryregister saves in absolute addressing mode.
6.3 Flushing on Page Freeing
as was documented in section 2.3, we need tofind a way of flushing a user virtual addressaf-ter its translation is gone. Actually, this turnsout to be quite easy on PARISC. We alreadyhave an area of memory (called the tmpaliasspace) that we use to copy to priming the usercache (it is simply a 4MB memory area we dy-namically program to map to the page). There-fore, as long as we know the user virtual ad-dress, we can simply flush the page throughthe tmpalias space. In order to confound anyattempted kernel use of this page, we reservea separate 4MB virtual area that produces apage fault if referenced, and point the page’s
virtual address into this when it isremovedfrom process mappings (so that any kernel at-tempt to use the page produces an immediatefault). Then, when the page is freed, if itsvirtual pointer is within this range, we con-vert it to a tmpalias address and flush it usingthe tmpalias mechanism.
7 Results and Conclusion
The best result is that on a parisc machine, thetotal amount of memory the operational kernelkeeps mapped is around 10MB (although thisalters depending on conditions).
The current implementation makes all pagescongruent or equivalent, but the allocation rou-tine containsBUG_ON()asserts to detect if werun out of equivalent addresses. So far, underfairly heavy stress, none of these has tripped.
Although the primary reason for the unmap-ping was to move parisc back within its archi-tectural requirements, it also produces a knockon effect of speeding up I/O by eliminating thecache flushing from kernel to user space. Atthe time of writing, the effects of this were stillunmeasured, but expected to be around 6% orso.
As a final side effect, the flush on free necessityreleases the parisc from a very stringent “flushthe entire cache on process death or exec” re-quirement that was producing horrible laten-cies in the parisc fork/exec. With this code inplace, we see a vast (50%) improvement in thefork/exec figures.
References
[1] Andrea Arcangeli3:1 4:4 100HZ1000HZ comparison with the HINTbenchmark7 April 2004http://www.kernel.org/pub/

Linux Symposium 2004 • Volume One • 111
linux/kernel/people/andrea/misc/31-44-100-1000/31-44-100-1000.html
[2] Ingo Molnar[announce, patch] 4G/4Gsplit on x86, 64 GB RAM (and more)support8 July 2003http://marc.theaimsgroup.com/?t=105770467300001
[3] James E.J. BottomleyUnderstandingCachingLinux Journal January 2004,Issue 117 p58
[4] Ingo Molnar[patch] simpler ‘highpte’design18 February 2002http://marc.theaimsgroup.com/?l=linux-kernel&m=101406121032371
[5] Rik van RielRe: Rmap code?22 August2001http://marc.theaimsgroup.com/?l=linux-mm&m=99849912207578

112 • Linux Symposium 2004 • Volume One

Linux Virtualization on IBM POWER5 Systems
Dave BoutcherIBM
Dave EngebretsenIBM
Abstract
In 2004 IBM® is releasing new systems basedon the POWER5™ processor. There is newsupport in both the hardware and firmware forvirtualization of multiple operating systems ona single platform. This includes the ability tohave multiple operating systems share a pro-cessor. Additionally, a hypervisor firmwarelayer supports virtualization of I/O devicessuch as SCSI, LAN, and console, allowinglimited physical resources in a system to beshared.
At its extreme, these new systems allow 10Linux images per physical processor to runconcurrently, contending for and sharing thesystem’s physical resources. All changes tosupport these new functions are in the 2.4 and2.6 Linux kernels.
This paper discusses the virtualization capabil-ities of the processor and firmware, as well asthe changes made to the PPC64 kernel to takeadvantage of them.
1 Introduction
IBM’s new POWER5∗∗ processor is being usedin both IBM iSeries® and pSeries® systemscapable of running any combination of Linux,AIX®, and OS/400® in logical partitions. Thehardware and firmware, including ahypervisor[AAN00], in these systems provide the abilityto create “virtual” system images with virtual
hardware. The virtualization technique used onPOWER™ hardware is known as paravirtual-ization, where the operating system is modifiedin select areas to make calls into the hypervi-sor. PPC64 Linux has been enhanced to makeuse of these virtualization interfaces. Note thatthe same PPC64 Linux kernel binary workson both virtualized systems and previous “baremetal” pSeries systems that did not offer a hy-pervisor.
All changes related to virtualization have beenmade in the kernel, and almost exclusively inthe PPC64 portion of the code. One chal-lenge has been keeping as much code commonas possible between POWER5 portions of thecode and other portions, such as those support-ing the Apple G5.
Like previous generations of POWER proces-sors such as the RS64 and POWER4™ fami-lies, POWER5 includes hardware enablementfor logical partitioning. This includes featuressuch as a hypervisor state which is more priv-ileged than supervisor state. This higher priv-ilege state is used to restrict access to systemresources, such as the hardware page table, tohypervisor only access. All current systemsbased on POWER5 run in a hypervised envi-ronment, even if only one partition is active onthe system.

114 • Linux Symposium 2004 • Volume One
Hypervisor
Linux OS/400 Linux AIX
CPU0
CPU1
CPU2
CPU3
1.50CPU
0.50CPU
1.0CPU
1.0CPU
Figure 1: POWER5 Partitioned System
2 Processor Virtualization
2.1 Virtual Processors
When running in a partition, the operatingsystem is allocated virtual processors (VP’s),where each VP can be configured in eithershared or dedicated mode of operation. Inshared mode, as little as 10%, or 10process-ing units, of a physical processor can be al-located to a partition and the hypervisor layertimeslices between the partitions. In dedicatedmode, 100% of the processor is given to thepartition such that its capacity is never multi-plexed with another partition.
It is possible to create more virtual processorsin the partition than there are physical proces-sors on the system. For example, a partition al-located 100 processing units (the equivalent of1 processor) of capacity could be configured tohave 10 virtual processors, where each VP has10% of a physical processor’s time. While notgenerally valuable, this extreme configurationcan be used to help test SMP configurations onsmall systems.
On POWER5 systems with multiple logicalpartitions, an important requirement is to beable to move processors (either shared or ded-
icated) from one logical partition to another.In the case of dedicated processors, this trulymeans moving a CPU from one logical parti-tion to another. In the case of shared proces-sors, it means adjusting the number of proces-sors used by Linux on the fly.
This “hotplug CPU” capability is far more in-teresting in this environment than in the casethat the covers are going to be removed from areal system and a CPU physically added. Thegoal of virtualization on these systems is to dy-namically create and adjust operating systemimages as required. Much work has been done,particularly by Rusty Russell, to get the archi-tecture independent changes into the mainlinekernel to support hotplug CPU.
Hypervisor interfaces exist that help the operat-ing system optimize its use of the physical pro-cessor resources. The following sections de-scribe some of these mechanisms.
2.2 Virtual Processor Area
Each virtual processor in the partition can cre-ate avirtual processor area(VPA), which is asmall (one page) data structure shared betweenthe hypervisor and the operating system. Itsprimary use is to communicate information be-tween the two software layers. Examples ofthe information that can be communicated inthe VPA include whether the OS is in the idleloop, if floating point and performance counterregister state must be saved by the hypervi-sor between operating system dispatches, andwhether the VP is running in the partition’s op-erating system.
2.3 Spinlocks
The hypervisor provides an interface that helpsminimize wasted cycles in the operating sys-tem when a lock is held. Rather than simplyspin on the held lock in the OS, a new hypervi-

Linux Symposium 2004 • Volume One • 115
sor call,h_confer , has been provided. Thisinterface is used to confer any remaining vir-tual processor cycles from the lock requesterto the lock holder.
The PPC64 spinlocks were changed to iden-tify the logical processor number of the lockholder, examine that processor’s VPAyieldcountfield to determine if it is not running inthe OS (even values indicate the VP is runningin the OS), and to make theh_confer callto the hypervisor to give any cycles remainingin the virtual processor’s timeslice to the lockholder. Obviously, this more expensive leg ofspinlock processing is only taken if the spin-lock cannot be immediately acquired. In caseswhere the lock is available, no additional path-length is incurred.
2.4 Idle
When the operating system no longer has ac-tive tasks to run and enters its idle loop, theh_cede interface is used to indicate to the hy-pervisor that the processor is available for otherwork. The operating system simply sets theVPA idle bit and callsh_cede . Under thiscall, the hypervisor is free to allocate the pro-cessor resources to another partition, or even toanother virtual processor within the same par-tition. The processor is returned to the operat-ing system if an external, decrementer (timer),or interprocessor interrupt occurs. As an alter-native to sending an IPI, the ceded processorcan be awoken by another processor calling theh_prodinterface, which has slightly less over-head in this environment.
Making use of the cede interface is especiallyimportant on systems where partitions config-ured to rununcappedexist. In uncapped mode,any physical processor cycles not used by otherpartitions can be allocated by the hypervisor toa non-idle partition, even if that partition hasalready consumed its defined quantity of pro-
cessor units. For example, a partition that isdefined as uncapped, 2 virtual processors, and20 processing units could consume 2 full pro-cessors (200 processing units), if all other par-titions are idle.
2.5 SMT
The POWER5 processor provides symmetricmultithreading (SMT) capabilities that allowtwo threads of execution to simultaneously ex-ecute on one physical processor. This re-sults in twice as many processor contexts be-ing presented to the operating system as thereare physical processors. Like other processorthreading mechanisms found in POWER RS64and Intel® processors, the goal of SMT is toenable higher processor utilization.
At Linux boot, each processor thread is dis-covered in the open firmware device treeand a logical processor is created for Linux.A command line option,smt-enabled =
[on, off, dynamic] , has been added to al-low the Linux partition to config SMT in oneof three states. Theon and off modes indi-cate that the processor always runs with SMTeither on or off. The dynamic mode allowsthe operating system and firmware to dynam-ically configure the processor to switch be-tween threaded (SMT) and a single threaded(ST) mode where one of the processor threadsis dormant. The hardware implementation issuch that running in ST mode can provide ad-ditional performance when only a single task isexecuting.
Linux can cause the processor to switch be-tween SMT and ST modes via theh_cede hy-pervisor call interface. When entering its idleloop, Linux sets the VPAidle state bit, and af-ter a selectable delay, callsh_cede . Underthis interface, the hypervisor layer determinesif only one thread is idle, and if so, switchesthe processor into ST mode. If both threads are

116 • Linux Symposium 2004 • Volume One
idle (as indicated by the VPAidle bit), then thehypervisor keeps the processor in SMT modeand returns to the operating system.
The processor switches back to SMT modeif an external or decrementer interrupt is pre-sented, or if another processor calls theh_prod interface against the dormant thread.
3 Memory Virtualization
Memory is virtualized only to the extent that allpartitions on the system are presented a con-tiguous range of logical addresses that startat zero. Linux sees these logical addressesas its real storage. The actual real memoryis allocated by the hypervisor from any avail-able space throughout the system, managingthe storage inlogical memory blocks(LMB’s).Each LMB is presented to the partition viaa memory node in the open firmware devicetree. When Linux creates a mapping in thehardware page table for effective addresses, itmakes a call to the hypervisor (h_enter ) in-dicating the effective and partition logical ad-dress. The hypervisor translates the logical ad-dress to the corresponding real address and in-serts the mapping into the hardware page table.
One additional layer of memory virtualizationmanaged by the hypervisor is areal mode off-set(RMO) region. This is a 128 or 256 MB re-gion of memory covering the first portion of thelogical address space within a partition. It canbe accessed by Linux when address relocationis off, for example after an exception occurs.When a partition is running relocation off andaccesses addresses within the RMO region, asimple offset is added by the hardware to gen-erate the actual storage access. In this manner,each partition has what it considers logical ad-dress zero.
4 I/O Virtualization
Once CPU and memory have been virtualized,a key requirement is to provide virtualized I/O.The goal of the POWER5 systems is to have,for example, 10 Linux images running on asmall system with a single CPU, 1GB of mem-ory, and a single SCSI adapter and Ethernetadapter.
The approach taken to virtualize I/O is a co-operative implementation between the hypervi-sor and the operating system images. One op-erating system image always “owns” physicaladapters and manages all I/O to those adapters(DMA, interrupts, etc.)
The hypervisor and Open Firmware then pro-vide “virtual” adapters to any operating sys-tems that require them. Creation of virtualadapters is done by the system administratoras part of logically partitioning the system. Akey concept is that these virtual adapters do notinteract in any way with the physical adapters.The virtual adapters interact with other operat-ing systems in other logical partitions, whichmay choose to make use of physical adapters.
Virtual adapters are presented to the operatingsystem in the Open Firmware device tree justas physical adapters are. They have very sim-ilar attributes as physical adapters, includingDMA windows and interrupts.
The adapters currently supported by the hyper-visor are virtual SCSI adapters, virtual Ether-net adapters, and virtual TTY adapters.
4.1 Virtual Bus
Virtual adapters, of course, exist on a virtualbus. The bus has slots into which virtualadapters are configured. The number of slotsavailable on the virtual bus is configured bythe system administrator. The goal is to make

Linux Symposium 2004 • Volume One • 117
the behavior of virtual adapters consistent withphysical adapters. The virtual bus isnot pre-sented as a PCI bus, but rather as its own bustype.
4.2 Virtual LAN
Virtual LAN adapters are conceptually the sim-plest kind of virtual adapter. The hypervisorimplements a switch, which supports 802.1Qsemantics for having multiple VLANs sharea physical switch. Adapters can be markedas 802.1Q aware, in which case the hypervi-sor expects the operating system to handle the802.1Q VLAN headers, or 802.1Q unaware, inwhich case the hypervisor connects the adapterto a single VLAN. Multiple virtual Ethernetadapters can be created for a given partition.
Virtual Ethernet adapters have an additional at-tribute called “Trunk Adapter.” An adaptermarked as a Trunk Adapter will be deliveredall frames that don’t match any MAC addresson the virtual Ethernet. This is similar, butnot identical, to promiscuous mode on a realadapter.
For a logical partition to have network connec-tivity to the outside world, the partition own-ing a “real” network adapter generally has boththe real Ethernet adapter and a virtual Ether-net adapter marked as a Trunk adapter. Thatpartition then performs either routing or bridg-ing between the real adapter and the virtualadapter. The Linux bridge-utils package workswell to bridge the two kinds of networks.
Note that there is no architected link betweenthe real and virtual adapters, it is the responsi-bility of some operating system to route trafficbetween them.
The implementation of the virtual Ethernetadapters involves a number of hypervisor inter-faces. Some of the more significant interfacesare h_register_logical_lan to establish
the initial link between a device driver anda virtual Ethernet device,h_send_logical_
lan to send a frame, andh_add_logical_
lan_buffer to tell the hypervisor about adata buffer into which a received frame is to beplaced. The hypervisor interfaces then supporteither polled or interrupt driven notification ofnew frames arriving.
For additional information on the virtual Ether-net implementation, the code is the documen-tation (drivers/net/ibmveth.c ).
4.3 Virtual SCSI
Unlike virtual Ethernet adapters, virtual SCSIadapters come in two flavors. A “client” vir-tual SCSI adapter behaves just as a regularSCSI host bus adapter and is implementedwithin the SCSI framework of the Linux ker-nel. The SCSI mid-layer issues standard SCSIcommands such as Inquiry to determine de-vices connected to the adapter, and issues reg-ular SCSI operations to those devices.
A “server” virtual SCSI adapter, generally in adifferent partition than the client, receives allthe SCSI commands from the client and is re-sponsible for handling them. The hypervisoris not involved in what the server does withthe commands. There is no requirement forthe server to link a virtual SCSI adapter to anykind of real adapter. The server can processand return SCSI responses in any fashion itlikes. If it happens to issue I/O operations to areal adapter as part of satisfying those requests,that is an implementation detail of the operat-ing system containing the server adapter.
The hypervisor provides two very primitiveinterpartition communication mechanisms onwhich the virtual SCSI implementation is built.There is a queue of 16 byte messages referredto as a “Command/Response Queue” (CRQ).Each partition provides the hypervisor with a

118 • Linux Symposium 2004 • Volume One
page of memory where its receive queue re-sides, and a partition wishing to send a messageto its partner’s queue issues anh_send_crqhypervisor call. When a message is receivedon the queue, an interrupt is (optionally) gen-erated in the receiving partition.
The second hypervisor mechanism is a facil-ity for issuing DMA operations between par-titions. Theh_copy_rdma call is used toDMA a block of memory from the memoryspace of one logical partition to the memoryspace of another.
The virtual SCSI interpartition protocol isimplemented using the ANSI “SCSI RDMAProtocol” (SRP) (available athttp://www.t10.org ). When the client wishes to issue aSCSI operation, it builds an SRP frame, andsends the address of the frame in a 16 byteCRQ message. The server DMA’s the SRPframe from the client, and processes it. TheSRP frame may itself contain DMA addressesrequired for data transfer (read or write buffers,for example) which may require additional in-terpartition DMA operations. When the oper-ation is complete, the server DMA’s the SRPresponse back to the same location as the SRPcommand came from and sends a 16 byte CRQmessage back indicating that the SCSI com-mand has completed.
The current Linux virtual SCSI server de-codes incoming SCSI commands and issuesblock layer commands (generic_make_request ). This allows the SCSI server toshare any block device (e.g.,/dev/sdb6 or/dev/loop0 ) with client partitions as a vir-tual SCSI device.
Note that consideration was given to using pro-tocols such as iSCSI for device sharing be-tween partitions. The virtual SCSI SRP de-sign above, however, is a much simpler designthat does not rely on riding above an existingIP stack. Additionally, the ability to use DMA
operations between partitions fits much betterinto the SRP model than an iSCSI model.
The Linux virtual SCSI client (drivers/
scsi/ibmvscsi/ibmvscsi.c ) is close, atthe time of writing, to being accepted into theLinux mainline. The Linux virtual SCSI serveris sufficiently unlike existing SCSI drivers thatit will require much more mailing list “discus-sion.”
4.4 Virtual TTY
In addition to virtual Ethernet and SCSIadapters, the hypervisor supports virtual serial(TTY) adapters. As with SCSI adapter, thesecan be configured as “client” adapters, and“server” adapters and connected between par-titions. The first virtual TTY adapter is used asthe system console, and is treated specially bythe hypervisor. It is automatically connected tothe partition console on the Hardware Manage-ment Console.
To date, multiple concurrent “consoles” havenot been implemented, but they could be. Sim-ilarly, this interface could be used for kerneldebugging as with any serial port, but such animplementation has not been done.
5 Dynamic Resource Movement
As mentioned for processors, the logical par-tition environment lends itself to moving re-sources (processors, memory, I/O) betweenpartitions. In a perfect world, such movementshould be done dynamically while the operat-ing system is running. Dynamic movement ofprocessors is currently being implemented, anddynamic movement of I/O devices (includingdynamically adding and removing virtual I/Odevices) is included in the kernel mainline.
The one area for future work in Linux is the dy-namic movement of memory into and out of an

Linux Symposium 2004 • Volume One • 119
active partition. This function is already sup-ported on other POWER5 operating systems,so there is an opportunity for Linux to catchup.
6 Multiple Operating Systems
A key feature of the POWER5 systems is theability to run different operating systems indifferent logical partitions on the same phys-ical system. The operating systems currentlysupported on the POWER5 hardware are AIX,OS/400, and Linux.
While running multiple operating systems, allof the functions for interpartion interaction de-scribed above must work between operatingsystems. For example, idle cycles from an AIXpartition can be given to Linux. A proces-sor can be moved from OS/400 to Linux whileboth operating systems are active.
For I/O, multiple operating systems must beable to communicate over the virtual Ethernet,and SCSI devices must be sharable from (say)an AIX virtual SCSI server to a Linux virtualSCSI client.
These requirements, along with the archi-tected hypervisor interfaces, limit the ability tochange implementations just to fit a Linux ker-nel internal behavior.
7 Conclusions
While many of the basic virtualization tech-nologies described in this paper existed in theLinux implementation provided on POWERRS64 and POWER4 iSeries systems [Bou01],they have been significantly enhanced forPOWER5 to better use the firmware providedinterfaces.
The introduction of POWER5-based systems
converged all of the virtualization interfacesprovided by firmware on legacy iSeries andpSeries systems to a model in line with thelegacy pSeries partitioned system architecture.As a result much of the PPC64 Linux virtual-ization code was updated to use these new vir-tualization interface definitions.
8 Acknowledgments
The authors would like to thank the entireLinux/PPC64 team for the work that went intothe POWER5 virtualization effort. In partic-ular Anton Blanchard, Paul Mackerras, RustyRusell, Hollis Blanchard, Santiago Leon, RyanArnold, Will Schmidt, Colin Devilbiss, KyleLucke, Mike Corrigan, Jeff Scheel, and DavidLarson.
9 Legal Statement
This paper represents the view of the authors, anddoes not necessarily represent the view of IBM.
IBM, AIX, iSeries, OS/400, POWER, POWER4,POWER5, and pSeries are trademarks or regis-tered trademarks of International Business Ma-chines Corporation in the United States, other coun-tries, or both.
Other company, product or service names may betrademerks or service marks of others.
References
[AAN00] Bill Armstrong, Troy Armstrong,Naresh Nayar, Ron Peterson, Tom Sand,and Jeff Scheel.Logical Partitioning,http://www-1.ibm.com/servers/
eserver/iseries/beyondtech/
lpar.htm .

120 • Linux Symposium 2004 • Volume One
[Bou01] David Boutcher,The iSeries LinuxKernel 2001 Linux Symposium, (July2001).

The State of ACPI in the Linux Kernel
A. Leonard BrownIntel
Abstract
ACPI puts Linux in control of configurationand power management. It abstracts the plat-form BIOS and hardware so Linux and theplatform can interoperate while evolving inde-pendently.
This paper starts with some background on theACPI specification, followed by the state ofACPI deployment on Linux.
It describes the implementation architecture ofACPI on Linux, followed by details on the con-figuration and power management features.
It closes with a summary of ACPI bugzilla ac-tivity, and a list of what is next for ACPI inLinux.
1 ACPI Specification Background
“ACPI (Advanced Configuration andPower Interface) is an open in-dustry specification co-developed byHewlett-Packard, Intel, Microsoft,Phoenix, and Toshiba.
ACPI establishes industry-standardinterfaces for OS-directed configura-tion and power management on lap-tops, desktops, and servers.
ACPI evolves the existing collec-tion of power management BIOScode, Advanced Power Manage-ment (APM) application program-
ming interfaces (APIs, PNPBIOSAPIs, Multiprocessor Specification(MPS) tables and so on into a well-defined power management and con-figuration interface specification.”1
ACPI 1.0 was published in 1996. 2.0 added64-bit support in 2000. ACPI 3.0 is expectedin summer 2004.
2 Linux ACPI Deployment
Linux supports ACPI on three architectures:ia64 , i386 , andx86_64 .
2.1 ia64 Linux/ACPI support
Most ia64 platforms require ACPI support,as they do not have the legacy configurationmethods seen oni386 . All the Linux distribu-tions that supportia64 include ACPI support,whether they’re based on Linux-2.4 or Linux-2.6.
2.2 i386 Linux/ACPI support
Not all Linux-2.4 distributions enabled ACPIby default on i386 . Often they usedjust enough table parsing to enable Hyper-Threading (HT), alaacpi=ht below, and re-lied on MPS and PIRQ routers to configure the
1http://www.acpi.info

122 • Linux Symposium 2004 • Volume One
setup_arch()dmi_scan_machine()
Scan DMI blacklistBIOS Date vs Jan 1, 2001
acpi_boot_init()acpi_table_init()
locate and checksum all ACPI tablesprint table headers to console
acpi_blacklisted()ACPI table headers vs. blacklist
parse(BOOT) /* Simple Boot Flags */parse(FADT) /* PM timer address */parse(MADT) /* LAPIC, IOAPIC */parse(HPET) /* HiPrecision Timer */parse(MCFG) /* PCI Express base */
Figure 1: Early ACPI init oni386
machine. Some included ACPI support by de-fault, but required the user to addacpi=on tothe cmdline to enable it.
So far, the major Linux 2.6 distributions allsupport ACPI enabled by default oni386 .
Several methods are used to make it more prac-tical to deploy ACPI ontoi386 installed base.Figure 1 shows the early ACPI startup on thei386 and where these methods hook in.
1. Most modern system BIOS support DMI,which exports the date of the BIOS. LinuxDMI scan ini386 disables ACPI on plat-forms with a BIOS older than January 1,2001. There is nothing magic about thisdate, except it allowed developers to focuson recent platforms without getting dis-tracted debugging issues on very old plat-forms that:
(a) had been running Linux w/o ACPIsupport for years.
(b) had virtually no chance of a BIOSupdate from the OEM.
Boot parameteracpi=force is avail-able to enable ACPI on platforms olderthan the cutoff date.
2. DMI also exports the hardware man-ufacturer, baseboard name, BIOS ver-
sion, etc. that you can observe withdmidecode .2 dmi_scan.c has a gen-eral purpose blacklist that keys off this in-formation, and invokes various platform-specific workarounds.acpi=off is themost severe—disabling all ACPI support,even the simple table parsing needed toenable Hyper-Threading (HT).acpi=htdoes the same, excepts parses enough ta-bles to enable HT.pci=noacpi disablesACPI for PCI enumeration and interruptconfiguration. Andacpi=noirq dis-ables ACPI just for interrupt configura-tion.
3. The ACPI tables also contain header in-formation, which you see near the topof the kernel messages. ACPI maintainsa blacklist based on the table headers.But this blacklist is somewhat primitive.When an entry matches the system, it ei-ther prints warnings or invokesacpi=off .
All three of these methods share the problemthat if they are successful, they tend to hideroot-cause issues in Linux that should be fixed.For this reason, adding to the blacklists is dis-couraged in the upstream kernel. Their mainvalue is to allow Linux distributors to quicklyreact to deployment issues when they need tosupport deviant platforms.
2.3 x86_64 Linux/ACPI support
All x86_64 platforms I’ve seen include ACPIsupport. The majorx86_64 Linux distribu-tions, whether Linux-2.4 or Linux-2.6 based,all support ACPI.
2http://www.nongnu.org/dmidecode

Linux Symposium 2004 • Volume One • 123
3 Implementation Overview
The ACPI specification describes platform reg-isters, ACPI tables, and operation of the ACPIBIOS. Figure 2 shows these ACPI componentslogically as a layer above the platform specifichardware and firmware.
The ACPI kernel support centers around theACPICA (ACPI Component Architecture3)core. ACPICA includes the AML4 interpreterthat implements ACPI’s hardware abstraction.ACPICA also implements other OS-agnosticparts of the ACPI specification. The ACPICAcode does not implement any policy, that is therealm of the Linux-specific code. A single file,osl.c , glues ACPICA to the Linux-specificfunctions it requires.
The box in Figure 2 labeled “Linux/ACPI” rep-resents the Linux-specific ACPI code, includ-ing boot-time configuration.
Optional “ACPI drivers,” such as Button, Bat-tery, Processor, etc. are (optionally loadable)modules that implement policy related to thosespecific features and devices.
3.1 Events
ACPI registers for a “System Control Inter-rupt” (SCI) and all ACPI events come throughthat interrupt.
The kernel interrupt handler de-multiplexes thepossible events using ACPI constructs. Insome cases, it then delivers events to a user-space application such asacpid via /proc/acpi/events .
3http://www.intel.com/technology/iapc/acpi
4AML, ACPI Machine Language.
���������
��� �����������������
��� �����������
������������
���������
����������
����� ����
�!"��
"��! �!"�
#��
$��
���
������
���!����
�����%
��
�&��� ���
������"!� �!�����
��� ����' ���
Figure 2: Implementation Architecture
4 ACPI Configuration
Interrupt configuration oni386 dominated theACPI bug fixing activity over the last year.
The algorithm to configure interrupts on ani386 system with an IOAPIC is shown in Fig-ure 3. ACPI mandates that all PIC mode IRQsbe identity mapped to IOAPIC pins. Excep-tions are specified in MADT5 interrupt sourceoverride entries.
Over-rides are often used, for example, to spec-ify that the 8254 timer on IRQ0 in PIC modedoes not use pin0 on the IOAPIC, but usespin2. Over-rides also often move the ACPI SCIto a different pin in IOAPIC mode than it hadin PIC mode, or change its polarity or triggerfrom the default.
5MADT, Multiple APIC Description Table.

124 • Linux Symposium 2004 • Volume One
setup_arch()acpi_boot_init()
parse(MADT);parse(LAPIC); /* processors */parse(IOAPIC)
parse(INT_SRC_OVERRIDE);add_identity_legacy_mappings();/* mp_irqs[] initialized */
init()smp_boot_cpus()
setup_IO_APIC()enable_IO_APIC();setup_IO_APIC_irqs(); /* mp_irqs[] */
do_initcalls()acpi_init()
"ACPI: Subsystem revision 20040326"acpi_initialize_subsystem();/* AML interpreter */acpi_load_tables(); /* DSDT */acpi_enable_subsystem();/* HW into ACPI mode */
"ACPI: Interpreter enabled"acpi_bus_init_irq();
AML(_PIC, PIC | IOAPIC | IOSAPIC);
acpi_pci_link_init()for(every PCI Link in DSDT)
acpi_pci_link_add(Link)AML(_PRS, Link);AML(_CRS, Link);
"... Link [LNKA] (IRQs 9 10 *11)"
pci_acpi_init()"PCI: Using ACPI for IRQ routing"
acpi_irq_penalty_init();for (PCI devices)
acpi_pci_irq_enable(device)acpi_pci_irq_lookup()
find _PRT entryif (Link) {
acpi_pci_link_get_irq()acpi_pci_link_allocate()
examine possible & current IRQsAML(_SRS, Link)
} else {use hard-coded IRQ in _PRT entry
}acpi_register_gsi()
mp_register_gsi()io_apic_set_pci_routing()
"PCI: PCI interrupt 00:06.0[A] ->GSI 26 (level, low) -> IRQ 26"
Figure 3: Interrupt Initialization
So after identifying that the system will be inIOAPIC mode, the 1st step is to record all theInterrupt Source Overrides inmp_irqs[] .The second step is to add the legacy identitymappings where pins and IRQs have not beenconsumed by the over-rides.
Step three is to digestmp_irqs[] insetup_IO_APIC_irqs() , just like itwould be if the system were running in legacyMPS mode.
But that is just the start of interrupt configu-ration in ACPI mode. The system still needsto enable the mappings for PCI devices, whichare stored in the DSDT6 _PRT7 entries. Fur-ther, the _PRT can contain both static entries,analogous to MPS table entries, or it can con-tain dynamic _PRT entries that use PCI Inter-rupt Link Devices.
So Linux enables the AML interpreter and in-forms the ACPI BIOS that it plans to run thesystem in IOAPIC mode.
Next the PCI Interrupt Link Devices areparsed. These “links” are abstract versions ofwhat used to be called PIRQ-routers, thoughthey are more general.acpi_pci_link_init() searches the DSDT for Link Devicesand queries each about the IRQs it can be setto (_PRS)8 and the IRQ that it is already set to(_CRS)9
A penalty table is used to help decide howto program the PCI Interrupt Link Devices.Weights are statically compiled into the ta-ble to avoid programming the links to wellknown legacy IRQs.acpi_irq_penalty_init() updates the table to add penalties tothe IRQs where the Links have possible set-
6DSDT, Differentiated Services Description Table,written in AML
7_PRT, PCI Routing Table8PRS, Possible Resource Settings.9CRS, Current Resource Settings.

Linux Symposium 2004 • Volume One • 125
tings. The idea is to minimize IRQ shar-ing, while not conflicting with legacy IRQ use.While it works reasonably well in practice, thisheuristic is inherently flawed because it as-sumes the legacy IRQs rather than asking theDSDT what legacy IRQs are actually in use.10
The PCI sub-system callsacpi_pci_irq_enable() for every device. ACPI looks upthe device in the _PRT by device-id and if ita simple static entry, programs the IOAPIC.If it is a dynamic entry,acpi_pci_link_allocate() chooses an IRQ for the link andprograms the link via AML (_SRS).11 Then theassociated IOAPIC entry is programmed.
Later, the drivers initialize and callrequest_irq(IRQ) with the IRQ the PCI sub-systemtold it to request.
One issue we have with this scheme is that itcan’t automatically recover when the heuris-tic balancing act fails. For example when theparallel port grabs IRQ7 and a PCI InterruptLinks gets programmed to the same IRQ, thenrequest_irq(IRQ) correctly fails to putISA and PCI interrupts on the same pin. Butthe system doesn’t realize that one of the con-tenders could actually be re-programmed to adifferent IRQ.
The fix for this issue will be to delete theheuristic weights from the IRQ penalty table.Instead the kernel should scan the DSDT toenumerate exactly what legacy devices reserveexactly what IRQs.12
10In PIC mode, the default is to keep the BIOS pro-vided current IRQ setting, unless cmdlineacpi_irq_balance is used. Balancing is always enabled inIOAPIC mode.
11SRS, Set Resource Setting12bugzilla 2733
4.1 Issues With PCI Interrupt Link Devices
Most of the issues have been with PCI InterruptLink Devices, an ACPI mechanism primarilyused to replace the chip-set-specific LegacyPIRQ code.
• The status (_STA) returned by a PCI Inter-rupt Link Device does not matter. Somesystems mark the ones we should use asenabled, some do not.
• The status set by Linux on a link is im-portant on some chip sets. If we donot explicitly disable some unused links,they result in tying together IRQs and cancause spurious interrupts.
• The current setting returned by a link(_CRS) can not always be trusted. Somesystems return invalid settings always.Linux must assume that when it sets alink, the setting was successful.
• Some systems return a current setting thatis outside the list of possible settings. Perabove, this must be ignored and a new set-ting selected from the possible-list.
4.2 Issues With ACPI SCI Configuration
Another area that was ironed out this yearwas the ACPI SCI (System Control Interrupt).Originally, the SCI was always configured aslevel/low, but SCI failures didn’t stop untilwe implemented the algorithm in Figure 4.During debugging, the kernel gained the cmd-line option that applies to either PIC or IOAPICmode: acpi_sci={level,edge,high,low} but production systems seem to be work-ing properly and this has seen use recently onlyto work around prototype BIOS bugs.

126 • Linux Symposium 2004 • Volume One
if (PIC mode) {set ELCR to level trigger();
} else { /* IOAPIC mode */if (Interrupt Source Override) {
Use IRQ specified in overrideif(trigger edge or level)
use edge or levelelse (compatible trigger)
use level
if (polarity high or low)use high or low
elseuse low
} else { /* no Override */use level-triggeruse low-polarity
}}
Figure 4: SCI configuration algorithm
4.3 Unresolved: Local APIC Timer Issue
The most troublesome configuration issue to-day is that many systems with no IO-APIC willhang during boot unless their LOCAL-APIChas been disabled, eg. by bootingnolapic .While this issue has gone away on several sys-tems with BIOS upgrades, entire product linesfrom high-volume OEMS appear to be subjectto this failure. The current workaround to dis-able the LAPIC timer for the duration of theSMI-CMD update that enables ACPI mode.13
4.4 Wanted: Generic Linux Driver Manager
The ACPI DSDT enumerates motherboard de-vices via PNP identifiers. This method is usedto load the ACPI specific devices today, eg.battery, button, fan, thermal etc. as well as8550_acpi . PCI devices are enumerated viaPCI-ids from PCI config space. Legacy devicesprobe out using hard-coded address values.
But a device driver should not have to know or13http://bugzilla.kernel.org 1269
�����������
������������
���������
������������
���������
���������
��������
���� ���
������� ��!"
�#���$�!�� ��
������������
�����%��&��'���''
���&�(�����''
)� �"
Figure 5: ACPI Global, CPU, and Sleep states.
care how it is enumerated by its parent bus. An8250 driver should worry about the 8250 andnot if it is being discovered by legacy means,ACPI enumeration, or PCI.
One fix would be to be to abstract the PCI-ids,PNP-ids, and perhaps even some hard-codedvalues into a generic device manager directorythat maps them to device drivers.
This would simply add a veneer to the PCIdevice configuration, simplifying a very smallnumber of drivers that can be configured byPCI or ACPI. However, it would also fix thereal issue that the configuration information inthe ACPI DSDT for most motherboard devicesis currently not parsed and not communicatedto any Linux drivers.
The Device driver manager would also beable to tell the power management sub-systemwhich methods are used to power-manage thedevice. Eg. PCI or ACPI.
5 ACPI Power Management
The Global System States defined by ACPI areillustrated in Figure 5. G0 is the working state,G1 is sleeping, G2 is soft-off and G3 is me-chanical off. The “Legacy” state illustrateswhere the system is not in ACPI mode.

Linux Symposium 2004 • Volume One • 127
5.1 P-states
In the context of G0 – Global Working State,and C0 – CPU Executing State, P-states (Per-formance states) are available to reduce powerof the running processor. P-states simultane-ously modulate both the MHz and the voltage.As power varies by voltage squared, P-statesare extremely effective at saving power.
While P-states are extremely important, thecpufreq sub-system handles P-states on anumber of different platforms, and the topic isbest addressed in that larger context.
5.2 Throttling
In the context of the G0-Working, C0-Executing state, Throttling states are defined tomodulate the frequency of the running proces-sor.
Power varies (almost) directly with MHz, sowhen the MHz is cut if half, so is the power.Unfortunately, so is the performance.
Linux currently uses Throttling only in re-sponse to thermal events where the processoris too hot. However, in the future, Linux couldadd throttling when the processor is already inthe lowest P-state to save additional power.
Note that most processors also include abackup Thermal Monitor throttling mecha-nism in hardware, set with higher temperaturethresholds than ACPI throttling. Most proces-sors also have in hardware an thermal emer-gency shutdown mechanism.
5.3 C-states
In the context of G0 Working system state, C-state (CPU-state) C0 is used to refer to the exe-cuting state. Higher number C-states are en-tered to save successively more power when
the processor is idle. No instructions are ex-ecuted when in C1, C2, or C3.
ACPI replaces the default idle loop so it canenter C1, C2 or C3. The deeper the C-state,the more power savings, but the higher the la-tency to enter/exit the C-state. You can ob-serve the C-states supported by the system andthe success at using them in/proc/acpi/processor/CPU0/power
C1 is included in every processor and hasnegligible latency. C1 is implemented withthe HALT or MONITOR/MWAIT instructions.Any interrupt will automatically wake the pro-cessor from C1.
C2 has higher latency (though always under100 usec) and higher power savings than C1.It is entered through writes to ACPI registersand exits automatically with any interrupt.
C3 has higher latency (though always under1000 usec) and higher power savings than C2.It is entered through writes to ACPI registersand exits automatically with any interrupt orbus master activity. The processor does notsnoop its cache when in C3, which is why bus-master (DMA) activity will wake it up. Linuxsees several implementation issues with C3 to-day:
1. C3 is enabled even if the latency is up to1000 usec. This compares with the Linux2.6 clock tick rate of 1000Hz = 1ms =1000usec. So when a clock tick causesC3 to exit, it may take all the way to thenext clock tick to execute the next kernelinstruction. So the benefit of C3 is lostbecause the system effectively pays C3 la-tency and gets negligible C3 residency tosave power.
2. Some devices do not tolerate the DMAlatency introduced by C3. Their devicebuffers underrun or overflow. This is cur-

128 • Linux Symposium 2004 • Volume One
rently an issue with the ipw2100 WLANNIC.
3. Some platforms can lie about C3 latencyand transparently put the system into ahigher latency C4 when we ask for C3—particularly when running on batteries.
4. Many processors halt their local APICtimer (a.k.a. TSC – Timer Stamp Counter)when in C3. You can observe thisby watching LOC fall behind IRQ0 in/proc/interrupts.
5. USB makes it virtually impossible to en-ter C3 because of constant bus master ac-tivity. The workaround at the moment isto unplug your USB devices when idle.Longer term, it will take enhancementsto the USB sub-system to address this is-sue. Ie. USB software needs to recognizewhen devices are present but idle, and re-duce the frequency of bus master activity.
Linux decides which C-state to enter on idlebased on a promotion/demotion algorithm.The current algorithm measures the residencyin the current C-state. If it meets a thresholdthe processor is promoted to the deeper C-stateon re-entrance into idle. If it was too short, thenthe processor is demoted to a lower-numberedC-state.
Unfortunately, the demotion rules are overlysimplistic, as Linux tracks only its previoussuccess at being idle, and doesn’t yet accountfor the load on the system.
Support for deeper C-states via the _CSTmethod is currently in prototype. Hopefullythis method will also give the OS more accu-rate data than the FADT about the latency as-sociated with C3. If it does not, then we mayneed to consider discarding the table-providedlatencies and measuring the actual latency atboot time.
5.4 Sleep States
ACPI names sleeps states S0 – S5. S0 is thenon-sleep state, synonymous with G0. S1 isstandby, it halts the processor and turns off thedisplay. Of course turning off the display on anidle system saves the same amount of powerwithout taking the system off line, so S1 isn’tworth much. S2 is deprecated. S3 is suspend toRAM. S4 is hibernate to disk. S5 is soft-poweroff, AKA G2.
Sleep states are unreliable enough on Linux to-day that they’re best considered “experimen-tal.” Suspend/Resume suffers from (at least)two systematic problems:
• _init() and_initdata() on itemsthat may be referenced after boot, say,during resume, is a bad idea.
• PCI configuration space is not uniformlysaved and restored either for devices orfor PCI bridges. This can be observedby using lspci before and after a sus-pend/resume cycle. Sometimessetpcican be used to repair this damage fromuser-space.
5.5 Device States
Not shown on the diagram, ACPI definespower saving states for devices: D0 – D3. D0is on, D3 is off, D1 and D2 are intermediate.Higher device states have
1. more power savings,
2. less device context saved by hardware,
3. more device driver state restoring,
4. higher restore latency.

Linux Symposium 2004 • Volume One • 129
ACPI defines semantics for each device state ineach device class. In practice, D1 and D2 areoften optional - as many devices support onlyon and off either because they are low-latency,or because they are simple.
Linux-2.6 includes an updated device drivermodel to accommodate power management.14
This model is highly compatible with PCI andACPI. However, this vision is not yet fully re-alized. To do so, Linux needs a global powerpolicy manager.
5.6 Wanted: Generic Linux Run-time PowerPolicy Manager
PCI device drivers today callpci_set_power_state() to enter D-states. This usesthe power management capabilities in the PCIpower management specification.
The ACPI DSDT supplies methods for ACPIenumerated devices to access ACPI D-states.However, no driver calls into ACPI to enter D-states today.15
Drivers shouldn’t have to care if they are powermanaged by PCI or by ACPI. Drivers should beable to up-call to a generic run-time power pol-icy manager. That manager should know aboutcalling the PCI layer or the ACPI layer as ap-propriate.
The power manager should also put those re-quests in the context of user-specified powerpolicy. Eg. Does the user want maximum per-formance, or maximum battery life? Currentlythere is no method to specify the detailed pol-icy, and the kernel wouldn’t know how to han-dle it anyway.
In a related point, it appears that devices cur-
14Patrick Mochel, Linux Kernel Power Management,OLS 2003.
15Actually, the ACPI hot-plug driver invokes D-states,but that is the only exception.
rently only suspend upon system suspend. Thisis probably not the path to industry leading bat-tery life.
Device drivers should recognize when their de-vice has gone idle. They should invoke a sus-pend up-call to a power manager layer whichwill decide if it really is a good idea to grantthat request now, and if so, how. In this case bycalling the PCI or ACPI layer as appropriate.
6 ACPI as seen by bugzilla
Over the last year the ACPI developers havemade heavy use of bugzilla16 to help prioritizeand track 460 bugs. 300 bugs are closed or re-solved, 160 are open.17
We cc: [email protected] on these bugs, andwe encourage the community to add that aliasto ACPI-specific bugs in other bugzillas so thatthe team can help out wherever the problemsare found.
We haven’t really used the bugzilla priorityfield. Instead we’ve split the bugs into cate-gories and have addressed the configuration is-sues first. This explains why most of the in-terrupt bugs are resolved, and most of the sus-pend/resume bugs are unresolved.
We’ve seen an incoming bug rate of 10-bugs/week for many months, but the new re-ports favor the power management featuresover configuration, so we’re hopeful that thetorrent of configuration issues is behind us.
16http://bugzilla.kernel.org/17The resolved state indicates that a patch is available
for testing, but that it is not yet checked into the ker-nel.org kernel.

130 • Linux Symposium 2004 • Volume One
����
�����
������
���
�������
�������
���
�������
������
�����
���
���� ���
���������
!����
�� "�#
��$���
% &' '% (' )%%
���� *�"��+��
�����
Figure 6: ACPI bug profile
7 Future Work
7.1 Linux 2.4
Going forward, I expect to back-port only crit-ical configuration related fixes to Linux-2.4.For the latest power management code, usersneed to migrate to Linux-2.6.
7.2 Linux 2.6
Linux-2.6 is a “stable” release, so it is notappropriate to integrate significant new fea-tures. However, the power management sideof ACPI is widely used in 2.6 and there will beplenty of bug-fixes necessary. The most visi-ble will probably be anything that makes Sus-pend/Resume work on more platforms.
7.3 Linux 2.7
These feature gaps will not be addressed inLinux 2.6, and so are candidates for Linux 2.7:
• Device enumeration is not abstracted ina generic device driver manager that canshield drivers from knowing if they’reenumerated by ACPI, PCI, or other.
• Motherboard devices enumerated byACPI in the DSDT are ignored, andprobed instead via legacy methods. Thiscan lead to resource conflicts.
• Device power states are not abstracted ina generic device power manager that canshield drivers from knowing whether tocall ACPI or PCI to handle D-states.
• There is no power policy manager totranslate the user-requested power policyinto kernel policy.
• No devices invoke ACPI methods to enterD-states.
• Devices do not detect that they are idleand request of a power manager whetherthey should enter power saving devicestates.
• There is no MP/SMT coordination of P-states. Today, P-states are disabled onSMP systems. Coordination needs to ac-count for multiple threads and multiplecores per package.
• Coordinate P-states and T-states. Throt-tling should be used only after the systemis put in the lowest P-state.
• Idle states above C1 are disabled on SMP.
• Enable Suspend in PAE mode.18
18PAE, Physical Address Extended—MMU mode tohandle > 4GB RAM—optional oni386 , always usedonx86_64 .

Linux Symposium 2004 • Volume One • 131
• Enable Suspend on SMP.
• Tick timer modulation for idle power sav-ings.
• Video control extensions. Video is a largepower consumer. The ACPI spec Videoextensions are currently in prototype.
• Docking Station support is completely ab-sent from Linux.
• ACPI 3.0 features. TBD after the specifi-cation is published.
7.4 ACPI 3.0
Although ACPI 3.0 has not yet been published,two ACPI 3.0 tidbits are already in Linux.
• PCI Express table scanning. This is thebasic PCI Express support, there will bemore coming. Those in the PCI SIGcan read all about it in the PCI ExpressFirmware Specification.
• Several clarifications to the ACPI 2.0bspec resulted directly from open sourcedevelopment,19 and the text of ACPI 3.0has been updated accordingly. For exam-ple, some subtleties of SCI interrupt con-figuration and device enumeration.
When the ACPI 3.0 specification is publishedthere will instantly be a multiple additions tothe ACPI/Linux feature to-do list.
7.5 Tougher Issues
• Battery Life on Linux is not yet compet-itive. This single metric is the sum of allthe power savings features in the platform,and if any of them are not working prop-erly, it comes out on this bottom line.
19FreeBSD deserves kudos in addition to Linux
• Laptop Hot Keys are used to controlthings such as video brightness, etc. ACPIdoes not specify Hot Keys. But when theywork in APM mode and don’t work inACPI mode, ACPI gets blamed. There are4 ways to implement hot keys:
1. SMI20 handler, the BIOS handlesinterrupts from the keys, and con-trols the device directly. This actslike “hardware” control as the OSdoesn’t know it is happening. Buton many systems this SMI method isdisabled as soon as the system tran-sitions into ACPI mode. Thus thecomplaint “the button works in APMmode, but doesn’t work in ACPImode.”But ACPI doesn’t specify how hotkeys work, so in ACPI mode one ofthe other methods listed here needsto handle the keys.
2. Keyboard Extension driver, such asi8k . Here the keys return scancodes like any other keys on the key-board, and the keyboard driver needsto understand those scan code. Thisis independent of ACPI, and gener-ally OEM specific.
3. OEM-specific ACPI hot key driver.Some OEMs enumerate the hotkeys as OEM-specific devices in theACPI tables. While the device isdescribed in AML, such devices arenot described in the ACPI spec sowe can’t build generic ACPI supportfor them. The OEM must supplythe appropriate hot-key driver sinceonly they know how it is supposedto work.
4. Platform-specific “ACPI” driver. To-day Linux includes Toshiba and
20SMI, System Management Interrupt; invisible to theOS, handled by the BIOS, generally considered evil.

132 • Linux Symposium 2004 • Volume One
Asus platform specific extensiondrivers to ACPI. They do not useportable ACPI compliant methods torecognize and talk to the hot keys,but generally use the methods above.
The correct solution to the the Hot Key is-sue on Linux will require direct supportfrom the OEMs, either by supplying doc-umentation, or code to the community.
8 Summary
This past year has seen great strides in the con-figuration aspects of ACPI. Multiple Linux dis-tributors now enable ACPI on multiple archi-tectures.
This sets the foundation for the next era ofACPI on Linux where we can evolve the moreadvanced ACPI features to meet the expecta-tions of the community.
9 Resources
The ACPI specification is published athttp://www.acpi.info .
The home page for the Linux ACPI de-velopment community is here:http://acpi.sourceforge.net/ It contains nu-merous useful pointers, including one to theacpi-devel mailing list.
The latest ACPI code can be found against var-ious recent releases in the BitKeeper repos-itories: http://linux-acpi.bkbits.net/
Plain patches are available onkernel.org .21 Note that Andrew Morton currentlyincludes the latest ACPI test tree in the-mm
21http://ftp.kernel.org/pub/linux/kernel/people/lenb/acpi/patches/
patch, so you can test the latest ACPI codecombined with other recent updates there.22
10 Acknowledgments
Many thanks to the following people whose di-rect contributions have significantly improvedthe quality of the ACPI code in the lastyear: Jesse Barnes, John Belmonte, DominikBrodowski, Bruno Ducrot, Bjorn Helgaas,Nitin, Kamble, Andi Kleen, Karol Kozimor,Pavel Machek, Andrew Morton, Jun Naka-jima, Venkatesh Pallipadi, Nate Lawson, DavidShaohua Li, Suresh Siddha, Jes Sorensen, An-drew de Quincey, Arjan van de Ven, MattWilcox, and Luming Yu. Thanks also to allthe bug submitters, and the enthusiasts onacpi-devel .
Special thanks to Intel’s Mobile PlatformsGroup, which created ACPICA, particularlyBob Moore and Andy Grover.
Linux is a trademark of Linus Torvalds. Bit-Keeper is a trademark of BitMover, Inc.
22http://ftp.kernel.org/pub/linux/kernel/people/akpm/patches/

Scaling Linux® to the ExtremeFrom 64 to 512 Processors
Jesse [email protected]
John [email protected]
Jeremy [email protected]
Jack [email protected]
Silicon Graphics, Inc.
Abstract
In January 2003, SGI announced the SGI® Al-tix® 3000 family of servers. As announced,the SGI Altix 3000 system supported up to64 Intel® Itanium® 2 processors and 512 GBof main memory in a single Linux® image.Altix now supports up to 256 processors ina single Linux system, and we have a fewearly-adopter customers who are running 512processors in a single Linux system; othersare running with as much as 4 terabytes ofmemory. This paper continues the work re-ported on in our 2003 OLS paper by describ-ing the changes necessary to get Linux to effi-ciently run high-performance computing work-loads on such large systems.
Introduction
At OLS 2003 [1], we discussed changes toLinux that allowed us to make Linux scale to64 processors for our high-performance com-puting (HPC) workloads. Since then, we havecontinued our scalability work, and we nowsupport up to 256 processors in a single Linuximage, and we have a few early-adopter cus-tomers who are running 512 processors in asingle-system image; other customers are run-ning with as much as 4 terabytes of memory.
As can be imagined, the type of changes neces-sary to get a single Linux system to scale on a512 processor system or to support 4 terabytesof memory are of a different nature than thosenecessary to get Linux to scale up to a 64 pro-cessor system, and the majority of this paperwill describe such changes.
While much of this work has been done inthe context of a Linux 2.4 kernel, Altix isnow a supported platform in the Linux 2.6 se-ries (www.kernel.org versions of Linux2.6 boot and run well on many small to mod-erate sized Altix systems), and our plan is toport many of these changes to Linux 2.6 andpropose them as enhancements to the commu-nity kernel. While some of these changes willbe unique to the Linux kernel for Altix, manyof the changes we propose will also improveperformance on smaller SMP and NUMA sys-tems, so should be of general interest to theLinux scalability community.
In the rest of this paper, we will first providea brief review of the SGI Altix 3000 hard-ware. Next we will describe why we believethat very large single-system image, shared-memory machine can be more effective toolsfor HPC than similar sized non-shared mem-ory clusters. We will then discuss changes thatwe made to Linux for Altix in order to make

134 • Linux Symposium 2004 • Volume One
that system a more effective system for HPCon systems with as many as 512 processors.A second large topic of discussion will be thechanges to support high-performance I/O onAltix and some of the hardware underpinningsfor that support. We believe that the latter setof problems are general in the sense that theyapply to any large scale NUMA system and thesolutions we have adopted should be of generalinterest for this reason.
Even though this paper is focused on thechanges that we have made to Linux to ef-fectively support very large Altix platforms, itshould be remembered that the total number ofsuch changes is small in relation to the over-all size of the Linux kernel and its support-ing software. SGI is committed to support-ing the Linux community and continues to sup-port Linux for Altix as a member of the Linuxfamily of kernels, and in general to support bi-nary compatibility between Linux for Altix andLinux on other Itanium Processor Family plat-forms.
In many cases, the scaling changes described inthis paper have already been submitted to thecommunity for consideration for inclusion inLinux 2.6. In other cases, the changes are un-der evaluation to determine if they need to beadded to Linux 2.6, or whether they are fixesfor problems in Linux 2.4.21 (the current prod-uct base for Linux for Altix) that are no longerpresent in Linux 2.6.
Finally, this paper contains forward-lookingstatements regarding SGI® technologies andthird-party technologies that are subject torisks and uncertainties. The reader is cautionednot to rely unduly on these forward-lookingstatements, which are not a guarantee of futureor current performance, nor are they a guaran-tee that features described herein will or willnot be available in future SGI products.
The SGI Altix Hardware
This section is condensed from [1]; the readershould refer to that paper for additional details.
An Altix system consists of a configurablenumber of rack-mounted units, each of whichSGI refers to as abrick. The most commontype of brick is the C-brick (or compute brick).A fully configured C-brick consists of two sep-arate dual-processor Intel Itanium 2 systems,each of which is a bus-connected multiproces-sor ornode.
In addition to the two processors on the bus,there is also a SHUB chip on each bus. TheSHUB is a proprietary ASIC that (1) acts asa memory controller for the local memory,(2) provides the interface to the interconnec-tion network, (3) manages the global cache co-herency protocol, and (4) some other functionsas discussed in [1].
Memory accesses in an Altix system are eitherlocal (i.e., the reference is to memory in thesame node as the processor) or remote. TheSHUB detects whether a reference is local, inwhich case it directs the request to the mem-ory on the node, or remote, in which case itforwards the request across the interconnectionnetwork to the SHUB chip where the memoryreference will be serviced.
Local memory references have lower latency;the Altix system is thus a NUMA (non-uniformmemory access) system. The ratio of remote tolocal memory access times on an Altix systemvaries from 1.9 to 3.5, depending on the sizeof the system and the relative locations of theprocessor and memory module involved in thetransfer.
The cache-coherency policy in the Altix sys-tem can be divided into two levels:localandglobal. The local cache-coherency proto-col is defined by the processors on the local

Linux Symposium 2004 • Volume One • 135
bus and is used to maintain cache-coherencybetween the Itanium processors on the bus.The global cache-coherency protocol is imple-mented by the SHUB chip. The global proto-col is directory-based and is a refinement of theprotocol originally developed for DASH [2].
The Altix system interconnection network usesrouting bricks to provide connectivity in sys-tem sizes larger than 16 processors. In systemswith 128 or more processors a second layerof routing bricks is used to forward requestsamong subgroups of 32 processors each. Therouting topology is a fat-tree topology with ad-ditional “express” links being inserted to im-prove performance.
Why Big SSI?
In this section we discuss the rationale forbuilding such a large single-system image(SSI) box as an Altix system with 512 CPU’sand (potentially) several TB of main memory:
(1) Shared memory systems are more flexibleand easier to manage than a cluster. One cansimulate message passing on shared memory,but not the other way around. Software forcluster management and system maintenanceexists, but can be expensive or complex to use.
(2) Shared memory style programming is gen-erally simpler and more easily understood thanmessage passing. Debugging of code is oftensimpler on a SSI system than on a cluster.
(3) It is generally easier to port or writecodes from scratch using the shared memoryparadigm. Additionally it is often possible tosimply ignore large sections of the code (e.g.those devoted to data input and output) andonly parallelize the part that matters.
(4) A shared memory system supports eas-ier load balancing within a computation. The
mapping of grid points to a node determinesthe computational load on the node. Some gridpoints may be located near more rapidly chang-ing parts of computation, resulting in highercomputational load. Balancing this over timerequires moving grid points from node to nodein a cluster, where in a shared memory systemsuch re-balancing is typically simpler.
(5) Access to large global data sets is simpli-fied. Often, the parallel computation dependson a large data set describing, for example, theprecise dimensions and characteristics of thephysical object that is being modeled. Thisdata set can be too large to fit into the nodememories available on a clustered machine, butit can readily be loaded into memory on a largeshared memory machine.
(6) Not everything fits into the cluster model.While many production codes have been con-verted to message passing, the overall compu-tation may still contain one or more phases thatare better performed using a large shared mem-ory system. Or, there may be a subset of usersof the system who would prefer a shared mem-ory paradigm to a message passing one. Thiscan be a particularly important consideration inlarge data-center environments.
Kernel Changes
In this section we describe the most significantkernel problems we have encountered in run-ning Linux on a 512 processor Altix system.
Cache line and TLB Conflicts
Cache line conflicts occur in every cache-coherent multiprocessor system, to one extentor another, and whether or not the conflict ex-hibits itself as a performance problem is depen-dent on the rate at which the conflict occurs andthe time required by the hardware to resolve

136 • Linux Symposium 2004 • Volume One
the conflict. The latter time is typically propor-tional to the number of processors involved inthe conflict. On Altix systems with 256 proces-sors or more, we have encountered some cacheline conflicts that can effectively halt forwardprogress of the machine. Typically, these con-flicts involve global variables that are updatedat each timer tick (or faster) by every processorin the system.
One example of this kind of problem is the de-fault kernel profiler. When we first enabledthe default kernel profiler on a 512 CPU sys-tem, the system would not boot. The reasonwas that once per timer tick, each processorin the system was trying to update the pro-filer bin corresponding to the CPU idle routine.A work around to this problem was to initial-ize prof_cpu_mask to CPU_MASK_NONEinstead of the default. This disables profil-ing on all processors until the user sets theprof_cpu_mask .
Another example of this kind of problem waswhen we imported some timer code fromRed Hat® AS 3.0. The timer code includeda global variable that was used to account fordifferences between HZ (typically a power of2) and the number of microseconds in a sec-ond (nominally 1,000,000). This global vari-able was updated by each processor on eachtimer tick. The result was that on Altix sys-tems larger than about 384 processors, forwardprogress could not be made with this versionof the code. To fix this problem, we made thisglobal variable a per processor variable. Theresult was that the adjustment for the differ-ence between HZ and microseconds is done ona per processor rather than on a global basis,and now the system will boot.
Still other cache line conflicts were remediedby identifying cases of false cache line sharingi.e., those cache lines that inadvertently containa field that is frequently written by one CPU
and another field (or fields) that are frequentlyread by other CPUs.
Another significant bottleneck is the ia64do_gettimeofday() with its use ofcmpxchg . That operation is expensive onmost architectures, and concurrentcmpxchgoperations on a common memory locationscale worse than concurrent simple writes frommultiple CPUs. On Altix, four concurrent usergettimeofday() system calls complete inalmost an order of magnitude more time than asinglegettimeofday() ; eight are 20 timesslower than one; and the scaling deterioratesnonlinearly to the point where 32 concurrentsystem calls is 100 times slower than one. Atthe present time, we are still exploring a way toimprove this scaling problem in Linux 2.6 forAltix.
While moving data to per-processor storage isoften a solution to the kind of scaling problemswe have discussed here, it is not a panacea,particularly as the number of processors be-comes large. Often, the system will want toinspect some data item in the per-processorstorage of each processor in the system. Forsmall numbers of processors this is not a prob-lem. But when there are hundreds of proces-sors involved, such loops can cause a TLB misseach time through the loop as well as a cou-ple of cache-line misses, with the result thatthe loop may run quite slowly. (A TLB missis caused because the per-processor storage ar-eas are typically isolated from one another inthe kernel’s virtual address space.)
If such loops turn out to be bottlenecks, thenwhat one must often do is to move the fieldsthat such loops inspect out of the per-processorstorage areas, and move them into a globalstatic array with one entry per CPU.
An example of this kind of problem in Linux2.6 for Altix is the current allocation schemeof the per-CPU run queue structures. Each

Linux Symposium 2004 • Volume One • 137
per-CPU structure on an Altix system requiresa unique TLB to address it, and each struc-ture begins at the same virtual offset in a page,which for a virtually indexed cache means thatthe same fields will collide at the same in-dex. Thus, a CPU scheduler that wishes todo a quick peek at every other CPU’snr_running or cpu_load will not only suffer aTLB miss on every access, but will also likelysuffer a cache miss because these same virtualoffsets will collide in the cache. Cache col-oring of these addresses would be one way tosolve this problem; we are still exploring waysto fix this problem in Linux 2.6 for Altix.
Lock Conflicts
A cousin of cache line conflicts are the lockconflicts. Indeed, the root mechanism of thelock bottleneck is a cache line conflict. Fora spinlock_t the conflict is thecmpxchgoperation on the word that signifies whether ornot the lock is owned. For arwlock_t theconflict is the cmpxchg or fetch-and-add op-eration on the count of the number of read-ers or the bit signifying whether or not thelock is owned exclusively by a writer. For aseqlock_t the conflict is the increment ofthe sequence number.
For some lock conflicts, such as thercu_ctrlblk.mutex , the remedy is to make thespinlock more fine-grained, e.g., by making ithierarchical or per-CPU. For other lock con-flicts, the most effective remedy is to reducethe use of the lock.
The O(1) CPU scheduler replaced the globalrunqueue_lock with per-CPU run queuelocks, and replaced the global run queue withper-CPU run queues. While this did substan-tially decrease the CPU scheduling bottleneckfor CPU counts in the 8 to 32 range, additionaleffort has been necessary to remedy additionalbottlenecks that appear with even large config-
urations.
For example, we discovered that at 256 pro-cessors and above, we encountered a live lockearly in system boot because hundreds of idleCPUs are load-balancing and are racing in con-tention on one or a few busy CPUs. The con-tention is so severe that the busy CPU’s sched-uler cannot itself acquire its own run queuelock, and thus the system live locks.
A remedy we applied in our Altix 2.4-basedkernel was to introduce a progressively longerback off between successive load-balancing at-tempts, if the load-balancing CPU continuesto be unsuccessful in finding a task to pull-migrate. Perhaps all the busiest CPU’s tasksare pinned to that CPU, or perhaps all thetasks are still cache-hot. Regardless of thereason, a load-balancing failure results in thatCPU delaying the next load-balance attemptby another incremental increase in time. Thisalgorithm effectively solved the live lock, aswell as improved other high-contention con-flicts on a busiest CPU’s run queue lock (e.g.,always finding pinned tasks that can never bemigrated).
This load-balance back off algorithm did notget accepted into the early 2.6 kernels. The lat-est 2.6.7 CPU scheduler, as developed by NickPiggin, incorporates a similar back off algo-rithm. However, this algorithm (at least as itappears in 2.6.7-rc2) continues to cause a boot-time live lock at 512 processors on Altix so weare continuing to investigate this matter.
Page Cache
Managing the page cache in Altix has been achallenging problem. The reason is that whilea large Altix system may have a lot of memory,each node in the system only has a relativelysmall fraction of that memory available as lo-cal memory. For example, on a 512 CPU sys-

138 • Linux Symposium 2004 • Volume One
tem, if the entire system has 512 GB of mem-ory, each node on the system has only 2 GB oflocal memory; less than 0.4% of the availablememory on the system is local. When you con-sider that it is quite common on such systemsto deal with files that are tens of GB in size, itis easy to understand how the page cache couldconsume all of the memory on several nodes inthe system just doing normal, buffered-file I/O.
Stated another way, this is the challenge of alarge NUMA system: all memory is address-able, but only a tiny fraction of that memoryis local. Users of NUMA systems need toplace their most frequently accessed data in lo-cal memory; this is crucial to obtain the max-imum performance possible from the system.Typically this is done by allocating pages on afirst-touch basis; that is, we attempt to allocatea page on the node where it is first referenced.If all of the local memory on a node is con-sumed by the page cache, then these local stor-age allocations will spill over to other (remote)nodes, the result being a potentially significantimpact on program performance.
Similarly, it is important that the amount offree memory be balanced across idle nodes inthe system. An imbalance could lead to somecomponents of a parallel computation runningslower than others because not all componentsof the computation were able to allocate theirmemory entirely out of local storage. Since theoverall speed of parallel computation is deter-mined by the execution of its slowest compo-nent, the performance of the entire applicationcan be impacted by a non-local storage alloca-tion on only a few nodes.
One might think thatbdflush or kupdated(in a Linux 2.4 system) would be responsi-ble for cleaning up unused page-cache pages.As the OLS reader knows, these daemonsare responsible not for deallocating page-cachepages, but cleaning them. It is the swap dae-
mon kswapd that is responsible for causingpage-cache pages to be deallocated. However,in many situations we have encountered, eventhough multiple nodes of the system would becompletely out of local memory, there wouldstill be lots of free memory elsewhere in thesystem. As a result,kswapd will never start.Once the system gets into such a state, thelocal memory on those nodes can remain al-located entirely to page-cache pages for verylong stretches of time since as far as the ker-nel is concerned there is no memory “pres-sure”. To get around this problem, particu-larly for benchmarking studies, users have of-ten resorted to programs that allocate and touchall of the memory on the system, thus causingkswapd to wake up and free unneeded buffercache pages.
We have dealt with this problem in a numberof ways, but the first approach was to changepage_cache_alloc() so that insteadof allocating the page on the local node, wespread allocations across all nodes in thesystem. To do this, we added a new GFPflag: GFP_ROUND_ROBINand a new proce-dure: alloc_pages_round_robin() .alloc_pages_round_robin() main-tains a counter in per-CPU storage; thecounter is incremented on each call topage_cache_alloc() . The value of thecounter, modulus the number of nodes inthe system, is used to select thezonelistpassed to__alloc_pages() . Like otherNUMA implementations, in Linux for Altixthere is azonelist for each node, and thezonelist s are sorted in nearest neighbororder with thezone for the local node as thefirst entry of thezonelist . The result is thateach timepage_cache_alloc() is called,the returned page is allocated on the next nodein sequence, or as close as possible to thatnode.
The rationale for allocating page-cache pages

Linux Symposium 2004 • Volume One • 139
in this way is that while pages are local re-sources, the page cache is a global resource, us-able by all processes on the system. Thus, evenif a process is bound to a particular node, ingeneral it does not make sense to allocate page-cache pages just on that node, since some otherprocess in the system may be reading that samefile and hence sharing the pages. So instead offlooding the current node with the page-cachepages for files that processes on that node haveopened, we “tax” every node in the system witha fraction of the page-cache pages. In thisway, we try to conserve a scarce resource (localmemory) by spreading page-cache allocationsover all nodes in the system.
However, even this step was not enough to keeplocal storage usage balanced among nodes inthe system. After reading a 10 GB file, forexample, we found that the node where thereading process was running would have up to40,000 pages more storage allocated than othernodes in the system. It turned out the reason forthis was that buffer heads for the read opera-tion were being allocated locally. To solve thisproblem in our Linux 2.4.21 kernel for Altix,we modifiedkmem_cache_grow() so thatit would pass theGFP_ROUND_ROBINflag tokmem_getpages() with the result that theslab caches on our systems are now also allo-cated out of round-robin storage. Of course,this is not a perfect solution, since there are sit-uations where it makes perfect sense to allocatea slab cache entry locally; but this was an expe-dient solution appropriate for our product. ForLinux 2.6 for Altix we would like to see theslab allocator be made NUMA aware. (Man-fred Spraul has created some patches to do thisand we are currently evaluating these changes.)
The previous two changes solved many of thecases where a local storage could be exhaustedby allocation of page-cache pages. However,they still did not solve the problem of local al-locations spilling off node, particularly in those
cases where storage allocation was tight acrossthe entire system. In such situations, the sys-tem would often start running the synchronousswapping code even though most (if not all) ofthe page-cache pages on the system were cleanand unreferenced outside of the page-cache.With the very-large memory sizes typical ofour larger Altix customers, entering the syn-chronous swapping code needs to be avoidedif at all possible since this tends to freeze thesystem for 10s of seconds. Additionally, theround robin allocation fixes did not solve theproblem of poor and unrepeatable performanceon benchmarks due to the existence of signif-icant amounts of page-cache storage left overfrom previous executions.
To solve these problems, we introduced a rou-tine calledtoss_buffer_cache_pages_node() (referred to here astoss() , forbrevity). In a related change, we made theactive and inactive lists per node rather thanglobal. toss() first scans the inactive list(on a particular node) looking for idle page-cache pages to release back to the free pagepool. If not enough such pages are foundon the inactive list, then the active list isalso scanned. Finally, iftoss() has notcalled shrink_slab_caches() recently,that routine is also invoked in order to moreaggressively free unused slab-cache entries.toss() was patterned after the main loopof shrink_caches() except that it wouldnever callswap_out() and if it encountereda page that didn’t look to be easily free able, itwould just skip that page and go on to the nextpage.
A call to toss() was added in__alloc_pages() in such a way that if allocation onthe current node fails, then before trying to al-locate from some other node (i. e. spillingto another node), the system will first see ifit can free enough page-cache pages from thecurrent node so that the current node alloca-

140 • Linux Symposium 2004 • Volume One
tion can succeed. In subsequent allocationpasses,toss() is also called to free page-cache pages on nodes other than the currentone. The result of this change is that cleanpage-cache pages are effectively treated as freememory by the page allocator.
At the same time that thetoss() codewas added, we added a new user com-mandbcfree that could be used to free allidle page-cache pages. (On the__alloc_pages() path, toss() would only try tofree 32 pages per node.) Thebcfree com-mand was intended to be used only for reset-ting the state of the page cache before running abenchmark, and in lieu of rebooting the systemin order to get a clean system state. However,our customers found that this command couldbe used to reduce the size of the page cacheand to avoid situations where large amountsof buffered-file I/O could force the system tobegin swapping. Sincebcfree kills the en-tire page-cache, however, this was regardedas a substandard solution that could also hurtread performance of cached data and we beganlooking for another way to solve this “BIGIO”problem.
Just to be specific, the BIGIO problem we weretrying to solve was based on the behavior of ourLinux 2.4.21 kernel for Altix. A customer re-ported that on a 256 GB Altix system, if 200GB were allocated and 50 GB free, that if theuser program then tried to write 100 GB of dataout to disk, the system would start to swap,and then in many cases fill up the swap space.At that point our Out-of-memory (OOM) killerwould wake up and kill the user program! (Seethe next section for discussion of our OOMkiller changes.)
Initially we were able to work around thisproblem by increasing the amount of swapspace on the system. Our experiments showedthat with an amount of swap space equal to
one-quarter the main memory size, the 256 GBexample discussed above would continue tocompletion without the OOM killer being in-voked. I/O performance during this phase wastypically one-half of what the hardware coulddeliver, since two I/O operations often had tobe completed: one to read the data in fromthe swap device, and one to write the data tothe output file. Additionally, while the swapscan was active, the system was very sluggish.These problems led us to search for another so-lution.
Eventually what we developed is an aggressivemethod of trimming the page cache when itstarted to grow too big. This solution involvedseveral steps:
(1) We first added a new page list, thereclaim_list . This increased the size ofstruct page by another 16 bytes. On oursystem,struct page is allocated on cache-aligned boundaries anyway, so this really didnot cause an increase in storage, since the cur-rent struct page size was less than 112bytes. Pages were added to the reclaim listwhen they were inserted into the page cache.The reclaim list is per node, with per nodelocking. Pages were removed from the reclaimlist when they were no longer reclaimable; thatis, they were removed from the reclaim listwhen they were marked as dirty due to bufferfile-I/O or when they were mapped into an ad-dress space.
(2) We rewrotetoss() to scan the reclaim listinstead of the inactive and active lists. Hereinwe will refer to the new version oftoss() astoss_fast() .
(3) We introduced a variant ofpage_cache_alloc() called page_cache_alloc_limited() . Associated with this newroutine were two control variables settablevia sysctl() : page_cache_limit andpage_cache_limit_threshold .

Linux Symposium 2004 • Volume One • 141
(4) We modified the generic_file_write() path to call page_cache_alloc_limited() instead of page_cache_alloc() . page_cache_alloc_limited() examines the size of the pagecache. If the total amount of free memoryin the system is less thanpage_cache_limit_threshold and the size of the pagecache is larger thanpage_cache_limit ,then page_cache_alloc_limited()calls page_cache_reduce() to freeenough page-cache pages on the system tobring the page cache size down belowpage_cache_limit . If this succeeds, thenpage_cache_alloc_limited() calls page_cache_alloc to allocate the page. If not,then we wakeupbdflush and the currentthread is put to sleep for 30ms (a tunableparameter)
The rationale for thereclaim_list andtoss_fast() was that when we needed totrim the page cache, practically all pages inthe system would typically be on the inactivelist. The existingtoss() routine scannedthe inactive list and thus was too slow to callfrom generic_file_write . Moreover,most of the pages on the inactive list werenot reclaimable anyway. Most of the pageson thereclaim_list are reclaimable. Asa resulttoss_fast() runs much faster andis more efficient at releasing idle page-cachepages than the old routine.
The rationale for thepage_cache_limit_threshold in addition to the page_cache_limit is that if there is lots of freememory then there is no reason to trim the pagecache. One might think that because we onlytrim the page cache on the file write path thatthis approach would still let the page cacheto grow arbitrarily due to file reads. Unfortu-nately, this is not the case, since the Linux ker-nel in normal multiuser operation is constantlywriting something to the disk. So, a page cache
limit enforced at file write time is also an effec-tive limit on the size of the page cache due tofile reads.
Finally, the rationale for delaying the callingtask whenpage_cache_reduce() fails isthat we do not want the system to start swap-ping to make space for new buffered I/O pages,since that will reduce I/O bandwidth by asmuch as one-half anyway, as well as take a lotof CPU time to figure out which pages to swapout. So it is better to reduce the I/O bandwidthdirectly, by limiting the rate of requested I/O,instead of allowing that I/O to proceed at ratethat causes the system to be overrun by page-cache pages.
Thus far, we have had good experience withthis algorithm. File I/O rates are not substan-tially reduced from what the hardware can pro-vide, the system does not start swapping, andthe system remains responsive and usable dur-ing the period of time when the BIGIO is run-ning.
Of course, this entire discussion is specific toLinux 2.4.21. For Linux 2.6, we have plans toevaluate whether this is a problem in the sys-tem at all. In particular, we want to see if anappropriate setting forvm_swappiness tozero can eliminate the “BIGIO causes swap-ping” problem. We also are interested in eval-uating the recent set of VM patches that NickPiggin [6] has assembled to see if they elimi-nate this problem for systems of the size of alarge Altix.
VM and Memory Allocation Fixes
In addition to the page-cache changes de-scribed in the last section, we have made anumber of smaller changes related to virtualmemory and paging performance.
One set of such changes increased the paral-lelism of page-fault handling for anonymous

142 • Linux Symposium 2004 • Volume One
pages in multi-threaded applications. Theseapplications allocate space using routines thateventually call mmap() ; the result is thatwhen the application touches the data area forthe first time, it causes a minor page fault.These faults are serviced while holding theaddress space’spage_table_lock . If theaddress space is large and there are a largenumber of threads executing in the addressspace, this spinlock can be an initialization-time bottleneck for the application. Examina-tion of the handle_mm_fault() path forthis case shows that thepage_table_lockis acquired unconditionally but then released assoon as we have determined that this is a not-present fault for an anonymous page. So, wereordered the code checks inhandle_mm_fault() to determine in advance whether ornot this was the case we were in, and if so, toskip acquiring the lock altogether.
The second place thepage_table_lockwas used on this path was indo_anonymous_page() . Here, thelock was re-acquired to make sure that theprocess of allocating a page frame and fillingin the pte is atomic. On Itanium, stores topage-table entries are normal stores (that is,the set_pte macro evaluates to a simplestore). Thus, we can usecmpxchg to updatethe pte and make sure that only one threadallocates the page and fills in the pte. Thecompare and exchange effectively lets us lockon each individual pte. So, for Altix, wehave been able to completely eliminate thepage_table_lock from this particularpage-fault path.
The performance improvement from thischange is shown in Figure 1. Here we show thetime required to initially touch 96 GB of data.As additional processors are added to the prob-lem, the time required for both the baseline-Linux and Linux for Altix versions decreaseuntil around 16 processors. At that point the
page_table_lock starts to become a sig-nificant bottleneck. For the largest number ofprocessors, even the time for the Linux for Al-tix case is starting to increase again. We be-lieve that this is due to contention for the ad-dress space’smmapsemaphore.
0
100
200
300
400
500
600
1 10 100
Tim
e to
Tou
ch D
ata
(Sec
onds
)
Number of Processors
baseline 2.4Linux 2.4 for Altix
Figure 1:Time to initially touch 96 GB of data.
This is particularly important for HPC applica-tions since OpenMP™[5], a common parallelprogramming model for FORTRAN, is imple-mented using a single address space, multiple-thread programming model. The optimizationdescribed here is one of the reasons that Al-tix has recently set new performance recordsfor the SPEC® SPEComp® L2001 benchmark[7].
While the above measurements were taken us-ing Linux 2.4.21 for Altix, a similar problemexists in Linux 2.6. For many other architec-tures, this same kind of change can be made;i386 is one of the exceptions to this statement.We are planning on porting our Linux 2.4.21based changes to Linux 2.6 and submitting thechanges to the Linux community for inclusionin Linux 2.6. This may require moving partof do_anonymous_page() to architecture

Linux Symposium 2004 • Volume One • 143
dependent code to allow for the fact that notall architectures can use the compare and ex-change approach to eliminate the use of thepage_table_lock in do_anonymous_page() . However, the performance improve-ment shown in Figure 1 is significant for Altixso we would we would like to explore someway of incorporating this code into the main-line kernel.
We have encountered similar scalability lim-itations for other kinds of page-fault behav-ior. Figure 2 shows the number of page faultsper second of wall clock time measured formultiple processes running simultaneously andfaulting in a 1 GB/dev/zero mapping. Un-like the previous case described here, in thiscase each process has its own private mapping.(Here the number of processes is equal to thenumber of CPUs.) The dramatic difference be-tween the baseline 2.4 and 2.6 cases and Linuxfor Altix is due to elimination of a lock in thesuper block for/dev/zero .
10000
100000
1e+06
1e+07
1 10 100
Page
Fau
lts/s
econ
d (w
all c
lock
)
CPUS
2.4 baselineLinux 2.4 for Altix
2.6 baseline
Figure 2: Page Faults per Second of Wall ClockTime.
The lock in the super block protects twocounts: One count limits the maximum num-ber of /dev/zero mappings to263; the sec-
ond count limits the number of pages assignedto a /dev/zero mapping to263. Neitherone of these counts is particularly useful fora /dev/zero mapping. We eliminated thislock and obtained a dramatic performance im-provement for this micro-benchmark (at 512CPUs the improvement was in excess of 800x).This optimization is important in decreasingstartup time for large message-passing appli-cations on the Altix system.
A related change is to distribute the count ofpages in the page cache from a single globalvariable to a per node variable. Because ev-ery processor in the system needs to updatethe page-cache count when adding or remov-ing pages from the page cache, contention forthe cache line containing this global variablebecomes significant. We changed this globalcount to a per-node count. When a page is in-serted into (or removed from) the page cache,we update the page cache-count on the samenode as the page itself. When we need thetotal number of pages in the page cache (forexample if someone reads/proc/meminfo )we run a loop that sums the per node counts.However, since the latter operation is much lessfrequent than insertions and deletions from thepage cache, this optimization is an overall per-formance improvement.
Another change we have made in the VMsubsystem is in the out-of-memory (OOM)killer for Altix. In Linux 2.4.21, theOOM killer is called from the top ofmemory-free and swap-out call chain.oom_kill() is called from try_to_free_pages_zone() when calls to shrink_caches() at memory priority levels 6through 0 have all failed. Insideoom_kill()a number of checks are performed, and if anyof these checks succeed, the system is declaredto not be out-of-memory. One of those checksis “if it has been more than 5 seconds sinceoom_kill() was last called, then we are not

144 • Linux Symposium 2004 • Volume One
OOM.” On a large-memory Altix system, it caneasily take much longer than that to completethe necessary calls toshrink_caches() .The result is that an Altix system never goesOOM in spite of the fact that swap space is fulland there is no memory to be allocated.
It seemed to us that part of the problem hereis the amount of time it can take for a swapfull condition (readily detectable intry_to_swap_out() to bubble all the way upto the top level intry_to_free_pages_zone() , especially on a large memory ma-chine. To solve this problem on Altix, wedecided to drive the OOM killer directly offof detection of swap-space-full condition pro-vided that the system also continues to try toswap out additional pages. A count of thenumber of successful swaps and unsuccess-ful swap attempts is maintained intry_to_swap_out() . If, in a 10 second interval, thenumber of successful swap outs is less thanone percent of the number of attempted swapouts, and the total number of swap out attemptsexceeds a specified threshold, thentry_to_swap_out() ) will directly wake the OOMkiller thread (also new in our implementation).This thread will wait another 10 seconds, andif the out-of-swap condition persists, it will in-vokeoom_kill() to select a victim and killit. The OOM killer thread will repeat this sleepand kill cycle until it appears that swap spaceis no longer full or the number of attempts toswap out new pages (since the thread went tosleep) falls below the threshold.
In our experience, this has made invocation ofthe OOM killer much more reliable than it wasbefore, at least on Altix. Once again, this im-plementation was for Linux 2.4.21; we are inthe process of evaluating this problem and theassociated fix on Linux 2.6 at the present time.
Another fix we have made to the VM sys-tem in Linux 2.4.21 for Altix is in handling
of HUGETLB pages. The existing implemen-tation in Linux 2.4.21 allocates HUGETLBpages to an address space atmmap() time (seehugetlb_prefault() ); it also zeroes thepages at this time. This processing is done bythe thread that makes themmap() call. Inparticular, this means that zeroing of the al-located HUGETLB pages is done by a sin-gle processor. On a machine with 4 TB ofmemory and with as much memory allocatedto HUGETLB pages as possible, our measure-ments have shown that it can take as long as5,000 seconds to allocate and zero all availableHUGETLB pages. Worse yet, the thread thatdoes this operation holds the address space’smmap_semand thepage_table_lock forthe entire 5,000 seconds. Unfortunately, manycommands that query system state (such aspsandw) also wish to acquire one of these locks.The result is that the system appears to be hungfor the entire 5,000 seconds.
We solved this problem on Altix by changingthe implementation of HUGETLB page allo-cation fromprefault to allocate on fault. Manyothers have created similar patches; our patchwas unique in that it also allowed zeroing ofpages to occur in parallel if the HUGETLBpage faults occurred on different processors.This was crucial to allow a large HUGETLBpage region to be faulted into an address spacein parallel, using as many processors as possi-ble. For example, we have observed speedupsof 25x using 16 processors to touch O(100 GB)of HUGETLB pages. (The speedup is superlinear because if you use just one processorit has to zero many remote pages, whereas ifyou use more processors, at least some of thepages you are zeroing are local or on nearbynodes.) Assuming we can achieve the samekind of speedup on a 4 TB system, we wouldreduce the 5,000 second time stated above to200 seconds.
Recently, we have worked with Kenneth Chen

Linux Symposium 2004 • Volume One • 145
to get a similar set of changes proposed forLinux 2.6 [3]. Once this set of changes is ac-cepted into the mainline this particular problemwill be solved for Linux 2.6. These changes arealso necessary for Andi Kleen’s NUMA place-ment algorithms [4] to apply to HUGETLBpages, since otherwise pages are placed athugetlb_prefault() time.
A final set of changes is related to large kerneltables. As previously mentioned, on an Altixsystem with 512 processors, less than 0.4% ofthe available memory is local. Certain tables inthe Linux kernel are sized to be on the order ofone percent of available memory. (An exam-ple of this is the TCP/IP hash table.) Allocat-ing a table of this size can use all of the localmemory on a node, resulting in exactly the kindof storage-allocation imbalance we developedthe page-cache changes to solve. To avoid thisproblem, we also implement round-robin allo-cation of these large tables. Our current tech-nique usesvm_alloc() to do this. Unfor-tunately, this is not portable across all archi-tectures, since certain architectures have lim-ited amounts of space that can be allocated byvm_alloc() . Nonetheless, this is a changethat we need to make; we are still exploringways of making this change acceptable to theLinux community.
Once we have solved the initial allocationproblem for these tables, there is still the prob-lem of getting them appropriately sized for anAltix system. Clearly if there are 4 TB of mainmemory, it does not make much sense to allo-cate a TCP/IP hash table of 40 GB, particularlysince the TCP/IP traffic into an Altix systemdoes not increase with memory size the wayone might expect it to scale with a traditionalLinux server. We have seen cases where sys-tem performance is significantly hampered dueto lookups in these overly large tables. At themoment, we are still exploring a solution ac-ceptable to the community to solve this partic-
ular problem.
I/O Changes for Altix
One of the design goals for the Altix systemis that it support standard PCI devices andtheir associated Linux drivers as much as pos-sible. In this section we discuss the perfor-mance improvements built into the Altix hard-ware and supported through new driver inter-faces in Linux that help us to meet this goalwith excellent performance even on very largeAltix systems.
According to the PCI specification, DMAwrites and PIO read responses are strongly or-dered. On large NUMA systems, however,DMA writes can take a long time to complete.Since most PIO reads do not imply completionof a previous DMA write, relaxing the orderingrules of DMA writes and PIO read responsescan greatly improve system performance.
Another large system issue relates to initiatingPIO writes from multiple CPUs. PIO writesfrom two different CPUs may arrive out of or-der at a device. The usual way to ensure order-ing is through a combination of locking and aPIO read (see Documentation/io_ordering.txt).On large systems, however, doing this read canbe very expensive, particularly if it must be or-dered with respect to unrelated DMA writes.
Finally, the NUMA nature of large machinesmake some optimizations obvious and desir-able. Many devices use so-called consis-tent system memory for retrieving commandsand storing status information; allocating thatmemory close to its associated device makessense.
Making non–dependent PIO reads fast
In its I/O chipsets, SGI chose to relax the order-ing between DMAs and PIOs, instead adding

146 • Linux Symposium 2004 • Volume One
a barrier attribute to certain DMA writes (toconsistent PCI allocations on Altix) and to in-terrupts. This works well with controllers thatuse DMA writes to indicate command com-pletions (for example a SCSI controller with aresponse queue, where the response queue isallocated usingpci_alloc_consistent ,so that writes to the response queue have thebarrier attribute). When we ported Linux toAltix, this behavior became a problem, be-cause many Linux PCI drivers use PIO read re-sponses to imply a status of a DMA write. Forexample, on an IDE controller, a bit status reg-ister read is performed to find out if a commandis complete (command complete status impliesthat DMA writes of that command’s data arecompleted). As a result, SGI had to implementa rather heavyweight mechanism to guaranteeordering of DMA writes and PIO reads. Thismechanism involves doing an explicit flush ofDMA write data after each PIO read.
For the cases in which strong ordering of PIOread responses and DMA writes are not nec-essary, a new API was needed so that driverscould communicate that a given PIO read re-sponse could used relaxed ordering with re-spect to prior DMA writes. Theread_relaxed API [8] was added early in the 2.6series for this purpose, and mirrors the normalread routines, which have variants for varioussized reads.
The results below show how expensive a nor-mal PIO read transaction can be, especially ona system doing a lot of I/O (and thus DMA).
Type of PIO Time (ns)normal PIO read 3875relaxed PIO read 1299
Table 1: Normal vs. relaxed PIO reads on anidle system
It remains to be seen whether this API will alsoapply to the newly added RO bit in the PCI-
Type of PIO Time (ns)normal PIO read 4889relaxed PIO read 1646
Table 2: Normal vs. relaxed PIO reads on abusy system
X specification—the author is hopeful! Eitherway, it does give hardware vendors who wantto support Linux some additional flexibility intheir design.
Ordering posted writes efficiently
On many platforms, PIO writes from differentCPUs will not necessarily arrive in order (i.e.,they may be intermixed) even when locking isused. Since the platform has no way of know-ing whether a given PIO read depends on pre-ceding writes, it has to guarantee that all writeshave completed before allowing a read trans-action to complete. So performing a read priorto releasing a lock protecting a region doingwrites is sufficient to guarantee that the writesarrive in the correct order.
However, performing PIO reads can be an ex-pensive operation, especially if the device is ona distant node. SGI chipset designers foresawthis problem, however, and provided a way toensure ordering by simply reading a registerfrom the chipset on the local node. When theregister indicates that all PIO writes are com-plete, it means they have arrived at the chipsetattached to the device, and so are guaranteedto arrive at the device in the intended order.The SGI sn2 specific portion of the Linux ia64port (sn2 is the architecture name for Altix inthe Linux kernel source tree) provides a smallfunction,sn_mmiob() (for memory–mappedI/O barrier, analogous to themb() macro), todo just that. It can be used in place of readsthat are intended to deal with posted writes andprovides some benefit:

Linux Symposium 2004 • Volume One • 147
Type of flush Time (ns)regular PIO read 5940relaxed PIO read 2619sn_mmiob() 1610(local chipset read alone) 399
Table 3: Normal vs. fast flushing of 5 PIOwrites
Adding this API to Linux (i.e., making it non-sn2-specific) was discussed some time ago [9],and may need to be raised again, since it doesappear to be useful on Altix, and is probablysimilarly useful on other platforms.
Local allocation of consistent DMA mappings
Consistent DMA mappings are used frequentlyby drivers to store command and status buffers.They are frequently read and written by thedevice that owns them, so making sure theycan be accessed quickly is important. The ta-ble below shows the difference in the num-ber of operations per second that can beachieved using local versus remote allocationof consistent DMA buffers. Local alloca-tions were guaranteed by changing thepci_alloc_consistent function so that it callsalloc_pages_node using the node closestto the PCI device in question.
Type I/Os per secondLocal consistent buffer 46231Remote consistent buffer 41295
Table 4: Local vs. remote DMA buffer alloca-tion
Although this change is platform specific, itcan be made generic if apci_to_node orpci_to_nodemask routine is added to theLinux topology API.
Concluding Remarks
Today, our Linux 2.4.21 kernel for Altix pro-vides a productive platform for our high-performance-computing users who desire toexploit the features of the SGI Altix 3000 hard-ware. To achieve this goal, we have made anumber of changes to our Linux for Altix ker-nel. We are now in the process of either movingthose changes forward to Linux 2.6 for Altix,or of evaluating the Linux 2.6 kernel on Altixin order to determine if these changes are in-deed needed at all. Our goal is to develop aversion of the Linux 2.6 kernel for Altix thatnot only supports our HPC customers equallywell as our existing Linux 2.4.21 kernel, butalso consists as much as possible of commu-nity supported code.
References
[1] Ray Bryant and John Hawkes, LinuxScalability for Large NUMA Systems,Proceedings of the 2003 Ottawa LinuxSymposium, Ottawa, Ontario, Canada,(July 2003).
[2] Daniel Lenoski, James Laudon, TrumanJoe, David Nakahira, Luis Stevens,Anoop Gupta, and John Hennesy, TheDASH prototype: Logic overhead andperformance,IEEE Transactions onParallel and Distributed Systems,4(1):41-61, January 1993.
[3] Kenneth Chen, “hugetlb demand pagingpatch part [0/3],”[email protected],2004-04-13 23:17:04,http://marc.theaimsgroup.com/?l=linux-kernel&m=108189860419356&w=2
[4] Andi Kleen, “Patch: NUMA API forLinux,” [email protected],

148 • Linux Symposium 2004 • Volume One
Tue, 6 Apr 2004 15:33:22 +0200,http://lwn.net/Articles/79100/
[5] http://www.openmp.org
[6] Nick Piggin, “MM patches,”http://www.kerneltrap.org/~npiggin/nickvm-267r1m1.gz
[7] http://www.spec.org/omp/results/ompl2001.html
[8] http://linux.bkbits.net:8080/linux-2.5/cset%4040213ca0d3eIznHTPAR_kLCsMZI9VQ?nav=index.html|ChangeSet@-1d
[9] http://www.cs.helsinki.fi/linux/linux-kernel/2002-01/1540.html
© 2004 Silicon Graphics, Inc. Permission to re-distribute in accordance with Ottawa Linux Sym-posium paper submission guidelines is granted; allother rights reserved. Silicon Graphics, SGI andAltix are registered trademarks and OpenMP is atrademark of Silicon Graphics, Inc., in the U.S.and/or other countries worldwide. Linux is a regis-tered trademark of Linus Torvalds in several coun-tries. Intel and Itanium are trademarks or registeredtrademarks of Intel Corporation or its subsidiariesin the United States and other countries. Red Hatand all Red Hat-based trademarks are trademarksor registered trademarks of Red Hat, Inc. in theUnited States and other countries. All other trade-marks mentioned herein are the property of theirrespective owners.

Get More Device Drivers out of the Kernel!
Peter Chubb∗
National ICT Australiaand
The University of New South [email protected]
Abstract
Now that Linux has fast system calls, good(and getting better) threading, and cheap con-text switches, it’s possible to write devicedrivers that live in user space for whole newclasses of devices. Of course, some devicedrivers (Xfree, in particular) have always runin user space, with a little bit of kernel support.With a little bit more kernel support (a way toset up and tear down DMA safely, and a gen-eralised way to be informed of and control in-terrupts) almost any PCI bus-mastering devicecould have a user-mode device driver.
I shall talk about the benefits and drawbacksof device drivers being in user space or ker-nel space, and show that performance concernsare not really an issue—in fact, on some plat-forms, our user-mode IDE driver out-performsthe in-kernel one. I shall also present profilingand benchmark results that show where time isspent in in-kernel and user-space drivers, anddescribe the infrastructure I’ve added to theLinux kernel to allow portable, efficient user-space drivers to be written.
∗This work was funded by HP, National ICT Aus-tralia, the ARC, and the University of NSW through theGelato programme (http://www.gelato.unsw.edu.au )
1 Introduction
Normal device drivers in Linux run in the ker-nel’s address space with kernel privilege. Thisis not the only place they can run—see Fig-ure 1.
Kernel
Own
Client
A
B C
D
UserKernel
Privilege
Add
ress
Spa
ce
Figure 1: Where a Device Driver can Live
Point A is the normal Linux device driver,linked with the kernel, running in the kerneladdress space with kernel privilege.
Device drivers can also be linked directly withthe applications that use them (Point B)—the so-called ‘in-process’ device drivers pro-posed by [Keedy, 1979]—or run in a separateprocess, and be talked to by an IPC mech-anism (for example, an X server, point D).They can also run with kernel privilege, butwith a separate kernel address space (Point

150 • Linux Symposium 2004 • Volume One
C) (as in the Nooks system described by[Swift et al., 2002]).
2 Motivation
Traditionally, device drivers have been devel-oped as part of the kernel source. As such, theyhaveto be written in the C language, and theyhave to conform to the (rapidly changing) in-terfaces and conventions used by kernel code.Even though drivers can be written as mod-ules (obviating the need to reboot to try outa new version of the driver1), in-kernel drivercode has access to all of kernel memory, andruns with privileges that give it access to all in-structions (not just unprivileged ones) and toall I/O space. As such, bugs in drivers can eas-ily cause kernel lockups or panics. And variousstudies (e.g., [Chou et al., 2001]) estimate thatmore than 85% of the bugs in an operating sys-tem are driver bugs.
Device drivers that run as user code, how-ever, can use any language, can be developedusing any IDE, and can use whatever inter-nal threading, memory management, etc., tech-niques are most appropriate. When the infras-tructure for supporting user-mode drivers is ad-equate, the processes implementing the drivercan be killed and restarted almost with im-punity as far as the rest of the operating systemgoes.
Drivers that run in the kernel have to be up-dated regularly to match in-kernel interfacechanges. Third party drivers are therefore usu-ally shipped as source code (or with a compi-lable stub encapsulating the interface) that hasto be compiled against the kernel the driver isto be installed into.
This means that everyone who wants to run a
1except that many drivers currently cannot be un-loaded
third-party driver also has to have a toolchainand kernel source on his or her system, or ob-tain a binary for their own kernel from a trustedthird party.
Drivers for uncommon devices (or devices thatthe mainline kernel developers do not use reg-ularly) tend to lag behind. For example, in the2.6.6 kernel, there are 81 drivers known to bebroken because they have not been updated tomatch the current APIs, and a number morethat are still using APIs that have been depre-cated.
User/kernel interfaces tend to change muchmore slowly than in-kernel ones; thus auser-mode driver has much more chance ofnot needing to be changed when the kernelchanges. Moreover, user mode drivers can bedistributed under licences other than the GPL,which may make them more attractive to somepeople2.
User-mode drivers can be either closely orloosely coupled with the applications that usethem. Two obvious examples are the X server(XFree86) which uses a socket to communicatewith its clients and so has isolation from ker-nel and client address spaces and can be verycomplex; and the Myrinet drivers, which areusually linked into their clients to gain perfor-mance by eliminating context switch overheadon packet reception.
The Nooks work [Swift et al., 2002] showedthat by isolating drivers from the kernel ad-dress space, the most common programmingerrors could be made recoverable. In Nooks,drivers are insulated from the rest of the kernelby running each in a separate address space,and replacing the driver↔ kernel interfacewith a new one that uses cross-domain pro-cedure calls to replace any procedure calls inthe ABI, and that creates shadow copies of any
2for example, the ongoing problems with the Nvidiagraphics card driver could possibly be avoided.

Linux Symposium 2004 • Volume One • 151
shared variables in the protected address spaceof the driver.
This approach provides isolation, but also hasproblems: as the driver model changes, thereis quite a lot of wrapper code that has to bechanged to accommodate the changed APIs.Also, the value of any shared variable is frozenfor the duration of a driver ABI call. TheNooks work is uniprocessor only; locking is-sues therefore have not yet been addressed.
Windriver [Jungo, 2003] allows developmentof user mode device drivers. It loads a pro-prietary device module/dev/windrv6 ; usercode can interact with this device to setup andteardown DMA, catch interrupts, etc.
Even from user space, of course, it is possi-ble to make your machine unusable. Devicedrivers have to be trusted to a certain extent todo what they are advertised to do; this meansthat they can program their devices, and possi-bly corrupt or spy on the data that they transferbetween their devices and their clients. Mov-ing a driver to user space does not change this.It does however make it less likely that a faultin a driver will affect anything other than itsclients
3 Existing Support
Linux has good support for user-mode driversthat do not need DMA or interrupt handling—see, e.g., [Nakatani, 2002].
The ioperm() andiopl() system calls al-low access to the first 65536 I/O ports; and,with a patch from Albert Calahan3 one canmap the appropriate parts of/proc/bus/pci/...togain access to memory-mapped registers. Oron some architectures it is safe tommap()/dev/mem.
3http://lkml.org/lkml/2003/7/13/258
It is usually best to use MMIO if it is avail-able, because on many 64-bit platforms thereare more than 65536 ports—the PCI specifi-cation says that there are232 ports available—(and on many architectures the ports are emu-lated by mapping memory anyway).
For particular devices—USB input devices,SCSI devices, devices that hang off the paral-lel port, and video drivers such as XFree86—there is explicit kernel support. By opening afile in /dev, a user-mode driver can talk throughthe USB hub, SCSI controller, AGP controller,etc., to the device. In addition, theinput han-dler allows input events to be queued back intothe kernel, to allow normal event handling toproceed.
libpci allows access to the PCI configurationspace, so that a driver can determine what in-terrupt, IO ports and memory locations are be-ing used (and to determine whether the deviceis present or not).
Other recent changes—an improved scheduler,better and faster thread creation and synchro-nisation, a fully preemptive kernel, and fastersystem calls—mean that it is possible to writea driver that operates in user space that is al-most as fast as an in-kernel driver.
4 Implementing the Missing Bits
The parts that are missing are:
1. the ability to claim a device from userspace so that other drivers do not try tohandle it;
2. The ability to deliver an interrupt from adevice to user space,
3. The ability to set up and tear-down DMAbetween a device and some process’smemory, and

152 • Linux Symposium 2004 • Volume One
4. the ability to loop a device driver’s con-trol and data interfaces into the appropri-ate part of the kernel (so that, for exam-ple, an IDE driver can appear as a standardblock device), preferably without havingto copy any payload data.
The work at UNSW covers only PCI devices,as that is the only bus available on all of thearchitectures we have access to (IA64, X86,MIPS, PPC, alpha and arm).
4.1 PCI interface
Each device should have only a single driver.Therefore one needs a way to associate a driverwith a device, and to remove that associationautomatically when the driver exits. This hasto be implemented in the kernel, as it is onlythe kernel that can be relied upon to clean upafter a failed process. The simplest way tokeep the association and to clean it up in Linuxis to implement a new filesystem, using thePCI namespace. Open files are automaticallyclosed when a process exits, so cleanup alsohappens automatically.
A new system call,usr_pci_open(intbus, int slot, int fn) returns a filedescriptor. Internally, it callspci_enable_device() andpci_set_master() to setup the PCI device after doing the standardfilesystem boilerplate to set up a vnode and astruct file .
Attempts to open an already-opened PCI de-vice will fail with -EBUSY.
When the file descriptor is finally closed, thePCI device is released, and any DMA map-pings removed. All files are closed when a pro-cess dies, so if there is a bug in the driver thatcauses it to crash, the system recovers ready forthe driver to be restarted.
4.2 DMA handling
On low-end systems, it’s common for the PCIbus to be connected directly to the memorybus, so setting up a DMA transfer meansmerely pinning the appropriate bit of memory(so that the VM system can neither swap it outnor relocate it) and then converting virtual ad-dresses to physical addresses.
There are, in general, two kinds of DMA, andthis has to be reflected in the kernel interface:
1. Bi-directional DMA, for holding scatter-gather lists, etc., for communication withthe device. Both the CPU and the deviceread and write to a shared memory area.Typically such memory is uncached, andon some architectures it has to be allo-cated from particular physical areas. Thiskind of mapping is calledPCI-consistent;there is an internal kernel ABI function toallocate and deallocate appropriate mem-ory.
2. Streaming DMA, where, once the devicehas either read or written the area, it hasno further immediate use for it.
I implemented a new system call4, usr_pci_map() , that does one of three things:
1. Allocates an area of memory suitable for aPCI-consistent mapping, and maps it intothe current process’s address space; or
2. Converts a region of the current process’svirtual address space into a scatterlist interms of virtual addresses (one entry perpage), pins the memory, and converts the
4Although multiplexing system calls are in generaldeprecated in Linux, they are extremely useful while de-veloping, because it is not necessary to change everyarchitecture-dependententry.Swhen adding new func-tionality

Linux Symposium 2004 • Volume One • 153
scatterlist into a list of addresses suitablefor DMA (by calling pci_map_sg() ,which sets up the IOMMU if appropriate),or
3. Undoes the mapping in point 2.
The file descriptor returned fromusr_pci_open() is an argument tousr_pci_map() . Mappings are tracked as part of theprivate data for that open file descriptor, so thatthey can be undone if the device is closed (orthe driver dies).
Underlyingusr_pci_map() are the kernelroutinespci_map_sg() andpci_unmap_sg() , and the kernel routinepci_alloc_consistent() .
Different PCI cards can address differentamounts of DMA address space. In the kernelthere is an interface to request that the dma ad-dresses supplied are within the range address-able by the card. The current implementationassumes 32-bit addressing, but it would be pos-sible to provide an interface to allow the realcapabilities of the device to be communicatedto the kernel.
4.2.1 The IOMMU
Many modern architectures have an IO mem-ory management unit (see Figure 2), to convertfrom physical to I/O bus addresses—in muchthe same way that the processor’s MMU con-verts virtual to physical addresses—allowingeven thirty-two bit cards to do single-cycleDMA to anywhere in the sixty-four bit mem-ory address space.
On such systems, after the memory has beenpinned, the IOMMU has to be set up to trans-late from bus to physical addresses; and thenafter the DMA is complete, the translation canbe removed from the IOMMU.
Device 1
Device 2
Device 3
IOMMUMain
Memory
PCI bus
Figure 2: The IO MMU
The processor’s MMU also protects one virtualaddress space from another. Currently ship-ping IOMMU hardware does not do this: allmappings are visible to all PCI devices, andmoreover for some physical addresses on somearchitectures the IOMMU is bypassed.
For fully secure user-space drivers, one wouldwant this capability to be turned off, and alsoto be able to associate a range of PCI bus ad-dresses with a particular card, and disallow ac-cess by that card to other addresses. Only thuscould one ensure that a card could performDMA only into memory areas explicitly allo-cated to it.
4.3 Interrupt Handling
There are essentially two ways that interruptscan be passed to user level.
They can be mapped onto signals, and sentasynchronously, or a synchronous ‘wait-for-signal’ mechanism can be used.
A signal is a good intuitive match for what aninterruptis, but has other problems:
1. One is fairly restricted in what one can doin a signal handler, so a driver will usually

154 • Linux Symposium 2004 • Volume One
have to take extra context switches to re-spond to an interrupt (into and out of thesignal handler, and then perhaps the inter-rupt handler thread wakes up)
2. Signals can be slow to deliver on busy sys-tems, as they require the process table tobe locked. It would be possible to shortcircuit this to some extent.
3. One needs an extra mechanism for regis-tering interest in an interrupt, and for tear-ing down the registration when the driverdies.
For these reasons I decided to map interruptsonto file descriptors./proc already has a di-rectory for each interrupt (containing a file thatcan be written to to adjust interrupt routing toprocessors); I added a new file to each such di-rectory. Suitably privileged processes can openand read these files. The files have open-oncesemantics; attempts to open them while theyare open return−1 with EBUSY.
When an interrupt occurs, the in-kernel inter-rupt handler masks just that interrupt in the in-terrupt controller, and then does anup() op-eration on a semaphore (well, actually, the im-plementation now uses a wait queue, but theeffect is the same).
When a process reads from the file, then kernelenables the interrupt, then callsdown() on asemaphore, which will block until an interruptarrives.
The actual data transferred is immaterial, andin fact none ever is transferred; theread()operation is used merely as a synchronisationmechanism.
poll() is also implemented, so a user pro-cess is not forced into the ‘wait for interrupt’model that we use.
Obviously, one cannot share interrupts be-
tween devices if there is a user process in-volved. The in-kernel driver merely passesthe interrupt onto the user-mode process; as itknows nothing about the underlying hardware,it cannot tell if the interrupt isreally for thisdriver or not. As such it always reports the in-terrupt as ‘handled.’
This scheme works only for level-triggered in-terrupts. Fortunately, all PCI interrupts arelevel triggered.
If one really wants a signal when an interrupthappens, one can arrange for aSIGIO usingfcntl() .
It may be possible, by more extensive rear-rangement of the interrupt handling code, todelay the end-of-interrupt to the interrupt con-troller until the user process is ready to get aninterrupt. As masking and unmasking inter-rupts is slow if it has to go off-chip, delay-ing the EOI should be significantly faster thanthe current code. However, interrupt deliveryto userspace turns out not to be a bottleneck,so there’s not a lot of point in this optimisa-tion (profiles show less than 0.5% of the timeis spent in the kernel interrupt handler and de-livery even for heavy interrupt load—around1000 cycles per interrupt).
5 Driver Structure
The user-mode drivers developed at UNSW arestructured as a preamble, an interrupt thread,and a control thread (see Figure 3).
The preamble:
1. Useslibpci.a to find the device or devicesit is meant to drive,
2. Calls usr_pci_open() to claim thedevice, and
3. Spawns the interrupt thread, then

Linux Symposium 2004 • Volume One • 155
GenericIRQ Handler
usrdrvDriver
Architecture−dependentDMA support
Driver
pci_map_sg()pci_unmap_sg()
pci_map()pci_unmap()
Client
IPC orfunction calls
pci_read_config()
read()
User
Kernel
libpci
Figure 3: Architecture of a User-Mode DeviceDriver
4. Goes into a loop collecting client requests.
The interrupt thread:
1. Opens/proc/irq/irq /irq
2. Loops callingread() on the resultingfile descriptor and then calling the driverproper to handle the interrupt.
3. The driver handles the interrupt, calls outto the control thread(s) to say that work iscompleted or that there has been an error,queues any more work to the device, andthen repeats from step 2.
For the lowest latency, the interrupt thread canbe run as a real time thread. For our bench-marks, however, this was not done.
The control thread queues work to the driverthen sleeps on a semaphore. When the driver,running in the interrupt thread, determines thata request is complete, it signals the semaphore
so that the control thread can continue. (Thesemaphore is implemented as a pthreads mu-tex).
The driver relies on system calls and threading,so the fast system call support now availablein Linux, and the NPTL are very important toget good performance. Each physical I/O in-volves at least three system calls, plus what-ever is necessary for client communication: aread() on the interrupt FD, calls to set upand tear down DMA, and maybe afutex()operation to wake the client.
The system call overhead could be reduced bycombining DMA setup and teardown into asingle system call.
6 Looping the Drivers
An operating system has two functions with re-gard to devices: firstly to drive them, and sec-ondly to abstract them, so that all devices of thesame class have the same interface. While astandalone user-level driver is interesting in itsown right (and could be used, for example, totest hardware, or could be linked into an appli-cation that doesn’t like sharing the device withanyone), it is much more useful if the drivercan be used like any other device.
For the network interface, that’s easy: usethe tun/tap interface and copy frames betweenthe driver and/dev/net/tun. Having to copyslows things down; others on the team here areplanning to develop a zero-copy equivalent oftun/tap.
For the IDE device, there’s no standard Linuxway to have a user-level block device, so I im-plemented one. It is a filesystem that has pairsof directories: a master and a slave. Whenthe filesystem is mounted, creating a file in themaster directory creates a set of block devicespecial files, one for each potential partition, in

156 • Linux Symposium 2004 • Volume One
the slave directory. The file in the master di-rectory can then be used to communicate viaa very simple protocol between a user levelblock device and the kernel’s block layer. Theblock device special files in the slave directorycan then be opened, closed, read, written ormounted, just as any other block device.
The main reason for using a mounted filesys-tem was to allow easy use of dynamic majornumbers.
I didn’t bother implementing ioctl; it was notnecessary for our performance tests, and whenthe driver runs at user level, there are cleanerways to communicate out-of-band data withthe driver, anyway.
7 Results
Device drivers were coded up by[Leslie and Heiser, 2003] for a CMD680IDE disc controller, and by another PhDstudent (Daniel Potts) for a DP83820 Gigabitethernet controller. Daniel also designed andimplemented the tuntap interface.
7.1 IDE driver
The disc driver was linked into a program thatread 64 Megabytes of data from a Maxtor 80Gdisc into a buffer, using varying read sizes.Measurements were also made using Linux’sin-kernel driver, and a program that read 64Mof data from the same on-disc location usingO_DIRECTand the same read sizes.
We also measured write performance, but theresults are sufficiently similar that they are notreproduced here.
At the same time as the tests, a low-priority process attempted to increment a 64-bit counter as fast as possible. The number ofincrements was calibrated to processor time on
an otherwise idle system; reading the counterbefore and after a test thus gives an indicationof how much processor time is available to pro-cesses other than the test process.
The initial results were disappointing; theuser-mode drivers spent far too much timein the kernel. This was tracked down tokmalloc() ; so theusr_pci_map() func-tion was changed to maintain a small cacheof free mapping structures instead of callingkmalloc() and kfree() each time (wecould have used the slab allocator, but it’s eas-ier to ensure that the same cache-hot descriptoris reused by coding a small cache ourselves).This resulted in the performance graphs in Fig-ure 4.
The two drivers compared are the newCMD680 driver running in user space, andLinux’s in-kernel SIS680 driver. As can beseen, there is very little to choose betweenthem.
The graphs show average of ten runs; the stan-dard deviations were calculated, but are negli-gible.
Each transfer request takes five system calls todo, in the current design. The client queueswork to the driver, which then sets up DMA forthe transfer (system call one), starts the trans-fer, then returns to the client, which then sleepson a semaphore (system call two). The in-terrupt thread has been sleeping inread() ,when the controller finishes its DMA, it causean interrupt, which wakes the interrupt thread(half of system call three). The interrupt threadthen tears down the DMA (system call four),and starts any queued and waiting activity, thensignals the semaphore (system call five) andgoes back to read the interrupt FD again (theother half of system call three).
When the transfer is above 128k, the IDE con-troller can no longer do a single DMA opera-

Linux Symposium 2004 • Volume One • 157
0
20
40
60
80
100
1 4 16 64 256 1024 4096 16384 65536 0
10
20
30
40
50C
PU
(%)
Thro
ughp
ut (M
iB/s
)
Transfer size (k)
kernel readuser read
Figure 4: Throughput and CPU usage for the user-mode IDE driver on Itanium-2, reading from adisk
tion, so has to generate multiple transfers TheLinux kernel splits DMA requests above 64k,thus increasing the overhead.
The time spent in this driver is divided asshown in Figure 5.
SignalClient
UserModeHandler
Work
QueueNewScheduler
Latency
IRQ
2.2 1
DMA...
Scheduler LatencyHardware
Kernel Stub 0.4
Figure 5: Timeline (inµseconds)
7.2 Gigabit Ethernet
The Gigabit driver results are more interest-ing. We tested these using [ipbench, 2004]with four clients, all with pause control turnedoff. We ran three tests:
1. Packet receive performance, where pack-ets were dropped and counted at the layerimmediately above the driver
2. Packet transmit performance, where pack-ets were generated and fed to the driver,and
3. Ethernet-layer packet echoing, where theprotocol layer swapped source and desti-nation MAC-addresses, and fed receivedpackets back into the driver.
We did not want to start comparing IP stacks,so none of these tests actually use higher levelprotocols.
We measured three different configurations: astandalone application linked with the driver,the driver looped back into/dev/net/tapandthe standard in-kernel driver, all with interrupt

158 • Linux Symposium 2004 • Volume One
holdoff set to 0, 1, or 2. (By default, the normalkernel driver sets the interrupt holdoff to 300µseconds, which led to too many packets be-ing dropped because of FIFO overflow) Not alltests were run in all configurations—for exam-ple the linux in-kernel packet generator is suf-ficiently different from ours that no fair com-parison could be made.
For the tests that had the driver residing in orfeeding into the kernel, we implemented a newprotocol module to count and either echo ordrop packets, depending on the benchmark.
In all cases, we used the amount of workachieved by a low priority process to measuretime available for other work while the test wasgoing on.
The throughput graphs in all cases are thesame. The maximum possible speed on thewire is given for raw ethernet by109 × p/(p +38) bits per second (the parameter38 is theethernet header size (14 octets), plus a4 octetframe check sequence, plus a7 octet pream-ble, plus a 1 octet start frame delimiter plusthe minimum12 octet interframe gap;p is thepacket size in octets). For large packets the per-formance in all cases was the same as the the-oretical maximum. For small packet sizes, thethroughput is limited by the PCI bus; you’ll no-tice that the slope of the throughput curve whenechoing packets is around half the slope whendiscarding packets, because the driver has to dotwice as many DMA operations per packet.
The user-mode driver (‘Linux user’ on thegraph) outperforms the in-kernel driver(‘Linux orig’)—not in terms of throughput,where all the drivers perform identically, butin usingmuchless processing time.
This result was so surprising that we repeatedthe tests using an EEpro1000, purportedly acard with a much better driver, but saw thesame effect—in fact the achieved echo perfor-
mance is worse than for the in-kernel ns83820driver for some packet sizes.
The reason appears to be that our driver hasa fixed number of receive buffers, which arereused when the client is finished with them—they are allocated only once. This is to pro-vide congestion control at the lowest possiblelevel—the card drops packets when the upperlayers cannot keep up.
The Linux kernel drivers have an essentiallyunlimited supply of receive buffers. Overheadinvolved in allocating and setting up DMA forthese buffers is excessive, and if the upper lay-ers cannot keep up, congestion is detected andthe packets dropped in the protocol layer—after significant work has been done in thedriver.
One sees the same problem with the user modedriver feeding the tuntap interface, as there isno feedback to throttle the driver. Of course,here there is an extra copy for each packet,which also reduces performance.
7.3 Reliability and Failure Modes
In general the user-mode drivers are very re-liable. Bugs in the drivers that would causethe kernel to crash (for example, a null pointerreference inside an interrupt handler) cause thedriver to crash, but the kernel continues. Thedriver can then be fixed and restarted.
8 Future Work
The main foci of our work now lie in:
1. Reducing the need for context switchesand system calls by merging system calls,and by trying new driver structures.
2. A zero-copy implementation of tun/tap.

Linux Symposium 2004 • Volume One • 159
0
20
40
60
80
100
0 200 400 600 800 1000 1200 1400 1600 2e+08
3e+08
4e+08
5e+08
6e+08
7e+08
8e+08
9e+08
1e+09
CP
U (%
)
Thro
ughp
ut (b
/s)
Packet size (octets)
Theoretical MaxKernel EEPRO1000 driver
User mode driver, 100usec holdoffKernel NS83820 driver, 100usec holdoff
Figure 6: Receive Throughput and CPU usage for Gigabit Ethernet drivers on Itanium-2
0
20
40
60
80
100
0 200 400 600 800 1000 1200 1400 1600 0
2e+08
4e+08
6e+08
8e+08
1e+09
CP
U (%
)
Thro
ughp
ut (b
/s)
Packet size (octets)
Theoretical MaxUser mode driver, 200 usec interrupt holdoffUser mode driver, 100 usec interrupt holdoff
User mode driver, 0 usec interrupt holdoff
Figure 7: Transmit Throughput and CPU usage for Gigabit Ethernet drivers on Itanium-2

160 • Linux Symposium 2004 • Volume One
0
20
40
60
80
100
0 200 400 600 800 1000 1200 1400 1600 0
2e+08
4e+08
6e+08
8e+08
1e+09
CP
U (%
)
Thro
ughp
ut
Packet size
Theoretical MaxUser mode driver
In-kernel EEPRO1000 driverNormal kernel driver
user-mode driver -> /dev/tun/tap0
Figure 8: MAC-layer Echo Throughput and CPU usage for Gigabit Ethernet drivers on Itanium-2
3. Improving robustness and reliability ofthe user-mode drivers, by experimentingwith the IOMMU on the ZX1 chipset ofour Itanium-2 machines.
4. Measuring the reliability enhancements,by using artificial fault injection to seewhat problems that cause the kernel tocrash are recoverable in user space.
5. User-mode filesystems.
In addition there are some housekeeping tasksto do before this infrastructure is ready for in-clusion in a 2.7 kernel:
1. Replace the ad-hoc memory cache with aproper slab allocator.
2. Clean up the system call interface
9 Where d’ya Get It?
Patches against the 2.6 kernel are sent to theLinux kernel mailing list, and are onhttp://www.gelato.unsw.edu.au/patches
Sample drivers will be made available from thesame website.
10 Acknowledgements
Other people on the team here did much workon the actual implementation of the user leveldrivers and on the benchmarking infrastruc-ture. Prominent among them were Ben Leslie(IDE driver, port of our dp83820 into the ker-nel), Daniel Potts (DP83820 driver, tuntap in-terface), and Luke McPherson and Ian Wien-and (IPbench).

Linux Symposium 2004 • Volume One • 161
References
[Chou et al., 2001] Chou, A., Yang, J., Chelf,B., Hallem, S., and Engler, D. R. (2001).An empirical study of operating systemserrors. InSymposium on OperatingSystems Principles, pages 73–88.http://citeseer.nj.nec.com/article/chou01empirical.html .
[ipbench, 2004] ipbench (2004). ipbench — adistributed framework for networkbenchmarking.
http://ipbench.sf.net/ .
[Jungo, 2003] Jungo (2003). Windriver.
http://www.jungo.com/windriver.html .
[Keedy, 1979] Keedy, J. L. (1979). Acomparison of two process structuringmodels. MONADS Report 4, Dept.Computer Science, Monash University.
[Leslie and Heiser, 2003] Leslie, B. andHeiser, G. (2003). Towards untrusteddevice drivers. Technical ReportUNSW-CSE-TR-0303, Operating Systemsand Distributed Systems Group, School ofComputer Science and Engineering, TheUniversity of NSW. CSE techreportswebsite,ftp://ftp.cse.unsw.edu.au/pub/doc/papers/UNSW/0303.pdf .
[Nakatani, 2002] Nakatani, B. (2002).ELJOnline: User mode drivers.
http://www.linuxdevices.com/articles/AT5731658926.html .
[Swift et al., 2002] Swift, M., Martin, S.,Leyand, H. M., and Eggers, S. J. (2002).Nooks: an architecture for reliable devicedrivers. InProceedings of the Tenth ACMSIGOPS European Workshop,Saint-Emilion, France.

162 • Linux Symposium 2004 • Volume One

Big Servers—2.6 compared to 2.4
Wim A. CoekaertsOracle Corporation
Abstract
Linux 2.4 has been around in production en-vironments at companies for a few years now,we have been able to gather some good dataon how well (or not) things scale up. Numberof CPU’s, amount of memory, number of pro-cesses, IO throughput, etc.
Most of the deployments in production today,are on relatively small systems, 4- to 8-ways,8–16GB of memory, in a few cases 32GB.The architecture of choice has also been IA32.64-bit systems are picking up in popularityrapidly, however.
Now with 2.6, a lot of the barriers are supposedto be gone. So, have they really? How muchmemory can be used now, how is cpu scalingthese days, how good is IO throughput withmultiple controllers in 2.6.
A lot of people have the assumption that 2.6resolves all of this. We will go into detail onwhat we have found out, what we have testedand some of the conclusions on how good themove to 2.6 will really be.
1 Introduction
The comparison between the 2.4 and 2.6 ker-nel trees are not solely based on performance.A large part of the testsuites are performancebenchmarks however, as you will see, theyhave been used to also measure stability. There
are a number of features added which improvestability of the kernel under heavy workloads.The goal of comparing the two kernel releaseswas more to show how well the 2.6 kernel willbe able to hold up in a real world productionenvironment. Many companies which have de-ployed Linux over the last two years are look-ing forward to rolling out 2.6 and it is impor-tant to show the benefits of doing such a move.It will take a few releases before the requiredstability is there however it’s clear so far thatthe 2.6 kernel has been remarkably solid, soearly on.
Most of the 2.4 based tests have been run onRed Hat Enterprise Linux 3, based on Linux2.4.21. This is the enterprise release of RedHat’s OS distribution; it contains a large num-ber of patches on top of the Linux 2.4 kerneltree. Some of the tests have been run on thekernel.org mainstream 2.4 kernel, to showthe benefit of having extra functionality. How-ever it is difficult to even just boot up the main-stream kernel on the test hardware due to lackof support for drivers, or lack of stability tocomplete the testsuite. The interesting thing tokeep in mind is that with the current Linux 2.6main stream kernel, most of the testsuites ranthrough completition. A number of test runs onLinux 2.6 have been on Novell/SuSE SLES9beta release.

164 • Linux Symposium 2004 • Volume One
2 Test Suites
The test suites used to compare the various ker-nels are based on an IO simulator for Oracle,called OraSim and a TPC-C like workload gen-erator called OAST.
Oracle Simulator (OraSim) is a stand-alonetool designed to emulate the platform-criticalactivities of the Oracle database kernel. Oracledesigned Oracle Simulator to test and charac-terize the input and output (I/O) software stack,the storage system, memory management, andcluster management of Oracle single instancesand clusters. Oracle Simulator supports bothpass-fail testing for validation, and analyticaltesting for debugging and tuning. It runs mul-tiple processes, with each process representingthe parameters of a particular type of systemload similar to the Oracle database kernel.
OraSim is a relatively straightforward IOstresstest utility, similar to IOzone or tiobench,however it is built to be very flexible and con-figurable.
It has its own script language which allows oneto build very complex IO patterns. The tool isnot released under any open source license to-day because it has some code linked in which ispart of the RDBMS itself. The jobfiles used forthe testing are available onlinehttp://oss.
oracle.com/external/ols/jobfiles/ .
The advantage of using OraSim over a realdatabase benchmark is mainly the simplicity.It does not require large amounts of memory orlarge installed software components. There isone executable which is started with the jobfileas a parameter.The jobfiles used can be easilymodified to turn on certain filesystem features,such as asynchronous IO.
OraSim jobfiles were created to simulate a rel-atively small database. 10 files are defined asactual database datafiles and two files are used
to simulate database journals.
OAST on the other hand is a complete databasestress test kit, based on the TPC-C benchmarkworkloads. It requires a full installation ofthe database software and relies on an actualdatabase environment to be created. TPC-Cis an on-line transaction workload. The num-bers represented during the testruns are not ac-tual TPC-C benchmarks results and cannot orshould not be used as a measure of TPC-Cperformance—they are TPC-C-like; however,not the same.
The database engine which runs the OASTbenchmark allocates a large shared memorysegment which contains the database cachesfor SQL and for data blocks (shared pool andbuffer cache). Every client connection can runon the same server or the connection can beover TCP. In case of a local connection, foreach client, 2 processes are spawned on thesystem. One process is a dedicated databaseprocess and the other is the client code whichcommunicates with the database server pro-cess through IPC calls. Test run parameters in-clude run time length in seconds and number ofclient connections. As you can see in the resultpages, both remote and local connections havebeen tested.
3 Hardware
A number of hardware configurations havebeen used. We tried to include various CPUarchitectures as well as local SCSI disk ver-sus network storage (NAS) and fibre channel(SAN).
Configuration 1 consists of an 8-way IA32Xeon 2 GHz with 32GB RAM attached to anEMC CX300 Clariion array with 30 147GBdisks using a QLA2300 fibre channel HBA.The network cards are BCM5701 BroadcomGigabit Ethernet.

Linux Symposium 2004 • Volume One • 165
Configuration 2 consists of an 8-way Itanium 21.3 GHz with 8GB RAM attached to a JBODfibre channel array with 8 36GB disks usinga QLA2300 fibre channel HBA. The networkcards are BCM5701 Broadcom Gigabit Ether-net.
Configuration 3 consists of a 2-way AMD64 2GHz (Opteron 246) with 6GB RAM attachedto local SCSI disk (LSI Logic 53c1030).
4 Operating System
The Linux 2.4 test cases were created usingRed Hat Enterprise Linux 3 on all architec-tures. Linux 2.6 was done with SuSE SLES9on all architectures; however, in a number oftests the kernel was replaced by the 2.6 main-stream kernel for comparison.
The test suites and benchmarks did not haveto be recompiled to run on either RHEL3 orSLES9. Of course different executables wereused on the three CPU architectures.
5 Test Results
At the time of writing a lot of changes werestill happening on the 2.6 kernel. As such,the actual spreadsheets with benchmark datahas been published on a website, the data isup-to-date with the current kernel tree and canbe found here:http://oss.oracle.com/
external/ols/results/
5.1 IO
If you want to build a huge database server,which can handle thousands of users, it is im-portant to be able to attach a large number ofdisks. A very big shortcoming in Linux 2.4was the fact that it could only handle 128 or256.
With some patches SuSE got to around 3700disks in SLES8, however that meant stealingmajor numbers from other components. Re-ally large database setups which also requirevery high IO throughput, usually have disks at-tached ranging from a few hundred to a fewthousand.
With the 64-bitdev_t in 2.6, it’s now possibleto attach plenty of disk. Without modificationsit can easily handle tens of thousands of de-vices attached. This opens the world to reallylarge scale datawarehouses, tens of terabytes ofstorage.
Another important change is the block IOlayer, the BIO code is much more efficientwhen it comes to large IOs being submitteddown from the running application. In 2.4,every IO got broken down into small chunks,sometimes causing bottlenecks on allocatingaccounting structures. Some of the tests com-pared 1MBread() and write() calls in2.4 and 2.6.
5.2 Asynchronous IO and DirectIO
If there is one feature that has always been ontop of the Must Have list for large databasevendors, it must be async IO. Asynchronous IOallows processes to submit batches of IO oper-ations and continue on doing different tasks inthe meantime. It improves CPU utilization andcan keep devices more busy. The Enterprisedistributions based on Linux 2.4 all ship withthe async IO patch applied on top of the main-line kernel.
Linux 2.6 has async IO out of the box. It isimplemented a little different from Linux 2.4however combined with support for direct IO itis very performant. Direct IO is very useful asit eliminates copying the userspace buffers intokernel space. On systems that are constantlyoverloaded, there is a nice performance im-

166 • Linux Symposium 2004 • Volume One
provement to be gained doing direct IO. Linux2.4 did not have direct IO and async IO com-bined. As you can see in the performancegraph on AIO+DIO, it provides a significantreduction in CPU utilization.
5.3 Virtual Memory
There has been another major VM overhaul inLinux 2.6, in fact, even after 2.6.0 was releaseda large portion has been re-written. This wasdue to large scale testing showing weaknessesas it relates to number of users that could behandled on a system. As you can see in the testresults, we were able to go from around 3000users to over 7000 users. In particular on 32-bit systems, the VM has been pretty much adisaster when it comes to deploying a systemwith more than 16GB of RAM. With the latestVM changes it is now possible to push a 32GBeven up to 48GB system pretty reliably.
Support for large pages has also been a bigwinner. HUGETLBFSreduces TLB misses bya decent percentage. In some of the tests itprovides up to a 3% performance gain. In ourtestsHUGETLBFSwould be used to allocatethe shared memory segment.
5.4 NUMA
Linux 2.6 is the first Linux kernel with realNUMA support. As we see high-end cus-tomers looking at deploying large SMP boxesrunning Linux, this became a real requirement.In fact even with the AMD64 design, NUMAsupport becomes important for performanceeven when looking at just a dual-CPU system.
NUMA support has two components; however,one is the fact that the kernel VM allocatesmemory for processes in a more efficient way.On the other hand, it is possible for applica-tions to use the NUMA API and tell the OSwhere memory should be allocated and how.
Oracle has an extention for Itanium2 to supportthe libnuma API from Andi Kleen. Making useof this extention showed a significant improve-ment, up to about 20%. It allows the databaseengine to be smart about memory allocationsresulting in a significant performance gain.
6 Conclusion
It is very clear that many of the features thatwere requested by the larger corporations pro-viding enterprise applications actually help ahuge amount. The advantage of having Asyn-chronous IO or NUMA support in the main-stream kernel is obvious. It takes a lot of effortfor distribution vendors to maintain patches ontop of the mainline kernel and when functional-ity makes sense it helps to have it be includedin mainline. Micro-optimizations are still be-ing done and in particular the VM subsystemcan improve quite a bit. Most of the stabilityissues are around 32-bit, where the LowMemversus HighMem split wreaks havoc quite fre-quently. At least with some of the features nowin the 2.6 kernel it is possible to run serverswith more than 16GB of memory and scale up.
The biggest surprise was the stability. It wasvery nice to see a new stable tree be so solidout of the box, this in contrast to earlier stablekernel trees where it took quite a few iterationsto get to the same point.
The major benefit of 2.6 is being able to run onreally large SMP boxes: 32-way Itanium2 orPower4 systems with large amounts of mem-ory. This was the last stronghold of the tradi-tional Unices and now Linux can play along-side with them even there. Very exciting times.

Multi-processor and Frequency ScalingMaking Your Server Behave Like a Laptop
Paul DevriendtAMD Software Research and Development
Copyright © 2004 Advanced Micro Devices, Inc.
Abstract
This paper will explore a multi-processor im-plementation of frequency management, usingan AMD Opteron™ processor 4-way server asa test vehicle.
Topics will include:
• the benefits of doing this, and why servercustomers are asking for this,
• the hardware, for case of the AMDOpteron processor,
• the various software components thatmake this work,
• the issues that arise, and
• some areas of exploration for follow onwork.
1 Introduction
Processor frequency management is commonon laptops, primarily as a mechanism for im-proving battery life. Other benefits include acooler processor and reduced fan noise. Fansalso use a non-trivial amount of power.
This technology is spreading to desktop ma-chines, driven both by a desire to reduce powerconsumption and to reduce fan noise.
Servers and other multiprocessor machines canequally benefit. The multiprocessor frequencymanagement scenario offers more complex-ity (no surprise there). This paper discussesthese complexities, based upon a test imple-mentation on an AMD Opteron processor 4-way server. Details within this paper are AMDprocessor specific, but the concepts are appli-cable to other architectures.
The author of this paper would like to makeit clear that he is just the maintainer of theAMD frequency driver, supporting the AMDAthlon™ 64 and AMD Opteron processors.This frequency driver fits into, and is totally de-pendent, on the CPUFreq support. The authorhas gratefully received much assistance andsupport from the CPUFreq maintainer (Do-minik Brodowski).
2 Abbreviations
BKDG: The BIOS and Kernel Developer’sGuide. Document published by AMD contain-ing information needed by system software de-velopers. See the references section, entry 4.
MSR: Model Specific Register. Processor reg-isters, accessable only from kernel space, usedfor various control functions. These regis-ters are expected to change across processorfamilies. These registers are described in the

168 • Linux Symposium 2004 • Volume One
BKDG[4].
VRM: Voltage Regulator Module. Hardwareexternal to the processor that controls the volt-age supplied to the processor. The VRM has tobe capable of supplying different voltages oncommand. Note that for multiprocessor sys-tems, it is expected that each processor willhave its own independent VRM, allowing eachprocessor to change voltage independently. Forsystems where more than one processor sharesa VRM, the processors have to be managed asa group. The current frequency driver does nothave this support.
fid: Frequency Identifier. The values writ-ten to the control MSR to select a core fre-quency. These identifiers are processor familyspecific. Currently, these are six bit codes, al-lowing the selection of frequencies from 800MHz to 5 Ghz. See the BKDG[4] for the map-pings from fid to frequency. Note that the fre-quency driver does need to “understand” themapping of fid to frequency, as frequencies areexposed to other software components.
vid: Voltage Identifier. The values written tothe control MSR to select a voltage. These val-ues are then driven to the VRM by processorlogic to achieve control of the voltage. Theseidentifiers are processor model specific. Cur-rently these identifiers are five bit codes, ofwhich there are two sets—a standard set anda low-voltage mobile set. The frequency driverdoes not need to be able to “understand” themapping of vid to voltage, other than perhapsfor debug prints.
VST: Voltage Stabilization Time. The lengthof time before the voltage has increased and isstable at a newly increased voltage. The driverhas to wait for this time period when steppingthe voltage up. The voltage has to be stableat the new level before applying a further stepup in voltage, or before transitioning to a newfrequency that requires the higher voltage.
MVS: Maximum Voltage Step. The maximumvoltage step that can be taken when increasingthe voltage. The driver has to step up voltagein multiple steps of this value when increasingthe voltage. (When decreasing voltage it is notnecessary to step, the driver can merely jumpto the correct voltage.) A typical MVS valuewould be 25mV.
RVO: Ramp Voltage Offset. When transition-ing frequencies, it is necessary to temporarilyincrease the nominal voltage by this amountduring the frequency transition. A typical RVOvalue would be 50mV.
IRT: Isochronous Relief Time. During fre-quency transitions, busmasters briefly lose ac-cess to system memory. When making mul-tiple frequency changes, the processor drivermust delay the next transition for this timeperiod to allow busmasters access to systemmemory. The typical value used is 80us.
PLL: Phase Locked Loop. Electronic circuitthat controls an oscillator to maintain a con-stant phase angle relative to a reference signal.Used to synthesize new frequencies which area multiple of a reference frequency.
PLL Lock Time: The length of time, in mi-croseconds, for the PLL to lock.
pstate: Performance State. A combination offrequency/voltage that is supported for the op-eration of the processor. A processor will typi-cally have several pstates available, with higherfrequencies needing higher voltages. The pro-cessor clock can not be set to any arbitrary fre-quency; it may only be set to one of a limitedset of frequencies. For a given frequency, thereis a minimum voltage needed to operate reli-ably at that frequency, and this is the correctvoltage, thus forming the frequency/voltagepair.
ACPI: Advanced Configuration and Power In-

Linux Symposium 2004 • Volume One • 169
terface Specification. An industry specifica-tion, initially developed by Intel, Microsoft,Phoenix and Toshiba. See the reference sec-tion, entry 5.
_PSS:Performance Supported States. ACPIobject that defines the performance states validfor a processor.
_PPC: Performance Present Capabilities.ACPI object that defines which of the _PSSstates are currently available, due to currentplatform limitations.
PSBPerformance State Block. BIOS provideddata structure used to pass information, to thedriver, concerning the pstates available on theprocessor. The PSB does not support multi-processor systems (which use the ACPI _PSSobject instead) and is being deprecated. Theformat of the PSB is defined in the BKDG.
3 Why Does Frequency Manage-ment Affect Power Consump-tion?
Higher frequency requires higher voltage.As an example, data for part numberADA3200AEP4AX:
2.2 GHz @ 1.50 volts, 58 amps max – 89 watts
2.0 GHz @ 1.40 volts, 48 amps max – 69 watts
1.8 GHz @ 1.30 volts, 37 amps max – 50 watts
1.0 GHz @ 1.10 volts, 18 amps max – 22 watts
These figures are worst case current/power fig-ures, at maximum case temperature, and in-clude I/O power of 2.2W.
Actual power usage is determined by:
• code currently executing (idle blocks inthe processor consume less power),
• activity from other processors (cache co-herency, memory accesses, pass-throughtraffic on the HyperTransport™ connec-tions),
• processor temperature (current increaseswith temperature, at constant workloadand voltage),
• processor voltage.
Increasing the voltage allows operation athigher frequencies, at the cost of higher powerconsumption and higher heat generation. Notethat relationship between frequency and powerconsumption is not a linear relationship—a10% frequency increase will cost more than10% in power consumption (30% or more).
Total system power usage depends on other de-vices in the system, such as whether disk drivesare spinning or stopped, and on the efficiencyof power supplies.
4 Why Should Your Server BehaveLike A Laptop?
• Save power. It is the right thing to dofor the environment. Note that powerconsumed is largely converted into heat,which then becomes a load on the air con-ditioning in the server room.
• Save money. Power costs money. Thepower savings for a single server are typi-cally regarded as trivial in terms of a cor-porate budget. However, many large or-ganizations have racks of many thousandsof servers. The power bill is then far fromtrivial.
• Cooler components last longer, and thistranslates into improved server reliability.
• Government Regulation.

170 • Linux Symposium 2004 • Volume One
5 Interesting Scenarios
These are real world scenarios, where the ap-plication of the technology is appropriate.
5.1 Save power in an idle cluster
A cluster would typically be kept running atall times, allowing remote access on demand.During the periods when the cluster is idle, re-ducing the CPU frequency is a good way toreduce power consumption (and therefore alsoair conditioning load), yet be able to quicklytransition back up to full speed (<0.1 second)when a job is submitted.
User space code (custom to the management ofthat cluster) can be used to offer cluster speedsof “fast” and “idle,” using the/proc or /sysfile systems to trigger frequency transitions.
5.2 The battery powered server
Or, the server running on a UPS.
Many production servers are connectedto a battery backup mechanism (UPS—uninterruptible power supply) in case themains power fails. Action taken on a mainspower failure varies:
• Orderly shutdown.
• Stay up and running for as long as thereis battery power, but orderly shutdown ifmains power is not restored.
• Stay up and running, mains power will beprovided by backup generators as soon asthe generators can be started.
In these scenarios, transitioning to lower per-formance states will maximize battery life, orreduce the amount of generator/battery powercapacity required.
UPS notification of mains power loss to theserver for administrator alerts is well under-stood technology. It is not difficult to add thesupport for transitioning to a lower pstate. Thiscan be done by either a cpufreq governor or byadding the simple user space controls to an ex-isting user space daemon that is monitoring theUPS alerts.
5.3 Server At Less Than Maximum Load
As an example, a busy server may be process-ing 100 transactions per second, but only 5transactions per second during quiet periods.Reducing the CPU frequency from 2.2 GHz to1.0 GHz is not going to impact the ability ofthat server to process 5 transactions per second.
5.4 Processor is not the bottleneck
The bottleneck may not be the processor speed.Other likely bottlenecks are disk access andnetwork access. Having the processor waitingfaster may not improve transaction throughput.
5.5 Thermal cutback to avoid over tempera-ture situations
The processors are the main generators of heatin a system. This becomes very apparent whenmany processors are in close proximity, suchas with blade servers. The effectiveness of theprocessor cooling is impacted when the proces-sor heat sinks are being cooled with hot air. Re-ducing processor frequency when idle can dra-matically reduce the heat production.
5.6 Smaller Enclosures
The drive to build servers in smaller boxes,whether as standalone machines or slim rack-mount machines, means that there is less spacefor air to circulate. Placing many slim rack-mounts together in a rack (of which the most

Linux Symposium 2004 • Volume One • 171
demanding case is a blade server) aggravatesthe cooling problem as the neighboring boxesare also generating heat.
6 System Power Budget
The processors are only part of the system. Wetherefore need to understand the power con-sumption of the entire system to see how sig-nificant processor frequency management is onthe power consumption of the whole system.
A system power budget is obviously plat-form specific. This sample DC (direct cur-rent) power budget is for a 4-processor AMDOpteron processor based system. The systemhas three 500W power supplies, of which oneis redundant. Analysis shows that for manyoperating scenarios, the system could run ona single power supply.
This analysis is of DC power. For the systemin question, the efficiency of the power sup-plies are approximately linear across varyingloads, and thus the DC power figures expressedas percentages are meaningful as predictors ofthe AC (alternating current) power consump-tion. For systems with power supplies that arenot linearly efficient across varying loads, thecalculations obviously have to be factored totake account of power supply efficiency.
System components:
• 4 processors @ 89W = 356W in the maxi-mum pstate, 4 @ 22W = 88W in the mini-mum pstate. These are worst case figures,at maximium case temperature, with theworst case instruction mix. The figures inTable1 are reduced from these maximumsby approximately 10% to account for a re-duced case temperature and for a work-load that does not keep all of the proces-sors’ internal units busy.
• Two disk drives (Western Digital 250GByte SATA), 16W read/write, 10W idle(spinning), 1.3W sleep (not spinning).Note SCSI drives typically consume morepower.
• DVD Drive, 10W read, 1W idle/sleep.
• PCI 2.2 Slots – absolute max of 25W perslot, system will have a total power budgetthat may not account for maximum powerin all slots. Estimate 2 slots occupied at atotal of 20W.
• VGA video card in a PCI slot. 5W. (AGPwould be more like 15W+).
• DDR DRAM, 10W max per DIMM, 40Wfor 4 GBytes configured as 4 DIMMs.
• Network (built in) 5W.
• Motherboard and components 30W.
• 10 fans @ 6W each. 60W.
• Keyboard + Mouse 3W
See Table 1 for the sample power budget underbusy and light loads.
The light load without any frequency reductionis baselined as 100%.
The power consumption is shown for the samelight load with frequency reduction enabled,and again where the idle loop incorporates thehlt instruction.
Using frequency management, the power con-sumption drops to 43%, and adding the use ofthe hlt instruction (assuming 50% time halted),the power consumption drops further to 33%.
These are significant power savings, for sys-tems that are under light load conditions attimes. The percentage of time that the systemis running under reduced load has to be knownto predict actual power savings.

172 • Linux Symposium 2004 • Volume One
system load 4 2 kbdcpus disks dvd pci vga dram net planar fans mou total
busy 320 32 10 20 5 40 5 30 60 3 525W90%
light load 310 22 1 15 5 38 5 20 60 3 479W87% 100%
light load, using 79 22 1 15 5 38 5 20 20 3 208Wfrequency reduction 90% 43%
light load, using 32 22 1 15 5 38 5 20 15 3 156frequency reduction 40% 33%and using hlt 50%
of the time
Table 1: Sample System Power Budget (DC), in watts
7 Hardware—AMD Opteron
7.1 Software Interface To The Hardware
There are two MSRs, the FIDVID_STATUSMSR and the FIDVID_CONTROL MSR, thatare used for frequency voltage transitions.These MSRs are the same for the single pro-cessor AMD Athlon 64 processors and for theAMD Opteron MP capable processors. Theseregisters are not compatible with the previ-ous generation of AMD Athlon processors, andwill not be compatible with the next generationof processors.
The CPU frequency driver for AMD proces-sors therefore has to change across processorrevisions, as do the ACPI _PSS objects that de-scribe pstates.
The status register reports the current fid andvid, as well as the maximum fid, the start fid,the maximum vid and the start vid of the par-ticular processor.
These registers are documented in theBKDG[4].
As MSRs can only be accessed by executingcode (the read msr or write msr instructions) on
the target processor, the frequency driver has touse the processor affinity support to force exe-cution on the correct processor.
7.2 Multiple Memory Controllers
In PC architectures, the memory controller isa component of the northbridge, which is tra-ditionally a separate component from the pro-cessor. With AMD Opteron processors, thenorthbridge is built into the processor. Thus,in a multi-processor system there are multiplememory controllers.
See Figure 1 for a block diagram of a two pro-cessor system.
If a processor is accessing DRAM that is phys-ically attached to a different processor, theDRAM access (and any cache coherency traf-fic) crosses the coherent HyperTransport inter-processor links. There is a small performancepenalty in this case. This penalty is of the or-der of a DRAM page hit versus a DRAM pagemiss, about 1.7 times slower than a local ac-cess.
This penalty is minimized by the processorcaches, where data/code residing in remoteDRAM is locally cached. It is also minimized

Linux Symposium 2004 • Volume One • 173
by Linux’s NUMA support.
Note that a single threaded application thatis memory bandwidth constrained may benefitfrom multiple memory controllers, due to theincrease in memory bandwidth.
When the remote processor is transitioned toa lower frequency, this performance penalty isworse. An upper bound to the penalty maybe calculated as proportional to the frequencyslowdown. I.e., taking the remote processorfrom 2.2 GHz to 1.0 GHz would take the 1.7factor from above to a factor of 2.56. Note thatthis is an absolute worst case, an upper boundto the factor. Actual impact is workload depen-dent.
A worst case scenario would be a memorybound task, doing memory reads at addressesthat are pathologically the worst case for thecaches, with all accesses being to remote mem-ory. A more typical scenario would see thispenalty alleviated by:
• processor caches, where 64 bytes willbe read and cached for a single access,so applications that walk linearly throughmemory will only see the penalty on 64byte boundaries,
• memory writes do not take a penalty(as processor execution continues withoutwaiting for a write to complete),
• memory may be interleaved,
• kernel NUMA optimizations for non-interleaved memory (which allocatememory local to the processor whenpossible to avoid this penalty).
7.3 DRAM Interface Speed
The DRAM interface speed is impacted by thecore clock frequency. A full table is published
in the processor data sheet; Table 2 shows asample of actual DRAM frequencies for thecommon specified DRAM frequencies, acrossa range of core frequencies.
This table shows that certain DRAM speed /core speed combinations are suboptimal.
Effective memory performance is influencedby many factors:
• cache hit rates,
• effectiveness of NUMA memory alloca-tion routines,
• load on the memory controller,
• size of penalty for remote memory ac-cesses,
• memory speed,
• other hardware related items, such astypes of DRAM accesses.
It is therefore necessary to benchmark the ac-tual workload to get meaningful data for thatworkload.
7.4 UMA
During frequency transitions, and when Hy-perTransport LDTSTOP is asserted, DRAM isplaced into self refresh mode. UMA graph-ics devices therefore can not access DRAM.UMA systems therefore need to limit the timethat DRAM is in self refresh mode. Time con-straints are bandwidth dependent, with highresolution displays needing higher memorybandwidth. This is handled by the IRT delaytime during frequency transitions. When tran-sitioning multiple steps, the driver waits an ap-propriate length of time to allow external de-vices to access memory.
174 • Linux Symposium 2004 • Volume One
AMD Opteron TM Processor
AMD Opteron TM Processor
AMD 8151 TM Graphics Tunnel
AMD 8131 TM PCI-X Tunnel
AMD 8111 TM
I/O Hub
ncHT
ncHT
DDR
8X AGP
Legacy PCI
USB
LPC
AC ‘97
EIDE
DDR
PCI-X
cHT
ncHT
Figure 1: Two Processor System
Processor 100MHz 133MHz 166MHz 200MHzCore DRAM DRAM DRAM DRAM
Frequency spec spec spec spec
800MHz 100.00 133.33 160.00 160.001000MHz 100.00 125.00 166.66 200.002000MHz 100.00 133.33 166.66 200.002200MHz 100.00 129.41 157.14 200.00
Table 2: DRAM Frequencies For A Range Of Processor Core Frequencies

Linux Symposium 2004 • Volume One • 175
7.5 TSC Varying
The Time Stamp Counter (TSC) register isa register that increments with the processorclock. Multiple reads of the register will seeincreasing values. This register increments oneach core clock cycle in the current generationof processors. Thus, the rate of increase of theTSC when compared with “wall clock time”varies as the frequency varies. This causesproblems in code that calibrates the TSC incre-ments against an external time source, and thenattempts to use the TSC to measure time.
The Linux kernel uses the TSC for such tim-ings, for example when a driver calls udelay().In this case it is not a disaster if the udelay()call waits for too long as the call is defined toallow this behavior. The case of the udelay()call returning too quickly can be fatal, and thishas been demonstrated during experimentationwith this code.
This particular problem is resolved by thecpufreq driver correcting the kernel TSC cal-ibration whenever the frequency changes.
This issue may impact other code that usesthe TSC register directly. It is interesting tonote that it is hard to define a correct behavior.Code that calibrates the TSC against an exter-nal clock will be thrown off if the rate of in-crement of the TSC should change. However,other code may expect a certain code sequenceto consistently execute in approximately thesame number of cycles, as measured by theTSC, and this code will be thrown off if the be-havior of the TSC changes relative to the pro-cessor speed.
7.6 Measurement Of Frequency TransitionTimes
The time required to perform a transition is acombination of the software time to execute the
required code, and the hardware time to per-form the transition.
Examples of hardware wait time are:
• waiting for the VRM to be stable at anewer voltage,
• waiting for the PLL to lock at the new fre-quency,
• waiting for DRAM to be placed into andthen taken out of self refresh mode arounda frequency transition.
The time taken to transition between two statesis dependent on both the initial state and thetarget state. This is due to :
• multiple steps being required in somecases,
• certain operations are lengthier (for ex-ample, voltage is stepped up in multiplestages, but stepped down in a single step),
• difference in code execution time depen-dent on processor speed (although this isminor).
Measurements, taken by calibrating the fre-quency driver, show that frequency transitionsfor a processor are taking less than 0.015 sec-onds.
Further experimentation with multiple proces-sors showed a worst case transition time of lessthan 0.08 seconds to transition all 4 processorsfrom minimum to maximum frequency, andslightly faster to transition from maximum tominimum frequency.
Note, there is a driver optimization underconsideration that would approximately halvethese transition times.

176 • Linux Symposium 2004 • Volume One
7.7 Use of Hardware Enforced Throttling
The southbridge (I/O Hub, example AMD-8111™ HyperTransport I/O Hub) is capableof initiating throttling via the HyperTransportstopclock message, which will ramp down theCPU grid by the programmed amount. Thismay be initiated by the southbridge for thermalthrottling or for other reasons.
This throttling is transparent to software, otherthan the performance impact.
This throttling is of greatest value in the lowestpstate, due to the reduced voltage.
The hardware enforced throttling is generallynot of relevance to the software managementof processor frequencies. However, a systemdesigner would need to take care to ensurethat the optimal scenarios occur—i.e., transi-tion to a lower frequency/voltage in preferenceto hardware throttling in high pstates. TheBIOS configurations are documented in theBKDG[4].
For maximum power savings, the southbridgewould be configured to initiate throttling whenthe processor executes thehlt instruction.
8 Software
The AMD frequency driver is a small part ofthe software involved. The frequency driverfits into the CPUFreq architecture, which ispart of the 2.6 kernel. It is also available as apatch for the 2.4 kernel, and many distributionsdo include it.
The CPUFreq architecture includes kernel sup-port, the CPUFreq driver itself (drivers/cpufreq ), an architecture specific driver tocontrol the hardware (powernow-k8.ko is thiscase), and/sys file system code for userlandaccess.
The kernel support code (linux/kernel/cpufreq.c ) handles timing changes such asupdating the kernel constantloops_per_jiffies , as well as notifiers (system com-ponents that need to be notified of a frequencychange).
8.1 History Of The AMD Frequency Driver
The CPU frequency driver for AMD Athlon(the previous generation of processors) wasdeveloped by Dave Jones. This driver sup-ports single processor transitions only, as thepstate transition capability was only enabled inmobile processors. This driver used the PSBmechanism to determine valid pstates for theprocessor. This driver has subsequently beenenhanced to add ACPI support.
The initial AMD Athlon 64 and AMD Opterondriver (developed by me, based upon Dave’searlier work, and with much input from Do-minik and others), was also PSB based. Thiswas followed by a version of the driver thatadded ACPI support.
The next release is intended to add a built-intable of pstates that will allow the checking ofBIOS supplied data, and also allow an overridecapability to provide pstate data when not sup-plied by BIOS.
8.2 User Interface
The deprecated /proc/cpufreq (and/proc/sys ) file system offers control overall processors or individual processors. Byechoing values into this file, the root usercan change policies and change the limits onavailable frequencies.
Examples:
Constrain all processors to frequencies be-tween 1.0 GHz and 1.6 GHz, with the perfor-mance policy (effectively chooses 1.6 GHz):

Linux Symposium 2004 • Volume One • 177
echo -n "1000000:16000000:
performance" > /proc/cpufreq
Constrain processor 2 to run at only 2.0 GHz:
echo -n "2:2000000:2000000:
performance" > proc/cpufreq
The “performance” refers to a policy, withthe other policy available being “powersave.”These policies simply forced the frequency tobe at the appropriate extreme of the availablerange. With the 2.6 kernel, the choice is nor-mally for a “userspace” governor, which allowsthe (root) user or any user space code (runningwith root privilege) to dynamically control thefrequency.
With the 2.6 kernel, a new interface in the/sys filesystem is available to the root user,deprecating the/proc/cpufreq method.
The control and status files exist under/sys/devices/system/cpu/cpuN/cpufreq , where N varies from 0 up-wards, dependent on which processors areonline. Among the other files in each proces-sor’s directory, scaling_min_freq andscaling_max_freq control the minimumand maximum of the ranges in which the fre-quency may vary. Thescaling_governorfile is used to control the choice of gov-ernor. See linux/Documentation/cpu-freq/userguide.txt for moreinformation.
Examples:
Constrain processor 2 to run only in the range1.6 GHz to 2.0 GHz:
cd /sys/devices/system/cpu
cd cpu2/cpufreq
echo 1600000 > scaling_min_freq
echo 2000000 > scaling_max_freq
8.3 Control From User Space And User Dae-mons
The interface to the/sys filesystem allowsuserland control and query functionality. Someform of automation of the policy would nor-mally be part of the desired complete imple-mentation.
This automation is dependent on the reason forusing frequency management. As an example,for the case of transitioning to a lower pstatewhen running on a UPS, a daemon will be no-tified of the failure of mains power, and thatdaemon will trigger the frequency change bywriting to the control files in the/sys filesys-tem.
The CPUFreq architecture has thus split theimplementation into multiple parts:
1. user space policy
2. kernel space driver for common function-ality
3. kernel space driver for processor specificimplementation.
There are multiple user space automationimplementations, not all of which currentlysupport multiprocessor systems. One thatdoes, and that has been used in thisproject is cpufreqd version 1.1.2 (http://
sourceforge.net/projects/cpufreqd ).
This daemon is controlled by a configurationfile. Other than making changes to the con-figuration file, the author of this paper has notbeen involved in any of the development workon cpufreqd, and is a mere user of this tool.
The configuration file specifies profiles andrules. A profile is a description of the systemsettings in that state, and my configuration fileis setup to map the profiles to the processor

178 • Linux Symposium 2004 • Volume One
pstates. Rules are used to dynamically choosewhich profile to use, and my rules are setupto transition profiles based on total processorload.
My simple configuration file to change proces-sor frequency dependent on system load is:
[General]pidfile=/var/run/cpufreqd.pidpoll_interval=2pm_type=acpi
# 2.2 GHz processor speed[Profile]name=hi_boostminfreq=95%maxfreq=100%policy=performance
# 2.0 GHz processor speed[Profile]name=medium_boostminfreq=90%maxfreq=93%policy=performance
# 1.0 GHz processor Speed[Profile]name=lo_boostminfreq=40%maxfreq=50%policy=powersave
[Profile]name=lo_powerminfreq=40%maxfreq=50%policy=powersave
[Rule]#not busy 0%-40%name=conservativeac=onbattery_interval=0-100
cpu_interval=0-40profile=lo_boost
#medium busy 30%-80%[Rule]name=lo_cpu_boostac=onbattery_interval=0-100cpu_interval=30-80profile=medium_boost
#really busy 70%-100%[Rule]name=hi_cpu_boostac=onbattery_interval=50-100cpu_interval=70-100profile=hi_boost
This approach actually works very well formultiple small tasks, for transitioning the fre-quencies of all the processors together basedon a collective loading statistic.
For a long running, single threaded task, thisapproach does not work well as the load is onlyhigh on a single processor, with the others be-ing idle. The average load is thus low, andall processors are kept at a slow speed. Sucha workload scenario would require an imple-mentation that looked at the loading of individ-ual processors, rather than the average. See thesection below on future work.
8.4 The Drivers Involved
powernow-k8.ko arch/i386/kernel/cpu/cpufreq/powernow-k8.c (the same source code is built as a 32-bitdriver in thei386 tree and as a 64-bit driverin thex86_64 tree)
drivers/acpi
drivers/cpufreq

Linux Symposium 2004 • Volume One • 179
The Test Driver
Note that thepowernow-k8.ko driver doesnot export any read, write, or ioctl interfaces.For test purposes, a second driver exists withan ioctl interface for test application use. Thetest driver was a big part of the test effort onpowernow-k8.ko prior to release.
8.5 Frequency Driver Entry Points
powernowk8_init()
Driver late_initcall . Initialization islate as the acpi driver needs to be initializedfirst. Verifies that all processors in the systemare capable of frequency transitions, and thatall processors are supported processors. Buildsa data structure with the addresses of the fourentry points for cpufreq use (listed below), andcallscpufreq_register_driver() .
powernowk8_exit()
Called when the driver is to be unloaded. Callscpufreq_unregister_driver() .
8.6 Frequency Driver Entry Points For Use ByThe CPUFreq driver
powernowk8_cpu_init()
This is a per-processor initialization routine.As we are not guaranteed to be executing onthe processor in question, and as the driverneeds access to MSRs, the driver needs to forceitself to run on the correct processor by usingset_cpus_allowed() .
This pre-processor initialization allows for pro-cessors to be taken offline or brought online dy-namically. I.e., this is part of the software sup-port that would be needed for processor hot-plug, although this is not supported in the hard-ware.
This routine finds the ACPI pstate data for this
processor, and extracts the (proprietary) datafrom the ACPI_PSSobjects. This data is ver-ified as far as is reasonable. Per-processor datatables for use during frequency transitions areconstructed from this information.
powernowk8_cpu_exit()
Per-processor cleanup routine.
powernowk8_verify()
When the root user (or an application runningon behalf of the root user) requests a change tothe minimum/maximum frequencies, or to thepolicy or governor, the frequency driver’s ver-ification routine is called to verify (and correctif necessary) the input values. For example,if the maximum speed of the processor is 2.4GHz and the user requests that the maximumrange be set to 3.0 GHz, the verify routine willcorrect the maximum value to a value that is ac-tually possible. The user can, however, chose avalue that is less than the hardware maximum,for example 2.0 GHz in this case.
As this routine just needs to access the per-processor data, and not any MSRs, it does notmatter which processor executes this code.
powernowk8_target()
This is the driver entry point that actually per-forms a transition to a new frequency/voltage.This entry point is called for each processorthat needs to transition to a new frequency.
There is therefore an optimization possible byenhancing the interface between the frequencydriver and the CPUFreq driver for the casewhere all processors are to be transitioned toa new, common frequency. However, it is notclear that such an optimization is worth thecomplexity, as the functionality to transition asingle processor would still be needed.
This routine is invoked with the processor

180 • Linux Symposium 2004 • Volume One
number as a parameter, and there is no guaran-tee as to which processor we are currently exe-cuting on. As the mechanism for changing thefrequency involves accessing MSRs, it is nec-essary to execute on the target processor, andthe driver forces its execution onto the targetprocessor by usingset_cpus_allowed() .
The CPUFreq helpers are then used to deter-mine the correct target frequency. Once a cho-sen targetfid andvid are identified:
• the cpufreq driver is called to warn that atransition is about to occur,
• the actual transition code withinpowernow-k8 is called, and then
• the cpufreq driver is called again to con-firm that the transition was successful.
The actual transition is protected with asemaphore that is used across all processors.This is to prevent transitions on one proces-sor from interfering with transitions on otherprocessors. This is due to the inter-processorcommunication that occurs at a hardware levelwhen a frequency transition occurs.
8.7 CPUFreq Interface
The CPUFreq interface provides entry points,that are required to make the system function.
It also provides helper functions, which neednot be used, but are there to provide commonfunctionality across the set of all architecturespecific drivers. Elimination of duplicate goodis a good thing! An architecture specific drivercan build a table of available frequencies, andpass this table to the CPUFreq driver. Thehelper functions then simplify the architecturedriver code by manipulating this table.
cpufreq_register_driver()
Registers the frequency driver as being thedriver capable of performing frequency transi-tions on this platform. Only one driver may beregistered.
cpufreq_unregister_driver()
Unregisters the driver, when it is being un-loaded.
cpufreq_notify_transition()
Used to notify the CPUFreq driver, and thus thekernel, that a frequency transition is occurring,and triggering recalibration of timing specificcode.
cpufreq_frequency_table_target()
Helper function to find an appropriate table en-try for a given target frequency. Used in thedriver’s target function.
cpufreq_frequency_table_verify()
Helper function to verify that an input fre-quency is valid. This helper is effectively acomplete implementation of the driver’s verifyfunction.
cpufreq_frequency_table_cpuinfo()
Supplies the frequency table data that is usedon subsequent helper function calls. Also aidswith providing information as to the capabili-ties of the processors.
8.8 Calls To The ACPI Driver
acpi_processor_register_performance()
acpi_processor_unregister_performance()
Helper functions used at per-processor initial-ization time to gain access to the data from the_PSS object for that processor. This is a prefer-able solution to the frequency driver having towalk the ACPI namespace itself.

Linux Symposium 2004 • Volume One • 181
8.9 The Single Processor Solution
Many of the kernel system calls collapse toconstants when the kernel is built withoutmultiprocessor support. For example,num_online_cpus() becomes a macro with thevalue 1. By the careful use of the defini-tions in smp.h, the same driver code handlesboth multiprocessor and single processor ma-chines without the use of conditional compi-lation. The multiprocessor support obviouslyadds complexity to the code for a single proces-sor code, but this code is negligible in the caseof transitioning frequencies. The driver ini-tialization and termination code is made morecomplex and lengthy, but this is not frequentlyexecuted code. There is also a small penalty interms of code space.
The author does not feel that the penalty of themultiple processor support code is noticeableon a single processor system, but this is obvi-ously debatable. The current choice is to havea single driver that supports both single proces-sor and multiple processor systems.
As the primary performance cost is in termsof additional code space, it is true that a sin-gle processor machine with highly constrainedmemory may benefit from a simplified driverwithout the additional multi-processor supportcode. However, such a machine would seegreater benefit by eliminating other code thatwould not be necessary on a chosen platform.For example, the PSB support code could beremoved from a memory constrained singleprocessor machine that was using ACPI.
This approach of removing code unnecessaryfor a particular platform is not a wonderful ap-proach when it leads to multiple variants ofthe driver, all of which have to be supportedand enhanced, and which makes Kconfig evenmore complex.
8.10 Stages Of Development, Test And DebugOf The Driver
The algorithm for transitioning to a new fre-quency is complex. See the BKDG[4] for agood description of the steps required, includ-ing flowcharts. In order to test and debug thefrequency/voltage transition code thoroughly,the author first wrote a simple simulation of theprocessor. This simulation maintained a statemachine, verified that fid/vid MSR control ac-tivity was legal, provided fid/vid status MSRresults, and wrote a log file of all activity. Thecore driver code was then written as an appli-cation and linked with this simulation code toallow testing of all combinations.
The driver was then developed as a skele-ton using printk to develop and test theBIOS/ACPI interfaces without having the fre-quency/voltage transition code present. This isbecause attempts to actually transition to an in-valid pstate often result in total system lock-ups that offer no debug output—if the proces-sor voltage is too low for the frequency, suc-cessful code execution ceases.
When the skeleton was working correctly, theactual transition code was dropped into place,and tested on real hardware, both single pro-cessor and multiple processor. (The single pro-cessor driver was released many months beforethe multi-processor capable driver as the multi-processor capable hardware was not availablein the marketplace.) The functional driver wastested, using printk to trace activity, and usingexternal hardware to track power usage, andusing a test driver to independently verify reg-ister settings.
The functional driver was then made availableto various people in the community for theirfeedback. The author is grateful for the ex-tensive feedback received, which included thechanged code to implement suggestions. Thedriver as it exists today is considerably im-

182 • Linux Symposium 2004 • Volume One
proved from the initial release, due to this feed-back mechanism.
9 How To Determine Valid PStatesFor A Given Processor
AMD defines pstates for each processor. Aperformance state is a frequency/voltage pairthat is valid for operation of that processor.These are specified as fid/vid (frequency iden-tifier/voltage identifier values) pairs, and aredocumented in the Processor Thermal and DataSheets (see references). The worst case proces-sor power consumption for each pstate is alsocharacterized. The BKDG[4] contains tablesfor mapping fid to frequency and vid to volt-age.
Pstates are processor specific. I.e., 2.0 GHz at1.45V may be correct for one model/revisionof processor, but is not necessarily correct fora different/revision model of processor.
Code can determine whether a processor sup-ports or does not support pstate transitions byexecuting the cpuid instruction. (For details,see the BKDG[4] or the source code for theLinux frequency driver). This needs to be donefor each processor in an MP system.
Each processor in an MP system could theoret-ically have different pstates.
Ideally, the processor frequency driver wouldnot contain hardcoded pstate tables, as thedriver would then need to be revised for newprocessor revisions. The chosen solution is tohave the BIOS provide the tables of pstates,and have the driver retrieve the pstate data fromthe BIOS. There are two such tables defined foruse by BIOSs for AMD systems:
1. PSB, AMD’s original proprietary mech-anism, which does not support MP. Thismechanism is being deprecated.
2. ACPI _PSS objects. Whereas the ACPIspecification is a standard, the data withinthe_PSSobjects is AMD specific (and, infact, processor family specific), and thusthere is still a proprietary nature of this so-lution.
The current AMD frequency driver obtainsdata from the ACPI objects. ACPI does in-troduce some limitations, which are discussedlater. Experimentation is ongoing with a built-in database approach to the problem in an at-tempt to bypass these issues, and also to allowchecking of validity of the ACPI provided data.
10 ACPI And Frequency Restric-tions
ACPI[5] provides the_PPCobject, that is usedto constrain the pstates available. This objectis dynamic, and can therefore be used in plat-forms for purposes such as:
• forcing frequency restrictions when oper-ating on battery power,
• forcing frequency restrictions due to ther-mal conditions.
For battery / mains power transitions, an ACPI-compliant GPE (General Purpose Event) inputto the chipset (I/O hub) is dedicated to assign-ing a SCI (System Control Interrupt) when thepower source changes. The ACPI driver willthen execute the ACPI control method (see the_PSR power source ACPI object), which is-sues a notify to the_CPUnobject, which trig-gers the ACPI driver to re-evaluate the_PPCobject. If the current pstate exceeds that al-lowed by this new evaluation of the_PPCob-ject, the CPU frequency driver will be called totransition to a lower pstate.

Linux Symposium 2004 • Volume One • 183
11 ACPI Issues
ACPI as a standard is not perfect. There is vari-ation among different implementations, andLinux ACPI support does not work on all ma-chines.
ACPI does introduce some overhead, and someusers are not willing to enable ACPI.
ACPI requires that pstates be of equivalentpower usage and frequency across all proces-sors. In a system with processors that are ca-pable of different maximum frequencies (forexample, one processor capable of 2.0 GHzand a second processor capable of 2.2 GHz),compliance with the ACPI specification meansthat the faster processor(s) will be restricted tothe maximum speed of the slowest processor.Also, if one processor has 5 available pstates,the presence of processor with only 4 availablepstates will restrict all processors to 4 pstates.
12 What Is There Today?
AMD is shipping pstate capable AMD Opteronprocessors (revision CG). Server processorsprior to revision CG were not pstate capable.All AMD Athlon 64 processors for mobile anddesktop are pstate capable.
BKDG[4] enhancements to describe the capa-bility are in progress.
AMD internal BIOSs have the enhancements.These enhancements are rolling out to the pub-licly available BIOSs along with the BKDGenhancements.
The multi-processor capable Linux frequencydriver has released under GPL.
The cpufreqd user-mode daemon, availablefor download fromhttp://sourceforge.
net/projects/cpufreqd supports multiple
processors.
13 Other Software-directed PowerSaving Mechanisms
13.1 Use Of TheHLT Instruction
The hlt instruction is normally used when theoperating system has no code for the processorto execute. This is the ACPI C1 state. Exe-cution of instructions ceases, until the proces-sor is restarted with an interrupt. The powersavings are maximized when the hlt state is en-tered in the minimum pstate, due to the lowervoltage. The alternative to the use of the hltinstruction is a do nothing loop.
13.2 Use of Power Managed Chipset Drivers
Devices on the planar board, such as a PCI-Xbridge or an AGP tunnel, may have the capabil-ity to operate in lower power modes. Enteringand leaving the lower power modes is under thecontrol of the driver for that device.
Note that HyperTransport attached devices cantransition themselves to lower power modeswhen certain messages are seen on the bus.However, this functionality is typically config-urable, so a chipset driver (or the system BIOSduring bootup) would need to enable this capa-bility.
14 Items For Future Exploration
14.1 A Built-in Database
The theory is that the driver could have a built-in database of processors and the pstates thatthey support. The driver could then use thisdatabase to obtain the pstate data without de-pendencies on ACPI, or use it for enhanced

184 • Linux Symposium 2004 • Volume One
checking of the ACPI provided data. The dis-advantage of this is the need to update thedatabase for new processor revisions. The ad-vantages are the ability to overcome the ACPIimposed restrictions, and also to allow the useof the technology on systems where the ACPIsupport is not enabled.
14.2 Kernel Scheduler—CPU Power
An enhanced scheduler for the 2.6 kernel(2.6.6-bk1) is aware of groups of processorswith different processing power. The powertating of each CPU group should be dynami-cally adjusted using a cpufreq transition noti-fier as the processor frequencies are changed.
See http://lwn.net/Articles/80601/ for a detailed acount of the schedulerchanges.
14.3 Thermal Management, ACPI ThermalZones
Publicly available BIOSs for AMD machinesdo not implement thermal zones. Obviouslythis is one way to provide the input control forfrequency management based on thermal con-ditions.
14.4 Thermal Management, Service Processor
Servers typically have a service processor,which may be compliant to the IPMI specifi-cation. This service processor is able to ac-curately monitor temperature at different lo-cations within the chassis. The 2.6 kernelincludes an IPMI driver. User space codemay use these thermal readings to control fanspeeds and generate administrator alerts. Itmay make sense to also use these accurate ther-mal readings to trigger frequency transitions.
The interaction between thermal events fromthe service processor and ACPI thermal zones
may be a problem.
Hiding Thermal Conditions
One concern with the use of CPU frequencymanipulation to avoid overheating is that hard-ware problems may not be noticed. Over tem-perature conditions would normally cause ad-ministrator alerts, but if the processor is firsttaken to a lower frequency to hold temperaturedown, then the alert may not be generated. Afailing fan (not spinning at full speed) couldtherefore be missed. Some hardware compo-nents fail gradually, and early warning of im-minent failures is needed to perform plannedmaintenance. Losing this data would be bad-ness.
15 Legal Information
Copyright © 2004 Advanced Micro Devices, Inc
Permission to redistribute in accordance with LinuxSymposium submission guidelines is granted; allother rights reserved.
AMD, the AMD Arrow logo, AMD Opteron,AMD Athlon and combinations thereof, AMD-8111, AMD-8131, and AMD-8151 are trademarksof Advanced Micro Devices, Inc.
Linux is a registered trademark of Linus Torvalds.
HyperTransport is a licensed trademark of the Hy-perTransport Technology Consortium.
Other product names used in this publication are foridentification purposes only and may be trademarksof their respective companies.
16 References
1. AMD Opteron™ Processor Data Sheet,publication 23932, available fromwww.amd.com
2. AMD Opteron™ Processor Power And

Linux Symposium 2004 • Volume One • 185
Thermal Data Sheet, publication 30417,available fromwww.amd.com
3. AMD Athlon™ 64 Processor Power AndThermal Data Sheet, publication 30430,available fromwww.amd.com
4. BIOS and Kernel Developer’s Guide (theBKDG) for AMD Athlon™ 64 and AMDOpteron™ Processors, publication 26094,available fromwww.amd.com. Chapter9 covers frequency management.
5. ACPI 2.0b Specification, fromwww.acpi.info
6. Text documentation files in the kernellinux/Documentation/cpu-freq/
directory:
• index.txt
• user-guide.txt
• core.txt
• cpu-drivers.txt
• governors.txt

186 • Linux Symposium 2004 • Volume One

Dynamic Kernel Module Support:From Theory to Practice
Matt Domsch & Gary LerhauptDell Linux Engineering
[email protected], [email protected]
Abstract
DKMS is a framework which allows individualkernel modules to be upgraded without chang-ing your whole kernel. Its primary audienceis fourfold: system administrators who wantto update a single device driver rather thanwait for a new kernel from elsewhere with itincluded; distribution maintainers, who wantto release a single targeted bugfix in betweenlarger scheduled updates; system manufactur-ers who need single modules changed to sup-port new hardware or to fix bugs, but do notwish to test whole new kernels; and driverdevelopers, who must provide updated devicedrivers for testing and general use on a widevariety of kernels, as well as submit drivers tokernel.org.
Since OLS2003, DKMS has gone from a goodidea to deployed and used. Based on end userfeedback, additional features have been added:precompiled module tarball support to speedfactory installation; driver disks for Red Hatdistributions; 2.6 kernel support; SuSE ker-nel support. Planned features include cross-architecture build support and additional dis-tribution driver disk methods.
In addition to overviewing DKMS and its fea-tures, we explain how to create a dkms.conf fileto DKMS-ify your kernel module source.
1 History
Historically, Linux distributions bundle devicedrivers into essentially one large kernel pack-age, for several primary reasons:
• Completeness: The Linux kernel as dis-tributed on kernel.org includes all the de-vice drivers packaged neatly together inthe same kernel tarball. Distro kernels fol-low kernel.org in this respect.
• Maintainer simplicity: With over 4000files in the kerneldrivers/ directory,each possibly separately versioned, itwould be impractical for the kernel main-tainer(s) to provide a separate package foreach driver.
• Quality Assurance / Support organizationsimplicity: It is easiest to ask a user “whatkernel version are you running,” and tocompare this against the list of approvedkernel versions released by the QA team,rather than requiring the customer to pro-vide a long and extensive list of packageversions, possibly one per module.
• End user install experience: End usersdon’t care about which of the 4000 pos-sible drivers they need to install, they justwant it to work.
This works well as long as you are able to makethe “top of the tree” contain the most current

188 • Linux Symposium 2004 • Volume One
and most stable device driver, and you are ableto convince your end users to always run the“top of the tree.” Thekernel.org develop-ment processes tend to follow this model withgreat success.
But widely used distros cannot ask their usersto always update to the top of the kernel.orgtree. Instead, they start their products from thetop of the kernel.org tree at some point in time,essentially freezing with that, to begin their testcycles. The duration of these test cycles canbe as short as a few weeks, and as long as afew years, but 3-6 months is not unusual. Dur-ing this time, the kernel.org kernels march for-ward, and some (but not all) of these changesare backported into the distro’s kernel. Theythen apply the minimal patches necessary forthem to declare the product finished, and movethe project into the sustaining phase, wherechanges are very closely scrutinized before re-leasing them to the end users.
1.1 Backporting
It is this sustaining phase that DKMS targets.DKMS can be used to backport newer devicedriver versions from the “top of the tree” ker-nels where most development takes place to thenow-historical kernels of released products.
The PATCH_MATCHmechanism was specif-ically designed to allow the application ofpatches to a “top of the tree” device driver tomake it work with older kernels. This allowsdriver developers to continue to focus their ef-forts on keeping kernel.org up to date, while al-lowing that same effort to be used on existingproducts with minimal changes. See Section 6for a further explanation of this feature.
1.2 Driver developers’ packaging
Driver developers have recognized for a longtime that they needed to provide backported
versions of their drivers to match their endusers’ needs. Often these requirements areimposed on them by system vendors suchas Dell in support of a given distro release.However, each driver developer was free toprovide the backport mechanism in any waythey chose. Some provided architecture-specific RPMs which contained only precom-piled modules. Some provided source RPMswhich could be rebuilt for the running ker-nel. Some provided driver disks with precom-piled modules. Some provided just source codepatches, and expected the end user to rebuildthe kernel themselves to obtain the desired de-vice driver version. All provided their ownMakefiles rather than use the kernel-providedbuild system.
As a result, different problems were encoun-tered with each developers’ solution. Somedevelopers had not included their drivers inthe kernel.org tree for so long that that therewere discrepancies, e.g.CONFIG_SMPvs__SMP__, CONFIG_2G vs. CONFIG_3G,and compiler option differences which wentunnoticed and resulted in hard-to-debug issues.
Needless to say, with so many different mech-anisms, all done differently, and all with differ-ent problems, it was a nightmare for end users.
A new mechanism was needed to cleanly han-dle applying updated device drivers onto anend user’s system. Hence DKMS was createdas the one module update mechanism to re-place all previous methods.
2 Goals
DKMS has several design goals.
• Implement only mechanism, not policy.
• Allow system administrators to easilyknow what modules, what versions, for

Linux Symposium 2004 • Volume One • 189
what kernels, and in what state, they haveon their system.
• Keep module source as it would be foundin the “top of the tree” on kernel.org. Ap-ply patches to backport the modules toearlier kernels as necessary.
• Use the kernel-provided build mecha-nism. This reduces the Makefile magicthat driver developers need to know, thusthe likelihood of getting it wrong.
• Keep additional DKMS knowledge adriver developer must have to a minimum.Only a small per-driver dkms.conf file isneeded.
• Allow multiple versions of any one mod-ule to be present on the system, with onlyone active at any given time.
• Allow DKMS-aware drivers to bepackaged in the Linux Standard Base-conformant RPM format.
• Ease of use by multiple audiences: driverdevelopers, system administrators, Linuxdistros, and system vendors.
We discuss DKMS as it applies to each of thesefour audiences.
3 Distributions
All present Linux distributions distribute de-vice drivers bundled into essentially one largekernel package, for reasons outlined in Sec-tion 1. It makes the most sense, most of thetime.
However, there are cases where it does notmake sense.
• Severity 1 bugs are discovered in a sin-gle device driver between larger sched-uled updates. Ideally you’d like your af-fected users to be able to get the singlemodule update without having to releaseand Q/A a whole new kernel. Only cus-tomers who are affected by the particularbug need to update “off-cycle.”
• Solutions vendors, for change control rea-sons, often certify their solution on a par-ticular distribution, scheduled update re-lease, and sometimes specific kernel ver-sion. The latter, combined with releasingdevice driver bug fixes as whole new ker-nels, puts the customer in the untenableposition of either updating to the new ker-nel (and losing the certification of the so-lution vendor), or forgoing the bug fix andpossibly putting their data at risk.
• Some device drivers are not (yet) includedin kernel.org nor a distro kernel, howeverone may be required for a functional soft-ware solution. The current support mod-els require that the add-on driver “taint”the kernel or in some way flag to the sup-port organization that the user is runningan unsupported kernel module. Tainting,while valid, only has three dimensionsto it at present: Proprietary—non-GPLlicensed; Forced—loaded viainsmod-f ; and Unsafe SMP—for some CPUswhich are not designed to be SMP-capable. A GPL-licensed device driverwhich is not yet in kernel.org or providedby the distribution may trigger none ofthese taints, yet the support organizationneeds to be aware of this module’s pres-ence. To avoid this, we expect to seethe distros begin to cryptographically signkernel modules that they produce, andtaint on load of an unsigned module. Thiswould help reduce the support organiza-tion’s work for calls about “unsupported”

190 • Linux Symposium 2004 • Volume One
configurations. With DKMS in use, thereis less a need for such methods, as it’s easyto see which modules have been changed.
Note: this is not to suggest that driver au-thors should not submit their drivers tokernel.org —absolutely they should.
• The distro QA team would like to test up-dates to specific drivers without waitingfor the kernel maintenance team to rebuildthe kernel package (which can take manyhours in some cases). Likewise, individ-ual end users may be willing (and often berequired, e.g. if the distro QA team can’treproduce the users’s hardware and soft-ware environment exactly) to show that aparticular bug is fixed in a driver, priorto releasing the fix toall of that distro’susers.
• New hardware support via driver disks:Hardware vendors release new hardwareasynchronously to any software vendorschedule, no matter how hard companiesmay try to synchronize releases. OS dis-tributions provide install methods whichuse driver diskettes to enable new hard-ware for previously-released versions ofthe OS. Generating driver disks has al-ways been a difficult and error-prone pro-cedure, different for each OS distribution,not something that the casual end-userwould dare attempt.
DKMS was designed to address all of theseconcerns.
DKMS aims to provide a clear separation be-tween mechanism (how one updates individualkernel modules and tracks such activity) andpolicy (when should one update individual ker-nel modules).
3.1 Mechanism
DKMS provides only the mechanism for up-dating individual kernel modules, not policy.As such, it can be used by distributions (pertheir policy) for updating individual devicedrivers for individual users affected by Severity1 bugs, without releasing a whole new kernel.
The first mechanism critical to a system admin-istrator or support organization is thestatuscommand, which reports the name, version,and state of each kernel module under DKMScontrol. By querying DKMS for this infor-mation, system administrators and distributionsupport organizations may quickly understandwhen an updated device driver is in use tospeed resolution when issues are seen.
DKMS’s ability to generate driver diskettesgives control to both novice and seasoned sys-tem administrators alike, as they can now per-form work which otherwise they would haveto wait for a support organization to do forthem. They can get their new hardware sys-tems up-and-running quickly by themselves,leaving the support organizations with time todo other more interesting value-added work.
3.2 Policy
Suggested policy items include:
• Updates must pass QA. This seems ob-vious, but it reduces broken updates (de-signed to fix other problems) from beingreleased.
• Updates must be submitted, and ideally beincluded already, upstream. For this weexpect kernel.org and the OS distributionto include the update in their next largerscheduled update. This ensures that whenthe next kernel.org kernel or distro update

Linux Symposium 2004 • Volume One • 191
comes out, the short-term fix provided viaDKMS is incorporated already.
• TheAUTOINSTALLmechanism is set toNOfor all modules which are shipped withthe target distro’s kernel. This preventsthe DKMS autoinstaller from installinga (possibly older) kernel module onto anewer kernel without being explicitly toldto do so by the system administrator. Thisfollows from the “all DKMS updates mustbe in the next larger release” rule above.
• All issues for which DKMS is used aretracked in the appropriate bug trackingdatabases until they are included up-stream, and are reviewed regularly.
• All DKMS packages are provided asDKMS-enabled RPMs for easy installa-tion and removal, per the Linux StandardBase specification.
• All DKMS packages are posted to the dis-tro’s support web site for download bysystem administrators affected by the par-tiular issue.
4 System Vendors
DKMS is useful to System Vendors such asDell for many of the same reasons it’s usefulto the Linux distributions. In addition, systemvendors face additional issues:
• Critical bug fixes for distro-provideddrivers: While we hope to never needsuch, and we test extensively with distro-provided drivers, occasionally we havediscovered a critical bug after the distri-bution has cut their gold CDs. We useDKMS to update just the affected devicedrivers.
• Alternate drivers: Dell occasionally needsto provide an alternate driver for a piece ofhardware rather than that provided by thedistribution natively. For example, Dellprovides the Intel iANS network channelbonding and failover driver for customerswho have used iANS in the past, and wishto continue using it rather than upgradingto the native channel bonding driver resi-dent in the distribution.
• Factory installation: Dell installs variousOS distribution releases onto new hard-ware in its factories. We try not to up-date from the gold release of a distributionversion to any of the scheduled updates,as customers expect to receive gold. Weuse DKMS to enable newer device driversto handle newer hardware than was sup-ported natively in the gold release, whilekeeping the gold kernel the same.
We briefly describe the policy Dell uses, in ad-dition to the above rules suggested to OS dis-tributions:
• Prebuilt DKMS tarballs are required forfactory installation use, for all kernelsused in the factory install process. Thisprevents the need for the compiler to berun, saving time through the factories.Dell rarely changes the factory install im-ages for a given OS release, so this is nota huge burden on the DKMS packager.
• All DKMS packages are posted to sup-port.dell.com for download by system ad-ministrators purchasing systems withoutLinux factory-installed.

192 • Linux Symposium 2004 • Volume One
Figure 1: DKMS state diagram.
5 System Administrators
5.1 Understanding the DKMS Life Cycle
Before diving into using DKMS to manage ker-nel modules, it is helpful to understand the lifecycle by which DKMS maintains your kernelmodules. In Figure 1, each rectangle repre-sents a state your module can be in and eachitalicized word represents a DKMS action thatcan used to switch between the various DKMSstates. In the following section we will lookfurther into each of these DKMS actions andthen continue on to discuss auxiliary DKMSfunctionality that extends and improves uponyour ability to utilize these basic commands.
5.2 RPM and DKMS
DKMS was designed to work well with RedHat Package Manger (RPM). Many times us-ing DKMS to install a kernel module is as easyas installing a DKMS-enabled module RPM.Internally in these RPMs, DKMS is used toadd , build , and install a module. Bywrapping DKMS commands inside of an RPM,you get the benefits of RPM (package version-ing, security, dependency resolution, and pack-age distribution methodologies) while DKMShandles the work RPM does not, versioningand building of individual kernel modules.For reference, a sample DKMS-enabled RPMspecfile can be found in the DKMS package.
5.3 Using DKMS
5.3.1 Add
DKMS manages kernel module versions atthe source code level. The first require-ment of using DKMS is that the modulesource be located on the build system andthat it be located in the directory/usr/src/<module>-<module-version>/ . Italso requires that a dkms.conf file exists withthe appropriately formatted directives withinthis configuration file to tell DKMS such thingsas where to install the module and how to buildit. Once these two requirements have beenmet and DKMS has been installed on your sys-tem, you can begin using DKMS by adding amodule/module-version to the DKMS tree. Forexample:
# dkms add -m megaraid2 -v 2.10.3
This example add command would addmegaraid2/2.10.3 to the already existent/var/dkms tree, leaving it in the Addedstate.
5.3.2 Build
Once in the Added state, the module is readyto be built. This occurs through the DKMSbuild command and requires that the properkernel sources are located on the system fromthe /lib/module/<kernel-version>/build symlink. The make command that is

Linux Symposium 2004 • Volume One • 193
used to compile the module is specified in thedkms.conf configuration file. Continuing withthe megaraid2/2.10.3 example:
# dkms build -m megaraid2-v 2.10.3 -k 2.4.21-4.ELsmp
The build command compiles the modulebut stops short of installing it. As can be seenin the above example,build expects a kernel-version parameter. If this kernel name is leftout, it assumes the currently running kernel.However, it functions perfectly well to buildmodules for kernels that are not currently run-ning. This functionality is assured through useof a kernel preparation subroutine that runs be-fore any module build is performed in orderto ensure that the module being built is linkedagainst the proper kernel symbols.
Successful completion of abuild creates, forthis example, the/var/dkms/megaraid2/
2.10.3/2.4.21-4.ELsmp/ directory aswell as the log and module subdirectorieswithin this directory. The log directory holdsa log file of the module make and the moduledirectory holds copies of the resultant binaries.
5.3.3 Install
With the completion of abuild , the mod-ule can now be installed on the kernel forwhich it was built. Installation copies the com-piled module binary to the correct location inthe /lib/modules/ tree as specified in thedkms.conf file. If a module by that name isalready found in that location, DKMS saves itin its tree as an original module so at a latertime it can be put back into place if the newermodule is uninstalled. An exampleinstallcommand:
# dkms install -m megaraid2-v 2.10.3 -k 2.4.21-4.ELsmp
If a module by the same name is alreadyinstalled, DKMS saves a copy in itstree and does so in the/var/dkms/<module-name>/original_module/directory. In this case, it would be saved to/var/dkms/megaraid2/original_module/2.4.21-4.ELsmp/ .
5.3.4 Uninstall and Remove
To complete the DKMS cycle, you can alsouninstall or remove your module from thetree. Theuninstall command deletes from/lib/modules the module you installedand, if applicable, replaces it with its originalmodule. In scenarios where multiple versionsof a module are located within the DKMS tree,when one version is uninstalled, DKMS doesnot try to understand or assume which of theseother versions to put in its place. Instead, ifa true “original_module” was saved from thevery first DKMS installation, it will be put backinto the kernel and all of the other module ver-sions for that module will be left in the Builtstate. An exampleuninstall would be:
# dkms uninstall -m megaraid2-v 2.10.3 -k 2.4.21-4.ELsmp
Again, if the kernel version parameter is un-set, the currently running kernel is assumed,although, the same behavior does not occurwith theremove command. Theremove anduninstall are very similar in thatremovewill do all of the same steps asuninstall .However, whenremove is employed, if themodule-version being removed is the last in-stance of that module-version for all kernelson your system, after the uninstall portion ofthe remove completes, it will delete all tracesof that module from the DKMS tree. To put itanother way, when anuninstall commandcompletes, your modules are left in the Built

194 • Linux Symposium 2004 • Volume One
state. However, when aremove completes,you would be left in the Not in Tree state. Hereare two sampleremove commands:
# dkms remove -m megaraid2-v 2.10.3 -k 2.4.21-4.ELsmp
# dkms remove -m megaraid2-v 2.10.3 --all
With the first exampleremove command,your module would be uninstalled and if thismodule/module-version were not installed onany other kernel, all traces of it would be re-moved from the DKMS tree all together. If,say, megaraid2/2.10.3 was also installed on the2.4.21-4.ELhugemem kernel, the firstremovecommand would leave it alone and it would re-main intact in the DKMS tree. In the secondexample, that would not be the case. It woulduninstall all versions of the megaraid2/2.10.3module from all kernels and then completelyexpunge all references of megaraid2/2.10.3from the DKMS tree. Thus,remove is whatcleans your DKMS tree.
5.4 Miscellaneous DKMS Commands
5.4.1 Status
DKMS also comes with a fully functional sta-tus command that returns information aboutwhat is currently located in your tree. If noparameters are set, it will return all informa-tion found. Logically, the specificity of infor-mation returned depends on which parametersare passed to your status command. Each sta-tus entry returned will be of the state: “added,”“built,” or “installed,” and if an original mod-ule has been saved, this information will alsobe displayed. Some example status commandsinclude:
# dkms status# dkms status -m megaraid2# dkms status -m megaraid2 -v 2.10.3# dkms status -k 2.4.21-4.ELsmp# dkms status -m megaraid2
-v 2.10.3 -k 2.4.21-4.ELsmp
5.4.2 Match
Another major feature of DKMS is the matchcommand. The match command takes the con-figuration of DKMS installed modules for onekernel and applies this same configuration tosome other kernel. When the match completes,the same module/module-versions that wereinstalled for one kernel are also then installedon the other kernel. This is helpful when youare upgrading from one kernel to the next, butwould like to keep the same DKMS modules inplace for the new kernel. Here is an example:
# dkms match--templatekernel 2.4.21-4.ELsmp-k 2.4.21-5.ELsmp
As can be seen in the example, the−−templatekernel is the “match-er”kernel from which the configuration is based,while the-k kernel is the “match-ee” uponwhich the configuration is instated.
5.4.3 dkms_autoinstaller
Similar in nature to the match command isthe dkms_autoinstaller service. This servicegets installed as part of the DKMS RPMin the /etc/init.d directory. Depending onwhether anAUTOINSTALL directive is setwithin a module’s dkms.conf configurationfile, the dkms_autoinstaller will automaticallybuild and install that module as you boot yoursystem into new kernels which do not alreadyhave this module installed.
5.4.4 mkdriverdisk
The last miscellaneous DKMS command ismkdriverdisk . As can be inferred from itsname,mkdriverdisk will take the proper

Linux Symposium 2004 • Volume One • 195
sources in your DKMS tree and create a driverdisk image for use in providing updated driversto Linux distribution installations. A samplemkdriverdisk might look like:
# dkms mkdriverdisk -d redhat-m megaraid2 -v 2.10.3-k 2.4.21-4.ELBOOT
Currently, the only supported distributiondriver disk format is Red Hat. For moreinformation on the extra necessary files andtheir formats for DKMS to create RedHat driver disks, seehttp://people.redhat.com/dledford . These filesshould be placed in your module source direc-tory.
5.5 Systems Management with DKMS Tar-balls
As we have seen, DKMS provides a simplemechanism to build, install, and track devicedriver updates. So far, all these actions haverelated to a single machine. But what if you’vegot many similar machines under your admin-istrative control? What if you have a compilerand kernel source on only one system (yourmaster build system), but you need to deployyour newly built driver to all your other sys-tems? DKMS provides a solution to this aswell—in the mktarball and ldtarballcommands.
Themktarball command rolls up copies ofeach device driver module file which you’vebuilt using DKMS into a compressed tar-ball. You may then copy this tarball to eachof your target systems, and use the DKMSldtarball command to load those into yourDKMS tree, leaving each module in the Builtstate, ready to be installed. This avoids theneed for both kernel source and compilers tobe on every target system.
For example:
You have built the megaraid2 device driver,version 2.10.3, for two different kernel fami-lies (here 2.4.20-9 and 2.4.21-4.EL), on yourmaster build system.
# dkms statusmegaraid2, 2.10.3, 2.4.20-9: builtmegaraid2, 2.10.3, 2.4.20-9bigmem: builtmegaraid2, 2.10.3, 2.4.20-9BOOT: builtmegaraid2, 2.10.3, 2.4.20-9smp: builtmegaraid2, 2.10.3, 2.4.21-4.EL: builtmegaraid2, 2.10.3, 2.4.21-4.ELBOOT: builtmegaraid2, 2.10.3, 2.4.21-4.ELhugemem: builtmegaraid2, 2.10.3, 2.4.21-4.ELsmp: built
You wish to deploy this version of thedriver to several systems, without rebuildingfrom source each time. You can use themktarball command to generate one tarballfor each kernel family:
# dkms mktarball -m megaraid2-v 2.10.3-k 2.4.21-4.EL,2.4.21-4.ELsmp,2.4.21-4.ELBOOT,2.4.21-4.ELhugemem
Marking /usr/src/megaraid2-2.10.3 for archiving...Marking kernel 2.4.21-4.EL for archiving...Marking kernel 2.4.21-4.ELBOOT for archiving...Marking kernel 2.4.21-4.ELhugemem for archiving...Marking kernel 2.4.21-4.ELsmp for archiving...Tarball location:
/var/dkms/megaraid2/2.10.3/tarball/megaraid2-2.10.3-manykernels.tgzDone.
You can make one big tarball containing mod-ules for both families by omitting the -k ar-gument and kernel list; DKMS will include amodule for every kernel version found.
You may then copy the tarball (renaming it ifyou wish) to each of your target systems usingany mechanism you wish, and load the mod-ules in. First, see that the target DKMS treedoes not contain the modules you’re loading:
# dkms statusNothing found within the DKMS tree forthis status command. If your modules werenot installed with DKMS, they will not showup here.
Then, load the tarball on your target system:

196 • Linux Symposium 2004 • Volume One
# dkms ldtarball--archive=megaraid2-2.10.3-manykernels.tgz
Loading tarball for module:megaraid2 / version: 2.10.3
Loading /usr/src/megaraid2-2.10.3...Loading /var/dkms/megaraid2/2.10.3/2.4.21-4.EL...Loading /var/dkms/megaraid2/2.10.3/2.4.21-4.ELBOOT...Loading /var/dkms/megaraid2/2.10.3/2.4.21-4.ELhugemem...Loading /var/dkms/megaraid2/2.10.3/2.4.21-4.ELsmp...Creating /var/dkms/megaraid2/2.10.3/source symlink...
Finally, verify the modules are present, and inthe Built state:
# dkms statusmegaraid2, 2.10.3, 2.4.21-4.EL: builtmegaraid2, 2.10.3, 2.4.21-4.ELBOOT: builtmegaraid2, 2.10.3, 2.4.21-4.ELhugemem: builtmegaraid2, 2.10.3, 2.4.21-4.ELsmp: built
DKMS ldtarball leaves the modules in theBuilt state, not the Installed state. For each ker-nel version you want your modules to be in-stalled into, follow the install steps as above.
6 Driver Developers
As the maintainer of a kernel module, the onlything you need to do to get DKMS interoper-ability is place a small dkms.conf file in yourdriver source tarball. Once this has been done,any user of DKMS can simply do:
dkms ldtarball --archive /path/to/foo-1.0.tgz
That’s it. We could discuss at length (whichwe will not rehash in this paper) the best meth-ods to utilizing DKMS within a dkms-enabledmodule RPM, but for simple DKMS usability,the buck stops here. With the dkms.conf filein place, you have now positioned your sourcetarball to be usable by all manner and skill levelof Linux users utilizing your driver. Effec-tively, you have widely increased your testingbase without having to wade into package man-agement or pre-compiled binaries. DKMS willhandle this all for you. Along the same line,
by leveraging DKMS you can now easily allowmore widespread testing of your driver. Sincedriver versions can now be cleanly tracked out-side of the kernel tree, you no longer must waitfor the next kernel release in order for the com-munity to register the necessary debugging cy-cles against your code. Instead, DKMS can becounted on to manage various versions of yourkernel module such that any catastrophic errorsin your code can be easily mitigated by a sin-gular dkms uninstall command.
This leaves the composition of the dkms.confas the only interesting piece left to discussfor the driver developer audience. With thatin mind, we will now explicate over twodkms.conf examples ranging from that whichis minimally required (Figure 2) to that whichexpresses maximal configuration (Figure 3).
6.1 Minimal dkms.conf for 2.4 kernels
Referring to Figure 2, the first thing that is dis-tinguishable is the definition of the version ofthe package and the make command to be usedto compile your module. This is only neces-sary for 2.4-based kernels, and lets the devel-oper specify their desired make incantation.
Reviewing the rest of the dkms.conf,PACKAGE_NAMEand BUILT_MODULE_NAME[0] appear to be duplicate in nature,but this is only the case for a package whichcontains only one kernel module within it.Had this example been for something likeALSA, the name of the package would be“alsa,” but theBUILT_MODULE_NAMEarraywould instead be populated with the names ofthe kernel modules within the ALSA package.
The final required piece of this minimal ex-ample is theDEST_MODULE_LOCATIONar-ray. This simply tells DKMS where in the/lib/modules tree it should install your module.

Linux Symposium 2004 • Volume One • 197
PACKAGE_NAME="megaraid2"PACKAGE_VERSION="2.10.3"
MAKE[0]="make -C ${kernel_source_dir}SUBDIRS=${dkms_tree}/${PACKAGE_NAME}/${PACKAGE_VERSION}/build modules"
BUILT_MODULE_NAME[0]="megaraid2"DEST_MODULE_LOCATION[0]="/kernel/drivers/scsi/"
Figure 2: A minimal dkms.conf
6.2 Minimal dkms.conf for 2.6 kernels
In the current version of DKMS, for 2.6 kernelsthe MAKE command listed in the dkms.confis wholly ignored, and instead DKMS will al-ways use:
make -C /lib/modules/$kernel_version/build \M=$dkms_tree/$module/$module_version/build
This jibes with the new external module buildinfrastructure supported by Sam Ravnborg’skernel Makefile improvements, as DKMS willalways build your module in a build subdi-rectory it creates for each version you haveinstalled. Similarly, an impending futureversion of DKMS will also begin to ig-nore thePACKAGE_VERSIONas specified indkms.conf in favor of the new modinfo pro-vided information as implemented by RustyRussell.
With regard to removing the requirement forDEST_MODULE_LOCATIONfor 2.6 kernels,given that similar information should be lo-cated in the install target of the Makefile pro-vided with your package, it is theoretically pos-sible that DKMS could one day glean suchinformation from the Makefile instead. Infact, in a simple scenario as this example, itis further theoretically possible that the nameof the package and of the built module couldalso be determined from the package Make-file. In effect, this would completely remove
any need for a dkms.conf whatsoever, thus en-abling all simple module tarballs to be auto-matically DKMS enabled.
Though, as these features have not been ex-plored and as package maintainers wouldlikely want to use some of the other dkms.confdirective features which are about to be elab-orated upon, it is likely that requiring adkms.conf will continue for the foreseeable fu-ture.
6.3 Optional dkms.conf directives
In the real-world version of the Dell’s DKMS-enabled megaraid2 package, we also specifythe optional directives:
MODULES_CONF_ALIAS_TYPE[0]="scsi_hostadapter"
MODULES_CONF_OBSOLETES[0]="megaraid,megaraid_2002"
REMAKE_INITRD="yes"
These directives tell DKMS to remake the ker-nel’s initial ramdisk after every DKMS installor uninstall of this module. They further spec-ify that before this happens, /etc/modules.conf(or /etc/sysconfig/kernel) should be edited in-telligently so that the initrd is properly assem-bled. In this case, if /etc/modules.conf alreadycontains a reference to either “megaraid” or“megaraid_2002,” these will be switched to“megaraid2.” If no such references are found,

198 • Linux Symposium 2004 • Volume One
then a new “scsi_hostadapter” entry will beadded as the last such scsi_hostadapter num-ber.
On the other hand, if it had also included:
MODULES_CONF_OBSOLETES_ONLY="yes"
then had no obsolete references been found,a new “scsi_hostadapter” line would not havebeen added. This would be useful in scenarioswhere you instead want to rely on somethinglike Red Hat’s kudzu program for adding ref-erences for your kernel modules.
As well one could hypothetically also specifywithin the dkms.conf:
DEST_MODULE_NAME[0]="megaraid"
This would cause the resultant megaraid2 ker-nel module to be renamed to “megaraid” be-fore being installed. Rather than having topropagate various one-off naming mechanismswhich include the version as part of the mod-ule name in /lib/modules as has been previouscommon practice, DKMS could instead be re-lied upon to manage all module versioning toavoid such clutter. Was megaraid_2002 a ver-sion or just a special year in the hearts of themegaraid developers? While you and I mightknow the answer to this, it certainly confusedDell’s customers.
Continuing with hypothetical additions to thedkms.conf in Figure 2, one could also include:
BUILD_EXCLUSIVE_KERNEL="^2\.4.*"BUILD_EXCLUSIVE_ARCH="i.86"
In the event that you know the code you pro-duced is not portable, this is how you can tellDKMS to keep people from trying to build it
elsewhere. The above restrictions would onlyallow the kernel module to be built on 2.4 ker-nels on x86 architectures.
Continuting with optional dkms.conf direc-tives, the ALSA example in Figure 3 is takendirectly from a DKMS-enabled package thatDell released to address sound issues on thePrecision 360 workstation. It is slightlyabridged as the alsa-driver as delivered actuallyinstalls 13 separate kernel modules, but for thesake of this example, only 9 are shown.
In this example, we have:
AUTOINSTALL="yes"
This tells the boot-time servicedkms_autoinstaller that this package should bebuilt and installed as you boot into a new ker-nel that DKMS has not already installed thispackage upon. By general policy, Dell onlyallows AUTOINSTALL to be set if the kernelmodules are not already natively includedwith the kernel. This is to avoid the scenariowhere DKMS might automatically installover a newer version of the kernel module asprovided by some newer version of the kernel.However, given the 2.6 modinfo changes,DKMS can now be modified to intelligentlycheck the version of a native kernel modulebefore clobbering it with some older version.This will likely result in a future policy changewithin Dell with regard to this feature.
In this example, we also have:
PATCH[0]="adriver.h.patch"PATCH_MATCH[0]="2.4.[2-9][2-9]"
These two directives indicate to DKMS thatif the kernel that the kernel module is beingbuilt for is >=2.4.22 (but still of the 2.4 fam-ily), the included adriver.h.patch should first be

Linux Symposium 2004 • Volume One • 199
PACKAGE_NAME="alsa-driver"PACKAGE_VERSION="0.9.0rc6"
MAKE="sh configure --with-cards=intel8x0 --with-sequencer=yes \--with-kernel=/lib/modules/$kernelver/build \--with-moddir=/lib/modules/$kernelver/kernel/sound > /dev/null; make"
AUTOINSTALL="yes"
PATCH[0]="adriver.h.patch"PATCH_MATCH[0]="2.4.[2-9][2-9]"
POST_INSTALL="alsa-driver-dkms-post.sh"MODULES_CONF[0]="alias char-major-116 snd"MODULES_CONF[1]="alias snd-card-0 snd-intel8x0"MODULES_CONF[2]="alias char-major-14 soundcore"MODULES_CONF[3]="alias sound-slot-0 snd-card-0"MODULES_CONF[4]="alias sound-service-0-0 snd-mixer-oss"MODULES_CONF[5]="alias sound-service-0-1 snd-seq-oss"MODULES_CONF[6]="alias sound-service-0-3 snd-pcm-oss"MODULES_CONF[7]="alias sound-service-0-8 snd-seq-oss"MODULES_CONF[8]="alias sound-service-0-12 snd-pcm-oss"MODULES_CONF[9]="post-install snd-card-0 /usr/sbin/alsactl restore >/dev/null 2>&1 || :"MODULES_CONF[10]="pre-remove snd-card-0 /usr/sbin/alsactl store >/dev/null 2>&1 || :"
BUILT_MODULE_NAME[0]="snd-pcm"BUILT_MODULE_LOCATION[0]="acore"DEST_MODULE_LOCATION[0]="/kernel/sound/acore"
BUILT_MODULE_NAME[1]="snd-rawmidi"BUILT_MODULE_LOCATION[1]="acore"DEST_MODULE_LOCATION[1]="/kernel/sound/acore"
BUILT_MODULE_NAME[2]="snd-timer"BUILT_MODULE_LOCATION[2]="acore"DEST_MODULE_LOCATION[2]="/kernel/sound/acore"
BUILT_MODULE_NAME[3]="snd"BUILT_MODULE_LOCATION[3]="acore"DEST_MODULE_LOCATION[3]="/kernel/sound/acore"
BUILT_MODULE_NAME[4]="snd-mixer-oss"BUILT_MODULE_LOCATION[4]="acore/oss"DEST_MODULE_LOCATION[4]="/kernel/sound/acore/oss"
BUILT_MODULE_NAME[5]="snd-pcm-oss"BUILT_MODULE_LOCATION[5]="acore/oss"DEST_MODULE_LOCATION[5]="/kernel/sound/acore/oss"
BUILT_MODULE_NAME[6]="snd-seq-device"BUILT_MODULE_LOCATION[6]="acore/seq"DEST_MODULE_LOCATION[6]="/kernel/sound/acore/seq"
BUILT_MODULE_NAME[7]="snd-seq-midi-event"BUILT_MODULE_LOCATION[7]="acore/seq"DEST_MODULE_LOCATION[7]="/kernel/sound/acore/seq"
BUILT_MODULE_NAME[8]="snd-seq-midi"BUILT_MODULE_LOCATION[8]="acore/seq"DEST_MODULE_LOCATION[8]="/kernel/sound/acore/seq"
BUILT_MODULE_NAME[9]="snd-seq"BUILT_MODULE_LOCATION[9]="acore/seq"DEST_MODULE_LOCATION[9]="/kernel/sound/acore/seq"
Figure 3: An elaborate dkms.conf

200 • Linux Symposium 2004 • Volume One
applied to the module source before a modulebuild occurs. In this way, by including vari-ous patches needed for various kernel versions,you can distribute one source tarball and en-sure it will always properly build regardless ofthe end user target kernel. If no correspondingPATCH_MATCH[0] entry were specified forPATCH[0] , then the adriver.h.patch would al-ways get applied before a module build. AsDKMS always starts off each module buildwith pristine module source, you can alwaysensure the right patches are being applied.
Also seen in this example is:
MODULES_CONF[0]="alias char-major-116 snd"
MODULES_CONF[1]="alias snd-card-0 snd-intel8x0"
Unlike the previous discussion of/etc/modules.conf changes, any entriesplaced into theMODULES_CONFarray areautomatically added into /etc/modules.confduring a module install. These are later onlyremoved during the final module uninstall.
Lastly, we have:
POST_INSTALL="alsa-driver-dkms-post.sh"
In the event that you have other scripts thatmust be run during various DKMS events,DKMS includesPOST_ADD, POST_BUILD,POST_INSTALL and POST_REMOVEfunc-tionality.
7 Future
As you can tell from the above, DKMS is verymuch ready for deployment now. However, aswith all software projects, there’s room for im-provement.
7.1 Cross-Architecture Builds
DKMS today has no concept of a platform ar-chitecture such as i386, x86_64, ia64, sparc,and the like. It expects that it is building ker-nel modules with a native compiler, not a crosscompiler, and that the target architecture is thenative architecture. While this works in prac-tice, it would be convenient if DKMS were ableto be used to build kernel modules for non-native architectures.
Today DKMS handles the cross-architecturebuild process by having separate /var/dkms di-rectory trees for each architecture, and usingthedkmstree option to specify a using a dif-ferent tree, and theconfig option to specifyto use a different kernel configuration file.
Going forward, we plan to add an−−archoption to DKMS, or have it glean it from thekernel config file and act accordingly.
7.2 Additional distribution driver disks
DKMS today supports generating driver disksin the Red Hat format only. We recognize thatother distributions accomplish the same goalusing other driver disk formats. This shouldbe relatively simple to add once we understandwhat the additional formats are.
8 Conclusion
DKMS provides a simple and unified mech-anism for driver authors, Linux distributions,system vendors, and system administrators toupdate the device drivers on a target systemwithout updating the whole kernel. It allowsdriver developers to keep their work aimed atthe “top of the tree,” and to backport that workto older kernels painlessly. It allows Linux dis-tributions to provide updates to single devicedrivers asynchronous to the release of a larger

Linux Symposium 2004 • Volume One • 201
scheduled update, and to know what drivershave been updated. It lets system vendorsship newer hardware than was supported in adistribution’s “gold” release without invalidat-ing any test or certification work done on the“gold” release. It lets system administratorsupdate individual drivers to match their envi-ronment and their needs, regardless of whosekernel they are running. It lets end users trackwhich module versions have been added totheir system.
We believe DKMS is a project whose time hascome, and encourage everyone to use it.
9 References
DKMS is licensed under the GNU GeneralPublic License. It is available at
http://linux.dell.com/dkms/ ,
and has a mailing list [email protected] to which you maysubscribe at http://lists.us.dell.com/ .

202 • Linux Symposium 2004 • Volume One

e100 Weight Reduction ProgramWriting for Maintainability
Scott FeldmanIntel Corporation
Abstract
Corporate-authored device drivers arebloated/buggy with dead code, HW andOS abstraction layers, non-standard usercontrols, and support for complicated HWfeatures that provide little or no value. e100in 2.6.4 has been rewritten to address theseissues and in the process lost 75% of the linesof code, with no loss of functionality. Thispaper gives guidelines to other corporate driverauthors.
Introduction
This paper gives some basic guidelines to cor-porate device driver maintainers based on ex-periences I had while re-writing the e100 net-work device driver for Intel’s PRO/100+ Eth-ernet controllers. By corporate maintainer, Imean someone employed by a corporation toprovide Linux driver support for that corpora-tion’s device. Of course, these guidelines mayapply to non-corporate individuals as well, butthe intended audience is the corporate driverauthor.
The assumption behind these guidelines is thatthe device driver is intended for inclusion inthe Linux kernel. For a driver to be acceptedinto the Linux kernel, it must meet both tech-nical and non-technical requirements. This pa-per focuses on the non-technical requirements,
specifically maintainability.
Guideline #1: Maintainability overEverything Else
Corporate marketing requirements documentsspecify priority order to features and per-formance and schedule (time-to-market), butrarely specify maintainability. However, main-tainability is themost important requirementfor Linux kernel drivers.
Why?
• You will not be the long-term driver main-tainer.
• Your company will not be the long-termdriver maintainer.
• Your driver will out-live your interest in it.
Driver code should be written so a like-skilledkernel maintainer can fix a problem in a rea-sonable amount of time without you or your re-sources. Here are a few items to keep in mindto improve maintainability.
• Use kernel coding style over corporatecoding style
• Document how the driver/device works, ata high level, in a “Theory of Operation”comment section

204 • Linux Symposium 2004 • Volume One
old driver v2 new driver v3
VLANs tagging/stripping
use SW VLAN sup-port in kernel
Tx/Rx checksum ofloading
use SW checksumsupport in kernel
interrupt moderation use NAPI support inkernel
Table 1: Feature migration in e100
• Document hardware workarounds
Guideline #2: Don’t Add Featuresfor Feature’s Sake
Consider the code complexity to support thefeature versus the user’s benefit. Is the de-vice still usable without the feature? Is the de-vice performing reasonably for the 80% use-case without the feature? Is the hardware of-fload feature working against ever increasingCPU/memory/IO speeds? Is there a softwareequivalent to the feature already provided inthe OS?
If the answer is yes to any of these questions, itis better to not implement the feature, keepingthe complexity in the driver low and maintain-ability high.
Table 1 shows features removed from the driverduring the re-write of e100 because the OS al-ready provides software equivalents.
Guideline #3: Limit User-Controls—Use What’s Built into the OS
Most users will use the default settings, so be-fore adding a user-control, consider:
1. If the driver model for your device classalready provides a mechanism for theuser-control, enable that support in the
old driver v2 new driver v3
BundleMax not needed – NAPIBundleSmallFr not needed – NAPIIntDelay not needed – NAPIucode not needed – NAPIRxDescriptors ethtool -GTxDescriptors ethtool -GXsumRX not needed – check-
sum in OSIFS always enablede100_speed_duplex ethtool -s
Table 2: User-control migration in e100
driver rather than adding a custom user-control.
2. If the driver model doesn’t provide a user-control, but the user-control is potentiallyuseful to other drivers, extend the drivermodel to include user-control.
3. If the user-control is to enable/disable aworkaround, enable the workaround with-out the use of a user-control. (Solvethe problem without requiring a decisionfrom the user).
4. If the user-control is to tune performance,tune the driver for the 80% use-case andremove the user-control.
Table 2 shows user-controls (implemented asmodule parameters) removed from the driverduring the re-write of e100 because the OSalready provides built-in user-controls, or theuser-control was no longer needed.
Guideline #4: Don’t Write Codethat’s Already in the Kernel
Look for library code that’s already used byother drivers and adapt that to your driver.Common hardware is often used between ven-dors’ devices, so shared code will work for all(and be debugged by all).

Linux Symposium 2004 • Volume One • 205
For example, e100 has a highly MDI-compliant PHY interface, so usemii.c forstandard PHY access and remove custom codefrom the driver.
For another example, e100 v2 used/proc/net/IntelPROAdapter to report driverinformation. This functionality was replacedwith ethtool , sysfs , lspci , etc.
Look for opportunities to move code out of thedriver into generic code.
Guideline #5: Don’t Use OS-abstraction Layers
A common corporate design goal is to reusedriver code as much as possible between OSes.This allows a driver to be brought up on one OSand “ported” to another OS with little work.After all, the hardware interface to the devicedidn’t change from one OS to the next, soall that is required is an OS-abstraction layerthat wraps the OS’s native driver model with ageneric driver model. The driver is then writtento the generic driver model and it’s just a mat-ter of porting the OS-abstraction layer to eachtarget OS.
There are problems when doing this withLinux:
1. The OS-abstraction wrapper code meansnothing to an outside Linux maintainerand just obfuscates the real meaning be-hind the code. This makes your codeharder to follow and therefore harder tomaintain.
2. The generic driver model may not map 1:1with the native driver model leaving gapsin compatibility that you’ll need to fix upwith OS-specific code.
3. Limits your ability to back-port contribu-tions given under GPL to non-GPL OSes.
Guideline #6: Use kcompat Tech-niques to Move Legacy Kernel Sup-port out of the Driver (and Kernel)
Users may not be able to move to the lat-est kernel.org kernel, so there is a needto provide updated device drivers that can beinstalled against legacy kernels. The need isdriven by 1) bug fixes, 2) new hardware sup-port that wasn’t included in the driver when thedriver was included in the legacy kernel.
The best strategy is to:
1. Maintain your driver code to work againstthe latest kernel.org developmentkernel API. This will make it easier tokeep the driver in thekernel.org ker-nel synchronized with your code base aschanges (patches) are almost always inreference to the latestkernel.org ker-nel.
2. Provide a kernel-compat-layer (kcompat)to translate the latest API to the supportedlegacy kernel API. The driver code is voidof anyifdef code for legacy kernel sup-port. All of the ifdef logic moves to thekcompat layer. The kcompat layer is notincluded in the latestkernel.org ker-nel (by definition).
Here is an example with e100.
In driver code, use the latest API:
s = pci_name(pdev);...free_netdev(netdev);

206 • Linux Symposium 2004 • Volume One
In kcompat code, translate to legacy kernelAPI:
#if ( LINUX_VERSION_CODE < \KERNEL_VERSION(2,4,22) )
#define pci_name(x) ((x)->slot_name)#endif
#ifndef HAVE_FREE_NETDEV#define free_netdev(x) kfree(x)#endif
Guideline #7: Plan to Re-write theDriver at Least Once
You will not get it right the first time. Plan onrewriting the driver from scratch at least once.This will cleanse the code, removing dead codeand organizing/consolidating functionality.
For example, the last e100 re-write reduced thedriver size by 75% without loss of functional-ity.
Conclusion
Following these guidelines will result in moremaintainable device drivers with better accep-tance into the Linux kernel tree. The basicidea is to remove as much as possible from thedriver without loss of functionality.
References
• The latest e100 driver code is available atlinux/driver/net/e100.c (2.6.4kernel or higher).
• An example of kcompat is here:http://sf.net/projects/gkernel

NFSv4 andrpcsec_gss for linux
J. Bruce FieldsUniversity of [email protected]
Abstract
The 2.6 Linux kernels now include support forversion 4 of NFS. In addition to built-in lock-ing and ACL support, and features designed toimprove performance over the Internet, NFSv4also mandates the implementation of strongcryptographic security. This security is pro-vided by rpcsec_gss, a standard, widely imple-mented protocol that operates at the rpc level,and hence can also provide security for NFSversions 2 and 3.
1 The rpcsec_gss protocol
The rpc protocol, which all version of NFSand related protocols are built upon, includesgeneric support for authentication mecha-nisms: each rpc call has two fields, the cre-dential and the verifier, each consisting of a32-bit integer, designating a “security flavor,”followed by 400 bytes of opaque data whosestructure depends on the specified flavor. Sim-ilarly, each reply includes a single “verifier.”
Until recently, the only widely implementedsecurity flavor has been the auth_unix flavor,which uses the credential to pass uid’s andgid’s and simply asks the server to trust them.This may be satisfactory given physical secu-rity over the clients and the network, but formany situations (including use over the Inter-net), it is inadequate.
Thus rfc 2203 defines the rpcsec_gss protocol,
which uses rpc’s opaque security fields to carrycryptographically secure tokens. The crypto-graphic services are provided by the GSS-API(“Generic Security Service Application Pro-gram Interface,” defined by rfc 2743), allowingthe use of a wide variety of security mecha-nisms, including, for example, Kerberos.
Three levels of security are provided by rpc-sec_gss:
1. Authentication only: The rpc header ofeach request and response is signed.
2. Integrity: The header and body of each re-quest and response is signed.
3. Privacy: The header of each request issigned, and the body is encrypted.
The combination of a security level with aGSS-API mechanism can be designated by a32-bit “pseudoflavor.” The mount protocolused with NFS versions 2 and 3 uses a listof pseudoflavors to communicate the securitycapabilities of a server. NFSv4 does not usepseudoflavors on the wire, but they are still use-ful in internal interfaces.
Security protocols generally require some ini-tial negotiation, to determine the capabilitiesof the systems involved and to choose sessionkeys. The rpcsec_gss protocol uses calls withprocedure number 0 for this purpose. Nor-mally such a call is a simple “ping” with noside-effects, useful for measuring round-trip

208 • Linux Symposium 2004 • Volume One
latency or testing whether a certain service isrunning. However a call with procedure num-ber 0, if made with authentication flavor rpc-sec_gss, may use certain fields in the credentialto indicate that it is part of a context-initiationexchange.
2 Linux implementation of rpc-sec_gss
The Linux implementation of rpcsec_gss con-sists of several pieces:
1. Mechanism-specific code, currently fortwo mechanisms: krb5 and spkm3.
2. A stripped-down in-kernel version of theGSS-API interface, with an interface thatallows mechanism-specific code to regis-ter support for various pseudoflavors.
3. Client and server code which uses theGSS-API interface to encode and decoderpc calls and replies.
4. A userland daemon, gssd, which performscontext initiation.
2.1 Mechanism-specific code
The NFSv4 RFC mandates the implementation(though not the use) of three GSS-API mecha-nisms: krb5, spkm3, and lipkey.
Our krb5 implementation supports threepseudoflavors: krb5, krb5i, and krb5p, pro-viding authentication only, integrity, andprivacy, respectively. The code is derived fromMIT’s Kerberos implementation, somewhatsimplified, and not currently supporting thevariety of encryption algorithms that MIT’sdoes. The krb5 mechanism is also supportedby NFS implementations from Sun, Network
Appliance, and others, which it interoperateswith.
The Low Infrastructure Public Key Mechanism(“lipkey,” specified by rfc 2847), is a public keymechanism built on top of the Simple PublicKey Mechanism (spkm), which provides func-tionality similar to that of TLS, allowing a se-cure channel to be established using a server-side certificate and a client-side password.
We have a preliminary implementation ofspkm3 (without privacy), but none yet of lip-key. Other NFS implementors have not yetimplemented either of these mechanisms, butthere appears to be sufficient interest from thegrid community for us to continue implemen-tation even if it is Linux-only for now.
2.2 GSS-API
The GSS-API interface as specified is verycomplex. Fortunately, rpcsec_gss only requiresa subset of the GSS-API, and even less is re-quired for per-packet processing.
Our implementation is derived by the im-plementation in MIT Kerberos, and initiallystayed fairly close the the GSS-API specifica-tion; but over time we have pared it down tosomething quite a bit simpler.
The kernel gss interface also provides APIsby which code implementing particular mech-anisms can register itself to the gss-api codeand hence can be safely provided by modulesloaded at runtime.
2.3 RPC code
The RPC code has been enhanced by the addi-tion of a new rpcsec_gss mechanism which au-thenticates calls and replies and which wrapsand unwraps rpc bodies in the case of integrityand privacy.

Linux Symposium 2004 • Volume One • 209
This is relatively straightforward, thoughsomewhat complicated by the need to handlediscontiguous buffers containing page data.
Caches for session state are also required onboth client and server; on the client a preex-isting rpc credentials cache is used, and on theserver we use the same caching infrastructureused for caching of client and export informa-tion.
2.4 Userland daemon
We had no desire to put a complete implemen-tation of Kerberos version 5 or the other mech-anisms into the kernel. Fortunately, the workperformed by the various GSS-API mecha-nisms can be divided neatly into context ini-tiation and per-packet processing. The formeris complex and is performed only once per ses-sion, while the latter is simple by comparisonand needs to be performed on every packet.Therefore it makes sense to put the packet pro-cessing in the kernel, and have the context ini-tiation performed in userspace.
Since it is the kernel that knows when contextinitiation is necessary, we require a mechanismallowing the kernel to pass the necessary pa-rameters to a userspace daemon whenever con-text initiation is needed, and allowing the dae-mon to respond with the completed securitycontext.
This problem was solved in different wayson the client and server, but both use spe-cial files (the former in a dedicated filesystem,rpc_pipefs, and the latter in the proc filesys-tem), which our userspace daemon, gssd, canpoll for requests and then write responses backto.
In the case of Kerberos, the sequence of eventswill be something like this:
1. The user gets Kerberos credentials using
kinit, which are cached on a local filesys-tem.
2. The user attempts to perform an operationon an NFS filesystem mounted with krb5security.
3. The kernel rpc client looks for the a secu-rity context for the user in its cache; notfinding any, it does an upcall to gssd to re-quest one.
4. Gssd, on receiving the upcall, reads theuser’s Kerberos credentials from the lo-cal filesystem and uses them to constructa null rpc request which it sends to theserver.
5. The server kernel makes an upcall whichpasses the null request to its gssd.
6. At this point, the server gssd has all itneeds to construct a security context forthis session, consisting mainly of a ses-sion key. It passes this context down tothe kernel rpc server, which stores it in itscontext cache.
7. The server’s gssd then constructs the nullrpc reply, which it gives to the kernel toreturn to the client gssd.
8. The client gssd uses this reply to constructits own security context, and passes thiscontext to the kernel rpc client.
9. The kernel rpc client then uses this con-text to send the first real rpc request to theserver.
10. The server uses the new context in itscache to verify the rpc request, and tocompose its reply.

210 • Linux Symposium 2004 • Volume One
3 The NFSv4 protocol
While rpcsec_gss works equally well on all ex-isting versions of NFS, much of the work onrpcsec_gss has been motivated by NFS version4, which is the first version of NFS to makerpcsec_gss mandatory to implement.
This new version of NFS is specified by rfc3530, which says:
“Unlike earlier versions, the NFS version 4protocol supports traditional file access whileintegrating support for file locking and themount protocol. In addition, support for strongsecurity (and its negotiation), compound oper-ations, client caching, and internationalizationhave been added. Of course, attention has beenapplied to making NFS version 4 operate wellin an Internet environment.”
Descriptions of some of these features follow,with some notes about their implementation inLinux.
3.1 Compound operations
Each rpc request includes a procedure number,which describes the operation to be performed.The format of the body of the rpc request (thearguments) and of the reply depend on the pro-gram number. Procedure 0 is reserved as a no-op (except when it is used for rpcsec_gss con-text initiation, as described above).
The NFSv4 protocol only supports one non-zero procedure, procedure 1, the compoundprocedure.
The body of a compound is a list of opera-tions, each with its own arguments. For exam-ple, a compound request performing a lookupmight consist of 3 operations: a PUTFH, witha filehandle, which sets the “current filehandle”to the provided filehandle; a LOOKUP, with aname, which looks up the name in the directory
given by the current filehandle and then modi-fies the current filehandle to be the filehandle ofthe result; a GETFH, with no arguments, whichreturns the new value of the current filehandle;and a GETATTR, with a bitmask specifying aset of attributes to return for the looked-up file.
The server processes these operations in order,but with no guarantee of atomicity. On encoun-tering any error, it stops and returns the resultsof the operations up to and including the oper-ation that failed.
In theory complex operations could thereforebe done by long compounds which performcomplex series of operations.
In practice, the compounds sent by the Linuxclient correspond very closely to NFSv2/v3procedures—the VFS and the POSIX filesys-tem API make it difficult to do otherwise—andour server, like most NFSv4 servers we knowof, rejects overly long or complex compounds.
3.2 Well-known port for NFS
RPC allows services to be run on differentports, using the “portmap” service to map pro-gram numbers to ports. While flexible, thissystem complicates firewall management; soNFSv4 recommends the use of port 2049.
In addition, the use of sideband protocols formounting, locking, etc. also complicates fire-wall management, as multiple connections tomultiple ports are required for a single NFSmount. NFSv4 eliminates these extra proto-cols, allowing all traffic to pass over a singleconnection using one protocol.
3.3 No more mount protocol
Earlier versions of NFS use a separate protocolfor mount. The mount protocol exists primarilyto map path names, presented to the server as

Linux Symposium 2004 • Volume One • 211
strings, to filehandles, which may then be usedin the NFS protocol.
NFSv4 instead uses a single operation, PUT-ROOTFH, that returns a filehandle; clients canthen use ordinary lookups to traverse to thefilesystem they wish to mount. This changesthe behavior of NFS in a few subtle ways: forexample, the special status of mounts in the oldprotocol meant that mounting/usr and thenlooking up local might get you a differentobject than would mounting/usr/local ;under NFSv4 this can no longer happen.
A server that exports multiple filesystems mustknit them together using a single “pseud-ofilesystem” which links them to a commonroot.
On Linux’s nfsd the pseudofilesystem is areal filesystem, marked by the export option“fsid=0”. An adminstrator that is content toexport a single filesystem can export it with“fsid=0”, and clients will find it just by mount-ing the path “/”.
The expected use for “fsid=0”, however, is todesignate a filesystem that is used just a collec-tion of empty directories used as mountpointsfor exported filesystems, which are mountedusingmount ---bind ; thus an administra-tor could export/bin and/local/src by:
mkdir -p /exports/homemkdir -p /exports/bin/mount --bind /home /exports/homemount --bind /bin/ /exports/bin
and then using an exports file something like:
/exports *.foo.com(fsid=0,crossmnt)/exports/home *.foo.com/exports/bin *.foo.com
Clients in foo.com can then mountserver.foo.com:/bin or server.
foo.com:/home . However the relationshipbetween the original mountpoint on the serverand the mountpoint under/exports (whichdetermines the path seen by the client) isarbitrary, so the administrator could just aswell export/home as/some/other/pathif desired.
This gives maximum flexibility at the expenseof some confusion for adminstrators used toearlier NFS versions.
3.4 No more lock protocol
Locking has also been absorbed into theNFSv4 protocol. In addition to advantagesenumerated above, this allows servers to sup-port mandatory locking if desired. Previouslythis was impossible because it was impos-sible to tell whether a given read or writeshould be ordered before or after a lock re-quest. NFSv4 enforces such sequencing byproviding a stateid field on each read or writewhich identifies the locking state that the oper-ation was performed under; thus for example awrite that occurred while a lock was held, butthat appeared on the server to have occurred af-ter an unlock, can be identified as belonging toa previous locking context, and can thereforebe correctly rejected.
The additional state required to manage lock-ing is the source of much of the additional com-plexity in NFSv4.
3.5 String representations of user and groupnames
Previous versions of NFS use integers to rep-resent users and groups; while simple to han-dle, they can make NFS installations difficult tomanage, particularly across adminstrative do-mains. Version 4, therefore, uses string namesof the formuser@domain .
This poses some challenges for the kernel im-

212 • Linux Symposium 2004 • Volume One
plementation. In particular, while the protocolmay use string names, the kernel still needs todeal with uid’s, so it must map between NFSv4string names and integers.
As with rpcsec_gss context initation, we solvethis problem by making upcalls to a userspacedaemon; with the mapping in userspace, it iseasy to use mechanisms such as NIS or LDAPto do the actual mapping without introducinglarge amounts of code into the kernel. So as notto degrade performance by requiring a contextswitch every time we process a packet carryinga name, we cache the results of this mapping inthe kernel.
3.6 Delegations
NFSv4, like previous versions of NFS, doesnot attempt to provide full cache consistency.Instead, all that is guaranteed is that if an openfollows a close of the same file, then data readafter the open will reflect any modificationsperformed before the close. This makes bothopen and close potentially high latency oper-ations, since they must wait for at least oneround trip before returning–in the close case,to flush out any pending writes, and in theopen case, to check the attributes of the file inquestion to determine whether the local cacheshould be invalidated.
Locks provide similar semantics—writes areflushed on unlock, and cache consistency isverified on lock—and hence lock operationsare also prone to high latencies.
To mitigate these concerns, and to encouragethe use of NFS’s locking features, delegationshave been added to NFSv4. Delegations aregranted or denied by the server in response toopen calls, and give the client the right to per-form later locks and opens locally, without theneed to contact the server. A set of callbacksis provided so that the server can notify the
client when another client requests an open thatwould confict with the open originally obtainedby the client.
Thus locks and opens may be performedquickly by the client in the common case whenfiles are not being shared, but callbacks ensurethat correct close-to-open (and unlock-to-lock)semantics may be enforced when there is con-tention.
To allow other clients to proceed when a clientholding a delegation reboots, clients are re-quired to periodically send a “renew” opera-tion to the server, indicating that it is still alive;a client that fails to send a renew operationwithin a given lease time (established when theclient first contacts the server) may have all ofits delegations and other locking state revoked.
Most implementations of NFSv4 delegations,including Linux’s, are still young, and wehaven’t yet gathered good data on the perfor-mance impact.
Nevertheless, further extensions, includingdelegations over directories, are under consid-eration for future versions of the protocol.
3.7 ACLs
ACL support is integrated into the protocol,with ACLs that are more similar to those foundin NT than to the POSIX ACLs supported byLinux.
Thus while it is possible to translate an arbi-trary Linux ACL to an NFS4 ACL with nearlyidentical meaning, most NFS ACLs have noreasonable representation as Linux ACLs.
Marius Eriksen has written a draft describingthe POSIX to NFS4 ACL translation. Cur-rently the Linux implementation uses this map-ping, and rejects any NFS4 ACL that isn’t ex-actly in the image of this mapping. This en-

Linux Symposium 2004 • Volume One • 213
sures userland support from all tools that cur-rently support POSIX ACLs, and simplifiesACL management when an exported filesys-tem is also used by local users, since both nfsdand the local users can use the backend filesys-tem’s POSIX ACL implementation. Howeverit makes it difficult to interoperate with NFSv4implementations that support the full ACL pro-tocol. For that reason we will eventually alsowant to add support for NFSv4 ACLs.
4 Acknowledgements and FurtherInformation
This work has been sponsored by Sun Mi-crosystems, Network Appliance, and theAccelerated Strategic Computing Initiative(ASCI). For further information, seewww.citi.umich.edu/projects/nfsv4/ .

214 • Linux Symposium 2004 • Volume One

Comparing and Evaluating epoll, select, and pollEvent Mechanisms
Louay Gammo, Tim Brecht, Amol Shukla, and David PariagUniversity of Waterloo
{lgammo,brecht,ashukla,db2pariag}@cs.uwaterloo.ca
Abstract
This paper uses a high-performance, event-driven, HTTP server (theµserver) to comparethe performance of the select, poll, and epollevent mechanisms. We subject theµserver toa variety of workloads that allow us to exposethe relative strengths and weaknesses of eachevent mechanism.
Interestingly, initial results show that the se-lect and poll event mechanisms perform com-parably to the epoll event mechanism in theabsence of idle connections. Profiling datashows a significant amount of time spent in ex-ecuting a large number ofepoll_ctl sys-tem calls. As a result, we examine a varietyof techniques for reducingepoll_ctl over-head including edge-triggered notification, andintroducing a new system call (epoll_ctlv )that aggregates severalepoll_ctl calls intoa single call. Our experiments indicate that al-though these techniques are successful at re-ducingepoll_ctl overhead, they only im-prove performance slightly.
1 Introduction
The Internet is expanding in size, number ofusers, and in volume of content, thus it is im-perative to be able to support these changeswith faster and more efficient HTTP servers.
A common problem in HTTP server scala-bility is how to ensure that the server han-dles a large number of connections simultane-ously without degrading the performance. Anevent-driven approach is often implemented inhigh-performance network servers [14] to mul-tiplex a large number of concurrent connec-tions over a few server processes. In event-driven servers it is important that the serverfocuses on connections that can be servicedwithout blocking its main process. An eventdispatch mechanism such asselect is usedto determine the connections on which for-ward progress can be made without invok-ing a blocking system call. Many differentevent dispatch mechanisms have been usedand studied in the context of network applica-tions. These mechanisms range fromselect ,poll , /dev/poll , RT signals, and epoll[2, 3, 15, 6, 18, 10, 12, 4].
The epoll event mechanism [18, 10, 12] is de-signed to scale to larger numbers of connec-tions thanselect and poll . One of theproblems withselect and poll is that ina single call they must both inform the kernelof all of the events of interest and obtain newevents. This can result in large overheads, par-ticularly in environments with large numbersof connections and relatively few new eventsoccurring. In a fashion similar to that describedby Banga et al. [3] epoll separates mech-anisms for obtaining events (epoll_wait )from those used to declare and control interest

216 • Linux Symposium 2004 • Volume One
in events (epoll_ctl ).
Further reductions in the number of generatedevents can be obtained by using edge-triggeredepoll semantics. In this mode events are onlyprovided when there is a change in the state ofthe socket descriptor of interest. For compat-ibility with the semantics offered byselectandpoll , epoll also provides level-triggeredevent mechanisms.
To compare the performance of epoll withselect andpoll , we use theµserver [4, 7]web server. Theµserver facilitates compara-tive analysis of different event dispatch mech-anisms within the same code base throughcommand-line parameters. Recently, a highlytuned version of the single process event drivenµserver usingselect has shown promisingresults that rival the performance of the in-kernel TUX web server [4].
Interestingly, in this paper, we found that forsome of the workloads consideredselectandpoll perform as well as or slightly bet-ter than epoll. One such result is shown inFigure 1. This motivated further investigationwith the goal of obtaining a better understand-ing of epoll’s behaviour. In this paper, we de-scribe our experience in trying to determinehow to best use epoll, and examine techniquesdesigned to improve its performance.
The rest of the paper is organized as follows:In Section 2 we summarize some existing workthat led to the development of epoll as a scal-able replacement forselect . In Section 3 wedescribe the techniques we have tried to im-prove epoll’s performance. In Section 4 we de-scribe our experimental methodology, includ-ing the workloads used in the evaluation. InSection 5 we describe and analyze the resultsof our experiments. In Section 6 we summarizeour findings and outline some ideas for futurework.
2 Background and Related Work
Event-notification mechanisms have a longhistory in operating systems research and de-velopment, and have been a central issue inmany performance studies. These studies havesought to improve mechanisms and interfacesfor obtaining information about the state ofsocket and file descriptors from the operatingsystem [2, 1, 3, 13, 15, 6, 18, 10, 12]. Someof these studies have developed improvementsto select , poll andsigwaitinfo by re-ducing the amount of data copied between theapplication and kernel. Other studies have re-duced the number of events delivered by thekernel, for example, the signal-per-fd schemeproposed by Chandra et al. [6]. Much of theaforementioned work is tracked and discussedon the web site, “The C10K Problem” [8].
Early work by Banga and Mogul [2] foundthat despite performing well under laboratoryconditions, popular event-driven servers per-formed poorly under real-world conditions.They demonstrated that the discrepancy is duethe inability of the select system call toscale to the large number of simultaneous con-nections that are found in WAN environments.
Subsequent work by Banga et al. [3] sought toimprove onselect ’s performance by (amongother things) separating the declaration of in-terest in events from the retrieval of events onthat interest set. Event mechanisms like se-lect and poll have traditionally combined thesetasks into a single system call. However, thisamalgamation requires the server to re-declareits interest set every time it wishes to retrieveevents, since the kernel does not remember theinterest sets from previous calls. This results inunnecessary data copying between the applica-tion and the kernel.
The /dev/poll mechanism was adaptedfrom Sun Solaris to Linux by Provos et al. [15],

Linux Symposium 2004 • Volume One • 217
and improved on poll’s performance by intro-ducing a new interface that separated the decla-ration of interest in events from retrieval. Their/dev/poll mechanism further reduced datacopying by using a shared memory region toreturn events to the application.
The kqueue event mechanism [9] addressedmany of the deficiencies ofselect andpollfor FreeBSD systems. In addition to sep-arating the declaration of interest from re-trieval, kqueue allows an application to re-trieve events from a variety of sources includ-ing file/socket descriptors, signals, AIO com-pletions, file system changes, and changes inprocess state.
The epoll event mechanism [18, 10, 12] inves-tigated in this paper also separates the declara-tion of interest in events from their retrieval.The epoll_create system call instructsthe kernel to create an event data structurethat can be used to track events on a numberof descriptors. Thereafter, theepoll_ctlcall is used to modify interest sets, while theepoll_wait call is used to retrieve events.
Another drawback ofselect and poll isthat they perform work that depends on thesize of the interest set, rather than the numberof events returned. This leads to poor perfor-mance when the interest set is much larger thanthe active set. The epoll mechanisms avoid thispitfall and provide performance that is largelyindependent of the size of the interest set.
3 Improving epoll Performance
Figure 1 in Section 5 shows the throughputobtained when using theµserver with the se-lect, poll, and level-triggered epoll (epoll-LT)mechanisms. In this graph the x-axis showsincreasing request rates and the y-axis showsthe reply rate as measured by the clients thatare inducing the load. This graph shows re-
sults for the one-byte workload. These re-sults demonstrate that theµserver with level-triggered epoll does not perform as well asselect under conditions that stress the eventmechanisms. This led us to more closely ex-amine these results. Usinggprof , we ob-served thatepoll_ctl was responsible for alarge percentage of the run-time. As can beenseen in Table 1 in Section 5 over 16% of thetime is spent inepoll_ctl . The gprof out-put also indicates (not shown in the table) thatepoll_ctl was being called a large num-ber of times because it is called for every statechange for each socket descriptor. We exam-ine several approaches designed to reduce thenumber ofepoll_ctl calls. These are out-lined in the following paragraphs.
The first method uses epoll in an edge-triggered fashion, which requires theµserverto keep track of the current state of the socketdescriptor. This is required because with theedge-triggered semantics, events are only re-ceived for transitions on the socket descriptorstate. For example, once the server reads datafrom a socket, it needs to keep track of whetheror not that socket is still readable, or if it willget another event fromepoll_wait indicat-ing that the socket is readable. Similar stateinformation is maintained by the server regard-ing whether or not the socket can be written.This method is referred to in our graphs andthe rest of the paperepoll-ET .
The second method, which we refer to asepoll2, simply callsepoll_ctl twice persocket descriptor. The first to register with thekernel that the server is interested in read andwrite events on the socket. The second call oc-curs when the socket is closed. It is used totell epoll that we are no longer interested inevents on that socket. All events are handledin a level-triggered fashion. Although this ap-proach will reduce the number ofepoll_ctlcalls, it does have potential disadvantages.

218 • Linux Symposium 2004 • Volume One
One disadvantage of the epoll2 method is thatbecause many of the sockets will continue to bereadable or writableepoll_wait will returnsooner, possibly with events that are currentlynot of interest to the server. For example, if theserver is waiting for a read event on a socket itwill not be interested in the fact that the socketis writable until later. Another disadvantage isthat these calls return sooner, with fewer eventsbeing returned per call, resulting in a largernumber of calls. Lastly, because many of theevents will not be of interest to the server, theserver is required to spend a bit of time to de-termine if it is or is not interested in each eventand in discarding events that are not of interest.
The third method uses a new system call namedepoll_ctlv . This system call is designed toreduce the overhead of multipleepoll_ctlsystem calls by aggregating several calls toepoll_ctl into one call toepoll_ctlv .This is achieved by passing an array of epollevents structures toepoll_ctlv , which thencallsepoll_ctl for each element of the ar-ray. Events are generated in level-triggeredfashion. This method is referred to in the fig-ures and the remainder of the paper as epoll-ctlv.
We useepoll_ctlv to add socket descrip-tors to the interest set, and for modifyingthe interest sets for existing socket descrip-tors. However, removal of socket descriptorsfrom the interest set is done by explicitly call-ing epoll_ctl just before the descriptor isclosed. We do not aggregate deletion oper-ations because by the timeepoll_ctlv isinvoked, theµserver has closed the descriptorand theepoll_ctl invoked on that descrip-tor will fail.
Theµserver does not attempt to batch the clos-ing of descriptors because it can run out ofavailable file descriptors. Hence, the epoll-ctlv method uses both theepoll_ctlv and
the epoll_ctl system calls. Alternatively,we could rely on theclose system call toremove the socket descriptor from the inter-est set (and we did try this). However, thisincreases the time spent by theµserver inclose , and does not alter performance. Weverified this empirically and decided to explic-itly call epoll_ctl to perform the deletionof descriptors from the epoll interest set.
4 Experimental Environment
The experimental environment consists of asingle server and eight clients. The server con-tains dual 2.4 GHz Xeon processors, 1 GB ofRAM, a 10,000 rpm SCSI disk, and two oneGigabit Ethernet cards. The clients are iden-tical to the server with the exception of theirdisks which are EIDE. The server and clientsare connected with a 24-port Gigabit switch.To avoid network bottlenecks, the first fourclients communicate with the server’s first Eth-ernet card, while the remaining four use a dif-ferent IP address linked to the second Ethernetcard. The server machine runs a slightly mod-ified version of the 2.6.5 Linux kernel in uni-processor mode.
4.1 Workloads
This section describes the workloads that weused to evaluate performance of theµserverwith the different event notification mecha-nisms. In all experiments, we generate HTTPloads usinghttperf [11], an open-loop work-load generator that uses connection timeouts togenerate loads that can exceed the capacity ofthe server.
Our first workload is based on the widely usedSPECweb99 benchmarking suite [17]. We usehttperf in conjunction with a SPECweb99 fileset and synthetic HTTP traces. Our traceshave been carefully generated to recreate the

Linux Symposium 2004 • Volume One • 219
file classes, access patterns, and number of re-quests issued per (HTTP 1.1) connection thatare used in the static portion of SPECweb99.The file set and server caches are sized so thatthe entire file set fits in the server’s cache. Thisensures that differences in cache hit rates donot affect performance.
Our second workload is called the one-byteworkload. In this workload, the clients repeat-edly request the same one byte file from theserver’s cache. We believe that this workloadstresses the event dispatch mechanism by min-imizing the amount of work that needs to bedone by the server in completing a particularrequest. By reducing the effect of system callssuch asread andwrite , this workload iso-lates the differences due to the event dispatchmechanisms.
To study the scalability of the event dispatchmechanisms as the number of socket descrip-tors (connections) is increased, we useidle-conn, a program that comes as part of thehttperf suite. This program maintains a steadynumber of idle connections to the server (in ad-dition to the active connections maintained byhttperf). If any of these connections are closedidleconn immediately re-establishes them. Wefirst examine the behaviour of the event dis-patch mechanisms without any idle connec-tions to study scenarios where all of the con-nections present in a server are active. We thenpre-load the server with a number of idle con-nections and then run experiments. The idleconnections are used to increase the numberof simultaneous connections in order to sim-ulate a WAN environment. In this paper wepresent experiments using 10,000 idle connec-tions, our findings with other numbers of idleconnections were similar and they are not pre-sented here.
4.2 Server Configuration
For all of our experiments, theµserver is runwith the same set of configuration parametersexcept for the event dispatch mechanism. Theµserver is configured to usesendfile to takeadvantage of zero-copy socket I/O while writ-ing replies. We use TCP_CORK in conjunc-tion with sendfile . The same server op-tions are used for all experiments even thoughthe use of TCP_CORK andsendfile maynot provide benefits for the one-byte workloadwhen compared with simply usingwritev .
4.3 Experimental Methodology
We measure the throughput of theµserver us-ing different event dispatch mechanisms. Inour graphs, each data point is the result of atwo minute experiment. Trial and error re-vealed that two minutes is sufficient for theserver to achieve a stable state of operation. Atwo minute delay is used between consecutiveexperiments, which allows the TIME_WAITstate on all sockets to be cleared before the sub-sequent run. All non-essential services are ter-minated prior to running any experiment.
5 Experimental Results
In this section we first compare the throughputachieved when using level-triggered epoll withthat observed when usingselect andpollunder both the one-byte and SPECweb99-like workloads with no idle connections. Wethen examine the effectiveness of the differ-ent methods described for reducing the num-ber of epoll_ctl calls under these sameworkloads. This is followed by a compari-son of the performance of the event dispatchmechanisms when the server is pre-loaded with10,000 idle connections. Finally, we describethe results of experiments in which we tune the

220 • Linux Symposium 2004 • Volume One
accept strategy used in conjunction with epoll-LT and epoll-ctlv to further improve their per-formance.
We initially ran the one byte and theSPECweb99-like workloads to compare theperformance of the select, poll and level-triggered epoll mechanisms.
As shown in Figure 1 and Figure 2, for bothof these workloads select and poll perform aswell as epoll-LT. It is important to note that be-cause there are no idle connections for theseexperiments the number of socket descriptorstracked by each mechanism is not very high.As expected, the gap between epoll-LT and se-lect is more pronounced for the one byte work-load because it places more stress on the eventdispatch mechanism.
0
5000
10000
15000
20000
25000
0 5000 10000 15000 20000 25000 30000
Rep
lies/
s
Requests/s
selectpoll
epoll-LT
Figure 1: µserver performance on one byteworkload using select, poll, and epoll-LT
0
5000
10000
15000
20000
25000
0 5000 10000 15000 20000 25000 30000
Rep
lies/
s
Requests/s
selectpoll
epoll-LT
Figure 2: µserver performance onSPECweb99-like workload using select,poll, and epoll-LT
We tried to improve the performance of theserver by exploring different techniques for us-
ing epoll as described in Section 3. The effectof these techniques on the one-byte workloadis shown in Figure 3. The graphs in this figureshow that for this workload the techniques usedto reduce the number ofepoll_ctl calls donot provide significant benefits when comparedwith their level-triggered counterpart (epoll-LT). Additionally, the performance of selectand poll is equal to or slightly better than eachof the epoll techniques. Note that we omit theline for poll from Figures 3 and 4 because it isnearly identical to the select line.
0
5000
10000
15000
20000
25000
0 5000 10000 15000 20000 25000 30000
Rep
lies/
s
Requests/s
selectepoll-LTepoll-ET
epoll-ctlvepoll2
Figure 3: µserver performance on one byteworkload with no idle connections
We further analyze the results from Figure 3by profiling theµserver using gprof at the re-quest rate of 22,000 requests per second. Table1 shows the percentage of time spent in sys-tem calls (rows) under the various event dis-patch methods (columns). The output for sys-tem calls andµserver functions which do notcontribute significantly to the total run-time isleft out of the table for clarity.
If we compare the select and poll columnswe see that they have a similar breakdown in-cluding spending about 13% of their time in-dicating to the kernel events of interest andobtaining events. In contrast the epoll-LT,epoll-ctlv, and epoll2 approaches spend about21 – 23% of their time on their equivalentfunctions (epoll_ctl , epoll_ctlv andepoll_wait ). Despite these extra overheadsthe throughputs obtained using the epoll tech-niques compare favourably with those obtained

Linux Symposium 2004 • Volume One • 221
select epoll-LT epoll-ctlv epoll2 epoll-ET pollread 21.51 20.95 21.41 20.08 22.19 20.97close 14.90 14.05 14.90 13.02 14.14 14.79select 13.33 - - - - -poll - - - - - 13.32epoll_ctl - 16.34 5.98 10.27 11.06 -epoll_wait - 7.15 6.01 12.56 6.52 -epoll_ctlv - - 9.28 - - -setsockopt 11.17 9.13 9.13 7.57 9.08 10.68accept 10.08 9.51 9.76 9.05 9.30 10.20write 5.98 5.06 5.10 4.13 5.31 5.70fcntl 3.66 3.34 3.37 3.14 3.34 3.61sendfile 3.43 2.70 2.71 3.00 3.91 3.43
Table 1: gprof profile data for theµserver under the one-byte workload at 22,000 requests/sec
usingselect andpoll . We note that whenusing select and poll the application re-quires extra manipulation, copying, and eventscanning code that is not required in the epollcase (and does not appear in the gprof data).
The results in Table 1 also show that theoverhead due toepoll_ctl calls is re-duced in epoll-ctlv, epoll2 and epoll-ET, whencompared with epoll-LT. However, in eachcase these improvements are offset by in-creased costs in other portions of the code.The epoll2 technique spends twice as muchtime in epoll_wait when compared withepoll-LT. With epoll2 the number of callsto epoll_wait is significantly higher, theaverage number of descriptors returned islower, and only a very small proportion ofthe calls (less than 1%) return events thatneed to be acted upon by the server. On theother hand, when compared with epoll-LT theepoll2 technique spends about 6% less timeon epoll_ctl calls so the total amount oftime spent dealing with events is comparablewith that of epoll-LT. Despite the significantepoll_wait overheads epoll2 performancecompares favourably with the other methodson this workload.
Using the epoll-ctlv technique, gprof indicatesthat epoll_ctlv and epoll_ctl com-bine for a total of 1,949,404 calls comparedwith 3,947,769epoll_ctl calls when us-ing epoll-LT. While epoll-ctlv helps to reducethe number of user-kernel boundary cross-ings, the net result is no better than epoll-LT. The amount of time taken by epoll-ctlvin epoll_ctlv and epoll_ctl systemcalls is about the same (around 16%) asthat spent by level-triggered epoll in invokingepoll_ctl.
When comparing the percentage of time epoll-LT and epoll-ET spend inepoll_ctl we seethat it has been reduced using epoll-ET from16% to 11%. Although theepoll_ctl timehas been reduced it does not result in an ap-preciable improvement in throughput. We alsonote that about 2% of the run-time (which isnot shown in the table) is also spent in theepoll-ET case checking, and tracking the stateof the request (i.e., whether the server shouldbe reading or writing) and the state of thesocket (i.e., whether it is readable or writable).We expect that this can be reduced but that itwouldn’t noticeably impact performance.
Results for the SPECweb99-like workload are

222 • Linux Symposium 2004 • Volume One
shown in Figure 4. Here the graph shows thatall techniques produce very similar results witha very slight performance advantage going toepoll-ET after the saturation point is reached.
0
5000
10000
15000
20000
25000
0 5000 10000 15000 20000 25000 30000
Rep
lies/
s
Requests/s
selectepoll-LTepoll-ET
epoll2
Figure 4: µserver performance onSPECweb99-like workload with no idleconnections
5.1 Results With Idle Connections
We now compare the performance of the eventmechanisms with 10,000 idle connections. Theidle connections are intended to simulate thepresence of larger numbers of simultaneousconnections (as might occur in a WAN envi-ronment). Thus, the event dispatch mechanismhas to keep track of a large number of descrip-tors even though only a very small portion ofthem are active.
By comparing results in Figures 3 and 5 onecan see that the performance of select and polldegrade by up to 79% when the 10,000 idleconnections are added. The performance ofepoll2 with idle connections suffers similarlyto select and poll. In this case, epoll2 suffersfrom the overheads incurred by making a largenumber ofepoll_wait calls the vast major-ity of which return events that are not of cur-rent interest to the server. Throughput withlevel-triggered epoll is slightly reduced withthe addition of the idle connections while edge-triggered epoll is not impacted.
The results for the SPECweb99-like workloadwith 10,000 idle connections are shown in Fig-
ure 6. In this case each of the event mecha-nisms is impacted in a manner similar to thatin which they are impacted by idle connectionsin the one-byte workload case.
0
5000
10000
15000
20000
25000
0 5000 10000 15000 20000 25000 30000
Rep
lies/
s
Requests/s
selectpoll
epoll-ETepoll-LT
epoll2
Figure 5: µserver performance on one byteworkload and 10,000 idle connections
0
5000
10000
15000
20000
25000
0 5000 10000 15000 20000 25000 30000
Rep
lies/
s
Requests/s
selectpoll
epoll-ETepoll-LT
epoll2
Figure 6: µserver performance onSPECweb99-like workload and 10,000idle connections
5.2 Tuning Accept Strategy for epoll
The µserver’s accept strategy has been tunedfor use withselect . Theµserver includes aparameter that controls the number of connec-tions that are accepted consecutively. We callthis parameter the accept-limit. Parameter val-ues range from one to infinity (Inf). A value ofone limits the server to accepting at most oneconnection when notified of a pending connec-tion request, while Inf causes the server to con-secutively accept all currently pending connec-tions.
To this point we have used the accept strategythat was shown to be effective forselect by

Linux Symposium 2004 • Volume One • 223
Brecht et al. [4] (i.e., accept-limit is Inf). Inorder to verify whether the same strategy per-forms well with the epoll-based methods weexplored their performance under different ac-cept strategies.
Figure 7 examines the performance of level-triggered epoll after the accept-limit has beentuned for the one-byte workload (other val-ues were explored but only the best valuesare shown). Level-triggered epoll with an ac-cept limit of 10 shows a marked improve-ment over the previous accept-limit of Inf,and now matches the performance of selecton this workload. The accept-limit of 10 alsoimproves peak throughput for the epoll-ctlvmodel by 7%. This gap widens to 32% at21,000 requests/sec. In fact the best acceptstrategy for epoll-ctlv fares slightly better thanthe best accept strategy for select.
0
5000
10000
15000
20000
25000
0 5000 10000 15000 20000 25000 30000
Rep
lies/
s
Requests/s
select accept=Infepoll-LT accept=Infepoll-LT accept=10
epoll-ctlv accept=Infepoll-ctlv accept=10
Figure 7: µserver performance on one byteworkload with different accept strategies andno idle connections
Varying the accept-limit did not improve theperformance of the edge-triggered epoll tech-nique under this workload and it is not shownin the graph. However, we believe that the ef-fects of the accept strategy on the various epolltechniques warrants further study as the effi-cacy of the strategy may be workload depen-dent.
6 Discussion
In this paper we use a high-performance event-driven HTTP server, theµserver, to compareand evaluate the performance of select, poll,and epoll event mechanisms. Interestingly,we observe that under some of the work-loads examined the throughput obtained usingselect andpoll is as good or slightly bet-ter than that obtained with epoll. While theseworkloads may not utilize representative num-bers of simultaneous connections they do stressthe event mechanisms being tested.
Our results also show that a main source ofoverhead when using level-triggered epoll isthe large number ofepoll_ctl calls. Weexplore techniques which significantly reducethe number ofepoll_ctl calls, includingthe use of edge-triggered events and a systemcall, epoll_ctlv , which allows theµserverto aggregate large numbers ofepoll_ctlcalls into a single system call. While thesetechniques are successful in reducing the num-ber of epoll_ctl calls they do not appearto provide appreciable improvements in perfor-mance.
As expected, the introduction of idle connec-tions results in dramatic performance degrada-tion when usingselect andpoll , while notnoticeably impacting the performance whenusing epoll. Although it is not clear thatthe use of idle connections to simulate largernumbers of connections is representative ofreal workloads, we find that the addition ofidle connections does not significantly alterthe performance of the edge-triggered andlevel-triggered epoll mechanisms. The edge-triggered epoll mechanism performs best withthe level-triggered epoll mechanism offer-ing performance that is very close to edge-triggered.
In the future we plan to re-evaluate some of

224 • Linux Symposium 2004 • Volume One
the mechanisms explored in this paper un-der more representative workloads that includemore representative wide area network condi-tions. The problem with the technique of us-ing idle connections is that the idle connectionssimply inflate the number of connections with-out doing any useful work. We plan to exploretools similar to Dummynet [16] and NIST Net[5] in order to more accurately simulate trafficdelays, packet loss, and other wide area net-work traffic characteristics, and to re-examinethe performance of Internet servers using dif-ferent event dispatch mechanisms and a widervariety of workloads.
7 Acknowledgments
We gratefully acknowledge Hewlett Packard,the Ontario Research and Development Chal-lenge Fund, and the National Sciences and En-gineering Research Council of Canada for fi-nancial support for this project.
References
[1] G. Banga, P. Druschel, and J.C. Mogul.Resource containers: A new facility forresource management in server systems.In Operating Systems Design andImplementation, pages 45–58, 1999.
[2] G. Banga and J.C. Mogul. Scalablekernel performance for Internet serversunder realistic loads. InProceedings ofthe 1998 USENIX Annual TechnicalConference, New Orleans, LA, 1998.
[3] G. Banga, J.C. Mogul, and P. Druschel.A scalable and explicit event deliverymechanism for UNIX. InProceedings ofthe 1999 USENIX Annual TechnicalConference, Monterey, CA, June 1999.
[4] Tim Brecht, David Pariag, and LouayGammo. accept()able strategies for
improving web server performance. InProceedings of the 2004 USENIX AnnualTechnical Conference (to appear), June2004.
[5] M. Carson and D. Santay. NIST Net – aLinux-based network emulation tool.Computer Communication Review, toappear.
[6] A. Chandra and D. Mosberger.Scalability of Linux event-dispatchmechanisms. InProceedings of the 2001USENIX Annual Technical Conference,Boston, 2001.
[7] HP Labs. The userver home page, 2004.Available athttp://hpl.hp.com/research/linux/userver .
[8] Dan Kegel. The C10K problem, 2004.Available athttp://www.kegel.com/c10k.html .
[9] Jonathon Lemon. Kqueue—a genericand scalable event notification facility. InProceedings of the USENIX AnnualTechnical Conference, FREENIX Track,2001.
[10] Davide Libenzi. Improving (network)I/O performance. Available athttp://www.xmailserver.org/linux-patches/nio-improve.html .
[11] D. Mosberger and T. Jin. httperf: A toolfor measuring web server performance.In The First Workshop on Internet ServerPerformance, pages 59–67, Madison,WI, June 1998.
[12] Shailabh Nagar, Paul Larson, HannaLinder, and David Stevens. epollscalability web page. Available athttp://lse.sourceforge.net/epoll/index.html .

Linux Symposium 2004 • Volume One • 225
[13] M. Ostrowski. A mechanism for scalableevent notification and delivery in Linux.Master’s thesis, Department of ComputerScience, University of Waterloo,November 2000.
[14] Vivek S. Pai, Peter Druschel, and WillyZwaenepoel. Flash: An efficient andportable Web server. InProceedings ofthe USENIX 1999 Annual TechnicalConference, Monterey, CA, June 1999.http://citeseer.nj.nec.com/article/pai99flash.html .
[15] N. Provos and C. Lever. Scalablenetwork I/O in Linux. InProceedings ofthe USENIX Annual TechnicalConference, FREENIX Track, June 2000.
[16] Luigi Rizzo. Dummynet: a simpleapproach to the evaluation of networkprotocols.ACM ComputerCommunication Review, 27(1):31–41,1997.http://citeseer.ist.psu.edu/rizzo97dummynet.html .
[17] Standard Performance EvaluationCorporation.SPECWeb99 Benchmark,1999. Available athttp://www.specbench.org/osg/web99 .
[18] David Weekly. /dev/epoll – a highspeedLinux kernel patch. Available athttp://epoll.hackerdojo.com .

226 • Linux Symposium 2004 • Volume One

The (Re)Architecture of the X Window System
James [email protected]
Keith [email protected]
HP Cambridge Research Laboratory
Abstract
The X Window System, Version 11, is the stan-dard window system on Linux and UNIX sys-tems. X11, designed in 1987, was “state ofthe art” at that time. From its inception, X hasbeen a network transparent window system inwhich X client applications can run on any ma-chine in a network using an X server runningon any display. While there have been somesignificant extensions to X over its history (e.g.OpenGL support), X’s design lay fallow overmuch of the 1990’s. With the increasing inter-est in open source systems, it was no longersufficient for modern applications and a sig-nificant overhaul is now well underway. Thispaper describes revisions to the architecture ofthe window system used in a growing fractionof desktops and embedded systems
1 Introduction
While part of this work on the X window sys-tem [SG92] is “good citizenship” required byopen source, some of the architectural prob-lems solved ease the ability of open source ap-plications to print their results, and some ofthe techniques developed are believed to be inadvance of the commercial computer industry.The challenges being faced include:
• X’s fundamentally flawed font architec-
ture made it difficult to implement goodWYSIWYG systems
• Inadequate 2D graphics, which had al-ways been intended to be augmentedand/or replaced
• Developers are loathe to adopt any newtechnology that limits the distribution oftheir applications
• Legal requirements for accessibility forscreen magnifiers are difficult to imple-ment
• Users desire modern user interface eyecandy, which sport translucent graphicsand windows, drop shadows, etc.
• Full integration of applications into 3 Denvironments
• Collaborative shared use of X (e.g. multi-ple simultaneous use of projector walls orother shared applications)
While some of this work has been publishedelsewhere, there has never been any overviewpaper describing this work as an integratedwhole, and the compositing manager work de-scribed below is novel as of fall 2003. Thiswork represents a long term effort that startedin 1999, and will continue for several yearsmore.

228 • Linux Symposium 2004 • Volume One
2 Text and Graphics
X’s obsolete 2D bit-blit based text and graph-ics system problems were most urgent. The de-velopment of the Gnome and KDE GUI envi-ronments in the period 1997-2000 had shownX11’s fundamental soundness, but confirmedthe authors’ belief that the rendering system inX was woefully inadequate. One of us par-ticipated in the original X11 design meetingswhere the intent was to augment the renderingdesign at a later date; but the “GUI Wars” of thelate 1980’s doomed effort in this area. Goodprinting support has been particularly difficultto implement in X applications, as fonts havewere opaque X server side objects not directlyaccessible by applications.
Most applications now composite images insophisticated ways, whether it be in Flash me-dia players, or subtly as part of anti-aliasedcharacters. Bit-Blit is not sufficient for theseapplications, and these modern applicationswere (if only by their use of modern toolk-its) all resorting to pixel based image manip-ulation. The screen pixels are retrieved fromthe window system, composited in clients, andthen restored to the screen, rather than directlycomposited in hardware, resulting in poor per-formance. Inspired by the model first imple-mented in the Plan 9 window system, a graph-ics model based on Porter/Duff [PD84] imagecompositing was chosen. This work resulted inthe X Render extension [Pac01a].
X11’s core graphics exposed fonts as a serverside abstraction. This font model was, at best,marginally adequate by 1987 standards. EvenWYSIWYG systems of that era found them in-sufficient. Much additional information em-bedded in fonts (e.g. kerning tables) were notavailable from X whatsoever. Current com-petitive systems implement anti-aliased outlinefonts. Discovering the Unicode coverage of afont, required by current toolkits for interna-
tionalization, was causing major performanceproblems. Deploying new server side fonttechnology is slow, as X is a distributed sys-tem, and many X servers are seldom (or never)updated.
Therefore, a more fundamental change in X’sarchitecture was undertaken: to no longer useserver side fonts at all, but to allow applicationsdirect access to font files and have the windowsystem cache and composite glyphs onto thescreen.
The first implementation of the new font sys-tem [Pac01b] taught a vital lesson. Xft1provided anti-aliased text and proper fontnaming/substitution support, but reverted tothe core X11 bitmap fonts if the Renderextension was not present. Xft1 includedthe first implementation what is called “sub-pixel decimation,” which provides higher qual-ity subpixel based rendering than Microsoft’sClearType [Pla00] technology in a completelygeneral algorithm.
Despite these advances, Xft1 received at besta lukewarm reception. If an application devel-oper wanted anti-aliased text universally, Xft1did not help them, since it relied on the Renderextension which had not yet been widely de-ployed; instead, the developer would be facedwith two implementations, and higher mainte-nance costs. This (in retrospect obvious) ratio-nal behavior of application developers showsthe high importance of backwards compatibil-ity; X extensions intended for application de-velopers’ use must be designed in a down-ward compatible form whenever possible, andshould enable a complete conversion to a newfacility, so that multiple code paths in appli-cations do not need testing and maintenance.These principles have guided later develop-ment.
The font installation, naming, substitution,and internationalization problems were sepa-

Linux Symposium 2004 • Volume One • 229
rated from Xft into a library named Fontcon-fig [Pac02], (since some printer only appli-cations need this functionality independent ofthe window system.) Fontconfig provides in-ternationalization features in advance of thosein commercial systems such as Windows orOS X, and enables trivial font installation withgood performance even when using thousandsof fonts. Xft2 was also modified to operateagainst legacy X servers lacking the Render ex-tension.
Xft2 and Fontconfig’s solving of several ma-jor problems and lack of deployment barriersenabled rapid acceptance and deployment inthe open source community, seeing almost uni-versal use and uptake in less than one calen-dar year. They have been widely deployed onLinux systems since the end of 2002. They also“future proof” open source systems againstcoming improvements in font systems (e.g.OpenType), as the window system is no longera gating item for font technology.
Sun Microsystems implemented a server sidefont extension over the last several years; forthe reasons outlined in this section, it has notbeen adopted by open source developers.
While Xft2 and Fontconfig finally freed ap-plication developers from the tyranny ofX11’s core font system, improved perfor-mance [PG03], and at a stroke simplified theirprinting problems, it has still left a substantialburden on applications. The X11 core graph-ics, even augmented by the Render extension,lack convenient facilities for many applicationsfor even simple primitives like splines, tastefulwide lines, stroking paths, etc, much less pro-vide simple ways for applications to print theresults on paper.
3 Cairo
The Cairo library [WP03], developed by one ofthe authors in conjunction with by Carl Worthof ISI, is designed to solve this problem. Cairoprovides a state full user-level API with sup-port for the PDF 1.4 imaging model. Cairo pro-vides operations including stroking and fillingBézier cubic splines, transforming and com-positing translucent images, and anti-aliasedtext rendering. The PostScript drawing modelhas been adapted for use within applications.Extensions needed to support much of the PDF1.4 imaging operations have been included.This integration of the familiar PostScript op-erational model within the native applicationlanguage environments provides a simple andpowerful new tool for graphics application de-velopment.
Cairo’s rendering algorithms use work donein the 1980’s by Guibas, Ramshaw, andStolfi [GRS83] along with work by JohnHobby [Hob85], which has never been ex-ploited in Postscript or in Windows. The im-plementation is fast, precise, and numericallystable, supports hardware acceleration, and isin advance of commercial systems.
Of particular note is the current development ofGlitz [NR04], an OpenGL backend for Cairo,being developed by a pair of master’s studentsin Sweden. Not only is it showing that a highspeed implementation of Cairo is possible, itimplements an interface very similar to the XRender extension’s interface. More about thisin the OpenGL section below.
Cairo is in the late stages of development andis being widely adopted in the open sourcecommunity. It includes the ability to renderto Postscript and a PDF back end is planned,which should greatly improve applications’printing support. Work to incorporate Cairo inthe Gnome and KDE desktop environments is

230 • Linux Symposium 2004 • Volume One
well underway, as are ports to Windows andApple’s MacIntosh, and it is being used by theMono project. As with Xft2, Cairo works withall X servers, even those without the Renderextension.
4 Accessibility and Eye-Candy
Several years ago, one of us implemented aprototype X system that used image composit-ing as the fundamental primitive for construct-ing the screen representation of the window hi-erarchy contents. Child window contents werecomposited to their parent windows whichwere incrementally composed to their parentsuntil the final screen image was formed, en-abling translucent windows. The problem withthis simplistic model was twofold—first, anaïve implementation consumed enormous re-sources as each window required two com-plete off screen buffers (one for the windowcontents themselves, and one for the windowcontents composited with the children) andtook huge amounts of time to build the finalscreen image as it recursively composited win-dows together. Secondly, the policy govern-ing the compositing was hardwired into the Xserver. An architecture for exposing the samesemantics with less overhead seemed almostpossible, and pieces of it were implemented(miext/layer). However, no complete systemwas fielded, and every copy of the code trackeddown and destroyed to prevent its escape intothe wild.
Both Mac OS X and DirectFB [Hun04] per-form window-level compositing by creatingoff-screen buffers for each top-level window(in OS X, the window system is not nested,so there are only top-level windows). Thescreen image is then formed by taking the re-sulting images and blending them together onthe screen. Without handling the nested win-dow case, both of these systems provide the
desired functionality with a simple implemen-tation. This simple approach is inadequatefor X as some desktop environments nest thewhole system inside a single top-level win-dow to allow panning, and X’s long historyhas shown the value of separating mechanismfrom policy (Gnome and KDE were developedover 10 years after X11’s design). The fix ispretty easy—allow applications to select whichpieces of the window hierarchy are to be storedoff-screen and which are to be drawn to theirparent storage.
With window hierarchy contents stored in off-screen buffers, an external application can nowcontrol how the screen contents are constructedfrom the constituent sub-windows and what-ever other graphical elements are desired. Thiseliminated the complexities surrounding pre-cisely what semantics would be offered inwindow-level compositing within the X serverand the design of the underlying X extensions.They were replaced by some concerns over theperformance implications of using an externalagent (the “Compositing Manager”) to executethe requests needed to present the screen im-age. Note that every visible pixel is under thecontrol of the compositing manager, so screenupdates are limited to how fast that applicationcan get the bits painted to the screen.
The architecture is split across three new ex-tensions:
• Composite, which controls which sub-hierarchies within the window tree arerendered to separate buffers.
• Damage, which tracks modified areaswith windows, informing the CompostingManager which areas of the off-screen hi-erarchy components have changed.
• Xfixes, which includes new Region ob-jects permitting all of the above computa-tion to be performed indirectly within the

Linux Symposium 2004 • Volume One • 231
X server, avoiding round trips.
Multiple applications can take advantage of theoff screen window contents, allowing thumb-nail or screen magnifier applications to be in-cluded in the desktop environment.
To allow applications other than the composit-ing manager to present alpha-blended contentto the screen, a new X Visual was added to theserver. At 32 bits deep, it provides 8 bits ofred, green and blue along with 8 bits of alphavalue. Applications can create windows usingthis visual and the compositing manager cancomposite them onto the screen.
Nothing in this fundamental design indicatesthat it is used for constructing translucent win-dows; redirection of window contents and no-tification of window content change seemspretty far removed from one of the final goals.But note the compositing manger can use what-ever X requests it likes to paint the com-bined image, including requests from the Ren-der extension, which does know how to blendtranslucent images together. The final imageis constructed programmatically so the possi-ble presentation on the screen is limited onlyby the fertile imagination of the numerous eye-candy developers, and not restricted to any pol-icy imposed by the base window system. Andvital to rapid deployment, most applicationscan be completely oblivious to this backgroundlegerdemain.
In this design, such sophisticated effects needonly be applied at frame update rates on onlymodified sections of the screen rather than atthe rate applications perform graphics; thisconstant behavior is highly desirable in sys-tems.
There is very strong “pull” from both commer-cial and non-commercial users of X for thiswork and the current early version will likelybe shipped as part of the next X.org Foun-
dation X Window System release, sometimethis summer. Since there has not been suffi-cient exposure through widespread use, furtherchanges will certainly be required further expe-rience with the facilities are gained in a muchlarger audience; as these can be made withoutaffecting existing applications, immediate de-ployment is both possible and extremely desir-able.
The mechanisms described above realize a fun-damentally more interesting architecture thaneither Windows or Mac OSX, where the com-positing policy is hardwired into the windowsystem. We expect a fertile explosion of ex-perimentation, experience (both good and bad),and a winnowing of ideas as these facilitiesgain wider exposure.
5 Input Transformation
In the “naïve,” eye-candy use of the new com-positing functions, no transformation of inputevents are required, as input to windows re-mains at the same geometric position on thescreen, even though the windows are first ren-dered off screen. More sophisticated use, forexample, screen readers or immersive environ-ments such as Croquet [SRRK02], or Sun’sLooking Glass [KJ04] requires transformationof input events from where they first occuron the visible screen to the actual position inthe windows (being rendered from off screen),since the window’s contents may have been ar-bitrarily transformed or even texture mappedonto shapes on the screen.
As part of Sun Microsystem’s award winningwork on accessibility in open source for screenreaders, Sun has developed the XEvIE exten-sion [Kre], which allows external clients totransform input events. This looks like a goodstarting point for the somewhat more generalproblem that 3D systems pose, and with some

232 • Linux Symposium 2004 • Volume One
modification can serve both the accessibilityneeds and those of more sophisticated applica-tions.
6 Synchronization
Synchronization is probably the largest re-maining challenge posed by compositing.While composite has eliminated much flashingof the screen since window exposure is elimi-nated, this does not solve the challenge of thecompositing manager happening to copy an ap-plication’s window to the frame buffer in themiddle of an application painting a sequenceof updates. No “tearing” of single graphics op-erations take place since the X server is singlethreaded, and all graphics operations are run tocompletion.
The X Synchronization extension(XSync) [GCGW92], widely availablebut to date seldom used, provides a general setof mechanisms for applications to synchronizewith each other, with real time, and potentiallywith other system provided counters. XSync’soriginal design intent intended system pro-vided counters for vertical retrace interrupts,audio sample clocks, and similar systemfacilities, enabling very tight synchronizationof graphics operations with these time bases.Work has begun on Linux to provide thesecounters at long last, when available, to fleshout the design originally put in place and testedin the early 1990’s.
A possible design for solving the applicationsynchronization problem at low overhead maybe to mark sections of requests with incre-ments of XSync counters: if the count is odd(or even) the window would be unstable/stable.The compositing manager might then copy thewindow only if the window is in a stable state.Some details and possibly extensions to XSyncwill need to be worked out, if this approach is
pursued.
7 Next Steps
We believe we are slightly more than half waythrough the process of rearchitecting and reim-plementing the X Window System. The ex-isting prototype needs to become a produc-tion system requiring significant infrastructurework as described in this section.
7.1 OpenGL based X
Current X-based systems which supportOpenGL do so by encapsulating the OpenGLenvironment within X windows. As such,an OpenGL application cannot manipulate Xobjects with OpenGL drawing commands.
Using OpenGL as the basis for the X server it-self will place X objects such as pixmaps andoff-screen window contents inside OpenGLobjects allowing applications to use the fullOpenGL command set to manipulate them.
A “proof of concept” of implementation of theX Render extension is being done as part ofthe Glitz back-end for Cairo, which is showingvery good performance for render based appli-cations. Whether the “core” X graphics will re-quire any OpenGL extensions is still somewhatan open question.
In concert with the new compositing exten-sions, conventional X applications can then beintegrated into 3D environments such as Cro-quet, or Sun’s Looking Glass. X applicationcontents can be used as textures and mappedonto any surface desired in those environments.
This work is underway, but not demonstrableat this date.

Linux Symposium 2004 • Volume One • 233
7.2 Kernel support for graphics cards
In current open source systems, graphics cardsare supported in a manner totally unlike thatof any other operating system, and unlike pre-vious device drivers for the X Window Systemon commercial UNIX systems. There is no sin-gle central kernel driver responsible for manag-ing access to the hardware. Instead, a large setof cooperating user and kernel mode systemsare involved in mutual support of the hardware,including the X server (for 2D graphic), thedirect-rendering infrastructure (DRI) (for ac-celerated 3D graphics), the kernel frame bufferdriver (for text console emulation), the Gen-eral ATI TV and Overlay Software (GATOS)(for video input and output) and alternate 2Dgraphics systems like DirectFB.
Two of these systems, the kernel frame bufferdriver and the X server both include code toconfigure the graphics card “video mode”—the settings needed to send the correct videosignals to monitors connected to the card.Three of these systems, DRI, the X serverand GATOS, all include code for managingthe memory space within the graphics card.All of these systems directly manipulate hard-ware registers without any coordination amongthem.
The X server has no kernel component for2D graphics. Long-latency operations cannotuse interrupts, instead the X server spins whilepolling status registers. DMA is difficult or im-possible to configure in this environment. Per-haps the most egregious problem is that theX server reconfigures the PCI bus to correctBIOS mapping errors without informing theoperating system kernel. Kernel access to de-vices while this remapping is going on mayfind the related devices mismapped.
To rationalize this situation, various groups andvendors are coordinating efforts to create a sin-
gle kernel-level entity responsible for basic de-vice management, but this effort has just be-gun.
7.3 Housecleaning and Latency Eliminationand Latency Hiding
Serious attempts were made in the early 1990’sto multi-thread the X server itself, with the dis-covery that the threading overhead in the Xserver is a net performance loss [Smi92].
Applications, however, often need to be multi-threaded. The primary C binding to the X pro-tocol is called Xlib, and its current implemen-tation by one of us dates from 1987. While itwas partially developed on a Firefly multipro-cessor workstation of that era, something al-most unheard of at that date, and some con-sideration of multi-threaded applications weretaken in its implementation, its internal trans-port facilities were never expected/intended tobe preserved when serious multi-threaded op-erating systems became available. Unfortu-nately, rather than a full rewrite as one of us ex-pected, multi-threaded support was debuggedinto existence using the original code base andthe resulting code is very bug-prone and hard tomaintain. Additionally, over the years, Xlib be-came a “kitchen sink” library, including func-tionality well beyond its primary use as a bind-ing to the X protocol. We have both seri-ously regretted the precedents both of us setintroducing extraneous functionality into Xlib,causing it to be one of the largest libraries onUNIX/Linux systems. Due to better facilitiesin modern toolkits and system libraries, morethan half of Xlib’s current footprint is obsoletecode or data.
While serious work was done in X11’s designto mitigate latency, X’s performance, particu-larly over low speed networks, is often lim-ited by round trip latency, and with retrospectmuch more can be done [PG03]. As this

234 • Linux Symposium 2004 • Volume One
work shows, client side fonts have made a sig-nificant improvement in startup latency, andwork has already been completed in toolkitsto mitigate some of the other hot spots. Muchof the latency can be retrieved by some sim-ple techniques already underway, but some re-quire more sophisticated techniques that thecurrent Xlib implementation is not capable of.Potentially 90the latency as of 2003 can berecovered by various techniques. The XCBlibrary [MS01] by Bart Massey and JameySharp is both carefully engineered to be mul-tithreaded and to expose interfaces that will al-low for latency hiding.
Since libraries linked against different basicX transport systems would cause havoc in thesame address space, a Xlib compatibility layer(XCL) has been developed that provides the“traditional” X library API, using the originalXlib stubs, but replacing the internal transportand locking system, which will allow for muchmore useful latency hiding interfaces. TheXCB/XCL version of Xlib is now able to runessentially all applications, and after a shake-down period, should be able to replace the ex-isting Xlib transport soon. Other bindings thanthe traditional Xlib bindings then become pos-sible in the same address space, and we maysee toolkits adopt those bindings at substantialsavings in space.
7.4 Mobility, Collaboration, and Other Topics
X’s original intended environment includedhighly mobile students, and a hope, never gen-erally realized for X, was the migration of ap-plications between X servers.
The user should be able to travel between sys-tems running X and retrieve your running ap-plications (with suitable authentication and au-thorization). The user should be able to log outand “park” applications somewhere for laterretrieval, either on the same display, or else-
where. Users should be able to replicate anapplication’s display on a wall projector forpresentation. Applications should be able toeasily survive the loss of the X server (mostcommonly caused by the loss of the underly-ing TCP connection, when running remotely).
Toolkit implementers typically did not under-stand and share this poorly enunciated visionand were primarily driven by pressing imme-diate needs, and X’s design and implemen-tation made migration or replication difficultto implement as an afterthought. As a re-sult, migration (and replication) was seldomimplemented, and early toolkits such as Xtmade it even more difficult. Emacs is the onlywidespread application capable of both migra-tion and replication, and it avoided using anytoolkit. A more detailed description of this vi-sion is available in [Get02].
Recent work in some of the modern toolkits(e.g. GTK+) and evolution of X itself makemuch of this vision demonstrable in current ap-plications. Some work in the X infrastructure(Xlib) is underway to enable the prototype inGTK+ to be finished.
Similarly, input devices need to become full-fledged network data sources, to enable muchlooser coupling of keyboards, mice, game con-soles and projectors and displays; the challengehere will be the authentication, authorizationand security issues this will raise. The HALand DBUS projects hosted at freedesktop.orgare working on at least part of the solutions forthe user interface challenges posed by hotplugof input devices.
7.5 Color Management
The existing color management facilities inX are over 10 years old, have never seenwidespread use, and do not meet current needs.This area is ripe for revisiting. Marti Maria Sa-

Linux Symposium 2004 • Volume One • 235
guer’s LittleCMS [Mar] may be of use here.For the first time, we have the opportunity to“get it right” from one end to the other if wechoose to make the investment.
7.6 Security and Authentication
Transport security has become an burning is-sue; X is network transparent (applications canrun on any system in a network, using remotedisplays), yet we dare no longer use X over thenetwork directly due to password grabbing kitsin the hands of script kiddies. SSH [BS01] pro-vides such facilities via port forwarding andis being used as a temporary stopgap. Ur-gent work on something better is vital to en-able scaling and avoid the performance and la-tency issues introduced by transit of extra pro-cesses, particularly on (Linux Terminal ServerProject (LTSP [McQ02]) servers, which are be-ginning break out of their initial use in schoolsand other non security sensitive environmentsinto very sensitive commercial environments.
Another aspect of security arises between ap-plications sharing a display. In the early andmid 1990’s efforts were made as a result of thecompartmented mode workstation projects tomake it much more difficult for applications toshare or steal data from each other on a X dis-play. These facilities are very inflexible, andhave gone almost unused.
As projectors and other shared displays be-come common over the next five years, appli-cations from multiple users sharing a displaywill become commonplace. In such environ-ments, different people may be using the samedisplay at the same time and would like somelevel of assurance that their application’s datais not being grabbed by the other user’s appli-cation.
Eamon Walsh has, as part of the SELinuxproject [Wal04], been working to replace the
existing X Security extension with an exten-sion that, as in SELinux, will allow multipledifferent security policies to be developed ex-ternal to the X server. This should allow multi-ple different policies to be available to suit thevaried uses: normal workstations, secure work-stations, shared displays in conference rooms,etc.
7.7 Compression and Image Transport
Many/most modern applications and desktops,including the most commonly used application(a web browser) are now intensive users of syn-thetic and natural images. The previous at-tempt (XIE [SSF+96]) to provide compressedimage transport failed due to excessive com-plexity and over ambition of the designers, hasnever been significantly used, and is now infact not even shipped as part of current X dis-tributions.
Today, many images are being read from diskor the network in compressed form, uncom-pressed into memory in the X client, movedto the X server (where they often occupy an-other copy of the uncompressed data). If weadd general data compression to X (or run Xover ssh with compression enabled) the datawould be both compressed and uncompressedon its way to the X server. A simple replace-ment for XIE (if the complexity slippery slopecan be avoided in a second attempt) would beworthwhile, along with other general compres-sion of the X protocol.
Results in our 2003 Usenix X Network Per-formance paper show that, in real applica-tion workloads (the startup of a Gnome desk-top), using even simple GZIP [Gai93] stylecompression can make a tremendous differ-ence in a network environment, with a fac-tor of 300(!) savings in bandwidth. Appar-ently the synthetic images used in many cur-rent UI’s are extremely good candidates for

236 • Linux Symposium 2004 • Volume One
compression. A simple X extension that couldencapsulate one or more X requests into theextension request would avoid multiple com-pression/uncompression of the same data inthe system where an image transport extensionwas also present. The basic X protocol frame-work is actually very byte efficient relative tomost conventional RPC systems, with a basicX request only occupying 4 bytes (contrast thiswith HTTP or CORBA, in which a simple re-quest is more than 100 bytes).
With the great recent interest in LTSP in com-mercial environments, work here would be ex-tremely well spent, saving both memory andCPU, and network bandwidth.
We are more than happy to hear from anyoneinterested in helping in this effort to bring Xinto the new millennium.
References
[BS01] Daniel J. Barrett and RichardSilverman.SSH, The SecureShell: The Definitive Guide.O’Reilly & Associates, Inc.,2001.
[Gai93] Jean-Loup Gailly.Gzip: TheData Compression Program.iUniverse.com, 1.2.4 edition,1993.
[GCGW92] Tim Glauert, Dave Carver, JamesGettys, and David Wiggins. XSynchronization ExtensionProtocol, Version 3.0. Xconsortium standard, 1992.
[Get02] James Gettys. The Future isComing, Where the X WindowSystem Should Go. InFREENIXTrack, 2002 Usenix AnnualTechnical Conference, Monterey,CA, June 2002. USENIX.
[GRS83] Leo Guibas, Lyle Ramshaw, andJorge Stolfi. A kinetic frameworkfor computational geometry. InProceedings of the IEEE 198324th Annual Symposium on theFoundations of ComputerScience, pages 100–111. IEEEComputer Society Press, 1983.
[Hob85] John D. Hobby.Digitized BrushTrajectories. PhD thesis,Stanford University, 1985. AlsoStanford ReportSTAN-CS-85-1070.
[Hun04] A. Hundt. DirectFB Overview(v0.2 for DirectFB 0.9.21),February 2004.http://www.directfb.org/documentation .
[KJ04] H. Kawahara and D. Johnson.Project Looking Glass: 3DDesktop Exploration. InXDevelopers Conference,Cambridge, MA, April 2004.
[Kre] S. Kreitman. XEvIE - X EventInterception Extension.http://freedesktop.org/~stukreit/xevie.html .
[Mar] M. Maria. Little CMS Engine1.12 API Definition. Technicalreport.http://www.littlecms.com/lcmsapi.txt .
[McQ02] Jim McQuillan. LTSP - LinuxTerminal Server Project, Version3.0. Technical report, March2002.http://www.ltsp.org/documentation/ltsp-3.0-4-en.html .
[MS01] Bart Massey and Jamey Sharp.XCB: An X protocol c binding.

Linux Symposium 2004 • Volume One • 237
In XFree86 TechnicalConference, Oakland, CA,November 2001. USENIX.
[NR04] Peter Nilsson and DavidReveman. Glitz: HardwareAccelerated Image Compositingusing OpenGL. InFREENIXTrack, 2004 Usenix AnnualTechnical Conference, Boston,MA, July 2004. USENIX.
[Pac01a] Keith Packard. Design andImplementation of the XRendering Extension. InFREENIX Track, 2001 UsenixAnnual Technical Conference,Boston, MA, June 2001.USENIX.
[Pac01b] Keith Packard. The Xft FontLibrary: Architecture and UsersGuide. InXFree86 TechnicalConference, Oakland, CA,November 2001. USENIX.
[Pac02] Keith Packard. FontConfiguration and Customizationfor Open Source Systems. In2002 Gnome User’s andDevelopers EuropeanConference, Seville, Spain, April2002. Gnome.
[PD84] Thomas Porter and Tom Duff.Compositing Digital Images.Computer Graphics,18(3):253–259, July 1984.
[PG03] Keith Packard and James Gettys.X Window System NetworkPerformance. InFREENIXTrack, 2003 Usenix AnnualTechnical Conference, SanAntonio, TX, June 2003.USENIX.
[Pla00] J. Platt. Optimal filtering forpatterned displays.IEEE SignalProcessing Letters,7(7):179–180, 2000.
[SG92] Robert W. Scheifler and JamesGettys.X Window System.Digital Press, third edition, 1992.
[Smi92] John Smith. The Multi-ThreadedX Server.The X Resource,1:73–89, Winter 1992.
[SRRK02] D. Smith, A. Raab, D. Reed, andA. Kay. Croquet: The UsersManual, October 2002.http://glab.cs.uni-magdeburg.de/~croquet/downloads/Croquet0.1.pdf .
[SSF+96] Robert N.C. Shelley, Robert W.Scheifler, Ben Fahy, Jim Fulton,Keith Packard, Joe Mauro,Richard Hennessy, and TomVaughn. X Image ExtensionProtocol Version 5.02. Xconsortium standard, 1996.
[Wal04] Eamon Walsh. IntegratingXFree86 WithSecurity-Enhanced Linux. InXDevelopers Conference,Cambridge, MA, April 2004.http://freedesktop.org/Software/XDevConf/x-security-walsh.pdf .
[WP03] Carl Worth and Keith Packard.Xr: Cross-device Rendering forVector Graphics. InProceedingsof the Ottawa Linux Symposium,Ottawa, ON, July 2003. OLS.

238 • Linux Symposium 2004 • Volume One

IA64-Linux perf tools for IO dorksExamples of IA-64 PMU usage
Grant [email protected]
Abstract
Itanium processors have very sophisticatedperformance monitoring tools integrated intothe CPU. McKinley and Madison ItaniumCPUs have over three hundred different typesof events they can filter, trigger on, and count.The restrictions on which combinations of trig-gers are allowed is daunting and varies acrossCPU implementations. Fortunately, the toolshide this complicated mess. While the toolsprevent us from shooting ourselves in the foot,it’s not obvious how to use those tools for mea-suring kernel device driver behaviors.
IO driver writers can use pfmon to measure twokey areas generally not obvious from the code:MMIO read and write frequency and preciseaddresses of instructions regularly causing L3data cache misses. Measuring MMIO reads hassome nuances related to instruction executionwhich are relevant to understanding ia64 andlikely ia32 platforms. Similarly, the ability topinpoint exactly which data is being accessedby drivers enables driver writers to either mod-ify the algorithms or add prefetching directiveswhere feasible. I include some examples onhow I used pfmon to measure NIC drivers andgive some guidelines on use.
q-syscollect is a “gprof without the pain” kindof tool. While q-syscollect uses the same ker-nel perfmon subsystem as pfmon, the former
works at a higher level. With some knowledgeabout how the kernel operates, q-syscollect cancollect call-graphs, function call counts, andpercentage of time spent in particular routines.In other words, pfmon can tell us how muchtime the CPU spends stalled on d-cache missesand q-syscollect can give us the call-graph forthe worst offenders.
Updated versions of this paper will be avail-able from http://iou.parisc-linux.
org/ols2004/
1 Introduction
Improving the performance of IO drivers is re-ally not that easy. It usually goes somethinglike:
1. Determine which workload is relevant
2. Set up the test environment
3. Collect metrics
4. Analyze the metrics
5. Change the code based on theories aboutthe metrics
6. Iterate on Collect metrics
This paper attempts to make the collect-analyze-change loop more efficient for three

240 • Linux Symposium 2004 • Volume One
obvious things: MMIO reads, MMIO writes,and cache line misses.
MMIO reads and writes are easier to locate inLinux code than for other OSs which supportmemory-mapped IO—just search forreadl()andwritel() calls. Butpfmon [1] can providestatistics of actual behavior and not just wherein the code MMIO space is touched.
Cache line misses are hard to detect. Noneof the regular performance tools I’ve usedcan precisely tell where CPU stalls are takingplace. We can guess some of them based ondata usage—like spin locks ping-ponging be-tween CPUs. This requires a level of under-standing that most of us mere mortals don’tpossess. Again,pfmon can help out here.
Lastly, getting an overview of system perfor-mance and getting run-time call graph usuallyrequires compiler support that gcc doesn’t pro-vide. q-tools[4] can provide that information.Driver writers can then manually adjust thecode knowing where the “hot spots” are.
1.1 pfmon
The author ofpfmon , Stephane Eranian [2],describespfmon as “the performance toolfor IA64-Linux which exploits all the featuresof the IA-64 Performance Monitoring Unit(PMU).” pfmon uses a command line inter-face and does not require any special privilegeto run. pfmon can monitor a single process, amulti-threaded process, multi-processes work-loads and the entire system.
pfmon is the user command line interface tothe kernel perfmon subsystem. perfmon doesthe ugly work of programming the PMU. Perf-mon is versioned separately frompfmon com-mand. When in doubt, use the perfmon in thelatest 2.6 kernel.
There are two major types of measurements:
counting and sampling. For counting,pfmonsimply reports the number of occurrences ofthe desired events during the monitoring pe-riod. pfmon can also be configured to sampleat certain intervals information about the exe-cution of a command or for the entire system.It is possible to sample any events provided bythe underlying PMU.
The information recorded by the PMU dependson what the user wants.pfmon contains a fewpreset measurements but for the most part theuser is free to set up custom measurements.On Itanium2,pfmon provides access to all thePMU advanced features such as opcode match-ing, range restrictions, the Event Address Reg-isters (EAR) and the Branch Trace Buffer.
1.2 pfmon command line options
Here is a summary of command line optionsused in the examples later in this paper:
–us-c use the US-style comma separator forlarge numbers.
–cpu-list=0 bind pfmon to CPU 0 and onlycount on CPU 0
–pin-command bind the command at the endof the command line to the same CPU aspfmon .
–resolve-addr look up addresses and print thesymbols
–long-smpl-periods=2000take a sample ofevery 2000th event.
–smpl-periods-random=0xfff:10 randomizethe sampling period. This is necessaryto avoid bias when sampling repetitivebehaviors. The first value is the maskof bits to randomize (e.g., 0xfff) and thesecond value is initial seed (e.g., 10).
-k kernel only.

Linux Symposium 2004 • Volume One • 241
–system-widemeasure the entire system (allprocesses and kernel)
Parameters only available on a to-be-releasedpfmon v3.1:
–smpl-module=dear-hist-itanium2 This par-ticular module is to be used ONLY inconjunction with the Data EAR (EventAddress Registers) and presents recordedsamples as histograms about the cachemisses. By default, the information is pre-sented in the instruction view but it is pos-sible to get the data view of the missesalso.
-e data_ear_cache_lat64pseudo event formemory loads with latency≥ 64 cy-cles. The real event isDATA_EAR_EVENT
(counts the number of times Data EARhas recorded something) and the pseudoevent expresses the latency filter for theevent. Use “pfmon -ldata_ear_cache* ” to list all valid values. Validvalues with McKinley CPU are powers oftwo (4 – 4096).
1.3 q-tools
The author of q-tools, David Mosberger [5],has described q-tools as “gprof without thepain.”
q-tools package containsq-syscollect ,q-view , qprof , and q-dot .q-syscollect collects profile infor-mation using kernel perfmon subsystem tosample the PMU.q-view will present thedata collected in both flat-profile and callgraph form. q-dot displays the call-graphin graphical form. Please see theqprof [6]website for details onqprof .
q-syscollect depends on the kernel perf-mon subsystem which is included in all 2.6
Linux kernels. Becauseq-syscollect usesthe PMU, it has the following advantages overother tools:
• no special kernel support needed (besidesperfmon subsystem).
• provides call-graph of kernel functions
• can collect call-graphs of the kernel whileinterrupts are blocked.
• measures multi-threaded applications
• data is collected per-CPU and can bemerged
• instruction level granularity (not bundles)
2 Measuring MMIO Reads
Nearly every driver uses MMIO reads to ei-ther flush MMIO writes, flush in-flight DMA,or (most obviously) collect status data from theIO device directly. While use of MMIO read isnecessary in most cases, it should be avoidedwhere possible.
2.1 Why worry about MMIO Reads?
MMIO reads are expensive—how expensivedepends on speed of the IO bus, the numberbridges the read (and its corresponding read re-turn) has to cross, how “busy” each bus is, andfinally how quickly the device responds to theread request. On most architectures, one canprecisely measure the cost by measuring a loopof MMIO reads and callingget_cycles()before/after the loop.
I’ve measured anywhere from 1µs to 2µs perread. In practical terms:
• ∼ 500–600 cycles on an otherwise-idle400 MHz PA-RISC machine.

242 • Linux Symposium 2004 • Volume One
• ∼ 1000 cycles on a 450 MHz Pentium ma-chine which included crossing a PCI-PCIbridge.
• ∼ 900–1000 cycles on a 800 MHz IA64HP ZX1 machine.
And for those who still don’t believe me, trywatching a DVD movie after turning DMA offfor an IDE DVD player:
hdparm -d 0 /dev/cdrom
By switching the IDE controller to use PIO(Programmed I/O) mode, all data will be trans-ferred to/from host memory under CPU con-trol, byte (or word) at a time.pfmon can mea-sure this. Andpfmon looks broken when itdisplays three and four digit “Average CyclesPer Instruction” (CPI) output.
2.2 Eh? Memory Reads don’t stall?
They do. But the CPU and PMU don’t “real-ize” the stall until the next memory reference.The CPU continues execution until memory or-der is enforced by the acquire semantics in theMMIO read. This means theData Event Ad-dress Registers record the next stalled mem-ory reference due to memory ordering con-straints, not the MMIO read . One has to lookat the instruction stream carefully to determinewhich instruction actually caused the stall.
This also means the following sequencedoesn’t work exactly like we expect:
writel(CMD,addr);readl(addr);udelay(1);y = buf->member;
The problem is the value returned byread(x) is never consumed. Memory
ordering imposes no constraint on non-load/store instructions. Henceudelay(1)begins before the CPU stalls. The CPU willstall on buf->member because of memoryordering restrictions if theudelay(1) com-pletes beforereadl(x) is retired. Drop theudelay(1) call andpfmon will always seethe stall caused by MMIO reads on the nextmemory reference.
Unfortunately, the IA32 Software Developer’sManual[3] Volume 3, Chapter 7.2 “MEMORYORDERING” is silent on the issue of howMMIO (uncached accesses) will (or will not)stall the instruction stream. This documentis very clear on how “IO Operations” (e.g.,IN/OUT) will stall the instruction pipeline untilthe read return arrives at the CPU. A direct re-sponse from Intel(R) indicatedreadl() doesnot stall like IN or OUT do and IA32 has thesame problem. The Intel® architect who re-sponded did hedge the above statement claim-ing a “udelay(10) will be as close as expected”for an example similar to mine. Anyone whohas access to a frontside bus analyzer can ver-ify the above statement by measuring timingloops between uncached accesses. I’m not thatprivileged and have to trust Intel® in this case.
For IA64, we considered putting an extra bur-den onudelay to stall the instruction streamuntil previous memory references were retired.We could use dummy loads/stores before andafter the actual delay loop so memory orderingcould be used to stall the instruction pipeline.That seemed excessive for something that wedidn’t have a bug report for.
Consensus was addingmf.a (memory fence)instruction toreadl() should be sufficient.The architecture only requiresmf.a serve asan ordering token and need not cause any de-lays of its own. In other words, the imple-mentation is platform specific.mf.a has notbeen added toreadl() yet because every-

Linux Symposium 2004 • Volume One • 243
thing was working without so far.
2.3 pfmon -e uc_loads_retired
IO accesses are generally the only uncachedreferences made on IA64-linux and normallywill represent MMIO reads. The basic mea-surement will tell us roughly how many cyclesthe CPU stalls for MMIO reads. Get the num-ber of MMIO reads per sample period and thenmultiply by the actual cycle counts a MMIOread takes for the given device. One needs tomeasure MMIO read cost by using a CPU in-ternal cycle counter and hacking the kernel toread a harmless address from the target devicea few thousand times.
In order to make statements about per trans-action or per interrupt, we need to knowthe cumulative number of transactions orinterrupts processed for the sample period.pktgen is straightforward in this regard sincepktgen will print transaction statistics whena run is terminated. And one can record/proc/interrupts contents before andafter eachpfmon run to collect interruptevents as well.
Drawbacks to the above are one assumes a ho-mogeneous driver environment; i.e., only onetype of driver is under load during the test. Ithink that’s a fair assumption for developmentin most cases. Bridges (e.g., routing trafficacross different interconnects) are probably theone case it’s not true. One has to work a bitharder to figure out what the counts mean inthat case.
For other benchmarks, like SpecWeb, we wantto grab/proc/interrupt and networkingstats before/afterpfmon runs.
2.4 tg3 Memory Reads
In summary, Figure 1 shows tg3 is do-ing 2749675/(1834959 − 918505) ≈ 3MMIO reads per interrupt and averaging about5000000/(1834959 − 918505) ≈ 5 packetsper interrupt. This is with the BCM5701 chiprunning in PCI mode at 66MHz:64-bit.
Based on code inspection, here is a break downof where the MMIO reads occur in temporalorder:
1. tg3_interrupt() flushes MMIOwrite toMAILBOX_INTERRUPT_0
2. tg3_poll() → tg3_enable_ints() → tw32(TG3PCI_MISC_HOST_CTRL)
3. tg3_enable_ints() flushes MMIOwrite to MAILBOX_INTERRUPT_0
It’s obvious when inspectingtw32() , theBCM5701 chip has a serious bug. Every callto tw32() on BCM5701 requires a MMIOread to follow the MMIO write. Only writes tomailbox registers don’t require this and a dif-ferent routine is used for mailbox writes.
Given the NIC was designed for zero MMIOreads, this is pretty poor performance. Us-ing a BCM5703 or BCM5704 would avoid theMMIO read in tw32().
I’ve exchanged email with David Miller andJeff Garzik (tg3 driver maintainers). They havevalid concerns with portability. We agree tg3could be reduced to one MMIO read after thelast MMIO write (to guarantee interrupts getre-enabled).
One would need to use the “tag” field in thestatus block when writing the mail box registerto indicate which “tag” the CPU most recently

244 • Linux Symposium 2004 • Volume One
gsyprf3:~# pfmon -e uc_loads_retired -k --system-wide \-- /usr/src/pktgen-testing/pktgen-single-tg3Adding devices to run.Configuring devicesRunning... ctrl^C to stop
57: 918505 0 IO-SAPIC-level eth1Result: OK: 7613693(c7613006+d687) usec, 5000000 (64byte) 656771pps 320Mb/sec(336266752bps) errors: 0
57: 1834959 0 IO-SAPIC-level eth1CPU0 2749675 UC_LOADS_RETIREDCPU1 1175 UC_LOADS_RETIRED}
Figure 1: tg3 v3.6 MMIO reads with pktgen/IRQ on same CPU
saw. Using Message Signaled Interrupts (MSI)instead of Line based IRQs would guaranteethe most recent status block update (transferredvia DMA writes) would be visible to the CPUbeforetg3_interrupt() gets called.
The protocol would allow correct operationwithout using MSI, too.
2.5 Benchmarking,pfmon , and CPU bindings
The purpose of bindingpktgen to CPU1 isto verify the transmit code path is NOT doingany MMIO reads. We split the transmit codepath and interrupt handler across CPUs to nar-row down which code path is performing theMMIO reads. This change is not obvious fromFigure 2 output since tg3 only performs MMIOreads from CPU 0 (tg3_interrupt() ).
But in Figure 2, performance goes up 30%!Offhand, I don’t know if this is due to CPUutilization (pktgen andtg3_interrupt()contending for CPU cycles) or if DMA is moreefficient because of cache-line flows. When Idon’t have any deadlines looming, I’d like todetermine the difference.
2.6 e1000 Memory Reads
e1000 version 5.2.52-k4 has a more efficientimplementation than tg3 driver. In a nut shell,MMIO reads are pretty much irrelevant to thepktgen workload with e1000 driver using de-fault values.
Figure 3 shows e1000 performs173315/(703829 − 622143) ≈ 2 MMIOreads per interrupt and5000000/(703829 −622143) ≈ 61 packets per interrupt.
Being the curious soul I am, I tracked downthe two MMIO reads anyway. One is in the in-terrupt handler and the second when interruptsare re-enabled. It looks like e1000 will alwaysneed at least 2 MMIO reads per interrupt.
3 Measuring MMIO Writes
3.1 Why worry about MMIO Writes?
MMIO writes are clearly not as significant asMMIO reads. Nonetheless, every time a driverwrites to MMIO space, some subtle things hap-pen. There are four minor issues to think about:memory ordering, PCI bus utilization, fillingoutbound write queues, and stalling MMIOreads longer than necessary.

Linux Symposium 2004 • Volume One • 245
gsyprf3:~# pfmon -e uc_loads_retired -k --system-wide \-- /usr/src/pktgen-testing/pktgen-single-tg3Adding devices to run.Configuring devicesRunning... ctrl^C to stop
57: 5809687 0 IO-SAPIC-level eth1Result: OK: 5914889(c5843865+d71024) usec, 5000000 (64byte) 845451pps 412Mb/sec (432870912bps) errors: 0
57: 6427969 0 IO-SAPIC-level eth1CPU0 1855253 UC_LOADS_RETIREDCPU1 950 UC_LOADS_RETIRED
Figure 2: tg3 v3.6 MMIO reads with pktgen/IRQ on diff CPU
gsyprf3:~# pfmon -e uc_loads_retired -k --system-wide \-- /usr/src/pktgen-testing/pktgen-single-e1000Configuring devicesRunning... ctrl^C to stop
59: 622143 0 IO-SAPIC-level eth3Result: OK: 10228738(c9990105+d238633) usec, 5000000 (64byte) 488854pps 238Mb/sec (250293248bps) errors: 81669
59: 703829 0 IO-SAPIC-level eth3CPU0 173315 UC_LOADS_RETIREDCPU1 1422 UC_LOADS_RETIRED
Figure 3: MMIO reads for e1000 v5.2.52-k4

246 • Linux Symposium 2004 • Volume One
First, memory ordering is enforced since PCIrequires strong ordering of MMIO writes. Thismeans the MMIO write will push all previousregular memory writes ahead. This is not a se-rious issue but it can make a MMIO write takelonger.
MMIO writes are short transactions (i.e., muchless than a cache-line). The PCI bus setup timeto select the device, send the target address anddata, and disconnect measurably reduces PCIbus utilization. It typically results in six ormore PCI bus cycles to send four (or eight)bytes of data. On systems which strongly or-der DMA Read Returns and MMIO Writes, thelatter will also interfere with DMA flows by in-terrupting in-flight, outbound DMA.
If the IO bridge (e.g., PCI Bus controller) near-est the CPU has a full write queue, the CPUwill stall. The bridge would normally queuethe MMIO write and then tell the CPU it’sdone. The chip designers normally make thewrite queue deep enough so the CPU neverneeds to stall. But drivers that perform manyMMIO writes (e.g., use door bells) and burstmany of MMIO writes at a time, could run intoa worst case.
The last concern, stalling MMIO reads longerthan normal, exists because of PCI orderingrules. MMIO reads and MMIO writes arestrongly ordered. E.g., if four MMIO writesare queued before a MMIO read, the read willwait until all four MMIO write transactionshave completed. So instead of say 1000 CPUcycles, the MMIO read might take more than2000 CPU cycles on current platforms.
3.2 pfmon -e uc_stores_retired
pfmon counts MMIO Writes with no sur-prises.
3.3 tg3 Memory Writes
Figure 4 shows tg3 does about 10M MMIOwrites to send 5M packets. However, wecan break the MMIO writes down into baselevel (feed packets onto transmit queue) andtg3_interrupt which handles TX (andRX) completions. Knowing which code paththe MMIO writes are in helps track down us-age in the source code.
Output in Figure 5 is after hacking thepktgen-single-tg3 script to bindpktgen kernel thread to CPU 1 wheneth1 is directing interrupts to CPU 0.The distribution between TX queue setupand interrupt handling is obvious now.CPU 0 is handling interrupts and performs3013580/(5803789 − 5201193) ≈ 5 MMIOwrites per interrupt. CPU 1 is handling TXsetup and performs5000376/5000000 ≈ 1MMIO write per packet.
Again, as noted in section 2.5, binding pktgenthread to one CPU and interrupts to another,changes the performance dramatically.
3.4 e1000 Memory Writes
Figure 6 shows 248891/(991082 −908366) ≈ 3 MMIO writes per inter-rupt and5001303/5000000 ≈ 1 MMIO writeper packet. In other words, slightly better thantg3 driver. Nonetheless, the hardware can’tpush as many packets. One difference is thee1000 driver is pushing data to a NIC behind aPCI-PCI Bridge.
Figure 7 shows a≈40% improvement inthroughput1 for pktgen without a PCI-PCIBridge in the way. Note the ratios of MMIOwrites per interrupt and MMIO writes per
1This demonstrates how the distance between the IOdevice and CPU (and memory) directly translates intolatency and performance.

Linux Symposium 2004 • Volume One • 247
gsyprf3:~# pfmon -e uc_stores_retired -k --system-wide -- /usr/src/pktgen-testing/pktgen-single-tg3Adding devices to run.Configuring devicesRunning... ctrl^C to stop
57: 4284466 0 IO-SAPIC-level eth1Result: OK: 7611689(c7610900+d789) usec, 5000000 (64byte) 656943pps 320Mb/sec(336354816bps) errors: 0
57: 5198436 0 IO-SAPIC-level eth1CPU0 9570269 UC_STORES_RETIREDCPU1 445 UC_STORES_RETIRED
Figure 4: tg3 v3.6 MMIO writes
gsyprf3:~# pfmon -e uc_stores_retired -k --system-wide -- /usr/src/pktgen-testing/pktgen-single-tg3Adding devices to run.Configuring devicesRunning... ctrl^C to stop
57: 5201193 0 IO-SAPIC-level eth1Result: OK: 5880249(c5811180+d69069) usec, 5000000 (64byte) 850340pps 415Mb/sec (435374080bps) errors: 0
57: 5803789 0 IO-SAPIC-level eth1CPU0 3013580 UC_STORES_RETIREDCPU1 5000376 UC_STORES_RETIRED
Figure 5: tg3 v3.6 MMIO writes with pktgen/IRQ split across CPUs
gsyprf3:~# pfmon -e uc_stores_retired -k --system-wide -- /usr/src/pktgen-testing/pktgen-single-e1000Running... ctrl^C to stop
59: 908366 0 IO-SAPIC-level eth3Result: OK: 10340222(c10104719+d235503) usec, 5000000 (64byte) 483558pps 236Mb/sec (247581696bps) errors: 82675
59: 991082 0 IO-SAPIC-level eth3CPU0 248891 UC_STORES_RETIREDCPU1 5001303 UC_STORES_RETIRED
Figure 6: MMIO writes for e1000 v5.2.52-k4
gsyprf3:~# pfmon -e uc_stores_retired -k --system-wide -- /usr/src/pktgen-testing/pktgen-single-e1000Running... ctrl^C to stop
71: 3 0 IO-SAPIC-level eth7Result: OK: 7491358(c7342756+d148602) usec, 5000000 (64byte) 667467pps 325Mb/sec (341743104bps) errors: 59870
71: 59907 0 IO-SAPIC-level eth7CPU0 180406 UC_STORES_RETIREDCPU1 5000939 UC_STORES_RETIRED
Figure 7: e1000 v5.2.52-k4 MMIO writes without PCI-PCI Bridge

248 • Linux Symposium 2004 • Volume One
packet are the same. I doubt the MMIOreads and MMIO writes are the limiting fac-tors. More likely DMA access to memory(and thus TX/RX descriptor rings) limits NICpacket processing.
4 Measuring Cache-line Misses
The Event Address Registers2 (EAR) can onlyrecord one event at a time. What is so interest-ing about them is that they record precise infor-mation about data cache misses. For instancefor a data cache miss, you get the:
• address of the instruction, likely a load
• address of the target data
• latency in cycles to resolve the miss
The information pinpoints the source of themiss, not the consequence (i.e., the stall).
The Data EAR (DEAR) can also tell us aboutMMIO reads via sampling. The DEAR canonly record loads that miss, not stores. Ofcourse, MMIO reads always miss because theyare uncached. This is interesting if we want totrack down which MMIO addresses are “hot.”It’s usually easier to track down usage in sourcecode knowing which MMIO address is refer-enced.
Collecting with DEAR sampling requires twoparameters be tweaked to statistically improvethe samples. One is the frequency at whichData Addresses are recorded and the other isthe threshold (how many CPU cycles latency).
Because we know the latency to L3 is about21 cycles, setting the EAR threshold to a valuehigher (e.g., 64 cycles) ensures only the load
2pfmon v3.1 is the first version to support EARand is expected to be available in August, 2004.
misses accessing main memory will be cap-tured. This is how to select which level ofcacheline misses one samples.
While high threshholds (e.g., 64 cycles) willshow us where the longest delays occur, it willnot show us the worst offenders. Doing a sec-ond run with a lower threshold (e.g., 4 cycles)shows all L1, L2, and L3 cache misses and pro-vides a much broader picture of cache utiliza-tion.
When sampling events with low threshholds,we will get saturated with events and need toreduce the number of events actually sampledto every 5000th. The appropriate value willdepend on the workload and how patient oneis. The workload needs to be run long enoughto be statistically significant and the samplingperiod needs to be high enough to not signifi-cantly perturb the workload.
4.1 tg3 Data Cache misses > 64 cycles
For the output in Figure 8, I’ve iteratively de-creased the smpl-periods until I noticed the to-tal pktgen throughput starting to drop. Fig-ure 8 output only shows the tg3 interrupt codepath sincepfmon is bound to CPU 0. Nor-mally, it would be useful to run this again withcpu-list=1 . We could then see what theTX code path and pktgen are doing.
Also, the pin-command option inthis example doesn’t do anything sincepktgen-single-tg3 directs a pktgenkernel thread bound CPU 1 to do the realwork. I’ve included the option only to makepeople aware of it.
4.2 tg3 Data Cache misses > 4 cycles
Figure 9 puts thelat64 output in Figure 8into better perspective. It shows tg3 is spendingmore time for L1 and L2 misses than L3 misses

Linux Symposium 2004 • Volume One • 249
gsyprf3:~# pfmon31 --us-c --cpu-list=0 --pin-command --resolve-addr \--smpl-module=dear-hist-itanium2 \-e data_ear_cache_lat64 --long-smpl-periods=500 \--smpl-periods-random=0xfff:10 --system-wide \-k -- /usr/src/pktgen-testing/pktgen-single-tg3
added event set 0only kernel symbols are resolved in system-wide modeAdding devices to run.Configuring devicesRunning... ctrl^C to stop
57: 7209769 0 IO-SAPIC-level eth1Result: OK: 5915877(c5845032+d70845) usec, 5000000 (64byte) 845308pps 412Mb/sec(432797696bps) errors: 0
57: 7827812 0 IO-SAPIC-level eth1# total_samples 672# instruction addr view# sorted by count# showing per per distinct value# %L2 : percentage of L1 misses that hit L2# %L3 : percentage of L1 misses that hit L3# %RAM : percentage of L1 misses that hit memory# L2 : 5 cycles load latency# L3 : 12 cycles load latency# sampling period: 500#count %self %cum %L2 %L3 %RAM instruction addr
38 5.65% 5.65% 0.00% 0.00% 100.00% 0xa000000100009141 ia64_spinlock_contention+0x21<kernel>
36 5.36% 11.01% 0.00% 0.00% 100.00% 0xa00000020003e580 tg3_interrupt[tg3]+0xe0<kernel>32 4.76% 15.77% 0.00% 0.00% 100.00% 0xa000000200034770 tg3_write_indirect_reg32[tg3]
+0x90<kernel>32 4.76% 20.54% 0.00% 0.00% 100.00% 0xa00000020003e640 tg3_interrupt[tg3]+0x1a0<kernel>30 4.46% 25.00% 0.00% 0.00% 100.00% 0xa000000200034e91 tg3_enable_ints[tg3]+0x91<kernel>29 4.32% 29.32% 0.00% 0.00% 100.00% 0xa00000020003e510 tg3_interrupt[tg3]+0x70<kernel>28 4.17% 33.48% 0.00% 0.00% 100.00% 0xa00000020003d1a0 tg3_tx[tg3]+0x2e0<kernel>27 4.02% 37.50% 0.00% 0.00% 100.00% 0xa00000020003cfa0 tg3_tx[tg3]+0xe0<kernel>24 3.57% 41.07% 0.00% 0.00% 100.00% 0xa00000020003cfd1 tg3_tx[tg3]+0x111<kernel>21 3.12% 44.20% 0.00% 0.00% 100.00% 0xa000000200034e60 tg3_enable_ints[tg3]+0x60<kernel>
.
.
.# level 0 : counts=0 avg_cycles=0.0ms 0.00%# level 1 : counts=0 avg_cycles=0.0ms 0.00%# level 2 : counts=672 avg_cycles=0.0ms 100.00%approx cost: 0.0s
Figure 8: tg3 v3.6 lat64 output

250 • Linux Symposium 2004 • Volume One
gsyprf3:~# pfmon31 --us-c --cpu-list=0 --resolve-addr --smpl-module=dear-hist-itanium2 \-e data_ear_cache_lat4 --long-smpl-periods=5000 --smpl-periods-random=0xfff:10 \--system-wide -k -- /usr/src/pktgen-testing/pktgen-single-tg3added event set 0only kernel symbols are resolved in system-wide modeAdding devices to run.Configuring devicesRunning... ctrl^C to stop
57: 8484552 0 IO-SAPIC-level eth1Result: OK: 5938001(c5866437+d71564) usec, 5000000 (64byte) 842034pps 411Mb/sec
(431121408bps) errors: 057: 9093642 0 IO-SAPIC-level eth1
# total_samples 795# instruction addr view# sorted by count# showing per per distinct value# %L2 : percentage of L1 misses that hit L2# %L3 : percentage of L1 misses that hit L3# %RAM : percentage of L1 misses that hit memory# L2 : 5 cycles load latency# L3 : 12 cycles load latency# sampling period: 5000# #count %self %cum %L2 %L3 %RAM instruction addr
95 11.95% 11.95% 0.00% 98.95% 1.05% 0xa00000020003d150 tg3_tx[tg3]+0x290<kernel>83 10.44% 22.39% 93.98% 4.82% 1.20% 0xa00000020003d030 tg3_tx[tg3]+0x170<kernel>21 2.64% 25.03% 0.00% 95.24% 4.76% 0xa0000001000180f0 ia64_handle_irq+0x170<kernel>20 2.52% 27.55% 5.00% 80.00% 15.00% 0xa00000020003d040 tg3_tx[tg3]+0x180<kernel>18 2.26% 29.81% 50.00% 11.11% 38.89% 0xa00000020003cfa0 tg3_tx[tg3]+0xe0<kernel>17 2.14% 31.95% 0.00% 0.00% 100.00% 0xa00000020003e671 tg3_interrupt[tg3]
+0x1d1<kernel>17 2.14% 34.09% 0.00% 100.00% 0.00% 0xa00000020003e700 tg3_interrupt[tg3]
+0x260<kernel>16 2.01% 36.10% 56.25% 43.75% 0.00% 0xa000000100012160 ia64_leave_kernel
+0x180<kernel>16 2.01% 38.11% 62.50% 0.00% 37.50% 0xa00000020003cf60 tg3_tx[tg3]+0xa0<kernel>15 1.89% 40.00% 86.67% 6.67% 6.67% 0xa00000020003cfd0 tg3_tx[tg3]+0x110<kernel>15 1.89% 41.89% 0.00% 0.00% 100.00% 0xa000000100016041 do_IRQ+0x1a1<kernel>15 1.89% 43.77% 0.00% 53.33% 46.67% 0xa00000020003e370 tg3_poll[tg3]+0x350<kernel>...
# level 0 : counts=226 avg_cycles=0.0ms 28.43%# level 1 : counts=264 avg_cycles=0.0ms 33.21%# level 2 : counts=305 avg_cycles=0.0ms 38.36%approx cost: 0.0s
Figure 9: tg3 v3.6 lat4 output

Linux Symposium 2004 • Volume One • 251
and in only two locations. Adding one prefetchto pull data from L3 into L2 would help for thetop offender. One needs to figure out which bitof data each recorded access refers to and de-termine how early one can prefetch that data.
We can also rule out MMIO accesses as the topculprit. tg3_interrupt+0x1d1 could bean MMIO read but it doesn’t show up in Fig-ure 8 like tg3_write_indirect_reg32does.
Note smpl-periods is 10x higher in Fig-ure 9 than in Figure 8. Collecting 10x moresamples with lat4 definitely disturbs theworkload.
5 q-tools
q-syscollect and q-view are trivial touse. An example and brief explanation for ker-nel usage follow.
Please remember most applications spend mostof the time in user space and not in the kernel.q-tools is especially good in user space.
5.1 q-syscollect
q-syscollect -c 5000 -C 5000 -t20 -k
This will collect system wide kernel data dur-ing the 20 second period. Twenty to thrity sec-onds is usually long enough to get sufficient ac-curacy3. However, if the workload generatesa very wide call graph with even distribution,one will likely need to sample for longer peri-ods to get accuracy in the±1% range. Whenin doubt, try sampling for longer periods to seeif the call-counts change significantly.
3See Page 7 of the David Mosberger’s Gelato talk[4] for a nice graph on accuracy whichonly applies tohis example.
The -c and -C set the call sample rate andcode sample rate respectively. The call sam-ple rate is used to collect function call counts.This is one of the key differences compared totraditional profiling tools: q-syscollect obtainscall-counts in a statistical fashion, just as hasbeen done traditionally for the execution-timeprofile. The code sample rate is used to collecta flat profile (CPU_CYCLESby default).
The -e option allows one to change the eventused to sample for the flat profile. The defaultis to sample CPU_CYCLES event. This pro-vides traditional execution time in the flat pro-file.
The data is stored in the current directory under.q/ directory. The next section demonstrateshowq-view displays the data.
5.2 q-view
I was running the netperf [7] TCP_RR test inthe background to another server when I col-lected the following data. As Figure 10 shows,this particular TCP_RR test isn’t costing manycycles in tg3 driver. Or, at least not ones I canmeasure.
tg3_interrupt() shows up in the flat pro-file with 0.314 seconds time associated withit. The time measurement is only possiblebecausehandle_IRQ_event() re-enablesinterrupts if the IRQ handler is not regis-tered with SA_INTERRUPT(to indicate la-tency sensitive IRQ handler).do_IRQ() andother functions in that same call graph do NOThave any time measurements because inter-rupts are disabled. As noted before, the call-graph is sampled using a different part of thePMU than the part which samples the flat pro-file.
Lastly, I’ve omitted the trailing output ofq-view which explains the fields andcolumns more completely. Read that first be-

252 • Linux Symposium 2004 • Volume One
gsyprf3:~# q-view .q/kernel-cpu0.info | moreFlat profile of CPU_CYCLES in kernel-cpu0.hist#0:
Each histogram sample counts as 200.510u seconds% time self cumul calls self/call tot/call name
68.88 13.41 13.41 215k 62.5u 62.5u default_idle2.90 0.56 13.97 431k 1.31u 1.31u finish_task_switch2.50 0.49 14.46 233k 2.09u 4.89u tg3_poll1.77 0.35 14.80 1.38M 251n 268n ipt_do_table1.61 0.31 15.12 240k 1.31u 1.31u tg3_interrupt1.51 0.29 15.41 240k 1.22u 5.95u net_rx_action...
Call-graph table:index %time self children called name
<spontaneous>[176] 69.4 30.5m 13.4 - cpu_idle
29.5m 0.285 231k/457k schedule [164]10.0m 0.00 244k/244k check_pgt_cache [178]
13.4 0.00 215k/215k default_idle [177]----------------------------------------------------
.
.
.----------------------------------------------------
0.293 1.14 240k __do_softirq [40][56] 7.4 0.293 1.14 240k net_rx_action
0.487 0.649 233k/233k tg3_poll [57]----------------------------------------------------
0.487 0.649 233k net_rx_action [56][57] 5.9 0.487 0.649 233k tg3_poll
- 0.00 229k/229k tg3_enable_ints [133]97.7m 0.552 225k/225k tg3_rx [61]
- 0.00 227k/227k tg3_tx [58]----------------------------------------------------
.
.
.----------------------------------------------------
- 1.88 348k ia64_leave_kernel [10][11] 9.7 - 1.88 348k ia64_handle_irq
- 1.52 239k/240k do_softirq [39]- 0.367 356k/356k do_IRQ [12]
----------------------------------------------------...
Figure 10:q-view output for TCP_RR over tg3 v3.6

Linux Symposium 2004 • Volume One • 253
fore going through the rest of the output.
6 Conclusion
6.1 More pfmon examples
CPU L2 cache misses in one kernel functionpfmon --verb -k \--irange=sba_alloc_range \-el2_misses --system-wide \--session-timeout=10Show all L2 cache misses insba_alloc_range . This is interestingsince sba_alloc_range() walksa bitmap to look for “free” resources.One can instead specify-el3_missessince L3 cache misses are much moreexpensive.
CPU 1 memory loadspfmon --us-c \--cpu-list=1 \-e loads_retired \-k --system-wide \-- /tmp/pktgen-single Onlycount memory loads on CPU 1. This isuseful for when we can bind the interruptto CPU 1 and the workload to a differentCPU. This lets us separate interrupt pathfrom base level code, i.e., when is theload happening (before or after DMAoccurred) and which code path shouldone be looking more closely at.
List EAR events supported pfmon -learList all EAR types supported bypfmon 4.
More info on Event pfmon -i DATA_EAR_
TLB_ALL pfmon can provide more infoon particular events it supports.
4EAR isn’t supported untilpfmon v3.1
6.2 And thanks to. . .
Special thanks to Stephane Eranian [2] for ded-icating so much time to the perfmon kerneldriver and associated tools. People might thinkthe PMU does it all—but only with a lot of SWdriving it. His review of this paper caught somegood bloopers. This talk only happened be-cause I sit across the aisle from him and couldpester him regularly.
Thanks to David Mosberger[5] for putting to-gether q-tools and making it so trivial to use.
In addition, in no particular order:Christophe de Dinechin, Bjorn Helgaas,Matthew Wilcox, Andrew Patterson, Al Stone,Asit Mallick, and James Bottomley for review-ing this document or providing technical guid-ance.
Thanks also to the OLS staff for making thisevent happen every year.
My apologies if I omitted other contributors.
References
[1] perfmon homepage,http://www.hpl.hp.com/research/linux/perfmon/
[2] Stephane Eranian,http://www.gelato.org/community/gelato_meeting.php?id=CU2004#talk22
[3] The IA-32 Intel(R) ArchitectureSoftware Developer’s Manuals,http://www.intel.com/design/pentium4/manuals/253668.htm
[4] q-tools homepage,http://www.hpl.hp.com/

254 • Linux Symposium 2004 • Volume One
research/linux/q-tools/
[5] David Mosberger,http://www.gelato.org/community/gelato_meeting.php?id=CU2004#talk19
[6] qprof homepage,http://www.hpl.hp.com/research/linux/qprof/
[7] netperf homepage,http://www.netperf.org/

Carrier Grade Server Features in the Linux KernelTowards Linux-based Telecom Plarforms
Ibrahim HaddadEricsson Research
Abstract
Traditionally, communications and data ser-vice networks were built on proprietary plat-forms that had to meet very specific availabil-ity, reliability, performance, and service re-sponse time requirements. Today, communica-tion service providers are challenged to meettheir needs cost-effectively for new architec-tures, new services, and increased bandwidth,with highly available, scalable, secure, andreliable systems that have predictable perfor-mance and that are easy to maintain and up-grade. This paper presents the technologicaltrend of migrating from proprietary to openplatforms based on software and hardwarebuilding blocks. It also focuses on the ongo-ing work by the Carrier Grade Linux workinggroup at the Open Source Development Labs,examines the CGL architecture, the require-ments from the latest specification release, andpresents some of the needed kernel featuresthat are not currently supported by Linux suchas a Linux cluster communication mechanism,a low-level kernel mechanism for improved re-liability and soft-realtime performance, sup-port for multi-FIB, and support for additionalsecurity mechanisms.
1 Open platforms
The demand for rich media and enhancedcommunication services is rapidly leading to
significant changes in the communication in-dustry, such as the convergence of data andvoice technologies. The transition to packet-based, converged, multi-service IP networksrequire a carrier grade infrastructure based oninteroperable hardware and software buildingblocks, management middleware, and appli-cations, implemented with standard interfaces.The communication industry is witnessing atechnology trend moving away from propri-etary systems toward open and standardizedsystems that are built using modular and flex-ible hardware and software (operating systemand middleware) common off the shelf com-ponents. The trend is to proceed forward de-livering next generation and multimedia com-munication services, using open standard car-rier grade platforms. This trend is motivatedby the expectations that open platforms are go-ing to reduce the cost and risk of developingand delivering rich communications services.Also, they will enable faster time to market andensure portability and interoperability betweenvarious components from different providers.One frequently asked question is: ’How can wemeet tomorrow’s requirements using existinginfrastructures and technologies?’. Proprietaryplatforms are closed systems, expensive to de-velop, and often lack support of the currentand upcoming standards. Using such closedplatforms to meet tomorrow’s requirements fornew architectures and services is almost impos-sible. A uniform open software environmentwith the characteristics demanded by telecom

256 • Linux Symposium 2004 • Volume One
applications, combined with commercial off-the-shelf software and hardware componentsis a necessary part of these new architectures.The following key industry consortia are defin-ing hardware and software high availabilityspecifications that are directly related to tele-com platforms:
1. The PCI Industrial Computer Manufactur-ers Group [1] (PICMG) defines standardsfor high availability (HA) hardware.
2. The Open Source Development Labs [2](OSDL) Carrier Grade Linux [3] (CGL)working group was established in Jan-uary 2002 with the goal of enhancing theLinux operating system, to achieve anOpen Source platform that is highly avail-able, secure, scalable and easily main-tained, suitable for carrier grade systems.
3. The Service Availability Forum [4] (SAForum) defines the interfaces of HA mid-dleware and focusing on APIs for hard-ware platform management and for appli-cation failover in the application API. SAcompliant middleware will provide ser-vices to an application that needs to be HAin a portable way.
Figure 1: From Proprietary to Open Solutions
The operating system is a core component insuch architectures. In the remaining of this pa-per, we will be focusing on CGL, its architec-ture and specifications.
2 The term Carrier Grade
In this paper, we refer to the term Carrier Gradeon many occasions. Carrier grade is a termfor public network telecommunications prod-ucts that require a reliability percentage up to 5or 6 nines of uptime.
• 5 nines refers to 99.999% of uptime peryear (i.e., 5 minutes of downtime peryear). This level of availability is usuallyassociated with Carrier Grade servers.
• 6 nines refers to 99.9999% of uptime peryear (i.e., 30 seconds of downtime peryear). This level of availability is usuallyassociated with Carrier Grade switches.
3 Linux versus proprietary operat-ing systems
This section describes briefly the motivatingreasons in favor of using Linux on CarrierGrade systems, versus continuing with propri-etary operating systems. These motivations in-clude:
• Cost: Linux is available free of charge inthe form of a downloadable package fromthe Internet.
• Source code availability: With Linux, yougain full access to the source code allow-ing you to tailor the kernel to your needs.
• Open development process (Figure 2):The development process of the kernel isopen to anyone to participate and con-tribute. The process is based on the con-cept of "release early, release often."
• Peer review and testing resources: Withaccess to the source code, people using a

Linux Symposium 2004 • Volume One • 257
wide variety of platform, operating sys-tems, and compiler combinations; cancompile, link, and run the code on theirsystems to test for portability, compatibil-ity and bugs.
• Vendor independent: With Linux, you nolonger have to be locked into a specificvendor. Linux is supported on multipleplatforms.
• High innovation rate: New features areusually implemented on Linux before theyare available on commercial or propri-etary systems.
Figure 2: Open development process of theLinux kernel
Other contributing factors include Linux’ sup-port for a broad range of processors andperipherals, commercial support availability,high performance networking, and the provenrecord of being a stable, and reliable serverplatform.
4 Carrier Grade Linux
The Linux kernel is missing several featuresthat are needed in a telecom environment. Itis not adapted to meet telecom requirementsin various areas such as reliability, security,and scalability. To help the advancement of
Linux in the telecom space, OSDL establishedthe CGL working group. The group specifiesand helps implement an Open Source platformtargeted for the communication industry thatis highly available, secure, scalable and easilymaintained. The CGL working group is com-posed of several members from network equip-ment providers, system integrators, platformproviders, and Linux distributors. They allcontribute to the requirement definition of Car-rier Grade Linux, help Open Source projectsto meet these requirements, and in some casesstart new Open Source projects. Many ofthe CGL members companies have contributedpieces of technologies to Open Source in orderto make the Linux Kernel a more viable optionfor telecom platforms. For instance, the OpenSystems Lab [5] from Ericsson Research hascontributed three key technologies: the Trans-parent IPC [6], the Asynchronous Event Mech-anism [7], and the Distributed Security Infras-tructure [8]. There are already Linux distri-butions, MontaVista [9] for instance, that areproviding CGL distribution based on the CGLrequirement definition. Many companies arealso either deploying CGL, or at least evaluat-ing and experimenting with it.
Consequently, CGL activities are giving muchmomentum for Linux in the telecom spaceallowing it to be a viable option to propri-etary operating system. Member companies ofCGL are releasing code to Open Source andare making some of their proprietary technolo-gies open, which leads to going forward fromclosed platforms to open platforms that useCGL Linux.
5 Target CGL applications
The CGL Working Group has identified threemain categories of application areas into whichthey expect the majority of applications imple-mented on CGL platforms to fall. These appli-

258 • Linux Symposium 2004 • Volume One
cation areas are gateways, signaling, and man-agement servers.
• Gateways are bridges between two dif-ferent technologies or administration do-mains. For example, a media gateway per-forms the critical function of convertingvoice messages from a native telecommu-nications time-division-multiplexed net-work, to an Internet protocol packet-switched network. A gateway processes alarge number of small messages receivedand transmitted over a large number ofphysical interfaces. Gateways performin a timely manner very close to hardreal-time. They are implemented on ded-icated platforms with replicated (ratherthan clustered) systems used for redun-dancy.
• Signaling servers handle call control, ses-sion control, and radio recourse control.A signaling server handles the routing andmaintains the status of calls over the net-work. It takes the request of user agentswho want to connect to other user agentsand routes it to the appropriate signaling.Signaling servers require soft real time re-sponse capabilities less than 80 millisec-onds, and may manage tens of thousandsof simultaneous connections. A signalingserver application is context switch andmemory intensive due to requirements forquick switching and a capacity to managelarge numbers of connections.
• Management servers handle traditionalnetwork management operations, as wellas service and customer management.These servers provide services such as: aHome Location Register and Visitor Lo-cation Register (for wireless networks)or customer information (such as per-sonal preferences including features the
customer is authorized to use). Typi-cally, management applications are dataand communication intensive. Their re-sponse time requirements are less strin-gent by several orders of magnitude, com-pared to those of signaling and gatewayapplications.
6 Overview of the CGL workinggroup
The CGL working group has the vision thatnext-generation and multimedia communica-tion services can be delivered using Linuxbased open standards platforms for carriergrade infrastructure equipment. To achieve thisvision, the working group has setup a strat-egy to define the requirements and architecturefor the Carrier Grade Linux platform, developa roadmap for the platform, and promote thedevelopment of a stable platform upon whichcommercial components and services can bedeployed.
In the course of achieving this strategy, theOSDL CGL working group, is creating the re-quirement definitions, and identifying existingOpen Source projects that support the roadmapto implement the required components and in-terfaces of the platform. When an Open Sourceproject does not exist to support a certain re-quirement, OSDL CGL is launching (or sup-port the launch of) new Open Source projectsto implement missing components and inter-faces of the platform.
The CGL working group consists of three dis-tinct sub-groups that work together. These sub-groups are: specification, proof-of-concept,and validation. Responsibilities of each sub-group are as follows:
1. Specifications: The specifications sub-group is responsible for defining a set of

Linux Symposium 2004 • Volume One • 259
requirements that lead to enhancements inthe Linux kernel, that are useful for car-rier grade implementations and applica-tions. The group collects, categorizes, andprioritizes the requirements from partici-pants to allow reasonable work to proceedon implementations. The group also in-teracts with other standard defining bod-ies, open source communities, develop-ers and distributions to ensure that the re-quirements identify useful enhancementsin such a way, that they can be adoptedinto the base Linux kernel.
2. Proof-of-Concept: This sub-group gener-ates documents covering the design, fea-tures, and technology relevant to CGL. Itdrives the implementation and integrationof core Carrier Grade enhancements toLinux as identified and prioritized by therequirement document. The group is alsoresponsible for ensuring the integrated en-hancements pass, the CGL validation testsuite and for establishing and leading anopen source umbrella project to coordi-nate implementation and integration ac-tivities for CGL enhancements.
3. Validation: This sub-group defines stan-dard test environments for developing val-idation suites. It is responsible for co-ordinating the development of validationsuites, to ensure that all of the CGL re-quirements are covered. This group isalso responsible for the development ofan Open Source project CGL validationsuite.
7 CGL architecture
Figure 3 presents the scope of the CGL Work-ing Group, which covers two areas:
• Carrier Grade Linux: Various require-ments such as availability and scalability
Figure 3: CGL architecture and scope
are related to the CGL enhancements tothe operating system. Enhancements mayalso be made to hardware interfaces, inter-faces to the user level or application codeand interfaces to development and debug-ging tools. In some cases, to access thekernel services, user level library changeswill be needed.
• Software Development Tools: These toolswill include debuggers and analyzers.
On October 9, 2003, OSDL announcedthe availability of the OSDL CarrierGrade Linux Requirements Definition,Version 2.0 (CGL 2.0). This latest re-quirement definition for next-generationcarrier grade Linux offers major advancesin security, high availability, and cluster-ing.
8 CGL requirements
The requirement definition document of CGLversion 2.0 introduced new and enhanced fea-tures to support Linux as a carrier grade plat-form. The CGL requirement definition dividesthe requirements in main categories describedbriefly below:

260 • Linux Symposium 2004 • Volume One
8.1 Clustering
These requirements support the use of multi-ple carrier server systems to provide higher lev-els of service availability through redundant re-sources and recovery capabilities, and to pro-vide a horizontally scaled environment sup-porting increased throughput.
8.2 Security
The security requirements are aimed at main-taining a certain level of security while not en-dangering the goals of high availability, perfor-mance, and scalability. The requirements sup-port the use of additional security mechanismsto protect the systems against attacks from boththe Internet and intranets, and provide specialmechanisms at kernel level to be used by tele-com applications.
8.3 Standards
CGL specifies standards that are required forcompliance for carrier grade server systems.Examples of these standards include:
• Linux Standard Base
• POSIX Timer Interface
• POSIX Signal Interface
• POSIX Message Queue Interface
• POSIX Semaphore Interface
• IPv6 RFCs compliance
• IPsecv6 RFCs compliance
• MIPv6 RFCs compliance
• SNMP support
• POSIX threads
8.4 Platform
OSDL CGL specifies requirements that sup-port interactions with the hardware platformsmaking up carrier server systems. Platform ca-pabilities are not tied to a particular vendor’simplementation. Examples of the platform re-quirements include:
• Hot insert: supports hot-swap insertion ofhardware components
• Hot remove: supports hot-swap removalof hardware components
• Remote boot support: supports remotebooting functionality
• Boot cycle detection: supports detectingreboot cycles due to recurring failures.If the system experiences a problem thatcauses it to reboot repeatedly, the systemwill go offline. This is to prevent addi-tional difficulties from occurring as a re-sult of the repeated reboots
• Diskless systems: Provide support fordiskless systems loading their ker-nel/application over the network
• Support remote booting across commonLAN and WAN communication media
8.5 Availability
The availability requirements support height-ened availability of carrier server systems, suchas improving the robustness of software com-ponents or by supporting recovery from failureof hardware or software. Examples of these re-quirements include:
• RAID 1: support for RAID 1 offers mir-roring to provide duplicate sets of all dataon separate hard disks

Linux Symposium 2004 • Volume One • 261
• Watchdog timer interface: support forwatchdog timers to perform certain speci-fied operations when timeouts occur
• Support for Disk and volume manage-ment: to allow grouping of disks into vol-umes
• Ethernet link aggregation and linkfailover: support bonding of multiple NICfor bandwidth aggregation and provideautomatic failover of IP addresses fromone interface to another
• Support for application heartbeat moni-tor: monitor applications availability andfunctionality.
8.6 Serviceability
The serviceability requirements support servic-ing and managing hardware and software oncarrier server systems. These are wide-rangingset requirements, put together, help support theavailability of applications and the operatingsystem. Examples of these requirements in-clude:
• Support for producing and storing kerneldumps
• Support for dynamic debug to allow dy-namically the insertion of software instru-mentation into a running system in thekernel or applications
• Support for platform signal handler en-abling infrastructures to allow interruptsgenerated by hardware errors to be loggedusing the event logging mechanism
• Support for remote access to event log in-formation
8.7 Performance
OSDL CGL specifies the requirements thatsupport performance levels necessary for theenvironments expected to be encountered bycarrier server systems. Examples of these re-quirements include:
• Support for application (pre) loading.
• Support for soft real time performancethrough configuring the scheduler to pro-vide soft real time support with latency of10 ms.
• Support Kernel preemption.
• Raid 0 support: RAID Level 0 pro-vides "disk striping" support to enhanceperformance for request-rate-intensive ortransfer-rate-intensive environments
8.8 Scalability
These requirements support vertical and hori-zontal scaling of carrier server systems such asthe addition of hardware resources to result inacceptable increases in capacity.
8.9 Tools
The tools requirements provide capabilities tofacilitate diagnosis. Examples of these require-ments include:
• Support the usage of a kernel debugger.
• Support for Kernel dump analysis.
• Support for debugging multi-threadedprograms

262 • Linux Symposium 2004 • Volume One
9 CGL 3.0
The work on the next version of the OSDLCGL requirements, version 3.0, started in Jan-uary 2004 with focus on advanced require-ment areas such as manageability, serviceabil-ity, tools, security, standards, performance,hardware, clustering and availability. With thesuccess of CGL’s first two requirement docu-ments, OSDL CGL working group anticipatesthat their third version will be quite beneficialto the Carrier Grade ecosystem. Official re-lease of the CGL requirement document Ver-sion 3.0 is expected in October 2004.
10 CGL implementations
There are several enhancements to the LinuxKernel that are required by the communicationindustry, to help adopt Linux on their carriergrade platforms, and support telecom applica-tions. These enhancements (Figure 4) fall intothe following categories availability, security,serviceability, performance, scalability, relia-bility, standards, and clustering.
Figure 4: CGL enhancements areas
The implementations providing theses en-hancements are Open Source projects andplanned for integration with the Linux ker-nel when the implementations are mature, andready for merging with the kernel code. In
some cases, bringing some projects into matu-rity levels takes a considerable amount of timebefore being able to request its integration intothe Linux kernel. Nevertheless, some of the en-hancements are targeted for inclusion in kernelversion 2.7. Other enhancements will follow inlater kernel releases. Meanwhile, all enhance-ments, in the form of packages, kernel modulesand patches, are available from their respectiveproject web sites. The CGL 2.0 requirementsare in-line with the Linux development com-munity. The purpose of this project is to form acatalyst to capture common requirements fromend-users for a CGL distribution. With a com-mon set of requirements from the major Net-work Equipment Providers, developers can bemuch more productive and efficient within de-velopment projects. Many individuals withinthe CGL initiative are also active participantsand contributors in the Open Source develop-ment community.
11 Examples of needed features inthe Linux Kernel
In this section, we provide some examplesof missing features and mechanisms from theLinux kernel that are necessary in a telecomenvironment.
11.1 Transparent Inter-Process and Inter-Processor Communication Protocol forLinux Clusters
Today’s telecommunication environments areincreasingly adopting clustered servers to gainbenefits in performance, availability, and scal-ability. The resulting benefits of a clusterare greater or more cost-efficient than what asingle server can provide. Furthermore, thetelecommunications industry interest in clus-tering originates from the fact that clustersaddress carrier grade characteristics such asguaranteed service availability, reliability and

Linux Symposium 2004 • Volume One • 263
scaled performance, using cost-effective hard-ware and software. Without being absoluteabout these requirements, they can be dividedin these three categories: short failure detectionand failure recovery, guaranteed availability ofservice, and short response times. The mostwidely adopted clustering technique is use ofmultiple interconnected loosely coupled nodesto create a single highly available system.
One missing feature from the Linux kernel inthis area is a reliable, efficient, and transpar-ent inter-process and inter-processor commu-nication protocol. Transparent Inter ProcessCommunication (TIPC) [6] is a suitable OpenSource implementation that fills this gap andprovides an efficient cluster communicationprotocol. This leverages the particular condi-tions present within loosely coupled clusters.It runs on Linux and is provided as a portablesource code package implementing a loadablekernel module.
TIPC is unique because there seems to be noother protocol providing a comparable com-bination of versatility and performance. Itincludes some original innovations such asthe functional addressing, the topology sub-scription services, and the reactive connec-tion concept. Other important TIPC fea-tures include full location transparency, sup-port for lightweight connections, reliable mul-ticast, signaling link protocol, topology sub-scription services and more.
TIPC should be regarded as a useful toolboxfor anyone wanting to develop or use CarrierGrade or Highly Available Linux clusters. Itprovides the necessary infrastructure for clus-ter, network and software management func-tionality, as well as a good support for de-signing site-independent, scalable, distributed,high-availability and high-performance appli-cations.
It is also worthwhile to mention that the
ForCES (Forwarding and Control ElementWG) [11] working group within IETF hasagreed that their router internal protocol (theForCES protocol) must be possible to carryover different types of transport protocols.There is consensus on that TCP is the pro-tocol to be used when ForCES messages aretransported over the Internet, while TIPC isthe protocol to be used in closed environments(LANs), where special characteristics such ashigh performance and multicast support is de-sirable. Other protocols may also be added asoptions.
TIPC is a contribution from Ericsson [5] tothe Open Source community. TIPC was an-nounced on LKML on June 28, 2004; it is li-censed under a dual GPL and BSD license.
11.2 IPv4, IPv6, MIPv6 forwarding tables fastaccess and compact memory with multi-ple FIB support
Routers are core elements of modern telecomnetworks. They propagate and direct billionof data packets from their source to their des-tination using air transport devices or throughhigh-speed links. They must operate as fast asthe medium in order to deliver the best qual-ity of service and have a negligible effect oncommunications. To give some figures, it iscommon for routers to manage between 10.000to 500.000 routes. In these situations, goodperformance is achievable by handling around2000 routes/sec. The actual implementation ofthe IP stack in Linux works fine for home orsmall business routers. However, with the highexpectation of telecom operators and the newcapabilities of telecom hardware, it appears asbarely possible to use Linux as an efficientforwarding and routing element of a high-endrouter for large network (core/border/accessrouter) or a high-end server with routing capa-bilities.

264 • Linux Symposium 2004 • Volume One
One problem with the networking stack inLinux is the lack of support for multipleforward-ing information bases (multi-FIB) with overlapping interface’s IP address, and thelack of appropriate interfaces for addressingFIB. Another problem with the curren t imple-mentation is the limited scalability of the rout-ing table.
The solution to these problems is to providesupport for multi-FIB with overlapping IP ad-dress. As such, we can have on differe ntVLAN or different physical interfaces, inde-pendent network in the same Linux box. Forexample, we can have two HTTP servers serv-ing two different networks with potentially thesame IP address. One HTTP server will servethe network/FIB 10, and the othe r HTTPserver will serves the network/FIB 20. The ad-vantage gained is to have one Linux box serv-ing two different customers usi ng the same IPaddress. ISPs adopt this approach by provid-ing services for multiple customers sharing thesame server (server pa rtitioning), instead ofusing a server per customer.
The way to achieve this is to have an ID (anidentifier that identifies the customer or user ofthe service) to completely separ ate the rout-ing table in memory. Two approaches exist:the first is to have a separate routing tables,each routing table is looked up by their ID andwithin tha t table the lookup is done one theprefix. The second approach is to have one ta-ble, and the lookup is done on the combinedkey = prefix + ID.
A different kind of problem arises when we arenot able to predict access time, with the chain-ing in the hash table of the routi ng cache (andFIB). This problem is of particular inter-est inan environment that requires predictable per-formance.
Another aspect of the problem is that the routecache and the routing table are not kept syn-
chronized most of the time (path MTU, justto name one). The route cache flush is exe-cuted regularly; therefore, any updates on thecache are lost. For example, if you have a rout-ing cache flush, you have to rebuild every routethat you are currently talking to, by going forevery route in the hash/try table and rebuildingthe information. First, you have to lookup inthe routing cache, and if you have a miss, thenyou need to go in the hash/try table. This pro-cess is very slow and not predictable since thehash/try table is implemented wi th linked listand there is high potential for collisions when alarge number of routes are present. This designis suitable fo r a home PC with a few routes, butit is not scalable for a large server.
To support the various routing requirementsof server nodes operating in high perfor-mance and mission critical envrionments,Linux should support the following:
• Implementation of multi-FIB using tree(radix, patricia, etc.): It is very impor-tant to have predictable performance in in-sert/delete/lookup from 10.000 to 500.000routes. In addition, it is favourable to havethe same data structure for both IPv4 andIPv6.
• Socket and ioctl interfaces for addressingmulti-FIB.
• Multi-FIB support for neighbors (arp).
Providing these implementations in Linux willaffect a large part of net/core, net/ipv4 andnet/ipv6; these subsystems (mostly networklayer) will need to be re-written. Other areaswill have minimal impact at the source codelevel, mostly at the transport layer (socket,TCP, UDP, RAW, NAT, IPIP, IGMP, etc.).
As for the availability of an Open Sourceproject that can provide these functionalities,

Linux Symposium 2004 • Volume One • 265
there exists a project called "Linux VirtualRouting and Forwarding" [12]. This projectaims to implement a flexible and scalablemechanism for providing multiple routing in-stances within the Linux kernel. The projecthas some potential in providing the neededfunctionalities, however no progress has beenmade since 2002 and the project seems to beinactive.
11.3 Run-time Authenticity Verification for Bi-naries
Linux has generally been considered immuneto the spread of viruses, backdoors and Tro-jan programs on the Internet. However, withthe increasing popularity of Linux as a desk-top platform, the risk of seeing viruses or Tro-jans developed for this platform are rapidlygrowing. To alleviate this problem, the sys-tem should prevent on run time the execu-tion of un-trusted software. One solution isto digitally sign the trusted binaries and havethe system check the digital signature of bina-ries before running them. Therefore, untrusted(not signed) binaries are denied the execution.This can improve the security of the systemby avoiding a wide range of malicious bina-ries like viruses, worms, Trojan programs andbackdoors from running on the system.
DigSig [13] is a Linux kernel module thatchecks the signature of a binary before runningit. It inserts digital signatures inside the ELFbinary and verifies this signature before load-ing the binary. It is based on the Linux SecurityModule hooks (LSM has been integrated withthe Linux kernel since 2.5.X and higher).
Typically, in this approach, vendors do not signbinaries; the control of the system remains withthe local administrator. The responsible ad-ministrator is to sign all binaries they trust withtheir private key. Therefore, DigSig guaranteestwo things: (1) if you signed a binary, nobody
else other than yourself can modify that binarywithout being detected. (2) Nobody can run abinary which is not signed or badly signed.
There has already been several initiatives inthis domain, such as Tripwire [14], BSign [15],Cryptomark [16], but we believe the DigSigproject is the first to be both easily accessible toall (available on SourceForge, under the GPLlicense) and to operate at kernel level on runtime. The run time is very important for Car-rier Grade Linux as this takes into account thehigh availability aspects of the system.
The DigSig approach has been using exist-ing solutions like GnuPG [17] and BSign (aDebian package) rather than reinventing thewheel. However, in order to reduce the over-head in the kernel, the DigSig project only tookthe minimum code necessary from GnuPG.This helped much to reduce the amount of codeimported to the kernel in source code of theoriginal (only 1/10 of the original GnuPG 1.2.2source code has been imported to the kernelmodule).
DigSig is a contribution from Ericsson [5] tothe Open Source community. It was releasedunder the GPL license and it is available from[8].
DigSig has been announced on LKML [18] butit not yet integrated in the Linux Kernel.
11.4 Efficient Low-Level Asynchronous EventMechanism
Carrier grade systems must provide a 5-ninesavailability, a maximum of five minutes peryear of downtime, which includes hardware,operating system, software upgrade and main-tenance. Operating systems for such systemsmust ensure that they can deliver a high re-sponse rate with minimum downtime. In ad-dition, carrier-grade systems must take intoaccount such characteristics such as scalabil-

266 • Linux Symposium 2004 • Volume One
ity, high availability and performance. In car-rier grade systems, thousands of requests mustbe handled concurrently without affecting theoverall system’s performance, even under ex-tremely high loads. Subscribers can expectsome latency time when issuing a request, butthey are not willing to accept an unboundedresponse time. Such transactions are not han-dled instantaneously for many reasons, and itcan take some milliseconds or seconds to re-ply. Waiting for an answer reduces applica-tions abilities to handle other transactions.
Many different solutions have been envisagedto improve Linux’s capabilities in this area us-ing different types of software organization,such as multithreaded architectures, imple-menting efficient POSIX interfaces, or improv-ing the scalability of existing kernel routines.
One possible solution that is adequate for car-rier grade servers is the Asynchronous EventMechanism (AEM), which provides asyn-chronous execution of processes in the Linuxkernel. AEM implements a native supportfor asynchronous events in the Linux kerneland aims to bring carrier-grade characteristicsto Linux in areas of scalability and soft real-time responsiveness. In addition, AEM offersevent-based development framework, scalabil-ity, flexibility, and extensibility.
Ericsson [5] released AEM to Open Source inFebruary 2003 under the GPL license. AEMwas announced on the Linux Kernel MailingList (LKML) [20], and received feedback thatresulted in some changes to the design and im-plementation. AEM is not yet integrated withthe Linux kernel.
12 Conclusion
There are many challenges accompanying themigration from proprietary to open platforms.The main challenge remains to be the availabil-
ity of the various kernel features and mecha-nisms needed for telecom platforms and inte-grating these features in the Linux kernel.
References
[1] PCI Industrial Computer ManufacturersGroup,http://www.picmg.org
[2] Open Source Development Labs,http://www.osdl.org
[3] Carrier Grade Linux,http://osdl.org/lab_activities
[4] Service Availability Forum,http://www.saforum.org
[5] Open System Lab,http://www.linux.ericsson.ca
[6] Transparent IPC,http://tipc.sf.net
[7] Asynchronous Event Mechanism,http://aem.sf.net
[8] Distributed Security Infrastructure,http://disec.sf.net
[9] MontaVista Carrier Grade Edition,http://www.mvista.com/cge
[10] Make Clustering Easy with TIPC,LinuxWorld Magazine, April 2004
[11] IETF ForCES working group,http://www.sstanamera.com/~forces
[12] Linux Virtual Routing and Forwardingproject,http://linux-vrf.sf.net
[13] Stop Malicious Code Execution atKernel Level, LinuxWorld Magazine,January 2004

Linux Symposium 2004 • Volume One • 267
[14] Tripwire,http://www.tripwire.com
[15] Bsign,http://packages.debian.org/bsign
[16] Cryptomark,http://immunix.org/cryptomark.html
[17] GnuPG,http://www.gnupg.org
[18] DigSig announcement on LKML,http://lwn.net/Articles/51007
[19] An Event Mechanism for Linux, LinuxJournal, July 2003
[20] AEM announcement on LKML,http://lwn.net/Articles/45633
Acknowledgments
Thank you to Ludovic Beliveau, MathieuGiguere, Magnus Karlson, Jon Maloy, MatsNaslund, Makan Pourzandi, and FredericRossi, for their valuable contributions and re-views.

268 • Linux Symposium 2004 • Volume One

Demands, Solutions, and Improvements for LinuxFilesystem Security
Michael Austin HalcrowInternational Business Machines, Inc.
Abstract
Securing file resources under Linux is a teameffort. No one library, application, or kernelfeature can stand alone in providing robust se-curity. Current Linux access control mecha-nisms work in concert to provide a certain levelof security, but they depend upon the integrityof the machine itself to protect that data. Oncethe data leaves that machine, or if the machineitself is physically compromised, those accesscontrol mechanisms can no longer protect thedata in the filesystem. At that point, data pri-vacy must be enforced via encryption.
As Linux makes inroads in the desktop market,the need for transparent and effective data en-cryption increases. To be practically deploy-able, the encryption/decryption process mustbe secure, unobtrusive, consistent, flexible, re-liable, and efficient. Most encryption mecha-nisms that run under Linux today fail in oneor more of these categories. In this paper, wediscuss solutions to many of these issues viathe integration of encryption into the Linuxfilesystem. This will provide access control en-forcement on data that is not necessarily un-der the control of the operating environment.We also explore how stackable filesystems, Ex-tended Attributes, PAM, GnuPG web-of-trust,supporting libraries, and applications (such asGNOME/KDE) can all be orchestrated to pro-vide robust encryption-based access controlover filesystem content.
1 Development Efforts
This paper is motivated by an effort on the partof the IBM Linux Technology Center to en-hance Linux filesystem security through bet-ter integration of encryption technology. Theauthor of this paper is working together withthe external community and several membersof the LTC in the design and development ofa transparent cryptographic filesystem layer inthe Linux kernel. The “we” in this paper refersto immediate members of the author’s devel-opment team who are working together on thisproject, although many others outside that de-velopment team have thus far had a significantpart in this development effort.
2 The Filesystem Security
2.1 Threat Model
Computer users tend to be overly concernedabout protecting their credit card numbers frombeing sniffed as they are transmitted over theInternet. At the same time, many do not thinktwice when sending equally sensitive informa-tion in the clear via an email message. Athief who steals a removable device, laptop, orserver can also read the confidential files onthose devices if they are left unprotected. Nev-ertheless, far too many users neglect to take thenecessary steps to protect their files from suchan event. Your liability limit for unauthorized

270 • Linux Symposium 2004 • Volume One
charges to your credit card is $50 (and mostcredit card companies waive that liability forvictims of fraud); on the other hand, confiden-tiality cannot be restored once lost.
Today, we see countless examples of neglectto use encryption to protect the integrity andthe confidentiality of sensitive data. Thosewho are trusted with sensitive information rou-tinely send that information as unencryptedemail attachments. They also store that infor-mation in clear text on disks, USB keychaindrives, backup tapes, and other removable me-dia. GnuPG[7] and OpenSSL[8] provide all theencryption tools necessary to protect this infor-mation, but these tools are not used nearly asoften as they ought to be.
If required to go through tedious encryption ordecryption steps every time they need to workwith a file or share it, people will select inse-cure passwords, transmit passwords in an inse-cure manner, fail to consider or use public keyencryption options, or simply stop encryptingtheir files altogether. If security is overly ob-structive, people will remove it, work aroundit, or misuse it (thus rendering it less effective).As Linux gains adoption in the desktop market,we need integrated file integrity and confiden-tiality that is seamless, transparent, easy to use,and effective.
2.2 Integration of File Encryption into theFilesystem
Several solutions exist that solve separatepieces of the problem. In one example high-lighting transparency, employees within an or-ganization that uses IBM™ Lotus Notes™ [9]for its email will not even notice the complexPKI or the encryption process that is integratedinto the product. Encryption and decryptionof sensitive email messages is seamless to theend user; it involves checking an “Encrypt”box, specifying a recipient, and sending the
message. This effectively addresses a signifi-cant file in-transit confidentiality problem. Ifthe local replicated mailbox database is alsoencrypted, then it also addresses confidential-ity on the local storage device, but the protec-tion is lost once the data leaves the domain ofNotes (for example, if an attached file is savedto disk). The process must be seamlessly in-tegrated intoall relevant aspects of the user’soperating environment.
In Section 4, we discuss filesystem securityin general under Linux, with an emphasison confidentiality and integrity enforcementvia cryptographic technologies. In Section6, we propose a mechanism to integrate en-cryption of files at the filesystem level, in-cluding integration of GnuPG[7] web-of-trust,PAM[10], a stackable filesystem model[2], Ex-tended Attributes[6], and libraries and applica-tions, in order to make the entire process astransparent as possible to the end user.
3 A Team Effort
Filesystem security encompasses more thanjust the filesystem itself. It is a team effort,involving the kernel, the shells, the login pro-cesses, the filesystems, the applications, the ad-ministrators, and the users. When we speak of“filesystem security,” we refer to the securityof the files in a filesystem, no matter what endsup providing that security.
For any filesystem security problem that ex-ists, there are usually several different ways ofsolving it. Solutions that involve modificationsin the kernel tend to introduce less overhead.This is due to the fact that context switches andcopying of data between kernel and user mem-ory is reduced. However, changes in the ker-nel may reduce the efficiency of the kernel’sVFS while making it both harder to maintainand more bug-prone. As notable exceptions,

Linux Symposium 2004 • Volume One • 271
Erez Zadok’s stackable filesystem framework,FiST[3], and Loop-aes, require no change tothe current Linux kernel VFS. Solutions thatexist entirely in userspace do not complicatethe kernel, but they tend to have more overheadand may be limited in the functionality they areable to provide, as they are limited by the inter-face to the kernel from userspace. Since theyare in userspace, they are also more prone toattack.
4 Aspects of Filesystem Security
Computer security can be decomposed intoseveral areas:
• Identifying who you are and having themachine recognize that identification (au-thentication).
• Determining whether or not you should begranted access to a resource such as a sen-sitive file (authorization). This is oftenbased on the permissions associated withthe resource by its owner or an adminis-trator (access control).
• Transforming your data into an encryptedformat in order to make it prohibitivelycostly for unauthorized users to decryptand view (confidentiality).
• Performing checksums, keyed hashes,and/or signing of your data to make unau-thorized modifications of your data de-tectable (integrity).
4.1 Filesystem Integrity
When people consider filesystem security, theytraditionally think about access control (filepermissions) and confidentiality (encryption).File integrity, however, can be just as impor-tant as confidentiality, if not more so. If a script
that performs an administrative task is alteredin an unauthorized fashion, the script may per-form actions that violate the system’s securitypolicies. For example, many rootkits modifysystem startup and shutdown scripts to facili-tate the attacker’s attempts to record the user’skeystrokes, sniff network traffic, or otherwiseinfiltrate the system.
More often than not, the value of the datastored in files is greater than that of the ma-chine that hosts the files. For example, if anattacker manages to insert false data into a fi-nancial report, the alteration to the report maygo unnoticed until substantial damage has beendone; jobs could be at stake and in more ex-treme cases even criminal charges against theuser could result . If trojan code sneaks into thesource repository for a major project, the pub-lic release of that project may contain a back-door.1
Many security professionals foresee a night-mare scenario wherein a widely propagated In-ternet worm quietly alters the contents of wordprocessing and spreadsheet documents. With-out any sort of integrity mechanism in placein the vast majority of the desktop machinesin the world, nobody would know if any datathat traversed vulnerable machines could betrusted. This threat could be very effectivelyaddressed with a combination of a kernel-levelmandatory access control (MAC)[11] protec-tion profile and a filesystem that provides in-tegrity and auditing capabilities. Such a com-bination would be resistant to damage done bya root compromise, especially if aided by aTrusted Platform Module (TPM)[13] using at-testation.
1A high-profile example of an attempt to do this oc-curred with the Linux kernel last year. Fortunately, thesource code management process used by the kernel de-velopers allowed them to catch the attempted insertionof the trojan code before it made it into the actual ker-nel.

272 • Linux Symposium 2004 • Volume One
One can approach filesystem integrity fromtwo angles. The first is to have strong au-thentication and authorization mechanisms inplace that employ sufficiently flexible policylanguages. The second is to have an auditingmechanism, to detect unauthorized attempts atmodifying the contents of a filesystem.
4.1.1 Authentication and Authorization
The filesystem must contain support for thekernel’s security structure, which requiresstateful security attributes on each file. MostGNU/Linux applications today use PAM[10](see Section 4.1.2 below) for authenticationand process credentials to represent their au-thorization; policy language is limited towhat can be expressed using the file ownerand group, along with the owner/group/worldread/write/execute attributes of the file. Theadministrator and the current owner have theauthority to set the owner of the file or theread/write/execute policies for that file. Inmany filesystems, files may also contain addi-tional security flags, such as an immutable orappend-only flag.
Posix Access Control Lists (ACL’s)[6] providefor more stringent delegations of access author-ity on a per-file basis. In an ACL, individ-ual read/write/execute permissions can be as-signed to the owner, the owning group, indi-vidual users, or groups. Masks can also be ap-plied that indicate the maximum effective per-missions for a class.
For those who require even more flexible ac-cess control, SE Linux[15] uses a powerfulpolicy language that can express a wide va-riety of access control policies for files andfilesystem operations. In fact, Linux SecurityModule (LSM)[14] hooks (see Section 4.1.3below) exist for most of the security-relevantfilesystem operations, which makes it easier to
implement custom filesystem-agnostic securitymodels. Authentication and authorization arepretty well covered with a combination of ex-isting filesystem, kernel, and user-space solu-tions that are part of most GNU/Linux distribu-tions. Many distributions could, however, do abetter job of aiding both the administrator andthe user in understanding and using all the toolsthat they have available to them.
Policies that safeguard sensitive data should in-clude timeouts, whereby the user must period-ically re-authenticate in order to continue toaccess the data. In the event that the autho-rized users neglect to lock down the machinebefore leaving work for the day, timeouts helpto keep the custodial staff from accessing thedata when they come in at night to clean theoffice. As usual, this must be implemented insuch a way as to be unobtrusive to the user. If auser finds a security mechanism overly impos-ing or inconvenient, he will usually disable orcircumvent it.
4.1.2 PAM
Pluggable Authentication Modules (PAM)[10]implement authentication-related security poli-cies. PAM offers discretionary access control(DAC)[12]; applications must defer to PAM inorder to authenticate a user. If the authenticat-ing PAM function that is called returns an af-firmative answer, then the application can usethat response to authorize the action, and viceversa. The exact mechanism that the PAMfunction uses to evaluate the authentication isdependent on the module called.2
In the case of filesystem security and encryp-tion, PAM can be employed to obtain and for-ward keys to a filesystem encryption layer inkernel space. This would allow seamless inte-
2This is parameterizable in the configuration filesfound under/etc/pam.d/

Linux Symposium 2004 • Volume One • 273
gration with any key retrieval mechanism thatcan be coded as a Pluggable AuthenticationModule.
4.1.3 LSM
Linux Security Modules (LSM) can providecustomized security models. One possible useof LSM is to allow decryption of certain filesonly when a physical device is connected to themachine. This could be, for example, a USBkeychain device, a Smartcard, or an RFID de-vice. Some devices of these classes can also beused to house the encryption keys (retrievablevia PAM, as previously discussed).
4.1.4 Auditing
The second angle to filesystem integrity is au-diting. Auditing should only fill in where au-thentication and authorization mechanisms fallshort. In a utopian world, where security sys-tems are perfect and trusted people always acttrustworthily, auditing does not have much ofa use. In reality, code that implements securityhas defects and vulnerabilities. Passwords canbe compromised, and authorized people canact in an untrustworthy manner. Auditing caninvolve keeping a log of all changes made tothe attributes of the file or to the file data itself.It can also involve taking snapshots of the at-tributes and/or contents of the file and compar-ing the current state of the file with what wasrecorded in a prior snapshot.
Intrusion detection systems (IDS), such asTripwire[16], AIDE[17], or Samhain[18], per-form auditing functions. As an example, Trip-wire periodically scans the contents of thefilesystem, checking file attributes, such as thesize, the modification time, and the crypto-graphic hash of each file. If any attributes forthe files being checked are found to be altered,
Tripwire will report it. This approach can workfairly well in cases where the files are not ex-pected to change very often, as is the case withmost system scripts, shared libraries, executa-bles, or configuration files. However, care mustbe taken to assure that the attacker cannot alsomodify Tripwire’s database when he modifiesa system file; the integrity of the IDS systemitself must also be assured.
In cases where a file changes often, such asa database file or a spreadsheet file in an ac-tive project, we see a need for a more dy-namic auditing solution - one which is per-haps more closely integrated with the filesys-tem itself. In many cases, the simple fact thatthe file has changed does not imply a secu-rity violation. We must also know who madethe change. More robust security require-ments also demand that we know what partsof the file were changed and when the changeswere made. One could even imagine scenarioswhere the context of the change must also betaken into consideration (i.e., who was loggedin, which processes were running, or what net-work activity was taking place at the time thechange was made).
File integrity, particularly in the area of au-diting, is perhaps the security aspect of Linuxfilesystems that could use the most improve-ment. Most efforts in secure filesystem devel-opment have focused on confidentiality moreso than integrity, and integrity has been reg-ulated to the domain of userland utilities thatmust periodically scan the entire filesystem.Sometimes, just knowing that a file has beenchanged is insufficient. Administrators wouldlike to know exactly how the attacker madethe changes and under what circumstances theywere made.
Cryptographic hashes are often used. Thesecan detect unauthorized circumvention of thefilesystem itself, as long as the attacker forgets

274 • Linux Symposium 2004 • Volume One
(or is unable) to update the hashes when mak-ing unauthorized changes to the files. Someauditing solutions, such as the Linux Audit-ing System (LAuS)3 that is part of SuSE LinuxEnterprise Server, can track system calls thataffect the filesystem. Another recent additionto the 2.6 Linux kernel is the Light-weightAuditing Framework written by Rik Faith[28].These are implemented independently of thefilesystem itself, and the level of detail in therecords is largely limited to the system call pa-rameters and return codes. It is advisable thatyou keep your log files on a separate machinethan the one being audited, since the attackercould modify the audit logs themselves oncehe has compromised the machine’s security.
4.1.5 Improvements on Integrity
Extended Attributes provide for a convenientway to attach metadata relating to a file to thefile itself. On the premise that possession ofa secret equates to authentication, every timean authenticated subject makes an authorizedwrite to a file, a hash over the concatenation ofthat secret to the file contents (keyed hashing;HMAC is one popular standard) can be writ-ten as an Extended Attribute on that file. Sincethis action would be performed on the filesys-tem level, the user would not have to conscien-tiously re-run userspace tools to perform suchan operation every time he wants to generatean integrity verifier on the file.
This is an expensive operation to perform overlarge files, and so it would be a good idea todefine extent sizes over which keyed hashes areformed, with the Extended Attributes includingextent descriptors along with the keyed hashes.That way, a small change in the middle of a
3Note that LAuS is being covered in more detail inthe 2004 Ottawa Linux Symposium by Doc Shankar,Emily Ratliff, and Olaf Kirch as part of their presenta-tion regarding CAPP/EAL3+ Certification.
large file would only require the keyed hashto be re-generated over the extent in which thechange occurs. A keyed hash over the sequen-tial set of the extent hashes would also keep anattacker from swapping around extents unde-tected.
4.2 File Confidentiality
Confidentiality means that only authorizedusers can read the contents of a file. Sometimesthe names of the files themselves or a directorystructure can be sensitive. In other cases, thesizes of the files or the modification times canbetray more information than one might wantto be known. Even the security policies pro-tecting the files can reveal sensitive informa-tion. For example, “Only employees of Novelland SuSE can read this file” would imply thatNovell and SuSE are collaborating on some-thing, and neither of them may want this factto be public knowledge as of yet. Many inter-esting protocols have been developed that canaddress these sorts of issues; some of them areeasier to implement than others.
When approaching the question of confiden-tiality, we assume that the block device thatcontains the file is vulnerable to physical com-promise. For example, a laptop that containssensitive material might be lost, or a databaseserver might be stolen in a burglary. In eitherevent, the data on the hard drive must not bereadable by an unauthorized individual. If anyindividual must be authenticated before he isable to access to the data, then the data is pro-tected against unauthorized access.
Surprisingly, many users surrender their owndata’s confidentiality (and more often than notthey do so unwittingly). It has been my per-sonal observation that most people do not fullyunderstand the lack of confidentiality affordedtheir data when they send it over the Inter-net. To compound this problem, comprehend-

Linux Symposium 2004 • Volume One • 275
ing and even using most encryption tools takesconsiderable time and effort on the part of mostusers. If sensitive files could beencrypted bydefault, only to be decrypted by those autho-rized at the time of access, then the user wouldnot have to expend so much effort toward pro-tecting the data’s confidentiality.
By putting the encryption at the filesystemlayer, this model becomes possible without anymodifications to the applications or libraries.A policy at that layer can dictate that certainprocesses, such as the mail client, are to re-ceive the encrypted version any files that areread from disk.
4.2.1 Encryption
File confidentiality is most commonly accom-plished through encryption. For performancereasons, secure filesystems use symmetric keycryptography, like AES or Triple-DES, al-though an asymmetric public/private keypairmay be used to encrypt the symmetric key insome key management schemes. This hybridapproach is in common use through SSL andPGP encryption protocols.
One of our proposals to extend Cryptfs is tomirror the techniques used in GnuPG encryp-tion. If the symmetric key that protects the con-tents of a file is encrypted with the public keyof the intended recipient of the file and storedas an Extended Attribute of the file, then thatfile can be transmitted in multiple ways (e.g.,physical device such as removable storage); aslong as the Extended Attributes of the file arepreserved across filesystem transfers, then therecipient with the corresponding private keyhas all the information that his Cryptfs layerneeds to transparently decrypt the contents ofthe file.
4.2.2 Key Management
Key management will make or break a cryp-tographic filesystem.[5] If the key can be eas-ily compromised, then even the strongest ci-pher will provide weak protection. If yourkey is accessible in an unencrypted file or inan unprotected region of memory, or if it isever transmitted over the network in the clear,a rogue user can capture that key and useit later. Most passwords have poor entropy,which means that an attacker can have prettygood success with a brute force attack againstthe password. Thus the weakest link in thechain for password-based encryption is usu-ally the password itself. The CryptographicFilesystem (CFS)[22] mandates that the userchoose a password with a length of at least 16characters.4
Ideally, the key would be kept in password-encrypted form on a removable device (like aUSB keychain drive) that is stored separatelyfrom the files that the key is used to encrypt.That way, an attacker would have to both com-promise the password and gain physical accessto the removable device before he could de-crypt your files.
Filesystem encryption is one of the most ex-citing applications for the Trusted ComputingPlatform. Given that the attacker has physi-cal access to a machine with a Trusted Plat-form Module, it is significantly more difficultto compromise the key. By using secret sharing(otherwise known askey splitting)[4], the ac-tual key used to decrypt a file on the filesystemcan be contained as both the user’s key and themachine’s key (as contained in the TPM). Inorder to decrypt the files, an attacker must not
4The subject of secure password selection, al-though an important one, is beyond the scope of thisarticle. Recommended reading on this subject is athttp://www.alw.nih.gov/Security/Docs/passwd.html .

276 • Linux Symposium 2004 • Volume One
only compromise the user key, but he must alsohave access to the machine on which the TPMchip is installed. This “binds” the encryptedfiles to the machine. This is especially usefulfor protecting files on removable backup me-dia.
4.2.3 Cryptanalysis
All block ciphers and most stream ciphers are,to various degrees, vulnerable to successfulcryptanalysis. If a cipher is used improperly,then it may become even easier to discover theplaintext and/or the key. For example, withcertain ciphers operating in certain modes, anattacker could discover information that aidsin cryptanalysis by getting the filesystem tore-encrypt an already encrypted block of data.Other times, a cryptanalyst can deduce infor-mation about the type of data in the encryptedfile when that data has predictable segments ofdata, like a common header or footer (thus al-lowing for a known-plaintext attack).
4.2.4 Cipher Modes
A block encryption mode that is resistant tocryptanalysis can involve dependencies amongchains of bytes or blocks of data. Cipher-block-chaining (CBC) mode, for example, pro-vides adequate encryption in many circum-stances. In CBC mode, a change to one blockof data will require that all subsequent blocksof data be re-encrypted. One can see how thiswould impact performance for large files, as amodification to data near the beginning of thefile would require that all subsequent blocks beread, decrypted, re-encrypted, and written outagain.
This particular inefficiency can be effectivelyaddressed by defining chaining extents. Bylimiting regions of the file that encompass
chained blocks, it is feasible to decrypt and re-encrypt the smaller segments. For example, ifthe block size for a cipher is 64 bits (8 bytes)and the block size, which is (we assume) theminimum unit of data that the block devicedriver can transfer at a time (512 bytes) thenone could limit the number of blocks in any ex-tent to 64 blocks. Depending on the plaintext(and other factors), this may be too few to ef-fectively counter cryptanalysis, and so the ex-tent size could be set to a small multiple of thepage size without severely impacting overallperformance. The optimal extent size largelydepends on the access patterns and data pat-terns for the file in question; we plan on bench-marking against varying extent lengths undervarying access patterns.
4.2.5 Key Escrow
The proverbial question, “What if the sysad-min gets hit by a bus?” is one that no organi-zation should ever stop asking. In fact, some-times no one person should alone have inde-pendent access to the sensitive data; multiplepasswords may be required before the data isdecrypted. Shareholders should demand thatno single person in the company have full ac-cess to certain valuable data, in order to miti-gate the damage to the company that could bedone by a single corrupt administrator or exec-utive. Methods for secret sharing can be em-ployed to assure that multiple keys be requiredfor file access, and (m,n)-threshold schemes [4]can ensure that the data is retrievable, even if acertain number of the keys are lost. Secret shar-ing would be easily implementable as part ofany of the existing cryptographic filesystems.
4.3 File Resilience
The loss of a file can be just as devastatingas the compromise of a file. There are many

Linux Symposium 2004 • Volume One • 277
well-established solutions to performing back-ups of your filesystem, but some cryptographicfilesystems preclude the ability to efficientlyand/or securely use them. Backup tapes tendto be easier to steal than secure computer sys-tems are, and if unencrypted versions of se-cure files exist on the tapes, that constitutes anoften-overlooked vulnerability.
The Linux 2.6 kernel cryptoloop device5
filesystem is an all-or-nothing approach. Mostbackup utilities must be given free reign onthe unencrypted directory listings in order toperform incremental backups. Most otherencrypted filesystems keep sets of encryptedfiles in directories in the underlying filesys-tem, which makes incremental backups possi-ble without giving the backup tools access tothe unencrypted content of the files.
The backup utilities must, however, maintainbackups of the metadata in the directories con-taining the encrypted files in addition to thefiles themselves. On the other hand, when thefilesystem takes the approach of storing thecryptographic metadata as Extended Attributesfor each file, then backup utilities need onlyworry about copying just the file in question tothe backup medium (preserving the ExtendedAttributes, of course).
4.4 Advantages of FS-Level, EA-Guided En-cryption
Most encrypted filesystem solutions either op-erate on the entire block device or operate onentire directories. There are several advantagesto implementing filesystem encryption at thefilesystem level and storing encryption meta-data in the Extended Attributes of each file:
• Granularity: Keys can be mapped to in-dividual files, rather than entire block de-
5Note that this is deprecated and is in the process ofbeing replaced with the Device Mapper crypto target.
vices or entire directories.
• Backup Utilities: Incremental backuptools can correctly operate without havingto have access to the decrypted content ofthe files it is backing up.
• Performance: In most cases, only cer-tain files need to be encrypted. Systemlibraries and executables, in general, donot need to be encrypted. By limiting theactual encryption and decryption to onlythose files that really need it, system re-sources will not be taxed as much.
• Transparent Operation: Individual en-crypted files can be easily transfered off ofthe block device without any extra trans-formation, and others with authorizationwill be able to decrypt those files. Theuserspace applications and libraries do notneed to be modified and recompiled tosupport this transparency.
Since all the information necessary to decrypta file is contained in the Extended Attributesof the file, it is possible for a user on a ma-chine that is not running Cryptfs to use user-land utilities to access the contents of the file.This also applies to other security-related op-erations, like verifying keyed hashes. This ad-dresses compatibility issues with machines thatare not running the encrypted filesystem layer.
5 Survey of Linux EncryptedFilesystems
5.1 Encrypted Loopback Filesystems
5.1.1 Loop-aes
The most well-known method of encrypt-ing a filesystem is to use a loopback en-

278 • Linux Symposium 2004 • Volume One
crypted filesystem.6 Loop-aes[20] is partof the 2.6 Linux kernel (CONFIG_BLK_DEV_
CRYPTOLOOP). It performs encryption at theblock device level. With Loop-aes, the admin-istrator can choose whatever cipher he wishesto use with the filesystem. Themountpack-age on most popular GNU/Linux distributionscontains thelosetuputility, which can be usedto set up the encrypted loopback mount (youcan choose whatever cipher that the kernel sup-ports; we use blowfish in this example):
root# modprobe cryptolooproot# modprobe blowfishroot# dd if=/dev/urandom of=encrypted.img \
bs=4k count=1000root# losetup -e blowfish /dev/loop0 \
encrypted.imgroot# mkfs.ext3 /dev/loop0root# mkdir /mnt/unencrypted-viewroot# mount /dev/loop0 /mnt/unencrypted-view
The loopback encrypted filesystem falls shortin the fact that it is an all-or-nothing solution.It is impossible for most standard backup util-ities to perform incremental backups on setsof encrypted files without being given accessto the unencrypted files. In addition, remoteusers will need to use IPSec or some other net-work encryption layer when accessing the files,which must be exported from the unencryptedmount point on the server. Loop-aes is, how-ever, the best performing encrypted filesystemthat is freely available and integrated with mostGNU/Linux distributions. It is an adequate so-lution for many who require little more thanbasic encryption of their entire filesystems.
5.1.2 BestCrypt
BestCrypt[23] is a non-free product that uses aloopback approach, similar to Loop-aes.
6Note that Loop-aes is being deprecated, in favor ofDevice Mapping (DM) Crypt, which also does encryp-tion at the block device layer.
5.1.3 PPDD
PPDD[21] is a block device driver that en-crypts and decrypts data as it goes to and comesfrom another block device. It works very muchlike Loop-aes; in fact, in the 2.4 kernel, it usesthe loopback device, as Loop-aes does. PPDDhas not been ported to the 2.6 kernel. Loop-aestakes the same approach, and Loop-aes shipswith the 2.6 kernel itself.
5.2 CFS
The Cryptographic Filesystem (CFS)[22] byMatt Blaze is a well established transparent en-crypted filesystem, originally written for BSDplatforms. CFS is implemented entirely inuserspace and operates similarly to NFS. Auserspace daemon, cfsd, acts as a pseudo-NFSserver, and the kernel makes RPC calls to thedaemon. The CFS daemon performs trans-parent encryption and decryption when writ-ing and reading data. Just as NFS can export adirectory from any exportable filesystem, CFScan do the same, while managing the encryp-tion on top of that filesystem.
In the background, CFS stores the metadatanecessary to encrypt and decrypt files withthe files being encrypted or decrypted on thefilesystem. If you were to look at those di-rectories directly, you would see a set of fileswith encrypted values for filenames, and therewould be a handful of metadata files mixed in.When accessed through CFS, those metadatafiles are hidden, and the files are transparentlyencrypted and decrypted for the user appli-cations (with the proper credentials) to freelywork with the data.
While CFS is capable of acting as a remoteNFS server, this is not recommended for manyreasons, some of which include performanceand security issues with plaintext passwordsand unencrypted data being transmitted over

Linux Symposium 2004 • Volume One • 279
the network. You would be better off, from asecurity perspective (and perhaps also perfor-mance, depending on the number of clients),to use a regular NFS server to handle remotemounts of the encrypted directories, with localCFS mounts off of the NFS mounts.
Perhaps the most attractive attribute of CFSis the fact that it does not require any mod-ifications to the standard Linux kernel. Thesource code for CFS is freely obtainable. It ispackaged in the Debian repositories and is alsoavailable in RPM form. Using apt, CFS is per-haps the easiest encrypted filesystem for a userto set up and start using:
root# apt-get install cfsuser# cmkdir encrypted-datauser# cattach encrypted-data unencrypted-view
The user will be prompted for his pass-word at the requisite stages. At this point,anything the user writes to or reads from/crypt/unencrypted-viewwill be transparentlyencrypted to and decrypted from files inencrypted-data. Note that any user on the sys-tem can make a new encrypted directory andattach it. It is not necessary to initialize andmount an entire block device, as is the casewith Loop-aes.
5.3 TCFS
TCFS[24] is a variation on CFS that includessecure integrated remote access and file in-tegrity features. TCFS assumes the client’sworkstation is trusted, and the server cannotnecessarily be trusted. Everything sent to andfrom the server is encrypted. Encryption anddecryption take place on the client side.
Note that this behavior can be mimicked witha CFS mount on top of an NFS mount. How-ever, because TCFS works within the kernel(thus requiring a patch) and does not necessi-
tate two levels of mounting, it is faster than anNFS+CFS combination.
TCFS is no longer an actively maintainedproject. The last release was made three yearsago for the 2.0 kernel.
5.4 Cryptfs
As a proof-of-concept for the FiST stackablefilesystem framework, Erez Zadok, et. al. de-veloped Cryptfs[1]. Under Cryptfs, symmet-ric keys are associated with groups of fileswithin a single directory. The key is generatedwith a password that is entered at the time thatthe filesystem is mounted. The Cryptfs mountpoint provides an unencrypted view of the di-rectory that contains the encrypted files.
The authors of this paper are currently work-ing on extending Cryptfs to provide seamlessintegration into the user’s desktop environment(see Section 6).
5.5 Userspace Encrypted Filesystems
EncFS[25] utilizes the Filesystem in Userspace(FUSE) library and kernel module to imple-ment an encrypted filesystem in userspace.Like CFS, EncFS encrypts on a per-file basis.
CryptoFS[26] is similar to EncFS, except ituses the Linux Userland Filesystem (LUFS) li-brary instead of FUSE.
SSHFS[27], like CryptoFS, uses the LUFS ker-nel module and userspace daemon. It limits it-self to encrypting the files via SFTP as they aretransfered over a network; the files stored ondisk are unencrypted. From the user perspec-tive, all file accesses take place as though theywere being performed on any regular filesys-tem (opens, read, writes, etc.). SSHFS trans-fers the files back and forth via SFTP with thefile server as these operations occur.

280 • Linux Symposium 2004 • Volume One
5.6 Reiser4
ReiserFS version 4 (Reiser4)[29], while still inthe development stage, features pluggable se-curity modules. There are currently proposedmodules for Reiser4 that will perform encryp-tion and auditing.
5.7 Network Filesystem Security
Much research has taken place in the domain ofnetworking filesystem security. CIFS, NFSv4,and other networking filesystems face specialchallenges in relation to user identification, ac-cess control, and data secrecy. The NFSv4 pro-tocol definition in RFC 3010 contains descrip-tions of security mechanisms in section 3[30].
6 Proposed Extensions to Cryptfs
Our proposal is to place file encryption meta-data into the Extended Attributes (EA’s) of thefile itself. Extended Attributes are a genericinterface for attaching metadata to files. TheCryptfs layer will be extended to extract thatinformation and to use the information to di-rect the encrypting and decrypting of the con-tents of the file. In the event that the filesys-tem does not support Extended Attributes, an-other filesystem layer can provide that func-tionality. The stackable framework effectivelyallows Cryptfs to operate on top ofanyfilesys-tem.
The encryption process is very similar to that ofGnuPG and other public key cryptography pro-grams that use a hybrid approach to encrypt-ing data. By integrating the process into thefilesystem, we can achieve a greater degree oftransparency, without requiring any changes touserspace applications or libraries.
Under our proposed design, when a new file iscreated as an encrypted file, the Cryptfs layer
generates a new symmetric keyKs for the en-cryption of the data that will be written. Filecreation policy enacted by Cryptfs can be dic-tated by directory attributes or globally definedbehavior. The owner of the file is automati-cally authorized to access the file, and so thesymmetric key is encrypted with the public keyof the owner of the fileKu, which was passedinto the Cryptfs layer at the time that the userlogged in by a Pluggable Authentication Mod-ule linked against libcryptfs. The encryptedsymmetric key is then added to the ExtendedAttribute set of the file:
{Ks}Ku
Suppose that the user at this point wants togrant Alice access to the file. Alice’s publickey, Ka, is in the user’s GnuPG keyring. Hecan run a utility that selects Alice’s key, ex-tracts it from the GnuPG keyring, and passesit to the Cryptfs layer, with instructions toadd Alice as an authorized user for the file.The new key list in the Extended Attribute setfor the file then contains two copies of thesymmetric key, encrypted with different publickeys:
{Ks}Ku
{Ks}Ka
Note that this is not an access control directive;it is rather a confidentiality enforcement mech-anism that extends beyond the local machine’saccess control. Without either the user’s or Al-ice’s private key, no entity will be able to accessthe decrypted contents of the file. The machinethat harbors such keys will enact its own ac-cess control over the decrypted file, based onstandard UNIX file permissions and/or ACL’s.
When that file is copied to a removable mediaor attached to an email, as long as the ExtendedAttributes are preserved, Alice will have allthe information that she needs in order to re-trieve the symmetric key for the file and de-

Linux Symposium 2004 • Volume One • 281
Kernel User
Cryptfs layer
Filesystem
Additional layers(optional)
Keystore
PAM
VFS syscall
Security Attributes
File Structure
Kernelcrypto API
Key retrievalPAM Module
cryptfslibrary
Login/GNOME/KDE/...
AuthenticationPAM Module
Prompt foruser authenticationaction (conversation)
Change fileencryption attributes
USB Keychain device,Smartcard, TPM,
GnuPG Keyring, etc...
Figure 1: Overview of proposed extended Cryptfs architecture
crypt it. If Alice is also running Cryptfs, whenshe launches an application that accesses thefile, the decryption process is entirely trans-parent to her, since her Cryptfs layer receivedher private key from PAM at the time that shelogged in.
If the user requires the ability to encrypt a filefor access by a group of users, then the usercan associate sets of public keys with groupsand refer to the groups when granting access.The userspace application that links againstlibcryptfs can then pass in the public keys toCryptfs for each member of the group and in-struct Cryptfs to add the associated key recordto the Extended Attributes. Thus no specialsupport for groups is needed within the Cryptfslayer itself.
6.1 Kernel-level Changes
No modifications to the 2.6 kernel itself arenecessary to support the stackable Cryptfslayer. The Cryptfs module’s logical divi-sions include a sysfs interface, a keystore, andthe VFS operation routines that perform theencryption and the decryption on reads and
writes.
By working with a userspace daemon, it wouldbe possible for Cryptfs to export public keycryptographic operations to userspace. In or-der to avoid the need for such a daemon whileusing public key cryptography, the kernel cryp-tographic API must be extended to support it.
6.2 PAM
At login, the user’s public and private keysneed to find their way into the kernelCryptfs layer. This can be accomplished bywriting a Pluggable Authentication Module,pamcryptfs.so. This module will link againstlibcryptfs and will extract keys from the user’sGnuPG keystore. The libcryptfs library willuse the sysfs interface to pass the user’s keysinto the Cryptfs layer.
6.3 libcryptfs
The libcryptfs library works with the Cryptfs’ssysfs interface. Userspace utilities, such aspamcryptfs.so, GNOME/KDE, or stand-aloneutilities, will link against this library and use it

282 • Linux Symposium 2004 • Volume One
ExtendedAttributes
Cryptfs Layer
Keystore
File SecurityAttributes
EA’s are parsedinto cryptfs layer’sfile attributestructure
File
Data
Calls to kernelCrypto API
Crypto callsparameterizedby file securityattributes
Keys retrievedfrom the keystore
Kernel Crypto APIVFS Syscalls
sysfs
Set private/public
keys
Symmetric keys usedfor encryption of filedata may needdecrypting with theauthorized user’sprivate key.
Userspacelibcryptfs
Figure 2: Structure of Cryptfs layer in kernel
to communicate with the kernel Cryptfs layer.
6.4 User Interface
Desktop environments such as GNOME orKDE can link against libcryptfs to provideusers with a convenient interface throughwhich to work with the files. For example,by right-clicking on an icon representing thefile and selecting “Security”, the user will bepresented with a window that can be used tocontrol the encryption status of the file. Suchoptions will include whether or not the file isencrypted, which users should be able to en-crypt and decrypt the file (identified by theirpublic keys from the user’s GnuPG keyring),what cipher is used, what keylength is used,an optional password that encrypts the sym-
metric key, whether or not to use keyed hash-ing over extents of the file for integrity, thehash algorithm to use, whether accesses to thefile when no key is available should result inan error or in the encrypted blocks being re-turned (perhaps associated with UID’s - goodfor backup utilities), and other properties thatare controlled by the Cryptfs layer.
6.5 Example Walkthrough
When a file’s encryption attribute is set, thefirst thing that the Cryptfs layer will do will beto generate a new symmetric key, which will beused for all encryption and decryption of thefile in question. Any data in that file is thenimmediately encrypted with that key. Whenusing public key-enforced access control, that

Linux Symposium 2004 • Volume One • 283
key will be encrypted with the process owner’sprivate key and stored as an EA of the file.When the process owner wishes to allow oth-ers to access the file, he encrypts the symmet-ric key with the their public keys. From theuser’s perspective, this can be done by right-clicking on an icon representing the file, select-ing “Security→Add Authorized User Key”,and having the user specify the authorized userwhile using PAM to retrieve the public key forthat user.
When using password-enforced access control,the symmetric key is instead encrypted using akey generated from a password. The user canthen share that password with everyone whohe authorized to access the file. In either case(public key-enforced or password-enforced ac-cess control), revocation of access to futureversions of the file will necessitate regenera-tion and re-encryption of the symmetric key.
Suppose the encrypted file is then copied to aremovable device and delivered to an autho-rized user. When that user logged into his ma-chine, his private key was retrieved by the keyretrieval Pluggable Authentication Module andsent to the Cryptfs keystore. When that userlaunches any arbitrary application and attemptsto access the encrypted file from the removablemedia, Cryptfs retrieves the encrypted sym-metric key correlating with that user’s publickey, uses the authenticated user’s private keyto decrypt the symmetric key, associates thatsymmetric key with the file, and then proceedsto use that symmetric key for reading and writ-ing the file. This is done in an entirely trans-parent manner from the perspective of the user,and the file maintains its encrypted status onthe removable media throughout the entire pro-cess. No modification to the application or ap-plications accessing the file are necessary toimplement such functionality.
In the case where a file’s symmetric key is en-
crypted with a password, it will be necessaryfor the user to launch a daemon that listens forpassword queries from the kernel cryptfs layer.Without such a daemon, the user’s initial at-tempt to access the file will be denied, and theuser will have to use a password set utility tosend the password to the cryptfs layer in thekernel.
6.6 Other Considerations
Sparse files present a challenge to encryptedfilesystems. Under traditional UNIX seman-tics, when a user seeks more than a block be-yond the end of a file to write, then that spaceis not stored on the block device at all. Thesemissing blocks are known as “holes.”
When holes are later read, the kernel simplyfills in zeros into the memory without actuallyreading the zeros from disk (recall that theydo not exist on the disk at all; the filesystem“fakes it”). From the point of view of what-ever is asking for the data from the filesystem,the section of the file being read appears to beall zeros. This presents a problem when thefile is supposed to be encrypted. Without tak-ing sparse files into consideration, the encryp-tion layer will naïvely assume that the zeros be-ing passed to it from the underlying filesystemare actually encrypted data, and it will attemptto decrypt the zeros. Obviously, this will re-sult in something other that zeros being pre-sented above the encryption layer, thus violat-ing UNIX sparse file semantics.
One solution to this problem is to abandon theconcept of “holes” altogether at the Cryptfslayer. Whenever we seek past the end of thefile and write, we can actually encrypt blocksof zeros and write them out to the underlyingfilesystem. While this allows Cryptfs to ad-here to UNIX semantics, it is much less effi-cient. One possible solution might be to store a“hole bitmap” as an Extended Attribute of the

284 • Linux Symposium 2004 • Volume One
file. Each bit would correspond with a block ofthe file; a “1” might indicate that the block is a“hole” and should be zero’d out rather than de-crypted, and a “0” might indicate that the blockshould be normally decrypted.
Our proposed extensions to Cryptfs in the nearfuture do not currently address the issues of di-rectory structure and file size secrecy. We rec-ognize that this type of confidentiality is im-portant to many, and we plan to explore waysto integrate such features into Cryptfs, possiblyby employing extra filesystem layers to aid inthe process.
Extended Attribute content can also be sensi-tive. Technically, only enough information toretrieve the symmetric decryption key need beaccessible by authorized individuals; all otherattributes can be encrypted with that key, justas the contents of the file are encrypted.
Processes that are not authorized to access thedecrypted content will either be denied accessto the file or will receive the encrypted con-tent, depending on how the Cryptfs layer is pa-rameterized. This behavior permits incremen-tal backup utilities to function properly, with-out requiring access to the unencrypted contentof the files they are backing up.
At some point, we would like to include file in-tegrity information in the Extended Attributes.As previously mentioned, this can be accom-plished via sets of keyed hashes over extentswithin the file:
H0 = H{O0, D0, Ks}H1 = H{O1, D1, Ks}. . .Hn = H{On, Dn, Ks}Hf = H{H0, H1, . . . , Hn, n, s, Ks}
wheren is the number of extents in the file,s is the extent size (also contained as anotherEA), Oi is the offset numberi within the file,
Di is the data from offsetOi to Oi + s, Ks isthe key that one must possess in order to makeauthorized changes to the file, andHf is thehash of the hashes, the number of extents, theextent size, and the secret key, to help detectwhen an attacker swaps around extents or altersthe extent size.
Keyed hashes prove that whoever modified thedata had access to the shared secret, which is,in this case, the symmetric key. Digital sig-natures can also be incorporated into Cryptfs.Executables downloaded over the Internet canoften be of questionable origin or integrity. Ifyou trust the person who signed the executable,then you can have a higher degree of certaintythat the executable is safe to run if the digitalsignature is verifiable. The verification of thedigital signature can be dynamically performedat the time of execution.
As previously mentioned, in addition to the ex-tensions to the Cryptfs stackable layer, this ef-fort is requiring the development of a cryptfslibrary, a set of PAM modules, hooks intoGNOME and KDE, and some utilities for man-aging file encryption. Applications that copyfiles with Extended Attributes must take stepsto make sure that they preserve the ExtendedAttributes.7
7 Conclusion
Linux currently has a comprehensive frame-work for managing filesystem security. Stan-dard file security attributes, process creden-tials, ACL, PAM, LSM, Device Mapping (DM)Crypt, and other features together provide goodsecurity in a contained environment. To ex-tend access control enforcement over individ-ual files beyond the local environment, youmust use encryption in a way that can be easily
7See http://www.suse.de/~agruen/ea-acl-copy/

Linux Symposium 2004 • Volume One • 285
applied to individual files. The currently em-ployed processes of encrypting and decryptingfiles, however, is inconvenient and often ob-structive.
By integrating the encryption and the decryp-tion of the individual files into the filesystemitself, associating encryption metadata with theindividual files, we can extend Linux securityto provide seamless encryption-enforced ac-cess control and integrity auditing.
8 Recognitions
We would like to express our appreciation forthe contributions and input on the part of allthose who have laid the groundwork for an ef-fort toward transparent filesystem encryption.This includes contributors to FiST and Cryptfs,GnuPG, PAM, and many others from whichwe are basing our development efforts, as wellas several members of the kernel developmentcommunity.
9 Legal Statement
This work represents the view of the author anddoes not necessarily represent the view of IBM.
IBM and Lotus Notes are registered trade-marks of International Business Machines Cor-poration in the United States, other countries,or both.
Other company, product, and service namesmay be trademarks or service marks of others.
References
[1] E. Zadok, L. Badulescu, and A. Shender.Cryptfs: A stackable vnode levelencryption file system.Technical ReportCUCS-021-98, Computer ScienceDepartment, Columbia University, 1998.
[2] J.S. Heidemann and G.J. Popek. Filesystem development with stackable layers.ACM Transactions on Computer Systems,12(1):58–89, February 1994.
[3] E. Zadok and J. Nieh. FiST: A Languagefor Stackable File Systems.Proceedingsof the Annual USENIX TechnicalConference, pp. 55–70, San Diego, June2000.
[4] S.C. Kothari, Generalized LinearThreshold Scheme,Advances inCryptology: Proceedings of CRYPTO 84,Springer-Verlag, 1985, pp. 231–241.
[5] Matt Blaze. “Key Management in anEncrypting File System,” Proc.Summer’94 USENIX Tech. Conference, Boston,MA, June 1994.
[6] For more information on ExtendedAttributes (EA’s) and Access Control Lists(ACL’s), seehttp://acl.bestbits.at/ orhttp://www.suse.de/~agruen/acl/chapter/fs_acl-en.pdf
[7] For more information on GnuPG, seehttp://www.gnupg.org/
[8] For more information on OpenSSL, seehttp://www.openssl.org/
[9] For more information on IBM LotusNotes, seehttp://www-306.ibm.com/software/lotus/ . Informationon Notes security can be obtained fromhttp://www-10.lotus.com/ldd/today.nsf/f01245ebfc115aaf8525661a006b86b9/232e604b847d2cad88256ab90074e298?OpenDocument
[10] For more information on PluggableAuthentication Modules (PAM), seehttp://www.kernel.org/pub/linux/libs/pam/

286 • Linux Symposium 2004 • Volume One
[11] For more information on MandatoryAccess Control (MAC), seehttp://csrc.nist.gov/publications/nistpubs/800-7/node35.html
[12] For more information on DiscretionaryAccess Control (DAC), seehttp://csrc.nist.gov/publications/nistpubs/800-7/node25.html
[13] For more information on the TrustedComputing Platform Alliance (TCPA), seehttp://www.trustedcomputing.org/home
[14] For more information on Linux SecurityModules (LSM’s), seehttp://lsm.immunix.org/
[15] For more information onSecurity-Enhanced Linux (SE Linux), seehttp://www.nsa.gov/selinux/index.cfm
[16] For more information on Tripwire, seehttp://www.tripwire.org/
[17] For more information on AIDE, seehttp://www.cs.tut.fi/~rammer/aide.html
[18] For more information on Samhain, seehttp://la-samhna.de/samhain/
[19] For more information on Logcrypt, seehttp://www.lunkwill.org/logcrypt/
[20] For more information on Loop-aes, seehttp://sourceforge.net/projects/loop-aes/
[21] For more information on PPDD, seehttp://linux01.gwdg.de/~alatham/ppdd.html
[22] For more information on CFS, seehttp://sourceforge.net/projects/cfsnfs/
[23] For more information on BestCrypt, seehttp://www.jetico.com/index.htm#/products.htm
[24] For more information on TCFS, seehttp://www.tcfs.it/
[25] For more information on EncFS, seehttp://arg0.net/users/vgough/encfs.html
[26] For more information on CryptoFS, seehttp://reboot.animeirc.de/cryptofs/
[27] For more information on SSHFS, seehttp://lufs.sourceforge.net/lufs/fs.html
[28] For more information on theLight-weight Auditing Framework, seehttp://lwn.net/Articles/79326/
[29] For more information on Reiser4, seehttp://www.namesys.com/v4/v4.html
[30] NFSv4 RFC 3010 can be obtained fromhttp://www.ietf.org/rfc/rfc3010.txt

Hotplug Memory and the Linux VM
Dave Hansen, Mike Kravetz, with Brad ChristiansenIBM Linux Technology Center
[email protected], [email protected], [email protected]
Matt TolentinoIntel
Abstract
This paper will describe the changes needed tothe Linux memory management system to copewith adding or removing RAM from a runningsystem. In addition to support for physicallyadding or removing DIMMs, there is an ever-increasing number of virtualized environmentssuch as UML or the IBM pSeries™ Hypervi-sor which can transition RAM between virtualsystem images, based on need. This paper willdescribe techniques common to all supportedplatforms, as well as challenges for specific ar-chitectures.
1 Introduction
As Free Software Operating Systems continueto expand their scope of use, so do the de-mands placed upon them. One area of con-tinuing growth for Linux is the adaptation toincessantly changing hardware configurationsat runtime. While initially confined to com-monly removed devices such as keyboards,digital cameras or hard disks, Linux has re-cently begun to grow to include the capabilityto hot-plug integral system components. Thispaper describes the changes necessary to en-able Linux to adapt to dynamic changes in oneof the most critical system resource—system
RAM.
2 Motivation
The underlying reason for wanting to changethe amount of RAM is very simple: availabil-ity. The systems that support memory hot-plugoperations are designed to fulfill mission crit-ical roles; significant enough that the cost ofa reboot cycle for the sole purpose of addingor replacing system RAM is simply too expen-sive. For example, some large ppc64 machineshave been reported to take well over thirty min-utes for a simple reboot. Therefore, the down-time necessary for an upgrade may compro-mise the five nine uptime requirement criticalto high-end system customers [1].
However, memory hotplug is not just impor-tant for big-iron. The availability of highspeed, commodity hardware has prompted aresurgence of research into virtual machinemonitors—layers of software such as Xen[2], VMWare [3], and conceptually even UserMode Linux that allow for multiple operatingsystem instances to be run in isolated, virtualdomains. As computing hardware density hasincreased, so has the possibility of splitting upthat computing power into more manageablepieces. The capability for an operating sys-tem to expand or contract the range of physical

288 • Linux Symposium 2004 • Volume One
memory resources available presents the pos-sibility for virtual machine implementations tobalance memory requirements and improve themanagement of memory availability betweendomains1. This author currently leases a smallUser Mode Linux partition for small Internettasks such as DNS and low-traffic web serving.Similar configurations with an approximately100 MHz processor and 64 MB of RAM arenot uncommon. Imagine, in the case of an acci-dental Slashdotting, how useful radically grow-ing such a machine could be.
3 Linux’s Hotplug Shortcomings
Before being able to handle the full wrath ofSlashdot. we have to consider Linux’s cur-rent design. Linux only has two data structuresthat absolutely limit the amount of RAM thatLinux can handle: the page allocator bitmaps,andmem_map[] (on contiguous memory sys-tems). The page allocator bitmaps are verysimple in concept, have a bit set one way whena page is available, and the opposite when ithas been allocated. Since there needs to be onebit available for each page, it obviously has toscale with the size of the system’s total RAM.The bitmap memory consumption is approxi-mately 1 bit of memory for each page of sys-tem RAM.
4 Resizingmem_map[]
Themem_map[] structure is a bit more com-plicated. Conceptually, it is an array, with onestruct page for each physical page whichthe system contains. These structures containbookkeeping information such as flags indicat-ing page usage and locking structures. Thecomplexity with thestruct page s is asso-ciated when their size. They have a size of
1err, I could write a lot about this, so I won’t go anyfurther
40 bytes each on i386 (in the 2.6.5 kernel).On a system with 4096 byte hardware pages,this implies that about 1% of the total sys-tem memory will be consumed bystructpage s alone. This use of 1% of the systemmemory is not a problem in and of itself. But,it does other problems.
The Linux page allocator has a limitation onthe maximum amounts of memory that it canallocate to a single request. On i386, thisis 4MB, while on ppc64, it is 16MB. It iseasy to calculate that anything larger than a4GB i386 system will be unable to allocateits mem_map[] with the normal page alloca-tor. Normally, this problem withmem_mapisavoided by using a boot-time allocator whichdoes not have the same restrictions as the allo-cator used at runtime. However, memory hot-plug requires the ability to grow the amount ofmem_map[] used at runtime. It is not feasibleto use the same approach as the page allocatorbitmaps because, in contrast, they are kept tosmall-enough sizes to not impinge on the max-imum size allocation limits.
4.1 mem_map[] preallocation
A very simple way around the runtime alloca-tor limitations might be to allocate sufficientmemory formmem_map[] at boot-time to ac-count for any amount of RAM that could pos-sibly be added to the system. But, this ap-proach quickly breaks down in at least one im-portant case. Themem_map[] must be allo-cated in low memory, an area on i386 whichis approximately 896MB in total size. Thisis very important memory which is commonlyexhausted [4],[5],[6]. Consider an 8GB systemwhich could be expanded to 64GB in the fu-ture. Its normalmem_map[] use would bearound 84MB, an acceptable 10% use of lowmemory. However, hadmem_map[] beenpreallocated to handle a total capacity of 64GBof system memory, it would use an astound-

Linux Symposium 2004 • Volume One • 289
ing 71% of low memory, giving any 8GB sys-tem all of the low memory problems associatedwith much larger systems.
Preallocation also has the disadvantage of im-posing limitations possibly making the userdecide how large they expect the system tobe, either when the kernel is compiled, orwhen it is booted. Perhaps the administra-tor of the above 8GB machine knows that itwill never get any larger than 16GB. Does thatmake the low memory usage more acceptable?It would likely solve the immediate problem,however, such limitations and user interven-tion are becoming increasingly unacceptableto Linux vendors, as they drastically increasepossible user configurations, and support costsalong with it.
4.2 Breakingmem_map[] up
Instead of preallocation, another solution isto break upmem_map[] . Instead of need-ing massive amounts of memory, smaller onescould be used to piece togethermem_map[]from more manageable allocations Interest-ingly, there is already precedent in the Linuxkernel for such an approach. The discontigu-ous memory support code tries to solve a dif-ferent problem (large holes in the physical ad-dress space), but a similar solution was needed.In fact, there has been code released to use thecurrent discontigmem support in Linux to im-plement memory hotplug. But, this has sev-eral disadvantages. Most importantly, it re-quires hijacking the NUMA code for use withmemory hotplug. This would exclude the useof NUMA and memory hotplug on the samesystem, which is likely an unacceptable com-promise due to the vast performance benefitsdemonstrated from using the Linux NUMAcode for its intended use [6].
Using the NUMA code for memory hotplug isa very tempting proposition because in addi-
tion to splitting upmem_map[] the NUMAsupport also handles discontiguous memory.Discontiguous memory simply means that thesystem does not lay out all of its physical mem-ory in a single block, rather there are holes.Handling these holes with memory hotplug isvery important, otherwise the only memorythat could be added or removed would be onthe end.
Although an approch similar to this “node hot-plug” approach will be needed when adding orremoving entire NUMA nodes, using it on aregular SMP hotplug system could be disas-trous. Each discontiguous area is representedby several data structures but each has at leastonestructzone . This structure is the basicunit which Linux uses to pool memory. Whenthe amounts of memory reach certain low lev-els, Linux will respond by trying to free orswap memory. Artificially creating too manyzones causes these events to be triggered muchtoo early, degrading system performance andunder-utilizing available RAM.
5 CONFIG_NONLINEAR
The solution to both themem_map[] and dis-contiguous memory problems comes in a sin-gle package: nonlinear memory. First imple-mented by Daniel Phillips in April of 2002 asan alternative to discontiguous memory, non-linear solves a similar set of problems.
Laying outmem_map[] as an array has sev-eral advantages. One of the most importantis the ability to quickly determine the physi-cal address of any arbitrarystruct page .Sincemem_map[N] represents the Nth pageof physical memory, the physical address of thememory represented by thatstruct pagecan be determined by simple pointer arith-metic:
Oncemem_map[] is broken up these simple

290 • Linux Symposium 2004 • Volume One
physical_address = (&mem_map[N] - &mem_map[0]) * sizeof(struct page)
struct page N = mem_map[(physical_address / sizeof(struct page)]
Figure 1: Physical Address Calculations
calculations are no longer possible, thus an-other approach is required. The nonlinear ap-proach is to use a set of two lookup tables, eachone complementing the above operations: onefor convertingstruct page to physical ad-dresses, the other for doing the opposite. Whileit would be possible to have a table with an en-try for every single page, that approach wastesfar too much memory. As a result, nonlinearhandles pages in uniformly sized sections, eachof which has its ownmem_map[] and an asso-ciated physical address range. Linux has someinteresting conventions about how addressesare represented, and this has serious implica-tions for how the nonlinear code functions.
5.1 Physical Address Representations
There are, in fact, at least three different waysto represent a physical address in Linux: aphysical address, astruct page , and apage frame number (pfn). A pfn is traditionallyjust the physical address divided by the sizeof a physical page (theN in the above in Fig-ure 1). Many parts of the kernel prefer to usea pfn as opposed to astruct page pointerto keep track of pages because pfn’s are eas-ier to work with, being conceptually just arrayindexes. The page allocator bitmaps discussedabove are just such a part of the kernel. To al-locate or free a page, the page allocator togglesa bit at an index in one of the bitmaps. Thatindex is based on a pfn, not astruct pageor a physical address.
Being so easily transposed, that decision doesnot seem horribly important. But it does causea serious problem for memory hotplug. Con-
sider a system with 100 1GB DIMM slotsthat support hotplug. When the system is firstbooted, only one of these DIMM slots is pop-ulated. Later on, the owner decides to hotpluganother DIMM, but puts it in slot 100 insteadof slot 2. Now, nonlinear has a bit of a problem:the new DIMM happens to appear at a physicaladdress 100 times higher address than the firstDIMM. The mem_map[] for the new DIMMis split up properly, but the allocator bitmap’slength is directly tied to the pfn, and thus thephysical address of the memory.
Having already stated that the allocator bitmapstays at manageable sizes, this still does notseem like much of an issue. However, thephysical address of that new memorycouldhave an even greater range than 100 GB; it hasthe capability to have many, many terabytes ofrange, based on the hardware. Keeping allo-cator bitmaps for terabytes of memory couldconceivably consume all system memory on asmall machine, which is quite unacceptable.Nonlinear offers a solution to this by intro-ducing a new way to represent a physical ad-dress: a fourth addressing scheme. With threeaddressing schemes already existing, a fourthseems almost comical, until its small scope isconsidered. The new scheme is isolated to useinside of a small set of core allocator functionsa single place in the memory hotplug code it-self. A simple lookup table converts these new“linear” pfns into the more familiar physicalpfns.

Linux Symposium 2004 • Volume One • 291
5.2 Issues withCONFIG_NONLINEAR
Although it greatly simplifies several issues,nonlinear is not without its problems. Firstly,it does require the consultation of a small num-ber of lookup tables during critical sections ofcode. Random access of these tables is likely tocause cache overhead. The more finely grainedthe units of hotplug, the larger these tables willgrow, and the worse the cache effects.
Another concern arises with the size of thenonlinear tables themselves. While they allowpfns andmem_map[] to have nonlinear rela-tionships, the nonlinear structures themselvesremain normal, everyday, linear arrays. Ifhardware is encountered with sufficiently smallhotplug units, and sufficiently large ranges ofphysical addresses, an alternate scheme to thearrays may be required. However, it is the au-thors’ desire to keep the implementation sim-ple, until such a need is actually demonstrated.
6 Memory Removal
While memory addition is a relatively black-and-white problem, memory removal has manymore shades of gray. There are many differ-ent ways to use memory, and each of them hasspecific challenges forunusing it. We will firstdiscuss the kinds of memory that Linux haswhich are relevant to memory removal, alongwith strategies to go about unusing them.
6.1 “Easy” User Memory
Unusing memory is a matter of either mov-ing data or simply throwing it away. The eas-iest, most straightforward kind of memory toremove is that whose contents can just be dis-carded. The two most common manifestationsof this are clean page cache pages and swappedpages. Page cache pages are either dirty (con-taining information which has not been writ-
ten to disk) or clean pages, which are simply acopy of something thatis present on the disk.Memory removal logic that encounters a cleanpage cache page is free to have it discarded,just as the low memory reclaim code does to-day. The same is true of swapped pages; a pageof RAM which has been written to disk is safeto discard. (Note: there is usually a brief pe-riod between when a page is written to disk,and when it is actually removed from memory.)Any page thatcanbe swapped is also an easycandidate for memory removal, because it caneasily be turned into a swapped page with ex-isting code.
6.2 Swappable User Memory
Another type of memory which is very simi-lar to the two types above is something whichis only used by user programs, but is forsome reason not a candidate for swapping.This at least includes pages which have beenmlock() ’d (which is a system call to preventswapping). Instead of discarding these pagesout of RAM, they must instead be moved. Thealgorithm to accomplish this should be verysimilar to the algorithm for a complete pageswapping: freeze writes to the page, move thepage’s contents to another place in memory,change all references to the page, and re-enablewriting. Notice that this is the same process asa complete swap cycle except that the writes tothe disk are removed.
6.3 Kernel Memory
Now comes the hard part. Up until now, wehave discussed memory which is being usedby user programs. There is also memory thatLinux sets aside for its own use and this comesin many more varieties than that used by userprograms. The techniques for dealing with thismemory are largely still theoretical, and do nothave existing implementations.

292 • Linux Symposium 2004 • Volume One
Remember how the Linux page allocator canonly keep track of pages in powers of two? TheLinux slab cache was designed to make up forthat [6], [7]. It has the ability to take those pow-ers of two pages, and chop them up into smallerpieces. There are some fixed-size groups forcommon allocations like 1024, 1532, or 8192bytes, but there are also caches for certainkinds of data structures. Some of these cacheshave the ability to attempt to shrink themselveswhen the system needs some memory back, buteven that is relatively worthless for memoryhotplug.
6.4 Removing Slab Cache Pages
The problem is that the slab cache’s shrinkingmechanism does not concentrate on shrinkingany particular memory, it just concentrates onshrinking, period. Plus, there’s currently nomechanism to tellwhichslab a particular pagebelongs to. It could just as easily be a simplydiscarded dcache entry as it could be a com-pletely immovable entry like apte_chain .Linux will need mechanisms to allow the slabcache shrinking to be much more surgical.
However, there will always be slab cache mem-ory which is not covered by any of the shrink-ing code, like for generickmalloc() alloca-tions. The slab cache could also make effortsto keep these “mystery” allocations away fromthose for which it knows how to handle.
While the record-keeping for some slab-cachepages is sparse, there is memory with evenmore mysterious origins. Some is allocatedearly in the boot process, while other uses pullpages directly out of the allocator never to beseen again. If hot-removal of these areas is re-quired, then a different approach must be em-ployed: direct replacement. Instead of simplyreducing the usage of an area of memory untilit is unused, a one-to-one replacement of thismemory is required. With the judicious use of
page tables, the best that can be done is to pre-serve the virtual address of these areas. Whilethis is acceptable for most use, it is not withoutits pitfalls.
6.5 Removing DMA Memory
One unacceptable place to change the phys-ical address of some data is for a device’sDMA buffer. Modern disk controllers and net-work devices can transfer their data directlyinto the system’s memory without the CPU’sdirect involvement. However, since the CPUis not involved, the devices lack access to theCPU’s virtual memory architecture. For thisreason, all DMA-capable devices’ transfers arebased on the physical address of the memoryto which they are transferring. Every user ofDMA in Linux will either need to be guar-anteed to not be affected by memory replace-ment, or to be notified of such a replacementso that it can take corrective action. It shouldbe noted, however, that the virtualization layeron ppc64 can properly handle this remappingin its IOMMU. Other architectures with IOM-MUs should be able to employ similar tech-niques.
6.6 Removal and the Page Allocator
The Linux page allocator works by keepinglists of groups of pages in sizes that are pow-ers of two times the size of a page. It keeps alist of groups that are available for each powerof two. However, when a request for a pageis made, the only real information provided isfor thesizerequired, there is no component forspecifically specifying which particular mem-ory is required.
The first thing to consider before removingmemory is to make sure that no other partof the system is using that piece of memory.Thankfully, that’s exactly what a normal al-location does: make sure that it is alone in

Linux Symposium 2004 • Volume One • 293
its use of the page. So, making the page al-locator support memory removal will simplyinvolve walking the same lists that store thepage groups. But, instead of simply taking thefirst available pages, it will be more finicky,only “allocating” pages that are among thoseabout to be removed. In addition, the allocatorshould have checks in thefree_pages()path to look for pages which were selected forremoval.
1. Inform allocator to catch any pages in thearea being removed.
2. Go into allocator, and remove any pagesin that area.
3. Trigger page reclaim mechanisms to trig-gerfree() s, and hopefully unuse all tar-get pages.
4. If not complete, goto 3.
6.7 Page Groupings
As described above, the page allocator is thebasis for all memory allocations. However,when it comes time to remove memory a fixedsize block of memory is what is removed.These blocks correspond to the sections de-fined in the the implementation of nonlinearmemory. When removing a section of mem-ory, the code performing the remove opera-tion will first try to essentially allocate all thepages in the section. To remove the section,all pages within the section must be made freeof use by some mechanism as described above.However, it should be noted that some pageswill not be able to be made available for re-moval. For example, pages in use for kernelallocations, DMA or via the slab-cache. Sincethe page allocator makes no attempt to grouppages based on usage, it is possible in a worstcase situation that every section contains onein-use page that can not be removed. Ideally,
we would like to group pages based on their us-age to allow the maximum number of sectionsto be removed.
Currently, the definition of zones providessome level of grouping on specific architec-tures. For example, on i386, three zones aredefined: DMA, NORMAL and HIGHMEM.With such definitions, one would expect mostnon-removable pages to be allocated out of theDMA and NORMAL zones. In addition, onewould expect most HIGHMEM allocations tobe associated with userspace pages and thusremovable. Of course, when the page allo-cator is under memory pressure it is possiblethat zone preferences will be ignored and allo-cations may come from an alternate zone. Itshould also be noted that on some architec-tures, such as ppc64, only one zone (DMA) isdefined. Hence, zones can not provide group-ing of pages on every architecture. It ap-pears that zones do provide some level of pagegrouping, but possibly not sufficient for mem-ory hotplug.
Ideally, we would like to experiment withteaching the page allocator about the use ofpages it is handing out. A simple thoughtwould be to introduce the concept of sectionsto the allocator. Allocations of a specific typeare directed to a section that is primarily usedfor allocations of that same type. For example,when allocations for use within the kernel areneeded the allocator will attempt to allocate thepage from a section that contains other inter-nal kernel allocations. If no such pages can befound, then a new section is marked for internalkernel allocations. In this way pages which cannot be easily freed are grouped together ratherthan spread throughout the system. In this waythe page allocator’s use of sections would beanalogous to the slab caches use of pages.

294 • Linux Symposium 2004 • Volume One
7 Conclusion
The prevalence of hotplug-capable Linux sys-tems is only expanding. Support for these sys-tems will make Linux more flexible and willmake additional capabilities available to otherparts of the system.
Legal Statement
This work represents the view of the authors anddoes not necessarily represent the view of IBM orIntel.
IBM is a trademarks or registered trademarks of In-ternational Business Machines Corporation in theUnited States and/or other countries.
Intel and i386 are trademarks or registered trade-marks of Intel Corporation in the United States,other countries, or both.
Linux is a registered trademark of Linus Torvalds.
VMware is a trademark of VMware, Inc.
References
[1] Five Nine at the IP Edgehttp://www.iec.org/online/
tutorials/five-nines
[2] Barham, Paul, et al.Xen and the Art ofVirtualizationProceedings of the ACMSymposium on Operating SystemPrinciples (SOSP), October 2003.
[3] Waldspurger, CarlMemory ResourceManagement in VMware ESX ServerProceedings of the USENIX AssociationSymposium on Operating System Designand Implementation, 2002. pp 181–194.
[4] Dobson, Matthew and Gaughen, Patriciaand Hohnbaum, Michael.Linux Supportfor NUMA HardwareProceedings of the
Ottawa Linux Symposium. July 2003. pp181–196.
[5] Gorman, MelUnderstanding the LinuxVirtual Memory ManagerPrentice Hall,NJ. 2004.
[6] Martin Bligh and Dave HansenLinuxMemory Management on LargerMachinesProceeedings of the OttawaLinux Symposium 2003. pp 53–88.
[7] Bonwick, JeffThe Slab Allocator: AnObject-Caching Kernel MemoryAllocator Proceedings of USENIXSummer 1994 Technical Conferencehttp://www.usenix.org/
publications/library/
proceedings/bos94/bonwick.html





























