Embed Size (px)
Citation preview

Prototypes for searching multiple databases
Presentation to CC:DA Taskforce on Metadata 1/16/2000 San Antonio, Texas
Steve Miller & Mary Woodley
Draft
c. 2000

1. Patron uses ONE search interface to access all information, whether it is a number of different metadata types and standards, databases, and OPAC(s)
CHARGE 4
Recommend ways in which libraries may bestincorporate the use of metadata schemes into thecurrent library methods or resource descriptionand resource discovery

CHARGE 4
2. provide a seamless transition to the user to all information available, moving from the ILS system of afront-end search mechanism that accesses numerousresources, to a search Interface that can access all information available in any standard, format, location,or subject. (Example: interface can search local OPAC, World Wide Web, metadata standards (EAD, TEI, GILS, Dublin Core), special collections, museum holdings,etc., and present results in a useable format to thepatron through one search mechanism)

DEFINITIONS
Prototype A virtually seamless access to information and relevantretrieval of information from the user's point of view.
Seamless Multiple sources of information can be searched, resulting in a single list of search results. A prototype system may provide the user with access to multipleauthority control lists, whether thesauri or LCSH or whatever, in order to assist in vocabulary usageand search definition, BEFORE the search is enabled.

DEFINITIONS
INTEROPERABILITY ability of two or more systems or components to exchange information and use the exchanged information without special effort on either system.

Different Kinds of Prototypes: Searching multiple databases vs. Collecting multiple metadata records into single
database or repository
Searching different metadata semantics vs. Converting / mapping diverse elements into single
semantics standard searched by the interface
Subject-specific vs. Universal search interfaces

Questions for Each Possible Prototype:
Can the user select which databases to search: one or all or a combination of them?
Can the user select specific thesauri, subject headings, name authorities, etc. to use as part of the search?
Can the search results be sorted into lists by type of metadata or by thesaurus/authority file, or are all search results merged together without differentiation?

Three Partial Prototype Interfaces:
NESSTAR: Networked Social Science Tools and Resources– funded by DGXIII of the European Commission under
the 4th Framework Telematics Applications Programme
AHDS: Arts and Humanities Data Service– Funded by the Joint Information Systems Committee of
the UK’s Higher Education Funding Council CORC: Cooperative Online Resource Catalog
– OCLC project

NESSTAR
= Networked Social Science Tools and Resources a joint development project between
– the Norwegian Social Science Data Services (NSD)– UK Data Archive– the Danish Data Archive (DDA)
Provides a common gateway to online social science data resources

Social Science Metadata
No single established standard. Many local "dialects" of the most common standard. Different data archives have adapted their metadata to fit
different storage and retrieval systems. = low level of standardization across archives. DDI: Data Documentation Initiative established in 1995 to
create a universally supported metadata standard for the social science community.
NESSTAR is using the XML-version of the DDI-standard as the fundamental structure of its metadata system.
Developed a set of metadata converters to ease translation of existing metadata.

Discovering Resources Across Archives
The resource discovery system of NESSTAR is metadata-driven.
The detailed structure of the DDI-DTD allows users to search for data with a very high precision.
Researchers interested in particular subjects can move beyond keywords and abstracts (normally included in OPACs) and search directly on variable descriptions, question texts, etc.
Searches can also be conducted on concepts such as method of data collection (e.g. telephone interviews, face-to-face interview or self-completion questionnaires) or sampling strategy (e.g. random, stratified, etc).


NESSTAR allows users to:
Locate multiple data sources across national boundaries
Browse detailed metadata about these data Analyse and visualise data online Download the appropriate subsets of data
in one of a number of formats for local use

Three Search Screens
Simple free text search Structured search on a selection of fields
– (like title, abstract, year etc.) Advanced boolean search on all relevant
fields of the DDI-DTD



NESSTAR Project “Dream Machine”(Social scientists’ ideal data search & retrieval scenario)
• All existing empirical data available on-line.• An integrated resource discovery gateway and search-system in order
to identify and locate these resources.• Extensive amounts of metadata available (multimedia, hyperlinked and
totally integrated with the data as such).• Ability to browse and visualise data on-line.• Ability to convert the data in one of a number of formats and copy,
with the metadata, to a local machine.• “Active research agents" (knowbots) mining the net and informing the
user when new data within their special field of interest are made available.
• Efficient hyperlinks from the data sources to every scientific publication ever produced on the basis of a dataset.
• Ditto e-mail/web addresses to all relevant researchers, departments etc.• Efficient feedback system to the body of metadata allowing the user to
add to the collective memory of a dataset.

AHDS: Arts and Humanities Data Service
Funded by the Joint Information Systems Committee of the UK’s Higher Education Funding Council
Five AHDS Databases: Archaeology Data Service History Data Service Oxford Text Archive Performing Arts Data Service Visual Arts Data Service

The AHDS Resource Discovery Challenge
Integrate users’ online access to distributed and heterogeneous information resources.
Each collection presents information about its holdings differently
Several service providers have data exchange and interoperability agreements with third-parties.
The collections comprise a wide variety of resource types, including electronic texts, databases, digital images, geospatial information systems, and time-based film data.
Services have adopted very different resource description and cataloguing practices.

Searching the Databases
Each collection can be accessed by one of two methods: 1) Through each service provider’s native catalog
– Different capabilities tailored to the information needs of different scholarly communities and to the resource description requirements of very different digital collections.
2) Through the common AHDS Gateway– Presents different collections’ catalogs as a virtual uniform catalog
and bases search and retrieval capabilities on an unqualified Dublin Core record.

The AHDS Gateway:
Provides a point of access to the electronic resources held by the five AHDS service providers
– such as electronic texts, databases, images and video and audio clips, online where possible
Allows users to search across a variety of independent and very different online catalogues as if they were a single catalogue.
Provides access to high-quality information providers of data from the disciplines of archaeology, history, literature and language, the performing and visual arts
Resources selected for their quality and for their relevance to those interested in the Arts & Humanities.
Users also benefit from a more refined approach to searching, being able to search against specified fields (creator, subject, title, etc), which is not possible through most Search engines available on the Internet.


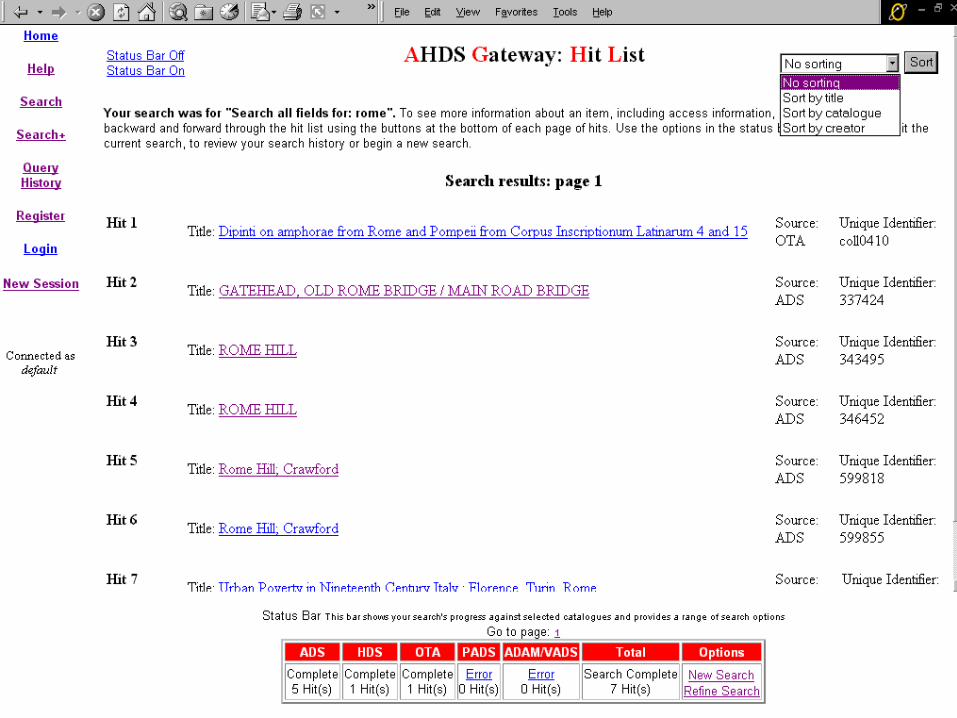


AHDS: “Challenges to be Confronted”
Digital Preservation and Archiving – Requires substantial infrastructural investment.
Controlled Vocabularies– No agreement likely among service providers about their use – OTA uses AACR; VADS uses AAT– Even greater variation in use of date and coverage elements. – How to assist users searching across catalogs with domain-specific controlled
vocabularies? Major challenge for the future. Z39.50 Interoperability
– Relatively immature standard; few guidelines for its use yet developed.– Different Z39.50-aware applications may conform to standards yet remain
incompatible with one another or interact in ways not meaningful or helpful to the user.
– In a wider and impersonal networked environments, means will need to be developed to ensure interoperability.

AHDS: “Challenges to be Confronted”
User Registration, Authentication, and Resource Ordering – AHDS benefits from its circumscribed service environment. – Problems will arise as it integrates third-party systems into its Gateway where such
services use independent registration, authentication, and resource ordering services. – A more automated approach will be required to support scholarly and heritage users
who wish to locate, scrutinise, and acquire access to information objects of interest irrespective of their location, format, and management.
Users’ Resource Discovery Preferences – AHDS has so far operated with numerous assumptions about users’ resource
discovery preferences in a distributed network environment. Those assumptions have shaped the development of the AHDS Gateway and associated systems.
– How users actually exploit the Gateway, particularly in relation to their use of underlying Service Provider catalogues, will provide useful feedback for the systems’ further development, but also for applied research into resource discovery systems more generally.

CORC: Cooperative Online Resource Catalog OCLC research project Web-based prototype system Offers both full USMARC cataloging and an
enhanced cataloging mode for Dublin Core Records can be imported into or exported from
CORC using: – (1) MARC– (2) HTML– (3) RDF-compliant XML






Authority Control in CORC
OCLC is defining how the authority component will work. CORC users will have access to a copy of the OCLC
Authority File and the ability to create provisional authority records for use by other CORC participants.
The first version of the CORC authority search interface will not offer all cross-references available in the Authority File.
CORC currently supports automation-assisted authority control during resource record creation and editing for selected fields.

The Future of the CORC Project
OCLC will introduce CORC as a production service in July 2000.
CORC 1.0 is the first phase of OCLC's next generation of cataloging services.
Version 1.0 will focus on an optimized metadata creation services for electronic resources and on providing an integrated view of those resources with other bibliographic records in WorldCat (the OCLC Online Union Catalog).

aka http://www.ahip.getty.edu/aka/ (retired)Faces of LA:
http://facesla.org (retired)Arthur
http://www.ahip.getty.edu/arthur/ (retired)
Getty Research Institute auction catalog records:http://opac.pub.getty.edu
Projects by the Getty Trust:

aka
•Developed by the Getty Information Institute whose mission was to create and support standards of description, tools, and guidelines for sharing cultural information
•Designed to demonstrate the value of controlled vocabulary in searching electronic resources, including the Web
•Public mode searched 4 databases with the option of using Art and Architecture Thesaurus, Union List of Artists Names; Staff mode searched over 26 databases: relational databases as well as texts in Web resources

aka System
System components:
•Web harvester (public domain)•WAIS text indexing system (public domain)•Vocabulary Searching Interface (Getty developed using Sybase)•Supported Boolean searching•Ability to expand, limit query & modify results

Multiple Collections
Text Searching Field
VocabularySearch Option
THE aka INTERFACE
Slide courtesy of Marty Harris

The Art and Archaeology Technical Abstracts Avery Index to Architectural Periodicals Bibliography of the History of Art (BHA) Getty Education Institute ArtsEdNet Web Site Getty Museum Collections Management System Getty Research Institute Integrated Catalog, IRIS GII Index of Cultural Heritage Web Sites GRI Photo Study Collection - Antiquities GRI Photo Study Collection - Illuminated
Manuscripts GRI Photo Study Collection - Max Hutzel Collection International Repertory of the Literature of Art
(RILA) Provenance Index Sale Catalogues Provenance Index Sale Contents The American Film Institute OnLine The Autry Museum of Western Heritage CSU Northridge: Special Collections and Archives
CSU Northridge: Special Collections and Archives Fine Arts Museum of San Francisco Art Imagebase Istituto Centrale per il Catalogo e la Documentazione
IIstituto Centrale per il Catalogo e la Documentazione II L.A. Library: People, Places and Events in Southern
California L.A. Library: Historic Photographs of Southern
California Lycos Image Index Museum of Tolerance: Photos of Children UCLA Fowler Museum of Cultural History USC Ethnic Studies Collection Alta Vista
aka provides internal searching access to 26 GII research, and partner databases and two general search resource databases.
aka IMPLEMENTATIONS
Slide courtesy of Marty Harris

©J. Paul Getty Trust Slide courtesy of Murtha Baca
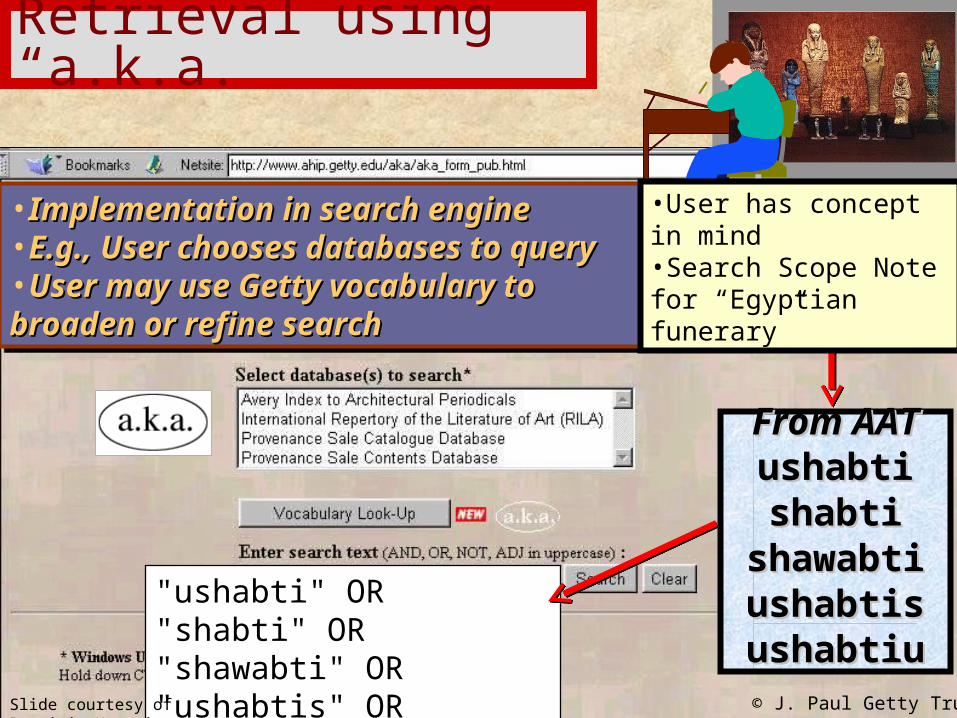
Retrieval using “a.k.a.”
"ushabti" OR "shabti" OR "shawabti" OR "ushabtis" OR "ushabtiu"
From AATFrom AATushabtiushabtishabtishabti
shawabtishawabtiushabtisushabtisushabtiuushabtiu
•Implementation in search engineImplementation in search engine•E.g., User chooses databases to E.g., User chooses databases to queryquery•User may use Getty vocabulary to User may use Getty vocabulary to broaden or refine searchbroaden or refine search
•Implementation in search engineImplementation in search engine•E.g., User chooses databases to E.g., User chooses databases to queryquery•User may use Getty vocabulary to User may use Getty vocabulary to broaden or refine searchbroaden or refine search
•User has concept in mind•Search Scope Note for “Egyptian funerary”
© J. Paul Getty TrustSlide courtesy of Patricia Harpring

aat Search results
©J. Paul Getty Trust Slide courtesy of Murtha Baca

aat Search results
©J. Paul Getty Trust Slide courtesy of Murtha Baca

aka Limitations
•Currency
•Labor intensive
•Although vocabularies increased precision, effectiveness reduced by the fact not all databases used the same vocabularies or used the vocabularies only in limited ways
•Could not generate a search from the Vocabulary lists but had to type in the terms

Multiple Collections
Text Searching Field
VocabularySearch Option
THE aka “FACES of LA“ INTERFACE
Slide courtesy of Marty Harris

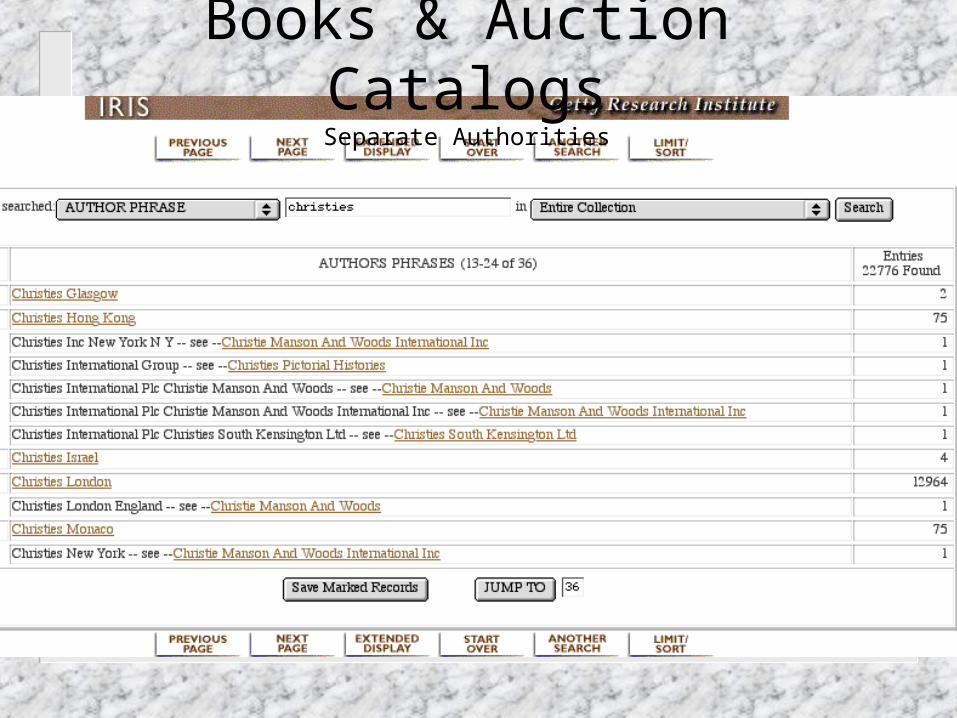
Books & Auction CatalogsSeparate Authorities

Auction Catalog Record
Different cataloging standard, same machine readable format (MARC)

FirstSearchPharos:
http://pharos.calstate.edu Searchlight: http://cdl.ucop.edu/libstaff/jan2000/
Z39.50 Projects
http//searchlight.cdlib.org/cgi-bin/searchlight/

FirstSearch
Provides the option of searching a single database or multiple databases (up to 3) within a category

FirstSearch


•Database contains catalog records for Web sites•Each record contains abstracts, LCSH, DDC & URLs

Pharos Project - CSU
•Goal is to provide to all 23 CSU campuses a gateway to electronic resources with a Z39.50 Web interface
•Portal for searching, Interlibrary loan and information competency tutorials
•Site is still under development

Pharos: capabilities & future enhancements
In development: Boolean searching
Limits Search history
Inclusion of non-Z39.50databases
Public Ve rsion
Quick search Search a specific database
Select databases incategories
Select a combination ofdatabases
Results displayed bydatabase


Option to Select aspecific database
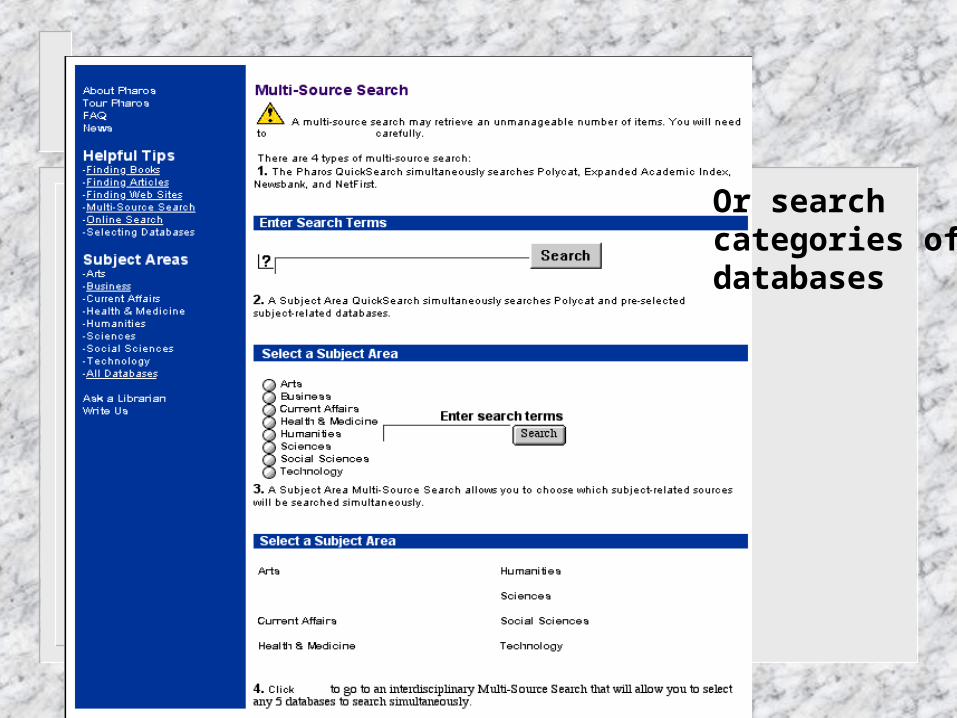
Or searchcategories ofdatabases

Select a combination of databases

Pharos Result Screen
High Recall -- Low Precision

SearchLight - UC project

Select specific database or category

Results sorted by categories of materials

Result differences due to how Server interprets request from Client

Strengths of Z39.50 cross-database searching
Circumvents 2 of the primary problems facing patrons:
1. Which database(s) is the most appropriate to use for the query
2. Finding which specific databases are available: a. Long A-Z lists b. Buried menu lists
Provides a single portal to the information universeMay link to Full-text resources
No need to duplicate access in OPAC & “lists”

Weaknesses of Z39.50 metasearching
Does not currently include non-Z39.50 databases
Relies on keyword searching
Results effected by: Which fields are indexed in the various databases How each Server interprets the query from the Client
Keyword searching can result in high recall with low precision:Search the individual databases to generate precise results
Diminishes the strengths of the catalog record: its access through controlled vocabulary

Weaknesses of MetaSearching
• Different databases under different vocabulary control
•Older relevant material not always available on the Web
•Not all resources on the Web have the same “value”, i.e., if a general Web search is included, they are given the same “status” as other resources on SearchLight

Comments & Feedback
Please send comments & feedback to: Mary Woodley [email protected] & Steve Miller [email protected]







![The Woodley Review Woodley R… · 4. To embed the Woodley Review recommendations within the Mental Health Strategys action plan [see pages 1-3]. 5. To embed the Mind the Gap report](https://img.pdfslide.net/doc/110x75/5faea62e0cf4423b81240c07/the-woodley-review-woodley-r-4-to-embed-the-woodley-review-recommendations-within.jpg)





















