Embed Size (px)
Citation preview

APEX INSTITUTE OF TECHNOLOGY
Program: BE CSE IBM (CC/IS/BD)
Course: System Programming (CST-281)
Prepared By: Er. Shifali Sharma
Important Definitions
System Programming: System programming involves designing and writing computer programs that allow the computer hardware to interface with the programmer and the user, leading to the effective execution of application software on the computer system. Typical system programs include the operating system and firmware, programming tools such as compilers, assemblers, I/O routines, interpreters, scheduler, loaders and linkers as well as the runtime libraries of the computer programming languages.
Text Editor: An Interactive text editor has become an important part of almost any computing environment. Text editor acts as a primary interface to the computer for all type of “knowledge workers” as they compose, organize, study, and manipulate computer-based information.
Assembler: An assembler is a program that takes basic computer instructions and converts them into a pattern of bits that the computer's processor can use to perform its basic operations. Some people call these instructions assembler language and others use the term assembly language.
Compiler: A compiler is a program that converts high-level language to assembly language. The C compiler, compiles the program and translates it to assembly program (low-level language). An assembler then translates the assembly program into machine code (object).
Debugger: A debugger is a computer program used by programmers to test and debug a target program. Debuggers may use instruction-set simulators, rather than running a program directly on the processor to achieve a higher level of control over its execution. They also can often modify the state of programs while they are running.
Linker and Loader: utility programs that plays a major role in the execution of a program. The Source code of a program passes through compiler, assembler, linker, loader in the respective order, before execution. On the one hand, where the linker intakes the object codes generated by the assembler and combine them to generate the

executable module. On the other hands, the loader loads this executable module to the main memory for execution.
Subroutine: In computer programming, a subroutine is a sequence of program instructions that performs a specific task, packaged as a unit. ... In different programming languages, a subroutine may be called a procedure, a function, a routine, a method, or a subprogram. The generic term callable unit is sometimes used.
Kernel: The kernel is a computer program that is the core of a computer's operating system, with complete control over everything in the system. On most systems, it is one of the first programs loaded on start-up (after the bootloader).
Bootstrap: A bootstrap is the program that initializes the operating system (OS) during startup. The term bootstrap or bootstrapping originated in the early 1950s. It referred to a bootstrap load button that was used to initiate a hardwired bootstrap program, or smaller program that executed a larger program such as the OS.
Tokenization: The process of demarcating and possibly classifying sections of a string of input characters. The resulting tokens are then passed on to some other form of processing. The process can be considered a sub-task of parsing input.

Important / Fundamentals / Theorems
System Programming:
System programming is an essential and important foundation in any computer’s application
development, and always evolving to accommodate changes in the computer hardware. This
kind of programming requires some level of hardware knowledge and is machine dependent;
the system programmer must therefore know the intended hardware on which the software is
required to operate.
Editors:
An Interactive text editor has become an important part of almost any computing environment. Text editor acts as a primary interface to the computer for all type of “knowledge workers” as they compose, organize, study, and manipulate computer-based information.
An interactive debugging system provides programmers with facilities that aid in testing and debugging of programs. Many such systems are available during these days. Our discussion is broad in scope, giving the overview of interactive debugging systems – not specific to any particular existing system.
Text Editors:
An Interactive text editor has become an important part of almost any computing environment.
Text editor acts as a primary interface to the computer for all type of “knowledge workers” as
they compose, organize, study, and manipulate computer-based information.
A text editor allows you to edit a text file (create, modify etc…). For example the Interactive text
editors on Windows OS - Notepad, WordPad, Microsoft Word, and text editors on UNIX OS -
vi, emacs, jed, pico.
Normally, the common editing features associated with text editors are, Moving the cursor,
Deleting, Replacing, Pasting, Searching, Searching and replacing, Saving and loading, and,
Miscellaneous(e.g. quitting).

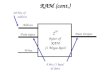
Editor Structure:
Source: https://ssmengg.edu.in
Assembler:
Fundamental functions includes translating mnemonic operation codes to their machine language
equivalents machine language equivalents and assigning machine addresses to symbolic labels.
Source: http://www.csie.ntnu.edu.tw

Pseudo-instructions
Not translated into machine instructions
Provide instructions to the assembler itself
Basic assembler directives
START: specify name and starting address of the program
END: specify end of program and (option) the first executable instruction in the
program o If not specified, use the address of the first executable instruction
BYTE: direct the assembler to generate constants
WORD
RESB: instruct the assembler to reserve memory location without generating data
values
RESW
One-pass assembler
The operation of a one-pass assembler is different. As its name implies, this assembler reads the source file once. During that single pass, the assembler handles both label definitions and assembly. The only problem is fu
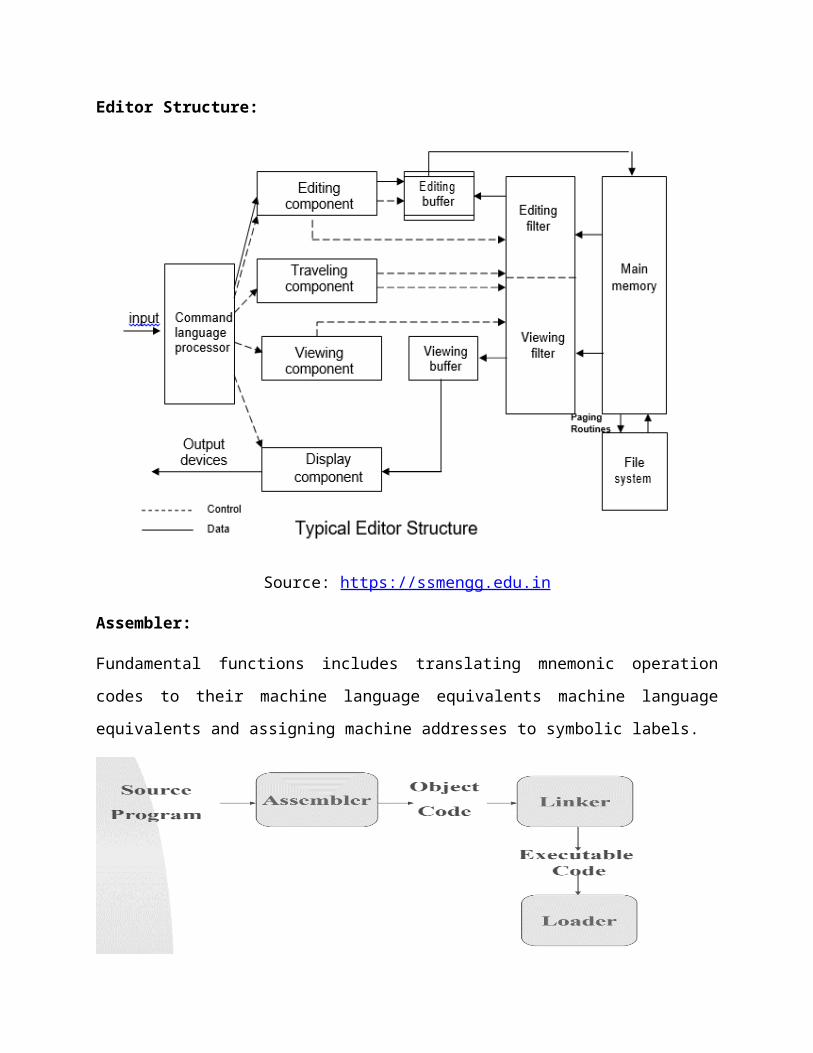

Two Pass Assembler:
Pass 1 and Pass 2:
Pass 1 (define symbols)
Assign addresses to all statements in the program
Save the addresses assigned to all labels for use in Pass 2
Perform assembler directives, including those for address assignment, such as BYTE and RESW
Pass 2 (assemble instructions and generate object program)
Assemble instructions (generate opcode and look up addresses)
Generate data values defined by BYTE, WORD
Perform processing of assembler directives not done during Pass 1
Write the object program and the assembly listing
Compiler:
Compilation is a process that translates a program in one language (the source language) into an equivalent program in another language (the object or target language).

Compilation Process:
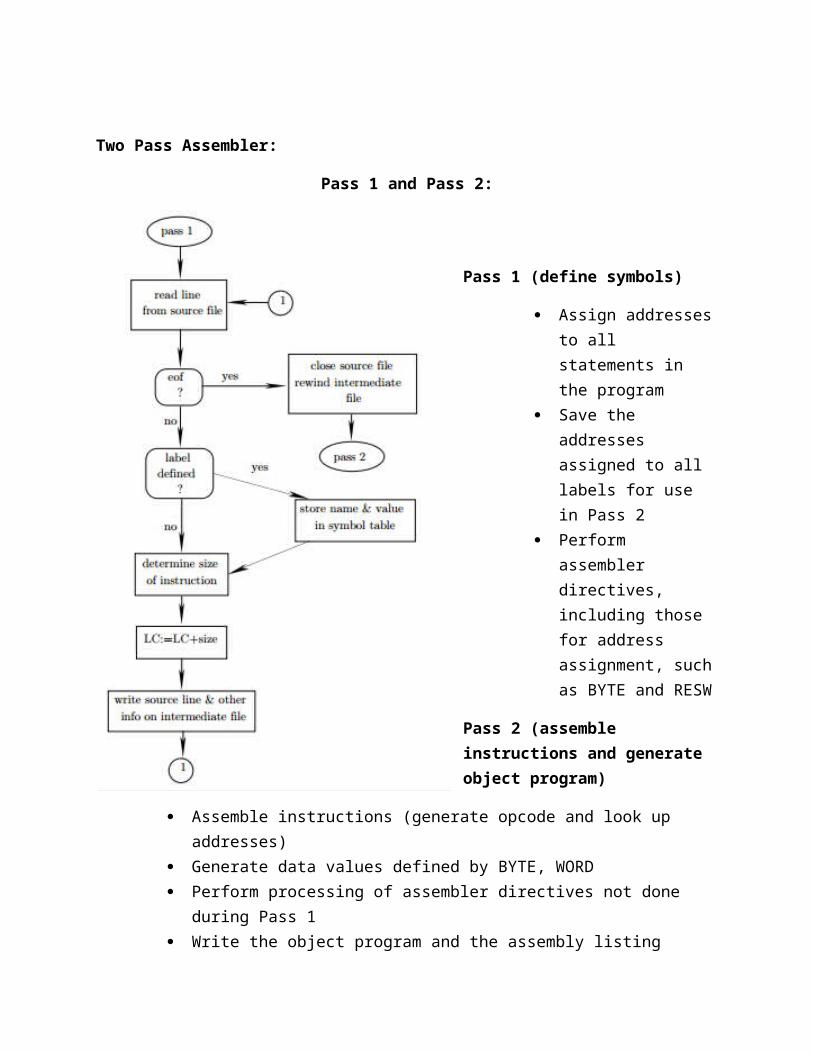
The Phases of a Compiler
The process of compilation is split up into six phases, each of which interacts with a symbol
table manager and an error handler. This is called the analysis/synthesis model of
compilation. There are many variants on this model, but the essential elements are the same.
Symbol Table – It is a data structure being used and maintained by the compiler, consists all the
identifier’s name along with their types. It helps the compiler to function smoothly by finding the
identifiers quickly.
The compiler has two modules namely front end and back end. Front-end constitutes of the
Lexical analyzer, semantic analyzer, syntax analyzer and intermediate code generator. And the
rest are assembled to form the back end.
1. Lexical Analyzer – It reads the program and converts it into tokens. It converts a stream of
lexemes into a stream of tokens. Tokens are defined by regular expressions which are
understood by the lexical analyzer. It also removes white-spaces and comments.

2. Syntax Analyzer – It is sometimes called as parser. It constructs the parse tree. It takes all
the tokens one by one and uses Context Free Grammar to construct the parse tree.
Why Grammar ?
The rules of programming can be entirely represented in some few productions. Using
these productions we can represent what the program actually is. The input has to be
checked whether it is in the desired format or not.
Syntax error can be detected at this level if the input is not in accordance with the grammar.
3. Semantic Analyzer – It verifies the parse tree, whether it’s meaningful or not. It
furthermore produces a verified parse tree.
4. Intermediate Code Generator – It generates intermediate code, that is a form which can
be readily executed by machine. We have many popular intermediate codes. Example –
Three address code etc. Intermediate code is converted to machine language using the last
two phases which are platform dependent.
Till intermediate code, it is same for every compiler out there, but after that, it depends on
the platform. To build a new compiler we don’t need to build it from scratch. We can take
the intermediate code from the already existing compiler and build the last two parts.
5. Code Optimizer – It transforms the code so that it consumes fewer resources and produces
more speed. The meaning of the code being transformed is not altered. Optimisation can be
categorized into two types: machine dependent and machine independent.
6. Target Code Generator – The main purpose of Target Code generator is to write a code
that the machine can understand. The output is dependent on the type of assembler. This is
the final stage of compilation.
COMPILER BOOTSTRAPPING
In computer science, bootstrapping is the process of writing a compiler (or assembler) in the
source programming language that it intends to compile. Applying this technique leads to a self-
hosting compiler. An initial minimal core version of the compiler is generated in a different
language (which could be assembly language); from that point, successive expanded versions of
the compiler are run using the minimal core of the language.
Many compilers for many programming languages are bootstrapped, including compilers
for BASIC, Pascal, PL/I, Factor, Haskell, Modula-2, and more.
Advantages
Bootstrapping a compiler has the following advantages:
it is a non-trivial test of the language being compiled, and as such is a form of dog fooding.
compiler developers and bug reporting part of the community only need to know the
language being compiled.
compiler development can be done in the higher level language being compiled.
improvements to the compiler's back-end improve not only general purpose programs but
also the compiler itself.
it is a comprehensive consistency check as it should be able to reproduce its own object code.

The chicken and egg problem
If one needs to compile a compiler for language X (written in language X), there is the issue of
how the first compiler can be compiled. The different methods that are used in practice to
solving this chicken or the egg problem include:
Implementing an interpreter or compiler for language X in language Y. Niklaus
Wirth reported that he wrote the first Pascal compiler in Fortran.
Another interpreter or compiler for X has already been written in another language Y; this is
how Scheme is often bootstrapped.
Earlier versions of the compiler were written in a subset of X for which there existed some
other compiler; this is how some supersets of Java, Haskell, and the initial Free
Pascal compiler are bootstrapped.
A compiler supporting non-standard language extensions or optional language features can
be written without using those extensions and features, to enable it being compiled with
another compiler supporting the same base language but a different set of extensions and
features. The main parts of the C++ compiler clang were written in a subset of C++ that can
be compiled by both g++ and Microsoft Visual C++. Advanced features are written with
some GCC extensions.
The compiler for X is cross compiled from another architecture where there exists a compiler
for X; this is how compilers for C are usually ported to other platforms. Also this is the
method used for Free Pascal after the initial bootstrap.
Writing the compiler in X; then hand-compiling it from source (most likely in a non-
optimized way) and running that on the code to get an optimized compiler. Donald
Knuth used this for his WEB literate programming system.
Lexical and Syntax Analysis
• Syntax analyzers are based directly on the grammars.
• Lexical and syntax analyzers are needed in numerous situations outside compiler design
including o program listing formatters o programs that compute the complexity of programs o
programs that must analyze and react to the contents of a configuration . Introduction Lexical

and Syntax Analysis are the first two phases of compilation as shown below. Lexical Analysis
(Scanner) Syntax Analysis (Parser) characters tokens abstract syntax tree. Lexical and Syntax
Analysis Languages are designed for both phases
• For characters, we have the language of regular expressions to recognize tokens.
• For tokens, we have context free grammars to recognize syntactically correct programs.
Reasons for separating lexical analysis from syntax analysis are:
1. Simplicity – Techniques for lexical analysis are less complex that those required for
syntax analysis, so the lexical-analysis process can be simpler if it separate. Also, removing the
low-level details of lexical analysis from the syntax analyze makes the syntax analyzer both
smaller and cleaner.
2. Efficiency – Although it pays to optimize the lexical analyzer, because lexical analysis
requires a significant portion of total compilation time, it is not fruitful to optimize the syntax
analyzer. Separation facilitates this selective optimization.
3. Portability – Because the lexical analyzer reads input program files and often includes
buffering of that input, it is somewhat platform dependent. However, the syntax analyzer can be
platform independent. It is always a good practice to isolate machine dependent parts of any
software system.
Lexical Analysis
• A lexical analyzer is a patter matcher.
• A lexical analyzer recognizes strings of characters as tokens.
• Lexical analyzers (scanners) extract lexemes (tokens) from a given input string.
• Lexical analyzers skip comments and blanks.
• There are three approaches to building a lexical analyzer:
1. Write a formal description of the token patterns of the language using a descriptive language
related to regular expressions. These descriptions are used as input to a software tool that
automatically generates a lexical analyzer. The oldest and most accessible of these, name lex, is
commonly included as part of UNIX systems.

2. Design a state transition diagram that describes the token patterns of the language and write a
program that implements the diagram. 3. Design a state transition diagram that describes the
token patterns of the language and hand-construct a table-driven implementation of the state
diagram.
• A state diagrams is a directed graph. The nodes of a state diagram are labeled with state names.
The edges are labeled with the input characters that cause the transitions among the states.
• Finite state machines are collections of related state diagrams called finite automata.
• A class of languages called regular languages or regular expression can be translated to finite
automata.
The Parsing Problem
• Analyzing a sequence of tokens to determine if they form a sentence in the grammar of the
programming language is called syntax analysis
• Syntax analysis is often called parsing.
Introduction to Parsing
• Parsers for programming languages construct parse trees for given programs.
• There are two distinct goals of syntax analysis:
1. The parser determines if the input program is syntactically correct.
2. If an error is found, the parser generates a diagnostic message indicating the location of
the error and a message that indicates why the program is not correct.
3. The parser produces a parse tree of a syntactically correct program.
There are two broad classes of parsers.
1. top-down: A top-down parser attempts to construct the parse tree from the root down to
its leaves.
2. bottom-up: A bottom-up parser attempts to construct the parse tree from its leaves
upward to the root.

Parsing terminology.
1. Terminal symbols – lowercase letters at the beginning of the alphabet. (𝑎, 𝑏, ⋯ ).
2. Nonterminal symbols – uppercase letters at the beginning of the alphabet. (𝐴, 𝐵, ⋯ ).
3. Terminals or non-terminals – uppercase letters at the end of the alphabet. (𝑊, 𝑋, 𝑌, 𝑍).
4. Strings of terminals – lowercase letters at the end of the alphabet. (𝑤, 𝑥, 𝑦, 𝑧).
5. Mixed strings (terminals or non-terminals) – lowercase Greek letters. (𝛼, 𝛽, 𝛾, 𝛿)
Programming language terminology.
1. Terminal symbols – terminal symbols are printed in bold. For example, for, while, +, -
2. Nonterminal symbols – Nonterminal symbols are printed in italics. For example,
expression, term, factor.
Top-Down Parsers
• A top-down parser traces or builds a parse tree in preorder. This corresponds to a leftmost
derivation.
• The general form of a left sentential form that is 𝑥𝐴𝛼, recalling that 𝑥 is a string of
terminal symbols, 𝐴 is a nonterminal, and 𝛼 is a mixed string,
• Because 𝑥 contains only terminal symbols, 𝐴 is the leftmost nonterminal in the sentential
form, so it is the one that must be expanded to get the next sentential form in a leftmost
derivation.
Bottom-Up Parsers
• A bottom-up parser constructs a parse tree by beginning at the leaves and progressing
toward the root.
• Give a right sentential form 𝛼, the parser must determine what substring of 𝛼 is the RHS
(right-hand side) of the rule in the grammar that must be reduced to its LHS (lefthand side) to
produce the previous sentential form in the rightmost derivation

Immediate Code Generation
During the translation of a source program into the object code for a target machine, a
compiler may generate a middle-level language code, which is known as intermediate
code or intermediate text. The complexity of this code lies between the source language
code and the object code. The intermediate code can be represented in the form of postfix
notation, syntax tree, directed acyclic graph (DAG), three-address code, quadruples, and
triples
Utility of Intermediate Code Generation:
1. Suppose we have n-source languages and m-Target languages. Without Intermediate code
we will change each source language into target language directly.
2. So, for each source-target pair we will need a compiler. Hence we will require (n*m)
Compilers, one for each pair. If we Use Intermediate code. We will require n-Compilers
to convert each source language into Intermediate code and mCompilers to convert
Intermediate code into m-target languages. Thus we require only (n+m) Compilers.
Different Types of Intermediate codes
Intermediate code must be easy to produce and easy to translate to machine code
It is a sort of universal assembly language.
It should not contain any machine-specific parameters (registers, addresses, etc.)
The type of intermediate code deployed is based on the application like Quadruples, triples,
indirect triples, abstract syntax trees are the classical forms used for machine-independent
optimizations and machine code generation.
Static Single Assignment form (SSA) is a recent form and enables more effective optimizations.
Conditional constant propagation and global value numbering are more effective on SSA
Program Dependence Graph (PDG) is useful in automatic parallelization, instruction scheduling,
and software pipelining
Three Address Code
Instructions are very simple

Examples: a = b + c, x = -y, if a > b goto L1
LHS is the target and the RHS has at most two sources and one operator
RHS sources can be either variables or constants
Three-address code is a generic form and can be implemented as quadruples, triples, indirect
triples, tree or DAG.
Example: The three-address code for a+b*c-d/(b*c) is below
t1 = b*c
t2 = a+t1
t3 = b*c
t4 = d/t3
t5 = t2-t4
Implementation of three address code
Code optimization techniques

Optimization is a program transformation technique, which tries to improve the code by making
it consume less resources i. e. CPU, Memory and deliver high speed. In optimization, high-level
general programming constructs are replaced by very efficient low-level programming codes.
A code optimizing process must follow the three rules given below: The output code must not,
in any way, change the meaning of the program.
Optimization should increase the speed of the program and if possible, the program should
demand less number of resources. Optimization should itself be fast and should not delay the
overall compiling process. Efforts for an optimized code can be made at various levels of
compiling the process.
At the beginning, users can change/rearrange the code or use better algorithms to write the code.
After generating intermediate code, the compiler can modify the intermediate code by address
calculations and improving loops.
While producing the target machine code, the compiler can make use of memory hierarchy and
CPU registers. Optimization can be categorized broadly into two types:
Machine independent
Machine dependent.
Machine-independent Optimization
In this optimization, the compiler takes in the intermediate code and transforms a part of the code
that does not involve any CPU registers and/or absolute memory locations. For example:
Machine-dependent optimization is done after the target code has been generated and when the
code is transformed according to the target machine architecture. It involves CPU registers and
may have absolute memory references rather than relative references.
Machine-dependent Optimization
Machine-dependent optimization is done after the target code has been generated and when the
code is transformed according to the target machine architecture. It involves CPU registers and
may have absolute memory references rather than relative references. Machine-dependent
optimizers put efforts to take maximum advantage of memory hierarchy.
Loop Optimization

Most programs run as a loop in the system. It becomes necessary to optimize the loops in order
to save CPU cycles and memory.
Loops can be optimized by the following techniques:
Invariant code: A fragment of code that resides in the loop and computes the same value at each
iteration is called a loop-invariant code. This code can be moved out of the loop by saving it to
be computed only once, rather than with each iteration.
Induction analysis: A variable is called an induction variable if its value is altered within the
loop by a loop-invariant value.
Strength reduction: There are expressions that consume more CPU cycles, time, and memory.
These expressions should be replaced with cheaper expressions without compromising the output
of expression. For example, multiplication x ∗ 2 is expensive in terms of CPU cycles than x <<
1 and yields the same result.
Dead-code Elimination Dead code is one or more than one code statements, which are: Either
never executed or unreachable, or if executed, their output is never used. Thus, dead code plays
no role in any program operation and therefore it can simply be eliminated.
Partially dead code There are some code statements whose computed values are used only
under certain circumstances, i.e., sometimes the values are used and sometimes they are not.
Such codes are known as partially dead-code. The above control flow graph.
Code Generation
Code generation is a mechanism where a compiler takes the source code as an input and converts
it into machine code. This machine code is actually executed by the system. Code generation is
generally considered the last phase of compilation, although there are multiple intermediate steps
performed before the final executable is produced. These intermediate steps are used to perform
optimization and other relevant processes.

Linker
Linking of the program with other programs for execution, which is performed by a separate
processor known as linker.
Relocation of the program to execute from the memory location allocated to it, which is
performed by a processor called loader.
Loading of the program in the memory for its execution, which is performed by a loader.
Linkage editor allows you to combine two or more objects defined in a program and supply
information needed to allow references between them. A linkage editor is also known as linker.
To allow linking in a program, you need to perform:
Program relocation
Program linking
The algorithm that you use for program relocation is:
1. program_linked_origin:= from linker command;
2. For each object module
3. t_origin :=translated origin of the object module; OM_size :=size of the object module;
4. relocation_factor :=program_linked_origin-t_origin;
5. Read the machine language program in work_area;
6. Read RELOCTAB of the object module
7. For each entry in RELOCTAB
A. translated_addr: = address in the RELOCTAB entry;
B. address_in_work: =address of work_area + translated_address – t_origin;
C. add relocation_factor to the operand in the wrd with the address
address_in_work_area.
D. program_linked_origin: = program_linked_origin + OM_size;
for each object module

A. t_origin: =translated origin of the object module;
B. program_linked_origin :=load_address from NTAB;
for each LINKTAB entry with type=EXT
address_in_work_area: =address of work_area + program_linked_origin - +
translated address – t_origin ƒ
search symbol in NTAB and copy its linked address. Add the linked address to the operand
address in the word with the address address_in_work_area.
Booting Techniques
Booting
Booting: When we start our Computer then there is an operation which is performed
automatically by the Computer which is also called as Booting. In the Booting, System will
check all the hardware’s and Software’s those are installed or Attached with the System and this
will also load all the Files those are needed for running a system.
In the Booting Process all the Files those are Stored into the ROM Chip will also be Loaded for
Running the System. In the Booting Process the System will read all the information from the
Files those are Stored into the ROM Chip and the ROM chip will read all the instructions those
are Stored into these Files. After the Booting of the System this will automatically display all the
information on the System. The Instructions those are necessary to Start the System will be read
at the Time of Booting.
There are two Types of Booting
1) Warm Booting: when the System Starts from the Starting or from initial State Means when we
Starts our System this is called as warm Booting. In the Warm Booting the System will be
Started from its beginning State means first of all, the user will press the Power Button , then this
will read all the instructions from the ROM and the Operating System will b Automatically gets
loaded into the System.
2) Cold Booting : The Cold Booting is that in which System Automatically Starts when we are
Running the System, For Example due to Light Fluctuation the system will Automatically
Restarts So that in this Chances Damaging of system are More. and the System will no be start

from its initial State So May Some Files will b Damaged because they are not Properly Stored
into the System.
Shell Designing
Most of the shells created for other operating systems offer equivalents to Unix shell
functionality. On Microsoft Windows systems, some users may never use the shell directly, as
services are handled automatically. In Unix, shells are created through the implementation of
system startup scripts. This happens in Windows too, but shell scripts are usually preconfigured
and run automatically as required by the system.
Unix shells are divided into four categories:
Bourne-like shells
C shell-like shells
Nontraditional shells
Historical shells
On some systems, the shell is just an environment where applications can run in protected
memory space so that resources can be shared among multiple active shells, with the kernel
managing the resource requests for input/output, CPU stack execution or memory access. Other
systems run everything inside a single shell
Various Management of OS
An Operating System (OS) is an interface between a computer user and computer hardware. An
operating system is a software which performs all the basic tasks like file management, memory
management, process management, handling input and output, and controlling peripheral
devices such as disk drives and printers.
Some popular Operating Systems include Linux, Windows, OS X, VMS, OS/400, AIX, z/OS,
etc.

Memory Management
Memory management refers to management of Primary Memory or Main Memory. Main
memory is a large array of words or bytes where each word or byte has its own address.
Main memory provides a fast storage that can be accessed directly by the CPU. For a program
to be executed, it must in the main memory. An Operating System does the following activities
for memory management −
Keeps tracks of primary memory, i.e., what part of it are in use by whom, what part are
not in use.
In multiprogramming, the OS decides which process will get memory when and how
much.
Allocates the memory when a process requests it to do so.
De-allocates the memory when a process no longer needs it or has been terminated.
Processor Management
In multiprogramming environment, the OS decides which process gets the processor when and
for how much time. This function is called process scheduling. An Operating System does the
following activities for processor management −

Keeps tracks of processor and status of process. The program responsible for this task is
known as traffic controller.
Allocates the processor (CPU) to a process.
De-allocates processor when a process is no longer required.
Device Management
An Operating System manages device communication via their respective drivers. It does the
following activities for device management −
Keeps tracks of all devices. Program responsible for this task is known as the I/O
controller.
Decides which process gets the device when and for how much time.
Allocates the device in the efficient way.
De-allocates devices.
File Management
A file system is normally organized into directories for easy navigation and usage. These
directories may contain files and other directions.
An Operating System does the following activities for file management −
Keeps track of information, location, uses, status etc. The collective facilities are often
known as file system.
Decides who gets the resources.
Allocates the resources.
De-allocates the resources.
Other Important Activities
Following are some of the important activities that an Operating System performs −
Security − By means of password and similar other techniques, it prevents unauthorized
access to programs and data.
Control over system performance − Recording delays between request for a service
and response from the system.
Job accounting − Keeping track of time and resources used by various jobs and users.

Error detecting aids − Production of dumps, traces, error messages, and other
debugging and error detecting aids.
Coordination between other software’s and users − Coordination and assignment of
compilers, interpreters, assemblers and other software to the various users of the
computer systems.
Socket Programming:
Socket is an abstraction through which an application may send and receive data. It provide generic access to inter-process communication services. e.g. IPX/SPX, Appletalk, TCP/IP. And are Standard API for networking.

Client-Server communication
Server
passively waits for and responds to clients passive socket
Client
initiates the communication must know the address and the port of the server active socket
Socket Procedures:
Socket creation in C: socket()
o int sockid = socket(family, type, protocol);o sockid: socket descriptor, an integer (like a file-handle)o family: integer, communication domain, e.g.,
PF_INET, IPv4 protocols, Internet addresses (typically used) PF_UNIX, Local communication, File addresses
o type: communication type SOCK_STREAM - reliable, 2-way, connection-based service

SOCK_DGRAM - unreliable, connectionless, messages of maximum length
o protocol: specifies protocol IPPROTO_TCP IPPROTO_UDP usually set to 0 (i.e., use default protocol)
Socket close in C: close()
When finished using a socket, the socket should be closed
status = close(sockid);
sockid: the file descriptor (socket being closed)
status: 0 if successful, -1 if error
Closing a socket: closes a connection (for stream socket) and frees up the port used by the socket
Exchanging data with stream socket
int count = send(sockid, msg, msgLen, flags);
msg: const void[], message to be transmitted
msgLen: integer, length of message (in bytes) to transmit
flags: integer, special options, usually just 0
count: # bytes transmitted (-1 if error)
int count = recv(sockid, recvBuf, bufLen, flags);
recvBuf: void[], stores received bytes
bufLen: # bytes received
flags: integer, special options, usually just 0
count: # bytes received (-1 if error)
Exchanging data with datagram socket
int count = sendto(sockid, msg, msgLen, flags, &foreignAddr, addrlen);
msg, msgLen, flags, count: same with send()

foreignAddr: struct sockaddr, address of the destination
addrLen: sizeof(foreignAddr)
int count = recvfrom(sockid, recvBuf, bufLen, flags, &clientAddr, addrlen);
recvBuf, bufLen, flags, count: same with recv()
clientAddr: struct sockaddr, address of the client
addrLen: sizeof(clientAddr)

FAQs
Unit-I and II
Q1 Why should we use base register, index register and displacement format for the formation of address?
Q 2 Consider the following program segments
PG 1 START
ENTRY SYM 11
EXTRN PG 2, SYM 23
DC A(PGA), A(PGB + 4)
SYM 11 DC A(SYM 11-PG 1), (SYM 23 –PG 2)
END
PG 2 START
ENTRY SYM 23
EXTRN PG 1, SYM 11
SYM 21 DC A(SYM 11-2),A(SYM 21)
SYM 22 DC A(PG 2+4),A(SYM 21 –PG 2)
SYM 23 DC A(SYM 21 –PG 1)
END
Assume these two programs are to be loaded starting at location 200 in order PG 1 and PG 2. Fill the GEST for each symbol. Also give the ESD and RLD card entries for the above program segments.
Q 3 When we study high level language, there are some differences between terms like keyword and tokens.
Study and write differences between these terms
i) Passes and Phases of compiler

ii) Syntax analysis and Semantic analysis
iii) Tokens and Uniform symbol
Q4. The lexical analysis for a modern computer language such as Java needs the power of which machine models in a necessary and sufficient sense? Also brief about thart model.
Q5. High level languages are preferred over low level while programming, throw light on advantages of using high level languages over that of assembly languages.
Q6. List down the major stages in the process of compilation?
Q7. A parser takes input in the form of a sequence of tokens or program instructions and usually builds a data structure in the form of a parse tree or an abstract syntax tree. What does parsing mean in the context of compilers?
Q8 Describe the syntax for a variable definition statement in C language for simple scalar variables using Context Free Grammar. Give the rightmost derivation sequence for the statement - short a, count, *p;
Q9 A breakpoint is an intentional stopping or pausing place in a program. Can you jot down few points that why is the feature of putting "break points" very important in debuggers?
Q10 In the entire process of program development errors may occur at various stages and efforts to detect and remove them may also be made at various stages. What are some essential features in program debuggers? How can these be implemented?
Q11 Find out the number of tokens in the following C statement is
printf("i = %d, &i = %x", i, &i);
Q12 What is the maximum number of reduce moves that can be taken by a bottom-up parser for a grammar with no epsilon- and unit-production (i.e., of type A -> ? and A -> a) to parse a string with n tokens? write in steps to explain the answer.
Q 13 Some code optimizations are carried out on the intermediate code. List down any four reasons for this.
Q 14 Consider the following C code segment. If there is some dead code try rewriting the code without dead code and if not, explain.
for (i = 0, i<n; i++)
{
for (j=0; j<n; j++)

{
if (i%2)
{
x += (4*j + 5*i);
y += (7 + 4*j);
}
}
}
Q 14 Consider the intermediate code given below and find out number of nodes and edges in CFG contructed by this code.
1. i = 1
2. j = 1
3. t1 = 5 * i
4. t2 = t1 + j
5. t3 = 4 * t2
6. t4 = t3
7. a[t4] = –1
8. j = j + 1
9. if j <= 5 goto(3)
10. i = i + 1
11. if i < 5 goto(2)
Q 15 In a resident- OS computer, which of the system software must reside in the main memory under all situations? Give reason too.
Q 16 List all purposes of using intermediate code in compilers.

Q17 Which compilation step makes sure that all the undefined symbols in the code are resolved? Explain with some example about the step of resolving.
Q 18 Differentiate between the terms binding and binding time.
Q 19 The a.out of linux systems file is in the which format of compiler if we consider gcc compiler. Explain formats of compiler too.
Q 20 In the preprocessing stage of compilation what happens to header files, macros and comments.
Q21 Give all possible error recovery actions in lexical analysis phase.
Q22 Write the regular expression for denoting the set containing the string a and all strings consisting of zero or more a’s followed by a b.
Q23 In phase diagram of compiler what do you mean by machine dependent and machine independent optimization.
Q24 An optimizing compiler is a compiler that tries to minimize or maximize some attributes of an executable computer program. Explain all the properties of optimizing compiler.
Q25 List all various ways to pass parameter in a function.
Q26 Mention the properties that a code generator should possess.
Q27 Brief about peep-hole optimization and list the characteristics of peep-hole optimization.
Q28 I have clicked some photos in my camera. I am trying to transfer photos to laptop using USB but camera is not getting connected. Give debugging steps.
Q29 List all the tools which are used in debugging C & C++ Programming languages.
Q30 When I am having printf/cout/system.out.println then what is the use of debugger?
Q31. What are Visual Debuggers?
Q32 If your web services are running slow, So where will you start debugging and what could be the reason for slow performance?
Q33 LEX and YACC are tools used to generate lexical analyzers and parsers. Differentiate between the two.
Q34 I have worked with LEX for executing some code whenever some regular expression is found, can YACC do something more than that? If yes, then what?
Q35 How to design a Debugger both HLD and LLD?

FAQs
Unit-III
1. Enumerate the different RAID levels.
2. Give factors that determine whether a detection-algorithm must be utilized in a deadlock avoidance system.
3. When designing the file structure for an operating system, what attributes are considered?
4. How would a file named EXAMPLEFILE.TXT appear when viewed under the DOS command console operating in Windows 98?
5. When we start our Computer then there is an operation which is performed automatically by the Computer which is also called as Booting. Explain the types of booting.
6. Differentiate between the terms routine and sub routine.
7. Linux Operating System has primarily three components: Kernel, System Library, and System Utility. Explain all three.
8. Explain Linux architecture system consist of following: shell and utilities
9. Kernel architectures are of different types i.e monolithic, micro kernel, hybrid. Which kernel architecture is used in linux and mac operating systems?
10 Explain Booting the system and Bootstrap program in operating system.
11 List down the main functions of a Kernel?
12 Differentiate between the terms compiler and interpreter.
13 How would you identify daemons in Unix and zombie processes
14 How can a VFS layer allow multiple file systems support?
15 Explain the booting process of a Windows XP system.
16 How are data structures handled by NTFS and how does it recover from a crash?
17 Give the benefits and losses of placing the functionality in a device controller rather than in placing it in the kernel?
18 Clock interrupts fire at a rate much slower than the underlying speed of the CPU. How can the speed of interrupt driven input output systems be improved?

19 There is option to increase virtual memory in system. Write down method to increase Virtual memory in Windows 10.
20 Certain object availability for a robot when it is assembled is ensured by a real time operating system. So explain about hard real time and soft real time system.
22. Flow Chart of General Loader Scheme
23. Differentiate between Complier and Interpreter?
24. Elucidate Load and Go Assembler.
25. Differentiate between Bootstrap Loaders and Relative Loader.
26. Elucidate Phases of linking loader.
27. Explicate Automatic Library Search.
28. List the Loader options INCLUDE and DELETE
29. Why are there two different kinds of linking, i.e. static and dynamic?
30. Illustrate Absolute Loader Algorithm.
31. Differentiate between linker and linkage
32. Construe Implicit And Explicit Linking In Dynamic Loading?
33. How We Use Dynamic Linking In Linux? Give Example?
34. How can be 16-bit Dll ported to A Win32 Dll?
35. I have a lot of lib files in a folder and I want them to be additional references in the linker. Write down the steps to manually add linker references.
36. Write the Difference Between The Conventional And Direct Path Loader.
37. Discuss the Case study of Linker in x86 machines

References:
1. Donovan, System Programming.2. https://www.iup.edu 3. Alan C. Shaw, System Programming. 4. Dhamdhere, System Programming, TMH, 2011.