Embed Size (px)
Citation preview

Psychological Review1969, Vol. 76, No. 2, 165-178
INTERACTION OF INFORMATION INWORD RECOGNITION1
JOHN MORTON
Applied Psychology Research Unit, Cambridge, England
Quantitative predictions are made from a model for word recognition. Themodel has as its central feature a set of "logogens": devices which accept in-formation relevant to a particular word response irrespective of the source ofthis information. When more than a threshold amount of information hasaccumulated in any logogen, that particular response becomes available forresponding. The model is tested against data available on the effect of wordfrequency on recognition, the effect of limiting the number of response alterna-tives, the interaction of stimulus and context, and the interaction of successivepresentations of stimuli. The implications of the underlying model are largelyupheld. Other possible models for word recognition are discussed as are theimplications of the Logogen Model for theories of memory.
In previous papers a functional model forword recognition has been developed(Morton, 1964a, 1964b, 1964d; Morton &Broadbent, 1967). The form of descriptionused only lent itself to qualitative predic-tions and while it seemed to have someheuristic value, the overall system was toocomplex to allow rigorous specification ofits properties. In the present paper themodel is first outlined in a slightly simplifiedway and then certain features of it areisolated in order to make quantitativepredictions about performance in wordrecognition. The various predictions madeare largely independent and have in com-mon only the fact that in all situationsthere is some stimulus information present.The effects of word frequency are taken toindicate relatively permanent changes inthe system; the effects of having a reducedset of alternative responses involve tem-porary changes in the same variable.Different predictions are made concerningthe interaction of a context with the stim-ulus and the effects of repeated presenta-tion, these differences arising from differ-ences in the potential sources of suchinformation. The model contrasts mostcompletely with explanations of word
1 Part of this paper was written while the authorwas at the Department of Psychology, Yale Uni-versity, supported by Grant MH 14229 from theNational Institutes of Mental Health to Yale Uni-versity. The author is grateful to W. R. Garner forthe use of much of his time.
recognition which would ascribe all theobserved effects as being due to "guessing"habits.
While in conception the model is verycomplex and highly interacting, it shouldbe noted that the separate sections can bejudged in isolation. In the description ofthe model a number of variables are intro-duced to account for primary observations.The implications of most of them are testedin the sections that follow.
DESCRIPTION OF THE MODEL
The basic unit in the model is termed alogogen.2 The logogen is a device whichaccepts information from the sensoryanalysis mechanisms concerning the proper-ties of linguistic stimuli and from context-producing mechanisms. When the logogenhas accumulated more than a certainamount of information, a response (in thepresent case the response of a single word)is made available. Each logogen is in effectdefined by the information which it canaccept and by the response it makes avail-able. Relevant information can be de-scribed as the members of the sets ofattributes [&], \_Vi], and [^4»], these beingsemantic, visual, and acoustic sets, respec-tively. More detailed suggestions as to theproperties of these sets are given elsewhere(Morton, 1968b). Incoming information
1 From logos—"word" and genus—"birth." Theauthor is indebted to Hallowell Davis for suggestingthe term.
165

166 JOHN MORTON
ContextSystem Semantic
Attributes
Logogen
'< AvailableResponses
OutputBuffer
RehearsalLoop
Responses
FIG. 1. Flow diagram for the Logogen Model.
has only a numerical effect upon anylogogen which merely counts the number ofmembers of its denning sets which occur,without regard to their origin. When thecount rises above a threshold value, thecorresponding response is made available.3
Available responses go to the OutputBuffer, whence they may emerge as actualresponses or be recirculated to the LogogenSystem in a "rehearsal loop." This ideal-ized model is diagrammed in Figure 1.
Since this system operates during readingand listening to continuous speech, it isnecessary to assume that the value of thecount decays very rapidly with time, re-turning to its original value in something ofthe order of 1 second. Otherwise wordswith a structural similarity to the onesspoken would become available uncon-trollably. When a context is presented inan experiment, however, the Context Sys-tem can operate almost continuously tomaintain constant the levels of the countsin logogens affected by that context.Stimulus effects must remain transitory
1 It should be noted that this use of the term"available response" differs slightly from the con-cept of "availability" as used by other writers onmemory (e.g., Tulving & Pearlstone, 1966) and wordrecognition (e.g., Eriksen & Browne, 1956). Pre-vious usage refers to a continuum of availabilitywhich corresponds more nearly to the current levelof the threshold of a logogen in the present model.An "available response" is related to the old term"implicit response" (Miller & Dollard, 1941) but ismore limited in its application in some rather funda-mental ways.
unless a portion of the stimulus has beenrecorded in some verbalizable form such as"A three-syllable word" or "A word withan initial p." Such verbalizations wouldact in a way similar to that of a context andproduce lasting effects, which might hinderthe subject if the information were in-correct.
In the complete model the nature of therelationship between the Logogen Systemand the Context System is such that thereis continuous exchange of information be-tween the two, which does not result inresponses becoming available and which isuncorrelated with the objective features ofthe experiment (see Morton, 1968b). Thisactivity affects the values of the counts inthe various logogens and it is assumed thatsamples of the values of the counts wouldbe distributed in a way which approximatesthe normal distribution and that all logo-gens would have identical distributions.It is further assumed that such activity isthe only source of apparent noise in thesystem. Logogens can thus be regarded asbehaving in a manner similar to detectorsdescribed by signal detection theory (Green& Swets, 1966). Figure 2 illustrates thestate of a logogen under various conditions.Diagram 2a represents its normal state, theordinate being a probability distribution.The range of the count is such that its valuevery rarely exceeds the level of the thresh-old and, on average, t items of relevantinformation are required at any one timebefore the corresponding response will beavailable. The effect of a context is toraise the mean of the count by an amountc, as in Diagram 2b. In this case only anaverage of (t—c) further units of informa-tion will be required to produce a response.The effect of a stimulus is similar, as shownin Diagram 2c, but, as previously men-tioned, the stimulus, unlike the context, isnot self-sustaining. When both contextand stimulus are present, the units ofinformation add, and an average of only[t—(s+c)~} units are required to produce aresponse, as shown in Diagram 2d.
Logogens have one further property, inthat following the availability of a response,the threshold of the logogen is lowered to a

WORD RECOGNITION 167
certain level 7, returning to a value slightlyless than the original value with a timeconstant which is very long in comparisonwith the time constant of the count decay.This property was originally required toexplain the fact that in a word-recognitionexperiment subjects often give as erroneousresponses words which have occurred asresponses earlier in the experiment (Morton1964c). It is assumed that such a propertyis also reflected in the fact that words ofhigh frequency of occurrence are, in general,more intelligible in noise than low-fre-quency words. In terms of the LogogenModel we would say that logogens cor-responding to words of high frequency inthe language have lower thresholds. Sincethe requirement for such threshold loweringis the response becoming available, and notnecessarily the response being made, bothfrequency of emission and frequency ofreception will affect the threshold.4 Theshort- and long-term effects of word repeti-tion are shown in Diagram 2e. The short-term effect is called the 7 factor (and will bea function of time); the long-term effectsare shown by the threshold lines markedH. F., M. F., and L. F., corresponding tohigh-, medium-, and low-frequency words.It can be seen that the effect of a lowerthreshold is equivalent to the effect ofhaving contextual information in that bothreduce the amount of sensory informationwhich would be required to take the levelof the count above threshold.
It is assumed that the system is passive,in the sense used by Morton and Broadbent(1967), as opposed to active. As the systemoperates, no comparisons are made by anymechanism external to the Logogen Systemof the levels of activation in differentlogogens. Decisions are only made withineach logogen. Thus more than one re-sponse could be available following thepresentation of a single stimulus. Thefurther assumption is made, however, thatthe exit from the Logogen System to anOutput Buffer is a single channel, and thusthe first such response to become availablewill have precedence.
* See Morton (1964d) for a discussion of the emis-sion versus reception controversy.
Normal state
Effect of context
Effect of stimulus
Effect of stimulusplus context
Effects of word frequencyand word repitition
FIG. 2. The effects of certain situations upon thestate of a logogen. (The horizontal axes representthe level of excitation—or similar analogy—in thelogogen. The curves correspond to probability dis-tributions of the excitation. The vertical linesrepresent the threshold of the logogen. When thelevel of excitation exceeds the threshold the corre-sponding word is available as a response.)
MATHEMATICAL TREATMENT
The full treatment of a system such asthe one described above by signal detectiontheory has not yet been worked out. In-stead predictions will be made from theresponse strength model (Luce, 1959).For present purposes Luce's model may beregarded as a logarithmic transformationof a Thurstonian or a signal detectionmodel. Thus where effects add in thelatter system, as in Figure 1, they are multi-plied in the response strength model. Thefirst step is to assign response strengths toall possible responses in a given situation.This is equivalent in the Logogen Model toassigning a value to the difference betweenthe current level of activation and thethreshold for every logogen. The proba-bility of any particular response becomingavailable is then given by the ratio of theresponse strength for that item divided bythe total of the response strengths for allthe possible responses. This is termed theRatio Rule. Since ratios and not absolutedifferences are critical in this form ofanalysis we are free to scale the assignedvalues. Thus when we are considering the

168 JOHN MORTON
effects of a stimulus we will say that theresponse strength of the correct logogen isa compared with a value of unity for allother logogens. This is not to say that thestimulus has no effect on the other logogens,merely that on average the effects will bethe same for all the others. The value of athen is properly regarded as the differencebetween the effects on the stimulus logogenand the average of all others. The state ofthe logogens when the stimulus is presentedis contrasted symbolically with the effect ofthe stimulus by use of the letter V. Thisletter will be used to designate the differ-ences in threshold between logogens andalso the differential effects of context.The combined effects of the stimulus to-gether with one of the other factors iscalculated by multiplying the responsestrengths of the two effects for each logogen.This is equivalent to adding the effects inFigure Id. In the case where we haveassigned a value of 1, as in Table 2, themultiplication in the response strengthanalysis is equivalent to saying that thereis no effect of the stimulus on that logogen.Throughout this paper it should be re-membered that the mathematics is onlyused to predict the operation of the systemwhich is described above.
PREDICTIONS FROM THE MODEL
Word-Frequency Threshold Effect
A number of authors have shown thatintelligibility in noise and the visual dura-tion threshold for words are strongly in-fluenced by the frequency of occurrence ofthe words, and there has been much con-troversy as to whether such results shouldbe attributed to "stimulus effects" or"response effects" (Broadbent, 1967).Within the Logogen Model, which in thisrespect resembles Broadbent's own treat-ment, the dichotomy is scarcely applicable(Morton, 1968a).
By the model the difference betweenwords of differing frequency of occurrenceis that the logogens have different thresh-olds. Thus the logogens corresponding tohigh-frequency words will require lessstimulus information for the count to rise
above the threshold. The amount ofstimulus information available to a logogenis, however, assumed to be independent ofthe frequency of the word and is a functiononly of the properties of the stimulus(duration, contrast, signal-to-noise ratio).Thus we will say that the presentation of astimulus increases the response strength ofthe stimulus logogen to an amount a com-pared with all other logogens, whosestrength remains at unity. (Since we areconcerned with ratios, the latter value isarbitrary and simply serves to scale a.)This is not to say that it is assumed that allother words are equally confusable with anystimulus word, merely that stimulus con-fusions are unrelated to word frequency.This is the "principle of acoustical equi-valence" suggested by Brown and Ruben-stein (1961). These authors investigatedthe word-frequency threshold effect, divid-ing the 6500 monosyllabic content wordsinto 13 classes of 500 words each, theclasses being formed by grouping the wordsby their frequency. They presented sub-jects (5s) with a total of 1300 words, con-sisting of a randomized selection of 100words from each frequency interval innoise, and calculated Ci, the number ofresponses which were correct in each inter-val, i, and s,-, the number of responses whichwere in the same frequency interval as thestimulus (but might have been incorrectresponses).8
The latter measure includes d, however,and so cannot be compared with it; insteadwe will use eit the number of incorrect re-sponses in the same frequency interval asthe stimulus.
Morton (1968a) has tested a series ofmodels against Brown and Rubenstein'sdata, rejecting single-threshold modelswhich claim that the word-frequency effectis entirely due to response bias and a modelby which the effect is entirely due to thestimulus, in which a would be a function ofword frequency. For the model at presentunder discussion, the response strengthsappropriate to the different responses inthis situation are given in Table 1. If the
6 The author is grateful to H. Rubenstein forkindly providing his original data.
WORD RECOGNITION 169
TABLE 1
RESPONSE STRENGTHS IN THE WORD-FREQUENCY EXPERIMENT
Stimu-
class
1»n
Correct
aponses
aiViaiVictnV*
Incorrect responses of interval
1
(M-l)FiMViMVi
i
MVf(M-l)Vi
MVi
n
MVnUVn
(M-DV,
Total ofstrengths
T,Tirn
assumption concerning the invariance of theamount of stimulus information with wordfrequency is correct, all a will be equal.
The differences in thresholds of logogensin different frequency classes are indicatedby the variables V\- • • W • • Vn. M is thenumber of responses in each frequencyclass. The probability of a correct re-sponse in the interval i is thus given by theequation
^• = ̂ 7'. [1]
The probability of an error responsebeing in the correct frequency interval isgiven by
«i = r '• C2]
Combining Equations 1 and 2 we obtain
ct =eg
M-l [3]
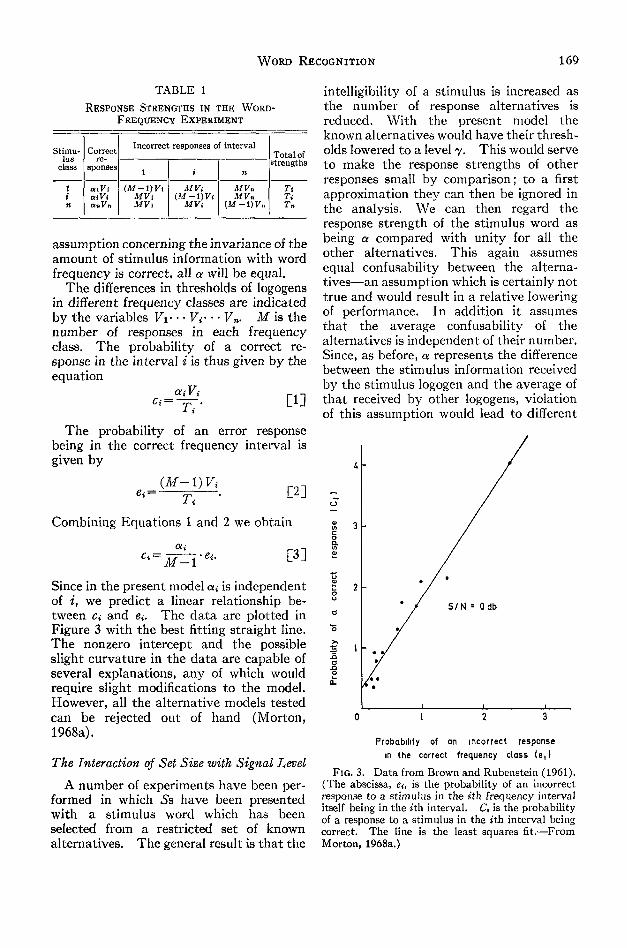
Since in the present model a, is independentof i, we predict a linear relationship be-tween d and ef. The data are plotted inFigure 3 with the best fitting straight line.The nonzero intercept and the possibleslight curvature in the data are capable ofseveral explanations, any of which wouldrequire slight modifications to the model.However, all the alternative models testedcan be rejected out of hand (Morton,1968a).
The Interaction of Set Size with Signal Level
A number of experiments have been per-formed in which 5s have been presentedwith a stimulus word which has beenselected from a restricted set of knownalternatives. The general result is that the
intelligibility of a stimulus is increased asthe number of response alternatives isreduced. With the present model theknown alternatives would have their thresh-olds lowered to a level 7. This would serveto make the response strengths of otherresponses small by comparison; to a firstapproximation they can then be ignored inthe analysis. We can then regard theresponse strength of the stimulus word asbeing a compared with unity for all theother alternatives. This again assumesequal confusability between the alterna-tives—an assumption which is certainly nottrue and would result in a relative loweringof performance. In addition it assumesthat the average confusability of thealternatives is independent of their number.Since, as before, a represents the differencebetween the stimulus information receivedby the stimulus logogen and the average ofthat received by other logogens, violationof this assumption would lead to different
S/N = Odb
0 1 2 3
Probability of an incorrect responsein the correct frequency class (e, l
FIG. 3. Data from Brown and Rubenstein (1961).(The abscissa, et, is the probability of an incorrectresponse to a stimulus in the *th frequency intervalitself being in the ith interval. C, is the probabilityof a response to a stimulus in the »th interval beingcorrect. The line is the least squares fit.—FromMorton, 1968a.)
170 JOHN MORTON
O.98
0.95
50.80
050
0.02
2 4 8 16 32 296 1000Number of Alternatives
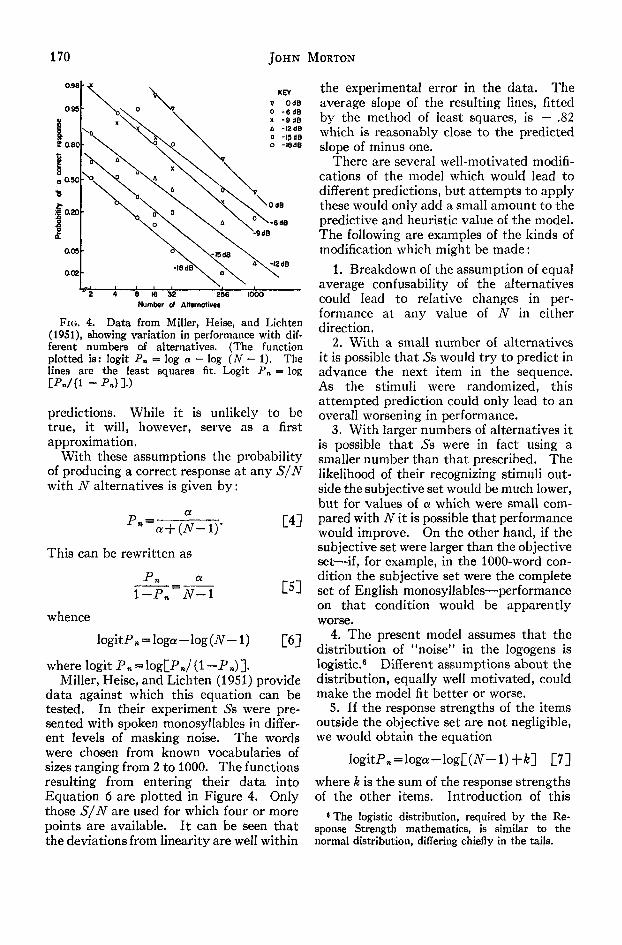
FIG. 4. Data from Miller, Heise, and Lichten(1951), showing variation in performance with dif-ferent numbers of alternatives. (The functionplotted is: logit P, = log a - log (N - 1), Thelines are the least squares fit. Logit Pn = log
predictions. While it is unlikely to betrue, it will, however, serve as a firstapproximation.
With these assumptions the probabilityof producing a correct response at any S/Nwith N alternatives is given by:
[4]±n a+(N-lY
This can be rewritten as
P»1-P. N-l
whence
[5]
[6]
where logit Pn = log[Pn/(l-Pn)].Miller, Heise, and Lichten (1951) provide
data against which this equation can betested. In their experiment 5s were pre-sented with spoken monosyllables in differ-ent levels of masking noise. The wordswere chosen from known vocabularies ofsizes ranging from 2 to 1000. The functionsresulting from entering their data intoEquation 6 are plotted in Figure 4. Onlythose S/N are used for which four or morepoints are available. It can be seen thatthe deviations from linearity are well within
the experimental error in the data. Theaverage slope of the resulting lines, fittedby the method of least squares, is — .82which is reasonably close to the predictedslope of minus one.
There are several well-motivated modifi-cations of the model which would lead todifferent predictions, but attempts to applythese would only add a small amount to thepredictive and heuristic value of the model.The following are examples of the kinds ofmodification which might be made:
1. Breakdown of the assumption of equalaverage confusability of the alternativescould lead to relative changes in per-formance at any value of N in eitherdirection.
2. With a small number of alternativesit is possible that 5s would try to predict inadvance the next item in the sequence.As the stimuli were randomized, thisattempted prediction could only lead to anoverall worsening in performance.
3. With larger numbers of alternatives itis possible that 5s were in fact using asmaller number than that prescribed. Thelikelihood of their recognizing stimuli out-side the subjective set would be much lower,but for values of a which were small com-pared with N it is possible that performancewould improve. On the other hand, if thesubjective set were larger than the objectiveset—if, for example, in the 1000-word con-dition the subjective set were the completeset of English monosyllables—performanceon that condition would be apparentlyworse.
4. The present model assumes that thedistribution of "noise" in the logogens islogistic.6 Different assumptions about thedistribution, equally well motivated, couldmake the model fit better or worse.
5. If the response strengths of the itemsoutside the objective set are not negligible,we would obtain the equation
logitPB = loga-log[(^-l)+fe] [7]
where k is the sum of the response strengthsof the other items. Introduction of this
8 The logistic distribution, required by the Re-sponse Strength mathematics, is similar to thenormal distribution, differing chiefly in the tails.

WORD RECOGNITION 171
constant could make the model fit the dataalmost perfectly.
None of these modifications would affectthe underlying principles of the model.The best we can say then is that the modelfits the data reasonably well. This is asmuch as any model can hope to do. It is,however, clear that by the above analysisthe effect of increasing the signal strengthis the same regardless of the number ofalternatives.
Alternative Models
1. Green and Birdsall (1958) have plottedMiller et al.'s data by calculating values ofd' for the different values of N, showingthat d' is approximately independent of N.This procedure closely approximates theone used above and has essentially the sameunderlying model.
2. Garner (1962) has plotted the samedata in terms of the number of bits ofinformation transmitted, showing that thismeasure is essentially independent of TV.This form of analysis makes no claims aboutthe form of the underlying model and isperhaps better regarded as indicating, ingeneral, that 5s' efficiency remains inde-pendent of N. As such it is not an alterna-tive model to the Logogen Model, butrather an alternative method of treating thedata.
3. Stowe, Harris, and Hampton (1963)propose a model whereby words are dis-criminated by identifying them on a num-ber of binary stimulus dimensions. Thecorrect response is only given followingcorrect identification on all the dimensions.Logs n dimensions would be required todiscriminate among n words. Thus in thetwo-choice situation only a single dimensionwould be used. If the probability of acorrect decision on one dimension were Pd,and if all dimensions were equally welldiscriminated, then the probability of acorrect identification among n alternativeswould be given by Pn= (P<0log2B. Thismodel gives a reasonable fit to Miller et al.'sdata. It appears to suffer a conceptualdrawback, however, in that as the numberof alternatives is reduced, the number ofdiscriminating dimensions which the system
uses is reduced. Some of the dimensionsexcluded from the discrimination process(presumably in some arbitrary way) couldin fact provide usable information. Themodel is insufficiently explicit to enablefurther discussion.
It has been suggested that the effect ofrestricting the number of alternatives is toreduce the thresholds of the appropriatelogogens to a common value 7. If thiswere so, then we would expect, as Pollack,Rubenstein, and Decker (1959) have shown,that word frequency does not exert ameasurable influence upon the intelligi-bility of words in known message sets.
The Interaction of Stimulus and Context
There is a large body of evidence whichindicates that the recognition of a word isgreatly facilitated by the prior presentationof a context. The extent of the facilitationis a function of the likelihood of the contexteliciting the word in a free-response situ-ation. In most cases the context consistsof an incomplete sentence which the stimu-lus word completes, but the analysis belowcan be generalized to any context. Threesources of data are required: the proba-bility of the target word being given as aresponse to the context alone, in theabsence of a stimulus; the probability of theresponse to a stimulus at a particular S/Nin the absence of a context; and theprobability of the response at that S/Nwhen the context has already been pre-sented.
Table 2 gives the appropriate response
TABLE 2
RESPONSE STRENGTHS WITH STIMULUS,WITH CONTEXT, AND WITH BOTH
Experimentalcondition
Stimulus only
Context only
Stimulus andcontext
Correctre-
sponse
a
Vt
>F<
Other responsesto individual
words
1 !•••!
ViVi-V.
Fl Vf'Vn
Total ofresponsestrengths
j
* B=a 2-i ' i
T+(a-l)Vt
Note.—The entries in the third line are obtained by multi-prying the entries in the first two lines. This is equivalent toadding the effects of stimulus and context in Figure 2d.
172 JOHN MORTON
strengths for stimulus alone, context alone,and for the combination of stimulus andcontext. The response strengths for thecombined condition are obtained by multi-plying the strengths in the other twoconditions. This table is intended, asbefore, to represent the average of allpossible outcomes.
The probability of a correct responsefrom the stimulus, Pa, alone is given by theequation
^ M
[9]
The probability of a correct response fromcontext alone, P0, is given by
from which we obtain
from which
. T
Vt/Pt.
[10]
o 8 word contexta 4 word context
A 0 word context
20 40 60 80 100
Exposure Duration in milliseconds
140
FIG. 5. Data from Tulving, Mandler, andBaumal (1964) on the joint effects of stimulus andcontext. (The function plotted is: logit P,c = a,+ bx, where x is the exposure duration, P,e is theprobability of a correct response, and a and b areconstants.)
With both context and stimulus, theprobability of a correct response, Psc, is
«V< [12]
If we substitute for a and T from Equations9 and 11 in this equation, F,- vanishes andwe are left, after rearrangement, with:
P.. P,1-P.. 1-P. I-Pc
•(N-l). [13]
If we take logarithms this equation can bewritten as :
logitPsc = lH-log(TV-l). [14]
It should be noted that the termlog (N — 1) is not a variable which can beconsidered as varying in the presence of acontext, with or without a stimulus, sinceit is derived entirely from the conditionwhere only a stimulus is given. It is thusunaffected by any effect the context mayhave in reducing the number of alternativeresponses. In fact, Equation 14 can bewritten as :
logitP8C = loga+logitPc. [15]
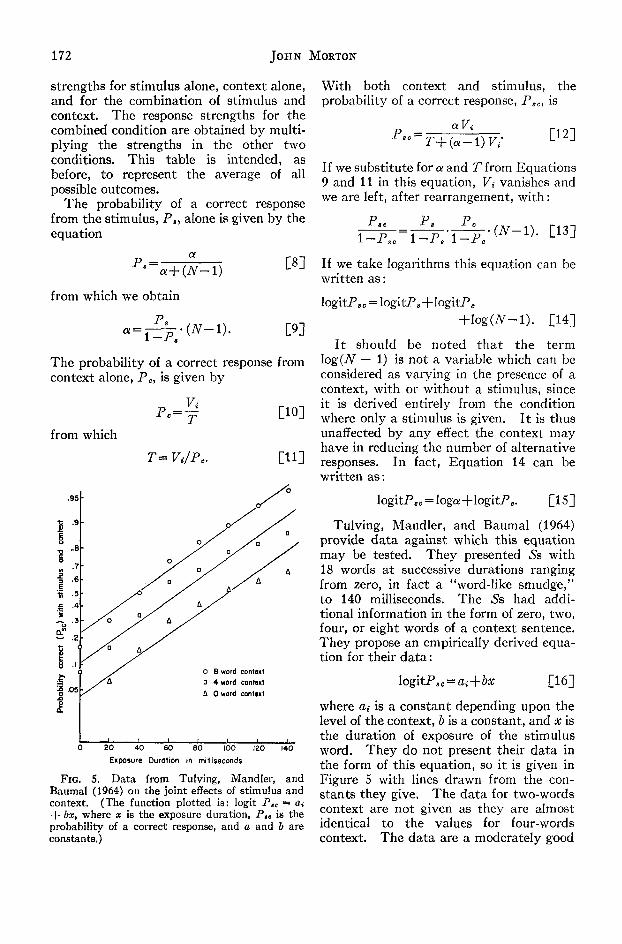
Tulving, Mandler, and Baumal (1964)provide data against which this equationmay be tested. They presented 5s with18 words at successive durations rangingfrom zero, in fact a "word-like smudge,"to 140 milliseconds. The 5s had addi-tional information in the form of zero, two,four, or eight words of a context sentence.They propose an empirically derived equa-tion for their data :
logitP« = [16]
where a,- is a constant depending upon thelevel of the context, & is a constant, and x isthe duration of exposure of the stimulusword. They do not present their data inthe form of this equation, so it is given inFigure 5 with lines drawn from the con-stants they give. The data for two-wordscontext are not given as they are almostidentical to the values for four-wordscontext. The data are a moderately good
WORD RECOGNITION 173
fit, but there is a curvilinear componentapparent in all three of the context con-ditions.
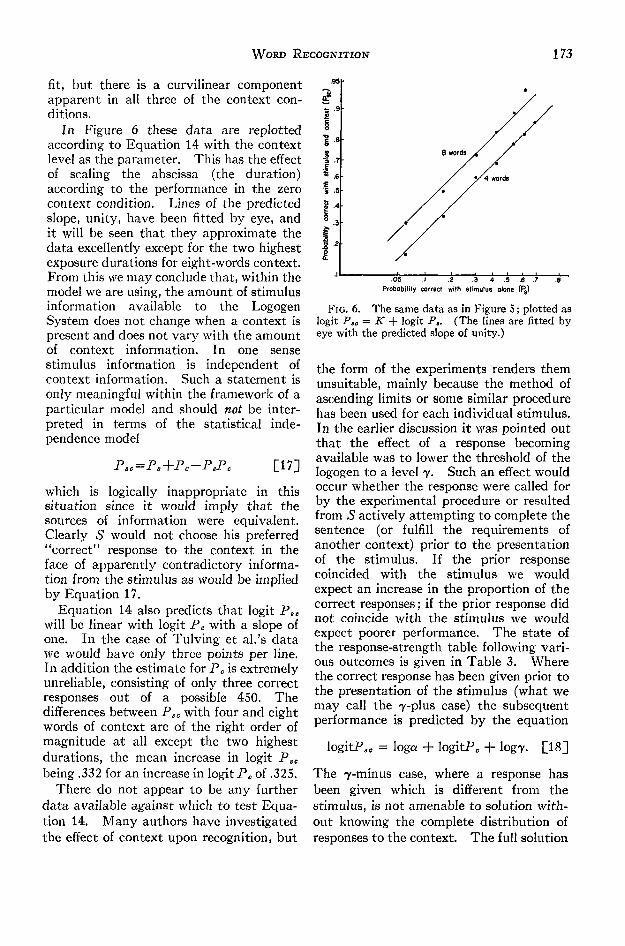
In Figure 6 these data are replottedaccording to Equation 14 with the contextlevel as the parameter. This has the effectof scaling the abscissa (the duration)according to the performance in the zerocontext condition. Lines of the predictedslope, unity, have been fitted by eye, andit will be seen that they approximate thedata excellently except for the two highestexposure durations for eight-words context.From this we may conclude that, within themodel we are using, the amount of stimulusinformation available to the LogogenSystem does not change when a context ispresent and does not vary with the amountof context information. In one sensestimulus information is independent ofcontext information. Such a statement isonly meaningful within the framework of aparticular model and should not be inter-preted in terms of the statistical inde-pendence model
1 sc—-t a\~± c -L B-L c [17]
which is logically inappropriate in thissituation since it would imply that thesources of information were equivalent.Clearly S1 would not choose his preferred"correct" response to the context in theface of apparently contradictory informa-tion from the stimulus as would be impliedby Equation 17.
Equation 14 also predicts that logit Pacwill be linear with logit Pc with a slope ofone. In the case of Tulving et al.'s datawe would have only three points per line.In addition the estimate for Pc is extremelyunreliable, consisting of only three correctresponses out of a possible 450. Thedifferences between Pac with four and eightwords of context are of the right order ofmagnitude at all except the two highestdurations, the mean increase in logit P80
being .332 for an increase in logit Pc of .325.There do not appear to be any further
data available against which to test Equa-tion 14. Many authors have investigatedthe effect of context upon recognition, but
.05 .1 .2 .3 A S .6 .7 .8Probability correct with stimulus alone (Ps)
FIG. 6. The same data as in Figure S; plotted aslogit P,e = K + logit P.. (The lines are fitted byeye with the predicted slope of unity.)
the form of the experiments renders themunsuitable, mainly because the method ofascending limits or some similar procedurehas been used for each individual stimulus.In the earlier discussion it was pointed outthat the effect of a response becomingavailable was to lower the threshold of thelogogen to a level y. Such an effect wouldoccur whether the response were called forby the experimental procedure or resultedfrom S actively attempting to complete thesentence (or fulfill the requirements ofanother context) prior to the presentationof the stimulus. If the prior responsecoincided with the stimulus we wouldexpect an increase in the proportion of thecorrect responses ; if the prior response didnot coincide with the stimulus we wouldexpect poorer performance. The state ofthe response-strength table following vari-ous outcomes is given in Table 3. Wherethe correct response has been given prior tothe presentation of the stimulus (what wemay call the 7-plus case) the subsequentperformance is predicted by the equation
logitP.. = loga + logitPc + [18]
The 7-minus case, where a response hasbeen given which is different from thestimulus, is not amenable to solution with-out knowing the complete distribution ofresponses to the context. The full solution

174 JOHN MORTON
TABLE 3
RESPONSE STRENGTHS WHEN AN ANTICIPATORY RESPONSE HAS BEEN GIVEN
Situation
No prior responseCorrect prior response (-v-plus)Incorrect prior response (7-minus)
Correctresponse
aVictyVtaVi
Incorrectresponses
y V • « • V •• . . VViVf-Vj---Vn7,7,".-yVy...7.
Total
r+(a- l )7 iT + (ay — 1) ViT + (a- 1)7,. + (7-DF,-
Note.—r =• 2 Vi throughout. The effects on the response strength of a prior response are obtained by multiplying the appro-priate entry by 7. This is equivalent to a reduction in threshold of an amount 7 in Figure 2e.
has the form
p _86
0V*)
where the values of Ps represent the prob-abilities of words other than the targetword (Word t) being elicited by the con-text, and P,c is the average outcome for anyone target word. An approximation basedon the assumption that all other responseshave equal response strengths gives theequation, to be compared with Equation 15,
logitP8C = loga + log
This equation would underestimate theeffects of 7, especially for low probabilitywords.
Rubenstein and Pollack (1963) providedata against which some of the implicationsof these equations can be tested. Theypresented their Ss with a context : an in-complete sentence, a word to be associatedto, a category name, or the first 1-5 lettersof the target word. Each 5 made a re-
TABLE 4DATA FROM RUBENSTEIN AND POLLACK (1964)
FOR A SENTENCE CONTEXT WITHS/N OF - 14db.
Group Performance
p.p..
7-plus (R)7-minus (F)
.02
1.00.02
.11
.92
.10
.20
.70
.15
.26
.99
.14
.35
.97
.20
.47
.94
.24
.68
.97
.25
.84
.95
.37
Note.—Data given were the overall probability correct (Q),the probability correct for the 7-minus group (F), and Po. The7-plus score (£) was estimated from Q = P,-E + (1 - P.)F,whence E - CQ - (1 - j
sponse to the context ("the word theythought most likely to occur") and thenwas presented with the stimulus word atsix increasingly favorable S/N, makinga response following each presentation.Rubenstein and Pollack present data in twoforms, the average proportion of correctresponses for the whole group and theproportion for those 5s who made aninitially "incorrect" response to a particularcontext, which we may call the -/-minusgroup. When the performance for the7-plus group is estimated from the data itis apparent that they made very few errorseven at the lowest S/N, as would be ex-pected from the above analysis. Theperformance of the 7-minus group is con-siderably worse, and at the lowest S/Ntheir performance is worse than that of thewhole group prior to the first stimuluspresentation. The relevant data are givenin Table 4.
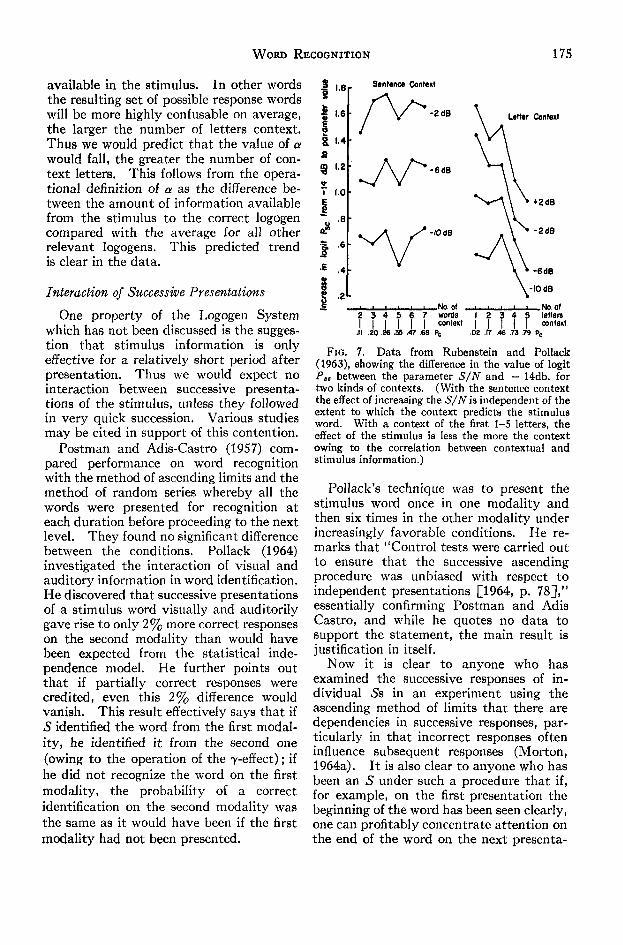
From Equation 20 it seems likely that,with a few more assumptions concerningthe effects of sequential presentation, theeffects of increasing the S/N will be inde-pendent of the value of Pe, provided thatthe set of possible responses remainsapproximately orthogonal with regard totheir stimulus properties. The results forthe sentence context are presented inFigure 7. The ordinate represents thedifference in logit Psc between the — 14db.condition and the parameter level; that is,effectively, the result of increasing thesignal level from —14 db. to the given level.It is apparent that there is no systematicchange. In contrast the data for theletter context are given. In this conditionthe context provides information which ishighly correlated with the information
WORD RECOGNITION 175
available in the stimulus. In other wordsthe resulting set of possible response wordswill be more highly confusable on average,the larger the number of letters context.Thus we would predict that the value of awould fall, the greater the number of con-text letters. This follows from the opera-tional definition of a as the difference be-tween the amount of information availablefrom the stimulus to the correct logogencompared with the average for all otherrelevant logogens. This predicted trendis clear in the data.
Interaction of Successive Presentations
One property of the Logogen Systemwhich has not been discussed is the sugges-tion that stimulus information is onlyeffective for a relatively short period afterpresentation. Thus we would expect nointeraction between successive presenta-tions of the stimulus, unless they followedin very quick succession. Various studiesmay be cited in support of this contention.
Postman and Adis-Castro (1957) com-pared performance on word recognitionwith the method of ascending limits and themethod of random series whereby all thewords were presented for recognition ateach duration before proceeding to the nextlevel. They found no significant differencebetween the conditions. Pollack (1964)investigated the interaction of visual andauditory information in word identification.He discovered that successive presentationsof a stimulus word visually and auditorilygave rise to only 2% more correct responseson the second modality than would havebeen expected from the statistical inde-pendence model. He further points outthat if partially correct responses werecredited, even this 2% difference wouldvanish. This result effectively says that if5 identified the word from the first modal-ity, he identified it from the second one(owing to the operation of the y-effect); ifhe did not recognize the word on the firstmodality, the probability of a correctidentification on the second modality wasthe same as it would have been if the firstmodality had not been presented.
Letter Context
2 3 4 5 6 7
.11 .20 .26 .35 .47 .68
2 3 4 5I I I I I.02 .17 .46 .73 .79 Pc
FIG. 7. Data from Rubenstein and Pollack(1963), showing the difference in the value of logitP,c between the parameter S/N and — 14db. fortwo kinds of contexts. (With the sentence contextthe effect of increasing the S/N is independent of theextent to which the context predicts the stimulusword. With a context of the first 1-5 letters, theeffect of the stimulus is less the more the contextowing to the correlation between contextual andstimulus information.)
Pollack's technique was to present thestimulus word once in one modality andthen six times in the other modality underincreasingly favorable conditions. He re-marks that "Control tests were carried outto ensure that the successive ascendingprocedure was unbiased with respect toindependent presentations [1964, p. 78],"essentially confirming Postman and AdisCastro, and while he quotes no data tosupport the statement, the main result isjustification in itself.
Now it is clear to anyone who hasexamined the successive responses of in-dividual 5s in an experiment using theascending method of limits that there aredependencies in successive responses, par-ticularly in that incorrect responses ofteninfluence subsequent responses (Morton,1964a). It is also clear to anyone who hasbeen an 5 under such a procedure that if,for example, on the first presentation thebeginning of the word has been seen clearly,one can profitably concentrate attention onthe end of the word on the next presenta-

176 JOHN MORTON
tion. What must not be forgotten, how-ever, is that such partial evidence can beincorrect as well as correct. If it is in-correct, then subsequent recognition will behampered, as apparently occurred withRubenstein and Pollack's y-minus 5s.What the experimental data show, then,is that these two competing effects tendto balance out over the course of an ex-periment. From this analysis we wouldpredict that if 5s were informed whether ornot their partial responses were correcttheir performance should improve on sub-sequent trials, since, it can be assumed, theincorrect information, sustained as it is inthe present model by some system equi-valent to the Context System, would notbe passed to the Logogen System. Such aresult was found by Pollack, Rubenstein,and Decker (1959).
In summary, it is apparent that a com-plete description of the processes contri-buting to the effects of repeated presenta-tion and the prediction of performance willrequire detailed consideration of partialresponses as well as full responses. Grossprobabilistic predictions ignore elements ofthe experimental situation which are clearlyimportant.
CONCLUSIONS
The model under discussion was origin-ally devised for qualitative reasons; in thispaper quantitative predictions have beenmade about 5s' behavior in a variety ofsituations. Although the model is ideal-ized in ways which have been discussed, thedata do not seem to contradict it. At themoment there is a lack of alternative func-tional models against which the LogogenModel can be tested. Purely mathematicalmodels have been ignored because, as wehave seen, it is relatively simple to add anextra parameter, albeit intuitively justifiedas a variable, which can produce a perfectfit to the data. Such a practice has notbeen indulged in since there are severalfactors with equal claim for inclusion whosequantitative effect cannot at the momentbe estimated outside the data they wouldbe accounting for.
The existing model has much in commonwith one recently put forward by Norman(1968). One difference hinges on the re-spective treatments of memory. Normanfirst points out that it seems necessary todistinguish between two forms of memorywhich correspond, respectively, to ourimmediate memories of events and memor-ies of events a few seconds old. Normanfollows William James in calling thesetypes "primary" and "secondary," butmakes the unnecessary assumption that theprimary memory must precede secondarymemory in the processing system, anassumption carried over from Waugh andNorman (1965). In the recent paperNorman argues that "there must besufficient interconnections between thestorages to allow a comparison of the just-perceived sensory events with the collectionof previously experienced perceptions [pp.524-525]". In fact, then, the two systemsbecome effectively a single system with twotypes of storage within it.
The Logogen Model does not suffer fromthese objections for we can say that thePrimary Memory is located in the OutputBuffer which follows the Logogen System.Traces remaining in logogens, either in thevalues of the count or the threshold, couldthen be regarded as two possible sources ofinformation (with different time charac-teristics) for Secondary Memory. Theproperties of these two stores, derived asthey are for reasons other than memoric,match fairly well the usual characteriza-tions of Primary and Secondary Memory.
The Output Buffer, which manifestsitself in the eye-voice span (Morton,1964b) and the ear-voice span (Treisman& Geffin, 1967) is seen as having a limitedcapacity, as is primary memory. Materialwithin it is coded in terms of articulationparameters (since the usual destination ofthe material is speech). Thus we wouldexpect to find articulatory confusions inImmediate Recall for visual stimuli, whichtask may be taken as involving primarymemory. Conrad (1964) has shown thaterrors in recall of visually presented lettersare highly correlated with errors made inrecognition of letter names presented audi-

WORD RECOGNITION 177
torily in noise. Conrad terms these "acous-tic confusions" but the correlation betweenacoustic and articulatory descriptionsleaves open the possibility that the correctdescription is "articulatory confusions."
The Logogen System, on the other hand,like secondary memory, is not subject tooverwriting insofar as the 7-effect is con-cerned. It would, however, be impossible,from the state of the appropriate logogen,to discover whether or not a stimulus hadbeen presented once or twice. Crowder(in press) has shown that lists of letters orwords containing repeated items are moredifficult than those without repeats. Suchinformation as is retrieved concerningrepeats would be available either in theOutput Buffer or in a long-term memorystore. The latter construct is necessary toaccount for our ability to maintain theeffect of a context, and could well accountfor such associative phenomena as aredemonstrated in memory tasks.
It is of interest that the present model,derived to account for phenomena of wordrecognition, requires at least three con-structs, each with different properties, fromwhich information could be retrieved in amemory experiment. Arguments based onparsimony as to whether there are one ortwo separate memory stores (Atkinson &Schiffrin, 1967; Melton, 1963) tend to losetheir force. It might be more profitablefor future work on memory to concentrateon attempting to specify the relative con-tributions of these different informationsources in different experimental conditions.7
The differences in detailed treatment ofmemory between Norman's model and theLogogen Model are almost trivial and arecertainly reconcilable. Of more interestare the similarities between the models.The core of Norman's model is a storagesystem into which sensory inputs and"pertinence" inputs are sent. The ele-ments of the storage system are almostidentical to logogens in their properties.Further, the sensory analysis systems inboth models are conceived of as passive, orautonomous. Although Norman refers to
7 R. G. Crowder and J. Morton. Precategoricalacoustic storage. Unpublished manuscript, 1968.
his model as a modified analysis-by-synthesis model, the synthesis is in terms of"expectations," and as such takes a differ-ent form from other analysis-by-synthesissystems which require that the synthesizedanticipation is in the same code as theinput. Norman's model also provides aframework within which problems of atten-tion and the retrieval of information can bediscussed, neither of which topics theLogogen Model is capable of handling in itspresent form. Thus the two models canbe seen as complementary to one another.
Perhaps the most important similarity isa strategic one. Both the models arecapable of expansion to deal with phenom-ena outside the areas for which they wereevolved without losing their essentialcharacter and without becoming too rigid.
REFERENCES
ATKINSON, R. T., & SHIFFRIN, R. M. Humanmemory: A proposed system and its control proc-esses. Technical Report No. 110, Institute forMathematical Studies in the Social Sciences,Stanford University, 1967.
BROADBENT, D. E. Word frequency effect and re-sponse bias. Psychological Review, 1967, 74, 1-15.
BROWN, C. R., & RUBENSTEIN, H. Test of responsebias explanation of word-frequency effect.Science, 1961, 133, 280-281.
CONRAD, R. Acoustic confusions in immediatememory. British Journal of Psychology, 1964, 55,75-84.
CROWDER, R. G. Intraserial repetition effects inimmediate memory. Journal of Verbal Learningand Verbal Behavior, in press.
ERIKSEN, C. W., & BROWNE, C. T. An experi-mental and theoretical analysis of perceptual de-fence. Journal of Abnormal and Social Psy-chology, 1956, 52, 224-230.
GARNER, W. R. Uncertainty and structure aspsychological concepts. New York: Wiley, 1962.
GREEN, D. M., & BIRDSALL, T. G. The effect ofvocabulary size on articulation score. Universityof Michigan: Electronic Defence Group, TechnicalMemorandum No. 81 and Technical Note AFCRC-TR-57-58, 1958. (Reprinted in J. A. Swets, Ed.,Signal detection and recognition by human observers.New York: Wiley, 1964.)
GREEN, D. M., & SWETS, J. A. Signal detectiontheory and psychophysics. New York: Wiley,1966.
LUCE, D. Individual choice behavior. New York:Wiley, 1959.
MELTON, A. Implications of short-term memoryfor a general theory of memory. Journal of

178 JOHN MORTON
Verbal Learning and Verbal Behavior, 1963, 2,1-21.
MILLER, G. A., HEISE, G. A., & LIGHTEN, W. Theintelligibility of speech as a function of the contextof Ihe test materials. Journal of ExperimentalPsychology, 1951, 41, 329-335.
MILLER, N. E., & BOLLARD, J. C. Social learningand imitation. New Haven: Yale UniversityPress, 1941.
MORTON, J. The effects of context on the visualduration threshold for words. British Journal ofPsychology, 1964, S5, 165-180. (a)
MORTON, J. The effects of context upon speed ofreading, eye-movements and eye-voice span.Quarterly Journal of Experimental Psychology,1964, 16, 340-354. (b)
MORTON, J. A model for continuous language be-havior. Language and Speech, 1964, 7,40-70. (c)
MORTON, J. A preliminary functional model forlanguage behavior. International Audiology,1964, 3, 216-225. (Reprinted in R. C. Oldfield& J. C. Marshall, Eds. Language. London:Penguin Books, 1968). (d)
MORTON, J. A retest of the response bias explana-tion of the word frequency threshold effect. Brit-ish Journal of Mathematical and Statistical Psy-chology, 1968, 21, 21-33. (a)
MORTON, J. Grammar and computation in lan-guage behavior. Progress Report No. 6, Centerfor Research in Language and Language Behavior,University of Michigan, May 1968. (b)
MORTON, J., & BROADBENT, D. E. Passive vs.active recognition models or Is your homunculusreally necessary? In W. Wathen-Dunn (Ed.),Models for the perception of speech and visual form.Cambridge, Mass.: M. I. T. Press, 1967.
NORMAN, D. A. Toward a theory of memory andattention. Psychological Review, 1968, 75, 522-536.
POLLACK, I. Interaction between auditory andvisual information sources in word identification.Language and Speech, 1964, 7, 76-83.
POLLACK, I., RUBENSTEIN, H., & DECKER, L. In-telligibility of known and unknown message sets.Journal of the Acoustical Society of America, 1959,31, 273-279.
POSTMAN, L., & ADIS-CASTRO, G. Psychophysicalmethods in the study of word recognition. Sci-ence, 1957, 125, 193-194.
RUBENSTEIN, H., & POLLACK, I. Word predicta-bility and intelligibility. Journal of VerbalLearning and Verbal Behavior, 1963, 2, 147-158.
STOWE, A. N., HARRIS, W. P., & HAMPTON, D. B.Signal and context components of word-recogni-tion behavior. Journal of the Acoustical Societyof America, 1963, 35, 639-644.
TREISMAN, A. M., & GEFFIN, G. Selective atten-tion: Perception or response? Quarterly Journalof Experimental Psychology, 1967, 19, 1-16.
TULVING, E., MANDLER, G., & BAUMAL, R. Inter-action of two sources of information in tachisto-scopic word recognition. Canadian Journal ofPsychology, 1964, 18, 62-71.
TULVING, E., & PEARLSTONE, Z. Availabilityversus accessibility of information in memory forwords. Journal of Verbal Learning and VerbalBehavior, 1966, 5, 381-391.
WAUGH, N. C., & NORMAN, D. A. Primarymemory. Psychological Review, 1965, 72, 89-104.
(Received January 19, 1968)
























![178 Ginga Brasil 178 [Junho 09]](https://img.pdfslide.net/doc/110x75/5571fdcb497959916999f535/178-ginga-brasil-178-junho-09.jpg)



