Embed Size (px)
DESCRIPTION
quantitative Methods for Economic Analysis 6nov2014
Citation preview

QUANTITATIVE METHODS FORECONOMIC ANALYSIS – 1
III SEMESTER
B A ECONOMICS
(2013 Admission )
UNIVERSITY OF CALICUT
SCHOOL OF DISTANCE EDUCATION
Calicut university P.O, Malappuram Kerala, India 673 635.
263 A
QUANTITATIVE METHODS FORECONOMIC ANALYSIS – 1
III SEMESTER
B A ECONOMICS
(2013 Admission )
UNIVERSITY OF CALICUT
SCHOOL OF DISTANCE EDUCATION
Calicut university P.O, Malappuram Kerala, India 673 635.
263 A
QUANTITATIVE METHODS FORECONOMIC ANALYSIS – 1
III SEMESTER
B A ECONOMICS
(2013 Admission )
UNIVERSITY OF CALICUT
SCHOOL OF DISTANCE EDUCATION
Calicut university P.O, Malappuram Kerala, India 673 635.
263 A

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 2
UNIVERSITY OF CALICUTSCHOOL OF DISTANCE EDUCATION
B.A. ECONOMICS(2013 ADMISSION )
III SEMESTER
QUANTITATIVE METHODS FORECONOMIC ANALYSIS – 1
Prepared by:
Module Materials Prepared by
Full Module
Chacko Jose P, PhDAssociate Professor of EconomicsSacred Heart CollegeChalakudy, Thrissur, Kerala(Formerly ReaderUGC-Academic Staff CollegeUniversity of Calicut)
Editor
Dr.C.KrishnanAssociate ProfessorPG Department of EconomicsGovt. College KodancheryKozhikode – 673580Email: [email protected]
Layout & Settings: Computer Section, SDE
© Reserved

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 3
CONTENTS PAGES
MODULE - I 5- 79
MODULE - II 80-100
MODULE - III 101-150
MODULE - IV 151-169

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 4
Quantitative Methods for Economic Analysis – 1Syllabus
Module I. Description of Data and SamplingStatistics-Meaning and limitations-Data: Elements, Variables, Observations-Scale of Measurement-Types of Data: Qualitative and Quantitative; Cross-section, Time series and Pooled Data-Frequency Distributions: Absolute andrelative-Graphs: Bar chart, Histogram etc. Summary Measure of Distributions:Measures of Central Tendency, Variability and Shape-Sampling: Populationand Sample, Methods of Sampling.
Module II. Correlation and Regression AnalysisCorrelation-Meaning, Types and Degrees of Correlation- Methods of Measuring
Correlation- Graphical Methods: Scatter Diagram and Correlation Graph;AlgebraicMethods: Karl Pearson’s Coefficient of Correlation and Rank CorrelationCoefficient -Properties and Interpretation of Correlation Coefficient
Module III. Index Numbers and Time Series AnalysisIndex Numbers: Meaning and Uses- Laspeyre’s, Paasche’s, Fisher’s, Dorbish-Bowley,Marshall-Edgeworth and Kelley’s Methods- Tests of Index Numbers: TimeReversal andFactor Reversal tests -Base Shifting, Splicing and Deflating- Special PurposeIndicesWholesale Price Index, Consumer Price Index and Stock Price Indices:BSE SENSEX and NSE-NIFTY. Time Series Analysis-Components of TimeSeries, Measurement of Trend by Moving Average and the Method of LeastSquares.
Module IV. Nature and Scope of EconometricsEconometrics: Meaning, Scope, and Limitations - Methodology of econometrics-Modern interpretation-Stochastic Disturbance term- Population RegressionFunction and Sample Regression Function-Assumptions of Classical Linearregression model.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 5
Module IDescription of Data and Sampling
1. STATISTICS-MEANING
Statistics is as old as the human race!. Its utility has been increasing as the ages goes by. In the
olden days it was used in the administrative departments of the states and the scope was limited.
Earlier it was used by governments to keep record of birth, death, population etc., for
administrative purpose. John Graunt was the first man to make a systematic study of birth and
death statistics and the calculation of expectation of life at different age in the 17th century
which led to the idea of Life Insurance.
The word ‘Statistics’ seems to have been derived from the Latin word ‘status’ or Italian word‘statista’ or the German word ‘Statistik’ each of which means a political state. Fields likeagriculture, economics, sociology, business management etc., are now using Statistical Methods
for different purposes.
Statistics has been defined differently by different writers. According to Webster "Statistics are
the classified facts representing the conditions of the people in a state. Specially those facts
which can be stated in numbers or any tabular or classified arrangement."
According to Bowley statistics are ‘statistics is the science of counting’, ‘science of averages’‘Numerical statements of facts in any department of enquiry placed in relation to each other.’According to Yule and Kendall, statistics means quantitative data affected to a marked extent by
multiplicity of causes.
More broad definition of statistics was given by Horace Secrist. According to him, statistics
means aggregate of facts affected to marked extent by multiplicity of causes, numerically
expressed, enumerated or estimated according to a reasonable standard of accuracy, collected in
a systematic manner for a predetermined purpose and placed in relation to each other.
This definition points out some essential characteristics that numerical facts must possess so that
they may be called statistics. These characteristics are:
1. They are enumerated or estimated according to a reasonable standard of accuracy
2. They are affected by multiplicity of factors
3. They must be numerically expressed
4. They must be aggregate of facts
W.I. King defines “the science of statistics is the method of judging collection, natural or socialphenomena from the results obtained from the analysis or enumeration or collection of
estimates”.Prof: Boddington has defined statistics as “science of estimate and probabilities”Let us also see some other definitions of statistics.
Statistics as a discipline is the development and application of methods to collect, analyse and
interpret data.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 6
Statistics is the science of learning from data, and of measuring, controlling, and communicating
uncertainty; and it thereby provides the navigation essential for controlling the course of
scientific and societal advances.
Statistics is a collection of mathematical techniques that help to analyse and present data.
Statistics is also used in associated tasks such as designing experiments and surveys and planning
the collection and analysis of data from these.
Statistics is the study of numerical information, called data. Statisticians acquire, organize, and
analyse data. Each part of this process is also scrutinized. The techniques of statistics are applied
to a multitude of other areas of knowledge.
Thus to sum up “statistics are the numerical statement of facts capable of analysis and
interpretation and the science of statistics is the study of the principles and the methods applied
in collecting, presenting, analysis and interpreting the numerical data in any field of inquiry.”
Characteristics of Statistics
1. Statistics are aggregate of facts: A single age of 20 or 30 years is not statistics, a series of ages
are. Similarly, a single figure relating to production, sales, birth, death etc., would not be
statistics although aggregates of such figures would be statistics because of their comparability
and relationship.
2. Statistics are affected to a marked extent by a multiplicity of causes: A number of causes
affect statistics in a particular field of enquiry, e.g., in production statistics are affected by
climate, soil, fertility, availability of raw materials and methods of quick transport.
3. Statistics are numerically expressed, enumrated or estimated: The subject of statistics is
concerned essentially with facts expressed in numerical form -with their quantitative details but
not qualitative descriptions. Therefore, facts indicated by terms such as ‘good’, ‘poor’ are notstatistics unless a numerical equivalent, is assigned to each expression. Also this may either be
enumerated or estimated, where actual enumeration is either not possible or is very difficult.
4. Statistics are numerated or estimated according to reasonable standard of accuracy: Personal
bias and prejudices of the enumeration should not enter into the counting or estimation of
figures, otherwise conclusions from the figures would not be accurate. The figures should be
counted or estimated according to reasonable standards of accuracy. Absolute accuracy is neither
necessary nor sometimes possible in social sciences. But whatever standard of accuracy is once
adopted, should be used throughout the process of collection or estimation.
5. Statistics should be collected in a systematic manner for a predetermined purpose: The
statistical methods to be applied on the purpose of enquiry since figures are always collected
with some purpose. If there is no predetermined purpose, all the efforts in collecting the figures
may prove to be wasteful. The purpose of a series of ages of husbands and wives may be to find
whether young husbands have young wives and the old husbands have old wives.
6. Statistics should be capable of being placed in relation to each other: The collected figure
should be comparable and well-connected in the same department of inquiry. Ages of husbands

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 7
are to be compared only with the corresponding ages of wives, and not with, say, heights of
trees.
Functions of Statistics
The functions of statistics may be enumerated as follows :
(i) To present facts in a definite form : Without a statistical study our ideas are likely to be vague,
indefinite and hazy, but figures helps as to represent things in their true perspective. For
example, the statement that some students out of 1,400 who had appeared, for a certain
examination, were declared successful would not give as much information as the one that 300
students out of 400 who took the examination were declared successful.
(ii) To simplify unwieldy and complex data : It is not easy to treat large numbers and hence they
are simplified either by taking a few figures to serve as a representative sample or by taking
average to give a bird’s eye view of the large masses. For example, complex data may besimplified by presenting them in the form of a table, graph or diagram, or representing it through
an average etc.
(iii) To use it as a technique for making comparisons: The significance of certain figures can be
better appreciated when they are compared with others of the same type. The comparison
between two different groups is best represented by certain statistical methods, such as average,
coefficients, rates, ratios, etc.
Uses of Statistics
Statistics is primarily used either to make predictions based on the data available or to make
conclusions about a population of interest when only sample data is available.
In both cases statistics tries to make sense of the uncertainty in the available data.
Statisticians apply statistical thinking and methods to a wide variety of scientific, social, and
business endeavours in such areas as astronomy, biology, education, economics, engineering,
genetics, marketing, medicine, psychology, public health, sports, among many. Many economic,
social, political, and military decisions cannot be made without statistical techniques, such as the
design of experiments to gain federal approval of a newly manufactured drug.
Statistics is of two types (a) Descriptive statistics involves methods of organizing, picturing and
summarizing information from data. (b) Inferential statistics involves methods of using
information from a sample to draw conclusions about the population.
These days statistical methods are applicable everywhere. There is no field of work in which
statistical methods are not applied. According to A L. Bowley, ‘A knowledge of statistics is likea knowledge of foreign languages or of Algebra, it may prove of use at any time under any
circumstances”. The importance of the statistical science is increasing in almost all spheres ofknowledge, e g., astronomy, biology, meteorology, demography, economics and mathematics.
Economic planning without statistics is bound to be baseless. Statistics serve in administration,
and facilitate the work of formulation of new policies. Financial institutions and investors utilise
statistical data to summaries the past experience. Statistics are also helpful to an auditor, when he
uses sampling techniques or test checking to audit the accounts of his client.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 8
(a) Statistics and Economics: In the year 1890 Prof. Alfred Marshall, the renowned economist
observed that “statistics are the straw out of which I, like every other economist, have to make
bricks”. This proves the significance of statistics in economics. Economics is concerned withproduction and distribution of wealth as well as with the complex institutional set-up connected
with the consumption, saving and investment of income. Statistical data and statistical methods
are of immense help in the proper understanding of the economic problems and in the
formulation of economic policies. In fact these are the tools and appliances of an economists
laboratory. In the field of economics it is almost impassible to find a problem which does not
require an extensive uses of statistical data. As economic theory advances use of statistical
methods also increase. The laws of economics like law of demand, law of supply etc can be
considered true and established with the help of statistical methods. Statistics of consumption
tells us about the relative strength of the desire of a section of people. Statistics of production
describe the wealth of a nation. Exchange statistics through light on commercial development of
a nation. Distribution statistics disclose the economic conditions of various classes of people.
There for statistical methods are necessary for economics.
(b) Statistics and business: Statistics is an aid to business and commerce. When a person enters
business, he enters into the profession of fore casting. Modern statistical devices have made
business forecasting more precise and accurate. A business man needs statistics right from the
time he proposes to start business. He should have relevant fact and figures to prepare the
financial plan of the proposed business. Statistical methods are necessary for these purposes. In
industrial concern statistical devices are being used not only to determined and control the
quality of products manufactured by also to reduce wastage to a minimum. The technique of
statistical control is used to maintain quality of products.
(c) Statistics and Research: Statistics is an indispensable tool of research. Most of the
advancement in knowledge has taken place because of experiments conducted with the help of
statistical methods. For example, experiments about crop yield and different types of fertilizers
and different types of soils of the growth of animals under different diets and environments are
frequently designed and analysed according to statistical methods. Statistical methods are also
useful for the research in medicine and public health. In fact there is hardly any research work
today that one can find complete without statistical data and statistical methods.
Other uses of statistics are as follows.
(1) Statistics helps in providing a better understanding and exact description of a phenomenon of
nature.
(2) Statistical helps in proper and efficient planning of a statistical inquiry in any field of study.
(3) Statistical helps in collecting an appropriate quantitative data.
(4) Statistics helps in presenting complex data in a suitable tabular, diagrammatic and graphic
form for an easy and clear comprehension of the data.
(5) Statistics helps in understanding the nature and pattern of variability of
a phenomenon through quantitative observations.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 9
(6) Statistics helps in drawing valid inference, along with a measure of their reliability about the
population parameters from the sample data.
Limitations of StatisticsStatistics is indispensable to almost all sciences - social, physical and natural. It is very often
used in most of the spheres of human activity. In spite of the wide scope of the subject it has
certain limitations. Some important limitations of statistics are the following:
1. Statistics does not study qualitative phenomena: Statistics deals with facts and figures. So
the quality aspect of a variable or the subjective phenomenon falls out of the scope of statistics.
For example, qualities like beauty, honesty, intelligence etc. cannot be numerically expressed. So
these characteristics cannot be examined statistically. This limits the scope of the subject.
2. Statistical laws are not exact: Statistical laws are not exact as incase of natural sciences.
These laws are true only on average. They hold good under certain conditions. They cannot be
universally applied. So statistics has less practical utility.
3. Statistics does not study individuals: Statistics deals with aggregate of facts. Single or
isolated figures are not statistics. This is considered to be a major handicap of statistics.
4. Statistics can be misused: Statistics is mostly a tool of analysis. Statistical techniques are
used to analyze and interpret the collected information in an enquiry. As it is, statistics does not
prove or disprove anything. It is just a means to an end. Statements supported by statistics are
more appealing and are commonly believed. For this, statistics is often misused. Statistical
methods rightly used are beneficial but if misused these become harmful. Statistical methods
used by less expert hands will lead to inaccurate results. Here the fault does not lie with the
subject of statistics but with the person who makes wrong use of it.
Other limitations are as follows.
(1) Statistics laws are true on average. Statistics are aggregates of facts. So single observation is
not a statistics, it deals with groups and aggregates only.
(2) Statistical methods are best applicable on quantitative data.
(3) Statistical cannot be applied to heterogeneous data.
(4) It sufficient care is not exercised in collecting, analyzing and interpretation the data,
statistical results might be misleading.
(5) Only a person who has an expert knowledge of statistics can handle statistical data
efficiently.
(6) Some errors are possible in statistical decisions. Particularly the inferential statistics involves
certain errors. We do not know whether an error has been committed or not.
2.DATA: ELEMENTS, VARIABLES, OBSERVATIONS, SCALE OFMEASUREMENT
Data may be defined as facts, observations, and information that come from investigations. Data
can be defined as groups of information that represent the qualitative or quantitative attributes of
a variable or set of variables, which is the same as saying that data can be any set of information
that describes a given entity. Data in statistics can be classified into grouped data and ungrouped
data.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 10
1. Elements: A data element is a unit of data for which the definition, identification,
representation, and permissible values are specified by means of a set of attributes. It is the
smallest named item of data that conveys meaningful information or condenses lengthy
description into a short code called data field in the structure of a database.
2. Variable - property of an object or event that can take on different values. A variable is any
measurable characteristic or attribute that can have different values for different subjects. Height,
age, amount of income, country of birth, grades obtained at school and type of housing are
examples of variables. For example, college major is a variable that takes on values like
mathematics, computer science, English, psychology, etc.
Discrete Variable - a variable with a limited number of values (e.g., gender (male/female),
college class (freshman/sophomore/junior/senior).
Continuous Variable - a variable that can take on many different values, in theory, any value
between the lowest and highest points on the measurement scale.
Independent Variable - a variable that is manipulated, measured, or selected by the researcher as
an antecedent condition to an observed behavior. In a hypothesized cause-and-effect
relationship, the independent variable is the cause and the dependent variable is the outcome or
effect.
Dependent Variable - a variable that is not under the experimenter's control -- the data. It is the
variable that is observed and measured in response to the independent variable.
Qualitative Variable - a variable based on categorical data.
Quantitative Variable - a variable based on quantitative data.
Qualitative vs. Quantitative Variables
Variables can be classified as qualitative (aka, categorical) or quantitative (aka, numeric).
Qualitative. Qualitative variables take on values that are names or labels. The color of a
ball (e.g., red, green, blue) or the breed of a dog (e.g., collie, shepherd, terrier) would be
examples of qualitative or categorical variables.
Quantitative. Quantitative variables are numeric. They represent a measurable quantity.
For example, when we speak of the population of a city, we are talking about the number
of people in the city - a measurable attribute of the city. Therefore, population would be a
quantitative variable.
In algebraic equations, quantitative variables are represented by symbols (e.g., x, y, or z).
Discrete vs. Continuous Variables
Quantitative variables can be further classified as discrete or continuous. If a variable can take on
any value between its minimum value and its maximum value, it is called a continuous variable;
otherwise, it is called a discrete variable.
Some examples will clarify the difference between discrete and continouous variables.
Suppose the fire department mandates that all fire fighters must weigh between 150 and
250 pounds. The weight of a fire fighter would be an example of a continuous variable;
since a fire fighter's weight could take on any value between 150 and 250 pounds.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 11
Suppose we flip a coin and count the number of heads. The number of heads could be any
integer value between 0 and plus infinity. However, it could not be any number between
0 and plus infinity. We could not, for example, get 2.3 heads. Therefore, the number of
heads must be a discrete variable.
Univariate vs. Bivariate Data
Statistical data are often classified according to the number of variables being studied.
Univariate data. When we conduct a study that looks at only one variable, we say that we
are working with univariate data. Suppose, for example, that we conducted a survey to
estimate the average weight of high school students. Since we are only working with one
variable (weight), we would be working with univariate data.
Bivariate data. When we conduct a study that examines the relationship between two
variables, we are working with bivariate data. Suppose we conducted a study to see if
there were a relationship between the height and weight of high school students. Since we
are working with two variables (height and weight), we would be working with bivariate
data.
3. ObservationsAn observation is the value, at a particular period, of a particular variable, such as the individual
price of an item at a given outlet. An observation is the value, at a particular period, of a
particular variable. It is thus a method of data collection in which the situation of interest is
watched and the relevant facts, actions and behaviors are recorded.
Observation units vary according to the specific survey or data collection: for statistical data
collected on persons the observation unit is usually one individual or a household.
4. Scale of MeasurementNormally, when one hears the term measurement, they may think in terms of measuring the
length of something (e.g., the length of a piece of wood) or measuring a quantity of something
(ie. a cup of flour).This represents a limited use of the term measurement. In statistics, the term
measurement is used more broadly and is more appropriately termed scales of measurement.
Scales of measurement refer to ways in which variables/numbers are defined and categorized.
Each scale of measurement has certain properties which in turn determines the appropriateness
for use of certain statistical analyses. The four scales of measurement are nominal, ordinal,
interval, and ratio.
Properties of Measurement Scales
Each scale of measurement satisfies one or more of the following properties of measurement.
Identity: Each value on the measurement scale has a unique meaning. It is not equal to any other
value on the scale.
Magnitude: All values on the measurement scale have an ordered relationship to one another.
That is, some values are larger and some are smaller.
Equal intervals: Scale units along the scale are equal to one another. This means, for example,
that the difference between 1 and 2 would be equal to the difference between 19 and 20.
A minimum value of zero: The scale has a true zero point that is now values exist below zero.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 12
Measurement scales are of four types, namely, Nominal Scale of Measurement, Ordinal Scale of
Measurement, Interval Scale of Measurement and Ratio Scale of Measurement
(a) Nominal Scale of Measurement
The nominal scale of measurement only satisfies the identity property of measurement. Values
assigned to variables represent a descriptive category, but have no inherent numerical value with
respect to magnitude.
Gender is an example of a variable that is measured on a nominal scale. Individuals may be
classified as "male" or "female", but neither value represents more or less "gender" than the
other. Religion and political affiliation are other examples of variables that are normally
measured on a nominal scale.
(b) Ordinal Scale of Measurement
The ordinal scale has the property of both identity and magnitude. Each value on the ordinal
scale has a unique meaning, and it has an ordered relationship to every other value on the scale.
An example of an ordinal scale in action would be the results of a horse race, reported as "win",
"place", and "show". We know the rank order in which horses finished the race. The horse that
won finished ahead of the horse that placed, and the horse that placed finished ahead of the horse
that showed. However, we cannot tell from this ordinal scale whether it was a close race or
whether the winning horse won by a mile.
(c) Interval Scale of Measurement
The interval scale of measurement has the properties of identity, magnitude, and equal intervals.
A perfect example of an interval scale is the Fahrenheit scale to measure temperature. The scale
is made up of equal temperature units, so that the difference between 40 and 50 degrees
Fahrenheit is equal to the difference between 50 and 60 degrees Fahrenheit.
With an interval scale, you know not only whether different values are bigger or smaller, youalso know how much bigger or smaller they are. For example, suppose it is 60 degreesFahrenheit on Monday and 70 degrees on Tuesday. You know not only that it was hotter onTuesday, you also know that it was 10 degrees hotter.
(d) Ratio Scale of Measurement
The ratio scale of measurement satisfies all four of the properties of measurement: identity,magnitude, equal intervals, and a minimum value of zero.
The weight of an object would be an example of a ratio scale. Each value on the weight scale hasa unique meaning, weights can be rank ordered, units along the weight scale are equal to oneanother, and the scale has a minimum value of zero.
Weight scales have a minimum value of zero because objects at rest can be weightless, but theycannot have negative weight.
The table below will help clarify the fundamental differences between the four scales ofmeasurement:

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 13
IndicationsDifference
Indicates Direction ofDifference
Indicates Amount ofDifference
AbsoluteZero
Nominal XOrdinal X XInterval X X XRatio X X X X
You will notice in the above table that only the ratio scale meets the criteria for all four
properties of scales of measurement.
Interval and Ratio data are sometimes referred to as parametric and Nominal and Ordinal data
are referred to as nonparametric. Parametric means that it meets certain requirements with
respect to parameters of the population (for example, the data will be normal--the distribution
parallels the normal or bell curve). In addition, it means that numbers can be added, subtracted,
multiplied, and divided. Parametric data are analyzed using statistical techniques identified as
Parametric Statistics. As a rule, there are more statistical technique options for the analysis of
parametric data and parametric statistics are considered more powerful than nonparametric
statistics. Nonparametric data are lacking those same parameters and cannot be added,
subtracted, multiplied, and divided. For example, it does not make sense to add Social Security
numbers to get a third person. Nonparametric data are analyzed by using Nonparametric
Statistics.
3. TYPES OF DATA: Qualitative and Quantitative; Cross-section, Timeseries and Pooled Data
3.1 Qualitative and QuantitativeData is a collection of facts, such as values or measurements. It can be numbers, words,
measurements, observations or even just descriptions of things.Some methods provide data
which are quantitative and some methods data which are qualitative.
Quantitative data are anything that can be expressed as a number, or quantified. Examples of
quantitative data are scores on achievement tests, number of hours of study, or weight of a
subject. These data may be represented by ordinal, interval or ratio scales and lend themselves to
most statistical manipulation. Thus qualitative data is one that approximates or characterizes but
does not measure the attributes, characteristics, properties, etc., of a thing or phenomenon.
Qualitative data describes whereas quantitative data defines.
Qualitative data cannot be expressed as a number. Data that represent nominal scales such as
gender, socio-economic status, religious preference are usually considered to be qualitative data.
Thus quantitative data is one that can be quantified and verified, and is amenable to statistical
manipulation. Quantitative data defines whereas qualitative data describes.
Both types of data are valid types of measurement. But only quantitative data can be analysed
statistically, and thus more rigorous assessments of the data are possible.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 14
Quantitative and qualitative data provide different outcomes, and are often used together to get a
full picture of a population. For example, if data are collected on annual income (quantitative),
occupation data (qualitative) could also be gathered to get more detail on the average annual
income for each type of occupation.
Quantitative and qualitative data can be gathered from the same data unit depending on whether
the variable of interest is numerical or categorical. For example:
Example 1:
Oil Painting
Qualitative data: blue/green color, gold frame
smells old and musty
texture shows brush strokes of oil
paint
peaceful scene of the country
masterful brush strokes
Oil Painting
Quantitative data: picture is 10" by 14"
with frame 14" by 18"
weighs 8.5 pounds
surface area of painting is 140 sq.
in.
cost Rs5000
Example 2
Dataunit
Numeric variable = Quantitativedata
Categoricalvariable
= Qualitativedata
A person "Howmany children doyou have?"
4 children "In whichcountry were yourchildren born?"
India
"How much do youearn?"
Rs. 50,000 p.a. "What is youroccupation?"
Banker
"How many hoursdo you work?"
45 hours perweek
"Do you work full-time or part-time?"
Full-time
A house "Plinth area ofyour house?"
1000 squaremetres
"In which city ortown is the houselocated?"
Thrissur
Abusiness
"Howmany workers arecurrentlyemployed?"
110 employees "What isthe industry of thebusiness?"
Textile retail

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 15
A farm "How many milkcows are locatedon the farm?
36 cows "What is themain activity ofthe farm?"
Dairy
And Quantitative data can also be Discrete data or Continuous data.Discrete data can only take certain values (like whole numbers)Continuous data can take any value (within a range)Put simply: Discrete data is counted, Continuous data is measured.See the following example.Example: What do we know about Arrow the Dog?
Description about Blacky, your pet dog
Qualitative:
He is brown and blackHe has long hairHe has lots of energy
Quantitative:
Discrete:He has 4 legsHe has 2 brothers
Continuous:He weighs 25.5 kgHe is 565 mm tall
3.2 Cross Section and Time Series Data
Time series data is data that is measured using a sequence of certain points at particular times.
The BSE SENSEX is an example of data that is measured using time series data, as the data
collected is listed at a certain time on each day. Line charts are used to plot time series data and
these enable the viewer of the data to analyze the data with ease, and to compare and contrast the
differences between one set of data at a particular time and another set of data at a particular
time.
Other examples of time-series would be staff numbers at a particular institution taken on a
monthly basis in order to assess staff turnover rates, weekly sales figures of ice-cream sold
during a holiday period at a seaside resort and the number of students registered for a particular
course on a yearly basis. All of the above would be used to forecast likely data patterns in the
future.
Cross-section data is data that is collected by analyzing different sets of data from different
sources at a particular time. This type of statistical information is useful when observing habits
within a country, such as eating habits, voting habits, and drinking habits. Applying a certain set
of questions to a certain number of people in different areas, and collating the information to
achieve a realistic picture that is relevant to a nation or an area as a whole makes this data useful.
Another example of cross-section data is business data collected to see the popularity of certain
products at a particular time, and this is known as market research.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 16
Other examples: if one considered the closing prices of a group of 20 different tech stocks of
BSE on September 15, 2014 this would be an example of cross-sectional data. Note that the
underlying population should consist of members with similar characteristics. For example,
suppose you are interested in how much companies spend on research and development
expenses. Firms in some industries such as retail spend little on research and development
(R&D), while firms in industries such as technology spend heavily on R&D. Therefore, it's
inappropriate to summarize R&D data across all companies. Rather, analysts should summarize
R&D data by industry, and then analyze the data in each industry group. Other examples of
cross-sectional data would be: an inventory of all ice creams in stock at a particular supermarket,
a list of grades obtained by a class of students for a specific test.
The major difference between time series data and cross-section data is that the former focuses
on results gained over an extended period of time, often within a small area, whilst the latter
focuses on the information received from surveys and opinions at a particular time, in various
locations, depending on the information sought.
4. FREQUENCY DISTRIBUTIONS: ABSOLUTE AND RELATIVEFrequency distribution is a specification of the way in which the frequencies of members of a
population are distributed according to the values of the variates which they exhibit. For
observed data the distribution is usually specified in tabular form, with some grouping for
continuous variates.
The frequency distribution or frequency table is a tabular organization of statistical data,
assigning to each piece of data its corresponding frequency.
Types of Frequencies
(a) Absolute Frequency
The absolute frequency is the number of times that a certain value appears in a statistical study.
It is denoted by .
The sum of the absolute frequencies is equal to the total number of data, which is denoted by N.+ + + ⋯ + =This sum is commonly denoted by the Greek letter Σ (capital sigma) which represents ‘sum’.
=(b) Relative Frequency
The relative frequency is the quotient between the absolute frequency of a certain value and the
total number of data. It can be expressed as a percentage and is denoted by .=The sum of the relative frequency is equal to 1.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 17
(c) Cumulative Frequency
The cumulative frequency is the sum of the absolute frequencies of all values less than or equal
to the value considered.
It is denoted by F i.
(d) Relative Cumulative Frequency
The relative cumulative frequency is the quotient between the cumulative
frequency of a particular value and the total number of data. It can be expressed as
a percentage.
Example
A city has recorded the following daily maximum temperatures during a month:
32, 31, 28, 29, 33, 32, 31, 30, 31, 31, 27, 28, 29, 30, 32, 31, 31, 30, 30, 29, 29, 30, 30, 31, 30, 31,
34, 33, 33, 29, 29.
Let us form a table based on this information. In the first column of the table are the variables
ordered from lowest to highest, in the second column is the count or the number or times this
variable has occurred and in the third column is the score of the absolute frequency.
xi Count fi Fi ni Ni
27 I 1 1 0.032 0.03228 II 2 3 0.065 0.09729 6 9 0.194 0.29030 7 16 0.226 0.51631 8 24 0.258 0.77432 III 3 27 0.097 0.87133 III 3 30 0.097 0.96834 I 1 31 0.032 1
31 1
Discrete variables are used for this type of frequency table.
5. GRAPHS OF FREQUENCY DISTRIBUTIONA frequency distribution can be represented graphically in any of the following ways.
The most commonly used graphs and curves for representation a frequency distribution areBar Charts
Histogram
Frequency Polygon
Smoothened frequency curve
Ogives or cumulative frequency curves.
(a)Bar ChartsA bar chart is used to present categorical, quantitative or discrete data.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 18
The information is presented on a coordinate axis. The values of the variable are represented on
the horizontal axis and the absolute, relative or cumulative frequencies are represented on the
vertical axis.
The data is represented by bars whose height is proportional to the frequency.
Example
A study has been conducted to determine the blood group of a class of 20 students. The resultsare as follows:
BloodGroup f i
A 6
B 4
AB 1
O 9
20
Based on this we can draw a bar chart as follows.
Step 1: Number the Y-axis with the dependent variable. The dependent variable is the one being
tested in an experiment. In this sample question, the study wanted to know how many students
belonged to each blood group. So the number of students is the dependent variable. So it is
marked on the Y-axis.
Step 2: Label the X-axis with what the bars represent. For this problem, label the x-axis “BloodGroup” and then label the Y-axis with what the Y-axis represents: “number of students.”Step 3: Draw your bars. The height of the bar should be even with the correct number on the Y-
axis. Don’t forget to label each bar under the x-axis.
Finally, give your graph a name. For this problem, call the graph ‘Blood group of students’.
0123456789
10
A B AB O
Num
ber o
f stu
dent
s
Blood Group
Blood group of students

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 19
Histogram:A histogram is a set of vertical bars whose one as are proportional to the frequencies
represented. While constructing histogram, the variable is always taken on the X axis and the
frequencies on the Y axis. The width of the bars in the histogram will be proportional to the
class interval. The bars are drawn without leaving space between them. A histogram generally
represents a continuous curve. If the class intervals are uniform for a frequency distribution,
then the width of all the bars will by equal.
Example:
Y50 -
40 -
30 -
20 -
10 -
X0 5 10 15 20 25 30
Marks
Frequency Polygon (or line graphs)
Frequency Polygon is a graph of frequency distribution. Frequency polygons are a
graphical device for understanding the shapes of distributions. They serve the same purpose as
histograms, but are especially helpful for comparing sets of data.
To create a frequency polygon, start just as for histograms, by choosing a class interval. Then
draw an X-axis representing the values of the scores in your data. Mark the middle of each class
interval with a tick mark, and label it with the middle value represented by the class. Draw the Y-
axis to indicate the frequency of each class. Place a point in the middle of each class interval at
the height corresponding to its frequency. Finally, connect the points. You should include one
class interval below the lowest value in your data and one above the highest value. The graph
will then touch the X-axis on both sides.
Another method of constructing frequency polygon is to take the mid points of the various class
intervals and then plot frequency corresponding to each point and to join all these points by a
straight lines. Here need not construct a histogram:-
Marks No. ofstudents
10-15 5
15-20 20
20-25 47
25-30 38
30-35 10
No.
of
stud
ents

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 20
Example:
Draw a frequency polygon to the following frequency distribution
Marks: 10-20 20-30 30-40 40-50 50-60 60-70 70-80
No. of
Students:
8 13 19 28 19 11 9
Y
20 -
15 -
10 -
5 -
0 10 20 30 40 50 60 70Marks
Frequency Curves
Frequency curves are derived from frequency polygons. Frequency curve is obtained by
joining the points of frequency polygon by a freehand smoothed curve. Unlike frequency
polygon, where the points we joined by straight lines, we make use of free hand joining of those
points in order to get a smoothed frequency curve. It is used to remove the ruggedness of
polygon and to present it in a good form or shape. We smoothen the angularities of the polygon
only without making any basic change in the shape of the curve. In this case also the curve
begins and ends at base line, as is in case of polygon. Area under the curve must remain almost
the same as in the case of polygon.
Example:
Marks: 10-20 20-30 30-40 40-50 50-60 60-70
No. ofStudents:
5 8 15 20 12 7
No.
of s
tude
nts
Marks No. ofstudents
10-15 5
15-20 20
20-25 47
25-30 38
30-35 10

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 21
Y
20 - x
15 - x
x10 -
xx
5 - x
| | | | | | | | | || | |
0 10 20 30 40 50 60 70 Marks
Difference between frequency polygon and frequency curveFrequency polygon is drawn to frequency distribution of discrete or continuous nature.
Frequency curves are drawn to continuous frequency distribution. Frequency polygon is
obtained by joining the plotted points by straight lines. Frequency curves are smooth. They are
obtained by joining plotted points by smooth curve.
Ogives (Cumulative frequency curve)A frequency distribution when cumulated, we get cumulative frequency distribution. A
series can be cumulated in two ways. One method is frequencies of all the preceding classes one
added to the frequency of the classes. This series is called less than cumulative series. Another
method is frequencies of succeeding classes are added to the frequency of a class. This is called
more than cumulative series. Smoothed frequency curves drawn for these two cumulative series
are called cumulative frequency curve or ogives. Thus corresponding to the two cumulative
series we get two ogive curves, known as less than ogive and more than ogive.
Less than ogive curve is obtained by plotting frequencies (cumulated) against the upper
limits of class intervals. More than ogive curve is obtained by plotting cumulated frequencies
against the lower limits of class intervals. Less than ogive is an increasing curve, slopping –upwards from left to right. More than ogive is a decreasing curve and slopes from left to right.
Example:From less than and more than cumulative frequency distribution for the following frequency
distribution. Cumulative frequency distribution:
Marks No. ofStudents
No.
of
stud
ents
Marks No. ofstudents
10-15 5
15-20 20
20-25 47
25-30 38
30-35 10

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 22
Marksless than
No. ofStudents
MarksMorethan
No. ofStudents
10 0 10 6020 4 20 5630 10 30 5040 20 40 4050 40 50 2060 58 60 270 60 70 0
Pie DiagramsOne of the most common ways to represent data graphically is called a pie chart. It gets its name
by how it looks, just like a circular pie that has been cut into several slices. This kind of graph is
helpful when graphing qualitative data, where the information describes a trait or attribute and is
not numerical. Each trait corresponds to a different slice of the pie. By looking at all of the pie
pieces, you can compare how much of the data fits in each category.
Pie charts are a form of an area chart that are easy to understand with a quick look. They show
the part of the total (percentage) in an easy-to-understand way. Pie charts are useful tools that
-10
0
10
20
30
40
50
60
70
0 20 40 60 80
No. of Students
No. of Students2
10-20 420-30 630-40 1040-50 2050-60 1860-70 2
No.
of
Stu
dent
s
Marks
More than ogive
Less than ogive

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 23
help you figure out and understand polls, statistics, complex data, and income or spending. They
are so wonderful because everybody can see what is going on.
Pie diagrams are used when the aggregate and their division are to be shown together.
The aggregate is shown by means of a circle and the division by the sectors of the circle. For
example: to show the total expenditure of a government distributed over different departments
like agriculture, irrigation, industry, transport etc. can be shown in a pie diagram. In constructing
a pie diagram the various components are first expressed as a percentage and then the percentage
is multiplied by 3.6. so we get angle for each component. Then the circle is divided into sectors
such that angles of the components and angles of the sectors are equal. Therefore one sector
represents one component. Usually components are with the angles in descending order are
shown.
Example:
You conducted a survey as part of a project work. You had taken a sample of 20 individuals and
you want to represent their occupation using a pie chart .
First, put your data into a table, then add up all the values to get a total:
Farmer Business Teacher Bank Driver TOTAL
4 5 6 1 4 20
Calculate the angle of each sector, using the formula
Divide each value by the total and multiply by 100 to get a percent:
Farmer Business Teacher Bank Driver TOTAL
4 5 6 1 4 20
4/20 =20% 5/20 =25% 6/20 =30% 1/20 = 5% 4/20 =20% 100%
Now you need to figure out how many degrees for each ‘pie slice’ (correctly
called a sector).
A Full Circle has 360 degrees, so we do this calculation:
Farmer Business Teacher Bank Driver TOTAL
4 5 6 1 4 20
4/20 =20% 5/20 =25% 6/20 =30% 1/20 = 5% 4/20 =20% 100%
4/20 × 360°
= 72°5/20 × 360°
= 90°6/20 × 360°
= 108°1/20 × 360°
= 18°4/20 × 360°
= 72°360°

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 24
Draw a circle using a pair of compasses.
Use a protractor to draw the angle for each sector.
Label the circle graph and all its sectors.
Pie charts are to be used with qualitative data, however there are some limitations in using them.
If there are too many categories, then there will be a multitude of pie pieces. Some of these are
likely to be very skinny, and can be difficult to compare to one another.
If we want to compare different categories that are close in size, a pie chart does not always help
us to do this. If one slice has central angle of 30 degrees, and another has a central angle of 29
degrees, then it would be very hard to tell at a glance which pie piece is larger than the other.
6. SUMMARY MEASURE OF DISTRIBUTIONS
We will discuss three sets of summary measures namely Measures of Central Tendency,
Variability and Shape. These are called summary measures because they summarise the data. For
example, one of summary measure very familiar to you is mean. (Mean comes under measure of
central tendency.) If we take mean mark of students in a class for a subject, it gives you a rough
idea of what the marks are like. Thus based on just one summary value, we get idea of the entire
data.
6.1 Measures of Central TendencyA measure of central tendency is a measure that tells us where the middle of a bunch of data lies.
A measure of central tendency is a single value that attempts to describe a set of data by
identifying the central position within that set of data. As such, measures of central tendency are
sometimes called measures of central location. They are also classed as summary statistics. The
mean (often called the average) is most likely the measure of central tendency that you are most
familiar with, but there are others, such as the median and the mode.
30%
5%
20%
SAMPLE POPULATION BY OCCUPATIONFarmer Business
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 24
Draw a circle using a pair of compasses.
Use a protractor to draw the angle for each sector.
Label the circle graph and all its sectors.
Pie charts are to be used with qualitative data, however there are some limitations in using them.
If there are too many categories, then there will be a multitude of pie pieces. Some of these are
likely to be very skinny, and can be difficult to compare to one another.
If we want to compare different categories that are close in size, a pie chart does not always help
us to do this. If one slice has central angle of 30 degrees, and another has a central angle of 29
degrees, then it would be very hard to tell at a glance which pie piece is larger than the other.
6. SUMMARY MEASURE OF DISTRIBUTIONS
We will discuss three sets of summary measures namely Measures of Central Tendency,
Variability and Shape. These are called summary measures because they summarise the data. For
example, one of summary measure very familiar to you is mean. (Mean comes under measure of
central tendency.) If we take mean mark of students in a class for a subject, it gives you a rough
idea of what the marks are like. Thus based on just one summary value, we get idea of the entire
data.
6.1 Measures of Central TendencyA measure of central tendency is a measure that tells us where the middle of a bunch of data lies.
A measure of central tendency is a single value that attempts to describe a set of data by
identifying the central position within that set of data. As such, measures of central tendency are
sometimes called measures of central location. They are also classed as summary statistics. The
mean (often called the average) is most likely the measure of central tendency that you are most
familiar with, but there are others, such as the median and the mode.
20%
25%
30%
20%
SAMPLE POPULATION BY OCCUPATIONBusiness Teacher Bank Driver
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 24
Draw a circle using a pair of compasses.
Use a protractor to draw the angle for each sector.
Label the circle graph and all its sectors.
Pie charts are to be used with qualitative data, however there are some limitations in using them.
If there are too many categories, then there will be a multitude of pie pieces. Some of these are
likely to be very skinny, and can be difficult to compare to one another.
If we want to compare different categories that are close in size, a pie chart does not always help
us to do this. If one slice has central angle of 30 degrees, and another has a central angle of 29
degrees, then it would be very hard to tell at a glance which pie piece is larger than the other.
6. SUMMARY MEASURE OF DISTRIBUTIONS
We will discuss three sets of summary measures namely Measures of Central Tendency,
Variability and Shape. These are called summary measures because they summarise the data. For
example, one of summary measure very familiar to you is mean. (Mean comes under measure of
central tendency.) If we take mean mark of students in a class for a subject, it gives you a rough
idea of what the marks are like. Thus based on just one summary value, we get idea of the entire
data.
6.1 Measures of Central TendencyA measure of central tendency is a measure that tells us where the middle of a bunch of data lies.
A measure of central tendency is a single value that attempts to describe a set of data by
identifying the central position within that set of data. As such, measures of central tendency are
sometimes called measures of central location. They are also classed as summary statistics. The
mean (often called the average) is most likely the measure of central tendency that you are most
familiar with, but there are others, such as the median and the mode.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 25
Mean: Mean is the most common measure of central tendency. It is simply the sum of the
numbers divided by the number of numbers in a set of data. This is also known as average.
Median: Median is the number present in the middle when the numbers in a set of data are
arranged in ascending or descending order. If the number of numbers in a data set is even, then
the median is the mean of the two middle numbers.
Mode: Mode is the value that occurs most frequently in a set of data.
The mean, median and mode are all valid measures of central tendency, but under different
conditions, some measures of central tendency become more appropriate to use than others. In
the following sections, we will look at the mean, mode and median, and learn how to calculate
them.
We will also discuss Geometric Mean and Harmonic Mean.
Requisites of a good averageSince an average is a single value representing a group of values, it is desired that such a
value satisfies the following properties.
1. Easy to understand:- Since statistical methods are designed to simplify the complexities.
2. Simple to compute: A good average should be easy to compute so that it can be used
widely. However, though case of computation is desirable, it should not be sought at the
expense of other averages. ie, if in the interest of greater accuracy, use of more difficult average
is desirable.
3. Based on all items:- The average should depend upon each and every item of the series,
so that if any of the items is dropped, the average itself is altered.
4. Not unduly affected by Extreme observations:- Although each and every item should
influence the value of the average, non of the items should influence it unduly. If one or two
very small or very large items unduly affect the average, ie, either increase its value or reduce its
value, the average can’t be really typical of entire series. In other words, extremes may distortthe average and reduce its usefulness.
5. Rigidly defined: An average should be properly defined so that it has only one
interpretation. It should preferably be defined by algebraic formula so that if different people
compute the average from the same figures they all get the same answer. The average should not
depend upon the personal prejudice and bias of the investigator, other wise results can be
misleading.
6. Capable of further algebraic treatment: We should prefer to have an average that could be
used for further statistical computation so that its utility is enhanced. For example, if we are
given the data about the average income and number of employees of two or more factories, we
should able to compute the combined average.
7. Sampling stability: Last, but not least we should prefer to get a value which has what the
statisticians called “sampling stability”. This means that if we pick 10 different group of collegestudents, and compute the average of each group, we should expect to get approximately the
same value. It does not mean, however that there can be no difference in the value of different

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 26
samples. There may be some differences but those samples in which this difference is less that
are considered better than those in which the difference is more.
(a) Mean (Arithmetic mean / average)The mean (or average) is the most popular and well known measure of central tendency. It can
be used with both discrete and continuous data, although its use is most often with continuous
data (see our Types of Variable guide for data types). The mean is equal to the sum of all the
values in the data set divided by the number of values in the data set. So, if we have n values in a
data set and they have values x1, x2, ..., xn, the sample mean, usually denoted by (pronounced x
bar), is:
This formula is usually written in a slightly different manner using the Greekcapitol letter, , pronounced "sigma", which means "sum of...":
Example
In a survey you collected information on monthly spending for mobile recharge by 20 students ofwhich 10 are male and 10 female. We illustrate below how the data is used to find mean.
1 2 3 4 5 6 7 8 9 10 Total MeanMale 250 150 100 175 150 250 200 200 150 170 1795 179.50Female 100 150 150 100 200 150 125 150 130 180 1435 143.50Both 350 300 250 275 350 400 325 350 280 350 3230 161.50
First we found the mean for male students. Here ∑x= 1795. n =10. So 1795/10 = 179.5.Similarly, the mean for female students. Here ∑x= 1435. n =10. So 1435/10 = 143.5.We also find the mean for male and female taken together.
Here ∑x= 3230. n =20. So 3230/20 = 161.50.
Based on the above we can make certain observations. Male students spend Rs. 179.50 on an
average in a month for mobile recharge. Female students spend Rs. 143.50. We may conclude
that male students spend more on monthly mobile recharges. As a researcher, you may now use
this information to make further studies as to why this is so. What are the factors that make male
students to spend more on mobile recharges. We have also calculated the average for all students
taken together. It is Rs. 161.50. Thus we observe that the male students spend more than the
average for ‘all students’ while female students spend less than the total for ‘all students’.Mean is also calculated using another method called the shortcut method asexplained below.
Short cut method: The arithmetic mean can also be calculated by short cut method. This method
reduces the amount of calculation. It involves the following steps
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 26
samples. There may be some differences but those samples in which this difference is less that
are considered better than those in which the difference is more.
(a) Mean (Arithmetic mean / average)The mean (or average) is the most popular and well known measure of central tendency. It can
be used with both discrete and continuous data, although its use is most often with continuous
data (see our Types of Variable guide for data types). The mean is equal to the sum of all the
values in the data set divided by the number of values in the data set. So, if we have n values in a
data set and they have values x1, x2, ..., xn, the sample mean, usually denoted by (pronounced x
bar), is:
This formula is usually written in a slightly different manner using the Greekcapitol letter, , pronounced "sigma", which means "sum of...":
Example
In a survey you collected information on monthly spending for mobile recharge by 20 students ofwhich 10 are male and 10 female. We illustrate below how the data is used to find mean.
1 2 3 4 5 6 7 8 9 10 Total MeanMale 250 150 100 175 150 250 200 200 150 170 1795 179.50Female 100 150 150 100 200 150 125 150 130 180 1435 143.50Both 350 300 250 275 350 400 325 350 280 350 3230 161.50
First we found the mean for male students. Here ∑x= 1795. n =10. So 1795/10 = 179.5.Similarly, the mean for female students. Here ∑x= 1435. n =10. So 1435/10 = 143.5.We also find the mean for male and female taken together.
Here ∑x= 3230. n =20. So 3230/20 = 161.50.
Based on the above we can make certain observations. Male students spend Rs. 179.50 on an
average in a month for mobile recharge. Female students spend Rs. 143.50. We may conclude
that male students spend more on monthly mobile recharges. As a researcher, you may now use
this information to make further studies as to why this is so. What are the factors that make male
students to spend more on mobile recharges. We have also calculated the average for all students
taken together. It is Rs. 161.50. Thus we observe that the male students spend more than the
average for ‘all students’ while female students spend less than the total for ‘all students’.Mean is also calculated using another method called the shortcut method asexplained below.
Short cut method: The arithmetic mean can also be calculated by short cut method. This method
reduces the amount of calculation. It involves the following steps
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 26
samples. There may be some differences but those samples in which this difference is less that
are considered better than those in which the difference is more.
(a) Mean (Arithmetic mean / average)The mean (or average) is the most popular and well known measure of central tendency. It can
be used with both discrete and continuous data, although its use is most often with continuous
data (see our Types of Variable guide for data types). The mean is equal to the sum of all the
values in the data set divided by the number of values in the data set. So, if we have n values in a
data set and they have values x1, x2, ..., xn, the sample mean, usually denoted by (pronounced x
bar), is:
This formula is usually written in a slightly different manner using the Greekcapitol letter, , pronounced "sigma", which means "sum of...":
Example
In a survey you collected information on monthly spending for mobile recharge by 20 students ofwhich 10 are male and 10 female. We illustrate below how the data is used to find mean.
1 2 3 4 5 6 7 8 9 10 Total MeanMale 250 150 100 175 150 250 200 200 150 170 1795 179.50Female 100 150 150 100 200 150 125 150 130 180 1435 143.50Both 350 300 250 275 350 400 325 350 280 350 3230 161.50
First we found the mean for male students. Here ∑x= 1795. n =10. So 1795/10 = 179.5.Similarly, the mean for female students. Here ∑x= 1435. n =10. So 1435/10 = 143.5.We also find the mean for male and female taken together.
Here ∑x= 3230. n =20. So 3230/20 = 161.50.
Based on the above we can make certain observations. Male students spend Rs. 179.50 on an
average in a month for mobile recharge. Female students spend Rs. 143.50. We may conclude
that male students spend more on monthly mobile recharges. As a researcher, you may now use
this information to make further studies as to why this is so. What are the factors that make male
students to spend more on mobile recharges. We have also calculated the average for all students
taken together. It is Rs. 161.50. Thus we observe that the male students spend more than the
average for ‘all students’ while female students spend less than the total for ‘all students’.Mean is also calculated using another method called the shortcut method asexplained below.
Short cut method: The arithmetic mean can also be calculated by short cut method. This method
reduces the amount of calculation. It involves the following steps

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 27
i. Assume any one value as an assumed mean, which is also known as working mean
or arbitrary average (A).
ii. Find out the difference of each value from the assumed mean
(d = X-A).
iii. Add all the deviations (∑d)iv. Apply the formulaX = A +
∑Where X → Mean,
∑ → Sum of deviation from assumed mean,A → Assumed mean
Example:
Calculate arithmetic mean
Roll No : 1 2 3 4 5 6Marks : 40 50 55 78 58 60
Roll Nos. Marks d = X - 55
1 40 -15
2 50 -5
3 55 0
4 78 23
5 58 3
6 60 5
∑d = 11
X = A + ∑= 55 + = 56.83
Calculation of arithmetic mean - Discrete series
To find out the total items in discrete series, frequency of each value is multiplies with
the respective size. The value so obtained are totaled up. This total is then divided by the total
number of frequencies to obtain arithmetic mean.
Steps
1. Multiply each size of the item by its frequency fX
2. Add all fX – (∑f X)3. Divide ∑fX by total frequency (N).The formula is X =
∑Example
X 1 2 3 4 5f 10 12 8 7 11

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 28
SolutionX f fX
1 10 10
2 12 24
3 8 24
4 7 28
5 11 55
N = ∑fX = 141
X = ∑ = .= 2.93
Short cut Method
Steps:
Take the value of assumed mean (A)
Find out deviations of each variable from Aie d.
Multiply d with respective frequencies (fd)
Add up the product (∑fd) Apply formulaX = A ±
∑Continuous series
In continuous frequency distribution, the value of each individual frequency distributionis unknown. Therefore an assumption is made to make them precise or on the assumption thatthe frequency of the class intervals is concentrated at the centre that the mid point of each classintervals has to be found out. In continuous frequency distribution, the mean can be calculatedby any of the following methods.
a. Direct methodb. Short cut methodc. Step deviation method
a. Direct MethodSteps:1. Find out the mid value of each group or class. The mid value is obtained by adding the
lower and upper limit of the class and dividing the total by two. (symbol = m)2. Multiply the mid value of each class by the frequency of the class. In other words m will
be multiplied by f.
3. Add up all the products - ∑fm4. ∑fm is divided by N
Example:
From the following find out the mean profitProfit/Shop: 100-200 200-300 300-400 400-500 500-600 600-700 700-800
No. of shops: 10 18 20 26 30 28 18

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 29
Solution
Profit ( ) Mid point - m No of Shops (f) fm100-200 150 10 1500200-300 250 18 4500300-400 350 20 7000400-500 450 26 11700500-600 550 30 16500600-700 650 28 18200700-800 750 18 13500
∑f = 150 ∑fm = 72900X = ∑= 486
b) Short cut methodSteps:1. Find the mid value of each class or group (m)2. Assume any one of the mid value as an average (A)3. Find out the deviations of the mid value of each from the assumed mean
(d)4. Multiply the deviations of each class by its frequency (fd).5. Add up the product of step 4 - ∑fd6. Apply formulaX = A +∑
Example: (solving the last example)Solving: Calculation of Mean
Profit ( ) m d = m - 450 f fd
100-200 150 -300 10 -3000
200-300 250 -200 18 -3600
300-400 350 -100 20 -2000
400-500 450 0 26 0
500-600 550 100 30 3000
600-700 650 200 28 5600
700-800 750 300 18 5400∑f = 150 ∑fd = 5400X = A +∑
=450 + = 486c) Step deviation method
The short cut method discussed above is further simplified or calculations are reduced to a
great extent by adopting step deviation methos.
Steps:
1. Find out the mid value of each class or group (m)
2. Assume any one of the mid value as an average (A)

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 30
3. Find out the deviations of the mid value of each from the assumed mean (d)
4. Deviations are divided by a common factor (d')
5. Multiply the d' of each class by its frequency (f d')
6. Add up the products (∑fd')7. Then apply the formulaX = A +
∑ ′× c Where c = Common factor
Example:
Calculate mean for the last problem
Solution
Profit m f d d' f d'
100-200 150 10 -300 -3 -30
200-300 250 18 -200 -2 -36
300-400 350 20 -100 -1 -20
400-500 450 26 0 0 0
500-600 550 30 100 1 30
600-700 650 28 200 2 56
700-800 750 18 300 3 54∑f = 150 ∑f d' = 540
X = A +∑ × c
450 + × 100450 + (0.36 × 100) = 486
The mean is essentially a model of your data set. It is the value that is most common. You will
notice, however, that the mean is not often one of the actual values that you have observed in
your data set. However, one of its important properties is that it minimises error in the prediction
of any one value in your data set. That is, it is the value that produces the lowest amount of error
from all other values in the data set.
An important property of the mean is that it includes every value in your data set as part of the
calculation. In addition, the mean is the only measure of central tendency where the sum of the
deviations of each value from the mean is always zero.
We complete our discussion on arithmetic mean by listing the merits and demerits of it.
Merits:
It is rigidly defined.
It is easy to calculate and simple to follow.
It is based on all the observations.
It is determined for almost every kind of data.
It is finite and not indefinite.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 31
It is readily put to algebraic treatment.
It is least affected by fluctuations of sampling.
Demerits:
The arithmetic mean is highly affected by extreme values.
It cannot average the ratios and percentages properly.
It is not an appropriate average for highly skewed distributions.
It cannot be computed accurately if any item is missing.
The mean sometimes does not coincide with any of the observed value.
We elaborate on only one of the demerits for your better understanding. The first demerit says
the arithmetic mean is highly affected by extreme values. What does this mean. See the
following example.
Consider the following table which gives information on the marks obtained by students in a test.
Student 1 2 3 4 5 6 7 8 9 10
Mark 15 18 16 14 15 15 12 17 90 95
The mean mark for these ten students is 30.7. However, inspecting the raw data suggests that this
mean value might not be the best way to accurately reflect the typical mark obtained by a
student, as most students have marks in the 12 to 18 range. Here we see that the mean is being
affected by the two large figures 90 and 95. This shows that arithmetic mean is highly affected
by extreme values.
Therefore, in this situation, we would like to have a better measure of central tendency. As we
will find out later, taking the median would be a better measure of central tendency in this
situation.
Weighted MeanSimple arithmetic mean gives equal importance to all items. Some times the items in a
series may not have equal importance. So the simple arithmetic mean is not suitable for those
series and weighted average will be appropriate.
Weighted means are obtained by taking in to account these weights (or importance).
Each value is multiplied by its weight and sum of these products is divided by the total weight to
get weighted mean.
Weighted average often gives a fair measure of central tendency. In many cases it is
better to have weighted average than a simple average. It is invariably used in the following
circumstances.1. When the importance of all items in a series are not equal. We associate weights to the
items.2. For comparing the average of one group with the average of an other group, when the
frequencies in the two groups are different, weighted averages are used.3. When rations percentages and rates are to be averaged, weighted average is used.4. It is also used in the calculations of birth and death rate index number etc.5. When average of a number of series is to be found out together weighted average is used.
Formula: Let x1+ x2 + x3 - - - - +xn be in values with corresponding weightsw1+ w2 + w3 - - - - +wn . Then the weighted average is

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 32
=
=∑∑
(b) Median
The median is also a frequently used measure of central tendency. The median is the midpoint of
a distribution: the same number of data points are above the median as below it. The median is
the middle score for a set of data that has been arranged in order of magnitude.
The median is determined by sorting the data set from lowest to highest values and taking the
data point in the middle of the sequence. There is an equal number of points above and below the
median. For example, in the data 7,8,9,10,11, the median is 9; there are two data points greater
than this value and two data points less than this value. Thus to find the median, we arrange the
observations in order from smallest to largest value. If there is an odd number of observations,
the median is the middle value.
If there is an even number of observations, the median is the average of the two middle values.
Thus, the median of the numbers 2, 4, 7, 12 is (4+7)/2 = 5.5.
In certain situations the mean and median of the distribution will be the same, and in some
situations it will be different. For example, in the data 1,2,3,4,5 the median is 3; there are two
data points greater than this value and two data points less than this value. In this case, the
median is equal to the mean. But consider the data 1,2,3,4,10. In this dataset, the median still is
three, but the mean is equal to 4.
The median can be determined for ordinal data as well as interval and ratio data. Unlike the
mean, the median is not influenced by outliers at the extremes of the data set. For this reason, the
median often is used when there are a few extreme values that could greatly influence the mean
and distort what might be considered typical. For data which is very skewed, the median often is
used instead of the mean.
Calculation of Median : Discrete series
Steps: Arrange the date in ascending or descending order Find cumulative frequencies Apply the formula Median
Median = Size of itemExample: Calculate median from the following
Size of shoes: 5 5.5 6 6.5 7 7.5 8Frequency : 10 16 28 15 30 40 34
Solution

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 33
Size f Cumulative f (f)5 10 10
5.5 16 266 28 54
6.5 15 697 30 99
7.5 40 1398 34 173
Median = Size of item
N = 173
Median = = 87th item = 7
Median = 7Calculation of median – Continuous frequency distributionSteps:
Find out the median by using N/2 Find out the class which median lies Apply the formula = + ℎ 2 −
Where L = lower limit of the median classh = class interval of the median class
f = frequency of the median classN = ∑ , ℎc = cumulative frequency of the preceding median class
Example: Calculate median from the following data
Age inyears
Below10
Below20
Below30
Below40
Below50
Below60
Below70
70 andover
No. ofpersons
2 5 9 12 14 15 15.5 15.6
Solution:
First we have to convert the distribution to a continuous frequency distribution as in thefollowing table and then compute median.
Age in years No. of persons (f) Cumulative frequency (cf) – less than
0-10 2 2
10-20 5-2=3 5
20-30 9-5=4 9
30-40 12-9=3 12
40-50 14-12=2 14
50-60 15-14=1 15
60-70 15.5-15=0.5 15.5
70 and above 15.6-15.5=0.1 15.6

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 34
= = .Median item = = . = 7.8Find the cumulative frequency (c.f) greater than 7.8 is 9. Thus the corresponding class 20-30 isthe median class. = 20, ℎ = 10, = 4, = 15.6 , = 5
Use the formula = + −= 20 + 104 (7.8 − 5) = 20 + 52 × 2.8= 20 + 5 × 1.4 = 27.So the median age is 27.
The Mean vs. the MedianAs measures of central tendency, the mean and the median each have advantages anddisadvantages. Some pros and cons of each measure are summarized below.
The median may be a better indicator of the most typical value if a set of scores has an outlier.An outlier is an extreme value that differs greatly from other values.
However, when the sample size is large and does not include outliers, the mean score usuallyprovides a better measure of central tendency.
(b) Mode
The mode of a data set is the value that occurs with the most frequency. This measurement is
crude, yet is very easy to calculate. Suppose that a history class of eleven students scored the
following (out of 100) on a test: 60, 64, 70, 70, 70, 75, 80, 90, 95, 95, 100. We see that 70 is in
the list three times, 95 occurs twice, and each of the other scores are each listed only once. Since
70 appears in the list more than any other score, it is the mode. If there are two values that tie for
the most frequency, then the data is said to be bimodal.
The mode can be very useful for dealing with categorical data. For example, if a pizza shop sells10 different types of sandwiches, the mode would represent the most popular pizza. The modealso can be used with ordinal, interval, and ratio data. However, in interval and ratio scales, thedata may be spread thinly with no data points having the same value. In such cases, the modemay not exist or may not be very meaningful.To find mode in the case of a continuous frequencydistribution, mode is found using the formula= + ℎ( − )( − ) − ( − )Rearranging we get = + ℎ( − )2 − −Where
is the lower limit of the model class
is the frequency of the model class

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 35
is the frequency of the class preceding the model class
is the frequency of the class succeeding the model class
his the class interval of the model class
See the following example where we compute mode using the above formula.(mean and median
are also computed)
Example
Find the values of mean, mode and median from the following data.
Weight
(kg)
93-97 98-102 103-
107
108-
112
113-
117
118-
122
123-
127
128-
132
No. of
students
3 5 12 17 14 6 3 1
Solution: Since the formula for mode requires the distribution to be continuous
with ‘exclusive type’ classes, we first convert the classes into class boundaries.
Wight Classboundaries
Midvalue (X)
Numberof
students(f)
= − 1105 fd Less thanc.f
93-97 92.5-97.5 95 3 -3 -9 398-102 97.5-102.5 100 5 -2 -10 8103-107 102.5-107.5 105 12 -1 -12 20108-112 107.5-112.5 110 17 0 0 37113-117 112.5-117.5 115 14 1 14 51118-122 117.5-122.5 120 6 2 12 57123-127 122.5-127.5 125 3 3 9 60128-132 127.5-132.5 130 1 4 4 61
== 61 == 8Mean = + ℎ ∑
= 110 + 5 × 861 = 110.66.Mean = 110.66kgs.Mode
Here maximum frequency is 17. The corresponding class 107.5-112.5 is the model class.Using the formula of mode = + ℎ( − )2 − −We get

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 36
= 107.5 + 5(17 − 12)2(17) − 12 − 14= 107.5 + 258 = 107.5 + 3.125 = 110.625Hence mode is 110.63 kgs.
Median
Use the formula = + ℎ 2 −Here 2 = 61 2 = 30.5The cumulative frequency (c.f.) just greater than 30.5 is 37. So the corresponding class 107.5-112.5 is the median class.Substituting values in the median formula = 107.5 + 517 612 − 20= 107.5 + 517 (30.5 − 20)
= 107.5 + 5 × 10.517= 107.5 + 3.09 = 110.59Median is 110.59 Kgs.
When to use Mean, Median, and ModeThe following table summarizes the appropriate methods of determining the middle or typicalvalue of a data set based on the measurement scale of the data.
Measurement Scale Best Measure
Nominal(Categorical)
Mode
Ordinal Median
Interval Symmetrical data: MeanSkewed data: Median
Ratio Symmetrical data: MeanSkewed data: Median
Merits and demerits of mean, median and mode
Merits and demerits of arithmetic mean has already been discussed. Please refer to that. Here we
discuss only median and mode.
Median:
The median is that value of the series which divides the group into two equal parts, one part

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 37
comprising all values greater than the median value and the other part comprising all the values
smaller than the median value.
Merits of median
(1) Simplicity:- It is very simple measure of the central tendency of the series. I the case of
simple statistical series, just a glance at the data is enough to locate the median value.
(2) Free from the effect of extreme values: - Unlike arithmetic mean, median value is not
destroyed by the extreme values of the series.
(3) Certainty: - Certainty is another merits is the median. Median values are always a certain
specific value in the series.
(4) Real value: - Median value is real value and is a better representative value of the series
compared to arithmetic mean average, the value of which may not exist in the series at all.
(5) Graphic presentation: - Besides algebraic approach, the median value can be estimated also
through the graphic presentation of data.
(6) Possible even when data is incomplete: - Median can be estimated even in the case of certain
incomplete series. It is enough if one knows the number of items and the middle item of the
series.
Demerits of median:
Following are the various demerits of median:
(1) Lack of representative character: - Median fails to be a representative measure in case of such
series the different values of which are wide apart from each other. Also, median is of limited
representative character as it is not based on all the items in the series.
(2) Unrealistic:- When the median is located somewhere between the two middle values, it
remains only an approximate measure, not a precise value.
(3) Lack of algebraic treatment: - Arithmetic mean is capable of further algebraic treatment, but
median is not. For example, multiplying the median with the number of items in the series will
not give us the sum total of the values of the series.
However, median is quite a simple method finding an average of a series. It is quite a commonly
used measure in the case of such series which are related to qualitative observation as and health
of the student.
Mode: The value of the variable which occurs most frequently in a distribution is called the
mode.
Merits of mode:
Following are the various merits of mode:
(1) Simple and popular: - Mode is very simple measure of central tendency. Sometimes, just at
the series is enough to locate the model value. Because of its simplicity, it s a very popular
measure of the central tendency.
(2) Less effect of marginal values: - Compared top mean, mode is less affected by marginal
values in the series. Mode is determined only by the value with highest frequencies.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 38
(3) Graphic presentation:- Mode can be located graphically, with the help of histogram.
(4) Best representative: - Mode is that value which occurs most frequently in the series.
Accordingly, mode is the best representative value of the series.
(5) No need of knowing all the items or frequencies: - The calculation of mode does not require
knowledge of all the items and frequencies of a distribution. In simple series, it is enough if one
knows the items with highest frequencies in the distribution.
Demerits of mode:
Following are the various demerits of mode:
(1) Uncertain and vague: - Mode is an uncertain and vague measure of the central tendency.
(2) Not capable of algebraic treatment: - Unlike mean, mode is not capable of further algebraic
treatment.
(3) Difficult: - With frequencies of all items are identical, it is difficult to identify the modal
value.
(4) Complex procedure of grouping:- Calculation of mode involves cumbersome procedure of
grouping the data. If the extent of grouping changes there will be a change in the model value.
(5) Ignores extreme marginal frequencies:- It ignores extreme marginal frequencies. To that
extent model value is not a representative value of all the items in a series.
Besides, one can question the representative character of the model value as its calculation does
not involve all items of the series.
Exercises
1. Find the measures of central tendency for the data set 3, 7, 9, 4, 5, 4, 6, 7, and 9.
Mean = 6, median = 6 and modes are 4, 7 and 9.Note that here mode is bimodal.
2. Four friends take an IQ test. Their scores are 96, 100, 106, 114. Which of the following
statements is true?
I. The mean is 103.
II. The mean is 104.
III. The median is 100.
IV. The median is 106.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 39
(A) I only
(B) II only
(C) III only
(D) IV only
(E) None is true
The correct answer is (B). The mean score is computed from the equation:
Mean score = Σx / n = (96 + 100 + 106 + 114) / 4 = 104Since there are an even number of scores (4 scores), the median is the average of the two middle
scores. Thus, the median is (100 + 106) / 2 = 103.
3. The owner of a shoe shop recorded the sizes of the feet of all the customers who bought shoes
in his shop in one morning. These sizes are listed below:
8 7 4 5 9 13 10 8 8 7 6 5 3 11 10 8 5 4 8 6
What is the mean of these values: 7.25
What is the median of these values: 7.5
What is the mode of these values: 8.
4. Eight people work in a shop. Their hourly wage rates of pay are:
Worker 1 2 3 4 5 6 7 8
Wage
Rs.
4 14 6 5 4 5 4 4
Work out the mean, median and mode for the values above.
Mean = 5.75, Median = 4.50, Mode = 4.00.
Using the above findings, if the owner of the shop wants to argue that the staff are paid well.
Which measure would they use? He will use mean. Because mean shows the highest value.
Using the above findings, if the staff in the shop want to argue that they are badly paid. Which
measure would they use? The staff will use mode as it is the lowest of the three measures of
central tendencies.
5. The table below gives the number of accidents each year at a particular road junction:
1991 1992 1993 1994 1995 1996 1997 19984 5 4 2 10 5 3 5
Work out the mean, median and mode for the values above.
Mean =4.75Median =4.5Mode =5
Using the above measures, a road safety group want to get the council to make this junction
safer.
Which measure will they use to argue for this? They will use mode as it is the figure which will
help them to justify their argument that the junction has a large number of accidents.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 40
Using the same data the council do not want to spend money on the road junction. Which
measure will they use to argue that safety work is not necessary? The council will use median as
this figure will help them to argue that the junction has less number of accidents.
6. Mr Sasi grows two different types of tomato plant in his greenhouse.
One week he keeps a record of the number of tomatoes he picks from each type of plant.
Day Mon Tue Wed Thu Fri Sat SunType A 5 5 4 1 0 1 5Type B 3 4 3 3 7 9 6
(a) Calculate the mean, median and mode for the Type A plants.
Mean =3, Median = 4, Mode = 5.
(b) Calculate the mean, median and mode for the Type B plants.
Mean =5, Median = 4, Mode = 3.
(c) Which measure would you use to argue that there is no difference between the types?
We will use median as it is the same for both plants.
(d) Which measure would you use to argue that Type A is the best plant?
We will use mode as mode for type A is higher than B. Note that for type A mean is lower than
type B and median is the same for both types.
(e) Which measure would you use to argue that Type B is the best plant?
We will use mean as mean for type A is higher than type B.
Geometric Mean:
The geometric mean is a type of mean or average, which indicates the central tendency or typical
value of a set of numbers. It is similar to the arithmetic mean, which is what most people think of
with the word "average", except that the numbers are multiplied and then the nth root (where n is
the count of numbers in the set) of the resulting product is taken.
Geometric mean is defined as the nth root of the product of N items of series. If there are two
items, take the square root; if there are three items, we take the cube root; and so on.
Symbolically;
GM = ( )( ) … … ( )Where X1, X2 ….. Xn are refer to the various items of the series.
For instance, the geometric mean of two numbers, say 2 and 8, is just the square root of theirproduct; that is √2 × 8 = 4. As another example, the geometric mean of three numbers 1, ½, ¼ is
the cube root of their product (1/8), which is 1/2; that is 1 × 1 2 × 1 4 = 1 8 = .
When the number of items are three or more, the task of multiplying the numbers and of
extracting the root becomes excessively difficult. To simplify calculations, logarithms are used.
GM then is calculated as follows.
log G.M =……

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 41
G.M. =∑
G.M. = Antilog∑ log XN
In discrete series GM = Antilog∑f log XN
In continuous series GM = Antilog∑f log mN
Where f = frequency
M = mid pointMerits of G.M
1. It is based on each and every item of the series.2. It is rigidly defined.3. It is useful in averaging ratios and percentages and in determining rates of increase and
decrease.4. It is capable of algebraic manipulation.
Limitations1. It is difficult to ounderstant2. It is difficult to compute and to interpret3. It can’t be computed when there are negative and positive values in a series or one or
more of values is zero.4. G.M has very limited applications.
Harmonic MeanHarmonic mean is a kind of average.It is the mean of a set of positive variables. It is calculatedby dividing the number of observations by the reciprocal of each number in the series.
Harmonic Mean of a set of numbers is the number of items divided by the sum of the reciprocalsof the numbers. Hence, the Harmonic Mean of a set of n numbers i.e. a1, a2, a3, ... an, is given as= + + + ⋯ +Example: Find the harmonic mean for the numbers 3 and 4.Take the reciprocals of the given numbers and sum them.13 + 14 = 4 + 312 = 712Now apply the formula. Since the number of observations is two, here n = 2.
= 27 12 = 2 × 127 = 247 = 3.43In discrete series, H.M = ∑ .In continuous series, H.M = ∑ . = ∑
Merits of Harmonic mean:
1. Its value is based on every item of the series.
2. It lends itself to algebraic manipulation.
Limitations
1. It is not easily understood

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 42
2. It is difficult to compute
3. It gives larges weight to smallest item.
7. MEASURES OF VARIABILITY / DISPERSIONThe terms variability, spread, and dispersion are synonyms, and refer to how spread out a
distribution is.Just as in the section on central tendency where we discussed measures of the
centre of a distribution of scores, here we discuss measures of the variability of a
distribution.Measures of variability provide information about the degree to which individual
scores are clustered about or deviate from the average value in a distribution.
Quite often students find it difficult to understand what is meant by variability or dispersion and
hence they find the measures of dispersion difficult. So will discuss the meaning of the term in
detail. First one should understand that dispersion or variability is a continuation of our
discussion of measure of central tendency. So for any discussion on measure of dispersion we
should use any of the measure of central tendency. We continue this discussion taking mean as
an example. The mean or average measures the centre of the data. It is one aspect observations.
Another feature of the observations is as to how the observations are spread about the centre. The
observation may be close to the centre or they may be spread away from the centre. If the
observation are close to the centre (usually the arithmetic mean or median), we say that
dispersion or scatter or variation is small. If the observations are spread away from the centre, we
say dispersion is large.
Let us make this clear with the help of an example. Suppose we have three groups of students
who have obtained the following marks in a test. The arithmetic means of the three groups are
also given below:
Group A: 46, 48, 50, 52, 54, for this the mean is 50.
Group B: 30, 40, 50, 60, 70, for this the mean is 50.
Group C: 40, 50, 60, 70, 80, for this the mean is 60.
In a group A and B arithmetic means are equal i.e. mean of Group A = Mean of Group B = 50.
But in group A the observations are concentrated on the centre. All students of group A have
almost the same level of performance. We say that there is consistence in the observations in
group A. In group B the mean is 50 but the observations are not closed to the centre. One
observation is as small as 30 and one observation is as large as 70. Thus there is greater
dispersion in group B. In group C the mean is 60 but the spread of the observations with respect
to the centre 60 is the same as the spread of the observations in group B with respect to their own
centre which is 50. Thus in group B and C the means are different but their dispersion is the
same. In group A and C the means are different and their dispersions are also different.
Dispersion is an important feature of the observations and it is measured with the help of the
measures of dispersion, scatter or variation. The word variability is also used for this idea of
dispersion.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 43
The study of dispersion is very important in statistical data. If in a certain factory there is
consistence in the wages of workers, the workers will be satisfied. But if some workers have high
wages and some have low wages, there will be unrest among the low paid workers and they
might go on strikes and arrange demonstrations. If in a certain country some people are very
poor and some are very high rich, we say there is economic disparity. It means that dispersion is
large. The idea of dispersion is important in the study of wages of workers, prices of
commodities, standard of living of different people, distribution of wealth, distribution of land
among framers and various other fields of life. Some brief definitions of dispersion are:
The degree to which numerical data tend to spread about an average value is called the
dispersion or variation of the data.
Dispersion or variation may be defined as a statistics signifying the extent of the scatteredness of
items around a measure of central tendency.
Dispersion or variation is the measurement of the scatter of the size of the items of a series about
the average.
There are five frequently used measures of variability: the Range, Interquartile range or quartile
deviation, Mean deviation or average deviation, Standard deviation and Lorenz curve.
7.1 Range
The range is the simplest measure of variability to calculate, and one you haveprobably encountered many times in your life. The range is simply the highestscore minus the lowest score.
Range: R = maximum – minimum
Let’s take a few examples. What is the range of the following group of numbers: 10, 2, 5, 6, 7, 3,
4. Well, the highest number is 10, and the lowest number is 2, so 10 - 2 = 8. The range is 8.
Let’s take another example. Here’s a dataset with 10 numbers: 99, 45, 23, 67, 45, 91, 82, 78, 62,
51. What is the range. The highest number is 99 and the lowest number is 23, so 99 - 23 equals
76; the range is 76.
Example2: Ms. Kesavan listed 9 integers on the blackboard. What is the range of these integers?
14, -12, 7, 0, -5, -8, 17, -11, 19
Ordering the data from least to greatest, we get:
-12, -11, -8, -5, 0, 7, 14, 17, 19
Range: R = highest - lowest = 19 - -12 = 19 + +12 = +31

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 44
The range of these integers is +31.
Example 3: A marathon race was completed by 5 participants. What is the range of times given
in hours below
2.7 hr, 8.3 hr, 3.5 hr, 5.1 hr, 4.9 hr
Ordering the data from least to greatest, we get:
2.7, 3.5, 4.9, 5.1, 8.3
Range: R = highest – lowest = 8.3 hr - 2.7 hr = 5.6 hr
The range of marathon race is 5.6 hr.
Merits and LimitationsMerits
Amongst all the methods of studying dispersion, range is the simplest to understand
easiest to compute.
It takes minimum time to calculate the value of range Hence if one is interested in getting
a quick rather than very accurate picture of variability one may compute range.
Limitation
Range is not based on each and every item of the distribution.
It is subject to fluctuation of considerable magnitude from sample to sample.
Range can’t tell us anything about the character of the distribution with the two.
According to kind “Range is too indefinite to be used as a practical measure of dispersionUses of Range
Range is useful in studying the variations in the prices of stocks, shares and other
commodities that are sensitive to price changes from one period to another period.
The meteorological department uses the range for weather forecasts since public is
interested to know the limits within which the temperature is likely to vary on a particular
day.
7.2 Inter – Quartile Range Or Quartile Deviation
So we have seen Range which is a measure of variability which concentrate on two extreme
values. If we concentrate on two extreme values as in the case of range, we do not get any idea
about the scatter of the data within the range ( i.e. what happens within the two extreme values ).
If we discard these two values the limited range thus available might be more informative. For
this reason the concept of interquartile range is developed. It is the range which includes middle
50% of the distribution. Here 1/4 ( one quarter of the lower end and 1/4 ( one quarter ) of the
upper end of the observations are excluded.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 45
Now the lower quartile ( Q1 ) is the 25th percentile and the upper quartile (Q3 ) is the 75th
percentile. It is interesting to note that the 50th percentile is the middle quartile ( Q2 ) which is in
fact what you have studied under the title ’ Median . Thus symbolically
Inter quartile range = Q3 - Q1
If we divide ( Q3 - Q1 ) by 2 we get what is known as Semi-Iinter quartile range.
i.e. . It is known as Quartile deviation ( Q. D or SI QR ).
Another look at the same issue is given here to make the concept more clear for the student.
In the same way that the median divides a dataset into two halves, it can be further divided intoquarters by identifying the upper and lower quartiles. The lower quartile is found one quarter ofthe way along a dataset when the values have been arranged in order of magnitude; the upperquartile is found three quarters along the dataset. Therefore, the upper quartile lies half waybetween the median and the highest value in the dataset whilst the lower quartile lies halfwaybetween the median and the lowest value in the dataset. The inter-quartile range is found bysubtracting the lower quartile from the upper quartile.
For example, the examination marks for 20 students following a particular module are arrangedin order of magnitude.
median lies at the mid-point between the two central values (10th and 11th)
= half-way between 60 and 62 = 61
The lower quartile lies at the mid-point between the 5th and 6th values
= half-way between 52 and 53 = 52.5
The upper quartile lies at the mid-point between the 15th and 16th values
= half-way between 70 and 71 = 70.5
The inter-quartile range for this dataset is therefore 70.5 - 52.5 = 18 whereas the range is: 80 - 43
= 37.
The inter-quartile range provides a clearer picture of the overall dataset by removing/ignoring the
outlying values.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 46
Like the range however, the inter-quartile range is a measure of dispersion that is based upon
only two values from the dataset. Statistically, the standard deviation is a more powerful measure
of dispersion because it takes into account every value in the dataset. The standard deviation is
explored in the next section.
Example 1
The wheat production (in Kg) of 20 acres is given as: 1120, 1240, 1320, 1040, 1080, 1200, 1440,
1360, 1680, 1730, 1785, 1342, 1960, 1880, 1755, 1720, 1600, 1470, 1750, and 1885. Find the
quartile deviation and coefficient of quartile deviation.
After arranging the observations in ascending order, we get
1040, 1080, 1120, 1200, 1240, 1320, 1342, 1360, 1440, 1470, 1600, 1680, 1720, 1730, 1750,
1755, 1785, 1880, 1885, 1960. = + 14 ℎ= 20 + 14 ℎ= (5.25) ℎ= 5 ℎ + 0.25(6 ℎ − 5 ℎ )= 1240 + 0.25(1320 − 1240)= 1240 + 20 = 1260= 3( + 1)4 ℎ= 3(20 + 1)4 ℎ= (15.75) ℎ= 15 ℎ + 0.75(16 ℎ − 15 ℎ )= 1750 + 0.75(1755 − 1750)= 1750 + 3.75 = 1753.75( . . ) = −2 = 1753.75 − 12602 = 492.752 = 246.88
= −+ = 1753.75 − 12601753.75 + 1260 = 0.164Example 2
Calculate the range and Quartile deviation of wages.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 47
Wages ( ) Labourers
30 – 32
32 – 34
34 – 36
36 – 38
38 – 40
40 – 42
42 - 44
12
18
16
14
12
8
6
SolutionRange : = L – SCalculation of Quartiles :
X f c.f
30 – 32
32 – 34
34 – 36
36 – 38
38 – 40
40 – 42
42 - 44
12
18
16
14
12
8
6
12
30
46
60
72
80
86
= Size of item
= = 21.5ie. Q. lies in the group 32 – 34
= L +.
× i
= 32 +.
× 2
= 32 += 32 + 1.06= 33.06
====
= Size of item

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 48
= 3 × = 64.5 itemlies in the group 38 – 40
= L +.
× i
= 38 +.
× 2= 38 + 0.75= 38.75
Q.D =
=. .
=.
= 2.85===
Coefficient of Q.D. =
=. .. .
=. .
= 0.08Merits of Quartile Deviation
1. It is simple to understand and easy to calculate.2. It is not influenced by extreme values.3. It can be found out with open end distribution.4. It is not affected by the presence of extreme values.
Demerits1. It ignores the first 25% of the items and the last 25% of the items.2. It is a positional average : hence not amenable to further mathematical treatment.3. The value is affected by sampling fluctuations.7.3 Mean Deviation or Average DeviationAverage deviations (mean deviation) is the average amount of variations(scatter) of the items in a distribution from either the mean or the median orthe mode, ignoring the signs of these deviations. In other words, the meandeviation or average deviation is the arithmetic mean of the absolutedeviations.
Example 1: Find the Mean Deviation of 3, 6, 6, 7, 8, 11, 15, 16
Step 1: Find the mean: = = = 9Step 2: Find the distance of each value from that mean:

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 49
Which looks like this diagrammatically:
Step 3. Find the mean of those distances:= 6 + 3 + 3 + 2 + 1 + 2 + 6 + 78 = 308 = 3.75So, the mean = 9, and the mean deviation = 3.75
It tells us how far, on average, all values are from the middle.
In that example the values are, on average, 3.75 away from the middle.
The formula is: = ∑| − |Where
μ is the mean (in our example μ = 9)
x is each value (such as 3 or 16)
N is the number of values (in our example N = 8)
Each distance we calculated is called an Absolute Deviation, because it is the
Absolute Value of the deviation (how far from the mean).To show "Absolute
Value" we put “|” marks either side like this: |-3| = 3. Thus absolute value is
one where we ignore sign. That is, if it is – or +, we consider it as +. Eg. -3 or +3
will be taken as just 3.
Value Distancefrom 9
3 66 36 37 28 111 215 616 7

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 50
Let us redo example 1 using the formula: Find the Mean Deviation of 3, 6, 6, 7,8, 11, 15, 16
Step 1: Find the mean:= 3 + 6 + 6 + 7 + 8 + 11 + 15 + 168 = 728 = 9Step 2: Find the Absolute Deviations:
x x - μ |x - μ|
3 -6 6
6 -3 3
6 -3 3
7 -2 2
8 -1 1
11 2 2
15 6 6
16 7 7| − | = 30Step 3. Find the Mean Deviation: = ∑| − | = 308 = 3.75Example 2
Calculate the mean deviation using mean for the following data
2-4 4-6 6-8 8-10
3 4 2 1
Solution
Class Mid
Value
(X)
Frequency
(f)
d = X-5 fd | − |= | − 5.2| | − |

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 51
2-4 3 3 -2 -6 2.2 6.6
4-6 5 4 0 0 0.2 0.8
6-8 7 2 2 4 1.8 3.6
8-10 9 1 4 4 3.8 3.8= 10 = 2 | − |= 14.8= + ∑ = 5 + 210 = 5.2= 1 | − | = 14.810 = 1.48
Example 3
Calculate mean deviation based on (a) Mean and (b) median
Class
Interval
0-10 10-20 20-30 30-40 40-50 50-60 60-70
Frequency
f
8 12 10 8 3 2 7
Solution
Let us first make the necessary computations.
Classinterval
Midvalue
(X)
Freq-uency
(f)
Lessthanc.f.
fX| − |= |− 29| |− | |− |= |− 22|
|− |0-10 5 8 8 40 24 192 17 136
10-20 15 12 20 180 14 168 7 84
20-30 25 10 30 250 4 40 3 30
30-40 35 8 38 280 6 48 13 104
40-50 45 3 41 135 16 48 23 69
50-60 55 2 43 110 26 52 33 66
60-70 65 7 50 455 36 252 43 301
N=50 = 1450 |− |= 800|− |= 790
(a) M.D. from Mean ( ) = 1 = 145050 = 29So mean =29. Let us now find men deviation about mean

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 52
. . = 1 | − | = 80050 = 16We see that mean deviation based on mean is 16.
Now let us compute M.D. about median
(b) M.D. from median
(N/2) =(50/2) = 25. The c.f. just greater than 25 is 30 in the table above. So the
corresponding class 20-30 is the median class.
Sol= lower limit of the median class = 20, f = frequency of the median class =
25, h = class interval of the median class =10,c = cumulative frequency of the
preceding median class =20.
Use the formula of median to substitute values.= + ℎ (2 − )= 20 + 1025 (25 − 20) = 20 + 2 = 22
Median = 22. Let us now find Mean Deviation about median.. . = 1 | − | = 79050 = 15.8Thus we have computed Mean Deviation from Mean and Median. Let us
compare the two results. MD from Mean is 16 and MD from median is 15.8.
So, M.D. from Median < M.D. from Mean. This implies that M.D. is least when
taken about median.
Merits of M.D.
i. It is simple to understand and easy to compute.ii. It is not much affected by the fluctuations of sampling.
iii. It is based on all items of the series and gives weight according to their size.iv. It is less affected by extreme items.v. It is rigidly defined.
vi. It is a better measure for comparison.Demerits of M.D.
i. It is a non-algebraic treatmentii. Algebraic positive and negative signs are ignored. It is mathematically unsound
and illogical.iii. It is not as popular as standard deviation.
Uses :

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 53
It will help to understand the standard deviation. It is useful in marketingproblems. It is used in statistical analysis of economic, business and socialphenomena. It is useful in calculating the distribution of wealth in acommunity or nation.
7.4 Standard DeviationThe concept, standard deviation was introduced by Karl Pearson in 1893. It is the most
important measure of dispersion and is widely used. It is a measure of the dispersion of a set of
data from its mean. The standard deviation is kind of the “mean of the mean,” and often can helpyou find the story behind the data.
The standard deviation is a measure that summarises the amount by which every value within a
dataset varies from the mean. Effectively it indicates how tightly the values in the dataset are
bunched around the mean value. It is the most robust and widely used measure of dispersion
since, unlike the range and inter-quartile range, it takes into account every variable in the dataset.
When the values in a dataset are pretty tightly bunched together the standard deviation is small.
When the values are spread apart the standard deviation will be relatively large.
Standard deviation is defined as a statistical measure of dispersion in the value of an asset around
mean. The standard deviation calculation tells you how spread out the numbers are in your
sample. Standard Deviation is represented using the symbol ( ℎ ).
For example if you want to measure the performance a mutual fund, SD can be used. It gives an
idea of how volatile a fund's performance is likely to be. It is an important measure of a fund's
performance. It gives an idea of how much the return on the asset at a given time differs or
deviates from the average return. Generally, it gives an idea of a fund's volatility i.e. a higher
dispersion (indicated by a higher standard deviation) shows that the value of the asset has
fluctuated over a wide range.
The formula for finding SD in a sentence form is : it is the square root of the Variance. So now
you ask, ‘What is the Variance’. Let us see what is variance.
The Variance is defined as:The average of the squared differences from the Mean.
We can calculate the variance follow these steps:
a. Work out the Mean (the simple average of the numbers)
b. Then for each number: subtract the Mean and square the result (the squared difference).
c. Then work out the average of those squared differences.
You may ask Why square the differences. If we just added up the differences from the mean ...
the negatives would cancel the positives as shown below. So we take the square.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 54
ExampleYou have figures of the marks obtained by your five bench mates which is asfollows: 600, 470, 170, 430 and 300. Find out the Mean, the Variance, and theStandard Deviation.Your first step is to find the Mean:
= 600 + 470 + 170 + 430 + 3005 = 19705 = 394So the mean (average) mark is 394. Let us plot this on the chart:
x − ( − )600 206 42436
470 76 5776
170 -224 50176
430 36 1296
300 -94 8836 ( − )= 108520To calculate the Variance, take each difference, square it, find the sum
(108520) and find average: = 1085205 = 21704So, the Variance is 21,704.The Standard Deviation is just the square root of Variance, so:SD = σ = √21704 = 147.32 ≈ 147
Now we can see which heights are within one Standard Deviation (147) of theMean.Please note that there is a slight difference when we find variance from apopulation and mean. In the above example we found out variance for datacollected from all your bench mates. So it may be considered as population.Suppose now you collect data only from some of your bench mates. Now it maybe considered as a sample. If you are finding variance for a sample data, in theformula to find variance, divide by N-1 instead of N.For example, if we say that in our problem the marks are of some students in aclass, it should be treated as a sample. In that caseVariance (or to be precise Sample Variance) = 108,520 / 4 = 27,130. Note thatinstead of N (i.e.5) we divided by N-1 (5-1=4).Standard Deviation (Sample Standard Deviation) = σ = √27130 = 164.31 ≈ 164

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 55
Based on the above information, let us build the formula for finding SD. Sincewe use two different formulae for data which is population and data which issample, we will have two different formula for SD also.
The "Population Standard Deviation":
The "Sample Standard Deviation":
Computation of Standard Deviation: There are different methods tocomputeSD. They are illustrated through examples below.
Example 1
Calculate SD for the following observations using different methods.
160, 160, 161, 162, 163, 163, 163, 164, 164, 170
(a) Direct method No.1
Formula = ∑ ℎ = − X = −
160 -3 9
160 -3 9
161 -2 4
162 -1 1
163 0 0
163 0 0
163 0 0
164 1 1
164 1 1
170 7 49= 1630 = 74ℎ = = ∑ = 163
Now compute SD = ∑= = √7.4 = 2.72

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 56
(b) Direct method No.2
Here the formula is
= ∑ − ∑ /X
160 25600
160 25600
161 25921
162 26244
163 26569
163 26569
163 26569
164 26896
164 26896
170 28900= 1630 = 2657640= 265764 − 1630 /1010= 7410 = √7.4 = 2.72(c)Method 3 (Short Cut Method) – in this method instead of finding the mean we assume afigure as mean. Here we have assumed 162 as mean arbitrarily.We use the formula= ∑ − ∑
X Deviation from assumed mean (herewe assume mean as162)
dx
( )160 -2 4160 -2 4161 -1 1162 0 0163 1 1

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 57
163 1 1163 1 1164 2 4164 2 4170 8 641630 +10 = 84
= 8410 − 1010= √8.4 − 1= √7.4 = 2.72Another example where we find many of the concepts together.Example:
Given the series: 3, 5, 2, 7, 6, 4, 9.
Calculate:
The (a)mode, (b)median and (c)mean.
(d) variance (e)standard deviation and (f)The average deviation.
(a)Mode: Does not exist because all the scores have the same frequency.
(b) Median
2, 3, 4, 5, 6, 7, 9.
Median = 5
(c)Mean = 2 + 3 + 4 + 5 + 6 + 7 + 97 = 5.143(d)Variance(d)Variance
= = 2 + 3 + 4 + 5 + 6 + 7 + 97 − 5.143 = 4.978(e)Standard Deviation = √4.978 = 2.231(f) Average Deviation | − |= | − 5.143|
2 3.1433 2.1434 1.1435 0.1436 0.8577 1.8579 3.857

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 58
| − |= 13.143= ∑| − | = 13.1437 = 1.878
Calculation of SD for continuous series
The step deviation method is easy to use to find SD for continuous
series.
= ∑ − ∑ ×ℎ = ( − ) ℎ =
Calculate Mean and SD for the following data
0-10 10-20 20-30 30-40 40-50 50-60 60-70
5 12 30 45 50 37 21
Make the necessary computations
x Midpoint(m)
f =( − 35)10 fd f×d2
0-10 5 5 -3 -15 45
10-20 15 12 -2 -24 48
20-30 25 30 -1 -30 30
30-40 35 45 0 0 0
40-50 45 50 1 50 50
50-60 55 37 2 74 148
60-70 65 21 3 63 189
N = 200 = 118 = 510= = + ∑ × = 35 + 118200 × 10 = 35 + 5.9 = 40.9

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 59
= ∑ − ∑ × = 510200 − 118200 × 10= √2.55 − 3481×10
=1.4839×10=14.839.
Merits of Standard Deviation
1. It is rigidly defined and its value is always definite and based on all observation.2. As it is based on arithmetic mean, it has all the merits of arithmetic mean.3. It is possible for further algebraic treatment.4. It is less affected by sampling fluctuations.
Demerits
1. It is not easy to calculate.
It gives more weight to extreme values, because the values are squared up.
Coefficient of Variation
Standard deviation is the absolute measure of dispersion. It is expressed interms of the units in which the original figures are collected and stated. The relativemeasure of standard deviation is known as coefficient of variation.
Variance : Square of Standard deviation
Symbolically;Variance =
= √Coefficient of standard deviation =
8. MEASURES OF VARIABILITY IN SHAPE- Graphic Method of Dispersion
Dispersion or variance can be represented using graphs also. We discuss here some of
the graphical methods which rely on the shape of the curve to represent the deviations.
We will see Lorenz Curve, Gini’s Coefficient, Skewness and Kurtosis

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 60
8.1 - LORENZ CURVELorenz Curve is a graphical representation of wealth distribution developed by
American economist Dr. Max O. Lorenz a popular Economic- Statistician in 1905. He
studied distribution of Wealth and Income with its help.. On the graph, a straight
diagonal line represents perfect equality of wealth distribution; the Lorenz curve lies
beneath it, showing the reality of wealth distribution. The difference between the
straight line and the curved line is the amount of inequality of wealth distribution, a
figure described by the Gini coefficient. One practical use of The Lorenz curve is that it
can be used to show what percentage of a nation's residents possess what percentage of
that nation's wealth. For example, it might show that the country's poorest 10% possess
2% of the country's wealth.
It is graphic method to study dispersion. It helps in studying the variability in different
components of distribution especially economic. The base of Lorenz Curve is that we
take cumulative percentages along X and Y axis. Joining these points we get the Lorenz
Curve. Lorenz Curve is of much importance in the comparison of two series
graphically. It gives us a clear cut visual view of the series to be compared.
Steps to plot 'Lorenz Curve'
Cumulate both values and their corresponding frequencies. Find the percentage of each of the cumulated figures taking the grand total of each
corresponding column as 100. Represent the percentage of the cumulated frequencies on X axis and those of the values
on the Y axis. Draw a diagonal line designated as the line of equal distribution. Plot the percentages of cumulated values against the percentages of the cumulated
frequencies of a given distribution and join the points so plotted through a free handcurve.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 61
The greater the distance between the curve and the line of equal distribution, thegreater the dispersion. If the Lorenz curve is nearer to the line of equal distribution, thedispersion or variation is smaller.
Based on data of annual income of 8 individuals we have drawn a Lorenz curvebelow using MS Excel.
Individual Income %population
%income
CumulativeIncome %
0 0 0 0 0
1 5000 12.5 1.204819 1.204819
2 12000 25 2.891566 4.096385
3 18000 37.5 4.337349 8.433735
4 30000 50 7.228916 15.66265
5 40000 62.5 9.638554 25.3012
6 60000 75 14.45783 39.75904
7 100000 87.5 24.09639 63.85542
8 150000 100 36.14458 100
415000

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 62
Example
From the following table giving data regarding income of workers in a factory, drawLorenz Curve to study inequality of income
The following method for constructing Lorenz Curve.
1. The size of the item and their frequencies are to be cumulated.
2. Percentage must be calculated for each cumulation value of the size andfrequency of items.
3. Plot the percentage of the cumulated values of the variable against thepercentage of the corresponding cumulated frequencies. Join these points with assmooth free hand curve. This curve is called Lorenz curve.
4. Zero percentage on the X axis must be joined with 100% on Y axis. This line iscalled the line of equal distribution.
IncomeMid value Cumulative
income% of
cumulativeincome
No. ofworkers (f)
Cumulativeno. of
workers
% ofCumulative
no. Ofworkers
0-500 250 250 2.94 6000 6000 37.50
500-1000 750 1000 11.76 4250 10250 64.06
1000-2000 1500 2500 29.41 3600 13850 86.56
2000-3000 2500 5000 58.82 1500 15350 95.94
3000-4000 3500 8500 100.00 650 16000 100.00
8500 16000
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 62
Example
From the following table giving data regarding income of workers in a factory, drawLorenz Curve to study inequality of income
The following method for constructing Lorenz Curve.
1. The size of the item and their frequencies are to be cumulated.
2. Percentage must be calculated for each cumulation value of the size andfrequency of items.
3. Plot the percentage of the cumulated values of the variable against thepercentage of the corresponding cumulated frequencies. Join these points with assmooth free hand curve. This curve is called Lorenz curve.
4. Zero percentage on the X axis must be joined with 100% on Y axis. This line iscalled the line of equal distribution.
IncomeMid value Cumulative
income% of
cumulativeincome
No. ofworkers (f)
Cumulativeno. of
workers
% ofCumulative
no. Ofworkers
0-500 250 250 2.94 6000 6000 37.50
500-1000 750 1000 11.76 4250 10250 64.06
1000-2000 1500 2500 29.41 3600 13850 86.56
2000-3000 2500 5000 58.82 1500 15350 95.94
3000-4000 3500 8500 100.00 650 16000 100.00
8500 16000
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 62
Example
From the following table giving data regarding income of workers in a factory, drawLorenz Curve to study inequality of income
The following method for constructing Lorenz Curve.
1. The size of the item and their frequencies are to be cumulated.
2. Percentage must be calculated for each cumulation value of the size andfrequency of items.
3. Plot the percentage of the cumulated values of the variable against thepercentage of the corresponding cumulated frequencies. Join these points with assmooth free hand curve. This curve is called Lorenz curve.
4. Zero percentage on the X axis must be joined with 100% on Y axis. This line iscalled the line of equal distribution.
IncomeMid value Cumulative
income% of
cumulativeincome
No. ofworkers (f)
Cumulativeno. of
workers
% ofCumulative
no. Ofworkers
0-500 250 250 2.94 6000 6000 37.50
500-1000 750 1000 11.76 4250 10250 64.06
1000-2000 1500 2500 29.41 3600 13850 86.56
2000-3000 2500 5000 58.82 1500 15350 95.94
3000-4000 3500 8500 100.00 650 16000 100.00
8500 16000

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 63
Uses of Lorenz Curve
1. To study the variability in a distribution.2. To compare the variability relating to a phenomenon for two regions.3. To study the changes in variability over a period.
8.2 - Gini index / Gini coefficientA Lorenz curve plots the cumulative percentages of total income received against the cumulative
number of recipients, starting with the poorest individual or household. The Gini index measures
the area between the Lorenz curve and a hypothetical line of absolute equality, expressed as a
percentage of the maximum area under the line. This is the most commonly used measure of
inequality. The coefficient varies between 0, which reflects complete equality and 1(100), which
indicates complete inequality (one person has all the income or consumption, all others have
none). Gini coefficient is found by measuring the areas A and B as marked in the following
diagram and using the formula A/(A+B). If the Gini coefficient is to be presented as a ratio or
percentage, A/(A+B)×100.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 64
The Gini coefficient (also known as the Gini index or Gini ratio) is a measure of statistical
dispersion intended to represent the income distribution of a nation's residents. This is the most
commonly used measure of inequality. The coefficient varies between 0, which reflects complete
equality and 1, which indicates complete inequality (one person has all the income or
consumption, all others have none). It was developed by the Italian statistician and sociologist
Corrado Gini in 1912.
8.3 - SkewnessWe have discussed earlier techniques to calculate the deviations of adistribution from its measure of central tendency (mean / median, mode ).Here we see another measure for that named Skewness. Skewness characterizesthe degree of asymmetry of a distribution around its mean. If there is only one mode (peak)in our data (unimodel) , and if the other data are distributed evenly to the left and right ofthis value, if we plot it in a graph, we get a curve like this, which is called a normal curve(See figure below). Here we say that there is no skewness or skewness = 0. If there is zeroskewness (i.e., the distribution is symmetric) then the mean = median for this distribution.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 65
However data need not always be like this. Sometimes the bulk of the data is at the left and theright tail is longer, we say that the distribution is skewed right or positively skewed. Positiveskewness indicates a distribution with an asymmetric tail extending towards more positivevalues.On the other hand, sometimes the bulk of the data is at is at the right and the left tail islonger, we say that the distribution is skewed left or negatively skewed. Negative skewnessindicates a distribution with an asymmetric tail extending towards more negative values"
Skewed Left Symmetric Skewed Right
Tests of Skewness
There are certain tests to know whether skewness does or does not exist in a frequencydistribution.They are :1. In a skewed distribution, values of mean, median and mode would not coincide. Thevalues of mean and mode are pulled away and the value of median will be at the centre.In this distribution, mean-Mode = 2/3 (Median - Mode).2. Quartiles will not be equidistant from median.3. When the asymmetrical distribution is drawn on the graph paper, it will not give abell shapedcurve.4. Sum of the positive deviations from the median is not equal to sum of negativedeviations.5. Frequencies are not equal at points of equal deviations from the mode.Nature of SkewnessSkewness can be positive or negative or zero.1. When the values of mean, median and mode are equal, there is no skewness.2. When mean > median > mode, skewness will be positive.3. When mean < median < mode, skewness will be negative.Characteristic of a good measure of skewness1. It should be a pure number in the sense that its value should be independent of theunit of the series and also degree of variation in the series.2. It should have zero-value, when the distribution is symmetrical.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 66
3. It should have a meaningful scale of measurement so that we could easily interpretthe measured value.Measures of Skewness
Skewness can be studied graphically and mathematically. When we studySkewness graphically, we can find out whether Skewness is positive or negative or zero.This is what we have shown above.
Mathematically Skewness can be studied as :(a) Absolute Skewness(b) Relative or coefficient of skewness
When the skewness is presented in absolute term i.e, in units, it is absoluteskewness. If the value of skewness is obtained in ratios or percentages, it is calledrelative or coefficient of skewness. When skewness is measured in absolute terms, wecan compare one distribution with the other if the units of measurement are same.When it is presented in ratios or percentages, comparison become easy. Relativemeasures of skewness is also called coefficient of skewness.
(a) Absolute measure of Skewness:
Skewness can be measured in absolute terms by taking the difference betweenmean and mode.
Absolute Skewness = – mode
If the value of the mean is greater than mode, the Skewness is positiveIf the value of mode is greater than mean, the Skewness is negative
Greater the amount of Skewness (negative or positive) the more tendencytowards asymmetry. The absolute measure of Skewness will be proper measure forcomparison, and hence, in each series a relative measure or coefficient of Skewenesshave to be computed.(b) Relative measure of skewnessThere are three important measures of relative skewness.
1. Karl Pearson’s coefficient of skewness.2. Bowley’s coefficient of skewness.3. Kelly’s coefficient of skewness.
(b 1) Karl Pearson’s coefficient of SkewnessThe mean, median and mode are not equal in a skewed distribution. The Karl Pearson’smeasure of skewness is based upon the divergence of mean from mode in a skeweddistribution.Karl Pearson's measure of skewness is sometimes referred to Skp= −Properties of Karl Pearson coefficient of Skewness
(1)−1 ≤ Skp ≤ 1.
(2) Skp = 0 ⇒ distribution is symmetrical about mean.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 67
(3)Skp> 0 ⇒ distribution is skewed to the right.
(4) Skp< 0 ⇒ distribution is skewed to the left.
Advantage of Karl Pearson coefficient of Skewness
Skp is independent of the scale. Because (mean-mode) and standard deviation have
same scale and it will be canceled out when taking the ratio.
Disadvantage of Karl Pearson coefficient of Skewness
Skp depends on the extreme values.
Example: 1Calculate the coefficient of skewness of the following data by using Karl Pearson'smethod for the data 2 3 3 4 4 6 6
Step 1. Find the mean:
Step 2. Find the standard deviation:
Then
Step 3. Find the coefficient of skeness:
Here skewness is negative.
(b 2) Bowley’s coefficient of skewness
Bowley's formula for measuring skewness is based on quartiles. For a symmetrical
distribution, it is seen that Q1, and Q3areequidistant from median (Q2).
Thus (Q3 − Q2) − (Q2 − Q1) can be taken as an absolute measure of skewness.= ( − ) − ( − )( − ) + ( − )= − − +− + −= + −−

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 68
Note:
In the above equation, where the Qs denote the interquartile ranges. Divide a set of data into twogroups (high and low) of equal size at the statistical median if there is an even number of datapoints, or two groups consisting of points on either side of the statistical median itself plus thestatistical median if there is an odd number of data points. Find the statistical medians of the lowand high groups, denoting these first and third quartiles by Q1 and Q3. The interquartile rangeis then defined by IQR = Q3 - Q1.
Properties of Bowley’s coefficient of skewness1 −1 ≤ Skq ≤ 1.2 Skq = 0 ⇒ distribution is symmetrical about mean.3 Skq> 0 ⇒ distribution is skewed to the right.4 Skq< 0 ⇒ distribution is skewed to the left.Advantageof Bowley’s coefficient of skewnessSkq does not depend on extreme values.Disadvantage of Bowley’s coefficient of skewnessSkq does not utilize the data fully.ExampleThe following table shows the distribution of 128 families according to the number ofchildren.
No of children No of families
0 20
1 15
2 25
3 30
4 18
5 10
6 6
7 3
8 or more 1
Compute Bowley’s coefficient of skewness
We use formula for measuring Bowley’s coefficient of skewness= + −−

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 69
Let us find the necessary values
No ofchildren
No offamilies
Cumulativefrequency
0 20 20
1 15 35
2 25 60
3 30 90
4 18 108
5 10 118
6 6 124
7 3 127
8 or more 1 128
= (32.25)th observation
= 1
= (64.5)th observation
= 3
= (96.75)th observation
= 4= + − ( )−= − 13 = −0.333Since Skq< 0 distribution is skewed left
(b 3) Kelly’s coefficient of skewness
Bowley’s measure of skewness is based on the middle 50% of the observations because
it leaves 25% of the observations on each extreme of the distribution.As an

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 70
improvement over Bowley’s measure, Kelly has suggested a measure based on P10 and,
P90 so that only 10% of the observations on each extreme are ignored.= ( − ) − ( − )( − ) + ( − )= − − +− + −= + − 2−8.4 - KURTOSISAs Wesaw above, Skewness is a measure of symmetry, or more precisely, the lack ofsymmetry. A distribution, or data set, is symmetric if it looks the same to the left andright of the center point.Kurtosis is a measure of whether the data are peaked or flat relative to a normaldistribution. That is, data sets with high kurtosis tend to have a distinct peak near themean, decline rather rapidly, and have heavy tails. Data sets with low kurtosis tend tohave a flat top near the mean rather than a sharp peak. A uniform distribution would bethe extreme case. Kurtosis has its origin in the Greek word ‘Bulginess.’Distributions of data and probability distributions are not all the same shape. Some areasymmetric and skewed to the left or to the right. Other distributions are bimodal andhave two peaks. In other words there are two values that dominate the distribution ofvalues. Another feature to consider when talking about a distribution is not just thenumber of peaks but the shape of them. Kurtosis is the measure of the peak of adistribution, and indicates how high the distribution is around the mean. The kurtosisof a distributions is in one of three categories of classification:
Mesokurtic
Leptokurtic
Platykurtic
We will consider each of these classifications in turn.Mesokurtic

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 71
Kurtosis is typically measured with respect to the normal distribution. A distributionthat is peaked in the same way as any normal distribution, not just the standard normaldistribution, is said to be mesokurtic. The peak of a mesokurtic distribution is neitherhigh nor low, rather it is considered to be a baseline for the two other classifications.Besides normal distributions, binomial distributions for which p is close to 1/2 areconsidered to be mesokurtic.
Leptokurtic
A leptokurtic distribution is one that has kurtosis greater than a mesokurticdistribution. Leptokurtic distributions are identified by peaks that are thin and tall. Thetails of these distributions, to both the right and the left, are thick and heavy.Leptokurtic distributions are named by the prefix "lepto" meaning "skinny."
There are many examples of leptokurtic distributions. One of the most wellknownleptokiurtic distributions is Student's t distribution.
Platykurtic
The third classification for kurtosis is platykurtic. Platykurtic distributions are thosethat have a peak lower than a mesokurtic distribution. Platykurtic distributions arecharacterized by a certain flatness to the peak, and have slender tails. The name of thesetypes of distributions come from the meaning of the prefix "platy" meaning "broad."
All uniform distributions are platykurtic. In addition to this the discrete probabilitydistribution from a single flip of a coin is platykurtic.
Measures of KurtosisMoment ratio and Percentile Coefficient of kurtosis are used to measure the kurtosisMoment Coefficient of Kurtosis= =Where M4 = 4th moment and M2 = 2nd momentIf = 3, the distribution is said to be normal. (ie mesokurtic)If > 3, the distribution is more peaked to curve is lepto kurtic.If < 3, the distribution is said to be flat topped and the curve is platy kurtic.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 72
Percentile Coefficient of Kurtosis = = . .where . . = ( − ) is the semi-interquartile range. For normal distribution thishas the value 0.263.A normal random variable has a kurtosis of 3 irrespective of its mean or standarddeviation. If a random variable’s kurtosis is greater than 3, it is said to be Leptokurtic. Ifits kurtosis is less than 3, it is said to be Platykurtic.Thus we conclude our discussion by saying that kurtosis is any measure of the‘peakedness’ of a distribution. The height and sharpness of the peak relative to the restof the data are measured by a number called kurtosis. Higher values indicate a higher,sharper peak; lower values indicate a lower, less distinct peak. This occurs because,higher kurtosis means more of the variability is due to a few extreme differences fromthe mean, rather than a lot of modest differences from the mean. A normal distributionhas kurtosis exactly 3. Any distribution with kurtosis =3 is called mesokurtic. Adistribution with kurtosis <3 is called platykurtic. Compared to a normal distribution,its central peak is lower and broader, and its tails are shorter and thinner. A distributionwith kurtosis >3 is called leptokurtic. Compared to a normal distribution, its centralpeak is higher and sharper, and its tails are longer and fatter.Comparison among dispersion, skewness and kurtosis
Dispersion, Skewness and Kurtosis are different characteristics of frequencydistribution. Dispersion studies the scatter of the items round a central value or amongthemselves. It does not show the extent to which deviations cluster below an average orabove it. Skewness tells us about the cluster of the deviations above and below ameasure of central tendency. Kurtosis studies the concentration of the items at thecentral part of a series. If items concentrate too much at the centre, the curve becomes‘leptokurtic’ and if the concentration at the centre is comparatively less, the curvebecomes ‘platykurtic’.
POPULATION AND SAMPLEThe study of statistics revolves around the study of data sets. Here describes twoimportant types of data sets – population and samples.PopulationIn statistics the term ‘population’ has a slightly different meaning from the one given toit in ordinary speech. It need not refer only to people or to animate creatures - thepopulation of India. When we think of the term ‘population,’ we usually think of peoplein our town, region, state or country and their respective characteristics such as gender,age, marital status, religion, caste and so on. In statistics the term ‘population’ takes on aslightly different meaning. The ‘population’ in statistics includes all members of adefined group that we are studying or collecting information on for data drivendecisions.A population is a group of phenomena that have something in common.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 73
A population is any entire collection of people, animals, plants or things from which wemay collect data. It is the entire group we are interested in, which we wish to describeor draw conclusions about.
A population is an entire set of individuals or objects, which may be finite or infinite.Examples of finite populations include the employees of a given company, the numberof airplanes owned by an airline, or the potential consumers in a target market.Examples of infinite populations include the number of watches manufactured by acompany that plans to be in business forever, or the grains of sand on the beaches of theworld or stars in the sky.
For a deeper understanding of a population, consider a market researcher for a fast foodchain who might want to determine the flavour preferences of Indian customersbetween the ages of 15 and 25. The population in this example is finite and includesevery Indian in this age group of 15-25.
Note that population does not refer to people only. Statisticians also speak of apopulation of objects, or events, or procedures, or observations, including such thingsas the quantity of haemoglobin in blood, number of visits to the doctor by a patient, ornumber surgical operations by a doctor. A population is thus an aggregate of creatures,things, cases and so on.
Sample
A population commonly contains too many individuals to study conveniently, so gathering data
from every individual in this population would be nearly impossible and prohibitively expensive.
So an investigation is often restricted to a part drawn from it, which is called a sample. A part of
the population is called a sample. It is a proportion of the population, a slice of it, a part of it and
all its characteristics.
A sample is a group of units selected from a larger group (the population). By studying the
sample it is hoped to draw valid conclusions about the larger group.
A sample is a smaller group of members of a population selected to represent the population.
A sample is a subset of population.
A sample is a scientifically drawn group that actually possesses the same characteristics as the
population – if it is drawn randomly. Thus a well-chosen sample will contain most of the
information about a particular population parameter but the relation between the sample and the
population must be such as to allow true inferences to be made about a population from that
sample.
The best example of sampling is what housewives do in a kitchen to see whether rice has cooked
enough by tasting just one piece of grain.
If the sample is to be used to make inferences about the population the sample data must be
unbiased. In order for a sample to be unbiased, it must be

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 74
representative of the population randomly selected sufficiently large
Representative of the population: A representative sample contains members from the
population of interest. In the case of the flavour preferences study we discussed above, the
sample would need to include Indians between the ages of 15 and 25. If people outside of the
target age range are included, the sample would not be representative.
Randomly selected: A random sample is one in which every member of a population has an
equal chance of being selected. In a random sample, each member of the population has an
equally likely chance of being selected for the sample. Suppose that the sample data for the
flavour preferences study discussed earlier came exclusively from students at one university in
the India. This sample is not random due to the limited opportunity for the rest of the population
to be involved in the study. Data from this sample would not be representative of the entire
Indian population between ages 15 and 25, because the students attending this university may
have a different preference than other groups of young people. Drawing conclusions about the
overall population from this sample could lead to mistakes. The most commonly used sample is a
simple random sample. It requires that every possible sample of the selected size has an equal
chance of being used.
Sufficiently large: A sample must also be large enough in order for its data to reflect the
population. A sample that is too small may bias population estimates. When larger samples are
used, data collected from idiosyncratic individuals have less influence than when smaller
samples are used.
Imagine what would happen if the flavour preferences study collected data from a sample of
three students and, based on the results from this sample, concluded that Indians between the
ages of 15 and 25 favour a particular flavour – say masala flavour. A sample of three people is
too small to serve as the basis for drawing conclusions about the population in general.
How many people must be included in a sample in order for it to represent the population? The
optimal sample size depends on, among other things, the desired confidence level and the
precision of the confidence interval. A sample size of 30 or more is often desired to ensure that
the distribution of the sample mean is normal. In general, more is better.
Population vs Sample
The main difference between a population and sample has to do with how observations are
assigned to the data set.
A populationincludes each element from the set of observations that can be made.
A sample consists only of observations drawn from the population.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 75
Depending on the sampling method, a sample can have fewer observations than the population,
the same number of observations, or more observations. More than one sample can be derived
from the same population.
Other differences are related to terms used. For example,
A measurable characteristic of a population, such as a mean or standard deviation, is
called a parameter; but a measurable characteristic of a sample is called a statistic.
The mean of a population is denoted by the symbol μ; but the mean of a sample isdenoted by the symbol x.
What is the difference between information based on a sample and information based on a
population: Information based on a sample is, by definition, incomplete; as such, a sample
demands that inferences be drawn regarding the population from which it came. Information
based on a population, however, is considered complete, and therefore requires no inferential
leap to be made.
What Characteristics are necessary before a sample can be considered random: The members of
the sample must be chosen based on chance from the population. Each member of the population
must have an equal likelihood of being chosen.
What is the consequence of failing to have a random sample from a population?: A sample is a
subset of a population. If a sample is randomly selected and sufficiently large, the information
obtained from the sample will be representative of the population. A small sample, or one that is
not drawn in a random fashion, may be biased. Making inferences from a biased sample to a
population is ill-advised and may lead to costly business mistakes.
Different methods of sampling
There are numerous sample selection methods for drawing the sample from the population,
broadly classified into random or probability-based sampling schemes or survey design methods,
and non-random or non-probability based sampling.
Probability Sampling
Probability samples are selected in such a way as to be representative of the population. They
provide the most valid or credible results because they reflect the characteristics of the
population from which they are selected.
The following sampling methods are types of probability sampling:
1. Simple Random Sampling (SRS)2. Stratified Sampling3. Cluster Sampling4. Multistage Sampling5. Random-Digit Dialing6. Systematic Sampling
1. Simple Random Sampling
The most widely known type of a random sample is the simple random sample (SRS). This is
characterized by the fact that the probability of selection is the same for every case in the

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 76
population. All have an equal chance of being selected. Simple random sampling is a method of
selecting n units from a population of size N such that every unit of the population has equal
chance of being selected.
There are two methods by which we can select a random sample
(a) Lottery Method
An example may make this easier to understand. Imagine you want to carry out a survey of 100
voters in a small town with a population of 1,000 eligible voters. One method of SRS is that we
write the names of all voters on a piece of paper, put all pieces of paper into a box and draw 100
tickets at random. The draw is done in this manner - Shake the box, draw a piece of paper and set
it aside, shake again, draw another, set it aside, etc. until we had 100 slips of paper. These 100
form our sample. And this sample would be drawn through a simple random sampling procedure
- at each draw, every name in the box had the same probability of being chosen. This is called
the lottery method of random sampling.
(b) Table of random numbers:
The lottery method is a clumsy physical process for choosing random samples. Often it is
convenient to use a ready-made table of random numbers. A random number table is a table of
digits. The digit given in each position in the table was originally chosen randomly from the
digits 1,2,3,4,5,6,7,8,9,0 by a random process in which each digit is equally likely to be chosen.
Thus a random number table is a series of digits (0 to 9) arranged randomly through the rows and
columns. Table 1 gives part of table of random numbers. The digits are often grouped in fives as
shown here.Table 1 : table of Random Numbers
The researcher can use the list of random numbers to draw a simple random sample from a
population.
Step 1: each element in the population from which the sample is to be drawn must be assigned a
unique number. This is usually done by numbering the elements in the population consecutively.
If there were 280 elements in the population, for example, they would be numbered 001, 002,
003. . . 280. Here is one procedure for using Table B.1 to select a simple random sample:
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 76
population. All have an equal chance of being selected. Simple random sampling is a method of
selecting n units from a population of size N such that every unit of the population has equal
chance of being selected.
There are two methods by which we can select a random sample
(a) Lottery Method
An example may make this easier to understand. Imagine you want to carry out a survey of 100
voters in a small town with a population of 1,000 eligible voters. One method of SRS is that we
write the names of all voters on a piece of paper, put all pieces of paper into a box and draw 100
tickets at random. The draw is done in this manner - Shake the box, draw a piece of paper and set
it aside, shake again, draw another, set it aside, etc. until we had 100 slips of paper. These 100
form our sample. And this sample would be drawn through a simple random sampling procedure
- at each draw, every name in the box had the same probability of being chosen. This is called
the lottery method of random sampling.
(b) Table of random numbers:
The lottery method is a clumsy physical process for choosing random samples. Often it is
convenient to use a ready-made table of random numbers. A random number table is a table of
digits. The digit given in each position in the table was originally chosen randomly from the
digits 1,2,3,4,5,6,7,8,9,0 by a random process in which each digit is equally likely to be chosen.
Thus a random number table is a series of digits (0 to 9) arranged randomly through the rows and
columns. Table 1 gives part of table of random numbers. The digits are often grouped in fives as
shown here.Table 1 : table of Random Numbers
The researcher can use the list of random numbers to draw a simple random sample from a
population.
Step 1: each element in the population from which the sample is to be drawn must be assigned a
unique number. This is usually done by numbering the elements in the population consecutively.
If there were 280 elements in the population, for example, they would be numbered 001, 002,
003. . . 280. Here is one procedure for using Table B.1 to select a simple random sample:
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 76
population. All have an equal chance of being selected. Simple random sampling is a method of
selecting n units from a population of size N such that every unit of the population has equal
chance of being selected.
There are two methods by which we can select a random sample
(a) Lottery Method
An example may make this easier to understand. Imagine you want to carry out a survey of 100
voters in a small town with a population of 1,000 eligible voters. One method of SRS is that we
write the names of all voters on a piece of paper, put all pieces of paper into a box and draw 100
tickets at random. The draw is done in this manner - Shake the box, draw a piece of paper and set
it aside, shake again, draw another, set it aside, etc. until we had 100 slips of paper. These 100
form our sample. And this sample would be drawn through a simple random sampling procedure
- at each draw, every name in the box had the same probability of being chosen. This is called
the lottery method of random sampling.
(b) Table of random numbers:
The lottery method is a clumsy physical process for choosing random samples. Often it is
convenient to use a ready-made table of random numbers. A random number table is a table of
digits. The digit given in each position in the table was originally chosen randomly from the
digits 1,2,3,4,5,6,7,8,9,0 by a random process in which each digit is equally likely to be chosen.
Thus a random number table is a series of digits (0 to 9) arranged randomly through the rows and
columns. Table 1 gives part of table of random numbers. The digits are often grouped in fives as
shown here.Table 1 : table of Random Numbers
The researcher can use the list of random numbers to draw a simple random sample from a
population.
Step 1: each element in the population from which the sample is to be drawn must be assigned a
unique number. This is usually done by numbering the elements in the population consecutively.
If there were 280 elements in the population, for example, they would be numbered 001, 002,
003. . . 280. Here is one procedure for using Table B.1 to select a simple random sample:

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 77
Step 2: determine a starting point in the table by closing your eyes and placing the point of your
pencil anywhere in the table.
Step 3:Using the starting point you have selected, begin reading the numbers in the table either
across the rows or down the columns. If your population consisted of 99 or fewer elements, read
the numbers in two-digit units; for 999 or fewer elements in the population, read the numbers in
three-digit units, and so forth. If a table number is larger than the number of elements in the
population (e.g., if the table number is 323 and the your population is 286), skip that number and
read the next. If you come to a number equivalent to one you have already drawn, you can either
skip the number and read the next one or count the data for that unit of analysis twice. Continue
until you have selected as many valid numbers as there are elements in your desired sample.
The population elements that comprise the simple random sample are those whosenumbers correspond to the numbers read from the table.
For example, you have to select a sample 5 students from a population of 75 students.First give numbers to all students from 1 to 75. Now through process in step two above,place your pencil anywhere on the table. Suppose you place on 62570 in 2nd column and4th row. Since ‘step 3’ above says ‘If your population consisted of 99 or fewer elements, read
the numbers in two-digit units’, we read only the first two digits, so it is 62. So the 62nd student is
our 1st sample. (If in case you get a number which is bigger than your sample, then you take the
next number from the table). Now to get the next sample, move in the table in any direction from
the number you have chosen. Suppose we decide to keep moving move down the column. So
the next digit is 26440. We take the first two digits, so the number is 26. This means 26th student
is our 2nd sample. Going down the column, we get 47174, so it is 47. So the 47th student is our 3rd
sample. Moving down, 34378, we take 34. So 34th student is our 4th sample. Next is 22466, so
22nd student is our 5th sample.
Stratified Random Sampling
In this form of sampling, the population is first divided into two or more mutually exclusive
segments based on some categories of variables of interest in the research. It is designed to
organize the population into homogenous subsets before sampling, then drawing a random
sample within each subset. With stratified random sampling the population of N units is divided
into subpopulations of units respectively. These subpopulations, called strata, are non-
overlapping and together they comprise the whole of the population. When these have been
determined, a sample is drawn from each, with a separate draw for each of the different strata.
The sample sizes within the strata are denoted by respectively. If a SRS is taken within each
stratum, then the whole sampling procedure is described as stratified random sampling.
The primary benefit of this method is to ensure that cases from smaller strata of the population
are included in sufficient numbers to allow comparison.
Systematic Sampling
This method of sampling is at first glance very different from SRS. In practice, it is a variant of
simple random sampling that involves some listing of elements - every nth element of list is then

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 78
drawn for inclusion in the sample. Say you have a list of 10,000 people and you want a sample of
1,000.
Creating such a sample includes three steps:
1. Divide number of cases in the population by the desired sample size. In this example,
dividing 10,000 by 1,000 gives a value of 10.
2. Select a random number between one and the value attained in Step 1. In this example,
we choose a number between 1 and 10 - say we pick 7.
3. Starting with case number chosen in Step 2, take every tenth record (7, 17, 27, etc.).
More generally, suppose that the N units in the population are ranked 1 to N in some order (e.g.,
alphabetic). To select a sample of n units, we take a unit at random, from the 1st k units and take
every k- unit thereafter.
Cluster Sampling
In some instances the sampling unit consists of a group or cluster of smaller units that we call
elements or subunits (these are the units of analysis for your study). There are two main reasons
for the widespread application of cluster sampling. Although the first intention may be to use the
elements as sampling units, it is found in many surveys that no reliable list of elements in the
population is available and that it would be prohibitively expensive to construct such a list. In
many countries there are no complete and updated lists of the people, the houses or the farms in
any large geographical region.
Even when a list of individual houses is available, economic considerations may point to the
choice of a larger cluster unit. For a given size of sample, a small unit usually gives more precise
results than a large unit. For example a SRS of 600 houses covers a town more evenly than 20
city blocks containing an average of 30 houses each. But greater field costs are incurred in
locating 600 houses and in traveling between them than in covering 20 city blocks. When cost is
balanced against precision, the larger unit may prove superior.
Nonprobability Sampling
Social research is often conducted in situations where a researcher cannot select the kinds of
probability samples used in large-scale social surveys. For example, say you wanted to study
homelessness - there is no list of homeless individuals nor are you likely to create such a list.
However, you need to get some kind of a sample of respondents in order to conduct your
research. To gather such a sample, you would likely use some form of non-probability sampling.
To restate, the primary difference between probability methods of sampling and non-probability
methods is that in the latter you do not know the likelihood that any element of a population will
be selected for study.
There are four primary types of non-probability sampling methods:
Availability Sampling
Availability sampling is a method of choosing subjects who are available or easy to find. This
method is also sometimes referred to as haphazard, accidental, or convenience sampling. The
primary advantage of the method is that it is very easy to carry out, relative to other methods. For

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 79
example if you want to collect data from women alone, you may stand in a crowded market place
and distribute your schedule as you wish
Quota Sampling
Quota sampling is designed to overcome the most obvious flaw of availability sampling. Rather
than taking just anyone, you set quotas to ensure that the sample you get represents certain
characteristics in proportion to their prevalence in the population. Note that for this method, you
have to know something about the characteristics of the population ahead of time. Say you want
to make sure you have a sample proportional to the population in terms of gender - you have to
know what percentage of the population is male and female, then collect sample until yours
matches. Marketing studies are particularly fond of this form of research design.
Purposive or judgmental Sampling
Purposive sampling is a sampling method in which elements are chosen based on purpose of the
study. Purposive sampling may involve studying the entire population of some limited group
(Economics BA students of Calicut University) or a subset of a population (Economics BA
students of Calicut University who are women). As with other non-probability sampling
methods, purposive sampling does not produce a sample that is representative of a larger
population, but it can be exactly what is needed in some cases - study of organization,
community, or some other clearly defined and relatively limited group.
Snowball Sampling
Snowball sampling is a method in which a researcher identifies one member of some population
of interest, speaks to him/her, then asks that person to identify others in the population that the
researcher might speak to. This person is then asked to refer the researcher to yet another person,
and so on. Snowball sampling is very good for cases where members of a special population are
difficult to locate.
The best sampling method is the sampling method that most effectively meets the particular
goals of the study in question. The effectiveness of a sampling method depends on many factors.
Because these factors interact in complex ways, the ‘best’ sampling method is seldom obvious.Good researchers use the following strategy to identify the best sampling method.
List the research goals (usually some combination of accuracy, precision, and/or cost).
Identify potential sampling methods that might effectively achieve those goals.
Test the ability of each method to achieve each goal.
Choose the method that does the best job of achieving the goals.
***********************************

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 80
Module II
CORRELATION AND REGRESSION ANALYSISModule II. Correlation and Regression Analysis
Correlation-Meaning, Types and Degrees of Correlation- Methods of Measuring Correlation-
Graphical Methods: Scatter Diagram and Correlation Graph; Algebraic Methods: Karl
Pearson’s Coefficient of Correlation and Rank Correlation Coefficient - Properties and
Interpretation of Correlation Coefficient
Introduction
Correlation is a statistical technique which tells us if two variables are related.For
example, consider the variables family income and family expenditure. It is well known that
income and expenditure increase or decrease together. Thus they are related in the sense that
change in any one variable is accompanied by change in the other variable.Again price and
demand of a commodity are related variables; when price increases demand will tend to
decreases and vice versa. If the change in one variable is accompanied by a change in the other,
then the variables are said to be correlated. We can therefore say that family income and family
expenditure, price and demand are correlated.
Correlation can tell us something about the relationship between variables. It is used to
understand:a. whether the relationship is positive or negative b. the strength of relationship.
Correlation is a powerful tool that provides these vital pieces of information.
In the case of family income and family expenditure, it is easy to see that they both rise or fall
together in the same direction. This is called positive correlation.
In case of price and demand, change occurs in the opposite direction so that increase in one is
accompanied by decrease in the other. This is called negative correlation.
Coefficient of Correlation
Correlation is measured by what is called coefficient of correlation (r). A correlation coefficient
is a statistical measure of the degree to which changes to the value of one variable predict change
to the value of another. Correlation coefficients are expressed as values between +1 and -1. Its
numerical value gives us an indication of the strength of relationship. In general, r > 0 indicates
positive relationship, r < 0 indicates negative relationship while r = 0 indicates no relationship
(or that the variables are independent and not related). Here r = +1.0 describes a perfect positive
correlation and r = −1.0 describes a perfect negative correlation. Closer the coefficients are to+1.0 and −1.0, greater is the strength of the relationship between the variables. As a rule ofthumb, the following guidelines on strength of relationship are often useful (though many experts
would somewhat disagree on the choice of boundaries).

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 81
Value of r Strength of relationship
−1.0 to −0.5 or 1.0 to 0.5 Strong
−0.5 to −0.3 or 0.3 to 0.5 Moderate
−0.3 to −0.1 or 0.1 to 0.3 Weak
−0.1 to 0.1 None or very weak
1 A perfect positive correlation
0 No Correlation (No relation between two variables)
− 1 A perfect negative correlation
Correlation is only appropriate for examining the relationship between meaningful quantifiable
data (e.g. air pressure, temperature) rather than categorical data such as gender, favourite colour
etc.
A key thing to remember when working with correlations is never to assume a correlation means
that a change in one variable causes a change in another. Sales of personal computers and
athletic shoes have both risen strongly in the last several years and there is a high correlation
between them, but you cannot assume that buying computers causes people to buy athletic shoes
(or vice versa).
The second caution is that the Pearson correlation technique (which we are about to see) works
best with linear relationships: as one variable gets larger (or smaller), the other gets larger (or
smaller) in direct proportion. It does not work well with curvilinear relationships (in which the
relationship does not follow a straight line). An example of a curvilinear relationship is age and
health care. They are related, but the relationship doesn't follow a straight line. Young children
and older people both tend to use much more health care than teenagers or young adults. (In such
cases, the technique of ‘multiple regression’ can be used to examine curvilinear relationships)
METHODS OF MEASURING CORRELATION
I. Graphical Method
(a) Scatter Diagram
(b) Correlation Graph
II. Algebraic Method (Coefficient of Correlation)
(a) Karl Pearson’s Coefficient of Correlation(b) Spearman’s Rank Correlation Coefficient
I. (a) Scatter Diagram
Scatter Diagram (also called scatter plot, X–Y graph) is a graph that shows the relationship
between two quantitative variables measured on the same individual. Each individual in the data
set is represented by a point in the scatter diagram. The predictor variable is plotted on the

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 82
horizontal axis and the response variable is plotted on the vertical axis. Do not connect the points
when drawing a scatter diagram. The scatter diagram graphs pairs of numerical data, with one
variable on each axis, to look for a relationship between them. If the variables are correlated, the
points will fall along a line or curve. The better the correlation, the tighter the points will hug the
line. Scatter Diagram is a graphical measure of correlation.
Examples of Scatter Diagram. Given below each diagram is the value of correlation.
Note that the value shows how good the correlation is (not how steep the line is), and if it is
positive or negative.
Scatter Diagram Procedure
1. Collect pairs of data where a relationship is suspected.
2. Draw a graph with the independent variable on the horizontal axis and the dependent variable
on the vertical axis. For each pair of data, put a dot or a symbol where the x-axis value intersects
the y-axis value. (If two dots fall together, put them side by side, touching, so that you can see
both.)
3. Look at the pattern of points to see if a relationship is obvious. If the data clearly form a line
or a curve, you may stop. The variables are correlated.
The data set below represents a random sample of 5 workers in a particular industry. The
productivity of each worker was measured at one point in time, and the worker was asked the
number of years of job experience. The dependent variable is productivity, measured in number
of units produced per day, and the independent variable is experience, measured in years.
Worker y=Productivity(output/day) x=Experience(inyears)
1 33 102 19 63 32 124 26 85 15 4

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 83
This scatter diagram tell us that the two variables, productivity and experience, are
positively correlated.
Merits of Scatter Diagram Method:
1. It is an easy way of finding the nature of correlation between two variables.
2. By drawing a line of best fit by free hand method through the plotted dots, the method
can be used for estimating the missing value of the dependent variable for a given value
of independent variable.
3. Scatter diagram can be used to find out the nature of linear as well as non-linear
correlation.
4. The values of extreme observations do not affect the method.
Demerits of Scatter Diagram Method:It gives only rough idea of how the two variables are related. It gives an idea about the
direction of correlation and also whether it is high or low. But this method does not give any
quantitative measure of the degree or extent of correlation.
I (b) Correlation Graph
Correlation graph is also used as a measure of correlation. When this method is usedthe correlation graph is drawn and the direction of curve is examined to understand the nature ofcorrelation. Under this method, separate curves are drawn for the X variable and Y variable onthe same graph paper. The values of the variable are taken as ordinates of the points plotted.From the direction and closeness of the two curves we can infer whether the variables arerelated. If both the curves move in the same direction (upward or downward), correlation is said
0
5
10
15
20
25
30
35
0 2 4 6 8 10 12 14
Prod
uctiv
ity
Experience
Scatter Chart for Worker Productivity VsExperience

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 84
to be positive. If the curves are moving in the opposite direction, correlation is said to benegative.
But correlation graphs are not capable of doing anything more than suggesting the factof a possible relationship between two variables. We can neither establish any casualrelationship between two variables nor obtain the exact degree of correlation through them.They only tell us whether the two variables are positively or negatively correlated. Example of agraph is given below.
II. Algebraic Method (Coefficient of Correlation)
II. (a) Karl Pearson’s Coefficient of Correlation (Pearson product-momentcorrelation coefficient)
Karl Pearson’s Product-Moment Correlation Coefficient or simply Pearson’s CorrelationCoefficient for short, is one of the important methods used in Statistics to measureCorrelation between two variables. Karl Pearson was a British mathematician,statistician, lawyer and a eugenicist. He established the discipline of mathematicalstatistics. He founded the world’s first statistics department In the University of Londonin the year 1911. He along with his colleagues Weldon and Galton founded the journal‘Biometrika’ whose object was the development of statistical theory.
The Pearson product-moment correlation coefficient (r) is a common measure of thecorrelation between two variables X and Y. When measured in a population the Pearson

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 85
Product Moment correlation is designated by the Greek letter rho (?). When computedin a sample, it is designated by the letter "r" and is sometimes called "Pearson's r."Pearson's correlation reflects the degree of linear relationship between two variables.Mathematical Formula:--
The quantity r, called the linear correlation coefficient, measures the strength and thedirection of a linear relationship between two variables. (The linear correlationcoefficient is a measure of the strength of linear relation between two quantitativevariables. We use the Greek letter ρ (rho) to represent the population correlationcoefficient and r to represent the sample correlation coefficient.)
Correlation coefficient for ungrouped data= ∑ ( − )( − )WhereXi is the ith observation of the variable XYi is the ith observation of the variable Y
is the mean of the observations of the variable Xis the mean of the observations of the variable Y
n is the number of pairs of observations of X and Yis the standard deviation of the variable Xis the standard deviation of the variable Y
The above formula may be presented in the following form
= ∑ ( − )( − )∑ ( − ) ∑ ( − )The same may be computed using Pearson product-moment correlation coefficient
formula as shown below.
= ∑ − ∑ ∑∑ − ∑ ∑ − ∑

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 86
Year(i)
Annualadvertising
expenditure Xi
Annual Sales
1 10 20
2 12 30
3 14 37
4 16 50
5 18 56
6 20 78
7 22 89
8 24 100
9 26 120
10 28 110
Compute the necessary values and substitute in the formula, we will solve using both
formula. We get = (∑ ⁄ ) = = 19. = (∑ ⁄ ) = = 69.Year
(i)Xi Annual
Sales(Yi)
( − ) ( − ) ( − ) ( − ) ( − )( − )1 10 20 -9 -49 81 2401 4412 12 30 -7 -39 49 1521 2733 14 37 -5 -32 25 1024 1604 16 50 -3 -19 9 361 575 18 56 -1 -13 1 169 136 20 78 1 9 1 81 97 22 89 3 20 9 400 608 24 100 5 31 25 961 1559 26 120 7 51 49 2601 35710 28 110 9 41 81 1681 369
190 690 0 0 330 11200 1894We make the additional computations for the Pearson product-moment correlation
coefficient formula.
200 100 400360 144 900518 196 1369

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 87
800 256 25001008 324 31361560 400 60841958 484 79212400 576 100003120 676 144003080 784 1210015004 3940 58810
Substitute the values in the respective formula.
Using the basic formula = ∑ ( )( )∑ ( ) ∑ ( )= 1894√330 √11200 = 0.985Now let us re do the problem using Pearson product-moment correlation coefficient
formula = ∑ − ∑ ∑∑ − (∑ ) ∑ − (∑ )= 10 × 15004 − 190 × 690√10 × 3940 − 190 √10 × 58810 − 690 = 0.985
The correlation coefficient between annual advertising expenditure and annual sales revenue is
0.985. This is a positive value and is very close to 1. So it implies there is very strong corelation
between annual advertising expenditure and annual sales revenue.
Properties of Correlation coefficient
1. The correlation coefficient lies between -1 & +1 symbolically ( - 1≤ r ≥ 1 )
2. The correlation coefficient is independent of the change of origin & scale.
3. The coefficient of correlation is the geometric mean of two regression coefficient.= ×The one regression coefficient is (+ve) other regression coefficient is also (+ve) correlation
coefficient is (+ve)

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 88
Assumptions of Pearson’s Correlation Coefficient
1. There is linear relationship between two variables, i.e. when the two variables are plotted on a
scatter diagram a straight line will be formed by the points.
2. Cause and effect relation exists between different forces operating on the item of the two
variable series.
Advantages of Pearson’s Coefficient
1. It summarizes in one value, the degree of correlation & direction of correlation also.
Disadvantages
While 'r' (correlation coefficient) is a powerful tool, it has to be handled with care.
1. The most used correlation coefficients only measure linear relationship. It is therefore
perfectly possible that while there is strong non-linear relationship between the variables,
r is close to 0 or even 0. In such a case, a scatter diagram can roughly indicate the
existence or otherwise of a non-linear relationship.
2. One has to be careful in interpreting the value of 'r'. For example, one could compute 'r'
between the size of shoe and intelligence of individuals, heights and income. Irrespective
of the value of 'r', it makes no sense and is hence termed chance or non-sense correlation.
3. 'r' should not be used to say anything about cause and effect relationship. Put differently,
by examining the value of 'r', we could conclude that variables X and Y are related.
However the same value of 'r' does not tell us if X influences Y or the other way round.
Statistical correlation should not be the primary tool used to study causation, because of
the problem with third variables.
Coefficient of Determination
The convenient way of interpreting the value of correlation coefficient is to use of square of
coefficient of correlation which is called Coefficient of Determination.
The Coefficient of Determination = r2.
Suppose: r = 0.9, r2 = 0.81 this would mean that 81% of the variation in the dependent variable
has been explained by the independent variable.
The maximum value of r2 is 1 because it is possible to explain all of the variation in y but it is
not possible to explain more than all of it.
Coefficient of Determination: An example
Suppose: r = 0.60 in one case and r = 0.30 in another case. It does not mean that the first
correlation is twice as strong as the second the ‘r’ can be understood by computing the value ofr2.
When r = 0.60, r2 = 0.36 -----(1)
When r = 0.30, r2 = 0.09 -----(2)
This implies that in the first case 36% of the total variation is explained whereas in second case
9% of the total variation is explained.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 89
II. (b) Spearman’s Rank Correlation Coefficient
The Spearman's rank-order correlation is the nonparametric version of the Pearson product-
moment correlation. Spearman's correlation coefficient, ( ℎ ℎ , )measures the strength of association between two ranked variables.
Data which are arranged in numerical order, usually from largest to smallest and numbered 1,2,3
---- are said to be in ranks or ranked data.. These ranks prove useful at certain times when two or
more values of one variable are the same. The coefficient of correlation for such type of data is
given by Spearman rank difference correlation coefficient.
Spearman Rank Correlation Coefficient uses ranks to calculate correlation. The Spearman Rank
Correlation Coefficient is its analogue when the data is in terms of ranks. One can therefore also
call it correlation coefficient between the ranks.
The Spearman's rank-order correlation is used when there is a monotonic relationship between
our variables. A monotonic relationship is a relationship that does one of the following: (1) as the
value of one variable increases, so does the value of the other variable; or (2) as the value of one
variable increases, the other variable value decreases. A monotonic relationship is an important
underlying assumption of the Spearman rank-order correlation. It is also important to recognize
the assumption of a monotonic relationship is less restrictive than a linear relationship (an
assumption that has to be met by the Pearson product-moment correlation). The middle image
above illustrates this point well: A non-linear relationship exists, but the relationship is
monotonic and is suitable for analysis by Spearman's correlation, but not by Pearson's
correlation.
Let us make the relevance of use of Spearman Rank Correlation Coefficient with the aid of an
example.
As an example, let us consider a musical talent contest where 10 competitors are evaluated by
two judges, A and B. Usually judges award numerical scores for each contestant after his/her
performance.
A product moment correlation coefficient of scores by the two judges hardly makes sense here as
we are not interested in examining the existence or otherwise of a linear relationship between the
scores.
What makes more sense is correlation between ranks of contestants as judged by the two judges.
Spearman Rank Correlation Coefficient can indicate if judges agree to each other's views as far
as talent of the contestants are concerned (though they might award different numerical scores) -
in other words if the judges are unanimous.
The numerical value of the correlation coefficient, rs, ranges between -1 and +1. The correlation
coefficient is the number indicating the how the scores are relating.
In general, rs > 0 implies positive agreement among ranks rs < 0 implies negative agreement (or agreement in the reverse direction) rs = 0 implies no agreement

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 90
Closer rs is to 1, better is the agreement while rs closer to -1 indicates strong agreement in thereverse direction.The formula for finding Spearman Rank Correlation Coefficient is= 1 − 6 ∑ ( + )( − 1)WhereXiis the rank of the ith observation of the variable XYiis the rank of the ith observation of the variable Yn is the number of payers of observations
Let us calculate Spearman Rank Correlation Coefficient for our example of the musical talent
contest where 10 competitors are evaluated by two judges, A and B. The scores are givenbelow,
Contestant Rating by judge 1 Rating by judge 2
1 1 2
2 2 4
3 3 5
4 4 1
5 5 3
6 6 6
7 7 7
8 8 9
9 9 10
10 10 8
Let us first make the necessary calculations
Contestant Rating by
judge 1 (Xi)
Rating by
judge 2(Yi)
− ( − )1 1 2 -1 1
2 2 4 -2 4
3 3 5 -2 4
4 4 1 3 9
5 5 3 2 4
6 6 6 0 0
7 7 7 0 0
8 8 9 -1 1
9 9 10 -1 1
10 10 8 2 4
28

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 91
= 1 − 6 ∑ ( + )( − 1) = = 1 − 6 × 2810 × (10 −) = 0.8303Spearman Rank Correlation Coefficient tries to assess the relationship between rankswithout making any assumptions about the nature of their relationship. Hence it is anon-parametric measure - a feature which has contributed to its popularity and widespread use.Interpretation of Rank Correlation Coefficient (R)
1. The value of rank correlation coefficient, R ranges from -1 to +12. If R = +1, then there is complete agreement in the order of the ranks and the ranks arein the same direction3. If R = -1, then there is complete agreement in the order of the ranks and the ranks arein the opposite direction4. If R = 0, then there is no correlationAdvantages Spearman’s Rank Correlation
1. This method is simpler to understand and easier to apply compared to karlearson’scorrelation method.2. This method is useful where we can give the ranks and not the actual data.(qualitative term)3. This method is to use where the initial data in the form of ranks.
Disadvantages Spearman’s Rank Correlation
1. It cannot be used for finding out correlation in a grouped frequency distribution.2. This method should be applied where N exceeds 30.3. As Spearman's rank only uses rank, it is not affected by significant variations inreadings. As long as the order remains the same, the coefficient will stay the same. Aswith any comparison, the possibility of chance will have to be evaluated to ensure thatthe two quantities are actually connected.4. A significant correlation does not necessarily mean cause and effect.
Advantages of Correlation studies1. Show the amount (strength) of relationship present.2. Can be used to make predictions about the variables under study.3. Can be used in many places, including natural settings, libraries, etc.
4. Easier to collect co relational data
REGRESSION ANALYSIS*
* Note: In the syllabus for III Semester BA Economics paper ‘Quantitative Methods forEconomic Analysis – 1’,though the tile of this module II is given as “Correlation and RegressionAnalysis”, regression is not included in the contents. Hence here we give a brief discussion onregression.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 92
If two variables are significantly correlated, and if there is some theoretical basis for doing so, it
is possible to predict values of one variable from the other. This observation leads to a very
important concept known as ‘Regression Analysis’.Regression analysis, in general sense, means the estimation or prediction of the unknown value
of one variable from the known value of the other variable. It is one of the most important
statistical tools which is extensively used in almost all sciences – Natural, Social and Physical. It
is specially used in business and economics to study the relationship between two or more
variables that are related causally and for the estimation of demand and supply graphs, cost
functions, production and consumption functions and so on.
Prediction or estimation is one of the major problems in almost all the spheres of human activity.
The estimation or prediction of future production, consumption, prices, investments, sales,
profits, income etc. are of very great importance to business professionals. Similarly, population
estimates and population projections, GNP, Revenue and Expenditure etc. are indispensable for
economists and efficient planning of an economy.
Regression analysis was explained by M. M. Blair as follows:
“Regression analysis is a mathematical measure of the average relationship between two or morevariables in terms of the original units of the data.”
Regression Analysis is a very powerful tool in the field of statistical analysis in predicting the
value of one variable, given the value of another variable, when those variables are related to
each other.Regression Analysis is mathematical measure of average relationship between two or
more variables.Regression analysis is a statistical tool used in prediction of value of unknown
variable from known variable.
Advantages of Regression Analysis
1. Regression analysis provides estimates of values of the dependent variables from the values of
independent variables.
2. Regression analysis also helps to obtain a measure of the error involved in using the
regression line as a basis for estimations .
3. Regression analysis helps in obtaining a measure of the degree of association or correlation
that exists between the two variable.
Assumptions in Regression Analysis
1. Existence of actual linear relationship.
2. The regression analysis is used to estimate the values within the range for which it is valid.
3. The relationship between the dependent and independent variables remains the same till the
regression equation is calculated.
4. The dependent variable takes any random value but the values of the independent variables are
fixed.
5. In regression, we have only one dependant variable in our estimating equation. However, we
can use more than one independent variable.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 93
Regression lineA regression line summarizes the relationship between two variables in the setting when one of
the variables helps explain or predict the other.
A regression line is a straight line that describes how a response variable y changes as an
explanatory variable x changes. A regression line is used to predict the value of y for a given
value of x. Regression, unlike correlation, requires that we have an explanatory variable and a
response variable.
Regression line is the line which gives the best estimate of one variable from the value of any
other given variable. The regression line gives the average relationship between the two variables
in mathematical form.
For two variables X and Y, there are always two lines of regression –Regression line of X on Y : gives the best estimate for the value of X for any specific given
values of Y :
X = a + b YWhere
a = X – intercept
b = Slope of the line
X = Dependent variable
Y = Independent variable
Regression line of Y on X : gives the best estimate for the value of Y for any specific given
values of X
Y = a + bxWhere
a = Y – intercept
b = Slope of the line
Y = Dependent variable
x= Independent variable
Simple Linear RegressionRegression analysis is most often used for prediction. The goal in regression analysis is to create
a mathematical model that can be used to predict the values of a dependent variable based upon
the values of an independent variable. In other words, we use the model to predict the value of Y
when we know the value of X. (The dependent variable is the one to be predicted). Correlation
analysis is often used with regression analysis because correlation analysis is used to measure the
strength of association between the two variables X and Y.
In regression analysis involving one independent variable and one dependent variable the values
are frequently plotted in two dimensions as a scatter plot. The scatter plot allows us to visually
inspect the data prior to running a regression analysis. Often this step allows us to see if the
relationship between the two variables is increasing or decreasing and gives only a rough idea of
the relationship. The simplest relationship between two variables is a straight-line or linear
relationship. Of course the data may well be curvilinear and in that case we would have to use a

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 94
different model to describe the relationship. Simple linear regression analysis finds the straight
line that best fits the data.
Fitting a Line to DataFitting a Line to data means drawing a line that comes as close as possible to the points. (Note
that, no straight line passes exactly through all of the points). The overall pattern can be
described by drawing a straight line through the points.
Example:The data in the table below were obtained by measuring the heights of 161 childrenfrom a village each month from 18 to 29 months of age.Table: Mean height of children
Age in
months
(x)
Height in
centimeters
(y)
18 76.1
19 77
20 78.1
21 78.2
22 78.8
23 79.7
24 79.9
25 81.1
26 81.2
27 81.8
28 82.8
29 83.5
Figure below is a scatterplot of the data in the above table.
Age is the explanatory variable, which is plotted on the x axis. Mean height (in cm) is
the response variable.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 95
We can see on the plot a strong positive linear association with no outliers. The correlation is
r=0.994, close to the r = 1 of points that lie exactly on a line.
If we draw a line through the points, it will describe these data very well. This line is called the
regression line and the process of doing so is called ‘Fitting a line’. This is done in figure below.
Let y is a response variable and x is an explanatory variable.
A straight line relating y to x has an equation of the form y = a + bx.
In this equation, b is the slope, the amount by which y changes when x increases by one unit.
The number a is the intercept, the value of y when x = 0
The straight line describing the data has the form
height = a + (b × age).
In Figure below the regression line has been drawn with the following equation
height = 64.93 + (0.635 × age).
75
76
77
78
79
80
81
82
83
84
16 18 20 22 24 26 28 30
Mea
n He
ight
Age in months

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 96
⇒The figure above shows that this line fits the data well.
The slope b = 0.635 tells us that the height of children increases by about 0.6 cm for eachmonth of age.
The slope b of a line y = a + bx is the rate of change in the response y as the explanatoryvariable x changes.
The slope of a regression line is an important numerical description of the relationshipbetween the two variables.
Regression for predictionWe use the regression equation for prediction of the value of a variable,
Suppose we have a sample of size ‘n’ and it has two sets of measures, denoted by x andy. We can predict the values of ‘y’ given the values of ‘x’ by using the equation, calledthe regression equation given below.
y* = a + bx
where the coefficients a and b are given by= ∑ − ∑= ∑ − (∑ )(∑ )(∑ ) − (∑ )
In the regreesion equation the symbol y* refers to the predicted value of y from a givenvalue of x from the regression equation.
Let us see with the aid of an example how regressions used for prediction.
Example:
y = 0.635x + 64.92
75767778798081828384
16 18 20 22 24 26 28 30
Mea
n He
ight
Age in months
Regression Line

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 97
Scores made by students in a statistics class in the mid - term and final examination aregiven here. Develop a regression equation which may be used to predict finalexamination scores from the mid – term score.
STUDENT MID TERM FINAL
1 98 90
2 66 74
3 100 98
4 96 88
5 88 80
6 45 62
7 76 78
8 60 74
9 74 86
10 82 80
Solution:We want to predict the final exam scores from the mid term scores. So let us designate‘y’ for the final exam scores and ‘x’ for the mid term exam scores. We open thefollowing table for the calculations.
STUDENT X Y X2 XY
1 98 90 9604 8820
2 66 74 4356 4884
3 100 98 10000 9800
4 96 88 9216 8448
5 88 80 7744 7040
6 45 62 2025 2790
7 76 78 5776 5928
8 60 74 3600 4440
9 74 86 5476 6364
10 82 80 6724 6560
785 810 64521 65074

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 98
First find b and then find a and substitute in the equation.
= ∑ − (∑ )(∑ )(∑ ) − (∑ ) = 10(65074) − (785)(810)10 (64521) − (785)= 650740 − 635850645210 − 616225 = 1489028985 = 0.514
= ∑ − ∑ = 810 − (0.514)(785)10 = 810 − 403.4910 = 406.5110 = 40.651So a = 40.651 and b =0.514
Substitute in the equation for regression line y* = a + bx
y* = 40.651 + (0.514)x
Now we can use this for making predictions.
We can use this to find the projected or estimated final scores of the students.
For example, for the midterm score of 50 the projected final score is
y* = 40.651 + (0.514) 50 = 40.651 + 25.70 = 66.351, which is a quite a good estimation.
To give another example, consider the midterm score of 70. Then the projected final
score is
y* = 40.651 + (0.514) 70 = 40.651 + 35.98= 76.631, which is again a very good estimation.
Applications (uses) of regression analysis
1. Predicting the Future :The most common use of regression in business is to predict events that
have yet to occur. Demand analysis, for example, predicts how many units consumers will
purchase. Many other key parameters other than demand are dependent variables in regression
models, however. Predicting the number of shoppers who will pass in front of a particular
billboard or the number of viewers who will watch the Champions Trophy Cricket may help
management assess what to pay for an advertisement.
2. Insurance companies heavily rely on regression analysis to estimate, for example, how many
policy holders will be involved in accidents or be victims of theft,.
3. Optimization: Another key use of regression models is the optimization of business processes.
A factory manager might, for example, build a model to understand the relationship between
oven temperature and the shelf life of the cookies baked in those ovens. A company operating a

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 99
call center may wish to know the relationship between wait times of callers and number of
complaints.
4. A fundamental driver of enhanced productivity in business and rapid economic advancement
around the globe during the 20th century was the frequent use of statistical tools in
manufacturing as well as service industries. Today, managers considers regression an
indispensable tool.
Limitations of Regression AnalysisThere are three main limitations:
1. Parameter Instability - This is the tendency for relationships between variables to change over
time due to changes in the economy or the markets, among other uncertainties. If a mutual fund
produced a return history in a market where technology was a leadership sector, the model may
not work when foreign and small-cap markets are leaders.
2. Public Dissemination of the Relationship - In an efficient market, this can limit the
effectiveness of that relationship in future periods. For example, the discovery that low price-to-
book value stocks outperform high price-to-book value means that these stocks can be bid
higher, and value-based investment approaches will not retain the same relationship as in the
past.
3. Violation of Regression Relationships - Earlier we summarized the six classic assumptions of
a linear regression. In the real world these assumptions are often unrealistic - e.g. assuming the
independent variable X is not random.
Correlation or Regression
Correlation and regression analysis are related in the sense that both deal with relationships
among variables. Whether to use Correlation or Regression in an analysis is often confusing for
researchers.
In regression the emphasis is on predicting one variable from the other, in correlation the
emphasis is on the degree to which a linear model may describe the relationship between two
variables. In regression the interest is directional, one variable is predicted and the other is the
predictor; in correlation the interest is non-directional, the relationship is the critical aspect.
Correlation makes no a priori assumption as to whether one variable is dependent on the other(s)
and is not concerned with the relationship between variables; instead it gives an estimate as to
the degree of association between the variables. In fact, correlation analysis tests for
interdependence of the variables.
As regression attempts to describe the dependence of a variable on one (or more) explanatory
variables; it implicitly assumes that there is a one-way causal effect from the explanatory
variable(s) to the response variable, regardless of whether the path of effect is direct or indirect.
There are advanced regression methods that allow a non-dependence based relationship to be
described (eg. Principal Components Analysis or PCA) and these will be touched on later.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 100
The best way to appreciate this difference is by example.
Take for instance samples of the leg length and skull size from a population of elephants. It
would be reasonable to suggest that these two variables are associated in some way, as elephants
with short legs tend to have small heads and elephants with long legs tend to have big heads. We
may, therefore, formally demonstrate an association exists by performing a correlation analysis.
However, would regression be an appropriate tool to describe a relationship between head size
and leg length? Does an increase in skull size cause an increase in leg length? Does a decrease in
leg length cause the skull to shrink? As you can see, it is meaningless to apply a causal
regression analysis to these variables as they are interdependent and one is not wholly dependent
on the other, but more likely some other factor that affects them both (eg. food supply, genetic
makeup).
Consider two variables: crop yield and temperature. These are measured independently, one by
the weather station thermometer and the other by Farmer Giles' scales. While correlation anaylsis
would show a high degree of association between these two variables, regression anaylsis would
be able to demonstrate the dependence of crop yield on temperature. However, careless use of
regression analysis could also demonstrate that temperature is dependent on crop yield: this
would suggest that if you grow really big crops you will be guaranteed a hot summer.
Thus, neither regression nor correlation analyses can be interpreted as establishing cause-and-
effect relationships. They can indicate only how or to what extent variables are associated with
each other. The correlation coefficient measures only the degree of linear association between
two variables. Any conclusions about a cause-and-effect relationship must be based on the
judgment of the analyst.
Uses of Correlation and Regression
There are three main uses for correlation and regression.
1. One is to test hypotheses about cause-and-effect relationships. In this case, the experimenter
determines the values of the X-variable and sees whether variation in X causes variation in Y.
For example, giving people different amounts of a drug and measuring their blood pressure.
2. The second main use for correlation and regression is to see whether two variables are
associated, without necessarily inferring a cause-and-effect relationship. In this case, neither
variable is determined by the experimenter; both are naturally variable. If an association is found,
the inference is that variation in X may cause variation in Y, or variation in Y may cause
variation in X, or variation in some other factor may affect both X and Y.
3.The third common use of linear regression is estimating the value of one variable
corresponding to a particular value of the other variable.
*************************

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 101
MODULE III
INDEX NUMBERS AND TIME SERIES ANALYSIS
Index Numbers: Meaning and Uses- Laspeyre’s, Paasche’s, Fisher’s, Dorbish-Bowley,
Marshall-Edgeworth and Kelley’s Methods- Tests of Index Numbers: Time Reversal and Factor
Reversal tests -Base Shifting, Splicing and Deflating- Special Purpose IndicesWholesale Price
Index, Consumer Price Index and Stock Price Indices: BSE SENSEX and NSE-NIFTY. Time
Series Analysis-Components of Time Series, Measurement of Trend by Moving Average and the
Method of Least Squares.
Introduction
Historically, the first index was constructed in 1764 to compare the Italian price index in
1750 with the price level in 1500. Though originally developed for measuring the effect of
change in prices, index numbers have today become one of the most widely used statistical
devices and there is hardly any field where they are not used. Newspapers headline the fact that
prices are going up or down, that industrial production is rising or falling, that imports are
increasing or decreasing, that crimes are rising in a particular period compared to the previous
period as disclosed by index numbers. They are used to feel the pulse of the economy and they
have come to be used as indicators of inflationary or deflationary tendencies, In fact, they are
described as ‘barometers of economic activity’, i.e., if one wants to get an idea as to what ishappening to an economy, he should look to important indices like the index number of
industrial production, agricultural production, business activity, etc.
Of the important statistical devices and techniques, Index Numbers have today become one of
the most widely used for judging the pulse of economy, although in the beginning they were
originally constructed to gauge the effect of changes in prices. Today we use index numbers for
cost of living, industrial production, agricultural production, imports and exports, etc.
Index numbers are the indicators which measure percentage changes in a variable (or a group of
variables) over a specified time. For example,if we say that the index of export for the year 2013
is 125, taking base year as 2010, it means that there is an increase of 25% in the country's export
as compared to the corresponding figure for the year 2000.
Definitions of Index number
According to
Spiegel: “An index number is a statistical measure, designed to measure changes in a variable,or a group of related variables with respect to time, geographical location or other characteristics
such as income, profession, etc.”
Patternson: “In its simplest form, an index number is the ratio of two index numbers expressed asa percent. An index is a statistical measure, a measure designed to show changes in one variable

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 102
or a group of related variables over time, with respect to geographical location or other
characteristics.”
Bowley: “Index numbers are used to measure the changes in some quantity which we cannotobserve directly”
We can thus say that index numbers are economic barometers to judge the inflation (increase in
prices) or deflationary (decrease in prices) tendencies of the economy. They help the government
in adjusting its policies in case of inflationary situations.
TYPES OF INDEX NUMBERSIndex numbers are names after the activity they measure. Their types are as under :
Price Index :Measure changes in price over a specified period of time. It is basically the ratio of
the price of a certain number of commodities at the present year as against base year.
Quantity Index: As the name suggest, these indices pertain to measuring changes in volumes of
commodities like goods produced or goods consumed, etc.
Value Index: These pertain to compare changes in the monetary value of imports, exports,
production or consumption of commodities
Purpose of Index NumbersAn index number, which is designed keeping, specific objective in mind, is a very powerful tool.
For example, an index whose purpose is to measure consumer price index, should not include
wholesale rates of items and the index number meant for slum-colonies should not consider
luxury items like A.C., Cars refrigerators, etc.
Index numbers are meant to study the change in the effects of such factors which cannot be
measured directly. For example, changes in business activity in a country are not capable of
direct measurement but it is possible to study relative changes in business activity by studying
the variations in the values of some such factors which affect business activity, and which are
capable of direct measurement.
CHARACTERISTICS OF INDEX NUMBERS
Following are some of the important characteristics of index numbers :
(a) Index numbers are expressed in terms of percentages to show the extent of relativechange
(b) Index numbers measure relative changes. They measure the relative change in thevalue of a variable or a group of related variables over a period of time or between places.
(c) Index numbers measures changes which are not directly measurable.
The cost of living, the price level or the business activity in a country are not directlymeasurable but it is possible to study relative changes in these activities by measuring thechanges in the values of variables/factors which effect these activities.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 103
PROBLEMS IN THE CONSTRUCTION OF INDEX NUMBERS
The decision regarding the following problems/aspect have to be taken before starting the actual
construction of any type of index numbers.
(i) Purpose of Index numbers under construction
(ii) Selection of items
(iii) Choice of an appropriate average
(iv) Assignment of weights (importance)
(v)Choice of base period
Let us discuss these one-by-one
(i) Purpose of Index Numbers
An index number, which is designed keeping, specific objective in mind, is a very powerful tool.
For example, an index whose purpose is to measure consumer price index, should not include
wholesale rates of items and the index number meant for slum-colonies should not consider
luxury items like A.C., Cars refrigerators, etc.
(ii) Selection of Items
After the objective of construction of index numbers is defined, only those items which are
related to and are relevant with the purpose should be included.
(iii) Choice of Average
As index numbers are themselves specialised averages, it has to be decided first as to which
average should be used for their construction. The arithmetic mean, being easy to use and
calculate, is preferred over other averages (median, mode or geometric mean). In this lesson, we
will be using only arithmetic mean for construction of index numbers.
(iv) Assignment of weights
Proper importance has to be given to the items used for construction of index numbers. It is
universally agreed that wheat is the most important cereal as against other cereals, and hence
should be given due importance.
(v) Choice of Base year
The index number for a particular future year is compared against a year in the near past, which
is called base year. It may be kept in mind that the base year should be a normal year and
economically stable year.
USES OF INDEX NUMBERSIndex numbers are commonly used statistical device for measuring the combined fluctuations in
a group related variables. If we wish to compare the price level of consumer items today with
that prevalent ten years ago, we are not interested in comparing the prices of only one item, but
in comparing some sort of average price levels. We may wish to compare the present agricultural
production or industrial production with that at the time of independence. Here again, we have to

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 104
consider all items of production and each item may have undergone a different fractional
increase (or even a decrease). How do we obtain a composite measure? This composite measure
is provided by index numbers which may be defined as a device for combining the variations that
have come in group of related variables over a period of time, with a view to obtain a figure that
represents the ‘net’ result of the change in the constitute variables.
Index numbers may be classified in terms of the variables that they are intended to measure. In
business, different groups of variables in the measurement of which index number techniques are
commonly used are (i) price, (ii) quantity, (iii) value and (iv) business activity. Thus, we have
index of wholesale prices, index of consumer prices, index of industrial output, index of value of
exports and index of business activity, etc. Here we shall be mainly interested in index numbers
of prices showing changes with respect to time, although methods described can be applied to
other cases. In general, the present level of prices is compared with the level of prices in the past.
The present period is called the current period and some period in the past is called the base
period.
1) Index numbers are used as economic barometers:
Index number is a special type of averages which helps to measure the economic
fluctuations on price level, money market, economic cycle like inflation, deflation etc.
G.Simpson and F.Kafka say that index numbers are today one of the most widely used
statistical devices. They are used to take the pulse of economy and they are used as indicators
of inflation or deflation tendencies. So index numbers are called economic barometers.
2) Index numbers helps in formulating suitable economic policies and planning etc.
Many of the economic and business policies are guided by index numbers. For
example while deciding the increase of DA of the employees; the employer’s have to dependprimarily on the cost of living index. If salaries or wages are not increased according to the
cost of living it leads to strikes, lock outs etc. The index numbers provide some guide lines that
one can use in making decisions.
3) They are used in studying trends and tendencies.
Since index numbers are most widely used for measuring changes over a period of
time, the time series so formed enable us to study the general trend of the phenomenon under
study. For example for last 8 to 10 years we can say that imports are showing upward
tendency.
4) They are useful in forecasting future economic activity.
Index numbers are used not only in studying the past and present workings of our
economy but also important in forecasting future economic activity.
5) Index numbers measure the purchasing power of money.
The cost of living index numbers determine whether the real wages are rising or falling
or remain constant. The real wages can be obtained by dividing the money wages by the

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 105
corresponding price index and multiplied by 100. Real wages helps us in determining the
purchasing power of money.
6) Index numbers are used in deflating.
Index numbers are highly useful in deflating i.e. they are used to adjust the wages for cost of
living changes and thus transform nominal wages into real wages, nominal income to real
income, nominal sales to real sales etc. through appropriate index numbers.
Methods of Constructing Index NumbersConstruction of index numbers can be divided into two types :
(a)Unweighted indices
(i) Simple Aggregative method
(ii) Simple average of price relative method
(b)Weighted indices
(i) Weighted Aggregative Indices
1. Laspayers Method
2. Paashe Method
3. Dorbish&Bowley’s method4. Fisher’s ideal Method5. Marshall –Edgeworth Method, and
6. Kelley’s Method(ii) Weighted Average of relatives
Let us see them in detail.
a (i) Simple Aggregative MethodThis is a simple method for constructing index numbers. In this method, the total of the prices of
commodities in a given (current) years is divided by the total of the prices of commodities in a
base year and expressed as percentage. = ∑∑ × 100∑ = Total of Current year prices for various commodities∑ = Total of base year prices for various commoditiesExample 1
Let us take an example to illustrate
Construct the price index number for 2013, taking the year 2010 as base year
Commodity Price in the year Price in the year2010 2013
A 60 80B 50 60C 70 100D 120 160E 100 150

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 106
Solution :
Calculation of simple Aggregative index number for 2013 (against the year 2010) using theformula.
CommodityPrice in the year2010 Price in the year2013
A 60 80B 50 60C 70 100D 120 160E 100 150= 400 = 550
Substitute in the formula = ∑∑ × 100 = 400550 × 100 = 137.50This means that the price index for the year 2013, taking 2010 as base year, is 137.5, showingthat there is an increase of 37.5% in the prices in 2013 as against 2010.Example 2Compute the index number for the years 2011, 2012, 2013 and 2014, taking 2010 as base year,from the following data.
Year 2010 2011 2012 2013 2014Price 120 144 168 204 216
Solution :
Price relatives for different years are
Year 2010 2011 2012 2013 2014Price 120120 × 100= 100 144120 × 100= 120 168120 × 100= 140 204120 × 100= 170 216120 × 100= 180
Price index for different years are as in the following table.
Year 2010 2011 2012 2013 2014Price Index 100 120 140 170 180
There are two main limitations of this method. They are ;(i)The units used in the price or quantity quotations can exert a big influence on the value of theindex, and
(ii) No consideration is given to the relative importance of the Commodities.
a (ii) Simple Average of price Relatives MethodPrice Relative means the ratio of price of a certain item in current year to the price of that item in
base year, expressed as a percentage (i.e. Price Relative = (p2/p1)×100). For example, if a fridge
TV cost Rs 12000 in 2005 and Rs. 18000 in 2013, the price relative is
(18000/12000)×100 = 150.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 107
When this method is used to construct a price index, first of all price relatives are
obtained for the various items included in the index and then arrange of these relatives is
obtained using any one of the measures of central value, ie, arithmetic mean, median, mode,
geometric or harmonic mean. When arithmetic mean is used for averaging the relatives, the
formula for computing the index is: ∑ × 100if A.M. is used as average where Is the price index, N is the number of items,P0 is the pricein the base year and P1 is the price of corresponding commodity in present year (for which indexis to be calculated).
Example
Construct by simple average of price relative method the price index of 2013, taking 2010 asbase year from the following data
Commodity A B C D E F
Price in2010
60 50 60 50 25 20
Price in2014
80 60 72 75 37.5 30
Solution
Find the price relatives for each, take the sum, substitute in formula.
Commodity A B C D E F
Price in2010 (P0)
60 50 60 50 25 20
Price in2014 (P1)
80 60 72 75 37.5 30
Pricerelative× 100
6080 × 100 6050 × 100 7260 × 100 7550 × 100 37.525 × 100 3020 × 100133.33 120.00 120.00 150.00 150.00 150.00
× 100 = 823.33Substituting we get ∑ × 100 = 823.336 = 137.22
Price index for 2013, taking 2010 for base year = 137.22
An un-weighted aggregate price index represents the changes in prices, over time, for anentire group of commodities. However, an un-weighted aggregate price index has twoshort comings. First, this index considers each commodity in the group as equally

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 108
important. Thus, the most expensive commodities per unit are overly influential. Second,not all the commodities are consumed at the same rate. In an un-weighted index, changesin the price of the least consumed commodities are overly influential.
(b) i. Weighted Aggregative Indices
Due to the shortcomings of un-weighted aggregate price indices, weighted aggregate price
indices are generally preferable. Weighted aggregate price indices account for differences in the
magnitude of prices per unit and differences in the consumption levels of the items in the market
basket.
When all commodities are not of equal importance, this method is used. Here we assign weight
to each commodity relative to its importance and index number computed from these weights is
called weighted index numbers.
b.i. (i) 1. Laspayers Method
In this index number the base year quantities are used as weights, so it also called base year
weighted index. = ∑∑ ×The primary disadvantage of the Laspeyres Method is that it does not take into consideration the
consumption pattern. The Laspeyres Index has an upward bias. When the prices increase, there
is a tendency to reduce the consumption of higher priced items. Similarly when prices decline,
consumers shift their purchase to those items which decline the most.
b. i. (ii) Paasche’s Method
Under this method weights are determined by quantities in the given year
= ∑∑ ×The Paasche price index uses the consumption quantities in the year of interest instead of using
the initial quantities. Thus, the Paasche index is a more accurate reflection of total consumption
costs at that point in time. However, there are two major drawbacks of the Paasche index. First,
accurate consumption values for current purchases are often difficult to obtain. Thus, many
important indices, such as the consumer price index (CPI), use the Laspeyres method. Second, if
a particular product increases greatly in price compared to the other items in the market basket,
consumers will avoid the high-priced item out of necessity, not because of changes in what they
might prefer to purchase.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 109
b.i. (iii) Dorbish&Bowley’s Method
Dorbish and Bowley have suggested simple arithmetic mean of the two indices (Laspeyres and
Paasche) mentioned above so s to take into account the influence of both the periods, i.e., current
as well as base periods. The formula for constructing the index is:
= +Where L = Laspeyres Index P = Paasche’s Index
OR it may be written as
= ∑∑ + ∑∑ ×b.i. (iv) Fisher’s Ideal Index
The geometric mean of Laspeyre’s and Paasche’s price indices is called Fisher’s price Index.
Fisher price index uses both current year and base year quantities as weight. This index corrects
the positive bias inherent in the Laspeyres index and the negative bias inherent in the Paasche
index. Fisher’s price index is also a weighted aggregative price index because it is an average
(G.M) of two weighted aggregative indices. The computational formula for the fisher ideal price
index is:
= ∑∑ × ∑∑ ×OR = √ ×Fischer’s Index is known as ‘ideal’ because (1) it is based on geometric mean, which
is considered to be the best average for constructing index numbers. (2) It takes into account
both current as well as base year prices and quantities (3) It satisfies both time reversal as well
as the factor reversal tests (which we will study soon) and (4) it is free from bias.
It is not, however, a practical index to compute because it is excessively laborious.
The data, particularly for the Paasche segment of the index, are not readily available.
b.i. (v) Marshall-Edgeworth Method
If the weights are taken as the arithmetic mean of base and current year quantities, then theweighted aggregative index is called Marshal-Edgeworth index. Like Fisher’s index, Marshall-Edgeworth index alsorequires too much labor in selection of commodities. In some cases theusage of this index is not suitable, for example the comparison of the price level of a large

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 110
country to a small country. Marshal-Edgeworth index can be calculated by using the formulagiven below. = ∑ + ∑∑ + ∑ ×
It is a simple, readily constructed measure, giving a very close approximation to theresults obtained by the ideal formula.
The Marshall-Edgeworth formula uses the arithmetic mean of the quantities purchased in the
base and current periods as weights. Like the Fisher 'Ideal' index it is impracticable to use as a
timely indicator of price change because it requires the use of quantities purchased in the current
period. In practice, the Marshall-Edgeworth index and the Fisher Ideal, index give similar
results.
b.i. (vi) Kelley’s Method
According to Truman L. Kelly the formula for constructing index numbers.= ∑∑ ×Where q refer to some period, not necessarily the base year or current year.
Example 1
From the following data calculate Price Index Numbers for 2000 with 2013 as base year by using
(i) Laspayers Method (ii) Paasche’s Method (iii) Dorbish&Bowley’s Method (iv) Fisher’s IdealIndex (v) Marshall-Edgeworth Method
Commodity2000 2013
Price Quantity Price QuantityA 20 8 40 6B 50 10 60 5C 40 15 50 15D 20 20 20 25
SolutionLet us first compute the necessary values.(i) Laspayers Method = ∑∑ × 100
2000 2013
Commodity P0 Q0 P1 Q1 P1Q0 P0Q0
A 20 8 40 6 320 160
B 50 10 60 5 600 500
C 40 15 50 15 750 600
D 20 20 20 25 400 400
2070 1660
= 20701660 × 100 = 124.70

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 111
(ii) Paasche’s Method
= ∑∑ × 1002000 2013
Commodity P0 Q0 P1 Q1 P1Q1 P0Q1
A 20 8 40 6 240 120
B 50 10 60 5 300 250
C 40 15 50 15 750 600
D 20 20 20 25 500 500
1790 1470
= 17901470 × 100 = 121.77(iii) Dorbish&Bowley’s Method = +2= 124.70 + 121.772 = 246.472 = 123.23(iv)Fisher’s Ideal Index = √ ×= √124.70 × 121.77 = √15184.56 = 123.23(v)Marshall-Edgeworth Method = ∑ + ∑∑ + ∑ × 100
2000 2013
Commodity P0 Q0 P1 Q1 P1Q1 P0Q1 P1Q0 P0Q0
A 20 8 40 6 240 120 320 160
B 50 10 60 5 300 250 600 500
C 40 15 50 15 750 600 750 600
D 20 20 20 25 500 500 400 400
1790 1470 2070 1660
= 2070 + 17901660 + 1470 × 100 = 38603130 × 100 = 1.233226837 × 100= 123.32

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 112
Example 2
Compute index number from the following data
Materials Unit Quantityrequired
Price2000 2010
Cement 100lb 500 lb 5.0 8.0Timber c.ft. 2000 c.ft. 9.5 14.2Steel Cwt. 50 cvt. 34.0 42.20
Bricks Per 000 20000 12.0 24.0
Solution
Since the quantities (weights) required of different materials are fixed for both base year and
current year, we will use Kelly’s formula.
For materials we have to do certain conversions. For example, for cement unit is in 100 lbs, and
the quantity required is 500 lbs. Hence, the quantity consumed per unit for cement is 500/100 =
5. Similarly, the quantity consumed per unit for brick is 20000/1000= 20.
By Kelley’s Method, = ∑∑ × 100Let us make the necessary computations.
Materials Unit Quantityrequired q
Price (Rs.)P1q P0q2000
P02010P1
Cement 100 lb 500 lb 5 5.0 8.0 25 40Timber c.ft. 2000 c.ft. 2000 9.5 14.2 19000 28400Steel Cwt. 50 cvt. 50 34.0 42.0 1700 2100
Bricks Per 000 20000 20 12.0 24.0 240 480Total 20965 31020
Substituting
= ∑∑ × 100 = 3102020965 × 100 = 1.4796100 = 147.96B. (II) WEIGHTED AVERAGE OF RELATIVES
I. Weighted Average of Price Relatives MethodIn this method, appropriate weights are assigned to the commodities according to the
relative importance of those commodities in the group. Thus the index for the whole group is

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 113
obtained on taking the weighted average of the price relatives. To find the average, Arithmetic
Mean or Geometric Mean can be used.
When AM is used, the index is = ∑∑Where P = Price relative
V = Value of weights i.e.
Example:
From the following data compute price index by supplying weighted average of price relatives
method using Arithmetic Mean
Commodity Sugar Flour Milk
3.0 1.5 1.0
20 Kg. 40 Kg. 10 Lit.
4.0 1.6 1.5
By using Arithmetic Mean
Commodity (v) x 100pvSugar 3.0 20 Kg 4 60
x 1008000
Flour 1.5 40 Kg. 1.6 60 .. x 1006400Milk 1.0 10 Lit. 1.5 10 .. x 1001500V = 130 PV= 15900
= ∑∑ = 15900130 = 122.31Instead of Arithmetic Mean, we can use Geometric Mean.
When GM is used, the index is = ∑ ∑Where P = x 100
V = Value of weight
The above example can be re worked using GM as follows.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 114
By using Geometric Mean
Commodity (v) p Log p V Log p3.0 20 Kg 4 60 133.3 2.1249 127.494
Flour 1.5 40 Kg. 1.6 60 106.7 2.0282 121.6921.0 10 Lit. 1.5 10 150.0 2.1761 21.761
= 130 .= 270.947= ∑ ∑ = 270.947130 = 2.084 = 120.9
Merits of weighted Average of Relative Indices When different index numbers are constructed by the average of relatives method, all of
which have the same base, they can be combined to form a new index. When an index is computed by selecting one item from each of the many sub groups of
items, the values of each sub subgroup may be used as weights. Then only the method ofweighted average of relatives is appropriate.
When a new commodity is introduced to replace the one formerly used, the relative forthe new it may be spliced to the relative for the old one, using the former value weights.
The price or quantity relatives each single item in the aggregate are in effect, themselvesa simple index that often yields valuable information for analysis.
TESTS OF INDEX NUMBERSThe following are the most important tests through which one can list the consistency of
index numbers.
1. The time Reversal Test2. The factor Reversal Test
1.The Time Reversal Test × =Where P01 is the price index for year ‘1’ with year ‘0’ as base year and P10 is the price index foryear ‘a’ with year ‘b’ as base.This test is not satisfied by both Laspeyres and Paasche’s index numbers.× =
∑∑ X∑∑ ≠
Paasche’s Method = × =∑∑ X
∑∑ ≠Fisher’s formula satisfies this test
Fisher’s Method = × = ∑∑ × ∑∑ × ∑∑ × ∑∑ =2. The Factor Reversal Test× =
∑∑Wheref stands for the price relative for the year ‘1’ with base year ‘0’ and stands forquantity relative for the year ‘1’ with base year ‘0’, then the condition isThis test is not satisfied by both Laspeyres and Paasche’s index numbers.
Laspeyre’sFormula = × =∑∑ × ∑∑ ≠ ∑∑
Paasche’sformula = × =∑∑ × ∑∑ ≠ ∑∑

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 115
Fisher’s formula satisfies this test
Fisher’s Formula = × =∑∑ × ∑∑ × ∑∑ × ∑∑
=∑∑ =
∑∑Fisher’s formula satisfies both time reversal and factor reversal test. This is why the
Fisher’s formula is often called Fisher’s Ideal Index Number.ExampleFor the following data prove that the Fisher’s Ideal Index satisfies both the Time Reversal Testand the Factor Reversal Test.
Commodity Base Year Current YearPrice Quantity Price Quantity
A 6 50 10 56B 2 100 2 120C 4 60 6 60D 10 30 12 24
Solution
P1
A 6 50 10 56 300 336 500 560
B 2 100 2 120 200 240 200 240
C 4 60 6 60 240 240 360 360
D 10 30 12 24 300 240 360 288
= 1040 = 1056 = 1420 = 1448Fisher’s price index number is gven by= ∑∑ × ∑∑ ×
Substituting the values we get= × × = .Time reversal test: × =
We have P01 = 1.3683 (without factor 100)And = ∑∑ × ∑∑ ( )

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 116
Substituting = × = .× = 1.3683 × 0.7308 = 0.9999 ≈ 1
Hence, Fischer’s index satisfies Time Reversal Test.
Factor Reversal Test × =∑∑
We have (without factor 100) = ∑∑ × ∑∑ = ×× = ×× × ××
= = = ∑∑ .BASE SHIFTING, SPLICING AND DEFLATING THE INDEX NUMBERS :
(a) Base shifting
Most index numbers are subjected to revision from time to time due to different reasons. In mostcases it becomes compulsory to change the base year because numerous changes took place withthe passage of time. For example changes may happen due to disappearance of old items,inclusion of new ones, changes in weights of commodities or changes in conditions, habits, andstandard of life etc.One of the most frequent operations necessary in the use of index numbers is changing the baseof an index from one period to another with out recompiling the entire series. Such a change isreferred to as ‘base shifting’. The reasons for shifting the base areIf the previous base has become too old and is almost useless for purposes of comparison.If the comparison is to be made with another series of index numbers having different base.
The following formula must be used in this method of base shifting is
Index number based on new base year = 100numberindexoldyearsbasenew
numberindexoldyearscurrent
Shifting from one fixed base to another fixed baseTo convert a fixed base to a new fixed base each old index is divided by the index of new basesought multiplied by 100. It can be illustrated with the help of following problem.
Example:

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 117
Following series is given to the base year 2000. Now convert it into the new series with baseyear 2003.
Year 2000 2001 2002 2003 2004 2005Index 100 130 145 155 205 255
Year Fixed Base IndexBase = 2000 Base = 2003
2000 100 100/155×100 = 64.522001 130 130/155×100 = 83.872002 145 145/155×100 = 93.552003 155 155/155×100 = 100.002004 205 205/155×100 = 132.262005 255 255/155×100 = 164.52
Shifting from chain base to fixed base
One of the disadvantages of chain base method is that the comparison between distant periods is
not immediately evident. Therefore it becomes necessary to convert chain base indices into fixed
base indices. This can be illustrated with the help of following example.
Example:
Convert the following chain indexes into the new series with base year 2005.
Year 2005 2006 2007 2008 2009 2010Index 100 105 110 107 112 107
Year Chain Base Index Fixed Index (1970 = 100)2005 100 1002006 105 100×105/100 = 1052007 110 105×110/100 = 115.52008 107 115.5×107/100 = 123.592009 112 123.59×112/100 = 138.422010 107 138.42×107/100 = 148.10
Shifting from Fixed to chain base
As discussed earlier, conditions change over a period due to revised weightings system, inclusion
of new items and disappearance of old ones etc. Due to all these factors, sometimes it is
necessary to convert the indices from fixed base to chain base. This can be explained with the
help of following problem. Problem: Convert the following indexes with base 1980 to chain
indexes.
Year 2005 2006 2007 2008 2009 2010FixedIndex
100 105 115 130 150 175
Year Fixed Index (Base= 1980)
Chain Base Index, = × 100⁄2005 1980 100 , = 100100 × 100 = 100

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 118
2006 1981 105 , = 105100 × 100 = 1052007 1982 115 , = 115105 × 100 = 109.522008 1983 130 , = 130115 × 100 = 113.042009 1984 150 , = 150130 × 100 = 115.382010 1985 175 , = 175150 × 100 = 116.67
Splicing of two series of index numbers
Splicing of index numbers mean combining two or more series of overlapping index numbers to
obtain a single index number on a common base. This is done by the same technique as used in
base shifting.
To combine two or more series of overlapping index numbers to obtain a single series of index
numbers on a common base.
It is of two types:-
(i) Splicing of new index numbers to old index numbers
(ii) Splicing of old index numbers to new index number.
Splicing of Index numbers can be done only if the index numbers are constructed with the same
items, and have an overlapping year. Suppose we have an index number with a base year of 2001
and another index number (using the same item as the first one) with a base of 2011. Suppose
both index numbers are continuing. Then we can splice the first series of index number to the
second series and have a common index with base 2011. We can also spice index number series
two with series one and have a common index number with base 2001. Splicing is generally
done when an old index number with an old base is being discontinued and a new index with a
new base is being started.
The following formula must be used in this method of splicing
Index number after splicing =
100
baseexistingofnumberindexoldsplicedbenumber toindex
Example
Index Number A given below was started in 1981 and discontinued in 2001 when another indexB was started which continues up to date. From the data given in the table below splice the indexnumber B to index number A so that a continuous series of index numbers from 1951 up to dateis available.
Splicing of Index B to Index A
Here we multiply index B with a common factor which is the ratio of index B to index A in
the overlapping year 2001.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 119
Year Index A Index B Index B Spliced to A1981….….….
100 - -
2000 180 - -2001 200 100 200100 × 100 = 2002002 - 120 200100 × 120 = 2402003…….….
- 140 200100 × 140 = 2802013 - 250 200100 × 250 = 500
Thus we have a continuous series of index numbers with base 1981 which continues up todate.
DEFLATING THE INDEX NUMBERS
By deflating we mean making allowances for the effect of changing price levels. A rise in price
level means a reduction in the purchasing power of money. To take the case of a single
commodity suppose the price of wheat rises from ₹ 500 per quintal in 1999 to ₹ 1,000 perquintal in 2009 it means that in 2009 one can buy only half of wheat if the spends the same
amount which he was spending on wheat in 1999. Thus the value (or purchasing power) of a
rupee is simply the reciprocal of an appropriate price index written as a proportion. If prices
increase by 60 per cent, the price index is 1.60 and what a rupee will busy is only 1/1.60 or 5/8 of
what it used to buy. In other words the purchasing power of rupee is 5/8 of what it was.
Similarly, if prices increase by 25 per cent the price index is 1.25 (125 per cent). And the
purchasing power of the rupee is 1/1.25 = 0.80.
Thus the purchasing power of money =indexprice
1
In times of rising prices the money wages should be deflated by the price index to get the
figure of real wages. The real wages alone tells whether a wage earner is in better position or in
worst position.
For calculating real wage, the money wages or income is divided by the corresponding
price index and multiplied by 100.
i.e. Real wages = 100Pr
indexice
wagesMoney
Thus Real Wage Index= 100Re
Re
yearbaseofwageal
yearcurrentofwageal
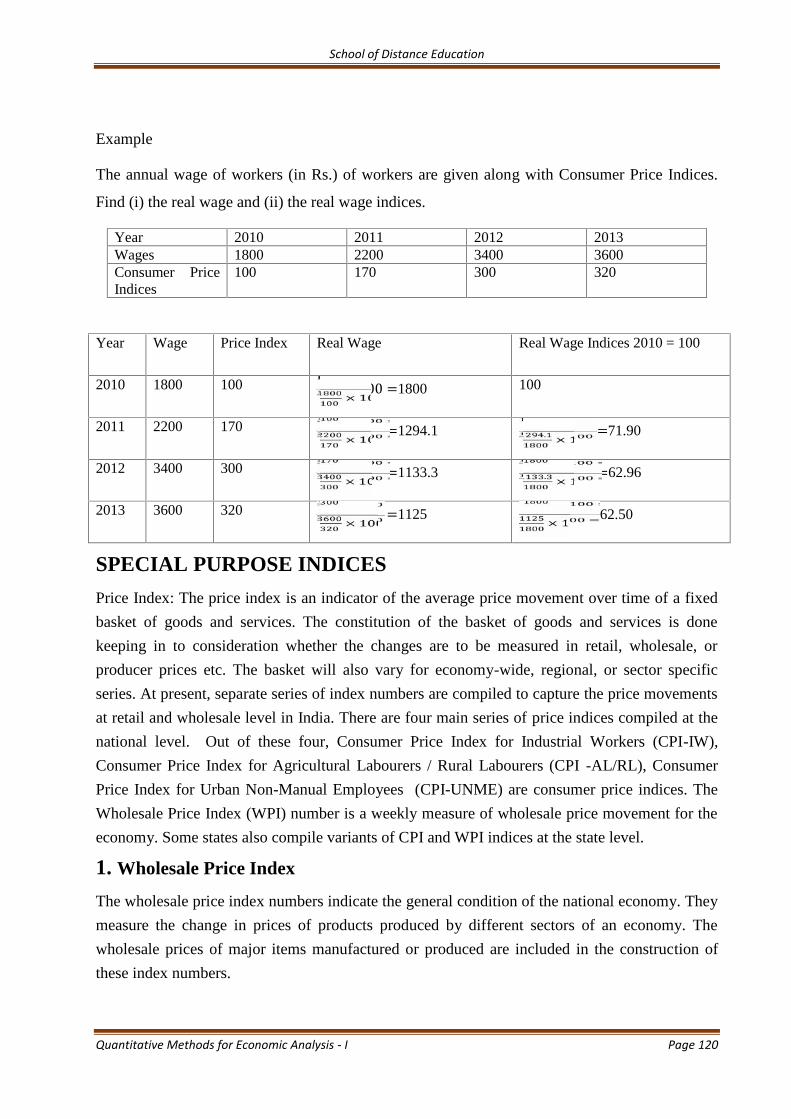
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 120
Example
The annual wage of workers (in Rs.) of workers are given along with Consumer Price Indices.
Find (i) the real wage and (ii) the real wage indices.
Year 2010 2011 2012 2013Wages 1800 2200 3400 3600Consumer PriceIndices
100 170 300 320
Year Wage Price Index Real Wage Real Wage Indices 2010 = 100
2010 1800 100 × 100 =1800 100
2011 2200 170 × 100 =1294.1. × 100 =71.90
2012 3400 300 × 100 =1133.3. × 100 =62.96
2013 3600 320 × 100 =1125 × 100 =62.50
SPECIAL PURPOSE INDICES
Price Index: The price index is an indicator of the average price movement over time of a fixed
basket of goods and services. The constitution of the basket of goods and services is done
keeping in to consideration whether the changes are to be measured in retail, wholesale, or
producer prices etc. The basket will also vary for economy-wide, regional, or sector specific
series. At present, separate series of index numbers are compiled to capture the price movements
at retail and wholesale level in India. There are four main series of price indices compiled at the
national level. Out of these four, Consumer Price Index for Industrial Workers (CPI-IW),
Consumer Price Index for Agricultural Labourers / Rural Labourers (CPI -AL/RL), Consumer
Price Index for Urban Non-Manual Employees (CPI-UNME) are consumer price indices. The
Wholesale Price Index (WPI) number is a weekly measure of wholesale price movement for the
economy. Some states also compile variants of CPI and WPI indices at the state level.
1. Wholesale Price Index
The wholesale price index numbers indicate the general condition of the national economy. They
measure the change in prices of products produced by different sectors of an economy. The
wholesale prices of major items manufactured or produced are included in the construction of
these index numbers.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 121
Wholesale Price Index (WPI) represents the price of goods at a wholesale stage i.e. goods that
are sold in bulk and traded between organizations instead of consumers. WPI is used as a
measure of inflation in some economies.
Uses
In a dynamic world, prices do not remain constant. Inflation rate calculated on the basis of the
movement of the Wholesale Price Index (WPI) is an important measure to monitor the dynamic
movement of prices. As WPI captures price movements in a most comprehensive way, it is
widely used by Government, banks, industry and business circles. Important monetary and fiscal
policy changes are often linked to WPI movements. Similarly, the movement of WPI serves as
an important determinant, in formulation of trade, fiscal and other economic policies by the
Government of India. The WPI indices are also used for the purpose of escalation clauses in the
supply of raw materials, machinery and construction work.
WPI is used as an important measure of inflation in India. Fiscal and monetary policy changes
are greatly influenced by changes in WPI.
WPI is an easy and convenient method to calculate inflation. Inflation rate is the difference
between WPI calculated at the beginning and the end of a year. The percentage increase in WPI
over a year gives the rate of inflation for that year.
WPI computation in India
WPI is the most widely used inflation indicator in India. This is published by the Office of
Economic Adviser, Ministry of Commerce and Industry. WPI captures price movements in a
most comprehensive way. It is widely used by Government, banks, industry and business
circles. Important monetary and fiscal policy changes are linked to WPI movements. It is in use
since 1939 and is being published since 1947 regularly. We are well aware that with the
changing times, the economies too undergo structural changes. Thus, there is a need for
revisiting such indices from time to time and new set of articles / commodities are required to be
included based on current economic scenarios. Thus, since 1939, the base year of WPI has been
revised on number of occasions. The current series of Wholesale Price Index has 2004-05 as
the base year.
Wholesale price index comprises as far as possible all transactions at first point of bulk sale in
the domestic market. Provisional monthly WPI for All Commodities is released on 14th of every
month (next working day, if 14th is holiday). Detailed item level WPI is put on official website
(http://www.eaindustry.nic.in/) for public use. The provisional index is made final after a period
of eight weeks/ two months.
The Office of the Economic Adviser to the Government of India undertook to publish for the
first time, an index number of wholesale prices, with base week ended August 19, 1939 = 100,
from the week commencing January 10, 1942. The index was calculated as the geometric mean

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 122
of the price relatives of 23 commodities classified into four groups: (1) food & tobacco; (2)
agricultural commodities; (3) raw materials; and (4) manufactured articles. Each item was
assigned equal weight and for each item, there was a single price quotation. That was a modest
beginning to what became an important weekly activity for the monitoring and management of
the Indian economy and a benchmark for business transactions.
Step-in compilation of WPI in India
Like most of the price indices, WPI is based on Laspeyres formula for reason of practical
convenience. Therefore, once the concept of wholesale price is defined and the base year is
finalized, the exercise of index compilation involve finalization of item basket, allocation of
weights (W) at item, groups/ sub-groups level. Simultaneously, the exercise to collect base prices
(Po), current prices (P1), finalization of item specifications, price data sources, and data
collection machinery is undertaken. These steps are
1. Definition of the Concept of Wholesale Prices:
Wholesale price has divergent connotations adopted by the different departments using them.
There is no uniform definition for agricultural and non- agricultural commodities as all the
wholesale prices cannot be collected from the established markets. So proper definition has to be
made by the competent authority.
For example in the case of agricultural commodities, in practice, there are three types of
wholesale markets viz., primary, secondary and terminal in the agricultural sector. The price
movements and price levels in all three vary. Price movement in the terminal market may tend to
converge toward the retail prices. Option to collect the wholesale prices for these three different
stages of wholesale transactions exists for agricultural commodities though the primary market is
prepared. So, the Ministry of Agriculture has defined wholesale price as the rate at which
relatively large transaction of purchase, usually for further sale, is effected.
Similarly, for non-agricultural commodities, which are predominantly manufacturing items, the
problem arises, as there are no established sources in markets. This is true of mining and fuel
items also. The issue of ex-factory vis-à-vis wholesale prices for non-agriculture items have been
discussed by the successive Working Groups set up for the revision of WPI and all have reached
the conclusion that in practice, it is not feasible to collect wholesale prices for most of the
manufacturing items. It has also been observed that the margin of wholesalers in case of non-
agricultural commodities remains unchanged for over a long period of time. As a result, it is felt
that the trends in the index compiled on the basis of ex-factory prices would not be much
different from the index if compiled on the basis of wholesale prices if it were feasible to get
these prices. The last Working Group has recommended collecting wholesale prices from the

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 123
markets as far as possible, because the economy is moving towards globalization and open
trade with inputs increasing in the commodities set.
2) Choice of Base Year
The second step is choice of base year. The well-known criteria for the selection of base year
are (i) a normal year i.e. a year in which there are no abnormalities in the level of production,
trade and in the price level and price variations, (ii) a year for which reliable production, price
and other required data are available and (iii) a year as recent possible and comparable with
other data series at national and state level. The National Statistical Commission has
recommended that base year should be revised every five year and not later than ten years.
3. Selection of Items, Varieties/ Grades, Markets:
To ensure that the items in the index basket are as best representatives as possible, efforts are
made to include all the important items transacted in the economy during the base year. The
importance of an item in the free market will depend on its traded value during the base year. At
wholesale level, bulk transactions of goods and services need to be captured. As the services are
not covered so far, the WPI basket mainly consists of items from goods sector. In the absence of
single source of data on traded value, the selection procedures followed for agricultural
commodities and non-agricultural commodities have also been different.
For example, in the case of agricultural commodities: As there is a little scope of emergence of
new commodities in the agriculture, the selection of new items in the basket is done on the basis
of increased importance in wholesale markets. Varieties, which have declined in importance,
need to be dropped in the revised series. Final inclusion or exclusion of an item in the basket is
based on the process of consultation with the various departments. The exercise of adding
/deleting commodities, specifications and markets is completed once the consultation process is
over. In the existing WPI series, items, their specifications and markets have been finalized in
consultation of with the Directorate of E&S (M/O Agriculture), National Horticulture Board,
Spices Board, Tea board, Coffee Board and Rubber Board, Silk Board, Directorate Of Tobacco,
Cotton Corporation of India etc.
4. Derivation of Weighting Diagram
Weights used in the WPI are value weights not quantity weights as its difficult to assign quantity
weights. Distribution of the appropriate weight to each of the item is most important exercise for
reliable index. Unlike consumer price indices, where weights are derived on the basis of results
of Expenditure Surveys, several sources of data are used for derivation of weights for WPI.
5) Collection of Prices
In WPI pricing methodology used is specification pricing. Under this, in consultation with the
identified source agencies, precise specifications of all items in the basket are defined for repeat

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 124
pricing every week. All characteristics like make, model, features along with the unit of sale,
type of packaging, if applicable, etc are recorded and printed in the price collection schedule. At
the time of scrutiny of price data all these are kept in mind. This pricing to constant quality
technique is the cornerstone of Laspeyres formula. In case of changes in quality and
specifications, due adjustments are made as per the standard procedures.
The collection of base prices is done concurrently while the work on finalisation of index basket
is on. Therefore, price collection is normally done for larger number of items pending
finalisation. Once the basket is ready, current prices are collected only as per the final basket
from the designated sources. Weekly prices need to be collected for pre-determined day of the
week. For the current series prices are quoted on the basis of the prevailing prices of every
Friday. Agricultural wholesale prices are for bulk transactions and include transport cost. Non-
agricultural prices are ex-mine or ex-factory inclusive of excise duty but exclusive of rebate if
any.
6) Treatment of prices collected from open market & administered prices:
There are some items which constitute part of index baskets but the prices for these items are
either totally administered by the Government or are under dual pricing policy. The issue of
using administered prices for index compilation is resolved by taking into account appropriate
ratio between the levy and non-levy portions. Where these ratios are not available, the issues can
be resolved through taking the appropriate number of price quotations of the administered prices
and the open market prices after periodic review.
Due to variation in quality and different price movements of the commodities belonging to
unorganized sector, separate quotations from organized and unorganized units have to be taken
and merged based on the turnover value of both the sectors at item level. For pricing from
unorganized sector, adequate number of price quotations has to be drawn out of the list of units
by criteria of share of production as far as possible.
7) Classification structure:
The Working Groups over the period have been suggesting to bring the classification of various
items under different groups and sub-groups as per the latest revised National Industrial
Classification (NIC) which in turn is comparable to International Standard Industrial
Classification (ISIC). The classification based on NIC renders the WPI data amenable to
comparison with the Index of Industrial Production (IIP) and National Income data.
Major Group/Groups: I. Primary Articles II. Fuel, Power, Light & Lubricants III. Manufactured
Products
8) Methodology of Index Calculation
Actual index compilation is done in stages.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 125
In the first stage, once the price data are scrutinized, price relative for each price quote is
calculated. Price relative is calculated as the ratio of the current price to the base price multiplied
by 100 i.e. (P1/Po)×100.
In the next stage, commodity/item level index is arrived at as the simple arithmetic average of
the price relatives of all the varieties (each quote) included under that commodity. An average of
price ratio/ relative is used under implicit assumption that each price quotation collected for an
item/commodity index compilation has equal importance i.e. the shares of production value is
equal.
Next, the indices for the sub groups/groups/ major groups are compiled and the aggregation
method is based on Laspeyres formula as below:
I= S (Ii x Wi) / S Wi
Where,
I = Index numbers of wholesale prices of a sub- group/group/ major group/ all commodities
S = represents the summation operation,
Ii = Index of the ith item / sub- group/ group/ major group.
Wi = Weight assigned to the ith item of sub- group/group/ major group.
The weights are value weights. Aggregation is first done at sub-group and group level. All
commodities index is compiled by aggregating Major group indices.
9) Handling of the Seasonal Commodities :
There are number of agriculture items, especially some fruits and vegetables, which are of
seasonal nature. When a particular seasonal item disappears from the market and its prices are
not available because of its being out of season, the weights of such item is imputed amongst the
other items on pro rata basis with in the sub-group of vegetables or fruits. The underlying
assumption is that if the items remained available, the prices of these items would have moved in
the same proportion as the prices of the other items in the sub-group, which did remain available.
This is equivalent to giving a greater weight to the remaining items. The seasonality problem can
be sorted by adopting other methods like, i) prices of unavailable items can also be extrapolated
forward from the period of availability or ii) if such seasonal item has insignificant weight it can
be taken permanently from the basket etc.
2. Consumer Price Index Number
The Consumer Price Index (CPI) is a measure of the average change over time in the prices of
consumer items -goods and services that people buy for day-to-day living. The CPI is a complex
construct that combines economic theory with sampling and other statistical techniques and uses

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 126
data from several surveys to produce a timely and precise measure of average price change for
the consumption sector.
Consumer Price Index is a comprehensive measure used for estimation of price changes in a
basket of goods and services representative of consumption expenditure is called consumer price
index. The calculation involved in the estimation of CPI is quite rigorous. Various categories and
sub-categories have been made for classifying consumption items and on the basis of consumer
categories like urban or rural. Based on these indices and sub indices obtained, the final overall
index of price is calculated mostly by national statistical agencies. It is one of the most important
statistics for an economy and is generally based on the weighted average of the prices of
commodities. It gives an idea of the cost of living.
Inflation is measured using CPI. The percentage change in this index over a period of time gives
the amount of inflation over that specific period, i.e. the increase in prices of a representative
basket of goods consumed.
The CPI frequently is called a cost-of-living index, but it differs in important ways from a
complete cost-of-living measure. A cost-of-living index would measure changes over time in the
amount that consumers need to spend to reach a certain utility level or standard of living. Both
the CPI and a cost-of-living index would reflect changes in the prices of goods and services, such
as food and clothing that are directly purchased in the marketplace; but a complete cost-of-living
index would go beyond this role to also take into account changes in other governmental or
environmental factors that affect consumers' well-being. It is very difficult to determine the
proper treatment of public goods, such as safety and education, and other broad concerns, such as
health, water quality, and crime, that would constitute a complete cost-of-living framework.
How do we read or interpret an index?
An index is a tool that simplifies the measurement of movements in a numerical series. Most of
the specific CPI indexes have a 1982-84 reference base. That is, the agency computing the index
sets the average index level (representing the average price level)-for the 36-month period
covering the years 1982, 1983, and 1984-equal to 100. The agency then measures changes in
relation to that figure. An index of 110, for example, means there has been a 10-percent increase
in price since the reference period; similarly, an index of 90 means a 10-percent decrease.
Movements of the index from one date to another can be expressed as changes in index points
(simply, the difference between index levels), but it is more useful to express the movements as
percent changes. This is because index points are affected by the level of the index in relation to
its reference period, while percent changes are not.
Item A Item B Item CYear I 112.500 225.000 110.000Year II 121.500 243.000 128.000Change in indexpoints
9.000 18.000 18.000
Percent change 9.0/112.500 x 100 =8.0
18.0/225.000 x 100 =8.0
18.0/110.000 x 100 =16.4

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 127
In the table above, Item A increased by half as many index points as Item B between Year I and
Year II. Yet, because of different starting indexes, both items had the same percent change; that
is, prices advanced at the same rate. By contrast, Items B and C show the same change in index
points, but the percent change is greater for Item C because of its lower starting index value.
Uses of cost of living index numbers:
1. Cost of living index numbers indicate whether the real wages are rising or falling. Inother words they are used for calculating the real wages and to determine the change inthe purchasing power of money.
numberindexlivingofCost
1moneyofpowerPurchasing
100umbersindexlivingofCost
wagesMoneyR Wageseal
2. Cost of living indices are used for the regulation of D.A or the grant of bonus to theworkers so as to enable them to meet the increased cost of living.
3. Cost of living index numbers are used widely in wage negotiations.
4. These index numbers also used for analyzing markets for particular kinds of goods.
Main steps or problems in construction of cost of living index numbers
Production of the CPI requires the skills of many professionals, including economists,statisticians, computer scientists, data collectors, and others.
The cost of living index numbers measures the changes in the level of prices of commoditieswhich directly affects the cost of living of a specified group of persons at a specified place. Thegeneral index numbers fails to give an idea on cost of living of different classes of people atdifferent places.
Different classes of people consume different types of commodities, people’s consumptionhabit is also vary from man to man, place to place and class to class i.e. richer class, middle classand poor class. For example the cost of living of rickshaw pullers at BBSR is different from therickshaw pullers at Kolkata. The consumer price index helps us in determining the effect of riseand fall in prices on different classes of consumers living in different areas.
The following are the main steps in constructing a cost of living index number.
1. Decision about the class of people for whom the index is meantIt is absolutely essential to decide clearly the class of people for whom the index
is meant i.e. whether it relates to industrial workers, teachers, officers, labors, etc. Alongwith the class of people it is also necessary to decide the geographical area covered by theindex, such as a city, or an industrial area or a particular locality in a city.
2. Conducting family budget enquiry
Once the scope of the index is clearly defined the next step is to conduct a sample
family budget enquiry i.e. we select a sample of families from the class of people for
whom the index is intended and scrutinize their budgets in detail. The enquiry should be
conducted during a normal period i.e. a period free from economic booms or depressions.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 128
The purpose of the enquiry is to determine the amount; an average family spends on
different items. The family budget enquiry gives information about the nature and quality
of the commodities consumed by the people. The commodities are being classified under
following heads
i) Food ii) Clothing iii)Fuel and Lighting iv)House rent v) miscellaneous
3. Collecting retail prices of different commodities
The collection of retail prices is a very important and at the same time very
difficult task, because such prices may vary from lace to place, shop to shop and person
to person. Price quotations should be obtained from the local markets, where the class of
people reside or from super bazaars or departmental stores from which they usually make
their purchases.
Method of Constructing the Index
The index may be constructed by applying any of the following methods :
1) Aggregate Expenditure Method or Aggregation Method
2) Family Budget Method or the Method of Weighted Relatives.
1. Aggregate Expenditure Method.
When this method is applied the quantities of commodities consumed by the particular group in
the base year are estimated and these figures are used as weights. Then the total expenditure on
each commodity for each year is calculated. = ∑∑ ×Where
and stand for the prices of the current year and base year.
and stand for the quantities of the current year and base year.
Steps:
i) The prices of commodities for various groups for the current year is multiplied by the quantitiesof the base year and their aggregate expenditure of current year is obtained .i.e. 01qp
ii) Similarly obtain 00qp
iii) The aggregate expenditure of the current year is divided by the aggregate expenditure of thebase year and the quotient is multiplied by 100.
Symbolically 10000
01
qp
qp
2. Family Budget Method
When this method is applied the family budgets of a large number of are carefully studied andthe aggregate expenditure of the average family on various items is estimated. These values areused as weights.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 129
= ∑∑Where 1001
op
pp for each item
00qpv , value on the base year
ExampleConstruct the Consumer price index number of 2013 on the basis of 2009 from the followingdata using 1) the aggregate expenditure method and 2) the family budget method.
Commodity Quantity in units in2009
Price per unit in 2000(₹)
Price per unit in 2013(₹)
A 100 8 12B 25 6 7.50C 10 5 5.25D 20 48 52E 25 15 16.50F 30 9 27
Solution
(1) Aggregate expenditure method
Formula for aggregate expenditure method == ∑∑ × 100Commodity Price
per unitin 2000
(₹)P0
Priceper unitin 2013
(₹)P1
Quantityin unitsin 2009
q0
A 8 12 100 800 1200
B 6 7.5 25 150 187.5
C 5 5.25 10 50 52.5
D 48 52 20 960 1040
E 15 16.5 25 375 412.5
F 9 27 30 270 810
Total 0 0= 2605 1 0= 3702.50= ∑∑ × 100

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 130
= 3702.502605 × 100 = 142.132. The family budget method = ∑∑Where = × 100
for each item= , value on the base year
Commodity Price perunit in
2000 (₹)P0
Price perunit in
2013 (₹)P1
Quantity inunits in2009
q0
= × 100 =,
A 8 12 100 150 800 120000
B 6 7.5 25 125 150 18750
C 5 5.25 10 105 50 5250
D 48 52 20 108.33 960 104000
E 15 16.5 25 110 375 41250
F 9 27 30 300 270 81000
898.33 2605 370250
= ∑∑ = 3702502605 = 142.13Note: It should be noted that the answer obtained by applying the aggregate expenditure methodand family budget method is the same.
Given below is an example of Consumer Price Index for Kerala

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 131
Possible errors in construction of cost of living index numbers:
Cost of living index numbers or its recently popular name consumer price index numbers
are not accurate due to various reasons.
1. Errors may occur in the construction because of inaccurate specification of groups for
whom the index is meant.
2. Faulty selection of representative commodities resulting out of unscientific family budget
enquiries.
3. Inadequate and unrepresentative nature of price quotations and use of inaccurate weights
4. Frequent changes in demand and prices of the commodity
5. The average family might not be always a representative one.
Wholesale price index numbers (Vs) consumer price index numbers:
1. The wholesale price index number measures the change in price level in a country as awhole. For example economic advisors index numbers of wholesale prices.
Where as cost of living index numbers measures the change in the cost of living

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 132
of a particular class of people stationed at a particular place. In this index number we takeretail price of the commodities.
2. The wholesale price index number and the consumer price index numbers are generallydifferent because there is lag between the movement of wholesale prices and the retailprices.
3. The retail prices required for the construction of consumer price index number increasedmuch faster than the wholesale prices i.e. there might be erratic changes in the consumerprice index number unlike the wholesale price index numbers.
4. The method of constructing index numbers in general the same for wholesale prices andcost of living. The wholesale price index number is based on different weighting systemsand the selection of commodities is also different as compared to cost of living indexnumber
Limitations or demerits of index numbers:
Although index numbers are indispensable tools in economics, business, management
etc, they have their limitations and proper care should be taken while interpreting them. Some of
the limitations of index numbers are
1. Since index numbers are generally based on a sample, it is not possible to take into
account each and every item in the construction of index.
2. At each stage of the construction of index numbers, starting from selection of
commodities to the choice of formulae there is a chance of the error being introduced.
3. Index numbers are also special type of averages, since the various averages like mean,
median, G.M have their relative limitations, their use may also introduce some error.
4. None of the formulae for the construction of index numbers is exact and contains the so
called formula error. For example Lasperey’s index number has an upward bias while
Paasche’s index has a downward bias.
5. An index number is used to measure the change for a particular purpose only. Its misuse
for other purpose would lead to unreliable conclusions.
6. In the construction of price or quantity index numbers it may not be possible to retain the
uniform quality of commodities during the period of investigation.
3. STOCK MARKET INDEX NUMBER
A stock market index is a measure of the relative value of a group of stocks in numerical terms.
As the stocks within an index change value, the index value changes. An index is important to
measure the performance of investments against a relevant market index.
An Index is used to give information about the price movements of products in the financial,
commodities or any other markets. Financial indexes are constructed to measure price
movements of stocks, bonds, T-bills and other forms of investments. Stock market indexes are
meant to capture the overall behaviour of equity markets. A stock market index is created by

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 133
selecting a group of stocks that are representative of the whole market or a specified sector or
segment of the market. An Index is calculated with reference to a base period and a base index
value.
Stock indexes are useful for benchmarking portfolios, for generalizing the experience of all
investors, and for determining the market return used in the Capital Asset Pricing Model
(CAPM).
A hypothetical portfolio encompassing all possible securities would be too broad to measure, so
proxies such as stock indexes have been developed to serve as indicators of the overall market's
performance. In addition, specialized indexes have been developed to measure the performance
of more specific parts of the market, such as small companies.
It is important to realize that a stock price index by itself does not represent an average return to
shareholders. By definition, a stock price index considers only the prices of the underlying stocks
and not the dividends paid. Dividends can account for a large percentage of the total investment
return.
An stock market index (or just “index) is a number that measures the relative value of a group of
stocks. As the stocks in this group change value, the index also changes value. If an index goes
up by 1% then that means the total value of the securities which make up the index have gone up
by 1% in value.
A stock market index measures the change in the stock prices of the index's components.
How it works/Example:
Let's say we want to measure the performance of the Indian stock market. Assume there arecurrently four public companies that operate in the United States: Company A, Company B,Company C, and Company D.
In the year 2000, the four companies' stock prices were as follows:
Company A ₹10
Company B ₹8
Company C ₹12
Company D ₹25
Total ₹55
To create an index, we simply set the total (₹55) in the year 2000 equal to 100 and measure anyfuture periods against that total. For example, let's assume that in 2001 the stock prices were:
Company A ₹4
Company B ₹38
Company C ₹12
Company D ₹24
Total ₹78

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 134
Because ₹78 is 41.82% higher than the 2000 base, the index is now at 141.82. Every day,month, year, or other period, the index can be recalculated based on current stock prices.
Note that this index is price-weighted (i.e., the larger the stock price, the more influence it has onthe index). Indexes can be weighted by any number of metrics, including shares outstanding,market capitalization, or stock price.
Some Important Stock Market Indices
Symbol NameXAX Amex CompositeVOLNDX
DWS NASDAQ-100 Volatility Target Index
FTSEQ500
FTSE NASDAQ 500 Index
RCMP NASDAQ Capital Market Composite IndexIXIC NASDAQ CompositeNQGM NASDAQ Global Market CompositeNQGS NASDAQ Global Select Market CompositeQOMX NASDAQ OMX 100 IndexILTI NASDAQ OMX AeA Illinois Tech IndexQMEA NASDAQ OMX Middle East North Africa IndexIXNDX NASDAQ-100NYA NYSE CompositeOMXB10 OMX Baltic 10OMXC20 OMX Copenhagen 20OMXH25 OMX Helsinki 25OMXN40 OMX Nordic 40OMXS30 OMX Stockholm 30 IndexRUI Russell 1000RUT Russell 2000RUA Russell 3000OEX S&P 100SPX S&P 500MID S&P MidCapNDXE The NASDAQ-100 Equal Weighted IndexVINX30 VINX 30WLX Wilshire 5000
Types of Stock Market Indices (National Stock Exchange)(a) Broad Market Indices
These indices are broad-market indices, consisting of the large, liquid stocks listed on theExchange. They serve as a benchmark for measuring the performance of the stocks or portfoliossuch as mutual fund investments.
Examples
CNX Nifty(The CNX Nifty is a well diversified 50 stock index accounting for 23 sectorsof the economy. It is used for a variety of purposes such as benchmarking fund portfolios,index based derivatives and index funds.)
CNX Nifty Junior
LIX15 Midcap

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 135
CNX 100
Nifty Midcap 50
CNX Midcap
CNX Smallcap Index
India VIX
(b) Sectoral Indices
Sector-based index are designed to provide a single value for the aggregate performance of anumber of companies representing a group of related industries or within a sector of theeconomy.
Examples
CNX Auto Index (The CNX Auto Index is designed to reflect the behaviour and performance ofthe Automobiles sector which includes manufacturers of cars & motorcycles, heavy vehicles,auto ancillaries, tyres, etc. The CNX Auto Index comprises of 15 stocks that are listed on theNational Stock Exchange.)
CNX Bank Index
CNX Energy Index
CNX Finance Index
CNX FMCG Index
CNX IT Index
CNX Media Index
CNX Metal Index
CNX Pharma Index
CNX PSU Bank Index
CNX Realty Index
IISL CNX Industry Indices
(c) Thematic Indices
Thematic indices are designed to provide a single value for the aggregate performance of anumber of companies representing a theme.
Examples
CNX Commodities Index (The CNX Commodities Index is designed to reflect the behaviour andperformance of a diversified portfolio of companies representing the commodities segmentwhich includes sectors like Oil, Petroleum Products, Cement, Power, Chemical, Sugar, Metalsand Mining. The CNX Commodities Index comprises of 30 companies that are listed on theNational Stock Exchange (NSE).)
CNX Consumption Index
CPSE Index
CNX Infrastructure Index
CNX MNC Index
CNX Service Sector Index
CNX Shariah25
CNX Nifty Shariah / CNX 500 Shariah
CNX PSE Index
(d) Strategy Indices
Strategy indices are designed on the basis of quantitative models / investment strategies to
provide a single value for the aggregate performance of a number of companies. Strategic indices
are designed on the basis of quantitative models / investment strategies to provide a single value
for the aggregate performance of a number of companies.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 136
CNX 100 Equal Weight (The CNX 100 Equal Weight Index comprises of same constituents as
CNX 100 Index (free float market capitalization based Index).
The CNX 100 tracks the behavior of combined portfolio of two indices viz. CNX Nifty and CNX
Nifty Junior. It is a diversified 100 stock index. The maintenance of the CNX Nifty and the CNX
Nifty Junior are synchronized so that the two indices will always be disjoint sets; i.e. a stock will
never appear in both indices at the same time.)
CNX Alpha Index
CNX Defty
CNX Dividend Opportunities Index
CNX High Beta Index
CNX Low Volatility Index
CNX Nifty Dividend
NV20 Index
NI15 Index
Nifty TR 2X Leverage
Nifty TR 1X Inverse
(e) Fixed Income Indices
Fixed income index is used to measure performance of the bond market. The fixed income
indices are useful tool for investors to measure and compare performance of bond portfolio.
Fixed income indices also used for introduction of Exchange Traded Funds.
Examples
GSEC10 NSE Index (GSEC10 NSE index is constructed using the prices of top 5 ( in terms of
traded value) liquid GOI bonds with residual maturity between 8 to 13 years and have
outstanding issuance exceeding Rs.5000 crores. The individual bonds are assigned weights
considering the traded value and outstanding issuance in the ratio of 40:60.The index measures
the changes in the prices of the bond basket.)
GSECBM NSE Index
(f) Index Concepts
Indices and index-linked investment products provide considerable benefits. Important concepts
and terminologies are associated with Index construction. These concepts are important for
investors to learn from the information that indices contain about investment opportunities.
In the investment world, however, risk is inseparable from performance and, rather than being
desirable or undesirable, is simply necessary. Understanding risk is one of the most important
parts of a financial education.
Indices and index-linked investment products provide considerable benefits. But it is equally
important to know the associated risk that comes as part of such exposure. Important concepts
and terminologies are associated with Indices. For e.g. Beta helps us to understand the concepts
of passive and active risk. Impact cost represents the cost of executing a transaction in a given
stock, for a specific predefined order size, at any given point of time. These concepts are
important for to understanding indices and investment opportunities.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 137
(g) Index Funds
An Index Fund is a type of mutual fund with a portfolio constructed to match the constituents of
the market index, such as CNX Nifty. An index fund provides broad market exposure and lower
operating expenses for investors.
Index Funds today are a source of investment for investors looking at a long term, less risky form
of investment. The success of index funds depends on their low volatility and therefore the
choice of the index.Examples
1 Principal Index Fund
2 UTI Nifty Index Fund
3 Franklin India Index Fund
4 SBI Nifty Index Fund
5 ICICI Prudential Index Fund
6 HDFC Index Fund - Nifty Plan
7 Birla Sun Life Index Fund
8 LIC NOMURA MF Index Fund - Nifty Plan
Uses of Stock Market Indices
With any type of investment it's important to measure the performance of that investment.
Otherwise there's no way for you to distinguish between a good return on your money versus a
bad one.
A relevant stock market index serves that purpose. If your investments consistently lag behind
the index then you know you have a poor performer, and it may be time to find a new
investment.
Stock market indexes are useful for a variety of reasons. Some of them are :
They provide a historical comparison of returns on money invested in the stock market
against other forms of investments such as gold or debt.
They can be used as a standard against which to compare the performance of an equity
fund.
In It is a lead indicator of the performance of the overall economy or a sector of the
economy
Stock indexes reflect highly up to date information
Modern financial applications such as Index Funds, Index Futures, Index Options play an
important role in financial investments and risk management
BSE SENSEX (Bombay Stock Exchange Sensitive Index)
The Sensex is an "index". What is an index? An index is basically an indicator. It gives you ageneral idea about whether most of the stocks have gone up or most of the stocks have gonedown. The Sensex is an indicator of all the major companies of the BSE.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 138
BSE SENSEX is considered as the Barometer of Indian Capital Markets. If the Sensex goes up,
it means that the prices of the stocks of most of the major companies on the BSE have gone up.
If the Sensex goes down, this tells you that the stock price of most of the major stocks on the
BSE have gone down.
BSE SENSEX, first compiled in 1986, was calculated on a "Market Capitalization-Weighted"
methodology of 30 component stocks representing large, well-established and financially sound
companies across key sectors. The base year of S&P BSE SENSEX was taken as 1978-79. S&P
BSE SENSEX today is widely reported in both domestic and international markets through print
as well as electronic media. It is scientifically designed and is based on globally accepted
construction and review methodology. Since September 1, 2003, BSE SENSEX is being
calculated on a free-float market capitalization methodology. The "free-float market
capitalization-weighted" methodology is a widely followed index construction methodology on
which majority of global equity indices are based; all major index providers like MSCI, FTSE,
STOXX, and Dow Jones use the free-float methodology.
The BSE Sensex currently consists of the following 30 major Indian companies as of October
2014Axis Bank Ltd ITC LtdBajaj Auto Ltd Larsen & Toubro LtdBharat Heavy Electricals Ltd Mahindra and Mahindra LtdBharti Airtel Ltd Maruti Suzuki India LtdCipla Ltd NTPC LtdCoal India Ltd Oil and Natural Gas Corporation LtdDr.Reddy's Laboratories Ltd Reliance Industries LtdGAIL (India) Ltd Sesa Goa LtdHDFC Bank Ltd State Bank of IndiaHero MotoCorp Ltd Sun Pharmaceutical Industries LtdHindalco Industries Ltd Tata Consultancy Services LtdHindustan Unilever Ltd Tata Motors LtdHousing Development Finance Corporation Ltd Tata Power Company LtdICICI Bank Ltd Tata Steel LtdInfosys Ltd Wipro Ltd
Nifty (National Stock Exchange Index)
Just like the Sensex which was introduced by the Bombay stock exchange, Nifty is a major stock
index in India introduced by the National stock exchange.
NIFTY was coined fro the two words ‘National’ and ‘FIFTY’. The word fifty is used because;the index consists of 50 actively traded stocks from various sectors.
So the nifty index is a bit broader than the Sensex which is constructed using 30 actively traded
stocks in the BSE.
Nifty is calculated using the same methodology adopted by the BSE in calculating the Sensex –but with three differences. They are:
The base year is taken as 1995
The base value is set to 1000

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 139
Nifty is calculated on 50 stocks actively traded in the NSE
50 top stocks are selected from 24 sectors.
The selection criteria for the 50 stocks are also similar to the methodology adopted by the
Bombay stock exchange.
Nifty, is a weighted average of 50 stocks, meaning some stocks hold more “value” than otherstocks. For example ITC has more weight than Lupin.
List of 50 stocks that have been included in the nifty as on October 2014.Name Sector
ACC Ltd. CEMENT AND CEMENT PRODUCTSAmbuja Cements Ltd. CEMENT AND CEMENT PRODUCTSAsian Paints Ltd. PAINTSAxis Bank Ltd. BANKSBajaj Auto Ltd. AUTOMOBILES - 2 AND 3 WHEELERSBank of Baroda BANKSBharat Heavy Electricals Ltd. ELECTRICAL EQUIPMENTBharat Petroleum Corporation Ltd. REFINERIESBharti Airtel Ltd. TELECOMMUNICATION - SERVICESCairn India Ltd. OIL EXPLORATION/PRODUCTIONCipla Ltd. PHARMACEUTICALSCoal India Ltd MININGDLF Ltd. CONSTRUCTIONDr. Reddy's Laboratories Ltd. PHARMACEUTICALSGAIL (India) Ltd. GASGrasim Industries Ltd. CEMENT AND CEMENT PRODUCTSHCL Technologies Ltd. COMPUTERS - SOFTWAREHDFC Bank Ltd. BANKSHero Honda Motors Ltd. AUTOMOBILES - 2 AND 3 WHEELERSHindalco Industries Ltd. ALUMINIUMHindustan Unilever Ltd. PERSONAL CAREHousing Development Finance Corporation Ltd. FINANCE - HOUSINGI T C Ltd. CIGARETTESICICI Bank Ltd. BANKSIndusInd Bank Ltd. BANKSInfosys Technologies Ltd. COMPUTERS - SOFTWAREInfrastructure Development Finance Co. Ltd. FINANCIAL INSTITUTIONJindal Steel & Power Ltd. STEEL AND STEEL PRODUCTSKotak Mahindra Bank Ltd. BANKSLarsen & Toubro Ltd. ENGINEERINGLupin Ltd. PHARMACEUTICALSMahindra & Mahindra Ltd. AUTOMOBILES - 4 WHEELERSMaruti Suzuki India Ltd. AUTOMOBILES - 4 WHEELERSNMDC Ltd. MININGNTPC Ltd. POWEROil & Natural Gas Corporation Ltd. OIL EXPLORATION/PRODUCTIONPower Grid Corporation of India Ltd. POWERPunjab National Bank BANKSReliance Industries Ltd. REFINERIESSesaSterlite Ltd. MININGState Bank of India BANKSSun Pharmaceutical Industries Ltd. PHARMACEUTICALS

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 140
Tata Consultancy Services Ltd. COMPUTERS - SOFTWARETata Motors Ltd. AUTOMOBILES - 4 WHEELERSTata Power Co. Ltd. POWERTata Steel Ltd. STEEL AND STEEL PRODUCTSTech Mahindra Ltd. COMPUTERS - SOFTWAREUltraTech Cement Ltd. CEMENT AND CEMENT PRODUCTSUnited Spirits Ltd. BREW/DISTILLERIESWipro Ltd. COMPUTERS - SOFTWARE
Nifty and the Sensex
The Sensex and Nifty are both Indices. The Sensex, also called the BSE 30, is a stock market
index of 30 well-established and financially sound companies listed on Bombay Stock Exchange
(BSE). The Nifty, similarly, is an indicator of the 50 top major companies on the National Stock
Exchange (NSE).
The Sensex and Nifty are both indicators of market movement. If the Sensex or Nifty go up, it
means that most of the stocks in India went up during the given period. If the Nifty goes down,
this tells you that the stock price of most of the major stocks on the BSE have gone down.
Just in case you are confused, the BSE, is the Bombay Stock Exchange and the NSE is the
National Stock Exchange. The BSE is situated at Bombay and the NSE is situated at Delhi.
These are the major stock exchanges in the country. There are other stock exchanges like the
Calcutta Stock Exchange etc. but they are not as popular as the BSE and the NSE.Most of the
stock trading in the country is done though the BSE & the NSE.
TIME SERIES ANALYSIS
In plain English, a time series is simply a sequence of numbers collected at regular intervals overa period of time. In statistics, a time series is a sequence of numerical data points in successiveorder, usually occurring in uniform intervals. This concerns the analysis of data collected overtime, such as weekly values, monthly values, quarterly values, yearly values, etc.
Many statistical methods relate to data which are independent, or at least uncorrelated. There are
many practical situations where data might be correlated. This is particularly so where repeated
observations on a given system are made sequentially in time. Data gathered sequentially in time
are called a time series.
Here are some examples in which time series arise:
• Economics and Finance•Environmental Modelling•Meteorology and Hydrology•Demographics
•Medicine•Engineering•Quality Control
The simplest form of data is a longish series of continuous measurements at equally spaced time
points. That is observations are made at distinct points in time, these time points being

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 141
equally spaced and, the observations may take values from a continuous distribution.
The above setup could be easily generalized: for example, the times of observation need not be
equally spaced in time, the observations may only take values from a discrete distribution . . .
If we repeatedly observe a given system at regular time intervals, it is very likely that the
observations we make will be correlated. So we cannot assume that the data constitute a random
sample. The time-order in which the observations are made is vital.
Objectives of time series analysis:
• description - summary statistics, graphs
• analysis and interpretation - find a model to describe the time dependence in the data, can we
interpret the model
• forecasting or prediction - given a sample from the series, forecast the next value, or the next
few values
• control - adjust various control parameters to make the series fit closer to a target
• adjustment - in a linear model the errors could form a time series of correlated observations,
and we might want to adjust estimated variances to allow for this
Types of time Series
1. continuous
2. discrete
Discrete means that observations are recorded in discrete times – it says nothing about the natureof the observed variable. The time intervals can be annually, quarterly, monthly, weekly, daily,hourly, etc.
Continuous means that observations are recorded continuously -e.g. temperature and/or humidityin some laboratory. Again, time series can be continuous regardless of the nature of the observedvariable.
Discrete time series can result when continuous time series are sampled. Sometimes quantitiesthat don't have an instantaneous value get aggregated also resulting in a discrete time series e.g.daily rainfall We will mostly study discrete time series in this course. Note that discrete timeseries are often the result of discretization of continuous time series (e.g. monthly rainfall).
Uses of time series
There are two main uses of time series analysis: (a) identifying the nature of the phenomenon
represented by the sequence of observations, and (b) forecasting (predicting future values of the
time series variable). Both of these goals require that the pattern of observed time series data is
identified and more or less formally described. Once the pattern is established, we can interpret
and integrate it with other data (i.e., use it in our theory of the investigated phenomenon, e.g.,
seasonal commodity prices). Regardless of the depth of our understanding and the validity of our
interpretation (theory) of the phenomenon, we can extrapolate the identified pattern to predict
future events.
The usage of time series models is twofold:

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 142
Obtain an understanding of the underlying forces and structure that produced the
observed data
Fit a model and proceed to forecasting, monitoring or even feedback and feedforward
control.
Time Series Analysis is used for many applications such as:
Economic Forecasting Sales Forecasting Budgetary Analysis Stock Market Analysis Yield Projections Process and Quality Control Inventory Studies Workload Projections Utility Studies Census Analysis
Time series analysis can be useful to see how a given asset, security or economic variable
changes over time or how it changes compared to other variables over the same time period. For
example, in stock market investments, suppose you wanted to analyze a time series of daily
closing stock prices for a given stock over a period of one year. You would obtain a list of all the
closing prices for the stock over each day for the past year and list them in chronological order.
This would be a one-year, daily closing price time series for the stock. Delving a bit deeper, you
might be interested to know if a given stock's time series shows any seasonality, meaning it goes
through peaks and valleys at regular times each year. Or you might want to know how a stock’sshare price changes as an economic variable, such as the unemployment rate, changes.
The analysis of time series if of great significance not only to the economists and business man
but also to the scientist, astronomist, geologist etc. for the reasons given below.
1) It helps in understanding past behavior. It helps to understand what changes have taken
place in the past. Such analysis is helpful in predicting the future behavior.
2) It helps in planning future operations : Statistical techniques have been evolved which
enable time series to be analysed in such a way that the influence which have determined
the form of that series may be ascertained. If the regularity of occurrence of any feature
over a sufficient long period could be clearly established then. Within limits, prediction
of probable future variations would become possible.
3) It helps in evaluating current accomplishments. The actual performance can be compared
with the expected performance and the cause of variation analysed. For example, if
expected sale for 2000-01 was 10,000 washing machine and the actual sale was only
9000. One can investigate the cause for the shortfall in achievement.
4) It facilitates comparison. Different time series are often compared and important
conclusions drawn therefrom.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 143
Components of Time Series
The fluctuations of time series can be classified into four basic type of variations, They
are often called components or elements of a time series. They are :
(1) Secular Trend or Long Term Movements (T)
(2) Seasonal Variations (S)
(3) Cyclical Variations (C)
(4) Irregular Variations (I)
The value (y) of a phenomenon observed at any point of time (t) is the net effect of all the above
mentioned categories of components of a time series. We will see them in detail here.
(1) Secular Trend
The secular trend is the main component of a time series which results from long term effect of
socio-economics and political factors. This trend may show the growth or decline in a time series
over a long period. This is the type of tendency which continues to persist for a very long period.
Prices, export and imports data, for example, reflect obviously increasing tendencies over time.
(2) Seasonal Variations (Seasonal Trend)
These are short term movements occurring in a data due to seasonal factors. The short term is
generally considered as a period in which changes occur in a time series with variations in
weather or festivities. For example, it is commonly observed that the consumption of ice-cream
during summer us generally high and hence sales of an ice-cream dealer would be higher in some
months of the year while relatively lower during winter months. Employment, output, export etc.
are subjected to change due to variation in weather. Similarly sales of garments, umbrella,
greeting cards and fire-work are subjected to large variation during festivals like Onam, Eid,
Christmas, New Year etc. These types of variation in a time series are isolated only when the
series is provided biannually, quarterly or monthly.
(3) Cyclical Variations (Cyclical Variations)
These are long term oscillation occurring in a time series. These oscillations are mostly observed
in economics data and the periods of such oscillations are generally extended from five to twelve
years or more. These oscillations are associated to the well known business cycles. These cyclic
movements can be studied provided a long series of measurements, free from irregular
fluctuations is available.
(4) Irregular Variations (Irregular Fluctuations)
These are sudden changes occurring in a time series which are unlikely to be repeated, it id that
component of a time series which cannot be explained by trend, seasonal or cyclic movements .It
is because of this fact these variations some-times called residual or random component. These
variations though accidental in nature, can cause a continual change in the trend, seasonal and
cyclical oscillations during the forthcoming period. Floods, fires, earthquakes, revolutions,
epidemics and strikes etc,.are the root cause of such irregularities.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 144
Measurement of Trend : Moving Average and the Method of least squares :
Mean of time series data (observations equally spaced in time) from several consecutive periods.Called 'moving' because it is continually recomputed as new data becomes available, itprogresses by dropping the earliest value and adding the latest value. For example, the movingaverage of six-month sales may be computed by taking the average of sales from January toJune, then the average of sales from February to July, then of March to August, and so on.Moving averages (1) reduce the effect of temporary variations in data, (2) improve the 'fit' ofdata to a line (a process called 'smoothing') to show the data's trend more clearly, and (3)highlight any value above or below the trend.
1. Method of Moving Averages
Let us explain the concept of Moving Average with the aid of an example.
Suppose that the demand for skilled laborers for a construction project is given for the last 7months as shown in the following table:
Month Demand1 1202 1103 904 1155 1256 1177 121
The engineer who is in charge of this project needs to predict the demand for the next month (the
8th month) based on the available data. He decided to take the average of the data and predicted
the demand as follows.
Average = (120 + 110 + 90 + 115 + 125 + 117 + 121)/7 = 114
But this method has a disadvantage. The above method is known as the Simple Mean
Forecasting Method. The main problem with this method is the space limitation for storing all of
the past data. If the data contains several thousand items, each of which has several hundred data
records, you need a lot of memory space to store this data on your computer. In addition, this
method is not very sensitive to a shift in recent data if it contains a large number of data points.
A solution to the these problems is the Moving Averages technique. Using this method, you need
to maintain only the N most recent periods of data points. At the end of each period, the oldest
period's data is discarded and the newest period's data is added to the data base. The average is
then divided by N and used as a forecast for the next period.
The formula for a three period moving average is given below:ℎ = (3) = = [ + + ]3

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 145
Now using the three period moving average, the average for the above problem can be calculatedas follows. = (3) = = [ + + ]3 = 125 + 117 + 1213 = 121So from the above example we can summarize as follows.
When a trend is to be determined by the method of moving average value for a number of yearsis secured and this average is taken as the normal or trend value for the unit of time falling at themiddle of the period covered in the calculation of the average. While applying this method, it isnecessary to select a period for moving average such as 3 yearly, 5 yearly or 8 yearly movingaverage etc.
The 3 yearly moving average shall be computed as follows :+ +3 , + +3 , + +3 , + +3 … … … … … … … … … … … ..5 yearly moving average+ + + +5 , + + + +3 , + + + +3 … … … … … … … … … … … ..Example
Calculate the 3 yearly moving average and 5yearly moving average of the producing figuresgiven below .
For computing three yearly trend, first find three yearly moving totals a+b+c, b+c+d, c+d+eetc
(Column 3 in the following table). Then find average of each. Since it is sum of three
observations, divide each by 3 to get average. , , , . Repeat the same
process for 5 years taking 5 instead of 3.
Year
(1)
Y
(2)
3 yearlymoving totals
(3)
3 yearlymoving averages
(trend values)(4) =(3)÷3
5 yearlymovingtotals
(5)
5 yearlymovingaverages
(trend values)(6) = (5) ÷ 5
1990 242 _ _ _ _
1991 250 744 248.0 1246 249.2
1992 252 751 250.3 1259 251.8
1993 249 754 251.3 1260 252
1994 253 757 252.3 1265 253
1995 255 759 253.0 1276 255.2
1996 251 763 254.3 1288 257.6
1997 257 768 256.0 1295 259
1998 260 782 260.7 _ _
1999 265 787 262.3 _ _
2000 262 _ _ _ _
School of Distance Education
Quantitative Methods for Economic Analysis - I Page 146
246.0
248.0
250.0
252.0
254.0
256.0
258.0
260.0
262.0
264.0
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000
Three yearly moving average
248
250
252
254
256
258
260
1990 1991 1992 1993 1994 1995 1996 1997 1998
Five yearly moving average
230235240245250255260265270
Valu
e
Data Point
Moving Average
Actual
Forecast
3 per. Mov. Avg. (Forecast)

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 147
Merits of Moving Average Method
It is simple as compared to the method of least squares. It is flexible, If a few more figures are added to the data, the entire calculations are not
changed. It has the advantage that it follows the general movements of the data and that its shape is
determined by the data rather than statisticians choice of a mathematical function. It is particularly effective if the trend of a series is very irregular.
Limitations :
Trend values cannot be computed for all the years. The moving averages for the first fewyears and last few years cannot be obtained. It is often these extreme years in which hwe may be interested.
Selection of proper period is a great difficulty. If a wrong period is selected, there is everlikelihood that conclusions may be misleading.
Since the moving average is not represented by a mathematical function, this methodcannot be used for forecasting.
Itcan be applied only to those series which show periodically.
2. METHOD OF LEAST SQUARES:
Least Squares Method is astatistical technique to determine the line of best fit for a model. The
least squares method is specified by an equation with certain parameters to observed data. This
method is extensively used in regression analysis and estimation.
In the most common application - linear or ordinary least squares - a straight line is sought to be
fitted through a number of points to minimize the sum of the squares of the distances (hence the
name "least squares") from the points to this line of best fit.
In contrast to a linear problem, a non-linear least squares problem has no closed solution and is
generally solved by iteration. The earliest description of the least squares method was by Carl
Freidrich Gauss in 1795.
Field data is often accompanied by noise. Even though all control parameters (independent
variables) remain constant, the resultant outcomes (dependent variables) vary. A process of
quantitatively estimating the trend of the outcomes, also known as regression or curve fitting,
therefore becomes necessary.
The curve fitting process fits equations of approximating curves to the raw field data.
Nevertheless, for a given set of data, the fitting curves of a given type are generally NOT unique.
Thus, a curve with a minimal deviation from all data points is desired. This best-fitting curve can
be obtained by the method of least squares.The principle of least squares provides us an analytical or mathematical device to obtain an
objective fit to the trend of the given time series. Most of the data relating to economic and
business time series conform to definite laws of growth or predictions. This technique can be
used to fit linear as well as nonlinear trends.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 148
Fitting linear trend
A straight line can be fitted to the data by the method of curve fitting based on the most popular
principle called the principle of least squares. Such a straight line is also known as Line of Best
fit. Let the line of best fit be described by an equation of the type y = a+bx where y is the value
of dependent variable, a and b are two unknown constants whose values are to be determined.
To find a and b, we apply the method of least squares. Let ‘E’ be the sum of the squaresof the deviations of all the original values from their respective values derived from the
equations. So that E = [y – (a+bx)] 2
By Calculus method, for minimum = 0 . Thus we get the two equations known as
Normal equations. They are : = += +Solving these two normal equations, we get a and b. Substituting these values in the
equation y = a+bx, we get the trend equation.
Example:
Fit a linear trend to the following data by the least square method.
Year 2000 2002 2004 2006 2008
Production 18 21 23 27 16
Solution
Let x = t -2004 ….(I)Let the trend line of y (production) on x be= + , ( 2004)…..(II)
Year (t) y x=t-2004 x2 xy Ye=21+0.1x Y-Ye2000 18 -4 16 -72 20.6 -2.62002 21 -2 4 -42 20.8 0.22004 23 0 0 0 21 22006 27 2 4 54 21.2 5.82008 16 4 16 64 21.4 -5.4∑ =105 ∑ =0 ∑ =40 ∑ =4 (− ) = 0
The normal equations for estimating and b in (II) are= + = +

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 149
105 = 5 + × 0 4 = × 0 + × 40= 1055 = 21 = 440 = 110 = 0.1
Substituting in (II), the straight line trend equation is given by
Y = 21+0.1x, (Origin :2004) ……..(III)
[x units = 1 year and y = production in 000 units)]
Putting x = −4, −2,0,2 and 4 in (III), we obtain the trend values ( ) for the years 2000,2002…2008 respectively, as given in last but one column of the table above.
The difference ( − ) is calculated in the last column of the table.
We have ( − ) = −2.6 + 0.2 + 2.0 + 5.8 − 5.4 = 8 − 8 = 0, .Uses of Method of Least Squares
The least square methods (LSM)is probably the most popular technique in statistics. This is due
to several factors.
First, most common estimators can be casted within this framework. For example, the mean of a
distribution is the value that minimizes the sum of squared deviations of the scores.
Second, using squares makes LSM mathematically very tractable because the Pythagorean
theorem indicates that, when the error is independent of an estimated quantity, one can add the
squared error and the squared estimated quantity.
Third, the mathematical tools and algorithms involved in LSM (for eg. derivatives) have been
well studied for a relatively long time.
The use of LSM in a modern statistical framework can be traced to Galton (1886) who used it in
his work on the heritability of size which laid down the foundations of correlation and (also gave
the name to) regression analysis. The two antagonistic giants of statistics Pearson and Fisher,
who did so much in the early development of statistics, used and developed it in different
contexts (factor analysis for Pearson and experimental design for Fisher).
Nowadays, the least square method is widely used to find or estimate the numerical values of the
parameters to fit a function to a set of data and to characterize the statistical properties of
estimates. It exists with several variations: Its simpler version is called ordinary least
squares(OLS), a more sophisticated version is called weighted least squares (WLS), which often
performs better than OLS because it can modulate the importance of each observation in the final
solution. Recent variations of the least square method are alternating least squares (ALS) and
partial least squares (PLS).

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 150
Problems with least squares
Despite its popularity and versatility, LSM has its problems. Probably, the most important
drawback of LSM is its high sensitivity to outliers (i.e., extreme observations). This is a
consequence of using squares because squaring exaggerates the magnitude of differences (e.g.,
the difference between 20 and 10 is equal to 10 but the difference between 20 2and 102 is equal
to 300) and therefore gives a much stronger importance to extreme observations. This problem is
addressed by using robust techniques which are less sensitive to the effect of outliers. This field
is currently under development and is likely to become more important in the next future.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 151
MODULE IV
NATURE AND SCOPE OF ECONOMETRICS
Econometrics: Meaning, Scope, and Limitations - Methodology of econometrics-Modern
interpretation-Stochastic Disturbance term- Population Regression Function and Sample
Regression Function-Assumptions of Classical Linear regression model.
Introduction
Between the world wars, advances in mathematical statistics and a cadre of
mathematically trained economists led to econometrics, which was the name proposed for the
discipline of advancing economics by using mathematics and statistics. The roots of modern
econometrics can be traced to the American economist Henry L. Moore. Moore studied
agricultural productivity and attempted to fit changing values of productivity for plots of corn
and other crops to a curve using different values of elasticity. Moore made several errors in his
work, some from his choice of models and some from limitations in his use of mathematics.
Ragnar Frisch coined the word “econometrics” and helped to found both the EconometricSociety in 1930 and the Journal Econometrica in 1933.
It may be described as a branch of economics in which economic theory and statistical
methods are fused in the analysis of numerical and institutional data. The term econometrics
means ‘economic measurement,’ which is synonymous with empirical research in economics.
Econometrics is concerned with the measurement of data or the application of statistical
procedures, which have been formulated in mathematical terms. It is therefore a branch of
mathematical economics. Statistical data and statistical procedures are employed to provide
numerical results, which may be used for verification of or to help in verification of economic
theorems. Econometrics provides the quantitative information that may be used to make a
qualitative analysis empirically truer and more meaningful.
The term econometrics is formed from two Greek words which means, economy and measure.
Econometrics is a rapidly developing branch of economics. Econometrics aims to give empirical
content to economic relations. The term econometrics was first used by PawelClompa in 1910.
But the credit of coining the term econometrics should be given to Ragnar Frisch (1936), one of
the founders of the Econometric Society. He was the person who established the subject in the
sense in which it is known today. Econometrics can be defined generally as “the application ofmathematics and statistical methods to the analysis of economic data”. In the words ofSamuelson, Koopmans and Stone, econometrics is defined as the quantitative analysis of actual
economic phenomena based on the concurrent development of the theory and observation,
related by appropriate methods of inference (1954). Other definitions of econometrics are:
Every application of mathematics or of statistical methods to the study of economic phenomena
(Malinvaud 1966)

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 152
The production of quantitative economic statements that either explain the behaviour of variables
we have already seen, or forecast (ie. predict) behaviour that we have not yet seen, or both
(Christ 1966)
Econometrics is the art and science of using statistical methods for the measurement of economic
relations (Chow, 1983).
Need for econometrics
Economic theory makes statements or hypotheses that are mostly qualitative in nature.
For eg. Micro economic theory states that other thing remaining the same, a reduction in the
price of a commodity is expected to increase the quantity demanded of that commodity. Thus
economic Theory postulates a negative or inverse relation between price and quantity. But the
theory does not provide any numerical measure of the relationship between the two. It is the job
of the econometrician to provide such numerical estimates. Econometrics give empirical content
to most economic theory.
Scope of Econometrics
To make the meaning of econometrics more clear and detailed, it is appropriate to quote Frish
(1933) in full. “……econometrics is by no means the same as economic statistics. Nor is itidentical with what we call general economic theory, although a considerable portion of this
theory has a definitely quantitative character. Nor should econometrics be taken as synonymous
with the application of mathematics to economics. Experience has shown that each of these
three view points, that of statistics, economic theory, and mathematics, is necessary, but not by
itself a sufficient, condition for a real understanding of the quantitative relations in modern
economic life. It is this unification of all three that is powerful. And it is this unification that
constitutes econometrics”.
Let us consider the following example to understand this unification more clearly. From +2
classes onwards we learn demand function which explains that demand is a function of price,
assuming ceteris paribus. When we relax the assumption of ceteris paribus, we argue that
demand is influenced by four factors namely, price, price of substitutes, income and taste of the
consumer. So when we consider these four factors together, it is a case of exact relation. This
exact relation can be expressed in the form of a regression model, where quantity demanded is
dependent variable and price, price of substitutes, income and taste are the independent variables.
So this mathematical representation is again an exact relation. But practical wisdom suggests
that there are many more factors which influence the quantity demanded. Some new factors are
expectation of a price rise, coming of a new product, government policy and so on. Because of
the influence of these factors, our price quantity relation becomes not exact. Then, naturally
there should be a provision to incorporate the influence of “other factors”. The inclusion ofprovision for other factors is the uniqueness of econometrics and how it is done can be explained
in later pages.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 153
Goals of econometrics
There are three main goals
1. Analysis- the testing of economic theory
2. Policy making -supplying numerical estimates which can be used for decision making
3. Forecasting – using numerical estimates to forecast future values.
1. Analysis: Testing Economic theory
The earlier economic theories started from a set of observations concerning the behaviour
of individuals as consumers or producers. Some basic assumptions were set regarding the
motivations of individual economic units. From these assumptions the economists by pure
logical reasoning derive some general conclusion regarding the working process of the economic
system. Economic theories thus developed in an abstract level were not tested against economic
reality. No attempt was made to examine whether the theories explained adequately the actual
economic behaviour of individuals.
Econometrics aims primarily at the verifications of economic theories. That is obtaining
empirical evidence to test the explanatory power of economic theories. To decide how well they
explain the observed behaviour of the economic units.
2. Policy making
Various econometric techniques can be obtained in order to obtain reliable estimates of
the individual coefficients of economic relationships .The knowledge of numerical value of these
coefficients is very important for the decision of the firm as well as the formulation of the
economic policy of the government. It helps to compare the effects of alternative policy
decisions.
For eg. If the price elasticity of demand for a product is less than one (inelastic demand)
it will not benefit the manufacturer to decrease its price, because his revenue would be reduced.
Since econometrics can provide numerical estimate of the co-efficients of economic relationships
it becomes an essential tool for the formulation of sound economic policies.
3. Forecasting future values
In formulating policy decisions it is essential to be able to forecast the value of the
economic variables. Such forecasts will enable the policy makers to make efficient decision. In
formulating policy decisions, it is essential to be able to forecast the value of the economic
magnitudes. For example, what will be the demand for food grains in India by 2020? Estimates
about this are essential for formulating agriculture production policies. Similarly, what will be
the impact of a rise in deposit rate in share market and so on? It is known that if the bank deposit
rates go up, day to day demand for shares will come down. Econometric tools help in such
decision makings.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 154
Methodology of Econometric model building
As mentioned earlier, the scope of econometrics is widening day by day. The development of
computers further promoted the use of econometric tools. Thus it is relevant and useful to have
an insight into the methodology of developing an econometric model. The development of an
econometric model undergoes the following important stages or phases.
1. Specification of the model
2. Estimation of the model
3. Evaluation of estimates
4. Forecasting power of the model
1 Specification of the model
In econometric analysis we have to identify the relevant variables, express the relationship in
appropriate mathematical form and make estimates. In order the complete this process, we have
to go step by step.
The first step is to identify the relation to be studied and express that relation in the form of a
hypothesis. For example, if we are interested in testing the relevance of law of demand, choose
law of demand and express it in the form of a hypothesis. The law of demand states that there is
an inverse relation between price and quantity demanded. This can be expressed in the form of a
null hypothesis and alternative hypothesis.
The null hypothesis is: Quantity demanded and price is unrelated or quantity demanded and
price is independent.
When we formulate null hypothesis, automatically an alternative hypothesis is also formed.
In this example, the alternative hypothesis will be “quantity demanded and price are related”
If we consider another example, the validity of psychological law of Keynes which relates
consumption expenditure and income, the suitable null hypothesis is consumption expenditure
and income are unrelated and the alternative hypothesis will be consumption expenditure and
income are related. These hypotheses will be used for testing the validity of estimated
coefficients, which will discussed later.
Now let us discuss how to develop econometric models to test these hypotheses. First let us
start with law of demand. The first step is identifying the relevant variables
(a)Identification of variables:The most important and difficult part in developing an
econometric model is identification of relevant variables. One source of identifying the variables
is theory. Based on the law of demand we know that the variables are quantity demanded, price,
price of substitutes, income and taste of the consumers. Conventionally we believe that demand
depends on these factors. Thus demand is the dependent variable or regressand and price, price

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 155
of substitutes, income and taste are independent variables or regressors. There are certain
practical difficulties at this stage (1) there may be a host of variables influencing a phenomenon.
Then is it possible to identify all those variables? Even if we could identify all those variables, is
it appropriate to include all those variables in the model? If we are omitting certain important
variables, it will be leading to errors. Similarly if we are including large number of variables or
unnecessary variables, it will also lead to errors. When such errors are committed in the
development of an econometric model, it is called as specification bias or specification error. So
let us assume that we are considering only price as the variable influencing quantity demanded,
assuming other factors remain constant. So let us write,
D = f (P)
where D represents quantity demanded, P represents price.
(b) Sign and magnitude of parameters: Once the function is identified, next task is to
attribute signs to the coefficients. Based on the general theory, we know that price takes a
negative sign. Thus we can convert the demand function into a demand equation as follows
D = + βP where represents intercept of demand equation and β represents the slope of thedemand equation.
But we know that price is not the only factor influencing demand, but at the same time it is
difficult to add all the variables. Thus to accommodate the unexplained variables or variables
which are not included in the model, we add a stochastic term U into the model, called
disturbance term or error term. The inclusion of an error term makes an econometric model
unique and distinct from a mathematical model or exact model. When an error term is included,
our demand equation model will become,
D = + βP + U , This is a unique econometric model.
Similarly, in the case of consumption function, the variables are consumption expenditure,
income, savings, and government policy and so on. Conventionally we assume that consumption
expenditure depends on income, assuming other factors remain constant. Thus our consumption
function model will be,
C = + βY + U where C is consumption expenditure, Y is income, is intercept and β isslope of consumption function.
(c) Mathematical form of the model: There are two issues discussed here. First issue is
whether we should follow a single equation approach or simultaneous equation approach.
Second issue is whether we should follow a linear equation or non linear equation. Economic
theory does not explain whether the system follows single equation or simultaneous models. It is
true that demand is a function of price. But at the same time, demand is a function of supply
also. If we are considering the interrelationships among economic variables, the appropriate

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 156
method is simultaneous equation model. However, in the present discussions let us limit to
single equation models.
The second issue is also very relevant. If we use a linear equation, there is an implied
assumption that, in the case of linear equations, the growth rate remains constant or more
precisely β coefficient remain constant. When we estimate a demand equation, we assume thatthe rate of change in quantity demanded for a change in price is constant. Similarly, in the case
of consumption function, we assume that the slope (β) remains constant; otherwise, marginalpropensity remains constant. If we apply little numerical wisdom, we can realize that marginal
propensity to consume can never be constant. Then what is the logic in assuming a linear
equation? Thus we have to keep in mind that linear equations are suitable for class room
analysis but not for policy research. However, after this caution, for the time being let us assume
that we follow a linear equation for the purpose of simple understanding and explanation.
When we develop an econometric model, time specifications are also very important.
Conventionally, for all current values we give suffix “t”, for previous values “t-1” and for allfuture values “t+1”(t*). Thus our models can be written as,
Dt = + βPt + Ut ………….Demand equation
Ct = + βYt + Ut ……… Consumption equation
Normally, the dependent variable is denoted by Y and independent variable by X. Thus
general framework of an econometric model can be written as,
Yt = + βXt + Ut
When we incorporate only one independent variable, it is only a narrow situation of the
reality. When we want to make our model more realistic, we have to incorporate more number
of independent variables. When we use two independent variables, the model can be written as,
Yt = 1+ β1Xt1 + β2Xt2 +Ut+ …………+ βnXn
This is the most simple multiple regression model. When we have two or more independent
variables, the model becomes multiple regression models. The general form of a multiple
regression model can be written as,
Yt = 1 + β1X1t + β2X2t + β3X3t + …………+ βnXn +Ut,
this is also written as,
Yt = +∑βiXti + Ut
Just like incorporating current variables, it is easy to incorporate lagged variables or expected
variables in a model. See the following example.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 157
Yt = + β1Pt +β2Yt-1 + β3W* +Utwhere the new variables are Yt-1which is the lagged
value of the variable Y and W* is the expected value of W (wt+1).
Similarly there are situations where we can not measure variables directly. In such situations, we
can define a proxy variable or an instrument variable and incorporate in the system as usual. See
the following example
Yt = + β1X1t + β2Zt + Ut
where Z is an instrument variable or proxy variable. Proxy variable is a variable used to
represent qualitative or non measurable phenomenon.
Another important question in developing an econometric model is whether we should go for
linear models or non linear models. This is a highly debatable issue and beyond the scope of this
course. The following are the other forms available.
Lin log model Yt = + βLog X t +Ut
Log linmodel LogYt = + βXt + Ut
Double log model Log Yt = + βlog Xt + Ut
The choice of the model depends on many factors, particularly the scatter diagram of the
dependent and independent variables. Among the following, the best is double log model
because the coefficients of the double log models give directly elasticity values.
Thus in the model specification stage we consider mainly, the variables to be included in the
model, and also the mathematical form of the model. Any error committed in this stage will lead
to errors termed as “specification bias or specification error”, as mentioned earlier.
2 Estimation of the model
As mentioned above, one of the objectives of econometric models is to estimate the
coefficients. Estimations are possible only if data are gathered. Data can be collected either by
census method or sample method. Important sampling methods used are simple random sample,
stratified sample, systematic sample, multistage sampling, cluster sampling and quota sampling.
Similarly, data are classified into primary data, secondary data, time series data, cross section
data and pooled data.
In econometric models, the distinction between time series data and cross section data are
important. To make its distinction clear, let us consider the following example,
Year 1999 2000 2002 2003 2004 2005 2007 2008 2010
Sales 15 14 17 14 12 14 17 14 12

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 158
A casual look into the data set gives an impression that it belongs to time series, because it is
ordered in time. But the given set is neither time series nor cross section. Why?
For a data set to be time series, there are two conditions. Data collection interval should be
equal and gather information on a single entity. The given set of data does not obey these
conditions and hence not time series. But if we are provided with sales data for a few years, with
regular intervals, on year, six months etc, definitely they constitute time series data.
Now what is cross section data? When we gather information on multiple entities at a point
of time, it is called cross section data. For example, if we are gathering details of income,
savings, education, occupation etc of a group of 35 persons at a point of time, it is the best
example of cross section data. In other words, survey data are broadly cross section data.
In short, time series data is gathered at an interval of time while cross section data are
gathered at a point of time. The classification of time series and cross section data are important
because, the use of appropriate techniques depends on the nature of the data, whether it is time
series or cross section.
Another set of data used in econometric modelling is pooled data. Pooled data, in a simple
way is the integration or mixing of time series and cross section data. But the treatment pooled
data set is little complicated.
Aggregation problem
Once the data are collected, another issue to be dealt is the aggregation problem. Aggregation
problem arises from the irrational pooling of data. Aggregation problems are classified into
aggregation over individuals, over commodities, over space and over time.
Aggregation over individuals arises when we get the sum total of income of a few individuals
or income of firms. When we do this exercise, we are likely to commit errors. For example, if
the income of three persons namely, X, Y and Z are, Rs100000, Rs10000 and Rs500
respectively, their aggregate income can be easily computed as Rs110500 and average income as
36833, but this computation as well comparison is unscientific and leads to aggregation problem
over individuals. We may aggregate over the quantities of various commodities using
appropriate quantity indexes or over the prices of a group of commodities using some
appropriate price index. But these aggregations may lead to errors called as aggregation over
commodities.
While we collect data for different purposes, periodicity is very important. But in many
practical situations, this periodicity is not maintained. For example, in India, data are gathered at
two levels. One classification is recording of data at calendar year while the other one is
recording of data at financial year. Accountants admit that these differences create sufficient
difficulties while computing certain ratios or while comparing different years. This problem is
called aggregation over time.
At last, the aggregation of population of different towns, countries, regions also create
problems. This problem is called aggregation over space. The above sources of aggregation

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 159
create various complications which may impart some aggregation bias in the estimates of the
coefficients.
Identification problem
While discussing the econometric methodology, econometricians mention the problem of
identification of coefficients. This problem arises seriously only in the case of simultaneous
equation models, but a mentioned is made below.
We know that demand is a function of price. Similarly, supply is also a function of price.
Thus, at equilibrium point, demand equals supply. Thus at this point, we do not know whether
we are estimating the parameters of the demand function or the supply function. The problem
becomes more complex while we deal with a system of large number of equations.
Choice of the appropriate econometric technique: Next issue is the selection of the
appropriate method for estimating the coefficient of economic relationships. The kit of
econometric tools provides different techniques which can be split into single equation
techniques and simultaneous equation techniques. The important single equation techniques are
Ordinary Least Square method, Indirect Squares or Reduced form technique, Two Stage least
Square method and Limited Information Maximum Likelihood method and mixed estimation.
Simultaneous equation techniques are techniques which applied to all equations of a system at
once, and give estimates of the coefficients of all the functions simultaneously. The most
important are the three stage least squares method and the full information maximum likelihood
method. The selection of the method depends on the following.
1. The nature of the relation and its identification condition.
2. The properties of the estimates of the coefficients obtained from each technique
3. Simplicity of the method
4. Time and cost requirements of the method
5. The desirable properties expected for the coefficients.
3 Evaluation of estimates
After the estimation of the model, the econometrician must proceed with the evaluation of
the results of the computations. That is, we are testing the reliability of the results. The
evaluation consists of deciding whether the estimates of the parameters are theoretically
meaningful and statistically satisfactory. For this purpose, we use different criteria, namely
apriori criteria, statistical criteria and econometric criteria.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 160
Economic or apriori criteria
This is decided by the principles of economic theory and refers to the sign and magnitude of the
parameters of economic relationships. Consider the example of demand equation. In the case of
demand equation, D = +βP, the coefficient of β should be negative in the case of a normalgood. Similarly there is a range in which the value of and β can vary. Similarly, when weconsider the case of consumption function, and β respectively represent autonomousconsumption and marginal propensity to consume. Normally the sign of β will be positive and itvaries within a range (0-1). Once our coefficients take an unexpected sign or magnitude, the
reliability of the estimates is doubtful and needs a review.
Statistical criteria (First order test):The coefficients estimated may be apriori true but need
not be statistically valid. Thus the validity of the model is to be ascertained using statistical
criteria. The frequently used tests are standard error, “t” test, Coefficient of determination and F
ratio. These tests are discussed later in detail.
Econometric Criteria (Second order test):The validity of the model also depends on the
validity of the assumptions of the model or more specifically the stochastic assumptions. If the
assumptions of the econometric method applied by the investigators are not satisfied, either the
estimates of the parameters cease to possess some of their desirable properties or the statistical
criteria lose their validity and become unreliable for the determination of the significance of
these estimates.
When the model does not satisfy the economic, statistical or econometric criteria, it is
appropriate to re specify the model. This process and re estimation should continue until we get
reliable estimates.
3 Evaluating the forecasting power of the estimated model
Forecasting is one of the prime aims of econometric analysis and research. The forecasting
power will be based on the stability of the estimates, their sensitivity to changes in the size of the
sample. We must establish whether the estimated function performs adequately outside the
sample of data whose average variation it represents. One way of establishing the forecasting
power of a model is to use the estimates of the model for a period not included in the sample.
The estimated value or forecast value is compared with the actual or realized magnitude of the
relevant dependent variable. Usually there will be a difference between the actual and the
forecast value of the variable, which is tested with the aim of establishing whether it is
statistically significant. If, after conducting the relevant test of significance, we find that the
difference between the realized value of the dependent variable and that estimated from the
model is statistically significant, we conclude that the forecasting power of the model is poor.
Another way of establishing the stability of the estimates and the performance of the model
outside the sample of data, from which it has been estimated, is to re estimate the function with
an expanded sample that is a sample including additional observations. The original estimates

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 161
will normally differ from the new estimates. The difference is tested for statistical significance
with appropriate methods.
Desirable properties of an Econometric model
1. Theoretical plausibility: The model should explain clearly the economic theory or
phenomena to which it relates.
2. Explanatory ability: The model should be able to explain the observations of the actual
world.
3. Accuracy of the estimates of the parameters: The estimates of the coefficients should be
accurate in the sense that they should possess the desirable properties of unbiasedness,
consistency and efficiency.
4. Forecasting ability: The model should produce satisfactory predictions of future values
of independent variables.
5. Simplicity: The model should represent the economic relationships with possible
simplicity. If the number of equations is less and if the mathematical form is less
complicated, that model is said to be a good model.
Types of econometrics
Econometrics may be divided into two broad categories. Theoretical econometrics and applied
econometrics.
Theoretical econometrics is concerned with the development of appropriate method for
measuring economic relationships specified by econometric models. For e.g. one of the methods
used extensively is the principle of least squares.
In applied econometrics, the tools of theoretical econometrics, is used to study some special area
of economics and business such as the production function, investment function, demand &
supply functions etc.
Uses of Econometrics
1.Econometrics is widely used in policy formulation
For eg. Suppose the government wants to devalue its currency to correct the balance of
payment problem. For estimating the consequences of devaluation, the price elasticities of
imports and exports is needed. If imports and exports are inelastic then devaluation will not
produce the necessary change. If imports and exports are elastic then the BOP of the country
will improve by devaluation. Price elasticity can be estimated with the help of demand function
of import and export. An econometric model can be built through which the variables can be
estimated.
2. Econometrics helps the producers in making rational calculations.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 162
3. Econometrics is also useful in verifying theories.
4. Studies of econometrics mainly consist of testing of hypothesis, estimation of the parameters
and ascertaining the proper functional form of the economic relations.
5 Limitations of Econometric Approach
Econometrics has come a long way over a relatively short period of time. Important advances
have been made in the compilation of data, development of concepts, theories and tools for the
construction and evaluation of a wide variety of econometric models. Applications of
econometrics can be found in almost every field of economics. Nowadays, even there is a
tendency to use econometric tools in certain other sciences like sociology, political science,
agriculture and management. Econometric models have been used frequently by government
departments, international organizations and commercial enterprises. At the same time,
experience has brought out a number of difficulties also in the use of econometric tools. The
important limitations are,
1. Quality of data: Econometric analysis and research depends on intensive data base. One
of the serious problems of Indian econometric research is non availability of accurate,
timely and reliable data.
2. Imperfections in economic theory: Earlier it was felt that the economic theory is
sufficient to provide base for model building. But later it was realized that many of the
economic theories are illusory because they are based on the assumption of ceteris
paribus and hence models can not fully accommodate the dynamic forces behind a
phenomena.
3. There are institutional features and accounting conventions that have to be allowed for in
econometric models but which are either ignored or are only partially dealt with at the
theoretical level.
4. Any economic phenomenon is influenced by social, cultural, political, physiological and
even physical factors. These factors can not be easily quantified. Even if quantified, they
may not be capable of explaining the phenomenon properly. For example, it is said that
the intelligentsia of Indian planners gave birth to very beautiful mathematical models, but
they forgot to feed the hungry masses.
Thus we may conclude our discussion on econometrics by restating the following.
Economists develop economic models to explain consistently recurring relationships. Their
models link one or more economic variables to other economic variables. For example,
economists connect the amount individuals spend on consumer goods to disposable income and
wealth, and expect consumption to increase as disposable income and wealth increase (that is,
the relationship is positive).

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 163
There are often competing models capable of explaining the same recurring relationship, called
an empirical regularity, but few models provide useful clues to the magnitude of the association.
Yet this is what matters most to policymakers. When setting monetary policy, for example,
central bankers need to know the likely impact of changes in official interest rates on inflation
and the growth rate of the economy. It is in cases like this that economists turn to econometrics.
Econometrics uses economic theory, mathematics, and statistical inference to quantify economic
phenomena. In other words, it turns theoretical economic models into useful tools for economic
policymaking. The objective of econometrics is to convert qualitative statements (such as “therelationship between two or more variables is positive”) into quantitative statements (such as“consumption expenditure increases by 95 cents for every one dollar increase in disposable
income”). Econometricians—practitioners of econometrics—transform models developed by
economic theorists into versions that can be estimated. As Stock and Watson put it, “econometricmethods are used in many branches of economics, including finance, labor economics,
macroeconomics, microeconomics, and economic policy.” Economic policy decisions are rarelymade without econometric analysis to assess their impact.
Econometrics can be divided into theoretical and applied components.
Theoretical econometricians investigate the properties of existing statistical tests and procedures
for estimating unknowns in the model. They also seek to develop new statistical procedures that
are valid (or robust) despite the peculiarities of economic data—such as their tendency to change
simultaneously. Theoretical econometrics relies heavily on mathematics, theoretical statistics,
and numerical methods to prove that the new procedures have the ability to draw correct
inferences.
Applied econometricians, by contrast, use econometric techniques developed by the theorists to
translate qualitative economic statements into quantitative ones. Because applied
econometricians are closer to the data, they often run into—and alert their theoretical
counterparts to—data attributes that lead to problems with existing estimation techniques. For
example, the econometrician might discover that the variance of the data (how much individual
values in a series differ from the overall average) is changing over time.
The main tool of econometrics is the linear multiple regression model, which provides a formal
approach to estimating how a change in one economic variable, the explanatory variable, affects
the variable being explained, the dependent variable—taking into account the impact of all the
other determinants of the dependent variable. This qualification is important because a regression
seeks to estimate the marginal impact of a particular explanatory variable after taking into
account the impact of the other explanatory variables in the model.
The methodology of econometrics is fairly straightforward. It involves 4 steps as explained
below.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 164
The first step is to suggest a theory or hypothesis to explain the data being examined. The
explanatory variables in the model are specified, and the sign and/or magnitude of the
relationship between each explanatory variable and the dependent variable are clearly stated. At
this stage of the analysis, applied econometricians rely heavily on economic theory to formulate
the hypothesis. For example, a tenet of international economics is that prices across open borders
move together after allowing for nominal exchange rate movements (purchasing power parity).
The empirical relationship between domestic prices and foreign prices (adjusted for nominal
exchange rate movements) should be positive, and they should move together approximately one
for one.
The second step is the specification of a statistical model that captures the essence of the theory
the economist is testing. The model proposes a specific mathematical relationship between the
dependent variable and the explanatory variables—on which, unfortunately, economic theory is
usually silent. By far the most common approach is to assume linearity—meaning that any
change in an explanatory variable will always produce the same change in the dependent variable
(that is, a straight-line relationship).
Because it is impossible to account for every influence on the dependent variable, a catchall
variable is added to the statistical model to complete its specification. The role of the catchall is
to represent all the determinants of the dependent variable that cannot be accounted for—because
of either the complexity of the data or its absence. Economists usually assume that this “error”term averages to zero and is unpredictable, simply to be consistent with the premise that the
statistical model accounts for all the important explanatory variables.
The third step involves using an appropriate statistical procedure and an econometric software
package to estimate the unknown parameters (coefficients) of the model using economic data.
This is often the easiest part of the analysis thanks to readily available economic data and
excellent econometric software. Just because something can be computed doesn’t mean it makeseconomic sense to do so.
The fourth step is by far the most important: administering the smell test. Does the estimated
model make economic sense—that is, yield meaningful economic predictions? For example, are
the signs of the estimated parameters that connect the dependent variable to the explanatory
variables consistent with the predictions of the underlying economic theory? (In the household
consumption example, for instance, the validity of the statistical model would be in question if it
predicted a decline in consumer spending when income increased). If the estimated parameters
do not make sense, how should the econometrician change the statistical model to yield sensible
estimates? And does a more sensible estimate imply an economically significant effect? This
step, in particular, calls on and tests the applied econometrician’s skill and experience.
REGRESSION ANALYSIS
The term regression was introduced by Francis Galton. Regression analysis is concerned

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 165
with the study of the dependence of one variable (dependent variable) on one or more other
variables (explanatory variables) with a view to estimating the average (mean) valve of the
former in terms of known (fixed) values of the latter.
Galton found that, although there was a tendency for tall parents to have tall children and for
short parents to have short children, the average height of children born of parents of a given
height tended to more or regress towards the average height in the population as a whole. In
other words, the height of the children of unusually tall or unusually shorts parents tends to more
towards the average height of the population. In the modern view of regression, the concern is
with finding out how the average height of sons changes, given the fathers height. Regression
analysis is largely concerned with estimating and/or predicting the (population) mean value of
the dependent variable on the basis of the known or fixed values of the explanatory variable.
Origin of the Linear Regression Model
There are different methods for estimating the coefficients of the parameters. Of these different
methods, the most popular and widely used is the regression technique using Ordinary Least
Square (OLS) method. This method is used because of the inherent properties of the estimates
derived using this method. But, first let us try to understand the rationale of this method. For
this purpose, let us go back to the demand theory as well as the consumption function which we
discussed in the earlier chapter. Demand theory says that there is a negative relation between
price and quantity demanded certeris paribus. In the case of consumption function, there is a
positive relation between consumption expenditure and income. There are three important
questions here.
1. Which is the dependent variable and which is the independent variable?
2. Which is the appropriate mathematical form which explains the phenomenon?
3. What is the expected sign and magnitude of the coefficients?
In order to answer these questions, the theory will give the necessary support.
In the case of demand equation, quantity demanded is the dependent variable, and price is the
independent variable. Economic theory does not discuss the choice between single equation
models or simultaneous equation models to discuss the relationship. So naturally we may
assume that the relation is explained with the help of single equation, that too assuming a linear
relation. As far as the sign and magnitude of the coefficients are concerned, in the equation,
D = α + βP + U, ∞ can take any value but preferably zero or positive. It actually shows thequantity demanded at price zero. So chances of demanding negative quantity is very rare and
hence if we get negative quantity, it can be approximated to zero. In the case of β, it can bepositive or negative. But normally it will be negative assuming that the commodity demanded is
a normal good. Of course, elasticity nature of the commodity also influences the magnitude and
nature of this value.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 166
In the case of consumption function, consumption is the dependent variable and income is the
independent variable. Whether the relation is linear or non linear, is a debatable issue. For
instance, psychological law of Keynes suggests that when income increases, consumption also
increases, but less than proportionate. So assuming that consumption and income are linearly
related is in one way, over simplification. But for the time being let us assume so just for
explanatory purpose. Regarding the sign and magnitude of parameters ∞ and β. There is somemeaning and interpretation. ∞ represents the consumption when income takes the value zero,that is, according to theory, it is autonomous consumption. Similarly, β is nothing but the valueof marginal propensity to consume which is normally less than 1 and can not be negative.
Based on the above discussed rationale and logic, let us rewrite the demand equation as D =
α+ βP + U , where D is the quantity demanded, P is price, α and β are the parameters to beestimated. In order to estimate these parameters, we use Ordinary Least Square (OLS) method.
Once we plot this on a graph, we will be able to get the deviations between actual and estimated
observations, popularly called as errors. Naturally, a rational decision is to minimize these
errors. Thus from all possible lines, we choose the one for which the deviations of the points is
the smallest possible. The least squares criterion requires that the regression line be drawn in
such a way, so as to minimize the sum of the squares of the deviations of the observations from
it. The first step is to draw the line so that the sum of the simple deviations of the observations is
zero. Some observations will lie above the line and will have a positive deviation, some will lie
below the line, in which case, they will have a negative deviation, and finally the points lying on
the line will have a zero deviation. In summing these deviations the positive values will offset
the negative values, so that the final algebraic sum of these residuals will equal zero.
Mathematically, ∑e = 0. Since the sum total of deviations is 0, it can not be minimized as such.So we try to square the deviations and minimize the sum of the squares. ∑e2. Thus we call thismethod as least square method,
Population Regression Function (PRF)
Mathematically a population regression function (PRF) or Conditional Expectation Function
(CEF) can be defined as the average value of the dependent value for a given value of the
explanatory or independent variable. In other words, PRF tries to find out how the average value
of the dependent variable varies with the given value of the explanatory variable. On the other
hand, when we estimate the average value of the dependent variable with the help of a sample, it
is called stochastic sample regression function (SRF).
E(Y | Xi) = f (Xi)
where f (Xi) denotes some function of the explanatory variable X.
E(Y | Xi) is a linear function of Xi. This is known as the conditional expectation function(CEF) or population regression function (PRF). It states merely that the expected value of the

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 167
distribution of Y given Xi is functionally related to Xi.In simple terms, it tells how the mean oraverage response of Y varies with X. For example, an economist might posit that consumptionexpenditure is linearly related to income. Therefore, as a first approximation or a workinghypothesis, we may assume that the PRF E(Y | Xi) is a linear function of Xi,
E(Y | Xi) = β1 + β2Xi
where β1 and β2 are unknown but fixed parameters known as the regression coefficients;β1 and β2 are also known as intercept and slope coefficients, respectively.
we can express the deviation of an individual Yi around its expected value as follows: ui= Yi − E(Y | Xi) or
Yi = E(Y | Xi) + ui where the deviation ui is an unobservable random variable takingpositive or negative values. Technically, ui is known as the stochastic disturbance or stochasticerror term.
We can say that the expenditure of an individual family, given its income level, can be
expressed as the sum of two components: (1) E(Y | Xi), which is simply the mean consumption
expenditure of all the families with the same level of income. This component is known as the
systematic, or deterministic, component, and (2) ui, which is the random, or nonsystematic,
component is a surrogate or proxy for all the omitted or neglected variables that may affect Y but
are not (or cannot be) included in the regression model.
If E(Y | Xi) is assumed to be linear in Xi, it may be written as
Yi = E(Y | Xi) + ui
= β1 + β2Xi+ ui
Sample regression function (SRF)
Since the entire population is not available to estimate y from given xi, we have to
estimate the PRF on the basis of sample information. From a given sample we can estimate the
mean value of y corresponding to chosen xi values. The estimated PRF value may not be
accurate because of sampling fluctuations. Because of this only an approximate value of PRF
can be obtained. In general, we would get N different sample regression function (SRFs) for N
different samples and these SRFs are not likely to be the same.
we can develop the concept of the sample regression function (SRF) to represent thesample regression line.
Y = β1˄ + β2
˄Xi
where ˆY is read as “Y-hat’’ or “Y-cap’’
ˆYi = estimator of E(Y | Xi)
ˆ β1 = estimator of β1
ˆ β2 = estimator of β2
Note that an estimator, also known as a (sample) statistic, is simply a method that tellshow to estimate the population parameter from the information provided by the sample at hand.

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 168
we can express the SRF in its stochastic form as follows:
Yi = ˆ β1 + ˆ β2Xi + ˆuiwhere, in addition to the symbols already defined, ˆui denotes theestimate of the error term.
Significance of the stochastic Error term
The disturbance term ui is a surrogate for all those variables that are omitted from themodel but that collectively affect Y.
1. Vagueness of theory
The theory determining the behavior of Y may be, incomplete. We might know for certain thatweekly income X influences weekly consumption expenditure Y, but we might be ignorant orunsure about the other variables affecting Y. Therefore ui may be used as a substitute for all theexcluded or omitted variables from the model.
2. Unavailability of data
Even if we know what some of the excluded variables are we may not have quantitativeinformation about these variables. For example, in principle we could introduce family wealth asan explanatory variable in addition to the income to explain family consumption expenditure.But unfortunately, information on family wealth generally is not available.
3. Core variables versus peripheral variables
Assume in our consumption income example that besides income X1, the number of children perfamily X2, sex X3, religion X4, education X5, and geographical region X6 also affectconsumption expenditure. But it is quite possible that the joint influence of all these variablesmay be so small that it need not be introduced in the model. Their combined effect can be treatedas a random variable ui.
4. Intrinsic randomness in human behavior
Even if all the relevant variables affecting y are introduced into the model, there may bevariations due to intrinsic randomness in individual which cannot be explained. The disturbanceterm ui also include this intrinsic randomness.
5. Poor proxy variables
Although the classical regression model assumes that variables y and x are measured accurately,it is possible that there may be errors of measurement. Variables which are used as proxy maynot provide accurate measurement. The disturbance term u can also be used to include errors ofmeasurement.
6.Principle of parsimony
Regression model should be formulated as simple as possible. If the behavior of y can beexplained with the help of two or three explanatory variables then more variation need not beincluded in the model. Let ui represent all other variables. This does not mean that relevant andimportant variables should be excluded to keep the regression model simple.
7. Wrong functional form
Even if we have theoretically correct variables exploring a phenomenon and even if it is possible
to get data on these variables, very often the functional relationship between the dependent and
independent variable may be uncertain. In two variable models functional relation can be
ascertained with the help of scattergram. But in multiple regression model it is not easy to

School of Distance Education
Quantitative Methods for Economic Analysis - I Page 169
determine the, approximate functional form. Scattergram cannot be visualised in multi-
dimensional form. For all these reasons, the stochastic disturbance ui assumes an extremely
critical role in regression analysis.
Assumptions of Classical Linear Regression Model
1. U is a random real variable. The value which may assume in any one period depends onchance. It may be positive, zero or negative. Each value has a certain probability ofbeing assumed by U in any particular instance.
2. The mean value of U in any particular period is zero. If we consider all the possiblevalues of U, for any given value of X, they would have an average value equal to zero.With this assumption we may say that Y = ∞ +βX + U gives the relationship betweenX and Y on the average. That is, when X assumes the value X1, the dependent variablewill on the average assume the value Y1, although the actual value of Y observed in anyparticular occasion may display some variation.
3. The variance of U is constant in each period. The variance of U about its mean isconstant at all values of X. In other words, for all values of X, the U will show the samedispersion round their mean.
4. The variable U has a normal distribution
5. The random terms of different observations are independent. This means that all thecovariance of any U (ui) with any other U (uj) are equal to zero
6. U is independent of the explanatory variables
The above mentioned assumptions are really classic to regression estimations and make the
method OLS efficient.
There are a few other assumptions also used in OLS estimated. They are,
(i) The explanatory variables are measured without error. In other words, the explanatory
variables are measured without error. In the case of dependent variable, error may or may not
arise.
(ii) The explanatory variables are not perfectly linearly correlated. If there is more than one
explanatory variable in the relationship, it is assumed that they are not perfectly correlated with
each other. More specifically, we are assuming the absence of multicollinearity.
(iii) There is no aggregation problem. In the previous chapter, we discussed aggregation over
individuals, time, space and commodities. So we assume the absence of all these problems.
(iv) The relationship being estimated is identified. This means that we have to estimate a unique
mathematical form. There is no confusion about the coefficients and the equations to which it
belong.
(v) The relationship is correctly specified. It is assumed that we have not committed any
specification error in determining the explanatory variables, in deciding the mathematical form
etc.
*************














