Embed Size (px)
Citation preview
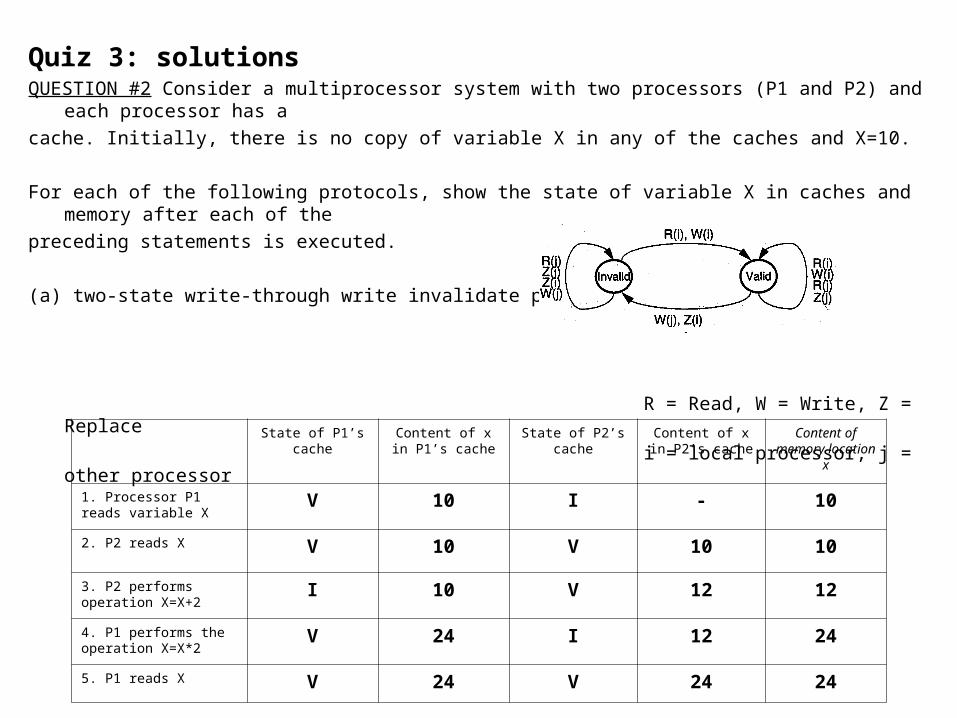
Quiz 3: solutionsQUESTION #2 Consider a multiprocessor system with two processors (P1 and P2) and each processor has a
cache. Initially, there is no copy of variable X in any of the caches and X=10.
For each of the following protocols, show the state of variable X in caches and memory after each of the
preceding statements is executed.
(a) two-state write-through write invalidate protocol
R = Read, W = Write, Z = Replace
i = local processor, j = other processor
State of P1’s cache Content of x in P1’s cache
State of P2’s cache Content of x in P2’s cache
Content of memory location x
1. Processor P1 reads variable X
V 10 I - 10
2. P2 reads X V 10 V 10 10
3. P2 performs operation X=X+2
I 10 V 12 12
4. P1 performs the operation X=X*2
V 24 I 12 24
5. P1 reads X V 24 V 24 24

Quiz 3: solutionsQUESTION #2
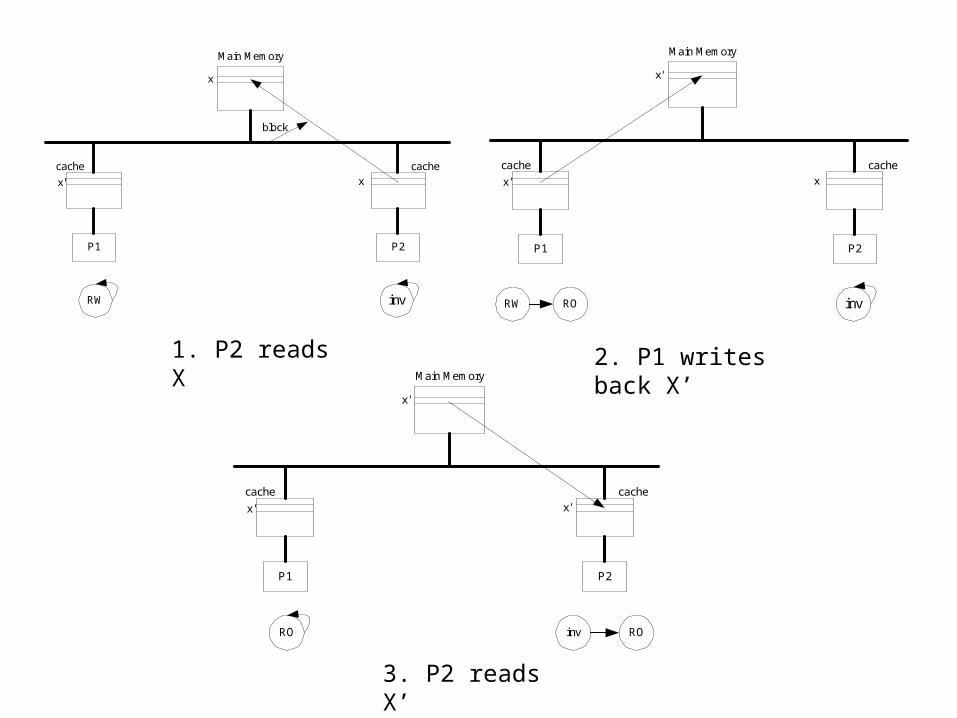
(b) basic MSI write-back invalidation protocol
State of P1’s cache Content of x in P1’s cache
State of P2’s cache Content of x in P2’s cache
Content of memory location x
1. Processor P1 reads variable X
RO 10 INV - 10
2. P2 reads X RO 10 RO 10 10
3. P2 performs operation X=X+2
INV 10 RW 12 10
4. P1 performs the operation X=X*2
RW 24 INV 12 10
5. P1 reads X RO 24 RO 24 24
P1 P2
Main Memory
cache cache
x
x' x
block
invRW
P1 P2
Main Memory
cache cache
x'
x' x
invRORW
1. P2 reads X 2. P1 writes back X’
3. P2 reads X’
P1 P2
Main Memory
cache cache
x'
x' x'
RORO inv

Quiz 3: solutionsQUESTION #3(a) The following MPI program is given. What is the order of printing? Why?
#include <stdio.h>
#include "mpi.h"
main(int argc, char** argv)
{
int my_PE_num;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_PE_num);
printf("Hello from %d.\n", my_PE_num);
MPI_Finalize();
}
MPI_Init initiate computation
MPI_Comm_rank determine the integer identifier assigned to the current process (processes
in a process group are identified with unique, contiguous integers numbered from 0)
MPI_COMM_WORLD default value which identifies all processes involved in a computation
MPI_Finalize terminate computation
There is no defined order of printing the order in which processes are executing the printf command is
not defined by MPI_Comm_rank
• Hello from 3.
• Hello from 1.
• Hello from 0.
• Hello from 2.

Quiz 4:QUESTION #1
4. Explain how scheduling in-forest / out-forest task graphs works:
• First, determine the level of each node, which is the maximum number of nodes (including itself) on any path from the given node to a terminal node the level of each node is used as each node’s priority
• Whenever a processor becomes available, assign it the unexecuted ready task with the highest priority

Quiz 4:QUESTION #2
Task graph is shown bellow together with the execution and communication times:
a. Draw Gantt chart with communication when this program is executed on two processors. Schedule program on these processor so that the overall time is minimized. What is the total time needed?
total time is 30
y15
a
b c
x
Task Graph
Task Execution time
abc
101515
y
Arc Communication
(a,b) y=5
(a,c) x=10
P1 P2
a idle10
25
c
30
b
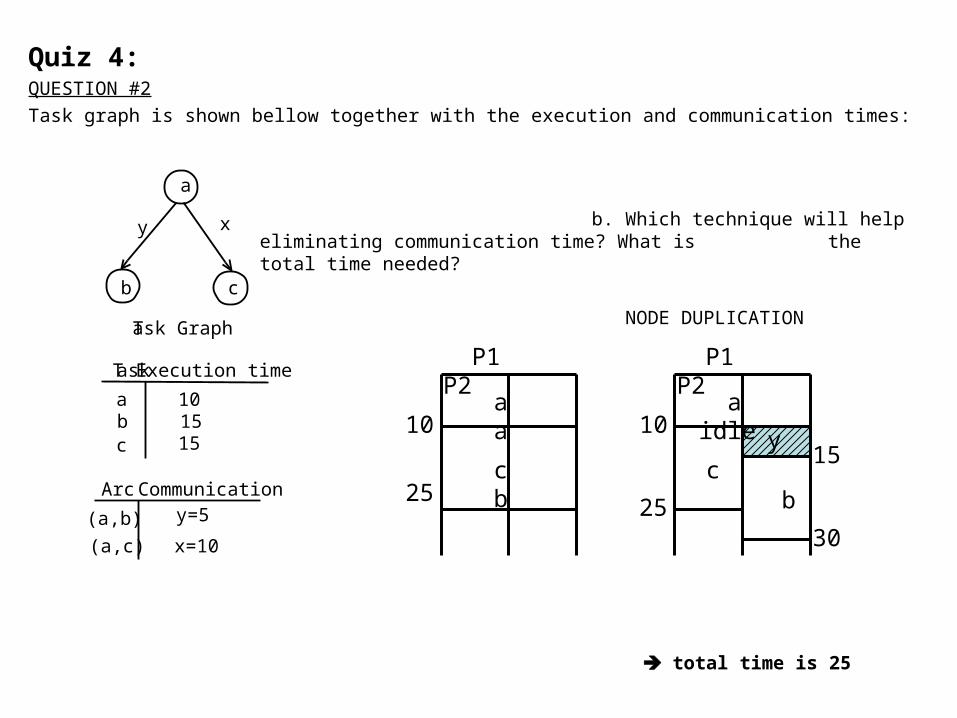
Quiz 4:QUESTION #2
Task graph is shown bellow together with the execution and communication times:
b. Which technique will help eliminating communication time? What is the total time needed?
NODE DUPLICATION
total time is 25
a
b c
x
Task Graph
Task Execution time
abc
101515
y
Arc Communication
(a,b) y=5
(a,c) x=10
P1 P2
a a10
c b25
y15
P1 P2
a idle10
25
c
30
b

Quiz 4:QUESTION #1
1. Which of the following statements is false?
a) Node duplication reduces the overall number of computational operations in the system
b) Node duplication reduces communication delays
c) Node duplication is used to reduce the idle time

Vector Processing:Architectures that have high-level operations that work on linear arrays of numbers or “vectors’
Some typical vector-based instructions:

Convoy set of vector instructions that could potentially begin execution together in one clock period:
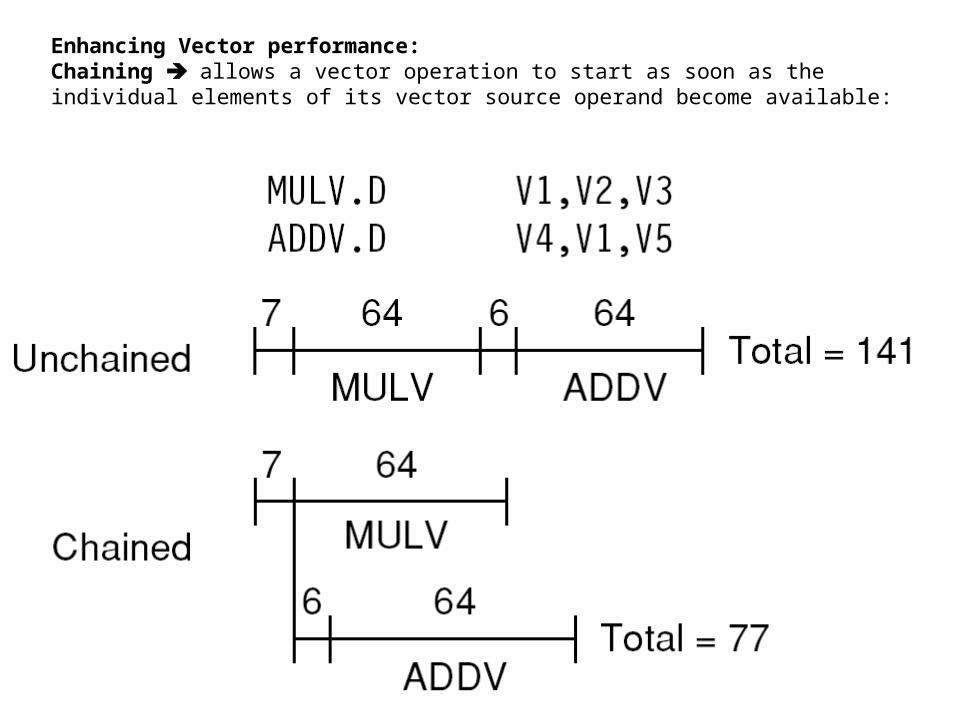
Enhancing Vector performance:Chaining allows a vector operation to start as soon as the individual elements of its vector source operand become available:

Quiz 4:QUESTION #1
3. If we compare a program that deals with arrays written for the vector and for the scalar processor, we
can see that the vector program has the smaller number of instructions and it also executes the smaller
number of operations. Why?
The number of instructions is reduced
because the whole loops can be replaced
with one (or a few) instruction. The number
of operations is reduced as well because
the operations needed to handle the loop
such as incrementing indexes do not need
to be executed in software.

Quiz 4:QUESTION #3 (a, b, 17 points each, total 34 points)
Consider a vector program given bellow for Y=X*Z+Y. All vectors have length of 64. Suppose that the
hardware have 2 load/store units capable of performing 2 loads, or 2 stores, or 1 load and 1 store vector
operation at the same time, one pipelined vector multiplier and one pipelined vector adder. Suppose that
chaining is not allowed and that the start-up times are 12 for LV and SV, 7 for MULV and 6 for ADDV.
a. How many convoys do we have?
b. What is the total execution time?
LV V5,Rz ;load vector Z
LV V1,Rx ;load vector X
MULV V2,V1,V5 ;vector multiply
LV V3,Ry ;load vector Y
ADDV V4,V2,V3 ;vector add
SV Ry,V4 ;store the result
4 convoys:
1. LV, LV
2. MULV, LV
3. ADDV
4. SV
4 x 16 + 12 + 12 + 6 + 12 = 298
12 64
7 64
12 64
12 64
6 64
12 64
LV
LV
MULV
LV
ADDV
SV
1
12 64
7 64
12 64
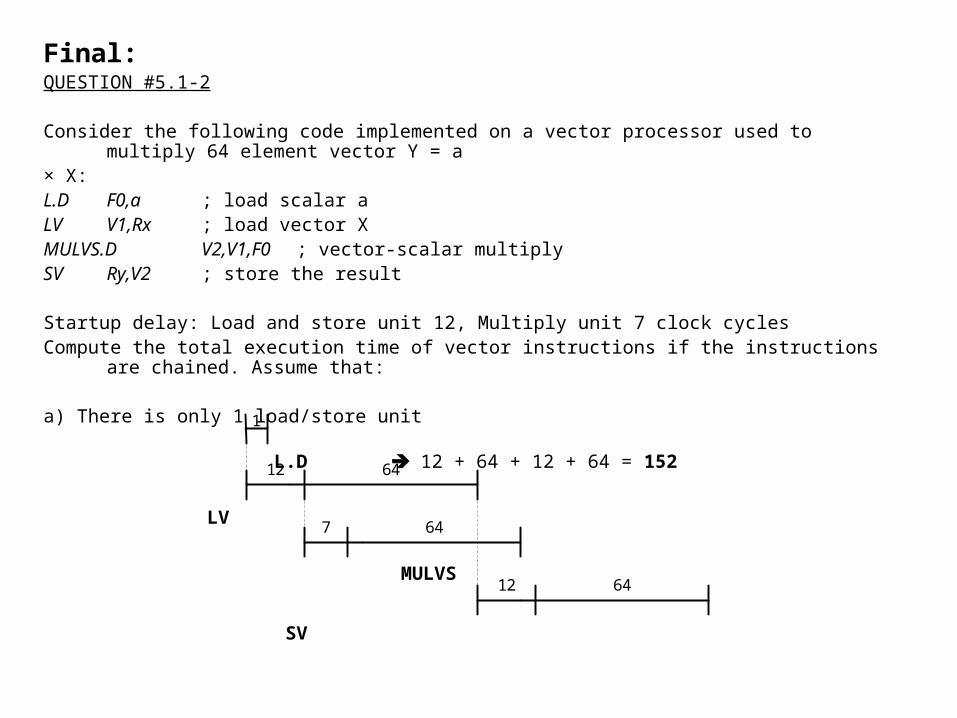
Final:QUESTION #5.1-2
Consider the following code implemented on a vector processor used to multiply 64 element vector Y = a
× X:L.D F0,a ; load scalar aLV V1,Rx ; load vector XMULVS.D V2,V1,F0 ; vector-scalar multiplySV Ry,V2 ; store the result
Startup delay: Load and store unit 12, Multiply unit 7 clock cyclesCompute the total execution time of vector instructions if the instructions are chained. Assume that:
a) There is only 1 load/store unit
L.D 12 + 64 + 12 + 64 = 152
LV
MULVS
SV

Final:QUESTION #5.1-2
Consider the following code implemented on a vector processor used to multiply 64 element vector Y = a
× X:
L.D F0,a ; load scalar a
LV V1,Rx ; load vector X
MULVS.D V2,V1,F0 ; vector-scalar multiply
SV Ry,V2 ; store the result
Startup delay: Load and store unit 12, Multiply unit 7 clock cycles
Compute the total execution time of vector instructions if the instructions are chained. Assume that:
b) There are one load and one store unit
L.D 12 + 7 + 12 + 64 = 95
LV
MULVS
SV
12 64
7 64
12 64
1





























