Embed Size (px)
Citation preview

Randomisation: necessary but not sufficient
Doug Altman
Centre for Statistics in MedicineUniversity of Oxford

2
Randomisation is not enough
The aim of an RCT is to compare groups equivalent in all respects other than the treatment itself
Randomisation can only produce groups that are comparable at the start of a study
Other aspects of good trial design are required to retain comparability to the end
Randomised trials are conceptually simple but– easy to do badly– hard to do well

3
… what could possibly go wrong?”

4
“Clinical trials are only as strong as the weakest elements of design, execution
and analysis”
[Hart HG. NEJM 1992]

5
Randomised trials
An incomplete compendium of errors:Design AnalysisInterpretationSelective publication Reporting
Implications

6
DESIGN

7
Trial was not really randomised
Pediatrics 2009;123;e661-7
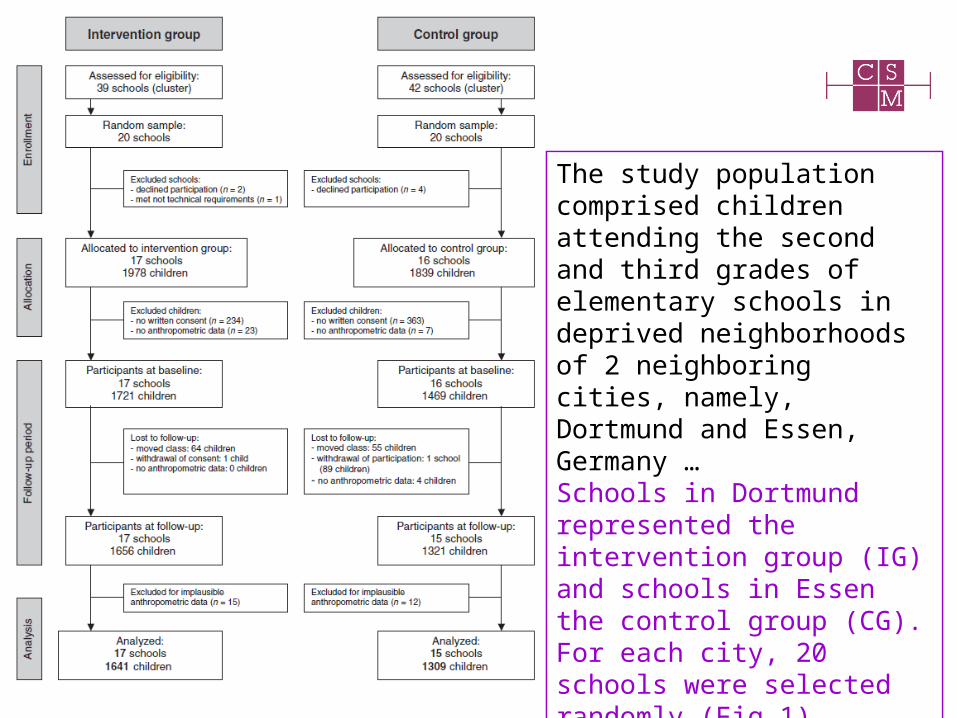
8
The study population comprised children attending the second and third grades of elementary schools in deprived neighborhoods of 2 neighboring cities, namely, Dortmund and Essen, Germany … Schools in Dortmund represented the intervention group (IG) and schools in Essen the control group (CG). For each city, 20 schools were selected randomly (Fig 1).
The study population comprised children attending the second and third grades of elementary schools in deprived neighborhoods of 2 neighboring cities, namely, Dortmund and Essen, Germany … Schools in Dortmund represented the intervention group (IG) and schools in Essen the control group (CG). For each city, 20 schools were selected randomly (Fig 1).

9
Improper randomisation
“Randomization was alternated every 10 patients, such that the first 10 patients were assigned to early atropine and the next 10 to the regular protocol, etc. To avoid possible bias, the last 10 were also assigned to early atropine.”
[Lessick et al, Eur J Echocardiography 2000]

Inadequate blinding
“… the patients were randomly assigned to prophylaxis or nonprophylaxis groups according to hospital number. Both the physician and the nurse technician were blind as to which assignment the patient received. Patients in group A received nitrofurantoin 50 mg four times and phenazopyridine hydrochloride 200 mg three times for 1 day. Patients in group B received phenazopyridine hydrochloride only. The code was broken at the completion of the study.”
10


Sources of bias Pre-randomisation Post-randomisation
12

13

Sample size
The aim should be to have a large enough sample size to have a high probability (power) of detecting a clinically worthwhile treatment effect if it exists
Larger trials have greater power to detect beneficial (or detrimental) effects
Many clinical trials are far too small– Median 40 patients per arm in 616 trials on PubMed
in 2006– Most trials have very low power to detect clinically
meaningful treatment effects

15
ANALYSIS

Analysis does not match design
16

Analysis does not match designswitched from crossover to parallel
17
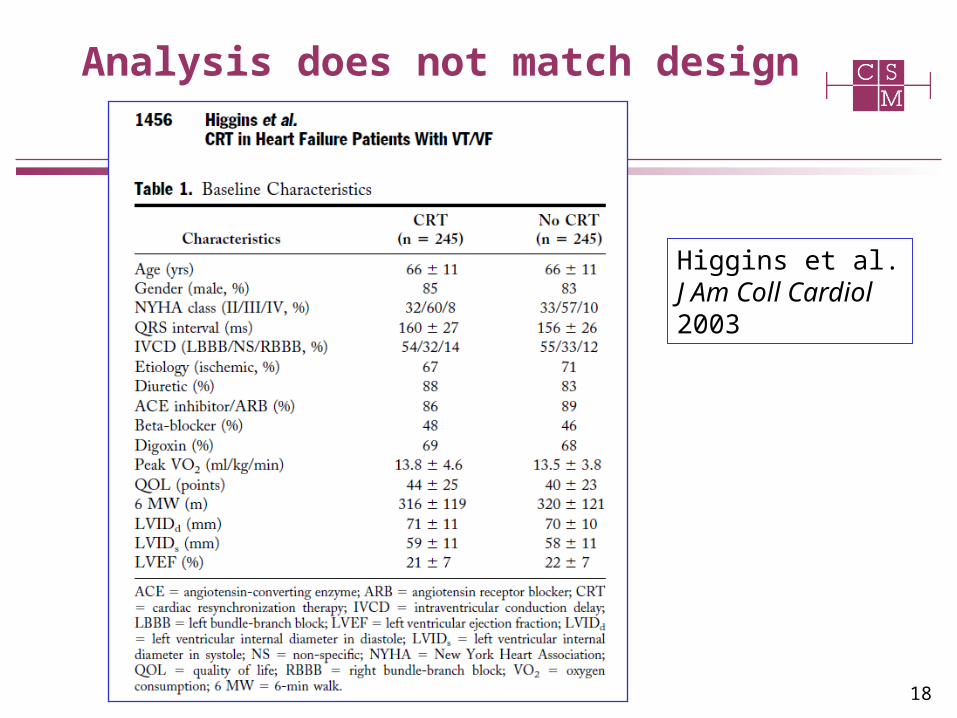
18
Analysis does not match design
Higgins et al. J Am Coll Cardiol 2003

Analysis does not match design
Primary end point: Progression of heart failure, defined as a composite of all-cause mortality, hospitalization for worsening HF, or ventricular tachyarrhythmias requiring device therapy
19

20
Analysis does not match design
TARGET trial, Lancet
2004
In fact this was two separate 1:1 comparisons: Lumiracoxib vs naproxen
Lumiracoxib vs ibuprofen

21

22
Stender et al, Lancet 2000

23
What is an intention to treat analysis?
Which patients are included in an intention to treat analysis?
– Should be all randomised patients, retained in the original groups as randomised
Most RCTs with ‘intention to treat’ analyses have some missing data on the primary outcome variable
– 75% of 119 RCTs - Hollis & Campbell, BMJ 1999
– 58% of 100 RCTs - Kruse et al, J Fam Pract 2002
– 77% of 249 RCTs – Gravel et al, Clin Trials 2007
– Really ‘available case analysis’

24
Improper comparison
Labrie et al, Prostate 2004;59:311-318.

25
Post hoc data and analysis decisions
Huge scope for post hoc selection from multiple analyses– omitting data– adjustment – categorisation/cutpoints– log transformation– etc
“The “art” part of science is focussed in large part on dealing with these matters in a way that is most likely to preserve fundamental truths, but the way is open for deliberate skewing of results to reach a predetermined conclusion.”
Bailar JC. How to distort the scientific record without actually lying: truth, and the arts of science. Eur J Oncol 2006;11:217-24.

26
INTERPRETATION


Spin in a representative sample of 72 trials [Boutron et al, JAMA 2010]
Title– 18% Title
Abstract– 38% Results section of abstract– 58% Conclusions section of abstract
Main text – 29% Results– 41% Discussion– 50% Conclusions– >40% had spin in at least 2 sections of main text

“Spin”
Review of breast cancer trials“… spin was used frequently to influence, positively, the interpretation of negative trials, by emphasizing the apparent benefit of a secondary end point. We found bias in reporting efficacy and toxicity in 32.9% and 67.1% of trials, respectively, with spin and bias used to suggest efficacy in 59% of the trials that had no significant difference in their primary endpoint.”
[Vera-Badillo et al, Ann Oncol 2013]

30
SELECTIVEPUBLICATION

31
Consistent evidence of study publication bias
Studies with significant results are more likely to be published than those with non-significant results– Statistically significant results are about 20% more
likely to be published [Song et al, HTA 2000]
Studies reported at conferences are less likely to be fully published if not significant
[Scherer et al, CDMR 2004]
Even when published, nonsignificant studies take longer to reach publication that those with significant findings
[Hopewell et al, CDMR 2001]

Of 635 clinical trials completed by Dec 2008, 294(46%) were published in a peer reviewed biomedical journal, indexed by Medline, within 30 months of trial completion.
Country
Size
Phase
Funder
32
Ross JS, Mulvey GK, Hines EM, Nissen SE, Krumholz HM. Trial publication after registration in ClinicalTrials.gov: a cross-sectional analysis. PLoS Med 2009.

Consequences of failure to publish
Non-publication of research findings always leads to a reduced evidence-base
Main concern is that inadequate publication distorts the evidence-base – if choices are driven by results
Even if there is no bias the evidence-base is diminished and thus there is extra (and avoidable) imprecision and clinical uncertainty

Clustering of P values just below 0.05
Pocock et al, BMJ 2004
P=0.05
P=0.01

PLoS One 2013
“There is strong evidence of an association between significant results and publication; studies that report positive or significant results are more likely to be published and outcomes that are statistically significant have higher odds of being fully reported. Publications have been found to be inconsistent with their protocols.”

36
REPORTING

37
Evidence of poor reporting
Poor reporting: key information is missing or ambiguous
There is considerable evidence that many published articles do not contain the necessary information – We cannot tell exactly how the research was done

Poor description of non-pharmacological interventions in RCTs
Hoffmann et al, BMJ 2013
Only 53/137 (39%) interventions were adequately described– increased to 59% by using responses from
contacted authors
38

Perry et al, J Exp Criminol 2010
39

Reporting of harms in randomized controlled trials of psychological interventions for mental and behavioral disorders: A review of current practice [Jonsson et al, CCT 2014]
104 (79%) reports did not indicate that adverse events, side effects, or deterioration had been monitored
40

“None of the psychological intervention trials mentioned the occurrence of an adverse event in their final report. Trials of drug treatments were more likely to mention adverse events in their protocols compared with those using psychological treatments. When adverse events were mentioned, the protocols of psychological interventions relied heavily on severe adverse events guidelines from the National Research Ethics Service (NRES), which were developed for drug rather than psychological interventions and so may not be appropriate for the latter.” 41

CONSORT – reporting RCTs
Structured advice, checklist and flow diagram Based on evidence, consensus of relevant
stakeholders Explanation and elaboration paper
42

Liu et al.,Transplant Int 2013
43

44
Review of 87 RCTs • Primary Outcome specification never matched
precisely!• 21% failed to register or publish primary outcomes [PO] • discrepancies in 79% of the registry–publication pairs • Percentages did not differ significantly between industry
and non-industry-sponsored trials• 30% of trials contained unambiguous PO
discrepancies• e.g., omitting a registered PO from the publication,
‘‘demoting’’ a registered PO to a published secondary outcome
• 48% non-industry-sponsored, 21% industry-sponsored (P=0.01)

State of play
Not all trials are published
Methodological errors are common
Research reports are seriously inadequate– Improvement over time is very slow
Reporting guidelines exist
It’s much easier to continue to document the problems than to change behaviour
45

46
Can we do better?

47

48
Some (partial) solutions to improving published randomised trials
Prevention of outcome reporting bias requires changing views about P<0.05
All primary and secondary outcomes should be specified a priori and then fully reported
Monitoring/regulation– Ethics committees, data monitoring committees,
funders Trial registration Journal restrictions Publication of protocols Availability of raw data (data sharing or
publication)

Publication of protocols
Publication is strongly desirable
Copy of protocol is required by some journals– Some publish this as a Web Appendix
Practice is likely to increase


Int J Stroke 2012


53
Finally …
“There may be greater danger to the public welfare from statistical dishonesty than from almost any other form of dishonesty”[Bailar JC. Clin Pharmacol Ther 1976;20:113-20.]
As an author– Be honest and transparent
As a reader– Beware

54

55
Vasopressin vs epinephrine for out-of-hospital cardiopulmonary resuscitation[Wenzel et al, NEJM 2004]
Primary outcome – hospital admission (alive) The overall comparison gives
OR = 0.79 (95% CI 0.62 to 1.02) [P=0.06]

56
Wenzel et al, NEJM 2004 Vasopressin
(N=589) Epinephrine
(N=597) P
Value Odds Ratio (95% CI)
All patients Hospital admission
214/ 589 (36.3) 186/ 597 (31.2) 0.06 0.8 (0.6–1.0)
Ventricular fibrillation
Hospital admission
103/ 223 (46.2) 107/ 249 (43.0) 0.48 0.9 (0.6–1.3)
Pulseless electrical activity Hospital admission
35/ 104 (33.7) 25/ 82 (30.5) 0.65 0.8 (0.5–1.6)
Asystole Hospital admission
76/ 262 (29.0) 54/ 266 (20.3) 0.02 0.6 (0.4–0.9)

57
Wenzel et al, NEJM 2004
Vasopressin (N=589)
Epinephrine (N=597)
P Value
Odds Ratio (95% CI)
All patients Hospital admission
214/ 589 (36.3) 186/ 597 (31.2) 0.06 0.8 (0.6–1.0)
Ventricular fibrillation
Hospital admission
103/ 223 (46.2) 107/ 249 (43.0) 0.48 0.9 (0.6–1.3)
Pulseless electrical activity
Hospital admission
35/ 104 (33.7) 25/ 82 (30.5) 0.65 0.8 (0.5–1.6)
Asystole
Hospital admission
76/ 262 (29.0) 54/ 266 (20.3) 0.02 0.6 (0.4–0.9)
No mention in Methods of planning to look at subgroups
Comparison of P values is wrong No significant difference between 3 groups
(interaction test)

58
Chan et al, Lancet 2014

59
What is a double blind trial?
Survey of 91 physicians [Devereaux et al. JAMA 2001]– single, double, and triple blind trials
Which groups are blinded in a double blind trial?– participants– health care providers– data collectors– data analysts– judicial assessors of outcomes

60
Physician interpretations
Participants + + + + + + + + Health care providers + + + + + + Data collectors + + + + + Data analysts + + Outcome assessors + + + +
% 38 5 5 7 1 7 13 10[13% gave other answers]
Only 29% specified outcome assessors
[Devereaux et al. JAMA 2001]

“The main limitation of our trial was the lack of blinded outcome assessment; this is probably impossible to achieve in such trials because it is difficult to disguise or mask the mattresses and it would be unethical to frequently move seriously ill, elderly people on to a standard surface for their skin to be assessed. We took steps to minimise the potential for bias this allows by collecting independent skin assessments carried out by both the ward staff and the clinical research nurses. Although ward nurses were not blind to allocation, we have no evidence that this influenced the care given. The frequent mattress changes were a strength of this trial as they represent the use of mattresses in real life and provide generalisable data.
BMJ 2006





























