Embed Size (px)
Citation preview

J SupercomputDOI 10.1007/s11227-014-1094-0
Randomized approximation scheme for resourceallocation in hybrid-cloud environment
MohammadReza HoseinyFarahabady · Young Choon Lee ·Albert Y. Zomaya
© Springer Science+Business Media New York 2014
Abstract Using the virtually unlimited resource capacity of public cloud, dynamicscaling out of large-scale applications is facilitated. A critical question arises prac-tically here is how to run such applications effectively in terms of both cost andperformance. In this paper, we explore how resources in the hybrid-cloud environ-ment should be used to run Bag-of-Tasks applications. Having introduced a simpleyet effective objective function, our algorithm helps the user to make a better decisionfor realization of his/her goal. Then, we cope with the problem in two different casesof “known” and “unknown” running time of available tasks. A solution to approxi-mate the optimal value of user’s objective function will be provided for each case.Specifically, a fully polynomial-time randomized approximation scheme based on aMonte Carlo sampling method will be presented in case of unknown running time.The experimental results confirm that our algorithm approximates the optimal solutionwith a little scheduling overhead.
This paper was originally published in the Thirteenth International Conference on Parallel and DistributedComputing, Applications and Technologies, Beijing, China, Dec. 2012.
M. HoseinyFarahabady (B) · Y. C. Lee · A. Y. ZomayaCentre for Distributed and High Performance Computing, School of Information Technologies,The University of Sydney, Room: 409, Building J12, Sydney, NSW 2006, Australiae-mail: [email protected]
Y. C. Leee-mail: [email protected]
A. Y. Zomayae-mail: [email protected]
M. HoseinyFarahabadyNational ICT Australia (NICTA), Australian Tech. Park, Sydney, NSW 1430, Australia
123

M. HoseinyFarahabady et al.
Keywords Cloud resource allocation · Randomized approximation scheme ·MonteCarlo sampling ·Bag-of-Tasks applications ·Divisible load theory (DLT) ·Optimalitycriterion
1 Introduction
To dynamically expand the capacity of in-house computing systems, public cloudcomputing can be considered as a promising solution. Particularly, flexibility of pub-lic cloud resources with a pay-as-you-go pricing model enables tightly budgeted users,such as small organizations and individuals to “cost effectively” access massive com-puting resources.
Several applications in science and engineering exhibit massive parallelism; and canbe classified as bag-of-Tasks (BoT) applications. As reported in [1] and [2], BoT-typeworkloads are very common in the parallel and distributed systems. These applicationsare often composed of a set with hundreds of thousands of independent tasks; hence,they can remarkably exploit the computing power provided in the cloud environmentby dynamically renting the available resources.
However, the reality is that the degree of performance gain is often not stronglycorrelated with the usage cost of these resources; this is particularly true whenCPU-intensive applications run on cloud resources with the non-proportional costto performance ratios (e.g., Amazon EC2 m1.small and c1.medium with such ratiosof 1 and 5, respectively). This issue in scaling out is a major obstacle that mustbe resolved for the cost-effective deployment of application into multiple cloudenvironment.
In this paper, we present some resource allocation algorithms to enable the exe-cution of BoT applications spanning beyond the private system/cloud (i.e., hybridcloud) by explicitly taking into account the cost efficiency—the cost to performanceratio. This paper substantially extends our previous studies [3], [4] in the followingrespects. While in [3], we only considered applications with the unknown runningtime, here, we extend the solution of proposed objective function in both known andunknown cases. In addition, an extension to our previous solution is represented tocover all possible values of parameter r in the objective function (see Sect. 3 formore details). Furthermore, the private cloud model in [3] was assumed to pos-sess only homogeneous resources; this restriction is removed in this study and theprivate cloud can possess several types of resources (resource heterogeneity). Thiscomplies with the practical situation which an in-house system can evolve over timeexpanding it with more powerful machines and keeping legacy systems (delaying theirdecommissioning).
To cope with the “unknown running time” case, we develop a fully polynomial-timerandomized approximation scheme (FPRAS). Such an FPRAS algorithm takes twoparameters of (1) ε > 0 as an approximation factor, and (2) δ > 0 as a confidenceinterval, and produces a solution that lies within a factor (1 + ε) of being optimalwith high probability (exact definition will be reported in Sect. 3.2). The runningtime of an FPRAS algorithm is guaranteed to be polynomial in terms of job size(n or the number of tasks in a given job), the approximation factor (ε−1), and the
123

Hybrid-cloud environment
confidence interval (log(1/δ)). To address the resource allocation problem withoutany advanced knowledge about the processing time, we incorporate a Monte Carlosampling method inspired by the work in [5] to estimate the average of tasks’ runningtime.
This paper is structured as follows: In Sect. 2, we present our model of hybridclouds, BoT application, and the resource allocation problem. Section 3 details bothour near-optimal solution and resource allocation algorithm. Section 4 presents theresults obtained from experiments as part of our algorithm evaluation. Related workis described in Sect. 5 followed by our conclusion in Sect. 6.
2 Problem formulation
This section aims to identify our research problem formally. We start by describingboth the hybrid-cloud model and BoT application, and continue by formulating theresource allocation problem as an optimization problem.
2.1 Cloud and application model
Having considered the benefits of integrating in-house cluster system (called pri-vate cloud) and resources in public cloud, we select a hybrid-cloud approach for thisresearch. We first start by introducing our hybrid-cloud model.
– Public cloud: Current public IaaS cloud providers offer virtual machines on demand.We denote an specific resource bundle as a public cloud instance type and showthe set of all available resources by �u . We assume that there exist different kinstance types offered by the provider. We also assume that the capacity of eachresource i = 1...k is guaranteed at level of si , i.e., the CPU speed or the amountof RAM assigned at any point of time. We refer this resource capacity as resourceperformance or resource speed interchangeably throughout this paper.Each type of the public resources is associated with a rental cost, too. We show thecost of renting a resource of type i with ci . The amount of ci does not change duringapplication life-cycle phase, we assume. Current cloud provider charges users forrenting resources based on their usage during an specific period of time known asaccountable time unit or ATU. We adopt one hour as ATU in this study as manycloud providers (such as Amazon) calculate the usage hourly. In addition, theremight be a limitation on the total number of resources that a user can rent froma particular instance of type i . If such a limitation exists, we denote it with Li .for example, Li is limited to be 20 in the current Amazon EC2 environment for aregular user.
– Private cloud: The organization’s infrastructures and/or data center resources canbe defined as the private cloud, whether hosted on either inside or outside of theorganization. We use�v to show the pool of resources provided by the private cloud,e.g., CPU, Memory, etc. Again, we assume that there are different k′ resource typesin the private cloud. The capacity of private cloud resource is shown by si ′ fori ′ = 1...k′. Because the organization has to buy and manage the private resourcesby itself, it is imaginable that a cost can be associated with each of these resources,
123

M. HoseinyFarahabady et al.
which might be even higher than the cost of public resource with the same capacity.We use ci ′ to refer to the cost of the private resource i ′ based on ATU period, fori ′ = 1...k′. It is worth to mention that despite its high initial cost and unpredictablerunning cost, private cloud provides normally more flexibility in terms of bothcustomization and privacy.
– Bag-of-Task application: In our study, we consider a BoT application, B, to consistof n independent tasks and be CPU-intensive. Here, the size of BoT application(n) is so large that overwhelm the capacity of resources provided by the privatecloud. Each task j; 1 ≤ j ≤ n, required the running time of Pj to accomplish,providing that it is assigned to run on a resource with unitary speed, si = 1. Fur-ther, we assume that each Pj value is a random variable comes from an unknowndistribution density F . We denote the mean and variance of this random variableby μ and σ 2, respectively. The processing times are apparently non-negative andmutually independent. In this study, task preemption is not allowed, so once a taskis assigned to run on a resource, the whole part of it must be executed without anyinterruption.If task j is assigned to run on a resource of speed si , and cost of ci , then the processingtime and the cost of executing task j is equal to
Pjsi
andci×Pj
si, respectively. As a
user hires a public cloud resource in whole hour duration, the total cost to finish a
set of tasks in a specific public cloud resource is ci�∑
j∈JiPj
si�, where Ji is the set
of all tasks assigned to resource i .– Use case scenario: A sample use case scenario of our proposed system (as depicted
in Fig. 1) can be described as follows : the user submits a BoT job along with severalother parameters (the details of these parameters, such as r and desirable weightingof each resource, will be described in the next section). If the tasks’ running time isnot known in advance, the framework will perform an estimation phase, which willbe discussed in detail in Sect. 3.2.1, to estimate the total workload submitted to thescheduler. Otherwise, the system jumps up to the next step of finding the optimalresource allocation.In the next step, the framework tries to solve a system of equations (givenby Eqs. 14 and 16), to figure out the optimal workload value that must beassigned to each resource. The next step is answering the question of how toassign properly a set of tasks that does not exceed the optimal workload cal-culated in the previous step. To overcome this, we apply a FFD-based alloca-tion algorithm which is given in detail by Algorithms 2 and 3. Finally, everytasks will be deployed to run on the proper resource located either in private orpublic cloud. During the execution phase, some sort of performance monitoringactions can be done to report the user the overall system performance time-to-time.
2.2 Cloud resource allocation problem
When a user submits an application to be run using the cloud resources, there arenormally two conflicting objectives of “minimizing the total cost” and “maximizingthe performance” (a.k.a. minimizing the makespan) that the user had to reach a com-
123

Hybrid-cloud environment
Fig. 1 The storyline of process flow through our proposed system. In this scenario, we assume that usersubmits a BoT job without any knowledge about tasks’ running times
promise between them in a rational way. Let σ denote a particular resource allocationscheme for a given application. Further, let C(σ ) and T (σ ) denote the total cost andthe makespan reached by this resource allocation scheme, respectively. Comparably,assume Ci (σ ), Ti (σ ), andψi (σ ) denote the corresponding cost, time (in terms of houror ATU), and the assigned workload of resource i reached by σ . Here, resource i maybelong to either public or private cloud.
Using preliminary calculus, an interested reader will be able to check the accuracyof the following equations.
C(σ ) =∑
i∈�u∪�vCi (σ ) (1)
T (σ ) = maxi∈�u∪�v
(Ti (σ )) = limr→∞
⎛
⎝∑
i∈�u∪�vTi (σ )
r
⎞
⎠
1r
(2)
Ci (σ ) ={
ci�Ti (σ )� if i ∈ �u
ci Ti (σ ) if i ∈ �v(3)
Ti (σ ) = ψi (σ )/si (4)
123

M. HoseinyFarahabady et al.
Equation 2 comes from the fact that in the L p-norm space (Lebesgue spaces) of avector z, L∞-norm is equal to the maximum norm of that vector [6].1
Inspiring from the definition of L p-norm, we introduce the following user-tunableobjective function to correlate two goals of minimizing the total cost and makespantogether.
min Z(σ ) =∑
i∈�u∪�vαi × (Ci (σ ))
r ; r ≥ 1 (5)
In the above, αi can be considered as a restriction weight that user assigns to eachresource based on his/her previous knowledge or assumption. When αi is large, itmeans that user does not have a desire for spending too much money to rent resourcesof type i . One reason can be imagined as the user has some previous experience aboutthe unexpected breakdown of that resource.
Parameter r , on the other hand, enables user to express his/her preference for eachcriterion. Two values of r have been already extensively studied.
– r = 1: In this case, a large makespan scheduling with minimum value of total costis achieved. The scheduling scheme normally comprise of a solution that assign alltasks to the most efficient resource types; i.e., the resource type that has the highestvalue of si
αi ci(turns Eq. 5 to be similar to Eq. 1).
– r = ∞: This case turns basically Eq. 5 to have an exact behavior as Eq. 2 has (meansthat they both have same minimum point). So, this leads to a solution that make theentire tasks’ load equally (or wighted) balanced between all available resources. Inthis case, the result normally has the least value of makespan with a large total costvalue.
In the next section, we reformulate Eq. 5 as a binary nonlinear optimization problemand then in Sect. 3.1, we provide solutions of different values of r .
2.3 Formulation as binary nonlinear programming
A nonlinear program (NLP) is an minimization (or maximization) problem such thata nonlinear “objective” function, Z(x), must be minimized (or maximized) subjectto some other (nonlinear) “constraint” functions that define limitations on the valuesof vector x. In binary problems, each variable can only take on the value of 0 or 1.Optimization problem of Eq. 5 can be restated as a binary nonlinear programming asfollows:
min Z(σ ) =∑
i∈�u ,1≤ j≤n
αi ci� xi, j Pj
si�r +
∑
i∈�v,1≤ j≤n
αi ci
(xi, j Pj
si
)r
(6)
1 L p-norm (p-norm) of a vector z can be defined by (∀p ≥ 1 ∈ �): ‖z‖p =(|z1|p + |z2|p + · · · + |zn |p
) 1p . The L∞-norm or Chebyshev distance is the limit of the L p-norms when
p → ∞ which has the same definition as: ‖z‖∞ = max {|z1|, |z2|, . . . , |zn |}.
123

Hybrid-cloud environment
s.t.∑
i∈�u∪�v, j=1···nxi, j = n (7)
xi, j ∈ {0, 1}; ∀i ∈ �u ∪ �v, j = 1 · · · n (8)
In the above equations, the binary variable xi, j represents whether task j is assignedto resource i or not.
Integer programming problems are well known to be NP-hard. So, it is usuallyimpossible to find any method to reach even a close optimal solution. Relaxation isa traditional technique to deal with IP problems. However, a solution for the relaxedversion of above-mentioned “Binary Integer” problem (which obtained by replacingConstraint 8 with 0 ≤ xi, j ≤ 1) is most likely far from the optimal value.
To overcome this issue, we reformulate Eqs. 6–8 to remove the binary constraint. Letus defineψi as the total workload assigned to resource i . Then, we substitute the valueof
∑xi, j Pj with the ψi to reach a relaxed version of the original problem as follows:
min∑
i∈�u
αi ci�ψi
si�r +
∑
i∈�vαi ci
(ψi
si
)r
(9)
s.t.∑
i∈�u∪�vψi =
∑
j=1···nPj (10)
A solution for Eqs. 9 and 10 can be considered as a close solution of the optimalvalue for the original problem. In the following section, we present a solution for Eqs.9 and 10 to approximate the optimal value of Eq. 6.
3 A near-optimal task assignment
In this section, we provide a solution for optimization problem stated by Eq. 9 in twoseparate cases. First, we discuss if all tasks’ running times are known in advance, andthen we extend our solution in case that there is no beforehand information about thetasks’ running time.
3.1 Solution for known tasks’ running time
To solve the optimization problem stated by Eq. 9, we first relax it by removing theintegral condition. It can be seen that the relaxed version satisfies Karush–Kuhn–Tucker (KKT) conditions, so, we can apply Lagrange multipliers method to reacha system of equations to find the minimum value. Let us show the total number ofavailable resources in both cloud by m, i.e., m = |�u∪�v|, and define βi as αi×ci/sr
i .Eq. 9 can be relaxed as follows:
minm∑
i=1
αi ci
(ψi
si
)r
s.t.m∑
i=1
ψi =n∑
j=1
Pj
(11)
123

M. HoseinyFarahabady et al.
By introducing Lagrange multiplier (λ), the Lagrange function can be written as:
(ψi , λ) =m∑
i=1
βiψri − λ
⎛
⎝m∑
i=1
ψi −n∑
j=1
Pj
⎞
⎠ (12)
One can find the optimal solution of relaxed version by solving the following systemof equations.
∇ψi ,λ = 0 (13)
or equivalently:
∂(ψi , λ)
∂ψ j= rβ jψ
r−1j +
∑
i=1..m;i �= j
βiψri − λ = 0 ; ∀ j = 1..m
∂(ψi , λ)
∂λ=
m∑
i=1
ψi −n∑
j=1
Pj = 0 (14)
Let ψ∗ = 〈ψ∗1 , ψ∗2 · · ·ψ∗m〉 be the optimal solution of Eq. 13 (or Eq. 14). Each ψ∗ishows the amount of workload in resource i in optimal case. The next step is to find asubset of tasks which add up exactly or as close as possible to the value of ψ∗i . Suchtask assignment will be presented later in Sect. 3.3, after discussing our method offinding optimal value in the non-clairvoyant case.
3.2 Solution for unknown tasks’ running time (non-clairvoyant case)
In this section, we deal with the task assignment problem if Pj ’s in Eq. 10 are not knowna priori. We present an FPRAS algorithm which consists of two steps: estimation andtask assignment. For a given optimization problem, an FPRAS algorithm can producea solution within a factor of (1+ε) of the optimal value with a confidence intervalof δ. The running time of such algorithm is polynomial in terms of input size, ε−1,and log(δ−1). Naturally, an FPRAS scheme can be considered as the most efficientrandomized algorithm for tackling NP-hard problem in the stochastic manner.
3.2.1 Estimation
To solve the system of equations given by Eq. 14, we need to estimate the unknownvalue of
∑nj=1 Pj . To this end, an estimation procedure based on a well-known Monte
Carlo sampling method called AA Algorithm [5] can be employed. This samplingalgorithm uses the minimum possible number of experiments to predict the averagetask running time, μ̂, (which is equivalent to
∑Pj/n) and satisfies the following
condition.
Pr[μ(1− ε) ≤ μ̂ ≤ μ(1+ ε)] ≥ 1− δ (15)
123

Hybrid-cloud environment
Here,μ is the actual average value, μ̂ is the estimated value ofμ, ε is the approximationfactor, and δ is called the confidence factor.
The estimation procedure is presented formally in Algorithm 1. It consists of threemain steps. Each step can be recognized by a while loop. In the first step, it producesan initial estimation of μ̃Z. In the second step, it determines the number of experimentsneeded to produce ρ̂Z as an estimation for unknown value ρ with a probability of atleast 1−δ′. The last step (third while) takes both of previous outputs, μ̃Z and ρ̂Z, to setthe minimum number of experiments needed to be run on the private cloud to produceμ̂ which is an (ε, δ)-estimate of μZ.
Algorithm 1: Estimation of μ based on AA algorithminput : ε, δ, n, �v ∪ �u , B;output: μ̂Z; //an estimation of average tasks’ running time in Bbegin
S← 0; c← 0; ε′ ← min{ 12 ,√ε}; δ′ ← δ/3;
ϒ1 = 1+ (1+ ε′) 2.87ln(2/δ′)ε′2 ;
while S < ϒ1 doPick a random integer number, h, in range [1,n];Run task indexed by h, Th , in private cloud;S← S + Ph ; //Ph : running time of Thc← c + 1;B ← B − Th ;
endμ̃Z ← S/c;
ϒ2 = 5.75ln(2/δ′)ε′μ̃2
Z;
S← 0; c← 0;while c < ϒ2 do
Pick two random integer numbers, h1 and h2, in range [1,n];Run tasks Th1 and Th2 in private cloud;
S← S + (Ph1 − Ph2 )2/2;
c← c + 1;B ← B − {Th1 , Th2 };
endρ̂Z = max{S/ϒ2, ε.μ̃Z}ϒ3 = 5.75ln(2/δ′).ρ̂Z
ε′2μ̃2Z
;
S← 0; c← 0;while c < ϒ3 do
Pick a random integer number, h, in [1,n];Run task Th in private cloud;S← S + Ph ;c← c + 1;B ← B − Th ;
endμ̂Z = S/ϒ3
end
After finding an estimation of μ, we replace the value of∑n
j=1 Pj (in either Eq.10 or 14) by the estimation value of μ̂× n as follows:
123

M. HoseinyFarahabady et al.
∂(ψ̂i , λ)
∂ψ̂ j= rβ j ψ̂
r−1j +
∑
i=1..m;i �= j
βi ψ̂ri − λ = 0 ; ∀ j = 1..m
∂(ψ̂i , λ)
∂λ=
m∑
i=1
ψ̂i − μ̂× n = 0 (16)
Let us show the solution of the Eq. 16 by vector ψ̂ = 〈ψ̂1, ψ̂2 · · · ψ̂m〉. We will continueby giving our task assignment in the next section.
3.3 Task assignment
In Sects. 3.1 and 3.2, we discussed how to find the optimal workload received by eachresource. In this section, we present two algorithms to find a subset of tasks whichadds up as close as possible to the value of ψ∗ (in case of known tasks’ running time)or ψ̂ (in case of unknown tasks’ running time). This problem can be considered as ageneral case of bin packing, knapsack, or subset sum problem. For example, in thestandard version of subset sum problem a set of integers and an integer target t aregiven, and aim is to find a non-empty subset sum to t . All of the above-mentionedproblems belong to NP-complete class [7]. There are many well-known approximationalgorithms in the literature [8–11] to solve these basic problems efficiently. They areoften too difficult to understand or implement, however. Therefore, for the purposeof this research, we take advantage of a simple and fast approach based on First FitDecreasing (FFD) algorithm [12], which generates reasonably a good outcome. FFDsolution for bin packing problem can be described as follows: in the first step, we mustsort both the items into their decreasing sizes and the bins according to their capacities.Then, the next item is put into the first bin where it fits. Slightly modified versionsof this approach are given in Algorithms 2 and 3, where our aim is to decrease theamount of wasted capacity of resources as much as possible.
In the case of known task’s running time, i.e., Algorithm 2, we do as follows:Knowing that each resource i should not receive a total workload more thanψ∗i (in theoptimal solution), we assign a task j to an already allocated resource i if its currentworkload plus Pj (the task’s running time) does not exceed ψ∗i . Applying this rule inaddition to the rule of “selecting the most cost-effective resource first” can produce anear-optimal solution.
Similarly, in the case of unknown task’s running time, i.e., Algorithm 3, we pick atask from tasks’ queue and add it to the next efficient resource if the expected valueof this task’s running time, i.e., μ̂, plus the current assigned workload of that resourcedoes not exceed the value of ψ̂i .
Variable S[i] in these two algorithms holds the current assigned workload of eachresource i . With these simple controls, we are able to assign a task to the most cost-efficient resource provided there is sufficient residual capacity in it. By applying thesimilar approach given in [12], one can expect that both Algorithms 2 and 3 are constantapproximation algorithms with approximation ratio of 11/9. In complexity theory, aconstant-factor approximation algorithm is a polynomial-time approximation algo-rithm with approximation ratio bounded by a constant c. In other words, it guaranteesto provide a solution which is at most c times worse than the optimal solution.
123

Hybrid-cloud environment
Algorithm 2: Hybrid-Cloud resource allocation algorithm in known tasks’ run-ning time case
input : αi ’s, r , n, �u ∪ �v , and B with known Tj ’s;output: resource allocation schemebegin
Sort resources by cost efficiency, i.e., siαi ci
S[i] ← 0; ∀1 ≤ i ≤ |�u ∪ �v |Calculate ψ∗i from Equation 14;Sort tasks in B into their decreasing running time;while B is not empty do
Pick the next available task Tj in B;if there exists a resource i such that S[i] < ψ∗i − Tj then
Assign task Tj to resource i ;else
Assign all remaining tasks in B to resources in �v using List scheduling;end
endAfter detection of completion of task Tj on resource i :S[i] ← S[i] + Pj ;B ← B − Tj ;
end
Algorithm 3: Hybrid-Cloud resource allocation algorithm in unknown tasks’running time case
input : ε, δ, αi ’s, r , n, �u ∪ �v , B with unknown Tj ’s;output: resource allocation schemebegin
Sort resources by cost efficiency, i.e., siαi ci
S[i] ← 0; ∀1 ≤ i ≤ |�u ∪ �v |Run Algorithm 1 to find μ̂;Calculate ψ̂i from Equation 16;while B is not empty do
if there exists a resource i such that S[i] < ψ̂i − μ̂ thenPick an integer number, h, from [1..|B|];Assign task h, Th , to resource i ;
elseAssign all remaining tasks in B to resources in �v using List scheduling;
endendAfter detection of completion of task Tj on resource i :S[i] ← S[i] + Pj ;B ← B − Tj ;
end
4 Experimental evaluation
In this section, the performance evaluation results of the proposed approach usingrunning BoT application on a hybrid-cloud infrastructure are represented. It followsthe model we already discussed in Sect. 2.1.
123

M. HoseinyFarahabady et al.
4.1 Hybrid-cloud and BoT application setting
The private cloud used in our study was composed of our in-house 4×10 core clusterwith 2.4 GHz Intel Xeon processors, with a total of 256GB RAM. Public cloud consistsof instance types from Amazon EC2 cloud. We use four different instant types fromEC2 which called “M1 Small Instance”, “M1 Large Instance”, “High-CPU MediumInstance”, and “High-CPU Extra Large Instance”, respectivley. Standard instances nor-mally supply a balanced set of RAM and CPU capacity, suitable for a variety of appli-cation types. On the other hand, high-CPU instances possess more CPU capacity thanRAM which make them best fit for CPU-intensive applications. Details of processingcapacity and the cost of each resource are shown in Table 1. In this table, process-ing capacities are relative speeds based on the reference resource considered as public“m1.small” isntance. To mimic a real BoT workload, we created several sets of tasks inwhich their characteristics are similar to the patterns reported by Iosup et al. [13]. Taskcharacteristics are summarized in Table 2. The running time of each task is defined interms of how much CPU time is required for its execution if we assign it to a standardsmall instance (m1.small) in Amazon EC2 public cloud. In Table 2, we categorize BoTapplications into short, long and mixture of both based on task running time. Symbolsof U (a, b) and N (μ, σ ) show a uniform distribution with the minimum and maximumvalues of a and b, and a normal distribution with mean μ and standard deviation of σ ,respectively.
We compared our proposed algorithm with a heuristic algorithm which choosestasks with some order (if possible) and assigns them to the next most cost-efficient resource. A resource i is more cost-efficient than another resource j if andonly if si
αi ci>
s jα j c j
. This heuristic acts similar to the traditional List schedulingalgorithm.
For different values of parameter r , we run the heuristic algorithm as follows: forr = 1, the heuristic algorithm tries to balance the tasks’ load among all available
Table 1 Hybrid-cloud settingswith different cost toperformance ratios
Cloud Instance type Processing capacity(normalized)
Cost(per hour)
Amazon EC2 m1.small 1 $0.080
c1.medium 5 $0.165
US East (VA) m1.large 4 $0.320
c1.xlarge 20 $0.660
Private 4× 10 XeonProcessors
10 $0.320
Table 2 Different BoTworkload characteristics used inthis study
Type Task’s running time (min)
Short U(0,8)
Long N(36,6)
Mixture N(12,3)
123

Hybrid-cloud environment
resources in both private and public clouds. For r = ∞, it only chooses most cost-efficient resources for load balancing. For other values of r , the greedy approachchooses m − r + 1 most cost-efficient resource types for load balancing, where mshows the total resource types.
4.2 Result
Experimental results are analyzed and discussed based on three performance metrics:makespan, total cost, and objective function value (z). In all of the experiments, weused different values for ε ranging from 0.1 to 0.4 with an step of 0.1 as well asdifferent values for δ as 5, 10, 15, and 20 %.
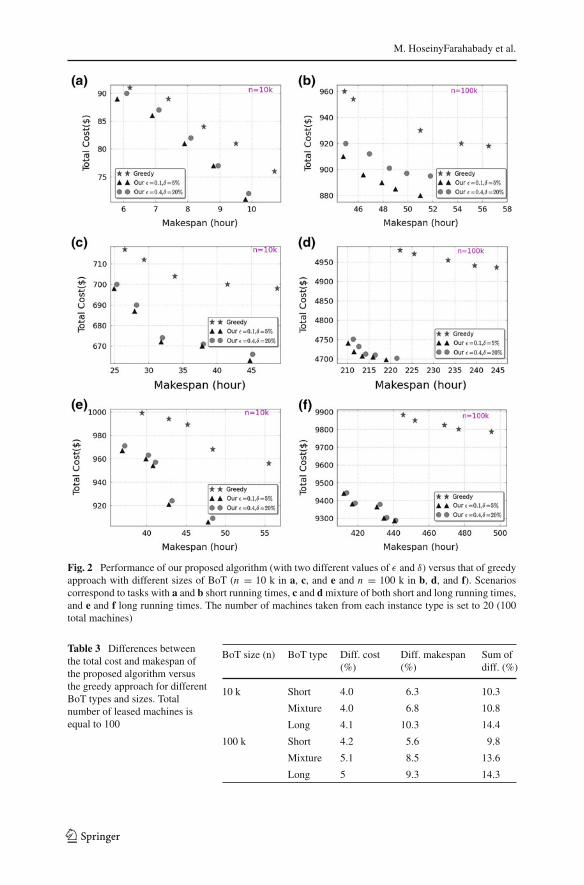
In Fig. 2, we compare performance of our algorithm with the heuristic algorithm.2
Due to the similar patterns, only those graphs concerning two extreme values of εand δ are presented. The results confirm that our approach can successfully reduceboth time and cost (hence, the objective value) of using hybrid-cloud resources. Theaverage reductions in makespan and total cost in each scenarios are given in Table 3.The average reductions of makespan and cost usage are approximately 7.5 and 4.8 %,respectively. It can be seen that though the greedy algorithm can reach to an acceptablesolution when the BoT comprised only short tasks, it fails to reach a good result in theother situations. One reason for this phenomena is that greedy heuristic assigns blindlythe long tasks to resources without any per-calculation, while our approach consid-ers a limitation on the maximum workload of each resource, based on the solutionfor Eq. 14 or 16. Therefore, we can conclude that the performance of greedy algo-rithm degrades significantly when the granularity of task, in terms of running time, isincreased.
Another observation is that performance of our algorithm is not too sensitive to thelarge values of either ε or δ. One may expect that when either ε and δ gets larger,the quality of solution must be decrease. In practice, however, this does not happenand Algorithm 1 produces a good estimation of μ. Interestingly, one anomaly hasbeen detected when the values of ε and/or δ are chosen very small, for example below5 %. While one expect that small values of ε and/or δ may result in higher accuracyof both prediction of μ and the performance of algorithm, in reality, the algorithm’sperformance decreases significantly.
In fact, by choosing a small value for either ε or δ, the number of tasks used forAlgorithm 1 increases; this leaves little room to optimize the assignment of rest oftasks. As an example, to reach an estimation with ε = 1 % and δ = 1 %, nearly halfof the available jobs should be used for prediction process; which leads clearly to apoor performance. We have observed that the values of ε and δ around 10 ≈ 30 %and 5 ≈ 15 %, respectively, are most appropriate.
The overhead of our scheduling algorithm can be negligible as compared to theactual value of BoT application running time. For example, for acceptable values ofε = 10 % and δ = 5 %, the overhead is <1 % of total BoT application runningtime.
2 Each point in Fig. 2 shows a particular value of r starting from 1 and being incremented by 1.
123
M. HoseinyFarahabady et al.
Fig. 2 Performance of our proposed algorithm (with two different values of ε and δ) versus that of greedyapproach with different sizes of BoT (n = 10 k in a, c, and e and n = 100 k in b, d, and f). Scenarioscorrespond to tasks with a and b short running times, c and d mixture of both short and long running times,and e and f long running times. The number of machines taken from each instance type is set to 20 (100total machines)
Table 3 Differences betweenthe total cost and makespan ofthe proposed algorithm versusthe greedy approach for differentBoT types and sizes. Totalnumber of leased machines isequal to 100
BoT size (n) BoT type Diff. cost(%)
Diff. makespan(%)
Sum ofdiff. (%)
10 k Short 4.0 6.3 10.3
Mixture 4.0 6.8 10.8
Long 4.1 10.3 14.4
100 k Short 4.2 5.6 9.8
Mixture 5.1 8.5 13.6
Long 5 9.3 14.3
123

Hybrid-cloud environment
5 Related work
There have been a large number of studies to effectively execute BoT applicationsin large-scale distributed computing systems, such as grids and more recently clouds[14–16]. These previous attempts typically aim to minimize either makespan or cost. Inother words, the performance improvement and cost trade-off are still not thoroughlystudied, particularly when dealing with public clouds. Unlike those attempts, ouralgorithm is specifically designed to optimize cost efficiency of running BoT in ahybrid cloud without the availability of prior knowledge of task processing times.Discovering the best scheme has been known as an NP-complete problem in eitherhomogeneous or heterogeneous environments for many years [17].
In [18,19], authors show why a heterogeneous environment is preferable to onethat is homogeneous. They discussed that the scheduling scheme must take advantageof heterogeneity carefully to benefit from it. If not, it will drive to undesirable effects.Another troublesome issue in this area is foretelling the each task’s execution time inadvance. In practice, there exist three kinds of explanation to the problem of estimationof execution time: (1) code analysis [20], (2) analytic benchmarking/code profiling[21], and (3) statistical prediction [22].
In code analysis, an analysis of the source code is done to estimate running timeof the task. While it produces a high accurate estimation, it normally limited to codetypes or specific architectures. In the second method, some benchmarks and profilersare used to discover the primitive code types as well as the composition of a task.These two results are combined then for producing the estimation. It normally suffersfrom variations in the set of input data or running on different algorithms and archi-tectures. In the third class, statistical prediction on previous observations are done tomake predictions. They normally do not need knowledge about the intrinsic charac-teristic of the algorithm. However, these methods normally need adequate large set ofobservations.
Broadly, works on running BoT applications can be classified into either dynamic orstatic resource allocation. While authors in [16] assume static settings of task executiontime, those in [14] and [15] make scheduling decisions without such an assumption.What distinguishes our work from these studies is ours’ produces a near-optimal solu-tion that can approximate the optimal one. The estimation procedure in our algorithmeffectively deals with non-clairvoyance of task assignment problem.
Another work to note is [23] that addresses the scheduling of jobs (deadline-constrained and best-effort jobs) using public cloud resources to improve jobs’response times. Although the objective of this scheduling is similar to ours, the workin [23] mainly differs in its application model of individual jobs.
Our study has a close relation with the problem of job scheduling using divisible loadtheory which has extensively been investigated in distributed systems. In the previousstudies, the number of available resources (machines) is normally considered fixed.In this study, we consider the situation that the number of machines in the privatesystem can be added by renting extra machines from cloud provider. DLT model hasproven to be a very useful tool to deal with large-scale workloads on distributed systemsuch as grid or even cloud environment [24–26]. Some successful usage of it in severaldomains like image processing [27] has been reported. While in the traditional version
123

M. HoseinyFarahabady et al.
of DLT, a linear modeling often used extensively, we show how to apply a nonlinearversion can be successfully exploited.
In the both recent works [27,26], authors consider only minimizing the overallmakespan for performing large-scale computation, while our solution tries to give ageneral tunable objective function to combine two competitive objectives into one.To our best knowledge, this is the first study that uses a nonlinear objective functionconsidering minimizing both the makespan and the total cost in DLT paradigm.
6 Conclusion
In this paper, we have addressed the problem of BoT task assignment on a hybrid-cloud environment. When a large-scale BoT application runs with support of thepublic cloud resources, the assignment of tasks should explicitly take into account thecost efficiency. Introducing a novel objective function, we dealt with the problem byformulating it as an optimization problem.
We have used an FPRAS algorithm in case of unknown running time of tasks, whereour algorithm combines a Monte Carlo sampling method to estimate the unknownvalues. Our work in this paper provides an effective means for the user to run large-scaleCPU-intensive BoT applications with/without prior knowledge of task processingtime. The quality of our task assignment is evaluated by running experiments usingour in-house cluster as the private cloud and Amazon EC2 instances as the publiccloud.
Acknowledgments (1) Professor Albert Zomaya’s work is supported by the Australian Research CouncilDiscovery Grant (DP1097110). (2) M. Reza HoseinyFarahabady’s work is partially supported by NationalICT Australia (NICTA). NICTA is funded by the Australian Government as represented by the Departmentof Broadband, Communications and the Digital Economy and the Australian Research Council through theICT Centre of Excellence program.
References
1. Iosup A, Jan M, Sonmez OO, Epema DHJ (2007) The characteristics and performance of groups ofjobs in grids. In: Proceedings of the International European Conference on Parallel Processing, LNCS,vol 4641. Springer, pp 382–393
2. Minh TN, Wolters L, Epema DHJ (2010) A realistic integrated model of parallel system workloads.In: International Symposium on Cluster, Cloud the Grid, CCGRID’10. IEEE, pp 464–473
3. HoseinyFarahabady MR, Lee YC, Zomaya AY (2012) Non-clairvoyant assignment of bag-of-tasksapplications across multiple clouds. In: PDCAT’12. China
4. HoseinyFarahabady MR, Lee YC, Liu X, Reisi Dehkordi H, Zomaya AY (2011) Approximation algo-rithm for scaling outlarge-scale bag-of-tasks applicationsacross multiple clouds. The University ofSydney, Tech. Rep. 684
5. Dagum P, Karp R, Luby M, Ross S (1995) An optimal algorithm for monte carlo estimation. In:Foundations of Computer Science, pp 142–149
6. Adams R, Fournier J (2003) Sobolev spaces. Pure and applied mathematics. Elsevier Science, Philadel-phia
7. Cormen TH, Leiserson CE, Rivest RL, Stein C (2009) Introduction to algorithms, 3rd edn. The MITPress, Cambridge
8. Chekuri C, Khanna S (2000) A ptas for the multiple knapsack problem. In: Proceedings of the eleventhannual ACM-SIAM symposium on Discrete algorithms., SODA ’00Society for Industrial and AppliedMathematics, Philadelphia, pp 213–222
123

Hybrid-cloud environment
9. Kellerer H, Mansini R, Pferschy U, Speranza MG (2003) An efficient fully polynomial approx-imation scheme for the subset-sum problem. J Comput Syst Sci 66(2) 349–370. doi:10.1016/S0022-0000(03)00006-0
10. Lawler EL (1979) Fast approximation algorithms for knapsack problems. Math Oper Res 4(4):339–35611. Arora S, Karger D, Karpinski M (1995) Polynomial time approximation schemes for dense instances
of np-hard problems. In: Proceedings of the twenty-seventh annual ACM symposium on theory ofcomputing. ACM, Las Vegas, Nevada, USA, pp 284–293. doi:10.1145/225058.225140
12. Dsa G (2007) The tight bound of first fit decreasing bin-packing algorithm is ffd(i)=(11/9)opt(i)+6/9.In: Chen B, Paterson M, Zhang G (eds) ombinatorics, algorithms, probabilistic and experimentalmethodologies, Lecture Notes in Computer Science, vol 4614. Springer, Berlin Heidelberg, pp 1–11
13. Iosup A, Sonmez O, Anoep S, Epema D (2008) The performance of bags-of-tasks in large-scaledistributed systems. In: International Symposium on High Performance Distributed Computing, HPDC08, USA, pp 97–108
14. Fujimoto N, Hagihara K (2003) Near-optimal dynamic task scheduling of independent coarse-grainedtasks onto a computational grid. In: Proceedings of the International Conference on Parallel Processing,ICPP’03, Taiwan, pp 391–398
15. Lee YC, Zomaya AY (2007) Practical scheduling of bag-of-tasks applications on grids with dynamicresilience. IEEE Trans Comput 56(6):815–825
16. Silberstein M, Sharov A, Geiger D, Schuster A (2009) Gridbot: execution of bags of tasks in multiplegrids. In: Proceedings of the Conference on High Performance Computing Networking, Storage andAnalysis, SC’09. ACM
17. Ibarra OH, Kim CE (1977) Heuristic algorithms for scheduling independent tasks on nonidenticalprocessors. J ACM 24(2):280–289
18. Almeida VAF, Vasconcelos IMM, Árabe JNC, Menascé DA (1992) Using random task graphs toinvestigate the potential benefits of heterogeneity in parallel systems. In: Proceedings of the ACM/IEEEconference on Supercomputing, Supercomputing ’92. IEEE, USA, pp 683–691
19. Menasce D, Almeida V (1990) Cost-performance analysis of heterogeneity in supercomputer architec-tures. In: Proceedings of the ACM/IEEE conference on Supercomputing, Supercomputing ’90. IEEE,USA pp 169–177
20. Reistad B, Gifford DK (1994) Static dependent costs for estimating execution time. In: Proceedingsof the Conference on LISP and functional programming. ACM, pp 65–78
21. Yang J, Ahmad I, Ghafoor A (1993) Estimation of execution times on heterogeneous supercomputerarchitectures. In: Proceedings of International Conference on Parallel Processing, ICPP ’93. IEEE,USA, pp 219–226
22. Iverson MA, Ozguner F, Follen GJ (1996) Run-time statistical estimation of task execution times forheterogeneous distributed computing. In: Proceedings of International Symposium on High Perfor-mance Distributed Computing, HPDC ’96. IEEE, USA, p 263
23. de Assunccao MD, di Costanzo A, Buyya R (2009) Evaluating the cost-benefit of using cloud computingto extend the capacity of clusters. In: Proceedings of the International Symposium on High Performance,Distributed Computing, HPDC’09. pp 141–150
24. Othman M, Abdullah M, Ibrahim H, Subramaniam S (2008) A2dlt: Divisible load balancing modelfor scheduling communication-intensive grid applications. In: Bubak M, Albada G, Dongarra J, SlootP (eds) Computational Science ICCS 2008, Lecture Notes in Computer Science, vol. 5101. Springer,New York, pp 246–253
25. Othman, M., Abdullah, M., Ibrahim, H., Subramaniam, S.: New optimal load allocation for schedulingdivisible data grid applications. In: Gabrielle A, Jaroslaw N, Edward S, GeertDick A, Jack D, Peter SMA(eds) Computational Science ICCS 2009, Lecture Notes in Computer Science, vol. 5544. Springer,New York, pp 165–174. doi:10.1007/978-3-642-01970-8_17
26. Abdullah M, Othman M (2013) Cost-based multi-qos job scheduling using divisible load theory incloud computing. Procedia Computer Science 18. 2013 International Conference on ComputationalScience. pp 928–935
27. Iyer G, Veeravalli B, Krishnamoorthy S (2012) On handling large-scale polynomial multiplicationsin compute cloud environments using divisible load paradigm. Aerosp Electron Syst IEEE Trans48(1):820–831
123












![RESEARCHARTICLE · PDF filetwostudiesreportedfollow-upresults,namely 1month[39]and3months[41]after treat-ment,long-termeffects werenotstudied. ... (2013) [41] Allocation: randomized,](https://img.pdfslide.net/doc/110x75/5aaa8ac77f8b9a9a188e5be7/researcharticle-namely-1month39and3months41after-treat-mentlong-termeffects.jpg)















