Embed Size (px)
Citation preview

Rapid Prototyping of Machine Translation Systems
A Tale of Two Case Studies
Srinivas Bangalore
Giuseppe Riccardi
AT&T Labs-Research
Joint work with German Bordel and Vanessa Gaudin

Many thanks…to
• Alicia Abella• Tirso Alonso• Iker Arizmendi• Barbara Hollister• Mike Peñagarikano

Outline
• Machine Translation (MT) Past and Present
• Data Bottleneck and MT bootstrapping
• Consensus-based MT
• MT Evaluation
• Subjective and Objective Measures
• The Two Case Studies• Demo

Machine Translation: Past and Present
1947-1954
1954-1966
1966-1980s
1980-1990
1990-present
MT as code breaking, IBM-Georgetown Univ. demonstration
Large bilingual dictionaries, linguistic and formal grammar motivated syntactic reordering, lots of funding, little progress
ALPAC report: “there is no immediate or predictable prospect of useful machine translation”.1966
Translation continued in Canada, France and Germany. Beyond English-Russian translation. Meteo for translating weather reports. Systran in 1970
Emphasis on ‘indirect’ translation: semantic and knowledge-based.Advent of microcomputers. Translation companies: Systran, Logos, GlobalLink. Domain specific machine-aided translation systems.
Corpus-based methods: IBM’s Candide, Japanese ‘example-based’ translation.Speech-to-Speech translation: Verbmobil, Janus. ‘Pure’ to practical MT for embedded applications: Cross-lingual IR

Corpus-based Translation• Direct-translation methods relying on large
parallel corpora.– Statistical Translation (IBM in early 90’s)
• stochastic generative model; parameters estimated for lexical choice, lexical reordering
• reordering based on string positions• robust when encountered with new data
– Example-based Translation (Japanese research)• corpus of example translations• match previous instances, retrieve closest match• performs well for minor variants of previously
encountered examples; typical in limited domains
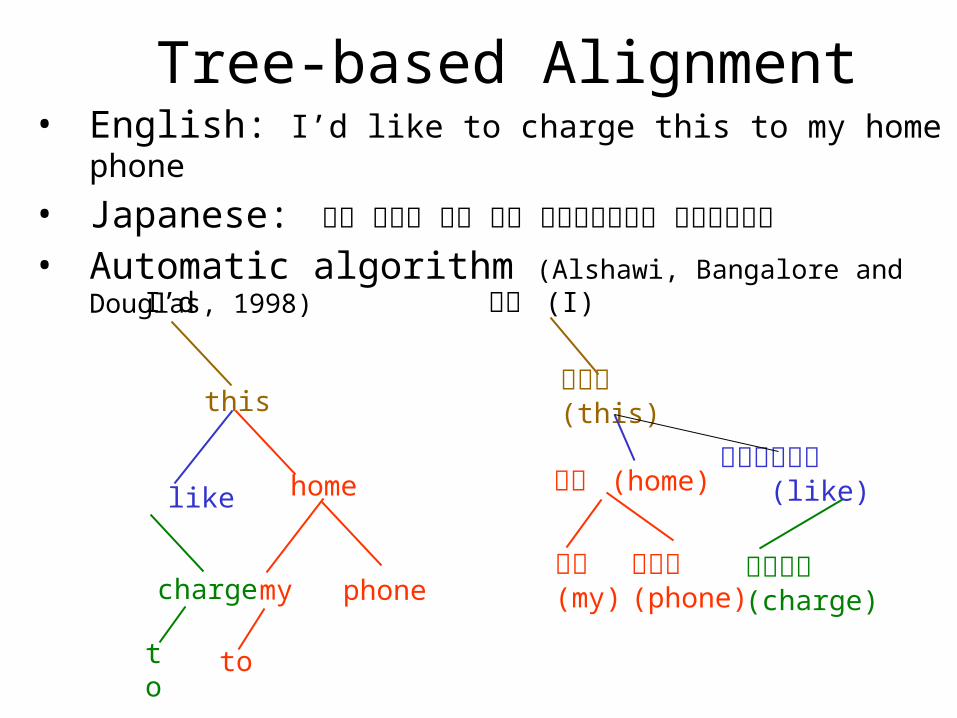
Tree-based Alignment• English: I’d like to charge this to my home phone
• Japanese: 私は これを 私の 家の 電話にチャージ したいのです• Automatic algorithm (Alshawi, Bangalore and Douglas, 1998)
私は (I)
これを (this)
したいのです (like)
チャージ(charge)
家の (home)
私の(my)
電話に(phone)
I’d
this
like
charge
home
my phone
toto

Statistical Translation Models• Head Transducer Model (Alshawi, Bangalore and
Douglas, 1998)
– Context-free grammar based transduction model
– Parsing complexity: O(n^6)• Stochastic Finite-State Transducer Model
(Bangalore and Riccardi 2000)
– Approximation of context-free grammar based transduction model
– Parsing complexity: O(n)– Tightly integrated with ASR

Translation in HMIHY

Bilingual Parallel Corpus
• Statistical translation techniques crucially depend on bilingual parallel corpus
• Typically, monolingual corpus is available
• How to create bilingual parallel corpus?
• Solution: Create bilingual parallel data with the help of translation houses+ high quality translations- expensive and longer turn around time

Alleviating the Bilingual Data Bottleneck
• Creating Parallel Corpora: – Use of off-the-shelf translation engines (via the web)
+ Per sentence translation
– No translation engine may be perfect; combine multiple translations
• Inducing Parallel Corpora:– Use of documents in multiple languages
+ Highly accurate translations
+ Unlimited data source
– Document translations not sentence translations
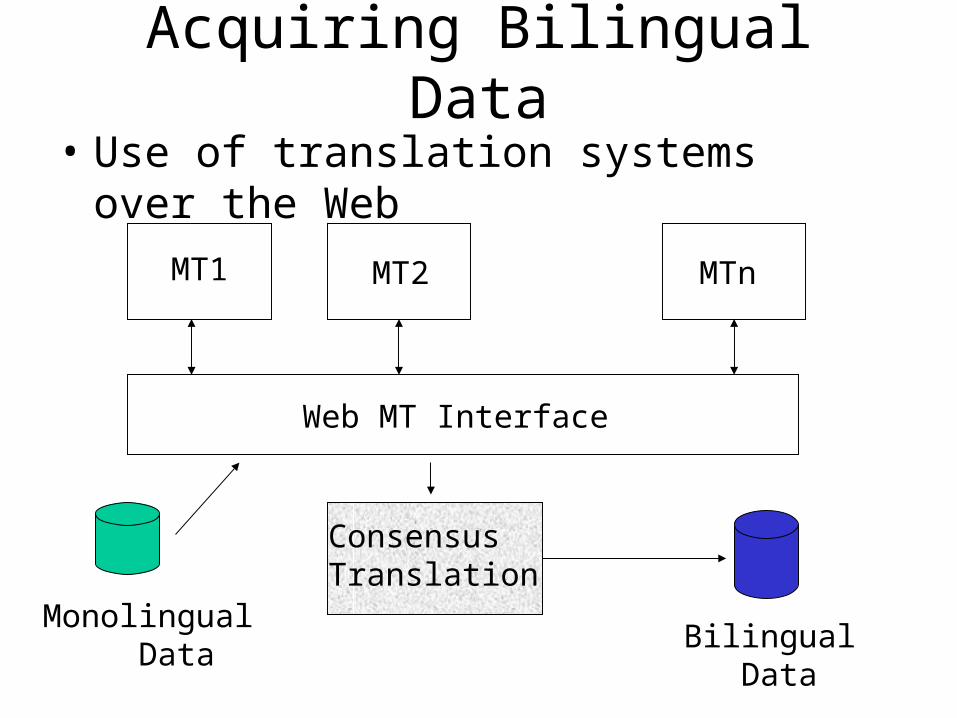
Acquiring Bilingual Data
• Use of translation systems over the Web
MT1 MT2 MTn
Web MT Interface
ConsensusTranslation
Monolingual Data
Bilingual Data

Consensus Translation• Translations differ in
– Lexical choice– Word order
• Create consensus among different translations: – Multi-string alignment
English: give me driving directions pleaseMT1: deme direccionnes impulsoras por favorMT2: deme direccionnes por favorMT3: deme direccionnes conductores por favorMT4: deme las direccionnes que conducen satisfacenMT5: deme que las direccionnes tendencia a gradan

String Alignment• Alignment of tokens between two strings
– Insertion, deletion and substitution operations
• Two string alignment complexity: O(n^2)
• Multi-string alignment complexity: O(n^m)– Exponential in the number of strings (m)
MT1: deme direccionnes impulsoras por favor
MT2: deme direccionnes por favor
Profile: * * d * *

Multi-String Alignment• Progressive multi-sequence alignment (Feng
and Doolittle 87)
– Compute the edit distance and profiles for m*(m-1)/2 pairs
– Repeat the following until one profile remains• Construct profile strings for least edit distance
string-string, string-profile or profile-profile pairs.
• Compute the edit distance between selected profile and the remaining strings and profiles
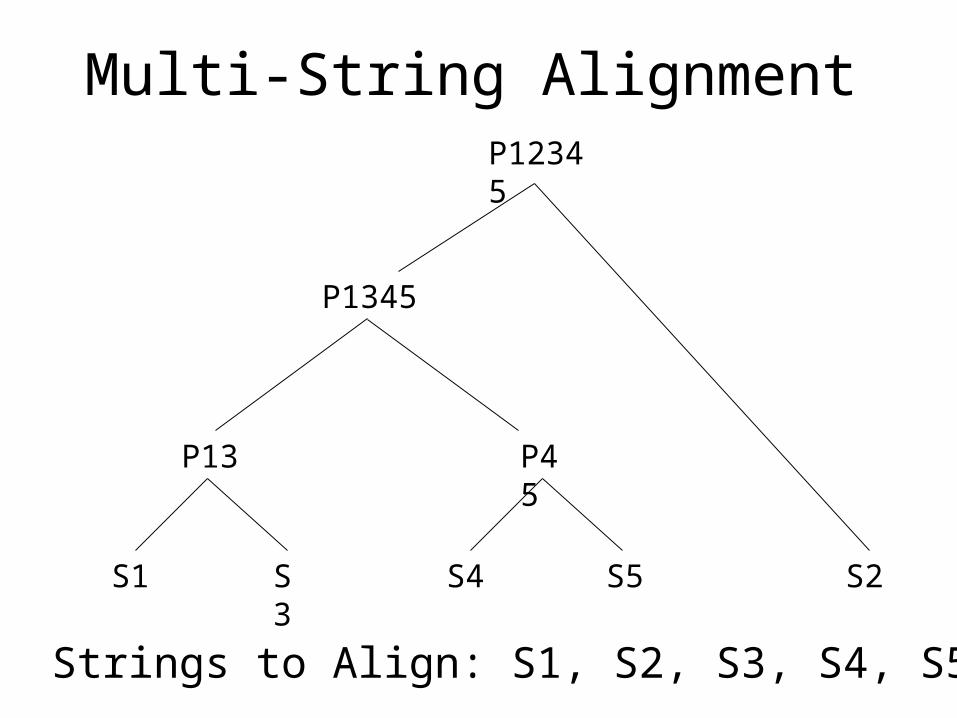
Multi-String Alignment
S2S1 S3
P13
S4 S5
P45
P1345
P12345
Strings to Align: S1, S2, S3, S4, S5
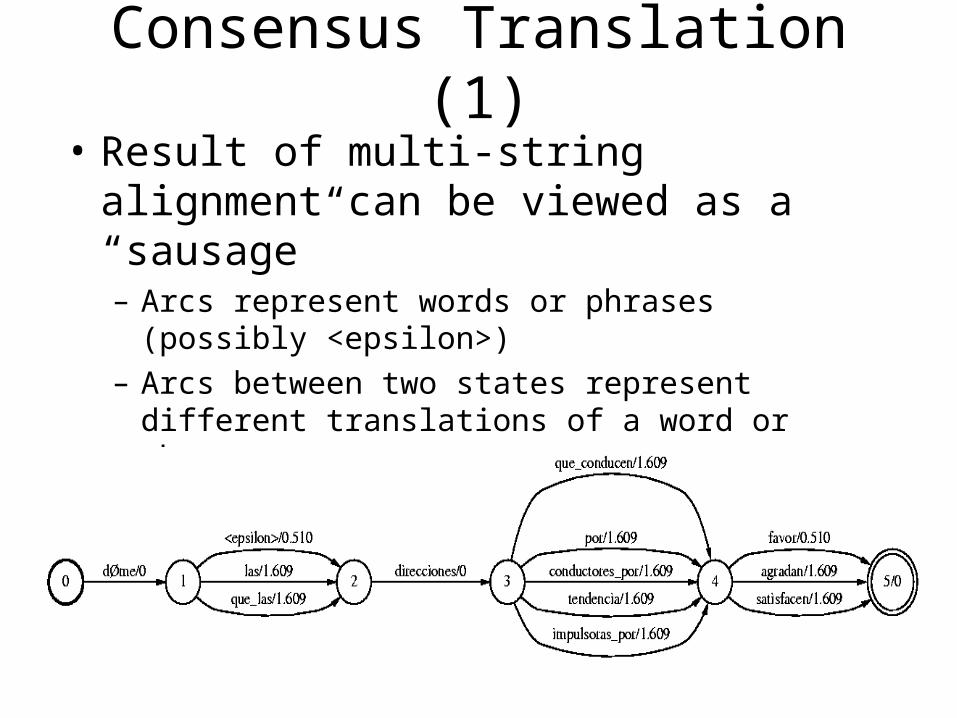
Consensus Translation (1)
• Result of multi-string alignment can be viewed as a “sausage”– Arcs represent words or phrases (possibly <epsilon>)
– Arcs between two states represent different translations of a word or phrase
– Fan out at a states indicates disagreement in translation
– Weights can be associated with each arc

Consensus Translation (2)• Retrieving the consensus translation
– Concatenate substrings from each segment of sausage
– Majority vote: Substring with most number of votes from each segment of the lattice
CMV = BestCostPath(Sausage)
• Some segments do not have a clear majority
• Use a posterior n-gram language model (λ) with weighting factor (α)
CMV+LM = BestCostPath(Sausage o α*λ)
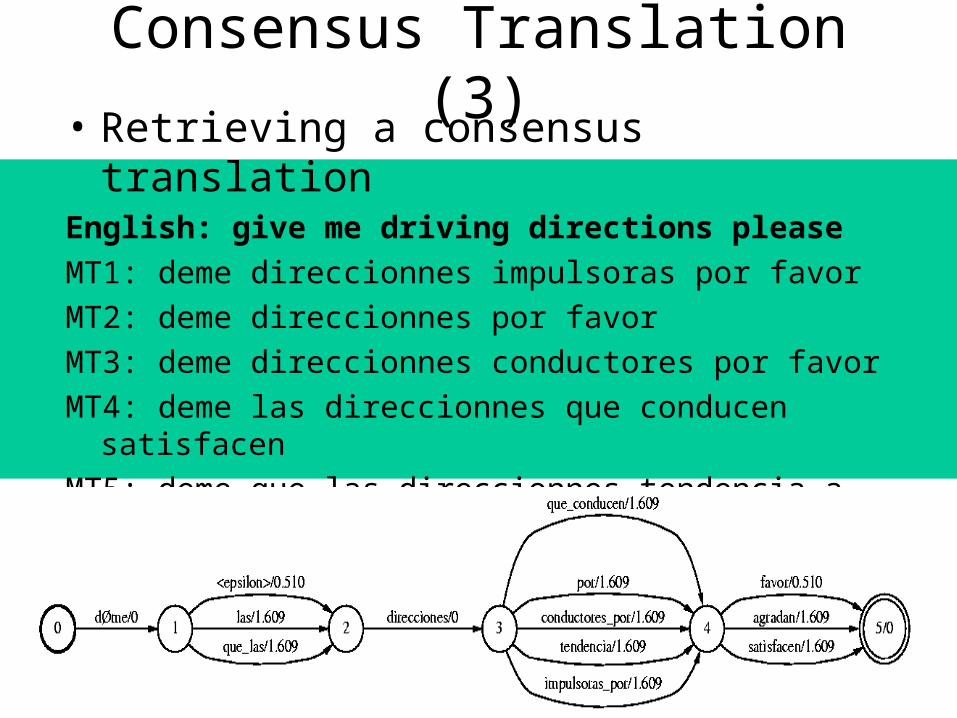
Consensus Translation (3)• Retrieving a consensus translationEnglish: give me driving directions please
MT1: deme direccionnes impulsoras por favor
MT2: deme direccionnes por favor
MT3: deme direccionnes conductores por favor
MT4: deme las direccionnes que conducen satisfacen
MT5: deme que las direccionnes tendencia a gradan
CT: deme direccionnes por favor

Outline
• Machine Translation (MT) Past and Present
• Data Bottleneck and MT bootstrapping
• Consensus-based MT
• MT Evaluation
• Subjective and Objective Measures
• The two Case Studies• Demo

• Spoken Dialog Corpus– Conference Registration System (“Innovation Forum”)– Average sentence length ~7 words/utt– Utterance from all dialog contexts
• Evaluation data
– Small (~0.5K) (labeler agreement)– Large (~4K) (MT performance)
Spoken Language Database

• Criteria– Objective (string accuracy, parse accuracy)– Subjective (Labeler Annotation)
• Translator agreement (disagreement)– Not as straightforward as speech utterance transcriptions (ASR)– One-to-Many mapping (Language Generation)– Local phenomena
ENGLISH Would you like to go out tomorrow night?ITALIAN Vuoi uscire domani sera? Vorresti uscire domani sera? Vuoi uscire fuori con me domani sera? Vuoi uscire con me domani sera?
MT Evaluation

MT Evaluation (1)objective
• String alignment– no direct relation with semantics/syntax
+ objective
+ system incremental evaluation
• Test set of manual translation (300 sentences)
• String edit distance between reference string and result string (length in words: R)Translation String Accuracy = 1 – (M + I + D + S) / R

Evaluation Results (1)objective
• Translation accuracy
CMV+LM 51.0%
CMV 47.7%
MT 1 29.8%
MT 2 23.7%
MT 3 35.2%
MT 4 46.9%
MT 5 49.7%

• Semantic/Syntactic scale (1-3)1 = The translation is semantically and syntactically correct
2 = The translation is semantically correct and the syntax has some flaws.
3 = The translation is neither semantically nor syntactically correct.
• Two Labelers
• The source language text was presented together with all hypotheses for the target language
MT Evaluation (2)subjective
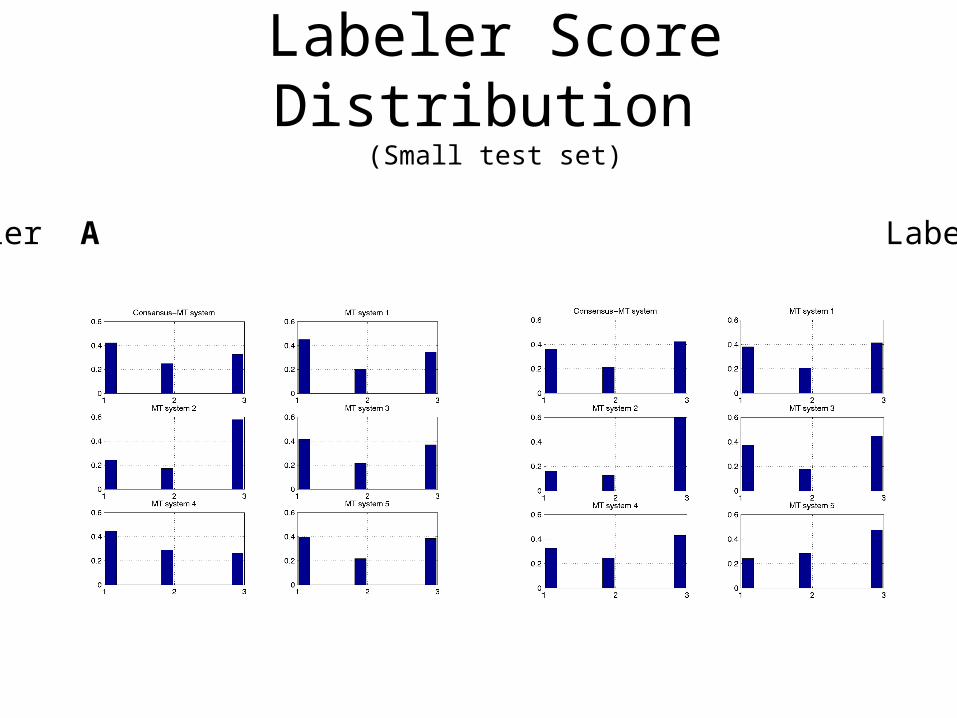
Labeler Score Distribution (Small test set)
Labeler A Labeler B

Labeler Distributional Agreement
CMV+LM 0.02
MT system 1 0.01
MT system 2 0.05
MT system 3 0.02
MT system 4 0.13
MT system 5 0.08
Binary random variablep_A(x=1) = 0.8p_B(x=1) = 0.2
KL(p_A || p_B) ~ 1
x
/p_B(x))log(p_A(x) (x)p_A
p_B) ||KL(p_A
Kulback-Leibler Distance
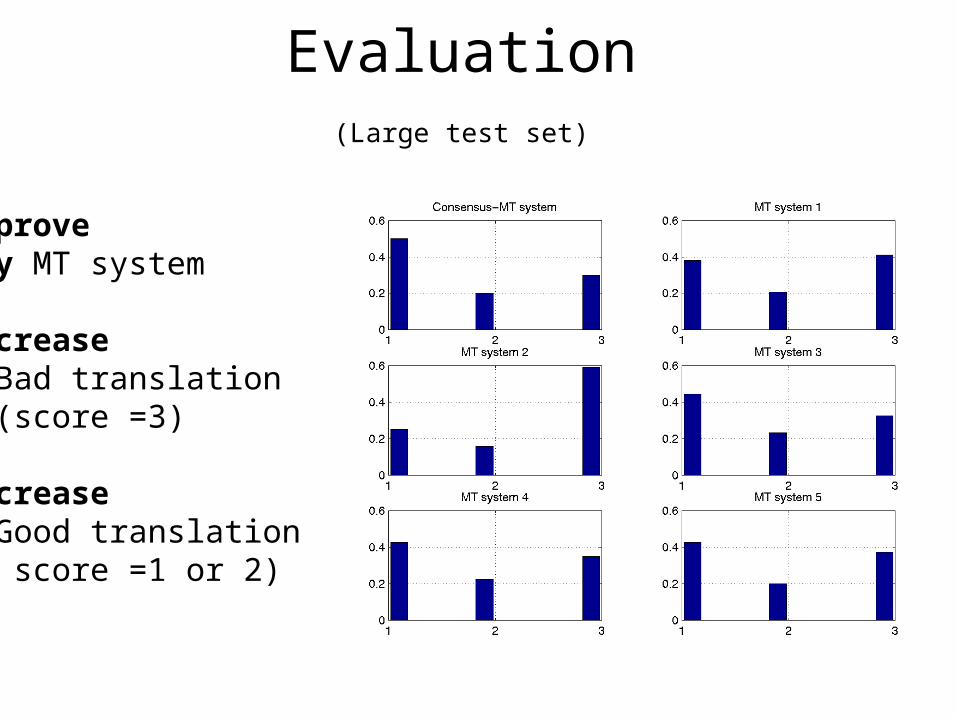
Evaluation (Large test set)
Improve any MT system
Decrease # Bad translation (score =3)
Increase# Good translation ( score =1 or 2)
Hubbub…me(Instant Messaging)

Characteristics of Hubbub Data• Human-human text-based interactions• Open domain, conversations can be on any topic,
may not be even task oriented• Spontaneous chatty style of language (average 8
words per turn)• Ungrammatical utterances and spelling errors• Visual conversation context plays a crucial role in
disambiguation• Translation errors may be compensated based on
the context of the conversation

Translation Accuracy• Test set: 300 sentences
0.380.39
0.40.410.420.430.440.450.460.470.48
3 7 15 29 44 58
Training Set Size (x 1000 sentences)
Tran
slatio
n A
ccur
acy
ConsensusTranslationMT 1
MT 2
MT 3

Summary
• Data Bottleneck solved by bootstrapping off existing MT systems
• Refine and Improve MT accuracy with Consensus-based MT
• Subjective and Objective Evaluation supports the improvement
Hubbub…me





























