Embed Size (px)
Citation preview

Real-Time Web Text Classification and Analysis of Reading Difficulty
Eleni MiltsakakiGraduate School of EducationUniversisty of Pennsylvania,
Philadelphia, PA 19104, [email protected]
Audrey TrouttComputer and Information Science
University of PennsylvaniaPhiladelphia, PA 19104, USA
Abstract
The automatic analysis and categorization ofweb text has witnessed a booming interest dueto the increased text availability of differentformats, content, genre and authorship. Wepresent a new tool that searches the web andperforms in real-time a) html-free text extrac-tion, b) classification for thematic content andc) evaluation of expected reading difficulty.This tool will be useful to adolescent and adultlow-level reading students who face, amongother challenges, a troubling lack of readingmaterial for their age, interests and readinglevel.
1 Introduction
According to the National Center for EducationStatistics, 29% of high school seniors in publicschools across America were below basic achieve-ment in reading in 2005 (U.S. Department of Edu-cation 2005). Once these students enter high school,their reading problems, which began much earlierin their education, are compounded by many fac-tors including a lack of suitable reading material fortheir age, interests and reading level. Most mate-rial written at a lower reading level is designed formuch younger students; high-school students find itboring or embarrassing. On the other hand materialdesigned for older students, while probably more in-teresting, is incomprehensible to such a student andleads to frustration and self-doubt. The internet isa vast resource for potential reading material and isoften utilized by educators in the classroom, but it isnot currently possible to filter the results of a search
engine query by levels of readability. Instead, thesoftware that some schools have adopted restrictsstudents to lists and directories of hand-selected edu-cational sites. This severely limits the content avail-able to students and requires near-constant mainte-nance to keep current with new information avail-able on the web.
We are developing a new system, Read-X, thatsearches the web and performs in real-time a) html-free text extraction, b) classification for thematiccontent and c) evaluation of expected reading dif-ficulty. For the thematic classification task we col-lected a manually labeled corpus to train and com-pare three text classifiers. Our system is part oflarger research effort to improve existing readabil-ity metrics by taking into account the profile of thereader. As a first step in this direction, we computedvocabulary frequencies per thematic area. We usethese frequencies to predict unknown words for thereader relative to her familiarity with thematic areas(Toreador). These tools (Read-X and Toreador) willbe useful to adolescent and adult low-level readingstudents who face, among other challenges, a trou-bling lack of reading material for their age, interestsand reading level.
The remainder of the paper is organized as fol-lows: first we will describe our motivation for cre-ating Read-X and Toreador, which is based on stud-ies that show that older struggling readers can makeimprovements in literacy and that those improve-ments can have a profound impact on their lives.Next we will describe existing technologies for liter-acy improvement and research related to our currentproject. Finally, we will give a detailed description

of Read-X and Toreador, including our methods ofevaluating the readability of texts, thematically clas-sifying the texts and modeling reader profiles intoreadability predictions, before concluding with anoutline of future work.
2 Educational motivation
Low reading proficiency is a widespread problemevident in the performance of adolescents in U.S.schools. The National Center for Education Statis-tics (NCES) in 2005, the latest year for which datais available, reports that only 29% of eight gradersin the United States achieved proficient or abovereading, meaning the remaining 71% of studentshad only part of the reading skills needed for pro-ficient work at their level or less (Snyder et al.,2006). (Hasselbring and Goin, 2004) reported that”as many as 20 percent of 17-year-olds have beenestimated to be functionally illiterate, and 44 per-cent of all high-school students have been describedas semi-literate”. Reading below grade level is a se-rious problem for adolescents as it may hinder com-prehension of textbooks and classroom materials inall fields. (Denti, 2004) mentions that ”most highschool textbooks are written at the tenth throughtwelfth grade levels with some textbooks used forU. S. government written at the seventeenth gradelevel”. Reading skills are tied to academics suc-cess and are highly correlated with with ”higher in-come and less unemployment, increased access tolifelong learning, greater amounts of personal read-ing for pleasure, and increased civic participation”(Strucker et al., 2007).
Recent research has shown that it is possibleto identify adult literacy students on the brink ofachieving reading fluency in order to provide themwith concentrated instruction, dramatically improv-ing their chances of attaining a high quality of life(Strucker et al., 2007). (Weinstein and Walberg,1993) studied the factors related to achievement inreading and found that ”frequent and extensive en-gagement in literacy-promoting activities as a youngadult was associated with higher scores on literacyoutcomes (independent of earlier-fixed characteris-tics and experiences),” which implies that throughample reading exercise students can achieve literacyregardless of their background.
The current and future versions of the system thatwe are developing uses natural language processingtechniques to provide learning tools for strugglingreaders. The web is the single most varied resourceof content and style, ranging from academic papersto personal blogs, and is thus likely to contain in-teresting reading material for every user and readingability. The system presented here is the first to ourknowledge which performs in real time a)keywordsearch, b)thematic classification and c)analysis ofreading difficulty. We also present a second sys-tem which analyzes vocabulary difficulty accordingto reader’s prior familiarity with thematic content.
3 Related work
In this section we discuss two main systems that aremost closely related to our work on text classifica-tion and analysis of readability.
NetTrekker is a commercially available searchtool especially designed for K-12 students and ed-ucators.1 NetTrekker’s search engine has access toa database of web links which have been manuallyselected and organized by education professionals.The links are organized thematically per grade leveland their readability level is evaluated on a scale of1-5. Level 1 corresponds to reading ability of grades1-3 and 5 to reading ability of grades 11-13. Net-trekker has been adopted by many school districtsin the U.S., because it offers a safe way for K-12students to access only web content that is age ap-popriate and academically relevant. On the otherhand, because the process of web search and classi-fication is not automated, it is practically impossiblefor NetTrekker to dynamically update its database sothat new material posted on the web can be included.However, Nettrekker’s manual classification of weblinks is a valuable resource of manually labeled data.In our project, we use this resource to build labeleddataset for training statistical classifiers. We discussthe construction and use of this corpus in more detailin Section 5.1).
The REAP tutor, developed at the Language Tech-nologies Institute at Carnegie Mellon, is designed toassist second language learners to build new vocabu-lary and facilitates student specific practice sessions(Collins-Thompson and Callan, 2004), (Heilman et
1Available at http://www.nettrekker.com.

al., 2006). The tutor allows the user to search fortextual passages as well as other text retrieved fromthe web that contains specific vocabulary items. Theeducational gain for students practicing with the tu-tor has been shown in several studies (e.g., (Heil-man et al., 2006)). Like NetTrekker, REAP retrievesand classifies web text off-line. Unlike, Nettrekker,however, textual analysis is automated. REAP’s in-formation retrieval system (Collins-Thompson andCallan, 2004) contains material from about 5 millionpages gathered with web crawling methods. Thedata have been annotated and indexed off-line. An-notations include readability level computed with anearlier version of the method developed by (Heilmanet al., 2007), (Heilman et al., 2006) described be-low, rough topic categorizations (e.g., fiction, non-fiction) and some elements of grammatical structure(e.g., part-of-speech tagging).
(Heilman et al., 2007) experiment with a systemfor evaluation of reading difficulty which employsboth grammatical features and vocabulary. Thegrammatical features built in the model were iden-tified from grammar books used in three ESL lev-els. (Heilman et al., 2007) find that while the vo-cabulary model alone outperformed the grammar-based model, the combined model performed best.All models performed better in English text and lesswell in ESL text. It would be very interesting to in-tegrate this system with Read-X and evaluate its per-formance.
To address issues specific to struggling read-ers, (Hasselbring and Goin, 2004) developedthe Peabody Literacy Lab (PLL), a completelycomputer-based program, using a variety of tech-nologies to help students improve their ability toread. We will not elaborate further on this workbecause the PPL’s focus in not in developing newtechnologies. PLL develops experimental programsusing existing technologies.
4 Read-X project overview
In the Read-X project, we have developed two toolswhich are currently independent of each other. Thefirst tool Read-X, performs a web search and classi-fies text as detailed in (5.1). The second tool Tore-ador, analyzes input text and predicts vocabulary dif-ficulty based on grade or theme-specific vocabulary
frequencies. The vocabulary predicted to be unfa-miliar can be clicked on. This action activates a dic-tionary look-up search on Wordnet whose display ispart of the tool’s interface. More details and screen-shots are given in (??).
5 Description of Read-X
Below we describe in detail the technical compo-nents of Read-X: internet search, text extraction andanalysis of readability.
5.1 Read-X: Web search and text classification
Internet search. Read-X performs a search of theinternet using the Yahoo! Web Services. Whenthe search button is clicked or the enter key de-pressed after typing in a keyword, Read-X sends asearch request to Yahoo! including the keywordsand the number of results to return and receives re-sults including titles and URLs of matching web-sites in an XML document. The Yahoo! WebService is freely available for non-commercial usewith a limit of 5000 requests per day. If Read-Xis deployed for use by a wide number of users, itmay be necessary to purchase the ability to processmore requests with Yahoo or another search engine.Read-X is currently available at http://net-read.blogspot.com.
Text extraction. Read-X then retrieves the html,xml, doc or PDF document stored at each URLand extracts the human-readable text.2 text is ex-tracted from html and xml documents using thescraper provided by Generation Java by Henri Yan-dell, see www.generationjava.com. The MicrosoftWord document scraper is part of the Apache Jakartaproject by the Apache Software Foundation, seewww.apache.org. The PDF scraper is part of theApache Lucene project, see www.pdfbox.org. Allthree of these external tools are available under acommon public license as open source software un-der the condition that any software that makes use ofthe tools must also make the source code available tousers.
2Being able to identify appopriate web pages whose contentis reading material and not “junk” is a non-trivial task. (Petersenand Ostendorf, 2006) use a classifier for this task with moderatesuccess. We “read” the structure of the html text to decide if thecontent is appropriate and when in doubt, we err on the side ofthrowing out potentially useful content.
Readability analysis. For printed materials, thereare a number of readability formulas used to mea-sure the difficulty of a given text; the New Dale-Chall Readability Formula, The Fry ReadabilityFormula, the Gunning-Fog Index, the AutomatedReadability Index, and the Flesch Kincaid ReadingEase Formula are a few examples. Usually these for-mulas count the number of syllables, long sentences,or difficult words in randomly selected passagesof the text. To automate the process of readabil-ity analysis, we chose three Readability algorithms:Lix, Rix, see (Anderson, 1983), and Coleman-Liau,(Coleman and Liau, 1975), which were best suitedfor fast calculation and provide the user with eitheran approximate grade level for the text or a readabil-ity classification of very easy, easy, standard, diffi-cult or very difficult. When each text is analyzed byRead-X the following statistics are computed: to-tal number of sentences, total number of words, to-tal number of long words (seven or more characters,and total number of letters in the text. Below we de-scribe how each of the three readability scores arecalculated using these statistics. Steps taken to de-velop more sophisticated measures for future imple-mentations are presented in Section 7).
Lix readability formula: The Lix readability al-gorithm distinguishes between five levels of read-ability: very easy, easy, standard, difficult, or verydifficult. If W is the number of words, LW is thenumber of long words (7 or more characters), andS is the number of sentences, them the Lix index isLIX = W/S + (100 * LW) / W. An index of 0-24corresponds to a very easy text, 25-34 is easy, 35-44standard, 45-54 difficult, and 55 or more is consid-ered very difficult.
Rix readability formula: The Rix readabilityformula consists of the ratio of long words to sen-tences, where long words are defined as 7 or morecharacters. The ratio is translated into a grade levelas indicated in Table (1).
Coleman-Liau readability formula: TheColeman-Liau readability formula is similar to theRix formula in that it gives the approximate gradelevel of the text. Unlike the Lix and Rix formulas,the Coleman-Liau formula requires the randomselection of a 100 word excerpt from the text.Before the grade level can be calculated, the clozepercent must be estimated for this selection. The
Ratio GradelLevel7.2 and above College6.2 and above 125.3 and above 114.5 and above 103.7 and above 93.0 and above 82.4 and above 71.8 and above 61.3 and above 50.8 and above 40.5 and above 30.2 and above 2Below 0.2 1
Table 1: Rix translation to grade level
Classifier Supercategories SubcategoriesNaive Bayes 66% 30%MaxEnt 78% 66%MIRA 76% 58%
Table 2: Performance of text classifiers.
cloze percent is the percent of words that, if deletedfrom the text, can be correctly filled in by a collegeundergraduate. If L is the number of letters in the100 word sample and S is the number of sentences,then the estimated cloze percent is C = 141.8491- 0.214590 * L + 1.079812 * S. The grade levelcan be calculated using the Coleman-Liau formula,where grade level is -27.4004 * C + 23.06395. Inthe SYS display we round the final result to thenearest whole grade level.
6 Text classification
The automated classification of text into predefinedcategories has witnessed strong interest in the pastten years. The most dominant approach to this prob-lem is based on machine learning techniques. Clas-sifiers are built which learn from a prelabeled set ofdata the characteristics of the categories. The perfor-mance of commonly used classifiers varies depend-ing on the data and the nature of the task. For the textclassification task in Read-X, we a) built a corpus ofprelabeled thematic categories and b)compared theperformance of three classifiers to evaluate their per-

formance on this task.We collected a corpus of approximately 3.4 mil-
lion words and organized it into two sets of label-ing categories. We hand collected a subset of labels(most appropriate for a text classification task) fromthe set of labels used for the organization of web textin NetTrekker (see 3). We retrieved text for eachcategory by following the listed web links in Net-Trekker and manually extracting text from the sites.Our corpus is organized into a small hierarchy, withtwo sets of labels: a)labels for supercategories andb)labels for subcategories. There are 8 supercate-gories (Arts, Career and business, Literature, Phi-losophy and religion, Science, Social studies, Sportsand health, Technology) and 41 subcategories (e.g.,the subcategories for Literature are Art Criticism,Art History, Dance, Music, Theater). Subcategoriesare a proper subset of supercategories but in the clas-sification experiments reported below the classifierstrained independently in the two data sets.
We trained three classifiers for this task: a NaiveBayes classifier, a Maximum Entropy classifier andMIRA, a new online learning algorithm that incor-porates a measure of confidence in the algorithm(fordetails see (Crammer et al., 2008)). 3 The perfor-mance of the classifiers trained on the supercate-gories and subcategories data is shown in Table (2).All classifiers perform reasonably well in the super-categories classification task but are outperformedby the MaxEnt classifier in both the supercategoriesand subcategories classifications. The Naive Bayesclassifiers performs worst in both tasks. As ex-pected, the performance of the classifiers deterio-rates substantially for the subcategories task. Thisis expected due to the large number of labels and thesmall size of data available for each subcategory. Weexpect that as we collect more data the performanceof the classifiers for this task will improve. In an ear-lier implementation of Read-X, thematic classifica-tion was a coarser three-way classificaition task (lit-erature, science, sports). In that implementation theMaxEnt classifier performed at 93% and the NaiveBayes classifier performed at 88% correct. In futureimplementations of the tool, we will make available
3We gratefully acknowledge MALLET, a collection ofstatistical NLP tools written in Java, publicly available athttp://mallet.cs.umass.edu and Mark Dredze forhis help installing and running MIRA on our data.
all three levels thematic classification.
6.1 Runtime and interface
The first implementation of Read-X, coded in Java,has been made publicly available. The jar file iscalled from the web through a link and runs on Win-dows XP or Vista with Java Runtime Environment 6and internet connection. Search results and analysisare returned within a few seconds to a maximum of aminute or two depending on the speed of the connec-tion. The Read-X interface allows the user to con-strain the search by selecting number of returned re-sults and level of reading difficulty. A screenshot ofRead-X (cropped for anonymity) is shown in Figure(1). The rightmost column is clickable and showsthe retrieved html-free text in an editor. From thiseditor the text can be saved and further edited on theuser’s computer.
7 Description of Toreador
The analysis of reading difficulty based on standardreadability formulas gives a quick and easy way tomeasure reading difficulty but it is problematic inseveral ways. First, readability formulas computesuperficial features of word and sentence length. Itis easy to show that such features fail to distin-guish between sentences which have similar wordand sentence lengths but differ in ease of interpreta-tion. Garden path sentences, bountiful in the linguis-tic literature, demonstrate this point. Example (1) isharder to read than example (2) although the latter isa longer sentence.
(1) She told me a little white lie will come backto haunt me.
(2) She told me that a little white lie will comeback to haunt me.
Secondly, it is well known that there are aspectsof textual coherence such as topic continuity andrhetorical structure which are not captured in countsof words and sentences (e.g., (Higgins et al., 2004),(Miltsakaki and Kukich, 2004))
Thirdly, readability formulas do not take into ac-count the profile of the reader. For example, a readerwho has read a lot of literary texts will have less dif-ficulty reading new literary text than a reader, with asimilar educational background, who has never read

Figure 1: Search results and analysis of readability
any literature. In this section, we discuss the firststep we have taken towards making more reliablepredictions on text readability given the profile ofthe reader.
Readers who are familiar with specific thematicareas, are more likely to know vocabulary that isrecurring in these areas. So, if we have vocabu-lary frequency counts per thematic area, we are in abetter position to predict difficult words for specificreaders given their reading profiles. Vocabulary fre-quency lists are often used by test developers as anindicator of text difficulty, based on the assumptionthat less frequent words are more likely to be un-known. However, these lists are built from a varietyof themes and cannot be customized for the reader.We have computed vocabulary frequencies for allsupercategories in the thematically labeled corpus.The top 10 most frequent words per supercategoryare shown in Table (3). Vocabulary frequencies pergrade level have also been computed but not shownhere.
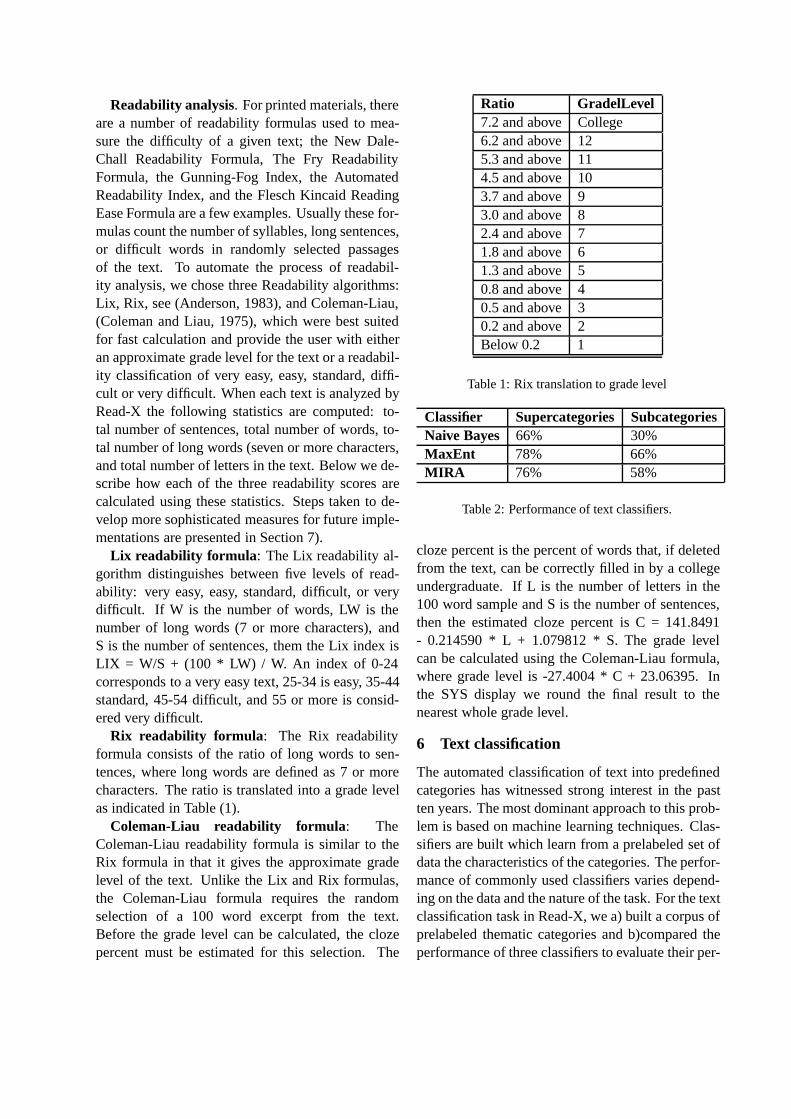
Toreador is a tool which runs independently ofRead-X and it’s designed to predict unknown vocab-ulary for specific reader and grade profiles currently
specified by the user. A screenshot of Toreador isshown in Figure (2). The interface shows two tabslabeled “Enter text here” and “Read text here”. The“Enter text here” tab allows the user to customizevocabulary difficulty predictions by selecting the de-sired grade or theme.4 Then, text can be copied fromanother source and pasted in the window of the tool.The tool will analyze the text and in a few secondsreturn the results fo the analysis in the tab labeled“Read text here”, shown in Figure (3). Toreadorchecks the vocabulary frequency of the words in thepasted text and returns the text highlighted with thewords that do not rank high in the vocabulary fre-quency index for the chosen categories (grade ortheme). The highlighted words are clickable. Whenthey are clicked, they entry information from Word-Net appears on the right panel. The system hasnot been evaluated yet so some tuning will be re-quired to determine the optimal cut-off frequencypoint for highlighting words. An option is also avail-able to deactivate highlights for ease of read or read-ing for global meaning. Words that the system has
4The screenshot in Figure (2) shows an earlier version of thetool where only three thematic categories were available.
Figure 2: Text analysis of vocabulary difficulty
Arts Career and Business Literature Philosophy Science Social Studies Sports, Health Technology
Word Freq Word Freq Word Freq Word Freq Word Freq Word Freq Word Freq Word Freqmusical 166 product 257 seemed 1398 argument 174 trees 831 behavior 258 players 508 software 584leonardo 166 income 205 myself 1257 knowledge 158 bacteria 641 states 247 league 443 computer 432instrument 155 market 194 friend 1255 augustine 148 used 560 psychoanalytic 222 player 435 site 333horn 149 price 182 looked 1231 belief 141 growth 486 social 198 soccer 396 video 308banjo 128 cash 178 things 1153 memory 130 acid 476 clemency 167 football 359 games 303american 122 analysis 171 caesar 1059 truth 130 years 472 psychology 157 games 320 used 220used 119 resources 165 going 1051 logic 129 alfalfa 386 psychotherapy 147 teams 292 systems 200nature 111 positioning 164 having 1050 things 125 crop 368 united 132 national 273 programming 174artist 104 used 153 asked 1023 existence 115 species 341 society 131 years 263 using 172wright 98 sales 151 indeed 995 informal 113 acre 332 court 113 season 224 engineering 170
Table 3: 10 top most frequent words per thematic category.
not seen before, count as unknown and can be erro-neously highlighted (for example, the verb “give” inthe screenshot example). We are currently runningevaluation studies with a group of volunteers. Whilewe recognize that the readability formulas currentlyimplemented in Read-X are inadequate measures ofexpected reading difficulty, Toreador is not designedas an improvement over Read-X but as a componentmeasuring expected vocabulary difficulty. Otherfactors contributing to reading difficulty such as syn-tactic complexity, propositional density and rhetor-ical structure will be modeled separately in the fu-ture.
8 Summary and future work
In this paper we presented preliminary versions oftwo tools developed to assist struggling readers iden-tify text that is at the desired level of reading diffi-
culty while at the same time interesting and relevantto their interests. Read-X is, to our knowledge, thefirst system designed to locate, classify and analyzereading difficulty of web text in real time, i.e., per-forming the web search and text analysis in seconds.Toreador analyzes the vocabulary of given text andpredicts which words are likely to be difficult for thereader. The contribution of Toreador is that its pre-dictions are based on vocabulary frequencies calcu-lated per thematic area and are different dependingon the reader’s prior familiarity with the thematic ar-eas.
We emphasize the shortcomings of the exist-ing readability formulas, currently implemented inRead-X, and the need to develop more sophisticatedmeasures of reading difficulty. We recognize thatperceived difficulty is the result of many factors,which need to be analyzed and modeled separately.

Figure 3: Text analysis of vocabulary difficutly
Our goal in this research project is not to provide asingle readability score. Instead, we aim at buidlingmodels for multiple factors and provide individualevaluation for each, e.g., measures of syntactic com-plexity, ambiguity, propositional density, vocabu-lary difficulty, required amount of inference to iden-tify discourse relations and prior knowledge of thereader.
In future work, several studies are needed. Toachieve satisfactory performance for the fine grainedthematic categories, we are collecting more data. Wealso plan to run the subcategories classification notas an independent classificaition task but as subclas-sification task on supercategories. We expect that theaccuracy of the classifier will improve but we alsoexpect that for very fine thematic distinctions alter-native approaches may be be required (e.g., give spe-cial weights for key vocabulary that will distinguishbetween sports subthemes) or develop new classi-fication features beyond statistical analysis of worddistributions.
More sophisticated textual, semantic and dis-course organization features need to be exploredwhich will reflect the perceived coherence of the textbeyond the choice of words and sentence level struc-ture. The recently released Penn Discourse Tree-
bank 2.0 (Prasad et al., 2008)) 5 is a rich source withannotations of explicit and implicit discourse con-nectives and semantic labels which can be used toidentify useful discourse features. Finally, more so-phisticated models are needed of reader profiles andhow they impact the perceived reading difficulty ofthe text.
9 Acknowledgments
We are grateful to Mark Dredze for his help run-ning MIRA and Ani Nenkoca for useful discussionson readability. We thank the CLUNCH group atthe Computer and Information Science departmentat the University of Pennsylvaniaand and two re-viewers for their very useful feedback. This work ispartially funded by the GAPSA/Provosts Award forInterdisciplinary Innovation to Audrey Troutt, Uni-versity of Pennsylvania.
References
Jonathan Anderson. 1983. Lix and rix: Variations ofa little-known readability index. Journal of Reading,26(6):490–496.
M Coleman and T. Liau. 1975. A computer readabil-ity formula designed for machine scoring. Journal ofApplied Psychology, 60:283–284.
5Project site, http://www.seas.upenn.edu/˜pdtb

K. Collins-Thompson and J. Callan. 2004. Informa-tion retrieval for language tutoring: An overview ofthe REAP project. In Proceedings of the Twenty Sev-enth Annual International ACM SIGIR Conference onResearch and Development in Information Retrieval(poster descritpion.
Koby Crammer, Mark Dredze, John Blitzer, and Fer-nando Pereira. 2008. Batch performance for an on-line price. In The NIPS 2007 Workshop on EfficientMachine Learning.
Lou Denti. 2004. Introduction: Pointing the way: Teach-ing reading to struggling readers at the secondary level.Reading and Writing Quarterly, 20:109–112.
Ted Hasselbring and Laura Goin. 2004. Literacy instruc-tion for older struggling readers: What is the role oftechnology? Reading and Writing Quarterly, 20:123–144.
M. Heilman, K. Collins-Thompson, J. Callan, and M. Es-kenazi. 2006. Classroom success of an intelligenttutoring system for lexical practice and reading com-prehension. In Proceedings of the Ninth InternationalConference on Spoken Language Processing.
M. Heilman, K. Collins-Thompson, J. Callan, and M. Es-kenazi. 2007. Combining lexical and grammaticalfeatures to improve readability measures for first andsecond language texts. In Proceedings of the HumanLanguage Technology Conference. Rochester, NY.
Derrick Higgins, Jill Burstein, Daniel Marcu, and Clau-dia Gentile. 2004. Evaluating multiple aspects of co-herence in student essays. In Proceedings of the Hu-man Language Technology and North American As-sociation for Computational Linguistics Conference(HLT/NAACL 2004).
Eleni Miltsakaki and Karen Kukich. 2004. Evaluationof text coherence for electronic essay scoring systems.Natural Language Engineering, 10(1).
Sarah Petersen and Mari Ostendorf. 2006. Assessing thereading level of web pages. In Proceedings of Inter-speech 2006 (poster), pages 833–836.
Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Milt-sakaki, Livio Robaldo, Aravind Joshi, and BonnieWebber. 2008. The penn discourse treebank 2.0. InProceedings of the 6th International Conference onLanguage Resources and Evaluation (LREC 2008).
T. D. Snyder, A.G. Tan, and C.M. Hoffman. 2006. Digestof education statistics 2005 (nces 2006-030). In U.S.Department of Education, National Center for Edu-cation Statistics. Washington, DC: U.S. GovernmentPrinting Office.
John Strucker, Yamamoto Kentaro, and Irwin Kirsch.2007. The relationship of the component skills ofreading to ials performance: Tipping points and fiveclasses of adult literacy learners. In NCSALL Reports
29. Boston: National Center for the Study of AdultLearning and Literacy (NCSALL).
Thomas Weinstein and Herbert J. Walberg. 1993. Practi-cal literacy of young adults: educational antecedentsand influences. Journal of Research in Reading,16(1):3–19.