Embed Size (px)
Citation preview

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
Aprendizagem Automática:
REDES NEURONAIS COMPUTACIONAIS
“The Connectionists”

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Redes Neuronais Computacionais: [Programas simulando ] redes massivamente paralelas, constituidas por elementos simples interligados (usualmente adaptativos), interagindo com o mundo real tentando simular o que o sistema nervoso biológico faz (Kohonen, 1987). • O conexionismo é um sério candidato à modelação de certos
comportamentos inteligentes e, por vezes, uma alternativa à Inteligência Artificial clássica.
Rumelhart e McClelland : RNAs não são uma alternativa à IA mas complementares. São uma estrutura distribuída para as primitivas suportando esquemas de representação mais abstratos.
James L. (Jay) McClelland
Chair of the Department of Psychology, and founding
Director of the Center for Mind, Brain and Computation.
Stanford University
David
Rumelhart

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
Conexionismo: Computação paralela, efetuada por grandes redes, utilizando a interconexão de elementos simples - processadores (neurónios). O conexionismo trabalha com modelos distribuídos, em que cada conceito é espalhado por várias unidades, e cada unidade representa uma combinação de caraterísticas.
Conexionismo: Bain e W. James psicólogos do Sec. XIX propuseram que o cérebro (e a memória) estava organizado em redes de neurónios interligados W. James precisou que as conexões eram elétricas e que a memória era um conjunto de circuitos aprendidos
William James
1842-1910

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
•No conexionismo, o conhecimento não é representado por expressões declarativas (modelos locais como na IA clássica), mas pela estrutura e estado de ativação da rede.
• O contexto necessário para um problema é toda a rede. Cada unidade é afetada pela atividade global de todas as outras unidades, e esta influência é modulada pelos pesos das conexões.
• Frank Rosenblat (fins dos anos 50 e início dos anos 60 do Sec. XX) propôs a rede neuronal mais simples: PERCEPTRON • Classificador linear:
• f(x) =1 se w . x + b>0 onde w é um vector (pesos), ‘.’ o produto =0 interno e b uma constante.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Marvin Minsky ataca o Perceptron no seu livro “Perceptrons” (com Seymour Papert) e que desqualifica a aproximação à IA através desse modelo. Mas também relança a discussão das Redes Neuronais Artificiais.
• Minsky originou o afastamento da IA das RNA durante os anos 70 e parte dos 80. Contribuindo para o “inverno da IA”.
•Rumelhart e McCleland ( anos 80 do sec. XX) desenvolvem o conexionismo através do que chamaram PDP- Parallel Distributed Processing
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• As Técnicas Conexionistas são particularmente prometedoras na resolução de problemas para os quais as aproximações algorítmicas tradicionais se revelam ineficazes e inoperantes. Por exemplo:
• Reconhecimento de Formas / padrões • Classificação e tratamento do sinal • Comando reativo de Robôs • Previsões baseados na análise de um historial
• O resultado da aproximação Conexionista pode ser vista como a Aprendizagem de um processo de classificação de uma população de casos pré-existentes.
• Problemas menos apropriados ao uso das RNA: - problemas resolúveis por passos sequenciais;
- quando existem procedimentos/regras fixos para a decisão; -- sempre que a justificação da solução é importante.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
A caraterização do conexionismo baseado em Redes Neuronais Computacionais implica:
• Aprendizagem: • Capacidade Adaptativa
Os sistemas não são programados no sentido convencional do termo.
O que é aprendido é a Rede de Conexão e suas interligações e não um conjunto de acontecimentos particulares.
O sistema deverá ser capaz de generalizar, o que implica a tolerância da utilização (a submissão à rede) de atributos com valores pouco precisos.
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
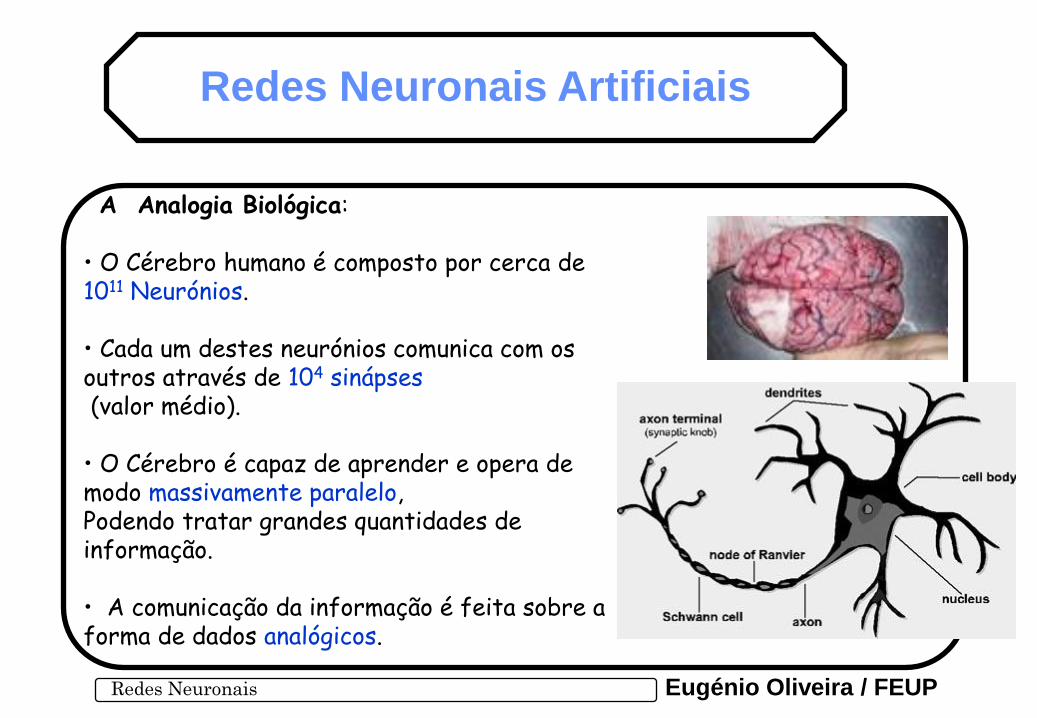
• O Cérebro humano é composto por cerca de 1011 Neurónios.
• Cada um destes neurónios comunica com os outros através de 104 sinápses (valor médio). • O Cérebro é capaz de aprender e opera de modo massivamente paralelo, Podendo tratar grandes quantidades de informação. • A comunicação da informação é feita sobre a forma de dados analógicos.
A Analogia Biológica:
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
Sinal analógico (Som)
Sinal digital

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
dendrites

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
Uma Rede Neuronal é estabelecida através da ligação entre os elementos unitários. • O peso representativo da conexão entre dois elementos, determina o grau de interação entre eles.
Esta interação pode ser de “excitação” ou de “inibição”, o que é indicado pelo sinal que afecta o peso respetivo da ligação.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Cada um dos elementos da Rede tenta manter ou modificar o seu estado, de acordo com as interações que tem com os elementos a que está diretamente ligado.
Estas operações são realizadas em paralelo por todos os elementos da rede (cooperação das unidades). • A informação encontra-se totalmente distribuída, e consiste no conjunto de valores representativos dos pesos das conexões entre todas as unidades.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Uma Rede Neuronal Computacional fica caraterizada depois de conhecermos:
1 - A unidade básica que é o elemento de processamento (denominado neurónio artificial) 2 - A estrutura das ligações (a topologia da Rede)
3 - A Lei de Aprendizagem

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
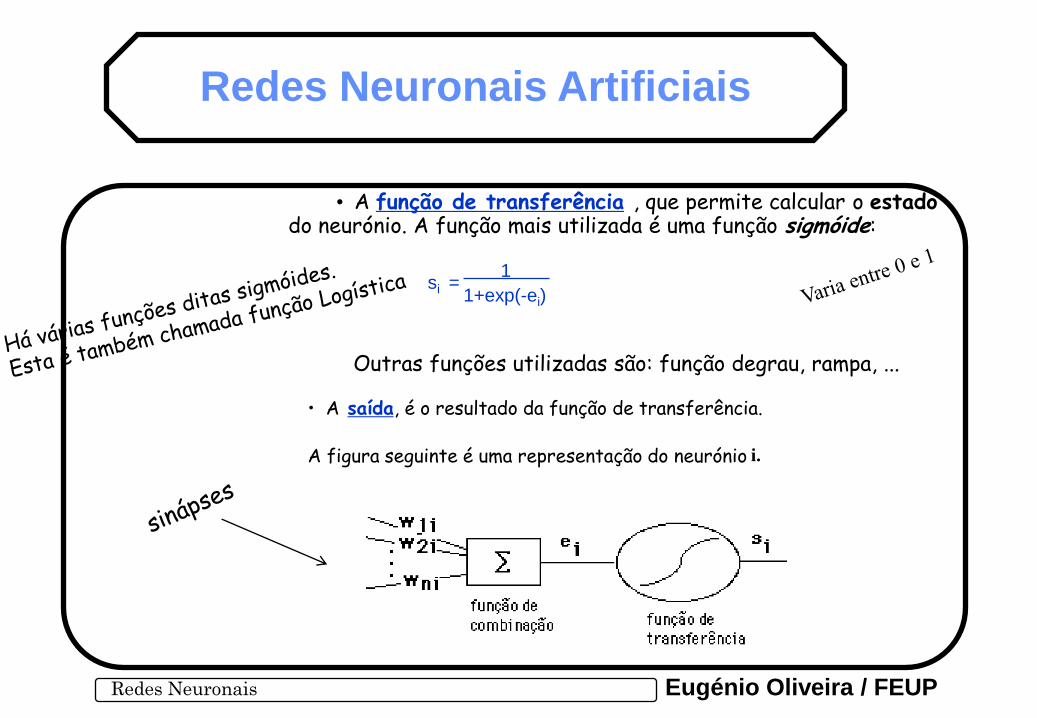
1. O ELEMENTO DE PROCESSAMENTO
Um neurónio é constituído por cinco partes fundamentais:
• A entrada , através da qual a unidade adquire a informação.
• Os pesos das conexões , com outros neurónios, que determinam a influência dos valores de entrada no estado deste neurónio.
• A função de combinação , que regra geral é uma soma ponderada das entradas (os coeficientes de ponderação são os pesos das conexões):
e i = j=1
n w ji *s j
Outras funções utilizadas são: máximo, mínimo, ...
j entradas no neurónio i
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• A função de transferência , que permite calcular o estado do neurónio. A função mais utilizada é uma função sigmóide:
si = 1
1+exp(-ei)
Outras funções utilizadas são: função degrau, rampa, ...
• A saída , é o resultado da função de transferência.
A figura seguinte é uma representação do neurónio i.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
2. ESTRUTURA DAS LIGAÇÕES
A Arquitetura das Redes Neuronais Computacionais pode ser dos tipos:
• redes totalmente conetadas
• redes de camada única
• redes de múltiplas camadas

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
SAÍDA
ESCONDIDAS
ENTRADA
TIPOS
DE
CONEXÕES
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
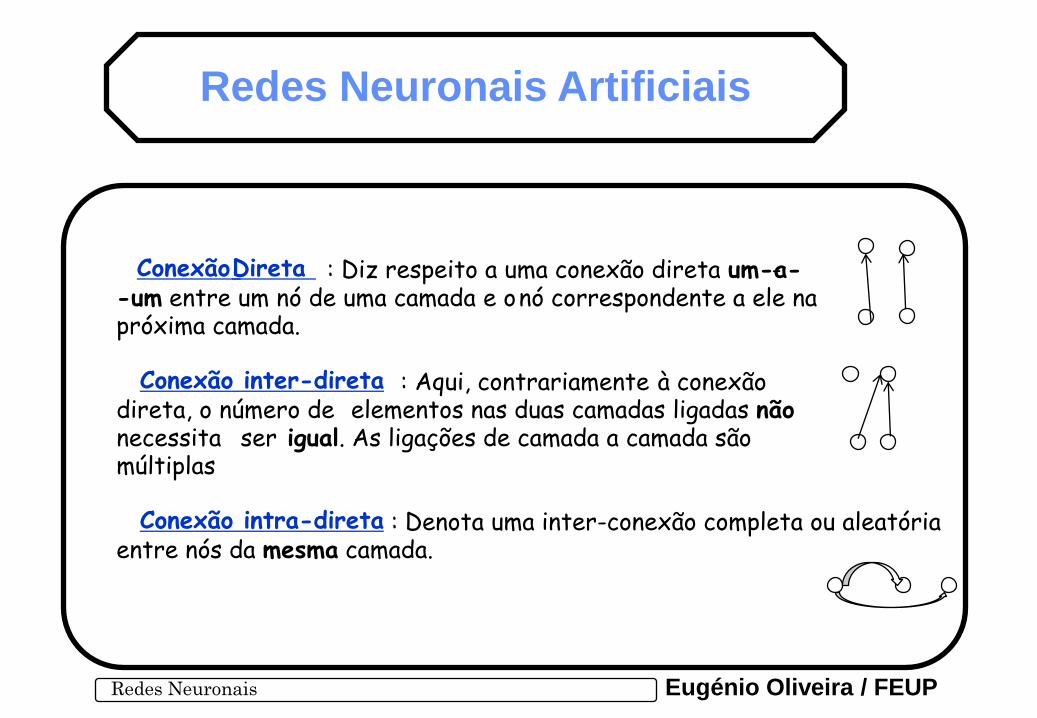
Conexão Direta : Diz respeito a uma conexão direta um-a- - -um entre um nó de uma camada e o nó correspondente a ele na próxima camada.
Conexão inter-direta : Aqui, contrariamente à conexão direta, o número de elementos nas duas camadas ligadas não necessita ser igual. As ligações de camada a camada são múltiplas
Conexão intra-direta : Denota uma inter-conexão completa ou aleatória entre nós da mesma camada.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
3. APRENDIZAGEM DA REDE
As redes neuronais artificiais são inspiradas em trabalhos de neuro-fisiologia. Sabemos que, no cérebro, a aprendizagem se efectua, em certa medida, por modificação devida aos contatos sinápticos.
Assim também, na aprendizagem da rede, os pesos das conexões são modificados para realizar, da melhor forma possível, a relação Entrada/ Saída desejada.
Os métodos de aprendizagem nas redes neuronais são:
• Aprendizagem por Reforço (Reinforcement Learning) • Aprendizagem supervisionada • Aprendizagem não supervisionada

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
3.1 APRENDIZAGEM POR REFORÇO ( aprendizagem por Recompensa)
Não são fornecidas as saídas corretas para as entradas consideradas mas são atribuídos prémios/castigos de acordo com o facto de a saída ter ou não interesse .
• As alterações dos pesos das conexões são apenas baseadas nos Níveis de Atividade entre unidades diretamente ligadas. Estas informações são locais. • Neste método, quando é efetuada a modificação de peso de uma conexão, não é conhecido o desempenho global de toda a Rede.
• A Aprendizagem deve terminar quando a atividade neuronal termina ou é suficientemente baixa. • Este método também é designado por “Aprendizagem com um Crítico”

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
D Wij = si * sj
3.1.1 HEBB
O estado de um neurónio pode possuir dois valores: valor 1 -- o neurónio está ativo. valor 2 -- o neurónio não está ativo.
A eficácia da sinápse entre duas unidades aumenta quando a atividade entre elas é correlacionada.
Os pesos das conexões são modificados pela lei:
D
3.1.2 HOPFIELD
Este método é idêntico ao apresentado anteriormente, mas a regra utilizada para a modificação dos pesos das conexões é:
w ij
= (2si -1)*(2sj -1)
Donald O. Hebb (1904 – 1985) Psicólogo
canadiano influente em Neuropsicologia

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Usam-se valores binários para os neurónios quer para a lei de Hebb quer para a lei de Hopfield • Neurónio i tem saída Si e está ligado ao neurónio j que tem saída Sj através de um peso Wij • A alteração no peso:
Wij(t+1) = Wij(t) + D Wij • Na lei de Hebb ou se mantém ou se aumenta o peso das sinápses
• Na lei de Hopfield: Quando: Si = Sj = 0 --> D =1 esta é a situação de nós correlacionados Si = Sj =1 --> D =1 Si = 0 e Sj = 1--> D = -1 esta é a situação de nós não correlacionados Si = 1 e Sj = 0 --> D = -1
D w ij = (2si -1)*(2sj -1)
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
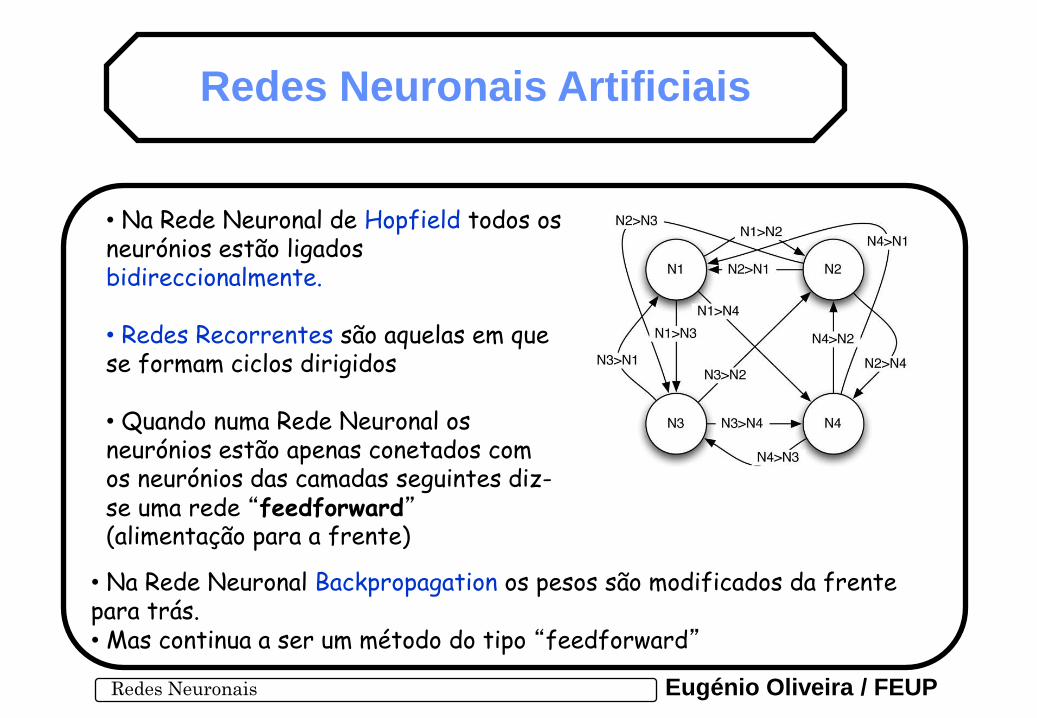
• Na Rede Neuronal de Hopfield todos os neurónios estão ligados bidireccionalmente. • Redes Recorrentes são aquelas em que se formam ciclos dirigidos • Quando numa Rede Neuronal os neurónios estão apenas conetados com os neurónios das camadas seguintes diz-se uma rede “feedforward” (alimentação para a frente)
• Na Rede Neuronal Backpropagation os pesos são modificados da frente para trás. • Mas continua a ser um método do tipo “feedforward”

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
3.2 APRENDIZAGEM SUPERVISIONADA
• A rede produz a sua própria resposta a uma configuração que é presente à entrada, após o que um supervisor apresenta a resposta correta.
• Se as duas respostas são idênticas, não há necessidade de modificar os pesos das conexões. • Caso contrário, a diferença entre estes dois valores é utilizada para
modificar o peso das conexões existentes na rede. Este método é também denominado "aprendizagem com um supervisor".
Si
3.2.1 PERCEPTRON
Este método é utilizado em redes de camada única. Os pesos das conexões são modificados de acordo com a lei:
c -- constante s j -- saída da unidade j d j -- saída correcta da unidade j (fornecida pelo supervisor)
D Wij = c *(sj-dj)*si
-- saída da unidade i
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
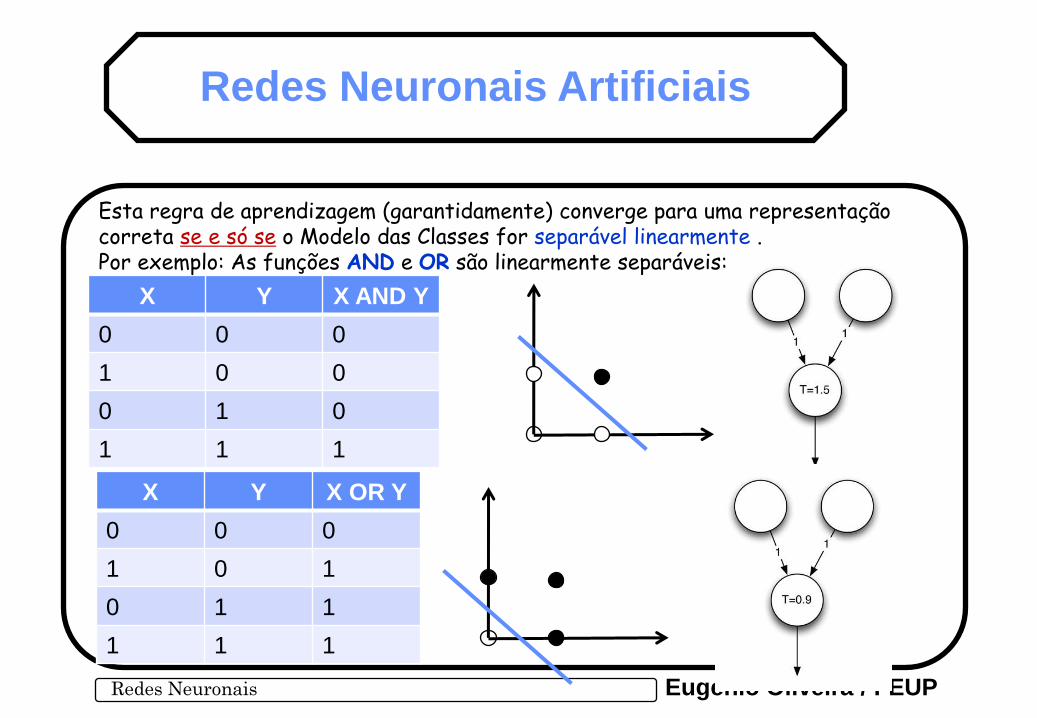
X Y X OR Y
0 0 0
1 0 1
0 1 1
1 1 1
X Y X AND Y
0 0 0
1 0 0
0 1 0
1 1 1
Esta regra de aprendizagem (garantidamente) converge para uma representação correta se e só se o Modelo das Classes for separável linearmente . Por exemplo: As funções AND e OR são linearmente separáveis:

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
Esta regra de aprendizagem converge (garantidamente) para uma representação correta se e só se a classe dos modelos for separável linearmente.
X Y X OR Y
0 0 0
1 0 1
0 1 1
1 1 0
A função XOR NÃO é linearmente separável!
Crítica de M. Minsky. Só ultrapassada pelo grupo PDP
D Wij = c *(sj-dj)*si
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
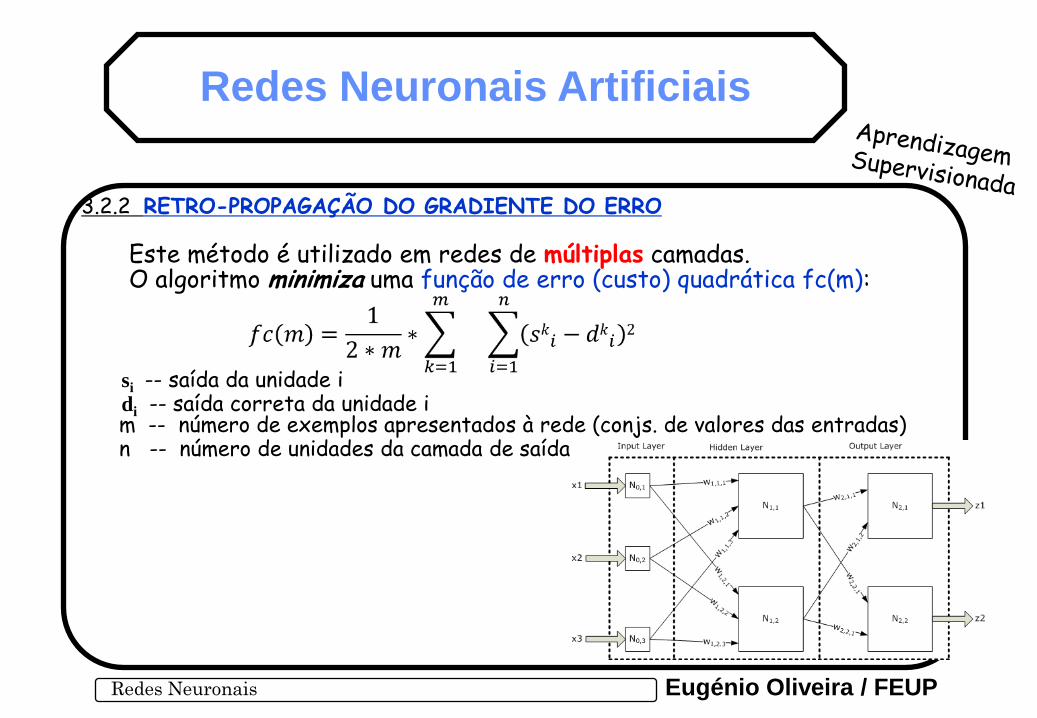
3.2.2 RETRO-PROPAGAÇÃO DO GRADIENTE DO ERRO
Este método é utilizado em redes de múltiplas camadas. O algoritmo minimiza uma função de erro (custo) quadrática fc(m):
si -- saída da unidade i di -- saída correta da unidade i
m -- número de exemplos apresentados à rede (conjs. de valores das entradas) n -- número de unidades da camada de saída

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
Vamos denominar os estados das unidades de entrada de ei (i=1...A), os estados das unidades intermédias de cj
(j=1...B) e os estados das unidades de saída de s k (k=1...C).
Os pesos das conexões que ligam a camada de entrada e a camada intermédia de w1 e que ligam a camada intermédia e a camada de saída de w2
.
3.2.2 RETRO-PROPAGAÇÃO DO GRADIENTE DO ERRO
Vamos apresentar o algoritmo deste método, que é o mais utilizado:
Suponhamos que a rede possui uma camada de entrada com A unidades, uma camada intermédia com B unidades e uma camada de saída com C unidades.
.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
S
A função de transferência utilizada é a função sigmoide:
1 -- Apresentar um exemplo ei , i=1 ... A
2 -- Propagar os estados da camada de entrada para a 1ª camada intermédia.
c j = 1
1+exp(- i w1 ij *e i) ,i=1 ... A j=1 ... B
S
3 -- Propagar os estados da camada intermédia para a camada de saída.
s k = 1
1+exp( - j w2 jk *c j ) ,j=1 ... B k=1 ... C
4 -- Cálculo dos erros nas unidades de saída. ds
k = sK *(1-s k )*(d k -s k ) , k=1 .. C
d k é a saída correcta da unidade k.
si = 1
1+exp(-ei)

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
A função de transferência utilizada é a função sigmoide: sk = 1
1+exp(-e i )
ds k = sK *(1-s k )*(d k -s
k ) , k=1 .. C
d k é a saída correcta da unidade k.
A derivada está relacionada com a variação das função (aqui de erro) A derivada de um quociente é: d(u/v) = [v*d(u) – u*d(v)] / v2 A derivada da exponencial: d(eu )= eu . d(u)
Então: d(sk) = [ 0- ( 1* d(1+exp(-ei)) ) ] / (1+exp(-ei))2 = -d(1+exp(-ei)) / (1+exp(-ei))2 =-d (exp(-ei)) / (1+exp(-ei))2 = - exp(-ei) * (-1) / (1+exp(-ei) )2 = exp(-ei) / (1+exp(-ei) )2= (1/ 1+exp(-ei) ) – (1/ (1+exp(-ei) )2 )
= (1/ 1+exp(-ei) ) * ( 1- (1/1+exp(-ei) ) ) = sk * (1-sk) é a derivada da saída sk e que será o fator de ponderação no erro daquela saída
x/(1+x)2 = [1/(1+x)] – [1/(1+x) 2 ]

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
NOTA: dsk está relacionado com o erro na saída uma vez que dk-sk é o erro. Então sk * (1- sk) é o peso (dependendo da derivada) associado a cada parcela (do erro em cada saída). 1º) sk perto de 0 ou de 1 : exemplos: 0,1 *0,9 = 0,09 0,9 * 0,1 = 0,09 resultam valores (pesos) menores e logo, variações mais pequenas
2º) sk com valores intermédios: exemplo. 0,5 * 0,5 = 0,25 resultam valores (pesos) maiores e logo, variações maiores O que quer dizer que no meio da curva (sigmóide) as variações são maiores que nos extremos. Dá-se maior importância ao erro quando a saída Sk
está no meio da sigmóide (por isso o fator que multiplica pelo erro é superior).
Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
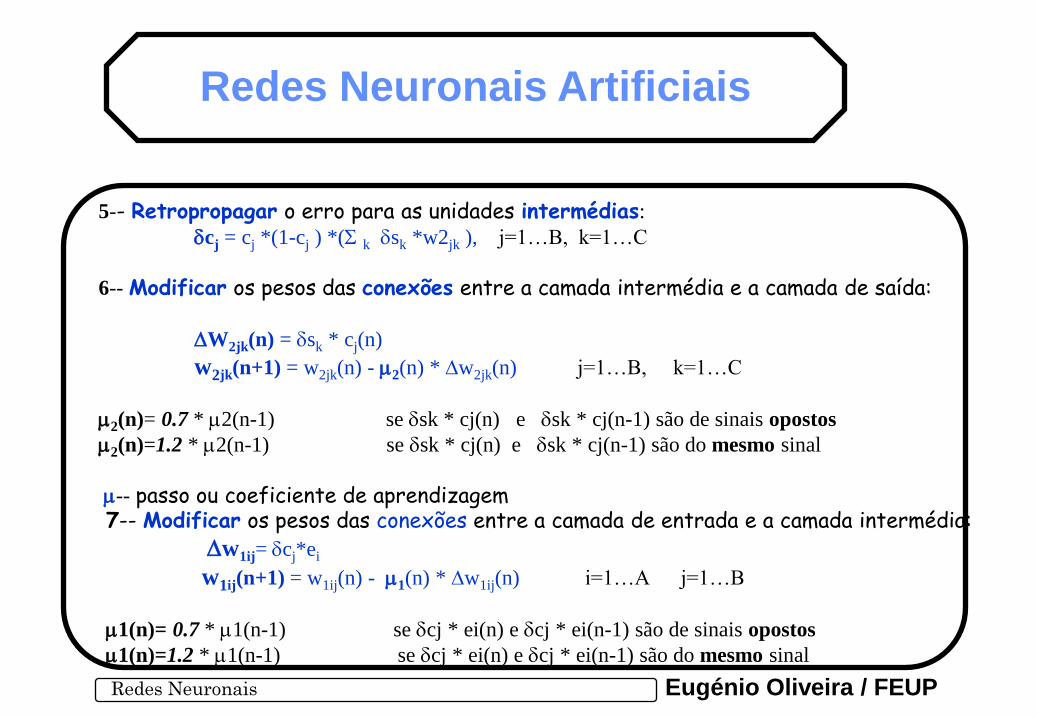
7-- Modificar os pesos das conexões entre a camada de entrada e a camada intermédia: Dw1ij= dcj*ei
w1ij(n+1) = w1ij(n) - m1(n) * Dw1ij(n) i=1…A j=1…B
m1(n)= 0.7 * m1(n-1) se dcj * ei(n) e dcj * ei(n-1) são de sinais opostos
m1(n)=1.2 * m1(n-1) se dcj * ei(n) e dcj * ei(n-1) são do mesmo sinal
5-- Retropropagar o erro para as unidades intermédias:
dcj = cj *(1-cj ) *(S k dsk *w2jk ), j=1…B, k=1…C
6-- Modificar os pesos das conexões entre a camada intermédia e a camada de saída:
DW2jk(n) = dsk * cj(n)
w2jk(n+1) = w2jk(n) - m2(n) * Dw2jk(n) j=1…B, k=1…C
m2(n)= 0.7 * m2(n-1) se dsk * cj(n) e dsk * cj(n-1) são de sinais opostos
m2(n)=1.2 * m2(n-1) se dsk * cj(n) e dsk * cj(n-1) são do mesmo sinal
m-- passo ou coeficiente de aprendizagem

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
8-- Se o número de exemplos já apresentados à rede é inferior ao número de exemplos que desejamos utilizar, retornar a 1. 9-- Retornar a 1 se pretendemos que o erro ( valor das modificações dos pesos das conexões: Dw ) seja diminuído. Com este método podemos classificar exemplos não linearmente separáveis !
Resposta à crítica feita por Marvin Minsky ao “perceptron” de Rosenblatt

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
NOTA:
• Quanto mais elevado for o parâmetro m , maiores são as modificações efectuadas no valor dos pesos, e mais rápida é a aprendizagem. • No entanto, se este valor for demasiado elevado, podem ocorrer oscilações nos pontos próximos de curvatura pronunciada na função de optimização. • Importa manter m baixo. Mas isso leva a uma aprendizagem lenta.
• Deve obtêr-se um compromisso. As equações apresentadas nos pontos 6 e 7 podem ser alteradas para: Dwijk(n) = dsk*cj + b * Dwijk(n-1) j=1…B, k=1…C
b- torna as variações relacionadas com as anteriores e diminui a probabilidade de encontrar um mínimo local.
Determina o efeito da variação anterior na variação da atual direcção de variação. “Filtra” as variações da superfície de erro; impede a curvatura pronunciada

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Como d(dik) é 0, ficámos com (Sik - dik) * d(Sik)
• mas d(Sik ) = d( 1/1+exp(-entradas)) = - d(1+exp(-entradas)) / (1+exp(-entradas)2 ) =
(-exp(-entradas) * -1) / (1+exp(-entradas))2
Ou seja, a derivada calculada é : (-exp(-entradas) * -1) / (1+exp(-entradas))2 * (Sik - dik)
•Consideremos a função do custo quadrática
que é a função a minimizar no algoritmo de retropropagação (apresentando m exemplos a uma rede com n saídas)
• Todas as parcelas do segundo somatório representam a mesma função e são positivas. Logo basta minimizar o somatório exterior dessa função. Como consideramos m exemplos (o somatório):
d[1/2m Skm (Sik - dik)2 ] = m*1/2m * d(Sik - dik)
2 = 1/2 * 2 * (Sik - dik) * d(Sik - dik) =
(Sik - dik) * d(Sik - dik)

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
•Por outro lado, se considerarmos o erro nas saídas da Rede dSk = Sk * (1- Sk ) * (Sk - dk) =
1/1+exp(-entradas) * [1- ( 1/1+exp(-entradas)) * (Sk - dk)] =
(1/1+exp(-entradas) - 1/(1+exp(-entradas))2 ) * (Sk - dk) = ( exemplo: 1/a-1/a2 = (a-1)/a2 )
(1+exp(-entradas) - 1) / (1+exp(-entradas))2 ) * (Sk - dk) =
exp(-entradas) / (1+exp(-entradas))2 * (Sk - dk)
• Logo, minimizar a função de custo inicial (através da sua derivada) é equivalente a minimizar o erro das saídas (dSk ).
Ou seja, ao alterar os pesos das ligações da rede através do algoritmo da retropropagação
(tentando minimizar os erros nas saídas),
está-se a fazer o erro tender para zero minimizando a função de custo do erro quadrático.
exp(-entradas) / (1+exp(-entradas))2 * (Sik - dik)

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
Algumas dificuldades são encontradas na determinação de:
- tamanho da rede - nº de ligações - arquitetura
• Se a rede cresce, aprende melhor, mas perde capacidade de generalização:
- efectua associações exatas entre as formas de saída e de entrada
- apresenta comportamento aleatório quando são apresentadas formas desconhecidas na entrada da rede.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Quanto menos ligações e camadas interiores existirem, mais se força a Rede a generalizar !!
• É necessário tentar encontrar a rede de menor tamanho que consiga memorizar o conjunto de entradas que lhe são apresentadas.
• O problema de determinação de uma configuração da rede pode ser visto como um sistema de equações em que:
nº ligações independentes nº de variáveis
nº saídas * nº exemplos de aprendizagem nº de equações
Deve ser verificada a relação:
nº ligações independentes ≤ nº saídas*nº exemplos aprendizagem

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
3.3 APRENDIZAGEM NÃO SUPERVISIONADA
A aprendizagem ocorre como uma adaptação própria da rede, na detecção
de regularidades no espaço de entrada, sem feedback directo de um supervisor. Extrai-se a estrutura inerente na amostra de entrada.
Este método de aprendizagem aplica-se quando não dispomos, à priori, de qualquer indicação sobre possíveis classificadores.
Este método é também denominado "aprendizagem sem supervisor".
3.3.1 APRENDIZAGEM COMPETITIVA
Quando é presente um exemplo à entrada da rede, todas as unidades vão
concorrer pelo direito à resposta. Aquela que responde mais fortemente, é a célula mais ativa. E assim, os pesos das conexões existentes nesta unidade são ajustados de forma a que a sua resposta seja reforçada, tornando assim mais provável que a identificação dessa qualidade particular da entrada seja efectuada por esta unidade.
O resultado da aprendizagem é que unidades individuais estão envolvidas na detecção de caraterísticas distintas, o que pode ser usado para classificar um conjunto de configurações de entrada.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
3.3.2 KOHONEN
Este método é utilizado em redes de camada única. No fim da aprendizagem, cada unidade responde
selectivamente a uma classe: isto é, para uma determinada configuração de entrada, uma unidade encontra-se mais ativa que as outras. Este método é idêntico ao anterior, mas neste caso, quando uma unidade vence a competição, são modificados os pesos das conexões que existem nesta unidade e em unidades vizinhas desta.
Para a determinação da unidade mais ativa, utiliza-se a regra seguinte:
min c j , c j = i=0
n
(s i -w ij ) 2 , j=1 ... m
n -- número de unidades da camada de entrada
m -- número de unidades da camada de saída

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
DEEP LEARNING
Deep learning (deep structured learning) descende do Neocognitrão de Fukushima (1980)
2 tipos de células, simples e complexa, em cascata. S-Cells extraem “features” locais e as
pequenas deformações são toleradas pelas c-cells. Camadas posteriores integram e
classificam gradualmente as “features” locais das entradas.
Algoritmos de Aprendizagem Automática que tentam modelar abstrações de alto nível a
partir de Dados usando múltiplas camadas de processamento incluindo estruturas
complexas de múltiplas transformações não-lineares.
•Deep learning baseia-se na representação dos dados observados.
Por Ex: uma observação de uma Imagem, pode ser representada por:
• vetor de intensidade de pixeis; conjunto de linhas (arestas); regiões do espaço
(faces) que corresponde a diferentes características.
Algumas são mais apropriadas para certas tarefas de aprendizagem (p.ex. Reconhecimento
de objetos)

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
• Usa multiplas camadas de unidades de processamento não lineares
• Cada camada aprende (supervisada ou não) características.
• Camadas em hierarquia desde a extração das caraterísticas mais simples às mais abstratas
•CAP (credit Path Assignment) é uma cadeia de transformações da entrada para a saída.
Descreve as ligações causais entrada-saída e varia em comprimento.
•Nas RN feedforward o comprimento do CAP é o nº de camadas escondidas +1.
•Nas RN recorrentes, os sinais podem atravessar uma camada mais que uma vez, CAP é
potencialmente ilimitado.
•CAP tem de ser >2 e se for >10 será um forte Deep Learning.
• Por vezes as camadas são ganaciosas, no sentido que só as melhores características dão
entradas da camada seguinte.
•Deep Learning usa algoritmos para, com eficiência, extrair de forma não (ou semi) -
supervisionada as características apropriadas à aprendizagem da tarefa.
•Várias arquiteturas: deep NN, Deep Belief Networks (não-supervisionada); Recurrent
NN…
•Aplicações: Visão por Computador, Reconhecimento da fala; NLP; Bioinformatica…

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
The term "deep learning" gained traction in the mid-2000s after a publication by Geoffrey Hinton
and Ruslan Salakhutdinov showed how a many-layered feedforward neural network could be
effectively pre-trained one layer at a time, treating each layer in turn as an unsupervised restricted
Boltzmann machine, then fine-tuned using supervised backpropagation.
The real impact of deep learning in industry began in large-scale speech recognition
around 2010. In late 2009, Li Deng invited Geoffrey Hinton to work with him and
colleagues at Microsoft Research to apply deep learning to speech recognition. They co-
organized the 2009 NIPS Workshop on Deep Learning for Speech Recognition.
A DNN can be discriminatively trained with the standard backpropagation algorithm. The
weight updates can be done via stochastic gradient descent using the following equation:
Wij(t+1) =wij(t) + h (dC/ dwij)
h learning rate; C cost function that depends on the activation function which depends
the learning type. Eg. Softmax.for the activation f. and cross entropy for C function.
História
Stacked autoencoders are not the only kind of deep learner. Another is based on Boltzmann
machines, and another—convolutional neural networks—on a model of the visual cortex.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
EXEMPLO DE APLICAÇÃO DE REDE NEURONAL:
PREVISÃO DO CONSUMO DE ÁGUA
Projectar um Sistema Computacional capaz de prevêr consumos de Água em uma Região, sendo conhecidos os consumos diários em anos anteriores
A rede neuronal utilizada é constituída por 4 camadas:
* uma camada de entrada com 26 neurónios,
* duas camadas escondidas com, respectivamente, 10 e 5 neurónios,
* e uma camada de saída com 1 neurónio.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
A informação presente na camada de entrada , que é a informação relativa
aos parâmetros utilizados para efectuar a previsão, encontra-se codificada em:
-- 7 neurónios para indicar o consumo dos 7 dias anteriores.
-- 4 neurónios para indicar a pluviosidade dos 4 dias anteriores.
-- 2 neurónios para indicar a temperatura máxima dos 2 dias anteriores.
-- 2 neurónios para indicar a temperatura mínima dos 2 dias anteriores.
-- 2 neurónios para indicar a queda de neve dos 2 dias anteriores.
-- 2 neurónios para indicar a nebulosidade dos 2 dias anteriores.
-- 7 neurónios para representar o dia da semana .
Pela análise dos dados recebidos, constatou-se que a informação relativa aos
dias feriados , ou períodos habituais de férias (férias escolares, ...), não era
relevante . Assim, esta informação não foi incluída no cálculo da previsão do
consumo de água.

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais
A aprendizagem da rede foi efectuada utilizando o
algoritmo backpropagation com a função de transferência
Sigmoide.
Os dados utilizados foram os valores dos parâmetros já
referidos, no período:
-- na fase de aprendizagem : de 1/1/1974 a 30/9/1988
-- na fase de teste : de 1/10/1988 a 30/9/1989
O erro obtido foi de 7.2%

Eugénio Oliveira / FEUP
Redes Neuronais Artificiais
Redes Neuronais





























