Embed Size (px)
Citation preview

CS 252 GRADUATE COMPUTER ARCHITECTURE, SPRING 2011 1
Reducing Communication-Based EnergyConsumption in HPC Memory Hierarchy
Meriem Ben-Salah and Gage Eads
Abstract—Excessive energy consumption is a limitationfor High-Performance Computers (HPC), especially as wemove towards exascale computing systems. In the 2008ExaScale Computing Study by Yelick et al., current mem-ory hierarchies are estimated to consume over 30% of sin-gle rack power. In this work, we model the energy con-sumption across the memory hierarchy (from L1 cache tomain memory) of a 96-node Cray XT4 system using simu-lation and analytical models. Using hardware performancecounters, we estimate the energy associated with MPI com-munication in the memory hierarchy for five NAS parallelbenchmarks. We propose cache injection to efficiently inte-grate I/O data into ongoing computation, and show that thismethod results in DRAM energy reduction up to 47% forwell-matched algorithms. We believe that the application ofour proposed memory technology will help accomplish theimplementation of energy efficient high performance com-puters.
I. Introduction
The energy problem is the ”single most difficult andpervasive challenge” for building HPC systems, accord-ing to [1]. Power is consumed by functional units (CPUsand GPUs), DRAM main memory, interconnect (on-chip,between chips, between boards, and between racks), sec-ondary storage, and cooling. The report’s “light nodestrawmen” - systems specially designed with customizedprocessors for massive replication, such as the Blue Genesupercomputer series [2] - are an example of current sys-tems and used as a baseline for comparison against newtechniques and technology. The “light node strawmen”dissipate about 20% of total single rack power into mainmemory and over 10% into the cache hierarchy and DDRcontroller, resulting in over 30% of single rack power con-sumed by the memory hierarchy.
Ways to reduce memory-related energy include new low-power technology and reducing total memory accesses.One exciting new memory technology is 3D chip packag-ing with through-silicon vias. This technology removes off-chip signaling and drastically reduces the distance betweenCPU and main memory, thus removing power due to rel-atively high pin capacitance and long interconnect. Onecan modify their software to best exploit temporal andspatial locality, with techniques such as cache blocking, toreduce the data bouncing between levels of the memory hi-erarchy. Microarchitectural optimizations can also reduceenergy consumption. Cache injection is a technique thatefficiently transfers I/O data into ongoing computation bywriting directly to a processor’s cache. If performed whendata is needed, this technique can remove cache hierarchytraversal and two main memory accesses, and the energy
[email protected]@berkeley.edu
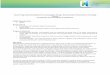
Fig. 1. AMD Opteron Microarchitecture Diagram [3]
cost associated with each access.Communication-related accesses can contribute some
amount to total memory accesses, and the standard data-transfer mechanisms leave much room for optimization.
Cache injection has been investigated previously as ameans to reduce memory traversal processor stalls, withoverall performance improvement.
In this work we explore cache injection’s effects on mem-ory access behavior and, using energy models from Cactiand DRAMSim2, estimate the impact on the total memoryhierarchy energy. We show that cache injection, which re-quires little architectural change, can greatly improve algo-rithms with frequent small (within the cache size) messagecommunication.
II. Background
Thanks to the courtesy of Kathy Yelick, etc., we have ac-cess to the NERSC supercomputers to run our benchmarksuite. We are using Silence, a single-cabinet 96-node soft-ware test platform that is predominantly unused. Thus,our results are not affected by other applications occupyingshared resources (i.e. the inter-node network and routers).
A. Silence
Each of Silence’s Cray XT4 nodes contain a 65-nm quad-core 2.3 GHz AMD Opteron ”Budapest” model. Each corehas a private 64-KB L1 instruction cache, 64-KB L1 datacache, and an exclusive 512-KB L2 cache. All four coresshare an exclusive 2-MB L3 cache. In addition, the chipcontains one memory controller and one HyperTransportlink which supports 8 GB memory (2 GB per core). Figure1 depicts the Opteron architecture.
B. Seastar Router
Each node is connected to a Seastar router through theHyperTransport link. The router contains a DMA engine,

2 CS 252 GRADUATE COMPUTER ARCHITECTURE, SPRING 2011
Fig. 2. Seastar Router Block Diagram [4]
384 KB scratch memory, and a PowerPC 440 controller[4]. The DMA engine transports reads and writes to thememory controller across the hypertransport link. The7-ported router provides one port to an AMD processor,and the other six to +x, -x, +y, -y, +z, and -z routingdirections. In addition, each port provides four virtualchannels to minimize packet blocking. A block diagram ofthe Seastar chip is shown in Figure 2.
C. Portals API
The Seastar chip is programmed through the Portalsmessaging interface. Portals provide one- and two-sidedcommunication, which map coherently to MPI’s blockingand non-blocking send and receive. Portals was primarilydesigned for scalability, making it an attractive option forthe 9,572-node Franklin supercomputer. It achieves scal-ability by requiring a minimal amount of state: a processis not required to establish a connection with another pro-cess, all message buffers are maintained in user space, andthe target (receiving) process determines how to respondto incoming messages.
A Portals ’put’ operation proceeds as follows: the initia-tor node fills a Memory Descripter (MD) with the data tobe sent and constructs a put request [5], [6]. The data maybe sent with the request, or in separate packets. The tar-get node reads the request to determine the desired portalstable (process ID), table index, and match bits. The tableentry contains a pointer to a match list, which is sequen-tially searched until one is found that matches the matchbits. If this procedure occurs without fault, the data isDMA’ed into the corresponding user-space buffer. If re-quested, the target MD’s corresponding Event Queue isupdated with the details of the put event. Once the trans-action is complete, an acknowledgment may optionally bereturned to the initiator.
D. MPI on Portals
A number of parallel programming APIs, such as MPI,UPC, and Co-array Fortran, have been implemented ontop of the Portals API. We initially considered UPC for
our work, due to our familiarity with UPC, its open-sourcecode, and recent interest in partitioned global addressspace (PGAS) languages. However, we soon learned thatthe CRAY’s robust performance analysis tool (CrayPAT)is not fully ported to the UPC API. In particular, we wereunable to trace sent message statistics. With MPI, how-ever, CrayPAT can trace message source, destination, size,and counts. This capability is crucial to our project, so wedecided to use MPI. The downside to using MPI is thatits Cray implementation is closed-source; as such, we arelimited to technical reports and user guides to understandits implementation.
The Portals MPI implementation is based on MPICH,an open-source MPI implementation, which defines sepa-rate optimized behavior for short and long messages [7].Each process-specific Portals table contains three entries:receive (for receiving messages), read (for unexpected longmessages), ack (for receiving acknowledgments from syn-chronous sends), and some space for unexpected shortmessages. The match bits are configured to encode thesend protocol, communicator, local rank (process ID, es-sentially), and MPI tag.
A short message is constructed in an initiator MD andset to respond to a single put operation. The messageis immediately transferred to a matching buffer or (if un-expected) is buffered at the receiver. The send completeswhen the target EQ is updated. Synchronous sends receivean acknowledgment once the message reaches a matchingreceive MD. Long messages are handled in the same wayas short, unless a matching receive isn’t posted. In thiscase, the data isn’t transferred and the sender must waituntil the receiver requests the data.
When a process calls receive, the MPI library constructsa Memory Descriptor for the user buffer. Before posting areceive, you must search for the message in the unexpectedmessage list.
E. Benchmarks
We chose the NAS Parallel Benchmark (NPB) suite totest the communication capabilities of Silence, because itsapplications exhibit a variety of different communicationbehavior.
F. Measurement Tools
The Silence system software packages include CrayPAT(Performance Analysis Tools), a package for instrumen-tation and tracing specific functions, including librariessuch as MPI [8]. We are using CrayPAT specifically forits ability to profile message source, message destination,and message size per MPI send call (and each static sendcan be distinguished by its call stack). In addition, Cray-PAT provides a convenient interface to AMD’s hardwareperformance counters. In order to measure cache accesses,we profiled L1 data cache reads, L2 reads, L3 reads, andL3 cache misses (to approximate main memory accesses).No memory controller performance counters are availablefor this platform.

REDUCING COMMUNICATION-BASED ENERGY CONSUMPTION IN HPC MEMORY HIERARCHY 3
Fig. 3. Communication Pattern of LU (left) and BT (right): (LightGreen: Short Communication, Red: Long Communication)
III. Benchmark Analysis
In this section, we study the communication patternsand the memory hierarchy activity of 5 NAS benchmarks:
• MG: solves the poisson equation qith a V-cycle multi-grid method.
• IS: sorts small integers using the bucket sort.• BT: solves a nonlinear partial differential equation
(PDE) using a block tridiagonal solver kernel.• LU: solves a nonlinear PDE using a lower-upper sym-
metric Gauss Seidel solver kernel.• FT: solves a three-dimensional PDE using the Fast
Fourier Transform.
These benchmarks exhibit memory, compute and networkintensities. Using the performance analysis tool CrayPat,we explore the benchmark execution on Silence for differentproblem sizes and processor pools by accessing the hard-ware performance counters and the message traffic reports.
A. Communication Patterns
The benchmarks exhibit different communication pat-terns that are interesting and complete for our energyand architectural analysis. The IS benchmark exhibits anearly balanced intra-chip communication structure. TheLU and BT solvers reveal an unbalanced and complexinter-chip communication behavior (Figure 3).
B. Memory Hierarchy Activity
We present the memory hierarchy activity across the L1,L2, L3 caches and main memory for all benchmarks ofsmall and large sizes parallelized with 4 and 64 processorsrespectively. Figure 4 reveals that MPI communicationdoes not utilize more than 3% of the total memory accesses.Figure 5 shows that the memory accesses prescribed bythe MPI communication are remarkable for large problemsand large processor pools. DRAM accesses can reach upto 20% of the total benchmark DRAM accesses, as it isthe case for FT. The dramatically increased L1 accessesdue to MPI in BT, FT, and MG can be traced to a specificsynchronizing barrier at the end of each benchmark. Whenprocesses finish computation earlier than the others, theyspin on a synchronization in the L1 cache for billions of
Fig. 4. Memory Hierarchy Activity (% of MPI Accesses with Respectto the Total Accesses) for a Small Problem with 4 Processors
cycles. We believe that BT exhibits high L2 accesses dueto cache thrashing. The IS benchmark L1 accesses aresimilarly inflated due to MPI synchronization functions,but not to the same extent. This study is a confirmationto our motivation thoughts.
IV. Memory Hierarchy Energy Analysis
In this section, we discuss our proposed method for an-alyzing the energy consumption across the memory hier-archy of Silence. We use the simulation tool CACTI 5.3to model the energy consumption within each cache level.We use DRAMSim2 to model the energy consumption in-ternally in the DRAM. Finally, we add an analytical modelto our study to evaluate the energy consumption inducedby the CPU to DRAM signaling.
A. Cache Energy
All cache levels of the machine Silence have a uniformcache access (UCA). They are manufactured using a 65 nmtechnology. They are built with 8 banks and a 64 bytescache line. In addition, the L1 cache compromises 65536bytes with 2-way associativity. The L2 cache is modeledwith 512 Kbytes and a 16-way associativity . The L3 cachehas the size of 2Mbytes and uses a 32-way associativity.The average energy consumption per read port for all cachelevels are given in table I.
CACTI 5.3 assumes a single model of wires neglectingfull-swing wires, which produce a significant power over-head. Figure 6 ([9]) shows that the energy produced byfull-swing wires for a varying range of wire sizes does notexceed the pico Joules. The overall energy spent in thedifferent cache levels is of the range of nano Joules. There-fore, in this case, the use of a single wire model does not

4 CS 252 GRADUATE COMPUTER ARCHITECTURE, SPRING 2011
!"
#"
$!"
$#"
%!"
%#"
&"'()"*+,'"
-."/.-01"*+,'"
,2234434"
!"
!5#"
$"
$5#"
%"
%5#"
6"
65#"
7"
75#"
&"'()"86"-."
/.-01"86"
,2234434"
!"
$!"
%!"
6!"
7!"
#!"
9!"
&"'()"8%"-."
/.-01"8%"
,2234434"
!"
$!"
%!"
6!"
7!"
#!"
9!"
&"'()"8$"-."
/.-01"8$"
,2234434"
Fig. 5. Memory Hierarchy Activity (% of MPI Accesses with Respectto the Total Accesses) for a Large Problem with 64 Processors
Energy (nJ)L1 Cache 0.4937L2 Cache 3.3066L3 Cache 6.995
TABLE I
Cache Energy Values
effect the energy study.The (UCA) model of CACTI 5.3 does not consider low-
swing wires for address and data transfers. This consider-ation amortizes the overall energy spent in caches. There-fore, our energy values are a slight overestimation. Never-theless, we decided to be on the conservative side. Hope-fully, the excess amount of energy might compensate forsomething else that has been omitted in our cache energymodels.
B. DRAM Energy Model
Silence is built with a 8GB DDR2 DRAM, which has 4banks and error code correction (ECC). The DRAM av-erage latency is 32.5 ns and clock cycle of 1.25 ns. TheDRAM device width is x72, where 64 is for data bits and 8is for ECC. We have modeled the DRAM with a partitionof 16380 rows and 12800 columns. The internal energyconsumption of the DRAM is 10.27 nJ. Since DRAMSim2accounts for the internal energy of the DRAM only, weuse an analytical model [10] to estimate the energy con-sumed by the DRAM memory requests issued by the func-tional units of the CPU. Signals transmitted by the CPUto DRAM can be categorized into input/output activationsignals (A), writing signals (W), reading signals (R) and in-put/output termination signals (T). The energy consumed
!"#$%!$&
'()"*)+,-
!"$$%!$&
.$"/"01,2345
!$"/"01,2345
6$/"01,2345
73(823
6"#$%!$&
!"#$!%&'
6"$$%!$&
(!
#"$$%!6$
$ $$%9$$$"$$%9$$
6 ! . : # ; < = & 6$
)*+!!,!-./0!%11'
(a) Delay characteristics of different wires at 32nm process
technology.
!"!!#$!!
%"!!#!&'
&"!!#!&(
&"%!#!&(
("!!#!&(
("%!#!&(
'"!!#!&(
'"%!#!&(
)"!!#!&(
& ( ' ) % * + , - &!
!"#$%&!!'()
*+$#!,#"%-.!'//)
./012/"30456
&!7"85/29
(!7"85/2
'!7
:04";4<=>"30456
(b) Energy characteristics of different wires at 32nm process
technology.
Figure 5. Power-delay properties of different wires
quadratically with length. Since such a wire cannot be pipelined, they also suffer from lower throughput. A
low-swing wire requires special transmitter and receiver circuits for signal generation and amplification. This
not only increases the area requirement per bit, but also assigns a fixed cost in terms of both delay and power
for each bit traversal. In spite of these issues, the power savings possible through low-swing signalling makes it
an attractive design choice. The detailed methodology for the design of low-swing wires and their overhead is
described in a later section. In general, low-swing wires have superior power characteristics but incur high area
and delay overheads. Figure 5 compares power delay characteristics of low-swing wires with global wires.
5 Analytical Models
The following sections discuss the analytical delay and power models for different wires. All the process
specific parameters required for calculating the transistor and wire parasitics are obtained from ITRS [1].
5.1 Wire Parasitics
The resistance and capacitance per unit length of a wire is given by the following equations [5]:
Rwire =!
d ! (thickness " barrier)(width " 2 barrier)(1)
where, d (< 1) is the loss in cross-sectional area due to dishing effect [1] and ! is the resistivity of the metal.
Cwire = "0(2K"horizthickness
spacing+ 2"vert
width
layerspacing) + fringe("horiz, "vert) (2)
In the above equation for the capacitance, the first term corresponds to the side wall capacitance, the second
term models the capacitance due to wires in adjacent layers, and the last term corresponds to the fringing
capacitance between the sidewall and the substrate.
10
Fig. 6. Energy Consumption of Different Wire Types (Low Swing,and Full Swing with Different Delay Penalties)
by these signals is given by:
• EA = [I1− I2×t1t2
]×V × V 2u
V 2 ×l, where I1 is the operatingcurrent, I2 is the active standby current, t1 is the rowaccess strobe in memory cycles, t2 is the activation-to-activation minimal cycle, Vu is the operating voltage,V is the maximum voltage supply of the device and lis the DRAM latency.
• EW = (I3−I2)× t3t2×V × fu
fV 2u
V 2 × l, where I3 is the op-erating current for write operations, t3 is the life timeof written data on the input/output pins in memorycycles, f is the processor frequency and fu is the op-erating frequency.
• ER = (I4 − I2) × t4t2
× V × fuf
V 2u
V 2 × l, where I4 is theoperating current for read operations, t4 is the lifetime of read data on the input/output pins in memorycycles.
• ET = [p1× (n1 +1)× t3t2
+p2× (n1)× t4t2
]× fuf ×0.5× l,
where p1 is the average termination power spent in awrite pin, p2 is the average termination power spentin a read pin, n1 and n2 are the output/input pins.
Specifically, for the built-in DRAM:
• EA = [90mA − 65mA×1418 ] × 1.4V × 1.052V 2
1.42V 2 × 32.5 =1.293825 nJ,
• EW = (170mA− 65mA)× 1818 × 1.4V × 800MHz
800MHz1.052
1.42 ×32.5 = 2.665 nJ,
• ER = (180mA− 65mA)× 1818 × 1.4V × 800MHz
800MHz1.052
1.42 =2.9432 nJ,
• ET = [8.2mW×(214+1)× 1818 +1.1mW×(214)× 18
18 ]×800MHz800MHz × 0.5× 32.5 = 32.47 nJ.
In total, the processor signals consumes an average of36.5625 nJ between read and write signals.
C. DRAM Energy Model Sensitivity Analysis
For our energy analysis, we did not have access to thespecification sheets of Cray XT4. We were missing theexact DRAM device width, the columns-to-rows partitionand the life time of read and write data on the data pins.

REDUCING COMMUNICATION-BASED ENERGY CONSUMPTION IN HPC MEMORY HIERARCHY 5
4816 32 64 128 2560
1
2
3
4
5
6
DRAM device width
Avera
ge D
RA
M P
ow
er(
watts)
Fig. 7. DRAM Power consumption with varying device width
Therefore, we have used reasonable guesses based on themachine geometry and implementation technology. In thissection, we inspect the sensitivity of the DRAM energymodel to variations of the estimated data.
• Device Width: We estimated the DRAM device widthbased on the machine size. We conduct our energysimulations for a range of device widths (x4, x8, x16,x32, etc.). Figure 7 shows that the DRAM averagepower consumption is very sensitive to DRAM devicewidths for small machines. Large device widths, andfor large machines, the average DRAM power remainsconstant. Therefore, our DRAM energy model is in-significantly sensitive to the device width.
• Columns-to-rows partition: The columns-to-rows par-tition of the DRAM was undisclosed to us. We investi-gate the sensitivity of the DRAM energy model withvarying partitions. Figure 8 reveal that the energymodel is partition oblivious.
• Life time of read and write data on the pins: Wedecide to take conservative actions regarding model-ing the life time of read and write data on the pins.We assume that the life time of data is equal to theactivation-to-activation cycle from CPU to DRAM.Figure 9 shows that our assumption leads to thelargest power consumption.
D. Benchmark Energy Activity
Using the memory energy models presented in sectionsA and B, we conduct an investigation into the energy con-sumption of the benchmarks, and specifically of the MPIcommunication, across the memory hierarchy. Figure 10shows the energy consumption for a small problem paral-lelized with 4 processors. The energy consumption of theMPI functions across the memory hierarchy is negligibleif compared with the overall energy consumption. Thiswas predictable based on the memory hierarchy activitypresented in section IV.
The total and MPI energy consumption of a large prob-lem implemented with 64 processors are given in figure11. In this case, the MPI functions consume a significantpercentage of the total energy needed by the memory hi-erarchy. This class of problems is a good representative of
0 2 4 6 8 10 12
x 106
5
5.02
5.04
5.06
5.08
5.1
5.12
5.14
5.16
Number of Rows
Ave
rag
e P
ow
er
(wa
tts)
0 2 4 6 8 10 12 14 16 18
x 105
5
5.02
5.04
5.06
5.08
5.1
5.12
5.14
5.16
Number of Columns
Avera
ge P
ow
er
(watts)
Fig. 8. DRAM power consumption with varying rows (top) &columns (bottom)
the energy activity within the scope of high performancecomputers.
V. DRAM-avoiding modifications
We considered two methods to reduce the number ofDRAM accesses due to inter-node communication: refillinterception and cache injection. Refill interception ex-ploits the fact that the core accesses main memory androuter through a common interface, the System RequestInterface (SRI). Cache injection expands the capability ofI/O devices, allowing them to write directly into a core’sL1 data cache.
A. Cache Injection
Cache injection is the process by which an external de-vice writes directly to a core’s cache. Standard coher-ence bus transactions do not typically support this behav-ior. However, most capabilities required for cache injection(bus snooping, address matching, cache modification) al-ready exist in cache controllers. What is lacking is the abil-ity to command a cache controller to listen for addressesbesides those currently cached.
A.1 Implementation
We implement injection with a coherence bus command:
Ext Fill <core>, <cache line address>, <data>

6 CS 252 GRADUATE COMPUTER ARCHITECTURE, SPRING 2011
0 2 4 6 8 10 12 14 16 180
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
life time of read data on pins (cycles)
sig
nal pow
er
(watts)
0 2 4 6 8 10 12 14 16 180
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
life time of write data on pins (cycles)
sig
nal pow
er
(watts)
Fig. 9. DRAM power consumption with varying life time of readdata (top) and life time of write data (bottom)
The “core” operand specifies the destination core L1cache, “cache line address” is the address and “data” isthe injected data. L1 caches snoop for a matching coreID when Ext Fill goes on the bus; if found, they storethe data and set the line to “modified” state, else theyinvalidate any cached copy. The required modificationsto cache controller logic consist of one log2(n)-bit core IDcomparator (where n is the number of on-chip hardwarethreads), one additional coherence command to decode,and the associated control logic.
The router needs to construct Ext Fill coherence packetsand pass them to the SRI. For simplicity, we propose send-ing the first full INJECTION SIZE LIMIT packets to thecache and DMA’ing remaining and partial lines to mainmemory. Caching a partial line may require one or moremain memory accesses to locate an up-to-date copy of itsunknown elements (either in cache or main memory) so wedo not consider these for injection.
Injection also requires modifying the Portals API. Therouter needs to know the core ID for the receiving processto construct Ext Fill packets. The per-process Portals ta-ble is an ideal structure to place a core ID, as long the ID ismaintained across process migration. Also, the API mustallow the user to set INJECTION SIZE LIMIT. We rec-ommend an upper bound equal to the amount of cachabledata, where any attempt to exceed this number will cause
!"
#$%&!"
'$%&!"
($%&!"
)$%&!"
&$%&&"
&*#$%&&"
&*'$%&&"
&*($%&&"
+,-'./01"
+,-'.23,"
4-'./01"
4-'.23,"
56-'./01"
56-'.23,"
78-'./01"
78-'.23,"
9:-'./01"
9:-'.23,"
/01";&"<6*"23,=7";&"
$>?@:A"B>CD"
!"#$%!E"'$%!E"($%!E")$%!E"&$%&!"
&*#$%&!"&*'$%&!"&*($%&!"&*)$%&!"#$%&!"
4-'./01"
4-'.23,"
+,-'./01"
+,-'.23,"
56-'./01"
56-'.23,"
78-'./01"
78-'.23,"
9:-'./01"
9:-'.23,"
/01";#"<6*"23,=7";#"
$>?@:A"B>CD"
!"#$%&!"&$%&&"
&'#$%&&"($%&&"
('#$%&&")$%&&"
)'#$%&&"*$%&&"
*'#$%&&"
+,*-./0"
+,*-123"
43,*-./0"
43,*-123"
56,*-./0"
56,*-123"
78,*-./0"
78,*-123"
9:,*-./0"
9:,*-123"
./0";<,."=6'"123>7"
;<,."$?@A:B"C?DE"
!"
($%!F"
*$%!F"
G$%!F"
H$%!F"
&$%&!"
+,*-./0"
+,*-123"
43,*-./0"
43,*-123"
56,*-./0"
56,*-123"
78,*-./0"
78,*-123"
9:,*-./0"
9:,*-123"
./0"I)"=6'"123>7"I)"
$?@A:B"C?DE"
Fig. 10. Energy Activity (MPI Energy Requirements (nJ) vs. TotalEnergy Requirements (nJ)) for a Small Problem with 4 Processors
a non-fatal error.
A.2 Injection Size
What defines a “reasonable” message size? The injec-tion of a reasonably-sized message will cause a net energyand/or performance benefit. Assume, for now, that mes-sage data is injected at the correct time - when it is imme-diately to be used in computation. A message greater thanthe total system cache size - L3 size (+ L2 size + L1 size, ifexclusive) - will evict injected message data to main mem-ory! Clearly a reasonable message size is within the totalsystem cache size. If the L1 cache is a Harvard Architec-ture, restricting injections to the L1 size has the benefit of

REDUCING COMMUNICATION-BASED ENERGY CONSUMPTION IN HPC MEMORY HIERARCHY 7
!"
#$%!&"
'$%!&"
($%!&"
)$%!&"
*$%*!"
*+#$%*!"
*+'$%*!"
",-."/*"01+"23456"/*"
$789:;"
!"*!!!!!!!!"#!!!!!!!!"<!!!!!!!!"'!!!!!!!!"=!!!!!!!!"(!!!!!!!!">!!!!!!!!")!!!!!!!!"
?@('A,-."
?@('A234"
6B@('A,-."
6B@('A234"
C:@('A,-."
C:@('A234"
D1@('A,-."
D1@('A234"
",-."/#"01+"23456"/#"
$789:;"
!"#!!!!!!!"$!!!!!!!"%!!!!!!!"&!!!!!!!"
'!!!!!!!!"'#!!!!!!!"'$!!!!!!!"'%!!!!!!!"'&!!!!!!!"#!!!!!!!!"
()%$*+,-"
()%$*./0"
12)%$*+,-"
12)%$*./0"
34)%$*+,-"
34)%$*./0"
56)%$*+,-"
56)%$*./0"
"+,-"78"96:"+,-"./0;1"
<=>?4@"
!"#!!!!!!!!"$!!!!!!!!"%!!!!!!!!"&!!!!!!!!"
'<A!B"':#<A!B"':$<A!B"':%<A!B"
()%$*+,-"
()%$*./0"
12)%$*+,-"
12)%$*./0"
34)%$*+,-"
34)%$*./0"
56)%$*+,-"
56)%$*./0"
"+,-"CDE+"96:"./0;1"
CDE+"<=>?4@"
Fig. 11. Energy Activity (MPI Energy Requirements (nJ) vs. TotalEnergy Requirements (nJ)) for a Large Problem with 64 Processors
evicting data only (although instructions could be evictedin the L2 as a result of evicted L1 data), though the L1 (64KB in our system) is typically quite smaller than the L2and L3 caches. Allowing injections of L2 size and greaterwill cause instruction eviction, which should be avoidedfor performance reasons: an n-way pipeline fetches n in-structions each cycle, while memory operations are unlikelyto exceed 50% of all instructions. Standard programmingconstructs, such as loops and function calls, make instruc-tion reuse likely.
We profiled B class benchmarks compiled for 16 cores,shown in Figure 12. 64 KB messages fit within the L1,576 KB messages fit within the L2 and L1, and 2624 KB
Fig. 12. Message Size Distribution
messages fit within the cache hierarchy. Notice that allapplications have at least 37.5% messages that fit withinthe L1. FT and IS have few overall messages, but manyare extremely large. FT performs multiple all-to-all sendsof (for B-class benchmarks) about 32 MB per message!LU and MG are much more likely to benefit from injec-tion; each process sends many small messages, so there willbe many communication-related main memory accessesand nearly all messages fit directly in the L1 (the rest inL2). For these benchmarks, we decided to use an INJEC-TION SIZE LIMIT of 1024, the number of L1 data cachelines. This is reflected in our analysis in section VI.
Cache injection has the potential to improve perfor-mance when invoked immediately or shortly before thedata is used. This can alleviate the memory retrieval bur-den from the CPU, and reduced coherence bus occupancycaused by L2- and L3-miss-induced bus reads. Perfor-mance effects of cache injection were previously studied in[11], [12], [13]. This technique has higher energy reductionpotential and requires fewer architectural modifications, sowe restrict our analysis to only cache injection.
VI. Analysis
We performed our analysis as follows. Per dynamicreceive call, the number of injected cache lines is defined as:
CLI = min(1024, ReceiveMessageSize(Bytes)CacheLineSize )
where 1024 is INJECTION SIZE LIMIT cache lines.We assume that injections are performed at the correcttime, i.e. during MPI RECV or MPI WAIT, so that theeffects of data displacement are equivalent to the baselinemethod of data retrieval. For larger messages and earlyinjections, one must consider performance degradationdue to displaced useful data/instructions.
Under these assumptions, the L1 data cache sees nochange in access behavior. As with the baseline method,every data load results in a request sent to the L1 cache.The L2 and L3 caches receive fewer requests - every requestfor a cache line that is injected will not require a requestto the L2 cache, and subsequently to the L3 cache. Theformula for change in L2 and L3 cache message requests is:
∆accessesL2/3 = −CLI ∗ (1Read
CacheLine) ∗ numReceived

8 CS 252 GRADUATE COMPUTER ARCHITECTURE, SPRING 2011
!"
#!!!!!!"
$!!!!!!!"
$#!!!!!!"
%!!!!!!!"
&'(")*+",-.)"
/0'123"456"789")*+"
,-.)"/0'123":0;<"
Fig. 13. MPI Energy Activity with and without Cache Injection fora Small Problem with 4 Processors
The variable numReceived is the number of times this par-ticular size of message is received by the process. For ourbenchmarks, nearly every call stack with MPI SEND at thehead refered to a particular sized message, allowing us toequate numReceived with number of MPI SENDs. Therewere eight cases where a unique call stack had varyingmessage sizes among processes - three in MG, one in BT,one in IS, and three in LU. In the worst cast, the messagesize varied 7.6% from an average 7418.86 byte message.The effect is negligible - the maximum and minimum-sizedmessages differ by 2 cache lines. We assume the L1 cacheis non-blocking with MSHRs that allow the controller torecognize multiple misses to the same block and submita single request. Thus, we consider one read request percache line.
The change in main memory accesses is defined similarly:
∆accessesmm = −2 ∗CLI ∗ (8Accesses
CacheLine) ∗ numReceived
.The 2 term is due to the write from I/O, then read fromprocessor, of each cache line. With an assumed bus widthof 64 bits, eight accesses are needed to read or write a fullcache line.
VII. Results
In this section, we investigate the gain in energy con-sumption when using the cache injection memory technol-ogy. We use the cost analysis presented in section VI.While the L1 cache is heavily working, energy gains areexpected to occur at the L2, L3 and DRAM levels. It isof interest to compare the energy consumption of the MPIfunctions across the memory hierarchy before and after thememory architectural modifications. For the benchmarksFT and IS, figures 13 and 14 show the energy consump-tion associated with the MPI calls with and without cacheinjection. The gain at the MPI level translates to a totalenergy gain. Larger problems benefit the most from cacheinjection.
Since the MPI workload is not substantial in the case ofsmall problems, the total energy gain is bounded by 5 %
!"######$
!%######$
&#######$
&'######$
&!######$
&"######$
&%######$
"#######$
()*$+,-$./0+$
123456$789$:3;$+,-$
./0+$123456$
Fig. 14. MPI Energy Activity with and without Cache Injection fora Large Problem with 64 Processors
(Figure 15). An energy gain of up to 47 % at the DRAMlevel and up to 7 % at the L3 cache level is recorded in thecase of large problems (Figure 16). The LU benchmarkbenefits the most of the memory technology .
VIII. Related Work
Studying the power consumption of high performancecomputers was of interest for a number of researchers.Shalf and Kamil [14] have conducted in-situ power mea-surements at different machine subset levels for severalhigh performance computational loads.
Cache injection is not a new technique to rapidly inte-grate data into ongoing computation. One approach tocache injection is an Injection Table [12]. The InjectionTable extends the listened-for address set of its cache con-troller, at the user’s behest. The typical usage is producer-consumer code: the consumer process will fill the injectiontable with Open Window commands, the producer processwill broadcast data with a Write Send command, and theconsumer process can close the address window with aClose Window call. This work focuses on handling memorylatency in shared memory multiprocessors for producer-consumer(s) relationships; similarly we explore a producer-consumer relationship, but focus on improving I/O data in-tegration without adding significant cache controller logicor any ISA modifications (thus no application recompila-tions). This work does not consider the energy impact ofthe design.
A similar work [13] proposed producer-initiated remote-cache write mechanisms. Specifically, they proposeWriteSend for remote cache writes and WriteThrough
which writes through to memory (useful if the consumer isunknown). The authors found that remote writes reducednetwork traffic, reduced L2 cache miss rates, and producedlower cache miss latencies. The WriteSend instruction isquite similar to Ext Fill, though WriteSend is intendedfor core-to-core data transfer instead of I/O-to-core anddoes not consider the energy impact of the design.
IX. Future Work
Both the energy and cache access data were derived fromsimplified models of the physical computer system. Assuch, future work includes verifying our results through

REDUCING COMMUNICATION-BASED ENERGY CONSUMPTION IN HPC MEMORY HIERARCHY 9
!"#
!$#
!%#
!&#
!'#
!(#
!!#
)**#
)*)#
+,$# -.,$# /0,$# 12,$# 34,$#
5#67.81#9:;#<=,>#
?@:A4B#.7#67.81#C1D#
<=,>#?@:A4B#
!!E'%#
!!E(#
!!E(%#
!!E!#
!!E!%#
)**#
)**E*%#
+,$# -.,$# /0,$# 12,$# 34,$#
5#67.81#9:;#FG#
?@:A4B#.7#67.81#C1D#
FG#?@:A4B#
!'E%#
!(#
!(E%#
!!#
!!E%#
)**#
)**E%#
+,$# -.,$# /0,$# 12,$# 34,$#
5#67.81#9:;#F"#
?@:A4B#.7#67.81#C1D#
F"#?@:A4B#
Fig. 15. Energy Activity with Cache Injection ( % of Total NewEnergy with Respect to Total Old Energy) for a Small Problem with4 Processors
full system simulation, such as with VLSI CAD tools andprogram and memory traces for transistor switching activ-ity. The experience of implementing our proposed modifi-cations in a simulated system is necessary to detect com-plex memory and core interactions that our models do notaccount for.
While cache injection appears to be an attractive mech-anism for energy reduction, there are a number of possibleimprovements available. In order to work with inclusivecache hierarchies (such as Intel processors), the Ext Fill
command must write data into inclusive caches as well asthe L1. This will use more energy than the exclusive ver-sion, due to the L2 and L3 activity, but could still produceoverall energy reductions by avoiding DRAM.
In order to support producer-consumers computation,Ext Fill requires the ability to simultaneously write mul-tiple L1 caches. This could be accomplished with a bitmask, assuming no more than 16-32 local cores, multipleID specifiers, or with an injection table-style cache-resident
!"#"$
!!$
!!#%$
!!#&$
!!#'$
!!#"$
())$
())#%$
*+,'&$ -,'&$ ./,'&$01,'&$ 23,'&$
4$56+7.$89:$;%$
<=9>[email protected]$
;%$<=9>1?$
""$
!)$
!%$
!&$
!'$
!"$
())$
()%$
*+,'&$ -,'&$ ./,'&$01,'&$ 23,'&$
4$56+7.$89:$;B$
<=9>[email protected]$;B$
<=9>1?$
)$
%)$
&)$
')$
")$
())$
(%)$
*+,'&$ -,'&$ ./,'&$ 01,'&$ 23,'&$
4$56+7.$89:$CDEF$
<=9>[email protected]$
CDEF$<=9>1?$
Fig. 16. Energy Activity with Cache Injection ( % of Total NewEnergy with Respect to Total Old Energy) for a Large Problem with64 Processors
configuration. This technique may benefit parallel compu-tation on I/O data, such as a video or audio stream, bydirectly feeding it to each involved core’s cache. (FIXME)do this section
X. Conclusion
In order to solve the energy problem in HPC, new tech-niques and optimizations must be made at all levels of thecomputing abstraction. We predicted the energy behav-ior of the memory hierarchy using the open-source sim-ulators CACTI and DRAMSim2, from which we derivedestimates of energy per access of each memory component.Memory hierarchy activity was gathered from hardwareperformance counters on our test system, Silence, a single-cabinet 96-node machine.
We have discussed a microarchitectural optimization,cache injection, which can reduce DRAM energy consump-tion by up to 47% according to the energy model. Thistechnique works best when programs send large numbersof small messages, which with standard I/O methods cancause many DRAM accesses for only a few cache lines. I/Odata injection exploits the fact that we can expect receivedmessages to be used soon after reception, so buffering them

10 CS 252 GRADUATE COMPUTER ARCHITECTURE, SPRING 2011
in main memory is likely not the best option.
This is one in a number of possible communication op-timizations. Most of the future work remains in extendingExt Fill, and exploring other energy-reducing communi-cation hardware.
XI. Acknowledgments
We’d like to thank the NERSC scientists, especially JohnShalf and David Skinner, who provided us with support,insight, and accounts for their supercomputers. We’d alsolike to thank our professor, John Kubiatowicz, who pro-vided valuable insight and guidance.
References
[1] K. Bergman, S. Borkar, D. Campbell, W. Carlson, W. Dally,M. Denneau, P. Franzon, W. Harrod, J. Hiller, S. Karp, S. Keck-ler, D. Klein, R. Lucas, M. Richards, A. Scarpelli, S. Scott,A. Snavely, T. Sterling, R. S. Williams, K. Yelick, K. Bergman,S. Borkar, D. Campbell, W. Carlson, W. Dally, M. Denneau,P. Franzon, W. Harrod, J. Hiller, S. Keckler, D. Klein, P. Kogge,R. S. Williams, and K. Yelick, “Exascale computing study:Technology challenges in achieving exascale systems peter kogge,editor & study lead,” 2008.
[2] F. Allen, G. Almasi, W. Andreoni, D. Beece, B. J. Berne,A. Bright, J. Brunheroto, C. Cascaval, J. Castanos, P. Coteus,P. Crumley, A. Curioni, M. Denneau, W. Donath, M. Eleft-heriou, B. Fitch, B. Fleischer, C. J. Georgiou, R. Germain,M. Giampapa, D. Gresh, M. Gupta, R. Haring, H. Ho,P. Hochschild, S. Hummel, T. Jonas, D. Lieber, G. Martyna,K. Maturu, J. Moreira, D. Newns, M. Newton, R. Philhower,T. Picunko, J. Pitera, M. Pitman, R. Rand, A. Royyuru,V. Salapura, A. Sanomiya, R. Shah, Y. Sham, S. Singh,M. Snir, F. Suits, R. Swetz, W. C. Swope, N. Vishnumurthy,T. J. C. Ward, H. Warren, and R. Zhou, “Blue gene: a visionfor protein science using a petaflop supercomputer,” IBM Syst.J., vol. 40, pp. 310–327, February 2001. [Online]. Available:http://dx.doi.org/10.1147/sj.402.0310
[3] N. E. R. S. C. Center. [Online].Available: http://www.nersc.gov/users/computational-systems/franklin/configuration/compute-nodes/
[4] D. Abts, “The Cray XT4 and Seastar 3-D Torus Interconnect,”Encyclopedia of Parallel Computing (to appear), 2011.
[5] R. Brightwell, B. Lawry, A. B. MacCabe, and R. Riesen,“Portals 3.0: Protocol Building Blocks for Low Over-head Communication,” in Proceedings of the 16th In-ternational Parallel and Distributed Processing Sympo-sium, ser. IPDPS ’02. Washington, DC, USA: IEEEComputer Society, 2002, pp. 268–. [Online]. Available:http://portal.acm.org/citation.cfm?id=645610.661545
[6] R. Riesen, R. Brightwell, K. Pedretti, K. Underwood, A. B.Maccabe, and T. Hudson, “The Portals 4.0 Message Pass-ing Interface,” Sandia National Laboratories, Technical reportSAND2008-2639, Apr. 2008.
[7] R. Brightwell, R. Riesen, and A. B. MacCabe, “Design, Imple-mentation, and Performance of MPI on Portals 3.0,” 2010.
[8] L. DeRose, “Performance measurement and visualization on thecray xt,” http://www.nics.tennessee.edu/sites/default/files/PerformanceCrayXT.pdf.
[9] “Cacti 6.0, cacti 6.0: A tool to model large caches.”[10] “Dramsim university of maryland memory system simulator
manual.”[11] A. Milenkovic and V. Milutinovic, “A performance evaluation of
cache injection in bus-based shared memory multiprocessors.”[12] A. Milenkovic, A. Milenkovic, and V. Milutinovic, “Cache injec-
tion on bus based multiprocessors,” in Seventeenth IEEE Sym-posium on Reliable Distributed Systems, 1998. Proceedings. 2032/34 Oct 1998 Page(s), 1998, pp. 341–346.
[13] H. Abdel-Shafi, J. Hall, S. V. Adve, and V. S. Adve,“An evaluation of fine-grain producer-initiated communica-tion in cache-coherent multiprocessors,” in Proceedings ofthe 3rd IEEE Symposium on High-Performance ComputerArchitecture, ser. HPCA ’97. Washington, DC, USA: IEEE
Computer Society, 1997, pp. 204–. [Online]. Available:http://portal.acm.org/citation.cfm?id=548716.822676
[14] E. S. Shoaib Kamil, John Shalf, “Power efficiency in high per-formance computing,” International Parallel & Distributed Pro-cessing Symposium, 2008.