Embed Size (px)
Citation preview

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
Swedish INTELECT
Summer School
on Multiprocessor
Systems on Chip
Reconfigurable Computing and its Compilation Techiques
Reiner Hartenstein
Kaiserslautern University of Technology
Örebro, Aug. 25-27, 2003
8.45 – 10.30 hrs
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
2
Reconfigurable Computing: a second programming domain
Migration of programming to the structural domain
The opportunity to introduce the structural domain to programmers ...
The structural domain has become RAM-based
... to bridge the gap by clever abstraction mechanisms using a simple new machine paradigm
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
3
>> outline <<
• why coarse grain reconfigurable ? • terminology • toward higher abstraction levels • flowware languages • why a new Machine Paradigm ? • (co-) compilation techniques • final remarks
http://www.uni-kl.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
4
granularity
Datapath width 1 bit CLB: fine grain
Word level CFB: coarse grain
bundling of nibble or byte width CFBs: multiple granularity
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
5
One more argument for coarse grain
100
1000
10
1
0.1
0.01
0.001 2 1 0.5 0.25 0.13 0.1 0,07
MOPS / mW
µ feature size
T. Claasen et al.: ISSCC 1999
Wiring by abutment: a 32 Bit KressArray example
if coarse grain cells are full custom and
mesh-connected, and 2nd level interconnect
ressources layouted over the cells
*) R. Hartenstein: ISIS 1997
the array is almost as
area-efficient as hardwired
we have already seen the first day:
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
6
rDPU not used used for routing only operator and routing port location markerLegend: backbus connect
array size: 10 x 16 = 160 rDPUs
mapping algorithms efficently onto rDPA
rout thru only
not used backbus connect
SNN filter on KressArray
by the way: example of scalability / relocatability by EDA support
also FPGA scalability (avoid routing congestion) by EDA solution

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
7
rDPU not used used for routing only operator and routing port location markerLegend: backbus connect
route-thru-only rDPU
3 vert. NNports, 32 bit
http://kressarray.de
Xplorer Plot: SNN Filter Example
+ [13]
2 hor. NNports, 32 bit
operator
result
operand
operand
route thru
backbus connect
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
8
PACT XPP: Reference Module: XPU128 Co-Processor
XPP128 rDPA
• Evaluation Board • XDS Development Tool with Simulator
buses not
shown
rDPU
CF
G
PAE
core
ALU CtrlALU
CF
GC
FG
PAE
core
CF
GC
FG
PAE
core
PAE
core
ALU CtrlALUALU CtrlALU
CF
GC
FG
CF
GC
FG
• all used by SIEMENS Corporation • Other contractors preparing .... : ask Ron Mabry (here in the audience)
• Full 32 or 24 Bit Design working silicon • 2 Configuration Hierarchies
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
9
microprocessor architectures (8)
TU Dresden, 09.05.2003
©Arndt Bode LRR-TUM 9
Mikroprozessorarchitekturen (8):
hochgradig parallele Systeme
E/A SRAM PE PE PE PE PE PE PE PE PE SRAM
E/A
SRAM PE PE PE PE PE PE PE PE PE SRAM
SRAM PE PE PE PE PE PE PE PE SRAM PE
SRAM PE PE PE PE PE PE PE PE SRAM PE
SRAM PE PE PE PE PE PE PE PE SRAM PE
SRAM PE PE PE PE PE PE PE PE SRAM PE
SRAM PE PE PE PE PE PE PE PE SRAM PE E/A E/A
Konfigu-
ration
Manager
©Arndt Bode LRR-TUM © 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
10
XPP64A: Platform Development Board
- SDR Board In Debug Phase -> XPP64A Chips from STMicro Fab
- Assembly & Test / Available March 2003
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
11
PACT Corp
• Xtreme Processor Platform (XPP) family of IP cores, high-speed data-stream-capable, scalable, reconfigurable clusters of arrays of 32-bit DPUs with embedded memories, and high-speed I/O ports -
• Application development support software featuring a flow graph-style algorithm mapping language - to minimize training requirements.
• XPP's fabrics, featuring automatic DataFlow synchronization and flagged Event Network to dynamically configure the execution flow,
• Supports dynamic RTR: hierarchical configuration managers free the designer from chip-level details and ensure that configurations are independently loaded in exactly the intended order.
• Automatic event-based task swapping along with data streams: released resources automatically reconfigured immediately
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
12
microprocessor architectures (1)
©Arndt Bode LRR-TUM 12
Entwicklung der Mikroprozessor Architekturen (1)
Bis 1995: Einschränkung - , seit 1995 Erhöhung der Typen- und Architekturvielfalt
Transistorzahl (Moore‘s Gesetz): Abwägung Rechenleistung-Leistungsaufnahme-Kosten-
Kompatibilität
MPR Analysts‘ Choice Awards Kategorien:
- PC Processors: Intel P4 (HyperThreading), AMD Athlon (x 86-64,
Hyper Transport), Transmeta (Binary Compilation, VLIW),...
- Server Processors: Intel Xeon MP und Itanium 2 (EPIC), AMD Opteron
(x86-64), HP Alpha EV-7, Fujitsu Sparc 64 V (out-of-order superscalar)
- High-Performance Embedded Processors: Broadcom BCM 1250, IBM 440
GX, Intrinsity FastMIPS, Motorola MPC 7455, NEC VR7701, PMC Sierra
RM9000x2
- Low-Power Embedded Processors: AMD Au1100, Intel PXA 250, NEC VR
4131, DragonBall MX1, NeoMagic MiMagic5 (1mW pro MHz)
- Extreme Processors: CmU PipeRench, Intrinsity FastMath, Micron Yukon,
NEC DRP, PACT XPP, Sandbridge Sand Blaster (bis 512 ALUs)
- Embedded IP Processor Cores: ARCtangent-A5, ARM 1026 EJ-S/1136JF-S,
Improv Crescendo, MIPS M4K, Tensilica Xtensa V
- Graphics Processors: 3Dlabs Wildcat VP900, ATI Radeon 9700, Nvidia GeForce FX

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
13
wide variety of speed-up factors
platform application speed-up factor method
PACT Xtreme 4-by-4 array [2003]
16 tap FIR filter x16 MOPS/mW straight forward
*) MPC fabrication via E.I.S. multi university project
key issue: algorithmic cleverness
MoM anti machine with DPLA* [1983]
grid-based DRC**
1-metal 1-poly nMOS 256 reference patterns
> x1000
(computation time)
multiple aspects
**) Design Rule Check
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
14
instruction stream-based Compilation Principles
scheduler
parser
source text
library
link/load instruction call placement
1-D memory space
execution order by location
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
15
Datastream-based Compilation Principles
library
data stream assembly
scheduler
mapper placement & routing
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
16
Sequential Processor Model
Conventional processors use the sequential model:
Each operation takes one clock cycle.
Multiple operations are computed consecutively.
Register Operation 1
Time
Operation 2
Operation 3
Operation 4
Operation 5
© 2003, PACT AG
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
17
A New Parallel Processor Paradigm
Multiple computations are configured as code sections onto
a two dimensional array.
Time
x
y
Data Buffer
© 2003, PACT AG
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
18
Parallel Processor Model
Multiple code sections are computed sequentially.
Time
y
x Operation 2
Section 1
Section 2
Section 3
© 2003, PACT AG
;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
19
Dataflow Performance
Traditional Microprocessor XPP Architecture
SHIFT
Instruction
Memory and cache
Configuration
Memory and cache
MULT
One operation
per cycle
Many
operations
per cycle FFT
Viterbi
Basic machine operations
performed on
single words
Complex Functions
performed on
data streams
ADD
Register
One word
ALU Buffer
Stream
of words
Array of ALUs
Filter
© 2003, PACT AG
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
20
1
8 7
3 2 4
3 13
5
3 13
6
3 13
Dataflow Synchronisation: Transport Triggered
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
21
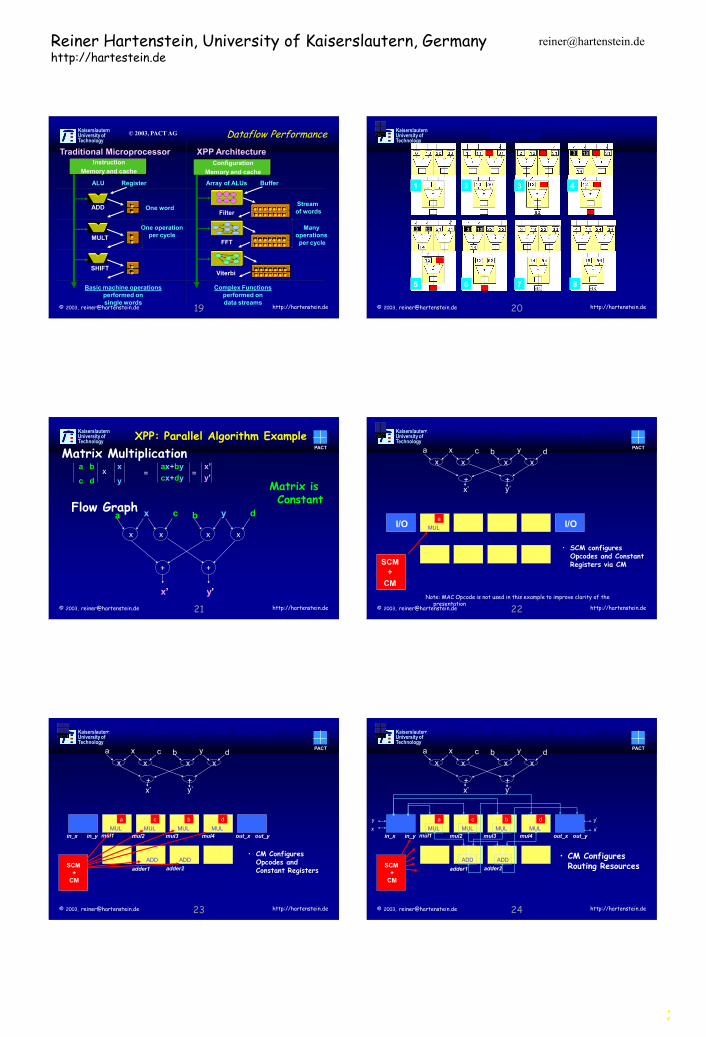
Matrix Multiplication
Flow Graph
x
+
x a
x
c
x
y b
x
d
+
x’ y’
a b
c d
x x
y =
ax+by
cx+dy =
x’
y’
Matrix is Constant
XPP: Parallel Algorithm Example PACT
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
22
I/O I/O
• SCM configures Opcodes and Constant Registers via CM
x
+
x a
x
c
x
y b
x
d
+
x’ y’
SCM
+
CM
MUL
a
Note: MAC Opcode is not used in this example to improve clarity of the presentation
XPP: Parallel Algorithm Example
PACT
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
23
MUL
a
MUL
c
MUL
d
MUL
b
ADD ADD • CM Configures
Opcodes and Constant Registers
x
+
x a
x
c
x
y b
x
d
+
x’ y’
out_x out_y in_x mul1 mul2 mul3 mul4 in_y
adder2 adder1
XPP: Parallel Algorithm Example
PACT
SCM
+
CM
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
24
MUL
a
MUL
c
MUL
d
MUL
b
ADD ADD • CM Configures
Routing Resources
x
+
x a
x
c
x
y b
x
d
+
x’ y’
out_x out_y in_x mul1 mul2 mul3 mul4 in_y
adder2 adder1
x
y
x’
y’
XPP: Parallel Algorithm Example
PACT
SCM
+
CM
;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
25
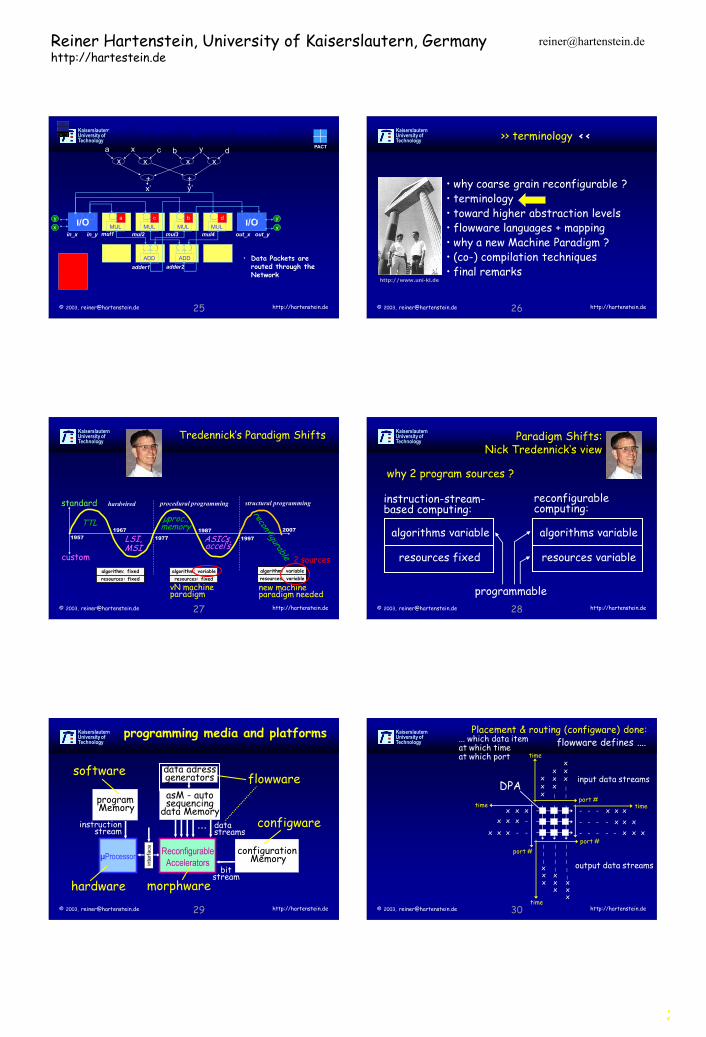
I/O I/O MUL
a
MUL
c
MUL
d
MUL
b
ADD ADD
x
+
x a
x
c
x
y b
x
d
+
x’ y’
• Data Packets are routed through the Network
out_x out_y in_x mul1 mul2 mul3 mul4 in_y
adder2 adder1
x
y
x’
y’
XPP: Parallel Algorithm Example
PACT
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
26
>> terminology <<
• why coarse grain reconfigurable ? • terminology • toward higher abstraction levels • flowware languages + mapping • why a new Machine Paradigm ? • (co-) compilation techniques • final remarks
http://www.uni-kl.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
27
Tredennick’s Paradigm Shifts
TTL µproc., memory
custom
standard
1957
1967
1977
1987
1997
2007
ASICs, accel’s
LSI, MSI
hardwired
algorithm: fixed
resources: fixed
procedural programming
algorithm: variable
resources: fixed
structural programming
algorithm: variable
resources: variable
vN machine paradigm
new machine paradigm needed
2 sources
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
28
Paradigm Shifts: Nick Tredennick‘s view
algorithms variable
resources fixed
instruction-stream-based computing:
algorithms variable
resources variable
reconfigurable computing:
programmable
why 2 program sources ?
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
29
Co-Compilation programming media and platforms
µProcessor
program Memory
instruction stream
configuration Memory
bit stream
Reconfigurable
Accelerators inte
rface
asM - auto sequencing
data Memory
data streams
...
data adress generators
hardware
configware
software
morphware
flowware
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
30
flowware defines ....
DPA
x x x
x x x
x x x
|
| |
x x
x
x
x
x
x x
x
- -
-
input data streams
x x
x
x
x
x
x x
x
- -
-
-
-
-
-
-
-
-
-
-
x x x
x x x
x x x
|
|
|
|
|
|
|
|
|
|
|
| output data streams
time
port #
time
time
port # time
port #
... which data item at which time at which port
Placement & routing (configware) done:

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
31
Terminology: Digital System Platforms clearly distinguished
platform source running on it
machine paradigm
hardware (not running on it)
none
morphware
fine grain rGA (FPGA) configware
coarse grain
rDPU, rDPA reconfigurable data stream processor
flowware & configware anti machine
data stream processor (hardwired) flowware
instruction stream processor software von Neumann machine
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
32
>> higher abstraction levels <<
• why coarse grain reconfigurable ? • terminology • toward higher abstraction levels • flowware languages + mapping • why a new Machine Paradigm ? • (co-) compilation techniques • final remarks
http://www.uni-kl.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
33
„EDA industry shifts into CS mentality“ [Wojciech Maly]
• patches instead of engineering
• innovation stalled many years ago
• netlist-based: do not care about efficiency, ...
• ... do not care about transistor density
• 85% users hate their tools
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
34
Paradigm
Shift
Mainstream
Tornado
Development of Hypergrowth Markets
Harper Business 1995
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
35
McKinsey Curve: dynamics of R&D disciplines
maturity of a discipline
year
fundmental issues
consolidation
saturation: limitations met
new discipline on top of it by ....
... by innovation
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
36
EDA Industry Revolutions
1978
Transistor entry: Applicon, Calma, CV ...
1992
Synthesis: Cadence, Synopsys ... 1985
Schematics entry: Daisy, Mentor, Valid ...
courtesy [Keutzer / Newton]
EDA industry paradigm switching every 7 years
1999 HLLs, (Co-) Compilation
Data-Stream-based DPU arrays
2006 coming closer to programmers‘ mind set

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
37
SoC System level Design: Embedded SW (ESW)
new design automation from high level descriptions
ESE becomes the main focus in system design:
HW-(E)SW codesign onto highly programmable platforms (SoC)
ESW becomes main vehicle to product differentiation
formal verification for (E)SW
HW-(E)SW-co-verificationH.]
SW synthesis included (SoC)
CW-
CW and
CW-
and CW
(ECW)
ECW
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
38
Complexity: System Level Design Challenge
language infrastructures for complex models (SystemC etc.)
must be leveraged by industry consensus on use-methodology and abstraction levels”
[ITRS 2001]
from HW + (processor-dependent embedded) C code level
“abstraction levels must be raised above present-day RT-level
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
39
>> flowware languages <<
• why coarse grain reconfigurable ? • terminology • toward higher abstraction levels • flowware languages + mapping • why a new Machine Paradigm ? • (co-) compilation techniques • final remarks
http://www.uni-kl.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
40
x x x
x x x
x x x
|
| |
x x
x
x
x
x
x x
x
- -
-
input data streams
x x
x
x
x
x
x x
x
- -
-
-
-
-
-
-
-
-
-
-
x x x
x x x
x x x
|
|
|
|
|
|
|
|
|
|
|
| output data streams
time
port #
time
time
port # time
port #
good reading: Nikolay Petkov: Systolic Parallel Processing; North-Holland; 1992
DPA
DPU architecture
math formula
linear projection or
algebraic method
preprocessing
only uniform DPA with linear pipes: only for applications with strictly regular data dependencies
mathematic methods for systolic array synthesis
map
ping
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
41
Compilation for (r)DPA of anti machine
mapper
scheduler
expressionmorphware
configware
streamware
tree
high level source program
wrapperparameters
codegenerators
DPU library
(software notation)
flowware
simulated annealing
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
42
Super Pipe Networks
pipeline properties array applications
shape resources
mapping scheduling
(data stream formation)
systolic array
regular data
dependencies only
linear only
uniform only
linear projection or algebraic synthesis
super-systolic rDPA
no restrictions simulated
annealing or P&R algorithm
(e.g. force-directed) scheduling algorithm
*
*) KressArray [1995]

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
43
Programming Language Paradigms
language category Computer Languages Languages f. Anti Machine
both deterministic procedural sequencing: traceable, checkpointable
operation sequence driven by:
read next instruction, goto (instr. addr.),
jump (to instr. addr.), instr. loop, loop nesting
no parallel loops, escapes, instruction stream branching
read next data item, goto (data addr.),
jump (to data addr.), data loop, loop nesting, parallel loops, escapes, data stream branching
state register program counter data counter(s)
address computation
massive memory cycle overhead overhead avoided
Instruction fetch memory cycle overhead overhead avoided
parallel memory bank access interleaving only no restrictions
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
44
Basics of Binding Time
run time
loading time
compile time
time of “Instruction Fetch”
microprocessor parallel computer
Reconfigurable Computing
anti machine
v.N. machine
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
45
Similar Programming Language Paradigms
language category Computer Languages Xputer Languages
both deterministic procedural sequencing: traceable, checkpointable
sequencingdriven by:
read next instruction, goto (instruction addr.), jump (to instruction addr.), instruction loop, instruction loop nesting no parallel loops, instruction loop escapes, instruction stream branching
read next data object, goto (data addr.), jump (to data addr.), data loop, data loop nesting, parallel data loops, data loop escapes, data stream branching
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
46
JPEG zigzag scan pattern
x
y
*> Declarations
HalfZigZag is EastScan loop 3 times SouthWestScan SouthScan NorthEastScan EastScan endloop end HalfZigZag;
goto PixMap[1,1]
HalfZigZag; SouthWestScan reverse(uturn(HalfZigZag))
HalfZigZag
data counter data counter
data counter data counter
HalfZigZag
EastScan is step by [1,0] end EastScan;
SouthWestScan is loop 8 times until [1,*] step by [-1,1] endloop end SouthWestScan;
SouthScan is step by [0,1] endSouthScan;
NorthEastScan is loop 8 times until [*,1] step by [1,-1] endloop end NorthEastScan;
Flowware language example (MoPL)
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
47
>> new Machine Paradigm <<
• why coarse grain reconfigurable ? • terminology • toward higher abstraction levels • flowware languages + mapping • why a new Machine Paradigm ? • (co-) compilation techniques • final remarks
http://www.uni-kl.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
48
CS: young ? dynamic?
.. but the von Neumann Paradigm is still the dominant doctrine ...
Microelectronics is ignored (except falling cost
of computational effort)
... still pushing he basic models from the times of mainframe dinosaurs
after >10 technology generations ...
• 1th 4004 • 2nd 8008 • 3rd 8086 • 4th 80286 • 5th 80386 • 6th 80486 • 7th P5 (Pentium) • 8th P6 (Pentium Pro / Pentium II) • 9th Pentium III • 10th .... • 11th
• .......
... the vN Microprocessor is a methusela, the steam engine of the silicon age.

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
49
MPU designs more complex
greatly complicates the verification process
chip-level multiprocessing + simultaneous multithreading
many bugs relate to concurrency issues
new kinds of concurrency are becoming important
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
50
„Pollack‘s Law“ (simplified) [intel]
growth factor
µm
0.1
performance
area efficiency
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
51
KressArray principles
• take systolic array principles
• replace classical synthesis by simulated annealing
• yields the super systolic array
• a generalization of the systolic array
• no more restricted to regular data dependencies
• now reconfigurability makes sense
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
52
control-procedural vs. data-procedural
The structural domain is primarily data-stream-based:
..... mostly not yet modelled that way: most flowware is hidden by its indirect
instruction-stream-based implementation
Flowware provides a (data-)procedural abstraction from the (data-stream-based) structural domain
Flowware converts „procedural vs. structural“ into „control-procedural vs. data-procedural“ ...
... a Troyan horse to introduce the structural domain to the procedural mind set of programmers
Flowware
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
53
Why a dichotomy of machine paradigms?
data stream machine:
• bad message: caches do not help
• good message: no vN bottleneck
• caches not needed stolen from Bob Colwell
vN bottleneck vN: unbalanced
The anti machine has no von Neumann bottleneck
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
54
computing paradigms and methodologies
1946: machine paradigm (von Neumann)
1980: data streams (Kung, Leiserson)
1989: anti machine paradigm
1990: rDPU (Rabaey)
1994: anti machine high level programming language
1995: super systolic rDPA
1996+: SCCC (LANL), SCORE, ASPRC, Bee (UCB), ...
1997+: discipline of distributed memory architecture
1997: configware / software partitioning compiler
flow
war
e*
;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
55
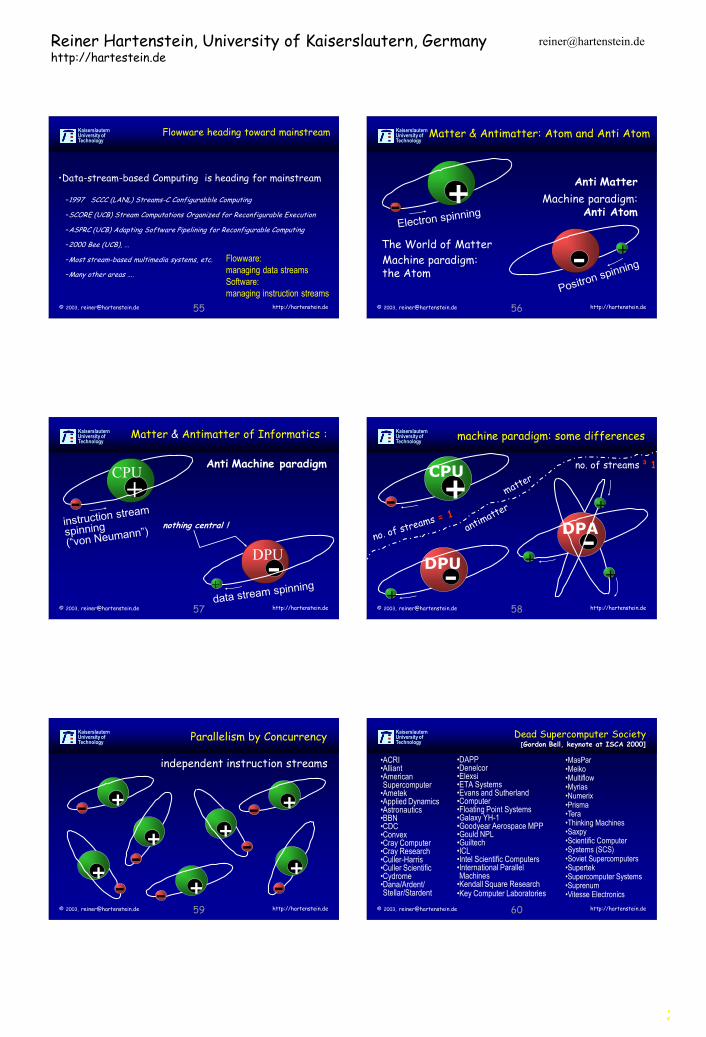
Flowware heading toward mainstream
•Data-stream-based Computing is heading for mainstream
–1997 SCCC (LANL) Streams-C Configurabble Computing
–SCORE (UCB) Stream Computations Organized for Reconfigurable Execution
–ASPRC (UCB) Adapting Software Pipelining for Reconfigurable Computing
–2000 Bee (UCB), ...
–Most stream-based multimedia systems, etc.
–Many other areas ....
Flowware:
managing data streams
Software:
managing instruction streams
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
56
Matter & Antimatter: Atom and Anti Atom
The World of Matter
Machine paradigm: the Atom
Anti Matter
Machine paradigm: Anti Atom
+ + -
- - +
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
57
Matter & Antimatter of Informatics :
- DPU
+
Anti Machine paradigm
+
CPU
-
nothing central !
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
58
machine paradigm: some differences
+ CPU
-
- DPA
+ +
+
- DPU
+
no. of streams ³ 1
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
59
Parallelism by Concurrency
+ -
+ -
- +
- +
+ -
- +
- +
independent instruction streams
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
60
Dead Supercomputer Society
•ACRI •Alliant •American Supercomputer
•Ametek •Applied Dynamics •Astronautics •BBN •CDC •Convex •Cray Computer •Cray Research •Culler-Harris •Culler Scientific •Cydrome •Dana/Ardent/ Stellar/Stardent
•DAPP •Denelcor •Elexsi •ETA Systems •Evans and Sutherland •Computer •Floating Point Systems •Galaxy YH-1 •Goodyear Aerospace MPP •Gould NPL •Guiltech •ICL •Intel Scientific Computers •International Parallel Machines
•Kendall Square Research •Key Computer Laboratories
[Gordon Bell, keynote at ISCA 2000]
•MasPar •Meiko •Multiflow •Myrias •Numerix •Prisma •Tera •Thinking Machines •Saxpy •Scientific Computer •Systems (SCS) •Soviet Supercomputers •Supertek •Supercomputer Systems •Suprenum •Vitesse Electronics

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
61
blinders:
„we are o.k. !“ (no new direction)
Lacking Sense of Direction ?
for ignoring the impact of RC © 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
62
Some Supercomputing people now looking at us
Reconfigurable Computing
Steroids for the aging microprocessor:
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
63
Machine paradigms
von Neumann instruction
stream machine M
I/O
instruction sequencer
CPU
instruction stream
I/O M M M M M
(r)DPU
DPU
Software
I/O M M M M M
(r)DPA
memory distributed memory architecture*
data stream
data-stream machine
M
DPU or rDPU
data address generator (data sequencer)
memory
I/O
asM**
Flowware
(Configware)
(reconf.)
*) the new discipline came just in time: see Herz et al.: Proc. IEEE ICECS 2002
+ CPU
- -
DPU
+
memory
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
64
heavy anti atoms: DPA = DPU array
- DPA
- DPU
- DPU
- DPU
- DPU
- DPU
- DPU
- DPU
- DPU
- DPU -
DPA
+
+
+
+
+
+
+ +
+
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
65
Distributed Memory
SA: scrambling and descrambling the data ?
Just in time: a new research area:
Application-specific distributed memory:
e. g. book by F. Catthoor et al. ...
Data address generators - 20 years research:
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
66
>> compilation techniques <<
• why coarse grain reconfigurable ? • terminology • toward higher abstraction levels • flowware languages + mapping • why a new Machine Paradigm ? • (co-) compilation techniques • final remarks
http://www.uni-kl.de

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
67
Co-Compilation
Xputer
“Soft” Machine Paradigm
Configware running on
partitioning compiler
high level programming language source
mProcessor Reconfigurable
Accelerators inte
rface
Reconfigurable Architecture (RA)
-- instead of hardwired
We introduce: Co-Compilation
Computer Machine Paradigm
Software running on
Xputer
“Soft” Machine Paradigm
Configware running on
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
68
The Secret of Success: Co-Compilation
Analyzer / Profiler
SW code
SW compiler
para d igm “vN" machine
CW Code
CW compiler
anti machine paradigm
Partitioner
Resource Parameters
supporting different platforms
supporting platform-based design
High level PL source
could provide the platforms
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
69
Loop Transformation Examples
loop 1-8 body body endloop
loop 1-8 body endloop
loop 9-16 body endloop
fork
join
strip mining
loop 1-4 trigger endloop
loop 1-2 trigger endloop
loop 1-8 trigger endloop
reconf.array: host: loop 1-16 body endloop
sequential processes: resource parameter driven Co-Compilation
loop unrolling
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
70
Machine Paradigms
machine category Computer (the Machine:
“v. Neumann”) The Anti Machine
driven by: Instruction streams data streams (no “dataflow”)
engine principles instruction sequencing sequencing data streams
state register single program counter (multiple) data counter(s)
Communication path set-up .
at run time at load time
resource DPU (e.g. single ALU) DPU or DPA (DPU array) etc. data path
operation sequential parallel pipe network etc.
( “instruction fetch” )
also hardwired implementations* *) e g. Bee project Prof. Broderson
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
71
KressArray Family generic Fabrics: a few examples
Examples of 2nd Level Interconnect: layouted over rDPU cell - no separate routing areas !
+
rout-through and function
rout-through
only more NNports:
rich Rout Resources
Select Function
Repertory
select Nearest Neighbour (NN) Interconnect: an example
16 32 8 24
4
2 rDPU
Select mode, number, width of NNports
http://kressarray.de © 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
72
DPSS
KressArray DPSS
VHDL Verilog
HDL Generator Simulator
User Interface
Architecture Editor
Mapping Editor
Power Estimator
Power Data
Selection
interm. form
Mapper Bus & I / O Schedule
Scheduler
User
ALEX Code
interm. form
ALE-X Compiler
Architecture Estimator
interm. form
Design Rules
Datapath Generator Generator
Kress rDPU
Layout Data Path Synthesis System

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
73
DPSS
KressArray DPSS
User Interface
Architecture Editor
Mapping Editor
Selection
interm. form
Mapper Bus & I / O Schedule
Scheduler
Application Set
Improvement Proposal Generator
User
ALEX Code
interm. form
ALE-X Compiler
Architecture Estimator
interm. form
Su
gg
estio
n
Delay Estim.
Sug- gest- ion
Inference Engine (FOX) Analyzer
statist. Data
KressArray (Design Space) (Platform Space) Xplorer
Xplorer
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
74
Ulrich Nageldinger‘s Ph. D. thesis
http://hartenstein.de
click „recent talks“
this page: also link to Ph. D thesis download
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
75
>> final remarks <<
• why coarse grain reconfigurable ? • terminology • toward higher abstraction levels • flowware languages + mapping • why a new Machine Paradigm ? • (co-) compilation techniques • final remarks
http://www.uni-kl.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
76
Where are we heading ?
1
2
0 10 12 18 months
factor
*) Department of Trade and Industry, London
90% by 2010
10 times more programmers
will write embedded applications
than computer software by 2010
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
77
data streams ...
PS: Personal Supercomputer replaces the PC
mainframes PC
1957
1967
1977
1987
1997
2007
PS: personal supercomputer
morphware
µProc. rDPA
co-compiler
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
78
What‘s the problem ?
.... by signals rippling through a network of transistors.
The typical programmer has problems to understand function evaluation without machine mechanisms....
Traditional CS: programming is (control-)procedural, instruction-stream-based – sources: software
accelerators accelerators µprocessor µprocessor
It‘s the gap between procedural and structural mind set
Crossing the Hardware / Software Chasm [Mike Butts]

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
79
What‘s the problem ?
accelerators accelerators µprocessor µprocessor
The brain hurts on paradigm shift ?
no, it can‘t ...
Brain usage: procedural-only
structural hemisphere missing
Crossing the Hardware / Software Chasm [Mike Butts]
solution only with user-friendly SW / CW / FW co-compilers
based on anti machine paradigm used as a Troyan Horse into CS
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
80
Annihilation?
- +
-
+ - + avoidable
by tools ....
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
81
>>> thank you <<<<<
thank you
for your
patience
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
82
>>> END <<<
END
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
83
Conclusion: all knowledge needed is available
•machine paradigm
•anti machine architectural resources
•sequencing methodology: hw & sw
•parallel memory IP core and module generator vendors
•anything else needed
•compilation techniques
•hw / sw partitioning methodology
• languages
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
84
The Situation in Computing Sciences
• Computing Sciences are in a severe crisis
• New fundamentals and R&D directions are inevitable
• my mission: getting you involved
• All knowledge needed is readily available ...
• ... even from Computing Sciences
• Silicon application and EDA provide useful concepts
• Reconfigurable Computing has the remedy

;
Reiner Hartenstein, University of Kaiserslautern, Germany http://hartestein.de
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
85
asM
Configware / Flowware Compilation
r. Data Path
Array
rDPA intermediate
high level source program
wrapper
configware configware
mapper
flowware flowware
scheduler
M M M M
M M M M
M
M
M
M
M
M
M
M
data streams
data sequencer
address generator
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
86 © 2001, [email protected]
University of Kaiserslautern
Xputer Lab
instructions
program cou n ter: state register
Compiler RAM
Datapath
har dw ired
Sequencer
Computer Computer tightly coupled
by compact instruction code
“von Neumann” “von Neumann” does not support soft data paths does not support soft data paths
Datapath
Xputer Xputer
Scheduler
Compiler
RAM
(multiple) sequencer
Datapath Array
“instructions”
University of Kaiserslautern
Xputer Lab
loosely coupled by decision data bits only
Xputer: Xputer: The Soft Machine Paradigm
The Soft Machine Paradigm reconfigurable reconfigurable
also for hardwired also for hardwired
Computer: the wrong Machine Paradigm
“von Neumann”
s d a ta cou n ter
(anti machine)
© 2003, [email protected] http://hartenstein.de
Kaiserslautern University of Technology
87
Sources: Proc ISSCC, ICSPAT, DAC, DSPWorld
Why Coarse Grain instead of FPGA ?
physical logical
FPGA logical
1980 1990 2000 2010
FPGA physical
100 000 000 000
10 000 000 000
1000 000 000
100 000 000
10 000 000
1000 000
100 000
10 000
1000
Tra
nsis
tors
/ c
hip
~ 10
~ 10 000
drastically smaller configuration memory
a lot of more benefits
much faster loading
FPGA routed
reduced reconfigurability overhead by up to ~ 1000





























