Embed Size (px)
Citation preview

Pengyi Shi
Krannert School of Management, Purdue University
Reinforcement Learning in Queueing Network: Applications to Patient Flow Management and
Criminal Justice System
1 Guest Lecture for Wharton OIDD 941 “Data-driven Decision Making”
April 9, 2021

About me
Pengyi Shi
Joined Purdue in January 2014
Ph.D. in Industrial Engineering (Georgia Tech)
Research area:
Healthcare operations, service operations
Integrate data analytics into decision making (reinforcement
learning, online learning)

Agenda
3
Reinforcement learning in queueing network
control
Hospital unit placement
Jail diversion
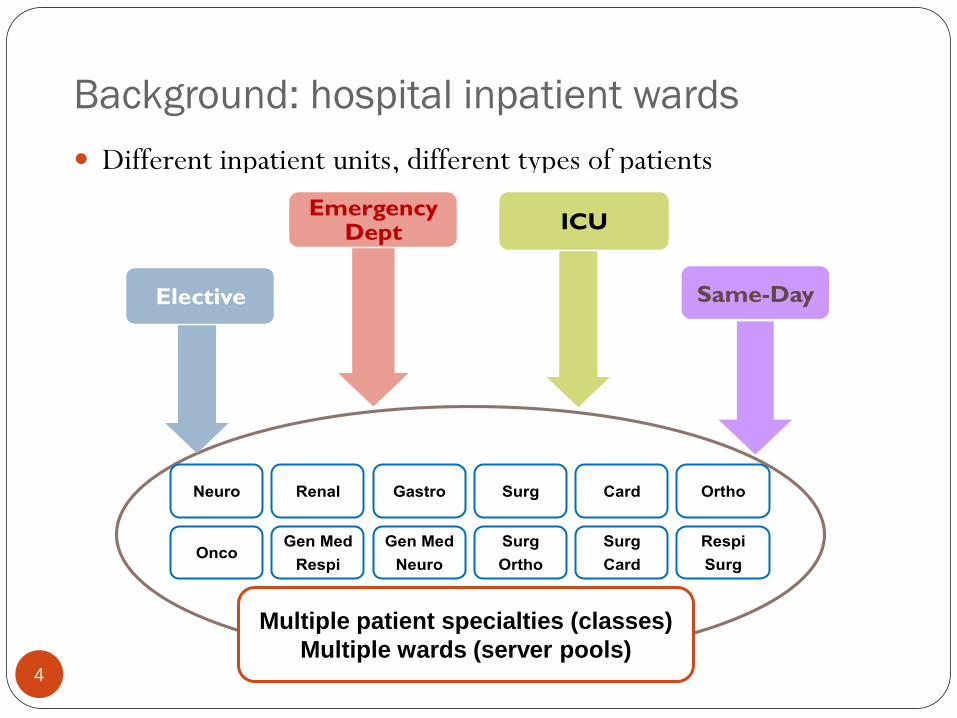
Background: hospital inpatient wards
Different inpatient units, different types of patients
4
Elective
Emergency Dept ICU
Neuro Renal Gastro Surg Card Ortho
Onco Gen Med
Respi
Gen Med
Neuro
Surg
Ortho
Surg
Card
Respi
Surg
Overflow I Overflow II Overflow
III
Same-Day
Multiple patient specialties (classes)
Multiple wards (server pools)
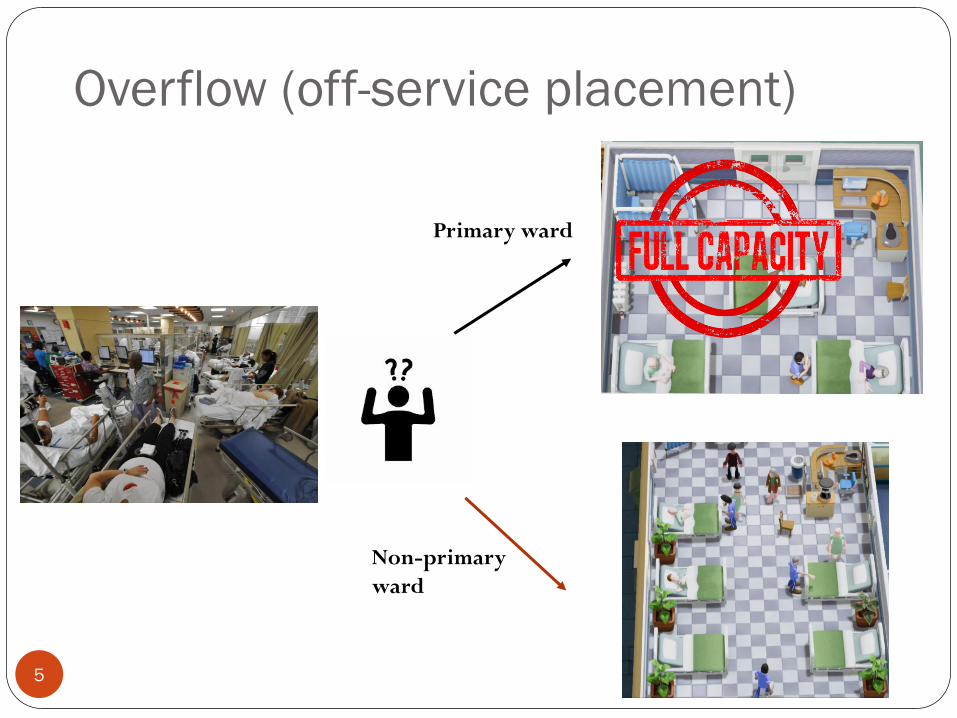
Overflow (off-service placement)
5
Primary ward
Non-primary
ward
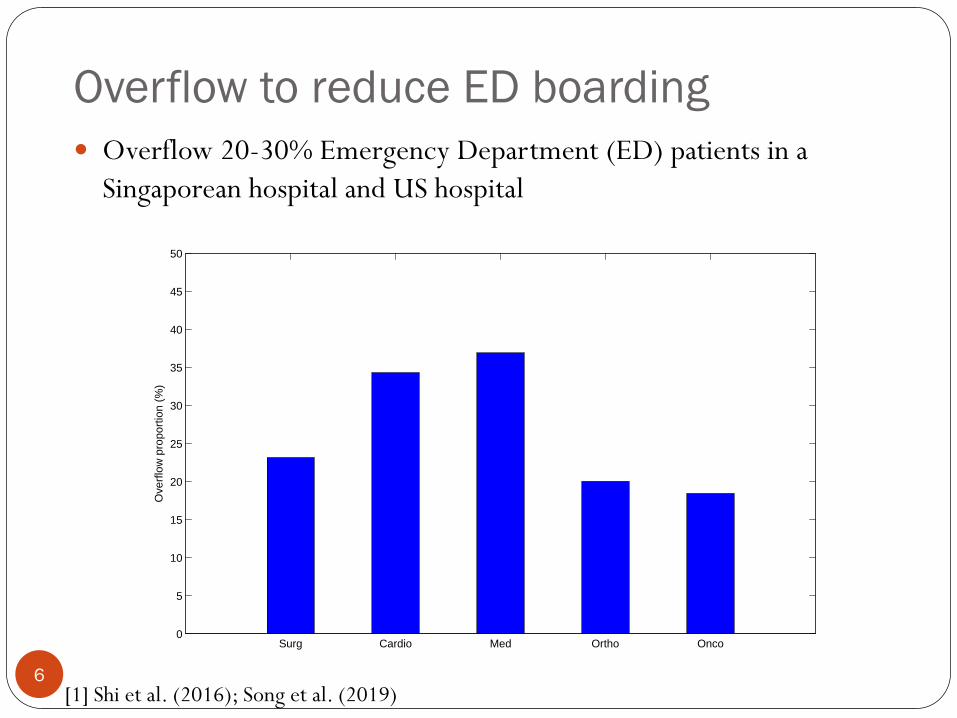
Overflow to reduce ED boarding
6
Overflow 20-30% Emergency Department (ED) patients in a
Singaporean hospital and US hospital
Surg Cardio Med Ortho Onco0
5
10
15
20
25
30
35
40
45
50
Overf
low
pro
port
ion (
%)
[1] Shi et al. (2016); Song et al. (2019)

Tradeoff between waiting and overflow
7
Helps reduce waiting time and alleviate congestion temporarily
Resource pooling
Not desirable
Compromise quality of care (Song et al. 2019)
More coordination (Rabin et al. 2012)
Overflow patients occupy capacity
Dong-Shi-Zheng-Jin 2020: “snowball effect”
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3306853

Research questions
8
Overflow decisions Overflow the patient now or wait for another hour?
Overflow to which wards? Medically closeness, distance to primary wards, ward
occupancy, etc
Challenging to make in real time and in uncertain environments
Main goal: provide a decision support tool
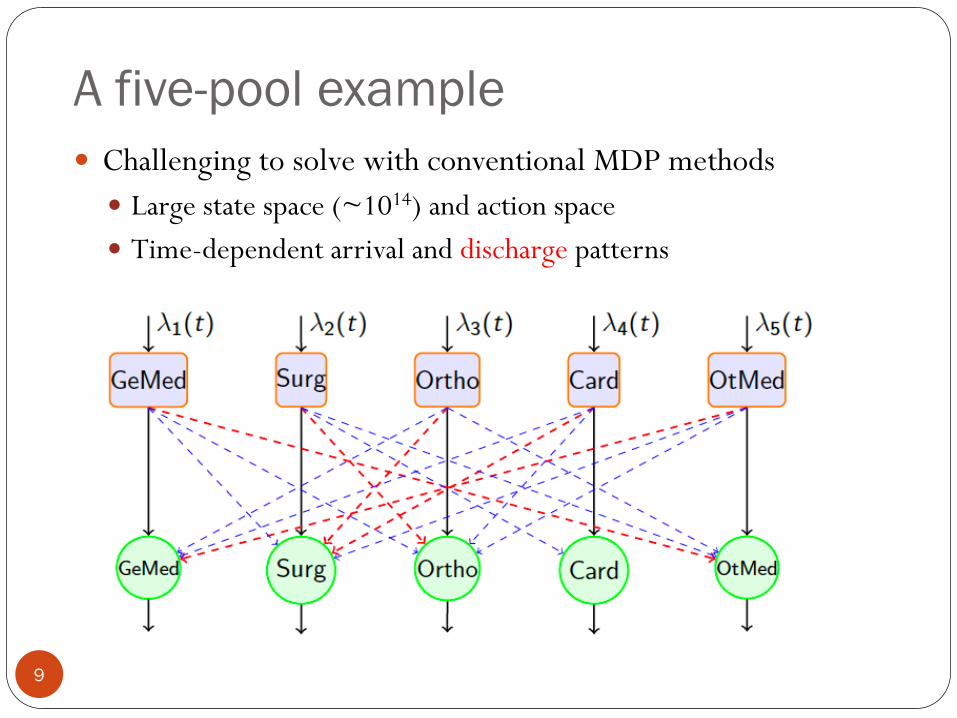
A five-pool example
9
Challenging to solve with conventional MDP methods
Large state space (~1014) and action space
Time-dependent arrival and discharge patterns
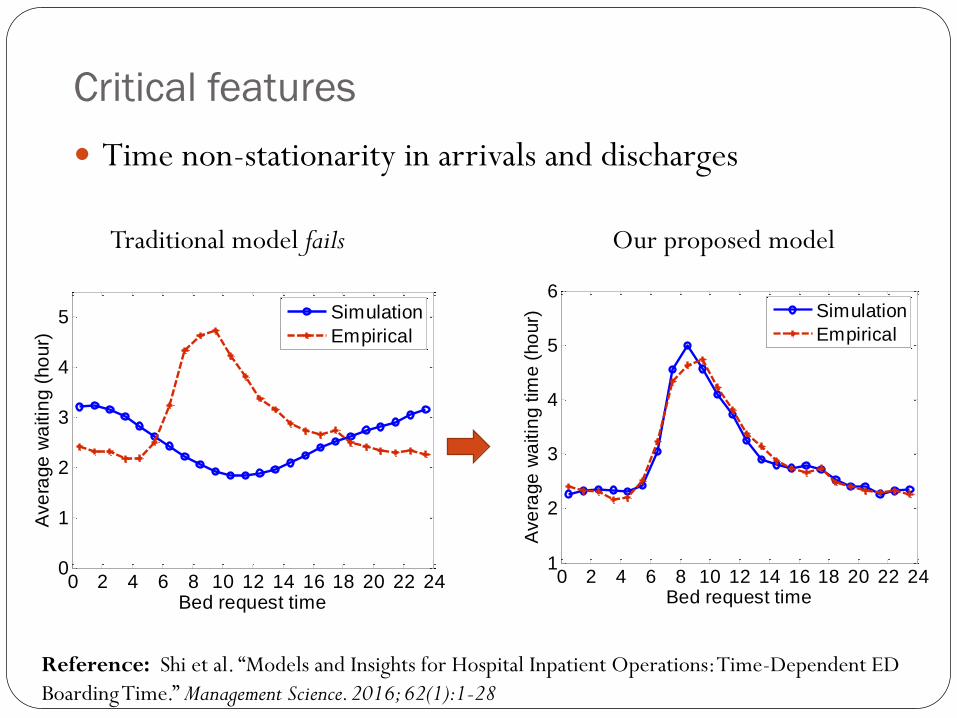
Critical features
Time non-stationarity in arrivals and discharges
Traditional model fails Our proposed model
0 2 4 6 8 10 12 14 16 18 20 22 240
1
2
3
4
5
Bed request time
Ave
rage
wa
itin
g (
ho
ur)
Simulation
Empirical
0 2 4 6 8 10 12 14 16 18 20 22 241
2
3
4
5
6
Bed request time
Ave
rage
wa
itin
g t
ime (
ho
ur) Simulation
Empirical
Reference: Shi et al. “Models and Insights for Hospital Inpatient Operations: Time-Dependent ED
Boarding Time.” Management Science. 2016; 62(1):1-28

Modeling overflow decisions
State at decision epoch tk
Patient count of each pool j at tk
To-be-discharge count from pool j
Time-of-day
indicator
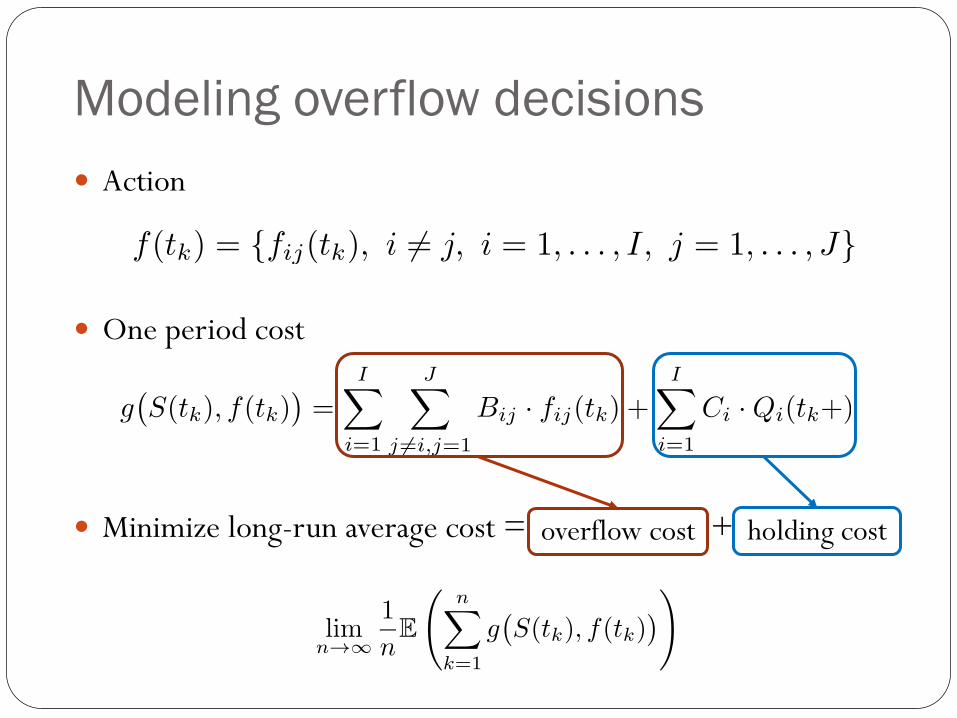
Modeling overflow decisions
Action
One period cost
Minimize long-run average cost = +overflow cost holding cost

Exact analysis
Bellman equation
v(s): value function for state s
Large state space O(XJ YJ) ~ 1014 and action space
Value iteration or policy iteration becomes infeasible
Cost-to-go

Tackling the curse of dimensionality
14
Large state space
Value function approximation + fluid-based feature selection
Large action space
Policy gradient (PPO)
Additional challenges from long-run average setting
Large variance in estimating value function

Value Function: Simulation-based ADP
Approximate value function by linear combination of “features”
Use temporal-difference (TD) learning to iteratively update
coefficients
Least-square TD [1]
Algorithm complexity is O(MJ2) with M being the number of
simulated days
[1] Boyan (1998); Konda (2002); Yu and Bertsekas (2009)

Basis function
Which features (basis functions) to choose is critical
Basic idea
Study a special midnight MDP and obtain approximation for the
midnight relative value function
Use backward induction to approximate other epochs of the day
Reference: J. G. Dai, P. Shi, “Inpatient Bed Overflow: An Approximate Dynamic
Programming Approach.” Manufacturing and Service Operations Management. 2019

Understand the midnight value function
17
Midnight MDP
State space only contains
Proposed approximation
solves an optimal fluid control problem
Captures the overflow cost
is the value function from a single-pool value function
Captures the holding cost
Integrated single-pool system under work-conserving policy
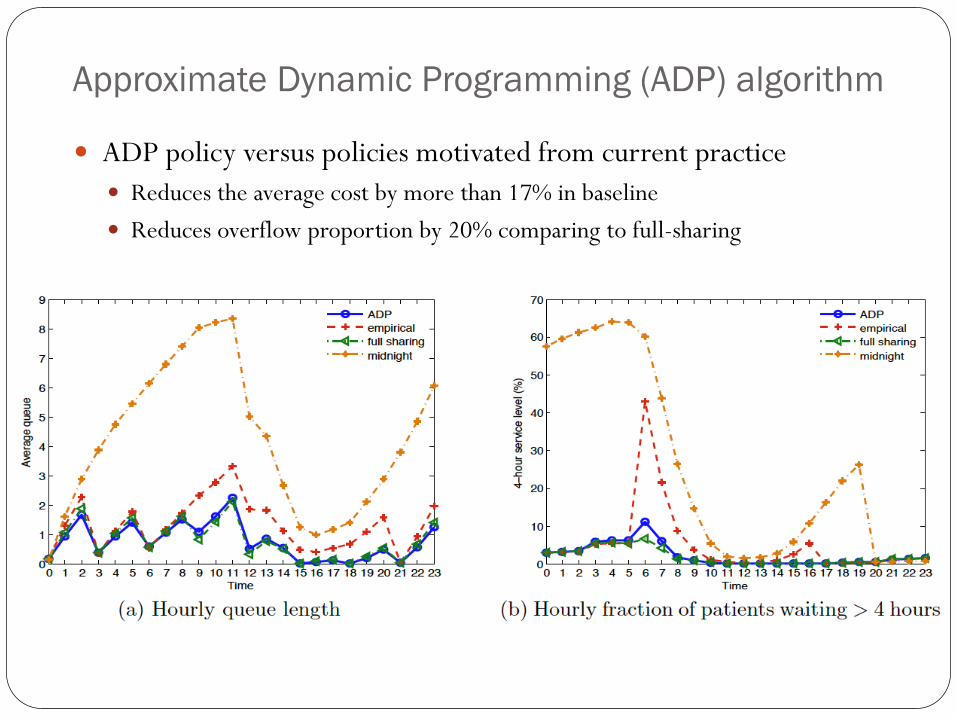
Approximate Dynamic Programming (ADP) algorithm
ADP policy versus policies motivated from current practice
Reduces the average cost by more than 17% in baseline
Reduces overflow proportion by 20% comparing to full-sharing

Action Space
19
Proximal Policy Optimization (PPO) Method
Randomized policy: 𝜋(𝑎)
Macro- and micro-decision process for batch arrivals

PPO Framework
20
In iteration 𝑖:
Policy evaluation: value function approximation ℎ𝜋𝜂(𝑡, 𝑠)
Estimate loss function
With
Update policy
Reference: J. G. Dai, M. Gluzman, P. Shi, J. Sun, “PPO for Inpatient Bed Overflow.”
Working Paper. 2021
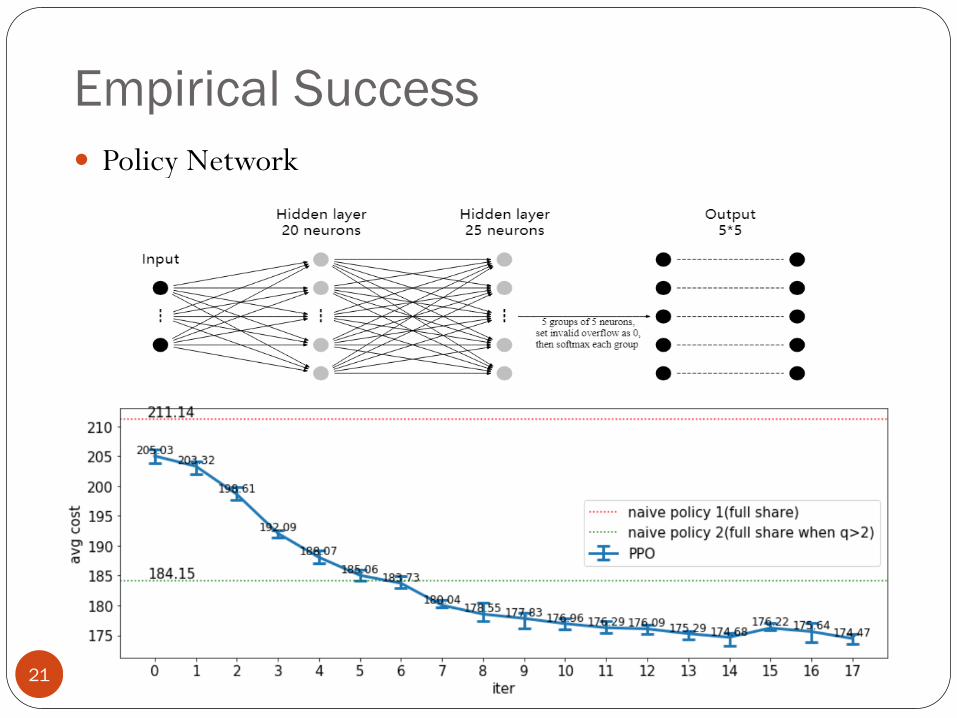
Empirical Success
21
Policy Network

Theoretical Justification – Ongoing
22
Separation of time-scales
Macro MDP value function ℎ𝜋𝜂(𝑡, 𝑠) is insensitive to actions in
micro MDP
Daily versus hourly decision: Averaging Principle
Decomposition for macro MDP
Convergence analysis for policy gradient method

References
23
Shi et al. “Models and Insights for Hospital Inpatient Operations: Time-
Dependent ED Boarding Time.” Management Science. 2016
J. G. Dai, P. Shi, “Inpatient Bed Overflow: An Approximate Dynamic
Programming Approach.” M&SOM. 2019
J. G. Dai, M. Gluzman, P. Shi, J. Sun, “PPO for Inpatient Bed Overflow.”
Working Paper. 2021
Jim Dai
ORIE, Cornell
Jingjing Sun
Joining CUHK-ShenzhenMark Gluzman
Applied Math, Cornell
Agenda
24
Reinforcement learning in queueing network
control
Hospital unit placement
Jail diversion

▪ Correctional facilities overcrowded with drug
offenders
• 2/3 of jail population are drug offenders
• Chronic disease
• Low level, non-violent offense
2
▪ Alternative to jail: Community Corrections
• Rehabilitation and Reintegration
• Treatment – medical and therapy
• Life skills training
• Education
Opioid Crisis and the Correctional System

3
Community Partners

Alleviating Jail Overcrowding
27
RCHE collaborators and research team
Recidivism prediction and post-incarceration resource allocation
Jonathan Helm and Iman Attari (Kelley@IU); Parker Crain
(Purdue)
Paul Griffin
RCHE, Purdue
PSU
Xiaoquan Gao
IE, PurdueNan Kong
BME, Purdue
Nicole Adams
Nursing,
Purdue
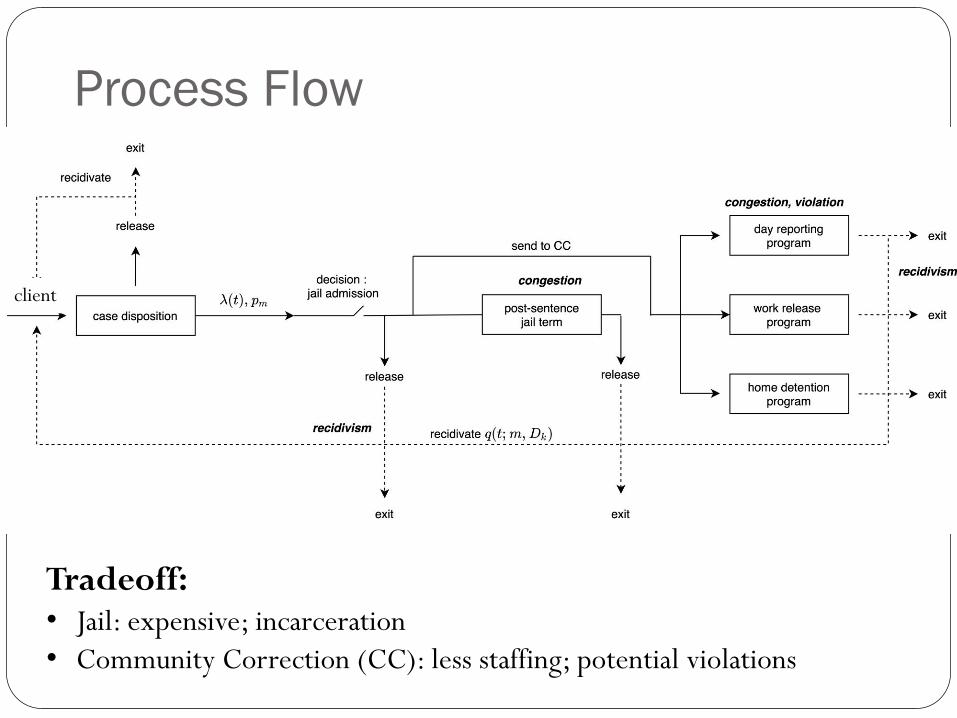
Process Flow
client
Tradeoff:• Jail: expensive; incarceration
• Community Correction (CC): less staffing; potential violations

Model: A Routing Problem
State 𝑋𝑗𝑚,𝑙 (𝑘): # of class 𝑚 clients in facility (or program) 𝑗 for 𝑙
epochs at 𝑘th epoch
Decision 𝐷𝑗1,𝑗2𝑚,𝑙 (𝑘): # of class 𝑚 clients in facility (or program) 𝑗1
for 𝑙 epochs to be routed to facility (or program) 𝑗2 at 𝑘th epoch
Cost function: operation cost + recidivism cost + violation cost
Curse of dimensionality!
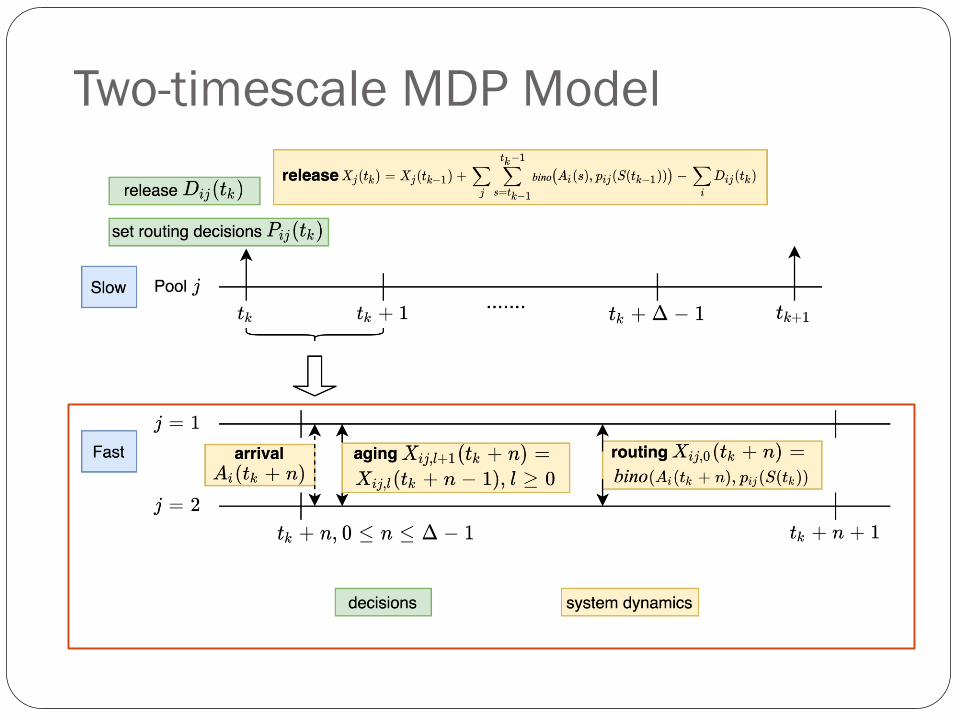
Two-timescale MDP Model

Age Approximation
Slow timescale (monthly decision) 𝑡1, 𝑡2 = 𝑡1 + Δ,…
• State S 𝑡𝑘 = {𝑋𝑖𝑗 𝑡𝑘 }, where 𝑋𝑖𝑗 𝑡𝑘 is # of class 𝑖 in 𝑗
Get rid of index 𝒍 using age distribution approx
Poisson process: conditional on # of arrivals, arrival time follows
ordered statistics from uniform distribution
• Decision 𝑝𝑖𝑗 𝑆 𝑡𝑘 : the probability of routing class 𝑖 to
facility 𝑗
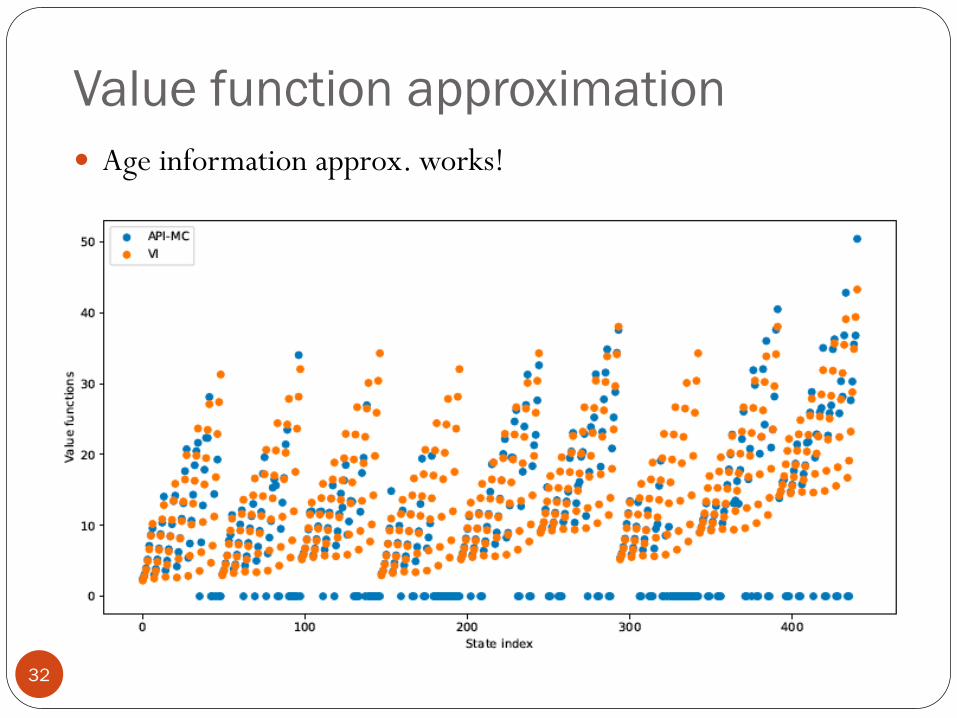
Value function approximation
32
Age information approx. works!

Policy Gradient Methods






























