Embed Size (px)
Citation preview

ReinforcementLearningtoRankwithMarkovDecisionProcess
JunXuICT,CAS
1

Outline
• Background:learningtorankforIR• Reinforcementlearningtorank• Summary
2

RankingisImportantforWebSearch
• Criteria– Relevance– Diversity– Freshness……
• Rankingmodel– Heuristic
• Relevance:BM25,LMIR• Diversity:MMR,xQuAD
– Learningtorank
3

RankinginInformationRetrieval
44
document index
D = 𝑑$
ranking model𝑓(𝑞,𝑑)
query𝑞
𝑑/,𝑓 𝑞, 𝑑/𝑑0, 𝑓 𝑞, 𝑑0
.
.
.𝑑1, 𝑓 𝑞, 𝑑1

LearningtoRankforInformationRetrieval
• Machine learning algorithms for relevance ranking
5
query
docu
men
t
training data
test data
learning to rank algorithm
ranking modelf (x; w)
online ranking
Point-wise: ranking as regression or classification over query-documentsPair-wise: ranking as binary classification over preference pairsList-wise: training/predicting ranking at query (document list) level

IndependentRelevanceAssumption
• Utilityofadocisindependentofotherdocs• Rankingasscoring&sorting– Eachdocumentscanbescoredindependently– Scoresareindependentoftherank
6
d1
d2
d3
0.9
0.5
1.1
sortingd3
d1
d2
q
d1
d2
d3
Scoring with f

BeyondIndependentRelevance• Morerankingcriteria,e.g.,searchresult
diversification– Coveringasmuchsubtopicsaspossiblewith
afewdocuments– Needconsiderthenovelty ofadocument
givenprecedingdocuments• Complexapplicationenvironment,e.g.,
InteractiveIR– Humaninteractswiththesystemduringthe
rankingprocess– Userfeedbackishelpfulforimprovingthe
remainingresults
7
Good Bad
Java Java
C++ Java
Python Java
Query:Programming language
Needmorepowerfulrankingmechanism!

Outline
• Background:learningtorankforIR• Reinforcementlearningtorank– RankingasMarkovdecisionprocess– AdaptingMDPforrelevanceanddiverseranking
• Summary
8
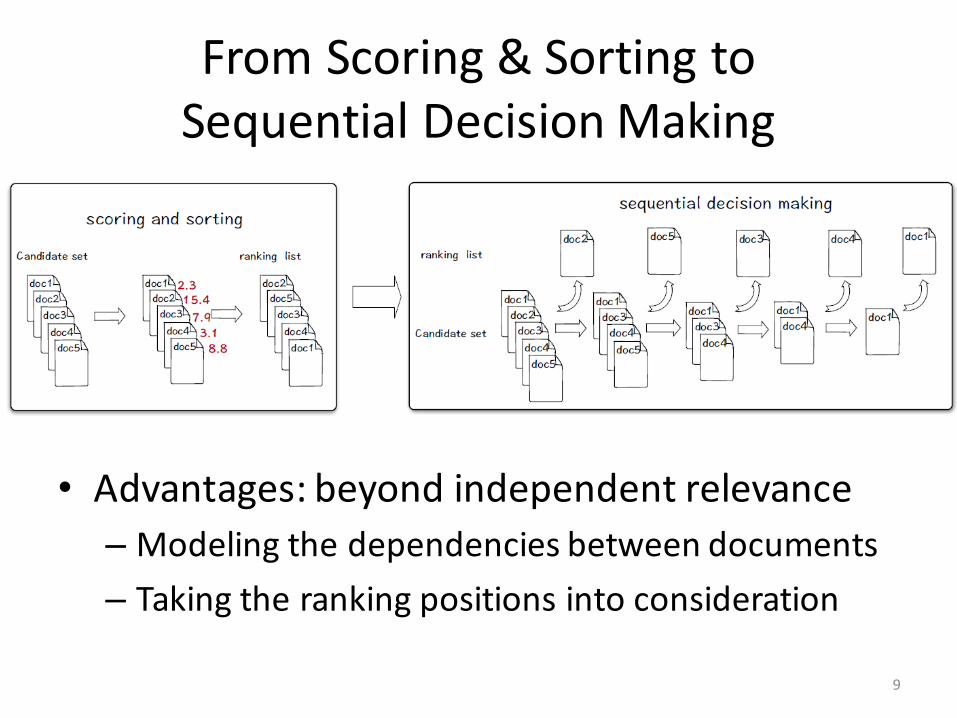
FromScoring&SortingtoSequentialDecisionMaking
• Advantages:beyondindependentrelevance– Modelingthedependenciesbetweendocuments– Takingtherankingpositionsintoconsideration
9

MarkovDecisionProcess(MDP)
10

RankingasMarkovDecisionProcess
• Timesteps:ranks• State:query,precedingdocs,candidates,……• Policy:distributionoverremainingcandidatedocuments• Action(Decision):selectingadocandplacingittocurrentpos• Reward
– Additional utility(e.g.,theincreaseofDCG)fromtheselecteddoc– Calculatedbasedonwidelyusedevaluationmeasures(e.g.,DCG,ERR-IA) 11
Candidatedocumentset
Decidewhichdocshouldbeselectedforthe2nd position
query
Rank1:doc1
Rank2:?

LearningandOnlineRanking
12
• Learningtheparameters– Modelparameters:policyfunction,stateinitializationandtransitionetc.
– Reinforcementlearning:policygradient– Rewardsbasedonrelevancelabelsassupervision
• Onlineranking–Withoutrewards(rewardsarebasedonrelevancelabels)
– Fullytrustthelearnedpolicy

Example1:LearningforSearchResultDiversification
13
Long Xia, Jun Xu, Yanyan Lan, et al., Adapting Markov Decision Process for Search Result Diversification. Proceedings of SIGIR 2017, pp. 535-544.

SearchResultDiversification
• Query:informationneedsareambiguousandmulti-faceted
• Searchresults:maycontainredundantinformation
• Goal:coveringasmuchsubtopicsaspossiblewithafewdocuments
14
Query:jaguar

ModelingDiverseRankingwithMDP
• Keypoints– Mimicusertop-downbrowsingbehaviors– ModeldynamicinformationneedswithMDPstate
• States𝑠3 = [𝑍3, 𝑋3, 𝐡3]– 𝑍3:sequenceof𝑡 precedingdocuments,𝑍: = 𝜙– 𝑋3:setofcandidatedocuments,𝑋: = 𝑋– 𝐡3 ∈ 𝑅> :latentvector,encodes userperceivedutilityfromprecedingdocuments,initializedwiththeinformationneedsformthequery:
𝐡: = 𝜎 𝐕A𝐪15

ModelingDiverseRankingwithMDP
16
MDPfactors Corresponding diverseranking factors
Time steps Therankingpositions
State 𝑠3 = 𝑍3,𝑋3, 𝐡3Policy
𝜋 𝑎3|𝑠3 = [𝑍3, 𝑋3,𝐡3] =exp 𝐱I JK
L 𝐔𝐡3𝑍
Action Selectingadoc andplacingittorank𝑡 + 1Reward Based onevaluationmeasureαDCG,SRecall etc.Forexample:
𝑅 = 𝛼DCG 𝑡 + 1 − 𝛼DCG 𝑡 ;𝑅 = SRecall 𝑡 + 1 − SRecall 𝑡
StateTransition 𝑠3Z/ = 𝑇 𝑠3 = [𝑍3, 𝑋3,𝐡3], 𝑎3= 𝑍3⨁ 𝐱I JK , 𝑋3\ 𝐱I JK ,𝜎 𝐕𝐱I JK + 𝐖𝐡3
𝐱I JK :documentembedding

RankingProcess:InitializeState
17
Documentranking Ranker
Candidatedocuments
Initialuserinf.needs
Query
𝑠: = 𝜙,𝑋, 𝜎 𝐕A𝐪

RankingProcess:Policy
18
Documentranking Ranker
Candidatedocuments
Query
Calculatethepolicy
𝜋 𝑎3|𝑠3 =exp 𝐱I JK
L 𝐔𝐡3𝑍

RankingProcess:Action
19
Documentranking Ranker
Candidatedocuments
Query
Sampleactionaccordingtopolicy
docatrank1

RankingProcess:Reward
20
Documentranking Ranker
Candidatedocuments
Query
Getreward,e.g.,𝑅 = 𝛼𝐷𝐶𝐺 𝑡 + 1 − 𝛼𝐷𝐶𝐺 𝑡
docatrank1
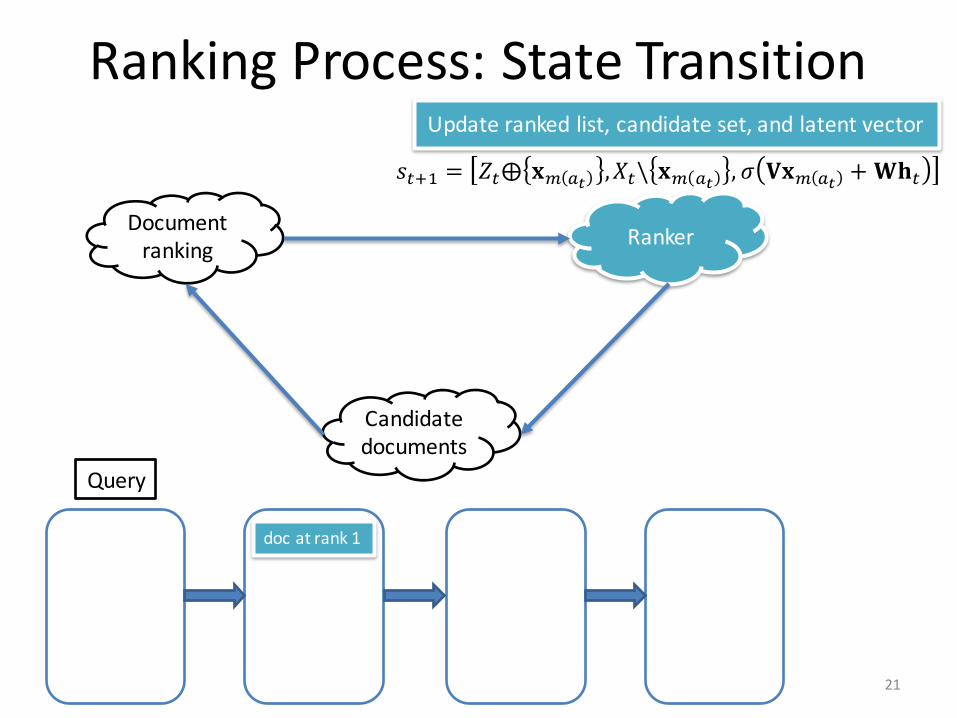
RankingProcess:StateTransition
21
Documentranking Ranker
Candidatedocuments
Query
docatrank1
𝑠3Z/ = 𝑍3⨁ 𝐱I JK ,𝑋3\ 𝐱I JK , 𝜎 𝐕𝐱I JK + 𝐖𝐡3
Updaterankedlist,candidateset,andlatentvector

RankingProcess:Iterate
22
Documentranking Ranker
Candidatedocuments
Query
docatrank1 docatrank1
docatrank2
docatrank1
docatrank2
docatrank3

LearningwithPolicyGradient
• Modelparameters𝚯 = 𝐕A,𝐔, 𝐕,𝐖• Learningobjective:maximizingexpectedreturn(discountedsumofrewards)ofeachtrainingquery
max𝚯
𝑣(𝐪) = 𝐸f𝐺: = 𝐸f g 𝛾i𝑟iZ/
kl/
im:– Directlyoptimizesevaluationmeasureas𝐺: = 𝛼DCG@𝑀
• Monte-Carlostochasticgradientascentisusedtoconducttheoptimization(REINFORCEalgorithm)
𝛻𝚯𝑣 𝐪q = 𝛾3𝐺3𝛻𝚯 log𝜋 𝑎3|𝑠3;𝚯
23

Analysis
24
• Optimizegeneraldiversityevaluationmeasures(e.g.,α-DCG,S-recall)
• Givenanepisodeandtimestept
discountedsumoftherewards,startingfromposition0(return)
Maximizing thereturnstartingfromposition t

TheLearningAlgorithm
25
Samplearanking

OnlineRanking Algorithm
• Fullytrustthepolicy
26
usingmaxinsteadofsampling

ExperimentalResults
• BasedoncombinationofTREC2009~2012WebTrack• Directlyoptimizeapredefinedmeasureviadefiningtherewardsbasedonthemeasure
27

Howitworks?UsingQuery93asExample
28

Howitworks?UsingQuery93asExample
29

Howitworks?UsingQuery93asExample
30

Howitworks?UsingQuery93asExample
31

Howitworks?UsingQuery93asExample
32

Howitworks?UsingQuery93asExample
33

Howitworks?UsingQuery93asExample
34

Howitworks?UsingQuery93asExample
35

UsingImmediateRewardsinTraining
36
Train with α-DCG@M
Train with α-DCG@k(k=1, …, M)

ConvergenceandOnlineRankingCriterion
37

Advantages
• Unifiedcriterion(additionalutilityusercanperceive)forselectingdocumentsateachiteration
• End-to-endlearningofthediverserankingmodel– Noneedofhandcraftedfeatures
• Utilizesboththeimmediaterewardsandthelong-termreturnsasthesupervisioninformationduringtraining
38

Example2:RelevanceRankingasanMDP
39
Wei Zeng, Jun Xu, Yanyan Lan, Jiafeng Guo, and Xueqi Cheng. Reinforcement Learning to Rank with Markov Decision Process. Proceedings of SIGIR 2017, pp. 945-948.

ModelingRelevanceRankingwithMDP
40
MDPfactors Corresponding relevanceranking factors
Time steps Therankingpositions
State 𝑠3 = [𝑡, 𝑋3]Policy
𝜋 𝑎3|𝑠3 = [𝑡,𝑋3] =exp 𝐰L𝐱I JK
∑ exp 𝐰L𝐱I JJ∈v 3
Action Selectingadoc andplacingittocurrentposition
Reward Based onevaluationmeasureDCG:
𝑅 = w2y zK − 1 𝑡 = 00| zK l/
}~�� 3Z/𝑡 > 0
StateTransition 𝑠3Z/ = 𝑇 𝑠3 = [𝑡, 𝑋3], 𝑎3 = 𝑡 + 1, 𝑋3\ 𝐱I JK ,
𝐱I JK :query-docrelevancefeatures

TheRankingProcess
41

LearningwithPolicyGradient
42

ExperimentalResults
• MDPRank isbetterbecause– UtilizetheIRmeasurescalculatedatalltherankingpositionsassupervisioninformationfortraining
– DirectlyoptimizestheIRmeasureonthetrainingdatawithoutanyapproximationorupperbounding
43

Outline
• Background:learningtorankforIR• Reinforcementlearningtorank• Summary
44

Summary
• Reinforcementlearningtorank– Rankingassequentialdecisionmaking– AdaptingMDPforthetask– Learningwithpolicygradient
• Twoexamples– Diverseranking– Relevanceranking
45

EasyMachineLearningProject
46

DesignofEasyMachineLearning
47
Data Storage and ManagementLarge scale data management
HDFSStructured data management
MySQL
Distributed Computing
Map-Reduce Spark TensorFlow
Scheduling: Oozie
Execute command lines Program status
Interactive GUI (GWT)
Dataflow DAG
Workflow DAG
Job status, program status
designer monitor
Submit Oozie job
Node: program / dataEdge: dataflow
Node: program / start / end / fork / joinEdge: dependency

DeployasWebServicehttp://159.226.40.104:18080/dev
• Advantages– Sharing:sharedata/programs/tasksamongusers– Collaborating:workingtogetherforonetask– Mobility:accessingwithwebbrowsersanywhere– Open:ETLfordataimport/export;canrunthird-partyprograms
482017/11/12
Brower Webserver Hadoop/Spark cluster

SourceSharedatGithubhttps://github.com/ICT-BDA/EasyML
• Top1JavaprojectatGithub trendingforoneweek
• 1400+starsand~300forks• CIKM2016bestdemocandidate
[Guo etal.,CIKM’16]
49











