Embed Size (px)
Citation preview

Relevance Feedback Users learning how to modify queries
Response list must have least some relevant documents Relevance feedback
`correcting' the ranks to the user's taste automates the query refinement process
Rocchio's method Folding-in user feedback To query vector
Add a weighted sum of vectors for relevant documents D+ Subtract a weighted sum of the irrelevant documents D-
.
q
D -D
d-dq'q

Relevance Feedback (contd.)
Pseudo-relevance feedback D+ and D- generated automatically
E.g.: Cornell SMART system top 10 documents reported by the first round of query execution
are included in D+ typically set to 0; D- not used
Not a commonly available feature Web users want instant gratification System complexity
Executing the second round query slower and expensive for major search engines
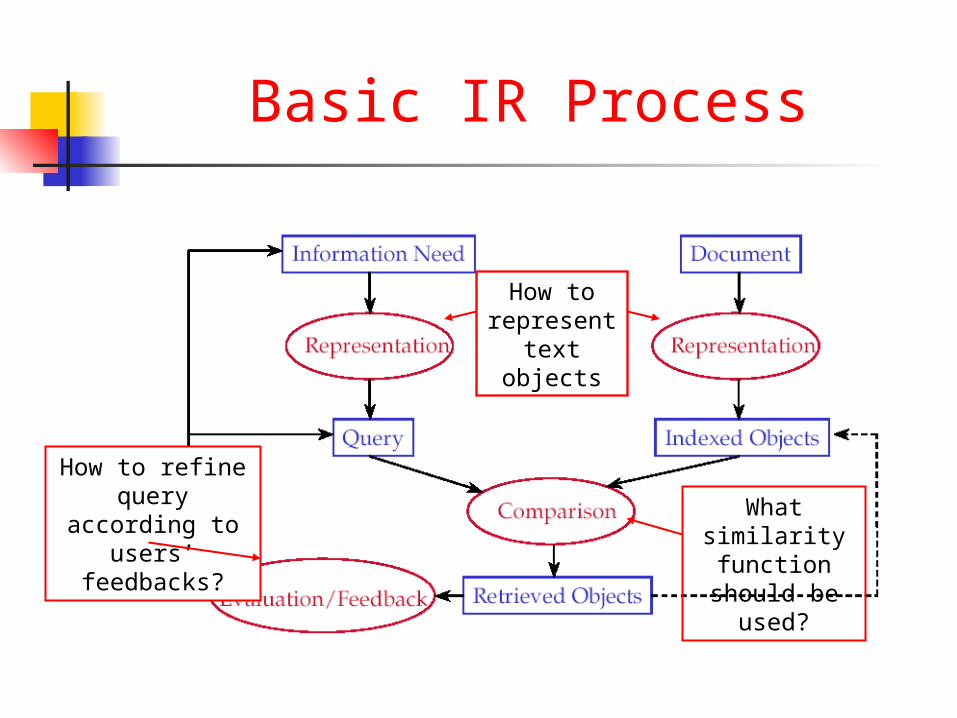
Basic IR Process
How to represent text
objects
What similarity function should
be used?
How to refine query according to users’
feedbacks?

A Brief Review of Probability
Probability space Random variable (discrete, continuous and
mixed) Probability distributions (binomial,
multinomial, Gaussian) Expectation, Variance Probability independent, conditional
independent, conditional probability, Bayesian theorem …

Definition of Probability Experiment: toss a coin twice Sample space: possible outcomes of an experiment
S = {HH, HT, TH, TT} Event: a subset of possible outcomes
A={HH}, B={HT, TH} Probability of an event : an number assigned to
an event Pr(A) Axiom 1: Pr(A) 0 Axiom 2: Pr(S) = 1 Axiom 3: For every sequence of disjoint events
Example: Pr(A) = n(A)/N: frequentist statisticsPr( ) Pr( )i iii
A A

Independence Two events A and B are independent
in casePr(A,B) = Pr(A)Pr(B)
Pr(A,B): probability for both A and B Independence Disjoint
Pr(A,B) = 0 when A and B are disjoint !

If A and B are events with Pr(A) > 0, the conditional probability of B given A is
Example:
Conditional Probability
Pr( , )Pr( | )
Pr( )
A BB A
A
Pr(Drug1 = Succ|Women) = ?
Pr(Drug2 = Succ|Women) = ?
Pr(Drug1 = Succ|Men) = ?
Pr(Drug2 = Succ|Men) = ?

Conditional Independence Event A and B are conditionally independent
given C in case Pr(A,B|C)=Pr(A|C)Pr(B|C)
Example A:success, B:women, C:drug I Will A and B conditional independent from C?

1
1
Pr( ) Pr( | ) Pr( )Pr( | )
Pr( ) Pr( )
Pr( | ) Pr( )
Pr( , )
Pr( | ) Pr( )
Pr( ) Pr( | )
i i ii
i in
ii
i in
ii
B A A B BB A
A A
A B B
A B
A B B
A A B
Bayes’ Rule Suppose that B1, B2, … Bn form a partition of sample
space S:
Suppose that Pr(A) > 0. Then
; i j iiB B B S

1
1
Pr( ) Pr( | ) Pr( )Pr( | )
Pr( ) Pr( )
Pr( | ) Pr( )
Pr( , )
Pr( | ) Pr( )
Pr( ) Pr( | )
i i ii
i in
ii
i in
ii
B A A B BB A
A A
A B B
A B
A B B
A A B
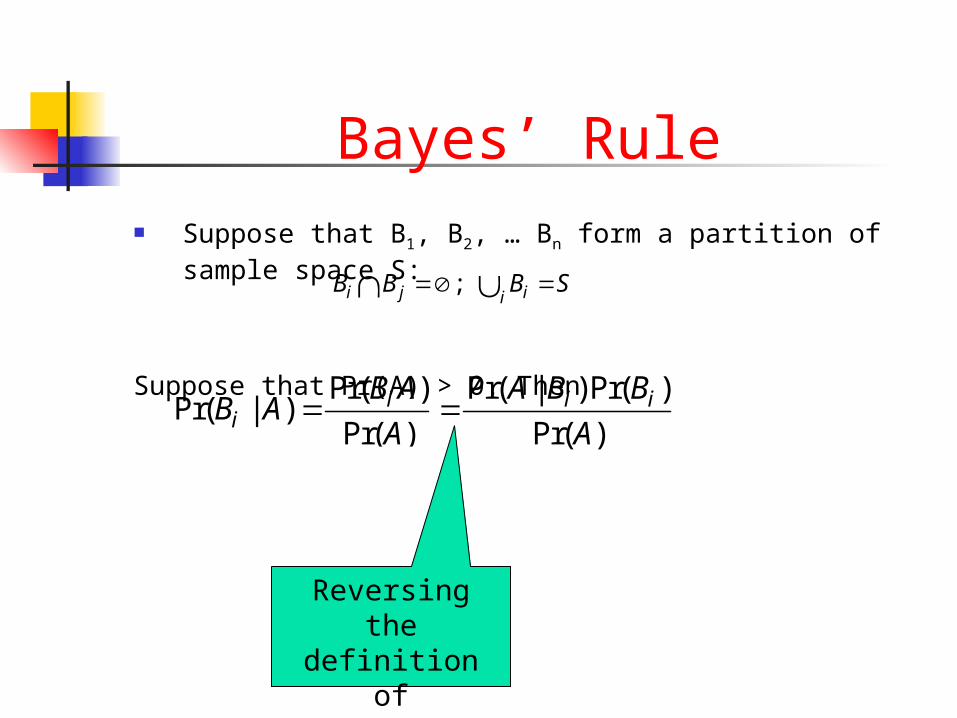
Bayes’ Rule Suppose that B1, B2, … Bn form a partition of sample
space S:
Suppose that Pr(A) > 0. Then
; i j iiB B B S
Derived from the definition of
conditional prob.
1
1
Pr( ) Pr( | ) Pr( )Pr( | )
Pr( ) Pr( )
Pr( | ) Pr( )
Pr( , )
Pr( | ) Pr( )
Pr( ) Pr( | )
i i ii
i in
ii
i in
ii
B A A B BB A
A A
A B B
A B
A B B
A A B
Bayes’ Rule Suppose that B1, B2, … Bn form a partition of sample
space S:
Suppose that Pr(A) > 0. Then
; i j iiB B B S
Reversing the definition of
conditional prob.

1
1
Pr( ) Pr( | ) Pr( )Pr( | )
Pr( ) Pr( )
Pr( | ) Pr( )
Pr( , )
Pr( | ) Pr( )
Pr( ) Pr( | )
i i ii
i in
ii
i in
ii
B A A B BB A
A A
A B B
A B
A B B
A A B
Bayes’ Rule Suppose that B1, B2, … Bn form a partition of sample
space S:
Suppose that Pr(A) > 0. Then
; i j iiB B B S
Using the property
; i j iiB B B S

Bayes’ Rule Suppose that B1, B2, … Bn form a partition of sample
space S:
Suppose that Pr(A) > 0. Then
; i j iiB B B S
Reversing the definition of
conditional prob.
n
i
ii
ii
n
i
i
ii
iiii
BAB
BBA
BA
BBA
A
BBA
A
ABAB
1
1
)|Pr()Pr(
)Pr()|Pr(
),Pr(
)Pr()|Pr(
)Pr(
)Pr()|Pr(
)Pr(
),Pr()|Pr(

Bayes’ Rule Suppose that B1, B2, … Bn form a partition of sample
space S:
Suppose that Pr(A) > 0. Then
; i j iiB B B S
Normalization Factor
n
i
ii
iii
BAB
BBAAB
1
)|Pr()Pr(
)Pr()|Pr()|Pr(

Bayes’ Rule Suppose that B1, B2, … Bn form a partition of sample
space S:
Suppose that Pr(A) > 0. Then
; i j iiB B B S
Pr(Bi|A) ~ Pr(Bi) * Pr(A|Bi)

Bayes’ Rule: Example
q: t, h, t, h, t, t C1: h, h, h, t, h,h bias b1 = 5/6 C2: t, t, h, t, h, h bias b2 = 1/2 C3: t, h, t, t, t, h bias b3 = 1/3---------------------------------------------------------------------------- p(C1) = p(C2) = p(C3) = 1/3 p(q|C1) 5.2*10-4, p(q|C2) 0.015, p(q|C3) 0.02---------------------------------------------------------------------------- p(C1|q) = ?, p(C2|q) = ?, p(C3|q) = ?
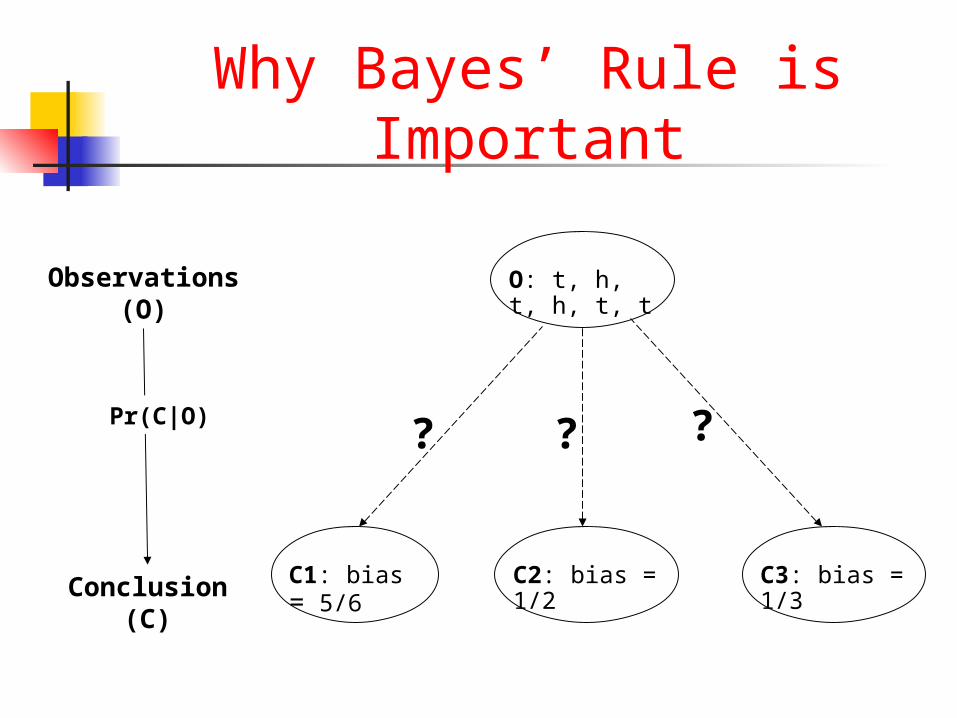
Why Bayes’ Rule is Important
C1: bias = 5/6 C2: bias = 1/2 C3: bias = 1/3
O: t, h, t, h, t, t
? ? ?
Observations (O)
Conclusion (C)
Pr(C|O)

Why Bayes’ Rule is Important
C1: bias = 5/6 C2: bias = 1/2 C3: bias = 1/3
O: t, h, t, h, t, t
? ? ?
Observations (O)
Conclusion (C)
Pr(C|O)
Pr(O|C) and Pr(C)
It is easy to compute Pr(O|Ci). Bayes’ rule helps us convert the computation of Pr(C|O) to the computation of Pr(O|C) and Pr(C).

Bayesian Learning
Pr(C|O) ~ Pr(C) * Pr(O|C)
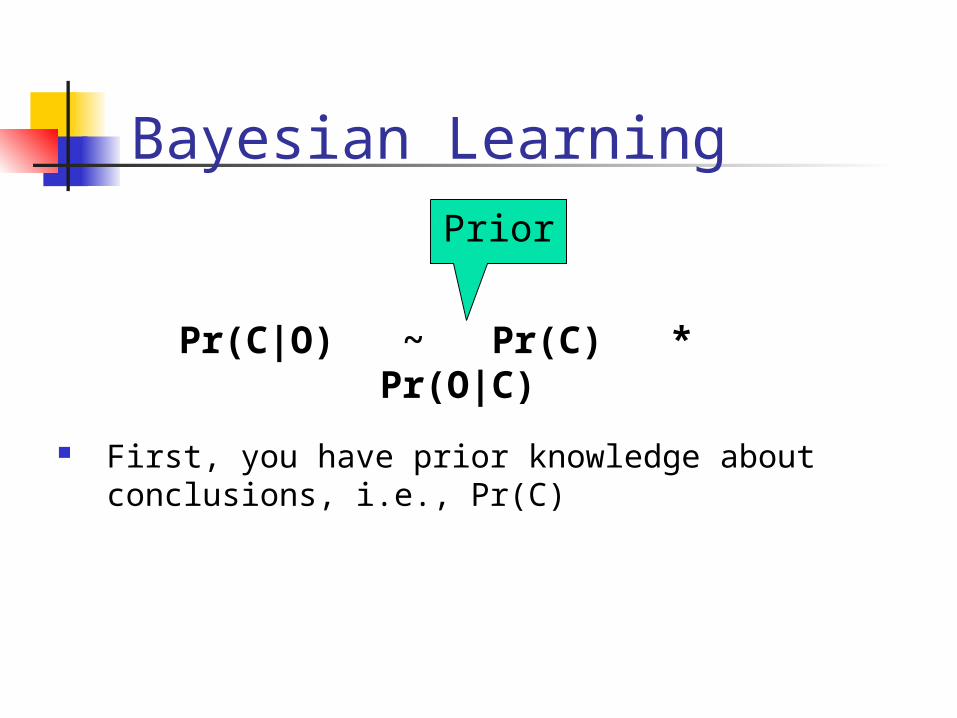
Bayesian Learning
Pr(C|O) ~ Pr(C) * Pr(O|C)
Prior
First, you have prior knowledge about conclusions, i.e., Pr(C)
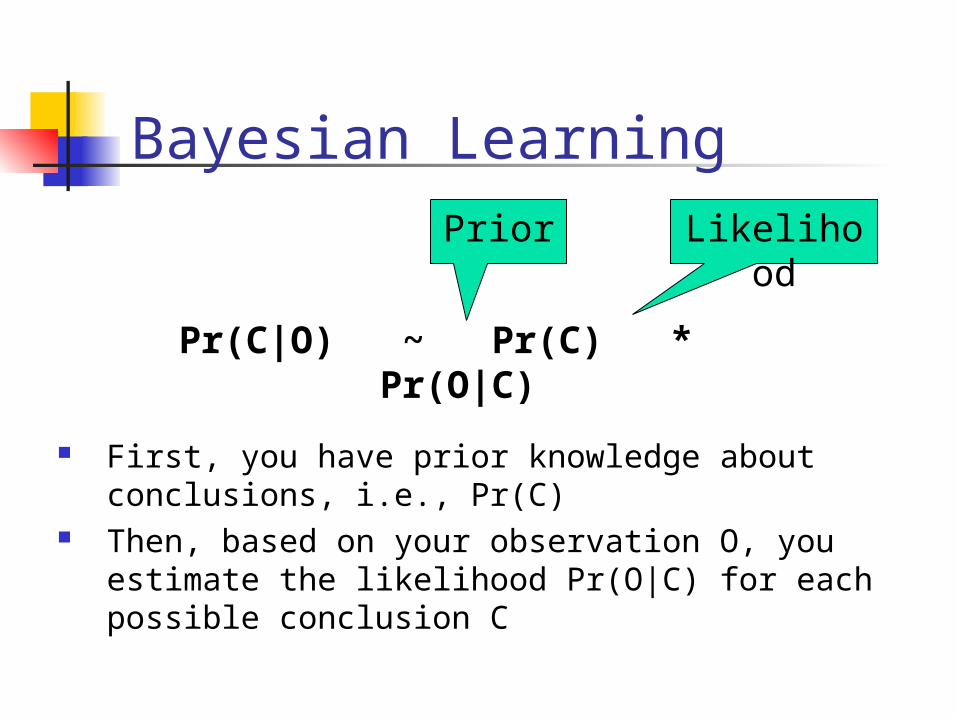
Bayesian Learning
Pr(C|O) ~ Pr(C) * Pr(O|C)
LikelihoodPrior
First, you have prior knowledge about conclusions, i.e., Pr(C)
Then, based on your observation O, you estimate the likelihood Pr(O|C) for each possible conclusion C
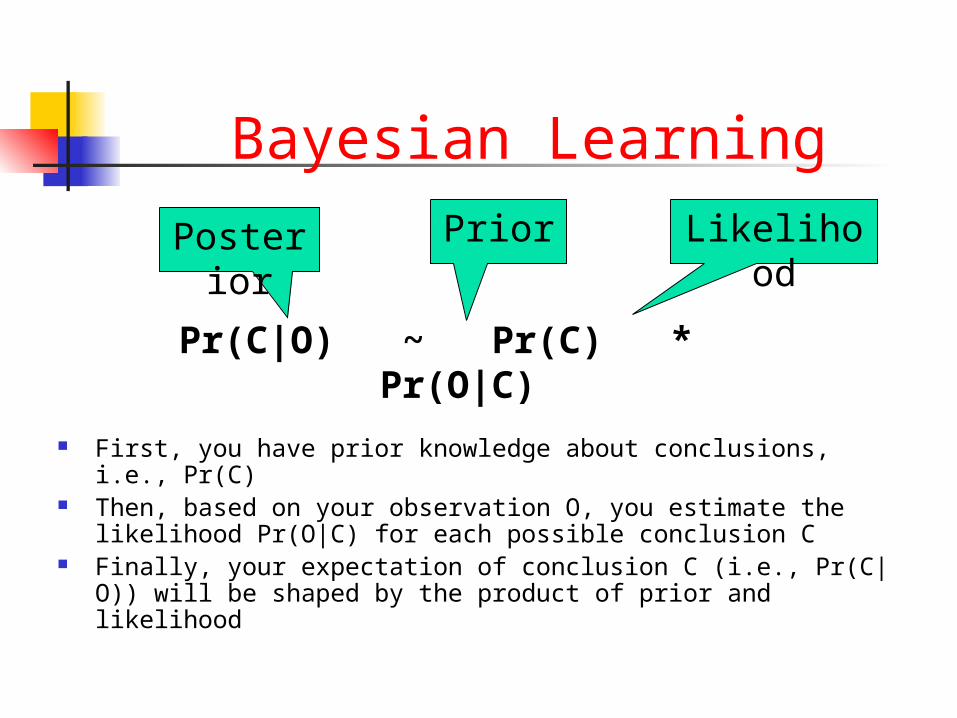
Bayesian Learning
Pr(C|O) ~ Pr(C) * Pr(O|C)
LikelihoodPriorPosterior
First, you have prior knowledge about conclusions, i.e., Pr(C)
Then, based on your observation O, you estimate the likelihood Pr(O|C) for each possible conclusion C
Finally, your expectation of conclusion C (i.e., Pr(C|O)) will be shaped by the product of prior and likelihood





























