Embed Size (px)
Citation preview

Presented by
Reliability, Availability, and Serviceability(RAS) for High-Performance Computing
Stephen L. ScottChristian Engelmann
Computer Science Research GroupComputer Science and Mathematics Division

2 Scott_RAS_SC07
Research and development goals
• Provide high-level RAS capabilities for current terascaleand next-generation petascale high-performancecomputing (HPC) systems
• Eliminate many of the numerous single points of failureand control in today’s HPC systems− Develop techniques to enable HPC systems to run computational
jobs 24/7− Develop proof-of-concept prototypes and production-type
RAS solutions

3 Scott_RAS_SC07
MOLAR: Adaptive runtime support forhigh-end computing operating andruntime systems
• Addresses the challenges for operating and runtime systems to runlarge applications efficiently on future ultrascale high-end computers
• Part of the Forum to Address Scalable Technology for Runtime andOperating Systems (FAST-OS)
• MOLAR is a collaborative research effort (www.fastos.org/molar)
4 Scott_RAS_SC07
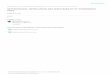
• Many active head nodes
• Workload distribution
• Symmetric replicationbetween head nodes
• Continuous service
• Always up to date
• No fail-over necessary
• No restore-over necessary
• Virtual synchrony model
• Complex algorithms
• Prototypes for Torqueand Parallel Virtual FileSystem metadata server
Active/active head nodes
Symmetric active/active redundancy
Compute nodes
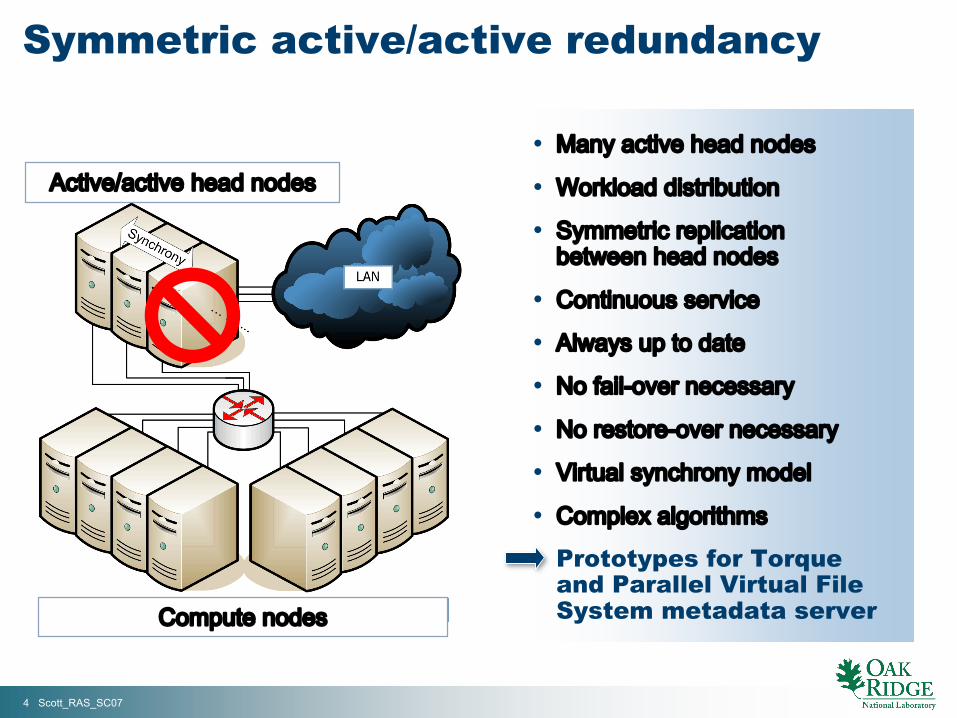
5 Scott_RAS_SC07
Writing throughput Reading throughput
Symmetric active/active Parallel VirtualFile System metadata server
Est. annual downtime Availability
1m, 30s
1h, 45m
5d, 4h, 21m
Nodes
99.9997%3
99.97%2
98.58%1
0
20
40
60
80
100
120
1 2 4 8 16 32Number of clients
Thro
ughp
ut (R
eque
sts/
sec)
PVFSA/A 1
A/A 2A/A 4
050
100150200250300350400
1 2 4 8 16 32Number of clients
Thro
ughp
ut (R
eque
sts/
sec)
1 server
2 servers
4 servers
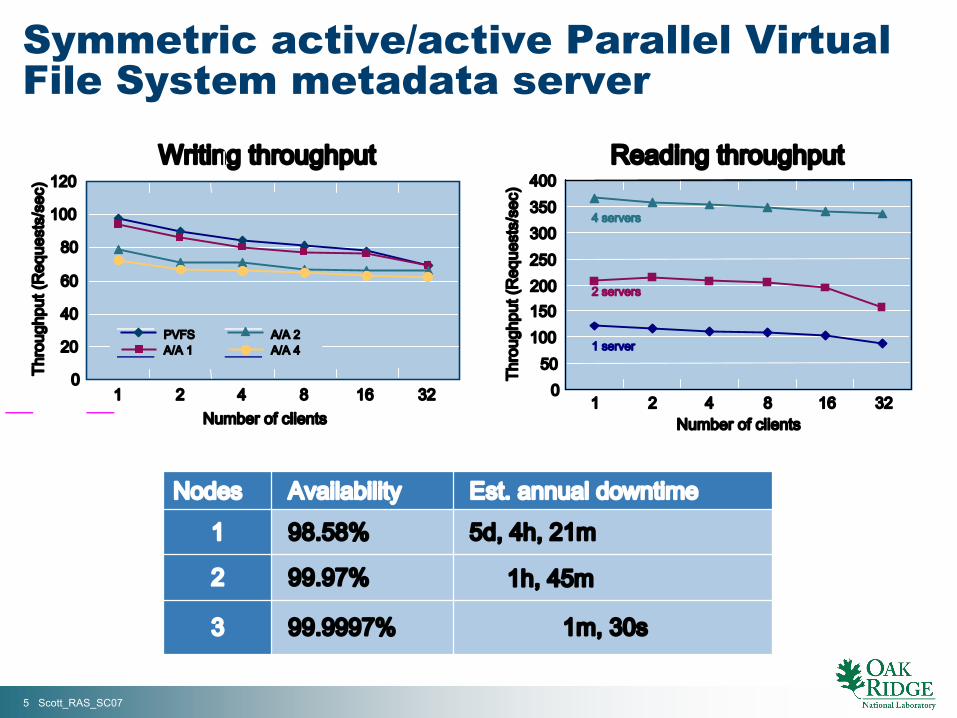
6 Scott_RAS_SC07
• Operational nodes: Pause− BLCR reuses existing processes
− LAM/MPI reuses existingconnections
− Restore partial process statefrom checkpoint
• Failed nodes: Migrate− Restart process on new node
from checkpoint
− Reconnect with pausedprocesses
• Scalable MPI membershipmanagement for low overhead
• Efficient, transparent, andautomatic failure recovery
Reactive fault tolerance for HPC withLAM/MPI+BLCR job-pause mechanism
Paused MPI process
Live node
Migrated MPI process
Spare node
Paused MPI process
Live node
Failed MPI process
Failed node
Shared storage
Failed
Processmigration
New connection
New connection
Faile
d
Existingconnection
7 Scott_RAS_SC07
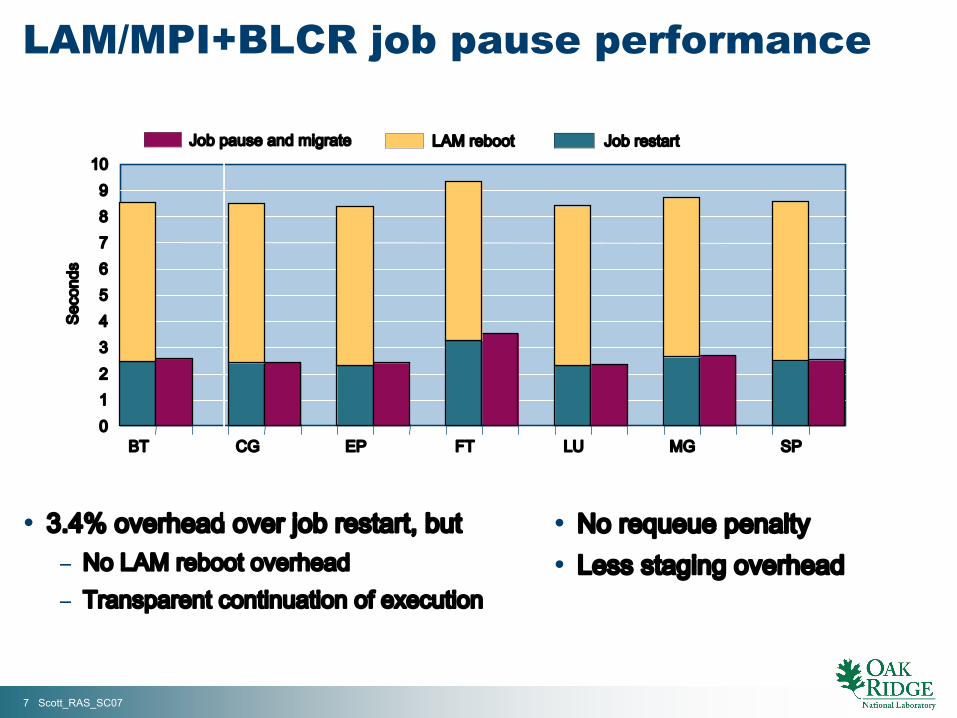
• 3.4% overhead over job restart, but− No LAM reboot overhead− Transparent continuation of execution
0123456789
10
BT CG EP FT LU MG SP
Sec
onds
Job pause and migrate LAM reboot Job restart
• No requeue penalty• Less staging overhead
LAM/MPI+BLCR job pause performance
8 Scott_RAS_SC07
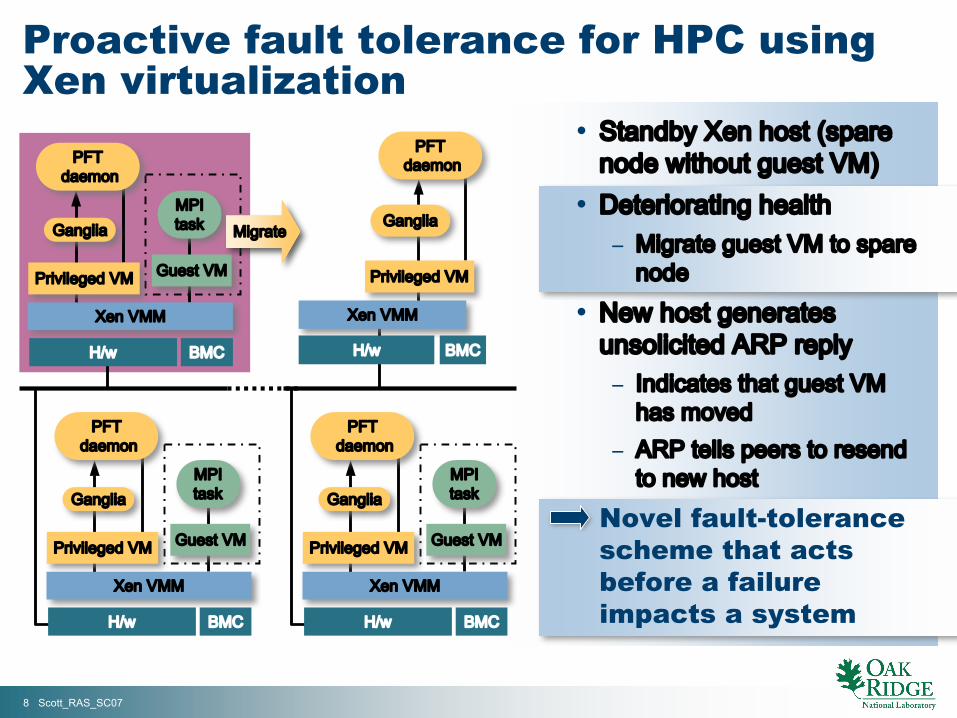
Proactive fault tolerance for HPC usingXen virtualization
• Standby Xen host (sparenode without guest VM)
• Deteriorating health− Migrate guest VM to spare
node
• New host generatesunsolicited ARP reply− Indicates that guest VM
has moved− ARP tells peers to resend
to new host
• Novel fault-tolerancescheme that actsbefore a failureimpacts a system
Xen VMM
Ganglia
Privileged VM
PFT daemon
H/w BMC
Xen VMM
Privileged VM Guest VM
MPItaskGanglia
PFT daemon
H/w BMC
Xen VMM
Privileged VM Guest VM
MPItaskGanglia
PFT daemon
H/w BMC
Xen VMM
Privileged VM Guest VM
MPItaskGanglia
PFT daemon
H/w BMC
Migrate
9 Scott_RAS_SC07
0
50
100
150
200
250
300
350
400
450
500
BT CG EP LU SP
Sec
onds
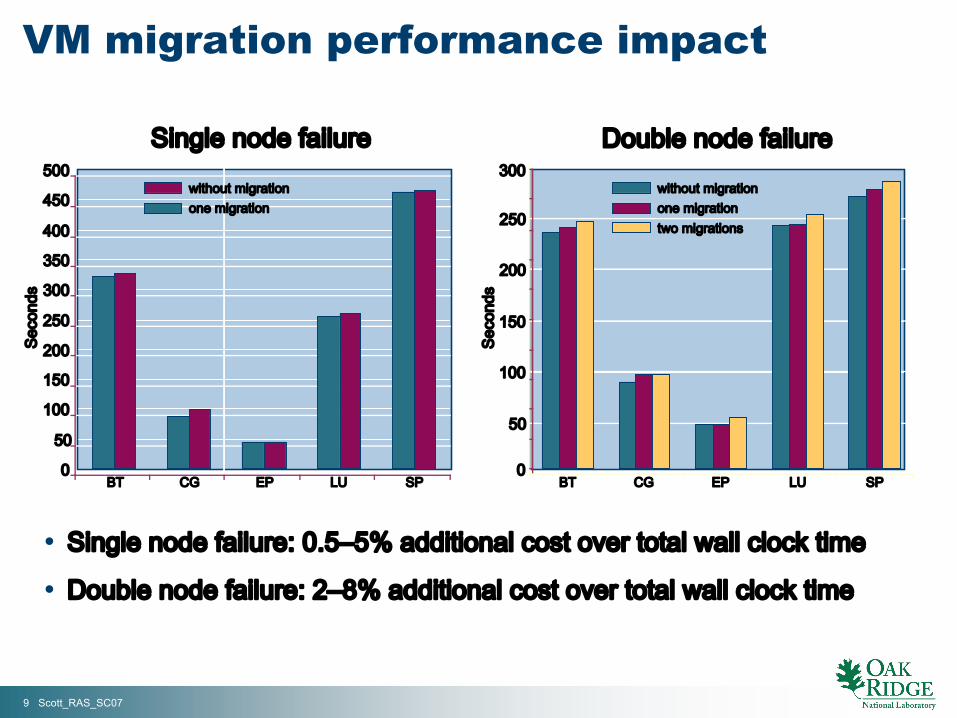
Single node failure
• Single node failure: 0.5–5% additional cost over total wall clock time
• Double node failure: 2–8% additional cost over total wall clock time
VM migration performance impact
without migrationone migration
Double node failure
BT CG EP LU SP0
50
100
150
200
250
300without migrationone migrationtwo migrations
Sec
onds
10 Scott_RAS_SC07
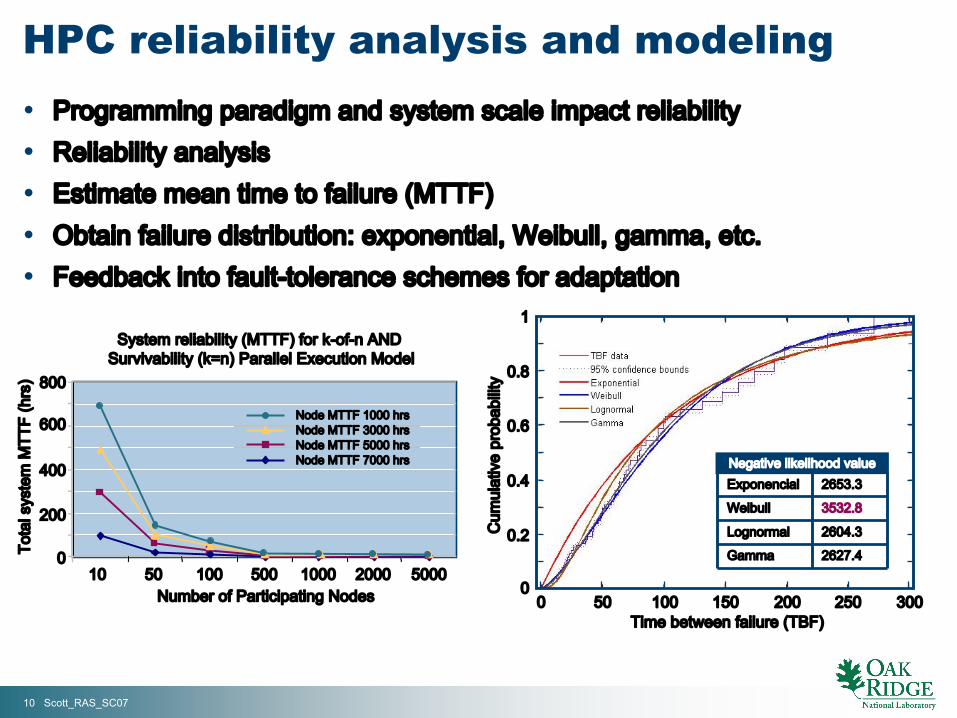
HPC reliability analysis and modeling
• Programming paradigm and system scale impact reliability• Reliability analysis• Estimate mean time to failure (MTTF)• Obtain failure distribution: exponential, Weibull, gamma, etc.• Feedback into fault-tolerance schemes for adaptation
010
Tota
l sys
tem
MTT
F (h
rs)
200
400
600
800
50 100 500 1000 2000 5000Number of Participating Nodes
System reliability (MTTF) for k-of-n AND Survivability (k=n) Parallel Execution Model
Node MTTF 1000 hrsNode MTTF 3000 hrsNode MTTF 5000 hrsNode MTTF 7000 hrs
2627.4Gamma
2604.3Lognormal
3532.8Weibull
2653.3ExponencialNegative likelihood value
Cum
ulat
ive
prob
abili
ty
1
0
0.2
0.4
0.6
0.8
0 50 100 150 200 250 300Time between failure (TBF)

11 Scott_RAS_SC0711 Scott_RAS_SC07
Contacts regarding RAS research
Stephen L. ScottComputer Science Research GroupComputer Science and Mathematics Division(865) [email protected]
Christian EngelmannComputer Science Research GroupComputer Science and Mathematics Division(865) [email protected]