Embed Size (px)
Citation preview

Reliability' Engineering 12 (1985) 161-173
Reliability of Software-Based Fire and Gas Detection Control Systems
David J. Smith
26 Orchard Drive, Tonbridge, Kent, Great Britain
(Received: 25 November, 1984)
ABSTRACT
Fire and gas detection systems involve the processing of signals from gas, temperature, smoke and ultra-violet instruments. There is a trend towards the use of micro-processor controlled programmable equipment and this paper reviews some of the advantages and disadvantages of its use. The effects of duplication and triplication are explained and it is suggested that the use of redundancy does not always enhance reliability. The particular quality assurance requirements which arise from the existence of software-related failures are also discussed.
1 I N T R O D U C T I O N
The use of fire and gas detection apparatus in both process plants and in commercial and public installations is rapidly increasing. The use of such systems on offshore installations is now mandatory under both British and Norwegian law.
Concentrations of gas are detected by means of catalytic action and the information is presented as an electrical signal. A number of methods of fire detection are used. These include measurements of ultra-violet radiation, smoke and the rate of temperature increase. Fire and gas
A version of this paper was presented at the 8th Advances in Reliability Technology Symposium ARTS' 84, 25 27 April 1984, University of Bradford, UK.
161

162 David J. Smith
detection systems involve the processing of this data to provide audio/visual alarms as well as automatic initiation of fire suppression apparatus and the controlled shutdown of processes. The primary constituents of a fire and gas detection system are therefore:
Sensors to detect the presence of fire or gas. Circuitry to interpret this information. An output facility to initiate various executive actions.
2 PROCESSOR CONTROL
The trend is towards the use of microprocessor-based programmable equipment which carries with it a number of advantages:
Easy changes of configuration since the information is held in software. Savings in size and weight. A lower package count, resulting in higher hardware reliability. More sophisticated diagnosis of information and displays.
One disadvantage of the equipment is that software-related failures are almost impossible to predict and, hence, integration and testing of the design becomes that much more complex. Test programmes involving software-controlled equipment require a far greater degree of structuring than do those involving only hardware. The result must be a planned hierarchy of testing if the system integration is to be achieved smoothly. Other disadvantages are susceptibility to electrical interference and the existence of more subtle (hard to diagnose) failures.
3 FAILURE MODES
The reliability of such equipment is of paramount importance since it relates to the frequency of two undesirable failure modes:
Failures causing a loss of fire or gas detection. Process shutdowns due to spuriously generated signals.
Failures in the first category may affect a single fire or gas area or, on the other hand, the entire system. A reliability study of any proposed system must evaluate both of these eventualities so that the design can be

Reliability of sqftware-based fire and gas detection control systems 163
adequately reviewed. Spurious fire and gas signals may cause events ranging from simple audio/visual annunciation to total process shutdown. The effect will depend upon the specific functions which each output is used to initiate. The actual "cause and effect' specifications which define a given system are therefore needed in order to carry out a full reliability analysis.
4 A SIMPLEX SYSTEM
A simplex system, shown in Fig. 1, involves a number of sensors, a single controller and a number of outputs to initiate executive action (e.g, process shutdown, alarms, halon).
INPUTS OUTPUTS
- d ½ --{ b - CONTROLLER
L I
Fig. 1.
Assuming random failures, then considering only a single input and output, the failure rate for either failure mode (where 2 is the symbol for failure rate) is
/~'sensor + )qnput + '~'processor + fi~output
Typical figures for a single circuit might yield, respectively:
spurious f a i l u r e r a t e = 1 0 x 1 0 - 6 + 5 x 1 0 - 6 + 5 0 x 10 6 + 5 x 10-6h 1
= 7 0 x 10-6h 1 =0-61 year 1
A system with as few as 100 circuits would therefore false alarm 18 times per year. This can be approximated by taking the processor failure rate

164 David J. Smith
plus 100 times the remaining failure rates. As can be seen from these values, systems with large numbers of detectors would involve totally unacceptable levels of failure.
5 UNAVAILABILITY
The reliability of component parts is characterised by means of failure rates. At the system level, however, a more useful parameter is the steady state unavailability. This is simply the proportion of time for which the system is in the failed state. It therefore involves the average downtime of the system, when it fails, and is obtained from:
)~MDT Unavailability - ~ 2 M DT
1 + 2 M D T
where 2 is the system failure rate and MDT is the mean downtime when the system fails.
In the example in Section 4 a failure rate of 18 times per year was predicted. If each failure involves a shutdown of some process for 3 h, then the unavailability is given by
3 Unavai labi l i ty-- x 18=6 .2 x 10 -3
8760
This means that the system would be in a failed state for 54 h of the year.
6 I N P U T VOTING
Considerable enhancement in reliability can be achieved by providing groups of detectors, in such a way that the simultaneous input from two or more is required. Either the 'spurious triggering' or the "failure to operate' of a single input is voted out, thereby reducing the rate of that failure mode by several orders of magnitude.
Typically, one fire or gas sensor would serve each of three inputs. The simultaneous triggering of two out of three would be required to initiate action. Figure 2 shows this arrangement with the appropriate failure r a t e s
0"001 x 1 0 - 6 + 5 0 x 10--~'+5 x 1 0 - 6 = 5 5 x 10-6h '-1
= 0"48 year - 1

Reliability of software-based fire and gas detection control systems 165
0--
_• SENSOR AND ] INPUT
0--
PROCESSOR OUTPUT
- - 0 - - t
Fig. 2.
Thus, an improvement of 27°,, is achieved over the simplex system described in Section 4. The spectacular improvement in reliability of the grouped inputs is due to the introduction of redundancy coupled with speedy repair (in the order of hours). Several orders of improvement are usually obtained. In the specific case of two out of three voting then the effective failure rate is given by:
)Lgroup ---~ 6~2l
where 2 is the failure rate of each input and sensor, and t is the repair time (note that 22 enhances the overall failure rate by orders of magnitude). A full explanation is available in Chapter 15 of Ref. 1.
7 DUPLICATED PROCESSORS
Further improvement is possible by duplicating the processor function. It is possible to vote the two processor outputs in one of two ways:
either channel is recognised as an alarm: both channels are required in order to recognise an alarm.
Unfortunately this configuration improves the reliability of only one of the two failure modes, and at the expense of the other. If, for example, one out of two voting is established then either channel can cause a shutdown to occur. In that way the failure to respond mode is much reduced at the

166 David J. Smith
expense of double the spurious failure rate. The example in ~-~ig~ 2 becomes:
)~spurious=0'00l X 1 0 - ( ' + ( 2 × 50) × 10 ( ' + 5 × 10-"
= 1 0 5 × 10-°h- t
= 0'92 yea r - 1
A two out of two voting configuration has the opposite effect. Namely it improves the spurious trip reliability at the expense of failures to respond.
8 T R I P L I C A T E D PROCESSORS
Figure 3 shows an arrangement with triplicated processors. Here the advantage of redundancy is applied to both the 'spurious' and "fail dangerous' modes. In either case, two of the three processors need to fhil for either a false alarm or a fail to respond to occur. As a result the critical sources of failure become:
The output circuitry, outside the voting. Any common mode failure which affects all the processors.
A typical analysis would therefore be as follows:
If a system has 50 groups of inputs + 20 outputs, then the spurious failure rate is given by:
50
~-~ "~'input groups + '4triplicated 1
2O
processor +~ '~ "/'outputs + )'common mode 1
which results in
failure rate = 0.001 x 50 x 10 ~
+0.01 × 10-~,+5 × 20 × 10 6 + 5 × 10-Oh- I
--- 105 x 10-6h -1
= 1 yea r - 1
If M D T = 3h, unavailability becomes 3.4 × 10 -4 (3h per year). The reliability is now dominated by the failure rate of the output stages since they are not protected by redundancy.
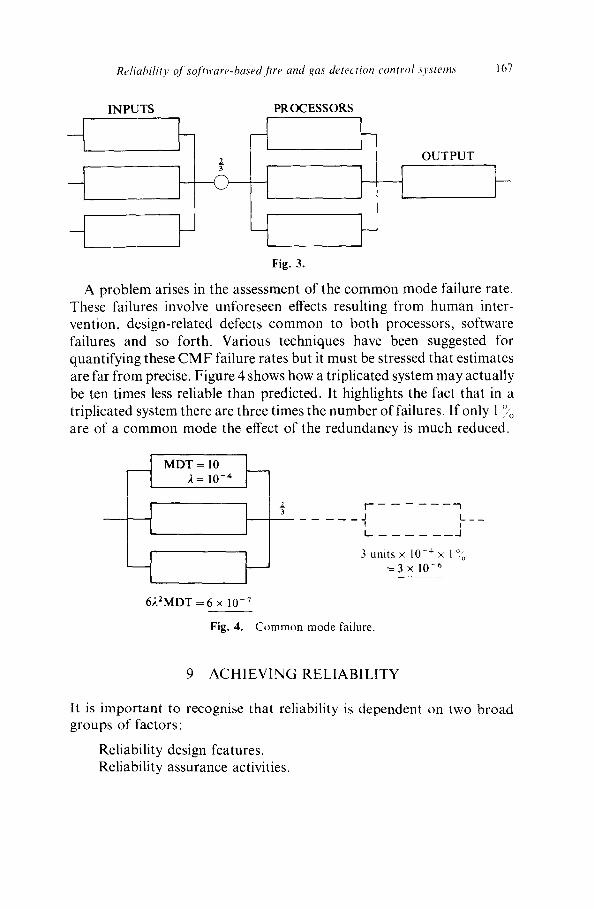
Reliability q/ soJ?ware-based [ire and gas detection control systems 167
I N P U T S
2 g --C>-
PROCESSORS
Fig. 3.
OUTPUT
A problem arises in the assessment of the common mode failure rate. These failures involve unforeseen effects resulting from human inter- vention, design-related defects common to both processors, software failures and so forth. Various techniques have been suggested for quantifying these C M F failure rates but it must be stressed that estimates are far from precise. Figure 4 shows how a triplicated system may actually be ten times less reliable than predicted. It highlights the fact that in a triplicated system there are three times the number of failures. If only 1 ''j /" 0
are of a common mode the effect of the redundancy is much reduced.
MDT = 10 2 = 10 -4
1
6~.2MDT = 6 x 10 -7
_2 F i 3 I L - - - -
I I L I
3 units x 10-4 x 1 ~',0 =3 x 10 -6
Fig. 4. Common mode failure.
9 A C H I E V I N G RELIABILITY
It is important to recognise that reliability is dependent on two broad groups of factors:
Reliability design features. Reliability assurance activities.

t68 David J. Smith
Design reliability 1 Design factors • Redundancy
Ratings of components Software QA
Field reliability
Assurance activities
Operating conditions
f QC Burn in Defect recording
t Maintenance Replacement strategy
Fig. 5. Concept of reliability.
Design features determine the theoretical reliability of a system as fixed by its component failure rates and the fault tolerance techniques employed. Other factors bring about a much lower figure of achieved reliability and it is the purpose of the assurance activities to minimise these additional failures. Figure 5 illustrates this concept.
10 RELIABILITY DESIGN FEATURES
Reliability design features include:
Derating of components. Component screening. Redundancy. Diversification of functions. Environmental protection. Qualification tests. Software quality assurance.
The most sensitive factor influencing component reliability is the ratio of applied to rated stress. Figure 6 shows the relationship of failure rate to both temperature and voltage for a particular type of capacitor.
It has already been stated that, at the system level, the combination of redundancy with speedy repair of failed redundant units can lift the reliability by orders of magnitude. It must be remembered, however, that redundancy carries with it the penalties of additional space, weight. power, maintenance and a proportional increase in the actual numbers of failures at the sub-system level. Furthermore. the increment in reliability
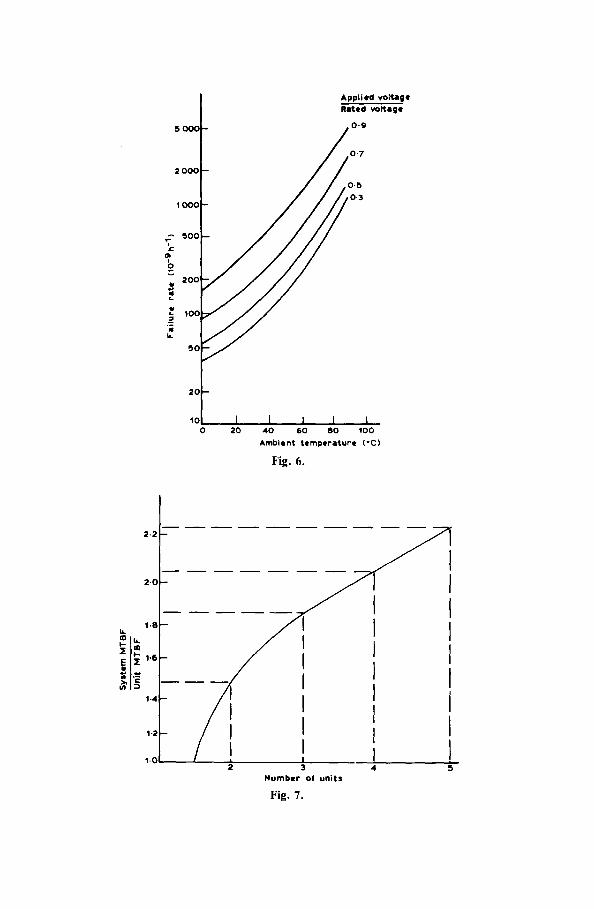
Z
o w
Sys
tem
MT
BF
Uni
t N
ITB
F
o ~,
.b
e
a~
0
I i
'1 J i I I I i J
o
3 4
Fa
ilu
re
rate
(1
0"9
h -1
)
t 70 David ,I. Smi th
with additional redundancy, without repair, decreases with each additional unit as shown in Fig. 7.
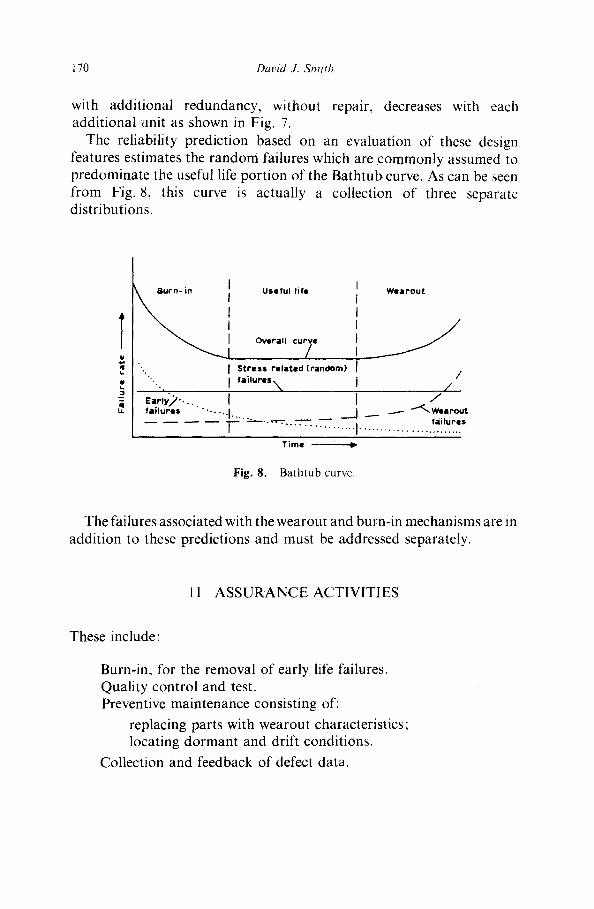
The reliability prediction based on an evaluation of these design features estimates the random failures which are commonly assumed to predominate the useful life portion of the Bathtub curve. As can be seen from Fig. 8, this curve is actually a collection of three separate distributions.
Burn- in ] Useful life
i Overall curve / "'. I Stress related (random)
"" ' , I failures'\ Eariyj ' . . . , failures
Wearout
/ / ,
I / • _~- ~¢-~ Wearout
Time
Fig. 8. B a t h t u b curve,
The failures associated with the wearout and burn-in mechanisms are in addition to these predictions and must be addressed separately.
11 ASSURANCE ACTIVITIES
These include:
Burn-in, for the removal of early life failures• Quality control and test. Preventive maintenance consisting of:
replacing parts with wearout characteristics; locating dormant and drift conditions.
Collection and feedback of defect data.
Reliability q[ so[?ware-based.fire and gas detection control systems 171
12 SOFTWARE FAILURES
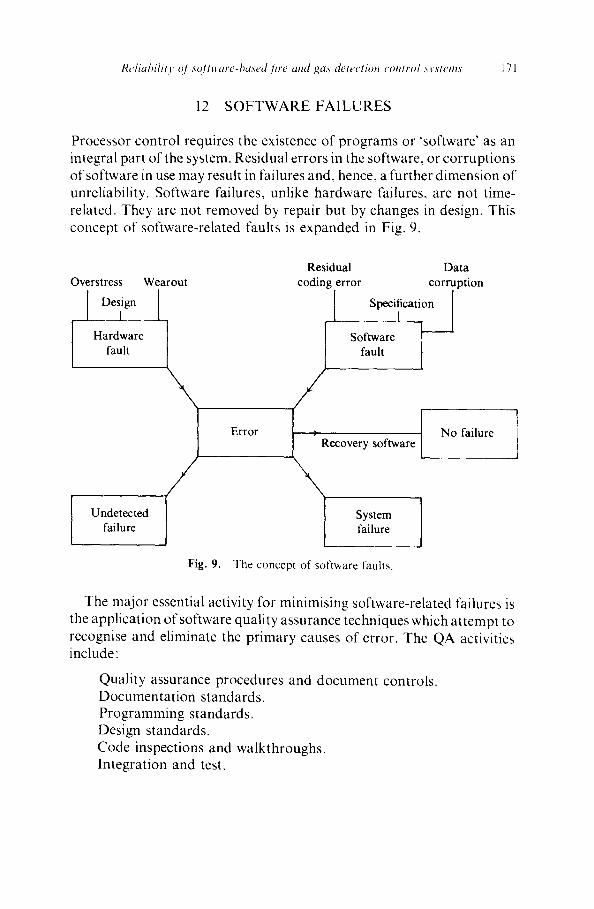
Processor control requires the existence of programs or ~software' as an integral part of the system. Residual errors in the software, or corruptions of software in use may result in failures and, hence, a further dimension of unreliability. Software failures, unlike hardware failures, are not time- related. They are not removed by repair but by changes in design. This concept of software-related faults is expanded in Fig. 9.
Overstress
.
Wearout Design ---1. [
Hardware fault
Undetected failure
Fig. 9.
Residual Data coding error corruption
Specification I
Error ~ "~R No failure ecovery software t
| System I / failure [
The concept of software faults.
l
The major essential activity for minimising software-related failures is the application of software quality assurance techniques which attempt to recognise and eliminate the primary causes of error. The QA activities include:
Quality assurance procedures and document controls. Documentation standards. Programming standards. Design standards. Code inspections and walkthroughs. Integration and test,

172 David J. Smith
A coherent and perceivable documentat ion hierarchy is essential to support complex software. Programming rules which dictate a structured 'decomposition' of the task are essential if errors are to be minimised. An appropriate document structure is necessary to support a structured programming activity.
Design standards involve applying proven features to optimise fault tolerance. These involve:
Protection from electrical interference. Redundant paths in the software. Error checking and correction programs. Use of fault display codes and diagnostics. Tolerance in timing functions. Permitting degraded modes of operation. Error confinement by program controls.
Design review at appropriate stages enables technical progress to be evaluated against milestones. Design reviews are not schedule progress meetings but design evaluations. The results of code inspections, or walkthroughs, should provide inputs to these reviews as will reliability predictions of the type illustrated.
Integration and testing needs to be structured in much the same way as the documentation. A logical build-up of testing from modules, via sub- system integration, to eventual system testing is necessary. In this waythe system elements are proved in a logical sequence and each test gives confidence for the next stage of design.
There are a number of useful guides and checklists to software QA. References 2 and 3 are good examples.
13 RELIABILITY PREDICTION
It is necessary to carry out detailed failure mode analyses of proposed equipment in order to assess the potential frequency of both spurious and non-response failures. Various methods of failure analysis exist and computer aids are available to assist in modelling the failure probabilities. In every case it is necessary to assign failure rates to components in order to compute the overall system reliability. Clearly, such failure rates are derived from a number of sources, some known and some unknown to the user. It is the inability to guarantee the relevance of such failure rates to

Reliability oJsoJtware-based fire and gas detection control systems t73
the precise component quality and operating conditions which is the main pitfall in reliability assessment.
The absolute numbers obtained by such a process must be interpreted in the light of the data sources used. It must also be stressed that this process involves the prediction of only hardware failures. There is, as yet, no viable method of forecasting software failure rates. In my opinion it is unlikely that such an exercise will ever be a realistic possibility. Hardware predictions are made possible by a knowledge of component failure history in a technology where the same component types persist from one product to another, The generation of software, however, involves original design specific to each production. Each is, therefore, a unique combination of coding and hardware and, as such, cannot be assessed other than by actual experience.
The major benefit to be gained in a hardware reliability prediction lies in the relative criticality of the various sources of failure. To establish that a small number of component types contribute to say 80 i~o of the system failures enables a timely and cost-effective redesign exercise to be carried out. In the final analysis, however, software and hardware reliability is achieved by the application of sound design rules backed by thorough QA techniques and controls.
REFERENCES
1. Smith, David J. Reliability and Maintainability in Perspectit'e, 2nd edn, Macmillan, London, 1985.
2. Guide to the QA of S~/hcare, Electronic Engineering Association, London. 3. Establishing a QA Function.[or Sqihcare, Electronic Engineering Association,
London. 4. Guide to the Achievement o~ Quality in SqHware, Ministry of Defence
Standard 00-16.





























