Embed Size (px)
Citation preview

CLARIN 2021Research Data Management,
Metadata and Curation (Part 1)
Chair: Juan Steyn
Day 1 Monday 27 September
15:00 - 15:15

Amy Isard & Elena Arestau
Curation criteria for multimodal and multilingual data: a mixed study within the Quest Project

The Quest Project
• Funded by the German Federal Ministry of Education and Research (BMBF) from 2019-2022
• Partners: University of Hamburg, the Leibniz-Centre General Linguistics (ZAS) in Berlin, the Archive for Spoken German (AGD)/Institute for the German Language (IDS) in Mannheim and the University of Cologne
• Aim: maximise the potential for reuse and secondary use of audiovisual, annotated language data in the humanities
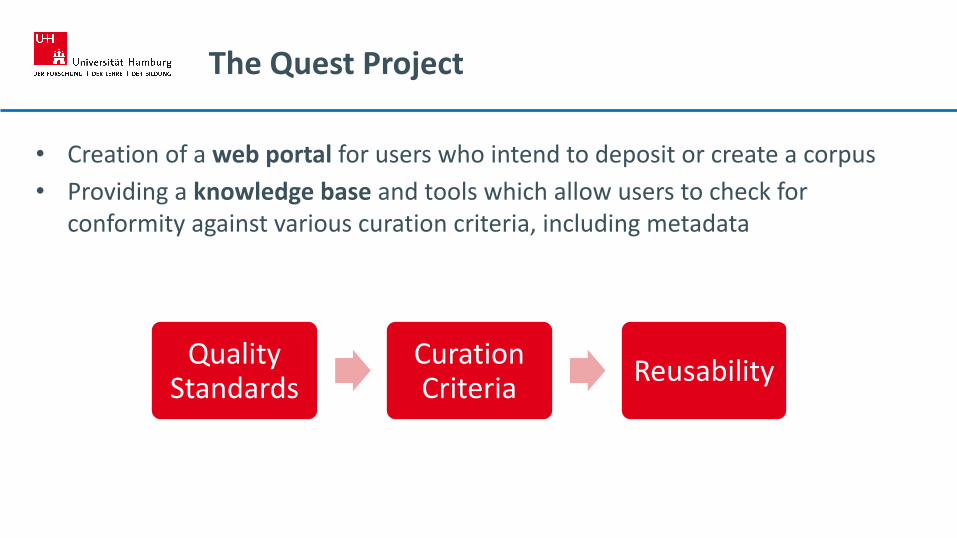
The Quest Project
• Creation of a web portal for users who intend to deposit or create a corpus
• Providing a knowledge base and tools which allow users to check for conformity against various curation criteria, including metadata
Quality Standards
Curation Criteria
Reusability
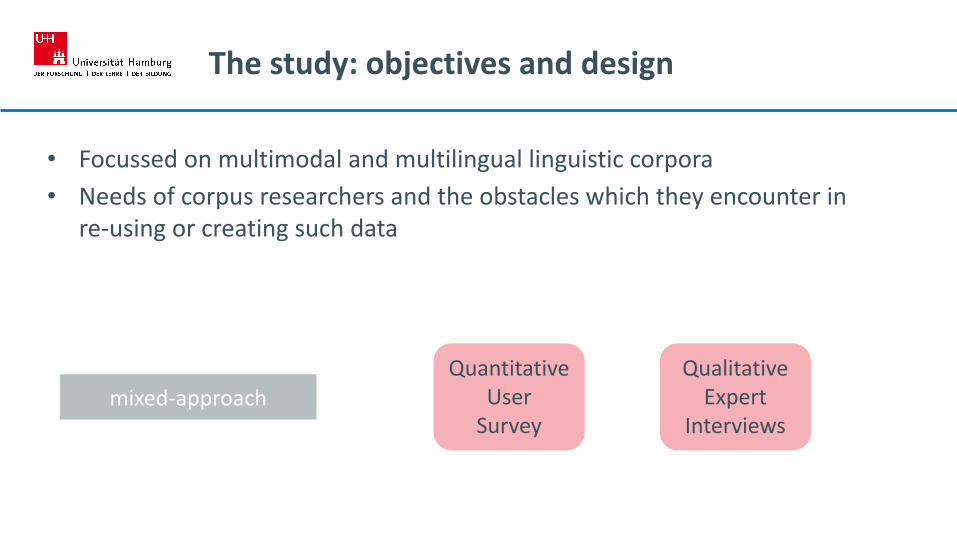
The study: objectives and design
• Focussed on multimodal and multilingual linguistic corpora
• Needs of corpus researchers and the obstacles which they encounter in re-using or creating such data
mixed-approachQualitative
ExpertInterviews
QuantitativeUser
Survey
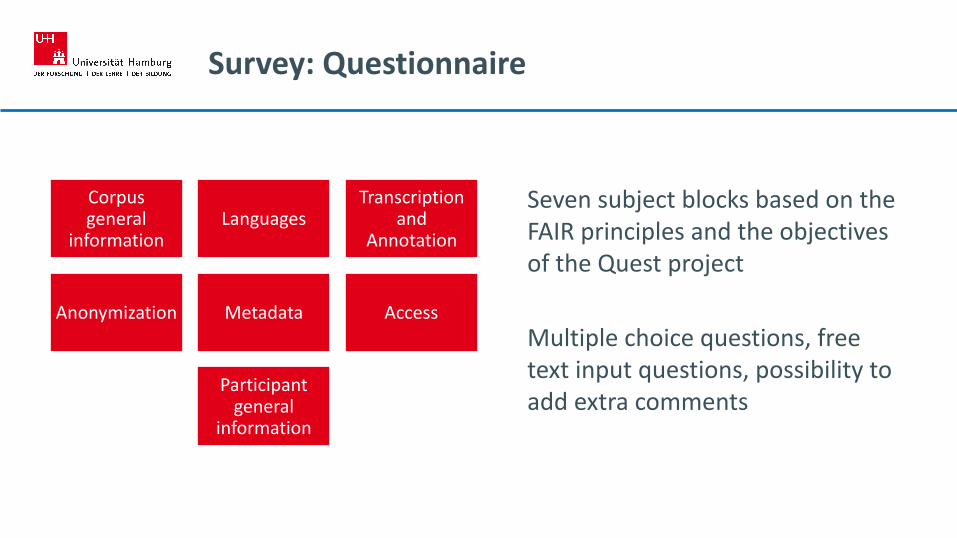
Survey: Questionnaire
Seven subject blocks based on the FAIR principles and the objectives of the Quest project
Multiple choice questions, free text input questions, possibility to add extra comments
Corpus general
informationLanguages
Transcription and
Annotation
Anonymization Metadata Access
Participant general
information

Survey statistics
• Fully completed by 44 participants
• Participants answered between 23 and 53 questions, average of 35
• Participants from 13 different countries, with the majority in Germany
• The majority employed by universities (72 %), data centres, companies and archives
• Corpora contained more than 30 different languages• Audio recordings (84 %), video (41 %) translations (36 %)• Metadata: 88 % of corpora provided metadata
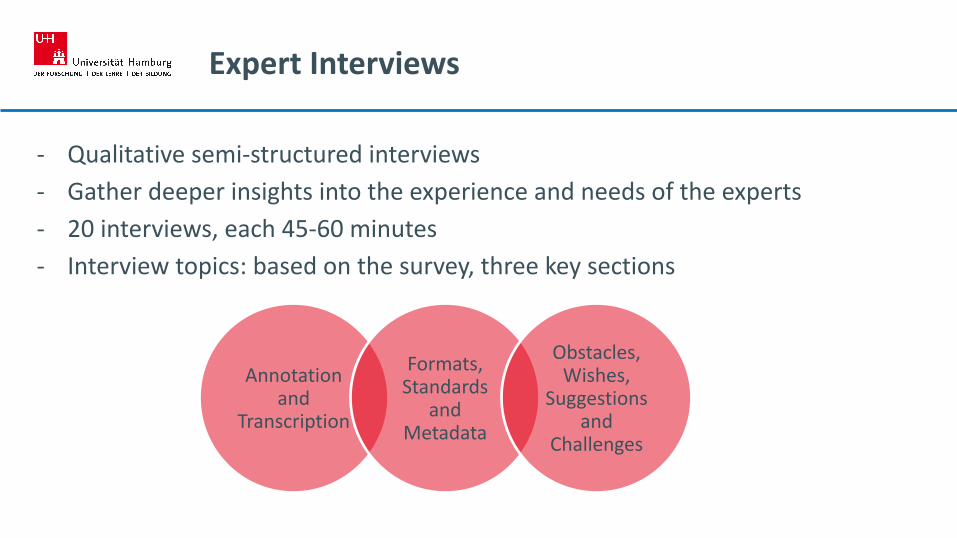
Expert Interviews
- Qualitative semi-structured interviews
- Gather deeper insights into the experience and needs of the experts
- 20 interviews, each 45-60 minutes
- Interview topics: based on the survey, three key sections
Annotation and
Transcription
Formats, Standards
and Metadata
Obstacles, Wishes,
Suggestions and
Challenges

Conclusions
• Recommendations:• Corpus documentation is crucial for reuse (detailed descriptions should be
kept at every stage of corpus creation)• Collection and publishing of metadata in standard formats• Reference to standards or best practices in the field• Need for standardised transcription formats• Translations into a widely known language
• Common Obstacles:• Difficult to discover and follow different national and international rules for
data protection• The storage of large amounts of video and audio data (cost and long-term
storage)

Amy Isard & Elena Arestau
Institute of Finno-Ugric and Uralic Studies andInstitute of German Sign Language and Communication of the DeafUniversity of Hamburg
E-Mail: [email protected], [email protected]
Contact

References
Christian Fandrych, Elena Frick, Hanna Hedeland, Anna Iliash, Daniel Jettka, Cordula Meißner, Thomas Schmidt, Franziska Wallner, Kathrin Weigert, and Swantje Westpfahl. 2016. User, who art thou? User Profiling for Oral Corpus Platforms. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), pages 280–287, Portoroz, Slovenia, May. European Language Resources Association ˇ (ELRA). https://www.aclweb.org/anthology/L16-1043.LimeSurvey GmbH. 2021. LimeSurvey: An Open Source survey tool. Hamburg, Germany. http://www.limesurvey.org.Mark D Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, Jan-Willem Boiten, Luiz Bonino da Silva Santos, Philip E Bourne, et al. 2016. The fair guiding principles for scientific data management and stewardship. Scientific data, 3(1):1–9.Timofey Arkhangelskiy, Hanna Hedeland, and Aleksandr Riaposov. 2020. Evaluating and Assuring Research Data Quality for Audiovisual Annotated Language Data. In Proceedings of CLARIN Annual Conference 2020, pages 131–135, October.

Seamless Integration of Continuous Quality Control
and Research DataManagement for Indigenous
Language Resources Anne Ferger & Daniel Jettka | Paderborn University, Germany

Seamless integration of Continuous Quality Control and
Version Control into existing workflows enhances the
acceptance of the measures.
13

Continuous Quality Control for research data is crucial for better research data.
14
We noticed a big difference after employing continuous quality control mechanisms in the project INEL in the
time needed for manual fixing of inconsistencies and the time needed to
prepare the data for publication.

Seamless integration of new workflows or tools is eased using a VCS.
15
Combining a simplified solution using git (with the tool Lama) and automatic
quality control fixes and checks (corpus services with automatic git scripts) doesn't change the existing data
creation workflows too much.
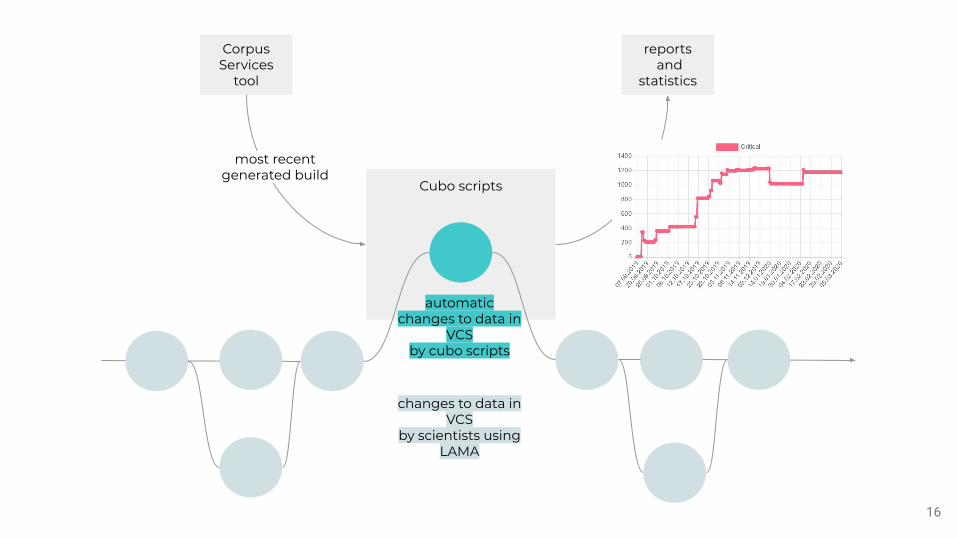
16
Cubo scripts
automatic changes to data in
VCSby cubo scripts
changes to data in VCS
by scientists using LAMA
Corpus Services
tool
reports and
statistics
most recent generated build

Further information and tools:
17
Simplified git solution for users: Lama
Quality checks and automatic fixes for linguistic corpora: corpus services
Automatic git solution for corpus services: cubo

Contact
18
Daniel Jettka [email protected]
https://twitter.com/DJettka
https://github.com/digitalhumanists
Anne [email protected]://twitter.com/anneferger1

Flexible Metadata Schemes for Research Data Repositories
The Common Framework in Dataverse and the CMDI use case
Slava TykhonovJerry de Vries
Andrea ScharnhorstEko Indarto
Femmy Admiraal(DANS-KNAW)
Context

5 challenges for CMDI
Challenge 1: A proposal of a core set of CMDI metadata as recommendation
Challenge 2: Extraction of CMDI metadata and transform and load the metadata fields into the Dataverse Core set of metadata
Challenge 3: Workflow for prediction and linking concepts from external controlled vocabularies to the CMDI metadata values
Challenge 4: Extension of the Common Framework with support of FAIR controlled vocabularies to create FAIR metadata
Challenge 5: Extension of the export functionality of Dataverse to export deposited CMDI metadata back to the original CMDI format
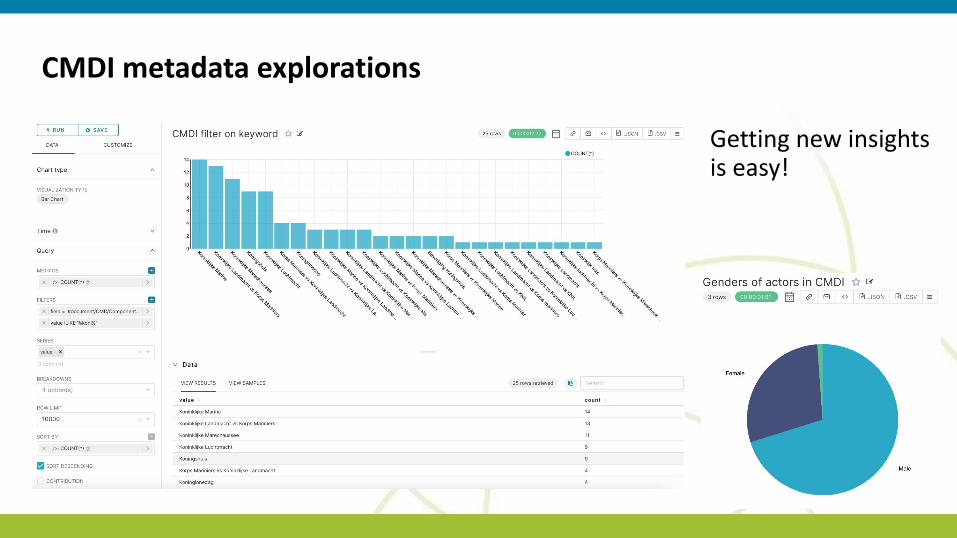
CMDI metadata explorations
Getting new insights is easy!

Questions?
Slava Tykhonov (DANS-KNAW)
Jerry de Vries (DANS-KNAW)
Andrea Scharnhorst (DANS-KNAW)
Eko Indarto (DANS-KNAW)
Femmy Admiraal (DANS-KNAW)
Presentation slides: https://bit.ly/3AIYCbm

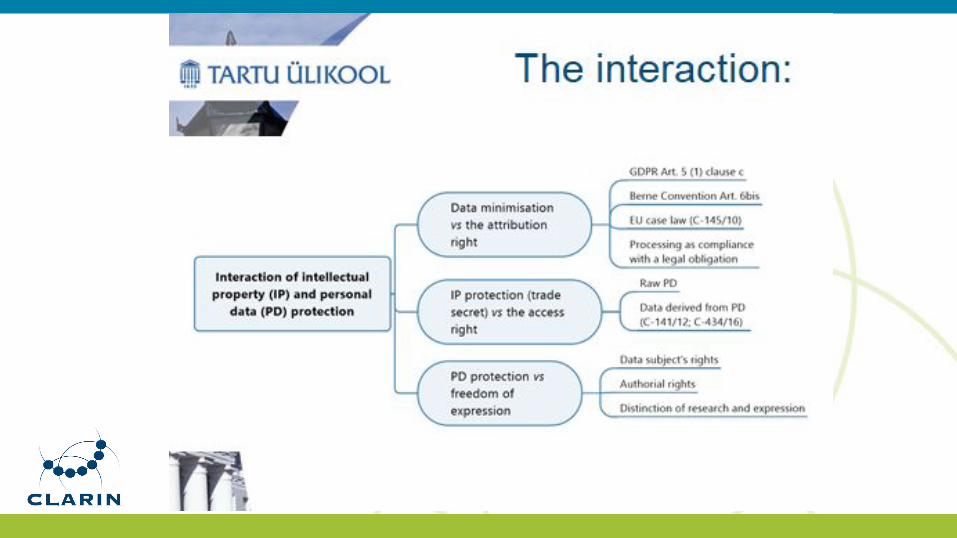
CLARIN 2021 Legal Issues Related to the Use of LRs in
Research (Part 1)
Moderator: Juan Steyn
Day 1 Monday 27 September
15:15 - 15:25


Less is more when FAIR. The minimum level of description in pathological oral
and written data
Rosalba Nodari, Silvia Calamai, Henk van den Heuvel
CLARIN Annual Conference, 27 - 29 September 2021

Questions
• How to define a protocol for the curation and dissemination of speech archives of vulnerable people, which appear to have – de jure – the highest restrictions on curation and dissemination
• How to find a balance between the rights of the recorded people (and their heirs) and the right of access to information and preservation of memory
• Problems with permissions and technical challenges

• Database Enterprise for Language And speech Disorders http://delad.net
• Guidance for sharing corpora of speech of individuals with communication disorders (CSD)
• Support from GDPR issues to safe repositories in the CLARIN infrastructure
• CLARIN data centers (The Language Archive, Talkbank)

Arezzo Neuropsychiatric Archive
• 1500 elements, (files, registers, envelopes, notebooks and filing cabinets, etc.)
- Written and spoken documents of unmonitored speech;
- Anna Maria Bruzzone’s speech archive (audio records and transcriptions for the book Ci chiamavano matti. Storie da un ospedale psichiatrico, Torino, Einaudi, 1979);
- Medical records of patients admitted to the mental and neurological wards;
- Diary of a mental health patient.

Personal diary of a patient with schizophrenia
• P.A.: born in 1916, unmarried, with only basic literacy.
• Hospitalized twice, later in life he admits himself voluntarily to the hospital, under the direction of Pirella.
• Personal diary of 323 pages.
• The diary is currently being transcribed.

Metadata of vulnerable speech archives: some issues
1. Heterogeneity of the archive: granularity and modularity
- Set of metadata that can be suitable for different resources at the same time
2. Metadata profile for restricted access corpora
- No sensitive data (i. e. medical diagnoses)
- Hybrid nature of the archive with different levels of description depending on specific bundles and subcollections
3. Uncertainty of historical archives
- Incomplete information

Conclusion
• Feasibility study for depositing the linguistic material from the Arezzo ONP archive into the Language Archive
• Good balance between GDPR issues and essential information suitable for other researchers
• Data protection, transparency, and accessibility

Thank you!
Rosalba Nodari, Silvia Calamai, Henk van den Heuvel

CLARIN 2021Resources (Part 2)
Moderator: Juan Steyn
Day 1 Monday 27 September
15:25 - 15:30

From Data Collection to Data Archiving: a Corpus of Italian Spontaneous Speech
Daniela Mereu (Free University of Bozen-Bolzano)[email protected]
CLARIN Annual Conference 2021, 27 – 29 September 2021, Virtual Edition

Introduction• Recently, the interest in speech sciences for spontaneous conversations has increased, and researchers have begun to study the characteristics of casual speech in different languages, such as German (Kohler 1990), Dutch (Ernestus 2000; Oostdijk 2000), English (Johnson 2004), French (Torreira et al. 2010) and Czech (Ernestus et al. 2014)
• This kind of research has been driven by the creation of spontaneous speech corpora that allow the systematic investigation on large amounts of data
• For research of this kind on Italian, the available resources, i.e. corpora of spontaneous speech that are also suitable for phonetic research, are very limited
• Resources available for the study of spoken Italian are not always accompanied by audio files, or the recordings are not suited to be used for acoustic analysis of speech
• exception: a subsection of the CLIPS corpus (Albano Leoni 2007; Savy & Cutugno, 2009), stored in the BAS repository

Aims of the presentation• Aims of this contribution:
a) to present a new corpus of Italian spontaneous speech, DIA corpus-Dialogic ItAlian (Mereu & Vietti 2021), that is suitable also for acoustic phonetic analysis
b) to reflect on the best practices for making this corpus available to the scientific community and archiving it in a safe and long-term way

DIA corpus: speaker sample• DIA-Dialogic ItAlian corpus (Mereu & Vietti 2021) is representative of the Italian language variety
spoken in the town of Bolzano (South Tyrol, Italy), both by native speakers and Tyrolean-native speakers
• Speaker sample made up of 40 speakers (age range 18-65; 14 M, 26 F), representing different types of
speakers: simultaneous bilinguals, sequential bilinguals, and late sequential bilinguals, or monolinguals
• Different social characteristics of the speakers, in terms of levels of education and type of occupation
Variable Sex Age Education L1
M F 18-40 41-65 Middle school
High school
University Ita Tir Biling
Speakers 14 26 20 20 4 26 10 23 12 5

DIA corpus: data collection• Data collection sessions:
1. a dialogic interaction in pairs, between people who know each other well
2. a questionnaire on social networks, elicited by means of EgoNet software (McCarty 2011)
3. the reading of a list of sentences
� 2 hours for each pair of speakers, recorded at 44,100 Hz and 16-bit depth with a Zoom H4 recorder, using headset microphones (Shure SM35)
� High acoustic quality: WADA SNR: M = 58.12 dB, SD = 28.32 dB; WADA SNR Waveform Amplitude Distribution Analysis measured using Matlab (cf. Kim & Stern 2008)

DIA corpus: data collection• In total, the corpus is made up of approximately 30 hours of speech:
• around 10 hours of dialogic spontaneous speech (9 h 49’ 32’’)
• 19 hours of speech from the interviews about social networks (19 h 03’ 26’’)
• 1 hour and 50 minutes of reading speech (1 h 50’ 27’’)

Orthographic transcription and phonological segmentation and annotation
• Orthographical transcription of spontaneous data (around 100,000 tokens) automatically generated using the YouTube subtitle system > output manually corrected in ELAN (Sloetjes & Wittenburg 2008)
• Audio files (with orthographic transcriptions) processed in WebMAUS (Kisler et al. 2017), using the tools of forced alignment, automatic segmentation and labelling of speech signals
• Output of this process: an audio file with a time-aligned transcription file (TextGrid format) containing:1. orthographic transcription at the word level
2. phonemic transcription of the entire words
3. phonetic segmentation in the SAMPA alphabet, created by means of a system of forced alignment (Kisler et al. 2015) > the result manually corrected
� At present, 4 minutes of spontaneous speech for 18 speakers phonologically segmented and corrected, i.e., more
than 70 minutes (Vietti & Mereu forthcoming)
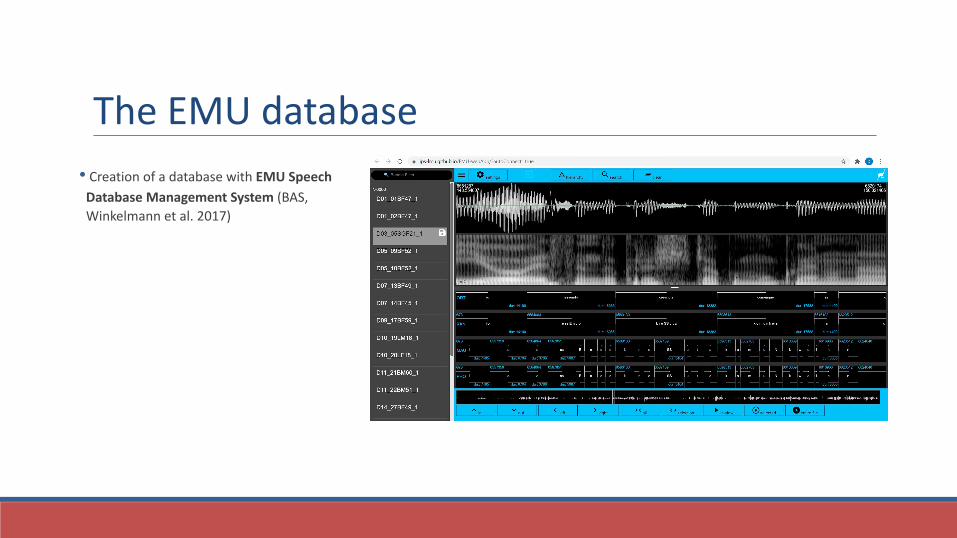
The EMU database
• Creation of a database with EMU Speech
Database Management System (BAS, Winkelmann et al. 2017)

Towards archiving the corpus• Data in archive format:
• 20 dialogues: WAV sound files (44,100 sampling frequency/16 bit resolution)
• the transcriptions of the audio files (in eaf and TextGrid format) anonymized (around 100,000 tokens)
• a rich set of metadata (in csv format)
• consent forms for registration and use of data for scientific purposes for all speakers

Towards archiving the corpus: next steps• Next step: the long-term preservation and accessibility of the corpus
• To archive the corpus in a CLARIN repository, a few processes still need to be addressed:
a) records metadata must be transformed into one of the accepted CMDI metadata profiles
b) informed consents with permission to share data from the participants must be obtained
c) audio files must be anonymized

References Albano Leoni, F. (2006), “Un frammento di storia recente della ricerca (linguistica) italiana. Il corpus CLIPS”. Bollettino d’Italianistica, 4:122–130.
Ernestus, M. (2000), Voice assimilation and segment reduction in Dutch: A corpus-based study of the phonology-phonetics interface. LOT, Utrecht, The Netherlands.
Ernestus, M., Kočková-Amortová, L. & Pollak, P. (2014), “The Nijmegen corpus of casual Czech”. In Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J. & Piperidis, S. (eds.), Proceedings of LREC 2014: 9th International Conference on Language Resources and Evaluation, 365–370.
Johnson, K. (2004), “Massive reduction in conversational American English”. In Yoneyama, K. & Maekawa, K. (eds.), Spontaneous Speech: Data and Analysis. Proceedings of the 1st Session of the 10th International Symposium. The National International Institute for Japanese Language, Tokyo:29–54.
Kim, C. & Stern, R.M. (2008), “Robust signal-to-noise ratio estimation based on waveform amplitude distribution analysis”. In Proc. Interspeech. 9th Annual Conference of the International Speech Communication Association, Brisbane, Australia: 2598–2601.
Kisler, T., Schiel, F., Reichel, U. & Draxler, C. (2015), “Phonetic/linguistic Web Services at BAS”. Interspeech 2015, 2609–2610.
Kohler, K. J. (1990), “Segmental reduction in connected speech in German: Phonological facts and phonetic explanations”. In Hardcastle, W. J. & Marchal, A. (eds.), Speech Production and Speech Modelling. Kluwer Academic Publishers, Dordrecht: 69–92.

References McCarty, C. (2011), EgoNet. https://sourceforge.net/projects/egonet/.
Mereu, D. & Vietti, A. (2021), “Dialogic ItAlian (DIA): the creation of a corpus of Italian spontaneous speech”. Speech Communication 130:1-14.
Vietti, A. & Mereu, D. (forthcoming), “Sistemi vocalici in contatto nell’italiano di Bolzano: un’analisi esplorativa corpus-based”. In: Romito, L. (ed.), La variazione linguistica in condizioni di contatto: contesti acquisizionali, lingue, dialetti e minoranze in Italia e nel mondo. Milano: Officinaventuno.
Oostdijk, N. (2000), “The spoken Dutch corpus. Overview and first evaluation”. In Gravilidou, M., Carayannis, G., Markantonatou, S., Piperidis, S. and Stainhaouer, G. (eds.), Proceedings of the Second International Conference on Language Resources and Evaluation, vol. 2:887–893, ELRA, Paris.
Savy, R. & Cutugno, F. (2009), “CLIPS. Diatopic, diamesic and diaphasic variations in spoken Italian”. In Mahlberg, M., Gonzalez-Diaz, V. & Smith, C. (eds.), Proceedings of the 5th Corpus Linguistics Conference 2009 (CL2009), Liverpool, 213:1–24.
Schiel, F. (1999), “Automatic phonetic transcription of non-prompted speech”. In: Proceedings of the ICPhS 1999:607–610.
Sloetjes, H. & Wittenburg, P. (2008), “Annotation by category – ELAN and ISO DCR”. In Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, 28-30 May 2008.
Torreira, F., Adda-Decker, M. & Ernestus, M. (2010), “The Nijmegen corpus of casual French”. Speech Communication, 52:201–212.
Winkelmann, R., Harrington, J. & Jänsch, K. (2017), “EMU-SDMS: Advanced speech database management and analysis in R”. Computer Speech & Language, 45:392–410.

Breakout sessions
48CLARIN
● Room 1: Research Use Cases (Martin Wynne)
● Room 2: Resources (Parts 1 and 2) (Martin Wynne)
● Room 3: Legal Issues Related to the Use of LRs in Research (Part 1)
(Juan Steyn)
● Room 4: Research Data Management, Metadata and Curation
(Part 1) (Juan Steyn)