Embed Size (px)
Citation preview

1
Research on Efficient Erasure-Coding-
Based Cluster Storage Systems
Patrick P. C. Lee
The Chinese University of Hong Kong
NCIS’14
Joint work with Runhui Li, Jian Lin, Yuchong Hu
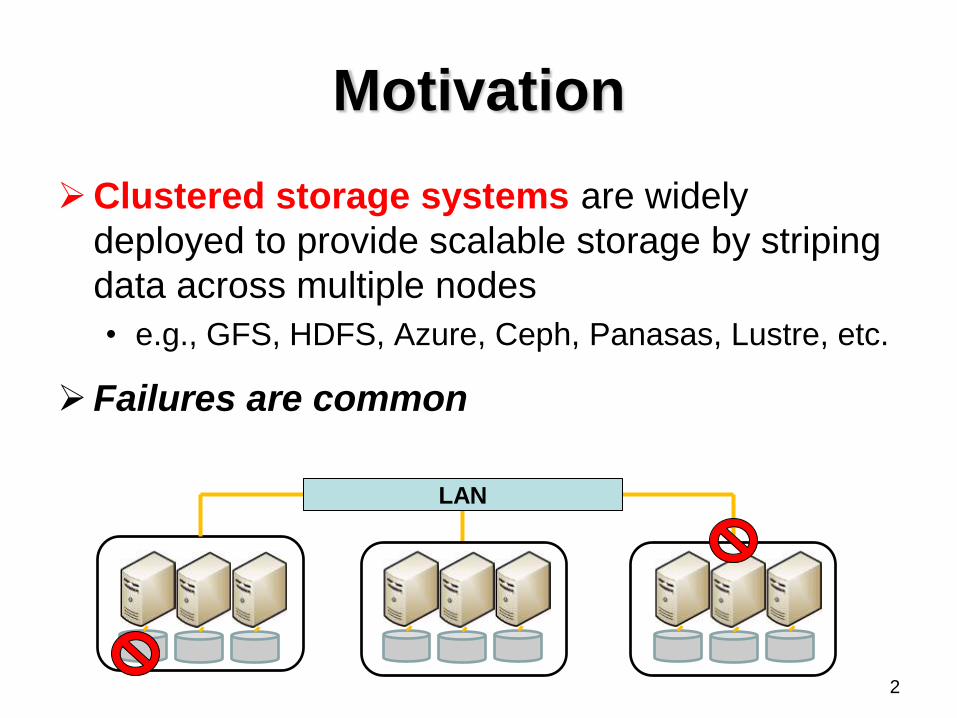
Motivation
Clustered storage systems are widely
deployed to provide scalable storage by striping
data across multiple nodes
• e.g., GFS, HDFS, Azure, Ceph, Panasas, Lustre, etc.
Failures are common
2
LAN

Failure Types
Temporary failures
• Nodes are temporarily inaccessible (no data loss)
• 90% of failures in practice are transient [Ford, OSDI’10]
• e.g., power loss, network connectivity loss, CPU
overloading, reboots, maintenance, upgrades
Permanent failures
• Data is permanently lost
• e.g., disk crashes, latent sector errors, silent data
corruptions, malicious attacks
3

Replication vs. Erasure Coding
Solution: Add redundancy:
• Replication
• Erasure coding
Enterprises (e.g., Google, Azure, Facebook)
move to erasure coding to save footprints due to
explosive data growth
• e.g., 3-way replication has 200% overhead; erasure
coding can reduce overhead to 33% [Huang, ATC’12]
4
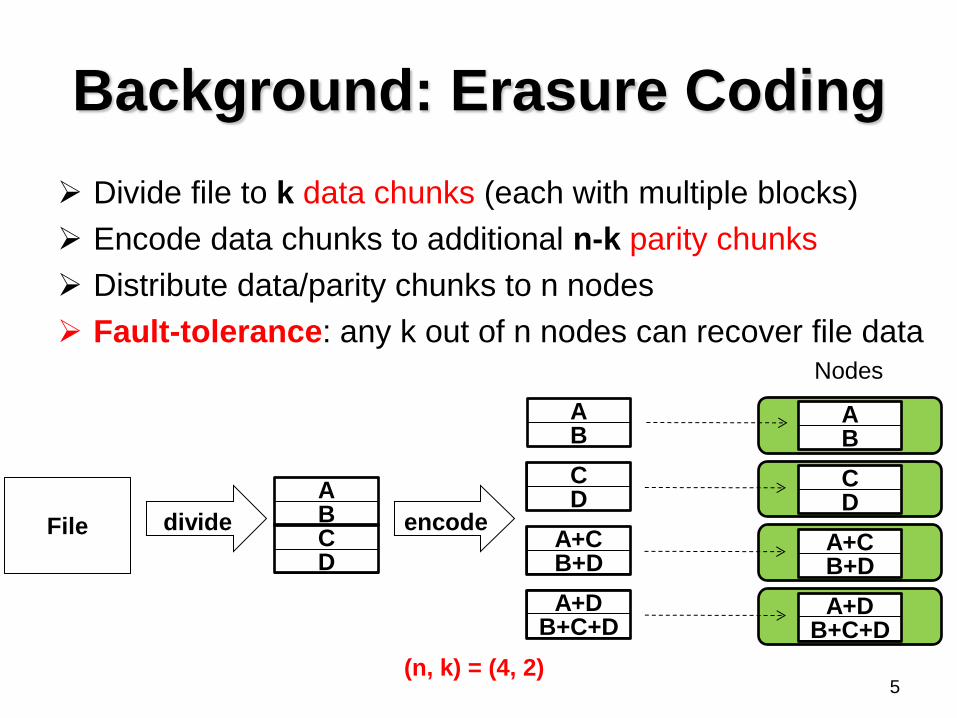
Background: Erasure Coding
Divide file to k data chunks (each with multiple blocks)
Encode data chunks to additional n-k parity chunks
Distribute data/parity chunks to n nodes
Fault-tolerance: any k out of n nodes can recover file data
5
File encode divide
Nodes
(n, k) = (4, 2)
A B C D
A+C B+D
A+D B+C+D
A B
C D
A+C B+D
A+D B+C+D
A B
C D

Erasure Coding
Pros:
• Reduce storage space with high fault tolerance
Cons:
• Data chunk updates imply parity chunk updates
expensive updates
• In general, k chunks are needed to recover a single lost
chunk expensive recovery
Our talk: Can we improve recovery of erasure-
coding-based clustered storage systems, while
preserving storage efficiency?
6

Our Work
CORE [MSST’13, TC]
• Augments existing regenerating codes to support
both optimal single and concurrent failure recovery
Degraded-read scheduling [DSN’14]
• Improves MapReduce performance in failure mode
Designed, implemented, and experimented on
Hadoop Distributed File System
7
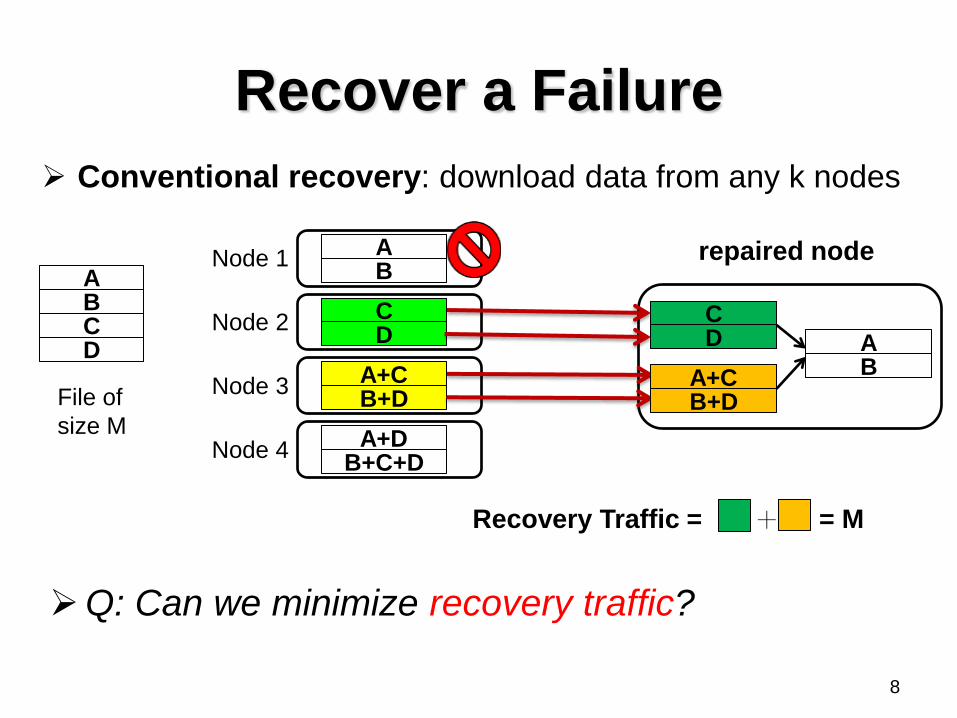
Recover a Failure
Q: Can we minimize recovery traffic?
8
Node 1
Node 2
Node 3
Node 4
repaired node
Conventional recovery: download data from any k nodes
Recovery Traffic = = M +
A B
C D
A+C B+D
A+D B+C+D
C D
A+C B+D
A B
File of
size M
A B C D
9
Node 1
Node 2
Node 3
Node 4
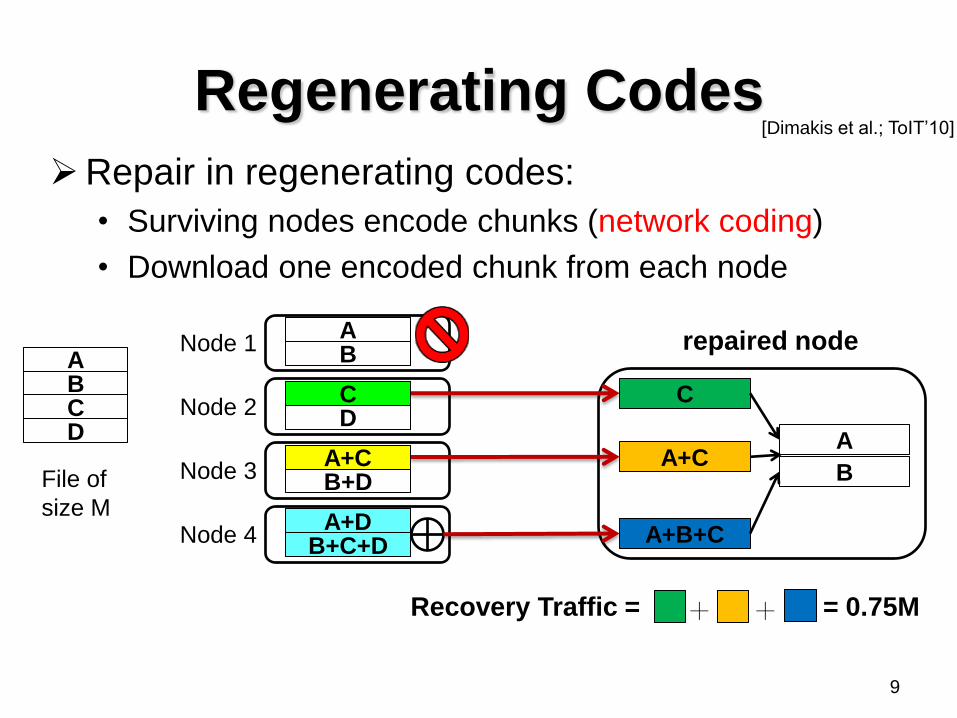
Regenerating Codes [Dimakis et al.; ToIT’10]
A B
C D
A+C B+D
A+D B+C+D
C
A+C
A+B+C
A
B
+ + Recovery Traffic = = 0.75M
repaired node
File of
size M
A B C D
Repair in regenerating codes:
• Surviving nodes encode chunks (network coding)
• Download one encoded chunk from each node

Concurrent Node Failures
Regenerating codes only designed for single
failure recovery
• Optimal regenerating codes collect data from n-1
surviving nodes for single failure recovery
Correlated and co-occurring failures are possible
• In clustered storage [Schroeder, FAST’07; Ford, OSDI’10]
• In dispersed storage [Chun NSDI’06; Shah NSDI’06]
CORE augments regenerating codes for optimal
concurrent failure recovery
• Retains regenerating code construction
10

CORE’s Idea
Consider a system with n nodes
Two functions for regenerating codes in single
failure recovery:
• Enc: storage node encodes data
• Rec: reconstruct lost data using encoded data from
n-1 surviving nodes
t-failure recovery (t > 1):
• Reconstruct each failed node as if other n-1 nodes
are surviving nodes
11
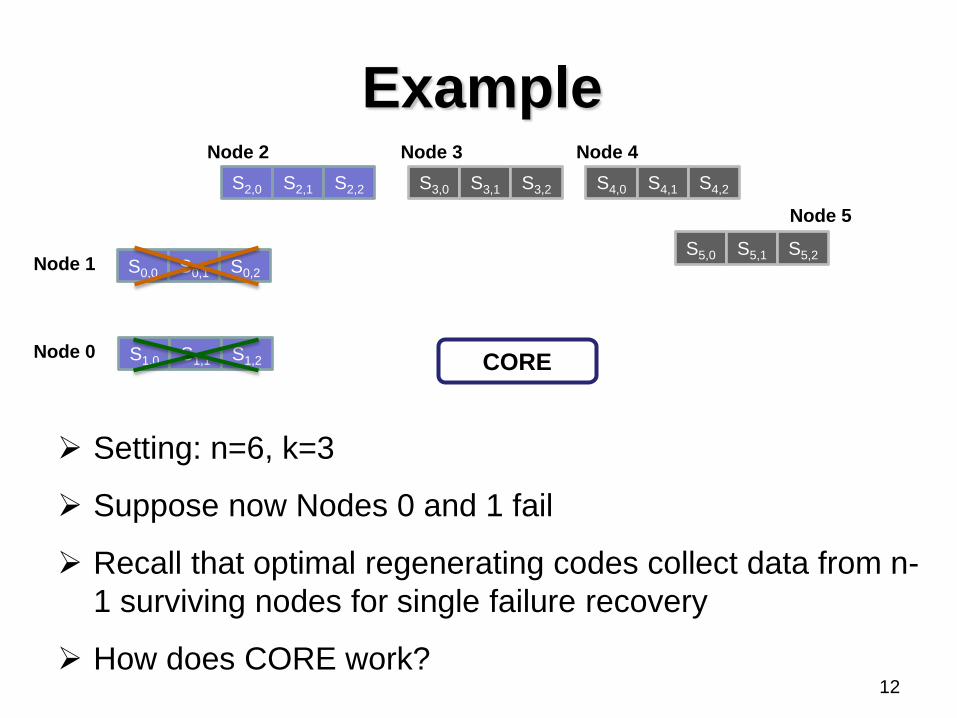
Example
12
CORE
S0,0 S0,1 S0,2
S1,0 S1,1 S1,2
S2,0 S2,1 S2,2 S3,0 S3,1 S3,2 S4,0 S4,1 S4,2
S5,0 S5,1 S5,2
Node 0
Node 1
Node 2 Node 3 Node 4
Node 5
Setting: n=6, k=3
Suppose now Nodes 0 and 1 fail
Recall that optimal regenerating codes collect data from n-
1 surviving nodes for single failure recovery
How does CORE work?
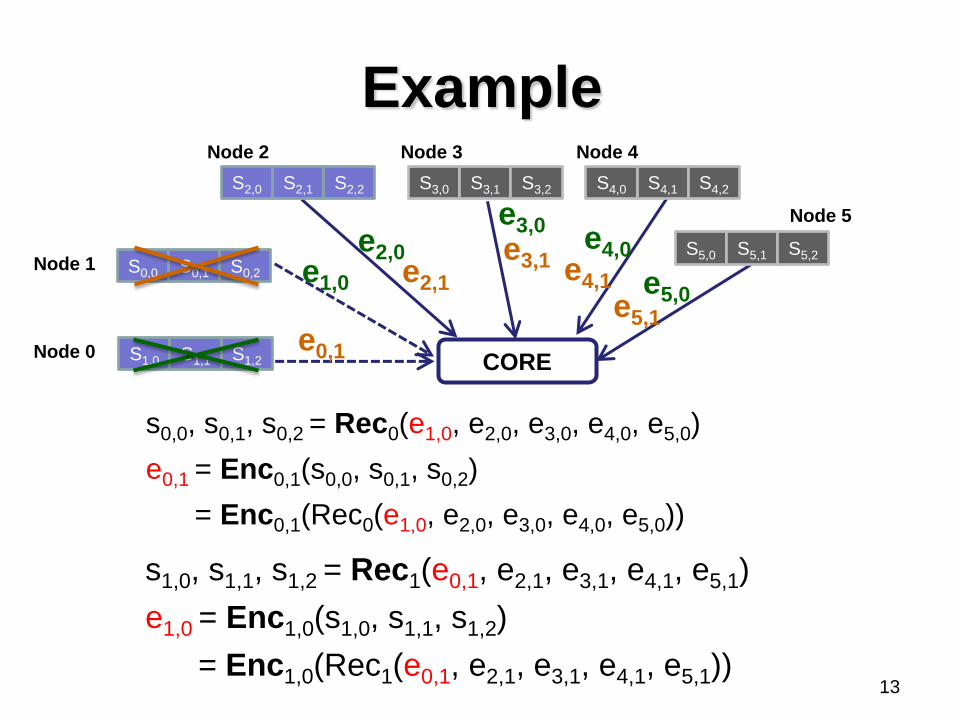
Example
s0,0, s0,1, s0,2 = Rec0(e1,0, e2,0, e3,0, e4,0, e5,0)
e0,1 = Enc0,1(s0,0, s0,1, s0,2)
= Enc0,1(Rec0(e1,0, e2,0, e3,0, e4,0, e5,0))
s1,0, s1,1, s1,2 = Rec1(e0,1, e2,1, e3,1, e4,1, e5,1)
e1,0 = Enc1,0(s1,0, s1,1, s1,2)
= Enc1,0(Rec1(e0,1, e2,1, e3,1, e4,1, e5,1))
CORE
S0,0 S0,1 S0,2
S1,0 S1,1 S1,2
S2,0 S2,1 S2,2 S3,0 S3,1 S3,2 S4,0 S4,1 S4,2
S5,0 S5,1 S5,2
e0,1
e2,1 e3,1 e4,1
e5,1 e1,0
e2,0 e3,0
e4,0
e5,0
13
Node 0
Node 1
Node 2 Node 3 Node 4
Node 5

Example
We have two equations
e0,1 = Enc0,1(Rec0(e1,0, e2,0, e3,0, e4,0, e5,0))
e1,0 = Enc1,0(Rec1(e0,1, e2,1, e3,1, e4,1, e5,1))
Trick: They form a linear system of equations
If the equations are linearly independent, we
can calculate e0,1 and e1,0
Then we obtain lost data by
s0,0, s0,1, s0,2 = Rec0(e1,0, e2,0, e3,0, e4,0, e5,0)
s1,0, s1,1, s1,2 = Rec1(e0,1, e2,1, e3,1, e4,1, e5,1)
14

Bad Failure Pattern
A system of equations may not have a unique
solution. We call this a bad failure pattern
Bad failure patterns count for less than ~1%
Our idea: reconstruct data by adding one
more node to bypass the bad failure pattern
• Suppose nodes 0,1 form a bad failure pattern and
nodes 0,1,2 form a good failure pattern.
Reconstruct lost data for nodes 0,1,2
• Still achieve bandwidth saving over conventional
15
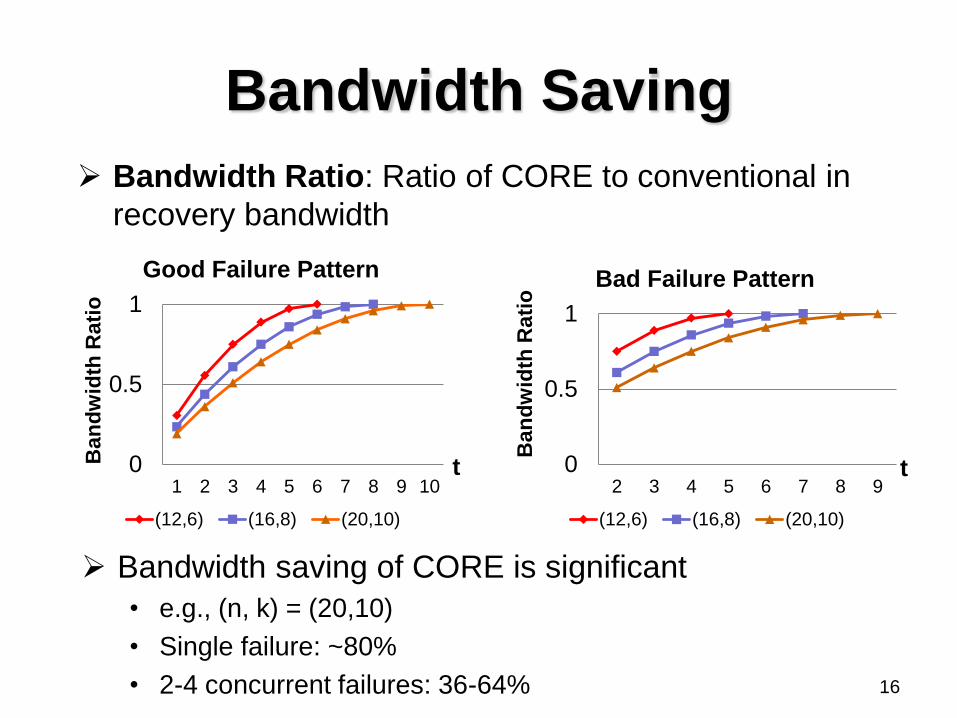
Bandwidth Saving
Bandwidth Ratio: Ratio of CORE to conventional in
recovery bandwidth
0
0.5
1
1 2 3 4 5 6 7 8 9 10
Ban
dw
idth
Rati
o
Good Failure Pattern
(12,6) (16,8) (20,10)
0
0.5
1
2 3 4 5 6 7 8 9
Ban
dw
idth
Rati
o Bad Failure Pattern
(12,6) (16,8) (20,10)
Bandwidth saving of CORE is significant
• e.g., (n, k) = (20,10)
• Single failure: ~80%
• 2-4 concurrent failures: 36-64% 16
t t

Theorem
Theorem: CORE, which builds on regenerating
codes for single failure recovery, achieves the
lower bound of recovery bandwidth if we recover
a good failure pattern with t ≥ 1 failed nodes
• Over ~99% of failure patterns are good
17
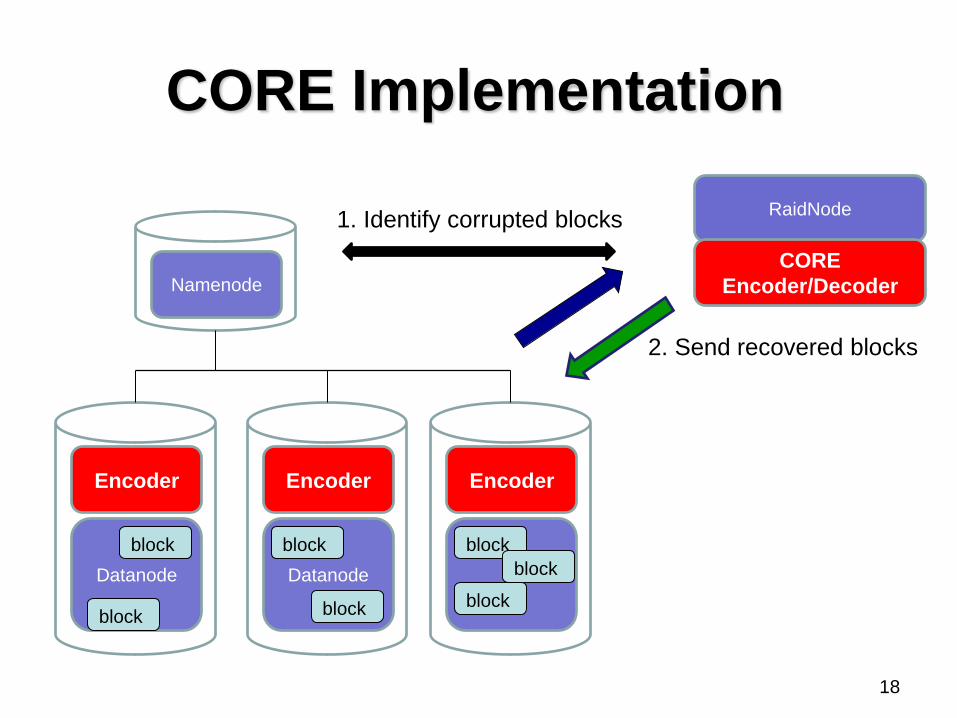
CORE Implementation
18
Namenode
Datanode Datanode
block
block
block
block
block
block
block
RaidNode 1. Identify corrupted blocks
2. Send recovered blocks
Encoder Encoder Encoder
CORE
Encoder/Decoder
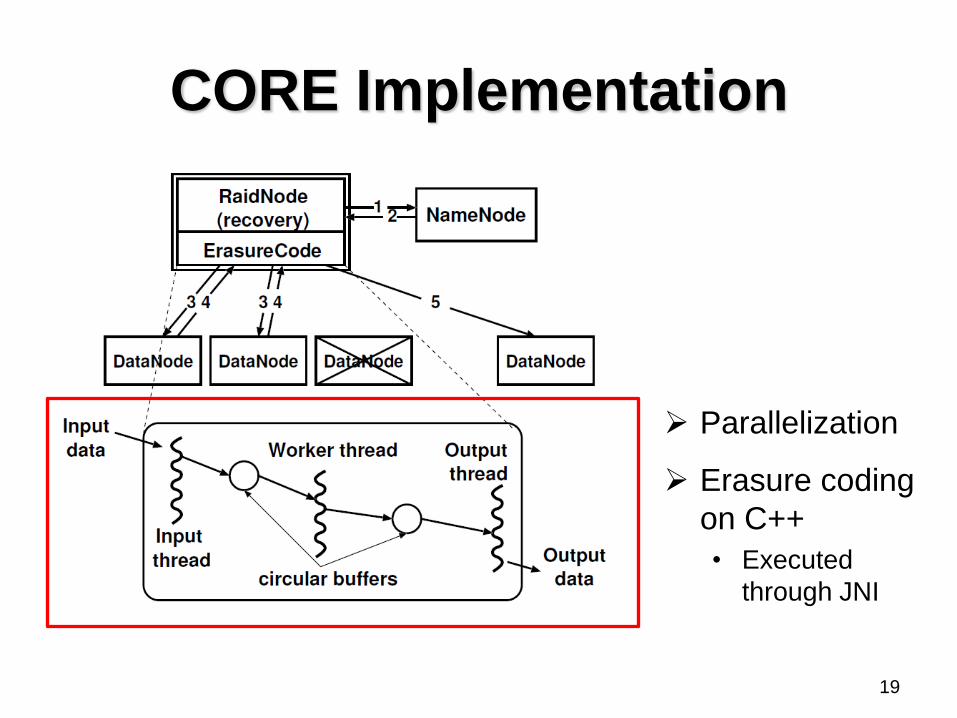
CORE Implementation
Parallelization
Erasure coding
on C++
• Executed
through JNI
19
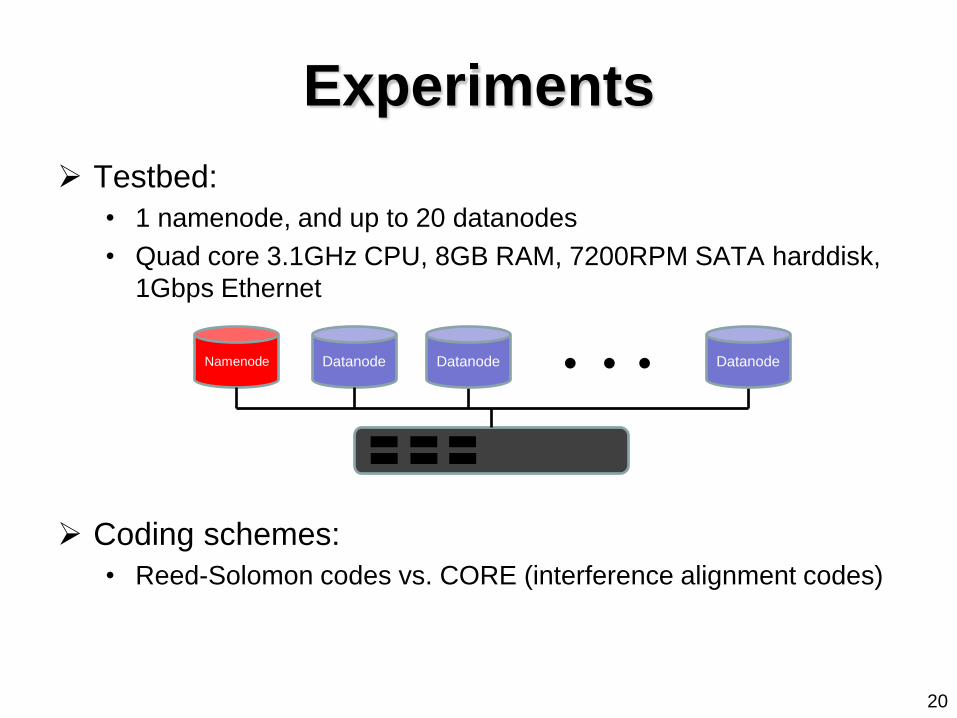
Experiments
Testbed:
• 1 namenode, and up to 20 datanodes
• Quad core 3.1GHz CPU, 8GB RAM, 7200RPM SATA harddisk,
1Gbps Ethernet
Coding schemes:
• Reed-Solomon codes vs. CORE (interference alignment codes)
20
Namenode Datanode Datanode Datanode
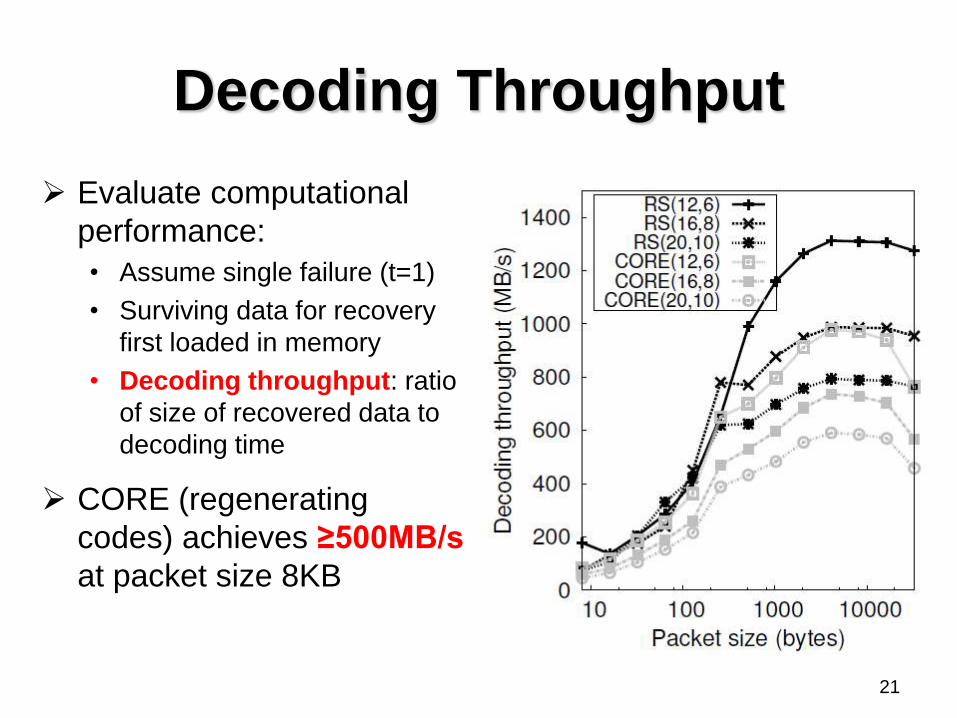
Decoding Throughput
Evaluate computational
performance:
• Assume single failure (t=1)
• Surviving data for recovery
first loaded in memory
• Decoding throughput: ratio
of size of recovered data to
decoding time
CORE (regenerating
codes) achieves ≥500MB/s
at packet size 8KB
21
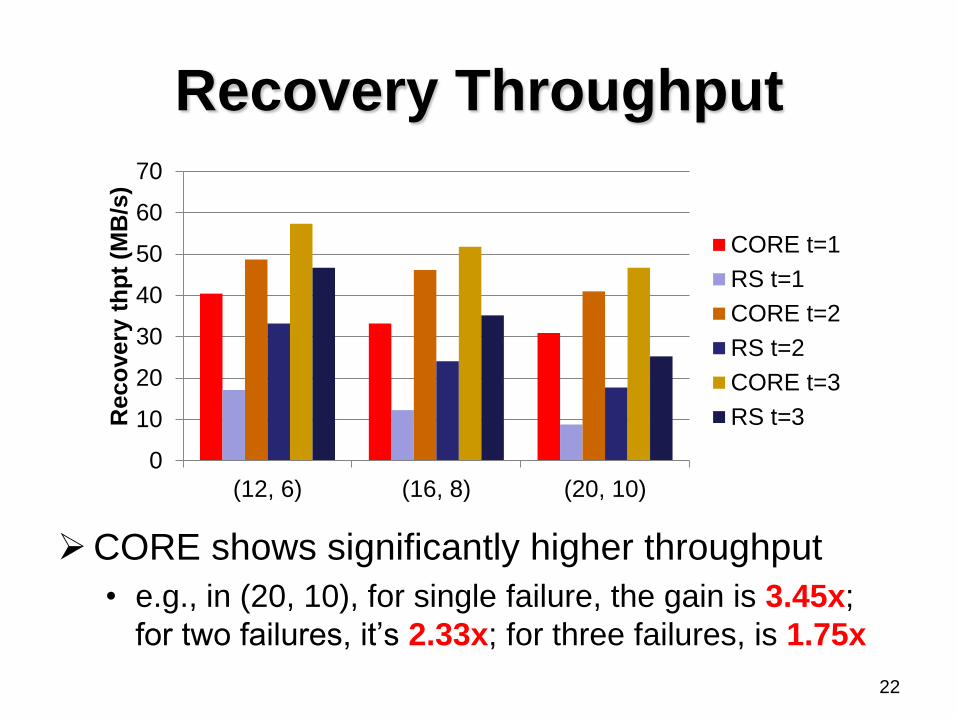
Recovery Throughput
CORE shows significantly higher throughput
• e.g., in (20, 10), for single failure, the gain is 3.45x;
for two failures, it’s 2.33x; for three failures, is 1.75x
0
10
20
30
40
50
60
70
(12, 6) (16, 8) (20, 10)
Reco
very
th
pt
(MB
/s)
CORE t=1
RS t=1
CORE t=2
RS t=2
CORE t=3
RS t=3
22

MapReduce
Q: How does erasure-coded storage affect
data analytics?
Traditional MapReduce is designed with
replication storage in mind
To date, no explicit analysis of MapReduce on
erasure-coded storage
• Failures trigger degraded reads in erasure coding
23
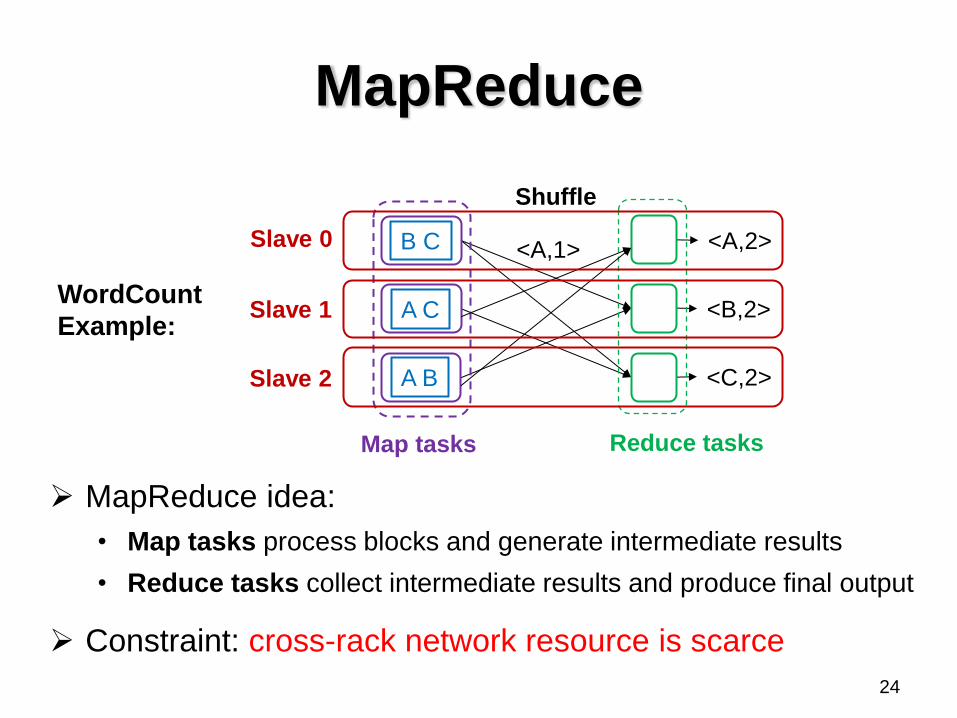
MapReduce
MapReduce idea:
• Map tasks process blocks and generate intermediate results
• Reduce tasks collect intermediate results and produce final output
Constraint: cross-rack network resource is scarce
24
WordCount
Example:
<A,2>
<B,2>
<C,2>
Map tasks Reduce tasks
<A,1> B C
A C
A B
Slave 0
Slave 1
Slave 2
Shuffle

MapReduce on Erasure Coding
Show that default scheduling hurts MapReduce
performance on erasure-coded storage
Propose Degraded-First Scheduling for
MapReduce task-level scheduling
• Improves MapReduce performance on erasure-coded
storage in failure mode
25
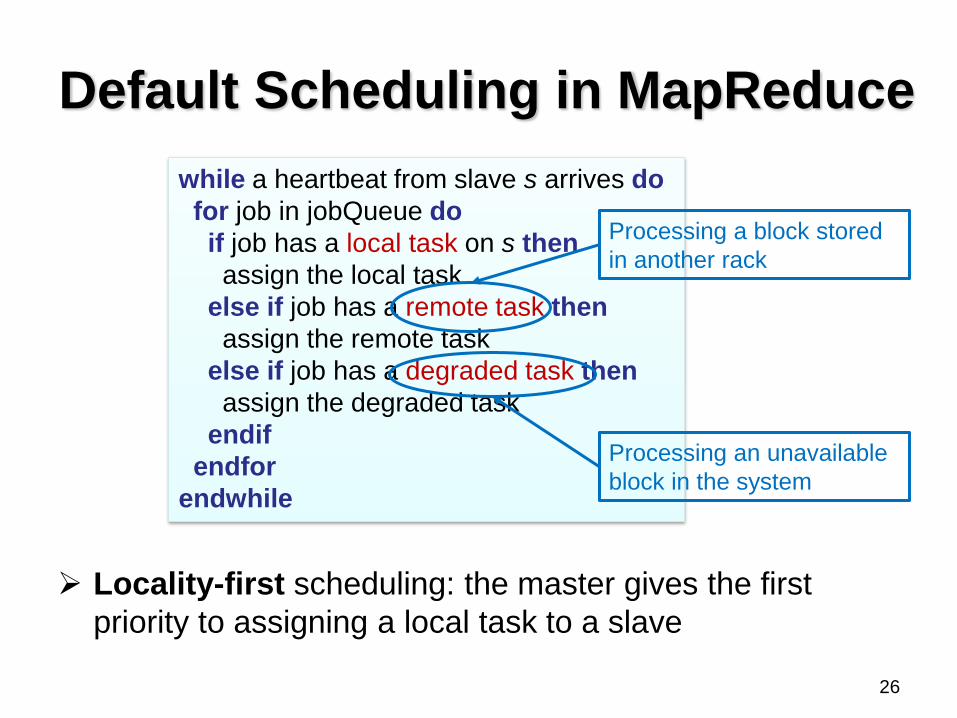
Default Scheduling in MapReduce
Locality-first scheduling: the master gives the first
priority to assigning a local task to a slave
26
while a heartbeat from slave s arrives do
for job in jobQueue do
if job has a local task on s then
assign the local task
else if job has a remote task then
assign the remote task
else if job has a degraded task then
assign the degraded task
endif
endfor
endwhile
Processing a block stored
in another rack
Processing an unavailable
block in the system
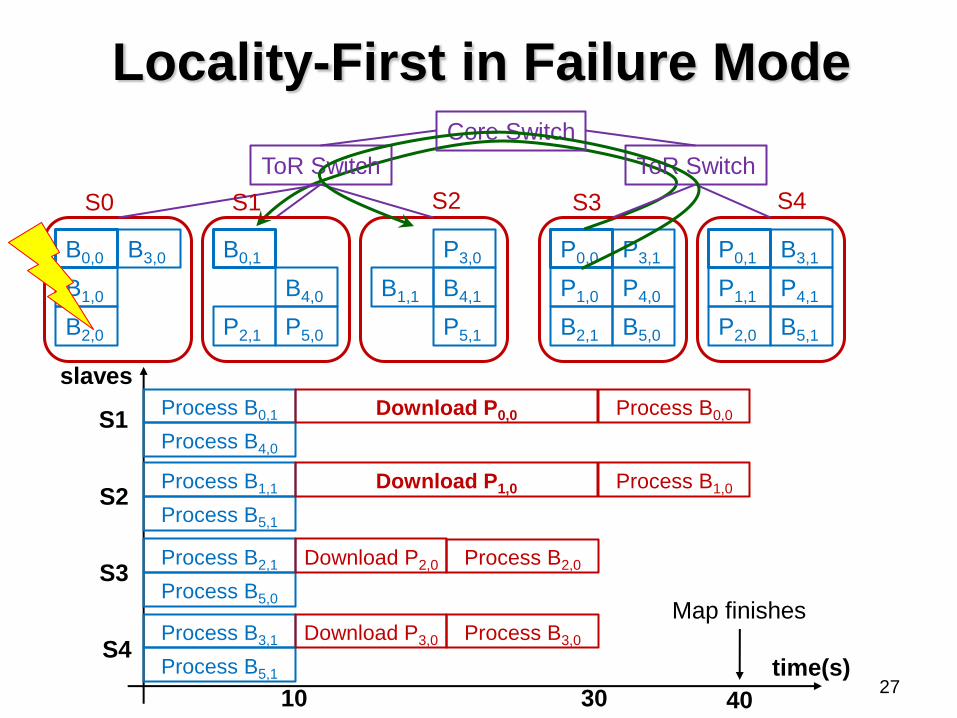
Locality-First in Failure Mode
27
B0,0 B0,1 P0,0 P0,1
B1,0
B2,0
B3,0
P2,1
B4,0
P5,0
B1,1
P3,0
B4,1
P5,1
P1,0
B2,1
P3,1
P4,0
B5,0
P1,1
P2,0
B3,1
P4,1
B5,1
Core Switch
ToR Switch ToR Switch
S0 S1 S2 S3 S4
10 30 40
time(s)
slaves
S1
S2
S3
S4
Process B1,1
Process B5,1
Process B2,1
Process B5,0
Process B3,1
Process B5,1
Process B0,1
Process B4,0
Download P2,0
Download P0,0
Download P1,0
Map finishes
Process B0,0
Process B3,0
Process B2,0
Download P3,0
Process B1,0

Problems & Intuitions
Problems:
• Degraded tasks are launched simultaneously
• Start degraded reads together and compete for network
resources
• When local tasks are processed, network resource is
underutilized
Intuitions: ensure degraded tasks aren’t running
together to complete for network resources
• Finish running degraded tasks before all local tasks
• Keep degraded tasks separated
28
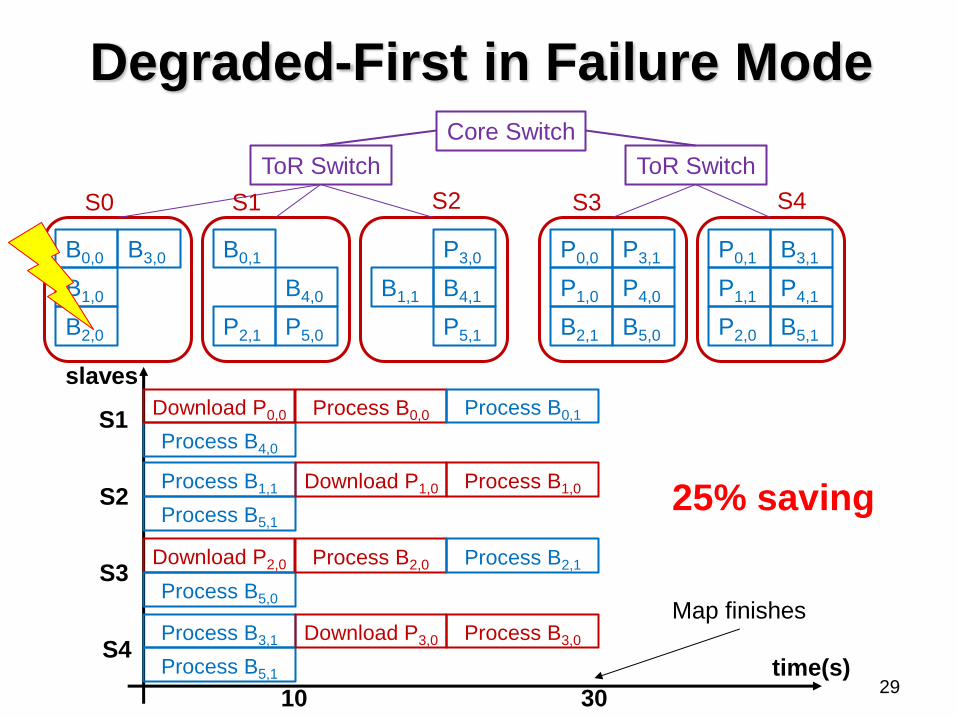
29
25% saving
Core Switch
ToR Switch ToR Switch
B0,0
B1,0
B2,0
B3,0 B0,1
P2,1
B4,0
P5,0
B1,1
P3,0
B4,1
P5,1
P0,0
P1,0
B2,1
P3,1
P4,0
B5,0
P0,1
P1,1
P2,0
B3,1
P4,1
B5,1
S0 S1 S2 S3 S4
10 30
Map finishes
time(s)
S1
S2
S3
S4
slaves
Degraded-First in Failure Mode
Process B1,1
Process B5,1
Process B4,0
Download P0,0
Download P2,0
Process B5,0
Process B3,1
Process B5,1
Process B0,0 Process B0,1
Process B2,0
Download P1,0
Download P3,0
Process B1,0
Process B2,1
Process B3,0

Degraded-First Scheduling
30
while a heartbeat from slave s arrives do
if 𝒎
𝑴≥𝒎𝒅
𝑴𝒅 and job has a degraded task then
assign the degraded task
endif
assign other map slots as in locality-first scheduling
endwhile
Idea: Launch a degraded task only if the fraction of
degraded tasks being launched (𝒎𝒅 / 𝑴𝒅) is no more
than the fraction of all map tasks being launched (𝒎 / 𝑴)
• Control the pace of launching degraded tasks
• Keep degraded tasks separated in whole map phase
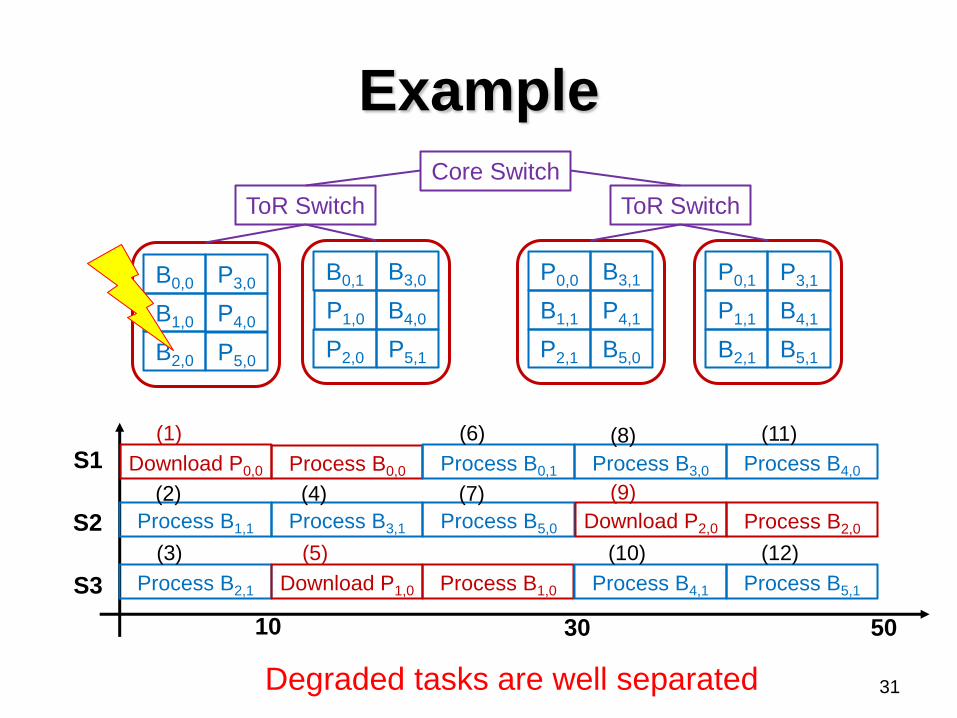
Example
31
Core Switch
ToR Switch ToR Switch
B0,0
B1,0
B2,0
B3,0 B0,1
P2,1
B4,0
P5,0
B1,1
P3,0
B4,1
P5,1
P0,0
P1,0
B2,1
P3,1
P4,0
B5,0
P0,1
P1,1
P2,0
B3,1
P4,1
B5,1
10 30 50
S1
S2
S3
Download P0,0 Process B0,0
Process B2,1
Process B1,1
(1)
(2)
(3)
Process B3,1
Download P1,0 Process B1,0
Process B0,1
Process B5,0
Process B3,0
Download P2,0 Process B2,0
Process B4,1
Process B4,0
Process B5,1
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
Degraded tasks are well separated

Properties
Gives higher priority to degraded tasks if
conditions are appropriate
• That’s why we call it “degraded-first” scheduling
Preserves MapReduce performance as in
locality-first scheduling in normal mode
Enhanced degraded first scheduling (EDF)
• Takes into account network topology when assigning
degraded tasks
32

Experiments
33
Prototype on HDFS-RAID
Hadoop cluster:
• Single master and 12 slaves
• Slaves grouped into three racks, four slaves each
• Both ToR and core switches have 1Gbps bandwidth
• 64MB per block
Workloads:
• Jobs: Grep, WordCount, LineCount
• Each job processes a 240-block file
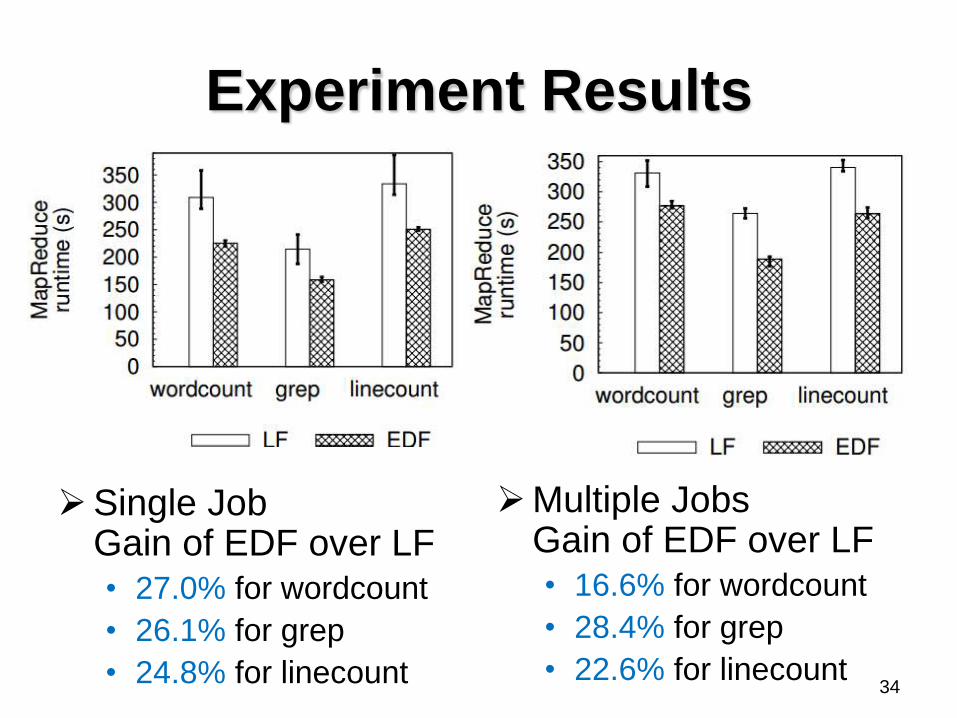
Experiment Results
Single Job Gain of EDF over LF • 27.0% for wordcount
• 26.1% for grep
• 24.8% for linecount
Multiple Jobs Gain of EDF over LF • 16.6% for wordcount
• 28.4% for grep
• 22.6% for linecount
34

Other Projects on Erasure Coding
Mixed failures
• STAIR codes: a general, space-efficient erasure code for tolerating both device
failures and latent sector errors [FAST’14]
• I/O-efficient integrity checking against silent data corruptions [MSST’14]
Efficient updates
• CodFS: enhanced parity logging to reduce network and disk I/Os in erasure-
coded storage [FAST’14]
Efficient recovery
• NCCloud: reduce bandwidth for archival storage [FAST’12, INFOCOM’13, TC’14]
• I/O-efficient recovery schemes for erasure codes [MSST’12, DSN’12, TC’14, TPDS’14]
Modeling of SSD RAID
• Stochastic model to capture reliability changes as SSDs age [SRDS’13, TC]
Secure outsourced storage
• FMSR-DIP: remote data checking for regenerating codes [SRDS’12, TPDS’14]
• Convergent dispersal: unifying security, deduplication, and erasure coding [HotStorage’14]
35

Conclusions
Provide insights into the use of erasure coding on
clustered storage systems
Two systems
• CORE: improve concurrent recovery performance
• Degraded-first scheduling: improve MapReduce performance
in erasure-coded storage in failure mode
Approach:
• Build prototypes, backed by extensive experiments and
theoretical analysis
• Open-source software
http://www.cse.cuhk.edu.hk/~pclee
36





























