Embed Size (px)
DESCRIPTION
Retrieval and Feedback Models for Blog Feed Search SIGIR 2008. Advisor : Dr. Koh Jia-Ling Speaker : Chou-Bin Fan Date : 2009.10.05. Outline. Introduction Approach Retrieval Models : Large Document Model Small Document Models Query Expansion Models : - PowerPoint PPT Presentation
Citation preview

1
Retrieval and Feedback Models for Blog Feed Search
SIGIR 2008
Advisor : Dr. Koh Jia-Ling
Speaker : Chou-Bin Fan
Date : 2009.10.05

2
Outline
• Introduction• Approach Retrieval Models : Large Document Model
Small Document Models
Query Expansion Models : Pseudo-Relevance Feedback
Wikipedia Link-based Query Expansion Wikipedia PRF Query Expansion
• Conclusion

3
Introduction• What is a feed ?
<xml>
<feed>
<entry>
<author>Peter …</>
<title>Good, Evil…</>
<content>I’ve said…</>
</entry>
<entry>
<author>Peter …</>
<title>Agreeing…</>
<content>Some peo…</>
</entry>
…
Entries Feed ( XML )
Posts Blog ( HMTL )

4
Introduction
• What is the task “feed search”?
Ranking feeds (collections of entries) in
response to a user’s query “Q” .
A relevant feed should have a principle and recurring
interest in Q .

5
Introduction
• Challenges in Feed Search:1. How does relevance at the entry level correspond to relevance at the
feed level?2. Can we favor entries close to the central topic of the feed?3. Feeds are noisy. (Spam blogs, Spam & off topic comments)
• Retrieval models: models for ranking collections, account for the topical diversity within the collection. (Solve Challenge 1,2.)
• Feedback models: overcome noise in the blog collection, aimed at addressing multifaceted information needs. (Solve Challenge 3.)

6
Retrieval models
• Challenge : ranking topically diverse collections.• Representation: feed ,entry .• Model topical relationship between entries.
7
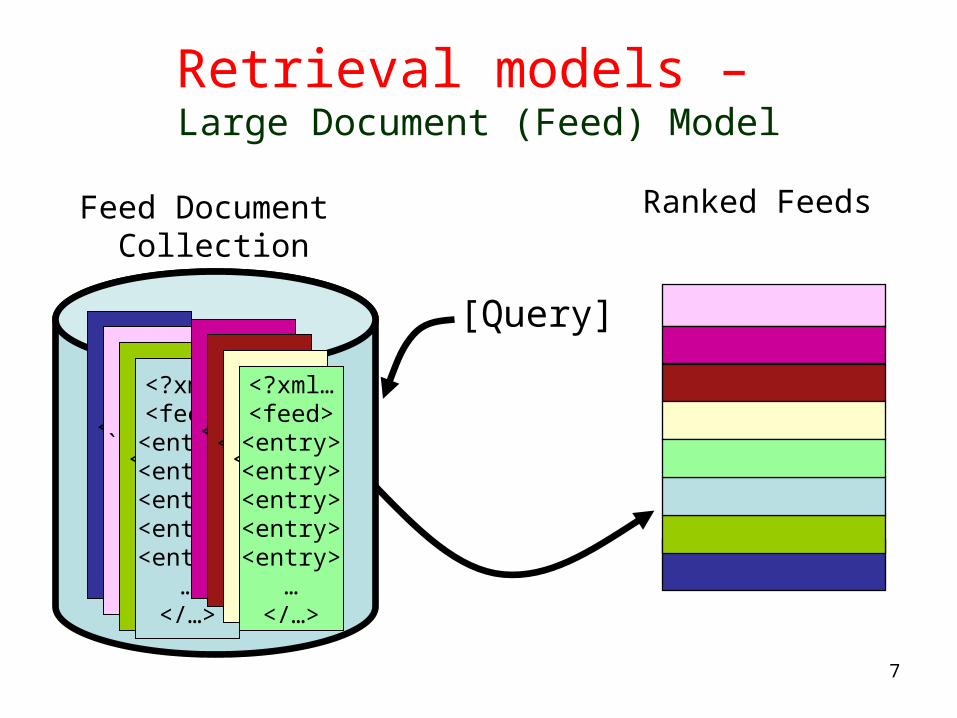
Retrieval models – Large Document (Feed) Model
<?xml……
</…>
`<?xml……
</…>
<?xml……
</…>
<?xml…<feed><entry><entry><entry><entry><entry>
…</…>
<?xml……
</…>
<?xml……
</…>
<?xml……
</…>
<?xml…<feed><entry><entry><entry><entry><entry>
…</…>
Feed Document Collection
[Query]
Ranked Feeds
8
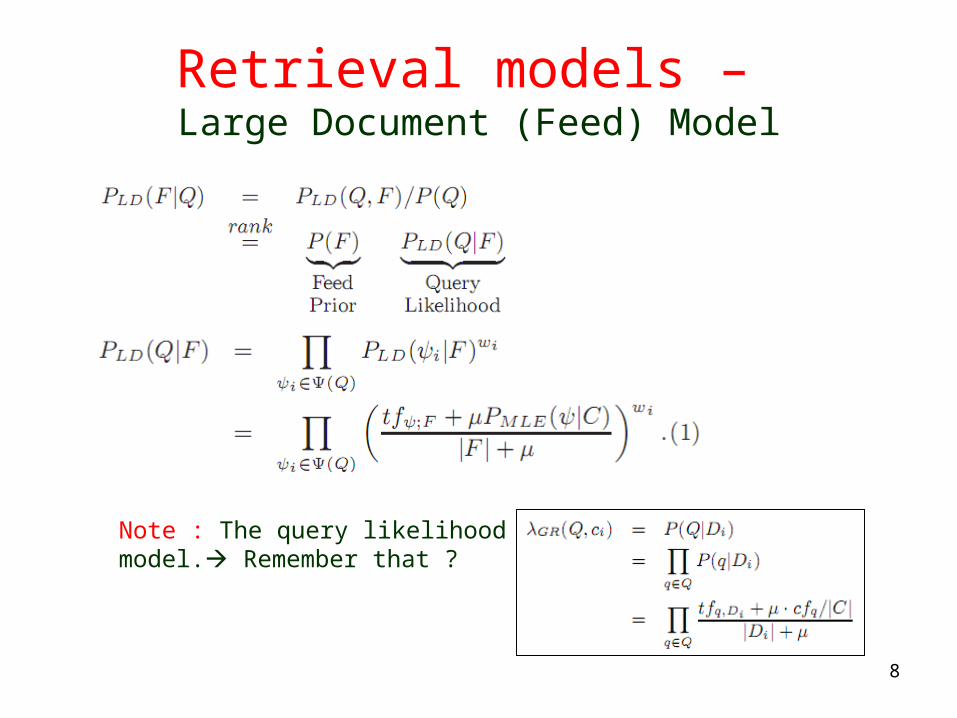
Retrieval models – Large Document (Feed) Model
Note : The query likelihood model. Remember that ?

9
Retrieval models – Large Document (Feed) Model
• Advantages : A straightforward application of existing retrieval techniq
ues.
• Potential Pitfalls:
Large entries dominate a feed’s language model.
Ignores relationship among entries.
10
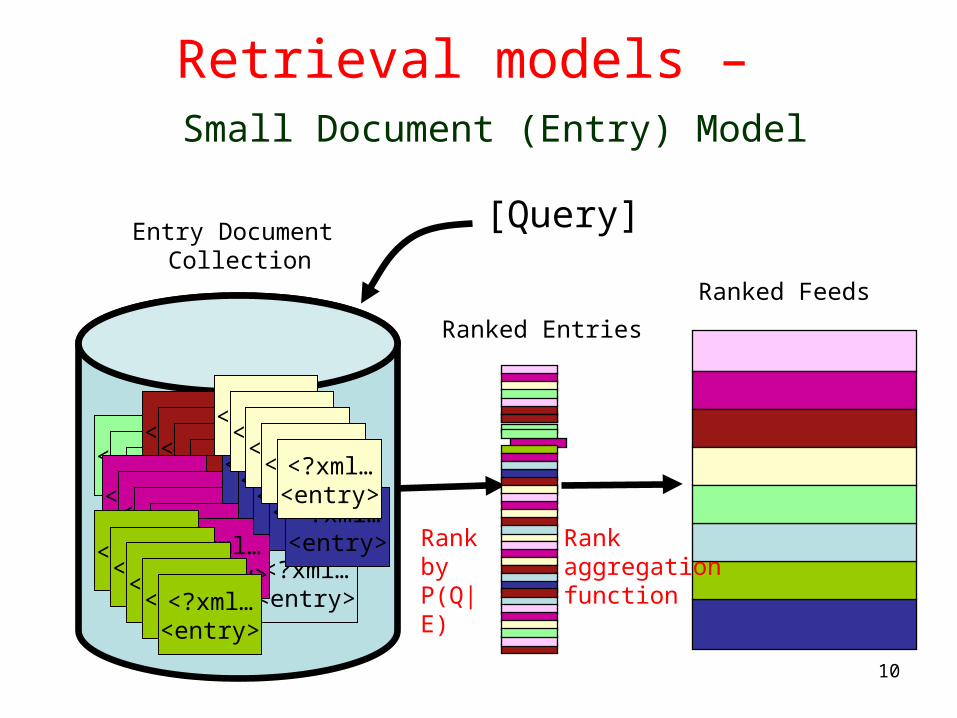
Retrieval models – Small Document (Entry) Model
<entry><entry>
<entry><entry><?xml…
<entry>
Entry Document Collection
<entry><entry>
<entry><entry><?xml…
<entry>
<entry><entry>
<entry><entry><?xml…
<entry><entry>
<entry><entry>
<entry><?xml…<entry>
<entry><entry>
<entry><entry><?xml…
<entry>
<entry><entry>
<entry><entry><?xml…
<entry>
<entry><entry>
<entry><entry><?xml…
<entry>
Ranked Feeds
Ranked Entries
[Query]
Rank by P(Q|E)
Rankaggregation function

11
Retrieval models – Small Document (Entry) Model
ReDDE Federated Resource Ranking Algortihma resource ranking algorithm which scores a document collection, Cj ,by the estimated number of relevant documents in that collection. |C| is an estimate of total number of documents in collection Cj .

12
Retrieval models – Small Document (Entry) Model
• Query Likelihood

13
Retrieval models – Small Document (Entry) Model
• Entry Centrality
Two purposes: To balance scoring across feeds with differing numbers of entrie
s. Without this balancing, the summation in the small document model, Equation 2, would favor longer feeds.
To favor some feeds over others based on their similarity to the feed’s language model.
In general, any measure of similarity
could be used here.
Geometric Mean : Uniform :

14
Retrieval models – Small Document (Entry) Model
Advantages:• Controls for differing entry length• Models topical relationship among entries
Disadvantages:• Centrality computation is slow(er).
• Feed Prior PLOG(F) log(N∝ F ) <grows logarithmically with the feed size>
PUNIF (F) 1.0 ∝ <does not influence the document ranking at all>
Q
Not only improves speed,Also performance

15
Retrieval models – Results
• 45 Queries from the TREC 2007 Blog Distillation Task• BLOG06 test collection, XML feeds only• 5-Fold Cross Validation for all retrieval model smoothing parameters
Statistical significance at the 0.05 level is indicated by † for improvement from φGM, + for improvement from PLOG , ∗ for improvements over the best LD model.

16
Feedback Models
• Challenge: Noisy collection with general & ongoing information needs.
• Use a cleaner external collection for query expansion (Wikipedia)• With an expansion technique designed to identify multiple query .
• Pseudo-Relevance Feedback (PRF) [Lavrenko & Croft, 2001]
• Wikipedia PRF Query Expansion [Diaz & Metzler, 2006]
• Wikipedia Link-based Query Expansion
17
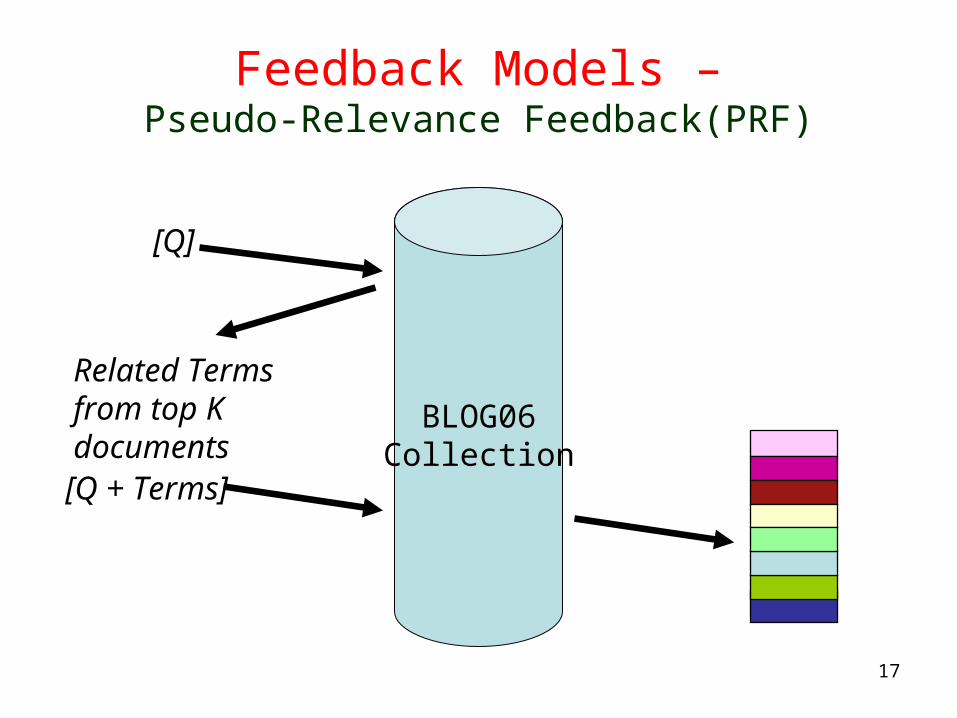
Feedback Models –Pseudo-Relevance Feedback(PRF)
[Q]
BLOG06Collection
Related Terms from top K documents[Q + Terms]

18
Feedback Models –Pseudo-Relevance Feedback(PRF)
• PRF assumes the top N retrieved documents, DN, are relevant to the base query and extracts highly discriminative terms or phrases from those document as query expansion terms.
• PRF.FEED: PRF where DN are the top N feeds.
• PRF.ENTRY: PRF where DN are the top N feed entries.
• PRF.WIKI: PRF where DN are the top N Wikipedia articles when the base query is run on the Wikipedia.
• PRF.WIKI.P: PRF where DN are the top N Wikipedia passages (sequences of at most 220 words,the average entry length in the BLOG06 corpus) when the query is run on the Wikipedia.

19
Feedback Models –Pseudo-Relevance Feedback(PRF)
• RF.TTR: RF where expansion terms originate from the
top 10 relevant feeds (TTR =“top 10 relevant”).
• RF.RTT: RF where expansion terms originate from the
relevant feeds within the top 10 (RTT =“relevant in top 10”).
• NO_EXP (baseline): No query expansion.

20
Feedback Models –Pseudo-Relevance Feedback(PRF)
• Example : give a query “Photography”
Idealdigital photography
depth of field
photographic film
photojournalism
cinematography
PRFphotography
nudeerotic
artgirlfreeteen
fashionwomen
21
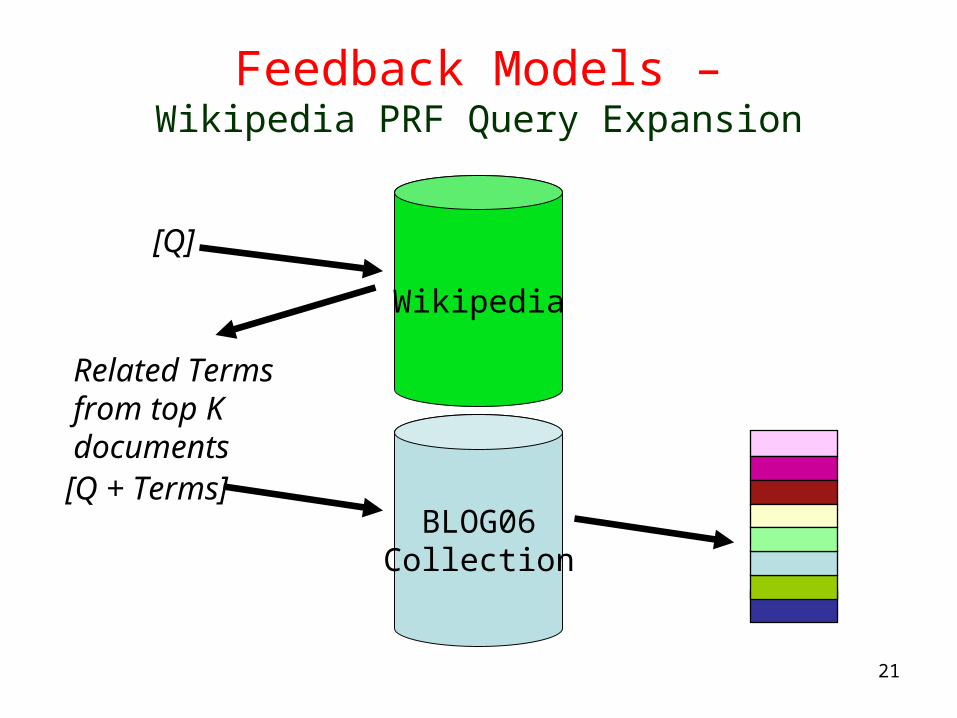
Feedback Models –Wikipedia PRF Query Expansion
[Q]
BLOG06Collection
[Q + Terms]
Wikipedia
Related Terms from top K documents

22
Feedback Models –Wikipedia PRF Query Expansion
• Example : give a query “Photography”
Idealdigital
photography
depth of field
photographic film
photojournalismcinematography
PRFphotography
nudeerotic
artgirlfreeteen
fashionwomen
Wikipedia PRFphotography
directorspecial
filmart
cameramusic
cinematographerphotographic
23
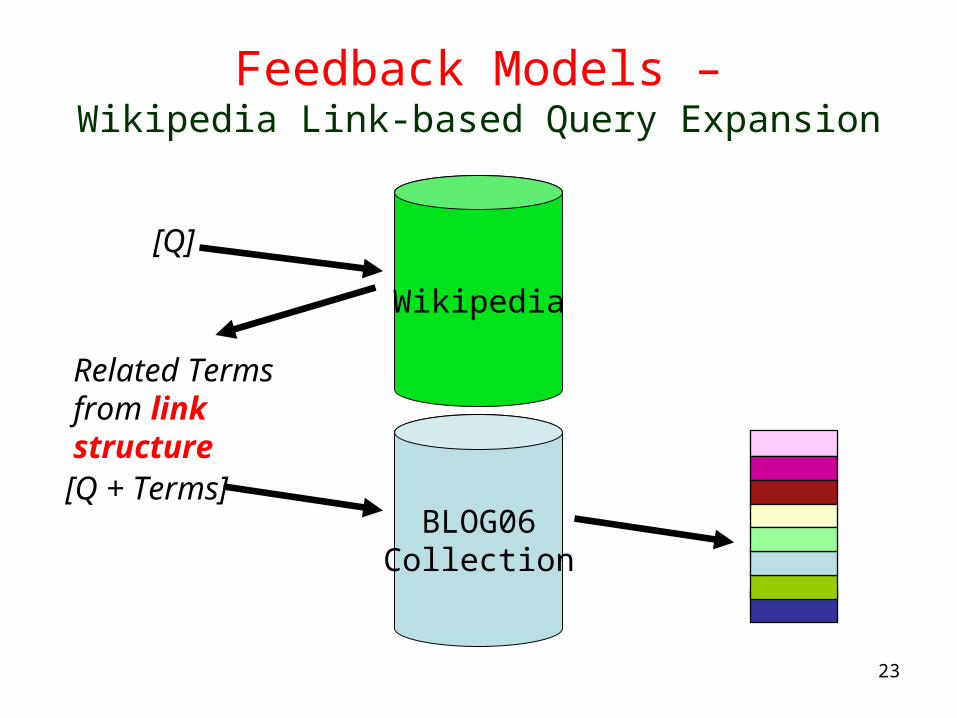
Feedback Models –Wikipedia Link-based Query Expansion
[Q]
BLOG06Collection
[Q + Terms]
Wikipedia
Related Terms from link structure

24
Feedback Models –Wikipedia Link-based Query Expansion
• Example : give a query “Photography”
Wikipedia Link-Basedphotographyphotographer
digital photographyphotographicdepth of field
feature photographyfilm
photographic filmphotojournalism
PRFphotography
nudeerotic
artgirlfreeteen
fashionwomen
Idealdigital photography
depth of field
photographic film
photojournalism
cinematography

25
Feedback Models –Wikipedia Link-based Query Expansion
• After we give a query to Wikipedia , two sets we can get:
The relevant and working sets, SR and SW, contain articles ranking within the top R or top W retrieved results.
• Then, each anchor phrase, ai, occuring in an article in SW and linking to an article in SR is scored according to
26
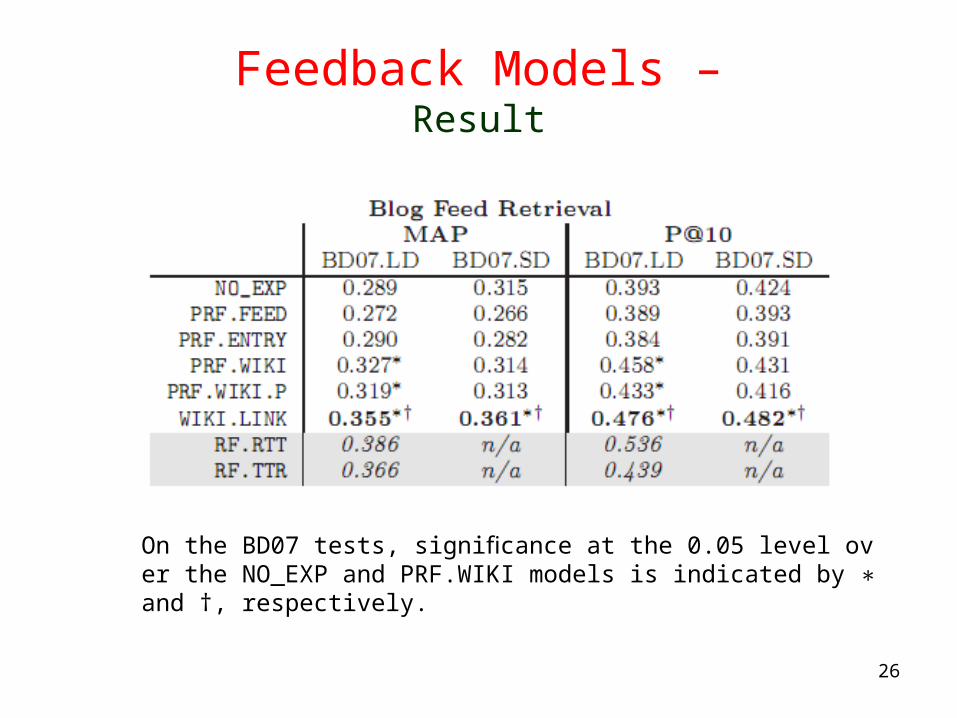
Feedback Models –Result
On the BD07 tests, significance at the 0.05 level over the NO_EXP and PRF.WIKI models is indicated by and †, respectively.∗
27
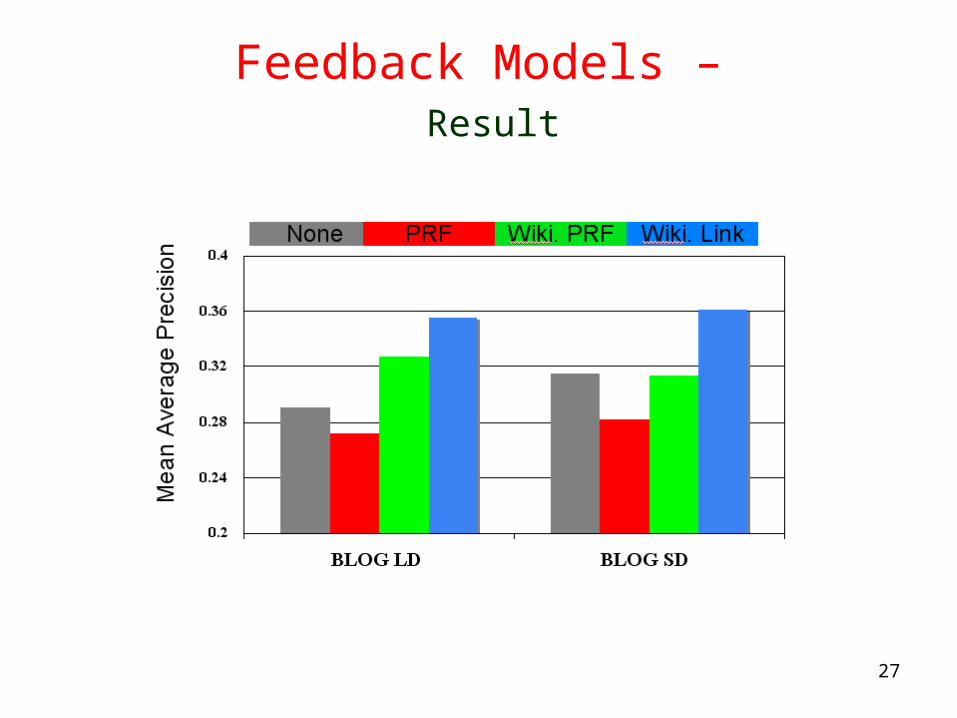
Feedback Models – Result

28
Conclusion
• Feed Search Challenges:– Feeds are topically diverse, noisy collections.– Ranked against ongoing & general information needs.
• Novel Retrieval Models:– Ranking collections, sensitive to topical relationship among
entries.
• Novel Feedback Models:– Discover multiple query facets & robust to collection noise.





























