Embed Size (px)
Citation preview

Role of Genetic PolymorphismsRole of Genetic Polymorphismsin Responses to Toxic Agentsin Responses to Toxic Agents
• Definitions• “Forward genetics” and toxicology• “Reverse genetics” and toxicology• Genetic markers• SNPs and their use in toxicology• Ethical, Legal and Social Issues (ELSI)
“Toxicology is concerned with the interaction between xenobiotics and biological molecules directly or indirectly coded in the DNA, and can be regarded as a branch of GENETICS.”
Michael F.W. Festing (2001)
Gregor Mendel (1822 – 1884)

TERMINOLOGYTERMINOLOGY
Gene: A sequence of DNA bases that encodes a proteinAllele: A sequence of DNA basesLocus: Physical location of an allele on a chromosomeLinkage: Proximity of two alleles on a chromosomeMarker: An allele of known position on a chromosomeDistance: Number of base-pairs between two allelescentiMorgan: Probabilistic distance of two allelesPhenotype: An outward, observable character (trait)Genotype: The internally coded, inheritable informationPenetrance: No. with phenotype / No. with allele
Modified from M.F. Ramoni, Harvard Medical School

The 80s Revolution and the Human Genome Project
Genetic Polymorphisms: naturally occurring DNA markers that identify regions of the genome and vary among individuals
The intuition that polymorphisms could be used as markers sparkled the revolution
On February 12, 2001 the Human GenomeProject announced the completion of a firstdraft of the human genome and declared:
“A SNP map promises to revolutionize both mapping diseases and tracing human history”
SNP are Single Nucleotide Polymorphisms – subtlevariations of the human genome across individuals
Modified from M.F. Ramoni, Harvard Medical School

DISTANCES ON A GENETIC MAPDISTANCES ON A GENETIC MAP
• Physical distances between alleles are base-pairs• But the recombination frequency is not constant• A useful measure of distance is based on the
probability of recombination: the Morgan• A distance of 1 centiMorgan (cM) between two alleles
means that they have 1% chance of being separated by recombination
• A genetic distance of 1 cM is roughly equal to a physical distance of 1 million base pairs (1Mb)
Modified from M.F. Ramoni, Harvard Medical School

Physical Maps: maps in base-pairsHuman physical map: 3000Mb (Mega-bases)
Genetic Maps: maps in centiMorganHuman Male Map Length: 2851cMHuman Female Map Length: 4296cM
Correspondence between maps:Male cM ~ 1.05 Mb; Female cM ~ 0.88Mb
MORE TERMINOLOGYMORE TERMINOLOGY
Modified from M.F. Ramoni, Harvard Medical School

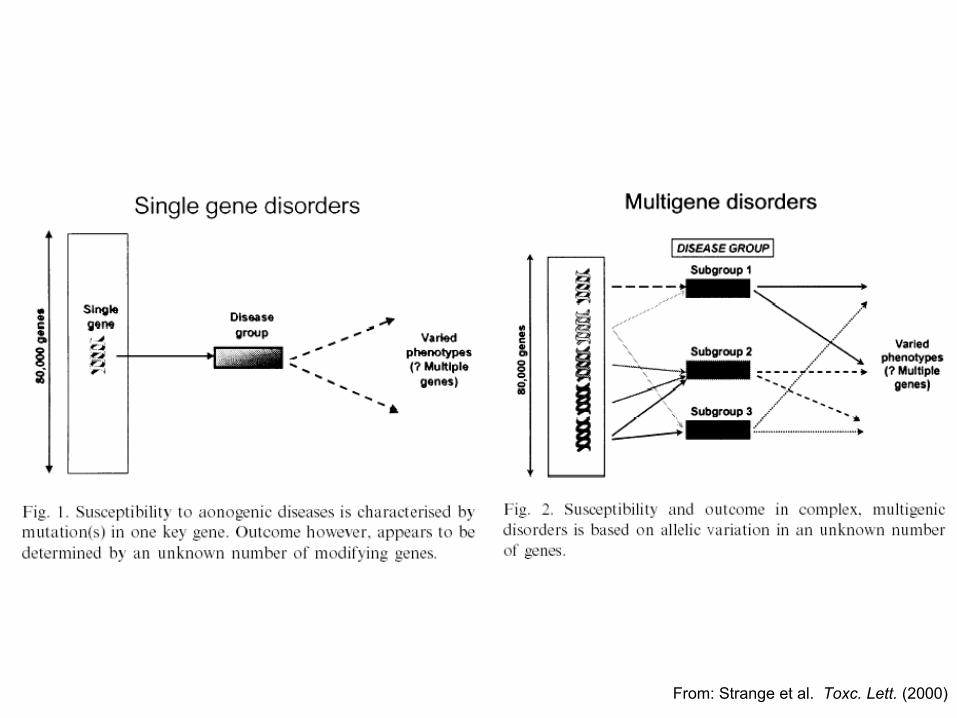
Single Gene (Mendelian) diseases:Autosomal dominant (Huntington)Autosomal recessive (Cystic Fibrosis)X-linked dominant (Rett)X-linked recessive (Lesch-Nyhan)
Today, over 400 single-gene diseases have been identified
Problem: traits don’t always follow single-gene modelsComplex Trait: phenotype/genotype interactionMultiple cause: multiple genes in several loci determine a phenotype in conjunction with non-genetic factors (accidents of development, social factors, environment, infections, other factors)Multiple effect: gene causes more than one phenotype
Simple and Complex TraitsSimple and Complex Traits
Modified from M.F. Ramoni, Harvard Medical School

Toxicology Toxicology ≈≈ GeneticsGeneticsThere is substantial polymorphism in genes that determine the
response to xenobiotics both in humans and animals
This has important implications for toxicology and pharmacology:
• adverse reactions to drugs cause thousands of deaths each year and many of those are associated with susceptible phenotypes
• are we protecting the most sensitive in human population when occupational/environmental limits of exposure are established?
• how to account for strain differences in susceptibility in animal studies (1000-fold differences have been reported for TCDD LD50 in rats)?
• genotyping of individuals from a sample of blood DNA is becomingincreasingly easy so it is possible to genotype people for loci that are thought to control susceptibility to certain drugs/xenobiotics
Adapted, in part, from M.F.W. Festing, Tox. Lett. 120:293-300 (2001)

…loci that are thought to control susceptibility to certain drugs/xenobiotics:
Before we can correctly interpret genotyping results we need to:• gain a much better understanding of the genetics of susceptibility
• know the mode of action of xenobiotics
Problem: relatively little research is done on the genetics of susceptibility and toxicologists in general seem to be unaware of the extent of genetic variation in responseamong the experimental animals that are being used
Problem: modes of action of an overwhelming majority of established toxic substances are still largely unknown (not even worth mentioning scores of compounds that are being newly developed)
Adapted, in part, from M.F.W. Festing, Tox. Lett. 120:293-300 (2001)
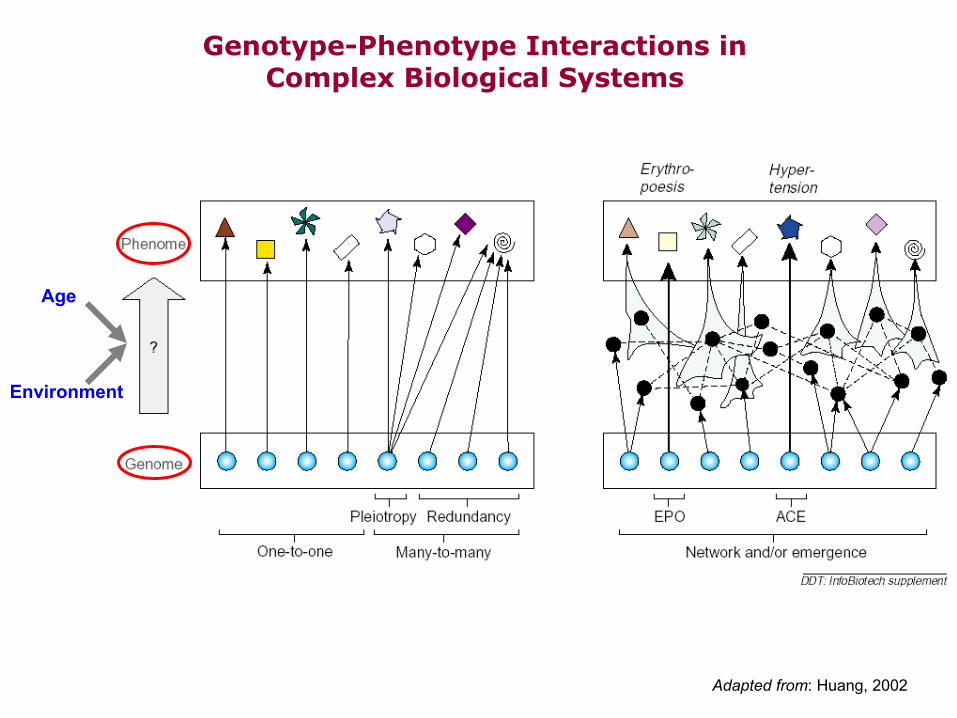
Adapted from: Huang, 2002
Genotype-Phenotype Interactions in Complex Biological Systems
Age
Environment
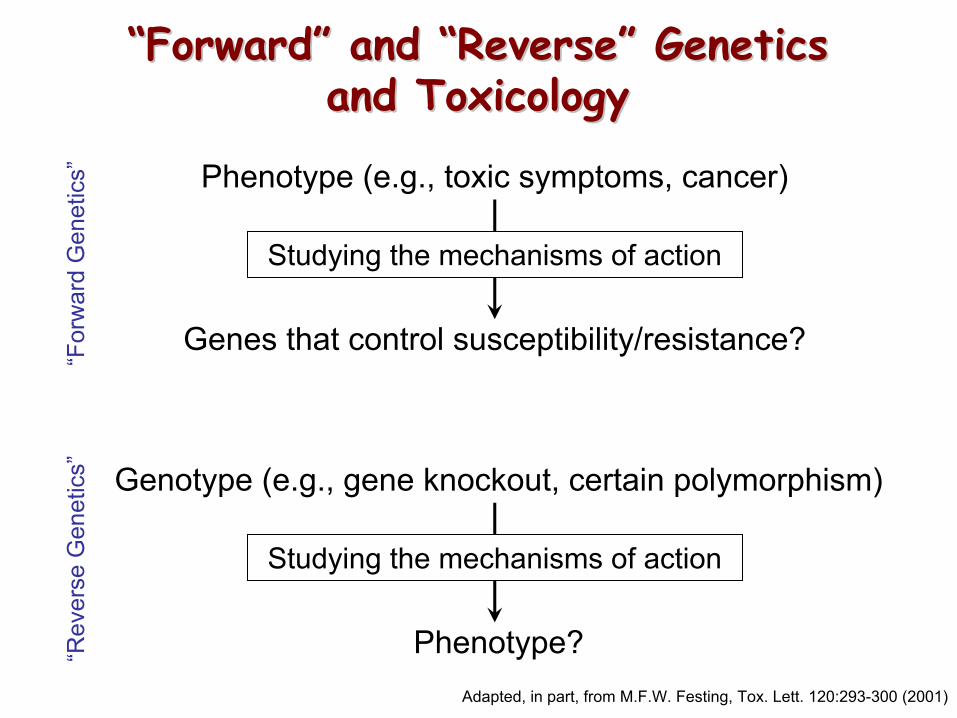
““ForwardForward”” and and ““ReverseReverse”” GeneticsGeneticsand Toxicologyand Toxicology
Phenotype (e.g., toxic symptoms, cancer)
Genes that control susceptibility/resistance?
Studying the mechanisms of action
“For
war
d G
enet
ics”
“Rev
erse
Gen
etic
s” Genotype (e.g., gene knockout, certain polymorphism)
Phenotype?
Studying the mechanisms of action
Adapted, in part, from M.F.W. Festing, Tox. Lett. 120:293-300 (2001)

““Forward GeneticsForward Genetics”” and Toxicologyand ToxicologyDifferent animal strains nearly always respond differently to the same agent/dose unless the toxic insult is so dramatic that all the animals die very quickly
Examples of strain differences (rats) in response to xenobiotics:3,2’-dimethyl-4-aminobiphenyl prostate tumors
48% F344, 41% ACI, 13% LEW, 7% CD, 0% Wistar
N-methyl-N-nitro-N-nitrosoguanidine(MNNG) stomach adenocarcinomas
67% WKY, 60% S-D, 53% LEW, 23% Wistar, 6% F344
There is no such thing as an “animal strain that is particularly susceptible/resistant to carcinogenesis” !
Adapted, in part, from M.F.W. Festing, Tox. Lett. 120:293-300 (2001)

Adapted, in part, from M.F.W. Festing, Tox. Lett. 120:293-300 (2001)
““Forward GeneticsForward Genetics”” and Toxicologyand Toxicology
Designing an IDEAL “forward genetics” animal study for investigating genetic variability in response to a toxic agent:
• Survey the known facts about susceptibility in different strains of rodents• Small numbers of animals (4-6 per strain) of several strains should be
used to characterize the response to the toxic agent “X”• At least 5 strains should be studied• Dose levels should be selected to elicit a suitable response• Endpoints should be quantitative (e.g., number of tumors)
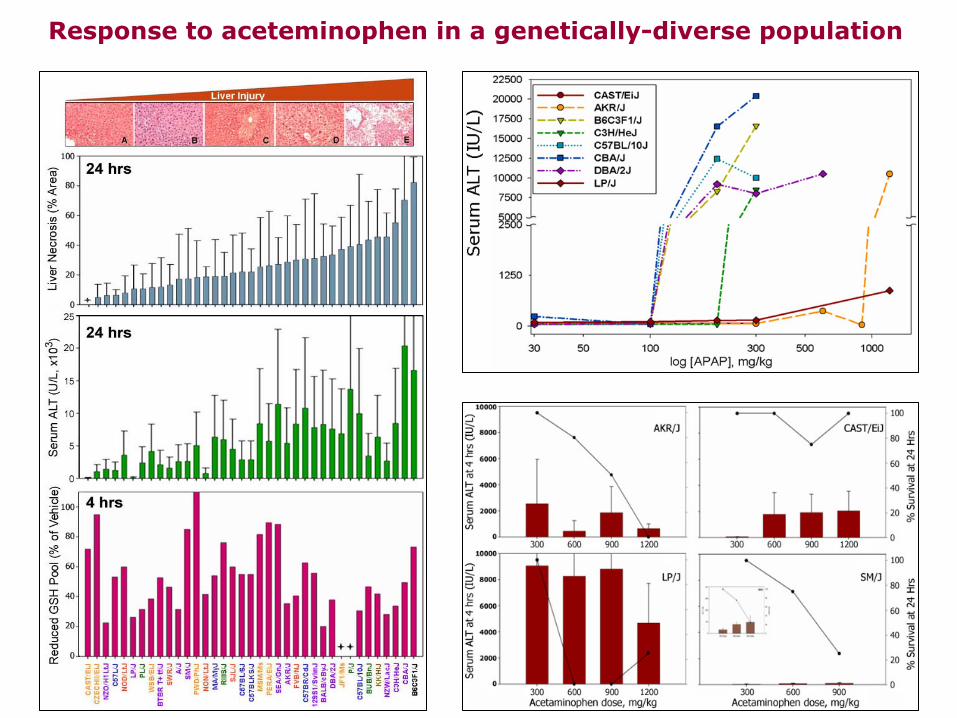
Response to aceteminophen in a genetically-diverse population

• Once a susceptible/resistant strains have been identified, loci can be mapped• In mice, Recombinant Inbread strains (susceptible x resistant) can be
generated• A set of RI strains can be tested for the susceptibility to agent “X”• Once the phenotype have been established, mice can be genotyped to
determine which loci segregated with susceptibility/resistance
Problems: large number of animals (100-300, or more)resolution of the genetic mapping is only about ± 20 cM (mouse genome is ~50K genes and 1900 cM 1cM ≈ 0.5 Mb) so the identified locus can contain ~500 genes
Adapted, in part, from M.F.W. Festing, Tox. Lett. 120:293-300 (2001)
From Threadgill et al. (2002)

““Reverse GeneticsReverse Genetics”” and Toxicologyand Toxicology
A knockout or over-expressor animal strain, or animals with a known polymorphism(s) in important genetic regions
Dose with a chemical(s)
Evaluate the phenotype
Looks MUCH easier than “Forward Genetics” experiment! Let’s do it!
Problems: if mutant to non-mutant comparison is being made, the geneticbackgrounds MUST be identical !if the strains have been crossed, care is needed to ensure that the observed differences are not due to a gene closely linked tothe gene of interestgenes do not act alone! Several alleles may be important, their effects can be additive or epistatic
Adapted, in part, from M.F.W. Festing, Tox. Lett. 120:293-300 (2001)

Genetic MarkersEven though we share most DNA, there are variations (polymorphisms)
Polymorphic: two or more forms of the same gene, or genetic marker exist with each form being too common in a population to be merely attributable to a new mutation
Classes of polymorphic genetic markers:Classes of polymorphic genetic markers:Single Nucleotide Polymorphisms (SNP): single base differences in population Microsatellites: short tandem repeat (e.g. GATA, 2 – 6 bp long)Minisatellites: simple sequence repeats (10 – 40 bp long)Variable Number of Tandem Repeats: the number of repeats may varyRestriction Fragment Length Polymorphisms: presence/absence of a siteDeletions, Duplications, Insertions: alterations on a chromosome levelComplex haplotypes: combinations of the above

Genetic Markers
Coding:Single Nucleotide Polymorphisms
Restriction Fragment Length Polymorphisms
Deletions, Duplications, Insertions
Non-coding:Microsatellites
Minisatellites
Variable Number of Tandem Repeats
Restriction Fragment Length Polymorphisms
Single Nucleotide Polymorphisms
Deletions, Duplications, Insertions

• Polymorphisms (allelic variations) are essential to:– Study inheritance patterns– Map phenotypes and anchor genes to the genetic map by co-
segregation analysis– Determine change in function: resistant/sensitive populations
• Genetically determined variability among humans is due to a difference in 0.1% of the genomic sequence!
• Polymorphisms can be silent, or be exhibited at levels of:– Morphology– Protein– DNA
Genetic Markers

Insertion Deletion
Chromosomal rearrangements: Deletions, Duplications, Insertions
Deletions: a certain part is lost, for example abc ac
Insertions: a part is added, for example ac abc
Duplications: can be tandem, for example abc abbc, or not, for example abc abcabc
Reversals: a part is turned around, head to tail abc cba
Transpositions: two parts change places, for example abcd acbd

• Original DNA fingerprinting technique• Relies on stretches of tandemly repeated sequences
(usually 15 - 100bp)• Alleles show high variability in numbers of repeats
Genotyping using minisatellites:• Digest genomic DNA• Run out on gel• Southern blot and probe with radiolabelled repeat DNA• Individuals appear with a set of bands unique to them,
although each band is shared with one of their parents
Minisatellites

Microsatellites
• Number of repeats varies greatly between individuals• Make up to 10-15% of the mammalian genome• Believed to have no function• Have high mutation rates• Used in forensic analysis• Can be amplified by PCR – fragments that are generated
have different length due to different number of repeats
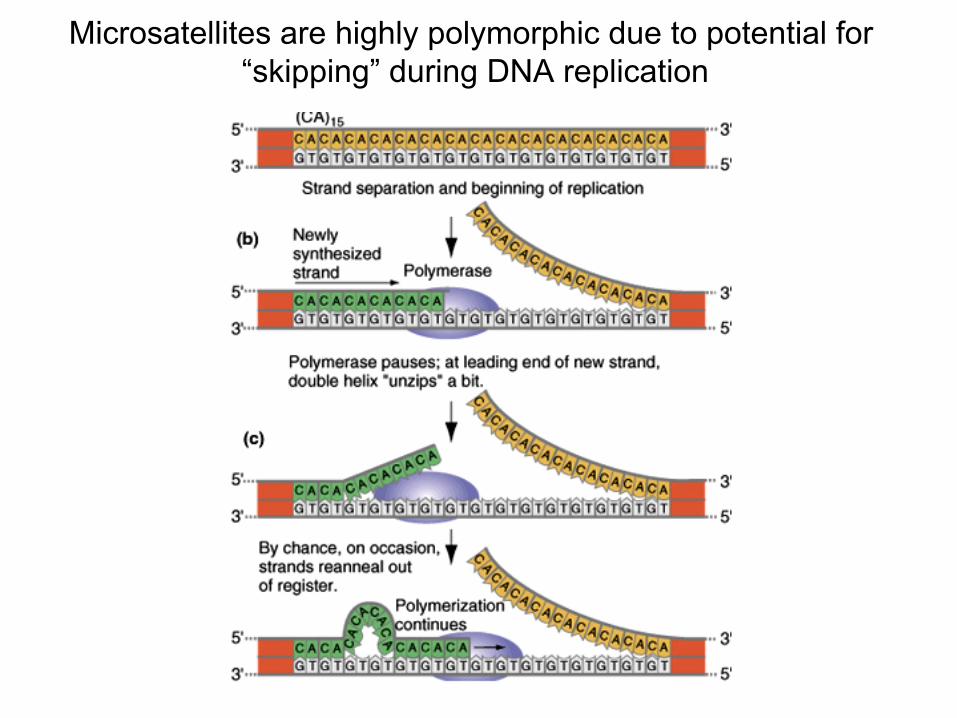
Microsatellites are highly polymorphic due to potential for “skipping” during DNA replication
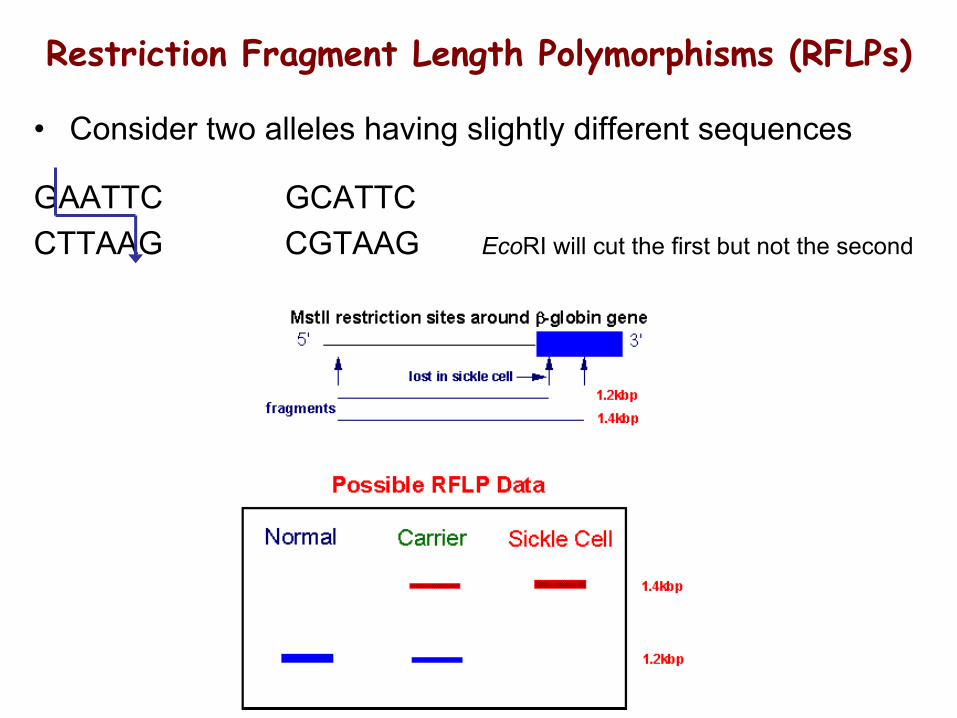
Restriction Fragment Length Polymorphisms (RFLPs)
• Consider two alleles having slightly different sequences
GAATTC GCATTCCTTAAG CGTAAG EcoRI will cut the first but not the second

Variations of a single base between individuals:
A most common form of genetic variation in humansThought to be a major cause of genetic diversities among different individuals in drug response, disease susceptibility...A SNP must occur in at least 1% of the populationOccur every 500-1000 bpAbout 50,000 – 100,000 SNPs in coding sequencesSNPs may occur in coding regions:
cSNP: SNP occurring in a coding regionrSNP: SNP occurring in a regulatory regionsSNP: Coding SNP with no change on amino acid
Single nucleotide polymorphisms (SNPs)
Modified from M.F. Ramoni, Harvard Medical School

• Two bases (one for chromosome) for each locus• Because of the A-T C-G complement, a SNP can have
only two variants: (AT) or (CG)• A SNP is a variable with two states:
Major allele: Allele (AT) or (CG) more frequentMinor allele: Allele (AT) or (CG) less frequent
• An individual can be, for each polymorphic locus:Homozygous on major alleleHeterozygous on major/minor alleleHomozygous on minor allele
Single nucleotide polymorphisms (SNPs)

The role of SNP analysis through all stages of drug development
Target Identification: disease association studies identify SNPs in candidate genes. The proteins encoded by such genes may represent novel drug targets
Target Validation: population analysis determines the level of variation within a candidate gene. The presence of several SNPs will generate a large number of potential variants and such candidates can be eliminated
Lead Identification: screens can be developed to identify lead compounds that interact with each variant of the drug target
Lead Validation: biological assays can be performed that incorporate different lead compounds and all variants of the target protein
Lead Optimization: knowledge of polymorphisms affecting the target can be used to develop drugs that work more efficiently over a broader group of patients or to identify drugs that work more efficiently in specific genotypes
Preclinical Testing: animal models can be developed incorporating all known variants of the target to provide more accurate predictions of drug efficacy in humans
Clinical Trials: trials can be carried out with groups of patients selected on the basis of genotype, to specifically test for adverse drug reactions at particular doses

SNP discovery and SNP genotyping
SNP discovery: detection of novel polymorphisms• DNA sequencing• In silico: comparing the sequences of genomic clones or ESTs
deposited in public and proprietary databases• Single strand conformational polymorphisms
SNP genotyping: identification of specific alleles in a known polymorphism1.Allele discrimination: allele-specific PCR, allele-specific single-base primer extension (mini-sequencing), allele-specific ligation, allele-specific enzymatic cleavage, etc.
2. Presence of allele(s) of interest in a given DNA sample:Fluorescence detection, fluorescence resonance energy transfer, fluorescence polarization, mass spectrometry, etc.
See details in: Twyman RM & Primrose SB, Techniques patents for SNP genotyping. Pharmacogenomics 4:67-79 (2003)

From Taylor et al. Trends Mol Med 7:507-512 (2001)
Well-studied genetic variants in human disease
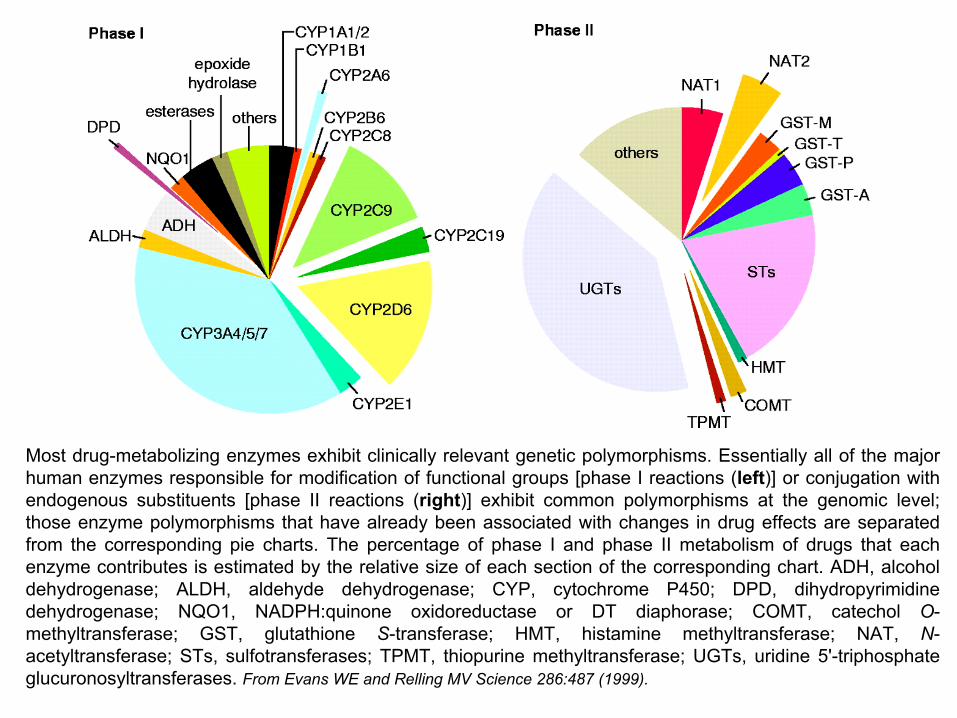
Most drug-metabolizing enzymes exhibit clinically relevant genetic polymorphisms. Essentially all of the major human enzymes responsible for modification of functional groups [phase I reactions (left)] or conjugation with endogenous substituents [phase II reactions (right)] exhibit common polymorphisms at the genomic level; those enzyme polymorphisms that have already been associated with changes in drug effects are separated from the corresponding pie charts. The percentage of phase I and phase II metabolism of drugs that each enzyme contributes is estimated by the relative size of each section of the corresponding chart. ADH, alcohol dehydrogenase; ALDH, aldehyde dehydrogenase; CYP, cytochrome P450; DPD, dihydropyrimidinedehydrogenase; NQO1, NADPH:quinone oxidoreductase or DT diaphorase; COMT, catechol O-methyltransferase; GST, glutathione S-transferase; HMT, histamine methyltransferase; NAT, N-acetyltransferase; STs, sulfotransferases; TPMT, thiopurine methyltransferase; UGTs, uridine 5'-triphosphate glucuronosyltransferases. From Evans WE and Relling MV Science 286:487 (1999).
Cytochrome P450 genotyping
From: Flockhart DA and Webb DJ. Lancet (1998)

The HapMap is a catalog of common genetic variants that occur in human beings. It describes what these variants are, where they occur in our DNA, and how they are distributed among people within populations and among populations in different parts of the world. The International HapMap Project is not using the information in the HapMap to establish connections between particular genetic variants and diseases. Rather, the Project is designed to provide information that other researchers can use to link genetic variants to the risk for specific illnesses, which will lead to new methods of preventing, diagnosing, and treating disease.
When DNA sequences on a part of chromosome 7 from two random individuals are compared, two single nucleotide polymorphisms (SNPs) occur in about 2,200 nucleotides.
The construction of the HapMap occurs in three steps. (a) Single nucleotide polymorphisms(SNPs) are identified in DNA samples from multiple indivduals. (b)Adjacent SNPs that are inherited together are compiled into "haplotypes." (c)"Tag" SNPs within haplotypes are identified that uniquely identify those haplotypes. By genotyping the three tag SNPs shown in this figure, researchers can identify which of the four haplotypes shown here are present in each individual.
http://www.hapmap.org/
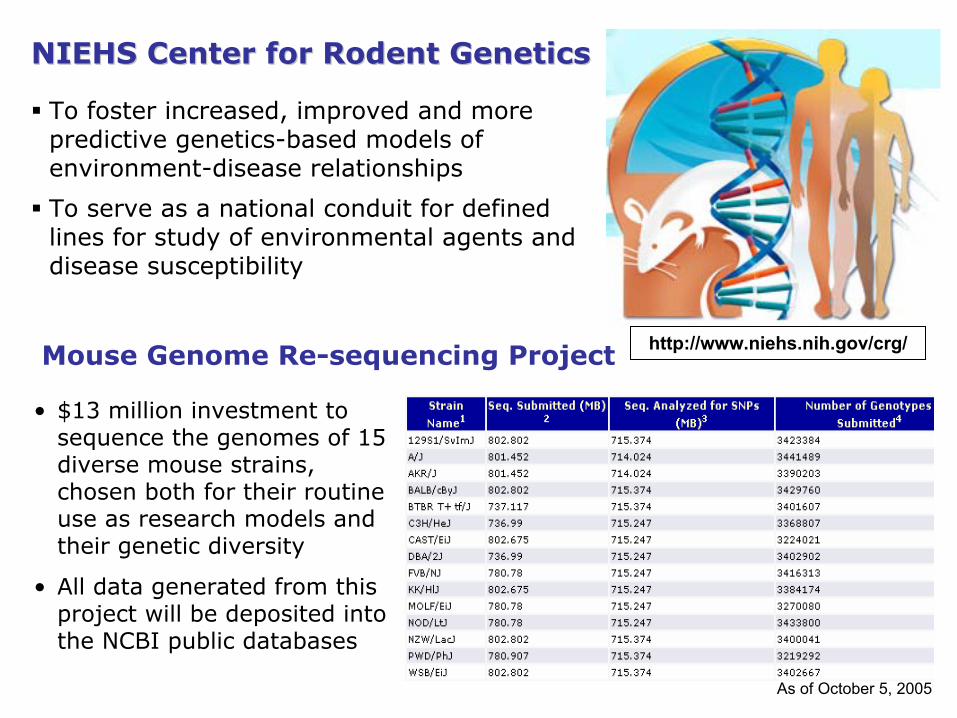
Mouse Genome Re-sequencing Project
NIEHS Center for Rodent GeneticsNIEHS Center for Rodent Genetics
To foster increased, improved and more predictive genetics-based models of environment-disease relationships
To serve as a national conduit for defined lines for study of environmental agents and disease susceptibility
• $13 million investment to sequence the genomes of 15 diverse mouse strains, chosen both for their routine use as research models and their genetic diversity
• All data generated from this project will be deposited into the NCBI public databases
As of October 5, 2005
http://www.niehs.nih.gov/crg/
http://www.ncbi.nlm.nih.gov/SNP/
From
: Hul
laet
al.
Tox
c. S
ci. (
1999
)
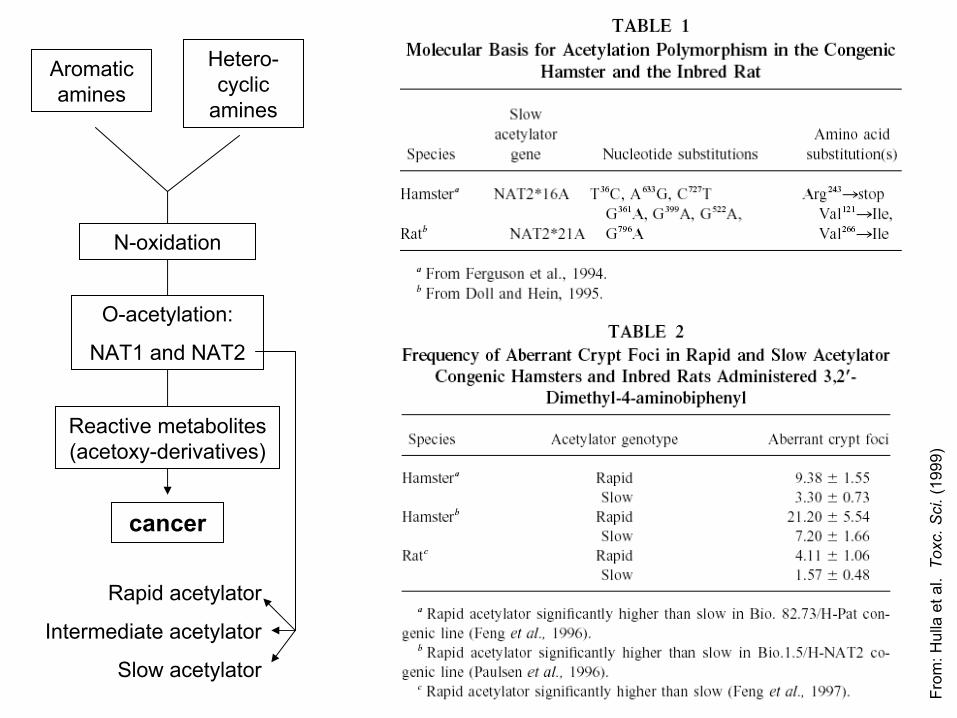
Aromatic amines
Hetero-cyclic
amines
cancer
N-oxidation
O-acetylation:
NAT1 and NAT2
Reactive metabolites (acetoxy-derivatives)
Rapid acetylator
Intermediate acetylator
Slow acetylator
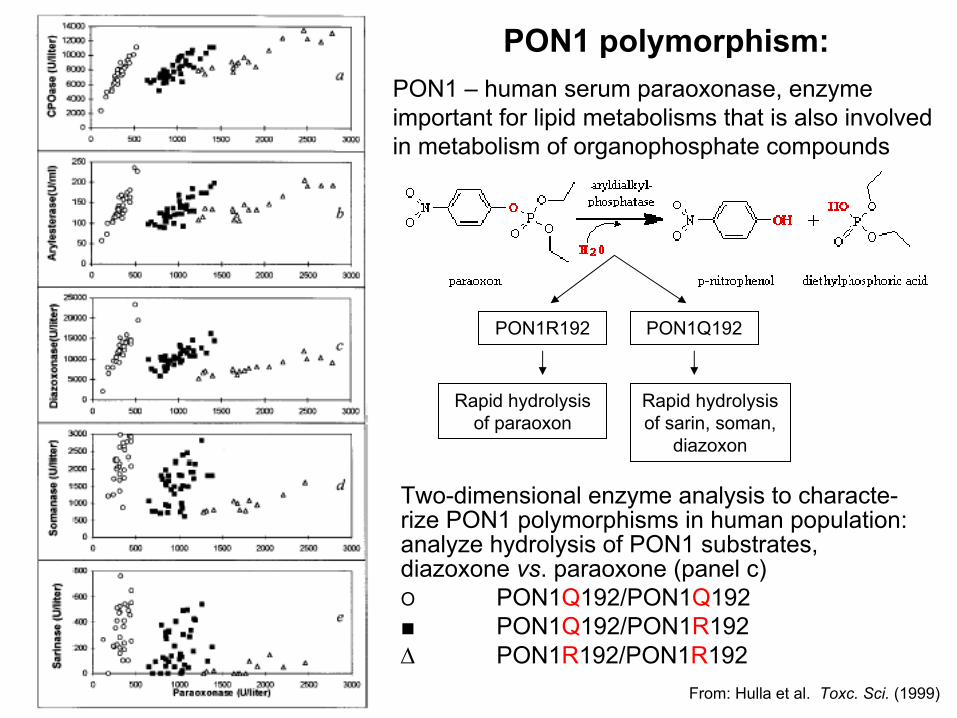
PON1 polymorphism:PON1 – human serum paraoxonase, enzyme important for lipid metabolisms that is also involved in metabolism of organophosphate compounds
From: Hulla et al. Toxc. Sci. (1999)
PON1R192 PON1Q192
Rapid hydrolysis of paraoxon
Rapid hydrolysis of sarin, soman,
diazoxon
Two-dimensional enzyme analysis to characte-rize PON1 polymorphisms in human population: analyze hydrolysis of PON1 substrates, diazoxone vs. paraoxone (panel c)O PON1Q192/PON1Q192■ PON1Q192/PON1R192∆ PON1R192/PON1R192
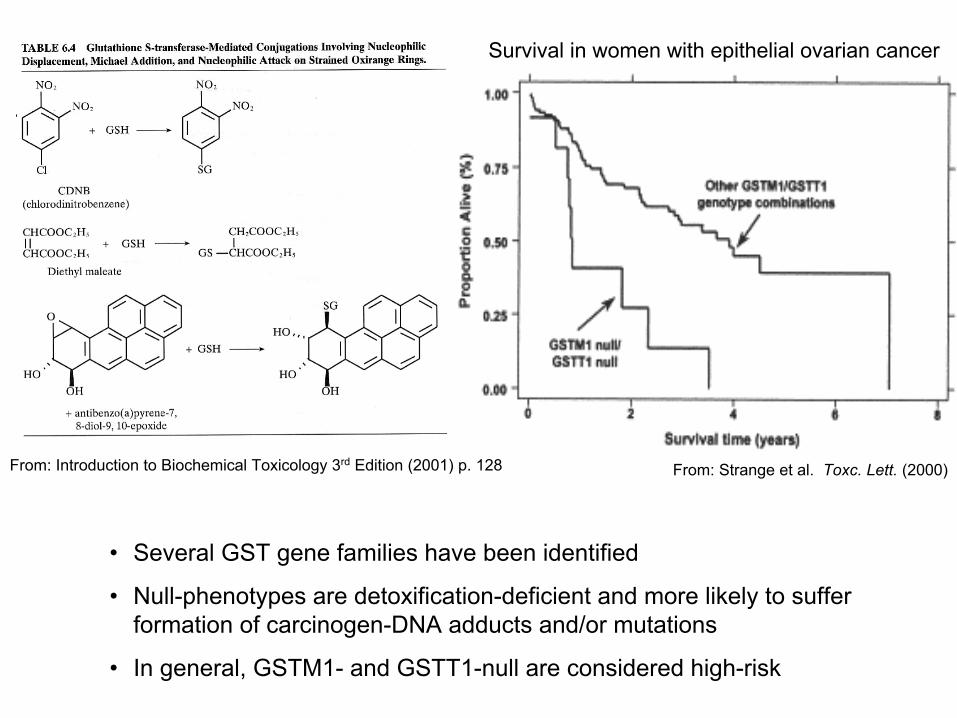
• Several GST gene families have been identified
• Null-phenotypes are detoxification-deficient and more likely to suffer formation of carcinogen-DNA adducts and/or mutations
• In general, GSTM1- and GSTT1-null are considered high-risk
Survival in women with epithelial ovarian cancer
From: Strange et al. Toxc. Lett. (2000)From: Introduction to Biochemical Toxicology 3rd Edition (2001) p. 128
From: Strange et al. Toxc. Lett. (2000)

Toxicogenetics: what’s next?Goal: When we find all polymorphisms in genes important
for metabolism/detoxification of xenobiotics, we can link them to particular drug or chemical toxicity and identify susceptible populations
Problem: Simple research questions generate erroneous results (e.g. CYP2D6 polymorphisms and lung cancer, CYP2E1 polymorphisms and alcoholic liver disease)
Problem: Biological complexity of mechanisms, ethnic variation, clinical heterogeneity, etc… both positive and negative results are true?
Linking complex trait diseases to genetic polymorphisms requires (Todd, 1999):
• large sample sizes and small p-values• Initial study + several replications• Genetic associations should make biological sense• Physiologically meaningful data should support a functional role of the polymorphism in question

Ethical, Legal and Social Issues in toxicogenetics are as complex as the studies of polymorphisms themselves
http://genomics.unc.edu/articles/elsi_article.htm