Embed Size (px)
Citation preview

S. Dasu, CHEP04, Interlacken, Switzerland 1
Use of Condor and GLOW Use of Condor and GLOW for CMS Simulation Productionfor CMS Simulation Production
Use of Condor and GLOW Use of Condor and GLOW for CMS Simulation Productionfor CMS Simulation Production
What are Condor & GLOW?• What is special about Condor & GLOW environment?
What is Jug?• Why is Jug needed?
What did we achieve for CMS?• What did it take to get there?
Summary• What is relevant for you?
D. Bradley, S. Dasu, M. Livny, V. Puttabuddhi, S. Rader, W. H. Smith
University of Wisconsin - Madison

S. Dasu, CHEP04, Interlacken, Switzerland 2
CondorCondorCondorCondor
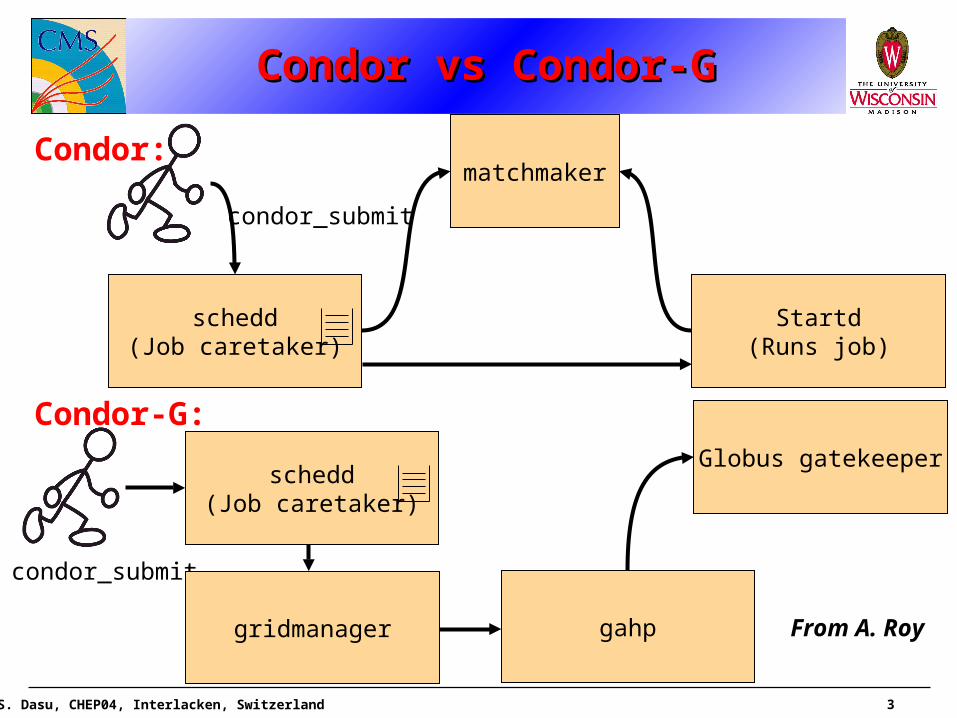
Most of you know what Condor is from Condor-G• This talk is about using Condor without Grid tools
• It is more than a simple batch queuing system
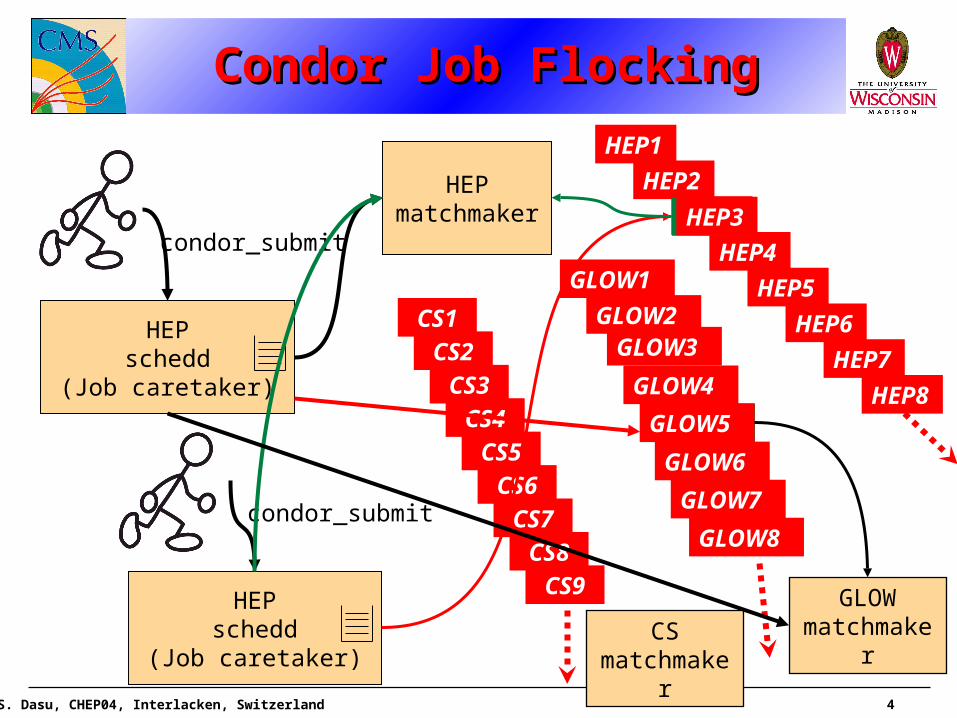
Condor in its full glory on UW campus Grid• Job scheduling• Job-Resource match-making• Job chaining (Dagman)• Job tracking to completion• Job flocking from one Condor pool to another
• Cannot assume availability of the same resources in all pools• Resource allocation priorities
• Foreign pools may give you idle resources but will want to preempt whenever they have work to do
• Condor makes another match for your job• You will be more efficient if you rerun from where you left of• Can be automatically achieved with check-pointing image or work status
• Resource usage monitoring
S. Dasu, CHEP04, Interlacken, Switzerland 3
Condor vs Condor-GCondor vs Condor-GCondor vs Condor-GCondor vs Condor-G
Condor:
Condor-G:
schedd(Job caretaker)
condor_submit
matchmaker
Startd(Runs job)
schedd(Job caretaker)
condor_submit
gridmanager gahp
Globus gatekeeper
From A. Roy
S. Dasu, CHEP04, Interlacken, Switzerland 4
Condor Job FlockingCondor Job FlockingCondor Job FlockingCondor Job Flocking
HEPschedd
(Job caretaker)
condor_submit
HEPmatchmaker
HEP1 HEP
2 HEP3 HEP
4 HEP5 HEP
6 HEP7 HEP
8
GLOW1 GLOW
2GLOW3GLOW4GLOW5GLOW6GLOW7GLOW
8
CS1CS2CS3CS4CS5CS6CS7CS8CS9
GLOW5
HEPschedd
(Job caretaker)
condor_submit
HEP3HEP3
GLOWmatchmakerCS
matchmaker

S. Dasu, CHEP04, Interlacken, Switzerland 5
Condor UniversesCondor UniversesCondor UniversesCondor Universes
Jobs can live in one of several Universes• Standard Universe
• Specially compiled jobs that can checkpoint images• Restricted system library access in Standard Universe
• Jobs see “submit machine” resources• IO is redirected
• Jobs can be preempted on a CPU when it receives higher priority match
• Another free CPU picks up the task using the checkpoint image
• Vanilla Universe• Job is scheduled and matched• No checkpointing of images• Users must checkpoint their work to be efficient
• Condor issues signals that can be trapped to save work status• When job is resumed elsewhere you continue from where left of• Suitable for HEP applications

S. Dasu, CHEP04, Interlacken, Switzerland 6
Condor Usage at UWCondor Usage at UWCondor Usage at UWCondor Usage at UW
Several collaborating Condor pools• Jobs from one pool of Condor machines can flock to another
• Important for sharing resources with other compute intensive researchers on campus
• A job submitted in hep.wisc.edu domain can run in all collaborating pools in campus
• Opportunistic use of idle resources• Everyone gains because all pools stay busy at all times• Buy resources for steady state operation rather than for peak needs

S. Dasu, CHEP04, Interlacken, Switzerland 7
Grid Laboratory Of WisconsinGrid Laboratory Of WisconsinGrid Laboratory Of WisconsinGrid Laboratory Of Wisconsin
GLOW - Inter-disciplinary collaboration• Astro-physics, Biochemistry,
Chemical Engineering, Computer Science, High-energy Physics & Medical Physics
• Resources distributed at 6 GLOW sites• Approximately 1/3 built
Operated collaboratively• Common hardware and software platform
• Intel Xeons running RH9• It was easy to agree on common platform!• Some customization for host sites
• For instance, higher storage for HEP, MPI for medical physics group, larger memory for biochemistry site

S. Dasu, CHEP04, Interlacken, Switzerland 8
GLOW DeploymentGLOW DeploymentGLOW DeploymentGLOW Deployment
First phase deployed in Spring 2004• Second phase in October 2004
• When done, 800 Xeon CPUs + 100 TB diskGLOW CPU @ HEP

S. Dasu, CHEP04, Interlacken, Switzerland 9
Resource SharingResource SharingResource SharingResource Sharing
Six GLOW sites
• Equal priority 16.67% average
• One can get more work done
• Chemical Engineering took 33%
Others scavenge idle resources
• Yet, they got 39%
Message is that efficient users can realize much more than they put in on average
Others39%
Chem Eng33%
Biochem14%
Comp Sci2%
HEP/CMS12%
GLOW Usage in September 2004

S. Dasu, CHEP04, Interlacken, Switzerland 10
CMS Jobs and CondorCMS Jobs and CondorCMS Jobs and CondorCMS Jobs and Condor
CMSIM - Simulation using Geant3• Can run in Standard Universe
• Adapting to Condor was simple
OSCAR - Simulation using Geant4• Uses multi-threaded & dynamically loaded libraries
• Cannot checkpoint images
• Runs only in Vanilla Universe
ORCA - Digitization (and DST production)• Vanilla Universe
• IO intensive - especially reading
• Efficient shared file system needed for pileup

S. Dasu, CHEP04, Interlacken, Switzerland 11
CMS Work BreakdownCMS Work BreakdownCMS Work BreakdownCMS Work BreakdownCMS work is done in multiple sequential steps
• Dataset: A collection of events of a particular physics event type• A dataset is too large for a single job• Requires multiple programs to process the data
• Assignment: A chunk of the work for a dataset• Split into several stages, cmkin, cmsim + hit formatting or OSCAR,
and ORCA• Split into several chunks of events
• Job: A particular processing step for a particular chunk of events• Several jobs make up an assignment
CMS Production manager hands out assignments• A database keeps track of which regional center got what
assignment and tracks progress• Publishes data for physicist use only upon completion of
processing and verification of returned job output
S. Dasu, CHEP04, Interlacken, Switzerland 12
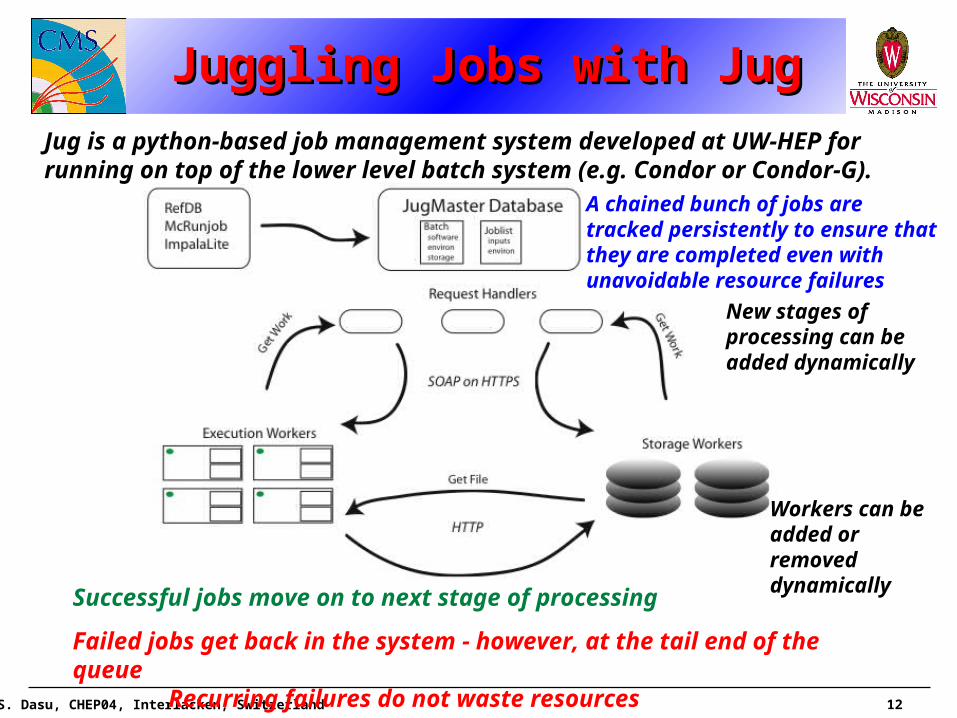
Juggling Jobs with JugJuggling Jobs with JugJuggling Jobs with JugJuggling Jobs with Jug
Jug is a python-based job management system developed at UW-HEP for running on top of the lower level batch system (e.g. Condor or Condor-G).
Successful jobs move on to next stage of processing
Failed jobs get back in the system - however, at the tail end of the queue
Recurring failures do not waste resources
A chained bunch of jobs are tracked persistently to ensure that they are completed even with unavoidable resource failures
Workers can be added or removed dynamically
New stages of processing can be added dynamically

S. Dasu, CHEP04, Interlacken, Switzerland 13
Filling the Jug DatabaseFilling the Jug DatabaseFilling the Jug DatabaseFilling the Jug Database
MCRunjob “configurator”Inserts a batch of job entries into Jug from a general
workflow description.May be driven by RefDB, the CERN assignment database.
Or native Jug syntax for stand-alone use
Batch #event generation name = “edde.cmkin” seed_low = 120000 seed_high = seed_low + 400 software = “/cms/sw/cmkin_edde” environment = EVENTS_PER_JOB = 250
Batch #event simulation name = “edde.oscar” parent name = “edde.cmkin” input_files = “*.ntpl” software = “/cms/sw/oscar_3_3_2” “/cms/pool” environment = DATASET = “edde” OWNER = “edde_oscar332”
S. Dasu, CHEP04, Interlacken, Switzerland 14
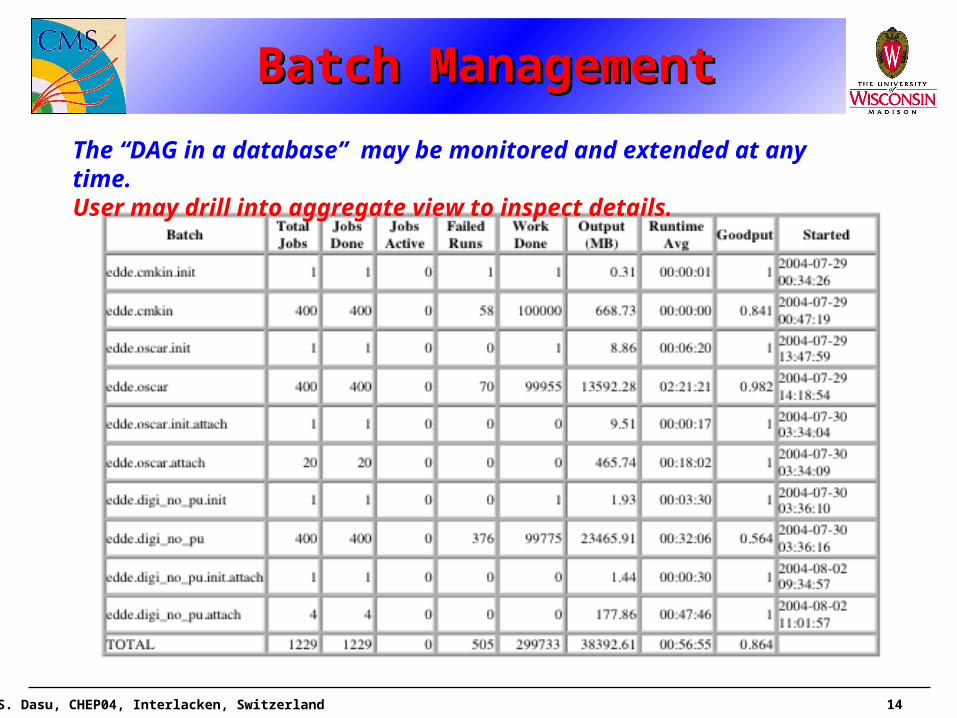
Batch ManagementBatch ManagementBatch ManagementBatch Management
The “DAG in a database” may be monitored and extended at any time.User may drill into aggregate view to inspect details.

S. Dasu, CHEP04, Interlacken, Switzerland 15
Drill-Down Run AnalysisDrill-Down Run AnalysisDrill-Down Run AnalysisDrill-Down Run Analysis

S. Dasu, CHEP04, Interlacken, Switzerland 16
Juggling with N>1Juggling with N>1Juggling with N>1Juggling with N>1
High level of redundancy• Any number of SOAP RPC handlers• Multiple points of submission to batch system
• Essential for scaling up, especially in the Standard Universe (remote IO burden)
• Any number of storage handlers
Even instances of the same job may be automatically mirrored
• Useful at tail end of a rush job when better machines become idle.
• When a job is likely to be stuck but a hard timeout is not appropriate.
• When paranoid of preemption.

S. Dasu, CHEP04, Interlacken, Switzerland 17
CMSIM Production on CondorCMSIM Production on CondorCMSIM Production on CondorCMSIM Production on Condor
CMSIM - Simulation using Geant3• Largest single contributor during PCP04 of any single CMS
institution• We could exploit idle cycles on UW campus Condor pools
efficiently• Standard Universe helps• Many submit machines cooperated by feeding on jobs from
the same database, balancing I/O load.
8.8M of 40M produced world-wide during this period.Waiting
for data transfer
S. Dasu, CHEP04, Interlacken, Switzerland 18
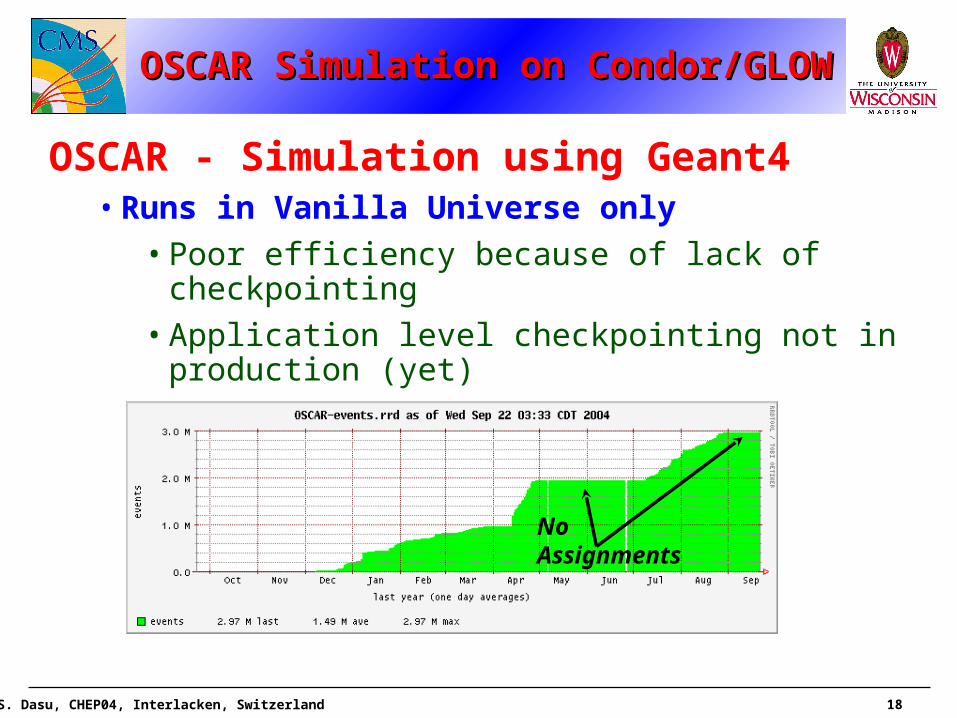
OSCAR Simulation on Condor/GLOWOSCAR Simulation on Condor/GLOWOSCAR Simulation on Condor/GLOWOSCAR Simulation on Condor/GLOW
OSCAR - Simulation using Geant4• Runs in Vanilla Universe only
• Poor efficiency because of lack of checkpointing
• Application level checkpointing not in production (yet)
No Assignments

S. Dasu, CHEP04, Interlacken, Switzerland 19
CMS Reconstruction on Condor/GLOWCMS Reconstruction on Condor/GLOWCMS Reconstruction on Condor/GLOWCMS Reconstruction on Condor/GLOW
ORCA - Digitization • Vanilla Universe only
• IO Intensive
• Used Fermilab/DESY dCache system
• Automatic replication of frequently accessed “pileup” events helps scalability.

S. Dasu, CHEP04, Interlacken, Switzerland 20
CMS Work Done on CMS Work Done on Condor/GLOWCondor/GLOW
CMS Work Done on CMS Work Done on Condor/GLOWCondor/GLOW
Shared resources at UW Condor/GLOW turned out to be a top source for CMS
• Largest single institution excluding DC04 DST production at CERN
UK7%
Others17%
CERN29%
Italy16%
US Grid315%
Wisconsin16%
Number of Jobs Completed in 2003-2004
http://cmsdoc.cern.ch/cms/production/www/cgi/SQL/RCFarmStatus.php on 22 Sep 04
* Includes DC04 DST production
* Includes all INFN sites
* Includes Wisconsin Grid3 site

S. Dasu, CHEP04, Interlacken, Switzerland 21
Data Movement to/from FNAL & CERNData Movement to/from FNAL & CERNData Movement to/from FNAL & CERNData Movement to/from FNAL & CERN
Stork was used to move large datasets between Wisconsin and Fermilab.
• Works in combination with DAGMan to provide reliable data transfer.
• Supports gridftp and other protocols.
• All data in Wisconsin was stored on a cluster of RAID arrays managed by dCache.
• Full handshake before files are removed at UW
Datasets moved after an assignment was complete
• Helps keep related files in the same tape cartridge
• Large cache (few TB) was needed
The system was reliable after initial learning

S. Dasu, CHEP04, Interlacken, Switzerland 22
SummarySummarySummarySummary
UW Campus Grid (Condor/GLOW)• Successful concept
• Embraced by widely differing science groups• Opportunistic use of idle resources
• Everyone gains by keeping the iron hot at all times• Gains due to efficient use of systems• Deploy for steady-state use• Realize much higher peak performance• Robust, checkpointable software is the key
CMS Usage of Condor/GLOW• Successful use of shared resources for CMS work• Top producer of CMS data in 2003-2004
Message• Get together with colleagues on campus and build shared grids• Join world-wide shared grids with your campus grid
• Open Science Grid (Ruth’s talk) and EGEE are the future





























