Embed Size (px)
Citation preview

Big Data׳s Impact on Privacy, Security and Consumer Welfare
By: Nir Kshetri
Kshetri, N. (2014). Big data's impact on privacy, security and consumer welfare. Telecommunications Policy, 38(11), 1134-1145. doi: 10.1016/j.telpol.2014.10.002
Made available courtesy of Elsevier: http://dx.doi.org/10.1016/j.telpol.2014.10.002 ***© Elsevier. Reprinted with permission. No further reproduction is authorized without written permission from Elsevier. This version of the document is not the version of record. Figures and/or pictures may be missing from this format of the document. ***
This is the author’s version of a work that was accepted for publication in Telecommunications Policy. Changes resulting from the publishing process, such as peer review, editing, corrections, structural formatting, and other quality control mechanisms may not be reflected in this document. Changes may have been made to this work since it was submitted for publication. A definitive version was subsequently published in Telecommunications Policy, Volume 38, Issue 11, (2014) DOI: 10.1016/j.telpol.2014.10.002
Abstract:
The purpose of this paper is to highlight the costs, benefits, and externalities associated with organizations׳ use of big data. Specifically, it investigates how various inherent characteristics of big data are related to privacy, security and consumer welfare. The relation between characteristics of big data and privacy, security and consumer welfare issues are examined from the standpoints of data collection, storing, sharing and accessibility. The paper also discusses how privacy, security and welfare effects of big data are likely to vary across consumers of different levels of sophistication, vulnerability and technological savviness.
Big data | Externalities | Privacy | Security | Personally identifiable information | Keywords:Consumer welfare | Unstructured data
Article:
1. Introduction
Advancements in telecommunications and computer technologies and the associated reductions in costs have led to an exponential growth and availability of data, both in structured and unstructured forms. The related phenomenon known as big data involves various costs, benefits and externalities. Before proceeding, a clarifying definition is offered. Following the research company Gartner, big data is defined as “high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making” (gartner.com, 2013). Owing to the increasing utilization

of big data, it is understandable that there has been a high degree of interest on this topic. It is argued that 2011 marks the year when big data gained widespread interest (Burrows & Savage, 2014).
Big data is becoming a key source of firms׳ competitive advantages and national competitiveness. For instance, McKinsey Global Institute (2013) estimated that annual overall economic gains from big data would be US$610 billion in annual productivity and cost savings. At the same time, big data׳s characteristics are tightly linked to privacy, security and effects on consumer welfare, which have attracted the attention of scholars, businesses and policy makers. For instance, a huge amount of data means that security breaches and privacy violations are likely to lead to more severe consequences and losses via reputational damage, legal liability, ethical harms and other issues, which is also referred as an amplified technical impact (ISACA, 2014). Second, a large proportion of big data entails high-velocity (fast) data such as those related to click-stream and GPS data from mobile devices, which can be used to make a short-term prediction with high level of accuracies (Taylor, Meyer, & Schroeder, 2014). Businesses׳ initiatives to collect such data have met stiff resistance from consumers (Arthur, 2008 and USA Today, 2012). Consumers have expressed growing concern over organizations׳ data collection methods, especially the use of tracking technologies, such as cookies and GPS trackers (Table 1). Yet a number of companies are engaged in questionable data collection and sharing practices. In 2012, a security blogger revealed that Nissan, without warning the owners, reported location, speed and direction of its Leaf brand cars to websites that other users could access through a built-in RSS reader. Likewise, there are reports that iPhones and Android phones have been secretly sending information about users׳ locations to Apple and Google (Cohen, 2013).
Table 1. Principal findings of surveys conducted with businesses and consumers regarding their perceptions of and responses to big data.
Survey conducted by Conducted/released in Sample Major findings
Surveys conducted among businesses
Software specialist, Informatica
2012 600 IT and business professionals
Data security and privacy raised concerns for 38% (Hernandez, 2012)
BARC Institute Second half of 2012 274 business/IT decision-makers (Germany, Austria, Switzerland, France, the U.K.)
25% respondents expected to encounter data privacy issues (BARC Institute, 2013).
Information Systems Audit and Control
2013 IT Risk/Reward Barometer
2013 Australian and New Zealand
5% said that their enterprises were “very prepared” to ensure effective governance and

Association (ISACA) IT professionals privacy. 45% reported “adequately prepared” and 25% “not prepared at all” (CSO Online, 2013).
Voltage Security April 2013 at InfoSecurity Europe
Over 300 senior-level IT and security professionals
76% expressed concerns about inability to secure data in big data initiatives.
56% reported that they could not start or finish cloud/big data projects due to security concerns (darkreading.com, 2013).
SAP 2014 (at GSMA Mobile World Congress 2014 in Barcelona, Spain)
300 mobile operators, fixed telecomm providers, over-the-top players and other executives
38% said that security and privacy prevented their organizations from fully unlocking big data׳s potential (SAP, 2014).
Ovum (sponsored by data security firm Vormetric)
Early 2014 500 IT decision-makers at mid- and large-sized organizations (the U.K., France, Germany)
53% were concerned about the security issues in the big data environment (Savvas, 2014).
Surveys conducted among consumers
Cable Forum (cableforum.co.uk)
2008 Forum visitors 95% of the respondents said that they would opt out of monitoring (even anonymous) of online activities by a third party (Arthur, 2008).
Pew Internet & American Life Project.
2012 (March 15–April 3).
National survey among 2254 U.S. adults
30% of smartphone owners said that they turned off location tracking features due to concerns that others would access this information (USA Today, 2012).
BCG 2013 Global Consumer 10,000 consumers Privacy of personal data was a “top issue” for 75%. Only 7%
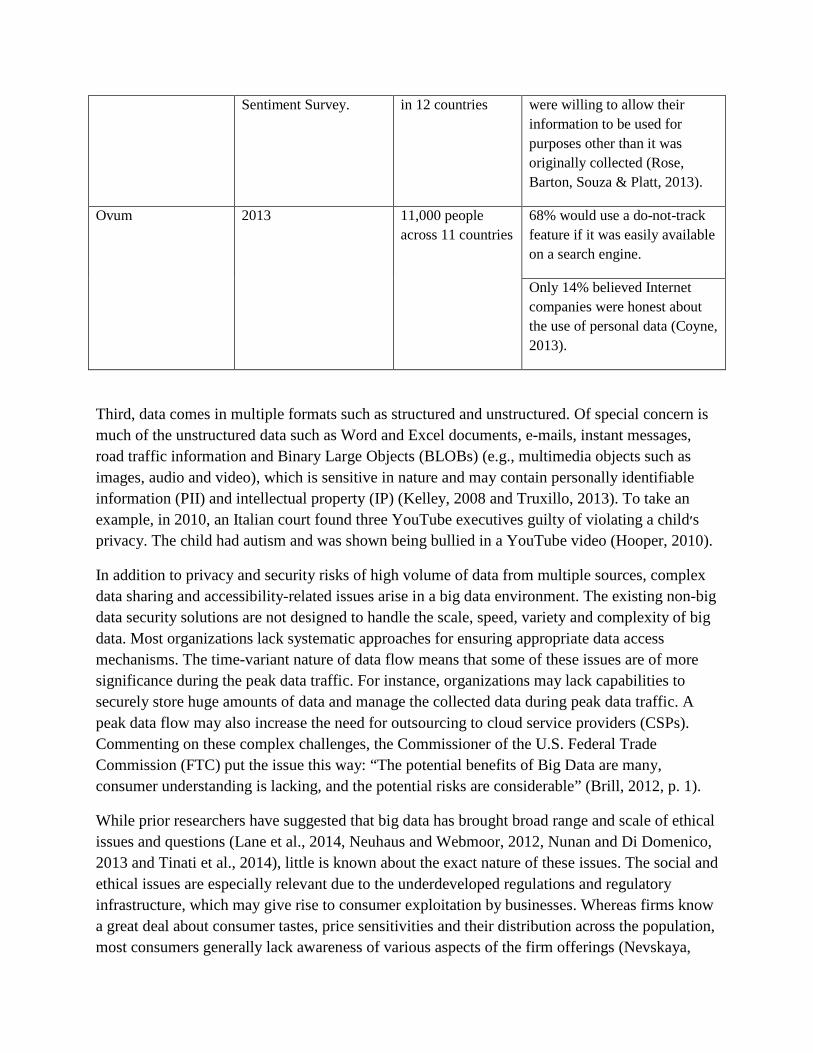
Sentiment Survey. in 12 countries were willing to allow their information to be used for purposes other than it was originally collected (Rose, Barton, Souza & Platt, 2013).
Ovum 2013 11,000 people across 11 countries
68% would use a do-not-track feature if it was easily available on a search engine.
Only 14% believed Internet companies were honest about the use of personal data (Coyne, 2013).
Third, data comes in multiple formats such as structured and unstructured. Of special concern is much of the unstructured data such as Word and Excel documents, e-mails, instant messages, road traffic information and Binary Large Objects (BLOBs) (e.g., multimedia objects such as images, audio and video), which is sensitive in nature and may contain personally identifiable information (PII) and intellectual property (IP) (Kelley, 2008 and Truxillo, 2013). To take an example, in 2010, an Italian court found three YouTube executives guilty of violating a child׳s privacy. The child had autism and was shown being bullied in a YouTube video (Hooper, 2010).
In addition to privacy and security risks of high volume of data from multiple sources, complex data sharing and accessibility-related issues arise in a big data environment. The existing non-big data security solutions are not designed to handle the scale, speed, variety and complexity of big data. Most organizations lack systematic approaches for ensuring appropriate data access mechanisms. The time-variant nature of data flow means that some of these issues are of more significance during the peak data traffic. For instance, organizations may lack capabilities to securely store huge amounts of data and manage the collected data during peak data traffic. A peak data flow may also increase the need for outsourcing to cloud service providers (CSPs). Commenting on these complex challenges, the Commissioner of the U.S. Federal Trade Commission (FTC) put the issue this way: “The potential benefits of Big Data are many, consumer understanding is lacking, and the potential risks are considerable” (Brill, 2012, p. 1).
While prior researchers have suggested that big data has brought broad range and scale of ethical issues and questions (Lane et al., 2014, Neuhaus and Webmoor, 2012, Nunan and Di Domenico, 2013 and Tinati et al., 2014), little is known about the exact nature of these issues. The social and ethical issues are especially relevant due to the underdeveloped regulations and regulatory infrastructure, which may give rise to consumer exploitation by businesses. Whereas firms know a great deal about consumer tastes, price sensitivities and their distribution across the population, most consumers generally lack awareness of various aspects of the firm offerings (Nevskaya,

2012). This asymmetry may put consumers in a relatively disadvantaged position. Negative welfare effects are especially noted for poor, unsophisticated and technologically less informed consumers. Some analysts have argued that firms׳ big data initiatives may affect the welfare of low-income and minority consumers more negatively (Talbot, 2013).
The paper seeks to shed some light on this complex and puzzling issue. While privacy, security and consumer welfare issues can be linked with collection, storing, analysis, processing, reuse and sharing of data, the paper analyzes the relation between big data characteristics and privacy, security and consumer welfare from the standpoints of data collection, storing, sharing and accessibility. As to the rationale of the focus on collecting and storing, most companies׳ involvement with big data has been on these activities due to a steep decrease in the costs of collecting and storing data. In addition, since a key concern has been with data sharing and accessibility, this paper׳s analysis also highlights how big data׳s characteristics are linked with these issues. IBM׳s chief scientist of Context Computing Jeff Jonas noted that “[t]he biggest obstacle preventing companies from taking full advantage of their data is likely outdated information-sharing policies” (Jonas, 2014, para 1).
This article contributes to the literature in at least two ways. First, it offers new insights into how different characteristics of big data are linked to privacy, security and consumer welfare issues. Due primarily to the newness of this phenomenon, these issues have not been well documented in the literature. A second contribution is to show how privacy, security and consumer welfare aspects of big data are linked to collection-, storing-, sharing- and accessibility-related issues.
The paper is structured as follows. It proceeds by first reviewing the findings of surveys conducted to measure businesses׳ and consumers׳ perceptions of and responses to big data. Then big data׳s costs, benefits and externalities are analyzed. Next, big data׳s characteristics are discussed in relation to privacy, security and consumer welfare. It is followed by a section on discussion and implications. The final section provides concluding comments.
2. Businesses׳ and consumers׳ perceptions of and responses to big data
Some representative surveys conducted in a range of countries to measure businesses׳ and consumers׳ perceptions of big data are presented in Table 1. These surveys have indicated that a large proportion of organizations lack preparedness to address security and privacy issues. Likewise, consumers have expressed concerns about the lack of honesty among businesses and the potential misuse of personal information.
Despite tremendous economic benefits, big data is not taking off as rapidly as expected. According to an EMC-sponsored study conducted by IDC, only 0.5% of the world׳s information was analyzed in 2012 (emc.com, 2012). Another study found that only a third of the businesses differentiated big data from traditional non-big data, and used distinct tools and management approaches. The survey also found that about 90% of respondents used conventional databases as the primary means of handling data (Biddick, 2012). As surveys conducted by Voltage Security

and others indicate, due primarily to privacy and security concerns, organizations have reported a low level of preparedness in managing big data projects. They have been unable to unlock and utilize big data׳s potential. Especially smaller firms find it more costly to gain from big data, which is likely to produce a lead-lag effect between big and small firms.
The surveys have also found that consumers are concerned about potential abuses and misuses of personal data. Especially businesses׳ initiatives to collect high-velocity data (e.g., click-stream, GPS data from mobile devices, and social media usage) have met stiff resistance from consumers. A 2013 national survey conducted in the U.S. by the Pew Internet & American Life Project found that a large proportion of respondents have taken actions such as turning off location tracking features (Table 1). Likewise, in a survey conducted by the non-profit Cable Forum 95% of the respondents said they would opt out of even anonymous monitoring of their online activities by a third party.
A key idea is that businesses store huge volume of personal data so that potential innovative uses can be discovered. Mayer-Schönberger and Cukier (2013, p. 153) emphasize that “most innovative secondary uses haven׳t been imagined when the data is first collected”. However, most consumers are against the secondary uses of their personal data (Table 1).
3. Benefits, costs, and externalities of big data
Crafting policy for big data requires that various costs, benefits and externalities be considered. Big data obviously has a number of private benefits and positive externalities. There are also social and economic costs and negative externalities.
3.1. Social and economic benefits and positive externalities
Data can help enhance economic efficiency, improve access to social services, strengthen security, personalize services and make increased availability of relevant information and innovative platforms for communications (Kang, 1998; Smolan & Erwitt, 2012). For instance, mapping apps provide drivers with real time information about road congestions, which would allow them to select efficient routes.
Big data can make organizations more efficient by improving operations, facilitating innovation and adaptability and optimizing resources allocations. For instance, combining and analyzing data from test drives of prototypes, workshop reports and other sources, BMW detects potential issues and vulnerabilities quickly and eliminates them before new models are launched. Big data and analytics technology shortened the time to analyze some type of data from several months to a few days. Timely discovery of the patterns and anomalies in the products and analysis of maintenance and repair data allowed the company to issue repair instructions on a timely basis, which significantly reduced the number of workshop visits and the time required to repair (IBM, 2014). Likewise, big data analytics allowed the yogurt company, Dannon to forecast the demand

of its retailer customers more accurately, which led to higher consumer satisfaction, less wastes, and a higher profitability (IBM, 2013).
Scientists can use big data in research that can improve human well-being. Huge volumes of information and patient data have helped detect drug interactions and design and implement optimal drug therapies (healthworkscollective.com, 2014 and Smolan and Erwitt, 2012). Information on individual patients available through state and federal health information exchanges can contribute to effective drug regulation and reduce direct costs of medical expenditures and indirect costs associated with lower productivity (Abbott, 2013).
Big data can also improve the performance of services provided by government agencies (Lane et al., 2014). For instance, big data helps law enforcement agencies to deploy resources more efficiently, respond quickly and increase presence in crime prone areas (Kang, 1998). Big data can also help fight the spread of communicable diseases. For instance, a retrospective analysis of the 2010 cholera outbreak in Haiti showed that mining data from Twitter and online news reports could have given the country׳s health officials an accurate indication of the disease׳s spread with a lead time of two weeks (Chunara, Andrews, & Brownstein, 2012).
Firms have access to a large amount of transactional data obtained from a variety of sources. Burrows and Savage (2014, p. 3) describe such data as a “crucial part of the informational infrastructures of contemporary capitalism”. Such data can be used to tailor pricing and product offerings, which enhance consumer welfare and increase firms׳ profits.
3.2. Social and economic costs and potential negative externalities
The creepy factor or big data׳s revelation of information which may be too intrusive and invasive to personal privacy has been a concern. It is possible to use non-personal data to make predictions of a sensitive nature such as sexual orientation and financial status (Daniels, 2013). For instance, researchers have demonstrated that Facebook Likes can be used to accurately predict highly sensitive personal attributes such as sexual orientation, ethnicity, religious/political views, personality traits, intelligence, degree of happiness, addictive substance consumption, parental separation, age, and gender (Kosinski, Stillwell, & Graepe, 2013). Big data also challenges the Fair Information Practices (FIPs), which are an established set of principles for addressing privacy concerns on which modern privacy laws are based (Rubinstein, 2013, Table 2). Big data may help firms come up with better advertising/promotional programs and persuasion attempts, which sometimes could be predatory. Some analysts suggest that firms could determine the probability that someone has suffered from a serious illness and use that information to market unnecessary insurance policies (Drum, 2013). Others point out that a medical insurance company can increase premiums in areas with a high incidence of certain diseases (King, 2014). Similarly, some life insurers reportedly predict life expectancy based on individuals׳ consumption patterns and use that information to offer rates, coverage and other

services. Likewise, gambling companies can identify problem gamblers and lure them with free bets (bigdataweek.com, 2014).
Table 2. Big data characteristics in relation to security, privacy and welfare concerns.
Characteristic Explanation Collection/storing Sharing/accessibility by third parties and various user types
Volume Huge amount of data is created from a wide range of sources such as transactions, unstructured streaming from text, images, audio, voice, VoIP, video, TV and other media, sensor and machine-to data.
• High data volume would likely attract a great deal of attention from cybercriminals. • Amplified technical impact • Violation of transparency principle of FIPs. • Likely to provide a set of information about the consumer required for a more advanced form of price discrimination.
• Firms may need to outsource to CSPs which may give rise to privacy and security issues.
Velocity (Fast Data)
Some data is time-sensitive for which speed is more important than volume. Data needs to be stored, processed and analyzed quickly.
• Increasing consumer concerns over privacy in the context of behavioral advertising based on real-time profiling and tracking technologies such as cookies. • Violation of the individual participation principle of FIPs.
• Increase in the supply and demand of location-based real time personal information, which has negative spillover effects (e.g., stalking people in real time). • Physical security risks.
Variety Data comes in multiple formats such as structured, numeric data in traditional database and unstructured text documents, e-mail, video, audio, financial transactions.
• Unstructured data is more likely to conceal PII. • A large variety of information would make it more difficult to detect security breaches, react appropriately and respond to attacks (freepatentsonline.com, 2003).
• Most organizations lack mechanisms to ensure that employees and third-parties have appropriate access to unstructured data and they are in compliance with data protection regulations (Varonis Systems, 2008).
Variability Data flows can vary greatly with periodic peaks and troughs. These are related to social media trends, daily, seasonal and event-triggered peak data loads and other factors.
• Organizations may lack capabilities to securely store huge amounts of data and manage the collected data during peak data traffic. • Attractiveness as a crime target increases during peak data traffic.
• Peak data traffic may cause higher needs to outsource to CSPs which give rise to important privacy and security issues.
Complexity Data comes from multiple sources which require linking, matching, cleansing and transforming across systems.
• Resulting data is often more personal than the set of data the person would consent to give. • Data collected from illicit sources is more likely to have information on technologically less savvy consumers, who are
• A party with whom de-identified personal data is shared may combine data from other sources to re-identify. • Violation of the security provision of FIPs.

likely to suffer a more negative welfare effect than technologically more savvy consumers.
Beales, Craswell, and Salop (1981, p. 506) pointed out that consumers often lack ability, desire and motivation to gather and rationally evaluate optimal amount of information and that they lack essential information-processing skills. However, the Internet, at least to some extent, has helped to overcome the traditional information asymmetry between producers and consumers. Consumers employ tools and approaches such as price-watch services, comparison sites and consumer reviews in order to fight the problem of information asymmetry. Some examples include activities such as liking a brand on Facebook, and posting reviews on TripAdvisor (Taillard & Glăveanu, 2012).
Prior researchers have found that quality and the number of on-line reviews about a product have positive effects on consumers׳ intention to purchase the product (Park, Lee, & Han, 2007). In the U.K. market, price comparison websites, also known as aggregators accounted for about 33% of all motor insurance sales in 2012 (Breckenridge, Farquharson, & Hendon, 2014). Consumers using aggregators often exhibit a high degree of price sensitivity. Only 7% chose a policy outside of the five cheapest quotes. In general, the availability of price comparison websites has reduced costs for consumers (Breckenridge et al., 2014).
This does not imply, however, that the problem of information asymmetry has completely disappeared. For instance, some price comparison websites allegedly distort information, or provide misinformation in a deliberate attempt to mislead consumers. In order to understand this better, it would be helpful to return to the example of the U.K. motor insurance market discussed earlier. The cheapest quotes often filter to a prominent position in search results and appear at the top of a price comparison website, which are highly likely to be accepted (Breckenridge et al., 2014). In the U.K., Google provides comparison services for car and travel insurance, credit cards, mortgages and bank accounts. Major comparison sites argue that Google gives undue prominence to its own services in search results (Norman, 2014).
Consumers also differ in the extent to which they can fight against businesses׳ potential informational advantage. A U.S. White House review found that government agencies and businesses could use big data to unfairly discriminate against certain classes of persons on housing, employment and other issues (Sullivan, 2014). Microsoft׳s principal researcher, Kate Crawford pointed out that low-income and minority shoppers are likely to face discrimination and be targeted by the sellers of inferior products such as sub-prime loans (Talbot, 2013). Likewise, there is a possibility that social media usage can be analyzed as indicators for future behaviors to determine honesty, responsibility, and trustworthiness required to be a productive employee or a potential credit risk (Brill, 2012).

Regarding the differential welfare effects on sophisticated and unsophisticated consumers, the median voter theory, developed and refined by Hotelling (1929), Smithies (1941), Black (1958), Downs (1957) and Abrams and Kenneth (1987) is of interest. These authors have specified the conditions and mechanisms under which competition between political parties would lead to an outcome that favors the median voter. Extending a median voter model in the context of big data, Strahilevitz (2013, p. 2032) predicted that the U.S. laws will “systematically favor the interests of sophisticated consumers, which are congruent with those of data miners, since sophisticated consumers are on the whole more politically engaged people who pay attention to legislative policy proposals and vote their interests”. Note that sophisticated consumers tend to be wealthier, better-educated and have a higher tendency to vote. These consumers arguably think they will lose nothing from policies that allow firms to access their data (Strahilevitz, 2013) and are likely to make the necessary efforts to fight against businesses’ informational advantage. Some argue that the general public outside this group may not necessary be a “winner” in economic or other terms in corporations’ big data initiatives that rely on “data accessibility and manipulation” (Allen, 2013, p. 247). Others maintain that gains associated with data-driven personalization primarily accrue to businesses that are resourceful and can see clear benefits of big data (The Aspen Institute, 2010).
4. Characteristics of big data in relation to privacy, security and consumer welfare
Despite its widespread use, there is no rigorous and universally accepted definition of big data (Mayer-Schönberger & Cukier, 2013). Einav and Levin (2013) noted that big data involves the availability of data in real time, at larger scale, with less structure, and on different types of variables than previously used. In Gartner׳s three Vs: volume, velocity and variety, the software company, SAS, has suggested two additional big data dimensions: variability and complexity (sas.com, 2013). As presented in Table 2, the various characteristics or dimensions of big data identified by Gartner and SAS are tightly linked to privacy, security and welfare issues. For instance, in order to create highly customized offerings (e.g., Target׳s offering based on a “pregnancy prediction score”), a company may need to mine a huge amount (volume) of structured and unstructured (variety) data from multiple sources (complexity). In some cases, this process may also involve the use of high velocity data.
Regarding data sharing and accessibility issues, outsourcing to CSPs and utilization of other third party tools, services and applications are critical for creating and capturing value. A major consideration is possible security breaches associated with outsourcing. According to Trustwave, 64% of security breaches in 2012 involved outsourcing providers (IFM, 2013). Since most organizations are not in a position to build a complete big data environment in-house (Wood, 2013), a reliance on CSPs becomes inevitable for analytical, storage and other needs. Prior research indicates that a number of key considerations need to be addressed in decisions related to outsourcing to CSPs (Kshetri, 2013). First, most CSPs are bigger than their clients and deal with higher data volumes. Information stored in the cloud is a potential gold mine for cybercriminals. Storing data in the cloud does not remove organizations׳ responsibility for

protecting both from regulatory and reputational perspectives (Wood, 2013). In general it is often cloud user organizations׳ (CUOs) responsibility to make sure that personal data are protected and are only used according to legal provisions. In Italy, for instance, CSPs take only the role of processor and are only part of the processing carried out by CUOs (Mantelero, 2012).
Second, some regulators have expressed concern that CSPs might use clients׳ data for their own benefits and violate privacy. For instance, in 2013, Sweden׳s data protection authority, Datainspektionen asked Salem Municipality to stop using Google Apps, e-mail and calendar services. Datainspektionen argued that Google writes the contract and sets the rules for handling information and has too much room to use the data for purposes other than specified by the municipality (Tung, 2013). Datainspektionen was concerned that the agreement gave Google too much power to process personal data for its own potential benefit.
4.1. Volume
An organization is often required to store all data in one location in order to facilitate analysis. The higher volume and concentration of data makes a more appealing target for hackers. Moreover, a higher data volume increases the probability that the data files and documents may contain inherently valuable and sensitive information. Information stored for the purpose of big data analytics is thus a potential goldmine for cybercriminals, which, as noted earlier, lead to an amplified technical impact (ISACA, 2014).
If inappropriately used, information contained in huge data volume may lead to psychological, emotional, economic, or social harm to consumers. For instance, big data predictive analysis may improve the accuracy of predictions of a customer׳s purchasing requirements or preferences. Highly customized offerings based on predicted preference and requirement data may, however, lead to unpleasant, creepy and frightening experiences for consumers. This phenomenon is also referred as predictive privacy harm (Crawford & Schultz, 2013). The example most often cited is that of a man׳s high school aged daughter tracked by the U.S. retailer, Target. The company׳s pregnancy prediction score indicated that she was pregnant before her father knew and sent promotional mails for products that pregnant women need (Duhigg, 2012).
The availability of a huge amount of data also increases the possibility that personal data can be put to new uses to create value. The U.S. FTC Commissioner pointed out the possibility that firms, “without our knowledge or consent, can amass large amounts of private information about people to use for purposes we don׳t expect or understand” (Brill, 2013). Such uses often violate the transparency principle of FIPs (Teufel, 2008).
A huge data volume is also related to the demand or even the necessity of outsourcing. An issue of more pressing concern is determining relevance within large data volumes and how to use analytics to create value from relevant data. Firms may thus rely on CSPs for analytic solutions.

There are also positive and negative welfare effects of huge data volume. Using such data, a firm can offer distinct products to different groups through quality discrimination or versioning and charge differential pricing (Clemons and Hitt, 2000 and Varian, 1997), which is especially effective for information goods (e.g., books, journals, computer software, music and videos). One way consumers may benefit from more advanced price discrimination as discussed above is as a result of a reduction of deadweight losses. For instance, if the price of a movie/music is outside a consumer׳s affordability range and if the supplier lacks the ability to price discriminate, the difference between the price the consumer is willing to pay and the marginal cost of a copy of the movie/music represents deadweight loss (Liebowitz & Margolis, 2005). With an advanced price discrimination strategy, the supplier can bring the price within the affordability range and thus overcome the inefficiencies associated with deadweight losses.
In a differential pricing strategy, some consumers pay higher prices if they have ability and willingness to do so. In the non-big data environment marketers mainly relied on exogenous and observable characteristics of the consumer such as membership in certain social/demographic groups, zip code, age and gender as variables that were likely to be correlated with ability and willingness to pay (Varian, 1997). Big data analytics would help identify variables with a much higher correlation than is obtainable from the non-big data techniques and design offerings and set prices based on such variables.
Preliminary evidence reported by Shiller (2013) indicated that by using demographic variables (e.g., ace, age, income, children, population density of residence) as well as variables derived from web-browsing histories to tailor prices, Netflix can increase variable profits by 1.39% higher than non-tailored second degree price discrimination (based on quantity demanded). The analysis also indicated that the use of only demographic variables to tailor prices raises profits by only 0.14% compared to that attainable under second degree price discrimination. If Netflix used what Shiller referred as the first degree price discrimination, some consumers would be charged more than twice as much as others.
As another example, Orbitz allegedly up-charged Apple׳s Mac users, who, according to its data spend up to 30% more on hotels than Windows users. It reportedly offered them costlier travel options (Mattioli, 2012).
New technologies are being introduced that would help firms maximize revenues and profits and reduce deadweight losses. In 2013, Google received a patent on a technology that allows companies to dynamically price electronic contents based on consumer profiles. If the technology determines that a consumer is more likely to buy an e-book than an average consumer, he/she is subject to a higher base price. It adjusts the price down as an incentive for consumers with a lower probability to purchase. A consumer may not realize that he/she is paying more than others for an identical product (Fertik, 2013).
4.2. Velocity

Various examples of high-velocity or fast data were discussed earlier. The quickly degrading quality of real-time data is noteworthy (scaledb.com, 2012). In particular, clickstream data (clickpaths), which constitute the route chosen by visitors when they click/navigate through a site, is typically collected by online advertisers, retailers, and ISPs. The fact that such data can be collected, stored, and reused indefinitely poses significant privacy risks (Skok, 2000). Some tracking tools can manipulate clickstreams to build a detailed database of personal profiles in order to target Internet advertising (CDT, 2000).
An important use of big data is real-time consumer profile-driven campaigns such as serving customized ads. For instance, location tracking technologies allow marketers to serve SMS and other forms of ads based on real-time location. This process often involves passive data collection without any overt consumer interaction. The lack of individual consent for the collection, use, and dissemination of such information means that such a practice violates the individual participation principle of FIPs (Teufel, 2008).
Recent studies show that there is an increasing consumer concern over privacy in the context of real time behavioral advertising and tracking technologies such as cookies (Cranor et al., 2002 and King and Jessen, 2010). In the U.S., consumer complaints related to unauthorized consumer profiles creation increased by 193% from 2007 to 2008 (Gomez, Pinnick, & Soltani, 2009). The Internet advertising firms DoubleClick and Avenue A, the software firm, Intuit and the web-tracking firm Pharmatrak have faced lawsuits for using cookies to target advertising.
Big data initiatives have led to an increase in both the supply and demand of location-based real time personal information. Data created and made available for use in the implementation of big data initiatives also have negative spillover effects. Particularly, the availability of location information to third parties may have some dangerous aspects. One example is the use of location data for stalking people in real time. For instance, the iOS app Girls Around Me, 1 which was developed by the Russian company I-Free, leveraged data from Foursquare to scan and detect women checking into a user׳s neighborhood. The user could identify a woman he liked to talk, connect with her through Facebook, see her full name, profile photos and also send her a message. The woman being tracked however would have no idea that someone was “snooping” on her ( Bilton, 2012). As of March 2012, the app was downloaded over 70,000 times ( Austin & Dowell, 2012).
There is also a physical risk of (near) real time data. In China, for instance, illegal companies buy databases from malicious actors and provide services to their clients, which include private investigation, illegal debt collection, asset investigation, and even kidnaping (Yan, 2012).
4.3. Variety
By combining structured and unstructured data from multiple sources, firms can uncover hidden connections between seemingly unrelated pieces of data. In addition to the amount, a high

variety of information in big data makes it more difficult to detect security breaches, react appropriately and respond to attacks (freepatentsonline.com, 2003).
One estimate suggested that only about 10% of available data is in a structured form (e.g., transactional data on customers, time-series data from statistical agencies on various macroeconomic and financial indicators) which can be presented in rows and columns (Gens, 2011). Especially because of the relative newness, most organizations lack capability to manage unstructured data, which arguably contains more sensitive information. Processes and technology solutions for securing unstructured data are still in nascent phase and governance issues are not addressed (Varonis Systems, 2008).
For instance, organizations often lack mechanisms to ensure that permanent and temporary employees and third-parties have appropriate access to unstructured data and they are in compliance with data protection regulations (Varonis Systems, 2008). In a survey conducted by Ponemon among IT professionals, only 23% of the respondents believed that unstructured data in their companies was properly secured and protected (Fonseca, 2008). Another study of DiscoverOrg indicated that over 50% of organizations were not focused on managing unstructured data and only 20% had unstructured data governance processes and procedures (Rosenbush, 2014).
4.4. Variability
The variability characteristic is related to the time-variant nature of security and privacy risks. The volume of data collected and stored, which need protection, will grow during the peak data collection and flow periods. It is during such periods that organizations may lack internal capacity and tools to manage and protect information. A related point is that the attractiveness as a crime target is high during such periods. In December 2013, Target announced that its high-profile security breach, which compromised 40 million credit and debit-card accounts and 70 million people‘s personal data, occurred during the peak holiday shopping season from November 27 to December 15. The virus tried to steal card data during peak customer visit times (10 AM–5 PM local times) of target stores (Yadron, 2014).
The variability characteristic of big data may also necessitate the outsourcing of hardware, software and business-critical applications to CSPs. Applications such as ERP and accounting systems are required to be configured for peak loads during daily and seasonal business periods or when quarterly and annual financial statements are prepared.
4.5. Complexity
Big data often constitutes aggregated data from various sources that are not necessarily identifiable. There is thus no process to request the consent of a person for the resulting data, which is often more personal than the set of data the person would consent to give (Pirlot, 2014). A related privacy risk involves re-identification. It is possible to use a data aggregation process

to convert semi-anonymous or certain personally non-identifiable information into non-anonymous or personally identifiable information ( ISACA, 2014). Health-related data is of special concern. Based on a consumer׳s search terms for disease symptoms, online purchases of medical supplies, and RFID tagging of drug packages can provide marketers with information about the consumer׳s health ( Talbot, 2013). Access to such information would enable an insurance underwriter to predict certain disease and disorder probabilities, which would not be possible using information voluntarily disclosed by consumers.
Firms also use data obtained from various sources to ensure that they serve only profitable markets. For instance, U.S. federal regulations do not allow financial institutions to discriminate in the pricing of and access to credits based on personal attributes such as racial, ethnicity or other characteristics. Technological advancements have made possible for lending companies to mine online and offline data and make offers only to populations with credit attractiveness (Singer, 2012). The U.S.-based predictive analytics company eBureau (http://www.ebureau.com) uses custom scoring algorithms to develop “eScores”, which predict an individual׳s likelihood of becoming a profitable or a money-losing customer. This allows financial institutions to undertake targeted marketing campaigns that exclude people with low credit scores. This means that customers that are determined to be potential money-losing by eScores may not even realize the availability of loans from some leading financial institutions to help them with personal or professional development (Singer, 2012).
Many of the innovations involving big data use multiple data sources and involve transferring data to third parties (Lenard & Rubin, 2013). A study of the Direct Marketing Association indicate that over US$150 billion in marketing services could be generated using individual-level data as a key component and over 70% of such services would require exchanging data among firms in the value delivery network (Deighton & Peter, 2013). Many organizations believe that making data anonymous before sharing with third parties would make it impossible to identify. This is often a convenient but possibly false assumption. Researchers have presented a variety of methods and techniques that can be used to de-identify personal data and reassociate with specific consumers (Brill, 2012). Big data processes can generate predictive models that have a high probability of revealing PII (Crawford & Schultz, 2013) and thus make anonymization impossible. Failure to protect PII and unintended or inappropriate disclosure violate the security provision of FIPs (Teufel, 2008). In some cases, the identified person may suffer physical, psychological, or economic harm. For instance, in 2011, customers of the U.S. drugstore Walgreens filed a lawsuit accusing the drugstore of illegally selling medical information from patient prescriptions. Walgreen allegedly sold the prescription information to data mining companies, which de-identified the data and then sold to pharmaceutical companies. The plaintiffs argued that Walgreens unfairly benefitted from the commercial value of their prescription information (Manos, 2011).
Some data may come from illicit sources. One example is the criminal outfit, Superzonda, which allegedly sent 30–40 million spam e-mails a day in the early 2000s (Sullivan, 2003).

Superzonda׳s most profitable venture was to provide information on consumers interested in a product (e.g., mortgage) to legitimate businesses for lead generation. Each package of data (consisting of name, phone number, address, amount of loan desired and current home value) was reportedly sold to mortgage companies for US$20 (Sullivan, 2003). Less sophisticated and vulnerable consumers are more likely to be fooled by the tricks of illicit actors such as Superzonda.
5. Discussion and implications
This paper has established explicit connections of privacy, security and welfare with key dimensions of big data and linked them with collection, storing, sharing and accessibility issues. It has demonstrated how risks associated with owning and storing data are likely to increase with the size, variety and complexity of data. For instance, the extent and nature of risks involved differ across data types (e.g., often high risk in unstructured data), source of data (higher risks for data obtained from illicit sources) and volume of data. The case of Target also indicates that a firm is subjected to higher risks during peak data traffic periods. In order to create value from big data, it is important to share and make data accessible to various entities. However, an organization is often responsible for any wrongdoing by third parties and various user types such as permanent and temporary employees, business partners and CSPs.
It is clear from Table 1 that big data presents different concerns and issues for IT professionals in organizations and consumers. IT professionals often emphasize on the risks and effects of security breaches and misconducts by external parties and insiders. Organizations׳ goals are to avoid fines, potential lawsuits, and reputation damage. Consumers on the other hand tend to worry most about what they consider businesses׳ questionable or unethical practices, which are not necessarily illegal. This is a critical issue from the public policy point of view because businesses seem to have a tendency to ignore consumers׳ desires for privacy. These differences are likely to result in strong pressure on the governments to intervene. Governments are likely to be forced to recognize the necessity for reasonable regulatory safeguards to protect the public interest of privacy and the development of higher privacy standards.
Proactive risk management also requires a deeper understanding of the root causes of risks. It is important to have detailed information on all the parties (employees and administrators of cloud vendors) who have access to an organization׳s data. Illicit and gray area businesses accessing data on consumers is not an uncommon practice. For instance, in 2008, Phorm signed deals to place its tracking software in the networks of three British ISPs, BT, Virgin Media and TalkTalk. Phorm had access to the datastream of all users. The Company previously operated 121Media and distributed a program known as PeopleOnPage, which was classified as spyware by the IT security company, F-Secure (Arthur, 2008).
While non-big data issues are still relevant and continue to attract the attention of privacy activists and security experts, new issues arise in the big data context. Location information,

which is a key component of high velocity data, is an issue that is a cause of concern. Not only real time, but also time-lagged or asynchronous location identification information may have potentially dangerous consequences. In this regard, while smart phones and camera are equipped with increasingly powerful and user-friendly packages and programs, their security features are often designed only for technologically sophisticated users. In order to illustrate this, the photos and videos posted online that are taken with GPS-equipped smartphones and digital cameras can be considered. There are concerns about privacy and safety since these photos and videos may contain location data, which are not visible to most viewers. Disabling the geotag feature in some GPS-equipped smartphones and digital cameras is complicated for casual users. A staff technologist at the Electronic Frontier Foundation noted that “ the only way you can turn off the function on your smartphone is through an invisible menu that no one really knows about” (Murphy, 2010). One way to address these concerns would be to incorporate security and privacy oriented features in cellphones and other technologies.
In theory, by mining personal data, firms may be able to realize lower production costs and deliver higher value to customers by lowering prices and other means. Some businesses, however, have come up with tactics and strategies that are more sophisticated and exceedingly difficult for consumers to counter. Nonetheless, it is important to note that firms are entitled to derive a profit from their activities under a capitalist market system as long as they do not violate provisions such as non‐discrimination, equal‐opportunities, and equal treatment. While the price discrimination examples discussed above (e.g., Orbitz, Netflix) may appear outrageous to some user groups, such strategy may benefit a number of consumers and even lead to an increase in the total consumer surplus.
One reason why less sophisticated consumers may not be benefiting as much as they could from big data is that they often lack knowledge about how businesses are using their information; they are dispersed, unorganized and uninterested in exercising their democratic and political rights. They lack the ability to respond to marketers׳ unfair or deceptive information collection and use practices. They are thus less likely to bring strong and focused pressure on the government and businesses. Prior research indicates that political processes tend to have built-in biases that often favor organized groups compared to those that are unorganized (Mitra, 1999). Organizational, inter-organizational and national measures are needed to put pressures to firms to utilize big data in such a way that they consider the interests of the majority of consumers. The case of customers׳ lawsuit against the U.S. drugstore Walgreens indicates that there is increasing consumer awareness of potential data misuses or abuses. These actions are also likely to drive legal and regulatory developments in this area.
The big data industry has grown up in what many consider a regulatory gray area. The seriousness of this issue is increased by the fact that regulations do not adequately protect consumers from the revelations of their information by advertisers, particularly if such information is not technically PII. Moreover, ethical standards and codes of conduct are not well established. Most companies also lack best practices and privacy policies to stop revelations of

sensitive information. What is more disturbing is that in some cases, illicit and gray area actors essentially draw on the same data sets and information as legitimate users. Due to the lack of regulations and guidelines, some dangerous, creepy and annoying practices of the uses of consumer information are not necessarily illegal. For instance, in a statement provided to the Wall Street Journal, I-Free said that Girls Around Me provides nothing more than data that was publicly available on Foursquare and Facebook (Austin & Dowell, 2012). By engaging in actions such as lawsuits, filing of complaints with regulatory bodies and applying formal pressures on businesses to use big data responsibly and ethically, consumers can help develop favorable formal and informal institutions around big data.
5.1. Future research
Before concluding, several potentially fruitful avenues for future research are suggested. First, laws and regulations governing key aspects of big data differ across countries. For instance, while Sweden׳s Datainspektionen was against using Google׳s services, Norway exhibited a more relaxed attitude. In 2012, Norwey׳s data protection authority, Datatilsynet approved local municipalities׳ use of Google Apps and Microsoft׳s Office 365 except for handling personal information (Tung, 2012). An area of future research is to analyze how and why privacy- and security-related institutional pressures faced by organizations in the big data environment vary across countries.
Most of the current discussion on this subject has been focused on industrialized countries (e.g., respondents in surveys reported in Table 1). One commentator noted that about 90% of the discussion at the 2013 Internet Governance Forum (IGF) held in Bali, Indonesia, referred to big data as a surveillance tool. At the same time, the debate focusing on developing countries treated big data as a means to observe people to fight poverty. The argument provided by IGF participants was that data can help provide access to clean drinking water, healthcare and other necessities. Some have challenged this view and noted that poor people have no less reason than rich people to be worried about surveillance (linnettaylor, 2013). Consequently, future research and policy should look at businesses׳ and consumers׳ perceptions of privacy and security issues associated with big data in developing countries.
One issue that was raised in this article but not fully developed concerns firms׳ unwillingness to use big data due partly to privacy and security concerns. In this regard, a final area of future research concerns an analysis of how privacy- and security-related barriers have hindered firms׳ big data initiatives and how these issues could be addressed. Future research could also seek to identify how such concerns are linked with key characteristics of big data. Future research is also needed to explore which big data-related activities and processes (e.g., collection, storing, analysis, processing, reuse and sharing) are of key concerns.
Finally, future research might also explore big data-led price discrimination through the lens of a rational choice theory of group solidarity (e.g., Hechter, 1988). For instance, consider the group

of customers with an ability to pay a higher price than the average consumer. It may be in the interest of this group to pay a higher price to ensure the continuous production of a good or service under consideration. However, whereas the state can impose coercive measures to force this group to pay more for public goods, the types of mechanisms and processes involved in big data-led price discrimination are not clear.
6. Concluding comments
Big data has some intrinsic features that are tightly linked to a number of privacy, security and welfare concerns. Moreover, these concerns are linked with the collection and storing of data as well as data sharing and accessibility by third parties and various user types. Overall firms׳ uses of big data raise a wide range of ethical issues because they may lead to potential exploitation of consumers and disregard their interests and sometimes firms even engage in deceptive practices. As the above discussion has already pointed out, while consumers׳ decisions to withhold information may hinder the ability of the society to benefit from big data, consumers are also rightly concerned about potential abuses and misuses of their information. Regarding the privacy issues, consumers are often uncomfortable and embarrassed when they feel that companies know more about them than they are willing to voluntarily provide.
Big data is likely to affect welfare of unsophisticated, vulnerable and technologically unsavvy consumers more negatively. Such consumers may lack awareness of multiple information sources and are less likely to receive up to date and accurate information about multiple suppliers in a manner that facilitates effective search and comparisons. They are also not in a position to assess the degree of sensitiveness of their online actions and are more likely to be tricked by illicit actors.
A number of uses of big data currently fall into a regulatory gray area. Due to the underdeveloped regulatory institutions, there is a need to have a firm-level big data policy, which must take into account the degree of sensitivity of information used in predictive modeling. Yet most organizations have not developed best practices to ensure privacy and security of customer data. There is also the question of whose welfare, preferences and opinions are to prevail in the formulation of big data related laws and policies in the future. The increasing consumer concerns are likely to force further regulatory response to ensure that consumers׳ interests are protected.
Acknowledgment
Two anonymous JTPO reviewers׳ comments on earlier versions helped to improve the paper substantially.
References
Abbott, R. (2013). Big data and pharmacovigilance: Using health information exchanges to revolutionize drug safety. Iowa Law Review, 99(1), 225–292.

Abrams, B. A., & Kenneth, A. L. (1987). A median-voter model of economic regulation. Public Choice, 52, 125–142.
Allen, A. L. (2013). Privacy law: Positive theory and normative practice. Howard Law Journal, 56(3), 241–251.
Arthur, C. (2008, March 6). Phorm fires privacy row for ISPs. Retrieved from ⟨http://www.theguardian.com/technology/2008/mar/06/internet.privacy⟩.
Austin, S., & Dowell, A. (2012, March 31). ‘Girls around me’ developer defends app after foursquare dismissal. Retrieved from ⟨http://blogs.wsj.com/digits/2012/03/31/girls-around-me-developer-defends-app-after-foursquare-dismissal/⟩.
BARC Institute (2013). Big data survey Europe, usage, technology and budgets in European best-practice companies. Wuerzburg, Germany. February.
Beales, H., Craswell, R., & Salop, S. C. (1981). The efficient regulation of consumer information. Journal of Law and Economics, 24, 491–539.
Biddick, M. (2012). Research: The big data management challenge. InformationWeek. Retrieved from ⟨http://reports.informationweek.com/abstract/81/8766/business-intelligence-and-information-management/research-the-big-data-management-challenge.html⟩.
bigdataweek.com. (2014). Gambling and big data: A safe bet? Retrieved from ⟨http://bigdataweek.com/2014/01/15/gambling-and-big-data-a-safe-bet/⟩
Bilton, N. (2012). Girls around Me: An app takes creepy to a new level. Retrieved from ⟨http://bits.blogs.nytimes.com/2012/03/30/girls-around-me-ios-apptakes-creepy-to-a-new-level/⟩.
Black, D. (1958). The theory of committees and elections. Cambridge: Cambridge University Press.
Breckenridge, J., Farquharson, J., & Hendon, R. (2014). The role of business model analysis in the supervision of insurers. Bank of England Quarterly Bulletin, 54(1), 49–57.
Brill, J. (2012, March 2). Big data, big issues. Fordham University School of Law. Retrieved from ⟨http://www.ftc.gov/public-statements/2012/03/big-data-big-issues⟩.
Brill, J. (2013). Demanding transparency from data brokers. Washington post opinions. Retrieved from ⟨http://www.washingtonpost.com/opinions/demanding-transparency-from-data-brokers/2013/08/15/00609680-0382-11e3-9259-e2aafe5a5f84_story.html⟩.
Burrows, R., & Savage, M. (2014). After the crisis? Big data and the methodological challenges of empirical sociology. Big data & society, April–June, 1–6.

CDT (2000).CDT's guide to online privacy. Center for Democracy & Technology, Retrieved from ⟨http://www.cdt.org/privacy/guide/start⟩.
Chunara, R., Andrews, J., & Brownstein, J. (2012). Social and news media enable estimation of epidemiological patterns early in the 2010 Haitian cholera outbreak. American Journal of Tropical Medicine and Hygiene, 86, 39–45.
Clemons, E. K., & Hitt, L. M. (2000). The Internet and the future of financial services: transparency, differential pricing and disintermediation. Retrieved from ⟨http://econpapers.repec.org/paper/woppennin/00-35.htm⟩.
Cohen, A. (2013, February 4). Will ‘stalking apps’ be stopped?. Retrieved from ⟨http://ideas.time.com/2013/02/04/will-stalking-apps-be-stopped/⟩.
Coyne, T., (2013, September 30). Avoiding the big data crisis: Managing disclosure. Retrieved from ⟨http://in2.holmesreport.com/2013/09/avoiding-the-big-data-crisis-managing-disclosure/⟩.
Cranor, L. F., Arjula, M., & Guduru, P. (2002). Use of a P3P user agent by early adopters. In WPES '02 Proceedings of the 2002 ACM workshop on privacy in the electronic society (pp. 1–10).
Crawford, K., & Schultz, J. M. (2013). Big data and due process: Toward a framework to redress predictive privacy harms. New York University public law and Legal theory working papers. Paper 429. Retrieved from ⟨http://lsr.nellco.org/nyu_plltwp/429/⟩.
CSO Online (2013, November 22). Big data policies lacking in Australian and New Zealand organisations: Survey. Retrieved from ⟨http://www.cso.com.au/article/532590/big_data_policies_lacking_australian_new_zealand_organisations_survey/⟩.
Daniels, B. L. (2013, September 26). Big data, big trouble? Privacy and legal concerns with big data. Pillsbury Winthrop Shaw Pittman LLP. Retrieved from ⟨http://www.lexology.com/library/detail.aspx?g=027d46af-e621-4714-8da4-27c07f7ee6e0⟩.
darkreading.com. (2013, May 23). Over half of big data & cloud projects stall because of security concerns. Retrieved from ⟨http://www.darkreading.com/management/over-half-of-big-data-cloud-projects-st/240155524⟩.
Deighton, J., & Peter, A. J. (2013, October). The value of data: Consequences for insight, innovation & efficiency in the US economy. The Data Driven Marketing Institute. Retrieved from ⟨http://ddminstitute.thedma.org/#valueofdata⟩.
Downs, A. (1957). An economic theory of democracy. New York: Harper and Row.

Drum, K. (2013, November/December). Privacy is dead. Long live transparency! Retrieved from ⟨http://www.motherjones.com/politics/2013/10/future-of-privacy-nsa-snowden⟩.
Duhigg, C. (2012, February 16). How companies learn your secrets. New York Times. Retrieved from ⟨http://www.nytimes.com/2012/02/19/magazine/shopping-habits.html?_r=1&pagewanted=all⟩.
Einav, L., & Levin, J. (2013, April). The data revolution and economic analysis. In NBER innovation policy and the economy conference. Retrieved from ⟨http://www.nber.org/papers/w19035⟩.
emc.com. (2012, December 11). New digital universe study reveals big data gap: Less than 1% of world's data is analyzed; less than 20% is protected. Retrieved from ⟨http://www.emc.com/about/news/press/2012/20121211-01.htm⟩.
Fertik, M. (2013, January 15). The rich see a different internet than the poor. Retrieved from ⟨http://www.scientificamerican.com/article/rich-see-different-internet-than-the-poor/⟩.
Fonseca, B. (2008, July 1). Unstructured data at risk in most firms, survey finds. Computerworld. ⟨http://www.computerworld.com/article/2534496/datacenter/unstructured-data-at-risk-in-most-firms–survey-finds.html⟩.
freepatentsonline.com (2003). Secure auditing of information systems. United States patent application 20030220940. Retrieved from ⟨http://www.freepatentsonline.com/y2003/0220940.html⟩.
gartner.com. (2013). Big data. Retrieved from ⟨http://www.gartner.com/it-glossary/big-data/⟩.
Gens, F. (2011, December). IDC Predictions 2012: Competing for 2020. IDC Analyze the Future. Retrieved from ⟨http://cdn.idc.com/research/Predictions12/Main/downloads/IDCTOP10Predictions2012.p⟩.
Gomez, J., Pinnick, T., & Soltani, A. (2009, June 1). Know privacy report. U.C. Berkeley School of Information, 5. Retrieved from ⟨http://knowprivacy.org/report/KnowPrivacy_Final_Report.pdf⟩.
healthworkscollective.com (2014, April 9). 5 ways big data is improving patient outcomes, 2014. Retrieved from ⟨http://healthworkscollective.com/dougbennet/158371/ways-big-data-healthcare-improving-patient-outcomes⟩.
Hechter, M. (1988). Principles of group solidarity. Berkley: University of California Press.
Hernandez, P. (2012, May 14). Survey: 70 percent of organizations have big plans for big data. Retrieved from ⟨http://www.enterpriseappstoday.com/data-management/survey-70-percent-enterprises-big-plans-for-big-data.html⟩.

Hooper, J. (2010, February 24). Google executives convicted in Italy over abuse video. The Guardian, ⟨http://www.theguardian.com/technology/2010/feb/24/google-video-italy-privacy-convictions⟩.
Hotelling, H. (1929). Stability in competition. The Economic Journal, 39, 41–57.
IBM (2013, May 22). The Dannon Company uses ibm smarter commerce to support yogurt market gains with big data analytics. Retrieved from ⟨http://www-03.ibm.com/press/us/en/pressrelease/41156.wss⟩.
IBM (2014, March 11). Leading German car manufacturer boosts customer satisfaction using IBM Big Data & Analytics. Retrieved from ⟨http://www-03.ibm.com/press/us/en/pressrelease/43392.wss⟩.
IFM (2013). Report finds data breaches mainly involve outsourced IT. Information Management Journal, 47(3), 16 (16).
ISACA. (2014, January). Generating value from big data analytics. White Paper. Retrieved from ⟨http://www.isaca.org/Knowledge-Center/Research/ResearchDeliverables/Pages/Generating-Value-From-Big-Data-Analytics.aspx⟩.
Jonas, J. (2014, March 30). How corporate departments totally mishandle big data. Retrieved from ⟨http://blogs.wsj.com/experts/2014/03/30/how-corporate-departments-totally-mishandle-big-data/⟩.
Kang, P. (1998). Stalking and domestic violence: The third annual report to congress under the violence against women act. Washington DC: U.S. Department of Justice, Office of Justice Programs, Violence Against Women Grants Office.
Kelley, D. (2008). Addressing the unstructured data protection challenge. SecurityCurve
King, L. (2014). Alarm over the ‘gold rush’ for citizens' big data. Retrieved from ⟨http://www.forbes.com/sites/leoking/2014/03/29/alarm-over-the-gold-rushfor-citizens-big-data/⟩.
King, N. J., & Jessen, P. W. (2010). Profiling the mobile customer – privacy concerns when behavioural advertisers target mobile phones – Part i. Computer Law and Security Review, 26(6), 595–612.
Kosinski, M., Stillwell, D., & Graepe, T. (2013). Private traits and attributes are predictable from digital records of human behavior (Retrieved from). Proceedings of the National Academy of Sciences of the USA ⟨http://www.pnas.org/content/early/2013/03/06/1218772110⟩.
Kshetri, N. (2013). Privacy and security issues in cloud computing: The role of institutions and institutional evolution. Telecommunications Policy, 37(4–5), 372–386.

Lane, J., Stodden, V., Bender, S., & Nissenbaum, H. (2014). Privacy, big data, and the public good: Frameworks for engagement. New York, NY: Cambridge University Press.
Lenard, T. M., & Rubin, P. H. (2013, December). The big data revolution: Privacy considerations. Retrieved from ⟨http://www.techpolicyinstitute.org⟩
Liebowitz, S. J., & Margolis, S. (2005). seventeen famous economists weigh in on copyright: The role of theory, empirics, and network effects. Harvard Journal of Law & Technology, 18(2), 435–457.
linnettaylor (2013) Surveil the rich, observe the poor: Big data at the Internet Governance Forum 2013. Retrieved from ⟨http://linnettaylor.wordpress.com/2013/10/25/surveil-the-rich-observe-the-poor-big-data-at-the-internet-governance-forum-2013/⟩.
Manos, D. (2011, March 18). Patients sue Walgreens for making money on their data, healthcareitnews.com. Retrieved from ⟨http://www.healthcareitnews.com/news/patients-sue-walgreens-making-money-their-data⟩.
Mantelero, A. (2012). Cloud computing, trans-border data flows and the European Directive 95/46/EC: Applicable law and task distribution. European Journal for Law and Technology, 3, 2.
Mattioli, D. (2012, August 23). On Orbitz, Mac users steered to pricier hotels. Retrieved from ⟨http://online.wsj.com/news/articles/SB10001424052702304458604577488822667325882?mg=reno64-wsj&url=http%3A%2F%2Fonline.wsj.com%2Farticle%2FSB10001424052702304458604577488822667325882.html⟩.
Mayer-Schönberger, V., & Cukier, K. (2013). Big Data: A revolution that will transform how we live, work and think. Boston: Houghton Mifflin Harcourt.
McKinsey Global Institute. (2013, July). Game changers: Five opportunities for US growth and renewal. Retrieved from ⟨http://www.mckinsey.com/insights/americas/us_game_changers⟩.
Mitra, D. (1999). Endogenous lobby formation and endogenous protection: A long-run model of trade policy determination. American Economic Review, 89(5), 1116–1134.
Murphy, K. (2010, August 11). Web photos that reveal secrets, like where you live. Retrieved from ⟨http://www.nytimes.com/2010/08/12/technology/personaltech/12basics.html?_r=0⟩.
Neuhaus, F., & Webmoor, T. (2012). Agile ethics for massified research and visualisation. Information, Communication and Society, 15(1), 43–65.
Nevskaya, Y. (2012). Consumer information asymmetry in online product reviews (Working paper). New York: William E. Simon Graduate School of Business, University of Rochester.

Norman, T. (2014, June 2). FCA reviews Google's price comparison service. Money Marketing (Online Edition). Retrieved from ⟨http://www.moneymarketing.co.uk/tessa-norman/3402.contributor⟩.
Nunan, D., & Di Domenico, M. L. (2013). Market research and the ethics of big data. International Journal of Market Research, 55(4), 2–13.
Park, D. H., Lee, J., & Han, I. (2007). The effect of on-line consumer reviews on consumer purchasing intention: The moderating role of involvement. International Journal of Electronic Commerce, 11(4), 125–148.
Pirlot, A. (2014, January 21). Big data: A tool for development or threat to privacy?. Retrieved from ⟨https://www.privacyinternational.org/blog/big-data-a-tool-for-development-or-threat-to-privacy⟩.
Rose, J., Barton, C., Souza, R., & Platt, J. (2013). The trust advantage: How to win with big data, November. Boston Consulting Group (BCG), 2013.
Rosenbush, S. (2014, April 2). Few businesses are focused on unstructured data. Retrieved from ⟨http://blogs.wsj.com/cio/2014/04/02/few-businesses-are-focused-on-unstructured-data/⟩.
Rubinstein, I. S. (2013). Big data: A pretty good privacy solution. New York: New York University School of Law.
SAP. (2014, March 6). SAP survey reveals big data-driven customer insight and real-time offers to open new revenue opportunities for operators. Retrieved from ⟨http://www.news-sap.com/sap-survey-reveals-big-data-driven-customer-insight-and-real-time-offers-to-open-new-revenue-opportunities-for-operators/⟩.
sas.com. (2013). Big Data: What it is and why it matters. Retrieved from ⟨https://www.sas.com/en_us/insights/big-data/what-is-big-data.html⟩.
Savvas, A. (2014). Cloud, big data raises spectre of insider data theft: Ovum. Retrieved from ⟨http://www.computerworld.in/news/cloud,-big-data-raises-spectre-of-insider-data-theft%3A-ovum-⟩.
scaledb.com (2012). High-velocity data – The data fire hose. Retrieved from ⟨http://scaledb.com/high-velocity-data.php⟩.
Shiller, B. R. (2013 20). First degree price discrimination using big data. MA: Economics Department, Brandeis University.
Singer, N. (2012, August 19). Secret e-scores chart consumers’ buying power. New York Times. Retrieved from ⟨http://www.nytimes.com/2012/08/19/business/electronic-scores-rank-consumers-by-potential-value.html?pagewanted=all⟩.

Skok, G. (2000). Establishing a legitimate expectation of privacy in clickstream data. Michigan Telecommunications & Technology Law Review. Retrieved from ⟨http://cyber.law.harvard.edu/privacy/PrivacyInClickstream%28Skok%29.htm⟩.
Smithies, A. (1941). Optimum location in spatial competition. Journal of Political Economy, 49, 423–439.
Smolan, R., & Erwitt, J. (2012). The human face of big data. Sausalito, California: Against All Odds Productions.
Strahilevitz, L. (2013). Toward a positive theory of privacy law. Harvard Law Review, 126, 2010–2042.
Sullivan, B. (2003, August 8).Who profits from spam? Surprise. Retrieved from ⟨http://www.msnbc.msn.com/id/3078642/ns/technology_and_science-security/t/who-profits-spam-surprise/#.TsZa31anz1U⟩.
Sullivan, E. (2014). Discrimination potential seen in 'big data' use. Retrieved from ⟨http://abcnews.go.com/Technology/wireStory/white-house-discrimination-potentialdata-23481770⟩.
Taillard, M., & Glăveanu, V. (2012). Creativity and marketing: Interview with Marie Taillard. Europe's Journal of Psychology, 8(4), 519–522.
Talbot, D. (2013, October 9). Data discrimination means the poor may experience a different Internet. Retrieved from ⟨http://www.technologyreview.com/
news/520131/data-discrimination-means-the-poor-may-experience-a-different-internet/⟩.
Taylor, L., Meyer, E. T., & Schroeder, R. (2014). Bigger and better, or more of the same? Emerging practices and perspectives on big data analysis in economics (p.1)Big Data and Society, 20141, http://dx.doi.org/10.1177/2053951714536877. ⟨http://bds.sagepub.com/content/1/2/2053951714536877⟩.
Teufel, H. II. (2008). Privacy policy guidance memorandum. Memorandum Number: 2008-01, December 29. The Privacy Office U.S. Department of Homeland Security.
The Aspen Institute. (2010). The promise and peril of big data. Communications and society program. The Aspen Institute, Queenstown, Maryland.
Tinati, R., Halford, S., Carr, L., & Pope, C. (2014). Big data: Methodological challenges and approaches for sociological analysis. Sociologyhttp://dx.doi.org/10.1177/0038038513511561.

Truxillo, C. (2013, July 8). Five myths about unstructured data and five good reasons you should be analyzing it. Retrieved from ⟨http://blogs.sas.com/content/sastraining/2013/07/08/five-myths-about-unstructured-data-and-five-good-reasons-you-should-be-analyzing-it/⟩.
Tung, L. (2012, September 27). No personal data on Google Apps, Norway tells its councils as it clears cloud use, zdnet.com. Retrieved from ⟨http://www.zdnet.com/no-personal-data-on-google-apps-norway-tells-its-councils-as-it-clears-cloud-use-7000004904/⟩.
Tung, L. (2013, June 14). Sweden tells council to stop using Google Apps. Retrieved from ⟨http://www.zdnet.com/sweden-tells-council-to-stop-using-google-apps-7000016850/⟩.
USA Today (2012, September 5). Survey: Cellphone users concerned about privacy in apps. Retrieved from ⟨http://usatoday30.usatoday.com/tech/products/story/2012-09-05/mobile-app-privacy/57599260/1⟩.
Varian, H. R. (1997). Versioning information goods (January). Mimeo: University of California, Berkeley.
Varonis Systems (2008, June 30). Ponemon study – Survey on the governance of unstructured data. Retrieved from ⟨http://www.varonis.com/metadata/ponemon-study/⟩.
Wood, P. (2013). How to tackle big data from a security point of view, March. Retrieved from ⟨http://www.computerweekly.com/feature/How-to-tackle-big-data-from-a-security-point-of-view⟩.
Yadron, D. (2014, January 16). Target hackers wrote partly in Russian, displayed high skill, report finds. Retrieved from ⟨http://online.wsj.com/news/articles/SB10001424052702304419104579324902602426862⟩.
Yan, Z. (2012, July 4). Personal data crimes set to be defined. Retrieved from ⟨http://www.chinadaily.com.cn/china/2012-07/04/content_15546503.htm⟩





























