Embed Size (px)
Citation preview

Scalable Dense Matrix Multiplication on Multi-Socket Many-Core Systems with Fast Shared MemoryRicardo Magana, Natalia Vassilieva

Acknowledgment
Ricardo Magaña [email protected]
And also many thanks to prof. Robert Van De Geijn, Field Van Zee and Tyler Smith!
2

Outline
– Motivation and The Machine pitch
– NUMA-aware extension of BLIS for multi-socket systems
– Experimental results
3

4
The Machine

5
I/O
Copper

6
Copper

7
Copper

8

9
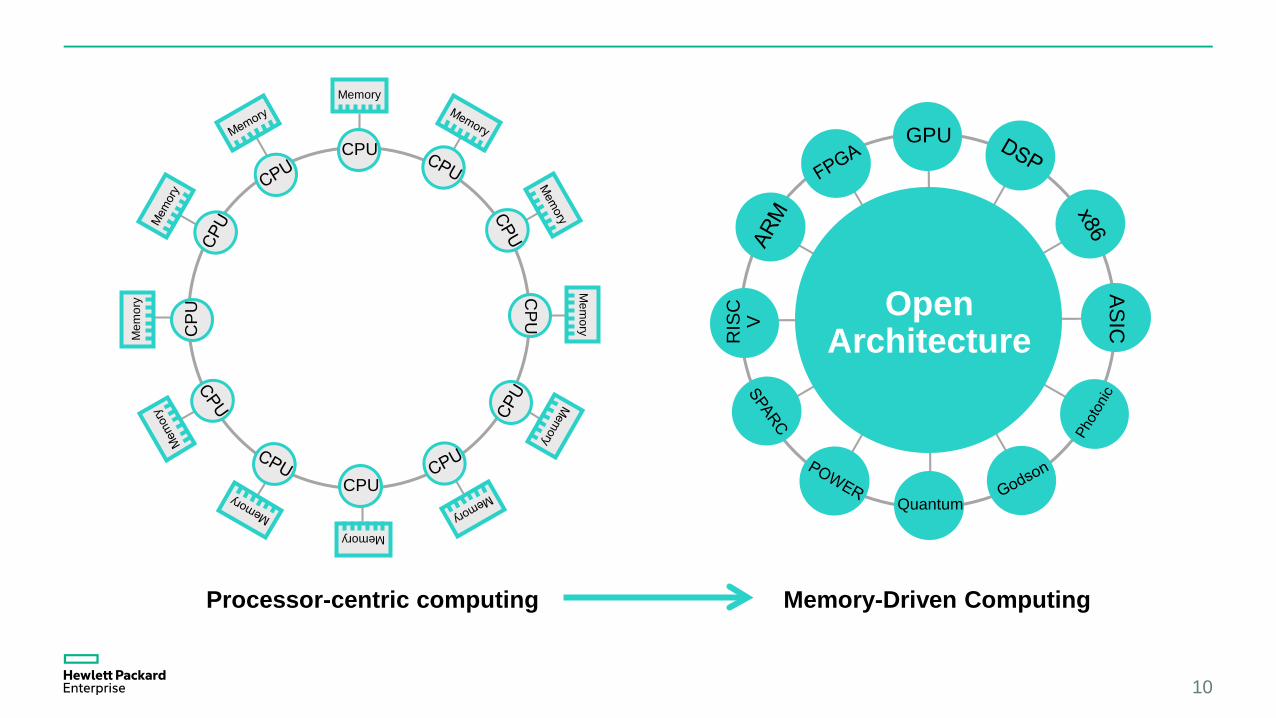
Processor-centric computing
10
Memory
Mem
ory
Memory
Mem
ory
GPUA
SIC
Quantum
RIS
CV
OpenArchitecture
CPU
CP
U
CPU
CP
U
Memory-Driven Computing
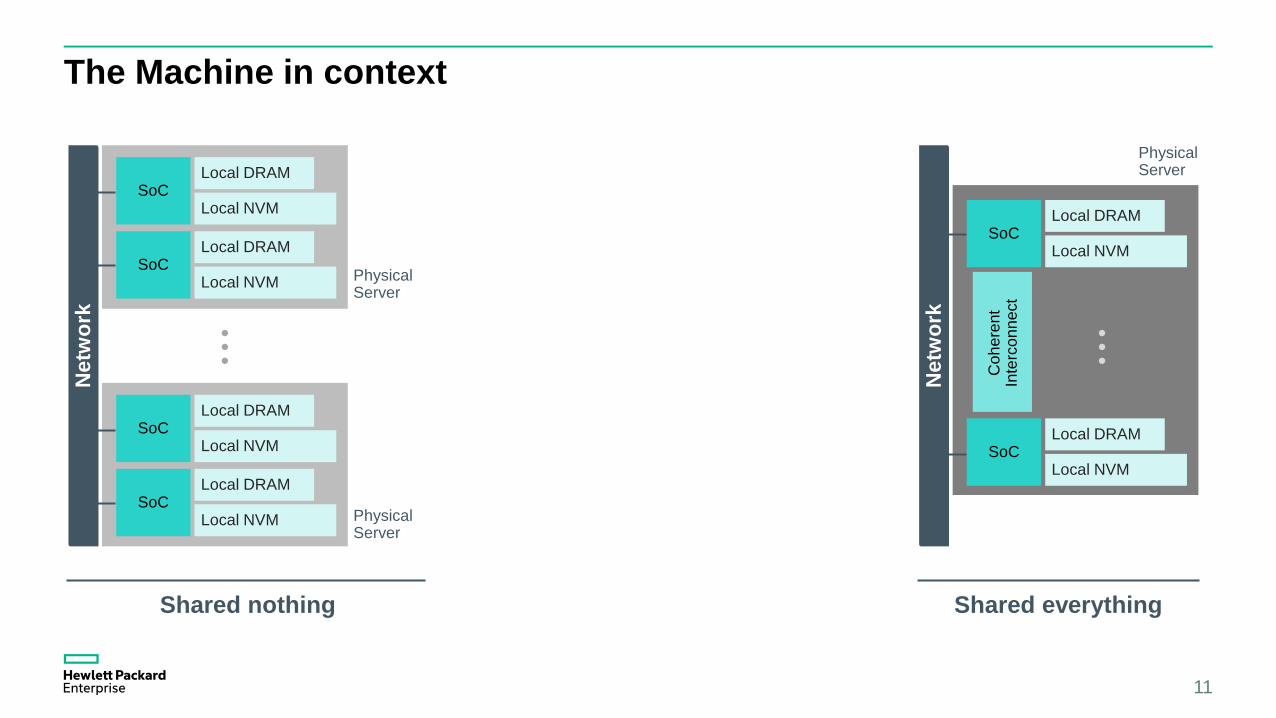
The Machine in context
11
Shared nothing
SoC
SoC
Local DRAM
Local DRAM
Local NVM
Local NVM
SoC
SoC
Local DRAM
Local DRAM
Local NVM
Local NVM
Net
wor
k
Shared everything
SoCLocal DRAM
Local NVM
SoCLocal DRAM
Local NVM
Net
wor
k
Physical Server
Coh
eren
t In
terc
onne
ct
Physical Server
Physical Server

The Machine in context
12C
omm
unic
atio
ns a
nd m
emor
y fa
bric
SoC
SoC
Local DRAM
Local DRAM
SoC
SoC
Local DRAM
Local DRAM
Shared something
NVM
NVM
NVM
NVM
Memory Pool
Shared nothing
SoC
SoC
Local DRAM
Local DRAM
Local NVM
Local NVM
SoC
SoC
Local DRAM
Local DRAM
Local NVM
Local NVM
Net
wor
k
Shared everything
SoCLocal DRAM
Local NVM
SoCLocal DRAM
Local NVM
Net
wor
k
Physical Server
Coh
eren
t In
terc
onne
ct
Physical Server
Physical Server

Our goal: efficient linear algebra library for The Machine
– Fast GEMM is crucial for fast machine learning (deep learning in particular)
– BLAS is essential for many problems in scientific computing, pattern recognition and optimization
– The ratio of compute/bandwidth on The Machine enables efficient scaling of GEMM for matrices of moderate sizes (up to 100000000 elements)
13

Linear algebra on The Machine: aspiration
14
Typical sizes of matrices
for deep learning
What do we need to be true:– High-performing single-node
multi-core GEMM for small matrices
– Scalable multi-node GEMM

Existing BLAS libraries
Proprietary Open Source– ATLAS
– OpenBLAS
– BLIS
– Armadillo
– Eigen
– ScaLAPACK
– PLAPACK
– PLASMA
– DPLASMA
– Elemental
15
– Intel MKL
– AMD ACML
– IBM ESSL and PESSL
– NVIDIA cuBLAS and NVBLAS

Existing BLAS libraries
Proprietary Open Source– ATLAS
– OpenBLAS
– BLIS
– Armadillo
– Eigen
– ScaLAPACK
– PLAPACK
– PLASMA
– DPLASMA
– Elemental
16
– Intel MKL
– AMD ACML
– IBM ESSL and PESSL
– NVIDIA cuBLAS and NVBLAS
Single-node• Access shared coherent memory• Threads don’t share data, only
synchronization messagesMulti-node• Distributed memory• Different processes transfer data and
synchronization messagesMulti-socket with shared memory
In The Machine we have different processes that can access shared memory

Existing BLAS libraries
Proprietary Open Source– ATLAS
– OpenBLAS
– BLIS
– Armadillo
– Eigen
– ScaLAPACK
– PLAPACK
– PLASMA
– DPLASMA
– Elemental
17
– Intel MKL
– AMD ACML
– IBM ESSL and PESSL
– NVIDIA cuBLAS and NVBLAS
– Open Source
– Different ways of parallelization
– Easier to optimize for a new CPU

Multi-socket systems today: NUMAThe ones we used
Superdome X– 16 sockets
– 18 haswell cores per socket (288 cores total)
– Theoretical peak: ~20 TFLOPS
DL580– 4 sockets
– 15 ivybridge/haswell cores per socket (60 cores total)
– Theoretical peak: ~2.6/5.2 TFLOPS
NUMA node 1
CPU
Memory
NUMA node 2
CPU
MemoryQPI
32 GB/s
NUMA node 3
CPU
Memory
NUMA node 4
CPU
MemoryQPI
32 GB/s
Crossbar fabric
NUMA node 1
CPU
Memory
NUMA node 1
CPU
Memory
NUMA node 1
CPU
Memory
NUMA node 1
CPU
Memory
…
…
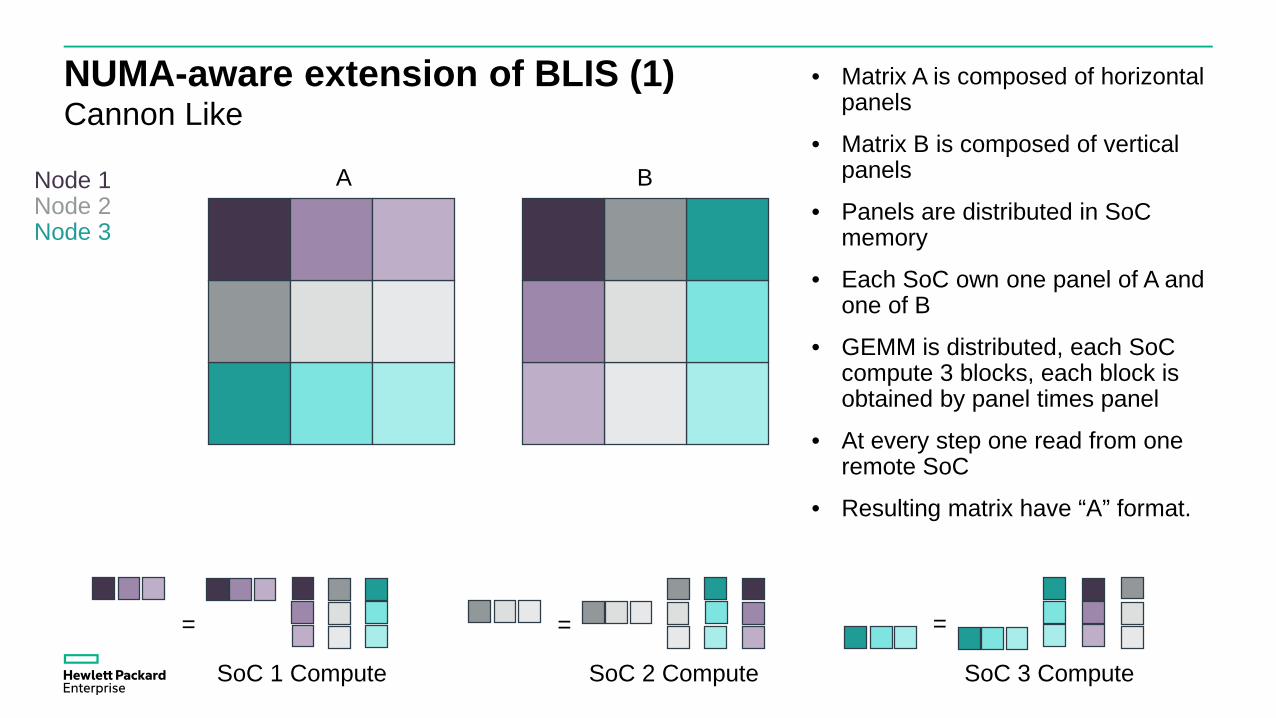
NUMA-aware extension of BLIS (1)Cannon Like
=
A B
SoC 1 Compute
=
SoC 2 Compute
=
SoC 3 Compute
Node 1 Node 2Node 3
• Matrix A is composed of horizontal panels
• Matrix B is composed of vertical panels
• Panels are distributed in SoCmemory
• Each SoC own one panel of A and one of B
• GEMM is distributed, each SoCcompute 3 blocks, each block is obtained by panel times panel
• At every step one read from one remote SoC
• Resulting matrix have “A” format.

NUMA-aware extension of BLIS (2)Blocks
=
A B
SoC 1 Compute
=
SoC 2 Compute
=
SoC 3 Compute
• A and B have the same format
• As previous every SoC reads from only one other SoC
• Unlike previous switch reading SoC after each block.
Node 1 Node 2Node 3

Other tricks
– Support for different memory pools (for different panels)– The entry point (bli_gemm) receives an array of obj_t that represent the panels of the matrix
– MCS barrier instead of linear
– Support for multiple thread entry points– To do not spawn new set of threads at every iteration (in every bli_gemm call)
– Affinity of threads– We pre-launch the threads, pin them to particular CPU cores using a #pragma omp (outside of blis), and then use
multiple threads entry points

SGEMM performance on Superdome X, comparison with a GPU system (2 NVIDIA Tesla K80)
22
0
2000
4000
6000
8000
10000
12000
14000
16000
0 10000 20000 30000 40000 50000 60000 70000
SG
EM
M P
ER
FOR
MA
NC
E (
GFL
OP
S )
MATRIX DIMENSION ( M=N=K )
DISTRIBUTED SGEMM PERFORMANCE
Intel ScaLAPACKPLASMA+OpenBLASCustom+BLIScuBLAS (1 GPU nocopy)cuBLAS (4 GPUs)cuBLAS (2 GPUs)
NUMA-BLIS v1

SGEMM performance on Superdome X
23
0
2000
4000
6000
8000
10000
12000
14000
16000
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
SG
EM
M P
ER
FOR
MA
NC
E (
GFL
OP
S )
MATRIX DIMENSION ( M=N=K )
DISTRIBUTED SGEMM PERFORMANCE
nvBLAS (4 GPUs)nvBLAS (2 GPUs)nvBLAS (1 GPU no copy)Custom + BLISnvBLAS (1 GPU)NUMA-BLIS v1
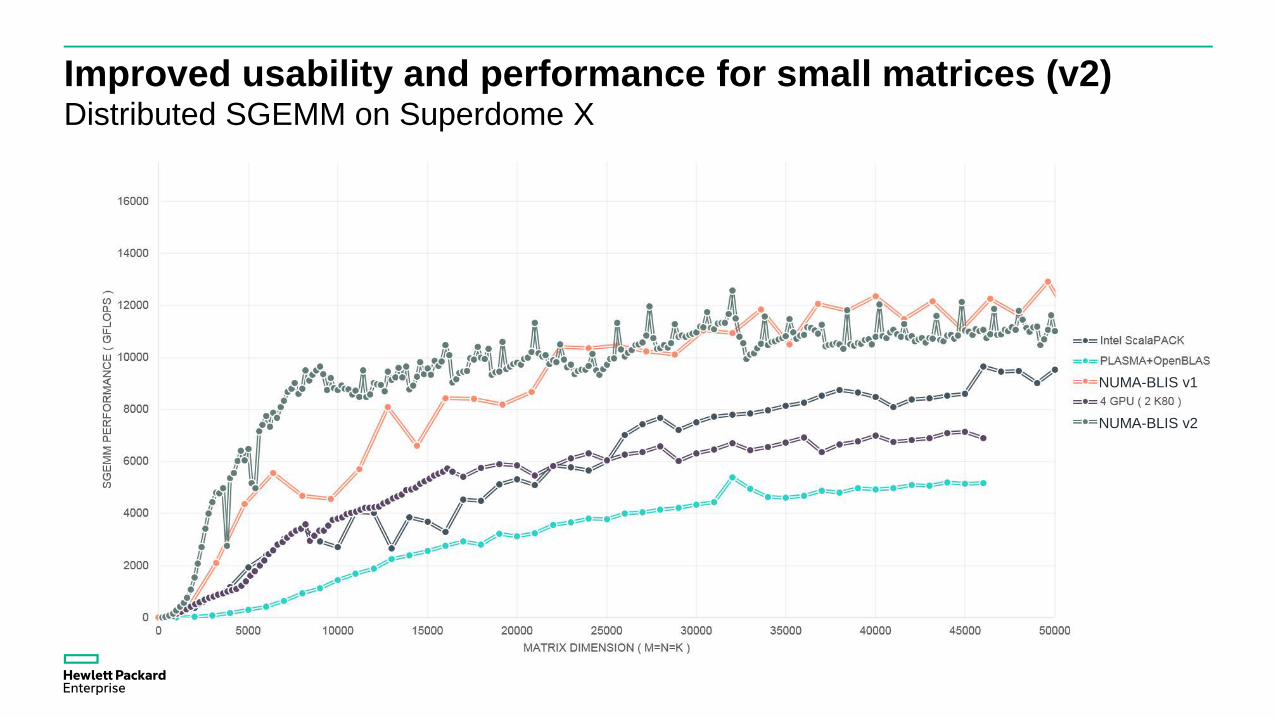
Improved usability and performance for small matrices (v2)Distributed SGEMM on Superdome X
NUMA-BLIS v1
NUMA-BLIS v2

Conclusion
– Done (almost): Extended BLIS (GEMM so far…) for multi-socket systems with shared memory– Matrix data is accessed directly– Synchronization via barriers– NUMA-aware
– In progress: Extended BLIS for The Machine– Matrix data is accessed directly– Matrix data is in NVM– Synchronization via MPI/RVMA

Thank [email protected]





























