Embed Size (px)
Citation preview

Scalable Replay with Partial-OrderDependencies for Message-Logging Fault
Tolerance
Jonathan Lifflander*, Esteban Meneses†, Harshitha Menon*,Phil Miller*, Sriram Krishnamoorthy‡, Laxmikant V. Kale*
[email protected], [email protected], {gplkrsh2,mille121}@illinois.edu,[email protected], [email protected]
*University of Illinois Urbana-Champaign (UIUC)†University of Pittsburgh
‡Pacific Northwest National Laboratory (PNNL)
September 23, 2014

Deterministic Replay & Fault Tolerance
� Fault tolerance often crosses over into replay territory!
� Popular usesI Online fault toleranceI Parallel debuggingI Reproducing results
� Types of replayI Data-driven replay
F Application/system data is recordedF Content of messages sent/received, etc.
I Control-driven replayF The ordering of events is recorded
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 2 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance2 / 33

Deterministic Replay & Fault Tolerance
� Fault tolerance often crosses over into replay territory!� Popular uses
I Online fault toleranceI Parallel debuggingI Reproducing results
� Types of replayI Data-driven replay
F Application/system data is recordedF Content of messages sent/received, etc.
I Control-driven replayF The ordering of events is recorded
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 2 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance2 / 33

Deterministic Replay & Fault Tolerance
� Fault tolerance often crosses over into replay territory!� Popular uses
I Online fault toleranceI Parallel debuggingI Reproducing results
� Types of replayI Data-driven replay
F Application/system data is recordedF Content of messages sent/received, etc.
I Control-driven replayF The ordering of events is recorded
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 2 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance2 / 33

Deterministic Replay & Fault Tolerance→ Our Focus
� Fault tolerance often crosses over into replay territory!� Popular uses
I Online fault toleranceI Parallel debuggingI Reproducing results
� Types of replayI Data-driven replay
F Application/system data is recordedF Content of messages sent/received, etc.
I Control-driven replayF The ordering of events is recorded
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 3 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance3 / 33

Online Fault Tolerance→ Hard failures
� Researchers have predicted that hard faults will increase
I Exascale!I Machines are getting largerI Projected to house more than 200,000 socketsI Hard failures may be frequent and only affect a small percentage of
nodes
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 4 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance4 / 33

Online Fault Tolerance→ Hard failures
� Researchers have predicted that hard faults will increaseI Exascale!
I Machines are getting largerI Projected to house more than 200,000 socketsI Hard failures may be frequent and only affect a small percentage of
nodes
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 4 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance4 / 33

Online Fault Tolerance→ Hard failures
� Researchers have predicted that hard faults will increaseI Exascale!I Machines are getting larger
I Projected to house more than 200,000 socketsI Hard failures may be frequent and only affect a small percentage of
nodes
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 4 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance4 / 33

Online Fault Tolerance→ Hard failures
� Researchers have predicted that hard faults will increaseI Exascale!I Machines are getting largerI Projected to house more than 200,000 sockets
I Hard failures may be frequent and only affect a small percentage ofnodes
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 4 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance4 / 33

Online Fault Tolerance→ Hard failures
� Researchers have predicted that hard faults will increaseI Exascale!I Machines are getting largerI Projected to house more than 200,000 socketsI Hard failures may be frequent and only affect a small percentage of
nodes
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 4 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance4 / 33

Online Fault Tolerance→ Approaches
� Checkpoint/restart (C/R)I Well-established methodI Save snapshot of system stateI Roll back to previous snapshot in case of failure
� Motivation beyond C/RI If a single node experiences a hard fault, why must all the nodes roll
back?I Recovering from C/R is expensive at large machine scales
F Complicated because it depends on many factors (e.g checkpointingfrequency)
� SolutionsI Application-specific fault toleranceI Other system-level approachesI Message-logging!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 5 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance5 / 33

Online Fault Tolerance→ Approaches
� Checkpoint/restart (C/R)I Well-established methodI Save snapshot of system stateI Roll back to previous snapshot in case of failure
� Motivation beyond C/RI If a single node experiences a hard fault, why must all the nodes roll
back?I Recovering from C/R is expensive at large machine scales
F Complicated because it depends on many factors (e.g checkpointingfrequency)
� SolutionsI Application-specific fault toleranceI Other system-level approachesI Message-logging!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 5 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance5 / 33

Online Fault Tolerance→ Approaches
� Checkpoint/restart (C/R)I Well-established methodI Save snapshot of system stateI Roll back to previous snapshot in case of failure
� Motivation beyond C/RI If a single node experiences a hard fault, why must all the nodes roll
back?I Recovering from C/R is expensive at large machine scales
F Complicated because it depends on many factors (e.g checkpointingfrequency)
� SolutionsI Application-specific fault toleranceI Other system-level approachesI Message-logging!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 5 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance5 / 33

Hard Failure System Model
� P processes that communicate via message passing
� Communication is across non-FIFO channelsI Sent asynchronouslyI Possibly out of order
� Guaranteed to arrive sometime in the future if the recipient processhas not failed
� Fail-stop model for all failuresI Failed processes do not recover from failuresI They do not behave maliciously (non-Byzantine failures)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 6 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance6 / 33

Hard Failure System Model
� P processes that communicate via message passing� Communication is across non-FIFO channels
I Sent asynchronouslyI Possibly out of order
� Guaranteed to arrive sometime in the future if the recipient processhas not failed
� Fail-stop model for all failuresI Failed processes do not recover from failuresI They do not behave maliciously (non-Byzantine failures)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 6 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance6 / 33

Hard Failure System Model
� P processes that communicate via message passing� Communication is across non-FIFO channels
I Sent asynchronouslyI Possibly out of order
� Guaranteed to arrive sometime in the future if the recipient processhas not failed
� Fail-stop model for all failuresI Failed processes do not recover from failuresI They do not behave maliciously (non-Byzantine failures)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 6 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance6 / 33

Hard Failure System Model
� P processes that communicate via message passing� Communication is across non-FIFO channels
I Sent asynchronouslyI Possibly out of order
� Guaranteed to arrive sometime in the future if the recipient processhas not failed
� Fail-stop model for all failuresI Failed processes do not recover from failuresI They do not behave maliciously (non-Byzantine failures)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 6 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance6 / 33

Sender-Based Causal Message Logging (SB-ML)
� Combination of data-driven and control-driven replayI Data-driven
F Messages sent are recordedI Control-driven
F Determinants are recorded to store the order of events
� Incurs costs in the form of time and storage overhead during forwardexecution
� Periodic checkpoints reduce storage overheadI Recovery effort is limited to work executed after the latest checkpointI Data stored before the checkpoint can be discarded
� Scalable implementation in Charm++
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 7 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance7 / 33

Sender-Based Causal Message Logging (SB-ML)
� Combination of data-driven and control-driven replayI Data-driven
F Messages sent are recordedI Control-driven
F Determinants are recorded to store the order of events
� Incurs costs in the form of time and storage overhead during forwardexecution
� Periodic checkpoints reduce storage overheadI Recovery effort is limited to work executed after the latest checkpointI Data stored before the checkpoint can be discarded
� Scalable implementation in Charm++
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 7 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance7 / 33

Sender-Based Causal Message Logging (SB-ML)
� Combination of data-driven and control-driven replayI Data-driven
F Messages sent are recordedI Control-driven
F Determinants are recorded to store the order of events
� Incurs costs in the form of time and storage overhead during forwardexecution
� Periodic checkpoints reduce storage overheadI Recovery effort is limited to work executed after the latest checkpointI Data stored before the checkpoint can be discarded
� Scalable implementation in Charm++
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 7 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance7 / 33

Sender-Based Causal Message Logging (SB-ML)
� Combination of data-driven and control-driven replayI Data-driven
F Messages sent are recordedI Control-driven
F Determinants are recorded to store the order of events
� Incurs costs in the form of time and storage overhead during forwardexecution
� Periodic checkpoints reduce storage overheadI Recovery effort is limited to work executed after the latest checkpointI Data stored before the checkpoint can be discarded
� Scalable implementation in Charm++
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 7 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance7 / 33
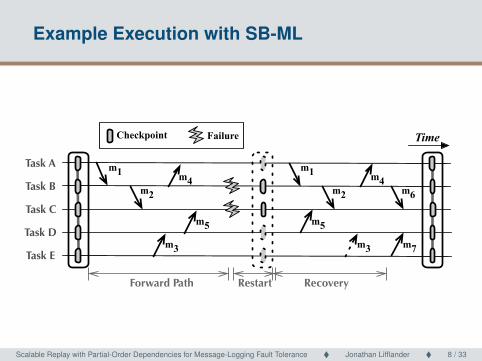
Example Execution with SB-ML
Checkpoint Failure
Task A
Task B
Task D
Task E
Restart
m1
m2
Time
Task C
m3
m4
m5
m1
m2
m3
m4
m5
Recovery
m6
m7
Forward Path
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 8 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance8 / 33
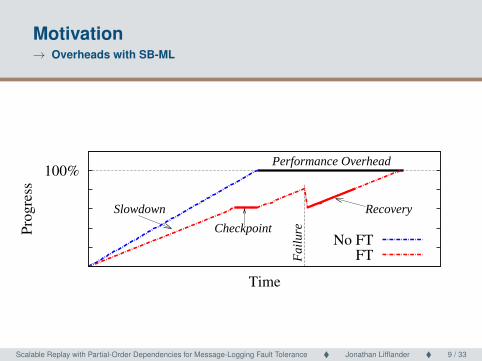
Motivation→ Overheads with SB-ML
100%
Pro
gre
ss
Time
Performance Overhead
Slowdown
Checkpoint
Recovery
Fai
lure
No FTFT
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 9 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance9 / 33

Forward Execution Overhead with SB-ML
� Logging the messagesI Just requires a pointer to be saved and message is not deallocated!I Increases memory pressure
� Determinants, 4-tuple of the form: <SPE,SSN,RPE,RSN>
I Components:F Sender processor (SPE)F Sender sequence number (SSN)F Receiver processor (RPE)F Receiver sequence number (RSN)
I Must be stored stably based on the reliability requirementsF Propagated to n processorsF Unacknowledged determinants are augmented onto new messages (to
avoid frequent synchronizations)I Recovery
F Messages must be replayed in a total order
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 10 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance10 / 33

Forward Execution Overhead with SB-ML
� Logging the messagesI Just requires a pointer to be saved and message is not deallocated!I Increases memory pressure
� Determinants, 4-tuple of the form: <SPE,SSN,RPE,RSN>I Components:
F Sender processor (SPE)F Sender sequence number (SSN)F Receiver processor (RPE)F Receiver sequence number (RSN)
I Must be stored stably based on the reliability requirementsF Propagated to n processorsF Unacknowledged determinants are augmented onto new messages (to
avoid frequent synchronizations)I Recovery
F Messages must be replayed in a total order
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 10 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance10 / 33

Forward Execution Overhead with SB-ML
� Logging the messagesI Just requires a pointer to be saved and message is not deallocated!I Increases memory pressure
� Determinants, 4-tuple of the form: <SPE,SSN,RPE,RSN>I Components:
F Sender processor (SPE)F Sender sequence number (SSN)F Receiver processor (RPE)F Receiver sequence number (RSN)
I Must be stored stably based on the reliability requirementsF Propagated to n processorsF Unacknowledged determinants are augmented onto new messages (to
avoid frequent synchronizations)
I RecoveryF Messages must be replayed in a total order
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 10 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance10 / 33

Forward Execution Overhead with SB-ML
� Logging the messagesI Just requires a pointer to be saved and message is not deallocated!I Increases memory pressure
� Determinants, 4-tuple of the form: <SPE,SSN,RPE,RSN>I Components:
F Sender processor (SPE)F Sender sequence number (SSN)F Receiver processor (RPE)F Receiver sequence number (RSN)
I Must be stored stably based on the reliability requirementsF Propagated to n processorsF Unacknowledged determinants are augmented onto new messages (to
avoid frequent synchronizations)I Recovery
F Messages must be replayed in a total order
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 10 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance10 / 33

Forward Execution Microbenchmark (SB-ML)
Component Overhead (%)
Determinants 84.75%Bookkeeping 11.65%
Message-envelope size increase 3.10%Message storage 0.50%
� Using the LeanMD (molecular dynamics) benchmark� Measured on 256 cores of Ranger� Largest source of overhead is determinants
I Creating, storing, sending, etc.
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 11 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance11 / 33

Benchmarks→ Runtime System—Charm++
� Decompose parallel computation into objects that communicateI More objects than number of processorsI Objects communicate by sending messagesI Computation is oblivious to the processors
� BenefitsI Load balancing, message-driven execution, fault tolerance, etc.
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 12 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance12 / 33

Benchmarks→ Runtime System—Charm++
� Decompose parallel computation into objects that communicateI More objects than number of processorsI Objects communicate by sending messagesI Computation is oblivious to the processors
� BenefitsI Load balancing, message-driven execution, fault tolerance, etc.
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 12 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance12 / 33

Benchmarks→ Configuration & Experimental Setup
Benchmark Configuration
STENCIL3D matrix: 40963, chunk: 643
LEANMD (mini-app for NAMD) 600K atoms, 2-away XY, 75 atoms/cellLULESH (shock hydrodynamics) matrix: 1024x5122, chunk: 16x82
� All experiments on IBM Blue Gene/P (BG/P), ‘Intrepid’� 40960-node system
I Each node consists of one quad-core 850MHz PowerPC 450I 2GB DDR2 memory
� Compiler: IBM XL C/C++ Advanced Edition for Blue Gene/P, V9.0� Runtime: Charm++ 6.5.1
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 13 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance13 / 33
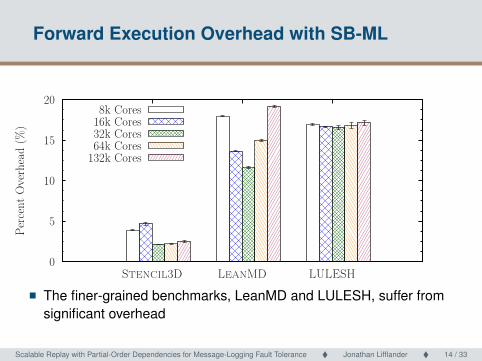
Forward Execution Overhead with SB-ML
0
5
10
15
20
Stencil3D LeanMD LULESH
Per
cent
Ove
rhea
d (
%)
8k Cores16k Cores32k Cores64k Cores
132k Cores
� The finer-grained benchmarks, LeanMD and LULESH, suffer fromsignificant overhead
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 14 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance14 / 33

Reducing the Overhead of Determinants
� Design CriteriaI We must maintain full determinism
I We must devolve well for all cases (even very non-deterministicprograms)
I Need to consider tasks or lightweight objects
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 15 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance15 / 33

Reducing the Overhead of Determinants
� Design CriteriaI We must maintain full determinismI We must devolve well for all cases (even very non-deterministic
programs)
I Need to consider tasks or lightweight objects
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 15 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance15 / 33

Reducing the Overhead of Determinants
� Design CriteriaI We must maintain full determinismI We must devolve well for all cases (even very non-deterministic
programs)I Need to consider tasks or lightweight objects
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 15 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance15 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinism
F Causality tracking (1988: Fidge, Partial orders for parallel debugging)F Racing messages (1992: Netzer, et al., Optimal tracing and replay for
debugging message-passing parallel programs)F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testing
and debugging in message passing parallel programs)F Block races (1995: Clemencon, An implementation of race detection and
deterministic replay with MPIF MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis for
debugging massively parallel programs)F . . .F Send-determinism (2011: Guermouche, et al., Uncoordinated
checkpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinismF Causality tracking (1988: Fidge, Partial orders for parallel debugging)
F Racing messages (1992: Netzer, et al., Optimal tracing and replay fordebugging message-passing parallel programs)
F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testingand debugging in message passing parallel programs)
F Block races (1995: Clemencon, An implementation of race detection anddeterministic replay with MPI
F MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis fordebugging massively parallel programs)
F . . .F Send-determinism (2011: Guermouche, et al., Uncoordinated
checkpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinismF Causality tracking (1988: Fidge, Partial orders for parallel debugging)F Racing messages (1992: Netzer, et al., Optimal tracing and replay for
debugging message-passing parallel programs)
F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testingand debugging in message passing parallel programs)
F Block races (1995: Clemencon, An implementation of race detection anddeterministic replay with MPI
F MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis fordebugging massively parallel programs)
F . . .F Send-determinism (2011: Guermouche, et al., Uncoordinated
checkpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinismF Causality tracking (1988: Fidge, Partial orders for parallel debugging)F Racing messages (1992: Netzer, et al., Optimal tracing and replay for
debugging message-passing parallel programs)F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testing
and debugging in message passing parallel programs)
F Block races (1995: Clemencon, An implementation of race detection anddeterministic replay with MPI
F MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis fordebugging massively parallel programs)
F . . .F Send-determinism (2011: Guermouche, et al., Uncoordinated
checkpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinismF Causality tracking (1988: Fidge, Partial orders for parallel debugging)F Racing messages (1992: Netzer, et al., Optimal tracing and replay for
debugging message-passing parallel programs)F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testing
and debugging in message passing parallel programs)F Block races (1995: Clemencon, An implementation of race detection and
deterministic replay with MPI
F MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis fordebugging massively parallel programs)
F . . .F Send-determinism (2011: Guermouche, et al., Uncoordinated
checkpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinismF Causality tracking (1988: Fidge, Partial orders for parallel debugging)F Racing messages (1992: Netzer, et al., Optimal tracing and replay for
debugging message-passing parallel programs)F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testing
and debugging in message passing parallel programs)F Block races (1995: Clemencon, An implementation of race detection and
deterministic replay with MPIF MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis for
debugging massively parallel programs)
F . . .F Send-determinism (2011: Guermouche, et al., Uncoordinated
checkpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinismF Causality tracking (1988: Fidge, Partial orders for parallel debugging)F Racing messages (1992: Netzer, et al., Optimal tracing and replay for
debugging message-passing parallel programs)F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testing
and debugging in message passing parallel programs)F Block races (1995: Clemencon, An implementation of race detection and
deterministic replay with MPIF MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis for
debugging massively parallel programs)F . . .
F Send-determinism (2011: Guermouche, et al., Uncoordinatedcheckpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Reducing the Overhead of Determinants
� ‘Intrinsic’ determinismI Many researchers have noticed that programs have internal
determinismF Causality tracking (1988: Fidge, Partial orders for parallel debugging)F Racing messages (1992: Netzer, et al., Optimal tracing and replay for
debugging message-passing parallel programs)F Theoretical races (1993: Damodaran-Kamal, Nondeterminancy: testing
and debugging in message passing parallel programs)F Block races (1995: Clemencon, An implementation of race detection and
deterministic replay with MPIF MPI and Non-determinism (2000: Kranzlmuller, Event graph analysis for
debugging massively parallel programs)F . . .F Send-determinism (2011: Guermouche, et al., Uncoordinated
checkpointing without domino effect for send-deterministic MPIapplications)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 16 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance16 / 33

Our Approach
� In many cases, only a partial order must be stored for full determinism
I Program = internal determinism + non-determinism + commutative
I Internal determinism requires no determinants!I Commutative events require no determinants!I Approach: use determinants to store a partial order for the
non-deterministic events that are not commutative
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 17 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance17 / 33

Our Approach
� In many cases, only a partial order must be stored for full determinism
I Program = internal determinism + non-determinism + commutativeI Internal determinism requires no determinants!
I Commutative events require no determinants!I Approach: use determinants to store a partial order for the
non-deterministic events that are not commutative
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 17 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance17 / 33

Our Approach
� In many cases, only a partial order must be stored for full determinism
I Program = internal determinism + non-determinism + commutativeI Internal determinism requires no determinants!I Commutative events require no determinants!
I Approach: use determinants to store a partial order for thenon-deterministic events that are not commutative
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 17 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance17 / 33

Our Approach
� In many cases, only a partial order must be stored for full determinism
I Program = internal determinism + non-determinism + commutativeI Internal determinism requires no determinants!I Commutative events require no determinants!I Approach: use determinants to store a partial order for the
non-deterministic events that are not commutative
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 17 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance17 / 33

Ordering Algebra→ Ordered Sets, O
� O(n, d)I Set of n events and d dependencies
I Can be accurately replayed from a given starting pointI Dependencies d can be among the events in the set, or on preceding
eventsI Intuitively, they are ordered sets of events
� Define sequencing operation, �:O(1, d1)�O(1, d2) = O(2, d1 + d2 + 1)I Intuitively, if we have two atomic events, we need a single dependency
to tell us which one comes first
� Generalization: O(n1, d1)�O(n2, d2) = O(n1 + n2, d1 + d2 + 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 18 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance18 / 33

Ordering Algebra→ Ordered Sets, O
� O(n, d)I Set of n events and d dependenciesI Can be accurately replayed from a given starting point
I Dependencies d can be among the events in the set, or on precedingevents
I Intuitively, they are ordered sets of events� Define sequencing operation, �:O(1, d1)�O(1, d2) = O(2, d1 + d2 + 1)I Intuitively, if we have two atomic events, we need a single dependency
to tell us which one comes first
� Generalization: O(n1, d1)�O(n2, d2) = O(n1 + n2, d1 + d2 + 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 18 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance18 / 33

Ordering Algebra→ Ordered Sets, O
� O(n, d)I Set of n events and d dependenciesI Can be accurately replayed from a given starting pointI Dependencies d can be among the events in the set, or on preceding
events
I Intuitively, they are ordered sets of events� Define sequencing operation, �:O(1, d1)�O(1, d2) = O(2, d1 + d2 + 1)I Intuitively, if we have two atomic events, we need a single dependency
to tell us which one comes first
� Generalization: O(n1, d1)�O(n2, d2) = O(n1 + n2, d1 + d2 + 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 18 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance18 / 33

Ordering Algebra→ Ordered Sets, O
� O(n, d)I Set of n events and d dependenciesI Can be accurately replayed from a given starting pointI Dependencies d can be among the events in the set, or on preceding
eventsI Intuitively, they are ordered sets of events
� Define sequencing operation, �:O(1, d1)�O(1, d2) = O(2, d1 + d2 + 1)I Intuitively, if we have two atomic events, we need a single dependency
to tell us which one comes first
� Generalization: O(n1, d1)�O(n2, d2) = O(n1 + n2, d1 + d2 + 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 18 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance18 / 33

Ordering Algebra→ Ordered Sets, O
� O(n, d)I Set of n events and d dependenciesI Can be accurately replayed from a given starting pointI Dependencies d can be among the events in the set, or on preceding
eventsI Intuitively, they are ordered sets of events
� Define sequencing operation, �:O(1, d1)�O(1, d2) = O(2, d1 + d2 + 1)I Intuitively, if we have two atomic events, we need a single dependency
to tell us which one comes first
� Generalization: O(n1, d1)�O(n2, d2) = O(n1 + n2, d1 + d2 + 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 18 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance18 / 33

Ordering Algebra→ Unordered Sets, U
� U(n, d)I Unordered set of n events and d dependencies
I Example is where several messages are sent to a single endpointI Depending the order of arrival, the eventual state will be different
� We decompose this into atomic events with an additional dependencybetween each successive pair:
U(n, d) = O(1, d1)�O(1, d2)� · · ·�O(1, dn)= O(n, d+ n− 1)
where d =∑
di
I Result: additional n− 1 dependencies required to fully order n events
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 19 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance19 / 33

Ordering Algebra→ Unordered Sets, U
� U(n, d)I Unordered set of n events and d dependenciesI Example is where several messages are sent to a single endpoint
I Depending the order of arrival, the eventual state will be different
� We decompose this into atomic events with an additional dependencybetween each successive pair:
U(n, d) = O(1, d1)�O(1, d2)� · · ·�O(1, dn)= O(n, d+ n− 1)
where d =∑
di
I Result: additional n− 1 dependencies required to fully order n events
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 19 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance19 / 33

Ordering Algebra→ Unordered Sets, U
� U(n, d)I Unordered set of n events and d dependenciesI Example is where several messages are sent to a single endpointI Depending the order of arrival, the eventual state will be different
� We decompose this into atomic events with an additional dependencybetween each successive pair:
U(n, d) = O(1, d1)�O(1, d2)� · · ·�O(1, dn)= O(n, d+ n− 1)
where d =∑
di
I Result: additional n− 1 dependencies required to fully order n events
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 19 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance19 / 33

Ordering Algebra→ Unordered Sets, U
� U(n, d)I Unordered set of n events and d dependenciesI Example is where several messages are sent to a single endpointI Depending the order of arrival, the eventual state will be different
� We decompose this into atomic events with an additional dependencybetween each successive pair:
U(n, d) = O(1, d1)�O(1, d2)� · · ·�O(1, dn)= O(n, d+ n− 1)
where d =∑
diI Result: additional n− 1 dependencies required to fully order n events
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 19 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance19 / 33

Ordering Algebra→ Interleaving Multiple Independent Sets, � operator
Lemma
Any possible interleaving of two ordered sets of events A = O(m, d) andB = O(n, e), where A ∩B = ∅, is given by:O(m, d)�O(n, e) = O(m+ n, d+ e+min(m,n))
Lemma
Any possible ordering of n ordered set of eventsO(m1, d1),O(m2, d2), . . . ,O(mn, dn), when
⋂iO(mi, di) = ∅, can be
represented as:n
�i=1O(mi, di) = O(m, d+m−maximi) where
m =n∑
i=1mi ∧ d =
n∑i=1
di
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 20 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance20 / 33

Internal Determinism→ D
� D(n) = O(n, 0)� n deterministically ordered events are structurally equivalent to an
ordered set of n events with no associated explicit dependencies!
� What happens if we interleave internal determinism with somethingelse?
� k interruption points => O(k, k − 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 21 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance21 / 33

Internal Determinism→ D
� D(n) = O(n, 0)� n deterministically ordered events are structurally equivalent to an
ordered set of n events with no associated explicit dependencies!� What happens if we interleave internal determinism with something
else?
� k interruption points => O(k, k − 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 21 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance21 / 33

Internal Determinism→ D
� D(n) = O(n, 0)� n deterministically ordered events are structurally equivalent to an
ordered set of n events with no associated explicit dependencies!� What happens if we interleave internal determinism with something
else?� k interruption points => O(k, k − 1)
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 21 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance21 / 33

Communtative Events→ C
� Some events in programs are communtativeI Regardless of the execution order the state will be identical
� All existing theories of message logging execute record a total orderon them
� However we can reduce a commutative set to:I C(n) = O(2, 1)I A beginning and end event sequenced togetherI Sequencing other sets of event around the region just puts them before
and after
I Interleaving other events puts them in three buckets:F (1) before the begin eventF (2) during the commutative regionF (3) after the end event
I This corresponds exactly to an ordered set of two events!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 22 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance22 / 33

Communtative Events→ C
� Some events in programs are communtativeI Regardless of the execution order the state will be identical
� All existing theories of message logging execute record a total orderon them
� However we can reduce a commutative set to:I C(n) = O(2, 1)I A beginning and end event sequenced togetherI Sequencing other sets of event around the region just puts them before
and after
I Interleaving other events puts them in three buckets:F (1) before the begin eventF (2) during the commutative regionF (3) after the end event
I This corresponds exactly to an ordered set of two events!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 22 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance22 / 33

Communtative Events→ C
� Some events in programs are communtativeI Regardless of the execution order the state will be identical
� All existing theories of message logging execute record a total orderon them
� However we can reduce a commutative set to:I C(n) = O(2, 1)I A beginning and end event sequenced togetherI Sequencing other sets of event around the region just puts them before
and after
I Interleaving other events puts them in three buckets:F (1) before the begin eventF (2) during the commutative regionF (3) after the end event
I This corresponds exactly to an ordered set of two events!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 22 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance22 / 33

Communtative Events→ C
� Some events in programs are communtativeI Regardless of the execution order the state will be identical
� All existing theories of message logging execute record a total orderon them
� However we can reduce a commutative set to:I C(n) = O(2, 1)I A beginning and end event sequenced togetherI Sequencing other sets of event around the region just puts them before
and afterI Interleaving other events puts them in three buckets:
F (1) before the begin eventF (2) during the commutative regionF (3) after the end event
I This corresponds exactly to an ordered set of two events!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 22 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance22 / 33

Communtative Events→ C
� Some events in programs are communtativeI Regardless of the execution order the state will be identical
� All existing theories of message logging execute record a total orderon them
� However we can reduce a commutative set to:I C(n) = O(2, 1)I A beginning and end event sequenced togetherI Sequencing other sets of event around the region just puts them before
and afterI Interleaving other events puts them in three buckets:
F (1) before the begin eventF (2) during the commutative regionF (3) after the end event
I This corresponds exactly to an ordered set of two events!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 22 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance22 / 33

Applying the Theory→ PO-REPLAY: Partial-Order Message Identification Scheme
� PropertiesI It tracks causality with Lamport clocksI It uniquely identifies a sent message, whether or not its order is
transposedI It requires exactly the number of determinants and dependencies
produced by the ordering algebra
� Determinant Composition (3-tuple): <SRN,SPE,CPI>I SRN: sender region number, incremented for every send outside a
commutative region and incremented once when a commutative regionstarts
I SPE: sender processor endpointI CPI: commutative path identifier, sequence of bits that represents the
path to the root of the commutative region
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 23 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance23 / 33

Applying the Theory→ PO-REPLAY: Partial-Order Message Identification Scheme
� PropertiesI It tracks causality with Lamport clocksI It uniquely identifies a sent message, whether or not its order is
transposedI It requires exactly the number of determinants and dependencies
produced by the ordering algebra� Determinant Composition (3-tuple): <SRN,SPE,CPI>
I SRN: sender region number, incremented for every send outside acommutative region and incremented once when a commutative regionstarts
I SPE: sender processor endpointI CPI: commutative path identifier, sequence of bits that represents the
path to the root of the commutative region
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 23 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance23 / 33
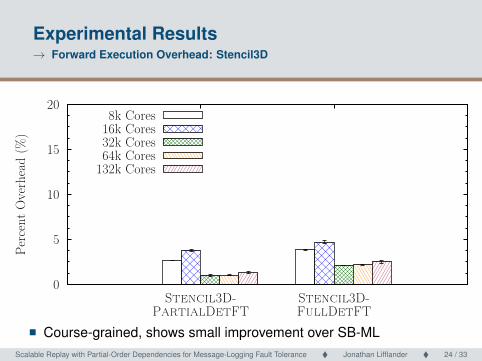
Experimental Results→ Forward Execution Overhead: Stencil3D
0
5
10
15
20
Stencil3D-
PartialDetFT
Stencil3D-
FullDetFT
Per
cent
Ove
rhea
d (
%)
8k Cores16k Cores32k Cores64k Cores
132k Cores
� Course-grained, shows small improvement over SB-MLScalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 24 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance24 / 33
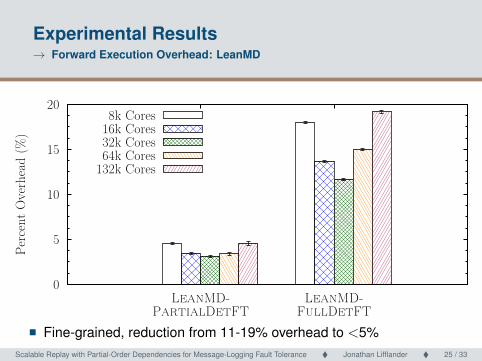
Experimental Results→ Forward Execution Overhead: LeanMD
0
5
10
15
20
LeanMD-
PartialDetFT
LeanMD-
FullDetFT
Per
cent
Ove
rhea
d (
%)
8k Cores16k Cores32k Cores64k Cores
132k Cores
� Fine-grained, reduction from 11-19% overhead to <5%Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 25 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance25 / 33
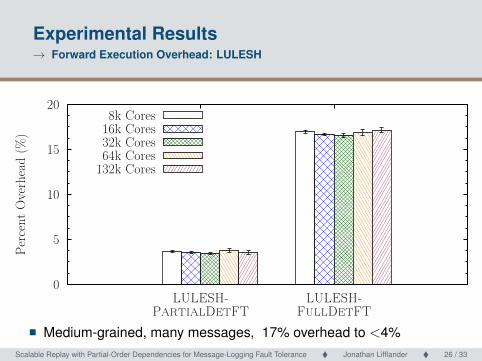
Experimental Results→ Forward Execution Overhead: LULESH
0
5
10
15
20
LULESH-
PartialDetFT
LULESH-
FullDetFT
Per
cent
Ove
rhea
d (
%)
8k Cores16k Cores32k Cores64k Cores
132k Cores
� Medium-grained, many messages, 17% overhead to <4%Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 26 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance26 / 33

Experimental Results→ Fault Injection
� Measure the recovery time for the different protocols
I We inject a simulated fault on a random nodeI During approximately the middle of the periodI We calculate the optimal checkpoint period duration using Daly’s
formulaF Assuming 64K–1M socket countF Assuming MTBF of 10 years
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 27 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance27 / 33

Experimental Results→ Fault Injection
� Measure the recovery time for the different protocolsI We inject a simulated fault on a random node
I During approximately the middle of the periodI We calculate the optimal checkpoint period duration using Daly’s
formulaF Assuming 64K–1M socket countF Assuming MTBF of 10 years
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 27 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance27 / 33

Experimental Results→ Fault Injection
� Measure the recovery time for the different protocolsI We inject a simulated fault on a random nodeI During approximately the middle of the period
I We calculate the optimal checkpoint period duration using Daly’sformulaF Assuming 64K–1M socket countF Assuming MTBF of 10 years
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 27 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance27 / 33

Experimental Results→ Fault Injection
� Measure the recovery time for the different protocolsI We inject a simulated fault on a random nodeI During approximately the middle of the periodI We calculate the optimal checkpoint period duration using Daly’s
formulaF Assuming 64K–1M socket countF Assuming MTBF of 10 years
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 27 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance27 / 33
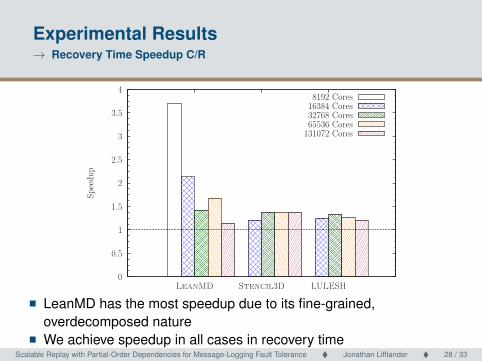
Experimental Results→ Recovery Time Speedup C/R
0
0.5
1
1.5
2
2.5
3
3.5
4
LeanMD Stencil3D LULESH
Spee
dup
8192 Cores16384 Cores32768 Cores65536 Cores
131072 Cores
� LeanMD has the most speedup due to its fine-grained,overdecomposed nature
� We achieve speedup in all cases in recovery timeScalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 28 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance28 / 33

Experimental Results→ Recovery Time Speedup SB-ML
0
0.5
1
1.5
2
2.5
LeanMD Stencil3D LULESH
Spee
dup
8192 Cores16384 Cores32768 Cores65536 Cores
131072 Cores
� Increased speedup with scale, due to expense of coordinatingdeterminants and ordering
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 29 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance29 / 33
Experimental Results→ Summary
� Our new message logging protocol has about <5% overhead for thebenchmarks tested
� Recover is significantly faster than C/R or causal� Depending on the frequency of faults, it may perform better than C/R
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 30 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance30 / 33

Experimental Results→ Summary
� Our new message logging protocol has about <5% overhead for thebenchmarks tested
� Recover is significantly faster than C/R or causal
� Depending on the frequency of faults, it may perform better than C/R
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 30 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance30 / 33

Experimental Results→ Summary
� Our new message logging protocol has about <5% overhead for thebenchmarks tested
� Recover is significantly faster than C/R or causal� Depending on the frequency of faults, it may perform better than C/R
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 30 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance30 / 33

Future Work
� More benchmarks
� Study for broader range of programming models� Memory overhead of message logging makes it infeasible for some
applications� Automated extraction of ordering and interleaving properties� Programming language support?
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 31 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance31 / 33

Future Work
� More benchmarks� Study for broader range of programming models
� Memory overhead of message logging makes it infeasible for someapplications
� Automated extraction of ordering and interleaving properties� Programming language support?
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 31 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance31 / 33

Future Work
� More benchmarks� Study for broader range of programming models� Memory overhead of message logging makes it infeasible for some
applications
� Automated extraction of ordering and interleaving properties� Programming language support?
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 31 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance31 / 33

Future Work
� More benchmarks� Study for broader range of programming models� Memory overhead of message logging makes it infeasible for some
applications� Automated extraction of ordering and interleaving properties
� Programming language support?
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 31 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance31 / 33

Future Work
� More benchmarks� Study for broader range of programming models� Memory overhead of message logging makes it infeasible for some
applications� Automated extraction of ordering and interleaving properties� Programming language support?
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 31 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance31 / 33

Conclusion
� Comprehensive approach for reasoning about execution orderingsand interleavings
� We observe that the information stored can be reduced in proportionto the knowledge of order flexibility
� Programming paradigms should make this cost model clearer!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 32 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance32 / 33

Conclusion
� Comprehensive approach for reasoning about execution orderingsand interleavings
� We observe that the information stored can be reduced in proportionto the knowledge of order flexibility
� Programming paradigms should make this cost model clearer!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 32 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance32 / 33

Conclusion
� Comprehensive approach for reasoning about execution orderingsand interleavings
� We observe that the information stored can be reduced in proportionto the knowledge of order flexibility
� Programming paradigms should make this cost model clearer!
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance � Jonathan Lifflander � 32 / 33 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance32 / 33

Questions?





























