Embed Size (px)
Citation preview

1
Scaling and Cloud ConceptsSGN-5226 Content Sharing Technologies and Services
21.11.2010

Background
2
Internet services are expected to serve a number of concurrent users
Some times the ”demand” is higher than the amount of users the infrastructure can handle That could be in terms of:infrastructure can handle. That could be in terms of:
• Processing power• Memory• Storage
Bandwidth• Bandwidth• …
One of the things that can “kill” a successful service, is its own success. Not being able to “scale” for the users that want to try/use the service, thus providing a poor user experience to them (e.g. slow)
21.11.2010
Twitter Fail Whale
3
Have you seen this?
21.11.2010

Scaling Up (and down)
4
When building a web infrastructure it is important to have a strategy/plan for growing and shrinking the system, so that it conservative both
• Timely• and Economicallyy
Definition of Scale?• How well a specific solution fits a problem, as the scope of the problem
increasesincreases
21.11.2010
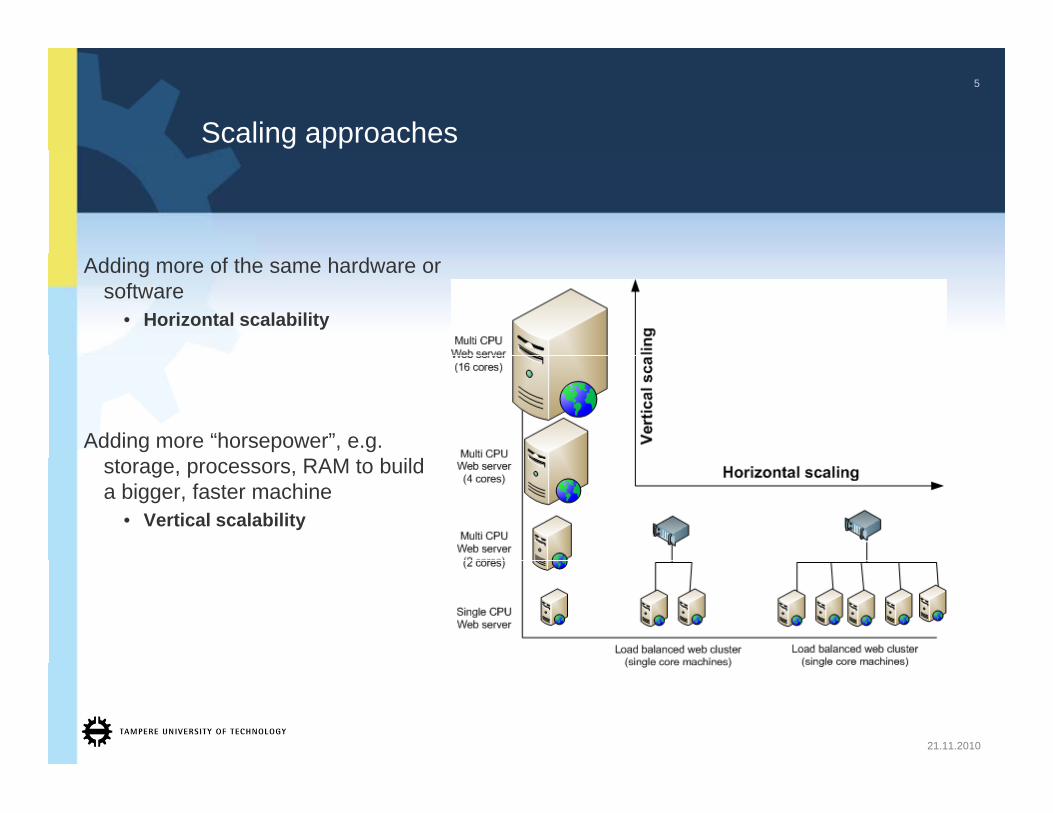
Scaling approaches
5
Adding more of the same hardware or software
• Horizontal scalability
Adding more “horsepower”, e.g. RAM b ildstorage, processors, RAM to build
a bigger, faster machine • Vertical scalability
21.11.2010

Scaling approaches
6
Adding more of the same hardware or software
• Horizontal scalability• The best and TRUE scalabilityy
Adding more “horsepower”, e.g. t RAM t b ildstorage, processors, RAM to build
a bigger, faster machine • Vertical scalability
21.11.2010

What goes up should go down
7
Typically, the term scalable is linked to the notion of a system scale up
Typical concerns:• That the architecture/system will break and not be able to offer its services• That the architecture/system will break and not be able to offer its services• Time and money will be spent to redesign the system, for handling the load
However, there is a need to have a planned scaling down approach• Having more hardware/resources than are really needed is also having a
financial impact
Scaling up is typically more difficult than scaling down, and it is easier to scale down if you have previously gone through the process of scaling up
Companies might collapse due to inability of reducing operating costs, when utilization of their infrastructure is decreasingwhen utilization of their infrastructure is decreasing
• Loyal users hanging in the air…
21.11.2010

Considerations in real life
8
When starting a scaling up attempt, the following are going to happen (for sure)
• Capital investment will be made• Complexity of the system will increaseComplexity of the system will increase• Running the system costs (maintenance) will increase• Time will be needed for acting and performing the scaling
21.11.2010

Typical approaches
9
• Small companies and start-ups• Emphasis on reducing up-front investment and time
• Large companiesLarge companies• Minimize risk• Maximize simplicity and maintainability of their systems
21.11.2010

10
Avoiding Failure
21.11.2010

Working in teams
11
Why work in teams• Typical work in a large system exceeds what is possible for an individual
human to achieve• Easier (and less expensive) to find individuals with deep focusedEasier (and less expensive) to find individuals with deep focused
expertise in one of the technologies used, than finding individuals with deep and broad expertise across all technologies
• There must be business continuity even if the “key man” is hit by a bus (or just quits the company)(or just quits the company)
21.11.2010

The obvious
12
• Nobody likes to lose data• Nobody likes to have services that cannot be accessed• Nobody likes to clean up a mess• Nobody likes to spend money• Nobody likes to spend money
21.11.2010

Some basic economics laws
13
• Law of diminishing returns• When workers are added to the wheat field, at some point, each additional
worker will contribute less than his predecessor
• Moore’s Law• Computers get faster every year, as they double their speed, capacity,
performance every 18 months• Great but…• What you buy today is obsolete tomorrow
• Combine those two… =• The “best” technology that you can buy today is expensive• The best technology that you can buy today is expensive• Effectively at the “top end” of the performance curve, more buys you less• The fast, big expensive machine you buy today will be inexpensive tomorrow
and obsolete the day after.• Or in other words you can actually get a better return if you buy• Or, in other words, you can actually get a better return if you buy
commodity hardware• Scale horizontally, not vertically
21.11.2010

Stability and Control
14
Stability and control is again an obvious requirement
Uncontrolled change is the most feared issue in a mission-critical system• Removing features• Removing features• Milestone changing (getting future features in earlier milestones)• Not strict version control• Premature and implementationp
As it has many forms, it can be difficult to recognize, until the failure happens (and the business might all go down…)
21.11.2010

Version Control
15
• Easy, simple and safe way to control changes and revert when needed• Both for code and configurations
• Routers, balancers, firewalls, servers… everything has a configuration fileRouters, balancers, firewalls, servers… everything has a configuration file
• Good idea to have an automatic process that will backup important files, from all production servers, to version control
C f f• Configuration files• Custom kernels• Package applications• Database schemas• …
• Be prepared for a bare-metal recovery (e.g. if hardware dies)
21.11.2010

16
High Availability
21.11.2010

High Availability
17
• Many times people confuse the terms high availability with load balancing
• High availability = things always available, even in the case of an unexpected failure (e g hardware fail) = fault tolerantunexpected failure (e.g. hardware fail) fault tolerant
Fault tolerance: The capacity of a system or component to continue to operate normally despite of hardware of software faults.
• Simple analogy: The show must go on, even if an actor dies…
21.11.2010

No fault tolerant network
18
If a component fails, the service cannot survive
How many components can fail?
21.11.2010
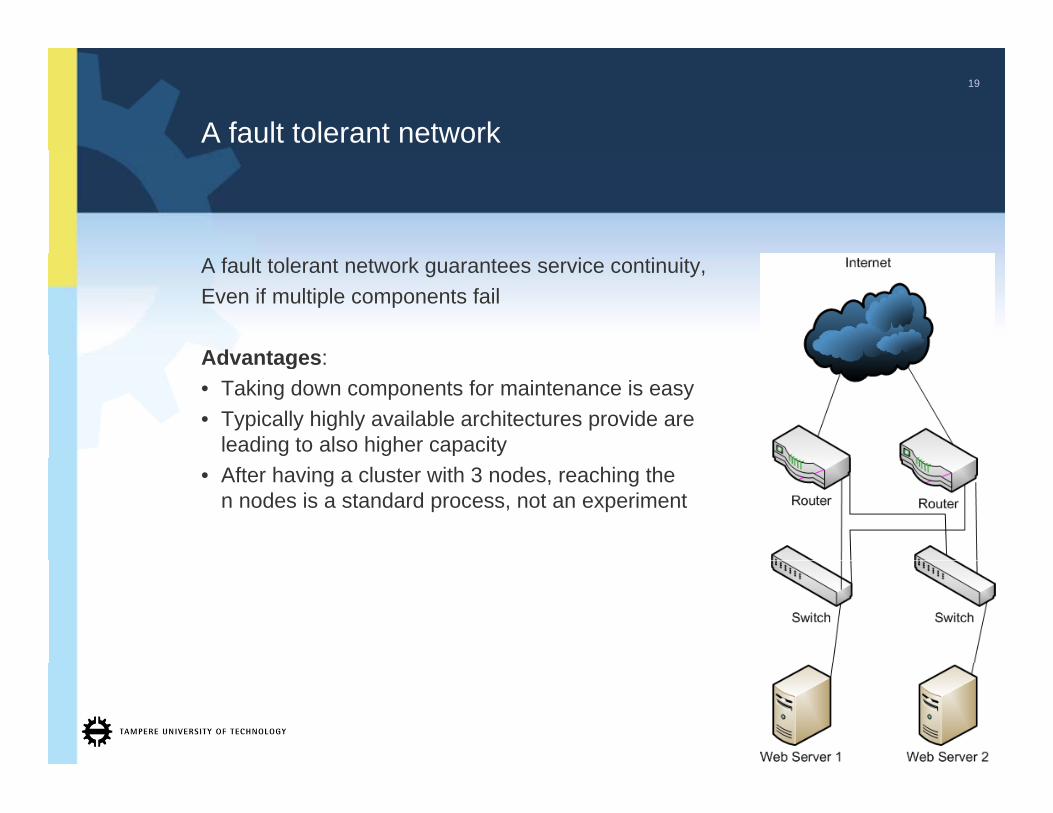
A fault tolerant network
19
A fault tolerant network guarantees service continuity,Even if multiple components fail
Advantages:Advantages:• Taking down components for maintenance is easy• Typically highly available architectures provide are
leading to also higher capacity• After having a cluster with 3 nodes, reaching the
n nodes is a standard process, not an experiment
21.11.2010
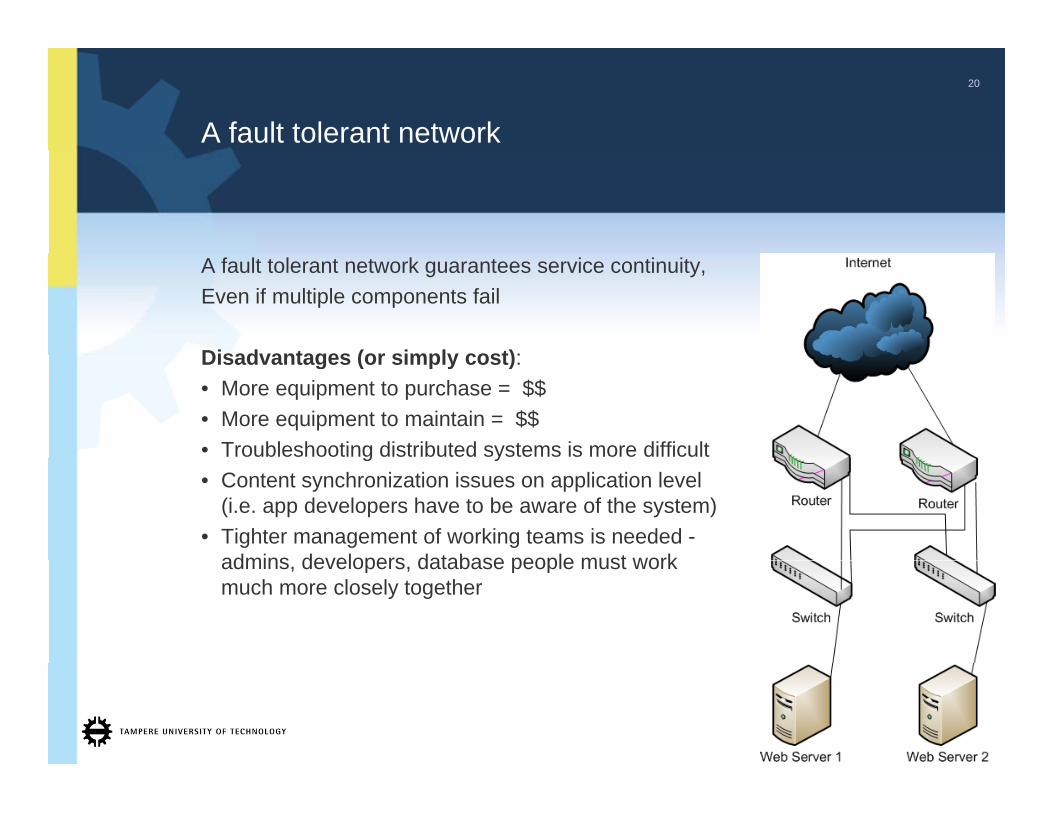
A fault tolerant network
20
A fault tolerant network guarantees service continuity,Even if multiple components fail
Disadvantages (or simply cost):Disadvantages (or simply cost):• More equipment to purchase = $$• More equipment to maintain = $$• Troubleshooting distributed systems is more difficultg y• Content synchronization issues on application level
(i.e. app developers have to be aware of the system)• Tighter management of working teams is needed -
admins developers database people must workadmins, developers, database people must work much more closely together
21.11.2010

High availability vs. Load balancing
21
• High availability : Remaining available despite of failures of components
• Load balancing : Providing a service from multiple separate systems where resources are effectively combined by distributing requests acrosswhere resources are effectively combined by distributing requests across these systems
21.11.2010

22
Load Balancing
21.11.2010

Load Balancing
23
• Lets not confuse it with system loadSystem load: The average length of the run queue in a system (processes in a runnable state waiting for the system processor), over a period of time
21.11.2010

Load Balancing
24
• Lets not confuse it with system loadSystem load: The average length of the run queue in a system (processes in a runnable state waiting for the system processor), over a period of time
Average length of queue over the last: 1 min 5 min 15 min
21.11.2010

Load Balancing
25
• Lets not confuse it with system loadSystem load: The average length of the run queue in a system (processes in a runnable state waiting for the system processor), over a period of time
Average length of queue over the last: 1 min 5 min 15 min
• Typically updated on 5-second intervals.
• What is wrong with thinking of load balancing as an attempt to even the load average across the machines in a cluster?load average across the machines in a cluster?
21.11.2010

Load Balancing
26
• Load balancing is intended to mean evenly balance the workload across the machines in a cluster
Cluster: A bunch (a number of things of the same kind) gathered together. In our scenarios, a set of similar machines providing a particular service, united to increase robustness and/or performance.
• In web based environment, work is very short.• Typical requests take a few milliseconds to complete and the server can handle
thousands of static page request per second
• These kinds of transactions make the concept of system load inappropriate
21.11.2010

Imagine
27
• Imaging a cluster of servers equally utilized• A new server is brought it. System load is 0 for the new machineg y• If balancing is done on system load alone, all subsequent requests will be
redirected to the new machine.• Thousands will arrive in the first second, and the load will be zero• Thousands more will arrive in the next second and the load will still be zero• Thousands more will arrive in the next second, and the load will still be zero• The system load will not update for the next 5 seconds, and when it does, it will
still be the 1-minute average• This does not reflect the current workload, because web requests are so short
and fast to measure in this wayand fast to measure in this way• By the time the load counter changes, the machine will be trashed. This
issue is called Staleness21.11.2010

What is the right approach to load balancing?
28
Well, there is no just one right answer.
But, the core concept is based around the effective resource utilization
Lets see some practical approaches taken…
21.11.2010

1. Round Robin
29
• Distribute one request per server, in a uniform rotation
• Issue: Servers that become overworked, might not have the chance to settle down
21.11.2010

2. Least Connections
30
• The machine that has the least active connections will serve the request
• Simple algorithm that works, if implementation is good
• There is no guarantee that the given resources are used optimally, but the faster a machine us for service connections (accept, satisfy and disconnect), the more work it will receive
• Similarly, a slow machine means backlogging of connections, it will receive less requests
• Issues is several levels of load balancers are used• Issues is several levels of load balancers are used.
21.11.2010

3. Predictive
31
• Based on one of the previous (round robin or least connections) with some added ad-hoc expressions to compensate in the staleness issues of the rapid transaction environments
• Vendors of equipment use own and proprietary algorithms
21.11.2010

4. Available Resources
32
• Utilize the machine with the most available resources
• The best model in theory
• Issue: The staleness problem is a sever one, and practically good results cannot be extracted from this model
21.11.2010

5. Random
33
• Distribute requests randomly to machines
• At first it might sound stupid (as the available resources are discarded from the decision making) but combining it with a resource-orientedfrom the decision making), but combining it with a resource oriented algorithm gives good solution to the staleness problem
21.11.2010

6. Weighted Random
34
• Assigning “weight” to some of the machines• E.g. faster machines in the cluster get a higher arbitrary constant (e.g. 2), thus
higher chance of getting chosen
• Issue: Requires a lot of manual tweaking when new machines are added or upgraded
21.11.2010

Other general issues with algorithm choosing
35
• Having multiple parallel load balancers (side by side, as peers) totally changes the game
• When another system attempts to make decisions on the sameWhen another system attempts to make decisions on the same information without cooperation of others, complicates the situation.
• E.g. if two machines make the came decision, the affects might be twice of the intended
21.11.2010

36
Approaches to Load Balancing
21.11.2010

IP Services
37
• Remember you cannot have two machines with the same IP address on the same network segment
• Because the Address Resolutions Protocol (ARP) does not allow it
• So, a way of ”virtually” distributing the requests to multiple machines is needed, as multiple IP addresses need to be used for the same service
21.11.2010
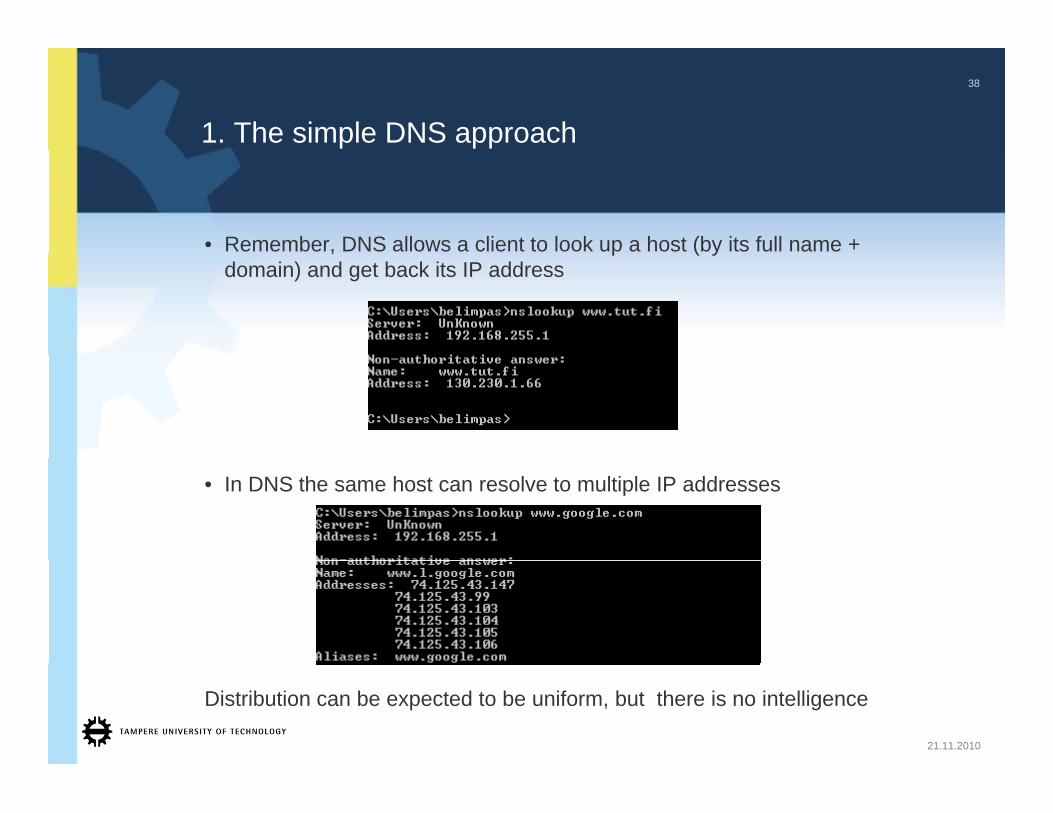
1. The simple DNS approach
38
• Remember, DNS allows a client to look up a host (by its full name + , p ( ydomain) and get back its IP address
• In DNS the same host can resolve to multiple IP addresses
Distribution can be expected to be uniform, but there is no intelligence
21.11.2010

2. Web Switches
39
• Web switches (or black box load balancers) are the most popular technology for highly trafficked websites
• The come in all sizes from small units to carrier-class unitsThe come in all sizes, from small units to carrier class units
• In simple terms they act as backwards Network Address Translation (NAT) routers
• In a cheap NAT router (which you have at home, multiple computers can access your Internet connection, via a single IP address)
• A web switch exposes server private IP machines through a single routable IP address, to other Internet hosts
• They have very good raw performance• Good market solutions: 15+ million concurrent connections, 50 gigabits/sec
• Question: do your really need such a heavy solution?
21.11.2010

3. IP Virtual Servers
40
• Similar to web switches, but not based on specific hardware. Rather just on traditional (commodity) servers
• Run specific user space applications• And/or modified IP stack
• Networking and configuration wise, IP Virtual Servers are identical to web switches
• They have however lower performance
21.11.2010

4. Application Layer Load Balancers
41
• They work entirely on user space• Lower performance, as they are forced to stay in the user space and use
the existing APIs (and are constrained by their limitations)
• Working on layer 7 makes them slower and complex, while the layer 3 (web switches) solutions are fairy simple and hardware accelerated
21.11.2010

Some issues with Load Balancing
42
• Session stickiness• Making sure that requests can be handled even if they land in different
machines (e.g. First call is handled by machine A, and the second call of the same client by machine B)
• Some applications needed consistency and need to store users state• In theory, we could make requests from the same client land on the same
machine X. However, balancing traffic based on this is not really load balancing• Solutions
• Centralized shared storage medium for important information can be used (e.g. all machines storing the data to a common database). However , this might require a lot of power at the database
• Client side cookies, off-load the storage to the clientA bi ti f b th• A combination of both
21.11.2010

43
Static Content & Content Delivery Networks (CDN)
21.11.2010

Static content
44
• Simple yet important observation: Most content, by volume and count, is static
• Photos videos graphics style sheetsPhotos, videos, graphics, style sheets
• A powerful solution:• Content Delivery Networks
21.11.2010

Content Delivery Network
45
• A content delivery network (CDN): a system of computers (computing devices) networked together (across the Internet) that cooperate to deliver content to end users, in order to improve performance, scalability, and cost efficiency.
• Distributed system• Transparent to end users
• MotivationMotivation• Google gets 5.5 billions visits a day• Yahoo! 1.5 billions• YouTube 200 million video watches a day
• This content needs to be served fast, so they users get no delay• Mass distribution
21.11.2010
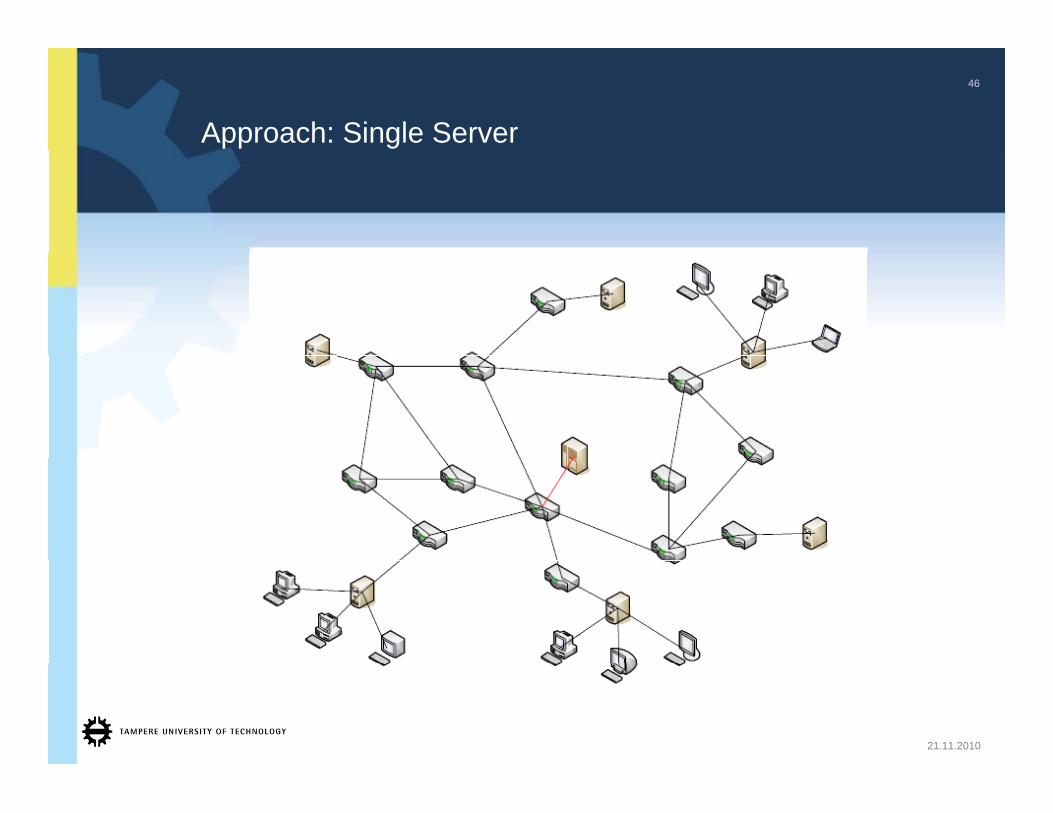
Approach: Single Server
46
21.11.2010
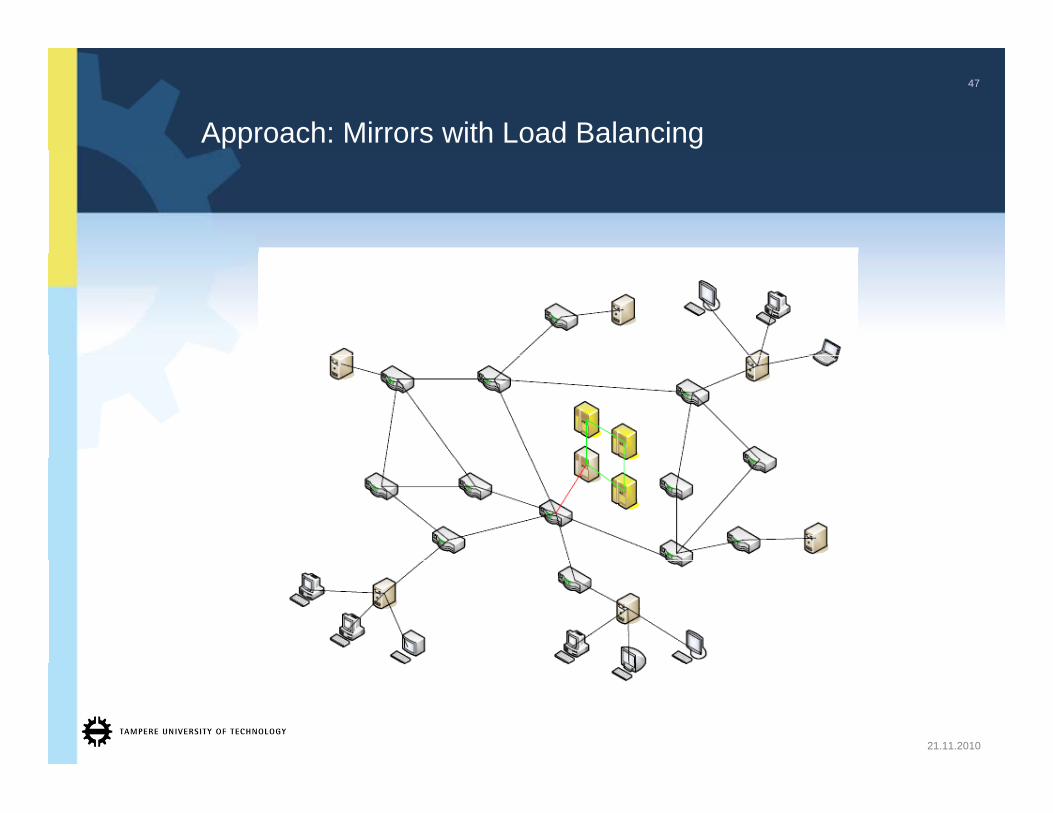
Approach: Mirrors with Load Balancing
47
21.11.2010
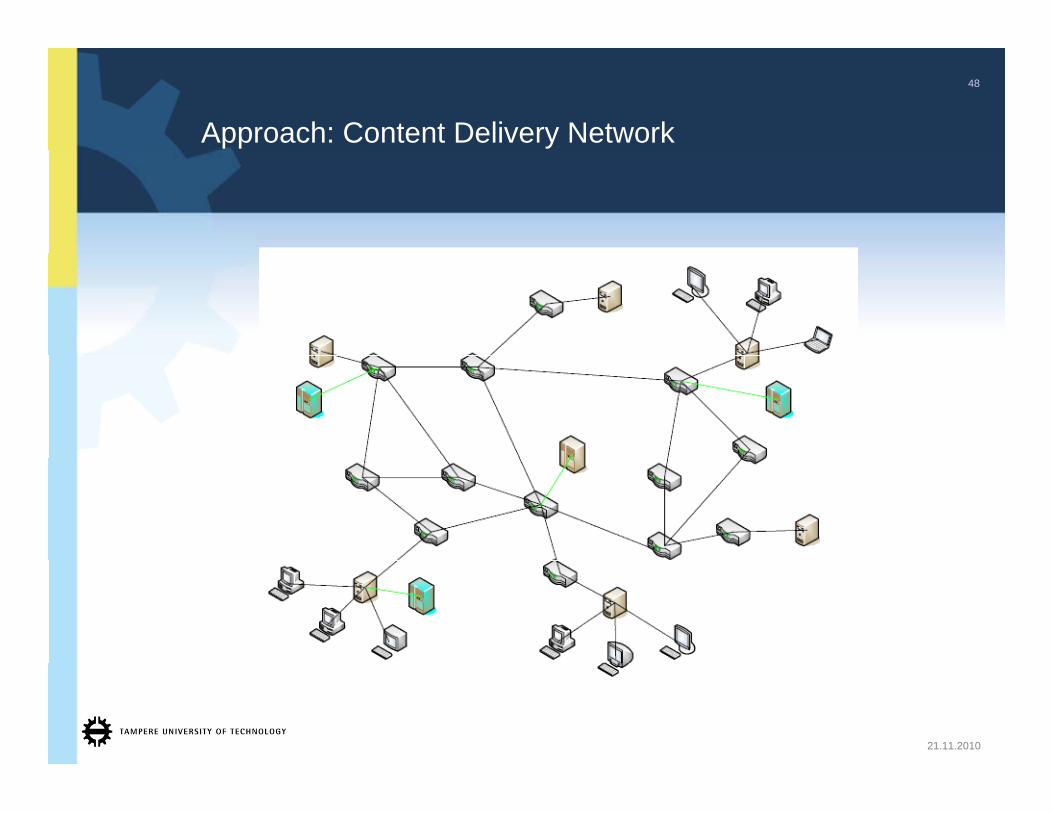
Approach: Content Delivery Network
48
21.11.2010

Terms
49
• Servers• Origin server• Surrogate servers / Edge servers
• Roles• CDN providers: Akamai, Digital Island…• CDN customers: Yahoo, AOL, CNN…• Clients / end users• Clients / end users
21.11.2010

Advantages of CDN
50
• Reduce (backbone) bandwidth costs• Improve end user performance
• Shorter latency / response quickly• Less delay jitterLess delay jitter• Higher bandwidth
• Increase global availability of content
21.11.2010

Redirection
51
• URL rewriting• Origin server redirects clients to different surrogate servers by rewriting the
page’s URL links• Dynamic• Static
• Bottleneck• Domain Name System (DNS) redirection
• DNS server direct requests to CDNDNS server direct requests to CDN
21.11.2010
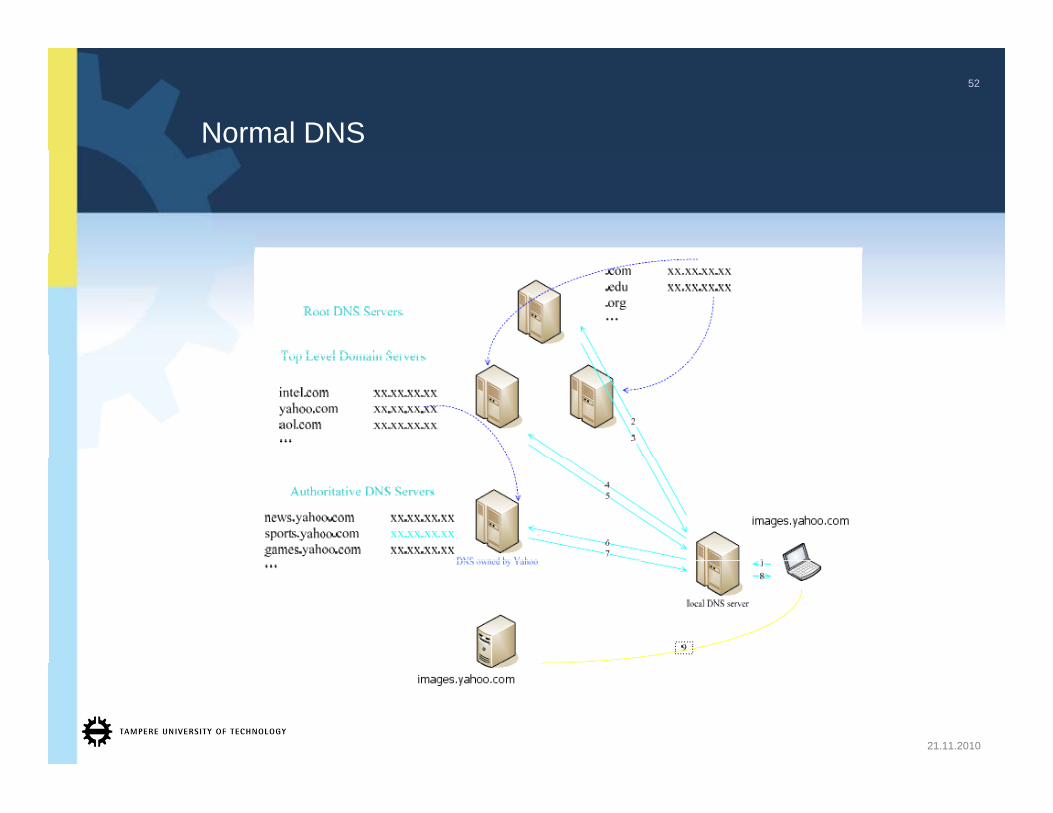
Normal DNS
52
21.11.2010
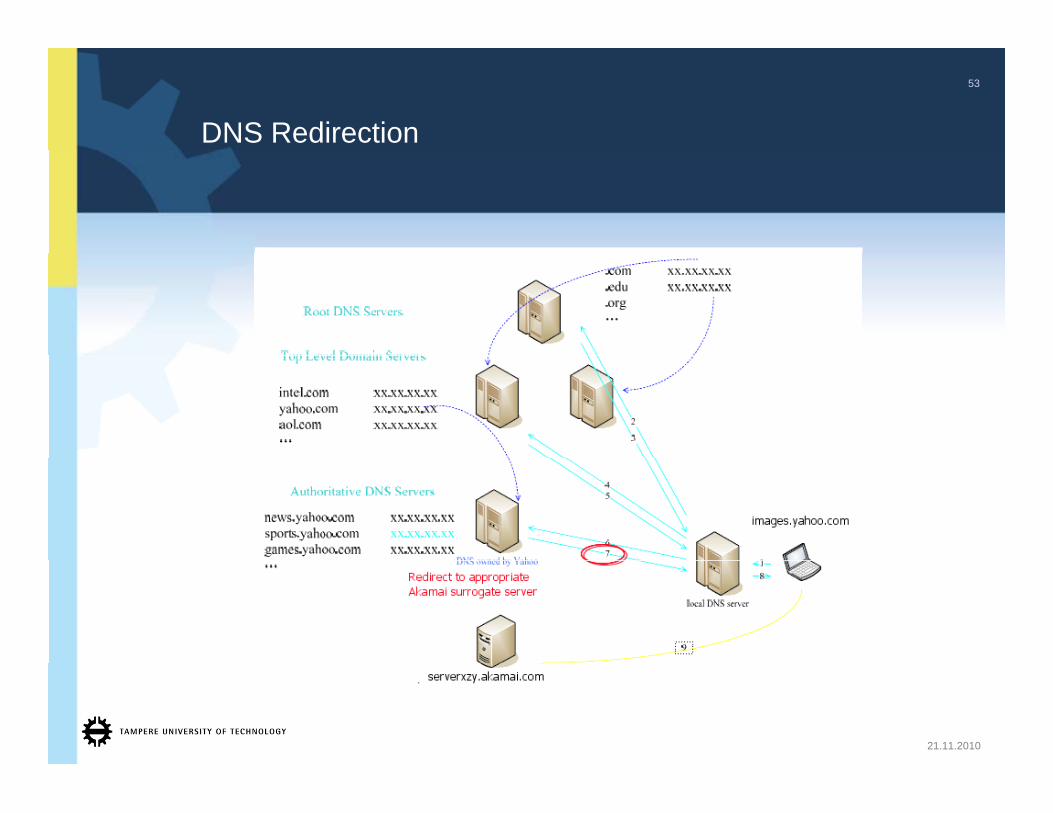
DNS Redirection
53
21.11.2010
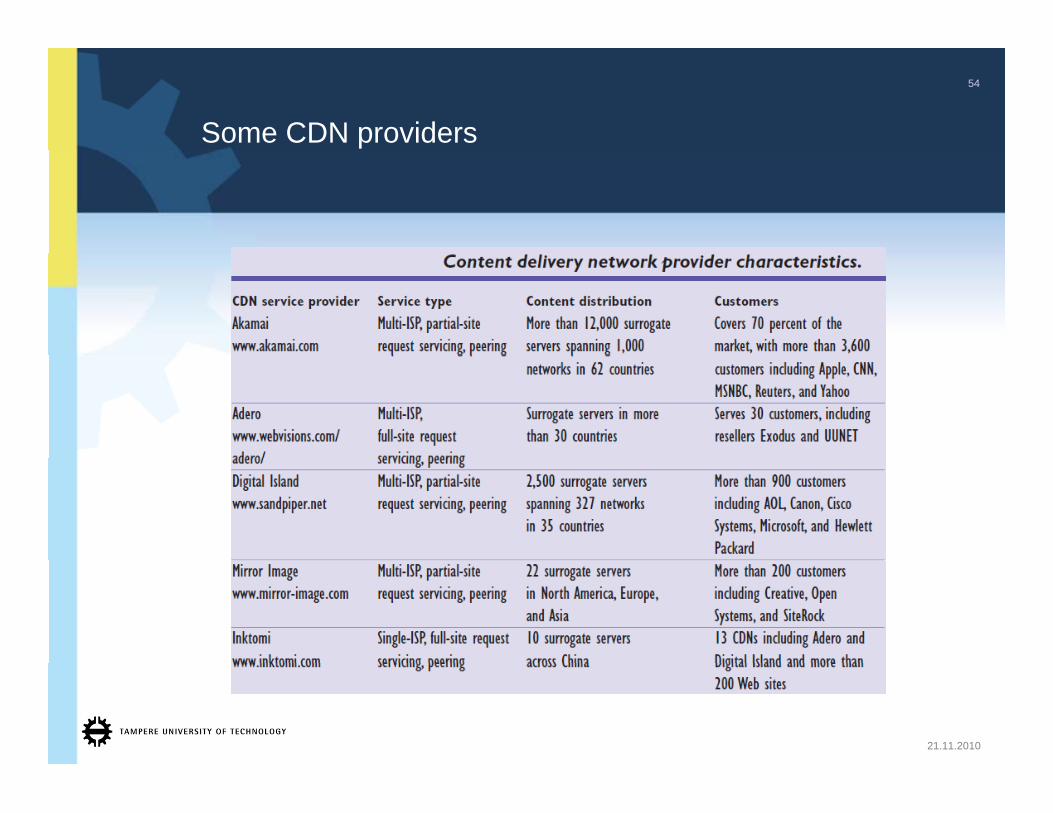
Some CDN providers
54
21.11.2010

55
Cloud Computing
21.11.2010

Definition
56
Wikipedia: Cloud computing is Internet-based computing, whereby shared resources,
software, and information are provided to computers and other devices on demand, like the electricity grid., y g
21.11.2010
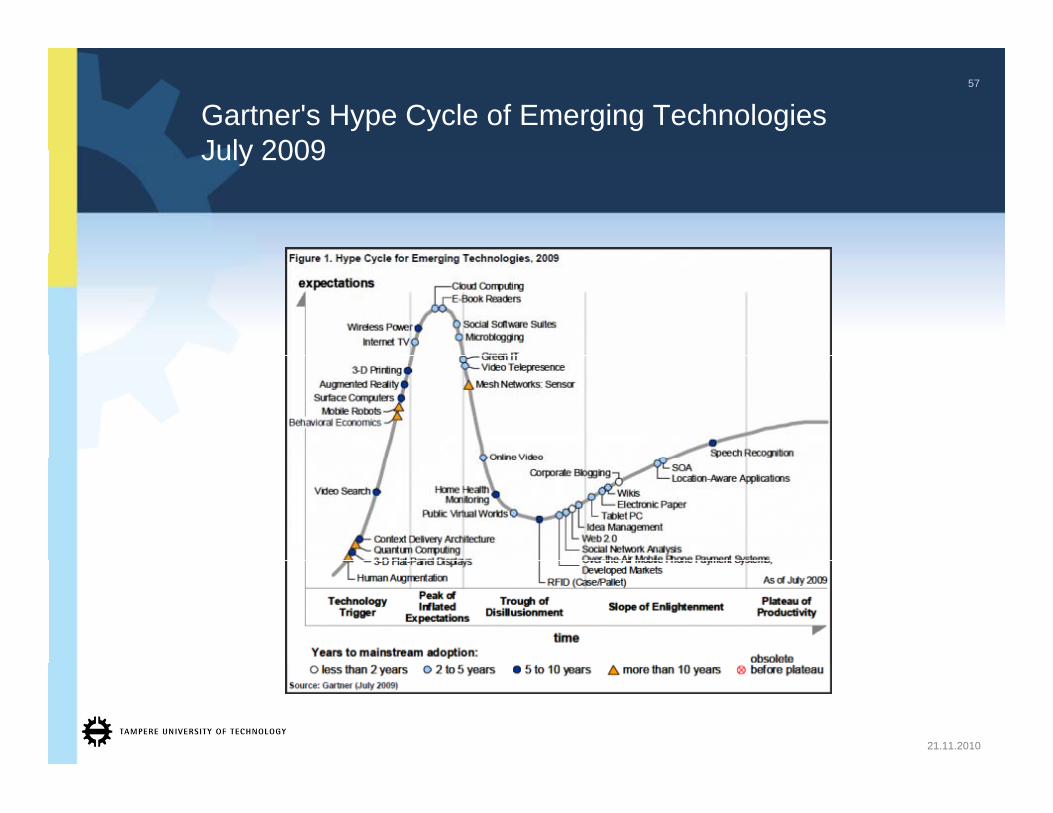
Gartner's Hype Cycle of Emerging TechnologiesJuly 2009
57
July 2009
21.11.2010
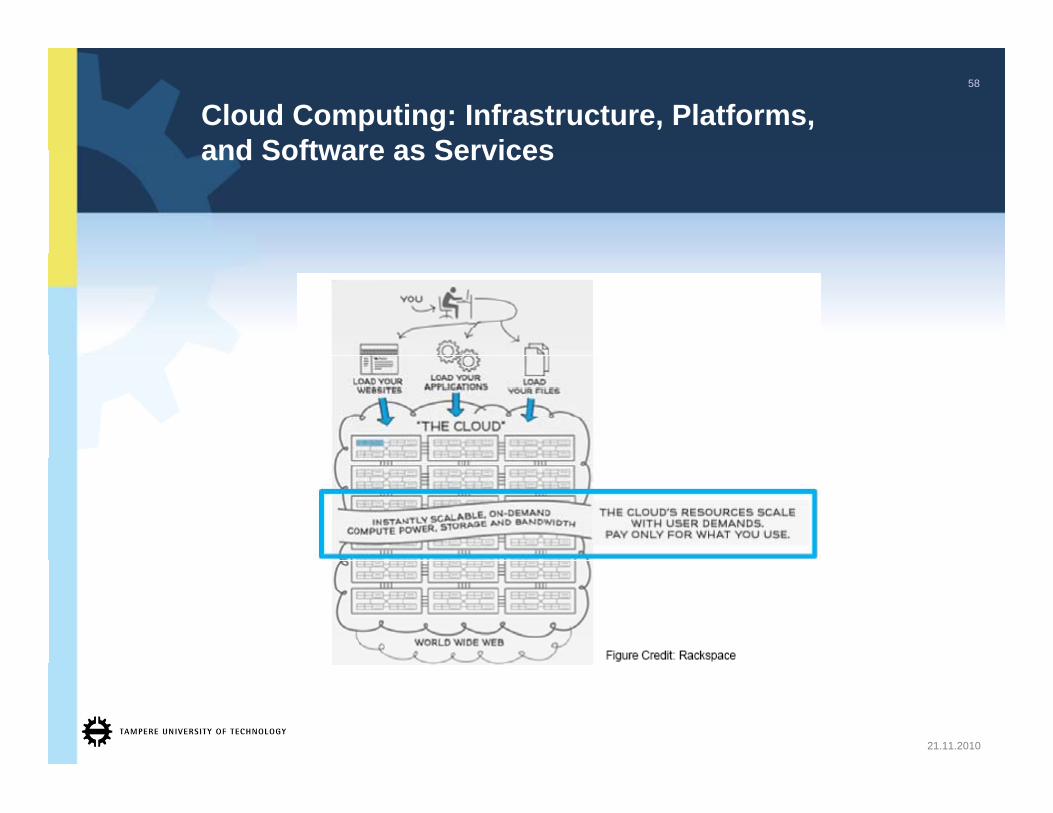
Cloud Computing: Infrastructure, Platforms,and Software as Services
58
and Software as Services
21.11.2010

Cloud Computing: Main Objectives
59
Enterprise-grade systems management• Under-utilized server resources waste computing power and energy• Over-utilized servers cause interruption or degradation of service levels
21.11.2010

Cloud Computing: Main Objectives
60
Internet-scale service computing• Provide and consume sophisticated infrastructure, platforms andbusiness applications as modular (Web) servicesbusiness applications as modular (Web) services• Disrupt traditional industries and offer rich, highly dynamicexperiences
Enterprise-grade systems management• Under-utilized server resources waste computing power and energy• Over-utilized servers cause interruption or degradation of service levels
21.11.2010

Cloud Computing: Main Objectives
61
Understanding business opportunitiesUnderstanding business opportunities• Faster time-to-market, and cost-effective innovation processes• Dynamic (trans-)formation of open service and business networks• Leveraging the participation Web and mass programming
Internet-scale service computing• Provide and consume sophisticated infrastructure, platforms andbusiness applications as modular (Web) servicesbusiness applications as modular (Web) services• Disrupt traditional industries and offer rich, highly dynamicexperiences
Enterprise-grade systems management• Under-utilized server resources waste computing power and energy• Over-utilized servers cause interruption or degradation of service levels
21.11.2010

A better definition
62
“Building on compute and storage virtualization,cloud computing provides scalable, network-centric,abstracted IT infrastructure, platforms, and applicationsas on demand services that are billed by consumption “as on-demand services that are billed by consumption.
“Cloud service engineering leverages cloudg g gcomputing in the context of the Internet in its combined
role as a platform for technical, economic,organizational and social networks.”
21.11.2010

Example 1: NY Times
63
• NY Times wanted to create a public digitalarchive of all newspapers from 1851 to 1922
• The needed to convert terabytes of scannedThe needed to convert terabytes of scanneddata (TIFF images) into PDF files, as TIFFs are not web friendly
Th h d i ffi i t it th i• They had insufficient capacity on their owncorporate servers, tight deadlines and addingnew hardware was not an option
• Solution: Using Amazon Could services they generated the needed PDFs in <24 h, for less than 500 USD
• Created 11,000 PDFs• Used about 100 server instancesUsed about 100 server instances• Uploaded 4TB of data, downloaded about 1.5TB of generated data
21.11.2010

Example 2: Animoto
64
• Animoto: A service for people to create videos with their ownphotos and music
• Link the service to Facebook, in order to attract more users
• Great success -> great spike in video creation -> unforeseen scalability i trequirements
• Within 3 days demand required scale-up for 50to 3500 servers!
• Solution: Virtualized, on demand infrastructure
21.11.2010

Example 3: Kenworth
65
• Needed design improvements for theaerodynamics of their trucks
• By identifying design flows in aerodynamics trucks’ gas consumption canBy identifying design flows in aerodynamics, trucks gas consumption can be reduced
• The company did not have, in-house, the need IT infrastructure for i th i d t i t i i l ti d l irunning the required compute-intensive simulations and analysis
• Solution: Worked with a cloud computing service• A small change in the mud flap design could save 1 million $ dollars, in gas, forA small change in the mud flap design could save 1 million $ dollars, in gas, for
a company that has 1000 truck fleet
21.11.2010

Example 4: US White House
66
• Centralized place for federal agencies to purchase cloud-basedIT services
• The previous practices where oftenresulting in inefficient use of purchased hardware
S l ti D l d l d ti i t• Solution: Developed own cloud computing environment• Lowered the 75 billion $ / year spending for IT services
21.11.2010

Other cloud compuring success stories
67
http://cloudtp.com/cloud-computing/cloud-computing-success-stories
21.11.2010

Technical Cloud Architecture: Stack
68
E ti S i
HuaaCrowdsourcing (e.g. Mechanical Turk) A
dm
Bus
Everyting as a Service
• Standard Layers• Infrastructure as a Service
aSS
aaS
Application (e.g. Google Docs)
Application Services (e.g. Opensocial & OpenID)
ministration (D
eployme
siness Support (M
eteri
• Platform as a Service• Software as a Service
• Additional Layers
Programming Environment (e.g. Django)
Execution Environment (e.g. Google App Eng)
PaaS
ent, Configuration, M
on
ng, Billing, A
uthentica• Additional Layers• Human as a Service• Admin/Business Support
IaaS
Infrastructure Services
Higher Infrastructure Services (e.g. Google Bigtable)
Basic Infrastructure Services
Computational (e.g. Hadoop MapReduce)
nitoring, etc.)
tion, etc.)
Resource Set
Virtual Resource Set (e.g. Amazon EC2)
Storage (e.g. GoogleFS)
Network (e.g. OpenFlow)
21.11.2010
Hardware
Physical Resource Set (e.g. Emulab)

Infrastructure as a Service
69
• Infrastructure Services• Storage• Computational• Network• Database• e.g. Google Bigtable, GoogleFS,
Hadoop MapReduce, HadoopFS• Resource SetResource Set
• Machine Images• e.g. EC2, Eucalyptus
IaaS
Infrastructure Services
Higher Infrastructure Services (e.g. Google Bigtable)
Basic Infrastructure Services
Computational (e.g. Hadoop MapReduce)
Resource Set
Virtual Resource Set (e.g. Amazon EC2)
Storage (e.g. GoogleFS)
Network (e.g. OpenFlow)
21.11.2010
Physical Resource Set (e.g. Emulab)

Platform as a Service
70
P i E i t• Programming Environment• Programming Language, Libraries• e.g. Django, Java
• Execution Environment• Runtime Environment • e.g. Google App Engine, Java Virtual
MachineProgramming Environment (e.g. Django)
Execution Environment (e.g. Google App Eng)
PaaS
21.11.2010

Software as a Service
71
A li ti• Applications• User Interface• Frontend Application• e.g. Google Docs, Yahoo Email
SaaS
Application (e.g. Google Docs)
Application Services (e.g. Opensocial & OpenID)
• Application Services• Webservices Interface• e g Opensocial Google Maps• e.g. Opensocial, Google Maps
21.11.2010
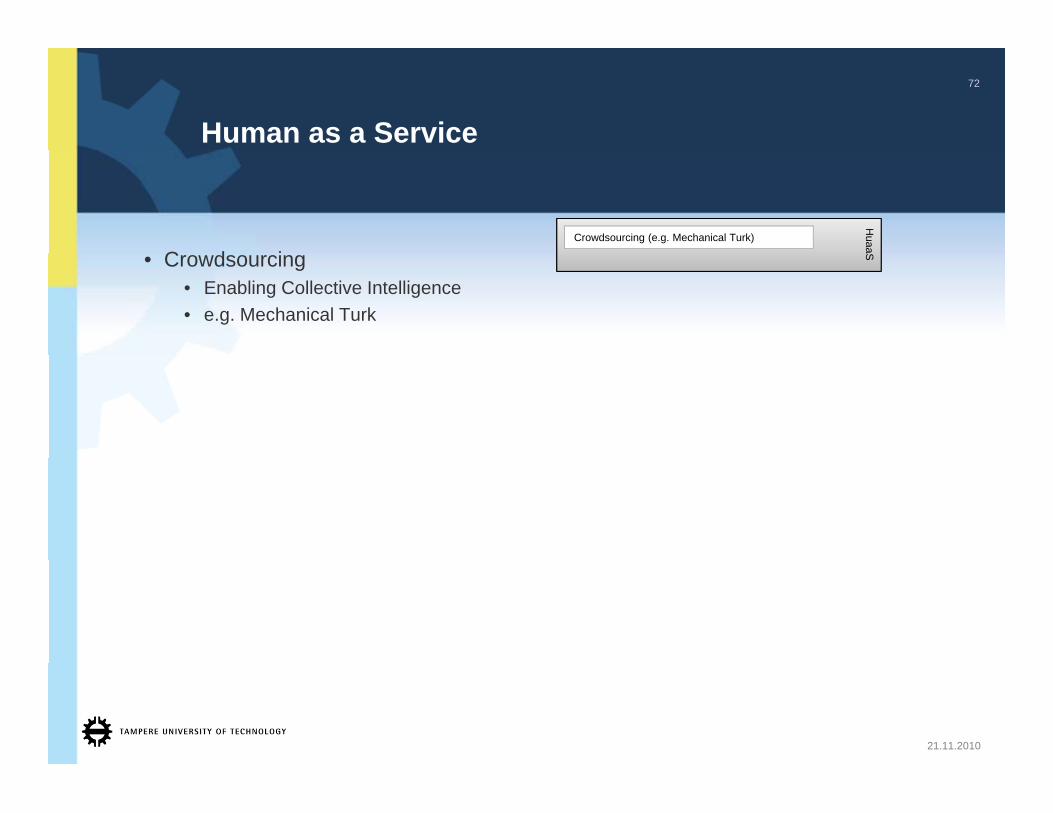
Human as a Service
72
C d i
HuaaCrowdsourcing (e.g. Mechanical Turk)
• Crowdsourcing• Enabling Collective Intelligence• e.g. Mechanical Turk
aS
21.11.2010

Administration/Business Support
73
A il bl ll l
Adm
Bus
Available on all layers
• Administration• Deployment
ministration (D
eployme
siness Support (M
eterip y• Configuration• Monitoring• Life cycle management
• Business support
ent, Configuration, M
on
ng, Billing, A
uthentica• Business support• Metering• Billing• Authentication
U t
nitoring, etc.)
tion, etc.)
• User management
21.11.2010

Players
74
• Cloud infrastructure service providers – raw cloud resourcesIaaS (infrastructure-as-a-service)• Cloud platform providers – resources + frameworks; PaaS(platform as a service)(platform-as-a-service)• Cloud intermediaries – help broker some aspect of raw resources and
frameworks, e.g.,• server managers, application assemblers, application hosting
• Cloud application providers (SaaS)• Cloud consumers – users of the above
21.11.2010

Players: Providers
75
• Programmatic access via Web Services and/or Web APIs• “Pure” virtualized resources• CPU, memory, storage, and bandwidth• Data store
Versus
• Virtualized resources plus application framework• (e.g., RoR, Python, .NET)
• Imposes an application and data architecture• Constrains how application is builtConstrains how application is built
21.11.2010

Players: Cloud Intermediaries
76
• Resells (aspects of) raw cloud resources, with added value propositions• Packaging resources as bundles• Facilitating cloud resource management,• e.g., setup, updates, backup, load balancing, etc.g , p, p , p, g,• Providing tools and dashboards
• Enabler of the cloud ecosystem
21.11.2010

Players: Application Providers
77
• Software as a Service (SaaS): Applications provided and consumed over the Web
• Infrastructure usage (mostly) hidden
21.11.2010
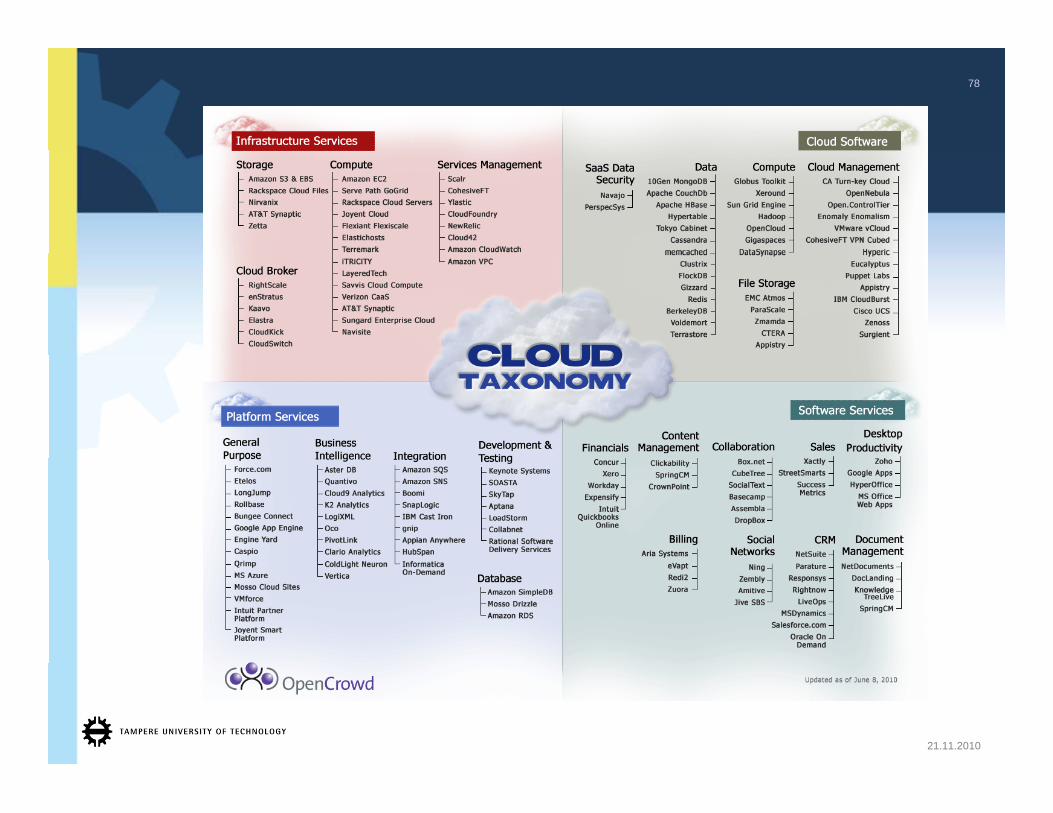
78
21.11.2010

79
Example: Amazon Web Servicesp
21.11.2010

Amazon Web Services
80
Amazon Web Services (AWS) Cloud Offerings:
• Amazon Elastic Compute Cloud (Amazon EC2)• Amazon Simple Storage Service (Amazon S3)• Amazon Simple Storage Service (Amazon S3)• Amazon Simple Queuing Service (Amazon SQS)• Amazon SimpleDB• Amazon ElasticMapReducep• Amazon CloudFront• Amazon DevPay• AWS Import/Export
21.11.2010

Amazon Elastic Compute Cloud (Amazon EC2)
81
• Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers.
• Amazon EC2’s simple web service interface • allows you to obtain and configure capacity with minimal friction.• It provides you with complete control of your computing resources • lets you run on Amazon’s proven computing environment• lets you run on Amazon s proven computing environment.
• Reduces the time required to obtain and boot new server instances to minutes, allowing you to quickly scale capacity, both up and down, as your computing requirements change.
• Changes the economics of computing by allowing you to pay only for capacity that you actually use.
• Provides developers the tools to build failure resilient applications and isolate themselves from common failure scenarios.
21.11.2010

In simpler words
82
• Virtual computing environment• Via web interfaces new instances, of different OSs, can be launched• Load them with custom applications• Manage network access and permissions• Manage network access and permissions• Run images (as many as required)
21.11.2010

EC2 instances
83
21.11.2010

Core concepts
84
• Amazon Machine Image (AMI): an encrypted file stored in Amazon S3, containing all the information necessary to boot instances of a customer’s software
• An AMI is like a bootable root disk, which can be pre-defined or user-built.• Public AMIs: Pre-configured, template AMIs• Private AMIs: User-built AMI containing private applications, libraries, data and
associated configuration settings
• Instance: The running system based on an AMI • All instances based on the same AMI begin executing identically. • An instance can be launched in very few minutes. Any information on them is
lost when the instances are terminated or if they fail.lost when the instances are terminated or if they fail.
21.11.2010
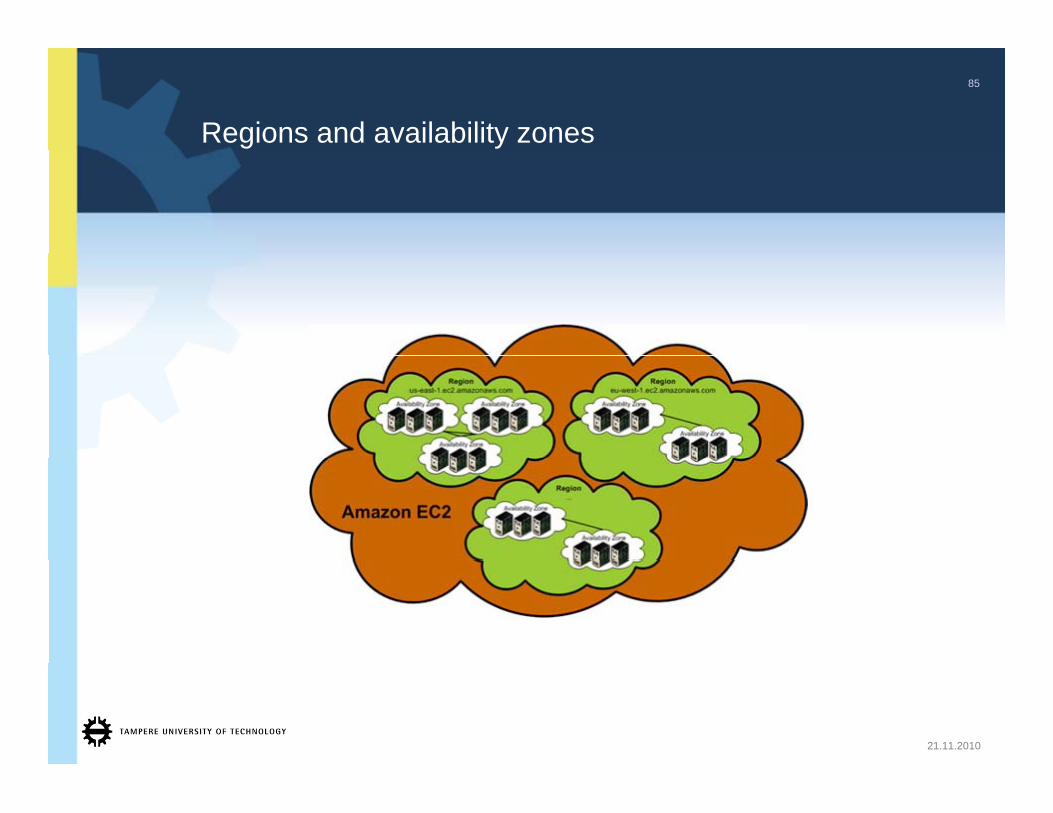
Regions and availability zones
85
21.11.2010
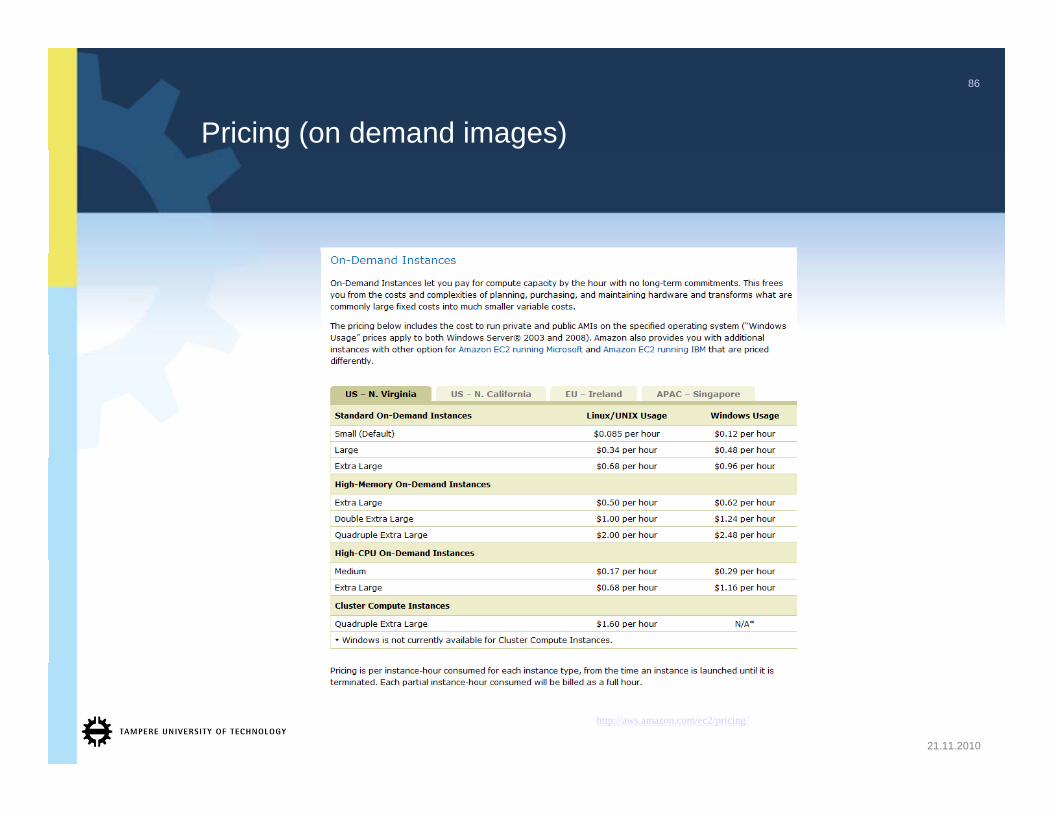
Pricing (on demand images)
86
21.11.2010
http://aws.amazon.com/ec2/pricing/

Pricing (reserved images)
87
21.11.2010
http://aws.amazon.com/ec2/pricing/

Pricing (data transfers)
88
21.11.2010
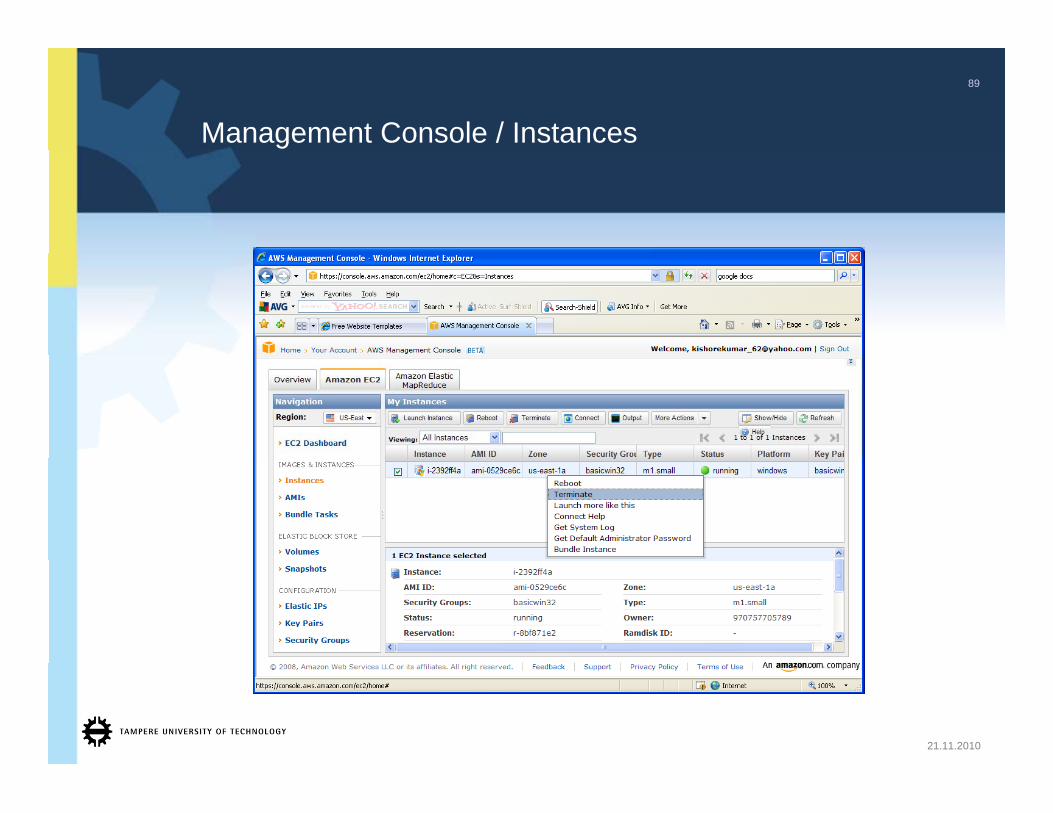
Management Console / Instances
89
21.11.2010

Management Console / AMIs
90
21.11.2010
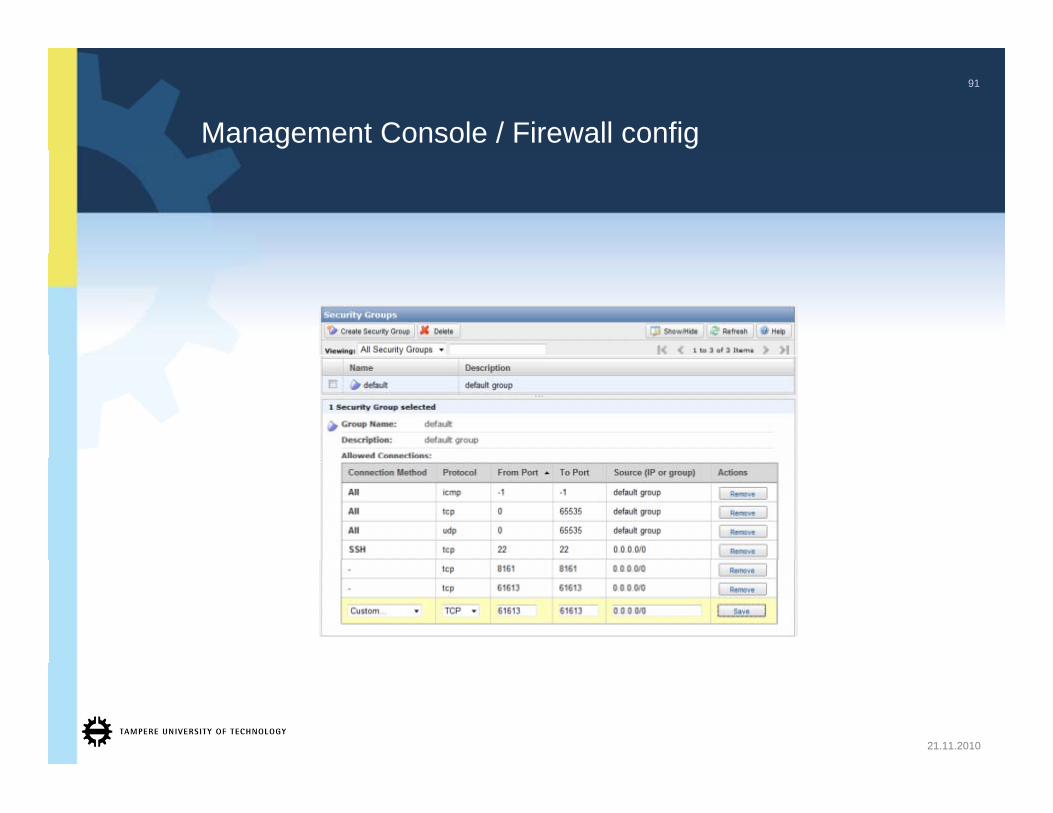
Management Console / Firewall config
91
21.11.2010

Doing the same via the SOAP API
92
the SOAP API
21.11.2010

Amazon Simple Storage Service (Amazon S3)
93
• Amazon S3 is storage for the Internet. It is designed to make web-scale computing easier for developers.
• Amazon S3 provides a simple web services interface that can be used toAmazon S3 provides a simple web services interface that can be used to store and retrieve any amount of data, at any time, from anywhere on the web.
It i d l t th hi hl l bl li bl• It gives any developer access to the same highly scalable, reliable, secure, fast, inexpensive infrastructure that Amazon uses to run its own global network of web sites. The service aims to maximize benefits of scale and to pass those benefits on to developers.
21.11.2010

Amazon S3
94
• Write read and delete objects containing from 1 byte to 5 gigabytes of• Write, read, and delete objects containing from 1 byte to 5 gigabytes ofdata each. The number of objects you can store is unlimited.
• Each object is stored in a bucket and retrieved via a unique, developer assigned key.
• A bucket can be located in the United States or in Europe. • All objects within the bucket will be stored in the bucket’s location, but the
objects can be accessed from anywhereobjects can be accessed from anywhere.• Authentication mechanisms are provided to ensure that data is kept
secure from unauthorized access.• Objects can be made private or public, and rights can be granted to
ifispecific users.• Uses standards-based REST and SOAP interfaces designed to work with
any Internet-development toolkit.• Default download protocol is HTTP. A BitTorrent™ protocol interface is p p
provided to lower costs for high-scale distribution.• Reliability backed with the Amazon S3 Service Level Agreement.
21.11.2010

Amazon S3 Service Level Agreement
95
21.11.2010

Sample S3 REST Usage
96
• Use standard HTTP requests to create, fetch, and delete buckets and objects
• A typical REST operation consists of a sending a single HTTP request to Amazon S3, followed by waiting for an HTTP response. , y g p
• Following is an example that shows how to get an object named "Nelson"
21.11.2010

Amazon S3 Pricing
97
21.11.2010

Amazon Simple Queue Service (Amazon SQS)
98
• Amazon Simple Queue Service (Amazon SQS) offers a reliable, highly scalable, hosted queue for storing messages as they travel between computers.
• developers can simply move data between distributed components of their applications that perform different tasks, without losing messages or requiring each component to be always available.
• makes it easy to build an automated workflow, working in close conjunction with the Amazon Elastic Compute Cloud (Amazon EC2) and the other AWS infrastructure web servicesinfrastructure web services.
• works by exposing Amazon’s web-scale messaging infrastructure as a web service. Any computer on the Internet can add or read messages without any installed software or special firewall configurations.
• Components of applications using Amazon SQS can run independently and do• Components of applications using Amazon SQS can run independently, and do not need to be on the same network, developed with the same technologies, or running at the same time.
21.11.2010

In simple words
99
• “Message queuing in the Cloud”• Basic message queuing model, except: queues are hosted by Amazon, and
queues are accessed using Web service protocols• Simple APIp• Platform agnostic• Basic support for access control and message locking• Reliability
• Runs within Amazon's high-availability data centers• Messages stored redundantly across multiple servers and locations
• Scalable to millions of messages a day
21.11.2010

Functionality
100
• Developers can create an unlimited number of Amazon SQS queues, each of which can send and receive an unlimited number of messages.
• New messages can be added to a queue at any time. The message body can contain up to 8 KB of text in any format.p y
• A computer can check a queue at any time for messages waiting to be read.
• A message is “locked” while a computer is processing it, keeping other computers from trying to process it simultaneously If processing fails thecomputers from trying to process it simultaneously. If processing fails, the lock will expire and the message will again be available.
• Messages can be retained in queues for up to 4 days.• Developers can access Amazon SQS through standards-based SOAP
and Query interfaces designed to work with any Internet development toolkit.
21.11.2010

SQS API
101
• CreateQueue: Create queues for use with your AWS account.• ListQueues: List your existing queues.• DeleteQueue: Delete one of your queues.• SendMessage: Add any data entries to a specified queue• SendMessage: Add any data entries to a specified queue.• ReceiveMessage: Return one or more messages from a specified queue.• DeleteMessage: Remove a previously received message from a specified
queue.• SetQueueAttributes: Control queue settings like the amount of time that
messages are locked after being read so they cannot be read again. • GetQueueAttributes: See information about a queue like thenumber of messages in itnumber of messages in it.
21.11.2010

Amazon SQS Pricing
102
21.11.2010

103
PaaS Example: Google App Engine
21.11.2010
http://code.google.com/appengine/
104
21.11.2010

Free to start
105
App Engine costs nothing to get started. Sign up for a free account, and you can develop and publish your application for the world to see, at no charge and with no obligation. A free account can use up to 500MB of persistent storage and enough CPU and bandwidth for about 5 million page views a month
Pay-per-use if you need more
21.11.2010

App Engine Components
106
1. Scalable Serving Infrastructure2. Python and Java Runtime3. Software Development Kit4 Datastore4. Datastore5. Web based Admin Console
21.11.2010

107
HuaaS Example: Amazon Mechanical Turk
21.11.2010

Amazon Mechanical Turk
108
21.11.2010

Amazon Mechanical Turk
109
• Amazon Mechanical Turk (MTurk) is a crowdsourcing marketplace that enables computer programs to co-ordinate the use of human intelligence to perform tasks which computers are unable to do.
• Requesters, the human beings that write these programs, are able to pose tasks known as HITs (Human Intelligence Tasks), such as choosing the best among several photographs of a storefront, writing product descriptions or identifying performers on music CDsdescriptions, or identifying performers on music CDs.
• Workers (called Providers in Mechanical Turk's Terms of Service) can then browse among existing tasks and complete them for a monetary
t t b th R t T l HIT th tipayment set by the Requester. To place HITs, the requesting programs use an open API (or a web interface)
21.11.2010
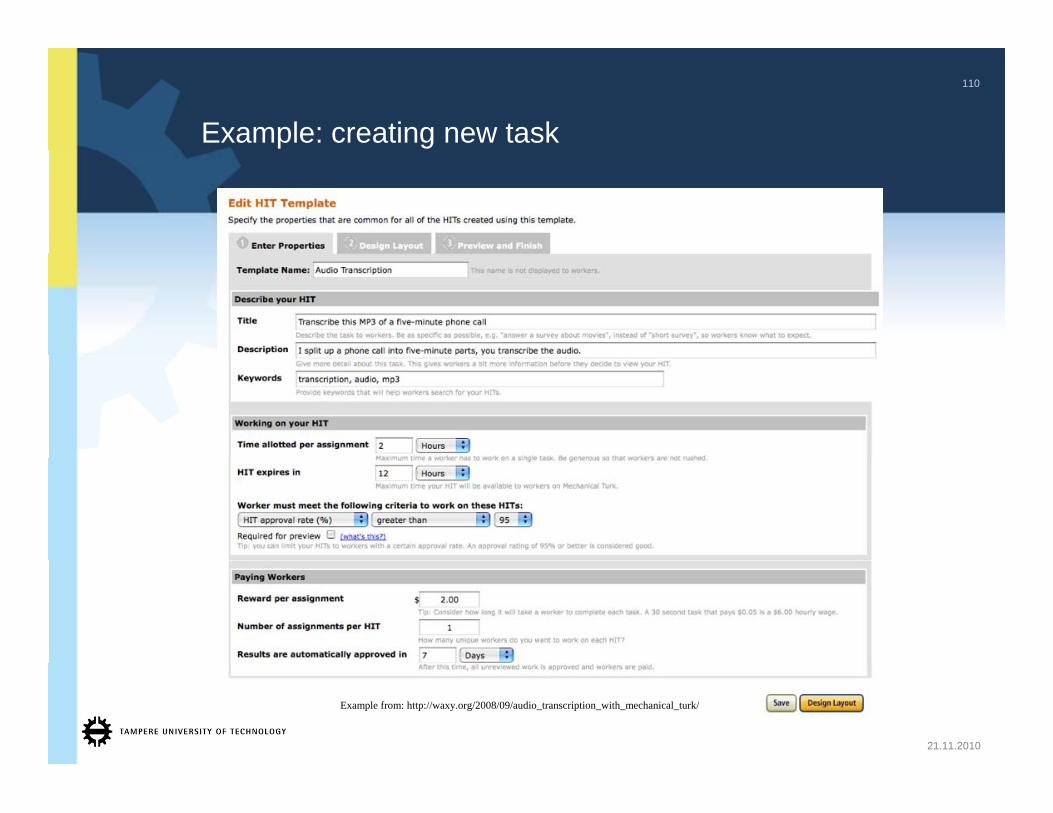
Example: creating new task
110
21.11.2010
Example from: http://waxy.org/2008/09/audio_transcription_with_mechanical_turk/
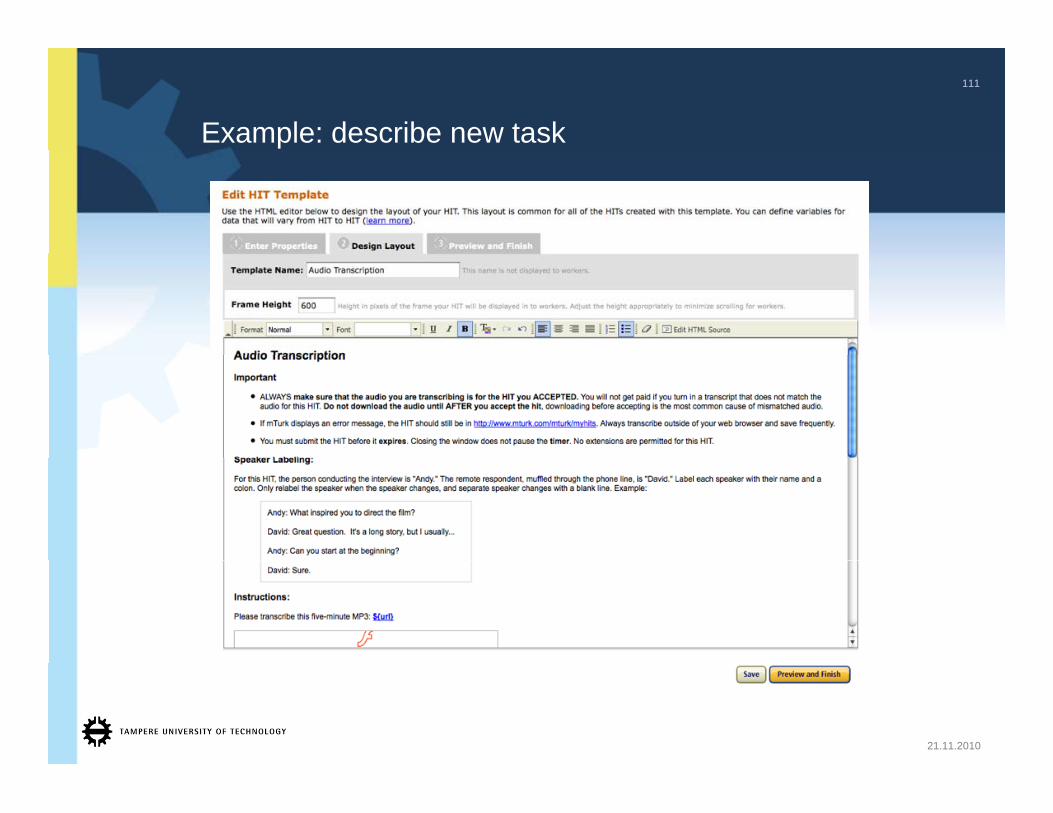
Example: describe new task
111
21.11.2010
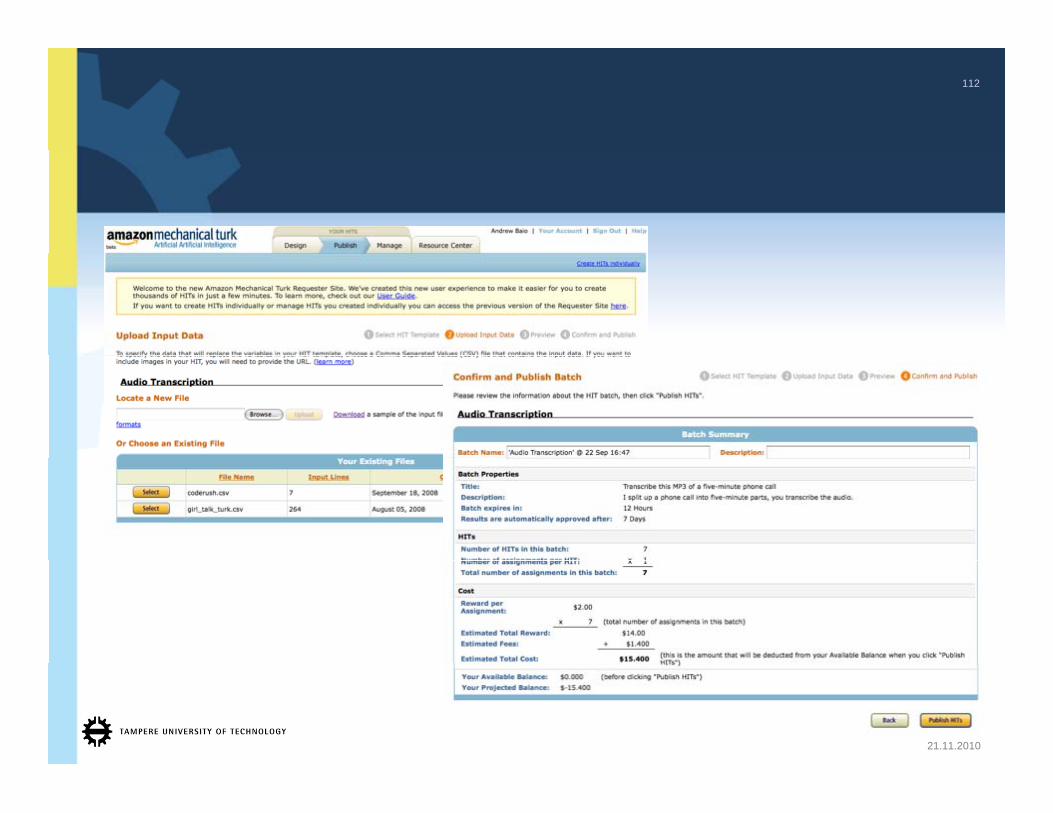
112
21.11.2010

Cloud Computing Obstacles and Opportunities
113
21.11.2010
Source: Above the Clouds: A Berkeley View of Cloud Computing. Armbrust et al., Technical Report No. UCB/EECS-2009-28.Electrical Engineering and Computer Sciences, University of California at Berkeley, USA, 2009.
References
114
This lecture has been based on material from :
• Theo Schlossnagle, “Scalable Internet Architectures”, Sams 2006.• http://www.amazon.com/Scalable-Internet-Architectures-Theo-Schlossnagle/dp/067232699Xp g p
• Stefan Tai, “Cloud Computing”, September 2009.• http://redcad.org/summerschool09/slides/Tai_CTDS09_Cloud%20Computing.pdf
21.11.2010





![[Tut]How to Crack WPA_2-PSK W_ BT4 [Tut]](https://img.pdfslide.net/doc/110x75/577d28121a28ab4e1ea52a3b/tuthow-to-crack-wpa2-psk-w-bt4-tut.jpg)























