Embed Size (px)
DESCRIPTION
Scanner wrap-up and Introduction to Parser. Automating Scanner Construction. RENFA (Thompson’s construction) Build an NFA for each term Combine them with -moves NFA DFA (subset construction ) Build the simulation DFA Minimal DFA (today) - PowerPoint PPT Presentation
Citation preview

Scanner wrap-up and Introduction to Parser

Automating Scanner Construction
RENFA (Thompson’s construction) Build an NFA for each term Combine them with -moves
NFA DFA (subset construction) Build the simulation
DFA Minimal DFA (today) Hopcroft’s algorithm
DFA RE (not really part of scanner construction) All pairs, all paths problem Union together paths from s0 to a final state

DFA Minimization
The Big PictureDiscover sets of equivalent statesRepresent each such set with just one
state

DFA Minimization
The Big Picture Discover sets of equivalent states Represent each such set with just one state
Two states are equivalent if and only if: The set of paths leading to them are equivalent , transitions on lead to equivalent states (DFA) -transitions to distinct sets states must be in distinct sets
A partition P of S Each s S is in exactly one set pi P
The algorithm iteratively partitions the DFA’s states

DFA Minimization
Details of the algorithm Group states into maximal size sets, optimistically Iteratively subdivide those sets, as needed States that remain grouped together are equivalent
Initial partition, P0 , has two sets: {F} & {Q-F} (D =(Q,,,q0,F))
Splitting a set (“partitioning a set by a”) Assume qa, & qb s, and (qa,a) = qx, & (qb,a) = qy
If qx & qy are not in the same set, then s must be split
qa has transition on a, qb does not a splits s
One state in the final DFA cannot have two transitions on a

DFA Minimization
The algorithmP { F, {Q-F}}
while ( P is still changing) T { } for each set S P for each partition S by into S1, and S2
T T S1 S2
if T P then P T
Why does this work? Partition P 2Q
Start off with 2 subsets of Q {F} and {Q-F}
While loop takes PiPi+1 by splitting 1 or more sets
Pi+1 is at least one step closer to the partition with |Q| sets
Maximum of |Q | splitsNote that Partitions are never combined Initial partition ensures that final
states are intactThis is a fixed-point
algorithm!

Key Idea: Splitting S around
S
T
R
The algorithm partitions S around
Original set S
Q
S has transitions on to R, Q, & T

Key Idea: Splitting S around
T
R
Original set S
Q
S1
S2
Could we split S2 further?
Yes, but it does not help asymptotically
S2 is everything in S - S1

DFA Minimization
Refining the algorithm As written, it examines every S P on each iteration
This does a lot of unnecessary work Only need to examine S if some T, reachable from S, has split
Reformulate the algorithm using a “worklist” Start worklist with initial partition, F and {Q-F}
When it splits S into S1 and S2, place S2 on worklist
This version looks at each S P many fewer times Well-known, widely used algorithm due to John Hopcroft

Hopcroft's Algorithm
W {F, Q-F}; P {F, Q-F}; // W is the worklist, P the current partition
while ( W is not empty ) do beginselect and remove S from W; // S is a set of states
for each in do begin
let I –1( S ); // I is set of all states that can reach S on
for each R in P such that R Iis not empty
and R is not contained in Ido begin
partition R into R1 and R2 such that R1 R I; R2 R –
R1;
replace R in P with R1 and R2 ;
if R W then replace R with R1 in W and add R2 to W ;
else if || R1 || ≤ || R2 ||
then add add R1 to W ;
else add R2 to W ;
endend
end

A Detailed Example
Remember ( a | b )* abb ?
Applying the subset construction:
Iteration 3 adds nothing to S, so the algorithm halts
a | b
q0 q1 q4 q2 q3
a bb
Iter. State Contains-closure(move(si,a))
-closure(move(si,b))
0 s0 q0, q1 q1, q2 q1
1 s1 q1, q2 q1, q2 q1, q3
s2 q1 q1, q2 q1
2 s3 q1, q3 q1, q2 q1, q4
3 s4 q1, q4 q1, q2 q1
contains q4
(final state)
Our first NFA

A Detailed Example
The DFA for ( a | b )* abb
Not much bigger than the original All transitions are deterministic Use same code skeleton as before
s0
as1
b
s3
bs4
s2
a
b
b
a
a
a
b
a bs0 s1 s2
s1 s1 s3
s2 s1 s2
s3 s1 s4
s4 s1 s2

A Detailed Example
Applying the minimization algorithm to the DFA
Current Partition Worklist s Split on a Split on b
P0 {s4} {s0,s1,s2,s3}{s4}
{s0,s1,s2,s3}{s4}
none{s0, s1, s2}
{s3}
P1 {s4} {s3} {s0,s1,s2}{s0,s1,s2}
{s3}{s3}
none{s0, s2}{s1}
P2 {s4} {s3} {s1} {s0,s2} {s0,s2}{s1} {s1} none none
s0 a s1
b
s3 b s4
s2
a
b
b
a
a
a
b
s0 , s2a s1
b
s3 b s4
b
a
a
a
b
final state

DFA Minimization
What about a ( b | c )* ?
First, the subset construction:
q0 q1 a
q4 q5 b
q6 q7 c
q3 q8 q2 q9
-closure(move(s,*))
NFA states a b c
s0 q0 q1, q2, q3, q4, q6, q9
none none
s1 q1, q2, q3,q4, q6, q9
none q5, q8, q9,q3, q4, q6
q7, q8, q9,q3, q4, q6
s2 q5, q8, q9,q3, q4, q6
none s2 s3
s3 q7, q8, q9,q3, q4, q6
none s2 s3
s3
s2
s0 s1
c
ba
b
b
c
c
Final states

DFA Minimization
Then, apply the minimization algorithm
To produce the minimal DFA
s3
s2
s0 s1
c
ba
b
b
c
c
Split onCurrent Partition a b c
P0 { s1, s2, s3} {s0} none none none
s0 s1
a
b | cMinimizing that DFA produces the one that a human would design!
final states

Limits of Regular Languages
Advantages of Regular Expressions Simple & powerful notation for specifying patterns Automatic construction of fast recognizers Many kinds of syntax can be specified with REs
Example — an expression grammar
Term [a-zA-Z] ([a-zA-z] | [0-9])*
Op + | - | | /
Expr ( Term Op )* Term
Of course, this would generate a DFA …
If REs are so useful …Why not use them for everything?

Limits of Regular Languages
Not all languages are regular
RL’s CFL’s CSL’s
You cannot construct DFA’s to recognize these languages L = { pkqk } (parenthesis languages) L = { wcw r | w *}
Neither of these is a regular language (nor an RE)
But, this is a little subtle. You can construct DFA’s for Strings with alternating 0’s and 1’s
( | 1 ) ( 01 )* ( | 0 ) Strings with and even number of 0’s and 1’s
RE’s can count bounded sets and bounded differences

What can be so hard?
Poor language design can complicate scanning Reserved words are important
if then then then = else; else else = then (PL/I)
Insignificant blanks (Fortran & Algol68)
do 10 i = 1,25
do 10 i = 1.25
String constants with special characters (C, C++, Java, …)
newline, tab, quote, comment delimiters, …
Finite closures (Fortran 66 & Basic) Limited identifier length Adds states to count length

What can be so hard? (Fortran 66/77)
INTEGERFUNCTIONA
PARA METER(A=6,B=2)
IMPLICIT CHARA CTER*(A-B)(A-B)
INTEGER FORMAT(10), IF(10), DO9E1
100 FORMAT(4H)=(3)
200 FORMAT(4 )=(3)
DO9E1=1
DO9E1=1,2
9 IF(X)=1
IF(X)H=1
IF(X)300,200
300 CONTINUE
END
C THIS IS A “COMMENT CARD” $ FILE(1)
END
How does a compiler scan this?
• First pass finds & inserts blanks
• Can add extra words or tags to create a scanable language
• Second pass is normal scanner
Example due to Dr. F.K. Zadeck

Building Faster Scanners from the DFA
Table-driven recognizers waste effort Read (& classify) the next character Find the next state Assign to the state variable Trip through case logic in action() Branch back to the top
We can do better Encode state & actions in the code Do transition tests locally Generate ugly, spaghetti-like code Takes (many) fewer operations per input character
char next character;state s0 ;
call action(state,char);while (char eof) state (state,char); call action(state,char); char next character;
if (state) = final then report acceptance;else report failure;

Building Faster Scanners from the DFA
A direct-coded recognizer for r Digit Digit*
Many fewer operations per character Almost no memory operations Even faster with careful use of fall-through cases
goto s0;s0: word Ø; char next character; if (char = ‘r’) then goto s1; else goto se;s1: word word + char; char next character; if (‘0’ ≤ char ≤ ‘9’) then goto s2; else goto se;
s2: word word + char; char next character; if (‘0’ ≤ char ≤ ‘9’) then goto s2; else if (char = eof) then report success; else goto se;
se: print error message; return failure;

Building Faster Scanners
Hashing keywords versus encoding them directly Some (well-known) compilers recognize keywords as identifiers
and check them in a hash table Encoding keywords in the DFA is a better idea
O(1) cost per transition Avoids hash lookup on each identifier
It is hard to beat a well-implemented DFA scanner

Building Scanners
The point All this technology lets us automate scanner construction Implementer writes down the regular expressions Scanner generator builds NFA, DFA, minimal DFA, and then
writes out the (table-driven or direct-coded) code This reliably produces fast, robust scanners
For most modern language features, this works You should think twice before introducing a feature that defeats a
DFA-based scanner The ones we’ve seen (e.g., insignificant blanks, non-reserved
keywords) have not proven particularly useful or long lasting

Some Points of Disagreement with EAC
Table-driven scanners are not fast EaC doesn’t say they are slow; it says you can do better
Faster code can be generated by embedding scanner in code This was shown for both LR-style parsers and for scanners in
the 1980s
Hashed lookup of keywords is slow EaC doesn’t say it is slow. It says that the effort can be folded
into the scanner so that it has no extra cost. Compilers like GCC use hash lookup. A word must fail in the lookup to be classified as an identifier. With collisions in the table, this can add up. At any rate, the cost is unneeded, since the DFA can do it for O(1) cost per character.

Building Faster Scanners from the DFA
Table-driven recognizers waste a lot of effort Read (& classify) the next character Find the next state Assign to the state variable Trip through case logic in action() Branch back to the top
We can do better Encode state & actions in the code Do transition tests locally Generate ugly, spaghetti-like code Takes (many) fewer operations per input character
char next character;state s0 ;
call action(state,char);while (char eof) state (state,char); call action(state,char); char next character;
if (state) = final then report acceptance;else report failure;
index
index
index

Parsing

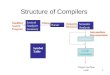
The Front End
Parser Checks the stream of words and their parts of speech (produced by
the scanner) for grammatical correctness Determines if the input is syntactically well formed Guides checking at deeper levels than syntax Builds an IR representation of the code
Think of this as the mathematics of diagramming sentences
Sourcecode Scanner
IRParser
Errors
tokens

The Study of Parsing
The process of discovering a derivation for some sentence Need a mathematical model of syntax — a grammar G Need an algorithm for testing membership in L(G) Need to keep in mind that our goal is building parsers, not
studying the mathematics of arbitrary languages
Roadmap1 Context-free grammars and derivations2 Top-down parsing
Hand-coded recursive descent parsers3 Bottom-up parsing
Generated LR(1) parsers

Specifying Syntax with a Grammar
Context-free syntax is specified with a context-free grammar
SheepNoise SheepNoise baa | baa
This CFG defines the set of noises sheep normally make
It is written in a variant of Backus–Naur form
Formally, a grammar is a four tuple, G = (S,N,T,P) S is the start symbol (set of strings in L(G)) N is a set of non-terminal symbols (syntactic variables) T is a set of terminal symbols (words) P is a set of productions or rewrite rules (P : N (N T)+ )

Deriving Syntax
We can use the SheepNoise grammar to create sentences use the productions as rewriting rules
And so on ...

A More Useful Grammar
To explore the uses of CFGs,we need a more complex grammar
Such a sequence of rewrites is called a derivation Process of discovering a derivation is called parsing
We denote this derivation: Expr * id – num * id

Derivations
At each step, we choose a non-terminal to replace Different choices can lead to different derivations
Two derivations are of interest Leftmost derivation — replace leftmost NT at each step Rightmost derivation — replace rightmost NT at each step
These are the two systematic derivations
(We don’t care about randomly-ordered derivations!)
The example on the preceding slide was a leftmost derivation Of course, there is also a rightmost derivation Interestingly, it turns out to be different

The Two Derivations for x – 2 * y
In both cases, Expr * id – num * id The two derivations produce different parse trees The parse trees imply different evaluation orders!
Leftmost derivation Rightmost derivation

Derivations and Parse Trees
Leftmost derivation G
x
E
E Op
–
2
E
E
E
y
Op
*This evaluates as x – ( 2 * y )

Derivations and Parse Trees
Rightmost derivation
x 2
G
E
Op EE
E Op E y
–
*
This evaluates as ( x – 2 ) * y

Derivations and Precedence
These two derivations point out a problem with the grammar:
It has no notion of precedence, or implied order of evaluation
To add precedence Create a non-terminal for each level of precedence Isolate the corresponding part of the grammar Force the parser to recognize high precedence subexpressions first
For algebraic expressions Multiplication and division, first (level one) Subtraction and addition, next (level two)

Derivations and Precedence
Adding the standard algebraic precedence produces:
This grammar is slightly larger
• Takes more rewriting to reach some of the terminal symbols
• Encodes expected precedence
• Produces same parse tree under leftmost & rightmost derivations
Let’s see how it parses x - 2 * y
levelone
leveltwo

Derivations and Precedence
The rightmost derivation
This produces x%2 – ( 2 * y ), along with an appropriate parse tree.
Both the leftmost and rightmost derivations give the same expression, because the grammar directly encodes the desired precedence.
G
E
–E
T
F
<id,x>
T
T
F
F*
<num,2>
<id,y>
Its parse tree

Ambiguous GrammarsOur original expression grammar had other problems
This grammar allows multiple leftmost derivations for x - 2 * y Hard to automate derivation if > 1 choice The grammar is ambiguous
different choice than the first time

Two Leftmost Derivations for x – 2 * y
The Difference: Different productions chosen on the second step
Both derivations succeed in producing x - 2 * yOriginal choice New choice

Ambiguous Grammars
Definitions If a grammar has more than one leftmost derivation for a single
sentential form, the grammar is ambiguous If a grammar has more than one rightmost derivation for a single
sentential form, the grammar is ambiguous The leftmost and rightmost derivations for a sentential form may
differ, even in an unambiguous grammar
Classic example — the if-then-else problem
Stmt if Expr then Stmt | if Expr then Stmt else Stmt | … other stmts …
This ambiguity is entirely grammatical in nature

Ambiguity
This sentential form has two derivations
if Expr1 then if Expr2 then Stmt1 else Stmt2
then
else
if
then
if
E1
E2
S2
S1
production 2, then production 1
then
if
then
if
E1
E2
S1
else
S2
production 1, then production 2

AmbiguityRemoving the ambiguityMust rewrite the grammar to avoid generating the problemMatch each else to innermost unmatched if (common sense rule)
With this grammar, the example has only one derivation
1 Stmt WithElse
2 | NoElse
3 WithElse if Expr then WithElse else WithElse
4 | OtherStmt
5 NoElse if Expr then Stmt
6 | if Expr then WithElse else NoElse

Ambiguity
if Expr1 then if Expr2 then Stmt1 else Stmt2
This binds the else controlling S2 to the inner if
Rule Sentential Form— Stmt2 NoElse5 if Expr then Stmt? if E1 then Stmt1 if E1 then WithElse3 if E1 then if Expr then WithElse else WithElse? if E1 then if E2 then WithElse else WithElse4 if E1 then if E2 then S1 else WithElse4 if E1 then if E2 then S1 else S2

Deeper Ambiguity
Ambiguity usually refers to confusion in the CFG
Overloading can create deeper ambiguity
a = f(17)In many Algol-like languages, f could be either a function or a
subscripted variable
Disambiguating this one requires context Need values of declarations Really an issue of type, not context-free syntax Requires an extra-grammatical solution (not in CFG) Must handle these with a different mechanism
Step outside grammar rather than use a more complex grammar

Ambiguity - the Final Word
Ambiguity arises from two distinct sources Confusion in the context-free syntax (if-then-else) Confusion that requires context to resolve (overloading)
Resolving ambiguity To remove context-free ambiguity, rewrite the grammar To handle context-sensitive ambiguity takes cooperation
Knowledge of declarations, types, … Accept a superset of L(G) & check it by other means†
This is a language design problem
Sometimes, the compiler writer accepts an ambiguous grammar Parsing techniques that “do the right thing” i.e., always select the same derivation