Embed Size (px)
Citation preview

This article was downloaded by: [Princeton University]On: 24 August 2014, At: 22:37Publisher: Taylor & FrancisInforma Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House,37-41 Mortimer Street, London W1T 3JH, UK
International Journal of Production ResearchPublication details, including instructions for authors and subscription information:http://www.tandfonline.com/loi/tprs20
Scheduling a single batch processing machine with non-identical job sizesR. UZSOY aa School of Industrial Engineering, Purdue University , 1287 Grissom Hall, West Lafayette, IN,47907-1287, USA.Published online: 07 May 2007.
To cite this article: R. UZSOY (1994) Scheduling a single batch processing machine with non-identical job sizes, InternationalJournal of Production Research, 32:7, 1615-1635, DOI: 10.1080/00207549408957026
To link to this article: http://dx.doi.org/10.1080/00207549408957026
PLEASE SCROLL DOWN FOR ARTICLE
Taylor & Francis makes every effort to ensure the accuracy of all the information (the “Content”) containedin the publications on our platform. However, Taylor & Francis, our agents, and our licensors make norepresentations or warranties whatsoever as to the accuracy, completeness, or suitability for any purpose of theContent. Any opinions and views expressed in this publication are the opinions and views of the authors, andare not the views of or endorsed by Taylor & Francis. The accuracy of the Content should not be relied upon andshould be independently verified with primary sources of information. Taylor and Francis shall not be liable forany losses, actions, claims, proceedings, demands, costs, expenses, damages, and other liabilities whatsoeveror howsoever caused arising directly or indirectly in connection with, in relation to or arising out of the use ofthe Content.
This article may be used for research, teaching, and private study purposes. Any substantial or systematicreproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in anyform to anyone is expressly forbidden. Terms & Conditions of access and use can be found at http://www.tandfonline.com/page/terms-and-conditions

INT. J. PROD. RES., 1994, VOL. 32, No.7, 1615-1635
Scheduling a single batch processing machinewith non-identical job sizes
R. UZSOY
The problem of scheduling jobs with non-identical capacity requirementsor sizeson a single batch processing machine to minimize total completion time andmakespan is studied.These problemsare proven to be NP-hard and heuristicsaredeveloped for both, as well as a branch and bound algorithm for the totalcompletion time problem.Computational experiments show that the heuristics arecapable of rapidly obtaining near-optimal solutions.
I. IntroductionWe address the problem of scheduling batch processing machines to maximize
throughput. A batch processing machine is one which can process a number or jobssimultaneously as a batch. All jobs processed in a batch begin and complete processingsimultaneously. The processing time of a batch is determined by the longest processingamong those of all in the batch. Eachjob has a certain size or capacity requirement, andthe capacity of the machine is limited. Hence the total size of the jobs in a batch cannotexceed the capacity of the machine.
Although batch processing machines are encountered in many different environments, such as heat treatment operations in the metalworking industries, this researchis motivated by burn-in operations in semiconductor manufacturing. The purpose ofburn-in operations is to subject the integrated circuits to thermal stress for an extendedperiod to bring out latent defects leading to infant mortality that might otherwisesurface in the operating environment. This is done by maintaining the circuit at aconstant temperature (generally around 120°C)in an oven. The burn-in time for eachcircuit is specified a priori. When a job, corresponding to a lot of circuits, arrives at theburn-in area, the circuits are loaded on to boards, each of which can hold a certainnumber of circuits. The boards are often product-specific, and the job cannot beprocessed without the necessary board. The boards are then loaded into the oven. Thecapacity of the oven is defined by the number of boards it can hold, and the size of a jobby the number of boards it requires. Boards loaded with different types of circuits maybe processed in the same oven. Thus a number of jobs are grouped into a batch to beprocessed in the same oven. The processing time of a batch is equal to the longestprocessing time among all jobs in the batch. This is because it is possible to keep acircuit in the oven for longer than its prescribed burn-in time, but not to take it outbefore that time has elapsed. Once processing is begun on a batch, no job can beremoved from the machine until the processing of the batch is complete. The processingtimes in burn-in operations can be long compared with other testing operations (e.g.120h as opposed to 4--5 h for other operations). Thus the burn-in operation constitutesa bottleneck in the final testing operation, and the efficient scheduling of these
Revision received July 1991Schoolofindustrial Engineering, 1287 Grissom Hall, Purdue University, West Lafayette, IN
47907-1287, USA.
0020-7543/94 £10-00 © 1994 Taylor & Francis Ltd.
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1616 R. Uzsoy
operations to maximize throughput and reduce flow time and work-in-processinventories is of great concern to management. This motivates the performancemeasures of makespan (Cm..) and total completion time (rc,) which we address in thisstudy.
2. Related workThe scheduling of batch processing machines has only recently begun to be
addressed in the scheduling literature. Ikura and Gimple (1986) provide an efficientalgorithm to determine whether a schedule where all jobs are completed by their duedate exists for the case where release times r j and due dates d, are agreeable (i.e. r.er,implies dj,,;;dj ) and all jobs have identical processing times. Glassey and Weng (1991)develop a heuristic which uses estimates of future job arrivals for this problem andevaluate its performance using a simulation model. Fowler el al. (1992) extend thisapproach to multiple machine and multiple product environments, assuming that onlylots of the same product can be batched together. Ahmadi el al. (1992)examine a class ofproblems defined by two or three machine flowshops with one batch processingmachine. Assuming identical processing times on the batch processing machine, theyprovide algorithms and complexity classifications for the problems of minimizing rC j
and Cm DX •
Lee et al. (1992)examine batch processing machines where different products can bebatched together but the processing time of the batch depends on the jobs in the batch.They provide efficient algorithms to minimize the number of tardy jobs and maximumtardiness under a number of assumptions. They also provide a heuristic for the problemof minimizing Cm D X on parallel identical batch processing machines and a tight worstcase error bound on its performance. Chandru et al. (I 993a) examine the problem ofminimizing rCi on a batch processing machine of this type. They provide optimal andheuristic algorithms for the case of a single machine, and heuristics for the parallelmachine problem. Chandru el al. (1993b) show that if there are only a fixed number ofjob families (i.e. different processing time values), the rCi problem can be solved inpolynomial time.
All the research cited above assumes that each job is of unit size, i.e. requires onlyone unit of machine capacity. The only research we are aware ofto discuss the problemwhere jobs have non-identical sizes is that of Dobson and Nambinadom (1992) andChandra and Gupta (1992). The former authors assume that only jobs from the samefamily can be processed together, and that jobs in the same family have identicalprocessing times. They study the problem of minimizing the total weighted completiontime (1:wi C,) on a batch processing machine, and provide an integer programmingformulation which they use to develop a lower bound on the value of the optimalsolution. They also prove that this problem is NP-hard and provide a number ofheuristics. Chandra and Gupta (1992)focus on the effect oflot sizes on waiting time fora combined assembly and test facility. These authors try to maximize the throughputsubject to constraints on oven capacity and compatibility between different products.They formulate this as a multiple-constrained bin-packing problem and provide aheuristic. This procedure is combined into a coordination scheme for the entirepackaging line and evaluated using simulation.
In this paper we assume that jobs of different families can be processed together, andthat the processing time of a batch depends on its contents. We study the case wherejobs have different sizes. Hence this paper differs from the work of Lee et al. (1992) andChandru et al. (1993a, b) by examining jobs with non-identical sizes, and that of
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

Scheduling single-batch processes with non-identicaljob sizes 1617
Chandra and Gupta (1992) and Dobson and Nambinadom (1992) by examining thecase where jobs of different families can be processed together and the processing timeof a batch depends on its contents.
In §3 we describe the assumptions and notation used in the rest of the paper. In §4we prove that the problem of minimizing Cmax is NP-hard and present a number ofheuristics, whose performance is evaluated empirically in §5. Section 6 examines theproblem of minimizing I:C i . We prove that this problem is also NP-hard, and provide anumber of different heuristics. For the sake of conciseness, we shall refer to the problemof minimizing Cmax as CMAX, and that of minimizing I:C i as SUMCI.
3. Assumptions and notationWe make the following assumptions:
(1) There are n jobs to be processed. The processing time of job i denoted by Pi'Since processing times are known a priori from the product test specification,all data are assumed to be deterministic.
(2) Each machine has a capacity B and each job has a size a; We assume that thesize of a job cannot exceed the machine capacity. In practice this is achieved bysplitting large lots into sublots of the appropriate size.
(3) Once processing of a batch is initiated, it cannot be interrupted and other jobscannot be introduced into the oven until processing is completed. Since it isacceptable to keep a job in the oven for longer than its specified burn-in timebut not for a shorter period, the processing time of a batch is given by the largestprocessing time of the jobs in the batch.
A batching refers to a grouping of the n jobs into subsets or batches such that the totalsize of all jobs in the batch does not exceed the machine capacity B. There are at most nand at least [I:aJB] batches, where [k] denotes the smallest integer greater than orequal to k. The processing time of a batch B" denoted by p", is equal to the largestprocessing time of the jobs in the batch i.e.l = max{p,liEB,}. The number of jobs inbatch B, will be denoted by IB,I. A schedule for a batch processing machine consists ofboth a batching and a sequence for the batches.
4. Minimizing makespan on a single batch processing machineIn this section we address the CMAX problem on a single machine in the presence
of different job size requirements. We first prove that the following special case of thisproblem is NP-hard:
Proposition I. When all jobs require identical processing times, CMAX is equivalentto a bin packing problem with bin capacity B and item sizes a.:
Proof The bin packing problem can be stated as follows: Given n items of sizes, and anumber of bins of size S, try to fit the items into bins such that the number of bins usedto accommodate all n items is minimized.
When all jobs in CMAX have identical processing times, the Cm• x value dependsonly on the number of batches in the schedule and is independent of the sequence inwhich the batches are processed. Consider a bin-packing problem with a bin capacity ofB, the capacity of the batch processing machine. For each job i, define an item with sizea; Items packed into the same bin in the bin-packing problem are processed in the samebatch in the scheduling problem. Since the optimal bin packing will result in the
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1618 R. Uzsoy
minimum number of bins and Cmu depends on the number of batches, the optimalsolution to the bin-packing problem corresponds to the optimal solution to thescheduling problem. QED
This leads directly to the following corollary:
Corollary I. CMAX is strongly NP-hard.
Proof By Proposition I, the special case ofCMAX with identical processing times isequivalent to the bin-packing problem which is strongly NP-hard (Garey and Johnson1979). Since this special case is strongly NP-hard, the result.follows, QED
Hence efficient algorithms to obtain optimal solutions are unlikely to exist, anddeveloping heuristics to rapidly obtain near-optimal solutionsis a useful approach. Weshall make extensive use of the First-Fit heuristic, developed for the bin-packing(Coffman et al. 1984). This algorithm can be stated as follows:
Algorithm FFStep I. Arrange the items in some arbitrary order.Step 2. Select the item at the head of the list and place it in the first bin with enough
space to accommodate it. If it fits in no existing bin, create a new bin.
This algorithm can be adapted to the scheduling problem as follows:
Algorithm BFF (Batch First Fit)Step I. Arrange the jobs in some arbitrary order.Step 2. Select the job at the head of the list and place it in the first batch with enough
space to accommodate it. If it fits in no existing batch, create a new batch.Repeat step 2 until all jobs have been assigned to a batch.
Step 3. Sequence the batches on the machine in any arbitrary order.
The worst-case performance of this algorithm can be quantified using results frombin-packing problems.
Proposition 2. For CMAX with identical processing times, let Cmax(BFF) denote theCm•• value obtained by the BFF algorithm, C:'u the optimal Cmu value and p theprocessing time common to all jobs. Then Cmax (BFF)";NC:'ax +p, and this bound istight.
Proof Follows directly from the result of Johnson et al. (1974) for the bin-packingproblem and its equivalence to CMAX with -identical processing times proven inProposition I. QED
When non-identical processing times are present in CMAX, it is no longer sufficientto consider only minimizing the number of batches since the processing time of a batchis determined by the jobs in the batch. The CMAX value is still independent of batchsequencing.
Combining the good performance ofthe FF algorithm for the bin packing problemwith our knowledge of the unit-size problem allows us to suggest an effective heuristicfor CMAX. The problem with unit job sizes is easily solved by ordering the jobs indecreasing order of processing time, successively grouping the B jobs with longestprocessing times into the same batch and then processing the batches in any order. Theintuition behind this algorithm is that to minimize Cm... long jobs should be batchedtogether to avoid their being batched with shorter jobs. We arrive at the followingheuristic:
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

Scheduling single-batch processes with non-identical job sizes 1619
Algorithm FFLPTStep I. Arrange the jobs in decreasing order of processing times Pi'Step 2. Apply algorithm OFF to the resulting list of jobs.
This heuristic attempts to address both the need to minimize the number of batchesand the need to group longjobs together. When all jobs have identical processing times,a tight error bound of 17/10 applies by Proposition 2. If all jobs have unit size, thisalgorithm produces an optimal schedule.
In addition to the FFLPT heuristic, we can develop other heuristics by ordering thejobs differently and applying BFF to the resulting list. This leads to the followingheuristics:
Algorithm FFDECRStep 1. Order the jobs in decreasing order of the job sizes a..Step 2. Apply algorithm OFF to the resulting list of jobs.
The motivation for using this heuristic, the first-fit-decreasing procedure. is itsexecellent worst-case performance for the bin-packing problem (Coffman et al. 1984).However, it does not take job processing times into account.
Algorithm FFPIAJ:Step I. Order the jobs in increasing order of pJai •
Step 2. Apply algorithm OFF to the resulting list of jobs.
This heuristic attempts to take both processing time and job size into account whendeveloping a schedule. It will group large, short jobs and small, long jobs together.
Algorithm FFSPT:Step I. Order the jobs in increasing order of processing times Pi'Step 2. Apply algorithm OFF to the resulting list of jobs.
This procedure tries to get jobs with similar processing times close together in theschedule but starts from the shortest job, instead of the longest.
A lower bound on the optimal Cmax value can be calculated by relaxing the problemto allow jobs to be split and processed in different batches. This is done by constructingan instance of CMAX with unit job sizes where each job i in the original problem isreplaced by a, jobs of unit size and processing time Pi' This can be solved easily and itsoptimal value yields a lower bound on the optimal Cmu for CMAX. This lower boundproves to be tight, and we use it as a benchmark in our computational experiments.
5. Computational results for CMAXTo evaluate the performance of the heuristics for CMAX described above, a series of
computational experiments were carried out in which the various algorithms weretested on a set of randomly generated test problems. Job processing times wereassumed to be uniformly distributed between I and 100.The uniform distribution wasselected because it has been commonly used in the scheduling literature for thegeneration of test problems. In addition, it is a high-variance distribution which allowsthe heuristics to be tested under unfavourable conditions. A batch machine capacity of10 was used in all experiments. All programs were coded in Pascal and run on a SunSPARC II workstation operating under UNIX.
Job sizes were assumed to be uniformly distributed between a minimum and amaximum job size (am;n and am..' respectively). Three different job size distributions
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1620 R. Uzsoy
were studied to examine the effect of job size distribution on the performance of thealgorithms as shown below:
Distribution amin amax
1 1 52 4 103 1 10
Distribution 1 represents the case where job sizes are small relative to the batchmachine capacity, allowing many possibilities for batching jobs together. In distribution 2, jobs are large relative to the batch machine capacity, and fewer jobs can beprocessed together in a batch. Distribution 3 represents a situation where job sizes varywidely. Distribution 1 results in problems similar to the unit-size problem, whiledistribution 2 is similar to a unit-capacity machine problem.
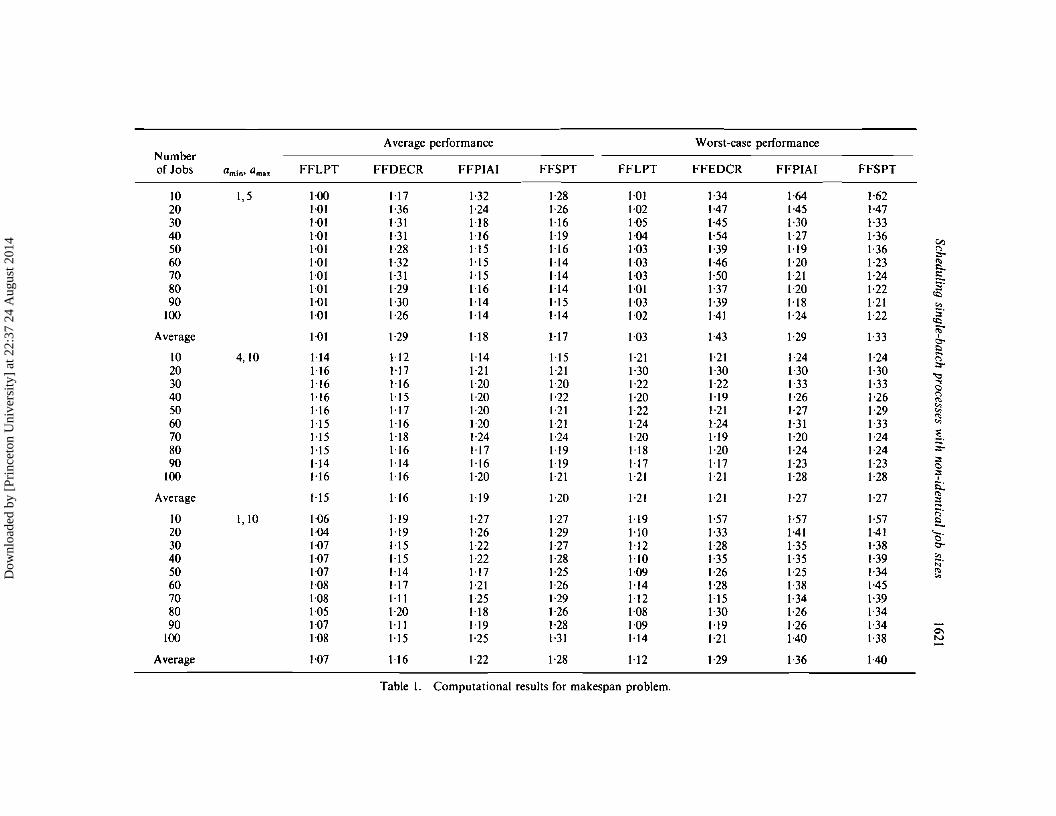
The performance ofthe heuristics was compared by solving problems containing upto 100 jobs for each job size distribution, resulting in 30 problem classes defined by anumber of jobs and a job size distribution. Ten instances of each problem class weresolved, resulting in a total of 300 randomly generated problem instances. The resultsare shown in Table I. The average performance lists the ratio of the Cm" value from theheuristic solution to the value ofthe lower bound described in the previous section. Theworst-case performance gives the maximum deviation of the heuristic from the lowerbound.
The results show that FFLPT is superior in terms of both average and worst-caseperformance. Its superiority is particularly clear for problems with small jobs. Thereason for the higher ratios for the problems with large jobs is that the lower boundfrom the unit-size relaxation is looser for these problems. It is interesting to note that asjob sizes increase, making it more difficult to batch jobs together, all proceduresperform comparably. This is intuitive since for problems with large jobs, all heuristicsapproach a solution where each job is scheduled in a batch on its own and thus generatesimilar solutions.
6. Minimizing total completion timeIn this section we address the problem of minimizing ~C, on a batch processing
machine with different job sizes, denoted by SUMCLThis problem is considerably more complicated than CMAX. Let C, denote the
completion time or batch B, in a given schedule containing k batches, and IB,I thenumber or jobs processed in that batch. Since all jobs processed in batch B, completetogether at time C" we have
k
LC,= L IB,IC,i= 1
Chandru et al. (1993a) have shown that an optimal schedule will have its batchessequenced in increasing order or p'/IB,I, where p' denotes the processing time or batch i.We shall refer to this ordering of jobs as batch-weighted shortest processing time(BWSPT) order.
Although, intuitively, keeping the machine as full as possible and minimizing thenumber of batches would seem to minimize ~C" the optimal solutions to the CMAX
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4
Average performance Worst-case performanceNumberof Jobs amin' amu FFLPT FFDECR FFPIAI FFSPT FFLPT FFEDCR FFPIAI FFSPT
10 1,5 HlO 1·17 1·32 1·28 1·01 ],34 1·64 1·6220 ],0] ],36 1·24 1·26 1·02 ],47 ],45 1·4730 ],0] ],3] 1·]8 1·16 1·05 ],45 1-30 1·3340 1·01 1·3] 1·16 1·19 1·04 1·54 1·27 1·36
'"50 1·01 1·28 1·15 1·16 1·03 1-39 1·19 1·36 "::>-60 1·01 1·32 1·15 ],14 1·03 1·46 1·20 ],23 '"...70 1·01 1-3] 1·15 1·14 ],03 ),50 ],21 ],24 "80 1·01 1·29 1'16 ]']4 1·01 ],37 1·20 ],22 ~
'"'90 ],01 1·30 ],14 1·15 1·03 1-39 1·18 1·2] ""100 1·01 1·26 1·14 ]']4 1·02 1-41 1·24 1·22 S·'"'
Average 1·01 1·29 ]']8 ],17 ],03 1·43 1·29 1-33 '",0-
'"10 4, ]0 1-14 ]·12 1·14 1·15 1·2] 1·21 1·24 ],24 -"20 ],16 1'17 1·21 1·21 1·30 1·30 1-30 1·30;:,-
'"30 1,]6 1'16 1·20 ],20 1·22 1·22 1-33 1·33 ...Cl
40 1,]6 1·15 1·20 1·22 1·20 1-19 ],26 1·26 "'"50 1·16 1·17 1·20 1·21 ],22 ],2] ],27 1·29 """"'"60 1·15 1·16 ],20 1·2] 1·24 ],24 ],31 1-33 ""70 1'15 1·18 ],24 ],24 1·20 1·19 1·20 ],24 ~.80 1·15 1·16 ],17 1·19 1·18 1·20 1·24 1·24 ::>-
90 1·14 1·14 1'16 1·19 1·17 1'17 ],23 1·23 "c100 1'16 1·16 1·20 1·21 1·21 1·21 1'28 1·28 7
0;,:Average 1·15 ],16 1·19 1·20 1·21 1·21 ]·27 1·27 '""
10 1,10 1·06 1,]9 1·27 1·27 1·19 ],57 1·57 1·57g.e..
20 1·04 1·19 1·26 1·29 1·10 1·33 1·41 1-41 '-.c30 1·07 1·15 1·22 1·27 1'12 1·28 1·35 1·38 0-
40 1·07 1·15 1·22 1·28 1·10 1·35 1·35 1·39 "";:;.50 1·07 1·14 1·17 1·25 1·09 1·26 1·25 1·34 '"""60 1·08 1·17 1·21 1·26 1·14 ],28 1·38 1·4570 1·08 1·11 ],25 1·29 1·12 ],15 1·34 1·3980 1·05 1·20 ],18 1·26 1·08 1-30 1·26 1-3490 1·07 1,]1 ],19 ],28 1·09 1,]9 1·26 1·34
0-100 1·08 1'15 1·25 ],31 1·14 1·21 1·40 1·38 N
Average ],07 ]']6 1·22 1'28 ],12 ],29 1·36 1'40
Table 1. Computational results for makespan problem.
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1622 R. Uzsoy
and SUMCI problems may have quite different structures. Consider the example witheight jobs where B =4, all processing times are equal to 1and the job sizes are given byI, I, I, 1,3,3,3,3. The minimum number of batches in this solution is four, with fourbatches each containing one job of size 3 and one of size I. The ~Ci of this schedule is 20.If, however, we batch all four unit size jobs together and the four jobs of size 3individually, we obtain a schedule with five batches, but a ~Ci of 18. We have thefollowing result:
Proposition 3: SUMCI with identical processing times is NP-hard.
The proof of this proposition is given in the appendix. This result implies that theunit weight version of the problem with job families addressed by Dobson andNambinadom (1992) is also NP-hard. Hence efficient optimal solution procedures forthis problem, and hence the more general SUMCI problem, are unlikely to exist,motivating us to search for effective heuristic procedures. We first develop an optimalbranch and bound procedure for this problem to allow us to benchmark the heuristics.We then outline a number of heuristics and evaluate their performance via a series ofcomputational experiments.
6.1. A branch and bound algorithm for SUMClIn order to develop an exact branch and bound algorithm, we first develop a lower
bound on the optimal value of the problem and outline the enumeration scheme. Wealso present a number of dominance conditions that allow us to reduce the effortrequired for the search. For the sake of brevity, the proofs of the propositions in thissection are given in the appendix.
To develop a lower bound, we relax SUMCI by splitting each job i of size ai into ai
unit-size jobs ij,j = I, ... , ai' and replacing the batch processing machine with B parallelidentical unit-capacity machines. This corresponds to relaxing the constraints that jobscannot be split and that all jobs processed in a batch must complete at the same time.We shall refer to this relaxed problem as (PR), and the unit-sized jobs ij resulting fromthe splitting of job i as segments. In (PR) the completion time of job i is given by thecompletion time of its last segment to complete. Index the segments ijofjob i in order oftheir completion time in an optimal solution to (PR). Then the optimal ~Ci of (PRJ,which is a lower bound on the ~Ci of SUMCI, is
where Ci • a, denotes the completion time of the last segment of job i in the optimalsolution to the relaxed problem. We have the following result:
Proposition 4: Let Cij denote the completion time of segment j of job i an optimalsolution to (PR), and ~q(PRj the optimal value of (PR). Then
This result shows that a lower bound on the optimal value of (PR) can be obtainedfrom the optimal solution to parallel machine total weighted completion time problem,with ~al jobs ij (corresponding to the segments of the original jobs) each having aweight of I[a; Hence a lower bound on the optimal value of SUMCI can be obtained
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

Scheduling single-batch processes with non-identical job sizes 1623
from the optimal LWjCj value of this problem. Although this problem is itself NP-hard,Bruno et al. (1974) and Eastman et al. (1964) have developed a lower bound which weuse to prove the following result:
Proposition 5: Let Lct denote the optimal LC i value for SUMCI. Then
where C1 denotes the optimal LwjCi value of the problem of scheduling all La i segmentsij with weights Ila i on a single unit-capacity machine.
This result gives us a lower bound which we can use in a branch and boundalgorithm.
The development of an enumeration scheme for this problem is complicated by thefact that we must enumerate all batchings as well as all sequences of batches. Oneapproach would be to generate all possible batchings of the jobs and then enumeratethe possible sequences of these batchings, taking care to ensure that no job is scheduledtwice. This approach works quite well for the unit-size problem (Chandru et al. 1993a),where properties of the optimal solution allow us to restrict the number of possiblebatches considered to O(nB). However, these properties no longer hold for the problemwith non-identical job sizes, and the number of possible batches becomes very large (inthe worst case, where all jobs are of unit size, the number of possible batchings would beequal to the number of subsets of the n jobs of cardinality B and less). Hence thisapproach is not practical for this problem, and a more efficient enumeration schememust be sought.
There are two potential ways in which a new job may be appended to a partialschedule P:
(I) The new job may be placed in a new batch on its own and appended to the rightof P. This type of addition will be referred to as a type-I addition to P.
(2) The new job may be inserted into the last batch of P, if there is sufficient space.This type of addition will be referred to as a type-2 addition to P.
Thus, given any node in the search tree corresponding to a partial schedule P, there aretwo families of child nodes, corresponding to the type-I and type-2 additions, whichneed to be examined.
We can develop an enumeration procedure based on these insights as follows. Atthe start of the enumeration, each partial schedule will contain exactly one job in abatch on its own. Whenever a node is selected for expansion, the list of unscheduledjobs eligible to be appended to this partial schedule will be considered. Eachunscheduled job will be appended to P to form both type-I and type-2 child nodeswhich will be added to the search tree.
An example of the enumeration scheme for a problem with three jobs of unit sizeand B= 3 is given in Fig. I. At the first level of the tree there are only type-I nodes, whereeach job is processed in a batch on its own. At subsequent levels we see that both type-Iand type-2 nodes are generated. Jobs listed in parentheses indicate jobs processedtogether in a batch. The node ((1)(3)), for example, has one type-I child ((1)(3)(2)) andone type-2 child ((1)(32)).
If implemented directly as described above, the enumeration scheme will result inconsiderable duplication. This is because it adds jobs to existing batches in a givensequence. Thus a batch containing jobs i and j will be enumerated twice, once in the
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1624 R. Uzsoy
//~""" /"\ <,/ \ 1\ /\ 1\
f1 )(2)(31 (1 )(231(1 )(31121 (111"1 11231 1121131 113)(21 11"1
Figure I. Example search tree to illustrate the enumeration scheme.
131
order (i .. .j) and again in the order(j ... i). However, since it is the set ofjobs in the batchthat determines batch processing time, the sequence within a batch is irrelevant. InFig. I, for example, the two schedules ((1)(23)) and ((1)(32)) are in fact identical for thisreason. We can eliminate a certain amount of this duplication using the followingresult:
Proposition 6: Suppose the jobs are indexed in increasing order or their processingtimes such that PI ~P2 ~ ... ~p•. Consider a partial schedule P and let the highestindexed job in the last batch be job j. Then it is sufficient to consider only unscheduledjobs with indices greater than j when performing type-2 additions to P.
The problem of fathoming nodes in this search tree is quite complex. Define acompletion of a partial schedule P to be a complete solution formed by appending newbatches to the right of P without inserting a new job into any batch in P. To obtaincompletions of P, we generate all immediate type-I children of P. Let J denote the set ofall jobs to be scheduled, and LBl(S) the lower bound of Proposition 4 calculated for thesubset of jobs S. We can calculate a lower bound LB(P) on the ~Ci value of allcompletions of P as
LB(P) = ~Ci(P)+ LB1(J /P)+ IJ\PICm..(P)
where emax (P) denotes the makespan of P. Hence, if for a partial schedule P,LB(P) > UB, where UB denotes the current upper bound, no completion of P can beoptimal and we can eliminate all type-I children of P from further consideration.However, there is no gaurantee that a type-2 addition to P cannot be completed to anoptimal solution. Hence these type-2 child nodes must be considered in theenumeration to guarantee its completeness.
We can derive dominance conditions that allow us to delete all completions of typeI additions to a partial schedule P from consideration.
Proposition 7: If either of the following conditions holds for a partial schedule P, thenno type-I addition to P can be completed to an optimal solution:
(a) There exist in P two batches B, and B, such that pi/IBil ~ pi/IBjl and batch B, isscheduled after batch Bj"
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

Scheduling single-batch processes with non-identical job sizes 1625
(b) There exists an unscheduled job k and a batch B, in P such that Pk ~ pi and
L ai+ak~BieBj
We have thus developed all the components of a branch and bound algorithm: theenumeration scheme, the lower bound used for fathoming and dominance conditionsto enhance the efficiencyof the search. An upper bound can be obtained using any of theheuristics described in the following section.
6.2. Heuristics for SUMCIThe heuristics we suggest for SUMCI can be classified into two main groups: those
based on the first-fit procedure for the bin-packing problem, which we shall refer to asthe first-fit (FF) heuristics; and those based on a greedy ratio procedure which takesinto account processing time and batch utilization information, referred to as thegreedy ratio (GR) heuristics.
The FF heuristics for SUMCI use different initial orderings for step I. They aredescribed as follows:
Algorithm MBFF (Modified Batch First Fit)Step 1. Order the jobs in some arbitrary order.Step 2. Select the job at the head of the list and place it in the first batch with
enough space to accommodate it. !fit fits in no existing batch, create a newbatch. Repeat step 2 until all jobs have been assigned to a batch.
Step 3. Sequence the batches in BWSPT order on the machine.
The FF heuristics for SUMCI use different initial orderings for step I. They aredescribed as follows:(I) Algorithm FFLPT. Jobs are ordered in decreasing order of processing times, andwithin this, in decreasing order of size.The underlying intuition is to try to batch jobs ofcomparable length together, starting from the longest.(2) Algorithm F FDECR. Jobs are ordered in decreasing order of sizes.This algorithmshould yield fewer batches, based on its performance for the bin-packing problem.(3) Algorithm FFSPT. The jobs are ordered in increasing order of their processingtimes. Here we try to batch jobs of comparable length together, beginning with theshortest job.
The G R family of heuristics can be described as follows:(I) Algorithm GR. This heuristic was developed by Chandru et al. (l993a) for theproblem with unit sizes. The intuition of algorithm GR is that a poor schedule is likelyto result ifjobs with widely different processing times are processed in the same batch.Hence the procedure tries to batch together consecutively indexed jobs, where jobs areindexed in ascending order of their processing times. The procedure, as modified totake into account job sizes, can be stated as follows:
Step I.Step 2.
Index the jobs in SPT order. Set i= I.Let t be the largest job index such that
t
L aj~Bj= 1
Find job k such that Pkl(k- i + 1)= min{p;,Pi+ ,/2, PH 2/3, ... ,p,/t- I} i.e.the job k such that the batch consisting ofjobs i to k has the minimum ratioof batch processing time to number ofjobs in the batch. Place jobs i to k in
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1626 R. Uzsoy
Step 4.
a batch together and schedule this batch on the machine. If all jobs havebeen scheduled, go to step 3. Otherwise, set i=k+ 1 and repeat step 2.
Step 3. Schedule all batches on the machine in BWSPT order.
(2) Algorithm EXGR (Extended Greedy Ratio). Algorithm GR examines only a limitedset of jobs, stopping as soon as it encounters one which does not fit into the currentbatch. EXGR tries to do better by looking at all remaining unscheduled jobs to seewhether there is one whose insertion in the current batch will improve the batch'sprocessing time to content ratio. EXGR may well create batches containing jobs withquite different processing times. However, due to the non-identical sizes of the jobs thisoften turns out to be beneficial. The algorithm can be described as follows:
Step I. Index the jobs in SPT order. Set i= I, C= {i}. Here i denotes the index ofthe first job to be considered and C the set of jobs in the current batch.
Step 2. Set j = i+ I. If
then set j = j + I. If j < n repeat step 2. If j = n, go to step 4.
Step 3. If
p max{pd
-IC-I~-I ~--::'='~--=C'---I -
i.e. the inclusion of job j in the batch results in a reduction of the ratio ofbatch processing time to number of jobs in the batch, thenjobj should beinserted into the current batch C. Set C = Cu{j}. Set j = j + 1 and go tostep 2.There are no unscheduled jobs that can be inserted into the current batchC. If all jobs have been scheduled, sequence the batches in BWSPT orderand stop. Otherwise, record the current batch. C, set i to the minimumindex corresponding to an unscheduled job, set C = {i} and repeat step 2.
To illustrate the operation of these two heuristics, consider the following example:
Example I. Consider an instance of SUMeI with B= 10 and the following data:
1234
5
2946577595
2747
5
Note that the jobs are indexed in SPT order. Algorithm GR will proceed as follows:
Step I. Set i= I.Step 2. t=2, since a,+a2 ( IO, a,+a2+a 3 > IO. The minimum ratio is min
{P"P2/2} =min {29,46/2} =23. Hence we batch jobs 1and 2 together. Seti=3.
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

Step 2.Step 2.Step 2.Step 3.
Scheduling single-batch processes with non-identical job sizes 1627
t = 3, since a3 +a. > 10. Place job 3 in a batch on its own, set i = 4.t = 4, since a4 +a, > 10. Place job 4 in a batch on its own, set i = 5.Place job 5 in a batch on its own.Schedule the batches in BWSPT order, resulting in the schedule shown inthe Gantt chart below and a LCi value of 645.
o
1,2
46
3
103
4
178
5
272
Algorithm EXGR, on the other hand, proceeds as follows:
Step I. i=l, C={l}.Step 2. j=2.Step 3. P2/2<PI, so we add job 2 to the current batch. C={I,2},j=3.Step 2. No other job can fit into the current batch.Step 4. We set i=3, C={3}.Step 2. j=4. a3+a4>IO.Step 2. j = 5. a3+a, < 10, and p,/2 < P3' so we batch jobs 3 and 5 together.Step 4. Set i=4, C={4}.Step 2. There are no further jobs to be batched,Step 4. Scheduling the batches in BWSPT order, we obtain the schedule shown in
the Gantt chart below, with a LCi value of 587.
o
1,2
46
3,5
140
4
215
Since the computational requirements of all these heuristics are extremely modest,we can develop a composite heuristic, Algorithm BEST, which can be described asfollows:
Algorithm BEST. Run each of the heuristics described above and return the bestsolution obtained.
The motivation for this procedure was the extremely modest computationalrequirements of all of the above heuristics and the observation from preliminarycomputational experiments that when one procedure performs poorly another oftendoes well. This observation was borne out in our subsequent experiments.
7. Computational results for SUMCIIn order to evaluate the performance of the heuristics for SUMCI, two sets of
computational experiments were carried out. The goal of the first set of experimentswas to evaluate the quality of the solutions obtained by the heuristics in terms of theircloseness to optimality. The second set of experiments compared the performance ofthe heuristics relative to each other. The structure of the randomly generated testproblems was the same as that used for CMAX and described in § 5.
In the first set of experiments the solutions obtained from the heuristics werecompared to the optimal solutions obtained using the branch and bound algorithm.For each of the threejob size distributions five sets of problems containing up to IS jobswere solved, resulting in 45 different problem classes. The computation time and
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4
Numberof Jobs amiD' a max FFLPT FFDECR FFSPT GR EXGR BEST Avg. CPU(s) Max CPU(s) Unsolved
5 \,5 \·\3 \·42 1'26 \'0\ \·02 \'00 2·65 2·678 1·09 \·35 1·1\ 1·04 \·04 1·02 2·96 3·15
10 1·\7 \·46 \·27 1·06 \·04 1'03 12·04 30·0512 \-14 \·31 \·22 1·06 1·06 1·05 108·80 419·7215 1'10 1·45 1·27 \·09 1·05 \·02 3125·\5 7633·22 2
Average 1·12 1-40 1·22 1·05 \·04 1·02 650·32
5 4,10 1·02 1·01 \·0\ 1·0\ 1·0\ 1·00 2·65 2'678 1·04 \·07 1·07 1·07 1·01 1·00 2·77 2·97
10 \·03 1·02 1·04 1·07 1·0\ \'00 5·07 9·0212 \·05 1·05 \·05 \·06 \·01 \'00 14·69 49'7215 1·03 \·06 \·07 \·09 \·02 1·0\ 1109·76 3930·52
Average 1·03 \·04 \·05 1·06 1·0\ 1'00 226'99
5 1,10 \·06 1·06 \·06 \·02 1·02 1·01 2·64 2-678 \·09 1·28 1·23 \'05 \'04 1·02 2-86 3·\8
10 1·08 1·\9 \·23 1·05 \·04 \·02 6·24 19·9512 1·\6 \·25 \·\6 1·\1 \·05 \'03 39-63 259·80\5 1·\6 \·26 1·18 1·\0 1·06 1·04 8\3-34 1483-30
Average \'11 \·21 1·\7 \·07 1·04 1·02 172-94
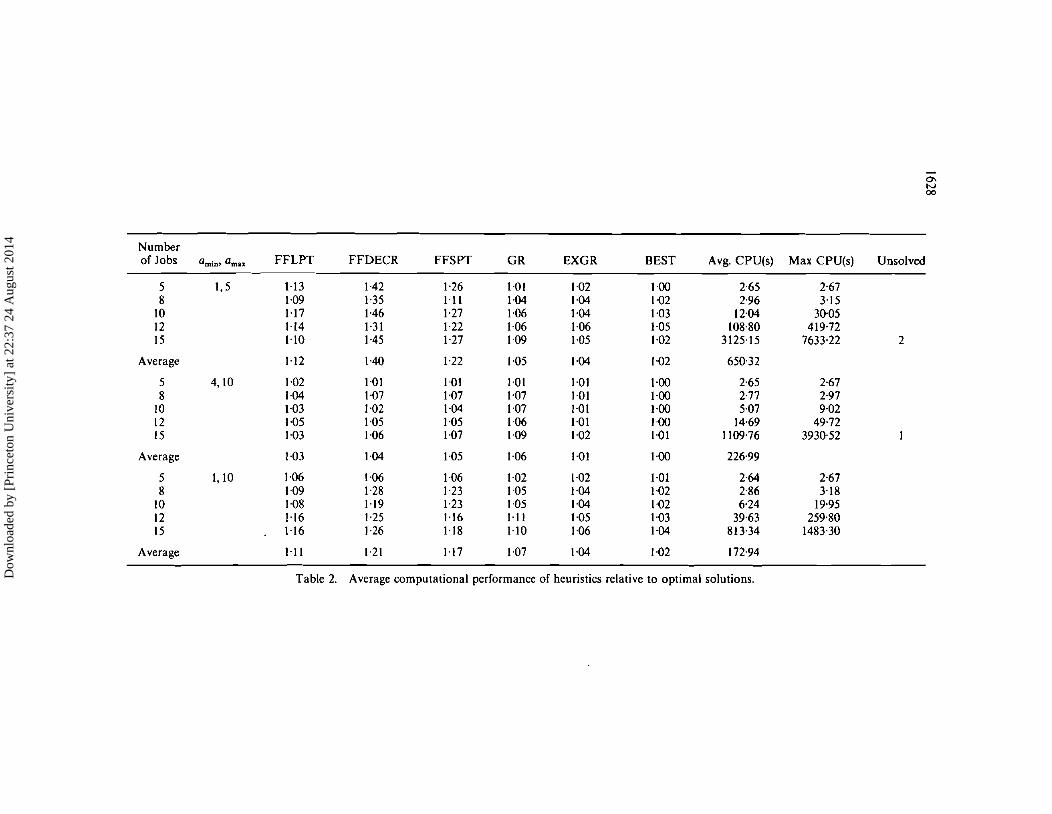
Table 2. Average computational performance of heuristics relative to optimal solutions.
aN00
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4
Scheduling single-batch processes with non-identical job sizes 1629
memory requirements of the branch and bound algorithm became excessive for largerproblems. Ten randomly generated problem instances were solved for each class, givinga total of 150 test problems.
The results of these experiments are shown in Tables 2 and 3. Table 2 lists theaverage ratio, over the 10 instances in each problem class, of the rei value obtained bythe heuristics to the optimal value. The CPU times shown are the average andmaximum, over the ten instances in each problem class, of the time required by thebranch and bound algorithm. The number in the 'unsolved' column indicates thenumber of instances in a problem class for which the branch and bound algorithm wasunable to obtain an optimal solution with available memory. In these instancescomparisons are made to the best solution returned by the branch and boundalgorithm upon its termination. The maximum deviation of the heuristic solutionsfrom the optimal are shown in Table 3.
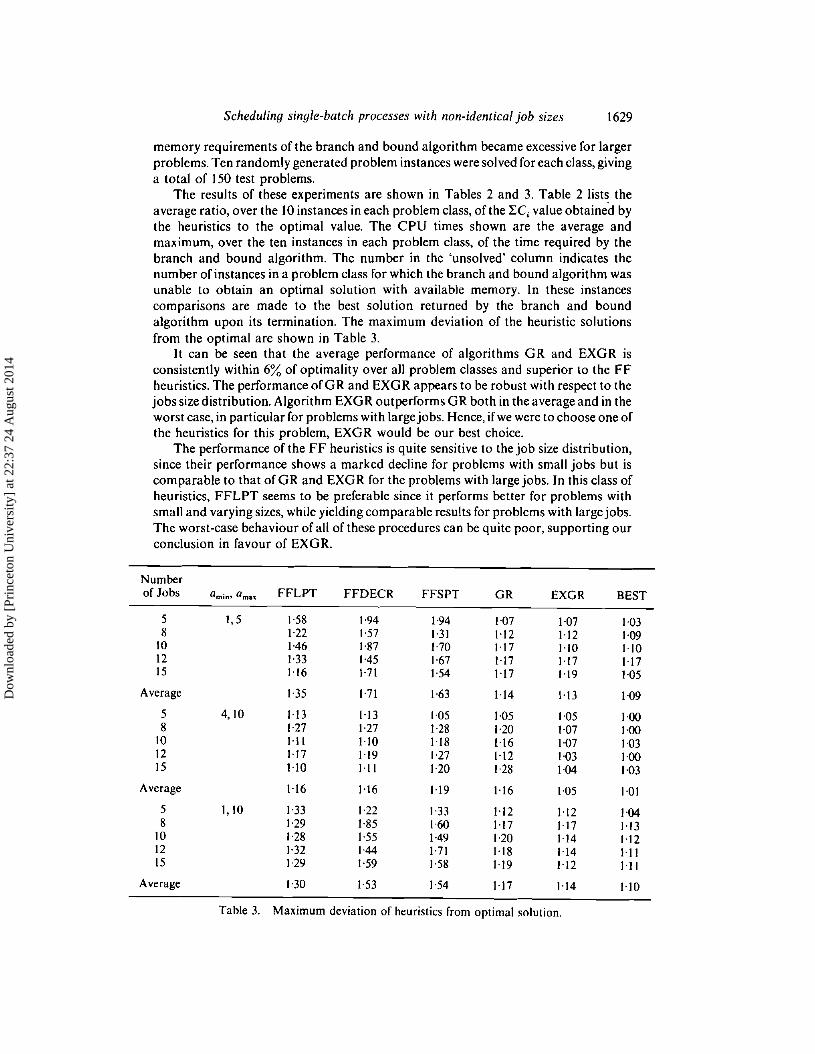
It can be seen that the average performance of algorithms GR and EXGR isconsistently within 6% of optimality over all problem classes and superior to the FFheuristics. The performance ofGR and EXGR appears to be robust with respect to thejobs size distribution. Algorithm EXG R outperforms G R both in the average and in theworst case, in particular for problems with large jobs. Hence, if we were to choose one ofthe heuristics for this problem, EXGR would be our best choice.
The performance of the FF heuristics is quite sensitive to the job size distribution,since their performance shows a marked decline for problems with small jobs but iscomparable to that ofGR and EXGR for the problems with large jobs. In this class ofheuristics, FFLPT seems to be preferable since it performs better for problems withsmall and varying sizes, while yielding comparable results for problems with large jobs.The worst-case behaviour of all of these procedures can be quite poor, supporting ourconclusion in favour of EXGR.
Numberof Jobs amin. Umu FFLPT FFDECR FFSPT GR EXGR BEST
5 1,5 \·58 1·94 1·94 1·07 1·07 1·038 1·22 [,57 1·31 1·\2 1·12 1·09
\0 1·46 \·87 1·70 1·17 1·10 1·1012 1·33 1·45 1-67 1·17 1·17 1·1715 1·16 1·71 1·54 1·17 1·19 1·05
Average 1·35 1·71 1·63 1·14 1'13 1·09
5 4,10 1·13 1·13 1·05 1·05 1·05 1·008 1·27 1·27 1·28 1·20 1·07 1·00
10 HI 1·\0 1·18 1·16 1'07 1·0312 1·17 1'19 1·27 1·12 1·03 1·0015 1·\0 1·11 1·20 1·28 1·04 1·03
Average 1·16 1·16 1'19 1'16 1'05 1·01
5 1, \0 1·33 1·22 1·33 1·l2 1'12 ',048 1·29 1-85 1·60 1'17 ',17 1'13
10 1·28 1·55 1·49 1·20 1·14 1·1212 1·32 1'44 1·71 1·18 1·14 I'll15 1·29 1·59 1·58 1'19 1'12 I'll
Average 1·30 1·53 1·54 1·17 1·14 1·\0
Table 3. Maximum deviation of heuristics from optimal solution.
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4
1630 R. Uzsoy
Numberof Jobs aml n' a ma1 FFLPT FFDECR FFSPT GR EXGR CPU(s)
10 1,5 1·14 1·28 \·14 1·05 \·03 0·0220 1·07 1·45 \·19 \·04 1·00 0·0430 1·03 1-36 1·09 1·04 1-02 0-0640 \·04 \·36 1-08 1-04 1-00 0·0850 \·04 1·33 1-10 \-05 1-01 0'1160 1-03 1-35 1·07 1·06 1·01 0·1470 1-02 (-37 1-10 1·05 1-02 0-1880 1-00 1·34 1-09 1-08 '-03 0-2190 1·01 1'35 \-08 1·08 1·03 0·26
100 1·0\ 1-30 1·09 1·06 1-03 0-30
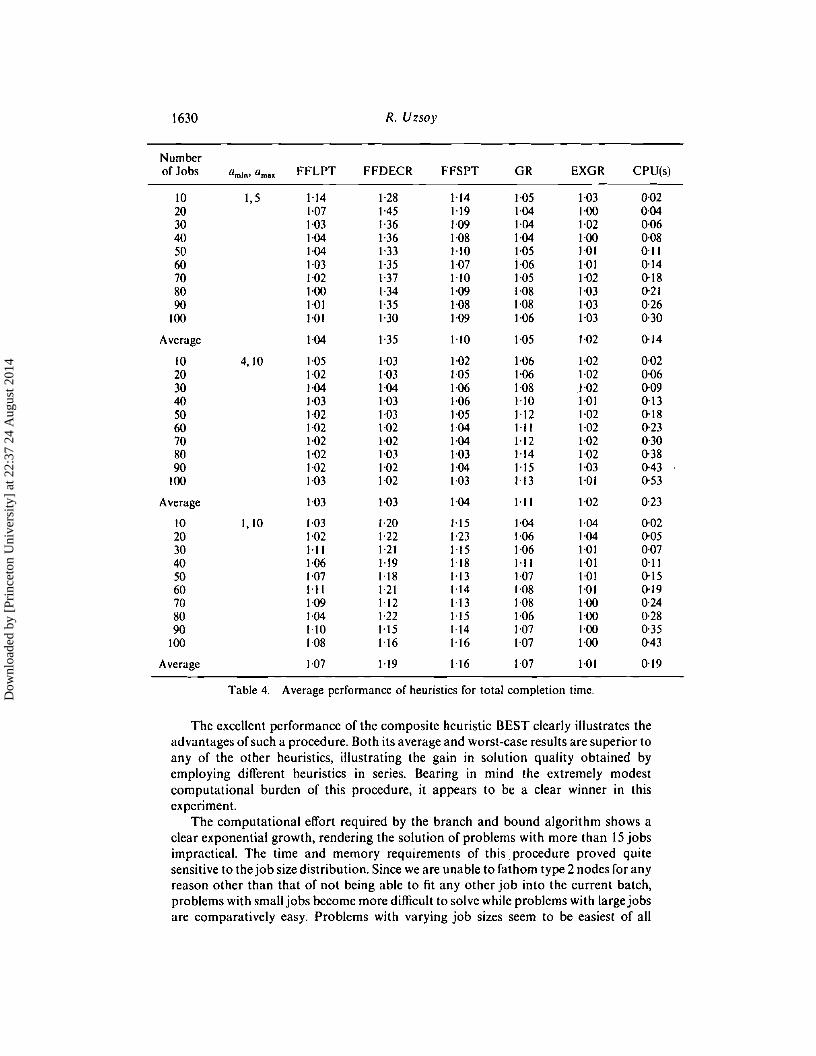
Average 1·04 1·35 1-10 I-OS /-02 0'14
10 4,10 \·05 1·03 \-02 1·06 1·02 0·0220 1-02 1-03 1·05 \·06 1-02 0-0630 1-04 \-04 1-06 1-08 }'02 0-0940 1·03 1·03 1-06 \-10 1·01 0-\350 1·02 1·03 1·05 1·12 1-02 0-1860 1-02 1-02 1·04 ru 1-02 0-2370 \-02 1-02 1-04 1-12 1-02 0·3080 1·02 1·03 \-03 H4 1·02 0-3890 1·02 1·02 1·04 1·15 1·03 0-43
100 1-03 1-02 1·03 1·13 1-01 0-53
Average \-03 \-03 1-04 I-II 1-02 0-23
10 1,10 1·03 1·20 1-15 1·04 1·04 0-0220 1-02 1-22 1·23 1·06 1'04 0-0530 \-11 1-21 1-\5 1-06 \·01 0·0740 \-06 1-19 1'18 I-II 1·01 0'\150 1·07 1·18 (,13 \-07 1·0\ 0-1560 \·\1 1·21 1-14 1·08 '-01 0-1970 1·09 1'12 1·\3 1·08 1·00 0·2480 1-04 1·22 1·15 1-06 1'00 0·2890 1·10 \-15 1-14 1-07 1·00 0-35
100 1·08 1'16 1-16 1-07 1-00 0-43
Average 1·07 1-\9 1·16 1·07 \-01 0'19
Table 4. Average performance of heuristics for total completion time.
The excellent performance of the composite heuristic BEST clearly illustrates theadvantages of such a procedure, Both its average and worst-case results are superior toany of the other heuristics, illustrating the gain in solution quality obtained byemploying different heuristics in series. Bearing in mind the extremely modestcomputational burden of this procedure, it appears to be a clear winner in thisexperiment.
The computational effort required by the branch and bound algorithm shows aclear exponential growth, rendering the solution of problems with more than 15 jobsimpractical. The time and memory requirements of this procedure proved quitesensitive to the job size distribution, Since we are unable to fathom type 2 nodes for anyreason other than that of not being able to fit any other job into the current batch,problems with small jobs become more difficult to solve while problems with largejobsare comparatively easy. Problems with varying job sizes seem to be easiest of all
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4
Scheduling single-batch processes with non-identicaljob sizes 1631
Numberof Jobs Umin' amu FFLPT FFDECR FFSPT GR EXGR CPU(s)
10 1,5 1'62 1'62 1·44 1·13 1·11 0·0320 1·71 1·71 1-36 1·1\ 1·03 0·0530 1·07 1·53 1·20 1·13 J-(l4 0·0740 \·12 1·63 1·31 1·08 \·03 0·0150 \·12 1·54 1-40 1·08 1·03 0·1360 1·10 1·51 1·17 1·09 t·03 0·1570 1·\0 1·65 1·34 1·11 1·11 0·1880 1·03 1·49 1·16 1·14 1·07 0·2390 \·04 1·49 \·18 1·13 1·06 0·30
100 \·05 1·50 \·17 1·12 1·08 0·32
Average 1·20 1·57 1·27 1·1\ 1·06 0·15
10 4,10 1·2\ \·10 1·\1 l-I9 1·09 0·0320 1·05 \·09 1·16 1·\3 \·09 0·0730 1·08 1·13 1·16 1·14 1·06 0·1240 1·08 1·08 t·13 1·\3 1·06 0·1550 1·05 1·06 1·10 1·20 1·04 0·2060 1·04 1·12 \·11 1·15 1·07 0·2570 \·07 1·05 \·09 1·16 1·07 0·3380 1·14 1·13 1·07 1·18 1·05 0·4090 1·06 1·06 1·09 1·20 1·07 0·48
100 1·06 \·07 1·08 1·17 1·03 0·58
Average 1·08 1·09 1·11 1·17 1·06 0·26
10 1,10 1·73 1·73 1·41 1·13 1·15 0·0320 1·06 1·41 \-47 \·19 \·08 0·0430 1·22 \·35 \·32 1·17 1·08 0·0840 1·\4 1-42 1·34 \·18 1·09 01350 1·17 1·32 1·23 1·15 1·03 0·\860 1·22 1·41 1·26 1·19 \·05 0·2070 \·17 1·21 \·21 1·\4 1·00 0·2780 1·09 1·34 1·27 1·11 \·00 0·3090 1·2\ 1·30 \·22 1·12 1·03 0·38
100 1·\9 1·26 1·24 1·10 1·01 0·48
Average \·22 1·37 \·30 1·15 1·05 0·21
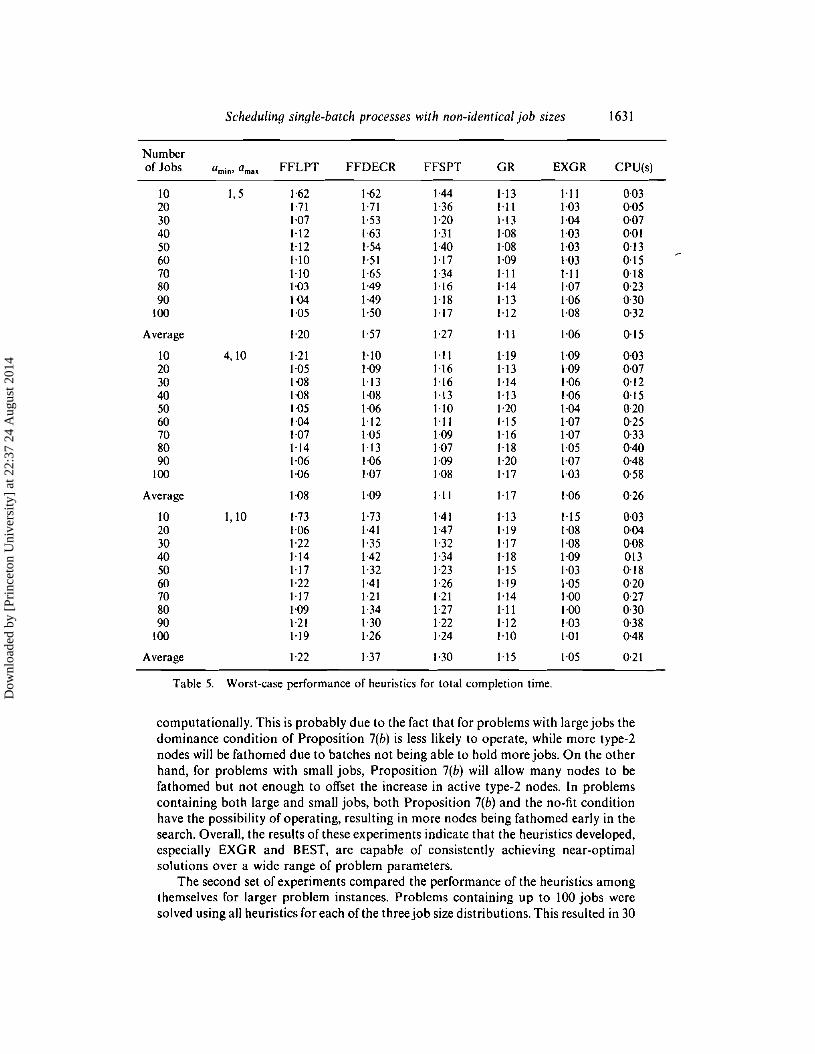
Table 5. Worst-case performance of heuristics for total completion time.
computationally. This is probably due to the fact that for problems with large jobs thedominance condition of Proposition 7(b) is less likely to operate, while more type-2nodes will be fathomed due to batches not being able to hold more jobs. On the otherhand, for problems with small jobs, Proposition 7(b) will allow many nodes to befathomed but not enough to offset the increase in active type-2 nodes. In problemscontaining both large and small jobs, both Proposition 7(b) and the no-fit conditionhave the possibility of operating, resulting in more nodes being fathomed early in thesearch. Overall, the results of these experiments indicate that the heuristics developed,especially EXGR and BEST, are capable of consistently achieving near-optimalsolutions over a wide range of problem parameters.
The second set of experiments compared the performance of the heuristics amongthemselves for larger problem instances. Problems containing up to 100 jobs weresolved using all heuristics for each of the three job size distributions. This resulted in 30
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1632 R. Uzsoy
problem classes containing a total of 300 randomly generated instances. The test datawas generated using the same scheme as for the previous set. Table 4 shows the averageratio of the ~Ci obtained by each heuristic to best value obtained by any heuristic,which corresponds to the solution from BEST. Table 5 shows the maximum deviationof each heuristic from the best solution obtained. In both tables the CPU times shownare the time required for algorithm BEST, which applies all the other heuristics insequence.
These results are in close correspondence with those in Tables 2 and 3. EXGR isconsistently superior to all the other procedures both on average and in the worst case.The superiority ofEXGR is clearest for the problems with varyingjob sizes. Among theFF heuristics FFLPT again emerges as the best choice overall. As in the previous set of
.experiments, the differences between the different procedures become less marked forproblems with large job sizes.
Taken together, the two sets of experiments indicate that algorithm BEST iscapable of obtaining consistently near-optimal solutions in very reasonable CPUtimes. Hence BEST should be the method of choice for this problem. Of the individualheuristics considered, EXGR is superior both in terms of average and worst-caseperformance. However, there are always a small number of instances for which one ofthe other procedures performs beller, which accounts for the composite heuristic BEST
'outperforming EXGR. While the FF heuristics can obtain good solutions for someproblem instances, their worst-case performance is quite unpredictable, which supportsthe choice of the more robust BEST and EXGR procedures.
8. Summary and conclusionsWe have examined the problem of scheduling jobs with different sizes on a single
batch processing machine to minimize Cmax and ~Ci' We have proven that bothproblems are NP-hard, and that efficient optimal solution procedures are unlikely toexist. Using results from bin-packing and from previous work on the unit-size problemwe have suggested a number of heuristics for these problems and evaluated theirperformance empirically. Our results show that these procedures are capable ofconsistently obtaining high-quality solutions with very reasonable computationaleffort. We have also presented a branch and bound procedure for the problem ofminimizing ~Ci' However, the computational burden of this algorithm rapidlybecomes excessive.
The most important directions for future research are the extension of these modelsto include due-date related performance measures and dynamic job arrivals. Theinsights obtained to date on unit-size problems, problems with job families and theproblems studied in this paper provide a strong basis for research in this direction. Thedevelopment of efficient heuristics for these problems will allow them to be integratedinto a decomposition scheme to schedule production facilities containing batchprocessing machines and other types of workcentres. A prototype decompositionprocedure of this type has been implemented by Ovacik and Uzsoy (1992) withencouraging results.
AcknowledgmentsThis research was supported by the National Science Foundation under Grant
DDM-910759l and by the NSF Purdue Engineering Research Centre for IntelligentManufacturing Systems.
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

Scheduling single-batch processes with non-identical job sizes 1633
Appendix. Proofs of Propositions 3-7Proof of Proposition 3
We prove the result by reduction from the knapsack problem (Garey and Johnson1979). The knapsack problem can be stated as follows:Given a set V items of size s, andvalue Vi> a size constraint C and a value goal K, does there exist a subset V' of V suchthat
L Si~C and L vi;>KieU' ieU'
We actually consider the equality version of the problem, where the inequality inthe second expression above is replaced by an equality, which is also NP-complete.
Consider an instance of SUMCI with n jobs, each with size a, and identicalprocessing times and a batch machine capacity of B. Construct an instance of Knapsackwhere Vi = I for all i= 1,... , n and size constraint is B. Set the value goal K = n/2. Thusthe answer to the knapsack problem is 'yes' if there exists a subset of the jobs thatcontains exactly n/2 jobs and has total item size less than or equal to B. If there existssuch a subset ofjobs, then we can construct a schedule with only two batches and a rCivalue of3np/2. If there exists a solution to the scheduling problem, then there must exista subset of the jobs containing n/2 jobs which are processed as a batch, implying theexistence of a solution to the Knapsack problem. QED
Proof of Proposition 4.Index the segments ij, j = I, ... , a, of job i in increasing order of their completion
times in an optimal schedule for (PR). By this indexing, we have
"Lq(PR)= L Ci •a ji= 1
and that Ci • aj;> Cii for all i and j = I, ... ,a.. Hence
aj
ajCi,tli ~ L c.,j= 1
Dividing both sides of this expression by ai and summing over all jobs i yields the result.QED
Proof of Proposition 5Eastman et al. (1964) have shown that for the parallel machine total weighted
completion time problem with m unit-capacity machines and n jobs
I[ I" JI"LWiq(m);>- Lwiq(l)--2.L WiPi +-2.L WiPim l=l 1= 1
where rwict(k) denotes the optimal solution to the parallel machine problem with kmachines. The solution to the one-machine problem is easily obtained using theweighted shortest processing time (WSPT) rule (French 1982), where the jobs aresequenced in increasing order of Pi/Wi'
We have shown in Proposition 4 that rCt;> rWict for the parallel machineproblem with B parallel identical unit-capacity machines and raijobs ij, i= I, ... ,n,j = I, ... , ai corresponding to the segments of the original jobs i = I, ... , n where each jobij has weight I/a i. Let C 1 denote the optimal rWi(:i value of the problem of schedulingall segments on a single unit-capacity machine, and observe that for the problem withrai machines the optimal value is simply r iPi> since each ofthe a, segments ofjob i has aweight of I/a i and will complete at time Pi' The result follows. QED
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

1634 R. Uzsoy
Proof of Proposition 6Suppose we attempt to develop a type-2 addition to P by insertion a job k <j into
the last batch. Let the set of jobs in the last batch be G. Clearly, this insertion is onlyfeasible if there is room for the new job in G, that is,
and k is not already scheduled in P. Suppose it is feasible to insert k into G. Order thejobs in G in increasing order of their indices, let i be the smallest index and q the largestindex in G that is less than k. Consider the partial schedule P' which is identical to Pexcept that its final batch contains only the set of jobs in G with indices t such thati:S; t:S; q. This will have been generated before P by the enumeration scheme. Since weknow that k and all the jobs in G can be processed as a batch, the enumeration schemewill develop type-2 children of P' by successively inserting the remaining jobs in G intothe final batch of P'. Hence a partial schedule consisting of the jobs in P with final batchcontaining job k in addition to the other jobs in G will be developed by considering thejobs to be inserted in increasing order of their indices. QED
Proof of Proposition 7(a) Chandru et al. (1992a) have shown that in an optimal solution, batches must be
sequenced in BWSPT order. Hence any completion of a partial schedule where thisproperty does not hold cannot be optimal.
(h)If this condition holds, this signifies that any completion of P can be improved byinserting job k into batch B j and resequencing the batches ;in BWSPT order. SincePk:S;Pj, no job in P will be delayed by the insertion of kin Bj, and the resequencing ofbatches can only improve the LC; value. Hence no completion of P can be optimal.
QED
ReferencesAHMADI, J. H., AHMADI, R. H., DASU, S.,and TANG, C. S., 1992, Batchingand schedulingjobs on
batch and discrete processors. Operations Research, 40, 750-763.BRUNO, J., COFFMAN, E. G., and SETHI, R., 1974, Scheduling independent tasks to reduce mean
finishing time. Communications of the ACM, 17, 382-387.CHANDRA, P., and GUPTA, S., 1992, An analysis of a last-station-bottleneck semiconductor
packaging line. Research Working Paper, Faculty of Management, McGill University.CHANDRU, V., LEE, C. Y., and UZSOY, R., 1993a, Minimizing total completion time on batch
processing machines. International J oumalof Production Research, 31, 2097-2121.,CHANDRU, V., LEE, C. Y., and UZSOY, R., 1993b, Minimizing total completion time on a batch
processing machine with job families. Operations Research Letters, 13, 61-65.COFFMAN, E. G., GAREY, M. R., and JOHNSON, D. S., 1984, Approximation algorithms for bin
packing-an updated survey Alqorithm Design for Computer System Design, edited byG. Ausiello, M. Lucertini and P. Serafini (New York: Springer-Verlag) pp.49-106
DOBSON, G., and NAMBINADOM, R.S.,1992, The batch loadingand schedulingproblem. ResearchReport, Simon School of Business Administration, University of Rochester, Rochester,NY.
EASTMAN, W.L, EVEN,S., and ISAACS, I. M., 1964, Bounds for the optimal schedulingofnjobs onm processors. Management Science, II, 268-279. '
FOWLER, J. W., HOGG, G. L., and .PHILLIPS, D. T., 1992, .Control of multiproduct bulk serverdiffusion/oxidation processes, II E Transactions on Scheduling and Logistics, 24, 84-96.
FRENCH, S., 1982, Sequencing and Scheduling: An Introduction to the Mathematics ofthe Job-shop(New York: Wiley).
GAREY, M. R.,and JOHNSON, D. S., 1979, Computers and Intractability: A Guide to the Theory ofN P-Completeness (San 'Francisco: NY. H:. Freeman),
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4

Scheduling single-batch processes with non-identical job sizes 1635
GLASSEY, C. R., and WENG, W. W., 1991, Dynamic batching heuristics for simultaneousProcessing. f EEE Transactions on Semiconductor Manufacturing, 4, 77-82.
IKURA, Y., and GIMPLE, M., 1986, Scheduling algorithms for a single batch processing machine.Operations Research Letters, 5, 61-65.
JOHNSON, D. S., DEMERS, A., ULLMAN, J., GAREY, M. R., and GRAHAM, R. L., 1974, Worst-caseperformance bounds for simple one-dimensional packing problems. Sf AM Journal onComputing, 3, 299-325.
LEE, C. Y., UZSOY, R., and MARTIN-VEGA, L. A., 1992, Efficient algorithms for schedulingsemiconductor burn-in operations. Operations Research, 40, 764-775.
OVACIK, I. M., and UZSOY, R., 1992, A shifting bottleneck algorithm for scheduling semiconductor testing operations. Journal of Electronics Manufacturing, 2, 119-134.
Dow
nloa
ded
by [
Prin
ceto
n U
nive
rsity
] at
22:
37 2
4 A
ugus
t 201
4




















![arXiv:1803.09820v2 [cs.LG] 24 Apr 2018 · Smith and Le (Smith & Le, 2017) explore batch sizes and correlate the optimal batch size to the learning rate, size of the dataset, and momentum](https://img.pdfslide.net/doc/110x75/5e16473f2fdf7450c26f66da/arxiv180309820v2-cslg-24-apr-2018-smith-and-le-smith-le-2017-explore.jpg)








