Embed Size (px)
Citation preview

SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Pedro C. Diniz, Mary W. Hall, Joonseok Park, Byoungro So and Heidi Ziegler
University of Southern California / Information Sciences Institute4676 Admiralty Way, Suite 1001Marina del Rey, California 90292
DEFACTO: Combining Parallelizing Compiler Technology with Hardware
Behavioral Synthesis*
* The DEFACTO project was funded by the Information technology Office (ITO) of the Defense Advanced research project Agency (DARPA) under contract #F30602-98-2-0113.

2SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Outline
Background & Motivation Part 1: Application Mapping Example Part 2: Design Space Exploration Part 3: Challenges for Future FPGAs Related Work Conclusion

3SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
DEFACTO Objective & Goals
Objectives:• Automatically Map High-Level Applications
to Field-Programmable Hardware (FPGAs)• Explore Multiple Design Choices
Goal:• Make Reconfigurable Technology
Accessible to the Average Programmer

4SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
What Are FPGAs: Key Concepts
• Configurable Hardware• Reprogrammable (ms latency)
Architecture• Configurable Logic Blocks
“Universal” logic Some input/outputs latched
• Passive network between CLBs• Memories, processor cores

5SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Why Use FPGAs?
Advantages over Application-Specific Integrated Circuits (ASICs)
• Faster Time to Market• “Post silicon” Modification Possible• Reconfigurable, Possibly Even at Run-time
Advantages Over General-Purpose Processors• Application-Specific Customization (e.g., parallelism, small
data-widths, arithmetic, bandwidth)
Disadvantages• Slow (typical automatic design @25MHz)• Low Density of Transistors

6SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
How to Program FPGAs?
Hardware-Oriented Languages• VHDL or Verilog• Very Low-Level Programming
Commercial Tools (e.g., MonetTM)• Choose Implementation Based on User Constraints• Time and Space Trade-Off• Provide Estimations for Implementation
Problem: Too Slow for Large Complex Designs• Place-and-Route Can Take up to 8 Hours for Large Designs• Unclear What to Do When Things Go Wrong

7SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Behavioral Synthesis Example
variable A is std_logic_vector(0..7)…X <= (A * B) - (C * D) + F
6 Registers2 Multipliers
2 Adders/Subtractors1 (long) clock cycle
9 Registers2 Multipliers
2 Adders/Subtractors2 (shorter) clock cycles
13 Registers1 Multiplier
2 Adders/Subtractors3 (shorter) clock cycles

8SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Synthesizing FPGA Designs: Status
Technology Advances have led to Increasingly Large Parts• FPGAs now have Millions of “gates”
Current Practice is to Handcode Designs for FPGAs in Structural VHDL • Tedious and Error Prone• Requires Weeks to Months Even for Fairly
Simple Designs Higher-level Approach Needed!

9SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
DEFACTO: Key Ideas Parallelizing Compiler Technology
• Complements Behavioral Synthesis
• Adjusts Parallelism and Data Reuse
• Optimizes External Memory Accesses
Design Space Exploration• Evaluates and Compares Designs before Committing
to Hardware
• Improves Design Time Efficiency
• a form of Feedback-directed Optimization

10SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Opportunities: Parallelism & Storage
Behavioral Synthesis Parallelizing Compiler
Optimizations: Optimizations: Scalar Variables only Scalars & Multi-Dimensional Arrays inside Loop Body inside Loop Body & Across
Iterations
Supports User-Controlled Analysis Guides Automatic LoopLoop Unrolling Transformations
Manages Registers and Evaluates Tradeoffs of Different inter-operator Communication Memories, On- and Off-chip
Considers one FPGA System-level View
Performs Allocation, Binding & No Knowledge of Hardware Scheduling of Hardware Implementation

SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Part 1: Mapping Complete Designs from C to FPGAs
Sobel Edge Detection Example

12SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Example - Sobel Edge Detection
char img[IMAGE_SIZE][IMAGE_SIZE], edge [IMAGE_SIZE][IMAGE_SIZE];
int uh1, uh2, threshold;
for (i=0; i < IMAGE_SIZE - 4; i++) {
for (j=0; j < IMAGE_SIZE - 4; j++) {
uh1= (((-img[i][j]) + (- (2* img[i+1][j])) + (-img[i+2][j])) +
((img[i][j-2]) + (2* img[i+1][j-2]) + (img[i+2][j-2])));
uh2= (((-img[i][j]) + (img[i+2][j])) + (- (2* img[i][j-1])) +
(2* img[i+2][j-1]) + ((- img[i][j-2]) + (img[i][j-2])));
if ((abs(uh1) + abs(uh2)) < threshold)
edge[i][j] =”0xFF”;
else
edge[i][j] =”0x00;
}
}edgeimg
-1 -2 -1 0 0 0 1 2 1
1 0 -1 2 0 -2 1 0 -1
threshold

13SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Sobel - A Naïve Implementation
Large Number of Adders and Multipliers (shifts in this case) Too Many Memory Accesses !
• 8 Reads and 1 Write per Iteration of the Loop• Observation
Across 2 Iterations 4 out of 8 Values Can Be Reused
0x00
0xFF
img[i][j] img[i][j+1] img[i][j+2]
img[i+2][j] img[i+2][j+1] img[i+2][j+2]
img[i+1][j+2]img[i+1][j]
edge[i][j]

14SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Data Reuse Analysis - Sobelimg[i][j+1]
img[i+2][j+1]
img[i][j+2]
img[i+2][j+2]
img[i+1][j+2]
img[i][j]
img[i+2][j]
img[i+1][j]
d = (1,0) d = (2,0) d = (1,0)
img[i][j+1]
img[i+2][j+1]
img[i][j+2]
img[i+2][j+2]
img[i+1][j+2]
img[i][j]
img[i+2][j]
img[i+1][j]
d = (0,1)
d = (0,2)
d = (0,1)

15SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Data Reuse using Tapped-Delay Lines Reduce the Number of Memory Accesses Exploit Array Layout and Distribution
• Packing• Stripping
Examples:
0x00
0xFF
img[i][j]
img[i+1][j]
img[i+2][j]edge[i][j] edge[i][j]
img[i][j] img[i][j+1] img[i][j+2]
0x00
0xFF
Accesses = 0.25 + 0.25 + 0.25 + 0.25 = 1.0 Accesses = 1.0 + 1.0 + 1.0 + 1.0 = 4.0

16SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Overall Design Approach
MEM
MEM
MEM
MEM
ApplicationData-path
ApplicationData-path
Application Data-paths• Extract Body of Loops• Uses Behavioral Synthesis
Memory Interfaces• Uses Data Access Patterns to Generate Channel Specs• VHDL Library Templates

17SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
WildStarTM: A Complex Memory Hierarchy
SharedSharedMemory0Memory0SharedShared
Memory0Memory0
SharedSharedMemory2Memory2SharedShared
Memory2Memory2SharedShared
Memory3Memory3SharedShared
Memory3Memory3
SharedSharedMemory1Memory1SharedShared
Memory1Memory1
FPGA 1FPGA 1FPGA 1FPGA 1 FPGA 0FPGA 0FPGA 0FPGA 0 FPGA 2FPGA 2FPGA 2FPGA 2
SRAM1SRAM1SRAM1SRAM1
SRAM0SRAM0SRAM0SRAM0
SRAM3SRAM3SRAM3SRAM3
SRAM2SRAM2SRAM2SRAM2
PCIPCIControllerController
PCIPCIControllerController
To Off-BoardMemory
32bits
64bits

18SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Project Status Complex Infrastructure• Different Programming
Languages (C vs. VHDL)• Different EDA Tools• Different Vendors• Experimental Target• In-House Tools
Combines Compiler Techniques and Behavioral Synthesis
• Different Execution Models• Reconcile Representation
It Works!• Fully Automated for Single
FPGA designs• Modest Manual Intervention for
Multi-FPGA designs (simulation OK)
Compiler AnalysisCompiler Analysis
SUIF2VHDLSUIF2VHDL
Behavioral SynthesisBehavioral Synthesis& Estimation (Monet)& Estimation (Monet)
Logic SynthesisLogic Synthesis(Synplicity)(Synplicity)
Place & RoutePlace & Route(Xilinx Foundations)(Xilinx Foundations)
Code TransformationsCode Transformationsand Annotationsand Annotations
Annapolis WildStar Board
Algorithm Description
Computation & Data
Partitioning
Design Space Exploration
Memory Access
Protocols

19SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Sobel on the Annapolis WildStar BoardInput Image Output Image
Manual vs. AutomatedMetrics Manual Automated
Space (slices) 2238 2279 (2% increase)
Cycles 326K 518K
Clock Rate (MHz) 42 40
Execution Time (one frame) 7.7 ms (100%) 12.95 ms (159%)
Design Time about 1 week 42 minutes

SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Part 2: Design Space Exploration
Using Behavioral Synthesis Estimates

21SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Design Space Exploration (Current Practice)
Logic Synthesis / Place&Route
Design Specification (Low-level VHDL)
DesignModification
Validation / Evaluation
2 Weeks for a Working Design 2 Months for an Optimized Design
Correct?Good design?

22SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Design Space Exploration (Our Approach)
Algorithm (C/Fortran)
Compiler Optimizations (SUIF)• Unroll and Jam• Scalar Replacement• Custom Data Layout
SUIF2VHDL Translation
Behavioral Synthesis Estimation
Unroll Factor Selection
Logic Synthesis / Place&Route
Overall, Less than 2 hours 5 Minutes for Optimized Design Selection

23SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Problem Statement
Execution Time
Exploit parallelism,Reuse dataon chip
Space Requirements
More copies of operators, More on-chip registers
Constraint: Size of design less than FPGA capacity Goal: Minimal execution time Selection Criteria: For given performance, minimal space
• Frees up more space for other computations• Better clock rate achieved• Desirable to use on-chip space efficiently

24SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Balance Definition: Data Fetch Rate Consumption Rate
• Consumption Rate[bits/cycle] = data bits consumed per computation time
Limited by the Data Dependences of the Computation
• Data fetch Rate[bits/cycle] = data bits required per computation time
Limited by the FPGA’s Effective Memory Bandwidth
If balance > 1, Compute Bound If balance < 1, Memory Bound Balance suggests whether more resources should
be devoted to enhance computation or storage.

25SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Do I=1,N, by 2 A(I) = A(I-2) + B(I) A(I+1) = A(I-1) + B(I+1)
Loop Unrolling
Exposes fine-grain parallelism by replicating the loop body.
Do I=1, N A(I) = A(I-2) + B(I)
A(I)
B(I)A(I)
A(I-2)A(I)
A(I+1)A(I-1)
B(I+1)
B(I)
As Unrolling Factor Increases, both Data Fetch and Consumption Rate Increase.
2 2
2

26SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Monotonicity Properties
unroll factor
Data Fetch Rate (bits/cycle)
Saturationpoint
Data Consumption Rate (bits/cycle)
Saturation point
Balance(= Fetch/Consumption)
unroll factor
unroll factor
Saturation point: unroll factor that saturates memory bandwidth for a given architecture

27SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Balance & Optimal Unroll Factor
Unroll factor
Rate (bits/cycle)1
3
5
2
4
Saturation point max
Data fetch rate
Data consumption rate
Optimal solution
Balance Guides the Design Space Exploration.

28SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Experiments Multimedia Kernels
• FIR (Finite Impulse Response)• Matrix Multiply• Sobel (Edge Detection)• Pattern Matching• Jacobi (Five Point Stencil)
Methodology• Compiler Translates C to SUIF and Behavioral VHDL• Synthesis Tool Estimates Space and Computational Latency• Compiler Computes Balance and Execution Time Accounting for
Memory Latency Memory Latency
• Pipelined: 1 cycle for read and write• Non-pipelined: 7 cycles for read and 3 cycles for write

29SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
FIR
+ +x x
* *
Outer Loop Unroll Factor 1
Outer Loop Unroll Factor 2
Outer Loop Unroll Factor 4
Outer Loop Unroll Factor 8
Outer Loop Unroll Factor 16
Outer Loop Unroll Factor 32
Outer Loop Unroll Factor 64
Speedup: 17.26
Selected Design

30SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Matrix Multiply
+ +x x
Outer Loop Unroll Factor 1
Outer Loop Unroll Factor 2
Outer Loop Unroll Factor 4
Outer Loop Unroll Factor 8
Outer Loop Unroll Factor 16
Outer Loop Unroll Factor 32
Selected Design
Speedup: 13.36
31SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
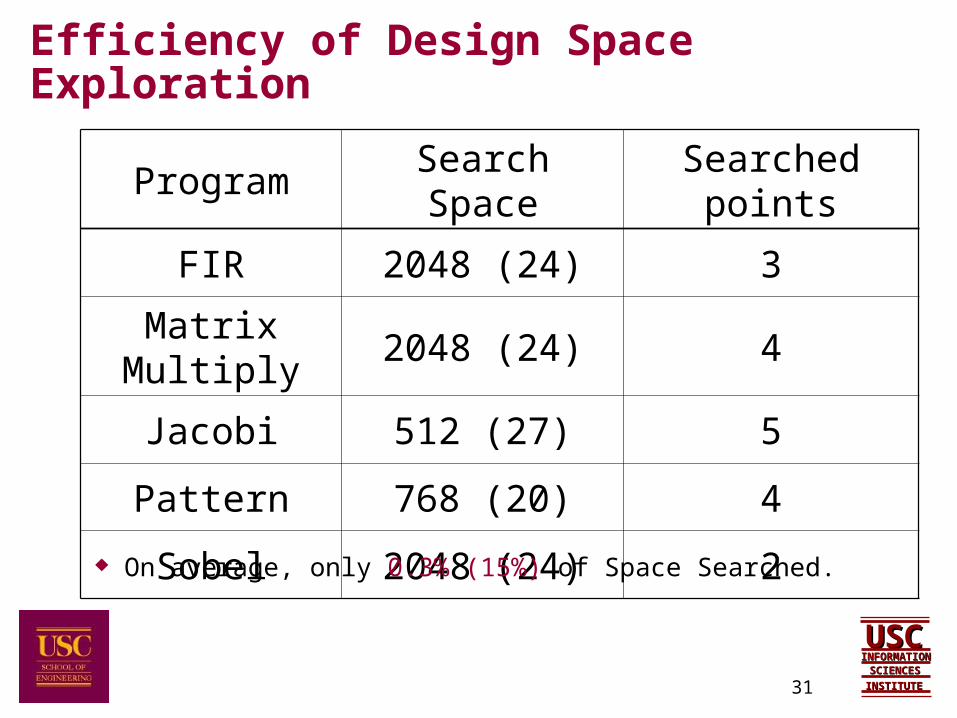
Efficiency of Design Space Exploration
Program Search Space Searched points
FIR 2048 (24) 3
Matrix Multiply 2048 (24) 4
Jacobi 512 (27) 5
Pattern 768 (20) 4
Sobel 2048 (24) 2
On average, only 0.3% (15%) of Space Searched.

32SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
FIR: Estimation vs. Accurate Data
Larger Designs Lead to Degradation in Clock Rates Compiler Can Use a Statistical Approach to Derive Confidence
Intervals for Space Our case: Compiler Makes Correct Decision using Imperfect Data

SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Part 3: Challenges for Future FPGAs
Heterogeneous Functional and Storage Resources
Data/Computation Partitioning and Scheduling Revisited

34SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Field-Programmable-Core-Arrays Large Number of Transistors
• Multiple Application Specific Cores• Customization of Interconnect• Other Specialized Logic
Challenges:• Data Partitioning:
Custom Storage Structures Allocation, Binding and Scheduling Replication and Reorganization
• Computation Partition Scheduling between Cores Coarse-Grain Pipelining
Revisiting Issues with Parallelizing Compiler Technology
IP CoreS-RAMD-RAM
IP CoreDSP
IP CoreARM

35SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Related Work Compilers for Special-purpose Configurable
Architectures• PipeRench (CMU), RaPiD (UW), RAW (MIT)
High-level Languages Oriented towards Hardware
• Handel-C, Cameron(CSU), PICO(HP), Napa-C (LANL)
Integrated Compiler and Logic Synthesis• Babb (MIT), Nimble (Synopsys)
Compiling from MatLab to FPGAs• Match compiler (Northwestern)

36SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Conclusion Combines Behavioral Synthesis and Parallelizing
Compiler Technologies Fast & Automated Design Space Exploration
• Trades Space with Functional Units via Loop Unrolling• Uses Balance and Monotonicity Properties• Searches only 0.3% of the Entire Design Space
Near-optimal Performance and Smallest Space Future FPGAs
• Coarser-grained, Custom Functional and Storage Structures• Multiprocessor on a Chip• Data and Computation Partitioning and Coarse Grain Scheduling

37SCIENCESSCIENCES
USCUSCINFORMATIONINFORMATION
INSTITUTEINSTITUTE
Thank You