Embed Size (px)
Citation preview

Expert Systems with Applications 38 (2011) 11167–11175
Contents lists available at ScienceDirect
Expert Systems with Applications
journal homepage: www.elsevier .com/locate /eswa
Segment confidence-based binary segmentation (SCBS) for cursivehandwritten words
Brijesh Verma ⇑, Hong LeeSchool of Computing Science, CQUniversity, North Rockhampton, Queensland 4702, Australia
a r t i c l e i n f o a b s t r a c t
Keywords:Neural networksSegmentation algorithmsHandwriting recognition
0957-4174/$ - see front matter � 2011 Elsevier Ltd. Adoi:10.1016/j.eswa.2011.02.162
⇑ Corresponding author.E-mail address: [email protected] (B. Verma).
A novel segment confidence-based binary segmentation (SCBS) for cursive handwritten words is pre-sented in this paper. SCBS is a character segmentation strategy for off-line cursive handwriting recogni-tion. Unlike the approaches in the literature, SCBS is an unordered segmentation approach. SCBS isrepetition of binary segmentation and fusion of segment confidence. Each repetition generates onlyone final segmentation point. The binary segmentation module is a contour tracing algorithm to find asegmentation path to divide a segment into two segments. A set of segments before binary segmentationis called pre-segments, and a set of segments after binary segmentation is called post-segments. SCBSuses over-segmentation technique to generate suspicious segmentation points on pre-segments. On eachsuspicious segmentation point, binary segmentation is performed and the highest fusion value isrecorded. If the highest fusion value is greater than the one of pre-segments, the suspicious segmentationpoint becomes the final segmentation point for the iteration. If not, no more segmentation is required.Segment confidence is obtained by fusing mean character, lexical and shape confidences. The proposedapproach has been evaluated on local and benchmark (CEDAR) databases.
� 2011 Elsevier Ltd. All rights reserved.
1. Introduction
Off-line cursive handwriting recognition (OffCHR) is an automaticprocess to convert an input handwritten document image intocomputer-recognizable character representations. OffCHR has beenactive research domain for decades, and industrial beneficiarieshave been trying to automate repetitive manpower oriented taskssuch as processing postal address, bank checks, form data, histori-cal manuscripts, etc. (Fujisawa, 2008). Despite sleepless research inOffCHR for decades, the performance of the state-of-the-art OffCHRis below the industrial standard to accommodate the real worldproblems (Das & Dulger, 2009; Djioua & Plamondon, 2009; Lu &Tan, 2008; Suresh & Arumugam, 2007; Zhang, Yip, Brown, & LimTan, 2009). The researchers in this field agree that the main con-tributor of the low OffCHR performance is the segmentation (Arica& Yarman-Vural, 2001, 2002; Bar-Yosef, Mokeichev, Kedem, Dinstein,& Ehrlich, 2009; Blumenstein & Verma, 2001; Casey & Lecolinet,1996; Vellasques, Oliveira, Britto, Koerich, & Sabourin, 2008a,2008b; Verma, Gader, & Chen, 2001; Zhao, Chi, Shi, & Yan, 2003).
Segmentation is a process to discriminate each letter from oth-ers, prior to recognition into electronic character representations.Typically, OffCHR involves a set of processes such as pre-process-ing, normalization, segmentation, recognition. Pre-processing is a
ll rights reserved.
cleanup process to remove unwanted information (Lu, Chi, Siu, &Shi, 1999; Nomura, Yamanaka, Shiose, Kawakami, & Katai, 2009;Sun et al., 2007). Noise removal is done in the pre-processing stage.Normalization is to standardize the information, so it can be fittedinto a data form that segmentation and recognition need. Nor-mally, thresholding or skeletonization, thinning, slant and slopecorrections are performed in normalization process. The normal-ized handwritten image passes through segmentation process tofind letter boundaries. A sub-image bound by two neighboringboundaries is called a segment. The recognition is to classify eachsegment into a character representation (Lorigo & Govindaraju,2006; Plamondon & Srihari, 2000; Vinciarelli, 2002). As seen inthe typical OffCHR framework in Fig. 1, the segmentation precedesthe recognition. In other words, the recognition process is based onthe outcomes of the segmentation process. It implies that betterrecognition performance can be achieved on better segmentationoutcomes. However, the segmentation is a very difficult processbecause of the nature of cursive handwriting and it has become amajor error contributor in OffCHR (Elnagar & Alhajj, 2003; Hussein,Agarwal, Gupta, & Wang, 1999; Sadri, Suen, & Bui, 2007; Xiao &Leedham, 2000; Xu, Lam, & Suen, 2003; Yanikoglu & Sandon,1998).
Therefore, the aim of the research presented in this paper is toinvestigate a novel segmentation algorithm which can avoid prob-lems of existing algorithms and improve the segmentation accu-racy. The proposed segmentation algorithm is based on novel

Fig. 1. Typical frameworks of off-line cursive handwriting recognition (OffCHR).
11168 B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175
ideas such as binary segmentation and use of multiple confidencevalues.
The rest of this paper is organized into five sections. Section 2presents a review of existing literature. The proposed algorithmis described in Section 3. Section 4 presents the experimental re-sults. An analysis of experimental results and a discussion are pre-sented in Section 5. Finally, Section 6 concludes the paper.
2. Review of segmentation in handwriting recognition
The review of handwriting recognition techniques focused onthe segmentation, is presented in this section.
2.1. Representation of segmentation
Traditionally, segmentation was manifested into x-coordinatesof input images. Especially in machine printed OCR, segmentationwas only a matter of finding zero foreground pixel from verticalhistogram of the recognizing image. However, in cursive handwrit-ing recognition, there is no guarantee that neighboring characterswill be separated by empty space. Therefore, new representationof segmentation must be introduced. Segmentation path is anothertechnique to represent segmentation between two characters. Seg-mentation path is a connected list of x–y coordinates to represent aboundary between two neighboring characters. It is virtuallyimpractical to separate two handwritten characters using a verticalline. However, segmentation paths are simply used to define thecharacter boundaries (Casey & Lecolinet, 1996; Elnagar & Alhajj,2003; Xiao & Leedham, 2000; Yanikoglu & Sandon, 1998).
2.2. The relation between handwriting recognition and segmentation
Researchers often describe relationship between segmentationand recognition processes in OffCHR, as chicken and egg relation-ship. It is arguable which one comes first. Similarly, segmentationcannot be completed until it is correctly recognized. On the otherhand, recognition cannot be done without segmenting the wholeword image into individual characters (Casey & Lecolinet, 1996).Segmentation is very difficult process in OffCHR, and it is one ofthe main factors for low accuracy. Researchers have found the con-tributors to make segmentation very hard. The major contributors
Fig. 2. Handwritten words showing characters for bro
are shape variability, connectivity, overlapping and brokenness.Some examples of difficult words are shown below in Fig. 2.
It is difficult to write characters in exact shapes by the sameperson. It would be even more difficult to write characters in exactshapes by two or more people. Handwriting projects unique char-acteristics of the writers. Uniqueness means variability of hand-written character shapes (Djioua & Plamondon, 2009). Connectedcharacters make segmentation the most difficult process in OffCHRbecause it makes difficult to know how many characters to be rec-ognized. OCR in machine printed character recognition has beensuccessful because segmentation in OCR is very easy. It is said easybecause segmentation can be done by locating empty spaces be-tween the characters. However, in OffCHR, majority of handwrittenwords are connected and letters can be overlapped. Unlike con-nected characters, the overlapping factor can be separated by usingpath finding algorithms. However, unlike vertical line separation,path finding algorithms involve navigating algorithms that comewith greater computational costs. Unlike machine printed charac-ters, in OffCHR there are often broken characters. The broken char-acters cause de-segmentation problem. De-segmentation is aprocess to recognize the broken characters and combine themand recognize them as one character. It is very hard process to findout whether a character is broken or not. There has been some re-search conducted and published on spotting broken characters(Arica & Yarman-Vural, 2001, 2002; Liu, Nakashima, Sako, & Fujis-awa, 2003).
2.3. Character segmentation methodologies for cursive handwritingrecognition
Many researchers have been tackling the segmentation of hand-written image using various approaches. The segmentation tech-niques used in the literature can be grouped into three groupssuch as holistic, dissection and knowledge-based.
Holistic approach is also called segmentation-free. In holisticapproach, global features of handwritten word image are usedagainst the list of words under consideration for recognition. Asthe name ‘holistic’ implies, recognizing individual characters is ig-nored. The recognition accuracy is generally linear to the size of listof words under consideration, which is called, lexicon. So, theholistic approach is appropriate for handwriting recognition prob-lems with small lexicon domain, such as bank checks processing(Aghbari & Brook, 2009; Benouareth, Ennaji, & Sellami, 2008; Gun-ter & Bunke, 2004; Lee & Kim, 2008; Ruiz-Pinales, Jaime-Rivas, &Castro-Bleda, 2007; Srihari et al., 2008; Su, Zhang, Guan, & Huang,2009; Wang, Govindaraju, & Srihari, 2000).
Dissection is a segmentation technique to find boundaries be-tween neighboring characters without involving knowledge aboutcharacters. One of the typical dissection approaches is using verti-cal histogram of foreground pixels of the input image. The verticalhistogram based approach was eminent technique in OCR. However,
kenness, overlapping, variability and connectivity.

B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175 11169
the dissection technique is no longer eligible to handle irregularhandwritten images (Verma & Lee, 2007).
Neither holistic nor dissection technique uses knowledge aboutcharacters during segmentation process. However, researchershave incorporated the idea of using classifiers equipped with char-acter knowledge to cope with the irregularities of handwriting nat-ure. In this type of knowledge based segmentation approach, thereare two mainstream techniques. One is to allocate segmentationpoint where the employed classifier recognizes up to. Typically, apair of sliding window and classifiers is implemented together. Inthe technique, a fixed-size sliding window (Al-Muhtaseb, Mah-moud, & Qahwaji, 2008; Awaidah & Mahmoud, 2009; Benouarethet al., 2008; Su et al., 2009) scans a handwritten word image fromleft to right. While scanning, the classifier confirms if the sub-im-age is recognizable as a legal character or not.
The other method combines the idea of dissection techniqueand the classifiers in the segmentation process. In this technique,the input image is dissected into many sub-images based on rulesand heuristics, namely over-segmentation. The preliminary dissec-tion is to locate all the possible segmentation points. Because of theidea to find all the possible letter boundaries, there might be exces-sive segmentation points. This technique is called, over-segmenta-tion. The following process is to remove the excessivesegmentation points, and the process is called, validation. The pri-mary objective of validation is to remove excessive segmentationpoints by incorporating classifiers. This technique anticipates theover-segmenter and validator, and that is the reason it is called‘Hybrid’ technique. The hybrid tends to find all the letter bound-aries. However, it is still unaccomplished problem to remove allthe excessive segmentation points and to keep the correct ones(Blumenstein & Verma, 2001; Chiang, 1998; Lee & Verma, 2008;Sadri et al., 2007; Verma, 2003).
As discussed so far, holistic is plausible for only small lexicondomains such as bank check legal amounts. When it comes tothe real word problem with large lexicon, the holistic methodshows very little success. It is also hard to draw universal heuristicsto find boundaries without knowledge because the nature of infor-mal handwriting. Past research shows that there was little successusing a dissection technique. However, knowledge-based segmen-tation can improve the performance if the accurate classifiers areemployed. According to the past results, knowledge-based recogni-tion techniques outperform the dissection technique, and that’swhy the method is continuously pursued by researchers. Thereare two types of knowledge-based segmentation techniques. Thefirst one is to put the character boundaries based on recognitionusing sliding window technique. The second one is hybrid tech-nique based on over-segmentation and validation. Over-segmenta-tion is to put boundaries wherever doubtful, and validation is toremove the excessive segmentation boundaries. Over-segmenta-tion tends to find all letter boundaries. However, there is little suc-cess in validating the excessive segmentation points. Therefore, byimproving the validation accuracy, the overall segmentation accu-racy can be improved.
2.4. Segmentation techniques
Tripathy and Pal (2006) incorporated water reservoir approachto segment the connected characters in Oriya text recognition. Awater reservoir is a region formed by connected components andthe region could retain water as if water were poured into. Waterreservoir technique is to detect and segment connected regionsbased on touching position, reservoir base-area points, topologicaland structural features. Their approach has been experimented on1840 images of Oriya scripts. The segmentation accuracy was96.7% on two-character touching images (1458), 95.1% on three-character touching images (311), and 93.3% on four or more
character touching images (71). However, the water reservoirapproach is for single connection between characters, and theydid not address the issues of multi connection between characters.Pal, BelaI[combining diaeresis above]d, and Choisy (2003) alsoused water reservoir approach to segment touching numeral digits,and experimented on French bank checks. The segmentationaccuracy was 94.8%.
Zhao and Chi (2000) proposed background thinning segmenta-tion algorithm to segment connected Chinese characters. The back-ground thinning generates feature points such as end points, forkpoints and corner points. Sub-strokes are the segments betweenfeature points and extracted. The connected points are located byidentifying the lengths of sub-strokes and the topological relation-ship between sub-strokes. Alhajj and Elnagar (2005) proposedmulti-agents to segment handwritten connected digits. Their strat-egy is to detect the deepest-top valley and the highest-bottom hillby dedicated agents. Each agent is responsible for nominating seg-mentation points where connected area, and the final segmenta-tion points are compromised by the degree of the confidenceassessed by the agents. This approach was experimented on 4095images written by 150 writers, and obtained 97.8% segmentationaccuracy. This approach is targeting to segment only two touchingdigits, so it is inappropriate to apply to problems involving multi-ple characters.
Liang and Shi (2005) proposed a meta synthetic approach tosegment handwritten Chinese character strings. They appliedViterbi algorithm to search linear segmentation paths, and theredundant paths are eliminated by heuristics. Non-linear segmen-tation paths are obtained by background thinning algorithms.Especially, touching characters are further investigated with fore-ground and background information. The final segmentation pathsare decided by mixture probabilistic density function. Their ap-proach was experimented on 921 Chinese character strings andachieved 87.6% segmentation accuracy. However, their experimentseems biased because their database may contain many linearlyseparable images shown in the examples.
Dawoud (2007) proposed the iterative cross section sequencegraph (ICSSG) for handwritten character segmentation. ICSSG is abinarization technique of grey scale image, and the result of thebinarization is the segmentation of connected characters. ICSSGis based on the idea that the stroke thickness of the connectedpoints between characters is greater than the average stroke thick-ness. This method was experimented on 2575 numeral charactersfrom bank checks, and obtained 76.9% recognition accuracy. How-ever, this algorithm would fail where the characters are connectedin a line.
Renaudin, Ricquebourg, and Camillerapp (2007) proposed over-segmentation and graph construction technique to segment touch-ing digits. Over-segmentation points were located on singular area.Singular areas are where the stroke is disrupted such as intersec-tions, high curvature, thickness variations, etc. Graph was con-structed based on over-segmented primitives, and the finalsegmentation points were found by searching the best path onthe graph. Their approach was experimented on touching two-digitimages, and produced 68.9% of correct segmentation and recogni-tion. General idea of their method is over-segmentation and best-path searching. Their method was only tested touching two-digitexamples. The searching time and complexity will rise when moredigits are involved and they are connected. Suwa (2005) proposedgraph representation technique to segment multiply connecteddigits. In their approach, the binary patterns are thinned and theedges and vertices are extracted. The patterns are represented asa connected graph. Graph theory and heuristic rules calculate thecandidate segmentation path. Also rules are incorporated to elim-inate the ligatures and the touching strokes are uniformed by digitboundary detection. The approach was experimented on 2000
11170 B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175
pairs of touching digits from NIST-19 database. The segmentationaccuracy was reported as 88.4%. They should expand the testingdatabase from two-digits to multiple digits. The real world exam-ples are more likely multiple character strings.
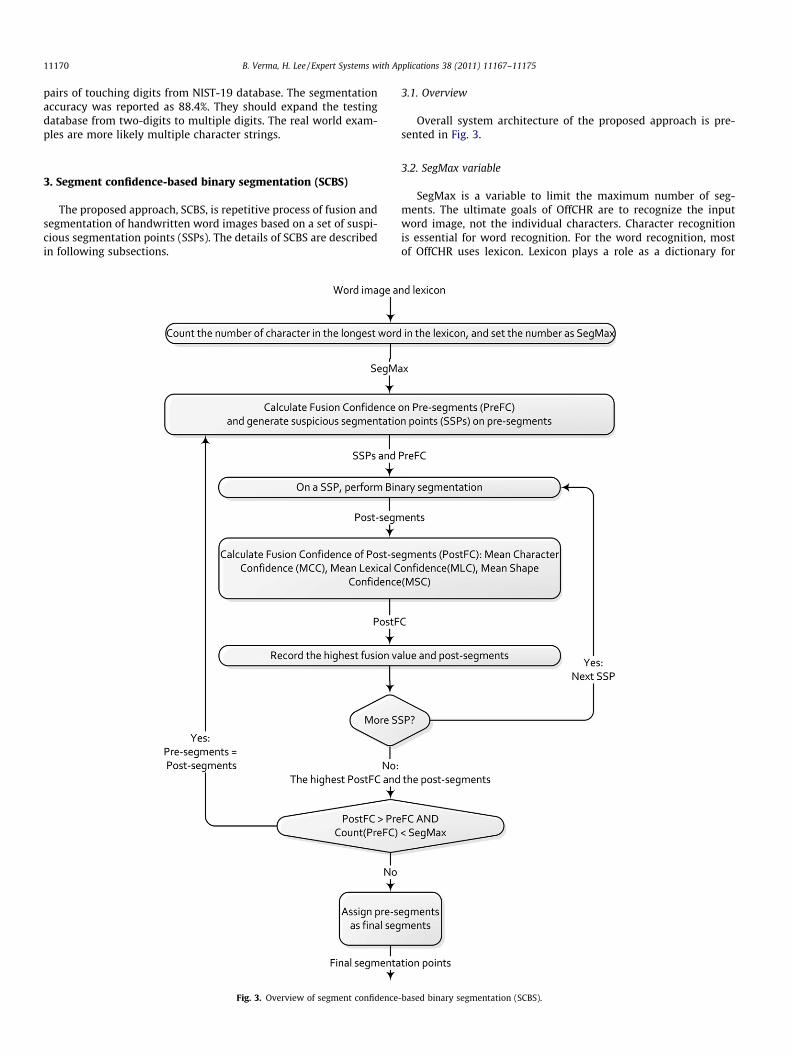
3. Segment confidence-based binary segmentation (SCBS)
The proposed approach, SCBS, is repetitive process of fusion andsegmentation of handwritten word images based on a set of suspi-cious segmentation points (SSPs). The details of SCBS are describedin following subsections.
Fig. 3. Overview of segment confidence
3.1. Overview
Overall system architecture of the proposed approach is pre-sented in Fig. 3.
3.2. SegMax variable
SegMax is a variable to limit the maximum number of seg-ments. The ultimate goals of OffCHR are to recognize the inputword image, not the individual characters. Character recognitionis essential for word recognition. For the word recognition, mostof OffCHR uses lexicon. Lexicon plays a role as a dictionary for
-based binary segmentation (SCBS).

Fig. 4. An example of generating a set of suspicious segmentation points (SSP) fromthe word, ‘Garthersburg’.
B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175 11171
the recognition domain. It provides an important clue that themaximum sub-images (segments) for a word image should be nomore than the number of characters of the longest word in the lex-icon. Since each segment represents a character, the maximumnumber of segments should be equal to the number of charactersin the longest word from considering lexicon. In our proposal,the variable SegMax has been set to the number of characters ofthe longest word in lexicon.
3.3. Generating suspicious segmentation points (SSPs)
The core idea of introducing over-segmentation into OffCHR isnot to miss any letter boundaries. So, successful over-segmentationgenerates a segmentation set containing all letter boundariesregardless of existence of excessive segmentation points, whichare called over-segmentation points. The best way to increase thechances to have successful over-segmentation is to locate as manysegmentation points as possible. Often many rules and heuristicsare applied to achieve successful over-segmentation. Every seg-mentation point from over-segmentation points can be a correctsegmentation point, so it is called suspicious segmentation point(SSP).
In the proposed approach, the SSPs are generated by using ver-tical foreground pixel density and stroke thickness variable. Thestroke thickness is the most occurring continuous foreground pixelcount. It is measured by scanning the segmenting word verticallyand horizontally. While scanning, the occurrences are recordedand the most occurring continuous foreground pixel count be-comes the stroke thickness of the segmenting word. The detailsof the stroke thickness measurement are described in Lee and Ver-ma (2008). Once the stroke thickness is estimated, the SSPs are lo-cated where the vertical foreground pixel density is less than thestroke thickness. However, to increase the chance of locating thecorrect boundaries, the SSPs are located where the vertical fore-ground pixel density is less than three times of the stroke thick-ness. The continuous SSPs are consolidated as a single SSP byfinding the one in the middle.
The suspicious segmentation points are screened by hole detec-tion module to remove the ones crossing hole regions. The reasonto incorporate this screening process is two-fold. Firstly, reducingthe number of SSP cuts down the computational costs significantly.The computational cost of validation for a SSP is much cheaperthan validation by classifier in the later stage. The second reasonis to reduce the number of segments. A segment is a sub-image de-fined by two neighboring segmentation points. The lesser seg-ments, the lesser spatial segment combinations for classifier haveto validate. An example of SSP generating process is described inFig. 4.
3.4. Calculating fusion of segment confidence (FSC)
The result of binary segmentation is a set of segments. A set ofsegments before the binary segmentation is defined as pre-seg-ments. A set of segments after the binary segmentation is definedas post-segments. Therefore, the number of post-segments is al-ways one bigger than the one of pre-segments. To calculate FSC,the three types of confidence values are estimated individually toa set of segments and they are fused together by applying pre-set weight factors. The three types of confidences are mean charac-ter confidence (MCC), mean lexical confidence (MLC) and meanshape confidence (MSC). Let WL, WC, WS be the weight factors forlexical, character and shape confidences accordingly. In the pro-posed approach, the weight factors were set as WL = 0.4,WC = 0.35 and WS = 0.25. The final FSC was calculated in the follow-ing equation. How to estimate MLC, MCC and MSC is described inthe following subsections:
FSC ¼MLC �WL þMCC �WC þMSC �WS:
3.4.1. Mean character confidence (MCC)A character confidence is measured by using the output from
the neural network based classifier, which is pre-trained on cor-rectly segmented characters. The classifier produces 52 confidencevalues (26 lowercases and 26 uppercases of English alphabets) foreach segment. The decision of the classification is made by findingthe highest confidence value out of 52. Therefore, the mean charac-ter confidence for a set of segments is found by dividing the sum ofindividual mean character confidence (MCC) with the number ofsegments.
Let S be a set of segments, n be the number of segments in SandTop(Si) be the highest confidence value of the ith segment in S:
MCC ¼Pn
i TopðSiÞn
:
3.4.2. Mean lexical confidence (MLC)A character matching confidence score between a segment and
a character is defined as finding a corresponding confidence valuefrom the segment’s neural outputs for the character. For example,the character matching confidence score for character ‘a’ is the firstneural confidence value for a segment, and the 27th neural confi-dence value for character ‘A’. In the following equation, the neuraloutput O(S) for segment S is described by subscripting the charac-ters for their corresponding values. In the equation, the charactermatching confidence scores between a segment and a characterare as follows: a = Oa, b = Ob, c = Oc . . . A = OA, B = OB, C = OC . . . Z = OZ
OðSÞ ¼ fOa;Ob;Oc; . . . ;Oz;OA;OB;OC ; . . . ;OZg:
A word matching confidence score between segments and char-acters (a lexical word) are calculated by dividing the total charactermatching score with the number of character matching compari-son. In the proposed approach, there are two types of charactermatching algorithms such as direct matching and neighbor match-ing. As shown in Fig. 5, the direct matching is a character matching

Fig. 5. Character matching: (1) performs total of seven character matching (3directs + 4 neighbors), (2) and (3) total of 13 matching (5 directs + 5 neighbors).
11172 B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175
where the segment index in the segments and the character indexin a word are the same. The neighbor matching is a charactermatching between Si in a set of segments S and C(i�1) in a wordC, or Si and C(i+1).
Let S be a set of segments, C be a set of characters in a word,M(Si, Ci) be the matching score between ith segment and ith char-acter. The total number of matching performed would be calcu-lated by the number of elements in S as ‘Q’ multiplied by 3, �2because the first and the last elements performed one less neigh-bor matching
MLC ¼PQ
i ðMðSi;CiÞ þMðSi; Ci�1Þ þMðSi;Ci�1Þ½ �ÞQ � 3� 2
:
Fig. 6. An example of binary segmentation algorithm (BSA).
3.4.3. Mean shape confidence (MSC)Shape confidence (SC) is to measure how well each segment fits
to the ideal character shape. The ideal shape is universally definedas related to the height and the width of a segment. The ideal char-acter shape satisfies the fact that the difference between the heightand the width of a segment is very close to zero.
Let h and w be the height and width of a segment, and the SC inthe proposed methodologies are calculated by the followingequation:
SC ¼ 1� w� hwþ h
� �2
:
Therefore, the mean shape confidence (MSC) is the sum of SC forall segments, and divided by the number of segments. Let S be a setof segments, n be the number of segments in S, and SC(Si) be thefunction to measure the shape confidence of ith element in S.MSC is estimated by the following equations:
MSC ¼Pn
i SCðSiÞn
:
Implementing MSC has two advantages. The first is to give high-er segmentation priority to the wider segment, which is likely tocontain more characters. The second is that MSC becomes the driv-ing force for segmentation to be performed when the mean charac-ter confidence and lexical confidence are lower than threshold.
3.4.4. Binary segmentation algorithm (BSA)The core idea of binary segmentation algorithm (BSA) is to split
an image/sub-image into two sub-images on a given suspicioussegmentation point. BSA is applied to the connected componentsor characters. Contour tracing algorithm is already introduced tosegment non-connected components. However, the contour trac-ing will not work on connected components because there is nopath through from lower bound to upper bound. BSA is devisedto work similar way as the contour tracing, but it can find a paththrough foreground pixels to make a path, where SSP lies.
As shown in Fig. 6, the tracing starts from a random tracing startpoint on the lower bound. A random tracing start point is a ran-domly picked background pixel on lower bound. The tracing con-tinues recursively through all the neighboring background pixelsuntil there are no more neighboring background pixels to be nav-igated. While navigating, the encountered coordinates of the fore-ground pixels lying on SSP are recorded. In the recordedcoordinates, the tracing algorithm takes one with smallest y-coor-dinate value, and continues navigating towards upper boundthrough neighboring foreground pixels on SSP until it reaches anuntraced background pixel. The tracing ends when a pixel on upperbound is reached. Until then, tracing through background pixelsand tunneling through foreground pixels on SSP are repeated. InFig. 6, the characters of ‘i’ and ‘g’ are connected. Since they are con-nected, BSA must be used to dissect them. There are two fore-ground crossings in SSP. However, the foreground crossing 2should not be crossed since the tracer can make to upper boundwithout crossing 2.
3.4.5. Termination of SCBSAs mentioned earlier, the SCBS is an iterative algorithm, which
repeats cycles of binary segmentation and evaluation of fusion ofsegment confidence. In the proposed approach, there are two ter-minating conditions. The first condition concerns the SegMax var-iable. SegMax variable defines the number of segments. The totalnumber of segments should not exceed the SegMax.

B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175 11173
The other condition is the improvement factor. The pre-seg-ments are the current set of segments before the binary segmenta-tion is applied. The post-segments are defined as a result set ofbinary segmentation on a set of pre-segments. The fusion of seg-ment confidence is estimated on pre-segments ad post-segments.If fusion of segment confidence on post-segments is greater thanthe one on pre-segments, then improvement has been made.Otherwise, no improvement can be made on any SSP. ThereforeSCBS terminates.
3.4.6. SCBS in stepsIn previous sections, sub-processes for SCBS are discussed. In
this section, stepwise algorithm for SCBS is presented.
Step 1. Input cursive handwritten word image.Step 2. Estimate parameter.Step 3. Generate suspicious segmentation points (SSPs).Step 4. Use binary segmentation for each SSP, calculate FSC and
record the highest confidence value.Step 5. Check if terminating conditions are met.Step 6. If not terminating, the post-segments become the pre-
segments.
Go to step 3. If terminating the post-segments become the finalsegmentation points.
4. Experimental results
4.1. Implementation
The proposed approach has been implemented in Java program-ming language and many experiments were conducted.
4.2. Database preparation
Two sets of experiments were conducted on a local databaseand CEDAR benchmark database to check the effectiveness of theproposed approach. The local database was created by our group,which has been obtained from multiple writers. The CEDAR bench-mark database was taken from CEDAR/TEST/CITIES/BD directory.
Table 1Segmentation performance results.
Database Size Segmentation rate (%)
Word Character Under Over Bad Average
Local 293 1215 7.82 0.74 3.13 3.90CEDAR 161 973 10.79 0.31 2.88 4.66
Table 2Characters or character pairs caused segmentation errors in each segmentation error cate
Category Character/character pair (frequency in %) from local
Under Ht(8.33) fo(7.29) ot(6.25) ir(6.25) it(6.25) in(6.25) ar(5.21) an(4.17) ll(3.1hi(1.04) ho(1.04) di(1.04) su(1.04) dn(1.04) sy(1.04) be(1.04) ew(1.04) is(ai(1.04) el(1.04) tu(1.04) ek(1.04) tt(1.04) ci(1.04) ep(1.04) en(1.04) ch(1.
Over w(33.33) c(22.22) f(11.11) g(11.11) d(11.11) o(11.11)Bad n(28.95) w(26.32) h(23.68) m(5.26) e(2.63) s(2.63) r(2.63) c(2.63) a(2.63)Category Character/character pair (frequency in %) from CEDARUnder Ch(5.71) al(5.71) el(4.76) no(3.81) il(3.81) er(3.81) ot(2.86) or(2.86) ls(2.8
as(1.90) im(1.90) ek(1.90) ac(1.90) et(1.90) nt(0.95) ny(0.95) bo(0.95) st(0ci(0.95) gs(0.95) go(0.95) lo(0.95) hs(0.95) lp(0.95) hi(0.95) dl(0.95) iv(0.9ad(0.95) en(0.95) ag(0.95) ah(0.95) es(0.95) ae(0.95)
Over w(33.33) e(33.33) s(33.33)Bad m(25.00) e(14.29) r(14.29) u(10.71) n(10.71) a(7.14) w(3.57) d(3.57) b(3.
4.3. Neural networks training
A MLP neural network with a single hidden layer was trained onpre-segmented characters with back-propagation learning algo-rithm. It takes 100 inputs, and produces 52 outputs. The 52 outputsrepresent 52 alphabets (upper and lower cases). The number ofhidden units and the number of iteration were varied during thetraining. The number of hidden units with the best training resultwas used in the experiment.
4.4. Segmentation performance criteria
As described in Yanikoglu and Sandon (1998), the numbers ofover-segmentation, under-segmentation, and bad-segmentationpoints are counted by manual inspection. The over-segmentationis defined as a character segmented into more than three seg-ments. Under-segmentation points are the missing segmentationpoints between two neighbouring characters. Finally, the bad-seg-mentation is the rest of inappropriate cuts that do not belong tounder-segmentation and over-segmentation and do not separatetwo characters correctly. The final segmentation results are calcu-lated by dividing each categorical result with total number of char-acters used in the experiment.
5. Analysis and discussion
As shown in Table 1, there are two experimental results for localand CEDAR databases. As mentioned in previous section, the seg-mentation results are analyzed by the number of segmentation er-rors in each category. The segmentation error categories are over,under and bad segmentation errors. For the experiment resultsfrom the local database, the highest segmentation error was gener-ated by the under segmentation, which recorded 7.82%. Over andbad segmentation errors were 0.74% and 3.13% accordingly. Theaverage segmentation error for the experiment on the local data-base was 3.90%. The result from the experiment on CEDAR bench-mark database shows that the highest error was generated fromunder segmentation error similar to the local database results.Over and bad segmentation errors were 0.31% and 2.88% accord-ingly. The average segmentation error for the CEDAR experimentwas 4.66%.
The overall segmentation error was higher in CEDAR experi-ments than in local. However, the similar segmentation error pat-tern has been shown that the under segmentation errors were thehighest in both experiments. Also, the bad segmentation errorswere the next highest errors in both experiments. Finally, the oversegmentation error was the lowest error category in bothexperiments.
Table 2 shows the segmentation error characters and their con-tribution percentage in each segmentation error category for both
gory from local and CEDAR databases.
2) ap(3.12) no(2.08) or(2.08) rs(2.08) et(2.08) er(2.08) ae(2.08) nu(1.04) ls(1.04)1.04) ev(1.04) mo(1.04) iv(1.04) at(1.04) aw(1.04) io(1.04) eh(1.04) al(1.04)04) es(1.04) ry(1.04)
y(2.63)
6) ir(2.86) ai(2.86) tt(2.86) cl(1.90) ce(1.90) lu(1.90) lt(1.90) di(1.90) dn(1.90).95) ou(0.95) op(0.95) oo(0.95) ko(0.95) ow(0.95) oz(0.95) gn(0.95) co(0.95)
5) ez(0.95) in(0.95) io(0.95) au(0.95) eg(0.95) tu(0.95) ap(0.95) ep(0.95) iy(0.95)
57) c(3.57) i(3.57)
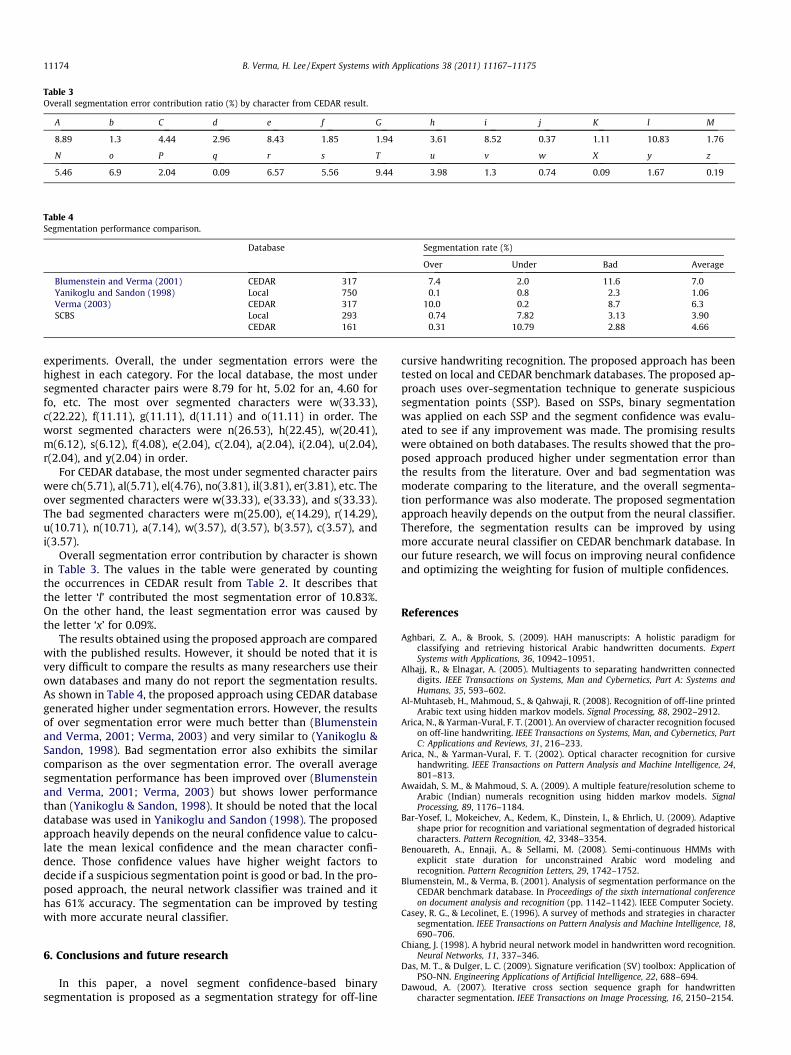
Table 3Overall segmentation error contribution ratio (%) by character from CEDAR result.
A b C d e f G h i j K l M
8.89 1.3 4.44 2.96 8.43 1.85 1.94 3.61 8.52 0.37 1.11 10.83 1.76
N o P q r s T u v w X y z
5.46 6.9 2.04 0.09 6.57 5.56 9.44 3.98 1.3 0.74 0.09 1.67 0.19
Table 4Segmentation performance comparison.
Database Segmentation rate (%)
Over Under Bad Average
Blumenstein and Verma (2001) CEDAR 317 7.4 2.0 11.6 7.0Yanikoglu and Sandon (1998) Local 750 0.1 0.8 2.3 1.06Verma (2003) CEDAR 317 10.0 0.2 8.7 6.3SCBS Local 293 0.74 7.82 3.13 3.90
CEDAR 161 0.31 10.79 2.88 4.66
11174 B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175
experiments. Overall, the under segmentation errors were thehighest in each category. For the local database, the most undersegmented character pairs were 8.79 for ht, 5.02 for an, 4.60 forfo, etc. The most over segmented characters were w(33.33),c(22.22), f(11.11), g(11.11), d(11.11) and o(11.11) in order. Theworst segmented characters were n(26.53), h(22.45), w(20.41),m(6.12), s(6.12), f(4.08), e(2.04), c(2.04), a(2.04), i(2.04), u(2.04),r(2.04), and y(2.04) in order.
For CEDAR database, the most under segmented character pairswere ch(5.71), al(5.71), el(4.76), no(3.81), il(3.81), er(3.81), etc. Theover segmented characters were w(33.33), e(33.33), and s(33.33).The bad segmented characters were m(25.00), e(14.29), r(14.29),u(10.71), n(10.71), a(7.14), w(3.57), d(3.57), b(3.57), c(3.57), andi(3.57).
Overall segmentation error contribution by character is shownin Table 3. The values in the table were generated by countingthe occurrences in CEDAR result from Table 2. It describes thatthe letter ‘l’ contributed the most segmentation error of 10.83%.On the other hand, the least segmentation error was caused bythe letter ‘x’ for 0.09%.
The results obtained using the proposed approach are comparedwith the published results. However, it should be noted that it isvery difficult to compare the results as many researchers use theirown databases and many do not report the segmentation results.As shown in Table 4, the proposed approach using CEDAR databasegenerated higher under segmentation errors. However, the resultsof over segmentation error were much better than (Blumensteinand Verma, 2001; Verma, 2003) and very similar to (Yanikoglu &Sandon, 1998). Bad segmentation error also exhibits the similarcomparison as the over segmentation error. The overall averagesegmentation performance has been improved over (Blumensteinand Verma, 2001; Verma, 2003) but shows lower performancethan (Yanikoglu & Sandon, 1998). It should be noted that the localdatabase was used in Yanikoglu and Sandon (1998). The proposedapproach heavily depends on the neural confidence value to calcu-late the mean lexical confidence and the mean character confi-dence. Those confidence values have higher weight factors todecide if a suspicious segmentation point is good or bad. In the pro-posed approach, the neural network classifier was trained and ithas 61% accuracy. The segmentation can be improved by testingwith more accurate neural classifier.
6. Conclusions and future research
In this paper, a novel segment confidence-based binarysegmentation is proposed as a segmentation strategy for off-line
cursive handwriting recognition. The proposed approach has beentested on local and CEDAR benchmark databases. The proposed ap-proach uses over-segmentation technique to generate suspicioussegmentation points (SSP). Based on SSPs, binary segmentationwas applied on each SSP and the segment confidence was evalu-ated to see if any improvement was made. The promising resultswere obtained on both databases. The results showed that the pro-posed approach produced higher under segmentation error thanthe results from the literature. Over and bad segmentation wasmoderate comparing to the literature, and the overall segmenta-tion performance was also moderate. The proposed segmentationapproach heavily depends on the output from the neural classifier.Therefore, the segmentation results can be improved by usingmore accurate neural classifier on CEDAR benchmark database. Inour future research, we will focus on improving neural confidenceand optimizing the weighting for fusion of multiple confidences.
References
Aghbari, Z. A., & Brook, S. (2009). HAH manuscripts: A holistic paradigm forclassifying and retrieving historical Arabic handwritten documents. ExpertSystems with Applications, 36, 10942–10951.
Alhajj, R., & Elnagar, A. (2005). Multiagents to separating handwritten connecteddigits. IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems andHumans, 35, 593–602.
Al-Muhtaseb, H., Mahmoud, S., & Qahwaji, R. (2008). Recognition of off-line printedArabic text using hidden markov models. Signal Processing, 88, 2902–2912.
Arica, N., & Yarman-Vural, F. T. (2001). An overview of character recognition focusedon off-line handwriting. IEEE Transactions on Systems, Man, and Cybernetics, PartC: Applications and Reviews, 31, 216–233.
Arica, N., & Yarman-Vural, F. T. (2002). Optical character recognition for cursivehandwriting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24,801–813.
Awaidah, S. M., & Mahmoud, S. A. (2009). A multiple feature/resolution scheme toArabic (Indian) numerals recognition using hidden markov models. SignalProcessing, 89, 1176–1184.
Bar-Yosef, I., Mokeichev, A., Kedem, K., Dinstein, I., & Ehrlich, U. (2009). Adaptiveshape prior for recognition and variational segmentation of degraded historicalcharacters. Pattern Recognition, 42, 3348–3354.
Benouareth, A., Ennaji, A., & Sellami, M. (2008). Semi-continuous HMMs withexplicit state duration for unconstrained Arabic word modeling andrecognition. Pattern Recognition Letters, 29, 1742–1752.
Blumenstein, M., & Verma, B. (2001). Analysis of segmentation performance on theCEDAR benchmark database. In Proceedings of the sixth international conferenceon document analysis and recognition (pp. 1142–1142). IEEE Computer Society.
Casey, R. G., & Lecolinet, E. (1996). A survey of methods and strategies in charactersegmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 18,690–706.
Chiang, J. (1998). A hybrid neural network model in handwritten word recognition.Neural Networks, 11, 337–346.
Das, M. T., & Dulger, L. C. (2009). Signature verification (SV) toolbox: Application ofPSO-NN. Engineering Applications of Artificial Intelligence, 22, 688–694.
Dawoud, A. (2007). Iterative cross section sequence graph for handwrittencharacter segmentation. IEEE Transactions on Image Processing, 16, 2150–2154.

B. Verma, H. Lee / Expert Systems with Applications 38 (2011) 11167–11175 11175
Djioua, M., & Plamondon, R. (2009). Studying the variability of handwriting patternsusing the kinematic theory. Human Movement Science, 28, 588–601.
Elnagar, A., & Alhajj, R. (2003). Segmentation of connected handwritten numeralstrings. Pattern Recognition, 36, 625–634.
Fujisawa, H. (2008). Forty years of research in character and document recognition– An industrial perspective. Pattern Recognition, 41, 2435–2446.
Gunter, S., & Bunke, H. (2004). HMM-based handwritten word recognition: On theoptimization of the number of states, training iterations and Gaussiancomponents. Pattern Recognition, 37, 2069–2079.
Hussein, K., Agarwal, A., Gupta, A., & Wang, P. (1999). A knowledge-basedsegmentation algorithm for enhanced recognition of handwritten courtesyamounts. Pattern Recognition, 32, 305–316.
Lee, H., & Verma, B. (2008). A novel multiple experts and fusion based segmentationalgorithm for cursive handwriting recognition. In IEEE international jointconference on neural networks, 2008. IJCNN 2008 (IEEE world congress oncomputational intelligence), 2008 (pp. 2994–2999).
Lee, S., & Kim, J. (2008). Complementary combination of holistic and componentanalysis for recognition of low-resolution video character images. PatternRecognition Letters, 29, 383–391.
Liang, Z., & Shi, P. (2005). A metasynthetic approach for segmenting handwrittenChinese character strings. Pattern Recognition Letters, 26, 1498–1511.
Liu, C., Nakashima, K., Sako, H., & Fujisawa, H. (2003). Handwritten digitrecognition: Benchmarking of state-of-the-art techniques. Pattern Recognition,36, 2271–2285.
Lorigo, L. M., & Govindaraju, V. (2006). Offline Arabic handwriting recognition: Asurvey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28,712–724.
Lu, Z., Chi, Z., Siu, W., & Shi, P. (1999). A background-thinning-based approach forseparating and recognizing connected handwritten digit strings. PatternRecognition, 32, 921–933.
Lu, S., & Tan, C. (2008). Retrieval of machine-printed latin documents through wordshape coding. Pattern Recognition, 41, 1799–1809.
Nomura, S., Yamanaka, K., Shiose, T., Kawakami, H., & Katai, O. (2009).Morphological preprocessing method to thresholding degraded word images.Pattern Recognition Letters, 30, 729–744.
Pal, U., BelaI[combining diaeresis above]d, A., & Choisy, C. (2003). Touching numeralsegmentation using water reservoir concept. Pattern Recognition Letters, 24,261–272.
Plamondon, R., & Srihari, S. N. (2000). Online and off-line handwriting recognition:A comprehensive survey. IEEE Transactions on Pattern Analysis and MachineIntelligence, 22, 63–84.
Renaudin, C., Ricquebourg, Y., & Camillerapp, J. (2007). A general method ofsegmentation–recognition collaboration applied to pairs of touching andoverlapping symbols. In Ninth international conference on document analysisand recognition, 2007. ICDAR 2007 (pp. 659–663).
Ruiz-Pinales, J., Jaime-Rivas, R., & Castro-Bleda, M. (2007). Holistic cursive wordrecognition based on perceptual features. Pattern Recognition Letters, 28,1600–1609.
Sadri, J., Suen, C. Y., & Bui, T. D. (2007). A genetic framework using contextualknowledge for segmentation and recognition of handwritten numeral strings.Pattern Recognition, 40, 898–919.
Srihari, S., Collins, J., Srihari, R., Srinivasan, H., Shetty, S., & Brutt-Griffler, J. (2008).Automatic scoring of short handwritten essays in reading comprehension tests.Artificial Intelligence, 172, 300–324.
Su, T., Zhang, T., Guan, D., & Huang, H. (2009). Off-line recognition of realisticChinese handwriting using segmentation-free strategy. Pattern Recognition, 42,167–182.
Sun, Y., Butler, T., Shafarenko, A., Adams, R., Loomes, M., & Davey, N. (2007). Wordsegmentation of handwritten text using supervised classification techniques.Applied Soft Computing, 7, 71–88.
Suresh, R. M., & Arumugam, S. (2007). Fuzzy technique based recognition ofhandwritten characters. Image and Vision Computing, 25, 230–239.
Suwa, M., (2005). Segmentation of connected handwritten numerals by graphrepresentation. In Proceedings eighth international conference on documentanalysis and recognition, 2005 (Vol. 2, pp. 750–754).
Tripathy, N., & Pal, U. (2006). Handwriting segmentation of unconstrained Oriyatext. Sadhana, 31, 755–769.
Vellasques, E., Oliveira, L. S., Britto, A. S., Jr., Koerich, A. L., & Sabourin, R. (2008a).Filtering segmentation cuts for digit string recognition. Pattern Recognition, 41,3044–3053.
Vellasques, E., Oliveira, L., Britto, A., Jr., Koerich, A., & Sabourin, R. (2008b). Filteringsegmentation cuts for digit string recognition. Pattern Recognition, 41,3044–3053.
Verma, B. (2003). A contour code feature based segmentation for handwritingrecognition. In Proceedings of the seventh international conference on documentanalysis and recognition, 2003 (pp. 1203–1207).
Verma, B., & Lee, H. (2007). A segmentation based adaptive approach for cursivehandwritten text recognition. In IEEE international joint conference on neuralnetworks, 2007 (pp. 2212–2216). Orlando, Florida, USA: IEEE IJCNN’07.
Verma, B., Gader, P., & Chen, W. (2001). Fusion of multiple handwritten wordrecognition techniques. Pattern Recognition Letters, 22, 991–998.
Vinciarelli, A. (2002). A survey on off-line cursive word recognition. PatternRecognition, 35, 1433–1446.
Wang, X., Govindaraju, V., & Srihari, S. (2000). Holistic recognition of handwrittencharacter pairs. Pattern Recognition, 33, 1967–1973.
Xiao, X., & Leedham, G. (2000). Knowledge-based English cursive scriptsegmentation. Pattern Recognition Letters, 21, 945–954.
Xu, Q., Lam, L., & Suen, C. (2003). Automatic segmentation and recognition systemfor handwritten dates on Canadian bank cheques. In Proceedings of the seventhinternational conference on document analysis and recognition, 2003 (pp. 704–708).
Yanikoglu, B., & Sandon, A. (1998). Segmentation of off-line cursive handwritingusing linear programming. Pattern Recognition, 31, 1825–1833.
Zhang, L., Yip, A. M., Brown, M. S., & Lim Tan, C. (2009). A unified framework fordocument restoration using inpainting and shape-from-shading. PatternRecognition, 42, 2961–2978.
Zhao, S., & Shi, P. (2000). Segmentation of connected handwritten Chinesecharacters based on stroke analysis and background thinning. In PRICAI 2000topics in artificial intelligence (pp. 608–616).
Zhao, S., Chi, Z., Shi, P., & Yan, H. (2003). Two-stage segmentation of unconstrainedhandwritten Chinese characters. Pattern Recognition, 36, 145–156.





























