Embed Size (px)
Citation preview

Segmentation and Targeting of Coffee Market
For New Coffee Product Introduction
Josh Lutz
12/14/15

Introduction
The purpose of this research study is to segment the coffee market and determine
which segment would respond most positively to the introduction of a new bottled iced coffee
product. Bottled iced coffee is meant to be a convenient alternative to traditional hot coffee
and would allow the consumer to quickly grab a coffee instead of waiting for it to be brewed.
The main research question this study is attempting to answer is: What are the preferences and
consumption habits of coffee drinkers? Analyzing the consumption habits will help determine
which segment is most likely to adopt this new product. Analyzing the preferences will help
show what aspects of coffee the consumers most value so that the product can be aligned to fit
the tastes of the coffee drinkers.
Methodology
The steps of the research study are as follows:
1. Create a survey using needs based questions and descriptor questions
2. Distribute survey and gather responses
3. Determine the number of segments using a Hierarchical Cluster Analysis
4. Analyze the segments using K-Means Analysis
5. Compare Demographics with segments using Cross Tabulation
6. Determine best segment to target
In order to gather data for the analysis, a survey was conducted using needs based
questions and descriptor questions. To view the survey and its questions, see Appendix 1. After

administering the survey and collecting the data, a cluster analysis was conducted to segment
the coffee market in order to address the research question. I chose a cluster analysis because
it is used to identify homogenous groups of respondents by analyzing the data points and
making connections between results. The first step of the cluster analysis is to determine the
number of segments in the coffee market using a Hierarchical Cluster Analysis. Once the
number of segments is determined, the number is used in the K-means Analysis to sort the
respondents into the specified number of segments. Once the K-means analysis had segmented
the respondents, the groupings were then compared with the demographics questions to
describe the segments for managerial purposes. For a more detailed explanation of the
methodology, see Appendix 2.
Data
To collect the necessary data for the cluster analysis, I created and administered a
survey online using Qualtrics.com. I surveyed friends and family by posting the survey onto my
Facebook page and asking friends who drink coffee to take the survey. Several of my friends
shared the survey link on their Facebook pages which greatly increased the number of
respondents. In total, 119 coffee drinkers were surveyed with 33 respondents male and 86
respondents female. To view the data collected, see Appendix 3. The survey was broken up into
four different sections: screening question, consumption questions, preference questions, and
demographics questions. For a detailed explanation of the questions in the survey, see
Appendix 4.

Analysis
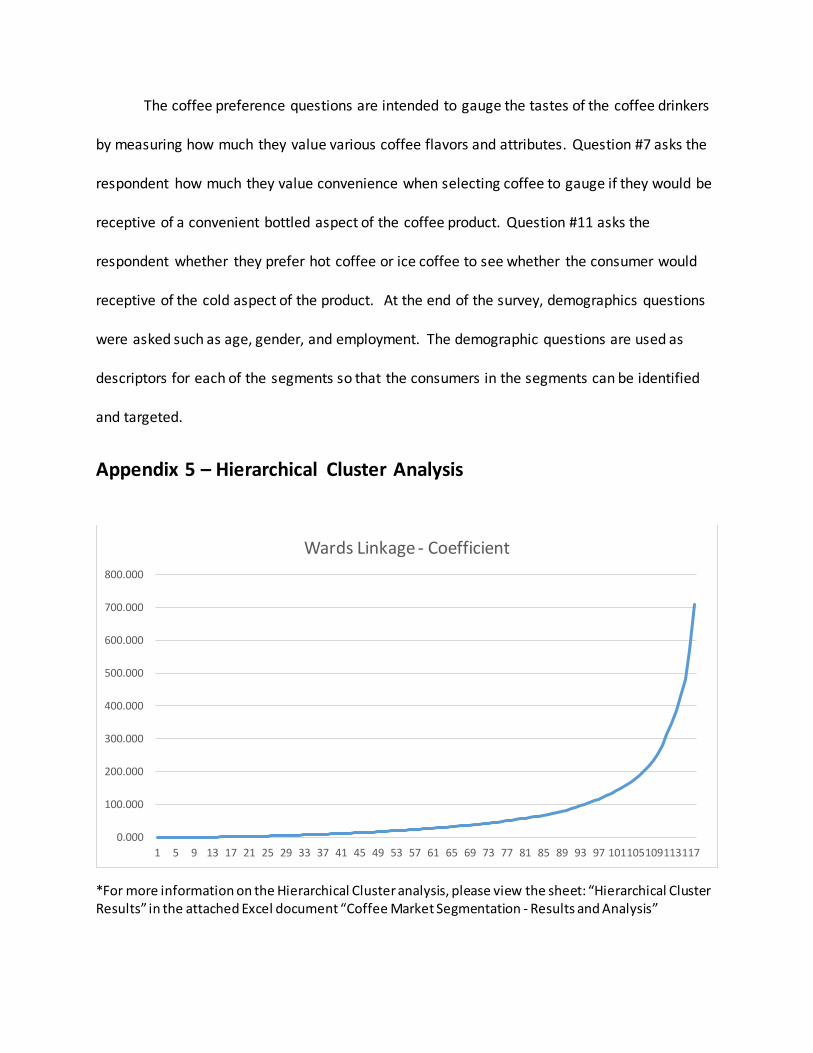
By using the Hierarchical Cluster Analysis I determined that there are 3 distinct
segments of coffee drinkers. The results of the Agglomeration Schedule’s coefficients showed a
break in direction on the line graph at the 116th point (see Appendix 5). I then subtracted the
116th point from the total number of points to come up with three different segments. The
Dendrogram of Wards Linkage confirmed the segments by depicting three clusters (see
Appendix 3). After establishing that there are three different clusters, I ran a K-means cluster
analysis to segment the respondents into three segments and to make sure three segments
would be ideal for this market (see Appendix 6). I also tested the K-means analysis using two
clusters, four clusters, and five clusters. Although after analyzing the four different outputs, the
hierarchical cluster analysis was proven to be correct with three clusters (see Appendix 3).
The K-means analysis placed each of the respondents into the three segments and
provided the preferences for each of the clusters. The average preferences of the groups are
used to differentiate the groups from each other. To view the K-means results, see Appendix 7.
After conducting the K-means analysis, I took the segment groupings and compared them with
the demographics questions using cross tabulations. The cross tabulations concluded that the
descriptors age and employment were able to predict the segments. Both age and employment
passed the significance test with significance levels under 0.05. This is beneficial to the study
because age and employment can be used as descriptors to define each of the segments for
managerial implications. By using the K-means analysis and the cross tabulations, the analysis
found that people in their 30s and 40s who work full time are most likely to be in Segment #1.

Young people aged 20-29 who go to college and work part time are most likely to be in
Segment #2. And consumers over 60 year’s old and retired people are most likely to be in
Segment #3.
The most attractive segment to enter is Segment #1 because the consumers drink coffee
multiple times a day and are willing to spend up to $5 per cup of coffee. These attributes make
Segment #1 a very lucrative segment since the consumers drink more coffee than the other two
segments and they also pay more money for coffee. However, the preferred method of
consumption of Segment #1 is by purchasing coffee grounds which is viewed as being the
opposite of bottled coffee. Because of this fact, it may be more profitable to change the bottled
iced coffee product to a coffee grounds product that would better fit the needs of the Segment
#1. For a full analysis of the segments and their attributes, see Appendix 8.
Conclusion
After completing the analysis, I have realized that there are several things I would do
differently if I were to conduct this survey again. One of the short comings of the experiment
was that the three different segments had several similarities. All three of the clusters preferred
hot coffee and perceived convenience to only be slightly important. Additionally, Segments #1
and #3 are both made up of consumers who drink coffee on the go. These similarities could
show that many coffee drinkers have similar taste. This is supported by the fact that 77.3% of
all coffee drinkers prefer hot coffee which may have prevented an ice coffee segment from

emerging. However, the similarities between the segments could be reduced by surveying a
more diverse group of coffee drinkers and wording the questions more precisely.
One of the indications that the respondents were not diverse enough was that there
were far more female who took the survey than males. Because 72.2% of respondents were
females, the cross tabulation concluded that the significance level test of Gender was above
0.05 which means that Gender does not predict the segments. To improve upon the results in
future studies, it would be important to survey a more diverse population with an equal
amount of male and female respondents.
In conclusion, the research and analysis did not turn out how I expected. The data has
shown that very few consumers are interested in a bottled ice coffee product. Only 2.5 % of
respondents stated they preferred bottled coffee which is an extremely low portion of the
population. Additionally, only 22.7% of respondents prefer ice coffee which makes this a niche
market. Targeting this small of a market would only be profitable if the new product is able to
gain a majority market share of this segment. However, it may be more profitable to change the
bottled iced coffee product to a product that would better fit the needs of consumers. If I were
to scrap the bottled ice coffee product and introduce a different coffee product that aligns
more closely to actual consumer tastes, then I would change product. to a high end coffee
grounds product to target Segment #1 which drinks coffee multiple times a day and is willing to
spend $5 per cup. This segment would be more profitable in the long run because the
consumers drink more coffee and are willing to spend more than the other segments.
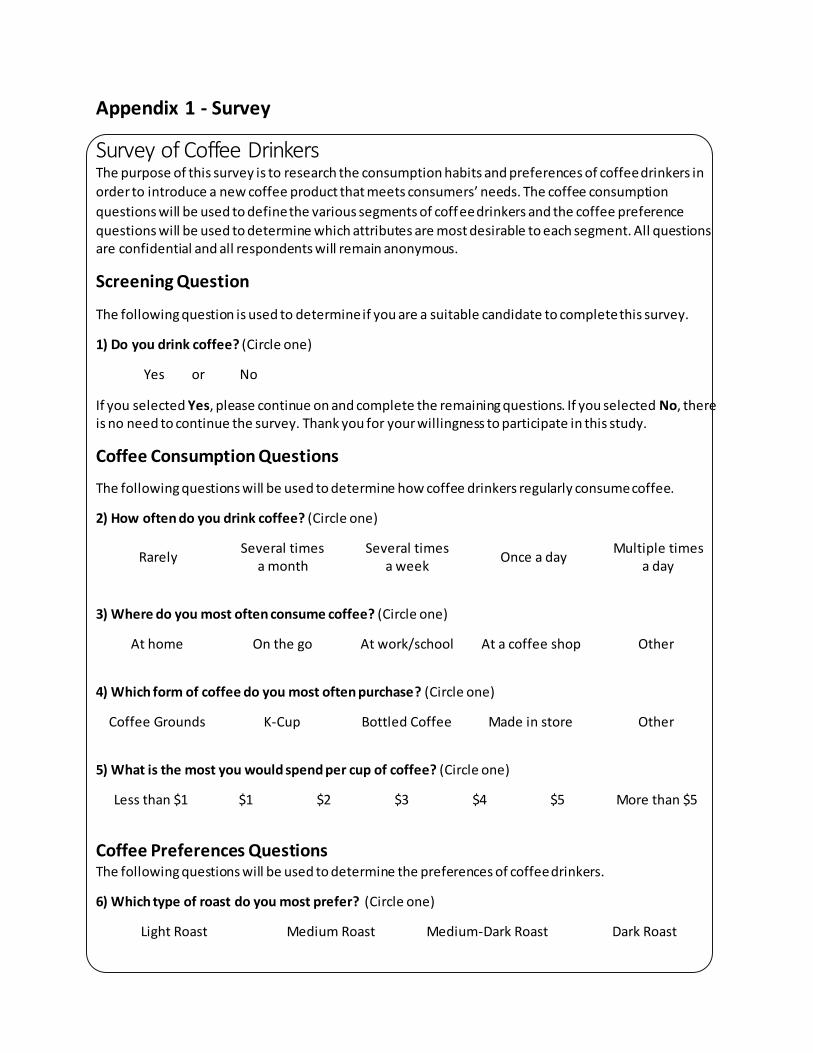
Appendix 1 - Survey
Survey of Coffee Drinkers The purpose of this survey is to research the consumption habits and preferences of coffee drinkers in
order to introduce a new coffee product that meets consumers’ needs. The coffee consumption
questions will be used to define the various segments of coffee drinkers and the coffee preference
questions will be used to determine which attributes are most desirable to each segment. All questions are confidential and all respondents will remain anonymous.
Screening Question
The following question is used to determine if you are a suitable candidate to complete this survey.
1) Do you drink coffee? (Circle one)
Yes or No
If you selected Yes, please continue on and complete the remaining questions. If you selected No, there is no need to continue the survey. Thank you for your willingness to participate in this study.
Coffee Consumption Questions
The following questions will be used to determine how coffee drinkers regularly consume coffee.
2) How often do you drink coffee? (Circle one)
Rarely Several times
a month Several times
a week Once a day
Multiple times a day
3) Where do you most often consume coffee? (Circle one)
At home On the go At work/school At a coffee shop Other
4) Which form of coffee do you most often purchase? (Circle one)
Coffee Grounds K-Cup Bottled Coffee Made in store Other
5) What is the most you would spend per cup of coffee? (Circle one)
Less than $1 $1 $2 $3 $4 $5 More than $5
Coffee Preferences Questions
The following questions will be used to determine the preferences of coffee drinkers.
6) Which type of roast do you most prefer? (Circle one)
Light Roast Medium Roast Medium-Dark Roast Dark Roast
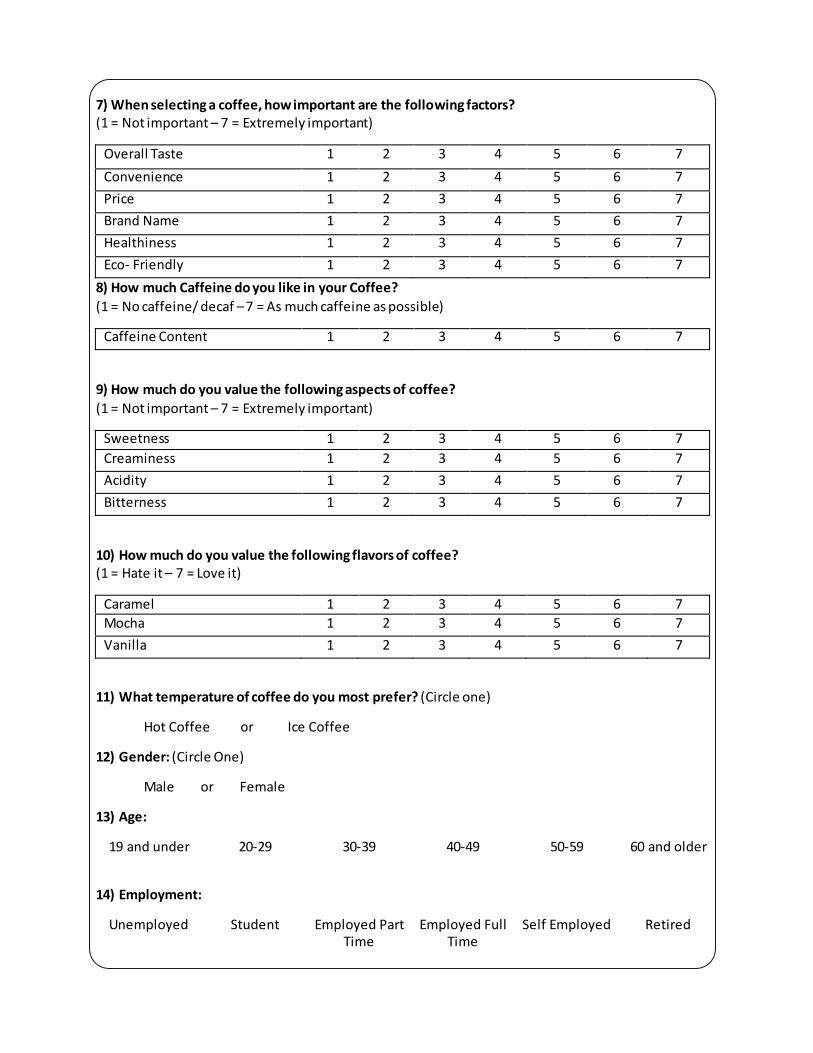
7) When selecting a coffee, how important are the following factors? (1 = Not important – 7 = Extremely important)
Overall Taste 1 2 3 4 5 6 7
Convenience 1 2 3 4 5 6 7
Price 1 2 3 4 5 6 7
Brand Name 1 2 3 4 5 6 7
Healthiness 1 2 3 4 5 6 7
Eco- Friendly 1 2 3 4 5 6 7
8) How much Caffeine do you like in your Coffee?
(1 = No caffeine/ decaf – 7 = As much caffeine as possible)
Caffeine Content 1 2 3 4 5 6 7
9) How much do you value the following aspects of coffee? (1 = Not important – 7 = Extremely important)
Sweetness 1 2 3 4 5 6 7
Creaminess 1 2 3 4 5 6 7
Acidity 1 2 3 4 5 6 7
Bitterness 1 2 3 4 5 6 7
10) How much do you value the following flavors of coffee? (1 = Hate it – 7 = Love it)
Caramel 1 2 3 4 5 6 7
Mocha 1 2 3 4 5 6 7
Vanilla 1 2 3 4 5 6 7
11) What temperature of coffee do you most prefer? (Circle one)
Hot Coffee or Ice Coffee
12) Gender: (Circle One)
Male or Female
13) Age:
19 and under 20-29 30-39 40-49 50-59 60 and older
14) Employment:
Unemployed Student Employed Part Time
Employed Full Time
Self Employed Retired

Appendix 2 – Methodology Explained
The first step of the cluster analysis is to determine the number of segments in the
coffee market. To determine the number of segments, I conducted a hierarchical cluster
analysis using Wards Linkage. A hierarchical cluster analysis creates groups by placing
respondents into a hierarchy where the groupings start out broad and then narrow as the
groups become more defined. To analyze the hierarchical cluster analysis, I used results of the
Agglomeration Schedule’s coefficients and plotted them into a line graph to find the “dog leg”
in the data. I then subtracted the point where the data turns from the total number of points to
determine the number of clusters. Additionally, I observed the Dendrogram of Wards Linkage
to match the grouping of the respondents with the number of segments found using the graph.
After determining the number of segments using the hierarchical cluster analysis, I then
preformed a K-Means cluster analysis to divide the respondents and place them into segments
based on their answers to the survey. Once the K-means analysis had segmented the
respondents, I then compared the groupings with the demographics questions to describe the
segments for managerial purposes.

Appendix 3 – Data and Analysis
Please see attached Excel document “Coffee Market Segmentation - Results and Analysis”
Included in the Excel document:
1. Raw Data
2. Cleaned Data
3. Hierarchical Cluster Results
4. K-Means Cluster Results
5. Cross Tabulation Cluster Results
Appendix 4 – Survey Questions Explained
The survey started with a screening question which asked if the respondent drinks
coffee or not. If the respondent selected “No”, then the survey would end and they were not
asked any further questions. If the respondent selected “Yes”, then they would continue on
with the survey. Respondents who did not drink coffee would not be helpful for this research
study so I excluded their responses from the study.
The next group of questions, #2 through #5, were based on the consumption of coffee.
The coffee consumption questions are intended to gauge coffee drinker’s acceptance of the
prepackaged ice coffees by measuring their coffee drinking habits. The survey asked how often
they drink coffee to help determine the segment with the highest amount of coffee
consumption. The next two questions asked where they usually consume coffee and in what
form do they usually purchase coffee. These questions were asked to gauge the interest of a
convenient bottled coffee vs other forms of coffee. Question #5 then asks what the most each
person is willing to spend on a cup of coffee to determine the highest selling price that I could
offer the new product for.
The coffee preference questions are intended to gauge the tastes of the coffee drinkers
by measuring how much they value various coffee flavors and attributes. Question #7 asks the
respondent how much they value convenience when selecting coffee to gauge if they would be
receptive of a convenient bottled aspect of the coffee product. Question #11 asks the
respondent whether they prefer hot coffee or ice coffee to see whether the consumer would
receptive of the cold aspect of the product. At the end of the survey, demographics questions
were asked such as age, gender, and employment. The demographic questions are used as
descriptors for each of the segments so that the consumers in the segments can be identified
and targeted.
Appendix 5 – Hierarchical Cluster Analysis
*For more information on the Hierarchical Cluster analysis, please view the sheet: “Hierarchical Cluster Results” in the attached Excel document “Coffee Market Segmentation - Results and Analysis”
0.000
100.000
200.000
300.000
400.000
500.000
600.000
700.000
800.000
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97 101105109113117
Wards Linkage - Coefficient

Appendix 6 – K-means Cluster Analysis
Final Cluster Centers
Cluster
1 2 3
Q2 5 3 4
Q3 2 3 2
Q4 1 4 2
Q5 6 5 3
Q7_2 5 5 5
Q11 1 1 1
Iteration Historya
Iteration
Change in Cluster Centers
1 2 3
1 3.338 3.299 3.837
2 .296 .352 .384
3 .223 .178 .175
4 .478 .244 .210
5 .338 .175 .094
6 .240 .087 .078
7 .294 .120 .139
8 .282 .243 .000
9 .106 .109 .000
10 .000 .000 .000
a. Convergence achieved due to no or small
change in cluster centers. The maximum
absolute coordinate change for any center is
.000. The current iteration is 10. The minimum
distance between initial centers is 6.708.
*For more information on the K-Means analysis, please view the sheet: “K-means Cluster Results” in the attached Excel document “Coffee Market Segmentation - Results and Analysis”
Initial Cluster Centers
Cluster
1 2 3
Q2 4 1 1
Q3 2 2 3
Q4 2 4 2
Q5 6 7 1
Q7_2 1 7 4
Q11 1 2 2
Number of Cases in each
Cluster
Cluster 1 35.000
2 38.000
3 46.000
Valid 119.000
Missing .000
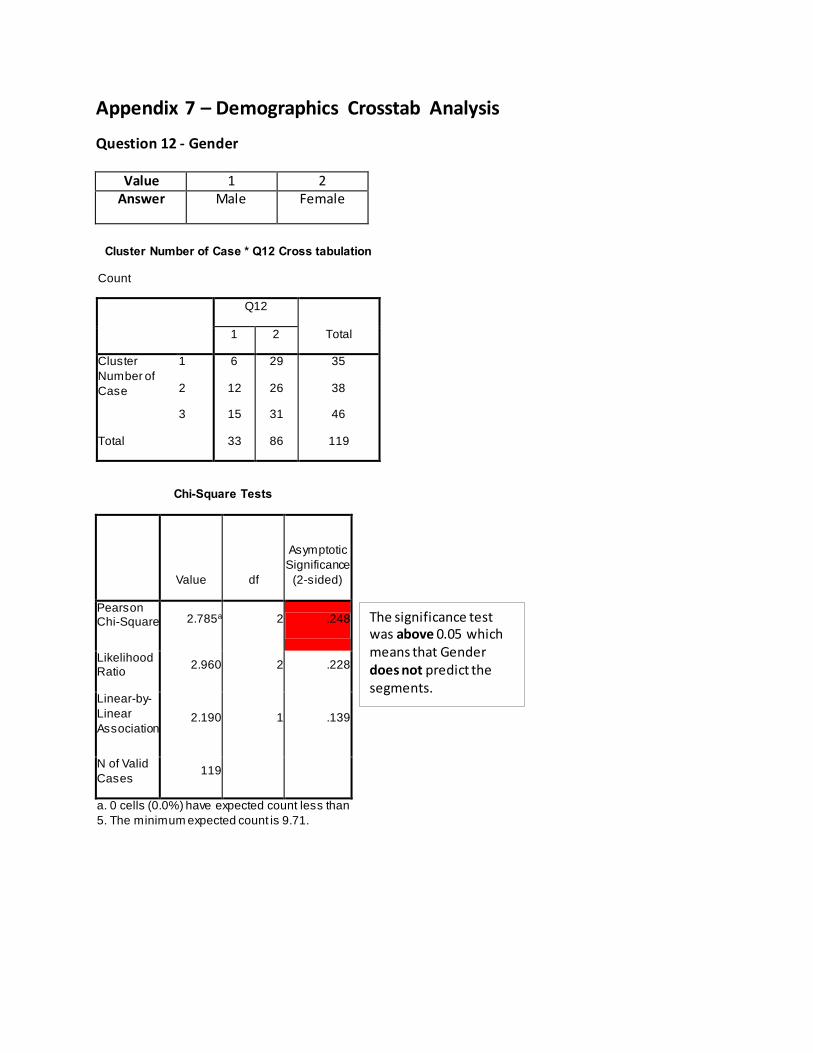
Appendix 7 – Demographics Crosstab Analysis
Question 12 - Gender
Value 1 2 Answer Male Female
Cluster Number of Case * Q12 Cross tabulation
Count
Q12
Total 1 2
Cluster
Number of
Case
1 6 29 35
2 12 26 38
3 15 31 46
Total 33 86 119
Chi-Square Tests
Value df
Asymptotic
Significance
(2-sided)
Pearson Chi-Square 2.785a 2 .248
Likelihood Ratio
2.960 2 .228
Linear-by-
Linear
Association 2.190 1 .139
N of Valid
Cases 119
a. 0 cells (0.0%) have expected count less than
5. The minimum expected count is 9.71.
The significance test was above 0.05 which means that Gender does not predict the segments.
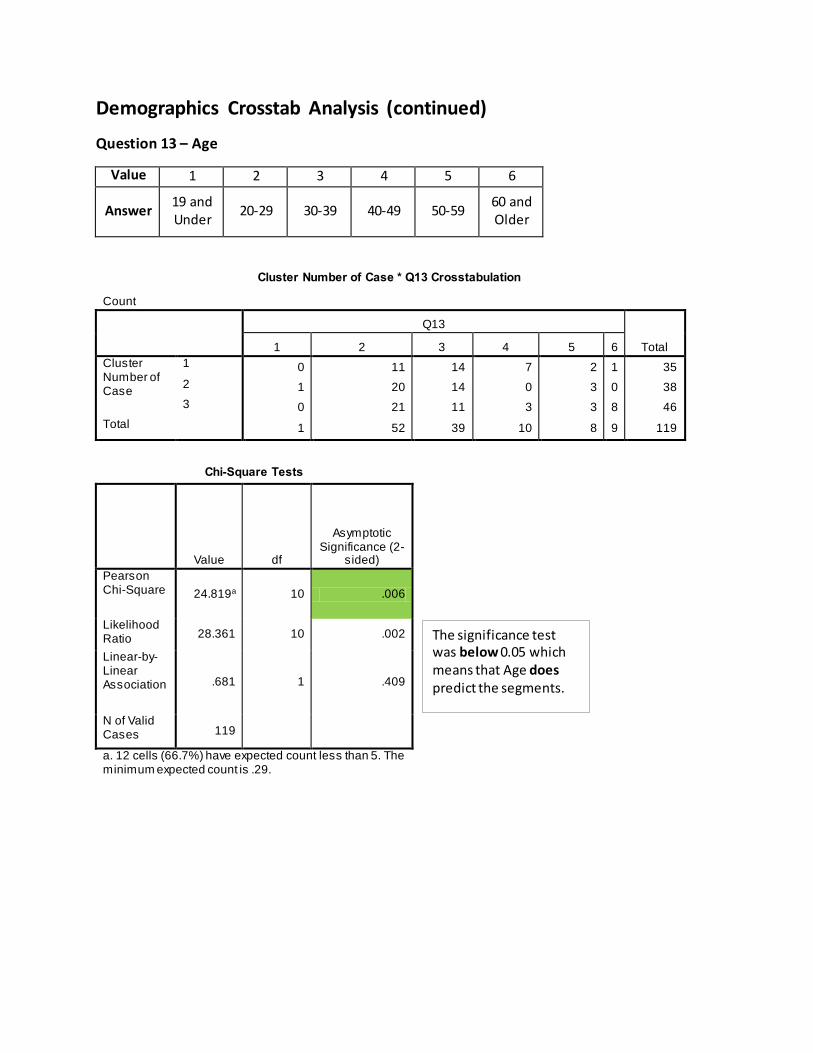
Demographics Crosstab Analysis (continued)
Question 13 – Age
Value 1 2 3 4 5 6
Answer 19 and Under
20-29 30-39 40-49 50-59 60 and Older
Cluster Number of Case * Q13 Crosstabulation
Count
Q13
Total 1 2 3 4 5 6
Cluster Number of Case
1 0 11 14 7 2 1 35
2 1 20 14 0 3 0 38
3 0 21 11 3 3 8 46
Total 1 52 39 10 8 9 119
Chi-Square Tests
Value df
Asymptotic Significance (2-
sided)
Pearson Chi-Square 24.819a 10 .006
Likelihood Ratio 28.361 10 .002
Linear-by-Linear Association .681 1 .409
N of Valid Cases 119
a. 12 cells (66.7%) have expected count less than 5. The minimum expected count is .29.
The significance test was below 0.05 which means that Age does predict the segments.

Demographics Crosstab Analysis (continued)
Question 14 – Employment
Value 1 2 3 4 5 6
Answer Unemployed Student Employed Part time
Employed Full Time
Self Employed
Retired
Cluster Number of Case * Q14 Crosstabulation
Count
Q14
Total 2 3 4 5 6
Cluster Number of Case
1 2 3 25 5 0 35
2 7 6 22 3 0 38
3 4 1 34 1 6 46
Total 13 10 81 9 6 119
Chi-Square Tests
Value df
Asymptotic Significance (2-
sided)
Pearson Chi-Square 21.878a 8 .005
Likelihood Ratio 24.301 8 .002
Linear-by-Linear Association .865 1 .352
N of Valid Cases 119
a. 11 cells (73.3%) have expected count less than 5. The minimum expected count is 1.76.
The significance test was below 0.05 which means that Employment does predict the segments.
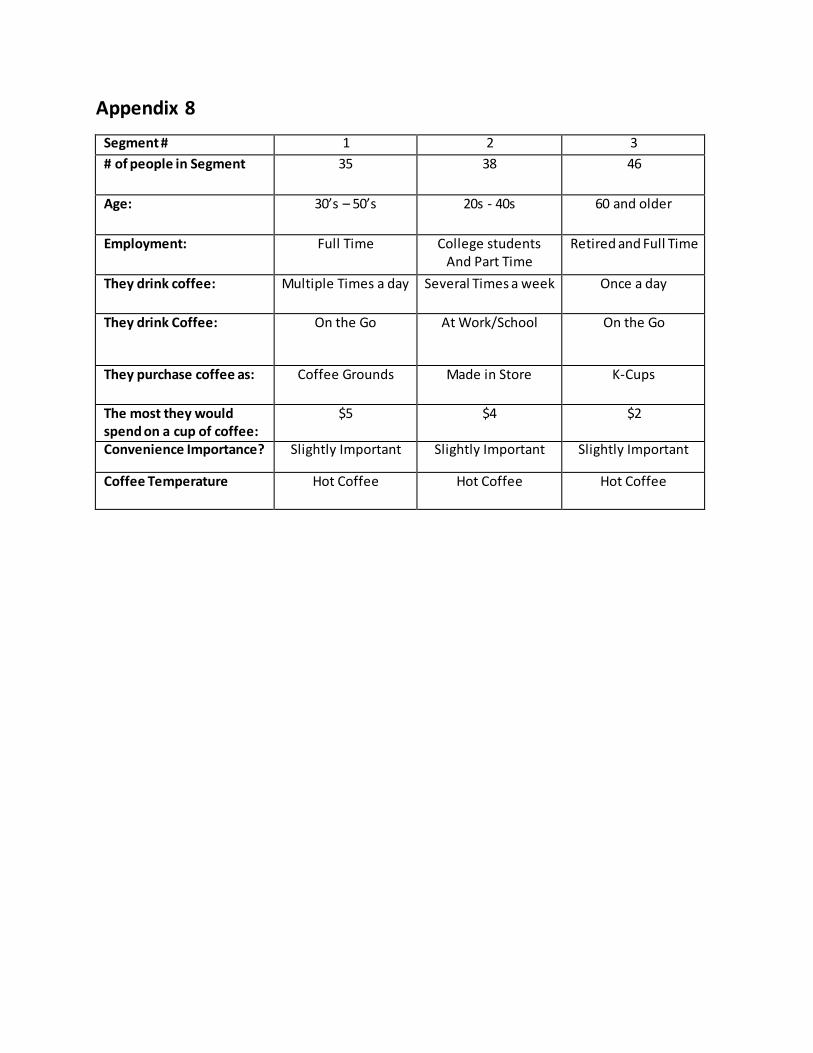
Appendix 8
Segment # 1 2 3
# of people in Segment 35 38 46
Age: 30’s – 50’s
20s - 40s 60 and older
Employment: Full Time College students And Part Time
Retired and Full Time
They drink coffee: Multiple Times a day Several Times a week Once a day
They drink Coffee: On the Go At Work/School On the Go
They purchase coffee as: Coffee Grounds Made in Store K-Cups
The most they would spend on a cup of coffee:
$5 $4 $2
Convenience Importance? Slightly Important Slightly Important Slightly Important
Coffee Temperature Hot Coffee Hot Coffee Hot Coffee









