Embed Size (px)
Citation preview

Federated OptimizationDistributed Optimization Beyond the Datacenter
Jakub Konečný, University of Edinburgh
Brendan McMahan, Google Inc.
Informs Annual Meeting, PhiladelphiaNovember 1-4, 2015

Outline
Optimization in Machine Learning
Empirical Risk Minimization
Distributed Optimization
Motivation
Current challenges
Federated Optimization
(possible) future of large-scale Machine Learning
Preliminary results
A lot of motivation for future research
2 Jakub Konečný

Machine Learning Setting
Space of input-output pairs
Unknown distribution
A relationship between inputs and outputs
Loss function to measure discrepancy between predicted and real output
Define Expected Risk
3

Machine Learning Setting
Ideal goal: Find such that,
But you cannot even evaluate
Define Expected Risk
4

Machine Learning Setting
We at least have IID samples
Define Empirical Risk
5

First learning principle – fix a family of candidate prediction functions
Find Empirical Minimizer
Define Empirical Risk
Machine Learning Setting
6

Problem structure
Typical objective
Many recent fast algorithms for single computer
SGD (Stochastic Gradient Descent)
SDCA (Stochastic Dual Coordinate Ascent)
SAG (Stochastic Avergae Gradient)
SVRG/S2GD (Stochastic Variance Reduced Gradient)
SAGA (Improvement on SAG)
…
Jakub Konečný7

Traditional efficiency analysis
Given algorithm , the time needed is
Main trend – Stochastic methods
Big , small
Target accuracy
Total number of iterations needed
Time needed to run one iterationof algorithm
8 Jakub Konečný

Distributed Optimization

Problem structure
Original objective
Functions described by data points
can be millions
Articles in major newspaper
can be billions
Users of Facebook
can be trillions
Ad click-through rate predictions
Jakub Konečný10

Problem structure
Original objective
Data distributed across machines
Partition of to
Number of local data points
Objective can be reformulated as
Computer k has direct access only to function Fk
Jakub Konečný11

Algorithms for distributed optimization
First trend
Naïve distributed variants of serial algorithms
Often inefficient; most time spent on communication
12 Jakub Konečný

Communication time
Let’s say
Time to read from memory (RAM)
100 ns
Time to send to another machine
500,000 ns
13 Jakub Konečný

Distributed efficiency analysis
There is lot of potential for improvement, if because most of the time is spent on communication
Time for round of communication
14 Jakub Konečný

Algorithms for distributed optimization
First trend Naïve distributed variants of serial algorithms
Often inefficient; most time spent on communication
Second trend Communication efficient algorithms
Idea: perform a lot of computation locallyfollowed by a round of communication
Very useful in practice
DANE (Shamir et al., 2014)
CoCoA (Jaggi et al., 2014, 2015)
DiSCO (Zhang, Xiao, 2015) (Session WE16)
15 Jakub Konečný

DANE
A communication efficient algorithm for
16 Jakub Konečný

DANE (necessary assumptions)
Explicit
Each node has access to IID sample of data points
Each node has the same number of data points
Implicit
Number of computers, , (relatively) small
Size of data available locally, , (relatively) big
In particular,
DANE relies on the assumptions heavily
Both in theory, and in practice
17 Jakub Konečný

Distributed Optimization (today)
Data are stored in datacenters
People worried about “Google knowing everything”
Relatively few computers, full of data
18
Big nk
Jakub Konečný
Small K
Major issue for big companies

Federated Optimization

Federated Optimization (motivation)
In order to even better protect privacy
Users keep their data on devices
Users provide computational power of devices
Consequences
Large number of computers (devices)
Few data points on each device
Very different patterns in data on different devices
20 Jakub Konečný

DANE reminder
Not stable / robust method
But solving the subproblem approximately…
21 Jakub Konečný
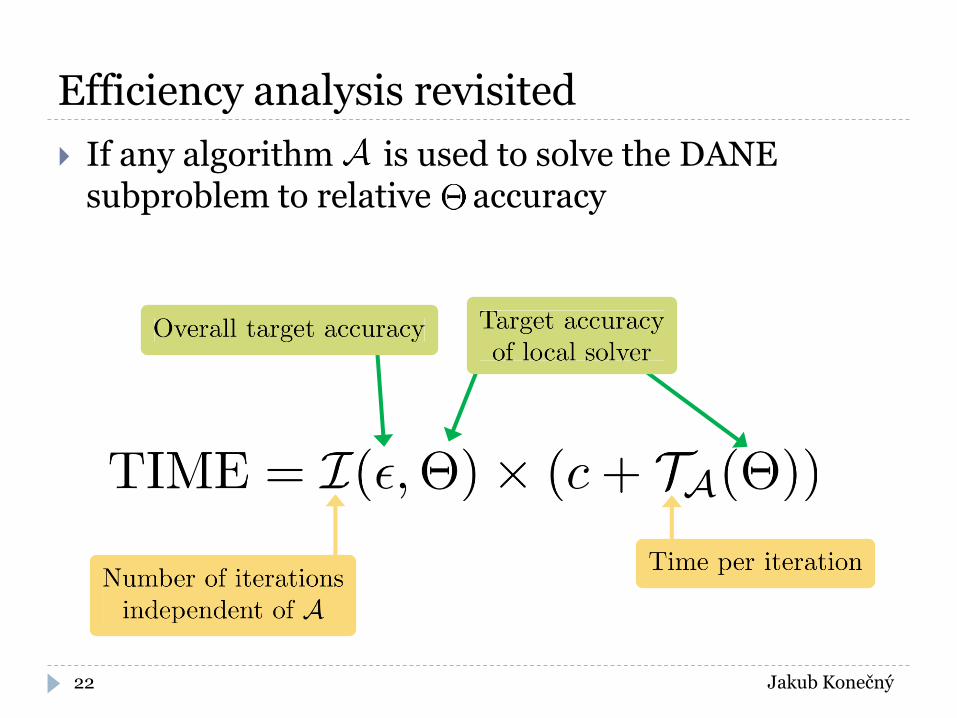
Efficiency analysis revisited
If any algorithm is used to solve the DANE subproblem to relative accuracy
22 Jakub Konečný

Efficiency analysis revisited – power
If chosen as Gradient Descent, run for 1 iteration
Equivalent to naïve distributed Gradient Descent
Greater flexibility with general subproblem
23 Jakub Konečný

SVRG/S2GD algorithm
24 Jakub Konečný

Apply SVRG/S2GD as local solver in DANE
Equivalent to
25 Jakub Konečný

Improving the algorithm (sparsity)
Sprasity
Data point in contains only very small number of non-zero elements
Extremely common in large-scale applications
Unbiasing stochastic gradients
Original update direction
New update direction
26
Diagonal; ratio of global and local appearance frequencies

Improving the algorithm (sparsity)
Sprasity
Data point in contains only very small number of non-zero elements
Extremely common in large-scale applications
Adaptive aggregation of updates
Original aggregation
Updated aggregation
27
Diagonal; Inverse coordinate appearance on computers Weighted average

Experiments
Setting
Data from public Google+ posts
Randomly chosen 10,000 users with 100 or more posts
Train/test split 75%/25%
Total 2,166,693 training posts
Extremes: 75 and 9,000 posts per user
See (simulate) each user as a separate computer
Simple bag-of-words language model
Dictionary of 20,000 most common English words
Prediction task
Post has comment or not (binary classification)
28 Jakub Konečný

Experiments
Optimization objective
29 Jakub Konečný

Experiments
Test error
30 Jakub Konečný

Federated Optimization
Very large number of computers K
Small number of data on each computer
Unbalanced – very different data sizes locally
Local data may be clustered; very far from IID
Potentially industrial reality within few years
Introduces many further questions
Jakub Konečný31
Summary

Future challenges
More rigorous experiments
Larger problems
Deep learning
Analysis missing!
Need for good public dataset
With naturally per-user clustered data
Asynchronous algorithms
Differential privacy
Google cannot learn anything
Many parts of ML pipelines need to be redesigned
Work for 1000+ people
32 Jakub Konečný





























