Embed Size (px)
Citation preview

Services, and Kew’s
(names) data
Nicky Nicolson, RBG Kew

Outline
• What we’re working on at the moment
• A names backbone
• Kew’s role
• What “services” we have just now
• … and why so few?
• Considerations
• Services on the names backbone & timescales
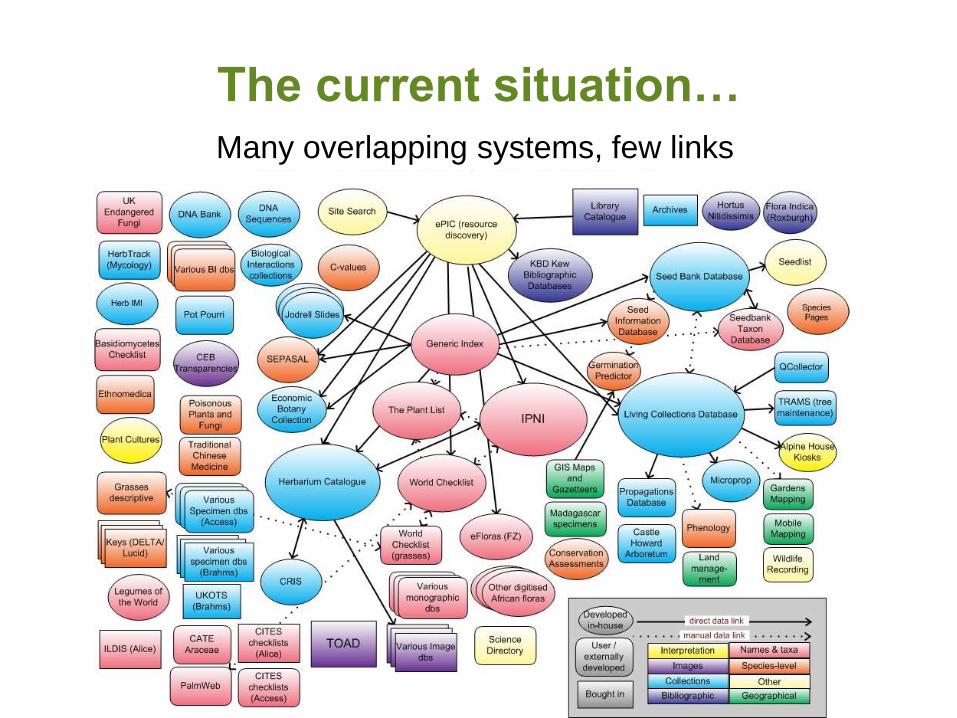
The current situation…
Many overlapping systems, few links
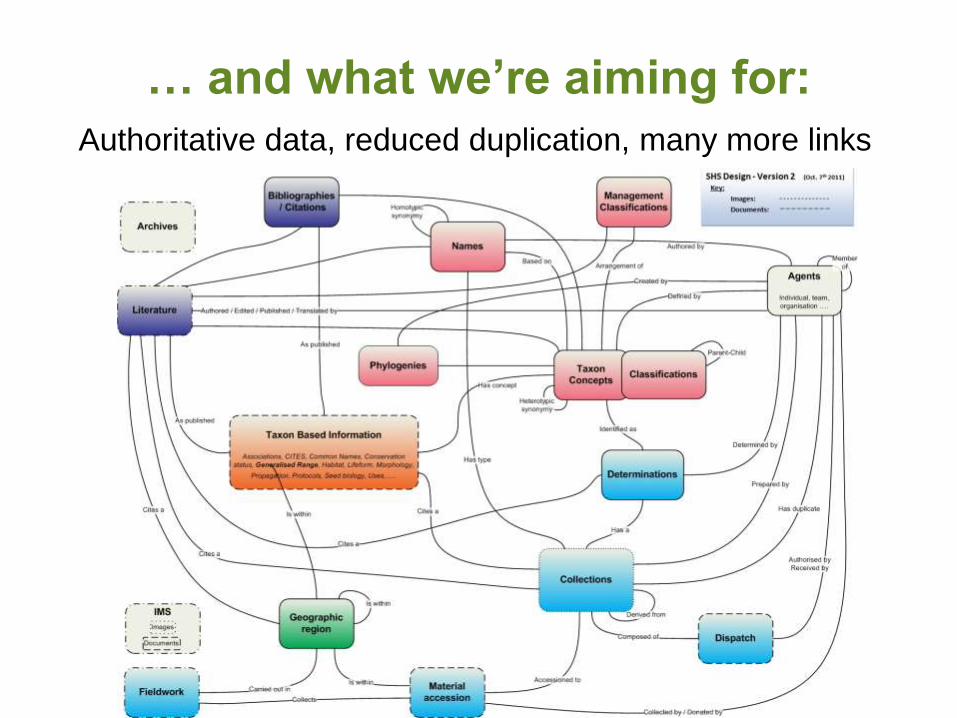
… and what we’re aiming for:
Authoritative data, reduced duplication, many more links

Names are key to linking the data:
build a “names backbone”
== “an environment for the management of multiple
overlapping classifications and tracking how these
change over time”
Not a monolith:
• Built on a layered view of the domain – clearly
separating names and taxonomy
• Names form the objective basis for higher layers
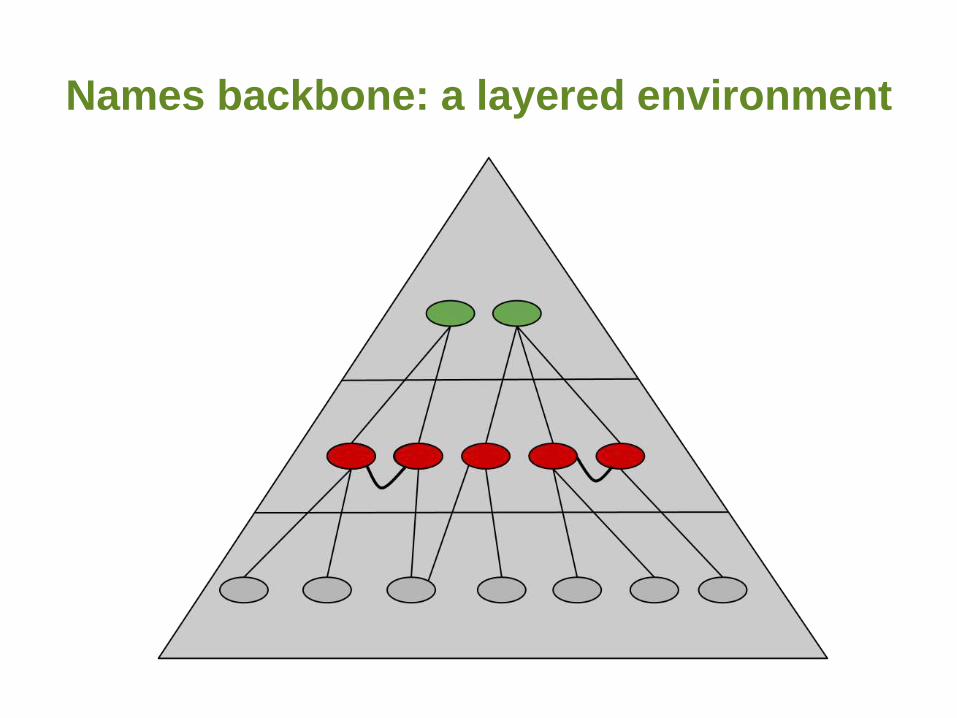
Names backbone: a layered environment
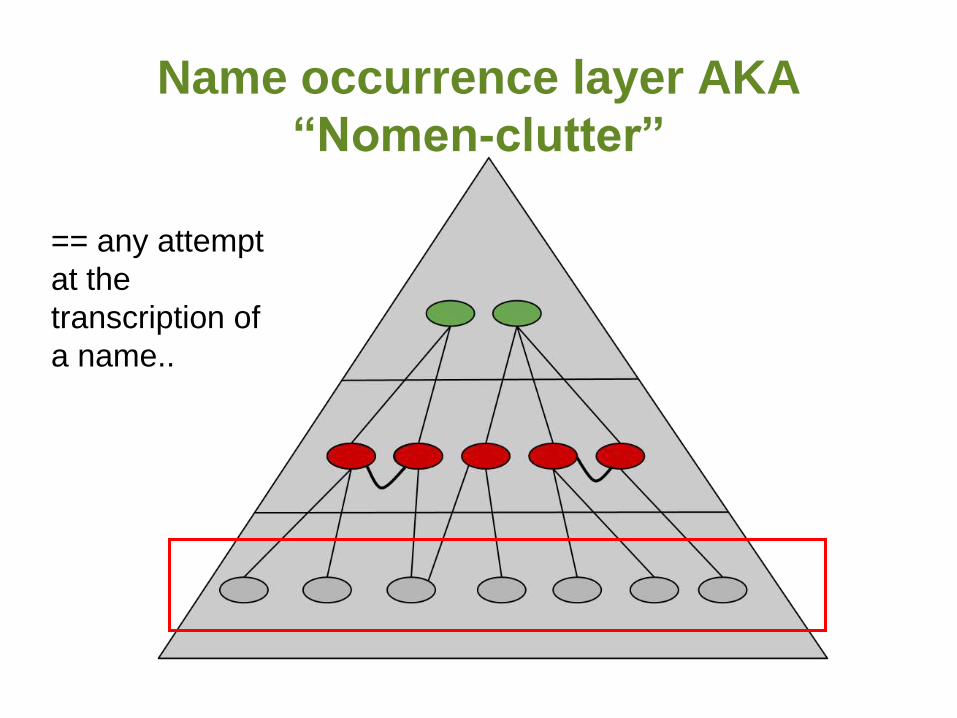
Name occurrence layer AKA
“Nomen-clutter”
== any attempt
at the
transcription of
a name..
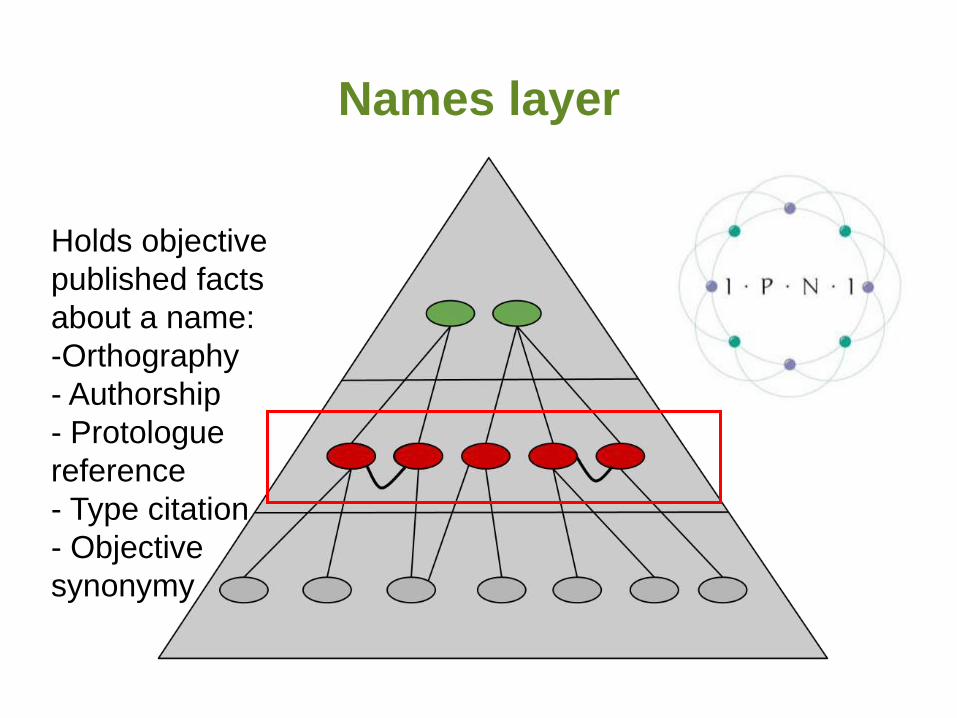
Names layer
Holds objective
published facts
about a name:
-Orthography
- Authorship
- Protologue
reference
- Type citation
- Objective
synonymy
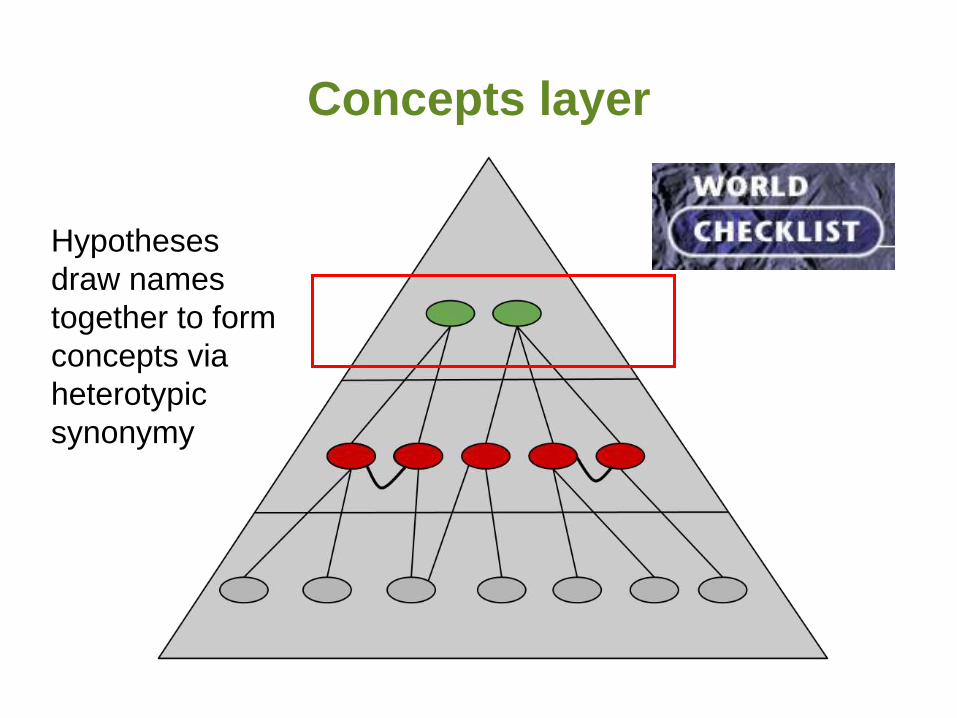
Concepts layer
Hypotheses
draw names
together to form
concepts via
heterotypic
synonymy

Names backbone is wider than
Kew
• We need to draw in data curated elsewhere, both
names and concepts:
• Vascular plants
• “Lower” plants
• Mycology
• ... and zoological names
…Kew’s role is as a service consumer as well as a
service provider

What services we have at the
moment
Various things for particular projects
… Used by known partners
... Answering specific, tactical needs
Are these really services?
• Not widely advertised
• Not opened up for anybody to use
...Not necessarily a strategic commitment

Service example: OpenUp
Name and concept checking for the data quality toolkit.
• Standard message format
But:
• Concepts not persistently identified
• No throughput management, so not widely available
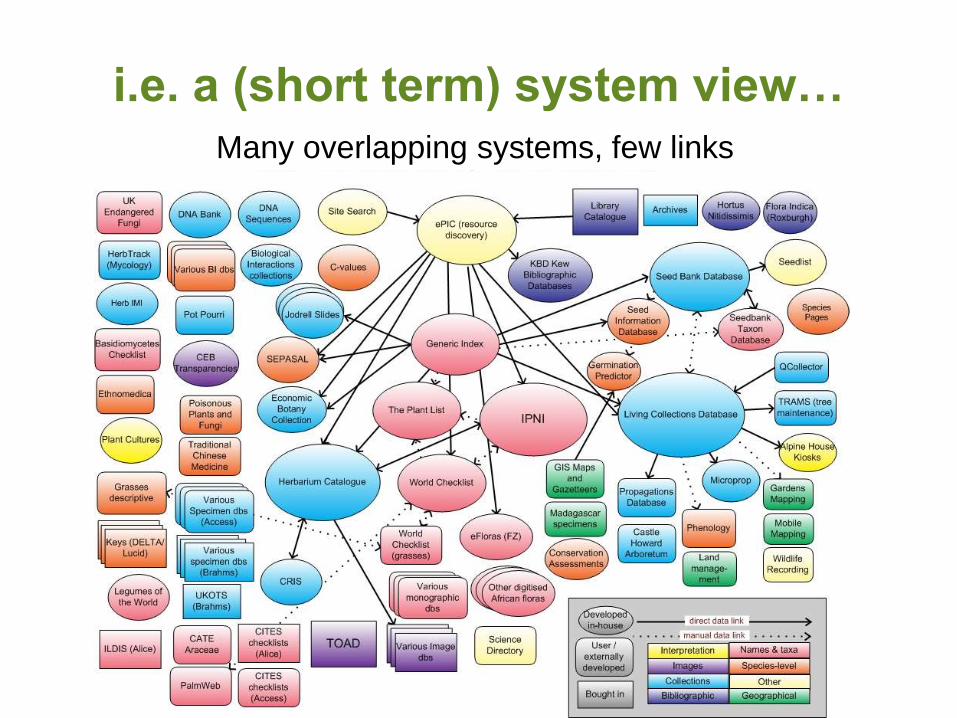
i.e. a (short term) system view…
Many overlapping systems, few links
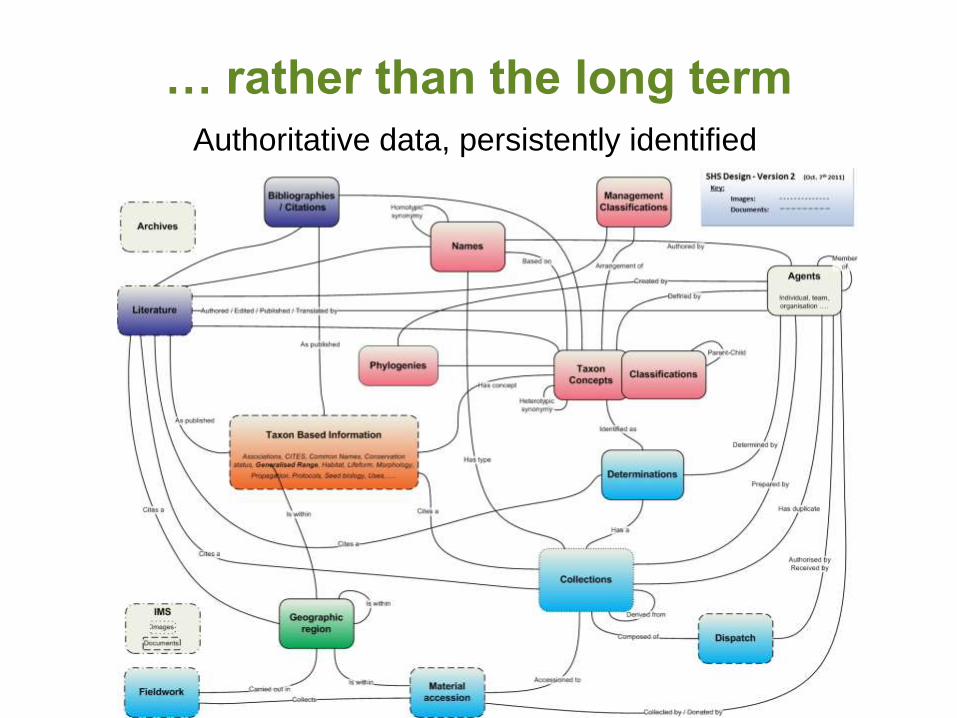
… rather than the long term
Authoritative data, persistently identified

Short term view == unhappy man
in Glasgow

A long-term, sustainable service:
1. Authoritative data
2. Persistently identified
3. Standards based

... and it also needs:
• Robustness / sustainability
• Management of throughput
• Communications with end users
• Support
• Help
• Example code
• Usage monitoring
• Sharing usage logs
• Terms of use

Analogy with collaborative
development
• Technical considerations
vs
• Social / political considerations
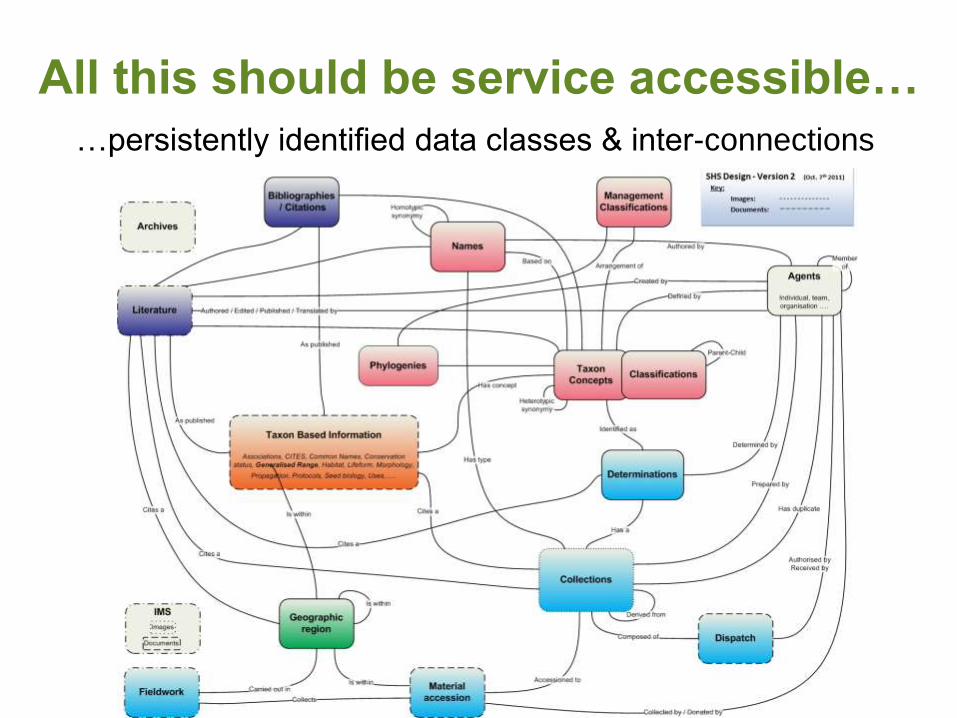
All this should be service accessible…
…persistently identified data classes & inter-connections
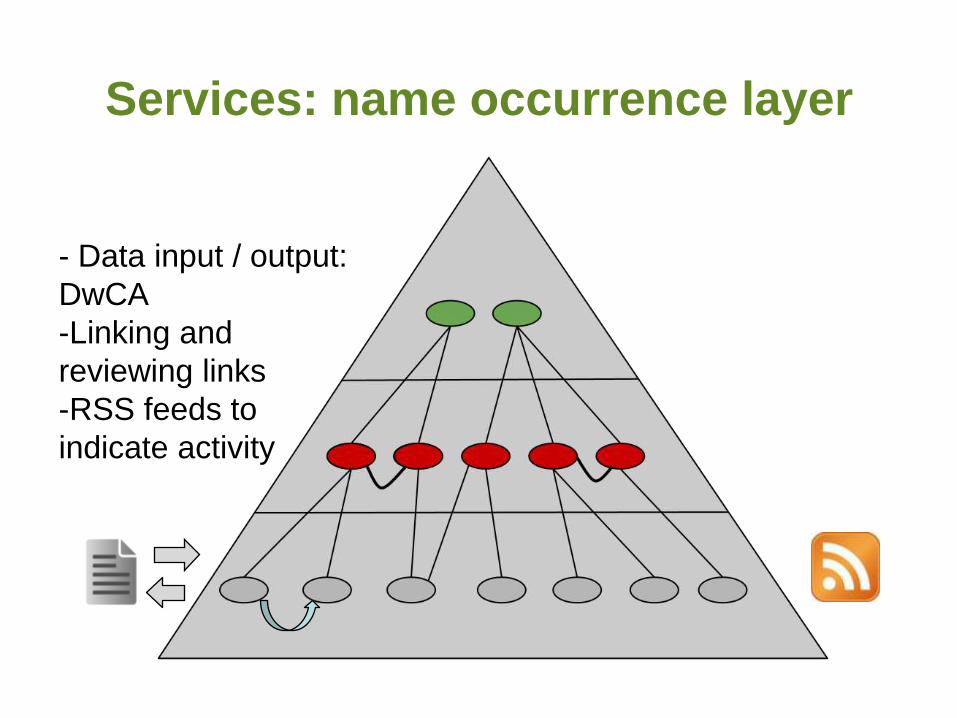
Services: name occurrence layer
- Data input / output:
DwCA
-Linking and
reviewing links
-RSS feeds to
indicate activity
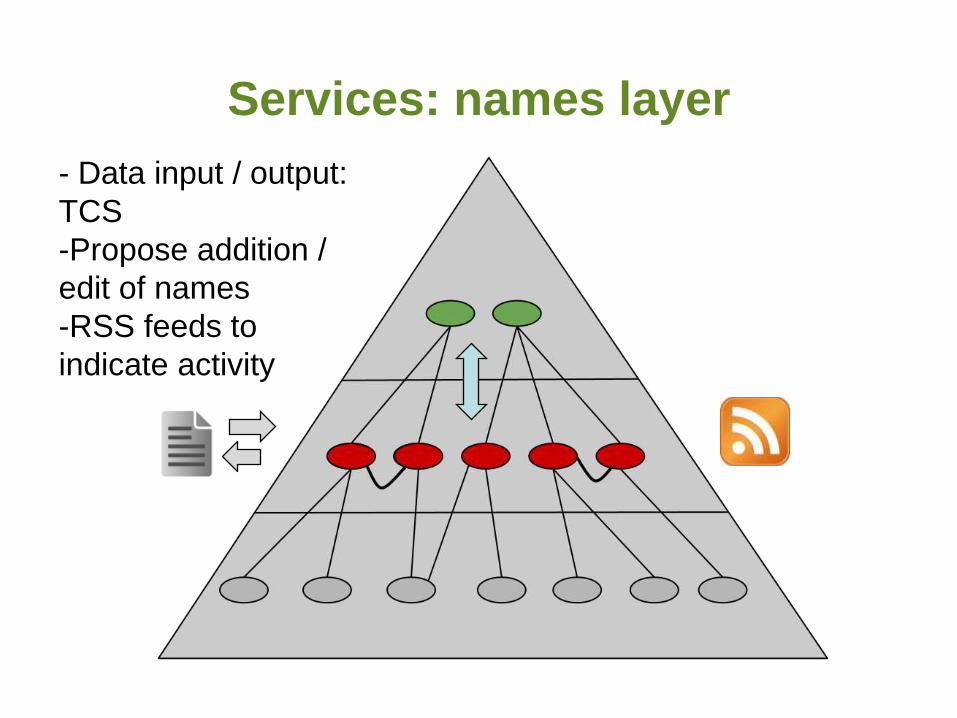
Services: names layer
- Data input / output:
TCS
-Propose addition /
edit of names
-RSS feeds to
indicate activity
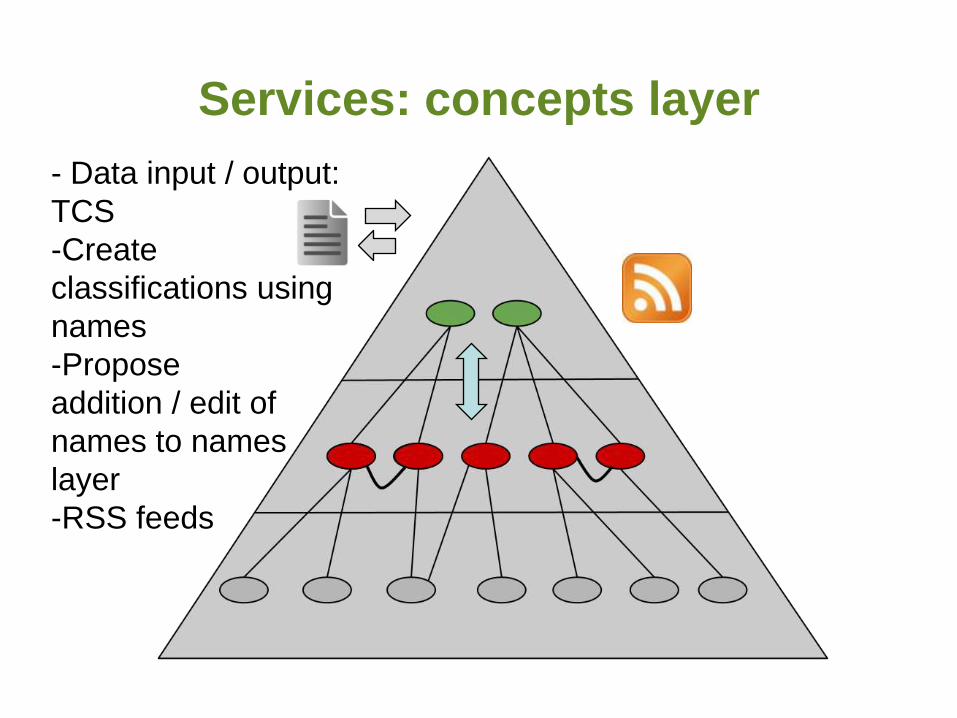
- Data input / output:
TCS
-Create
classifications using
names
-Propose
addition / edit of
names to names
layer
-RSS feeds
Services: concepts layer

How the names backbone will
support services
We’re working to enable service level access to the
data, by:
• Establishing authority
• Reducing duplication
• Data standards to represent well-known entities
• Persistent identifiers on those well-known entities
• Meaningful versioning – what changed, when
• Enabling remote curation

Timescales 2013
Till March:
First release : familial and generic classification
April – August:
Extend to name occurrence layer
Extend to species – incorporate WCS
Prioritise compilation process
September onwards (inc TDWG):
Comms w. service providers / consumers





![[MS-SSAS]: SQL Server Analysis Services Protocol Specification · SQL Server Analysis Services Protocol Specification ... domain names, e-mail addresses ... SQL Server Analysis Services](https://img.pdfslide.net/doc/110x75/5acea2fb7f8b9a1d328c0b57/ms-ssas-sql-server-analysis-services-protocol-specification-server-analysis-services.jpg)























